
A Decision-Fusion-Based Ensemble Approach for Malicious Websites Detection


Abstract
:1. Introduction
- Improving the accuracy of malicious website detection by exploiting the diversity of boosting (i.e., GB and XGB) and bagging (i.e., RF) techniques. In boosting, the approach can create sequential models by combining weak learners into strong learners, where the final model has the highest accuracy. Furthermore, in bagging, the approach can create different training subsets from a sample training set using replacement and the output of the final model is based on the majority voting.
- Reducing the class-imbalanced and over-fitting problems in malicious website classification due to the regularization ability of GB, XGB, and RF classifiers.
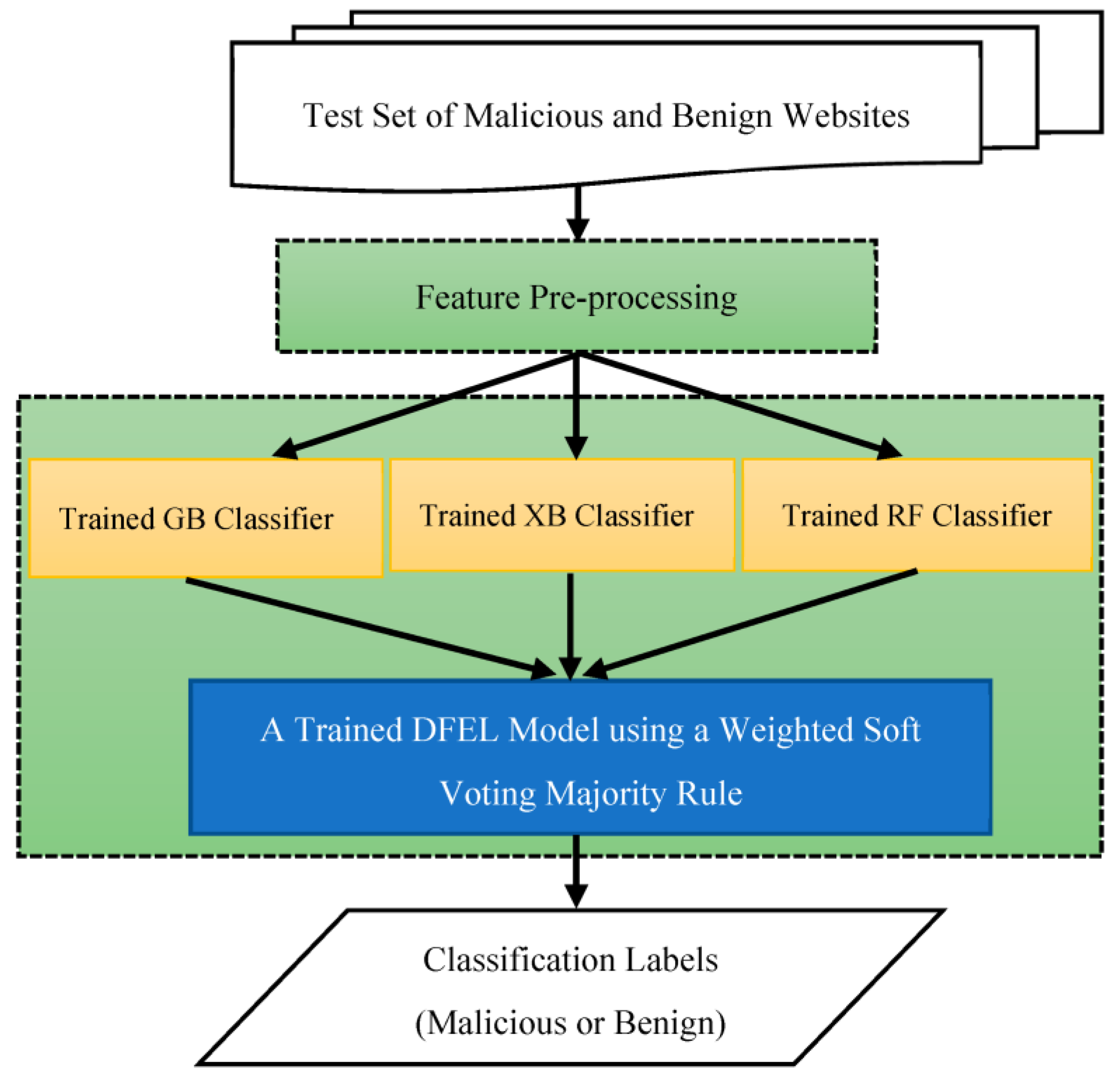
- Proposing a weighted soft voting rule to fuse the final classification scores utilizing the competence of well-calibrated and diverse classifiers such as the base classifiers in the approach. Furthermore, evaluating and comparing the accuracy of the proposed DFEL model with its base classifiers and some recent related work.
2. Related Work
3. Materials and Methods
3.1. Benchmark Dataset of Study
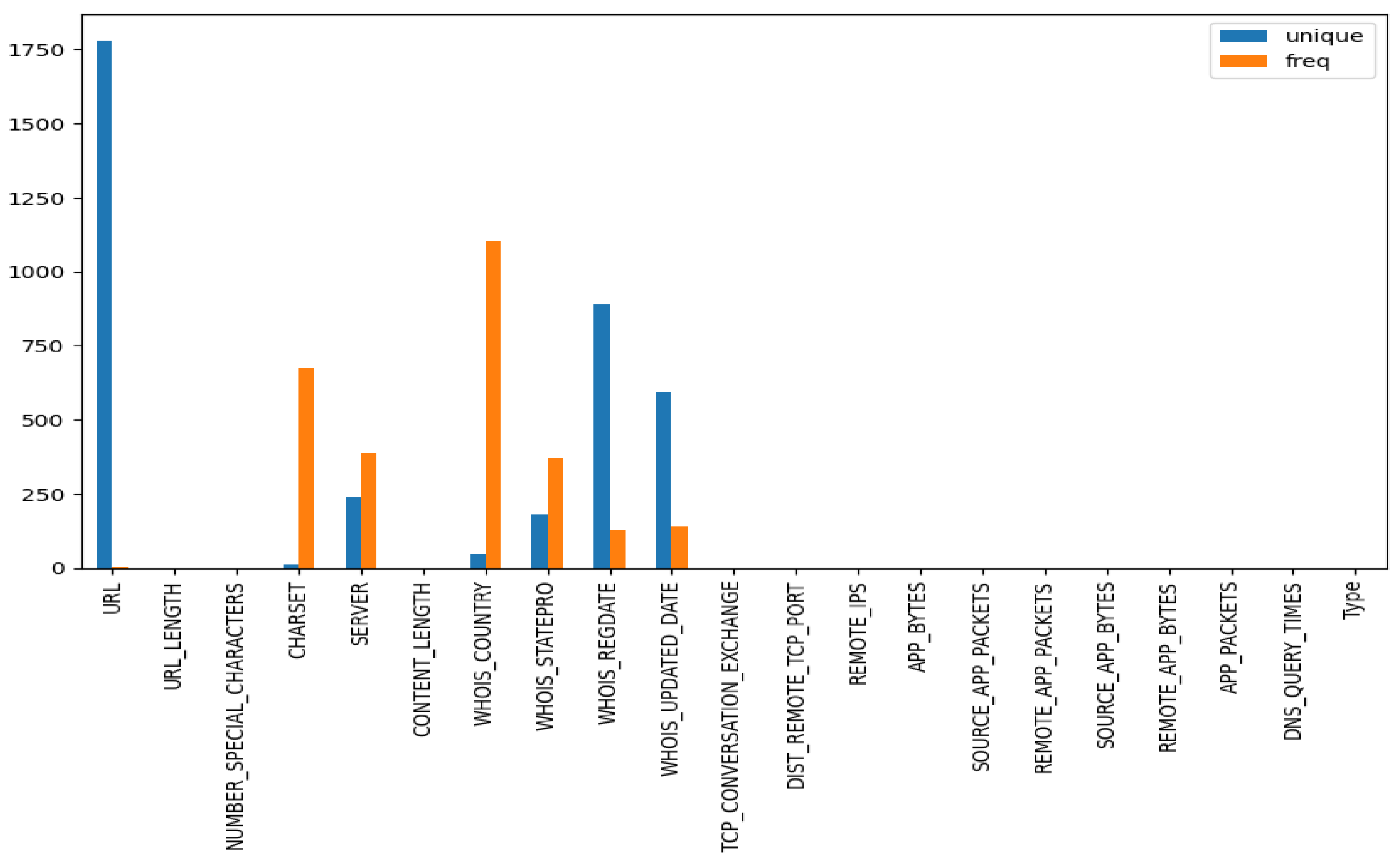
- The URL is a unique identification of the Uniform Resource Locators (URLs), analyzed in the collected dataset.
