
Cross-Modal Sentiment Analysis of Text and Video Based on Bi-GRU Cyclic Network and Correlation Enhancement

Abstract
:1. Introduction
- This paper proposes a sentiment analysis model (UA-BFET) based on feature enhancement technology in unaligned data scenarios. The model can be used to analyze the sentiment of unaligned text and video modality data in social media.
- It uses a cyclic memory enhancement network across time steps and canonical correlation analysis (CCA) to extract effective unimodal feature representations and explore the correlation and interaction between different modalities.
- The UA-BFET model proposed in this study reaches or even exceeds the sentiment analysis effect of text, video, and audio modalities fusion, which proves the feasibility of the proposed UA-BFET model.
2. Related Work
2.1. Multimodal Sentiment Analysis
2.2. Cross-Modal Sentiment Analysis
2.3. Sentiment Analysis Based on Unaligned Data Sequence Scenarios
- Sentiment analysis based on word alignment: In the scenario of unaligned data sequences, previous studies usually used P2FA [32] to perform the forced word alignment. Previous studies on the fusion of unaligned data sequences have mined the correlation between data of different modalities on the basis of effectively representing unimodal information [33]. Nevertheless, since the performance of sentiment analysis using shallow learning architecture is far from satisfactory, more complex models have been proposed successively [4,5,6,7,8,9,10,11,12,13], such as RMFN, MFM, HFFN, RAVEN, etc. We note that word alignment requires not only detailed information about the domain but also meta-information about the exact time range of words in the datasets, which leads to sentiment analysis not always being feasible in practical applications.
- Sentiment analysis based on unaligned words: This means that sentiment analysis is performed directly without explicitly aligning sequence data. In 2019, Tsai et al. [14] first extended the NMT Transformer [34] to multimodal sentiment analysis and proposed a multimodal MulT that can learn the interaction information between different modalities and directly perform the sentiment analysis of text, video, and audio without explicitly aligning the sequence data. Although better results are obtained, the complexity of the model increases. Given the above problems, Sahay et al. [35] proposed a low-rank fusion-based Transformer (LMT-MULT) to avoid any excessive parameterization of the model in 2020. Based on this, Fu et al. [15] designed a new lightweight network in 2021, which adopts a Transformer with cross-modal blocks to realize the complementary learning of different modalities. Although the accuracy is not the best, better results are obtained with the least model parameters. However, since the above studies use the same annotation methods in different modalities, the performance in capturing modal differentiation information is poor, and the additional unimodal annotation requires a lot of manpower and time. Based on this, Yu et al. [24] proposed a sentiment analysis method combining self-supervision and multi-task learning in 2021. The difference between different modalities is obtained through independent single-peak supervision, but using fused modal information for sentiment analysis may result in issues such as loss of unimodal information or inclusion of noise in the fused information. To address this problem, in 2021, He et al. [17] proposed a single-peak enhanced Transformer method to carry out sentiment analysis for text, video, and audio. Notwithstanding, the method of feature enhancement based on unimodal is far from enough. In 2022, Lv et al. [18] proposed the progressive modal reinforcement (PMR) method with a message center to enhance the accuracy of sentiment analysis of text, video, and audio through the complementary process of unimodal information and fusion information but ignored the impact of the interaction between different modalities on the final result of sentiment analysis.
