
High Speed and Accuracy of Animation 3D Pose Recognition Based on an Improved Deep Convolution Neural Network


Abstract
:1. Introduction
2. Methodology
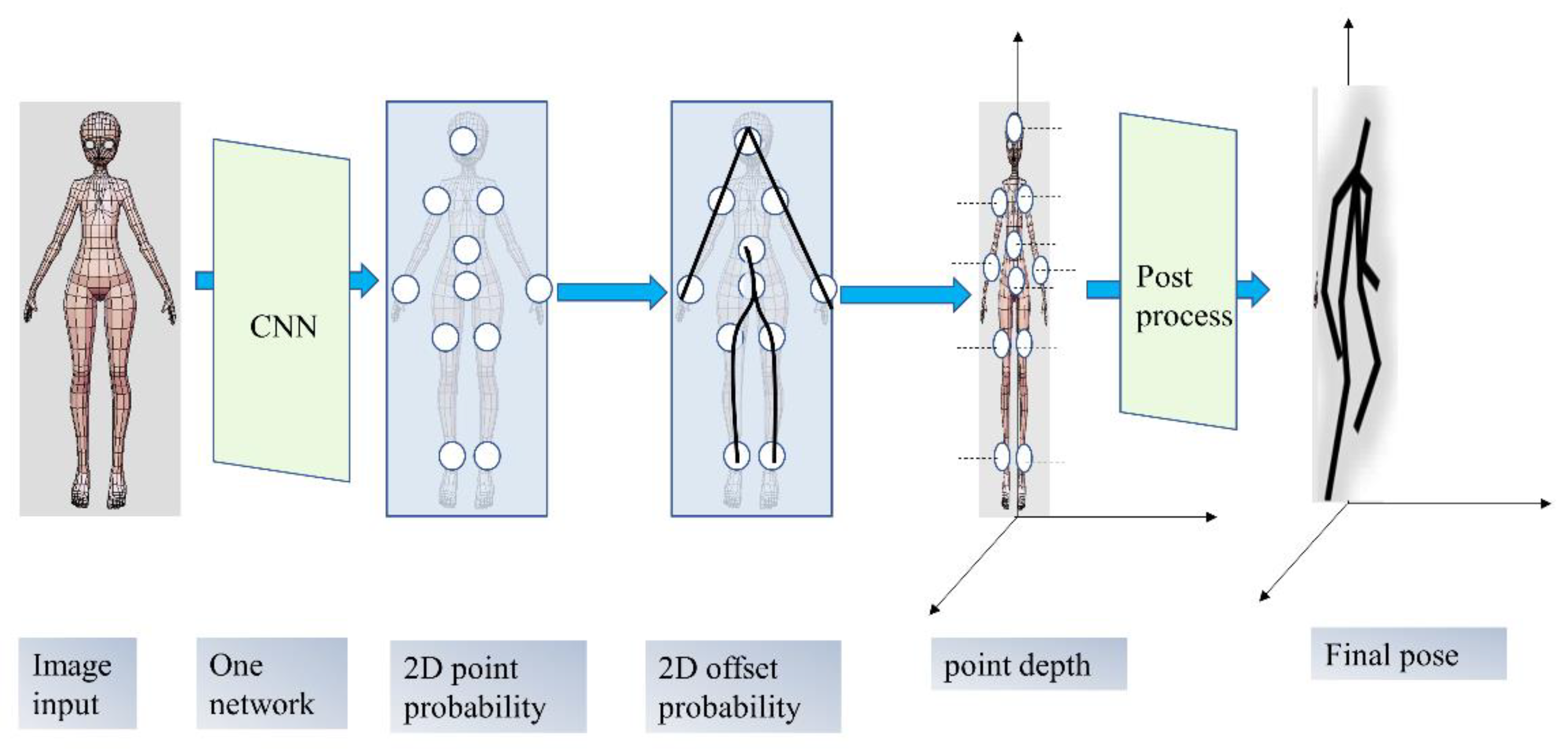
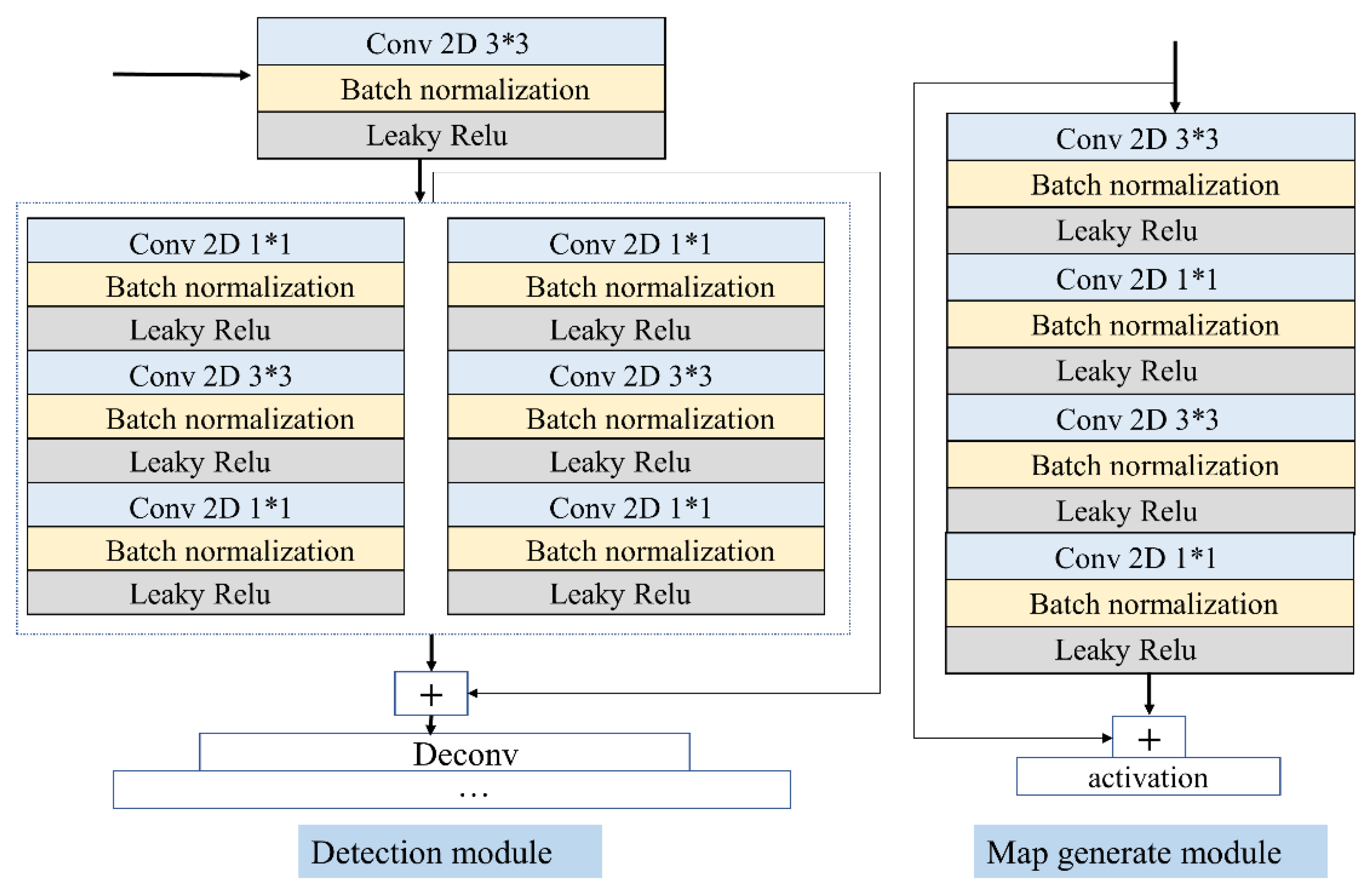
2.1. 3D Pose Recognition Based on Deep Learning
2.2. Network Postprocessing
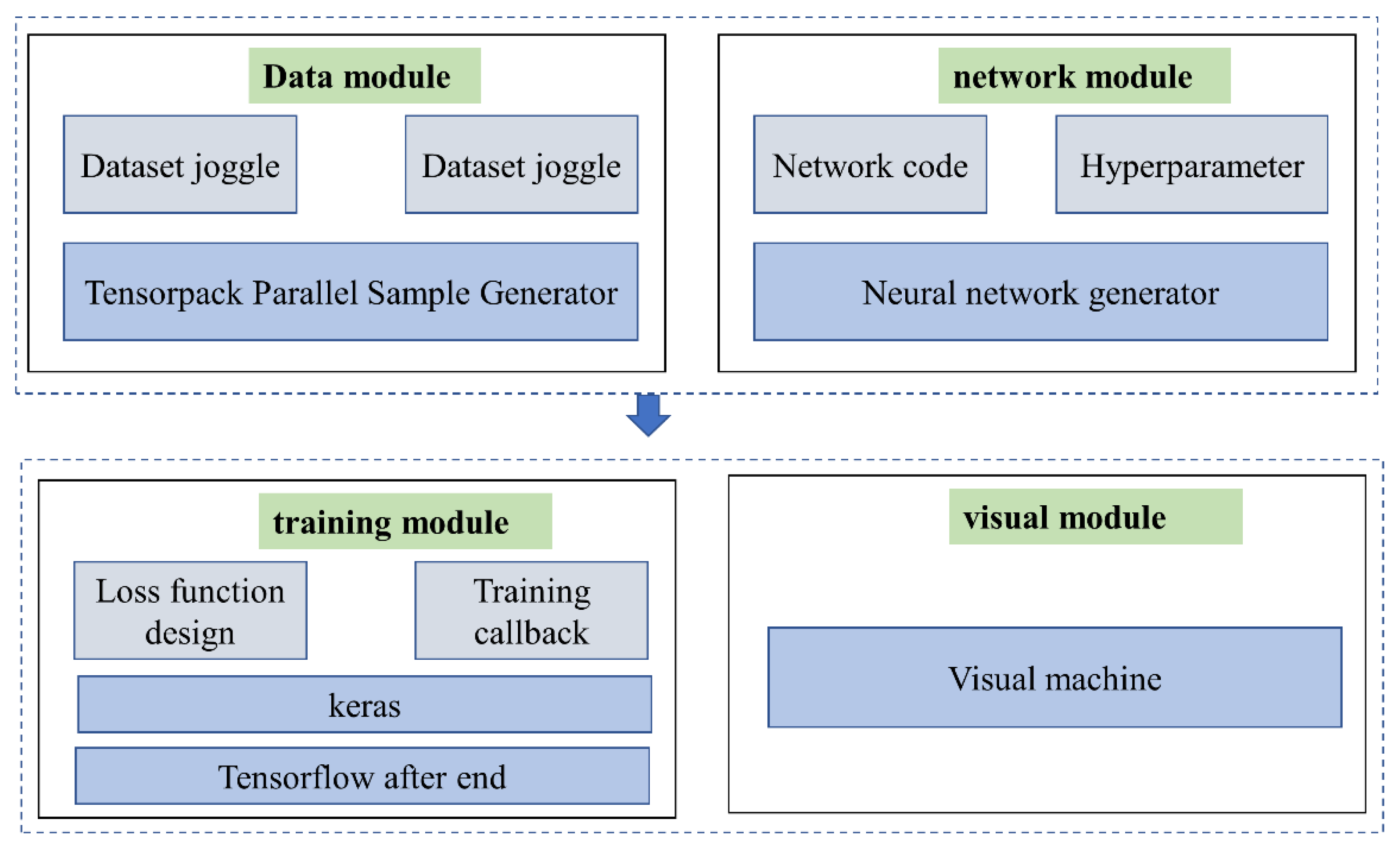
3. Training Experiment
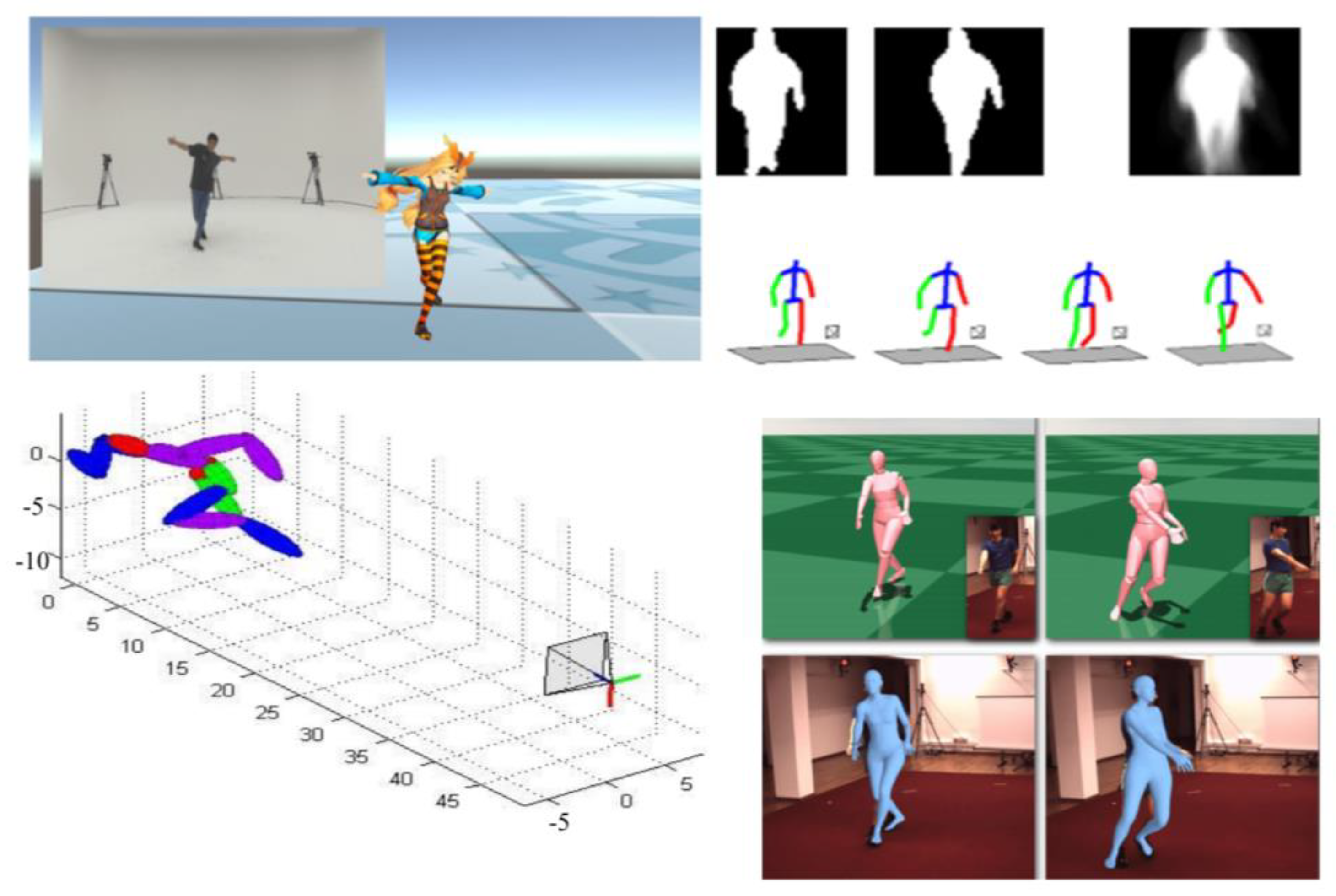
4. Results and Discussion
4.1. Error Analysis of Model
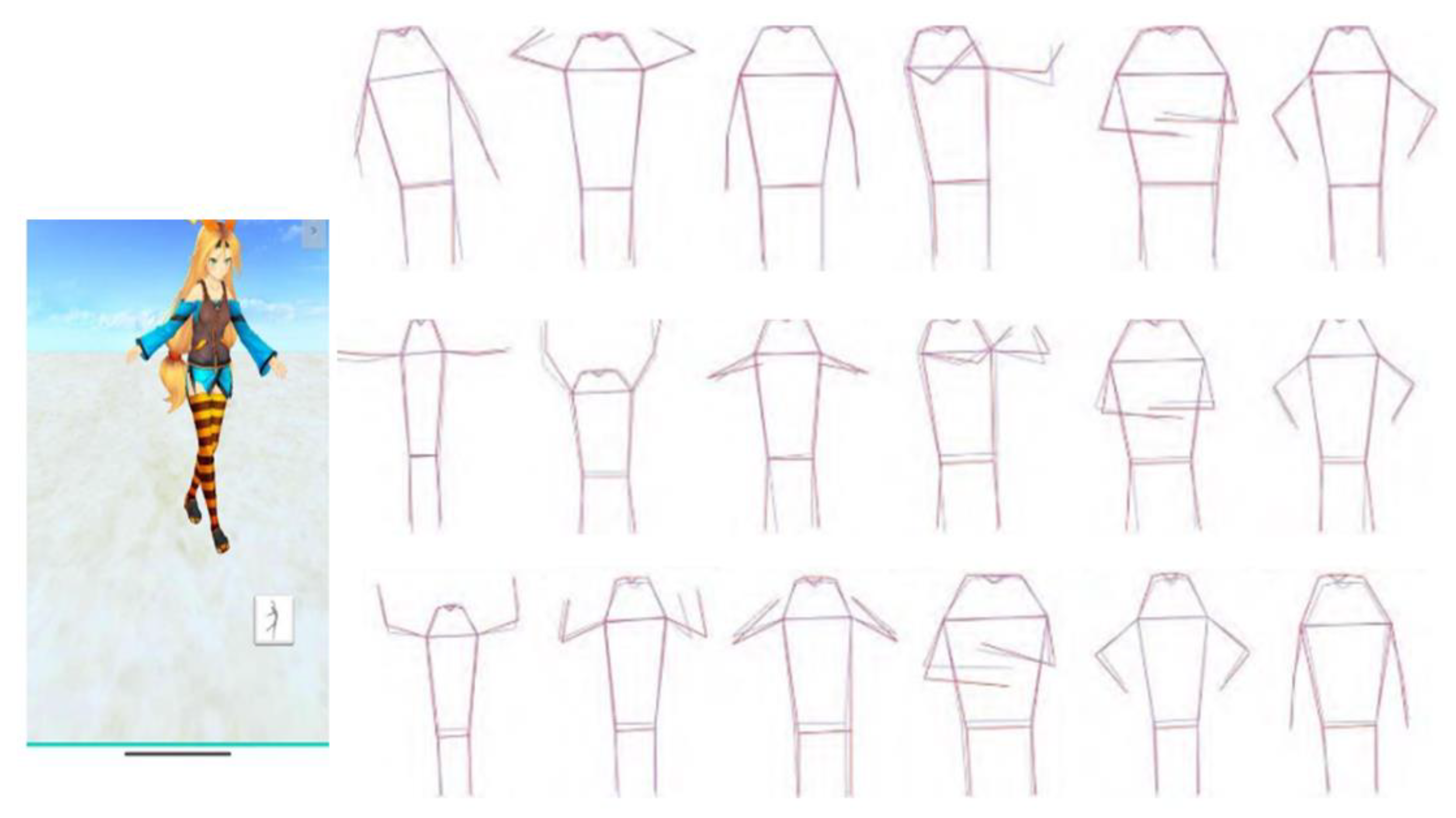
4.2. Performance between Multiple Datasets
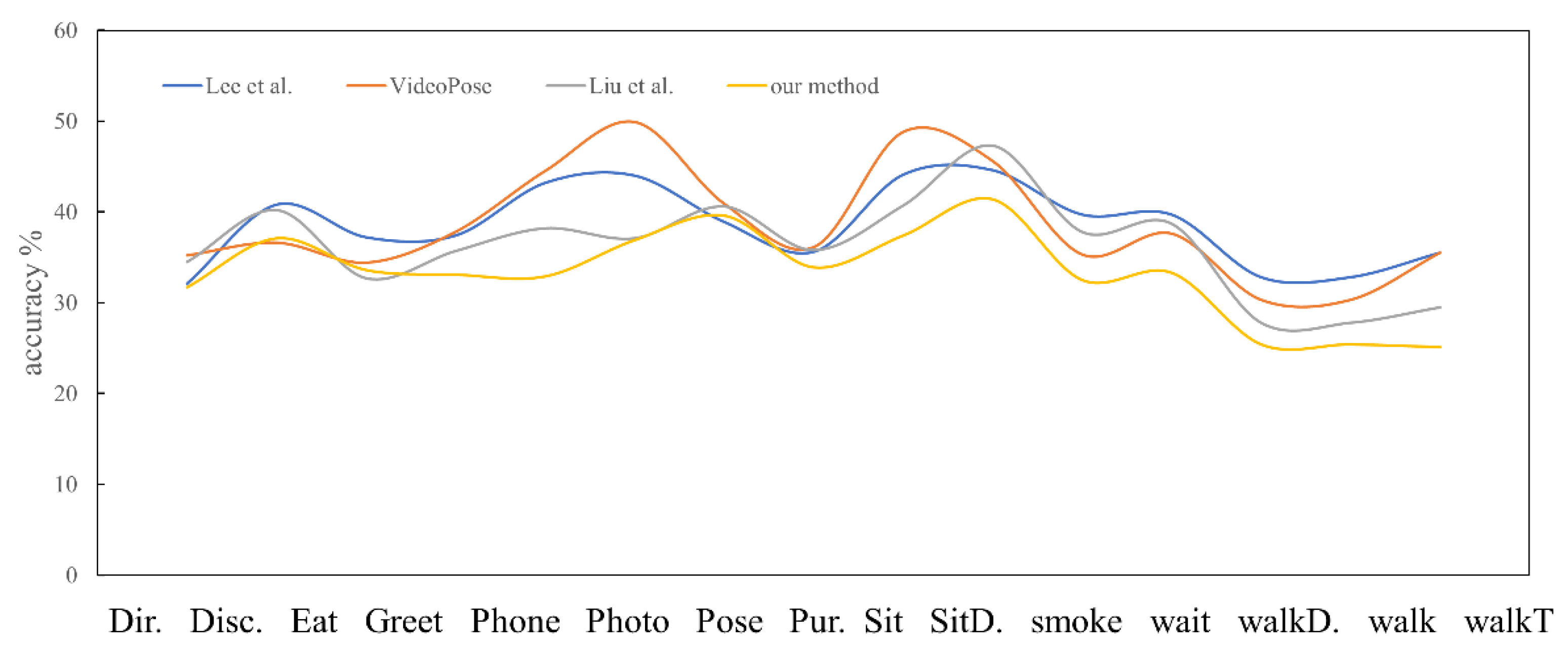
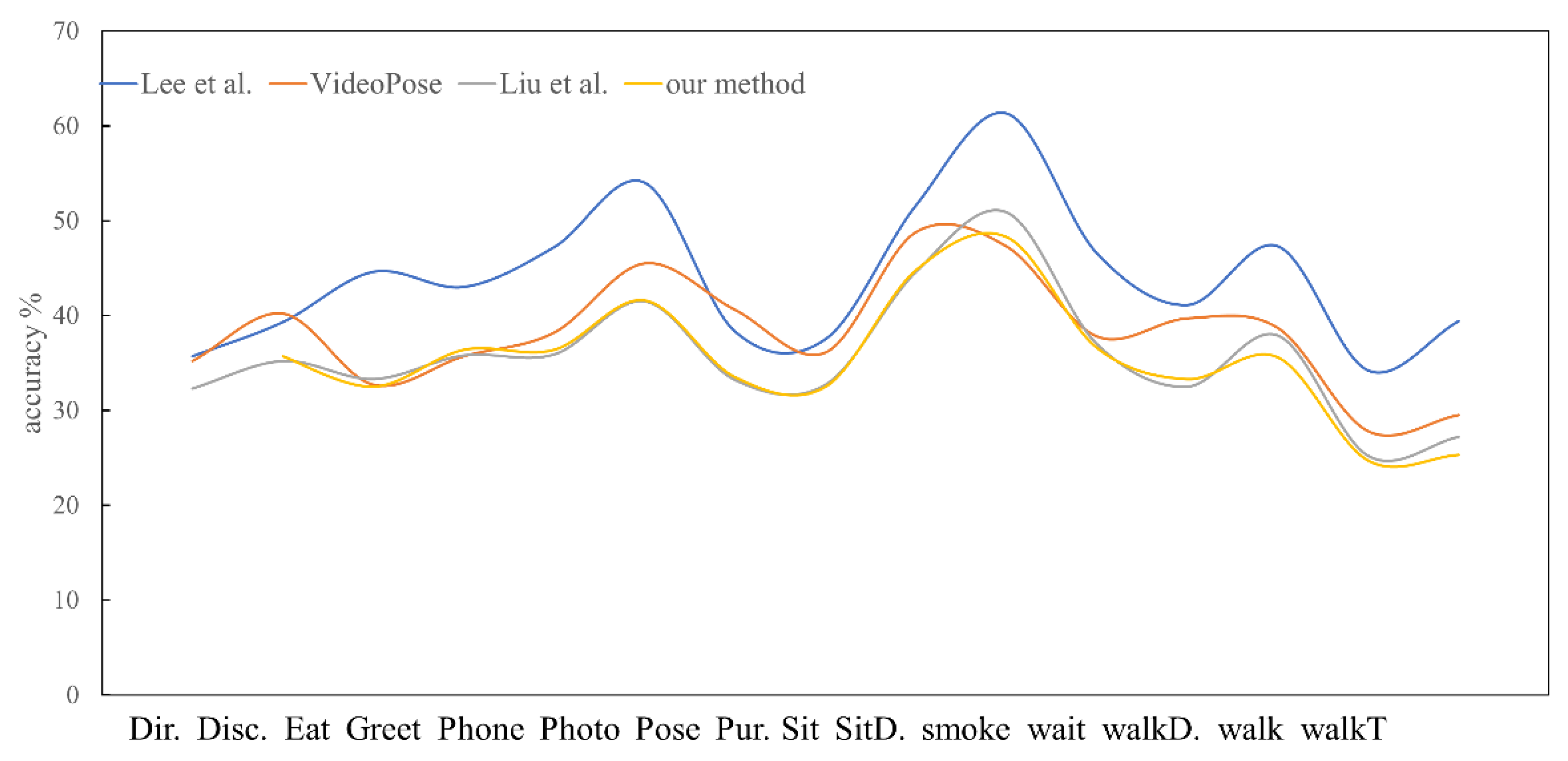
4.3. Comparative Experiment Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ha, J.; Ko, Y.; Kim, J.; Kim, C.-S. A catheter posture recognition method in three dimensions by using RF signal computation. Sens. Actuators A Phys. 2023, 354, 114292. [Google Scholar] [CrossRef]
- Zhang, H.; Li, Y.; Yang, H.; He, B.; Zhang, Y. Isomorphic model-based initialization for convolutional neural networks. J. Vis. Commun. Image Represent. 2022, 89, 103677. [Google Scholar] [CrossRef]
- Camacho, I.C.; Wang, K. Convolutional neural network initialization approaches for image manipulation detection. Digit. Signal Process. 2022, 122, 103376. [Google Scholar] [CrossRef]
- Li, X. Study on Volleyball-Movement Pose Recognition Based on Joint Point Sequence. Comput. Intell. Neurosci. 2023, 2023, 2198495. [Google Scholar] [CrossRef]
- Li, X.; Gong, Y.; Jin, X.; Shang, P. Sleep posture recognition based on machine learning: A systematic review. Pervasive Mob. Comput. 2023, 90, 101752. [Google Scholar] [CrossRef]