- The ‘URL_LENGTH’ is the number of characters in the URL.
- The ‘NUMBER_SPECIAL_CHARACTERS’ is the number of special characters in the URL.
- The ‘CHARSET’ is a character set that has a categorical value that represents the character encoding standard.
- The ‘SERVER’ is a categorical value that represents the server operative system extracted from the packet response.
- The ‘CONTENT_LENGTH’ is the HTTP header content size.
- The ‘WHOIS_COUNTRY’ indicates the country in which the website server is situated.
- The ‘WHOIS_STATEPRO’ represents the location at which the website is registered.
- The ‘WHOIS_REGDATE’ is the registration date of the website server.
- The ‘WHOIS_UPDATED_DATE’ is the date of the last update to the website server.
- The ‘TCP_CONVERSATION_EXCHANGE’ counts the number of packets between the honeypot and website using the TCP protocol.
- The ‘DIST_REMOTE_TCP_PORT’ is the total number of ports, rather than those exposed in TCP.
- The ‘REMOTE_IPS’ is the total number of Internet Protocols (IPs) in the connection of the honeypots.
- The ‘APP_BYTES’ is the number of transferred bytes.
- The ‘SOURCE_APP_PACKETS’ is the number of packets that were directed from the honeypot to the server.
- The ‘REMOTE_APP_PACKETS’ is the number of packets that arrived from the server.
- The ‘SOURCE_APP_BYTES’ is the number of bytes that were directed from the honeypot to the server.
- The ‘REMOTE_APP_BYTES’ is the number of bytes that arrived from the server.
- The ‘APP_PACKETS’ is the total number of IP packets produced through the communication between honeypot and server.
- The ‘DNS_QUERY_TIMES’ is the number of DNS packets produced through the communication between honeypot and server.
- The ‘Type’ is a categorical variable that represents the class name of the analyzed website; specifically, 0 denotes a benign website and 1 a malicious website.
3.2. Methodology of Proposed Approach
3.2.1. Gradient-Boosting (GB) Classifier Method
| Algorithm 1. Building GB classifier |
| Input: A training dataset with T is the number of random trees using distribution . Output: The final decision tree (GB classifier). Begin
|
3.2.2. Extreme Gradient-Boosting (XGB) Classifier Method
| Algorithm 2. Building XGB classifier model. |
| Input: is a training samples; is a maximum number of iterations; max-depth; regularization coefficients, and other parameters. Output: strong learner ; |
Begin
|
3.2.3. Random Forest (RF) Classifier Method
| Algorithm 3. Building RF classifier model. |
| Input: A training dataset with ; T is the number of decision trees using distribution . Output: The final decision tree (). |
Begin
|
3.3. Proposed Approach