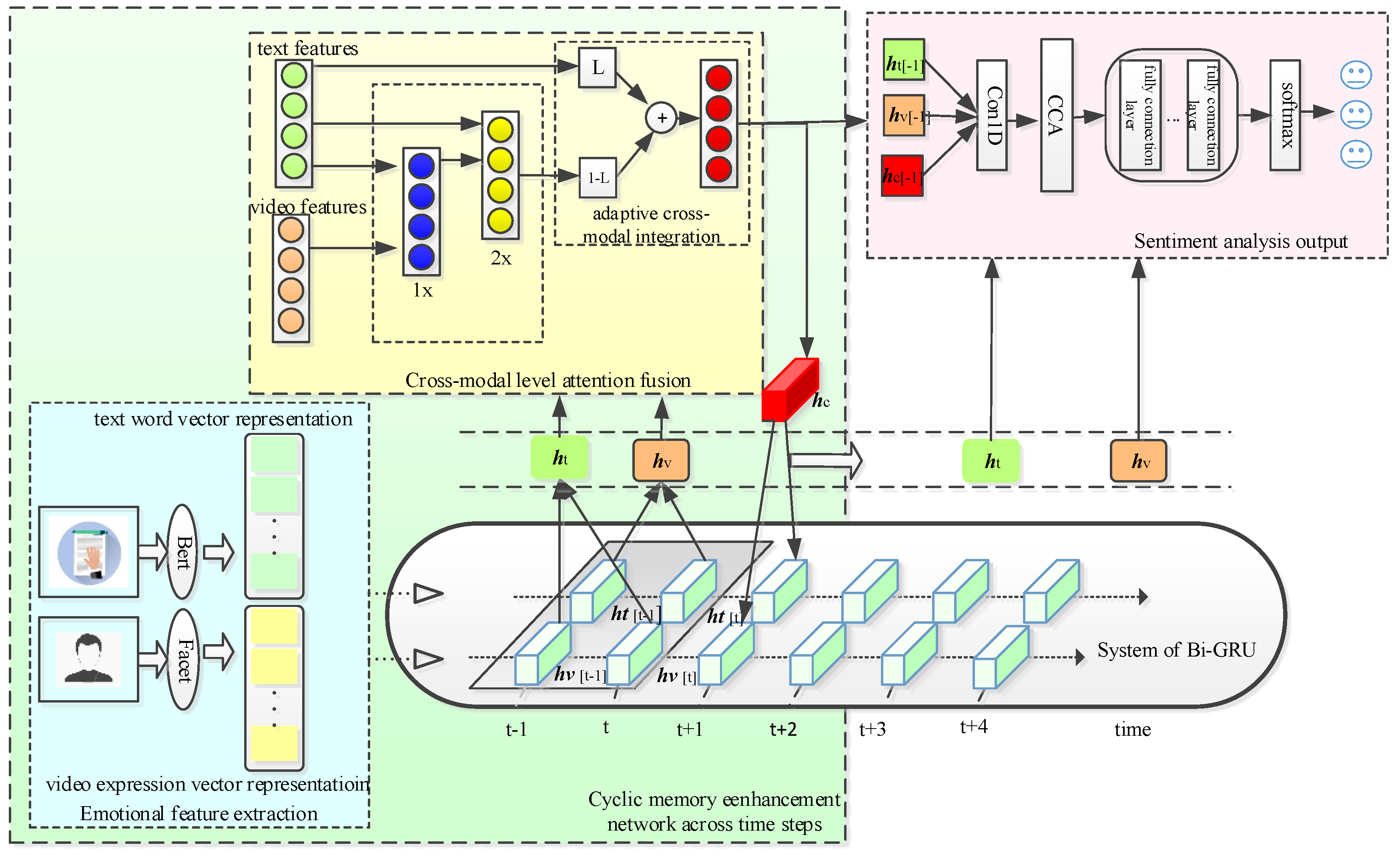
3. UA-BFET Sentiment Analysis Model
3.1. Unimodal Feature Extraction
3.2. Feature Enhancement Module
3.2.1. Cyclic Memory Enhancement Network across Time Steps
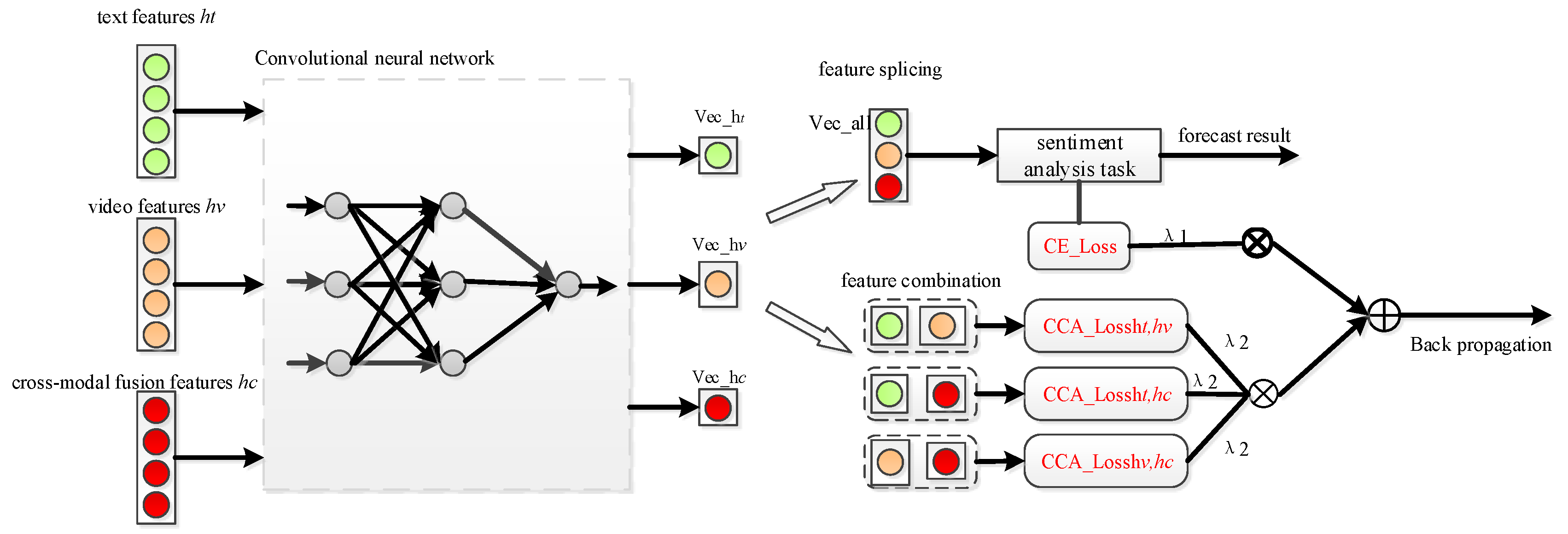
3.2.2. Feature Enhancement Based on Canonical Correlation Analysis
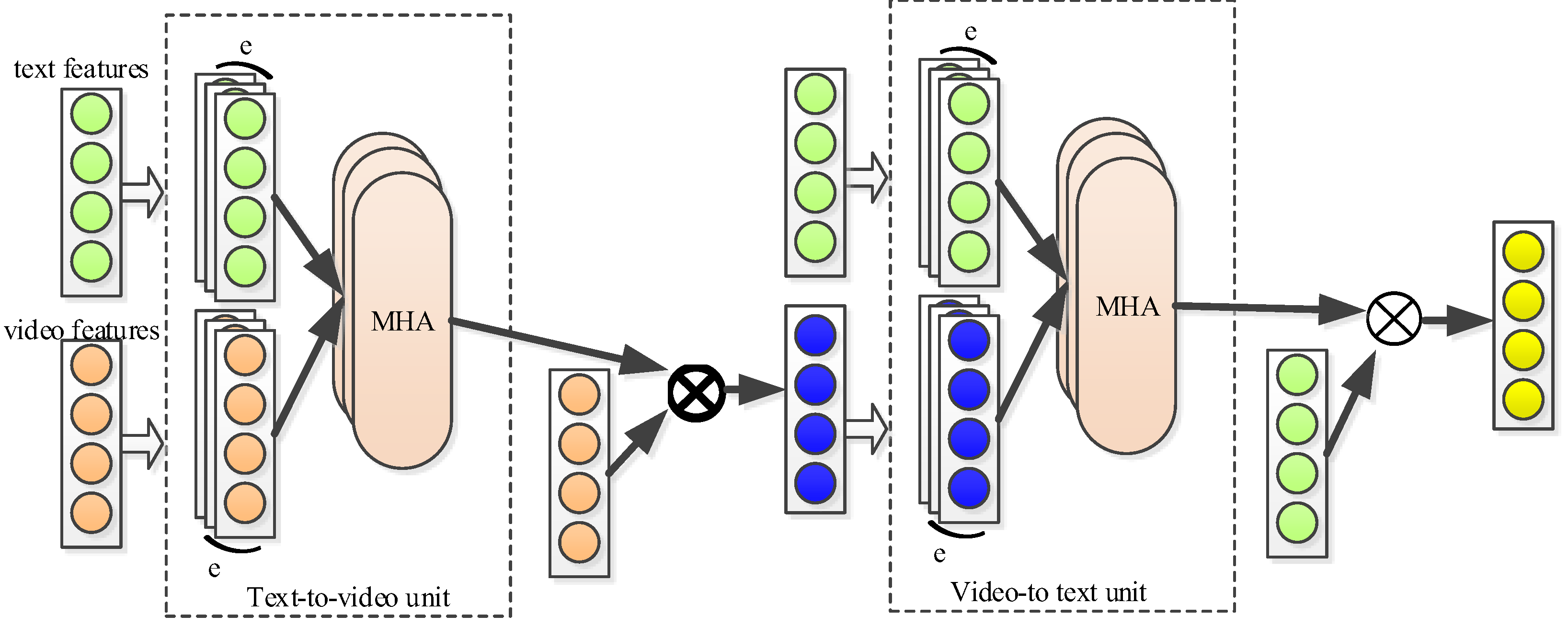
3.3. Cross-Modal Hierarchical Attention Fusion Module
3.3.1. Cross-Modal Interaction
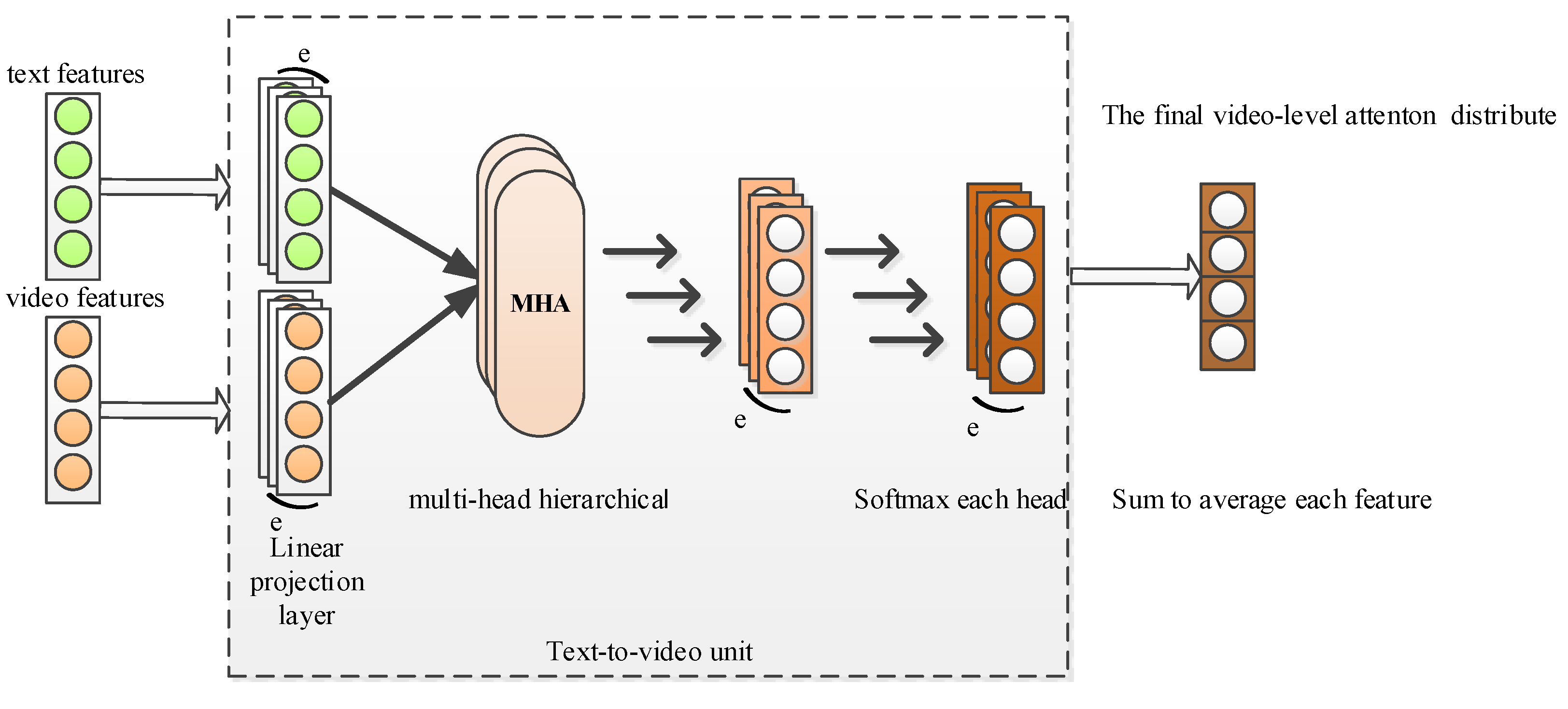
3.3.2. Multi-Head Processing
3.3.3. Adaptive Cross-Modal Integration
3.4. Sentiment Classification Output Module
4. Experimental Evaluation
4.1. Datasets
4.2. Experimental Setting
4.3. Evaluation Metrics
4.4. Quantitative Analysis
4.4.1. Word Alignment Setting
4.4.2. Unaligned Settings
4.5. Ablation Results
4.5.1. The Validity of CCA
4.5.2. The Validity of Cross-Modal Fusion of Text and Video in Unaligned Data Scenarios
4.6. Case Study
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, L.; Guan, Z.Y.; He, J.H.; Peng, J.Y. A survey on sentiment classification. J. Comput. Res. Dev. 2017, 54, 1150–1170. [Google Scholar]
- Lehrer, S.F.; Xie, T. The bigger picture: Combining econometrics with analytics improve forecasts of movie success. Manag. Sci. 2022, 68, 189–210. [Google Scholar] [CrossRef]
- O’Connor, B.; Balasubramanyan, R.; Routledgeb, B.R.; Smith, N.A. From tweets to polls: Linking text sentiment to public opinion time series. In Proceedings of the Fourth International Conference on Weblogs and Social Media, Washington, DC, USA, 23–26 May 2010. [Google Scholar] [CrossRef]
- Poria, S.; Cambria, E.; Hazarika, D.; Majumder, N.; Zadeh, A.; Morency, L.-P. Context-dependent sentiment analysis in user-generated videos. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, Canada, 30 July–4 August 2017. [Google Scholar] [CrossRef] [Green Version]
