
Semi-Automated Mapping of German Study Data Concepts to an English Common Data Model

 , , , ,
, , , ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data
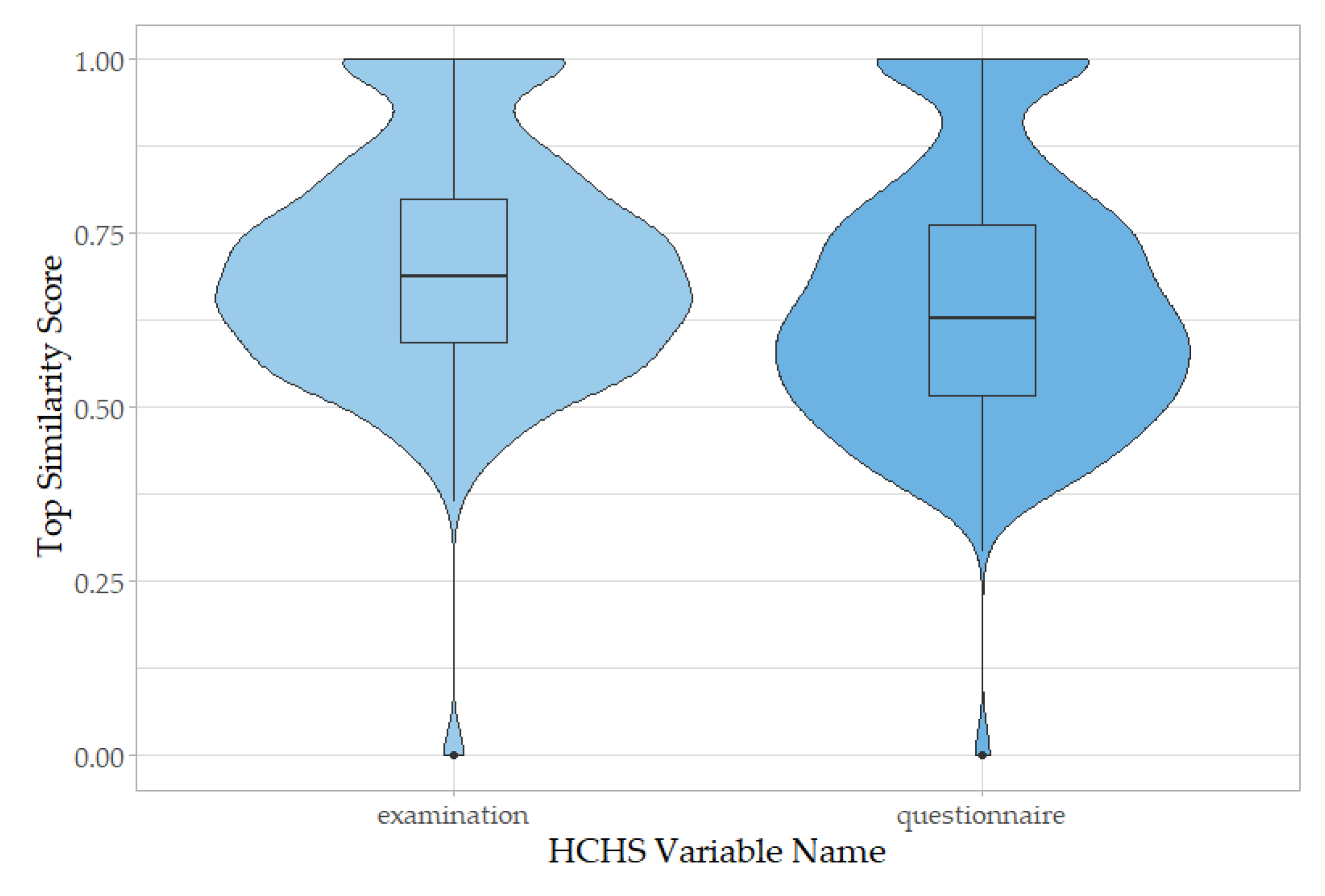
2.1.1. HCHS Dataset
2.1.2. Anesthesiology Dataset
2.2. Methods
2.2.1. Mapping to OMOP Concepts
2.2.2. Graphical User Interface
3. Results
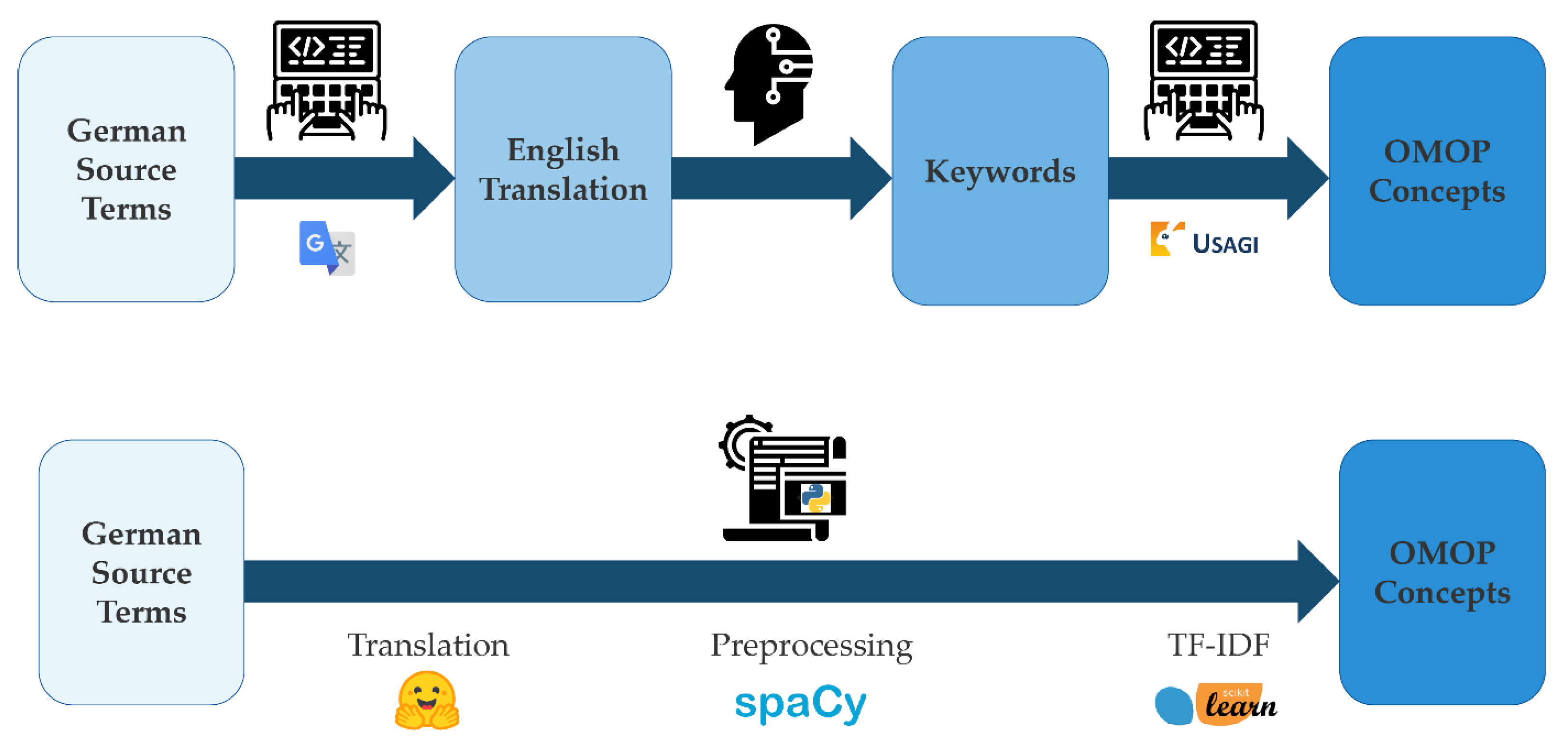
3.1. Concept of Mapping Pipeline
3.2. Code Refinement
3.3. Application to Independent Datasets
3.4. Graphical User Interface for Semiautomated Concept Mapping
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Institute of Medicine (US) Committee on Data Standards for Patient Safety. Patient Safety: Achieving a New Standard for Care; Aspden, P., Corrigan, J.M., Wolcott, J., Erickson, S.M., Eds.; National Academies Press (US): Washington, DC, USA, 2004; ISBN 978-0-309-09077-3. [Google Scholar]
- Haendel, M.A.; Chute, C.G.; Robinson, P.N. Classification, Ontology, and Precision Medicine. N. Engl. J. Med. 2018, 379, 1452–1462. [Google Scholar] [CrossRef] [PubMed]
- Ahmadi, N.; Peng, Y.; Wolfien, M.; Zoch, M.; Sedlmayr, M. OMOP CDM Can Facilitate Data-Driven Studies for Cancer Prediction: A Systematic Review. Int. J. Mol. Sci. 2022, 23, 11834. [Google Scholar] [CrossRef]
- Carus, J.; Nürnberg, S.; Ückert, F.; Schlüter, C.; Bartels, S. Mapping Cancer Registry Data to the Episode Domain of the Observational Medical Outcomes Partnership Model (OMOP). Appl. Sci. 2022, 12, 4010. [Google Scholar] [CrossRef]