- AlFayez, F.; Bouhamed, H. Machine learning and uLBP histograms for posture recognition of dependent people via Big Data Hadoop and Spark platform. Int. J. Comput. Commun. Control. 2023, 18, 4981. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Cai, X. WSN-Driven Posture Recognition and Correction towards Basketball Exercise. Int. J. Inf. Syst. Model. Des. 2022, 13, 1–14. [Google Scholar] [CrossRef]
- Ji, H.; Yu, J.; Lao, F.; Zhuang, Y.; Wen, Y.; Teng, G. Automatic Position Detection and Posture Recognition of Grouped Pigs Based on Deep Learning. Agriculture 2022, 12, 1314. [Google Scholar] [CrossRef]
- Yuan, Y.; Zheng, D. Deep Learning-Based Posture Recognition for Motion-Assisted Evaluation. Mob. Inf. Syst. 2022, 2022, 1–9. [Google Scholar] [CrossRef]
- Younsi, M.; Diaf, M.; Siarry, P. Comparative study of orthogonal moments for human postures recognition. Eng. Appl. Artif. Intell. 2023, 120, 105855. [Google Scholar] [CrossRef]
- Leone, A.; Rescio, G.; Caroppo, A.; Siciliano, P.; Manni, A. Human Postures Recognition by Accelerometer Sensor and ML Architecture Integrated in Embedded Platforms: Benchmarking and Performance Evaluation. Sensors 2023, 23, 1039. [Google Scholar] [CrossRef]
- Ding, W.M.H. Human Skeleton Coordinate Pose Recognition. Eng. Adv. 2023, 2, 194–197. [Google Scholar] [CrossRef]
- Zhang, X.; Fan, J.; Peng, T.; Zheng, P.; Zhang, X.; Tang, R. Multimodal data-based deep learning model for sitting posture recognition toward office workers’ health promotion. Sens. Actuators A Phys. 2023, 350, 114150. [Google Scholar] [CrossRef]