- Zadeh, A.; Liang, P.P.; Mazumder, N.; Poria, S.; Cambria, E.; Morency, L.-P. Memory fusion network for multi-view sequential learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar] [CrossRef]
- Gu, Y.; Yang, K.N.; Fu, S.Y.; Chen, S.H.; Li, X.Y.; Marsic, I. Multimodal affective analysis using hierarchical attention strategy with word-level alignment. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018. [Google Scholar]
- Liang, P.P.; Liu, Z.Y.; Zadeh, A.; Morency, L.-P. Multimodal Language Analysis with Recurrent Multistage Fusion. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018. [Google Scholar] [CrossRef]
- Tsai, Y.-H.H.; Liang, P.P.; Zadeh, A.; Morency, L.-P.; Salakhutdinov, R. Learning factorized multimodal representations. In Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar] [CrossRef]
- Pham, H.; Liang, P.P.; Manzini, T.; Morency, L.-P.; Poczos, B. Found in translation: Learning robust joint representations by cyclic translations between modalities. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar] [CrossRef] [Green Version]
- Mai, S.J.; Hu, H.F.; Xing, S.L. Divide, conquer and combine: Hierarchical feature fusion network with local and global perspectives for multimodal affective computing. In Proceedings of the 57th Conference of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar] [CrossRef]
- Hazarika, D.; Zimmermann, R.; Poria, S. MISA: Modality-invariant and-specific representations for multimodal sentiment analysis. In Proceedings of the 28th ACM international conference on multimedia, Seattle, WA, USA, 12–16 October 2022. [Google Scholar] [CrossRef]
- Dai, W.L.; Cahyawijaya, S.; Bang, Y.J.; Fung, P. Weakly-supervised Multi-task Learning for Multimodal Affect Recognition. arXiv 2021, arXiv:2104.11560. [Google Scholar] [CrossRef]
- Wang, Y.S.; Shen, Y.; Liu, Z.; Liang, P.P.; Zadeh, A. Words can shift: Dynamically adjusting word representations using nonverbal behaviors. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar] [CrossRef] [Green Version]
