1. Introduction
Hand detection and tracking are crucial front-end procedures for many human hand-gesture tasks and remain challenging topics for researchers. They play a vital role in various computer vision applications, including hand pose estimation, human–computer interaction (HCI) systems, virtual reality (VR), augmented reality (AR), and more. These tasks are essential in numerous human–machine applications, such as providing navigational assistance for the visually impaired [
1], enabling contactless navigation for surgeons to minimize contamination during surgery [
2], recognizing and interpreting sign language through hand gestures [
3], and facilitating interactive remote control for VR video games [
4].
Hand gestures can be classified into two categories: static gestures and dynamic gestures. Static hand gestures refer to hand postures where the position remains unchanged for a certain period of time, while dynamic hand gestures involve hand postures where the hand position changes over time. Static gestures are characterized by factors such as orientations, shape, and contextual environment, whereas dynamic gestures, also known as trajectory-based gestures, are characterized by factors such as trajectory and motion speed [
5]. In the context of trajectory-based gestures, the accurate detection and tracking of the hand play a vital role. Recognizing and interpreting dynamic hand gestures requires capturing the hand’s motion trajectory and accurately tracking its movement. Detection ensures that the hand is identified and localized within the frame, while tracking enables the continuous monitoring of the hand’s position, orientation, and motion throughout a sequence of frames. The detection and tracking of the hand are critical for trajectory-based gesture recognition. By extracting the trajectory pattern from landmarks such as the center of the palm, user can analyze the hand’s motion and obtain meaningful features for gesture recognition algorithms. The integration of detection and tracking techniques allows the user to capture and analyze the temporal dynamics of hand gestures, providing more accurate and reliable recognition results.
In general, two main approaches can be implemented for hand detection and tracking: marker-aided and vision-based marker-less methods. The former approach requires the user to wear a glove-like device, which provides more accurate results. However, wearing such a device inconveniences the user and restricts the naturalness of HCI [
6]. The latter technique is undoubtedly a better approach as it allows for natural HCI interaction without the need for wearable devices. However, its accuracy may vary when the vision system is exposed to external factors such as extreme lighting conditions and cluttered backgrounds.
In addition to accurate hand detection, tracking hand movement is essential for many hand-based computer vision applications. The hand tracking must be smooth, fast, and accurate to extract and decode information correctly. However, reliably detecting hands from cluttered scenes remains a challenging task. This is due to the complex appearance diversities of dexterous human hands in color images, including variations in hand shapes, skin colors, illuminations, orientations, scales, etc. [
7]. Human hands are dynamic and tend to move quickly, making tracking difficult (e.g., clenching and releasing a fist, scratching the nose, waving hands). Furthermore, occlusion is a common issue encountered in hand detection systems [
8]. Occlusion occurs when the hand is obstructed by other objects during real-time detection, such as covering the left hand with the right hand or placing the hand in front of the face. This introduces higher complexity to the system as the extracted information is limited for achieving the goal of hand detection.
Apart from the occlusion with external objects, the human hand can also be self-occluded; for example, when clenching a fist, the fingertips are occluded by the palm. Moreover, real-time object-detection mechanisms require heavy I/O operations and accurate processing [
9], making them computationally expensive. The system needs to continuously capture image frames from the camera feed, detect the object, draw the predicted bounding box, and track the target object in every frame. This heavy and complex computation can slow down the system, making it undesirable even with high accuracy. Therefore, a wise trade-off between speed and accuracy also needs to be considered.
2. Related Works and Motivation
Vision-based marker-less hand tracking holds great promise for HCI applications, including sign language recognition, augmented reality, telesurgery, home automation, and gaming. However, its implementation faces several challenges, including tracking inaccuracy caused by complex articulated hand motion, high appearance variability, and demanding computational and real-time requirements [
10,
11,
12,
13,
14]. Consequently, research in this field continues to be a challenging problem that has gained significant attention from the computer vision community.
Sharp et al. [
11] presented a real-time hand tracking system based on a single depth camera. The system tracked hands in various poses and environments and demonstrated fast and accurate recovery from tracking failures. They utilized the analysis by synthesis technique, generating candidate poses and scoring them against the input image to determine the most likely hand pose. Machine learning and temporal propagation contributed to a large set of candidate hand-pose hypotheses. The evaluation showed accurate tracking of different hand poses, including open, closed, and gesturing hands. However, the system had limitations regarding occlusions and changes in lighting conditions.
Recent studies have shown that the accuracy of vision-based tracking can be improved by the adoption of deep learning methods through the Convolutional Neural Network (CNN) technique. Mueller et al. [
15] proposed an innovative real-time 3D hand tracking method using monocular RGB images. Their approach combined a CNN with a kinematic 3D hand model to achieve accurate tracking. They predicted 2D joint heatmaps, enabling the 3D hand model to infer corresponding 3D joint positions. A noteworthy contribution was the introduction of a novel synthetic data generation method using a Generative Adversarial Network (GAN). This GAN was trained to generate hand images that closely resemble real images, enhancing the CNN’s robustness to variations in lighting, pose, and occlusion. However, the authors acknowledged certain limitations in their approach. They addressed scenarios where the hand and background had similar appearances, which posed challenges for their network model, leading to unstable tracking and inaccurate predictions. Furthermore, tracking became problematic when multiple hands were in close proximity within the input image, resulting in unreliable detections and posing a challenge for accurate tracking.
Zhang et al. [
16] proposed MediaPipe hands, a real-time hand detection and tracking system based on the BlazePalm CNN architecture. This method accurately predicted hand poses using image inputs and detected hand bounding boxes and landmarks. The system followed a “tracking by detection” approach, with the palm detector locating hand regions and the hand landmark model estimating precise 2.5D landmarks. These landmarks accurately depicted specific key points on the hand, such as fingertips, knuckles, and the center of the palm. However, challenges arose when hands were occluded, in extreme poses, or appeared very small in the image due to large distances. Additionally, factors such as lighting conditions and cluttered backgrounds could affect system performance. MediaPipe hands offered robust hand tracking with accurate pose estimation, but limitations had to be considered.