- Aftab, S.; Ali, S.F.; Mahmood, A.; Suleman, U. A boosting framework for human posture recognition using spatio-temporal features along with radon transform. Multimed. Tools Appl. 2022, 81, 42325–42351. [Google Scholar] [CrossRef]
- Bourahmoune, K.; Ishac, K.; Amagasa, T. Intelligent Posture Training: Machine-Learning-Powered Human Sitting Posture Recognition Based on a Pressure-Sensing IoT Cushion. Sensors 2022, 22, 5337. [Google Scholar] [CrossRef]
- Liang, Y.; Li, Y.; Yin, H.; Yin, L. Intelligent Active Correction Seat Based on Neural Network Sitting Posture Recognition. J. Artif. Intell. Pract. 2022, 5, 050205. [Google Scholar] [CrossRef]
- Rahmaniar, W.; Ma’Arif, A.; Lin, T.-L. Touchless Head-Control (THC): Head Gesture Recognition for Cursor and Orientation Control. IEEE Trans. Neural Syst. Rehabil. Eng. 2022, 30, 3187472. [Google Scholar] [CrossRef]
- Huf, P.A.; Carminati, J. TensorPack: A Maple-based software package for the manipulation of algebraic expressions of tensors in general relativity. J. Physics Conf. Ser. 2015, 633, 012021. [Google Scholar] [CrossRef] [Green Version]
- Wu, P.; Fei, L.; Li, S.; Zhao, S.; Fang, X.; Teng, S. Towards pen-holding hand pose recognition: A new benchmark and a coarse-to-fine PHHP recognition network. IET Biom. 2022, 11, 581–587. [Google Scholar] [CrossRef]
- Liu, F.; Zhang, W. Basketball Motion Posture Recognition Based on Recurrent Deep Learning Model. Math. Probl. Eng. 2022, 2022, 8314777. [Google Scholar] [CrossRef]
- Vallabhaneni, N.; Prabhavathy, P. Analysis of the Impact of Yoga on Health Care Applications and Human Pose Recognition. ECS Trans. 2022, 107, 7889–7898. [Google Scholar] [CrossRef]