- Maier, C.; Lang, L.; Storf, H.; Vormstein, P.; Bieber, R.; Bernarding, J.; Herrmann, T.; Haverkamp, C.; Horki, P.; Laufer, J.; et al. Towards Implementation of OMOP in a German University Hospital Consortium. Appl. Clin. Inform. 2018, 9, 54–61. [Google Scholar] [CrossRef] [Green Version]
- Fischer, P.; Stöhr, M.R.; Gall, H.; Michel-Backofen, A.; Majeed, R.W. Data Integration into OMOP CDM for Heterogeneous Clinical Data Collections via HL7 FHIR Bundles and XSLT. Stud. Health Technol. Inform. 2020, 270, 138–142. [Google Scholar] [CrossRef] [PubMed]
- Rinaldi, E.; Thun, S. From OpenEHR to FHIR and OMOP Data Model for Microbiology Findings. Stud. Health Technol. Inform. 2021, 281, 402–406. [Google Scholar] [CrossRef] [PubMed]
- Reinecke, I.; Zoch, M.; Wilhelm, M.; Sedlmayr, M.; Bathelt, F. Transfer of Clinical Drug Data to a Research Infrastructure on OMOP—A FAIR Concept. Stud. Health Technol. Inform. 2021, 287, 63–67. [Google Scholar] [CrossRef]
- Reinecke, I.; Kallfelz, M.; Sedlmayr, M.; Siebel, J.; Bathelt, F. Evaluation and Challenges of Medical Procedure Data Harmonization to SNOMED-CT for Observational Research. Stud. Health Technol. Inform. 2022, 294, 405–406. [Google Scholar] [CrossRef] [PubMed]
- Peng, Y.; Henke, E.; Reinecke, I.; Zoch, M.; Sedlmayr, M.; Bathelt, F. An ETL-process design for data harmonization to participate in international research with German real-world data based on FHIR and OMOP CDM. Int. J. Med. Inform. 2023, 169, 104925. [Google Scholar] [CrossRef]