- Tsai, Y.-H.H.; Bai, S.J.; Liang, P.P.; Kolter, J.Z.; Morency, L.-P.; Salakhutdinov, R. Multimodal transformer for unaligned multimodal language sequences. In Proceedings of the 57th Conference of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar] [CrossRef] [Green Version]
- Fu, Z.W.; Liu, F.; Wang, H.Y.; Shen, S.Y.; Zhang, J.H.; Qi, J.Y.; Fu, X.L.; Zhou, A.M. LMR-CBT: Learning Modality-fused Representations with CB-Transformer for Multimodal Emotion Recognition from Unaligned Multimodal Sequences. arXiv 2021, arXiv:2112.01697. [Google Scholar] [CrossRef]
- Zhang, R.; Xue, C.G.; Qi, Q.F.; Lin, L.Y.; Zhang, J.; Zhang, L. Bimodal Fusion Network with Multi-Head Attention for Multimodal Sentiment Analysis. Appl. Sci. 2023, 13, 1915. [Google Scholar] [CrossRef]
- He, J.X.; Mai, S.J.; Hu, H.F. A unimodal reinforced transformer with time squeeze fusion for multimodal sentiment analysis. IEEE Signal Process. Lett. 2021, 28, 992–996. [Google Scholar] [CrossRef]
- Lv, F.M.; Chen, X.; Huang, Y.Y.; Duan, L.X.; Lin, G.S. Progressive modality reinforcement for human multimodal emotion recognition from unaligned multimodal sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021. [Google Scholar] [CrossRef]
- Chen, J.Y.; Yan, S.K.; Wong, K.-C. Verbal aggression detection on Twitter comments: Convolutional neural network for short-text sentiment analysis. Neural Comput. Appl. 2020, 32, 10809–10818. [Google Scholar] [CrossRef]
- Rao, T.R.; Li, X.X.; Xu, M. Learning multi-level deep representations for image emotion classification. Neural Process. Lett. 2020, 51, 2043–2061. [Google Scholar] [CrossRef] [Green Version]
- Mcgurk, H.; Macdonald, J. Hearing lips and seeing voices. Nature 1976, 264, 746–748. [Google Scholar] [CrossRef]
