
Are You Depressed? Analyze User Utterances to Detect Depressive Emotions Using DistilBERT


Abstract
1. Introduction
2. Literature Review
2.1. Mental Illness Datasets
2.2. Text-Based Mental Illness Detection
2.3. Multi-Modal Mental Illness Detection
3. Dataset
3.1. Curation of the Reddit Data
3.1.1. Remove Cross Post, URL, and Null
3.1.2. Remove Comments without Posts
3.1.3. Sentence-by-Sentence Segmentation
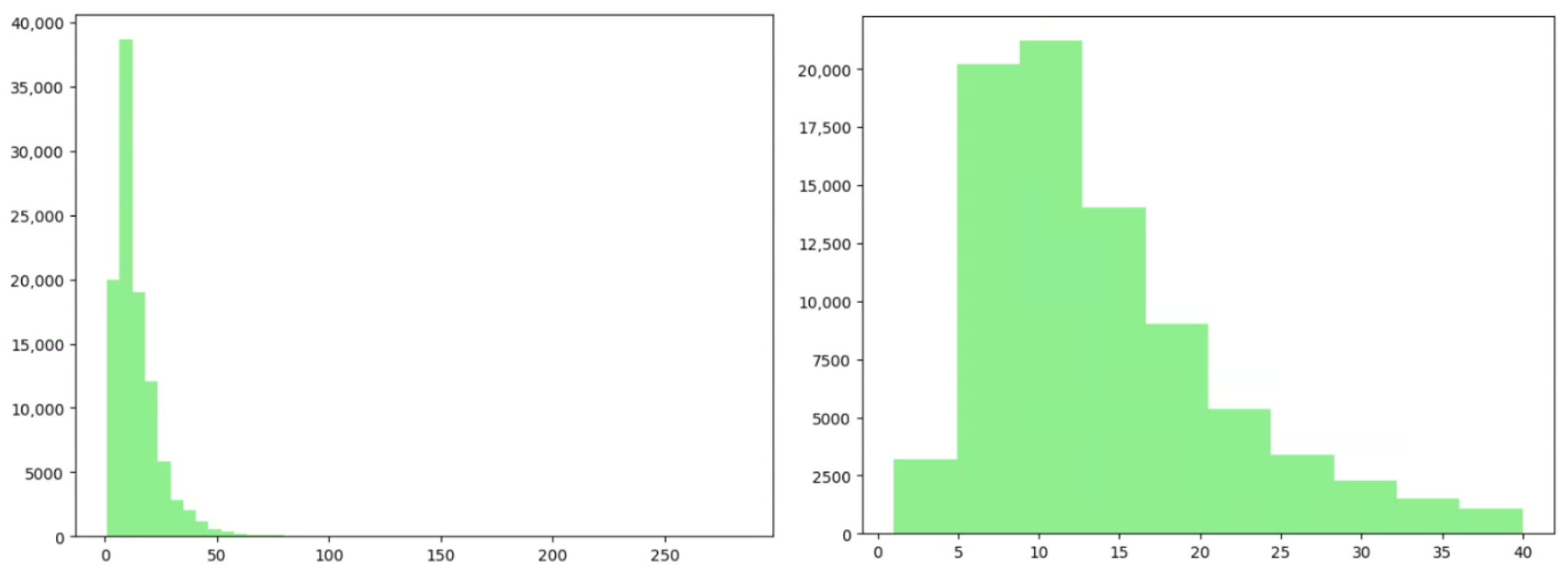
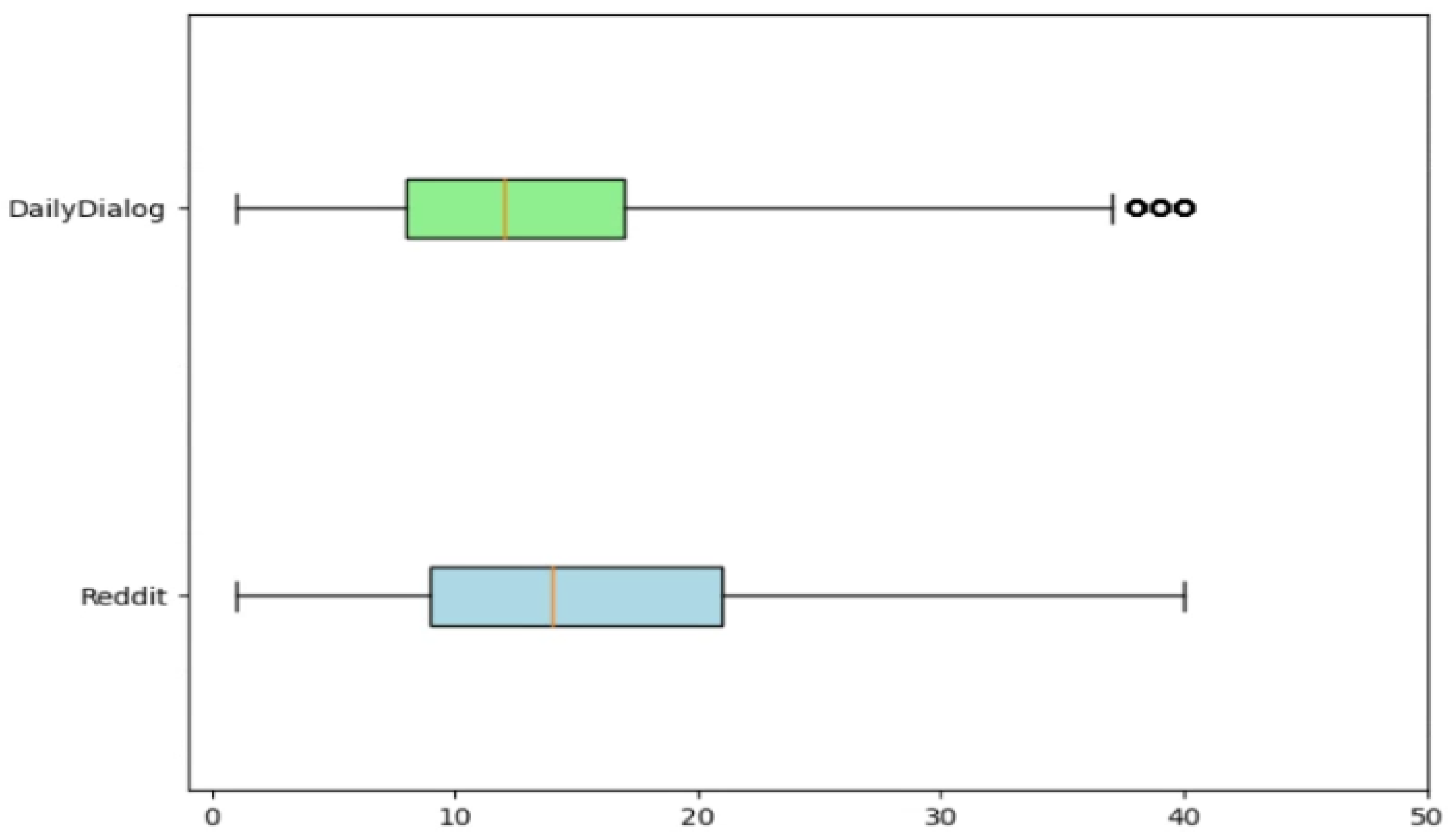
3.1.4. Length Filtering
3.1.5. Remove Non-English Text
3.1.6. Remove Personal Information Data
3.2. Curation of the DailyDialog Data
3.3. Best-Worst Scaling
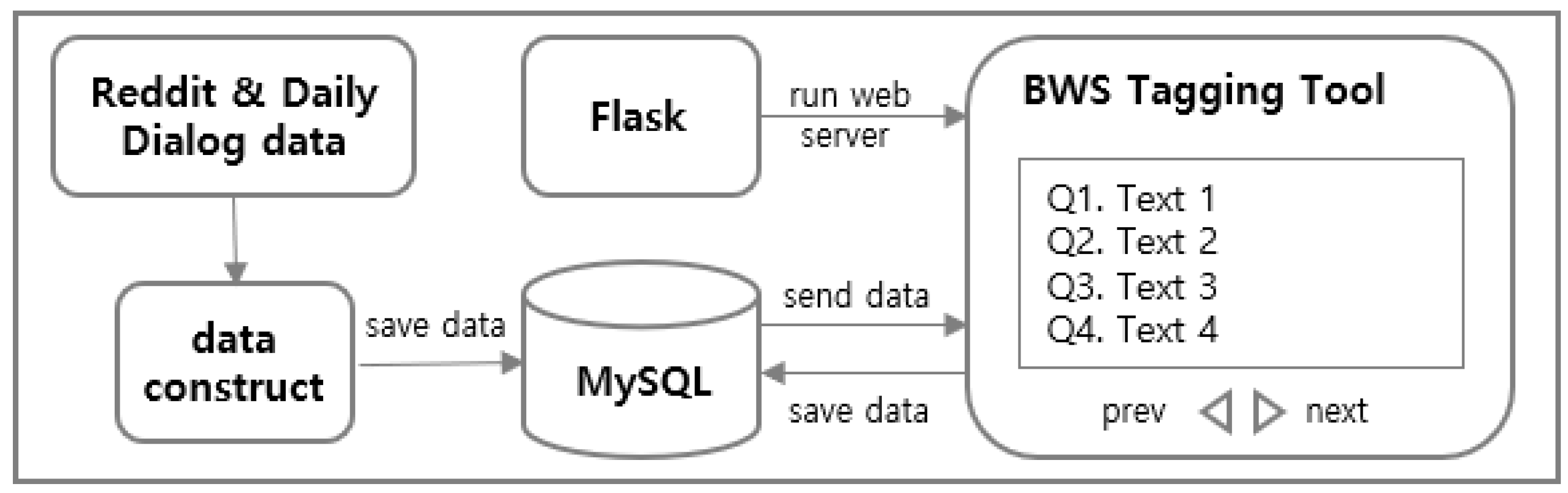
3.3.1. Data Construction for Best-Worst Scaling
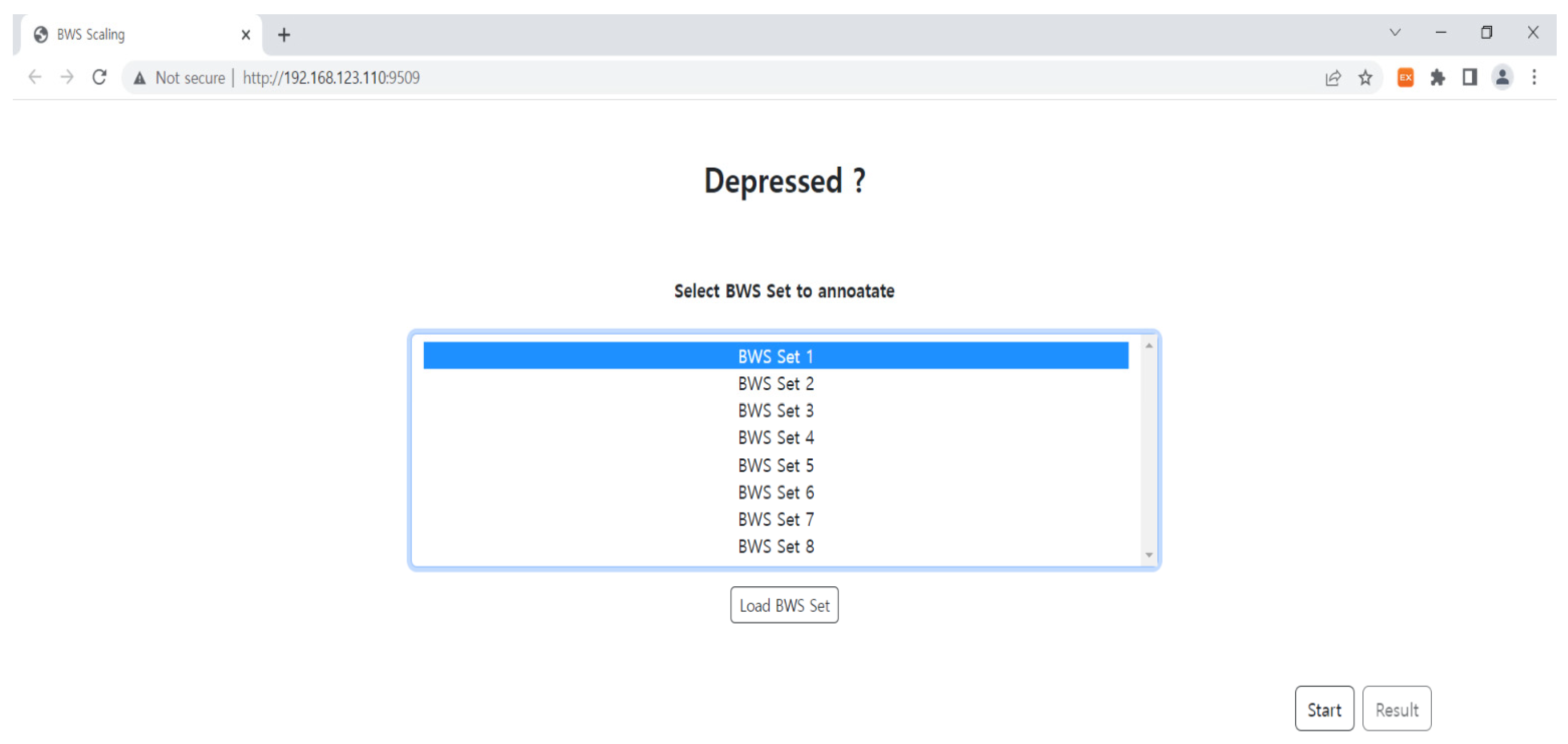
3.3.2. Annotation Work with Best-Worst Scaling
3.3.3. Best-Worst Scaling Scoring
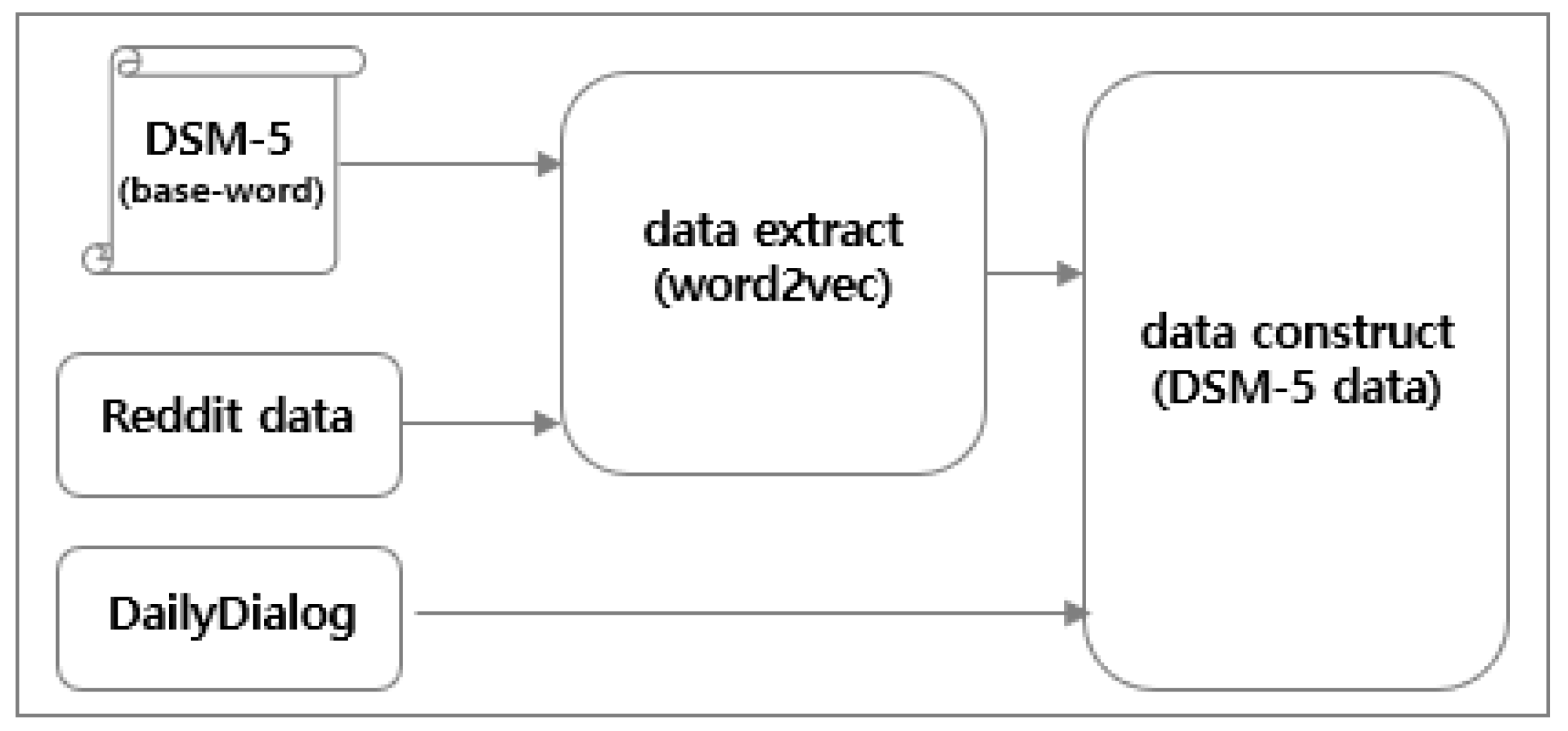
3.4. DSM-5 Dataset
3.4.1. Data Extraction
3.4.2. Data Construction Using Filters
4. Model
