
Improved Lightweight Multi-Target Recognition Model for Live Streaming Scenes


Abstract
:Featured Application
Abstract
1. Introduction
2. Related Work
2.1. Deep Learning and Emotion Recognition in Live Streaming Scenarios
2.2. Application of Yolov5 Algorithm for Object Detection
2.3. The Development and Application of Attention Mechanism in Deep Learning
3. Method
3.1. Data Pre-Processing
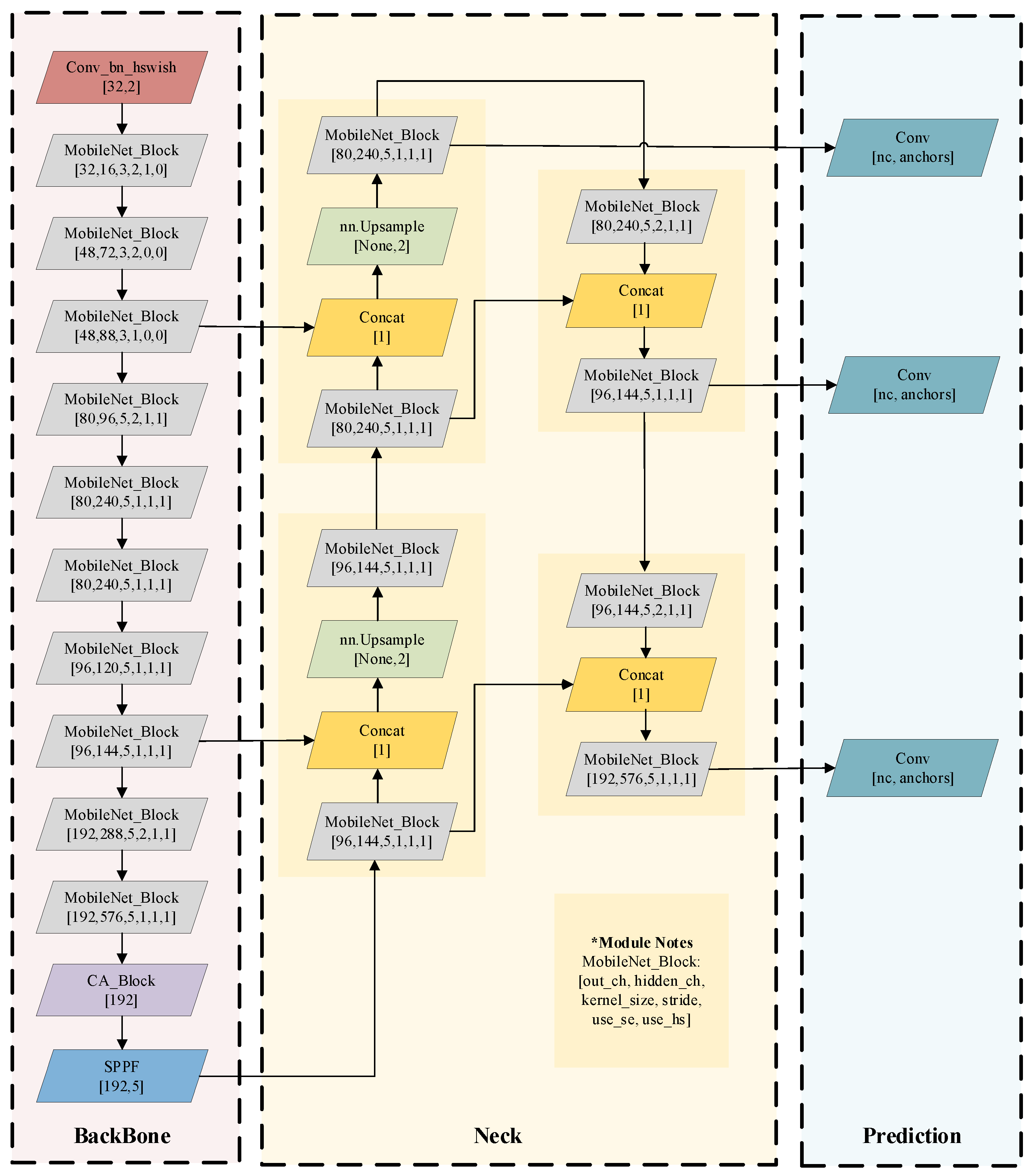
3.2. Improved Yolov5s Model
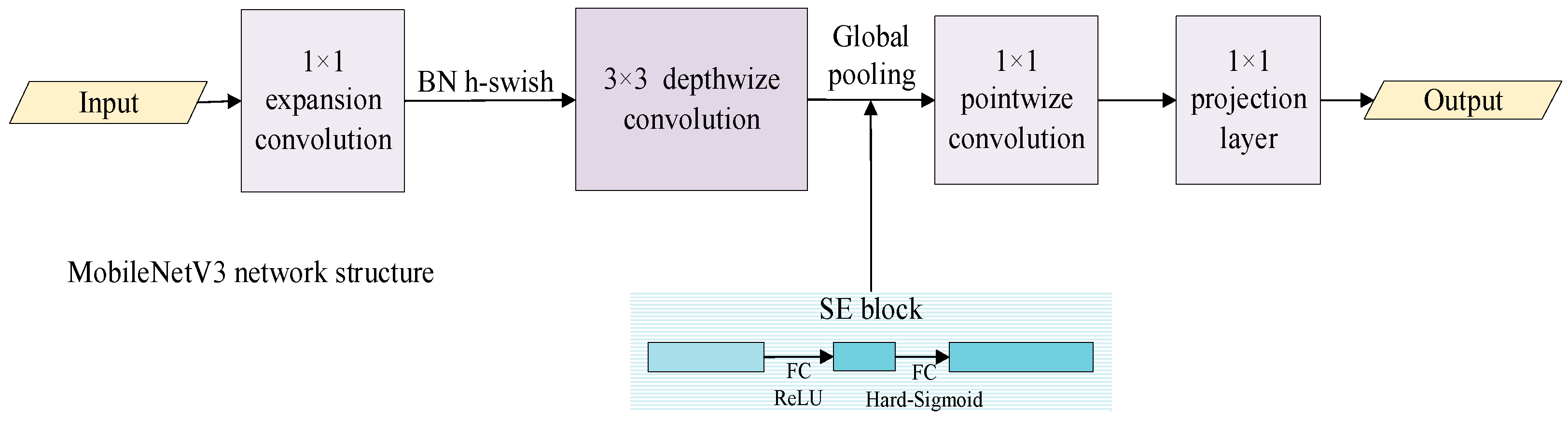
3.2.1. MobileNetV3 Modules
3.2.2. CA Attentional Mechanisms
4. Experience
4.1. Data Set and Experimental Environment
4.2. Experimental Results
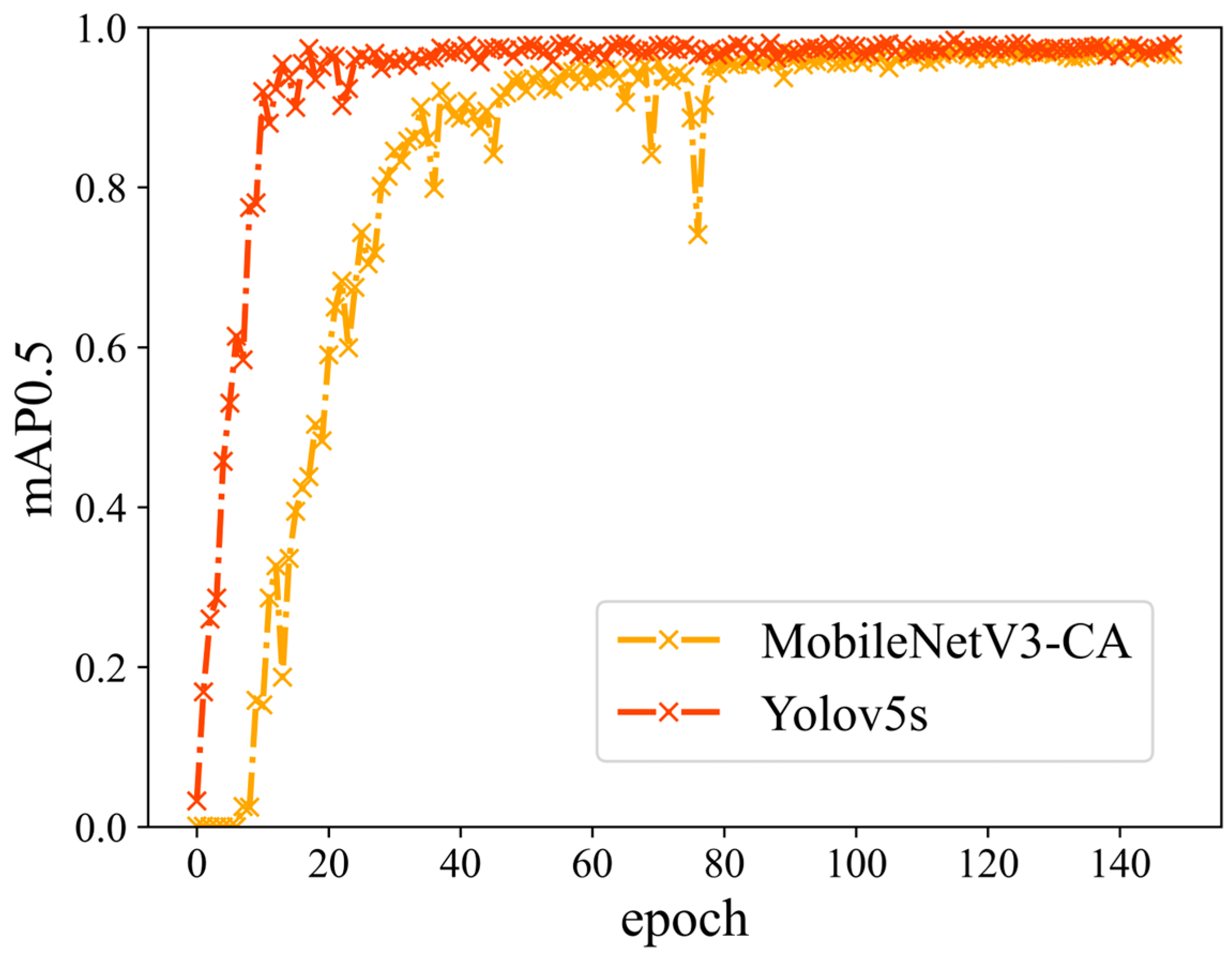
4.2.1. Ablation Experiments
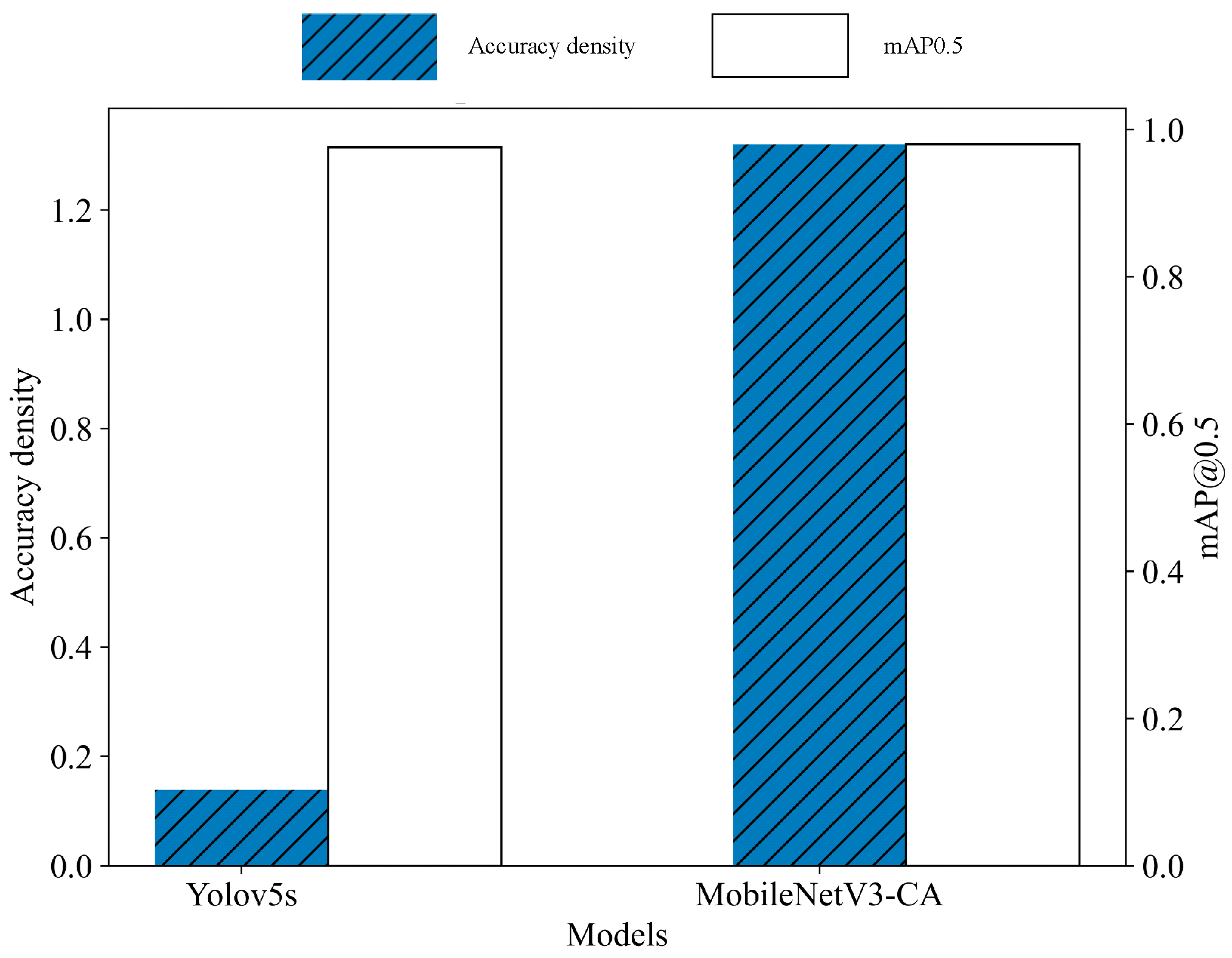
4.2.2. Comparison Experiments
5. Conclusions and Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zheng, S.; Chen, J.; Liao, J.; Hu, H.L. What motivates users’ viewing and purchasing behavior motivations in live streaming: A stream-streamer-viewer perspective. J. Retail. Consum. Serv. 2023, 72, 103240. [Google Scholar] [CrossRef]
- Zhang, X.; Cheng, X.; Huang, X. “Oh, My God, Buy It!” Investigating impulse buying behavior in live streaming commerce. Int. J. Hum. Comput. Interact. 2022, 39, 2436–2449. [Google Scholar] [CrossRef]
- Morris, T. Computer Vision and Image Processing; Palgrave Macmillan Ltd.: London, UK, 2004; pp. 1–320. [Google Scholar]
- Aziz, L.; Salam, M.S.B.H.; Sheikh, U.U.; Ayub, S. Exploring deep learning-based architecture, strategies, applications and current trends in generic object detection: A comprehensive review. IEEE Access 2020, 8, 170461–170495. [Google Scholar] [CrossRef]