The CNN sub-libraries such as Regional-based Convolutional Neural Network (R-CNN), Faster R-CNN, You Only Look Once (YOLO), and Single-Shot Detection (SSD) algorithms have also gained attention in this research field. In Wu et al. [
8], hand pose estimation was achieved by performing skeleton-difference network (SDNet) analysis to predict the locations of hand joints. To train the network for detecting hand location, a deep learning model based on CNN was implemented. For model training, the dataset was pre-processed by cropping the hand region and labelling the hand joints. The employed CNN network model had another layer added to it known as a position-sensitive region of interest (RoI) pooling layer, based on ZFnet, to further improve its accuracy. From their experiments, the proposed model was able to detect hands and three other classes accurately, achieving a mAP of 91.6%.
On the other hand, Liu et al. [
17] implemented two popular CNN backbones, the VGG-16 and ResNet 50 to compare their performance in a hand detection system. Both backbones were trained on the same dataset, ImageNet, to ensure a fair comparison. Additional features such as rotational map were introduced to the CNN network to enable the detector to draw bounding boxes near rotated hands in images. Implementation results showed a significant improvement in mAP, with the VGG-16 network achieving 92.3% mAP and a frame rate of 13.10 FPS and ResNet 50 attaining 94.8% mAP and frame rate of 19.80 FPS, outperforming the other existing detection benchmarks such as YOLO (76.4% mAP and frame rate of 35 FPS). In Gao et al. [
18], the existing SSD network was improved by replacing the original backbone of SSD, VGG-16 net with ResNet 101, and fusing the feature maps’ three Conv4 layers with two Conv6 layers. These improvements are aimed at improving the accuracy of the existing SSD network in detecting smaller objects, such as distanced hand gestures to a space robot in a space station. Results from their proposed design showed significant enhancement of SSD model in terms of mAP, as their model was able to achieve mAP of 89.4% on public hand datasets such as the Oxford hands dataset [
19], EgoHands dataset [
20], and self-developed Space Robot Simple Sign Language (SRSSL) dataset [
18].
In another recent work, Mukherjee et al. [
21] proposed the Faster R-CNN network in their fingertip detection and tracking system for air-writing recognition. The system was decomposed into several sections: detecting writing hand pose, keeping track of fingertips in every successive frame, and recognition of the air-writing characters. For hand pose detection, the Faster R-CNN network was trained on EgoFinger [
22] and EgoHands datasets with four losses: RPN regression loss, RPN classification loss, R-CNN regression loss, and R-CNN classification loss. Other than focusing on detecting the hand pose in video streams, they also proposed implementing hand centroid localization to locate the position of the hands accurately. Visual trackers such as Kernelized Correlation Filter (KCF) tracker [
23], Tracking-Learning-Detection (TLD) [
24] tracker, and Multiple Instance Learning (MIL) [
25] tracker were implemented as the hand tracking mechanism to assist the Faster R-CNN detector in keeping track with the fingertips movement during air-writing process. Their experimental results showed that the proposed method outperformed the rest of the visual trackers, achieving a mAP of 73.1% as compared with TLD tracker (mAP of 66.7%), KCF tracker (mAP of 55.4%), and MIL tracker (mAP of 42.4%).
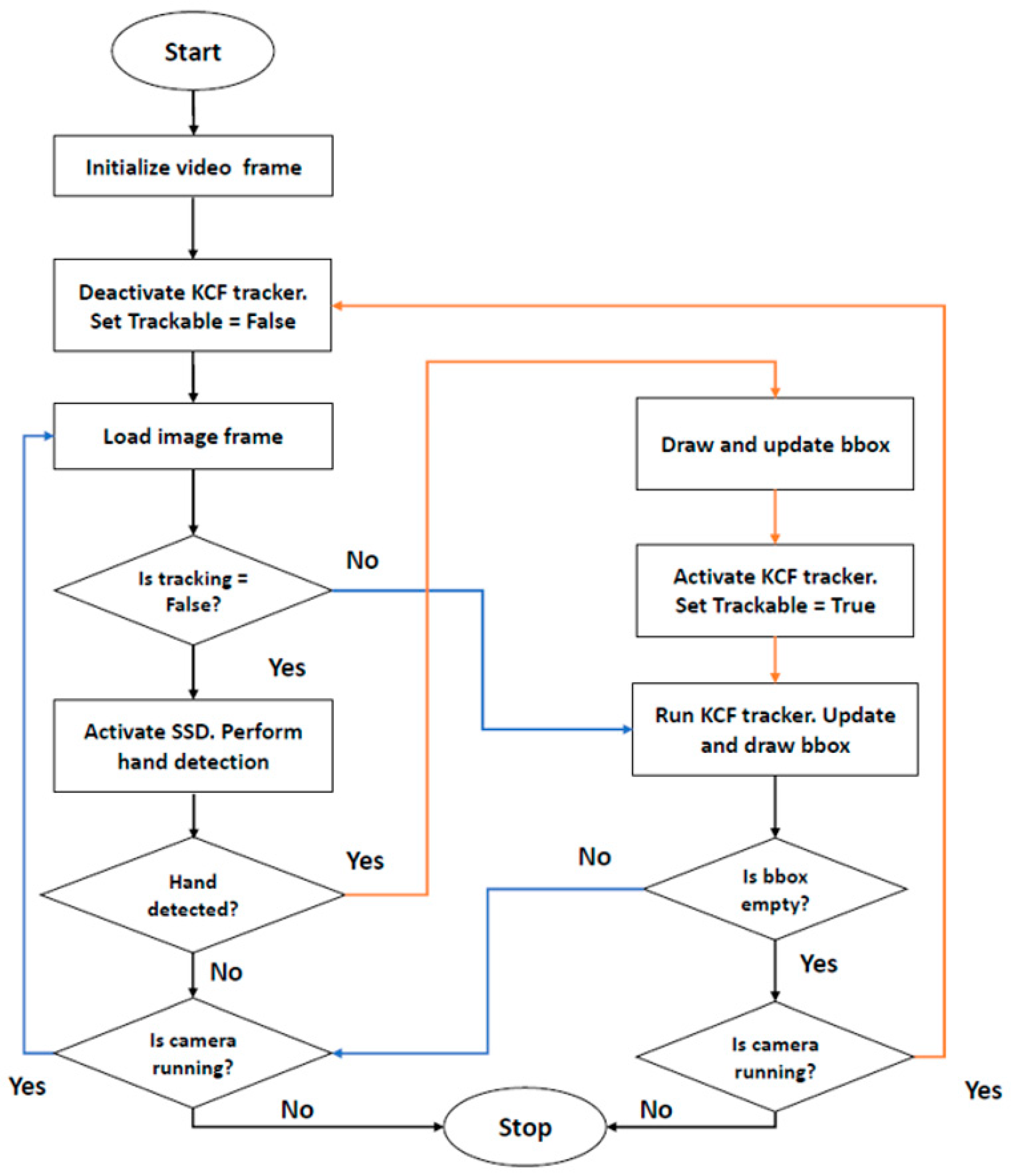
The focus of this work is to develop a fast and robust hand detection and tracking system that is reliable to support a real-time application. To achieve this objective, a tracking-by-detection algorithm is proposed by integrating the well-known correlation filter-based trackers, the KCF tracker [
23], with the state-of-the-art deep learning object-detection algorithm, Single-Shot Detection (SSD) [
26]. The KCF tracker is considered in this work because of its widespread acceptance due to its competitive performance in terms of speed and accuracy. For instance, the KCF tracker has been implemented in face tracking systems alongside a Continuously Adaptive Mean-Shift (CamShift) algorithm to optimize the tracking performance and to recover the tracker when the CamShift algorithm failed to track faces midway during inference [
27]. Despite its promising characteristics, the KCF tracker still struggles to maintain seamless tracking in the occurrence of occlusion and objects falling out-of-view, and it is unable to correct errors during the tracking process [