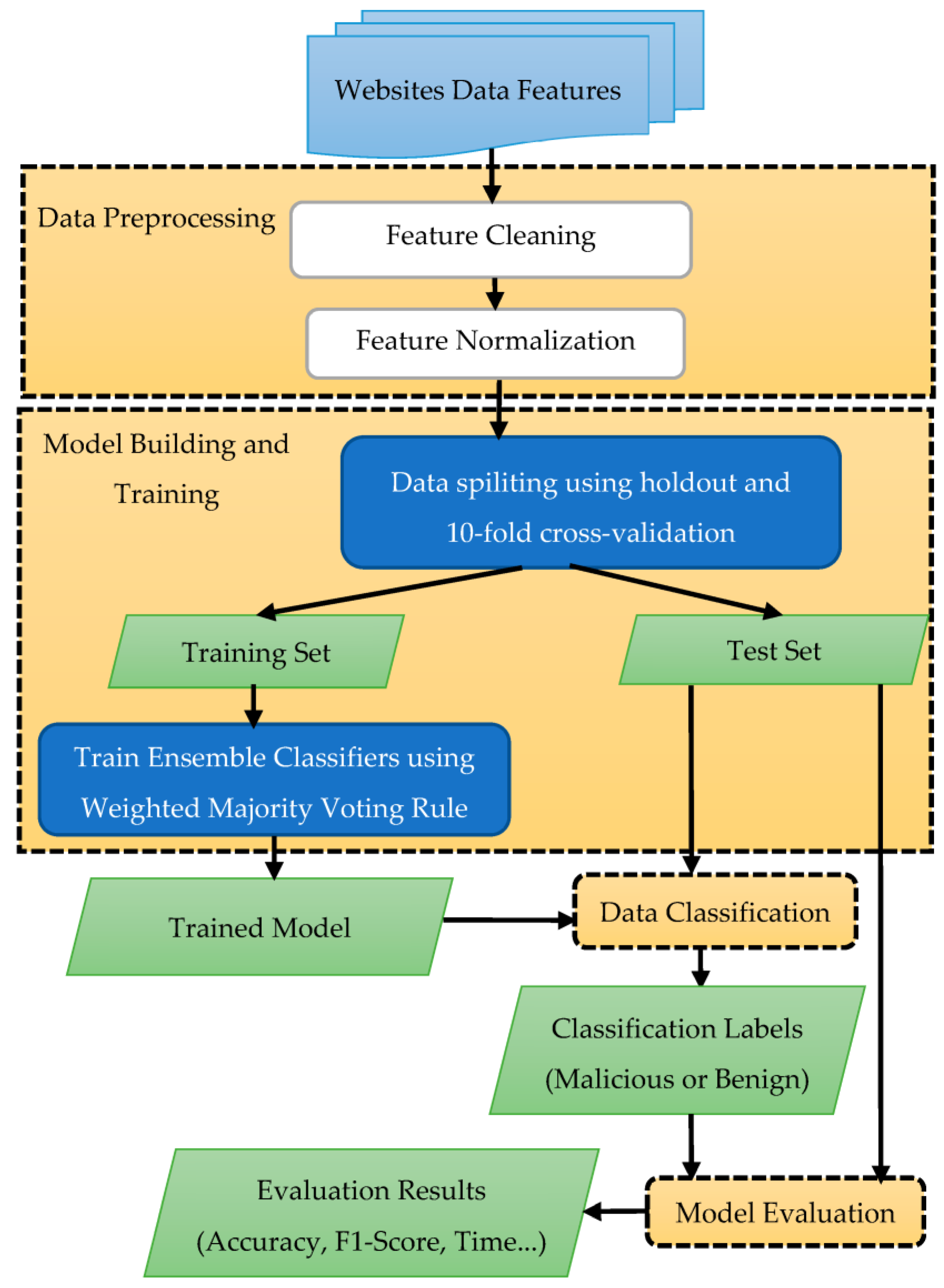
3.3.1. Data Pre-Processing
| Algorithm 4. Data pre-processing | |
| Begin | |
| 1. | %This loop is for initialization with zeros |
| 2. | |
| 3. | |
| 4. | |
| 5. | %This loop is for removing the unique features |
| 6. | |
| 7. | Remove ; |
| 8. | |
| 9. | % Encode categorical feature values to numbers |
| 10. | |
| 11. | Encode using the label encoding method; |
| 12. | |
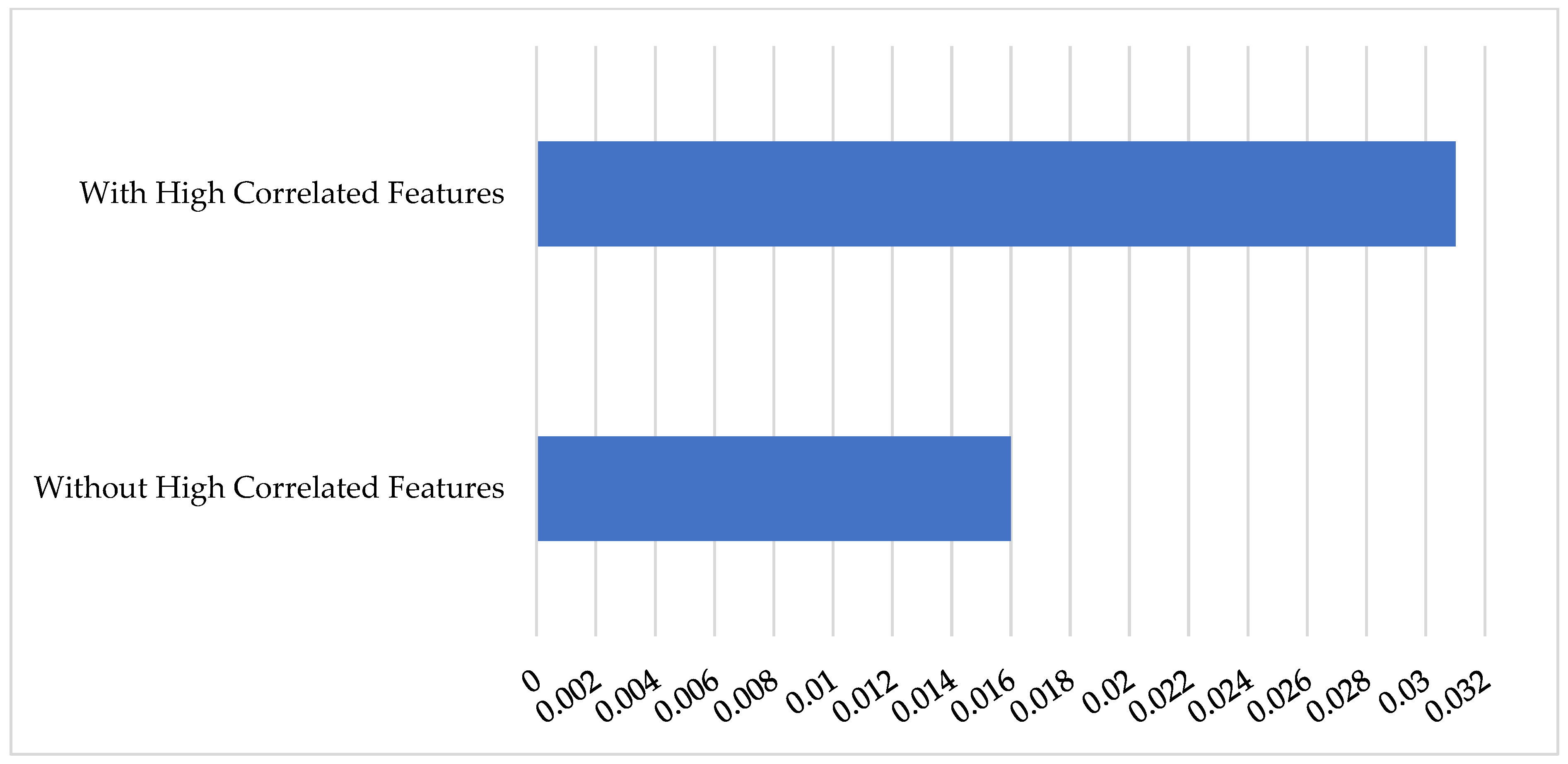
| 13. | % Remove highly correlated features |
| 14. | |
| 15. | |
| 16. | Return and |
| End | |
3.3.2. Model Building and Training
3.3.3. Data Classification
3.3.4. Model Evaluation
4. Experiments and Results
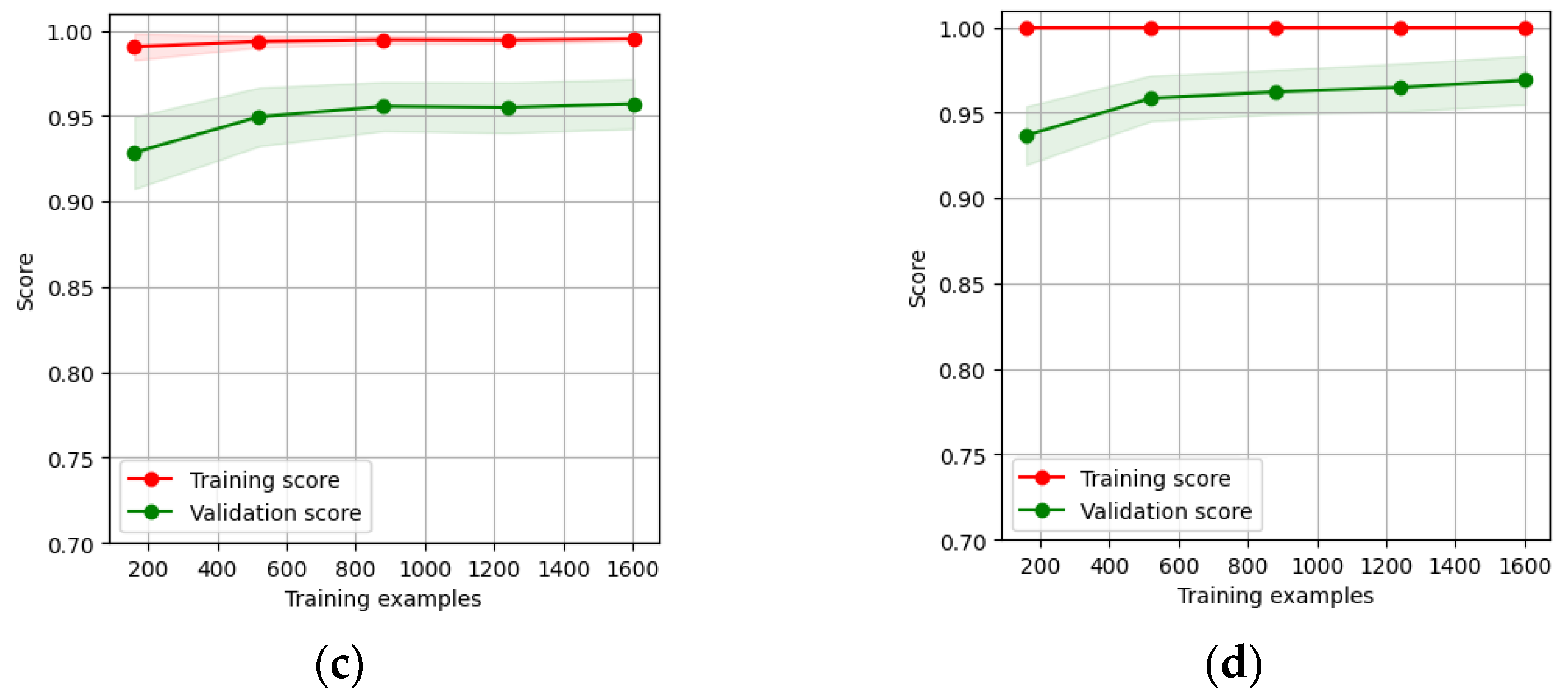
4.1. Results of First Experiment
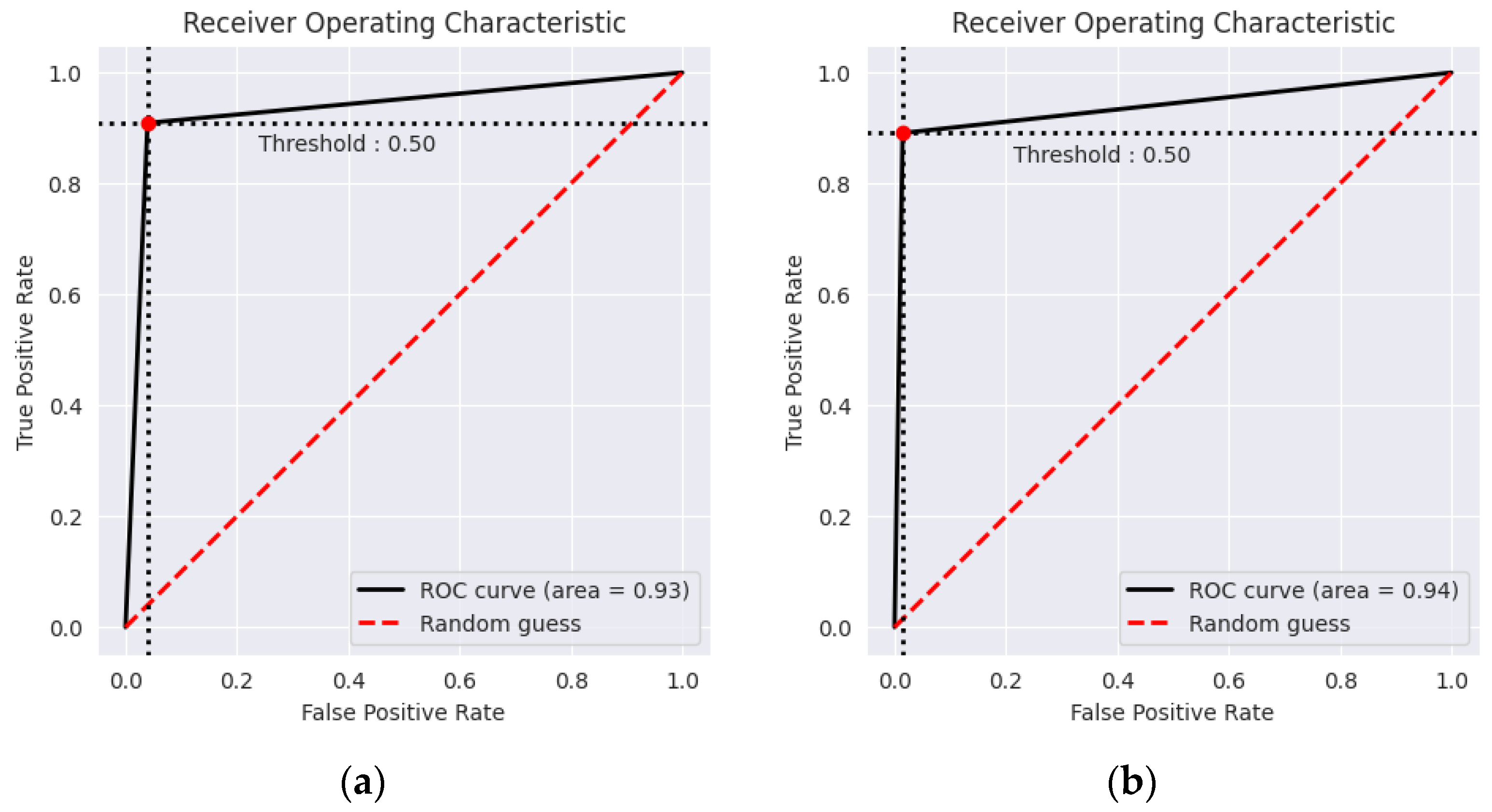
4.1.1. Evaluation Method 1
4.1.2. Evaluation Method 2
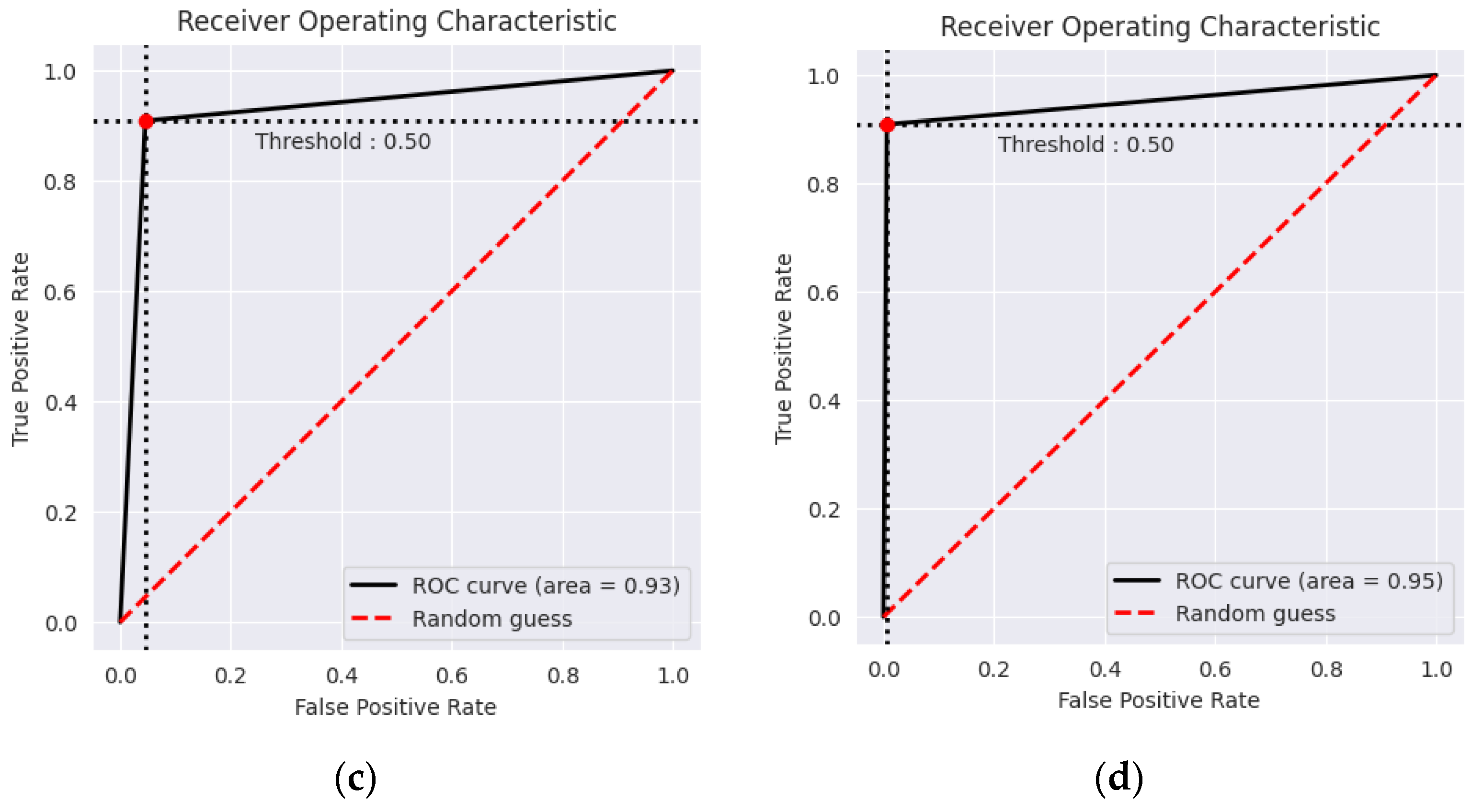
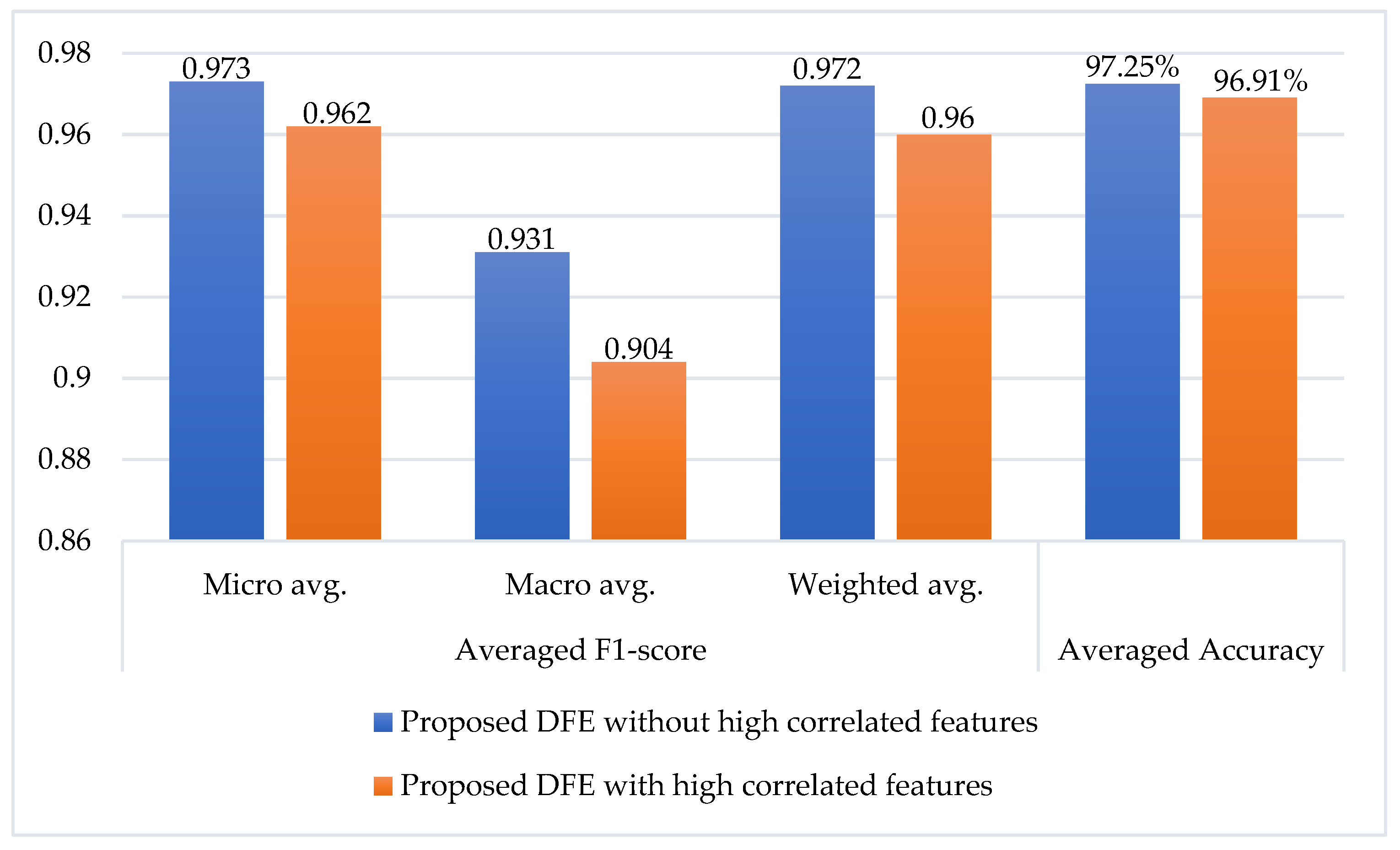
4.2. Results of Second Experiment
4.3. Comparison of Results with Related Work
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Catal, C.; Ozcan, A.; Donmez, E.; Kasif, A. Analysis of cyber security knowledge gaps based on cyber security body of knowledge. Educ. Inf. Technol. 2023, 28, 1809–1831. [Google Scholar] [CrossRef] [PubMed]
- Gopal, B.; Kuppusamy, P. A comparative study on 4G and 5G technology for wireless applications. IOSR J. Electron. Commun. Eng. 2015, 10, 2278–2834. [Google Scholar]
- Bensberg, F.; Buscher, G.; Czarnecki, C. Digital Transformation and IT Topics in the Consulting Industry: A Labor Market Perspective. In Advances in Consulting Research: Recent Findings Practical Cases; Springer: Berlin/Heidelberg, Germany, 2019; pp. 341–357. [Google Scholar]
- Bayarçelik, E.B.; Bumin Doyduk, H.B. Digitalization of Business Logistics Activities and Future Directions. In Digital Business Strategies in Blockchain Ecosystems: Transformational Design Future of Global Business; Springer: Berlin/Heidelberg, Germany, 2020; pp. 201–238. [Google Scholar]
- Jiang, Y.; Wu, S.; Yang, H.; Luo, H.; Chen, Z.; Yin, S.; Kaynak, O. Secure data transmission and trustworthiness judgement approaches against cyber-physical attacks in an integrated data-driven framework. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 7799–7809. [Google Scholar] [CrossRef]
- Mishra, S.; Gochhait, S. Emerging Cybersecurity Attacks in the Era of Digital Transformation. In Proceedings of the 2023 7th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 17–19 May 2023; pp. 1442–1447. [Google Scholar]