- Diwan, T.; Anirudh, G.; Tembhurne, J.V. Object detection using YOLO: Challenges, architectural successors, datasets and applications. Multimed. Tools Appl. 2023, 82, 9243–9275. [Google Scholar] [CrossRef] [PubMed]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Bazarevsky, V.; Kartynnik, Y.; Vakunov, A.; Raveendran, K.; Grundmann, M. Blazeface: Sub-millisecond neural face detection on mobile gpus. arXiv 2019, arXiv:1907.05047. [Google Scholar]
- Jin, R.; Xu, Y.; Xue, W.; Li, B.; Yang, Y.; Chen, W. An Improved Mobilenetv3-Yolov5 Infrared Target Detection Algorithm Based on Attention Distillation. In International Conference on Advanced Hybrid Information Processing; Springer International Publishing: Cham, Switzerland, 2021; pp. 266–279. [Google Scholar]
- Qi, J.; Liu, X.; Liu, K.; Xu, F.; Guo, H.; Tian, X.; Li, M.; Bao, Z.; Li, Y. An improved YOLOv5 model based on visual attention mechanism: Application to recognition of tomato virus disease. Comput. Electron. Agric. 2022, 194, 106780. [Google Scholar] [CrossRef]
- Xu, S.; Guo, Z.; Liu, Y.; Fan, J.; Liu, X. An improved lightweight yolov5 model based on attention mechanism for face mask detection. In Artificial Neural Networks and Machine Learning–ICANN 2022, Proceedings of the 31st International Conference on Artificial Neural Networks, Bristol, UK, 6–9 September 2022, Part III; Springer Nature: Cham, Switzerland, 2022; pp. 531–543. [Google Scholar]
- Li, Z.; Song, J.; Qiao, K.; Li, C.; Zhang, Y.; Li, Z. Research on efficient feature extraction: Improving YOLOv5 backbone for facial expression detection in live streaming scenes. Front. Comput. Neurosci. 2022, 16, 980063. [Google Scholar] [CrossRef]