28]. This limitation is due to the principle of the KCF tracker that traces the target based on the correlation of the appearance and position of the target in the previous frames. Therefore, the presence of challenging scenes that result in a significant mismatch between the appearance of the target and the reference object will lead to tracking failure [
10].
In this paper, a robust hand tracking method is proposed which integrates the correlation filter with a correction strategy using the fast object-detection model, the SSD algorithm. With this integration, the tracker can be reinitialized when hand movement is not tracked properly, ensuring consistent and accurate tracking. By detecting the tracked object only during the first frame and when it is lost by the tracker, heavy computational costs of the detector are minimized, leading to an improvement in real-time performance. To assess the performance of the proposed tracker, it is compared with the state-of-the-art KCF tracker in terms of mean average precision (mAP) and frame per second (FPS).
4. Result and Discussion
This section presents the performance analysis of the proposed hand detection and tracking framework. The evaluation primarily focuses on the performance of the SSD hand detection model on the EgoHands dataset, specifically the testing dataset portion. The evaluation utilizes COCO’s detection evaluation metrics, including mean Average Precision (mAP) at different Intersection over Union (IoU) thresholds, average recall (AR), and detection speed, to assess the model’s ability to detect hand objects from input images. The evaluation results are then compared with a benchmark model, the Faster R-CNN algorithm, which is widely recognized as one of the most popular and accurate object-detection models.
In the latter part of the experiments, the evaluations focused on the performance analysis of the proposed hand tracking algorithm, as well as the integration of the SSD model with the KCF tracker. The evaluation was performed by running the model inference on sequences of video containing hand movements forming trajectory-based hand gestures and some free hand motions without describing any specific gesture meaning. All videos were recorded using Microsoft LifeCam NX-3000 (Microsoft, China), and the relative distance from the camera to the subject (the hand object) was about 0.5 m. For the trajectory-based hand gestures, there were ten trajectories used to simulate the tracking of hand motion, which described gesture numbers zero to nine. For the free hand motion, there were seven video sequences used to simulate different scenes such as slow movement, fast movement, occlusion behind objects, outdoor lighting conditions, less background contrast, and deformable hand shapes. The tracking rate and accuracy of estimating hand position were evaluated using the TRDR (tracking detection rate) and OTE (object detection error) measures [
33]. To observe any improvements in tracking performance, the proposed algorithm was compared to the original KCF tracker. All experiments were conducted on a local computer equipped with an Intel Core i5 CPU 2.50 GHz processor, 8.00 GB RAM, and running the Windows 10 operating system.
Table 1 presents the performance of the SSD and Faster R-CNN hand detection models on the testing data of the EgoHands dataset. The computed metrics reveal that the overall detection accuracy of the SSD model is slightly lower than that of the Faster R-CNN model. However, in terms of detection speed, the Faster R-CNN model performs significantly slower, taking approximately 15 times longer for inference compared to the SSD model. The slower computation speed of the Faster R-CNN model can be attributed to the heavy workload of the selective search method utilized in the model. This method requires computing four similarity measures, including color similarity, texture similarity, size similarity, and shape similarity, for every detecting frame. Additionally, the Faster R-CNN model necessitates two shots of the image—one for region proposal generation and another for object detection—further contributing to slower real-time computation speed. Considering the trade-off between speed and accuracy, this evaluation justifies the selection of the SSD model for implementation in a real-time hand tracking system.
In the following experiments, the performance of the hand tracking framework is evaluated using image frames from the webcam feed. The SSD detection model is configured with an IoU threshold of 0.5 to suppress false positives during the inference process.
Table 2 presents the results of the proposed tracking-by-detection algorithm on video sequences captured from the webcam feed, specifically for ten trajectory-based gestures ranging from ‘0’ to ‘9’. The comparison with the original KCF tracker and the improvement achieved by the proposed algorithm are also provided.
