1. Introduction
Drone technology’s development has significantly advanced many industries, including animal monitoring and conservation [
1]. Drones can be considered a valuable tool for studying and monitoring bird populations [
2]. Drones offer unique capabilities for capturing high-resolution imagery, enabling researchers to conduct non-invasive surveys and observe bird species in their natural habitats [
3]. Computer vision with the aid of machine learning techniques can help these drone-captured videos and images in order to be further analysed to detect and identify birds with high accuracy and efficiency.
Accurate detection and identification of bird species from aerial imagery are crucial for understanding population dynamics, assessing habitat quality, and informing conservation strategies [
4]. However, it poses numerous challenges due to the small size of birds, their ability to move quickly and unpredictably, and the vast amount of data generated by drone footage. Traditional manual approaches to bird detection and identification are time-consuming, labour-intensive, and prone to human error. To overcome these limitations, computer vision methods have emerged as powerful tools to automate and enhance the process of wildlife bird detection from drone footage.
Furthermore, drones can provide high-resolution and high-precision data, which can improve wildlife bird detection and monitoring. Utilizing drones enables wildlife surveillance in challenging and hard-to-access environments, as depicted in
Figure 1. For example, drones equipped with thermal or multispectral sensors can detect subtle changes in temperature or vegetation that are indicative of animal presence or habitat changes. This can provide valuable insights for wildlife management and conservation, as it allows for targeted interventions and informed decision-making.
Computer vision [
5] encompasses a broad range of techniques that aim to enable machines to interpret and understand visual information. Within the field of wildlife monitoring, computer vision algorithms can be applied to analyse drone footage and automatically detect, track, and classify bird species based on their visual characteristics. These algorithms leverage deep learning [
6,
7] methods, which have shown remarkable performance in various image recognition tasks.
One popular computer vision method for object detection is the family of convolutional neural networks (CNNs) [
6]. CNNs are deep learning architectures specifically designed to extract and learn meaningful features from images. They have been successfully employed in numerous domains, including object recognition, face detection, and scene understanding. Recent advances in CNN-based methods such as the You Only Look Once (YOLO) algorithm [
8] have shown promising results in bird detection tasks.
Applying computer vision methods to wildlife bird detection from drone footage offers several advantages. Firstly, it allows for rapid and automated analysis of large-scale datasets, enabling researchers to process and extract valuable information more efficiently. Secondly, computer vision algorithms can handle the challenges posed by the small size and swift movements of birds, making them well suited for accurately detecting and identifying bird species. Additionally, the integration of computer vision techniques with drone technology provides an opportunity for real-time monitoring and decision-making, facilitating timely conservation interventions and adaptive management strategies.
Overall, convolutional neural network algorithms, including YOLO, have shown great promise for bird detection and identification in drone footage. These algorithms have the potential to greatly improve our understanding of bird populations and their behaviour and contribute to conservation efforts and ecological studies [
9].
In this manuscript, we present a comprehensive study of the application of computer vision methods for wildlife bird detection from drone footage. Our aim was to assess the performance and effectiveness of various computer vision algorithms, such as the YOLO method, for the accurate detection of bird species. We evaluated the algorithms using a diverse dataset of drone-captured imagery, encompassing different environments, lighting conditions, and bird species. Through this research, we aimed to contribute to the development of efficient and reliable tools for wildlife bird monitoring, which can enhance our understanding of avian populations, support conservation efforts, and inform management decisions.
The utilisation of computer vision methods for wildlife bird detection from drone footage has significant implications for ecological research and conservation. Firstly, it enables researchers to conduct large-scale bird surveys in a cost-effective and non-invasive manner. Drones can cover vast areas of land, allowing for the monitoring of bird populations in remote and inaccessible regions, as well as areas with challenging terrain. This expanded spatial coverage provides valuable insights into bird distributions, habitat preferences, and migratory patterns, which were previously difficult to obtain.
Moreover, the automated and standardised nature of computer vision algorithms ensures consistency in data processing and analysis. Manual bird surveys often suffer from inter-observer variability and subjectivity, leading to inconsistencies in data collection and interpretation. By employing computer vision methods, we can reduce these biases and increase the reliability and reproducibility of bird-monitoring efforts. Consistent and standardised data collection is crucial for accurate trend analysis, population assessments, and the identification of critical conservation areas.
