
Contrasting Dual Transformer Architectures for Multi-Modal Remote Sensing Image Retrieval

 ,
, 
 ,
,
Abstract
1. Introduction
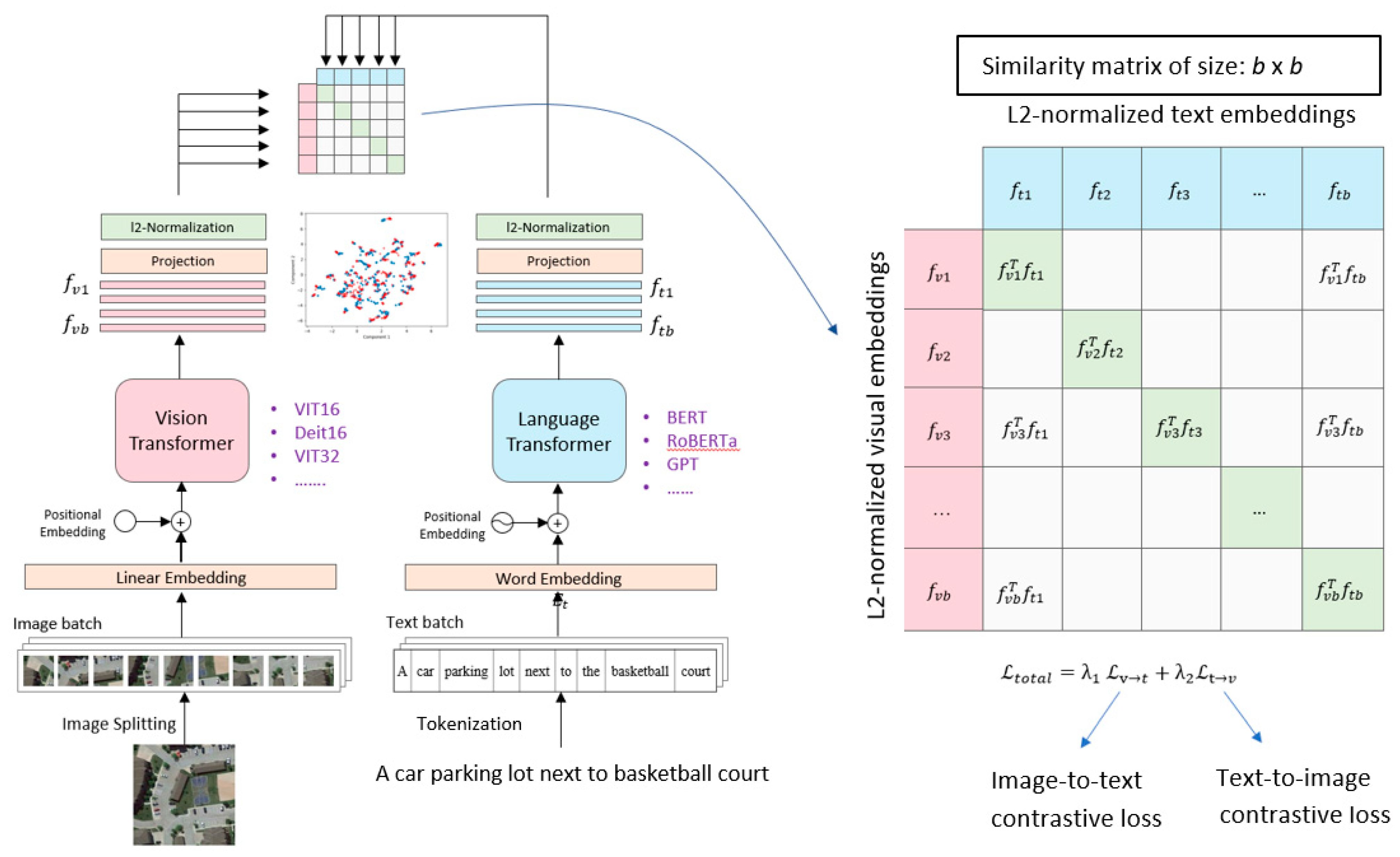
2. Materials and Methods
2.1. Language and Vision Representation Encoders
2.2. Model Optimization
| Algorithm 1: Cross-modal text–image matching PyTorch-style pseudocode |
| # Mini-batch size: default b=120, # Regularization parameters lmabda1=lambda2=0.5 # Initial value Temperature parameter: Taux=0.07 # model.f_NLP and model.f_ViT: NLP and Vision transformer encoders # Optimizer: SGD(lr=0.1, momentum=0.9, nesterov=True) # Criterion=nn.CrossEntropyloss(), Number of epochs: 100 # Load mini-batch of image-text pairs of size b from the training set for X, t in loader: # Feed the image-text pair into the model logits_image=model.f_ViT(X) logits_text=model.f_NLP(t) # L2 Normalization logits_image=logits_image/logits_image.norm(dim=-1,keepdim=True) logits_text= logits_text / logits_text.norm(dim=-1,keepdim=True) # Similarity matrix Sim_Mat= logits_image @ logits_Text.t()/Taux # Set class labels: 0,1,2,…,b-1 labels = torch.Tensor(np.arange(b)).long() # image-to-text and text-to-image classification losses (Equation (8)). loss=lmabda1*Criterion(Sim_Mat,labels)+lmabda2* Criterion(toch.transpose(Sim_Mat,0,1), labels) # Backward loss loss.backward() # Clip the gradients for numerical stability torch.nn.utils.clip_grad_norm_(model.parameters(),0.1) # Optimization step optimizer.step() optimizer.zero_grad() |
2.3. Encoders Architecture
3. Experimental Results and Discussion
3.1. Dataset Description
3.2. Experimental Protocol and Evaluation Metrics
3.3. Results Related to the First Configuration
3.4. Comparisons to the Second and Third Configurations
3.5. Comparisons to State-Of-The-Art RS Methods
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cheng, G.; Xie, X.; Han, J.; Guo, L.; Xia, G.-S. Remote Sensing Image Scene Classification Meets Deep Learning: Challenges, Methods, Benchmarks, and Opportunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3735–3756. [Google Scholar] [CrossRef]
- Hoxha, G.; Melgani, F.; Demir, B. Toward Remote Sensing Image Retrieval Under a Deep Image Captioning Perspective. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4462–4475. [Google Scholar] [CrossRef]
- Gella, G.W.; Bijker, W.; Belgiu, M. Mapping Crop Types in Complex Farming Areas Using SAR Imagery with Dynamic Time Warping. ISPRS J. Photogramm. Remote Sens. 2021, 175, 171–183. [Google Scholar] [CrossRef]
- Hu, B.; Li, Q.; Hall, G.B. A Decision-Level Fusion Approach to Tree Species Classification from Multi-Source Remotely Sensed Data. ISPRS Open J. Photogramm. Remote Sens. 2021, 1, 100002. [Google Scholar] [CrossRef]