- Mücher, C.A.; Los, S.; Franke, G.J.; Kamphuis, C. Detection, identification and posture recognition of cattle with satellites, aerial photography and UAVs using deep learning techniques. Int. J. Remote Sens. 2022, 43, 2377–2392. [Google Scholar] [CrossRef]
- Mu, J.; Xian, S.; Yu, J.; Zhao, J.; Song, J.; Li, Z.; Hou, X.; Chou, X.; He, J. Synergistic Enhancement Properties of a Flexible Integrated PAN/PVDF Piezoelectric Sensor for Human Posture Recognition. Nanomaterials 2022, 12, 1155. [Google Scholar] [CrossRef]
- Parra-Dominguez, G.S.; Sanchez-Yanez, R.E.; Garcia-Capulin, C.H. Towards Facial Gesture Recognition in Photographs of Patients with Facial Palsy. Healthcare 2022, 10, 659. [Google Scholar] [CrossRef]
- Guerra, B.M.V.; Schmid, M.; Beltrami, G.; Ramat, S. Neural Networks for Automatic Posture Recognition in Ambient-Assisted Living. Sensors 2022, 22, 2609. [Google Scholar] [CrossRef]
- Lee, J.-H.; Lee, J.; Park, S.-Y. 3D Pose Recognition System of Dump Truck for Autonomous Excavator. Appl. Sci. 2022, 12, 3471. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Zitnick, C.L.; Dollár, P. Microsoft Coco: Common Objects in Context. European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Joo, H.; Liu, H.; Tan, L.; Gui, L.; Nabbe, B.; Matthews, I.; Kanade, T.; Nobuhara, S.; Sheikh, Y. Panoptic studio: A massively multiview system for social motion capture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3334–3342. [Google Scholar]
- Fabbri, M.; Lanzi, F.; Calderara, S.; Palazzi, A.; Vezzani, R.; Cucchiara, R. Learning to detect and track visible and occluded body joints in a virtual world. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 430–446. [Google Scholar]