Finally, we highlight the advantages of our method in improving the efficiency, accuracy, non-invasiveness, replicability, and potential real-time monitoring capabilities for bird detection and conservation efforts. By leveraging deep learning techniques, the proposed methodology significantly improves the efficiency of bird detection compared to traditional manual methods. It eliminates the need for labour-intensive and time-consuming manual identification and tracking processes, allowing for rapid and automated analysis of bird populations. Next, the automatic-bird-detection approach enables non-intrusive monitoring of bird populations in their natural habitats. This non-invasive method minimises disturbance to the birds and reduces the potential of altering their behaviours, providing more reliable and ecologically meaningful data for conservation efforts. Finally, using lighter versions of the YOLO method (tinyYOLO [
10]), we proved that our methodology has the potential for real-time bird detection and monitoring. This capability enables a timely response to emerging threats, early detection of population changes, and informed decision-making for effective conservation strategies.
The choice of the tinyYOLO method instead of other popular methods, e.g., MobileSSD [
11], which is generally more lightweight and compact compared to tinyYOLO, is that it is suitable for resource-constrained environments or devices with limited computational power. MobileNetSSD and tinyYOLO differ in their underlying network architectures. MobileNetSSD employs depthwise separable convolutions, which enable more efficient use of parameters and reduce computation. In contrast, tinyYOLO utilises a smaller network architecture with multiple detection layers to achieve good accuracy.
3. Dataset
Drone footage detection of wildlife in suburban and protected environments is a challenging task due to multiple factors that need to be taken into consideration during the development of our dataset. Conservationists advised that a minimum of 30 to 40 m altitude is the appropriate safety measure for the animals to feel safe in their habitats without disturbing the wildlife during the nesting cycle [
26]. Building a reliable detection system in drone footage requires a well-developed dataset for the model to be accurate. Due to the problem in question not containing enough data online, the dataset was created using drone footage recorded from suburban and protected environments.
In our dataset, we recorded three videos. Two videos were used to build our dataset, which summed up to 10 min of footage. The 3rd video was used to visually evaluate our model. Each frame extracted from the footage had a one-second interval. The resulting number of images was 769, but with the help of image tiling/zooming, the samples increased to 10,653.
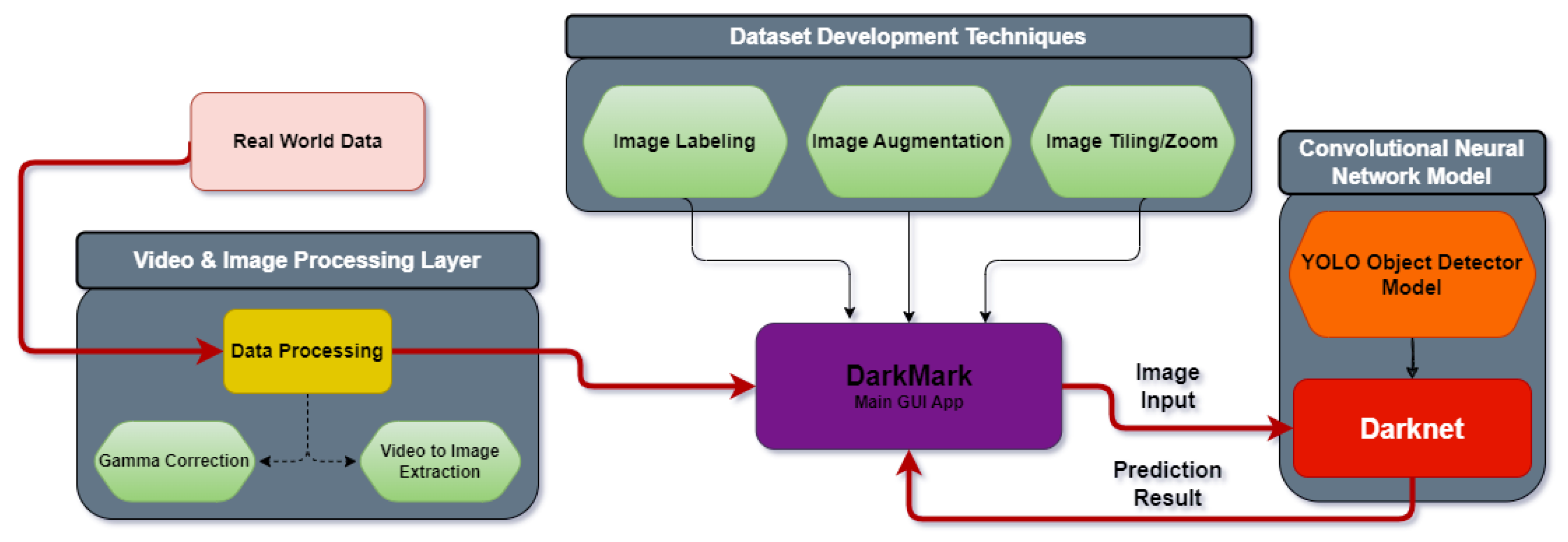
During the development of our dataset, we began by retrieving real-world data; this was achieved by recording footage of suburban environments with several bird species at certain altitudes. The footage we gathered suffered from high light level conditions, which aggravated the resulting predictions of the model. Applying an enhancement algorithm to balance the light condition of the dataset images increased the visibility of the images.