It can be observed that the integration of the SSD algorithm (i.e., the proposed algorithm) has significantly enhanced the overall accuracy and tracking rate of the KCF tracker. The proposed algorithm achieves a lower OTE value of 16.595 and a higher tracking rate of 94.3%. However, in terms of average frame rate, the performance of the KCF tracker surpasses that of the proposed algorithm, with an average speed of 36.3 FPS compared to 16.40 FPS achieved by the proposed algorithm. Although the KCF tracker exhibits faster processing speed, its overall accuracy is comparatively lower. The KCF tracker encounters challenges in accurately tracking hand gestures “0”, “3”, “8”, and “9” due to its inflexibility in adapting to scale variations and its susceptibility to drifting issues, especially during rapid hand movements.
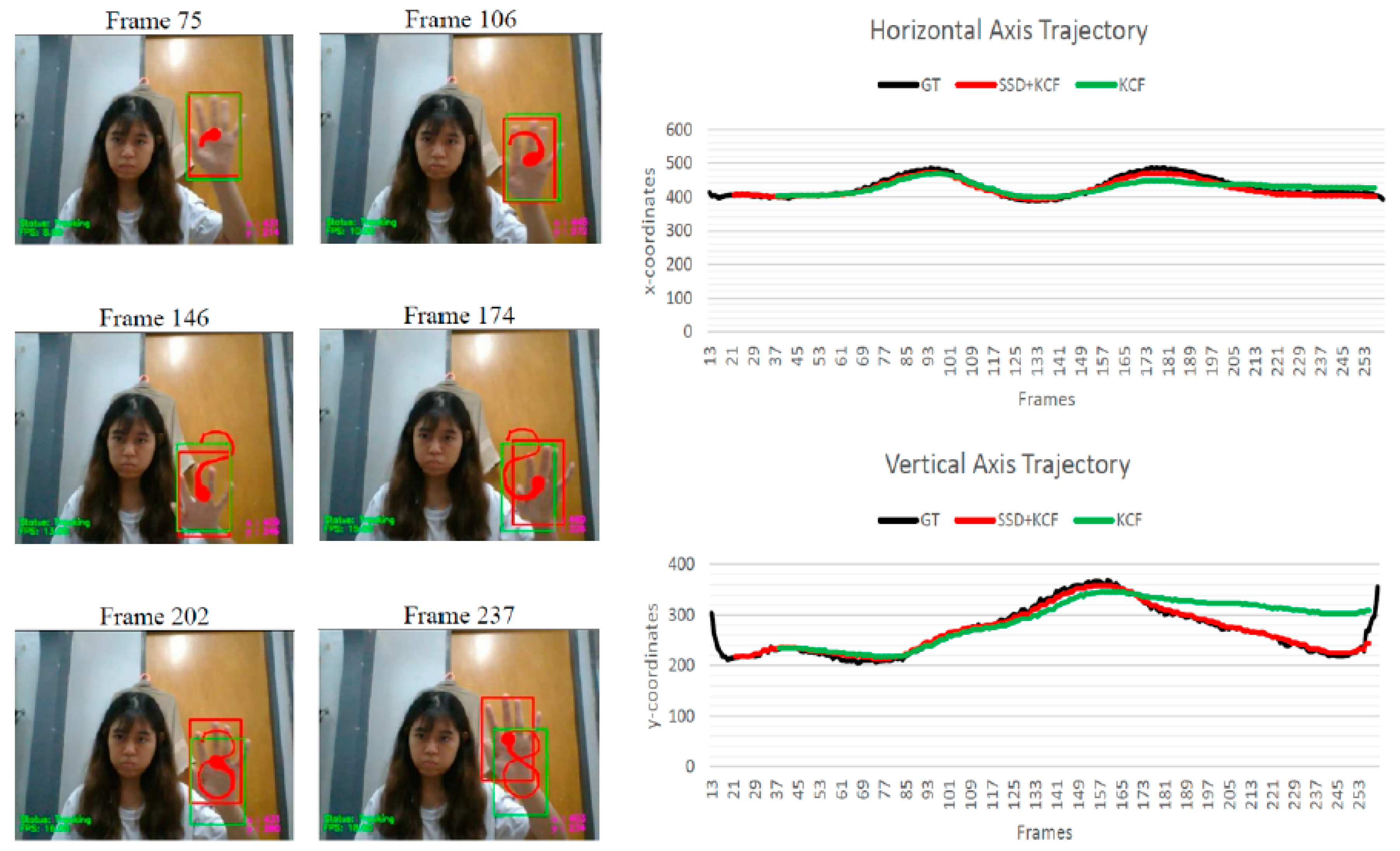
To provide a deeper understanding of these issues, we direct readers to
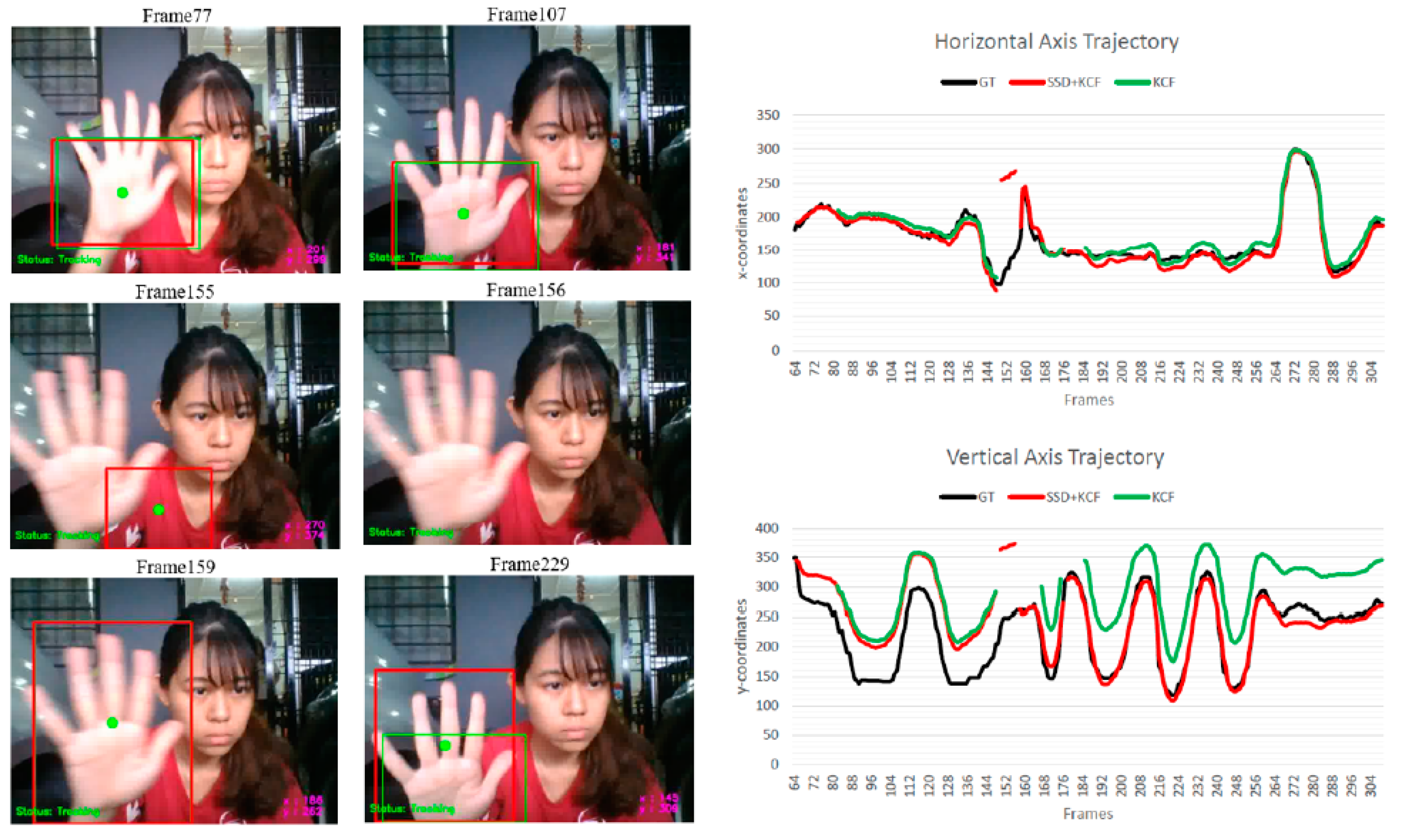
Figure 2, which presents an example showcasing the tracking results for gesture “8”. In this case, the proposed algorithm has demonstrated superior performance compared to the KCF tracker, achieving a promising tracking rate of 95.2% and a lower tracking error of 9.02. Conversely, despite the KCF tracker’s higher overall frame rate, it exhibits a higher tracking error of 32.3901, which is three times greater than that of the proposed algorithm.
Analyzing the tracking results depicted in
Figure 2, it becomes evident that the KCF tracker encountered drifting issues, as its bounding box drifted towards the arm when the hand continuously moved upwards, as shown in Frame 202 and Frame 237. On the other hand, the proposed algorithm exhibits excellent tracking results without any drifting issues. Moreover, both the horizontal and vertical axis trajectories of the proposed algorithm closely align with the ground truth trajectories. In contrast, the vertical axis trajectory of the KCF tracker deviates significantly from the ground truth trajectory.