- Zadeh, A.; Chen, M.H.; Poria, S.; Cambria, E.; Morency, L.-P. Tensor fusion network for multimodal sentiment analysis analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017. [Google Scholar] [CrossRef]
- Liu, Z.; Shen, Y.; Lakshminarasimhan, V.B.; Liang, P.P.; Zadeh, A.; Morency, L.-P. Efficient Low-rank Multimodal Fusion With Modality-Specific Factors. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018. [Google Scholar] [CrossRef]
- Yu, W.M.; Xu, H.; Yuan, Z.Q.; Wu, J.L. Learning modality-specific representations with self-supervised multi-task learning for multimodal sentiment analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 2–9 February 2021. [Google Scholar] [CrossRef]
- Lin, M.H.; Meng, Z.Q. Multimodal sentiment analysis based on attention neural network. Comput. Sci. 2020, 47, 508–514, 548. [Google Scholar]
- Guo, K.X.; Zhang, Y.X. Visual-textual sentiment analysis method based on multi-level spatial attention. J. Comput. Appl. 2021, 41, 2835–2841. [Google Scholar]
- Fan, T.; Wu, P.; Wang, H.; Ling, C. Sentiment analysis of online users based on multimodal co-attention. J. China Soc. Sci. Tech. Inf. 2021, 40, 656–665. [Google Scholar]
- You, Q.Z.; Luo, J.B.; Jin, H.L.; Yang, J.C. Robust image sentiment analysis using progressively trained and domain transferred deep networks. In Proceedings of the AAAI conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar] [CrossRef]
- Cai, G.Y.; Xia, B.B. Multimedia sentiment analysis based on convolutional neural network. J. Comput. Appl. 2016, 36, 428–431, 477. [Google Scholar]
- Shen, Z.Q. A cross-modal social media sentiment analysis method based on the fusion of image and text. Softw. Guide 2019, 18, 9–13, 16. [Google Scholar]
- Chen, Q.H.; Sun, J.J.; Sun, L.; Jia, Y.B. Image-text sentiment analysis based on multi-layer cross-modal attention fusion. J. Zhejiang Sci-Tech Univ. (Nat. Sci. Ed.) 2022, 47, 85–94. [Google Scholar]