- Clore, G.L.; Schwarz, N.; Conway, M. Affective causes and consequences of social information processing. Handb. Soc. Cogn. 1994, 1, 323–417. [Google Scholar]
- Deng, B.; Chau, M. The effect of the expressed anger and sadness on online news believability. J. Manag. Inf. Syst. 2021, 38, 959–988. [Google Scholar] [CrossRef]
- Bharadwaj, N.; Ballings, M.; Naik, P.A.; Moore, M.; Arat, M.M. A new livestream retail analytics framework to assess the sales impact of emotional displays. J. Mark. 2022, 86, 27–47. [Google Scholar] [CrossRef]
- Lin, Y.; Yao, D.; Chen, X. Happiness begets money: Emotion and engagement in live streaming. J. Mark. Res. 2021, 58, 417–438. [Google Scholar] [CrossRef]
- Krishna, A. An integrative review of sensory marketing: Engaging the senses to affect perception, judgment and behavior. J. Consum. Psychol. 2012, 22, 332–351. [Google Scholar] [CrossRef]
- Gardner, M.P. Mood states and consumer behavior: A critical review. J. Consum. Res. 1985, 12, 281–300. [Google Scholar] [CrossRef]
- Kahn, B.E.; Isen, A.M. The influence of positive affect on variety seeking among safe, enjoyable products. J. Consum. Res. 1993, 20, 257–270. [Google Scholar] [CrossRef]
- Ng, H.W.; Nguyen, V.D.; Vonikakis, V.; Winkler, S. Deep learning for emotion recognition on small datasets using transfer learning. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 443–449. [Google Scholar]
- Abbaschian, B.J.; Sierra-Sosa, D.; Elmaghraby, A. Deep learning techniques for speech emotion recognition, from databases to models. Sensors 2021, 21, 1249. [Google Scholar] [CrossRef]