- Winiwarter, L.; Anders, K.; Höfle, B. M3C2-EP: Pushing the Limits of 3D Topographic Point Cloud Change Detection by Error Propagation. ISPRS J. Photogramm. Remote Sens. 2021, 178, 240–258. [Google Scholar] [CrossRef]
- Cheng, Q.; Zhou, Y.; Huang, H.; Wang, Z. Multi-Attention Fusion and Fine-Grained Alignment for Bidirectional Image-Sentence Retrieval in Remote Sensing. IEEE/CAA J. Autom. Sin. 2022, 9, 1532–1535. [Google Scholar] [CrossRef]
- Cheng, Q.; Huang, H.; Xu, Y.; Zhou, Y.; Li, H.; Wang, Z. NWPU-Captions Dataset and MLCA-Net for Remote Sensing Image Captioning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5629419. [Google Scholar] [CrossRef]
- Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision Transformers for Remote Sensing Image Classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Bashmal, L.; Bazi, Y.; Al Rahhal, M.M.; Alhichri, H.; Al Ajlan, N. UAV Image Multi-Labeling with Data-Efficient Transformers. Appl. Sci. 2021, 11, 3974. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.; Shi, Z. Remote Sensing Image Change Detection With Transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5607514. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Advances in Neural Information Processing Systems, Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 5998–6008. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. In Advances in Neural Information Processing Systems, Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, BC, Canada, 6–12 December 2020; Curran Associates Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models Are Unsupervised Multitask Learners. Technical Report; OpenAI: San Francisco, CA, USA, 2019. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian Error Linear Units (GELUs). arXiv 2020, arXiv:1606.08415. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning, Virtual Event, 18–24 July 2021. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging Properties in Self-Supervised Vision Transformers. arXiv 2021, arXiv:2104.14294. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Gao, T.; Yao, X.; Chen, D. SimCSE: Simple Contrastive Learning of Sentence Embeddings. arXiv 2021, arXiv:2104.08821. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training Data-Efficient Image Transformers & Distillation through Attention. arXiv 2020, arXiv:2012.12877. [Google Scholar]
- Abdullah, T.; Bazi, Y.; Al Rahhal, M.M.; Mekhalfi, M.L.; Rangarajan, L.; Zuair, M. TextRS: Deep Bidirectional Triplet Network for Matching Text to Remote Sensing Images. Remote Sens. 2020, 12, 405. [Google Scholar] [CrossRef]
