
SANA: Sensitivity-Aware Neural Architecture Adaptation for Uniform Quantization


Abstract
:1. Introduction
- We propose sensitivity-aware neural architecture adaptation to automatically make the original model friendly to uniform quantization. Our model is cost-friendly compared to neural architecture search (NAS) and outperformed direct uniform quantization or mixed-precision quantization.
- We formulated four initialization strategies to quicken the quantization-aware fine-tuning process.
- Our approach provides a practical and simple solution, with the W4A8 ResNet-50-SANA model achieving 77.8% accuracy, which surpassed the 77.6% accuracy of the full-precision ResNet-50 model.
2. Related Work
2.1. Post-Training Quantization
2.2. Mixed-Precision Quantization
2.3. Neural Architecture Search
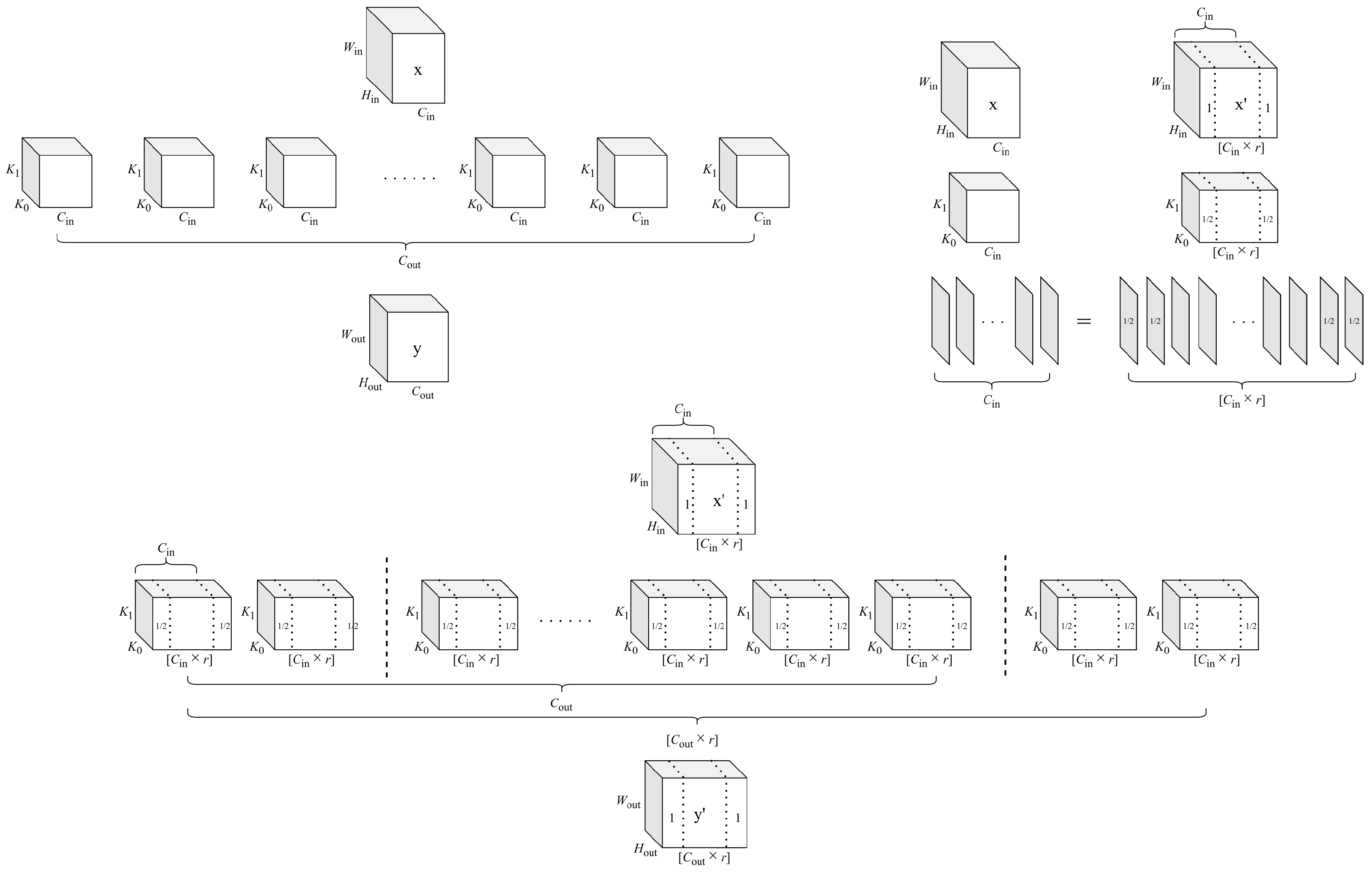
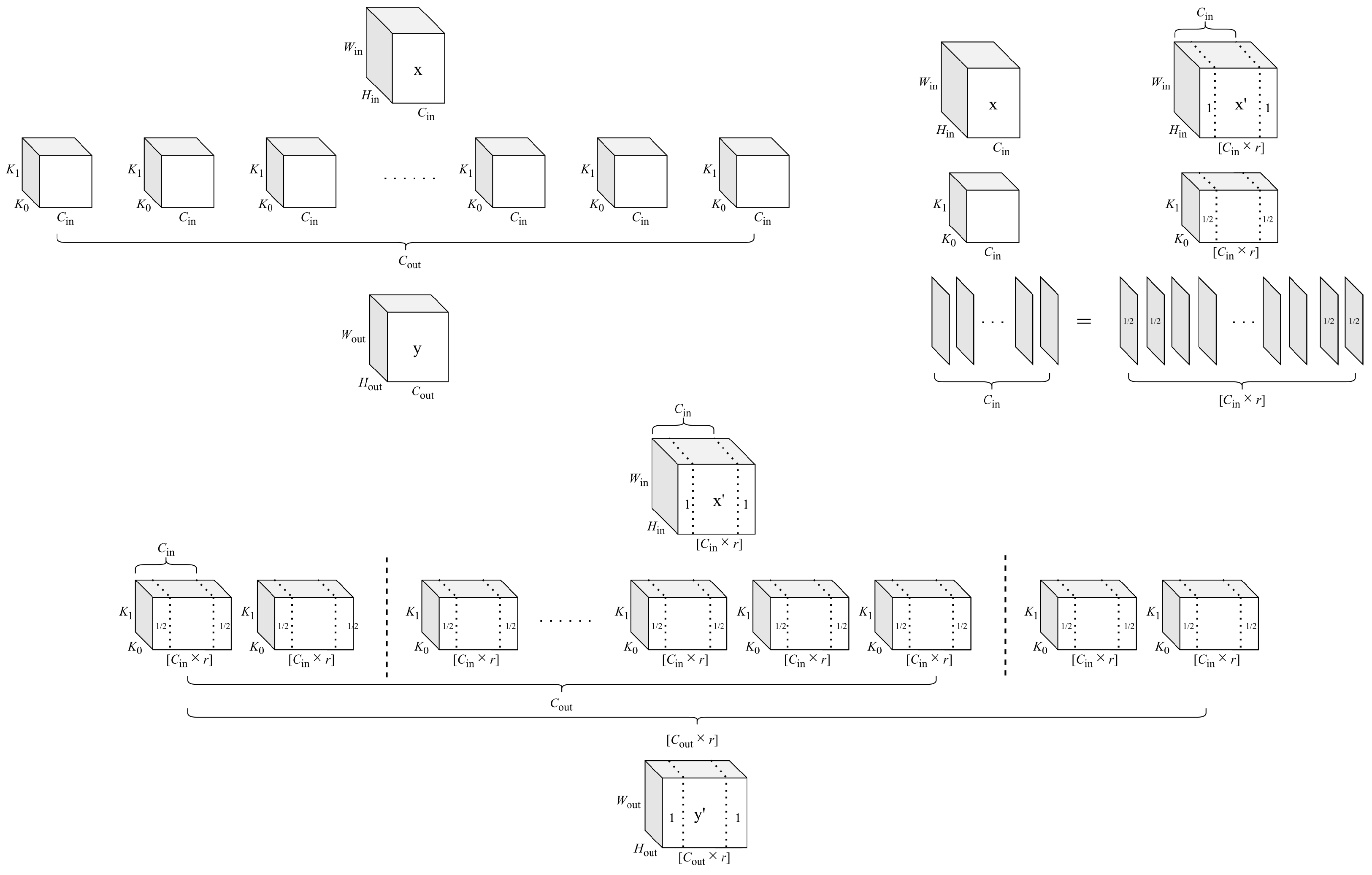
3. Methodology
3.1. Motivation
3.2. Uniform Quantization
3.3. Initialization
4. Experimental Results
4.1. Experimental Settings
4.2. Ablation Study
4.3. Results

{kind=link}
{kind=link}
| Method | Accuracy | Size (MB) | Mul | Precision |
|---|---|---|---|---|
| (a) | ||||
| Naive | 77.610 | 97.8 | 1 | FP |
| 77.318 | 24.5 | 1 | W8A8 | |
| 76.210 | 12.2 | 1 | W4A8 | |
| LQ-Net [49] | 76.400 | 12.2 | 1 | W4A32 |
| PACT [2] | 76.700 | 15.3 | 1 | W5A5 |
| 76.500 | 12.2 | 1 | W4A4 | |
| HAWQ-V3 [50] | 77.580 | 24.5 | 1 | W8A8 |
| 75.390 | 18.7 | 1 | MP4/8 | |
| SANA | 77.772 | 24.4 | 1.414 | W4A8 |
| 76.630 | 12.2 | 1.155 | W3A8 | |
| (b) | ||||
| Naive | 79.800 | 35.2 | 1 | FP |
| 78.006 | 8.8 | 1 | W8A8 | |
| 77.542 | 4.4 | 1 | W4A8 | |
| B0-HMQ [51] | 76.400 | 7.3 | 1 | W8A8 |
| B3-QN [52] | 67.800 | 5.8 | 1 | W4A8 |
| SANA | 78.120 | 8.8 | 1.414 | W4A8 |
| 74.132 | 4.4 | 1.155 | W3A8 | |
| Method | Accuracy | Size (MB) | Mul | Precision |
|---|---|---|---|---|