- Barsade, S.G. The ripple effect: Emotional contagion and its influence on group behavior. Adm. Sci. Q. 2002, 47, 644–675. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; IEEE: Columbus, OH, USA, 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE T. Pattern Anal. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Glenn, J. yolov5. Git Code. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 4 March 2023).
- Wang, D.; He, D. Channel pruned YOLO V5s-based deep learning approach for rapid and accurate apple fruitlet detection before fruit thinning. Biosyst. Eng. 2021, 210, 271–281. [Google Scholar] [CrossRef]
- Guo, K.; He, C.; Yang, M.; Wang, S. A pavement distresses identification method optimized for YOLOv5s. Sci. Rep. 2022, 12, 3542. [Google Scholar] [CrossRef]
- Li, Z.; Lu, K.; Zhang, Y.; Li, Z.; Liu, J.B. Research on Energy Efficiency Management of Forklift Based on Improved YOLOv5 Algorithm. J. Math. 2021, 2021, 5808221. [Google Scholar] [CrossRef]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 2, pp. 2017–2025. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Hu, H.; Li, Q.; Zhao, Y.; Zhang, Y. Parallel deep learning algorithms with hybrid attention mechanism for image segmentation of lung tumors. IEEE Trans. Ind. Inform. 2020, 17, 2880–2889. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Zhang, Q.L.; Yang, Y.B. Sa-net: Shuffle attention for deep convolutional neural networks. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 2235–2239. [Google Scholar]
- Pantic, M.; Valstar, M.; Rademaker, R.; Maat, L. Web-based database for facial expression analysis. In Proceedings of the IEEE International Conference on Multimedia and Expo, Amsterdam, The Netherlands, 6–8 July 2005; IEEE: Piscataway, NJ, USA, 2005; p. 5. [Google Scholar]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended Cohn–Kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar] [CrossRef]