The proposed tracking algorithm was further evaluated using several challenging video sequences, including scenarios involving slow and fast hand movements, occlusion behind other objects, outdoor environments, cluttered backgrounds with low contrast to skin tone, and deformable hand shapes while drawing alphabetical trajectory gestures. The evaluation results, along with a comparison to the original KCF tracker and the improvement achieved by the proposed algorithm, are summarized in
Table 3. Based on the obtained results, it is evident that the overall performance of the proposed algorithm surpasses that of the KCF tracker. The proposed algorithm achieves a higher average tracking rate of 93.406% and a lower tracking error of 26.199. It is worth noting that the integration of the SSD algorithm has also improved the overall performance of the KCF tracker, resulting in a 22.802% improvement in TRDR and a 24.841% improvement in OTE value.
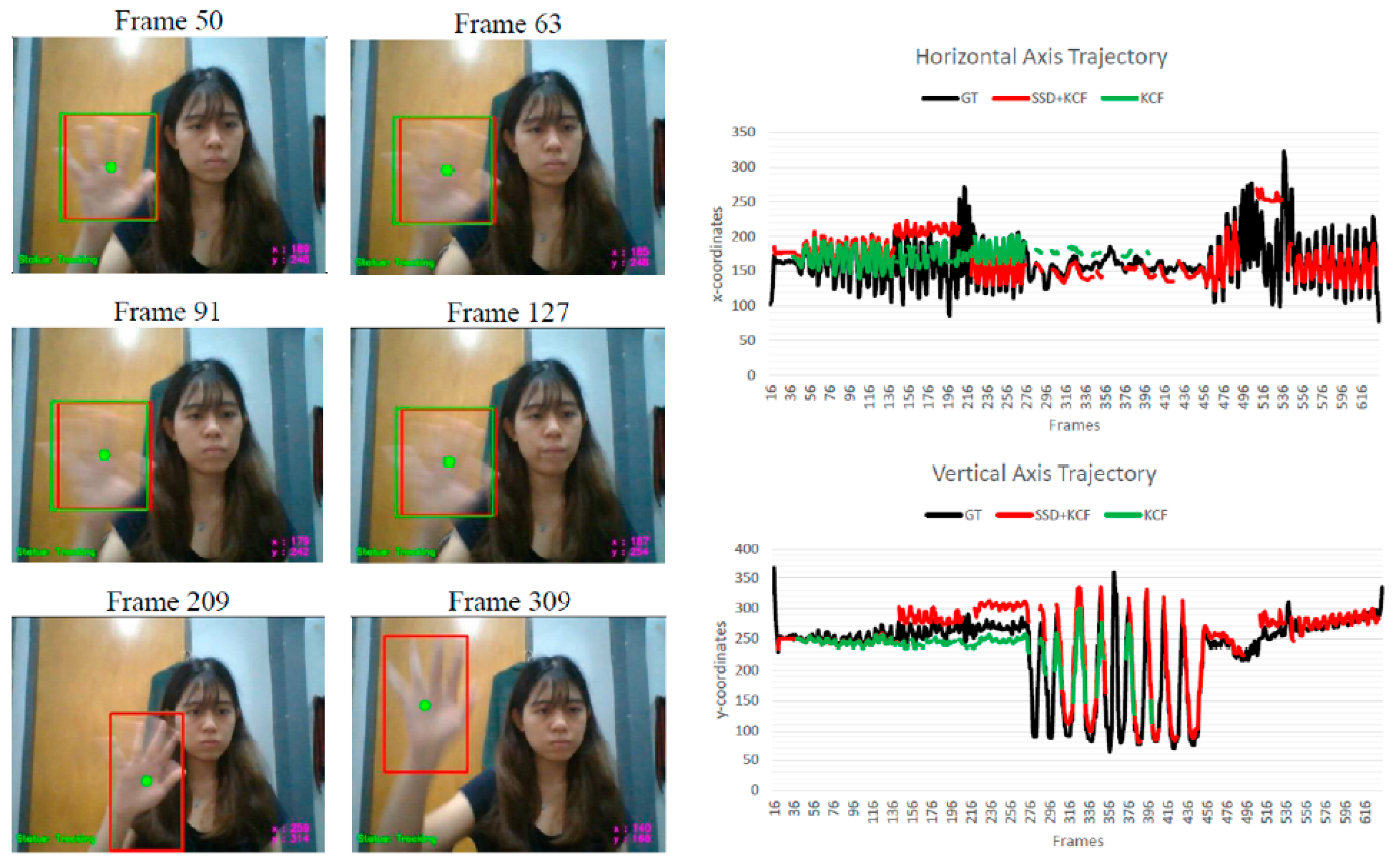
To gain a deeper understanding of the evaluation results, a qualitative analysis was conducted on specific tracking scenes. In the case of tracking slow hand movements, both the proposed algorithm and the KCF tracker exhibit similar performance. However, when it comes to handling fast and abrupt hand movements, the proposed algorithm outperforms the KCF tracker. The proposed algorithm achieves a higher tracking rate of 84.01%, which is twice that achieved by the KCF tracker. This indicates that the proposed algorithm is more effective at accurately tracking the hand during fast movements. While the proposed algorithm does have a relatively higher tracking error (OTE) of 30.341, it demonstrates a lower tendency of tracking failure compared to the KCF tracker. This can be observed in