Once the footage was retrieved, the next phase was to convert the data into images and begin labelling using DarkMark. Once labelling was complete, we could apply various transformations to our dataset to increase the number of samples, as well as the resulting average precision of our model. Image tiling was one of the more-important techniques that was applied to our image dataset to increase the performance of our model. Image tiling largely affected the outcome of our results, dramatically increasing our model’s overall precision, especially because of the task at hand containing small object detections.
The challenge of this computer vision task was the scale of the objects we attempted to detect. Some objects within the footage might appear to be too small for the model to detect. Several techniques and steps needed to be applied to the dataset in order to effectively detect small objects within the dataset at an estimated altitude of 30 to 40 m. Based on the altitude of the drone and the distance between each bird, we classified clusters of birds as small-flock or flock this reduced the complexity of the problem in certain scenarios where there was a very large cluster of birds and the altitude was very high. This method is likely to reduce the overall evaluated performance of the model including the average Intersection over Union (IoU) [
27].
In order to develop a large and well-structured dataset, techniques such as image enhancement [
15], image tiling/cropping/zooming [
28], and automatic image labelling using DarkMark were used. We applied gamma correction to each piece of footage to reduce the degradation caused by the sunlight within the footage, and an example of this was presented in
Figure 5.
Another technique that was originally not introduced into our dataset would be to include flip data augmentation. This would better assist the model to minimize any margin of error of any possible missing detections. This parameter works best if the objects are mirrored on both sides, left and right. As mentioned in earlier sections, we retrieved data in suburban environments located at Koronisia, Nisida Kamakia (
GPS Pin), and Balla (
GPS Pin) in the wetlands of Amvrakikos in the Logarou and Tsoukaliou Lagoons. During the surveillance of the wildlife, the drone’s approach to the Pelecanus crispus colonies [
29,
30] was carefully planned by highly qualified personnel of the management unit of Acheloos Valley and Amvrakikos Gulf Protected area to minimise the disturbance of the birds, following the methodology outlined below: (a) The drone maintained an altitude of 70 m above the surface of the lagoon during the flight from the starting point to the breeding islands. (b) As the drone approached the colony, it gradually descended from 70 m to a height of 50 m, ensuring continuous telescopic surveillance of the bird colonies and avoiding disturbance. (c) At a minimum height of 30 m above the colony, the drone conducted horizontal runs to capture visual material, ensuring no disturbance was observed in the colony. (d) Upon completing the data collection above the colony, the drone began a gradual climb, slowly ascending to a height of 70 m. At this point, it was ready to follow its flight plan back to its operator. This approach prioritised the well-being of the Pelecanus crispus colonies, ensuring minimal disruption while obtaining valuable visual material for the study.
4. Results
In this section, we present a comprehensive analysis of the outcomes achieved by the models we trained, along with a thorough explanation of the problem at hand. There are a diverse number of metrics such as visualisations and statistical analyses that offer a detailed understanding of the effectiveness of our model. Additionally, we evaluated the impact of using image tiling on the overall performance and accuracy of our model, as well as the difficulties the model faces in certain situations. Finally, we provide a visualisation and description of the training session of the models we trained.