- Qu, B.; Li, X.; Tao, D.; Lu, X. Deep Semantic Understanding of High Resolution Remote Sensing Image. In Proceedings of the 2016 International Conference on Computer, Information and Telecommunication Systems (CITS), Kunming, China, 6–8 July 2016; pp. 1–5. [Google Scholar]
- Lu, X.; Wang, B.; Zheng, X.; Li, X. Exploring Models and Data for Remote Sensing Image Caption Generation. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2183–2195. [Google Scholar] [CrossRef]
- Xia, G.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A Benchmark Data Set for Performance Evaluation of Aerial Scene Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Zhou, W.; Newsam, S.; Li, C.; Shao, Z. PatternNet: A Benchmark Dataset for Performance Evaluation of Remote Sensing Image Retrieval. ISPRS J. Photogramm. Remote Sens. 2018, 145, 197–209. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-Visual-Words and Spatial Extensions for Land-Use Classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; ACM: New York, NY, USA, 2010; pp. 270–279. [Google Scholar]
- Cheng, G.; Han, J.; Lu, X. Remote Sensing Image Scene Classification: Benchmark and State of the Art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Rahhal, M.M.A.; Bazi, Y.; Abdullah, T.; Mekhalfi, M.L.; Zuair, M. Deep Unsupervised Embedding for Remote Sensing Image Retrieval Using Textual Cues. Appl. Sci. 2020, 10, 8931. [Google Scholar] [CrossRef]
- Yuan, Z.; Zhang, W.; Fu, K.; Li, X.; Deng, C.; Wang, H.; Sun, X. Exploring a Fine-Grained Multiscale Method for Cross-Modal Remote Sensing Image Retrieval. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–19. [Google Scholar] [CrossRef]
- Cheng, Q.; Zhou, Y.; Fu, P.; Xu, Y.; Zhang, L. A Deep Semantic Alignment Network for the Cross-Modal Image-Text Retrieval in Remote Sensing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4284–4297. [Google Scholar] [CrossRef]
- Faghri, F.; Fleet, D.J.; Kiros, J.R.; Fidler, S. VSE++: Improving Visual-Semantic Embeddings with Hard Negatives. arXiv 2017, arXiv:1707.05612. [Google Scholar]
- Lee, K.-H.; Chen, X.; Hua, G.; Hu, H.; He, X. Stacked Cross Attention for Image-Text Matching. arXiv 2018, arXiv:1803.08024. [Google Scholar]
- Wang, T.; Xu, X.; Yang, Y.; Hanjalic, A.; Shen, H.T.; Song, J. Matching Images and Text with Multi-Modal Tensor Fusion and Re-Ranking. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; Association for Computing Machinery: New York, NY, USA, 15 October 2019; pp. 12–20. [Google Scholar]
- Zheng, F.; Li, W.; Wang, X.; Wang, L.; Zhang, X.; Zhang, H. A Cross-Attention Mechanism Based on Regional-Level Semantic Features of Images for Cross-Modal Text-Image Retrieval in Remote Sensing. Appl. Sci. 2022, 12, 12221. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Config. 1 | Config. 2 | Config. 3 | |
|---|---|---|---|