Figure 3, specifically in Frame 209 and Frame 309, where the proposed algorithm successfully keeps up with the fast-moving hand while the KCF tracker encounters tracking failure issues and fails to reinitialize its system. Furthermore, it was noted that the trajectory plots obtained from the proposed tracker are more complete compared to the implementation of the KCF tracker alone. It is important to acknowledge that, although the proposed algorithm tracks the hand object throughout a larger number of frames, offset errors between the estimated position and the ground truth tend to propagate. On the other hand, the KCF tracker fails to track the hand much earlier, resulting in lesser propagation of offset errors.
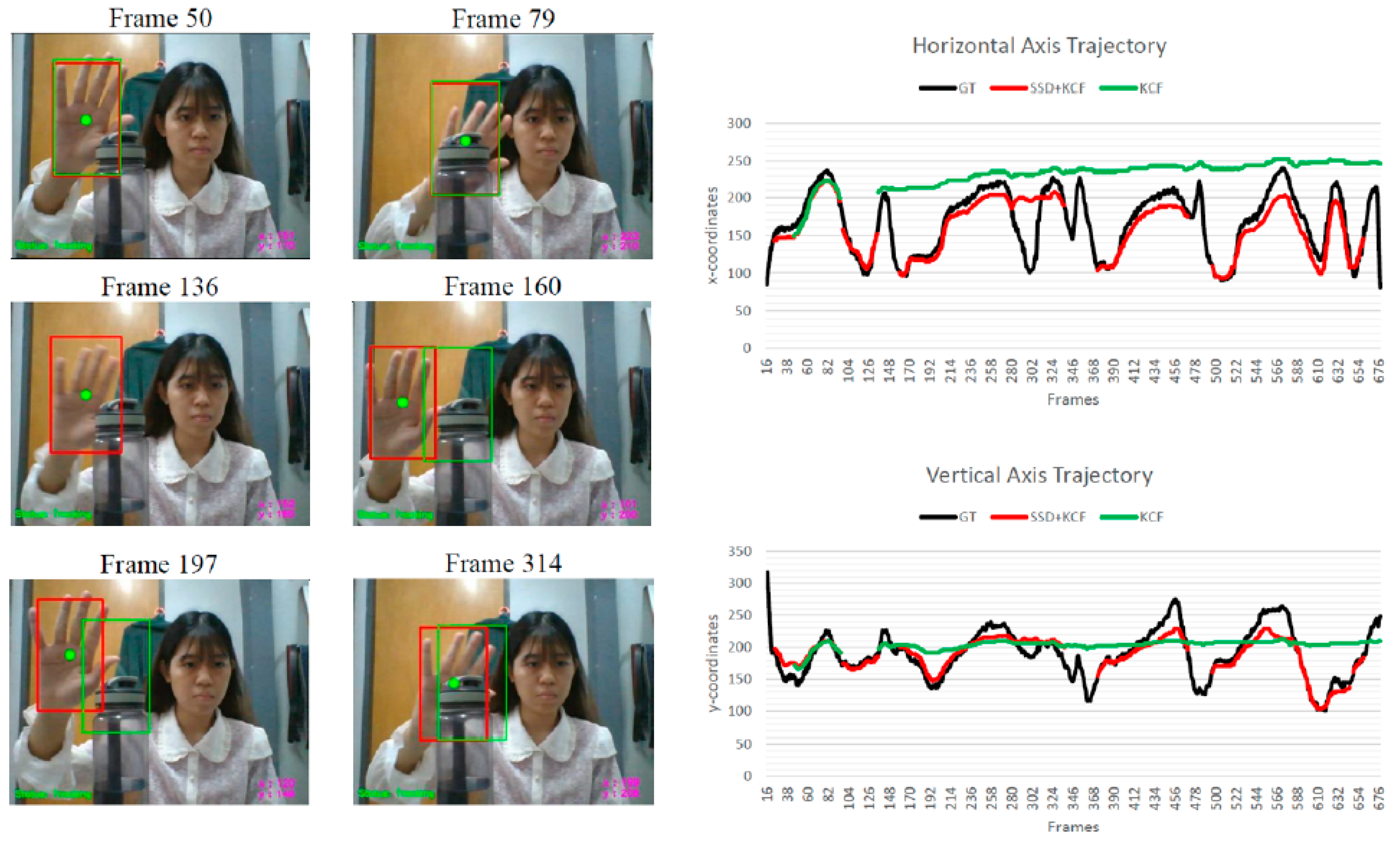
In the case of an occlusion-handling scenario, although the tracking rate of the proposed algorithm is relatively lower, its accuracy surpasses that of the KCF tracker, resulting in a lower tracking error. By examining the tracking results in
Figure 4, it becomes apparent that both the horizontal and vertical axis trajectories of the KCF tracker deviate significantly from the ground truth due to tracking failures and severe drifting issues. Despite the KCF tracker managing to track the heavily occluded hand, its bounding box drifts towards the occluded object and fails to recover even when the hand reappears in that region. In contrast, the proposed algorithm demonstrates the ability to recover from drifting issues by reinitializing the system, as illustrated in Frame 142 to Frame 160 in
Figure 4. Although tracking a heavily occluded hand remains challenging, the overall performance of the proposed tracker in handling occlusion has shown significant improvement.