- USAGI for Vocabulary Mapping. Available online: https://www.ohdsi.org/analytic-tools/usagi/ (accessed on 17 April 2023).
- Liu, H.; Carini, S.; Chen, Z.; Phillips Hey, S.; Sim, I.; Weng, C. Ontology-based categorization of clinical studies by their conditions. J. Biomed. Inform. 2022, 135, 104235. [Google Scholar] [CrossRef]
- Kang, B.; Yoon, J.; Kim, H.Y.; Jo, S.J.; Lee, Y.; Kam, H.J. Deep-learning-based automated terminology mapping in OMOP-CDM. J. Am. Med. Inform. Assoc. 2021, 28, 1489–1496. [Google Scholar] [CrossRef] [PubMed]
- Soysal, E.; Wang, J.; Jiang, M.; Wu, Y.; Pakhomov, S.; Liu, H.; Xu, H. CLAMP—A toolkit for efficiently building customized clinical natural language processing pipelines. J. Am. Med. Inform. Assoc. 2018, 25, 331–336. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, J.; Abu-El-Rub, N.; Gray, J.; Pham, H.A.; Zhou, Y.; Manion, F.J.; Liu, M.; Song, X.; Xu, H.; Rouhizadeh, M.; et al. COVID-19 SignSym: A fast adaptation of a general clinical NLP tool to identify and normalize COVID-19 signs and symptoms to OMOP common data model. J. Am. Med. Inform. Assoc. 2021, 28, 1275–1283. [Google Scholar] [CrossRef] [PubMed]
- OHDSI Natural Language Processing Working Group. Available online: https://www.ohdsi.org/web/wiki/doku.php?id=projects:workgroups:nlp-wg (accessed on 17 April 2023).