| ResNet-50-SANA | 76.630 | 12.2 | 1.155 | W3A8 |
| ResNet-50-SANA | 75.458 | 12.2 | 1.414 | W2A8 |
| ResNet-50-MP | 76.534 | 12.2 | 1 | MP4 |
| ResNet-50 | 76.210 | 12.2 | 1 | W4A8 |
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Gholami, A.; Kim, S.; Dong, Z.; Yao, Z.; Mahoney, M.W.; Keutzer, K. A survey of quantization methods for efficient neural network inference. arXiv 2021, arXiv:2103.13630. [Google Scholar]
- Choi, J.; Wang, Z.; Venkataramani, S.; Chuang, P.I.J.; Srinivasan, V.; Gopalakrishnan, K. Pact: Parameterized clipping activation for quantized neural networks. arXiv 2018, arXiv:1805.06085. [Google Scholar]
- Wang, K.; Liu, Z.; Lin, Y.; Lin, J.; Han, S. Haq: Hardware-aware automated quantization with mixed precision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8612–8620. [Google Scholar]
- Zhou, S.; Wu, Y.; Ni, Z.; Zhou, X.; Wen, H.; Zou, Y. Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients. arXiv 2016, arXiv:1606.06160. [Google Scholar]
- Dong, Z.; Yao, Z.; Gholami, A.; Mahoney, M.W.; Keutzer, K. Hawq: Hessian aware quantization of neural networks with mixed-precision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 293–302. [Google Scholar]
- Jeon, Y.; Lee, C.; Cho, E.; Ro, Y. Mr.BiQ: Post-Training Non-Uniform Quantization based on Minimizing the Reconstruction Error. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 12319–12328. [Google Scholar] [CrossRef]
- Nagel, M.; Fournarakis, M.; Amjad, R.A.; Bondarenko, Y.; van Baalen, M.; Blankevoort, T. A White Paper on Neural Network Quantization. arXiv 2021, arXiv:2106.08295. [Google Scholar]
- Nagel, M.; Fournarakis, M.; Bondarenko, Y.; Blankevoort, T. Overcoming Oscillations in Quantization-Aware Training. arXiv 2022, arXiv:2203.11086. [Google Scholar]