- Guo, J.; Wang, X.; Wu, Y. Positive emotion bias: Role of emotional content from online customer reviews in purchase decisions. J. Retail. Consum. Serv. 2020, 52, 101891. [Google Scholar] [CrossRef]
- Voss, K.E.; Spangenberg, E.R.; Grohmann, B. Measuring the hedonic and utilitarian dimensions of consumer attitude. J. Mark. Res. 2003, 40, 310–320. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the IEEE/CVF international conference on computer vision, Seoul, Republic of Korea, 10 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. Mnasnet: Platform-aware neural architecture search for mobile. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2820–2828. [Google Scholar]
- Borisyuk, F.; Gordo, A.; Sivakumar, V. Rosetta: Large scale system for text detection and recognition in images. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 71–79. [Google Scholar]
- Bianco, S.; Cadene, R.; Celona, L.; Napoletano, P. Benchmark analysis of representative deep neural network architectures. IEEE Access 2018, 6, 64270–64277. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Utilitarian | Hedonic |
|---|---|
| Milk, bread, cookies, raw meat, socks, underwear… | High-grade liquor, luxury goods, cosmetics, high-grade leather boots… |
| Item | Item Value |
|---|---|
| Operation system | Windows 10 |
| CPU | Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40 GHz |
| GPU | NVIDIA GeForce RTX 3090 |
| Hardware acceleration | CUDA11.6 |
| Model | mAP@0.5 (%) | mAP@0.5:0.95 (%) | Weights (MB) | GFLOPs | Parameters (M) | Accuracy Density | Time (ms) |
|---|---|---|---|---|---|---|---|
| Yolov5s | 0.976 | 0.716 | 14.4 | 15.8 | 7020913 | 0.139 | 14.9 |