In the case of outdoor conditions with exposed lighting, the proposed algorithm demonstrates significantly better performance compared to the KCF tracker. However, as shown in
Figure 5, it can be observed that the tracking bounding box of the proposed algorithm gets stuck in a region with visual characteristics similar to the skin features (Frame 155). When the hand rapidly moves away from this confusing region, the tracker loses its tracking position. Nevertheless, the proposed algorithm quickly recovers from this loss by reinitializing the tracking position with the assistance of the SSD algorithm. In contrast, the KCF tracker recovers from the tracking loss much later in the sequence when the hand approaches the previously lost location, relying on the correlation filter mechanism.
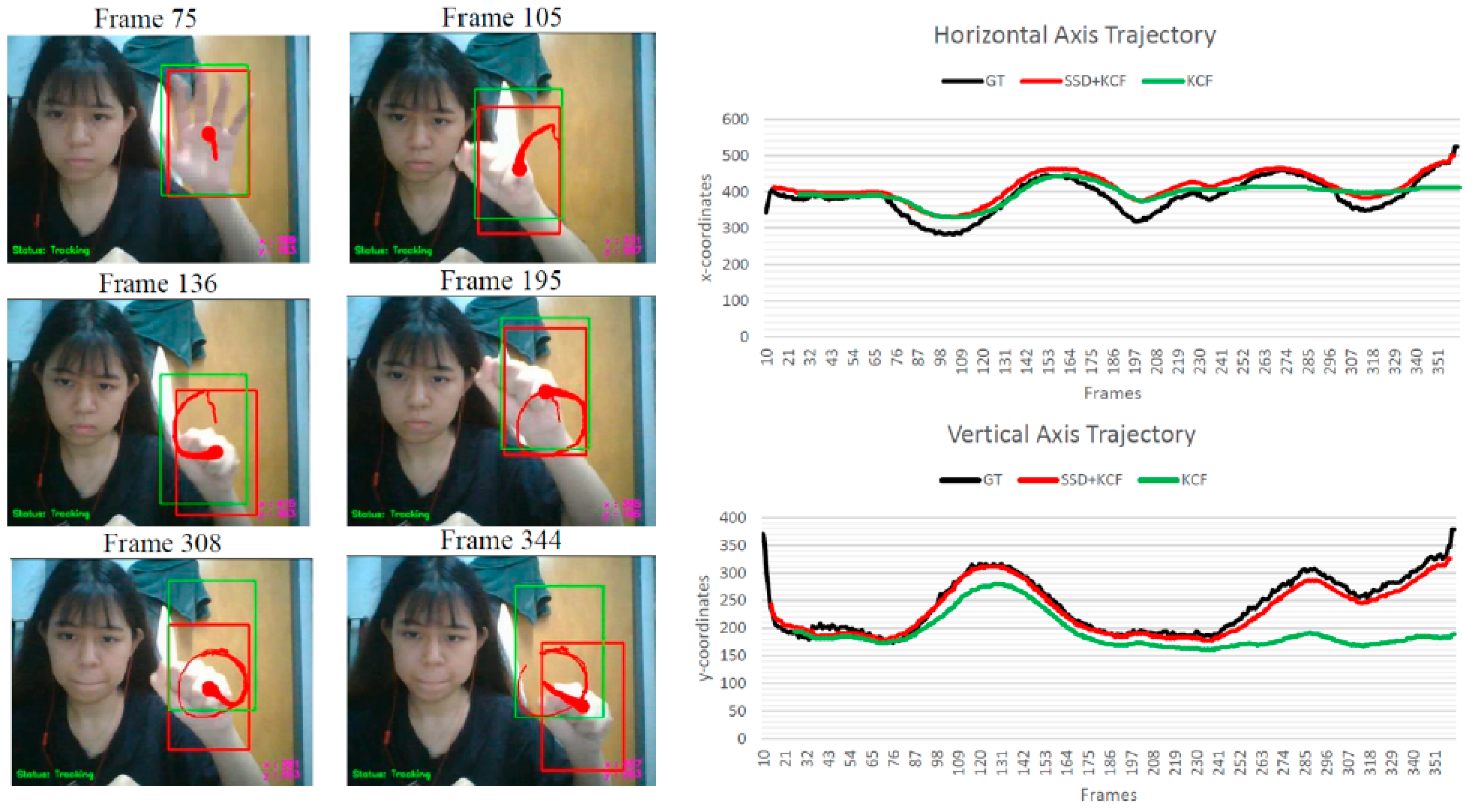
For the case of tracking deformable hand shapes while drawing gesture “Q”, the proposed algorithm outperforms the KCF tracker, achieving a higher tracking rate of 98.30% and a relatively lower tracking error of 29.1236. Although both algorithms are able to track the hand accurately with minimal failures, the KCF tracker experiences significant drifting issues, as observed in its tracking results depicted in
Figure 6 (Frame 308 and Frame 344). When the hand continuously moves downwards, the bounding box of the KCF tracker drifts and becomes stuck in the background, which shares a similar visual feature with the hand. The KCF tracker fails to recover from this issue throughout the video sequence, resulting in heavy deviations in both the horizontal and vertical axis trajectories and nearly doubling the obtained OTE value compared to the proposed algorithm. In contrast, the proposed algorithm greatly reduces the drifting issue through the error recovery framework facilitated by the integration of the SSD algorithm.