- Bai, H.; Hou, L.; Shang, L.; Jiang, X.; King, I.; Lyu, M.R. Towards Efficient Post-training Quantization of Pre-trained Language Models. arXiv 2021, arXiv:2109.15082. [Google Scholar]
- Yao, Z.; Aminabadi, R.Y.; Zhang, M.; Wu, X.; Li, C.; He, Y. ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers. arXiv 2022, arXiv:2206.01861. [Google Scholar]
- Choukroun, Y.; Kravchik, E.; Kisilev, P. Low-bit Quantization of Neural Networks for Efficient Inference. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 3009–3018. [Google Scholar]
- Banner, R.; Nahshan, Y.; Hoffer, E.; Soudry, D. Post-training 4-bit quantization of convolution networks for rapid-deployment. arXiv 2018, arXiv:1810.05723. [Google Scholar]
- Zhao, R.; Hu, Y.; Dotzel, J.; De Sa, C.; Zhang, Z. Improving neural network quantization without retraining using outlier channel splitting. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 7543–7552. [Google Scholar]
- Nagel, M.; Amjad, R.A.; van Baalen, M.; Louizos, C.; Blankevoort, T. Up or Down? Adaptive Rounding for Post-Training Quantization. arXiv 2020, arXiv:2004.10568. [Google Scholar]
- Liu, X.; He, P.; Chen, W.; Gao, J. Improving Multi-Task Deep Neural Networks via Knowledge Distillation for Natural Language Understanding. arXiv 2019, arXiv:1904.09482. [Google Scholar]
- Cai, Y.; Yao, Z.; Dong, Z.; Gholami, A.; Mahoney, M.W.; Keutzer, K. ZeroQ: A Novel Zero Shot Quantization Framework. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 13166–13175. [Google Scholar]
- Liu, Y.; Zhang, W.; Wang, J. Zero-shot Adversarial Quantization. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 1512–1521. [Google Scholar]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.G.; Adam, H.; Kalenichenko, D. Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2704–2713. [Google Scholar]