- Jagodzinski, A.; Johansen, C.; Koch-Gromus, U.; Aarabi, G.; Adam, G.; Anders, S.; Augustin, M.; der Kellen, R.B.; Beikler, T.; Behrendt, C.-A.; et al. Rationale and Design of the Hamburg City Health Study. Eur. J. Epidemiol. 2020, 35, 169–181. [Google Scholar] [CrossRef] [Green Version]
- Athena. Available online: https://athena.ohdsi.org (accessed on 17 April 2023).
- Kohse, E.K.; Siebert, H.K.; Sasu, P.B.; Loock, K.; Dohrmann, T.; Breitfeld, P.; Barclay-Steuart, A.; Stark, M.; Sehner, S.; Zöllner, C.; et al. A model to predict difficult airway alerts after videolaryngoscopy in adults with anticipated difficult airways—The VIDIAC score. Anaesthesia 2022, 77, 1089–1096. [Google Scholar] [CrossRef]
- Medizinische Abkürzungen. Available online: https://www.bionity.com/de/lexikon/Medizinische_Abk%C3%BCrzungen.html (accessed on 17 April 2023).
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations; Association for Computational Linguistics, Online, 16–20 November 2020; pp. 38–45. [Google Scholar]
- spaCy 2: Natural Language Understanding with Bloom Embeddings, Convolutional Neural Networks and Incremental Parsing. Available online: https://sentometrics-research.com/publication/72/ (accessed on 17 April 2023).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Tiedemann, J.; Thottingal, S. OPUS-MT—Building open translation services for the World. In Proceedings of the 22nd Annual Conference of the European Association for Machine Translation; European Association for Machine Translation, Lisboa, Portugal, 3–5 November 2020; pp. 479–480. [Google Scholar]
- Yang, X.; Chen, A.; PourNejatian, N.; Shin, H.C.; Smith, K.E.; Parisien, C.; Compas, C.; Martin, C.; Costa, A.B.; Flores, M.G.; et al. A large language model for electronic health records. NPJ Digit. Med. 2022, 5, 194. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Wang, X.; Hou, Y.; Li, G.; Wang, H.; Xu, H.; Xiang, Y.; Tang, B. Multimodal Data Matters: Language Model Pre-Training Over Structured and Unstructured Electronic Health Records. IEEE J. Biomed. Health Inform. 2022, 27, 504–514. [Google Scholar] [CrossRef] [PubMed]
- Naseem, U.; Dunn, A.G.; Khushi, M.; Kim, J. Benchmarking for biomedical natural language processing tasks with a domain specific ALBERT. BMC Bioinform. 2022, 23, 144. [Google Scholar] [CrossRef]
- Frei, J.; Frei-Stuber, L.; Kramer, F. GERNERMED++: Transfer Learning in German Medical NLP. arXiv 2022, arXiv:2206.14504. [Google Scholar] [CrossRef]
- Roller, R.; Seiffe, L.; Ayach, A.; Möller, S.; Marten, O.; Mikhailov, M.; Alt, C.; Schmidt, D.; Halleck, F.; Naik, M.; et al. A Medical Information Extraction Workbench to Process German Clinical Text. arXiv 2022, arXiv:2207.03885. [Google Scholar] [CrossRef]
- Kadioglu, D.; Breil, B.; Knell, C.; Lablans, M.; Mate, S.; Schlue, D.; Serve, H.; Storf, H.; Ückert, F.; Wagner, T.; et al. Samply.MDR—A Metadata Repository and Its Application in Various Research Networks. Stud. Health Technol. Inform. 2018, 253, 50–54. [Google Scholar] [PubMed]
- ISO/IEC 62366-1; Medical devices—Part 1: Application of Usability Engineering to Medical Devices. International Electrotechnical Commission: Geneva, Switzerland, 2015.