- Bindu, N.P.; Sastry, P.N. Automated brain tumor detection and segmentation using modified UNet and ResNet model. Soft Comput. 2023, 27, 9179–9189. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kang, L. A Dance Somersault Pose Recognition Model Using Multifeature Fusion Algorithm. Mob. Inf. Syst. 2022, 2022, 3034663. [Google Scholar] [CrossRef]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Martinez, J.; Hossain, R.; Romero, J.; Little, J.J. A simple yet effective baseline for 3d human pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2640–2649. [Google Scholar]
- Rogez, G.; Weinzaepfel, P.; Schmid, C. LCR-Net++: Multi-Person 2D and 3D Pose Detection in Natural Images. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1146–1161. [Google Scholar] [CrossRef] [Green Version]
- Lee, K.; Lee, I.; Lee, S. Propagating LSTM: 3D Pose Estimation Based on Joint Interdependency. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 119–135. [Google Scholar]
- Mehta, D.; Sridhar, S.; Sotnychenko, O.; Rhodin, H.; Shafiei, M.; Seidel, H.P.; Xu, W.; Casas, D.; Theobalt, C. VNect: Real-Time 3D Human Pose Estimation with a Single RGB Camera. ACM Trans. Graph. 2017, 36, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Liu, R.; Shen, J.; Wang, H.; Chen, C.; Cheung, S.C.; Asari, V. Attention Mechanism Exploits Temporal Contexts: Real-Time 3D Human Pose Reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5064–5073. [Google Scholar]
- Lam, S.K.; Pitrou, A.; Seibert, S. Numba: A llvm-based python JIT compiler. In Proceedings of the Second Workshop on the LLVM Compiler Infrastructure in HPC, Austin, TX, USA, 15 November 2015; pp. 1–6. [Google Scholar]