- Zhou, Y.; Moosavi-Dezfooli, S.M.; Cheung, N.M.; Frossard, P. Adaptive quantization for deep neural network. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Yao, Z.; Dong, Z.; Zheng, Z.; Gholami, A.; Yu, J.; Tan, E.; Wang, L.; Huang, Q.; Wang, Y.; Mahoney, M.; et al. Hawq-v3: Dyadic neural network quantization. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 18–24 July 2021; pp. 11875–11886. [Google Scholar]
- Hubara, I.; Nahshan, Y.; Hanani, Y.; Banner, R.; Soudry, D. Improving post training neural quantization: Layer-wise calibration and integer programming. arXiv 2020, arXiv:2006.10518. [Google Scholar]
- Wang, K.; Liu, Z.; Lin, Y.; Lin, J.; Han, S. Hardware-centric autoML for mixed-precision quantization. Int. J. Comput. Vis. 2020, 128, 2035–2048. [Google Scholar] [CrossRef]
- Yang, H.; Duan, L.; Chen, Y.; Li, H. BSQ: Exploring Bit-Level Sparsity for Mixed-Precision Neural Network Quantization. arXiv 2021, arXiv:2102.10462. [Google Scholar]
- Wu, B.; Wang, Y.; Zhang, P.; Tian, Y.; Vajda, P.; Keutzer, K. Mixed precision quantization of convnets via differentiable neural architecture search. arXiv 2018, arXiv:1812.00090. [Google Scholar]
- Liu, H.; Simonyan, K.; Yang, Y. Darts: Differentiable architecture search. arXiv 2018, arXiv:1806.09055. [Google Scholar]
- Dong, Z.; Yao, Z.; Arfeen, D.; Gholami, A.; Mahoney, M.W.; Keutzer, K. HAWQ-V2: Hessian Aware trace-Weighted Quantization of Neural Networks. Adv. Neural Inf. Process. Syst. 2020, 33, 18518–18529. [Google Scholar]
- Feurer, M.; Klein, A.; Eggensperger, K.; Springenberg, J.T.; Blum, M.; Hutter, F. Efficient and Robust Automated Machine Learning. In Proceedings of the NIPS, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Ren, P.; Xiao, Y.; Chang, X.; Huang, P.y.; Li, Z.; Chen, X.; Wang, X. A Comprehensive Survey of Neural Architecture Search: Challenges and Solutions. ACM Comput. Surv. 2021, 54, 76. [Google Scholar] [CrossRef]