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar] [CrossRef]
- Zhang, J.; Kowsari, K.; Harrison, J.H.; Lobo, J.M.; Barnes, L.E. Patient2Vec: A Personalized Interpretable Deep Representation of the Longitudinal Electronic Health Record. IEEE Access 2018, 6, 65333–65346. [Google Scholar] [CrossRef]
- Wang, L.; Wang, Q.; Bai, H.; Liu, C.; Liu, W.; Zhang, Y.; Jiang, L.; Xu, H.; Wang, K.; Zhou, Y. EHR2Vec: Representation Learning of Medical Concepts From Temporal Patterns of Clinical Notes Based on Self-Attention Mechanism. Front. Genet. 2020, 11, 630. [Google Scholar] [CrossRef]
- Medical Abbreviations. Available online: https://www.allacronyms.com/medical/abbreviations (accessed on 17 April 2023).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Comparison | Keywords | ORI | MIN | SYN | DUP | Similarity | USAGI Concept Name |
|---|---|---|---|---|---|---|---|
| SIMILAR (60%) | diagnose atrial fibrillation | 1 | Lone atrial fibrillation | ||||
| 1 | Atrial fibrillation | ||||||
| 0.89 | Atrial fibrillation detected | ||||||
| 0.87 | H/O: atrial fibrillation | ||||||
| 0.85 | Permanent atrial fibrillation | ||||||
| BETTER (20%) | diagnose heart attack | 1 | Myocardial infarction | ||||
| 0.81 | Diagnosis | ||||||
| 0.78 | Diagnostic proctoscopy | ||||||
| 0.63 | Diagnostic procedure on heart | ||||||
| 0.61 | Age at diagnosis | ||||||
| WORSE (10%) | artery detect | 0.64 | Arterial structure | ||||
| 0.63 | Procedure to identify antibody | ||||||
| 0.6 | Metal detector | ||||||
| 0.53 | Not detected | ||||||
| 0.49 | Cervical artery dissection | ||||||
| FAIL (10%) | diagnose open leg ulcus cruris | 0.69 | Prior diagnosis | ||||
| 0.49 | Diagnostic Doppler ultrasonography | ||||||
| 0.44 | Diagnostic procedure on ulna | ||||||
| 0.43 | Hematuria of undiagnosed cause | ||||||
| 0.41 | Caregiver unaware of diagnosis |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chechulina, A.; Carus, J.; Breitfeld, P.; Gundler, C.; Hees, H.; Twerenbold, R.; Blankenberg, S.; Ückert, F.; Nürnberg, S. Semi-Automated Mapping of German Study Data Concepts to an English Common Data Model. Appl. Sci. 2023, 13, 8159. https://doi.org/10.3390/app13148159
Chechulina A, Carus J, Breitfeld P, Gundler C, Hees H, Twerenbold R, Blankenberg S, Ückert F, Nürnberg S. Semi-Automated Mapping of German Study Data Concepts to an English Common Data Model. Applied Sciences. 2023; 13(14):8159. https://doi.org/10.3390/app13148159
Chicago/Turabian StyleChechulina, Anna, Jasmin Carus, Philipp Breitfeld, Christopher Gundler, Hanna Hees, Raphael Twerenbold, Stefan Blankenberg, Frank Ückert, and Sylvia Nürnberg. 2023. "Semi-Automated Mapping of German Study Data Concepts to an English Common Data Model" Applied Sciences 13, no. 14: 8159. https://doi.org/10.3390/app13148159
APA StyleChechulina, A., Carus, J., Breitfeld, P., Gundler, C., Hees, H., Twerenbold, R., Blankenberg, S., Ückert, F., & Nürnberg, S. (2023). Semi-Automated Mapping of German Study Data Concepts to an English Common Data Model. Applied Sciences, 13(14), 8159. https://doi.org/10.3390/app13148159