| Yolov5s-MobileNetV3-CA | 0.98 | 0.713 | 1.9 | 2.1 | 738619 | 1.32 | 22.2 |
| Model | mAP@0.5 (%) | mAP@0.5:0.95 (%) | Weights (MB) | GFLOPs | Parameters (M) | Accuracy Density |
|---|---|---|---|---|---|---|
| Yolov5s | 0.976 | 0.716 | 14.4 | 15.8 | 7.020913 | 0.139 |
| Yolov5s-CA | 0.98 | 0.716 | 14.4 | 15.8 | 7.045521 | 0.139 |
| Yolov5s-MobileNetV3 | 0.978 | 0.718 | 1.8 | 1.9 | 0.709883 | 1.37 |
| Yolov5s-MobileNetV3-CA | 0.98 | 0.713 | 1.9 | 2.1 | 0.738619 | 1.32 |
| Model | mAP@0.5 (%) | mAP@0.5:0.95 (%) | Weights (MB) | GFLOPs | Parameters (M) | Accuracy Density | Time (ms) |
|---|---|---|---|---|---|---|---|
| Yolov5s-MobileNetV3-SA | 0.971 | 0.711 | 1.9 | 2.1 | 0.738619 | 1.314 | 22.4 |
| Yolov5s-MobileNetV3-CBAM | 0.972 | 0.708 | 1.9 | 2.1 | 0.737549 | 1.317 | 22.7 |
| Yolov5s-MobileNetV3-CA | 0.98 | 0.713 | 1.9 | 2.1 | 0.738619 | 1.326 | 22.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Qiao, K.; Chen, J.; Li, Z.; Zhang, Y. Improved Lightweight Multi-Target Recognition Model for Live Streaming Scenes. Appl. Sci. 2023, 13, 10170. https://doi.org/10.3390/app131810170
Li Z, Qiao K, Chen J, Li Z, Zhang Y. Improved Lightweight Multi-Target Recognition Model for Live Streaming Scenes. Applied Sciences. 2023; 13(18):10170. https://doi.org/10.3390/app131810170
Chicago/Turabian StyleLi, Zongwei, Kai Qiao, Jianing Chen, Zhenyu Li, and Yanhui Zhang. 2023. "Improved Lightweight Multi-Target Recognition Model for Live Streaming Scenes" Applied Sciences 13, no. 18: 10170. https://doi.org/10.3390/app131810170
APA StyleLi, Z., Qiao, K., Chen, J., Li, Z., & Zhang, Y. (2023). Improved Lightweight Multi-Target Recognition Model for Live Streaming Scenes. Applied Sciences, 13(18), 10170. https://doi.org/10.3390/app131810170