- Liu, S.; Zhang, H.; Jin, Y. A Survey on Computationally Efficient Neural Architecture Search. arXiv 2022, arXiv:2206.01520. [Google Scholar] [CrossRef]
- Elsken, T.; Metzen, J.H.; Hutter, F. Neural Architecture Search: A Survey. arXiv 2019, arXiv:1808.05377. [Google Scholar]
- Zoph, B.; Le, Q.V. Neural Architecture Search with Reinforcement Learning. arXiv 2017, arXiv:1611.01578. [Google Scholar]
- Real, E.; Moore, S.; Selle, A.; Saxena, S.; Suematsu, Y.L.; Tan, J.; Le, Q.; Kurakin, A. Large-Scale Evolution of Image Classifiers. arXiv 2017, arXiv:1703.01041. [Google Scholar]
- Jin, Q.; Yang, L.; Liao, Z.A. AdaBits: Neural Network Quantization With Adaptive Bit-Widths. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2143–2153. [Google Scholar]
- Cai, H.; Gan, C.; Han, S. Once for All: Train One Network and Specialize it for Efficient Deployment. arXiv 2020, arXiv:1908.09791. [Google Scholar]
- Gong, C.; Jiang, Z.; Wang, D.; Lin, Y.; Liu, Q.; Pan, D.Z. Mixed Precision Neural Architecture Search for Energy Efficient Deep Learning. In Proceedings of the 2019 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Westminster, CO, USA, 4–7 November 2019; pp. 1–7. [Google Scholar]
- Wang, T.; Wang, K.; Cai, H.; Lin, J.; Liu, Z.; Han, S. APQ: Joint Search for Network Architecture, Pruning and Quantization Policy. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2075–2084. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Zhao, R.; Hu, Y.; Dotzel, J.; Sa, C.D.; Zhang, Z. Improving Neural Network Quantization without Retraining using Outlier Channel Splitting. arXiv 2019, arXiv:1901.09504. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the AAAI, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.S.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Wightman, R. PyTorch Image Models. 2019. Available online: https://github.com/rwightman/pytorch-image-models (accessed on 15 August 2021).