4.1. Prediction of Depressive Emotional Intensity
4.1.1. BWS Model
| Algorithm 1 BWS model |
| LOAD BWS data SET BWS data (score) = INT(BWS data(score) × 16) SPLIT data (train, val, test) LOAD pretrained language model, tokenizer, config ADD regression layer to pretrained model SET training config TRAIN BWS model (train, val data) TEST BWS model (test data) |
4.1.2. BWS Binary Model
| Algorithm 2 BWS binary model |
| LOAD depressed data (1200), not depressed data (400) SET LABEL depressed: 0, not depressed: 1 SPLIT data (train, val, test) LOAD pretrained language model, tokenizer, config ADD regression layer to pretrained language model SET training config TRAIN BWS binary model (train, val data) TEST BWS binary model (test data) |
4.2. Classification of Complex Depressive Emotions
| Algorithm 3 DSM-5 model |
| LOAD DSM-5 data DOWN SAMPLE DSM-5 data (A1, A7, A8, A9, daily) SPLIT DSM-5 data (train, val, test) LOAD pretrained language model, tokenizer, config SET training config TRAIN DSM-5 model (train, val data) TEST DSM-5 model (test data) |
4.3. Utilization of Attention Information
5. Analysis of Results
5.1. Comparison with Other Algorithms
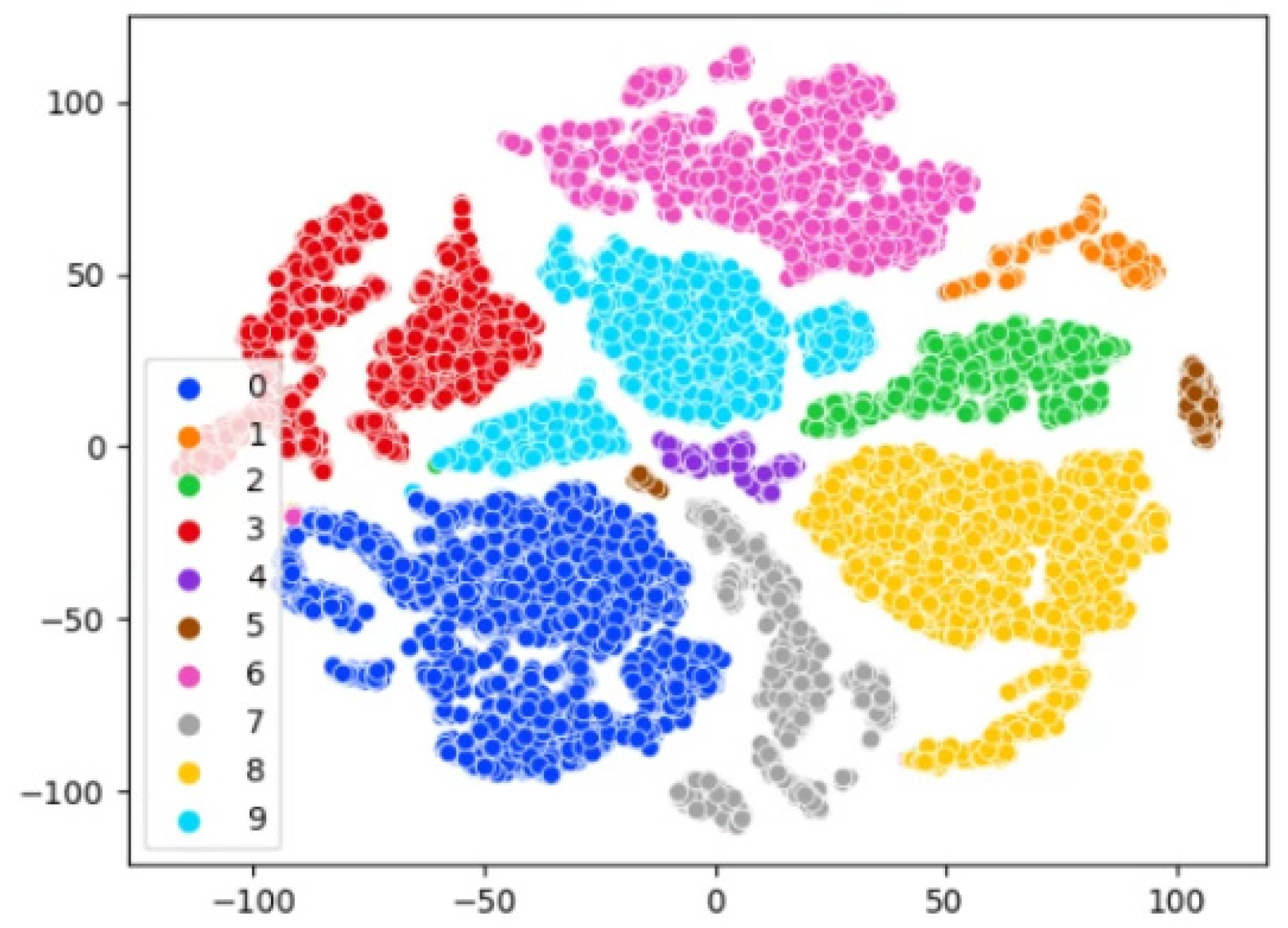
5.2. Visualization of Embedding Vectors
5.3. Experiment on a Virtual Conversation
5.3.1. Prediction of the BWS Model
5.3.2. Prediction of the DSM-5 Model
5.3.3. Attention Tokens
6. Conclusions
6.1. Results
6.2. Future Research Plan
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- A Red Light for Modern Mental Health and Stress Management Are Essential. Available online: http://www.medical-tribune.co.kr/news/articleView.html?idxno=100431 (accessed on 28 December 2022).
- Guangyao, S.; Jiang, J.; Liqiang, N.; Fuli, F.; Cunjun, Z.; Tianrui, H.; Tat-Seng, C.; Wenwu, Z. Depression detection via harvesting social media: A multimodal dictionary learning solution. In Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI'17), Sidney, Australia, 19–25 August 2017; AAAI Press: Washington, DC, USA; 2017; pp. 3838–3844. [Google Scholar]