- Gercek, H.; Unuvar, B.S.; Yemisci, O.U.; Aytar, A. Acute effects of instrument assisted soft tissue mobilization technique on pain and joint position error in individuals with chronic neck pain: A double-blind, randomized controlled trial. Somatosens. Mot. Res. 2022, 40, 25–32. [Google Scholar] [CrossRef]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Wang, C.; Li, J.; Liu, W.; Qian, C.; Lu, C. Hmor: Hierarchical multi-person ordinal relations for monocular multi-person 3d pose estimation. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 8–15. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded Pyramid Network for Multi-Person Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7103–7112. [Google Scholar]
- Ran, H.; Ning, X.; Li, W.; Hao, M.; Tiwari, P. 3D human pose and shape estimation via de-occlusion multi-task learning. Neurocomputing 2023, 548, 126284. [Google Scholar] [CrossRef]
- Tian, S.; Li, W.; Ning, X.; Ran, H.; Qin, H.; Tiwari, P. Continuous Transfer of Neural Network Representational Similarity for Incremental Learning. Neurocomputing 2023, 545, 126300. [Google Scholar] [CrossRef]
- Ning, X.; Tian, W.; He, F.; Bai, X.; Sun, L.; Li, W. Hyper-sausage coverage function neuron model and learning algorithm for image classi cation. Pattern Recognit. 2023, 136, 109216. [Google Scholar] [CrossRef]
- Ning, X.; Xu, S.; Nan, F.; Zeng, Q.; Wang, C.; Cai, W.; Jiang, Y. Face editing based on facial recognition features. IEEE Trans. Cogn. Dev. Syst. 2022, 15, 774–783. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Name | Output | 34 Layer |
|---|---|---|
| Input layer | 384 × 384 | |
| Conv1 | 192 × 192 | 7 × 7, 8, stride 2 |
| Conv2x | 96 × 96 | 3 × 3 max pool, stride 2 |