4.1. Terminology & Definitions
Below, we define various terms [
31] that are usually used in computer vision methods:
Confidence is a value that is determined by the model when it detects an object. The model has X amount of confidence that object Y is exactly that prediction. The confidence is irrelevant to the accuracy of the model’s prediction; it only represents the similarity of the predicted class, from the training dataset.
A True Positive (TP) is when the model’s results contain a prediction of an object and it is correct, based on the ground truth information. True positives are also detections of the correct class.
A False Positive (FP) is when the model’s results contain a prediction of an object and it is incorrect, based on the ground truth information. False positives are also detections of the wrong class.
A True Negative (TN) is when the model’s results contain no predictions and this is correct based on the ground truth information.
A False Negative (FN) is when the model’s results contain no prediction and it is incorrect based on the ground truth information. False negatives are detections not given by the model.
The mean Average Precision (mAP) is calculated using the true positive/negative and false positive/negative values. The mAP determines the performance of the model in a class.
Precision is the ratio between the correct predictions of the model and the incorrect classifications of the model, limited to the ground truth information:
The average Intersection over Union (IoU), is a statistical comparison between the bounding boxes of the model’s prediction and the ground truth’s bounding box. The average IoU value represents the difference between the prediction and the ground truth’s bounding box of multiple objects. The higher the value, the better the prediction is.
As outlined above, the average IoU is calculated using the ground truth and the prediction bounding box coordinates. In the case of Darknet and the YOLO models, we used DarkHelp to extract the coordinates of each prediction of our model and compared those predictions to the ground truth boxes that we labelled.
In order to calculate the IoU probability, the intersection’s box coordinates need to be defined. Using the intersection area, we can also calculate the union’s bounding box area. The ratio of the intersection divided by the union is equal to the IoU value.
4.2. Training Session Results
Both training sessions reached high mean Average Precision (mAP) and low average loss (a higher mAP is better, and a lower average loss is better) values.
Figure 9 contains two charts of the resulting training sessions of the YOLOv4-tiny and YOLOv4 models [
10,
19]. (a) YOLOv4-tiny’s training session lasted 7 h at 30,000 batches. The highest mean average precision achieved was 85.64%, whilst the average IoU was 47.90%. (b) YOLOv4’s training session lasted 64 h at 30,000 batches. During training, the highest mean average precision of the model based on the test dataset was 91.28%, whilst the average IoU was 65.10.
We developed an application capable of calculating the Intersection over Union (IoU) and accuracy metrics of our trained models using a validation dataset,
Figure 10. Additionally, the application provides visual overlays of the groundtruth information on top of the detected objects.
The training charts of YOLOv4-tiny and YOLOv4 in
Figure 9a,b provide a valuable visual understanding of the effectiveness of our dataset for both models, based on the rate at which the average precision and average loss changed. Both models were trained with a total of 30,000 max batches.
During the initial phase of the training session, we can observe a significant decrease in the average loss. That was due to a scaling factor given by the configuration files of the model. In the first few batches, the learning rate was gradually scaled up, accelerating the rate at which the model learned.
These steps were also an important milestone for the model, to change its learning behaviour and find the best-possible result. Similar to the initial phase of the training session, it scaled the learning rate based on the number of batches [
12]. Throughout the entirety of both training sessions, the mAP showed a gradual increase, depicting a progressive improvement in accurately detecting objects until it converged to a stable state.
Further advancing into the training session, beyond 30,000 batches increased the risk of the model encountering the overfitting problem [
32].
4.3. Model Performance Evaluation
The evaluation performance results of the models
YOLOv4 and
YOLOv4-tiny were by no means different. The main purpose of training the two models was to have a lightweight and a high-precision model. Both models demonstrated high evaluation performance results, although it can be observed that the average IoU was low for both models. This issue will be explored even further in the next sections. During the evaluation, we extracted the mAP and the average IoU. The relationship between the average IoU and the mAP in
Table 2 is an average estimation of the overall performance of the model.
The evaluation results in
Table 2 were adequate, although the average IoU was unusually low. This problem was due to the classes small-flock and flock since there was no exact determined distance between two birds that would be classified as a small-flock or bird. This is a major flaw in the model and is due for a change. An example of this issue will be displayed even further in later sections. The effect of reducing or increasing the average IoU threshold will vary based on the problem in question [
33].