- Yuan, J.H.; Liberman, M. Speaker identification on the SCOTUS corpus. J. Acoust. Soc. Am. 2008, 123, 3878. [Google Scholar] [CrossRef]
- Zeng, Z.H.; Tu, J.L.; Pianfetti, B.; Liu, M.; Zhang, T.; Zhang, Z.Q.; Huang, T.S.; Levinson, S.E. Audio-visual affect recognition through multi-stream fused HMM for HCI. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Advances in neural information processing systems, Long Beach, CA, USA, 4–9 December 2017. [CrossRef]
- Sahay, S.; Okur, E.; Kumar, S.H.; Nachman, L. Low Rank Fusion based Transformers for Multimodal Sequences. arXiv 2020, arXiv:2007.02038. [Google Scholar] [CrossRef]
- Chen, Q.P.; Huang, G.M.; Wang, Y.B. The Weighted Cross-Modal Attention Mechanism With Sentiment Prediction Auxiliary Task for Multimodal Sentiment Analysis. IEEE ACM Trans. Audio Speech Lang. Process. 2022, 30, 2689–2695. [Google Scholar] [CrossRef]
- Tian, Y.; Sun, X.; Yu, H.F.; Li, Y.; Fu, K. Hierarchical self-adaptation network for multimodal named entity recognition in social media. Neurocomputing 2021, 439, 12–21. [Google Scholar] [CrossRef]
- Yang, Q.; Zhang, Y.W.; Zhu, L.; Wu, T. Text sentiment analysis based on fusion of attention mechnism and BiGRU. Comput. Sci. 2021, 48, 307–311. [Google Scholar]
- Guo, X.B.; Kong, W.-K.A.; Kot, A.C. Deep Multimodal Sequence Fusion by Regularized Expressive Representation Distillation. IEEE Trans. Multimed. 2022. [CrossRef]
- Han, W.; Chen, H.; Poria, S. Improving Multimodal Fusion with Hierarchical Mutual Information Maximization for Multimodal Sentiment Analysis. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Virtual Event / Punta Cana, Dominican Republic, 7–11 November 2021. [Google Scholar] [CrossRef]
- Zhao, Z.P.; Wang, K. Unaligned Multimodal Sequences for Depression Assessment From Speech. In Proceedings of the 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Glasgow, Scotland, UK, 11–15 July 2022. [Google Scholar] [CrossRef]
