
Reinforcement Learning Based Vocal Fold Localization in Preoperative Neck CT for Injection Laryngoplasty

Abstract
1. Introduction
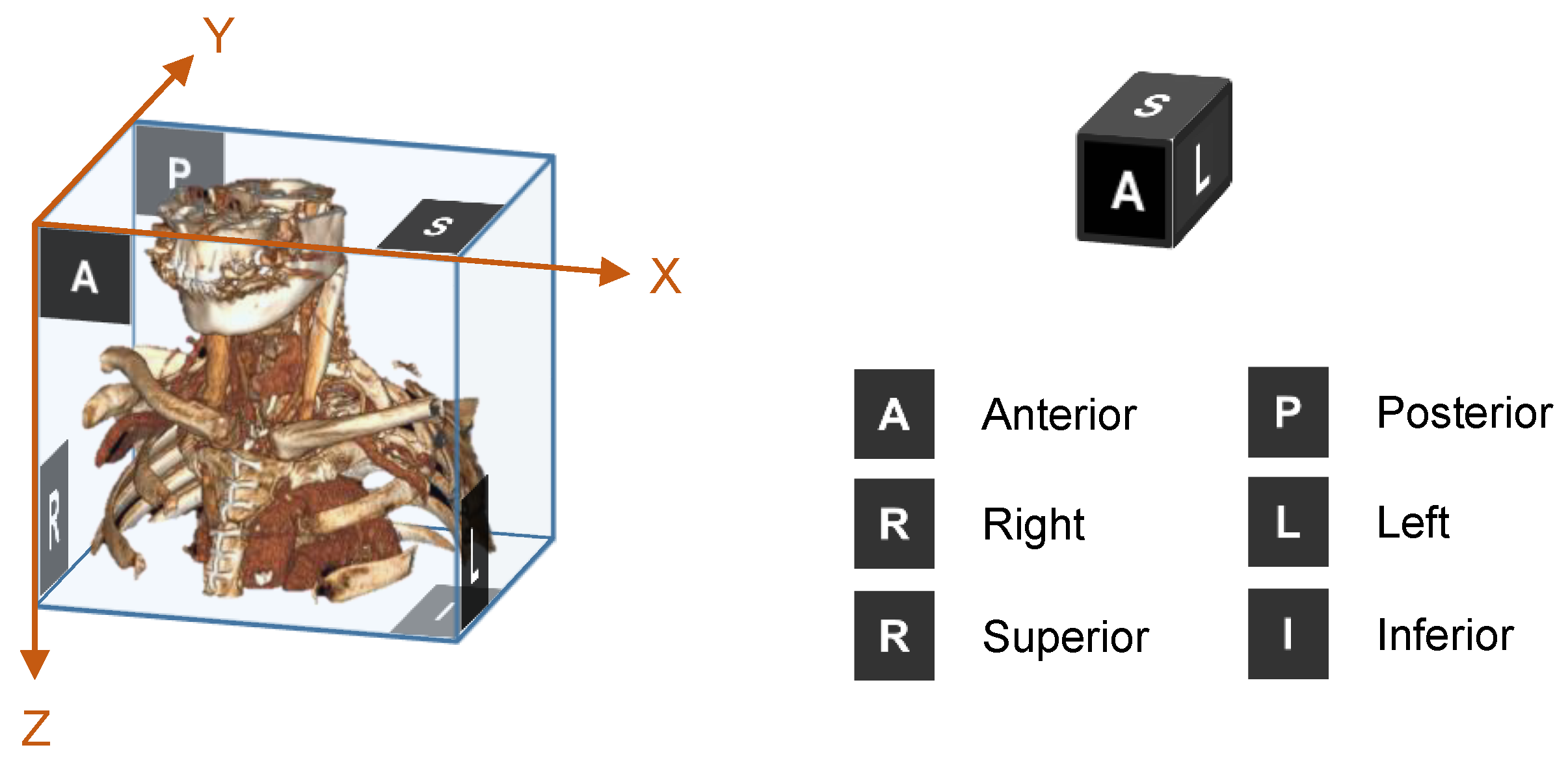
2. Methodology
Mirror Environment
| Algorithm 1: RL policy training with mirror environment |
 |
3. Results
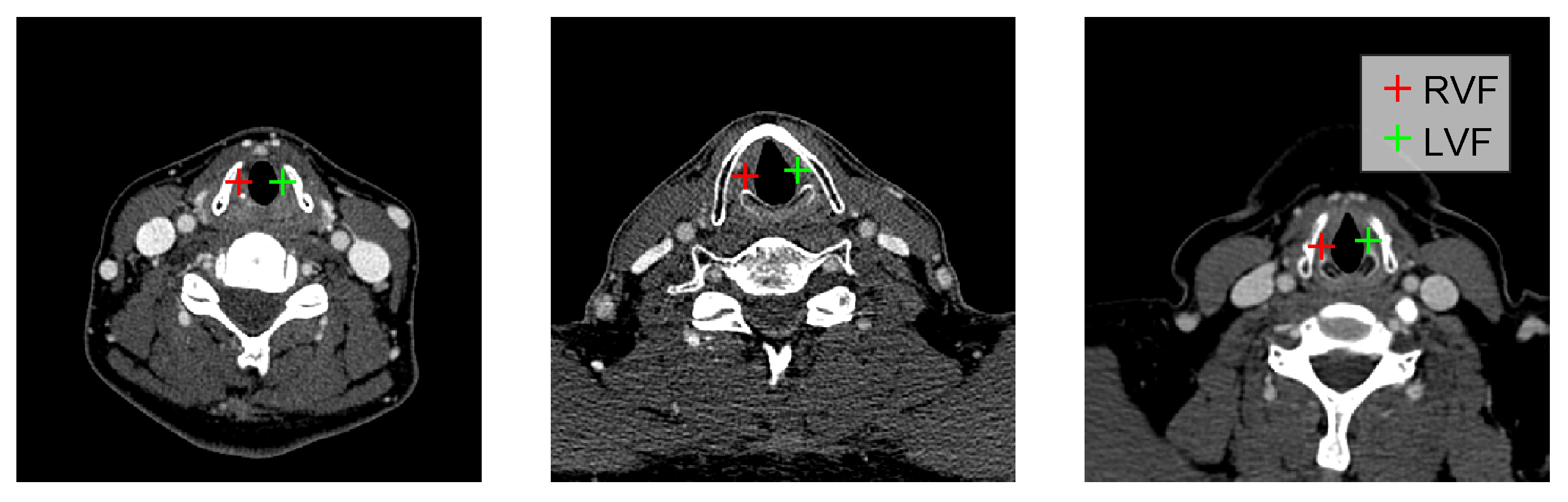
3.1. Data
3.2. Evaluation Method and Performance Metric
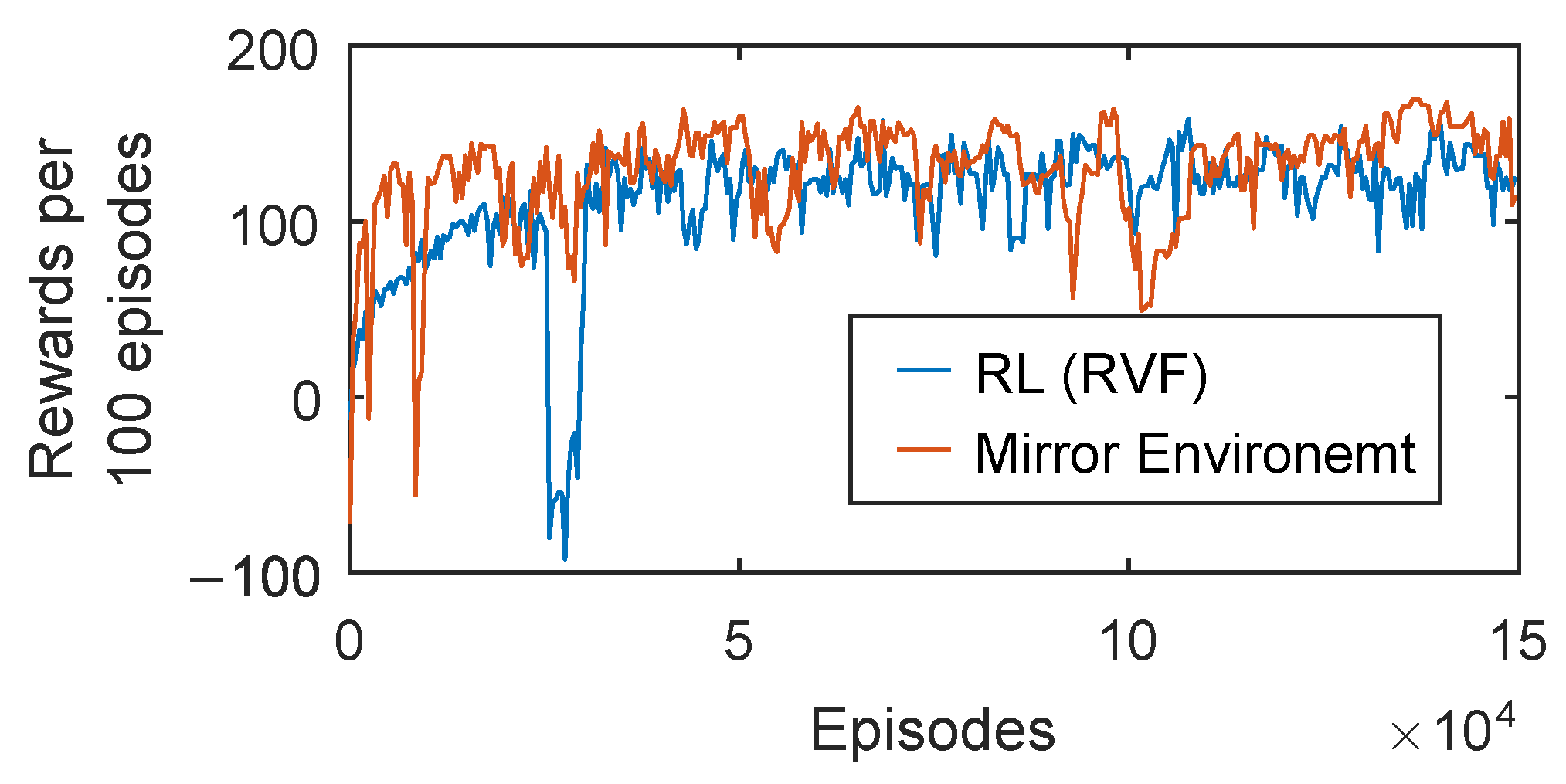
3.3. Training Efficiency
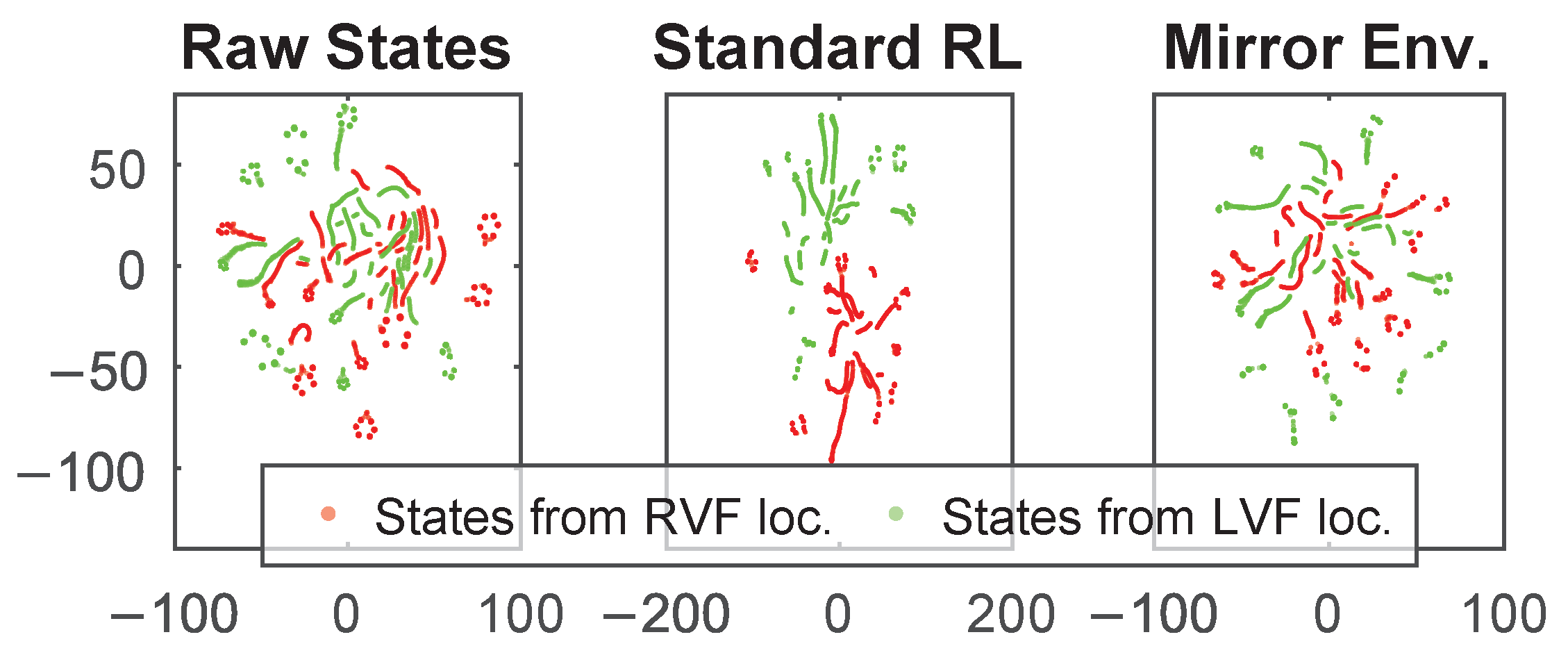
3.4. Localization Performance
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| LVF | Left vocal fold |
| RVF | Right vocal fold |
| RL | Reinforcement learning |
References
- Ahmad, S.; Muzamil, A.; Lateef, M. A study of incidence and etiopathology of vocal cord paralysis. Indian J. Otolaryngol. Head Neck Surg. 2002, 54, 294–296. [Google Scholar] [CrossRef] [PubMed]