The model’s performance results at a confidence threshold of 0.25 are also displayed in
Table 3. YOLOv4 performed very well considering the number of TPs and FPs. YOLOv4-tiny had a significant increase of the FP values, which can result in an unsatisfactory performance. With these values, we can obtain a better understanding of the performance of our trained models.
Table 3 demonstrates the overall accuracy of the model, with lower confidence thresholds of 0.25. By decreasing the confidence threshold, the model was more sensitive to detections and provided even more information. This may increase the total count of false negatives, which may further decrease or increase the precision of the model based on the task at hand.
4.4. Evaluation Result Analysis on Image Tiling
To evaluate the highest-possible mAP of our trained model, we enabled image tiling to the model in 4k images, in order to achieve the model’s maximum potential.
Other studies have highlighted the advantages of using image tiling during the evaluation and training of various computer vision problems. The effectiveness of image tiling becomes especially more evident when dealing with small objects, resulting in an overall increase in the mean Average Precision (mAP) [
28].
Figure 11 effectively conveys this issue with our results and displays the significant increase in model precision, by tiling the images.
A clear observation can be made from
Figure 11, as well as the effect of image tiling. It increased the precision of the model at the cost of computational performance.
Table 4 represents the evaluation results of the images in
Figure 11 and demonstrates the difference with or without image tiling.
4.5. Model Prediction Errors
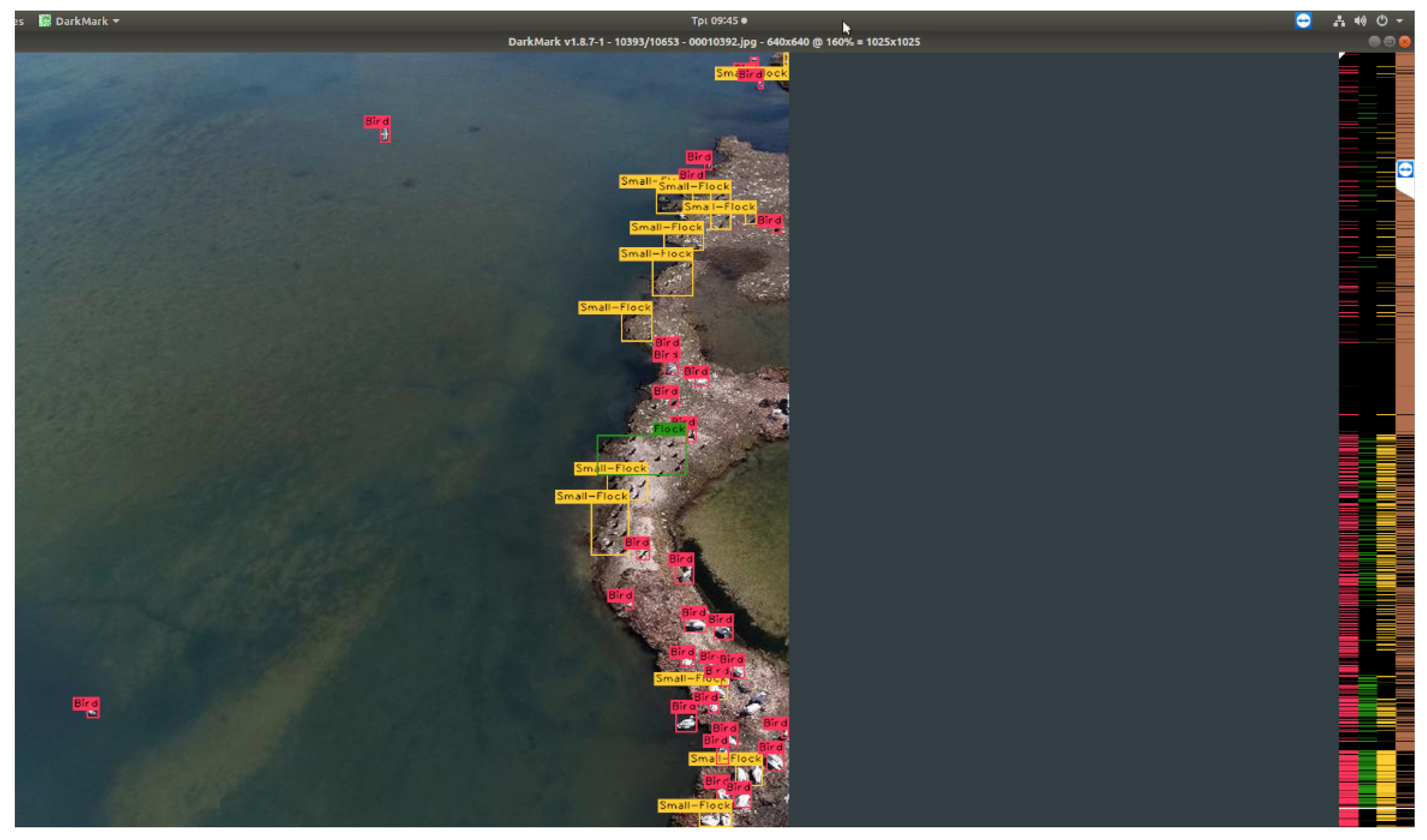
This section demonstrates the issues of the model for footage that the model has never been trained on. On several occasions, the drone’s camera faced upwards, and more objects could be observed, although there was more information to process, while the visibility was much lower at further distances, resulting in less-accurate predictions. In terms of real-time footage, the model’s detections regularly fluctuated, appearing to be inaccurate on a fully rendered video with the model’s predictions. A presentation of this issue can be observed in