- Desolda, G.; Ferro, L.S.; Marrella, A.; Catarci, T.; Costabile, M.F. Human factors in phishing attacks: A systematic literature review. ACM Comput. Surv. 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Rupa, C.; Srivastava, G.; Bhattacharya, S.; Reddy, P.; Gadekallu, T.R. A Machine Learning Driven Threat Intelligence System for Malicious URL Detection. In Proceedings of the 16th International Conference on Availability, Reliability and Security, Vienna, Austria, 17–20 August 2021; pp. 1–7. [Google Scholar]
- Aksu, D.; Turgut, Z.; Üstebay, S.; Aydin, M.A. Phishing Analysis of Websites using Classification Techniques. In Proceedings of the International Telecommunications Conference, Istanbul, Turkey, 28–29 December 2017; pp. 251–258. [Google Scholar]
- Vanhoenshoven, F.; Nápoles, G.; Falcon, R.; Vanhoof, K.; Köppen, M. Detecting Malicious URLs using Machine Learning Techniques. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016; pp. 1–8. [Google Scholar]
- Vanitha, N.; Vinodhini, V. Malicious-URL detection using logistic regression technique. Int. J. Eng. Manag. Res. 2019, 9, 108–113. [Google Scholar]
- Kaddoura, S. Classification of Malicious and Benign Websites by Network Features using Supervised Machine Learning Algorithms. In Proceedings of the 2021 5th Cyber Security in Networking Conference (CSNet), Abu Dhabi, United Arab Emirates, 12–14 October 2021; pp. 36–40. [Google Scholar]
- Odeh, A.; Keshta, I.; Abdelfattah, E. Machine Learningtechniquesfor Detection of Website Phishing: A Review for Promises and Challenges. In Proceedings of the 2021 IEEE 11th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 27–30 January 2021; pp. 0813–0818. [Google Scholar]
- Vijh, M.; Chandola, D.; Tikkiwal, V.A.; Kumar, A. Stock closing price prediction using machine learning techniques. Procedia Comput. Sci. 2020, 167, 599–606. [Google Scholar] [CrossRef]
- Singh, N.; Chaturvedi, S.; Akhter, S. Weather Forecasting using Machine Learning Algorithm. In Proceedings of the 2019 International Conference on Signal Processing and Communication (ICSC), Noida, India, 7–9 March 2019; pp. 171–174. [Google Scholar]
- Chaganti, S.Y.; Nanda, I.; Pandi, K.R.; Prudhvith, T.G.; Kumar, N. Image Classification using SVM and CNN. In Proceedings of the 2020 International Conference on Computer Science, Engineering and Applications (ICCSEA), Gunupur, India, 13–14 March 2020; pp. 1–5. [Google Scholar]
- Zendehboudi, A.; Baseer, M.A.; Saidur, R. Application of support vector machine models for forecasting solar and wind energy resources: A review. J. Clean. Prod. 2018, 199, 272–285. [Google Scholar] [CrossRef]
- Abu Alfeilat, H.A.; Hassanat, A.B.; Lasassmeh, O.; Tarawneh, A.S.; Alhasanat, M.B.; Eyal Salman, H.S.; Prasath, V.S. Effects of distance measure choice on k-nearest neighbor classifier performance: A review. Big Data 2019, 7, 221–248. [Google Scholar] [CrossRef] [PubMed]