- Tsai, M.S.; Yang, Y.H.; Liu, C.Y.; Lin, M.H.; Chang, G.H.; Tsai, Y.T.; Li, H.Y.; Tsai, Y.H.; Hsu, C.M. Unilateral vocal fold paralysis and risk of pneumonia: A nationwide population-based cohort study. Otolaryngol.—Head Neck Surg. 2018, 158, 896–903. [Google Scholar] [CrossRef] [PubMed]
- Chhetri, D.K.; Jamal, N. Percutaneous injection laryngoplasty. Laryngoscope 2014, 124, 742. [Google Scholar] [CrossRef] [PubMed]
- Nasir, Z.M.; Azman, M.; Baki, M.M.; Mohamed, A.S.; Kew, T.Y.; Zaki, F.M. A proposal for needle projections in transcutaneous injection laryngoplasty using three-dimensionally reconstructed CT scans. Surg. Radiol. Anat. 2021, 43, 1225–1233. [Google Scholar] [CrossRef] [PubMed]
- Lee, M.; Ang, C.; Andreadis, K.; Shin, J.; Rameau, A. An Open-Source Three-Dimensionally Printed Laryngeal Model for Injection Laryngoplasty Training. Laryngoscope 2021, 131, E890–E895. [Google Scholar] [CrossRef] [PubMed]
- Hamdan, A.L.; Haddad, G.; Haydar, A.; Hamade, R. The 3D printing of the paralyzed vocal fold: Added value in injection laryngoplasty. J. Voice 2018, 32, 499–501. [Google Scholar] [CrossRef] [PubMed]