| Image encoder | ViT base (layers = 12, hidden = 768, parameters = 86M image size: 224 × 224 pixels, patch size: 32 × 32 pixels). | ViT base (layers = 12, hidden = 768, parameters = 86M, input image size: 224 × 224 pixels, patch size=16 × 16 pixels). | Deit base distilled (layers = 12, hidden = 768, parameters = 87M, input image size: 224 × 224 pixels, patch size=16 × 16 pixels). |
| Text encoder | BERT base (layers = 12, hidden = 512, parameters = 63M). | RoBERTa base (layers = 12, hidden = 768, parameters = 110M). | BERT base (layers = 12, hidden = 768, parameters = 110M). |
| Pre-training mode | CLIP model for image text matching task. | Models were learned independently in a self-supervised mode on image and language tasks (DINO for image and SimCSE for text). | Models were learned independently in a standard supervised mode on image and language tasks. |
| Dataset | # of Images | Spatial Resolution (cm) | Image Size |
|---|---|---|---|
| TextRS | 2144 | [0.62, 30] | 256 × 256 pixels, and 600 × 600 pixels |
| Merced | 2100 | 30 | 256 × 256 pixels |
| Sydney | 613 | 50 | 500 × 500 pixels |
| RSICD | 10,921 | - | 224 × 224 pixels |
| Dataset | Text-To-Image | Image-To-Text | Train Time | ||||
|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | ||
| TextRS | 24.55 | 65.66 | 80.60 | 24.08 | 66.04 | 80.78 | 5.8 h |
| Merced | 19.33 | 64.00 | 91.42 | 19.04 | 53.33 | 77.61 | 7.9 h |
| Sydney | 26.76 | 57.59 | 73.53 | 24.95 | 57.44 | 72.32 | 0.6 h |
| RSICD | 9.14 | 28.96 | 44.59 | 10.70 | 29.64 | 41.53 | 102.7 h |
| Text to Image | Image to Text | |||||
|---|---|---|---|---|---|---|
| Config. 1 | Config. 2 | Config. 3 | Config. 1 | Config 2 | Config. 3 | |
| TextRS | 56.93 | 52.34 | 51.56 | 56.96 | 52.74 | 51.18 |
| Merced | 58.25 | 49.62 | 50.22 | 49.99 | 48.91 | 47.26 |
| Sydney | 52.62 | 51.52 | 51.32 | 51.57 | 49.46 | 50.97 |
| Approach | Text Retrieval | mR | Image Retrieval | mR | ||||
|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |||
| Bi-LSTM [28] | 19.02 | 55.25 | 71.72 | 48.66 | 22.95 | 59.52 | 77.23 | 53.23 |
| Triplet [21] | 12.55 | 41.62 | 62.09 | 38.75 | 12.55 | 39.53 | 59.53 | 37.20 |
| Ours | 24.55 | 65.66 | 80.60 | 56.93 | 24.08 | 66.04 | 80.78 | 56.96 |
| Approach | Text Retrieval | mR | Image Retrieval | mR | ||||
|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |||
| VSE++ [31] | 12.38 | 44.76 | 65.71 | 40.95 | 10.10 | 31.80 | 56.85 | 32.92 |
| SCAN [32] | 12.85 | 47.14 | 69.52 | 43.17 | 12.48 | 46.86 | 71.71 | 43.68 |
| MTFN [33] | 10.47 | 47.62 | 64.29 | 40.79 | 14.19 | 52.38 | 78.95 | 48.51 |
| AMFMN-soft [29] | 12.86 | 51.90 | 66.67 | 43.81 | 14.19 | 52.38 | 78.95 | 48.51 |
| AMFMN-fusion [29] | 16.67 | 45.71 | 68.57 | 43.65 | 12.86 | 53.24 | 79.43 | 48.51 |