- Charbuty, B.; Abdulazeez, A. Classification based on decision tree algorithm for machine learning. J. Appl. Sci. Technol. Trends 2021, 2, 20–28. [Google Scholar] [CrossRef]
- Halimaa, A.; Sundarakantham, K. Machine Learning Based Intrusion Detection System. In Proceedings of the 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 23–25 April 2019; pp. 916–920. [Google Scholar]
- Christodoulou, E.; Ma, J.; Collins, G.S.; Steyerberg, E.W.; Verbakel, J.Y.; Van Calster, B. A systematic review shows no performance benefit of machine learning over logistic regression for clinical prediction models. J. Clin. Epidemiol. 2019, 110, 12–22. [Google Scholar] [CrossRef]
- Hossin, M.; Sulaiman, M.N. A review on evaluation metrics for data classification evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1–11. [Google Scholar]
- Kaur, H.; Pannu, H.S.; Malhi, A.K. A systematic review on imbalanced data challenges in machine learning: Applications and solutions. ACM Comput. Surv. 2019, 52, 1–36. [Google Scholar] [CrossRef]
- Fernández, A.; García, S.; Galar, M.; Prati, R.C.; Krawczyk, B.; Herrera, F. Learning from Imbalanced Data Sets; Springer: Berlin/Heidelberg, Germany, 2018; Volume 10. [Google Scholar]
- Ul Hassan, I.; Ali, R.H.; Ul Abideen, Z.; Khan, T.A.; Kouatly, R. Significance of machine learning for detection of malicious websites on an unbalanced dataset. Digital 2022, 2, 501–519. [Google Scholar] [CrossRef]
- Brandt, J.; Lanzén, E. A Comparative Review of SMOTE and ADASYN in Imbalanced Data Classification; Uppsala Universitet, Statistiska Institutionen: Uppsala, Sweden, 2021. [Google Scholar]
- Teslenko, D.; Sorokina, A.; Khovrat, A.; Huliiev, N.; Kyriy, V. Comparison of Dataset Oversampling Algorithms and Their Applicability to the Categorization Problem. In Innovative Technologies Scientific Solutions for Industries; Kharkiv National University of Radioelectronics: Kharkiv, Ukraine, 2023; pp. 161–171. [Google Scholar]
- Singhal, S.; Chawla, U.; Shorey, R. Machine Learning & Concept Drift Based Approach for Malicious Website Detection. In Proceedings of the 2020 International Conference on COMmunication Systems & NETworkS (COMSNETS), Bengaluru, India, 7–11 January 2020; pp. 582–585. [Google Scholar]
- Amrutkar, C.; Kim, Y.S.; Traynor, P. Detecting mobile malicious webpages in real time. IEEE Trans. Mob. Comput. 2016, 16, 2184–2197. [Google Scholar] [CrossRef]