- Su, L.; Hu, C.Q.; Li, G.F.; Cao, D.P. MSAF: Multimodal split attention fusion. arXiv 2020, arXiv:2012.07175. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification | CMU-MOSI | CMU-MOSEI |
|---|---|---|
| Train set | 1284 | 16,326 |
| Valid set | 229 | 1871 |
| Test set | 686 | 4659 |
| Data set summation | 2199 | 22,856 |
| Setting | CMU-MOSI | CMU-MOSEI |
|---|---|---|
| Optimizer | Adam | Adam |
| Batch size | 32 | 32 |
| Learning_rate_bert | 5 × 10−5 | 5 × 10−5 |
| Epochs | 100 | 120 |
| Bi-GRU hidden sizes | 32 | 32 |
| Attention head | 8 | 10 |
| Kernel size (ht/hv/hc) | 1/1/1 | 1/1/1 |
| Dropout | 0.1 | 0.1 |
| Model | Acc-2/% | F1-Score/% | MAE | Corr |
|---|---|---|---|---|
| CMU-MOSI (Word alignment) | ||||
| EF-LSTM | 75.3 | 75.2 | 1.023 | 0.608 |
| LF-LSTM | 76.8 | 76.7 | 1.015 | 0.625 |
| MFM [8] | 78.1 | 78.1 | 0.951 | 0.662 |
| RAVEN [13] | 78.0 | 76.6 | 0.915 | 0.691 |
| HFFN [10] | 80.2 | 80.3 | - | - |
| MCTN [9] | 79.3 | 79.1 | 0.909 | 0.676 |
| MISA [11] | 81.8 | 81.7 | 0.783 | 0.761 |
| MSAF [42] | - | - | - | - |
| UA-BFET (ours) | 84.7 | 84.7 | 0.721 | 0.797 |
| CMU-MOSI (unaligned) | ||||
| MulT [14] | 81.1 | 81.0 | 0.889 | 0.686 |
| LMT-MulT [35] | 78.5 | 78.5 | 0.957 | 0.681 |
| LMR-CBT [15] | 81.2 | 81.0 | - | - |
| Self-MM [24] | 84.0 | 84.4 | 0.713 | 0.798 |
| UR-Transformer [17] | 82.2 | 82.4 | 0.603 | 0.662 |
| PMR [18] | 82.4 | 82.1 | - | - |
| Weighted Cross-modal Attention Echanism [36] | 84.7 | 84.6 | 0.716 | 0.786 |
| UA-BFET (ours) | 84.7 | 84.7 | 0.721 | 0.797 |
| Model | Acc-2/% | F1-Score/% | MAE | Corr |
|---|---|---|---|---|
| CMU-MOSEI (Word alignment) | ||||
| EF-LSTM | 78.2 | 77.9 | 0.642 | 0.616 |
| LF-LSTM | 80.6 | 80.6 | 0.619 | 0.659 |
| MFM [8] | - | - | 0.568 | 0.717 |
| RAVEN [13] | 79.1 | 79.5 | 0.614 | 0.662 |
| HFFN [10] | 60.4 | 59.1 | - | - |
| MCTN [9] | 79.8 | 80.6 | 0.609 | 0.670 |
| MISA [11] | 83.6 | 83.8 | 0.555 | 0.756 |