Figure 12, although this figure might present excellent results in areas closest to the drone, and the further the distance, the less accurate the model was.
Even though this error was apparent, we can also observe that several birds were easier to detect if they were on the water, due to the reduction of the noise resulting from the environmental differences around the birds/flocks.
This issue may suggest a potential bias towards our dataset in our training sessions. In order to mitigate this problem, we can increase the complexity and diversity, while reducing any inherent similarities. As discussed in
Section 3, the one-second interval between each frame resulted in a significant number of similar images, further indicating the possibility of dataset bias.
4.6. YOLOv4 and YOLOv4-Tiny Image Results
On paper, YOLOv4 performed best and excelled YOLOv4-tiny in terms of precision. YOLOv4-tiny performed worse in terms of precision, but we benefited from it, with 10x the computational performance during the evaluation compared to using YOLOv4.
4.7. Observation
Although YOLOv4-tiny may exhibit an increased count of false positives, as shown in
Table 3, it still maintained a satisfactory level of accuracy, as demonstrated in
Table 2.
Figure 13 and
Figure 14 are the results received from both trained models. YOLOv4 predicted all objects in the images with nearly 100% accuracy, whilst YOLOv4-tiny was not as accurate. The models can be highly inaccurate at longer distances and higher altitudes, as shown in
Figure 12. One of the major flaws in our training sessions was that including both the small-flock and flock classes, which can create conflict between them and the bird class.
The contents of
Table 5 represent an overall understanding of the results extracted from the images with the help of our trained models YOLOv4-tiny [
10] and YOLOv4 [
19], and the C++ library, DarkHelp [
14],
Figure 13 and
Figure 14.
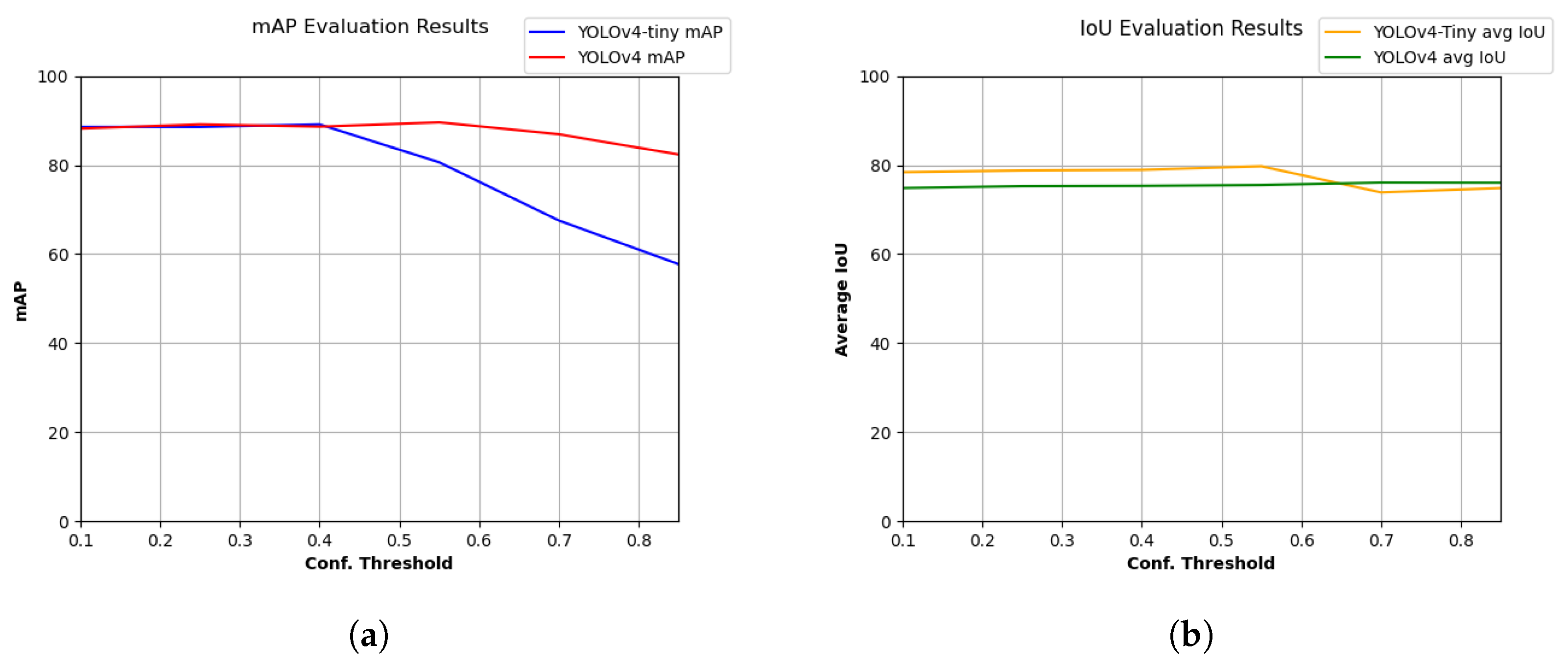
Further evaluations at different confidence thresholds were also produced, to further identify what threshold values fit best for the problem in question; see
Figure 15.
5. Conclusions
In this research, we trained a model capable of detecting birds and flocks in drone footage. The models we used were YOLOv4 and YOLOv4-tiny. The footage was recorded in suburban environments at an altitude of 30–50 m. Using this footage, we developed a dataset and applied various techniques in order to increase the quantity and quality of our dataset.