- Payer, C.; Štern, D.; Bischof, H.; Urschler, M. Integrating spatial configuration into heatmap regression based CNNs for landmark localization. Med. Image Anal. 2019, 54, 207–219. [Google Scholar] [CrossRef] [PubMed]
- Abdullah Al, W.; Yun, I.D. Partial Policy-Based Reinforcement Learning for Anatomical Landmark Localization in 3D Medical Images. IEEE Trans. Med. Imaging 2020, 39, 1245–1255. [Google Scholar] [CrossRef] [PubMed]
- Ghesu, F.C.; Georgescu, B.; Mansi, T.; Neumann, D.; Hornegger, J.; Comaniciu, D. An artificial agent for anatomical landmark detection in medical images. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Athens, Greece, 17–21 October 2016; pp. 229–237. [Google Scholar]
- Ghesu, F.C.; Georgescu, B.; Grbic, S.; Maier, A.; Hornegger, J.; Comaniciu, D. Towards intelligent robust detection of anatomical structures in incomplete volumetric data. Med. Image Anal. 2018, 48, 203–213. [Google Scholar] [CrossRef] [PubMed]
- Alansary, A.; Oktay, O.; Li, Y.; Le Folgoc, L.; Hou, B.; Vaillant, G.; Kamnitsas, K.; Vlontzos, A.; Glocker, B.; Kainz, B.; et al. Evaluating reinforcement learning agents for anatomical landmark detection. Med. Image Anal. 2019, 53, 156–164. [Google Scholar] [CrossRef] [PubMed]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Lv, J.; Shao, X.; Xing, J.; Cheng, C.; Zhou, X. A deep regression architecture with two-stage re-initialization for high performance facial landmark detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3317–3326. [Google Scholar]
- LJPvd, M.; Hinton, G. Visualizing high-dimensional data using t-SNE. J. Mach. Learn. Res. 2008, 9, 9. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Required Episodes | Final Reward |
|---|---|---|
| Standard RL (RVF) | ||
| Standard RL (LVF) | ||
| Standard RL (RVF and LVF) | ||
| Mirror Environment |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdullah Al, W.; Cha, W.; Yun, I.D. Reinforcement Learning Based Vocal Fold Localization in Preoperative Neck CT for Injection Laryngoplasty. Appl. Sci. 2023, 13, 262. https://doi.org/10.3390/app13010262
Abdullah Al W, Cha W, Yun ID. Reinforcement Learning Based Vocal Fold Localization in Preoperative Neck CT for Injection Laryngoplasty. Applied Sciences. 2023; 13(1):262. https://doi.org/10.3390/app13010262
Chicago/Turabian StyleAbdullah Al, Walid, Wonjae Cha, and Il Dong Yun. 2023. "Reinforcement Learning Based Vocal Fold Localization in Preoperative Neck CT for Injection Laryngoplasty" Applied Sciences 13, no. 1: 262. https://doi.org/10.3390/app13010262
APA StyleAbdullah Al, W., Cha, W., & Yun, I. D. (2023). Reinforcement Learning Based Vocal Fold Localization in Preoperative Neck CT for Injection Laryngoplasty. Applied Sciences, 13(1), 262. https://doi.org/10.3390/app13010262