- Wightman, R.; Touvron, H.; J’egou, H. ResNet strikes back: An improved training procedure in timm. arXiv 2021, arXiv:2110.00476. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Mané, D.; Vasudevan, V.; Le, Q.V. AutoAugment: Learning Augmentation Policies from Data. arXiv 2018, arXiv:1805.09501. [Google Scholar]
- Zhang, H.; Cissé, M.; Dauphin, Y.; Lopez-Paz, D. mixup: Beyond Empirical Risk Minimization. arXiv 2018, arXiv:1710.09412. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y.J. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27–28 October 2019; pp. 6022–6031. [Google Scholar]
- Graves, A. Generating Sequences With Recurrent Neural Networks. arXiv 2013, arXiv:1308.0850. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random Erasing Data Augmentation. In Proceedings of the AAAI, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Choukroun, Y.; Kravchik, E.; Yang, F.; Kisilev, P. Low-bit Quantization of Neural Networks for Efficient Inference. arXiv 2019, arXiv:1902.06822. [Google Scholar]
- Zhang, D.; Yang, J.; Ye, D.; Hua, G. LQ-Nets: Learned Quantization for Highly Accurate and Compact Deep Neural Networks. arXiv 2018, arXiv:1807.10029. [Google Scholar]
- Yao, Z.; Dong, Z.; Zheng, Z.; Gholami, A.; Yu, J.; Tan, E.; Wang, L.; Huang, Q.; Wang, Y.; Mahoney, M.W.; et al. HAWQV3: Dyadic Neural Network Quantization. arXiv 2021, arXiv:2011.10680. [Google Scholar]
- Habi, H.V.; Jennings, R.H.; Netzer, A. HMQ: Hardware Friendly Mixed Precision Quantization Block for CNNs. arXiv 2020, arXiv:2007.09952. [Google Scholar]
- Fan, A.; Stock, P.; Graham, B.; Grave, E.; Gribonval, R.; Jegou, H.; Joulin, A. Training with Quantization Noise for Extreme Model Compression. arXiv 2021, arXiv:2004.07320. [Google Scholar]

| Method | Precision | Mul | Size (MB) | Accuracy | Target | |||
|---|---|---|---|---|---|---|---|---|
| Halving | Zero Padding | Averaging | Small Int | |||||
| ResNet-50-SANA | W3A8 | 1.155 | 12.2 | 76.630 | 76.942 | 76.834 | 76.622 | 76.210 |
| EfficientNet-B2-SANA | W3A8 | 1.155 | 4.4 | 74.132 | 74.162 | 73.714 | 74.006 | 77.542 |
| EfficientNet-B2-SANA | W4A8 | 1.414 | 8.8 | 78.120 | 77.974 | 78.058 | 78.226 | 78.006 |
| Method | Accuracy | Size (MB) | Multiplier | Precision |
|---|---|---|---|---|
| Expanded-ResNet50 | 78.460 | 195.6 | 1.414 | FP |
| SANA | 77.984 | 24.4 | 1.414-layerwise | W4A8 |
| SANA | 77.772 | 24.4 | 1.414 | W4A8 |
| Mixed-Precision | 77.600 | 24.4 | 1.414 | MP4A8 |
| Expanded-ResNet50 | 79.346 | 130.5 | 1.155 | FP |
| SANA | 76.630 | 12.2 | 1.155 | W3A8 |
| ResNet50 | 77.610 | 97.8 | 1 | FP |
| Naive-Q | 77.318 | 24.4 | 1 | W8A8 |
| Mixed-Precision | 76.534 | 12.2 | 1 | MP4A8 |
| Naive-Q | 76.210 | 12.2 | 1 | W4A8 |
| Shrunk-ResNet50 | 74.710 | 48.9 | 0.707 | FP |
| Naive-Q | 74.860 | 12.2 | 0.707 | W8A8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, M.; Dong, Z.; Keutzer, K. SANA: Sensitivity-Aware Neural Architecture Adaptation for Uniform Quantization. Appl. Sci. 2023, 13, 10329. https://doi.org/10.3390/app131810329
Guo M, Dong Z, Keutzer K. SANA: Sensitivity-Aware Neural Architecture Adaptation for Uniform Quantization. Applied Sciences. 2023; 13(18):10329. https://doi.org/10.3390/app131810329
Chicago/Turabian StyleGuo, Mingfei, Zhen Dong, and Kurt Keutzer. 2023. "SANA: Sensitivity-Aware Neural Architecture Adaptation for Uniform Quantization" Applied Sciences 13, no. 18: 10329. https://doi.org/10.3390/app131810329
APA StyleGuo, M., Dong, Z., & Keutzer, K. (2023). SANA: Sensitivity-Aware Neural Architecture Adaptation for Uniform Quantization. Applied Sciences, 13(18), 10329. https://doi.org/10.3390/app131810329