- McGahagan, J.; Bhansali, D.; Gratian, M.; Cukier, M. A Comprehensive Evaluation of HTTP Header Features for Detecting Malicious Websites. In Proceedings of the 2019 15th European Dependable Computing Conference (EDCC), Naples, Italy, 17–20 September 2019; pp. 75–82. [Google Scholar]
- Patil, D.R.; Patil, J.B. Malicious URLs detection using decision tree classifiers and majority voting technique. Cybern. Inf. Technol. 2018, 18, 11–29. [Google Scholar] [CrossRef]
- Al-Milli, N.; Hammo, B.H. A Convolutional Neural Network Model to Detect Illegitimate URLs. In Proceedings of the 2020 11th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 7–9 April 2020; pp. 220–225. [Google Scholar]
- Jayakanthan, N.; Ramani, A.; Ravichandran, M. Two phase classification model to detect malicious URLs. Int. J. Appl. Eng. Res. 2017, 12, 1893–1898. [Google Scholar]
- Assefa, A.; Katarya, R. Intelligent Phishing Website Detection using Deep Learning. In Proceedings of the 2022 8th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 25–26 March 2022; pp. 1741–1745. [Google Scholar]
- Sandag, G.A.; Leopold, J.; Ong, V.F. Klasifikasi Malicious Websites Menggunakan Algoritma K-NN Berdasarkan Application Layers dan Network Characteristics. CogITo Smart J. 2018, 4, 37–45. [Google Scholar] [CrossRef]
- Alkhudair, F.; Alassaf, M.; Khan, R.U.; Alfarraj, S. Detecting Malicious URL. In Proceedings of the 2020 International Conference on Computing and Information Technology (ICCIT-1441), Tabuk, Saudi Arabia, 9–10 September 2020; pp. 1–5. [Google Scholar]
- Panischev, O.Y.; Ahmedshina, E.N.; Kataseva, D.V.; Katasev, A.; Akhmetvaleev, A. Creation of a fuzzy model for verification of malicious sites based on fuzzy neural networks. Int. J. Eng. Res. Technol. 2020, 13, 4432–4438. [Google Scholar]
- Labhsetwar, S.R.; Kolte, P.A.; Sawant, A.S. Rakshanet: Url-Aware Malicious Website Classifier. In Proceedings of the 2021 2nd International Conference on Secure Cyber Computing and Communications (ICSCCC), Jalandhar, India, 21–23 May 2021; pp. 308–313. [Google Scholar]
- Singh, A.; Roy, P.K. Malicious URL Detection using Multilayer CNN. In Proceedings of the 2021 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies (3ICT), Zallaq, Bahrain, 29–30 September 2021; pp. 340–345. [Google Scholar]
- Aljabri, M.; Alhaidari, F.; Mohammad, R.M.A.; Mirza, S.; Alhamed, D.H.; Altamimi, H.S.; Chrouf, S.M. An assessment of lexical, network, and content-based features for detecting malicious urls using machine learning and deep learning models. Comput. Intell. Neurosci. 2022, 2022, 3241216. [Google Scholar] [CrossRef]
- Anıl, U.; Ümit, C. Machine Learning-Based Effective Malicious Web Page Detection. Int. J. Inf. Secur. Sci. 2022, 11, 28–39. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Elith, J.; Leathwick, J.R.; Hastie, T. A working guide to boosted regression trees. J. Anim. Ecol. 2008, 77, 802–813. [Google Scholar] [CrossRef] [PubMed]