To evaluate the generalizability of the proposed approach, a comparison was made with a state-of-the-art tracker, the MediaPipe hand [
16]. For this comparison, ten video sequences from the Intelligent Biometric Group Hand Tracking (IBGHT) dataset [
34] were used. This dataset was chosen for the experiment as it provides dynamic hand trajectories along with ground truth data.
Table 4 provides detailed information about each sequence.
Table 5 presents a summary of the tracking results obtained by the proposed method and the MediaPipe hand tracker on ten trajectory-based hand gestures from the IBGHT dataset. The proposed method achieved an average target detection and tracking rate (TRDR) of 94.38% across all gestures, surpassing the performance of the MediaPipe hand tracker, which achieved 93.06%. However, it is worth noting that the MediaPipe hand tracker exhibited a lower object tracking error (OTE) with an average value of 7.59, compared to 10.59 for the proposed method. This indicates that the MediaPipe hand tracker excelled in accurately localizing the hand objects, resulting in fewer errors in object boundaries and position estimation. Despite the higher OTE, the proposed method demonstrated superior tracking speed, achieving an average frames per second (FPS) of 17.8, compared to the MediaPipe hand tracker’s 12.7 FPS. The higher TRDR achieved by the proposed method highlights its effectiveness in detecting and tracking hands in the given video sequences, even in challenging environments with cluttered backgrounds and occlusions. In conclusion, the proposed KCF + SSD method outperforms the MediaPipe hand tracker in terms of overall tracking accuracy (TRDR) and tracking speed (FPS). However, it is important to consider that the MediaPipe hand tracker excels in precise localization of hand objects, leading to lower object tracking errors (OTE). Therefore, the choice between the two methods depends on the specific requirements of the application, considering the trade-off between accuracy and speed. Further optimizations can be explored to improve the proposed method’s OTE while maintaining its superior tracking performance.
It should also be acknowledged that the proposed algorithm may encounter tracking failures, particularly when dealing with a fast-moving hand or a heavily occluded hand. Although the integrated SSD algorithm helps improve the tracking rate by reinitializing the system, it does not provide full support to the tracker during tracking. The absence of a motion-handling algorithm in the visual tracker poses challenges in accurately tracking fast-moving hands, where the target object may appear deformed or blurry to the tracker. Furthermore, the proposed algorithm has limitations in detecting and tracking small or distant hands due to the constraints of the SSD algorithm. The FPN Lite feature-extractor utilized in the SSD algorithm consists of a bottom-up pathway, top-down pathway, and lateral connections. However, the semantic values in the lowest layer of the bottom-up pathway are relatively low, resulting in poor performance when detecting small or distant hands. Additionally, the proposed system is designed to detect and track only one hand to reduce system complexity. Consequently, it may not be suitable for implementation in systems that require the detection and tracking of multiple hands, such as hand gesture recognition systems where interpreting gestures often requires the presence of a pair of hands. It is essential to consider these limitations when evaluating the applicability of the proposed algorithm in various contexts and to explore potential enhancements or alternative approaches to address these challenges effectively.
5. Conclusions
A tracking-by-detection algorithm, constructed by integrating the SSD algorithm with the KCF visual tracker, is developed to detect and track hands from color images sequences with cluttered background and exerting minimal constraints on the subject. The proposed algorithm was tested on 17 video sequences and the experimental results show that it is fast and robust for real-time applications, achieving a promising tracking rate of over 90% and overall frame rate of around 17 FPS.
Based on the hand detection analysis, it can be justified that the chosen SSD object-detection algorithm is more suitable to be employed in the proposed algorithm due to its higher frame rate and accuracy achieved, as compared to that of the Faster R-CNN algorithm. For hand tracking performance analysis, it can be concluded that the proposed algorithm is able to keep track of the hand seamlessly with a promising tracking rate and lower tracking error. Integration of the SSD algorithm has improved the KCF visual tracker in many aspects, including its long-duration tracking performance, tracking performance during occlusion, and reduced drifting tendency. However, the limitations of KCF tracker such as being unable to effectively track fast-moving hands and heavily occluded hands still remain, due to its intrinsic weakness which is that it solely relies on the single Histogram of Oriented Gradients (HOG) feature extracted during its initialization. In the future, SSD integration with different classes of visual trackers can be explored, such as implementing a Channel and Spatial Reliability Tracking (CSRT) tracker which is well-known for its higher accuracy at the cost of slower computation speed.
Although the proposed tracking-by-detection algorithms can reduce local resource computation for hand detection and tracking, the task remains challenging for researchers. Accuracy is often impacted by factors such as occlusion, fast-moving hands, and abrupt gesture changes. Integrating motion-handling features such as color can improve algorithm accuracy and reduce tracking loss. Retraining the SSD algorithm by adding new layers for fine-tuning can improve hand detection accuracy and expand the dataset with accurate images.



 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}