- Cohan, A.; Desmet, B.; Yates, A.; Soldaini, L.; MacAvaney, S.; Goharian, N. SMHD: A Large-Scale Resource for Exploring Online Language Usage for Multiple Mental Health Conditions. In Proceedings of the 27th International Conference on Computational Linguistics, Association for Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 1485–1497. [Google Scholar]
- Pratyaksh, J.; Srinivas, K.R.; Vichare, A. Depression and suicide analysis using machine learning and NLP. J. Phys. Conf. Series 2022, 2161, 1. [Google Scholar]
- Cha, J.; Kim, S.; Park, E. A lexicon-based approach to examine depression detection in social media: The case of Twitter and university community. Humanit. Soc. Sci. Commun. 2022, 9, 325. [Google Scholar] [CrossRef] [PubMed]
- Lin, L.; Chen, X.; Shen, Y.; Zhang, L. Towards Automatic Depression Detection: A BiLSTM/1D CNN-Based Model. Appl. Sci. 2020, 10, 8701. [Google Scholar] [CrossRef]
- Louviere, J.J.; Flynn, T.N.; Marley, A.A.J. Best-Worst Scaling: Theory, Methods and Applications; Cambridge University Press: Cambridge, MA, USA, 2015. [Google Scholar]
- American Psychiatric Association. Diagnostic And Statistical Manual of Mental Disorders, 5th ed.; American Psychiatric Association: Philadelphia, PA, USA, 2013. [Google Scholar]
- BWS Tagging Tool Github. Available online: https://github.com/Jaedong95/BWS-Tagging (accessed on 20 April 2023).
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MI, USA, 2–7 June 2019; Association for Computational Linguistics: Toronto, Canada, 2019; pp. 4171–4186. [Google Scholar]
- Clark, K.; Luong, M.-T.; Le Quoc, V.; Christopher, D. Manning: Electra: Pre-training text encoders as discriminators rather than generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]
- Major Depressive Disorder (Diagnosis). Available online: https://chsciowa.org/sites/chsciowa.org/files/resource/files/7_-_depression_dsm-5_checklist.pdf (accessed on 10 January 2023).