During the development of our dataset, we applied image enhancement, labelled each image, and applied various techniques to increase the overall mAP of our model. The highest mAP we reached for our testing dataset was 91.28% with an average IoU of 65.10%. One crucial technique we evaluated our models with and applied to our dataset was image tiling [
16], in order to detect small objects and maximise our model’s potential. Image tiling played an important role in improving the overall mAP, as proven in
Figure 11, and dramatically increased the overall mAP of the model. Additionally, we enhanced our dataset using gamma correction to further improve the mAP of our model, as well as the prediction results. Both models performed superbly, in the detection of small objects such as flocks and birds in drone footage.
Despite YOLOv4-tiny’s results containing less precision, we benefited from its overall increase in performance and how lightweight the model is. During the evaluation, the model was able to detect objects in images by up to 10× faster than YOLOv4. Whilst YOLOv4’s evaluation results were high, at 91.28% mAP and 65.10% avg IoU (
Table 2), YOLOv4’s drawback for its high accuracy was its overall performance in terms of its computational speed. Each frame took up to a second for the model to detect whilst using image tiling [
16].
The results produced from our dataset proved to perform excellently in terms of accuracy. This high accuracy was likely to be due to bias toward the dataset, which may result in false or missing detections in the footage the model was not trained on. It is essential to consider that different methods often utilise different datasets, making direct comparisons challenging. The goal of our presented methodology was to test deep learning methods such as the state-of-the-art YOLO detection algorithm (and the tinyYOLO model) from drone footage. We must point out that the detection of birds was a challenging problem since the drone video was captured at a relatively high altitude (30–50m above sea level) avoiding sea disturbance. Overall, we can conclude that, with the current dataset, the models performed excellently, and they effectively accomplished the task of object detection based on the given dataset.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}