| MSAF [42] | 85.5 | 85.5 | 0.559 | 0.738 |
| UA-BFET (ours) | 84.5 | 83.9 | 0.424 | 0.793 |
| CMU-MOSEI (unaligned) | ||||
| MulT [14] | 81.6 | 81.6 | 0.591 | 0.694 |
| LMT-MulT [35] | 80.8 | 81.3 | 0.620 | 0.668 |
| LMR-CBT [15] | 80.9 | 81.5 | - | - |
| Self-MM [24] | 82.8 | 82.5 | 0.530 | 0.765 |
| UR-Transformer [17] | 81.8 | 81.8 | 0.597 | 0.671 |
| PMR [18] | 83.1 | 82.8 | - | - |
| Weighted Cross-modal Attention Echanism [36] | 83.8 | 83.8 | 0.547 | 0.751 |
| UA-BFET (ours) | 84.5 | 83.9 | 0.424 | 0.793 |
| Input Modal | Acc-2/% | F1-Score/% | MAE | Corr |
|---|---|---|---|---|
| Without CCA | 84.1 | 83.9 | 0.413 | 0.794 |
| With CCA | 84.7 | 84.7 | 0.424 | 0.793 |
| text | 82.8 | 82.8 | 0.708 | 0.800 |
| video | 82.9 | 75.2 | 0.702 | 0.801 |
| audio | 83.2 | 75.5 | 0.697 | 0.811 |
| audio + video | 83.8 | 83.8 | 0.716 | 0.801 |
| text + video | 84.7 | 84.7 | 0.424 | 0.793 |
| text + audio | 84.5 | 84.5 | 0.727 | 0.793 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, P.; Qi, H.; Wang, S.; Cang, J. Cross-Modal Sentiment Analysis of Text and Video Based on Bi-GRU Cyclic Network and Correlation Enhancement. Appl. Sci. 2023, 13, 7489. https://doi.org/10.3390/app13137489
He P, Qi H, Wang S, Cang J. Cross-Modal Sentiment Analysis of Text and Video Based on Bi-GRU Cyclic Network and Correlation Enhancement. Applied Sciences. 2023; 13(13):7489. https://doi.org/10.3390/app13137489
Chicago/Turabian StyleHe, Ping, Huaying Qi, Shiyi Wang, and Jiayue Cang. 2023. "Cross-Modal Sentiment Analysis of Text and Video Based on Bi-GRU Cyclic Network and Correlation Enhancement" Applied Sciences 13, no. 13: 7489. https://doi.org/10.3390/app13137489
APA StyleHe, P., Qi, H., Wang, S., & Cang, J. (2023). Cross-Modal Sentiment Analysis of Text and Video Based on Bi-GRU Cyclic Network and Correlation Enhancement. Applied Sciences, 13(13), 7489. https://doi.org/10.3390/app13137489