- Yates, A.; Cohan, A.; Goharian, N. Depression and Self-Harm Risk Assessment in Online Forums. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; Association for Computational Linguistics: Toronto, ON, Canada, 2017; pp. 2968–2978. [Google Scholar]
- De Choudhury, M.; Gamon, M.; Counts, S.; Horvitz, E. Predicting Depression via Social Media. Proceed. Int. AAAI Conf. Web Soc. Media 2021, 7, 128–137. [Google Scholar] [CrossRef]
- Nasrullah, S.; Jalali, A. Detection of Types of Mental Illness through the Social Network Using Ensembled Deep Learning Model. Computat. Intel. Neurosci. 2022, 2022, 9404242. [Google Scholar] [CrossRef] [PubMed]
- Amanat, A.; Rizwan, M.; Javed, A.R.; Abdelhaq, M.; Alsaqour, R.; Pandya, S.; Uddin, M. Deep learning for depression detection from textual data. Electronics 2022, 11, 676. [Google Scholar] [CrossRef]
- Mohsinul, K.; Ahmed, T.; Hasan, M.B.; Laskar, M.T.R.; Joarder, T.K.; Mahmud, H.; Hasan, K. DEPTWEET: A typology for social media texts to detect depression severities. Comput. Human Behav. 2023, 139, 107503. [Google Scholar]
- Kim, N.H.; Kim, J.M.; Park, D.M.; Ji, S.R.; Kim, J.W. Analysis of depression in social media texts through the Patient Health Questionnaire-9 and natural language processing. Digital Health 2022, 8, 20552076221114204. [Google Scholar] [CrossRef] [PubMed]
- Ji, S.; Zhang, T.; Ansari, L.; Fu, J.; Tiwari, P.; Cambria, E. MentalBERT: Publicly Available Pretrained Language Models for Mental Healthcare. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, Marseille, France, 20–25 June 2022; European Language Resources Association: Paris, France, 2022; pp. 7184–7190. [Google Scholar]
- Rodrigues Makiuchi, M.; Warnita, T.; Uto, K.; Shinoda, K. Multimodal Fusion of BERT-CNN and Gated CNN Representations for Depression Detection. In Proceedings of the 9th International on Audio/Visual Emotion Challenge and Workshop (AVEC’19), Nice, France, 21 October 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 55–63. [Google Scholar] [CrossRef]
- Afef, S.; Othman, S.B.; Saoud, S.B. Hybrid CNN-SVM classifier for efficient depression detection system. In Proceedings of the 4th International Conference on Advanced Systems and Emergent Technologies (IC_ASET), Hammamet, Tunisia, 15–18 December 2020; IEEE: New York, NY, USA, 2020; pp. 229–234. [Google Scholar]
- Li, Y.; Su, H.; Shen, X.; Li, W.; Cao, Z.; Niu, S. DailyDialog: A Manually Labelled Multi-turn Dialogue Dataset. In Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Taipei, Taiwan, 27 November–1 December 2017; Asian Federation of Natural Language Processing: Taipei, Taiwan, 2017; pp. 986–995. [Google Scholar]
- Subreddit r/Depression. Available online: https://www.reddit.com/r/depression/ (accessed on 8 January 2023).
- Reddit Archive Data. Available online: https://files.pushshift.io/reddit/ (accessed on 8 January 2023).
- Papago API. Available online: https://developers.naver.com/docs/papago/papago-detectlangs-overview.md (accessed on 5 March 2023).
- Bert-Base-NER Model. Available online: https://huggingface.co/dslim/bert-base-NER (accessed on 28 February 2023).
- Mohammad, S.; Bravo-Marquez, F. Emotion Intensities in Tweets. In Proceedings of the 6th Joint Conference on Lexical and Computational Semantics (*SEM 2017), Vancouver, BC, Canada, 3–4 August 2017; Volume 1, pp. 65–77. [Google Scholar]
- Tweet Emotion Intensity Dataset Webpage. Available online: https://saifmohammad.com/WebPages/TweetEmotionIntensity-dataviz.html (accessed on 10 March 2023).
- Kiritchenko, S.; Saif, M.M. Capturing Reliable Fine-Grained Sentiment Associations by Crowdsourcing and Best–Worst Scaling. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2017; Association for Computational Linguistics: Toronto, ON, Canada, 2016; pp. 811–817. [Google Scholar]
- MaxDiff Analysis: Simple Counting, Individual-Level Logit, and HB. Available online: https://sawtoothsoftware.com/resources/technical-papers/maxdiff-analysis-simple-counting-individual-level-logit-and-hb (accessed on 14 March 2023).
- Min-Max Scale Using Sklearn. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MinMaxScaler.html (accessed on 14 March 2023).
- How to Scale into the 0–1 Range Using Min-Max Normalization. Available online: https://androidkt.com/how-to-scale-data-to-range-using-minmax-normalization/ (accessed on 19 February 2023).
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Clark, K.; Khandelwal, U.; Levy, O.; Manning. C, D. What Does BERT Look at? An Analysis of BERT’s Attention. In Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Florence, Italy, 1 August 2019; Volume 1, pp. 276–286. [Google Scholar]
- About BERT. Available online: https://heekangpark.github.io/nlp/huggingface-bert (accessed on 22 February 2023).
- BertViz Github. Available online: https://github.com/jessevig/bertviz (accessed on 24 February 2023).
- He, P.; Liu, X.; Gao, J.; Chen, W. Deberta: Decoding-enhanced bert with disentangled attention. arXiv 2020, arXiv:2006.03654. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Mariette, A.; Khanna, R.; Awad, M.; Khanna, R. Support vector regression. In Efficient Learning Machines: Theories, Concepts, and Applications for Engineers and System Designers; Springer: Berlin/Heidelberg, Germany, 2015; pp. 67–80. [Google Scholar]
- Peterson, L.E. K-nearest neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Leung, K.M. Naive Bayesian Classifier; Polytechnic University Department of Computer Science/Finance and Risk Engineering: New York, NY, USA, 2007; pp. 123–156. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Siino, M.; Di Nuovo, E.; Tinnirello, I.; La Cascia, M. Fake News Spreaders Detection: Sometimes Attention Is Not All You Need. Information 2022, 13, 426. [Google Scholar] [CrossRef]
- Abdi, H.; Williams, L.J. Principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- About t-SNE. Available online: https://lvdmaaten.github.io/tsne/ (accessed on 24 April 2023).