| AMFMN-sim | 14.76 | 49.52 | 68.10 | 44.13 | 13.43 | 51.81 | 76.48 | 47.24 |
| Ours | 19.33 | 64.00 | 91.42 | 58.25 | 19.04 | 53.33 | 77.61 | 49.99 |
| Approach | Text Retrieval | mR | Image Retrieval | mR | ||||
|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |||
| SAM t-i [30] | 9.60 | 34.60 | 55.80 | 33.53 | 5.80 | 32.70 | 48.10 | 30.57 |
| VSE++ [31] | 24.4 | 53.45 | 67.24 | 48.36 | 6.21 | 33.56 | 51.03 | 30.27 |
| MTFN [33] | 20.69 | 51.72 | 68.97 | 47.13 | 13.79 | 55.51 | 77.59 | 48.05 |
| SCAN [32] | 20.69 | 55.17 | 67.24 | 47.7 | 15.52 | 57.59 | 76.21 | 49.77 |
| AMFMN-soft [29] | 20.69 | 51.72 | 74.14 | 48.85 | 15.17 | 58.62 | 80.00 | 51.26 |
| AMFMN-fusion [29] | 24.14 | 51.72 | 75.86 | 50.57 | 14.83 | 56.55 | 77.89 | 49.76 |
| AMFMN-sim | 29.31 | 58.62 | 67.24 | 51.72 | 13.45 | 60.00 | 81.72 | 51.72 |
| Ours | 26.76 | 57.59 | 73.53 | 52.62 | 24.95 | 57.44 | 72.32 | 51.57 |
| Approach | Text Retrieval | mR | Image Retrieval | mR | ||||
|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |||
| AMFMN-fusion [29] | 4.90 | 18.28 | 31.44 | 18.21 | 5.39 | 15.08 | 23.40 | 14.62 |
| VSE++ [31] | 3.38 | 9.51 | 17.46 | 10.12 | 2.82 | 11.32 | 18.10 | 10.75 |
| MTFN [33] | 5.02 | 12.52 | 19.74 | 12.43 | 4.90 | 17.17 | 29.49 | 17.19 |
| AMFMN [29] | 5.39 | 15.08 | 23.40 | 14.62 | 4.90 | 18.28 | 31.44 | 18.21 |
| SCAN [32] | 5.85 | 12.89 | 19.84 | 12.86 | 3.71 | 16.40 | 26.73 | 15.61 |
| SAM t-i [28] | 6.59 | 19.85 | 31.04 | 19.16 | 4.69 | 19.48 | 32.13 | 18.77 |
| CABIR [34] | 8.59 | 16.27 | 24.13 | 16.33 | 5.42 | 20.77 | 33.85 | 20.01 |
| Ours | 9.14 | 28.96 | 44.59 | 27.56 | 10.70 | 29.64 | 41.53 | 27.29 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rahhal, M.M.A.; Bencherif, M.A.; Bazi, Y.; Alharbi, A.; Mekhalfi, M.L. Contrasting Dual Transformer Architectures for Multi-Modal Remote Sensing Image Retrieval. Appl. Sci. 2023, 13, 282. https://doi.org/10.3390/app13010282
Rahhal MMA, Bencherif MA, Bazi Y, Alharbi A, Mekhalfi ML. Contrasting Dual Transformer Architectures for Multi-Modal Remote Sensing Image Retrieval. Applied Sciences. 2023; 13(1):282. https://doi.org/10.3390/app13010282
Chicago/Turabian StyleRahhal, Mohamad M. Al, Mohamed Abdelkader Bencherif, Yakoub Bazi, Abdullah Alharbi, and Mohamed Lamine Mekhalfi. 2023. "Contrasting Dual Transformer Architectures for Multi-Modal Remote Sensing Image Retrieval" Applied Sciences 13, no. 1: 282. https://doi.org/10.3390/app13010282
APA StyleRahhal, M. M. A., Bencherif, M. A., Bazi, Y., Alharbi, A., & Mekhalfi, M. L. (2023). Contrasting Dual Transformer Architectures for Multi-Modal Remote Sensing Image Retrieval. Applied Sciences, 13(1), 282. https://doi.org/10.3390/app13010282