- Freund, Y.; Schapire, R.; Abe, N. A short introduction to boosting. J.-Jpn. Soc. Artif. Intell. 1999, 14, 771–780. [Google Scholar]
- Khalilia, M.; Chakraborty, S.; Popescu, M. Predicting disease risks from highly imbalanced data using random forest. BMC Med. Inform. Decis. Mak. 2011, 11, 51. [Google Scholar] [CrossRef]
- Teramoto, R. Balanced gradient boosting from imbalanced data for clinical outcome prediction. Stat. Appl. Genet. Mol. Biol. 2009, 8, 20. [Google Scholar] [CrossRef]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H.; Chen, K.; Mitchell, R.; Cano, I.; Zhou, T. Xgboost: Extreme gradient boosting. R Package Version 0.4-2 2015, 1, 1–4. [Google Scholar]
- González, S.; García, S.; Del Ser, J.; Rokach, L.; Herrera, F. A practical tutorial on bagging and boosting based ensembles for machine learning: Algorithms, software tools, performance study, practical perspectives and opportunities. Inf. Fusion 2020, 64, 205–237. [Google Scholar] [CrossRef]
- Bentéjac, C.; Csörgő, A.; Martínez-Muñoz, G. A comparative analysis of gradient boosting algorithms. Artif. Intell. Rev. 2021, 54, 1937–1967. [Google Scholar] [CrossRef]
- Zhang, L.; Suganthan, P.N. Random forests with ensemble of feature spaces. Pattern Recognit. 2014, 47, 3429–3437. [Google Scholar] [CrossRef]
- Biau, G.; Scornet, E. A random forest guided tour. TEST 2016, 25, 197–227. [Google Scholar] [CrossRef]
- Karlos, S.; Kostopoulos, G.; Kotsiantis, S. A Soft-Voting Ensemble Based Co-Training Scheme Using Static Selection for Binary Classification Problems. Algorithms 2020, 13, 26. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Feature | Data Type |
|---|---|---|
| 0 | URL | object |
| 1 | URL_LENGTH | int64 |
| 2 | NUMBER_SPECIAL_CHARACTERS | int64 |
| 3 | CHARSET | object |
| 4 | SERVER | object |
| 5 | CONTENT_LENGTH | float64 |
| 6 | WHOIS_COUNTRY | object |
| 7 | WHOIS_STATEPRO | object |
| 8 | WHOIS_REGDATE | object |
| 9 | WHOIS_UPDATED_DATE | object |
| 10 | TCP_CONVERSATION_EXCHANGE | int64 |
| 11 | DIST_REMOTE_TCP_PORT | int64 |
| 12 | REMOTE_IPS | int64 |
| 13 | APP_BYTES | int64 |
| 14 | SOURCE_APP_PACKETS | int64 |
| 15 | REMOTE_APP_PACKETS | int64 |
| 16 | SOURCE_APP_BYTES | int64 |
| 17 | REMOTE_APP_BYTES | int64 |
| 18 | APP_PACKETS | int64 |
| 19 | DNS_QUERY_TIMES | float64 |
| 20 | Type | int64 |
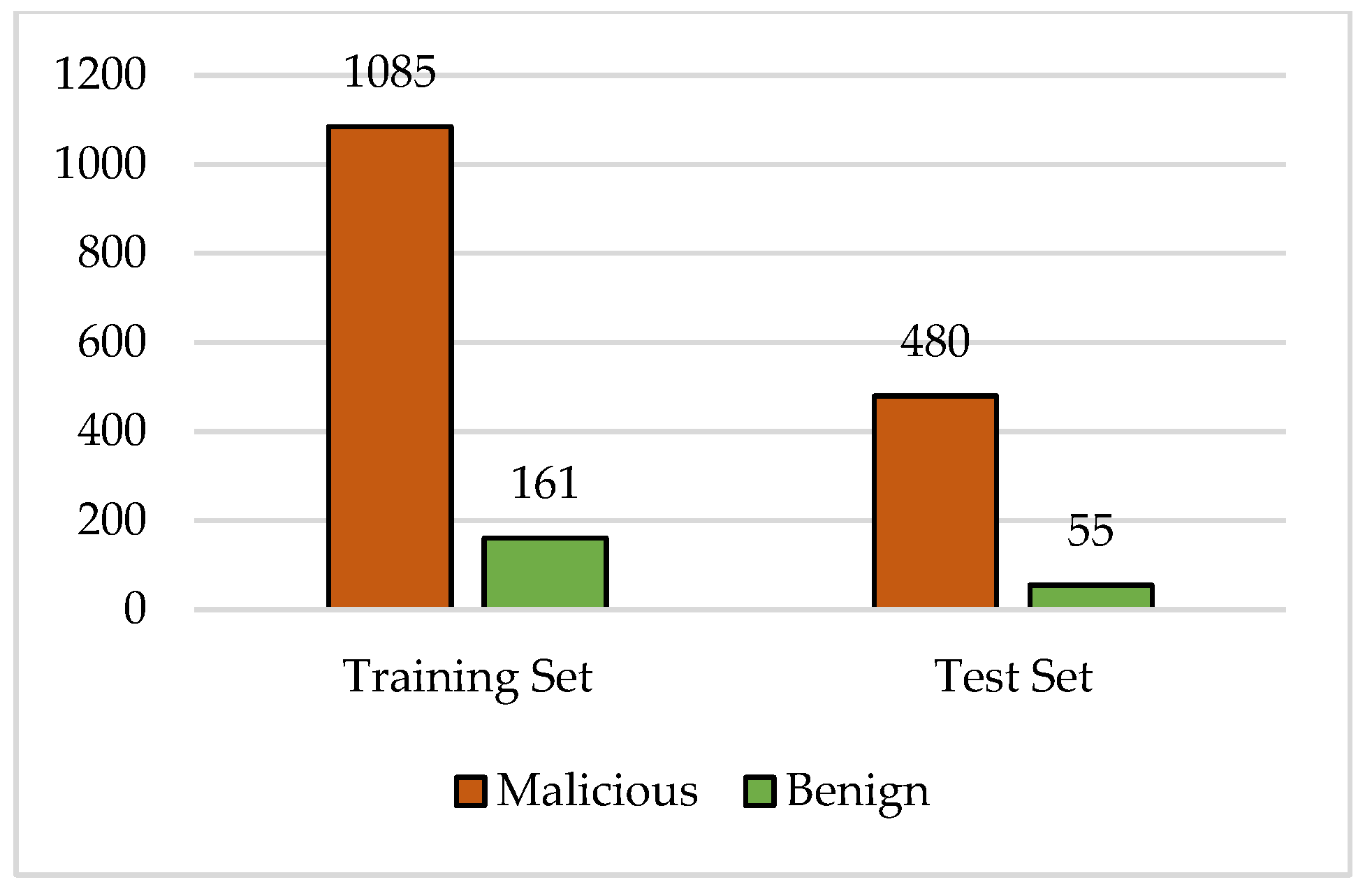
| Class Name | Percentage of Training Instances | Percentage of Test Instances |
|---|---|---|
| Malicious | 87.08% | 89.72% |