- PCA vs. t-SNE. Available online: https://skyeong.net/284 (accessed on 25 December 2022).
- Maaten, L.V.D.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample Text | Score (0~1) |
|---|---|
| I have tried to ignore my feelings but I really am depressed | 0.875 |
| I need to realize I am unhappy for no reason | 0.6875 |
| I don’t feel sad I just don’t really feel | 0.0625 |
| They want to change it because it’s too sour | 0 |
| Criteria | Label |
|---|---|
| A1 | depressed |
| A2 | lethargic |
| A3 | appetite/weight problem |
| A4 | sleep disorder |
| A5 | emotional instability |
| A6 | fatigue |
| A7 | excessive guilt/worthlessness |
| A8 | cognitive problems |
| A9 | suicidal thoughts |
| Etc | daily (not depressed) |
| Sample Text | Label |
|---|---|
| I am not happy, I always feel sad | depressed |
| I lost my appetite, I haven’t eaten anything but two hard boil eggs | appetite/weight problem |
| It made me insane with insomnia | sleep disorder |
| I am so fatigued and tired of waiting to be happy | fatigue |
| One day I am going to die by my own will | suicidal thoughts |
| Text | Total | Strongest | Weakest |
|---|---|---|---|
| I need to realize I am unhappy for no reason | 8 | 3 | 0 |
| I want to be alone but I am lonely | 8 | 4 | 0 |
| I am depressed I hate myself | 8 | 8 | 0 |
| Do you have lessons with me? | 8 | 0 | 8 |
| Criteria | Base Word | Similar Word |
|---|---|---|
| A1 | depressed | deppressed, sad, unhappy, lonely, unwell, moody, distressed |
| A2 | lethargic | fatigued, sluggish, groggy, unmotivated, listless, despondent, demotivated |
| A3 | appetite, weight | apetite, lbs, kg, metabolism, apatite |
| A4 | insomnia, hypersomnia, sleep | migraines, bruxism, nausea, ibs, tinnitus, sleeplessness, diarrhea, narcolepsy, sleepiness, drowsniess, disturbances, sleeping, bed, asleep |
| A5 | agitation, retardation | irritability, restlessness, nervousness, vertigo, impairment, instability psychomotor, unwellness |
| A6 | fatigue | tiredness |
| A7 | worthless, guilt | useless, pathetic, unlovable, unloveable, inadequate, helpless, miserable, talentless, hopeless, subhuman, shame, resentment, selfhatred, jealously, selfoathing, selfhate, frustration |
| A8 | concentrate, indecisive | focus, concentrate, concentrating, focusing, refocus, focused, forgetful, picky, forgetful, pessimistic |
| A9 | suicidal, die | sucidal, homicidal, sucidial, suicial, suicidial, selfharm, scuicidal, disappear, kill, starve, cease, dissappear |
| Criteria | Text |
|---|---|
| A1 | a fellow depressed stranger |
| A3 | not some overweight guy who has not been laid |
| A7 | being anti-social does not make you worthless |
| Criteria | Filter 1 | Filter 2 |
|---|---|---|
| A1 | am, is, are, feel | not, do(es)n’t feel |
| A2 | am, is, are, feel | not, do(es)n’t feel |
| A3 | loss, lost, gain, surge | - |
| A4 | too much, not much, can’t | - |
| A5 | - | not, do(es)n’t feel |
| A6 | am, is, are, feel | not, do(es)n’t feel |
| A7 | am, is, are, feel | not, do(es)n’t feel |
| A8 | (can’t), am, is, are | (can), not, do(es)n’t feel |
| A9 | (want, go, will, try, have) + to | not, do(es)n’t + have, want, go, will, try + to |
| A1 | A2 | A3 | A4 | A5 | |
|---|---|---|---|---|---|
| A6 | A7 | A8 | A9 | Daily | |
| DSM-5 | 152,734 | 3041 | 8984 | 17,760 | 2217 |
| 1865 | 99,988 | 23,154 | 37,409 | 81,290 |
| Train | Val | Test | All | |
|---|---|---|---|---|
| BWS data | 1152 | 128 | 320 | 1600 |
| DSM-5 data | 88,874 | 22,219 | 27,774 | 138,867 |
| Models | Regression | Classification | |||||
|---|---|---|---|---|---|---|---|
| RMSE | R2 | Precision | Recall | Specificity | F1 | ||
| Machine Learning | Support Vector Regressor [40] | 3.944 | 0.3518 | - | - | - | - |
| K-NN [41] Regression | 3.9181 | 0.3603 | - | - | - | - | |
| Naïve-Bayes [42] | - | - | 0.9156 | 0.573 | 0.9763 | 0.8089 | |
| K-NN Classification | - | - | 0.8504 | 0.6506 | 0.9699 | 0.7483 | |
| Random Forest [43] | - | - | 0.9586 | 0.8795 | 0.9927 | 0.9396 | |