| Conv3x | 48 × 48 | |
| Conv4x | 24 × 24 | |
| Conv5x | 12 × 12 |
| Methods | Input | MPJPE (mm) | Velocity |
|---|---|---|---|
| Zhou et al. [34] | Video | 65.1 | - |
| Martinez et al. [35] | 2D pose | 64.1 | - |
| Open Pose (high accuracy mode)/Martinez et al. [35] | RGB image | 71.2 | 834.0 |
| Open Pose (high speed mode)/Martinez et al. [35] | RGB image | 83.1 | 114.2 |
| LCR-Net [36] | RGB pose | 83.1 | - |
| This study | RGB pose | 113.2 | 47.1 |
| Joint Point | Base | 2D-3D Pose | Base + Anchor Pose | Base + Anchor 3D Pose | Our Method |
|---|---|---|---|---|---|
| Nose | 32.9 | 44.0 | 43.2 | 49.3 | 55.9 |
| Left eye | 38.6 | 46.7 | 45.6 | 50.9 | 58.6 |
| Right eye | 34.3 | 46.7 | 40.9 | 52.3 | 65.1 |
| Lest ear | 53.2 | 62.5 | 61.0 | 66.8 | 61.0 |
| Right ear | 49.9 | 63.9 | 60.9 | 68.9 | 65.5 |
| Left shoulder | 44.8 | 73.5 | 14.3 | 73.2 | 75.3 |
| Right shoulder | 45.0 | 73.5 | 18.6 | 33.0 | 74.5 |
| Left elbow | 7.2 | 32.1 | 5.5 | 28.4 | 35.5 |
| Right elbow | 10.4 | 28.4 | 5.0 | 7.0 | 33.5 |
| Left wrist | 3.4 | 6.9 | 42.1 | 5.4 | 6.5 |
| Right wrist | 2.8 | 5.3 | 33.6 | 54.9 | 5.5 |
| Left hip | 41.5 | 48.9 | 19.5 | 49.1 | 57.4 |
| Right hip | 19.2 | 45.1 | 18.5 | 25.8 | 50.3 |
| Left knee | 17.5 | 23.6 | 19.5 | 26.4 | 26.4 |
| Right knee | 11.8 | 25.9 | 18.6 | 10.6 | 27.3 |
| Left ankle | 7.8 | 11.9 | 16.6 | 14.0 | 8.1 |
| Right ankle | 3.7 | 13.6 | 7.9 | 11.2 | 12.2 |
| Average | 25.0 | 39.1 | 33.1 | 41.2 | 42.1 |
| Joint Point | Base | 2D-3D Pose | Base + Anchor Pose | Base + Anchor 3D Pose | Our Method |
|---|---|---|---|---|---|
| Nose | 22.2 | 55 | 60.1 | 61.7 | 67.2 |
| Left eye | 20.1 | 56.9 | 58.2 | 58.9 | 70.5 |