| Benign | 12.92% | 10.28% |
| Total | 100% | 100% |
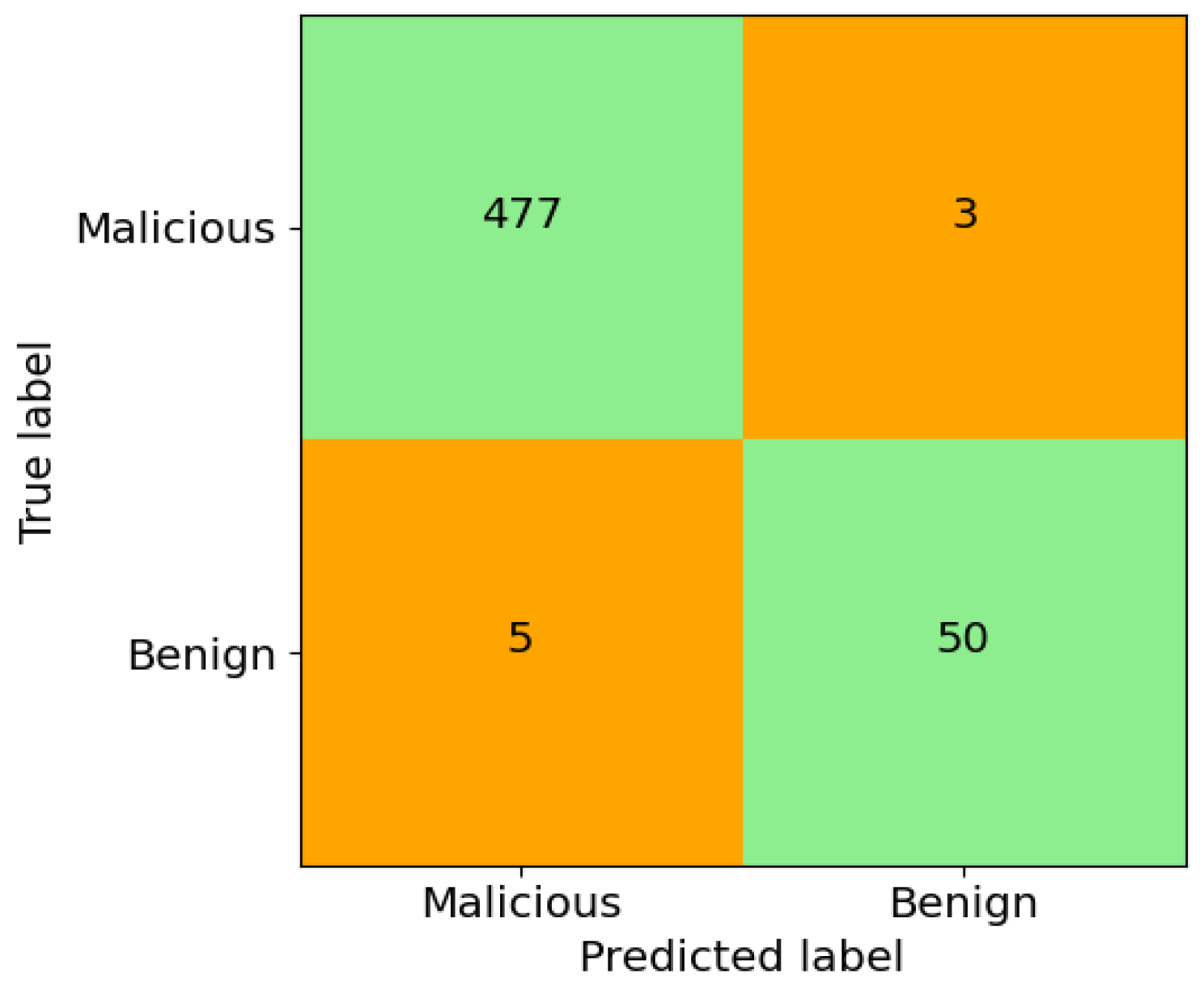
| Class Name | Precision | Recall | F1-Score |
|---|---|---|---|
| Malicious | 0.9896 | 0.9938 | 0.9917 |
| Benign | 0.9434 | 0.9091 | 0.9259 |
| Macro avg. | 0.9665 | 0.9514 | 0.9588 |
| Weighted avg. | 0.9849 | 0.9850 | 0.9849 |
| Accuracy | 98.50% | ||
| Class Name | Precision | Recall | F1-Score |
|---|---|---|---|
| Malicious | 0.9896 | 0.9917 | 0.9906 |
| Benign | 0.9259 | 0.9091 | 0.9174 |
| Macro avg. | 0.9578 | 0.9504 | 0.9540 |
| Weighted avg. | 0.9831 | 0.9832 | 0.9831 |
| Accuracy | 98.32% | ||
| Model | Averaged F1 Score | Averaged Accuracy | ||
|---|---|---|---|---|
| Micro Avg. | Macro Avg. | Weighted Avg. | ||
| GB | 0.955 | 0.888 | 0.954 | 95.45% |
| XGB | 0.958 | 0.895 | 0.957 | 95.85% |
| RF | 0.962 | 0.904 | 0.960 | 96.18% |
| RF + GB | 0.958 | 0.894 | 0.957 | 95.79% |
| GB + XGB | 0.963 | 0.905 | 0.962 | 96.29% |
| RF + XGB | 0.967 | 0.914 | 0.966 | 96.74% |
| Proposed DFEL | 0.973 | 0.931 | 0.972 | 97.25% |
| Authors [Reference] | Year | Methods/Techniques | Accuracy |
|---|---|---|---|
| Amrutkar et al. [29] | 2017 | kAYO | 90% |
| Sandag et al. [35] | 2018 | k-NN | 95% |
| McGahagan et al. [30] | 2019 | AB, ET, RF, GB, BG, LR, and k-NN | 89% |
| Alkhudair et al. [36] | 2020 | RF | 95% |
| Panischev et al. [37] | 2020 | RF | 95% |
| Al-milli et al. [32] | 2020 | 1D-CNN | 94.31% |
| Singhal et al. [28] | 2020 | RF, GB, DT, and DNN | 96.4% |
| Labhsetwar et al. [38] | 2021 | RF | 92% |
| Singh et al. [39] | 2021 | Multilayer CNN | 91% |
| Aljabri et al. [40] | 2022 | NB | 96% |
| Utku and Can [41] | 2022 | LightGBM, DT, SVM, k-NN, LR, MLP, RF, and XGB | 96% |
| Assefa et al. [34] | 2022 | Auto-encoder, DT, and SVM | 91.24% |
| Hassan et al. [25] | 2022 | DT, RF, SVC, LR, and SGD | 94.19% |
| This work | 2023 | DFEL | 98.50% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alanazi, A.; Gumaei, A. A Decision-Fusion-Based Ensemble Approach for Malicious Websites Detection. Appl. Sci. 2023, 13, 10260. https://doi.org/10.3390/app131810260
Alanazi A, Gumaei A. A Decision-Fusion-Based Ensemble Approach for Malicious Websites Detection. Applied Sciences. 2023; 13(18):10260. https://doi.org/10.3390/app131810260
Chicago/Turabian StyleAlanazi, Abed, and Abdu Gumaei. 2023. "A Decision-Fusion-Based Ensemble Approach for Malicious Websites Detection" Applied Sciences 13, no. 18: 10260. https://doi.org/10.3390/app131810260
APA StyleAlanazi, A., & Gumaei, A. (2023). A Decision-Fusion-Based Ensemble Approach for Malicious Websites Detection. Applied Sciences, 13(18), 10260. https://doi.org/10.3390/app131810260