| Deep Learning | DNN | 3.4472 | 0.5048 | 0.9718 | 0.9602 | 0.9956 | 0.9631 |
| DNN + Bi-LSTM | 2.59 | 0.72 | 0.9893 | 0.9874 | 0.9983 | 0.9863 | |
| CNN-1D [44] | 3.7623 | 0.4101 | 0.9723 | 0.9642 | 0.9963 | 0.969 | |
| BERT | 2.0557 | 0.8239 | 0.9984 | 0.9984 | 0.9998 | 0.9987 | |
| DeBERTa | 2.3020 | 0.7792 | 0.9983 | 0.9977 | 0.9998 | 0.9988 | |
| RoBERTa | 2.6558 | 0.7061 | 0.9974 | 0.997 | 0.9997 | 0.9981 | |
| ELECTRA | 2.5173 | 0.7360 | 0.9976 | 0.9983 | 0.9998 | 0.9983 | |
| DistilBERT (ours) | 2.1601 | 0.8056 | 0.9989 | 0.9988 | 0.9998 | 0.999 | |
| BERT | DeBERTa | RoBERTa | ELECTRA | DistilBERT (Ours) | |
|---|---|---|---|---|---|
| Inference Time (s) | 62.765(s) | 110.813(s) | 60.226(s) | 60.561(s) | 29.348(s) |
| Turn | Speaker | Text |
|---|---|---|
| 1 | User | Hey |
| 1 | Chatbot | Hello, nice to meet you |
| 2 | User | Who are you? |
| 2 | Chatbot | I am a psychological counseling chatbot. |
| 3 | User | Ah-huh |
| 3 | Chatbot | How are you? |
| 4 | User | I am very depressed today |
| 4 | Chatbot | What is the matter? |
| 5 | User | I do not know why but just depressed |
| 5 | Chatbot | When you are depressed, you have to move |
| 6 | User | Also I lost 30 pounds and I feel lethargic |
| 6 | Chatbot | That sounds too bad |
| 7 | User | Anyway, thanks for listening |
| 7 | Chatbot | Yes, see you next time |
| Turn | Text | Intensity |
|---|---|---|
| 1 | Hey | 0.1015 |
| 2 | Who are you? | 0.0346 |
| 3 | Ah-huh | 0.0195 |
| 4 | I am very depressed today | 12.7464 |
| 5 | I do not know why but just depressed | 8.6879 |
| 6 | Also I lost 30 pounds and I feel lethargic | 8.6295 |
| 7 | Anyway, thanks for listening | 0.0038 |
| Turn | Text | Intensity |
|---|---|---|
| 1 | Hey | 1.0265 |
| 2 | Who are you? | 1.0167 |
| 3 | Ah-huh | 1.0157 |
| 4 | I am very depressed today | 0.0003 |
| 5 | I do not know why but just depressed | 0.0012 |
| 6 | Also I lost 30 pounds and I feel lethargic | 0.0616 |
| 7 | Anyway, thanks for listening | 1.0158 |
| Turn | Text | Label |
|---|---|---|
| 1 | Hey | daily |
| 2 | Who are you? | daily |
| 3 | Ah-huh | daily |
| 4 | I am very depressed today | depressed |
| 5 | I do not know why but just depressed | depressed |
| 6 | Also I lost 30 pounds and I feel lethargic | lethargic |
| 7 | Anyway, thanks for listening | daily |
| Turn | Text | Label |
|---|---|---|
| 1 | Hey | daily |
| 2 | Who are you? | daily |
| 3 | Ah-huh | daily |
| 4 | I am very depressed today | depressed |
| 5 | I do not know why but just depressed | depressed |
| 6 | Also I lost 30 pounds and I feel lethargic | lethargic, appetite/weight problem |
| 7 | Anyway, thanks for listening | daily |
| Turn | Text | Attention Tokens |
|---|---|---|
| 1 | Hey | - |
| 2 | Who are you? | ‘?’, ‘you’ |
| 3 | Ah-huh | - |
| 4 | I am very depressed today | ‘depressed’, ‘i’ |
| 5 | I do not know why but just depressed | ‘depressed’, ‘i’, ‘but’ |
| 6 | Also I lost 30 pounds and I feel lethargic | ‘##har’, ‘##gic’, ‘let’ |
| 7 | Anyway, thanks for listening | ‘listening’, ‘thanks’ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oh, J.; Kim, M.; Park, H.; Oh, H. Are You Depressed? Analyze User Utterances to Detect Depressive Emotions Using DistilBERT. Appl. Sci. 2023, 13, 6223. https://doi.org/10.3390/app13106223
Oh J, Kim M, Park H, Oh H. Are You Depressed? Analyze User Utterances to Detect Depressive Emotions Using DistilBERT. Applied Sciences. 2023; 13(10):6223. https://doi.org/10.3390/app13106223
Chicago/Turabian StyleOh, Jaedong, Mirae Kim, Hyejin Park, and Hayoung Oh. 2023. "Are You Depressed? Analyze User Utterances to Detect Depressive Emotions Using DistilBERT" Applied Sciences 13, no. 10: 6223. https://doi.org/10.3390/app13106223
APA StyleOh, J., Kim, M., Park, H., & Oh, H. (2023). Are You Depressed? Analyze User Utterances to Detect Depressive Emotions Using DistilBERT. Applied Sciences, 13(10), 6223. https://doi.org/10.3390/app13106223