| Right eye | 22.5 | 49.7 | 54.8 | 56.8 | 64.0 |
| Lest ear | 52.9 | 62.5 | 55.5 | 56.8 | 70.5 |
| Right ear | 35.1 | 58.9 | 56.5 | 55.5 | 56.1 |
| Left shoulder | 51.5 | 63.5 | 58.2 | 56.2 | 63.3 |
| Right shoulder | 12.6 | 63.5 | 58.2 | 57.5 | 23.1 |
| Left elbow | 11.8 | 22.1 | 17.1 | 57.5 | 22.5 |
| Right elbow | 7.6 | 20.5 | 18.5 | 17.8 | 12.2 |
| Left wrist | 8.1 | 9.0 | 8.9 | 18.5 | 14.1 |
| Right wrist | 11.9 | 9.8 | 8.9 | 8.9 | 50.5 |
| Left hip | 7.6 | 49.0 | 41.8 | 8.9 | 41.9 |
| Right hip | 7.5 | 44.6 | 46.6 | 44.5 | 39.9 |
| Left knee | 22.6 | 33.5 | 40.4 | 41.8 | 31.2 |
| Right knee | 26.5 | 49.6 | 38.3 | 39.1 | 45.9 |
| Left ankle | 22.1 | 10.2 | 38.6 | 41.7 | 46.1 |
| Right ankle | 19.2 | 6.3 | 42.3 | 41.6 | 46 |
| Average | 25.6 | 39.0 | 40.1 | 41.7 | 46.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, W.; Li, W. High Speed and Accuracy of Animation 3D Pose Recognition Based on an Improved Deep Convolution Neural Network. Appl. Sci. 2023, 13, 7566. https://doi.org/10.3390/app13137566
Ding W, Li W. High Speed and Accuracy of Animation 3D Pose Recognition Based on an Improved Deep Convolution Neural Network. Applied Sciences. 2023; 13(13):7566. https://doi.org/10.3390/app13137566
Chicago/Turabian StyleDing, Wei, and Wenfa Li. 2023. "High Speed and Accuracy of Animation 3D Pose Recognition Based on an Improved Deep Convolution Neural Network" Applied Sciences 13, no. 13: 7566. https://doi.org/10.3390/app13137566
APA StyleDing, W., & Li, W. (2023). High Speed and Accuracy of Animation 3D Pose Recognition Based on an Improved Deep Convolution Neural Network. Applied Sciences, 13(13), 7566. https://doi.org/10.3390/app13137566