1. Introduction
Breast cancer (BC) causes cells in the breast to develop uncontrollably, which can lead to tumor growth and death if not detected early. In 2018, an estimated 627,000 women died from BC, which corresponds to 15% of the total cancer mortality in women [
1]. A recent study by the American Cancer Society (ACS) suggests that one in eight women in the US will develop cancer in their lifetime [
2]. Globally, BC is a leading type of cancer among women, affecting about 2.1 million women annually, and has been the leading cause of death associated with cancer among women [
3]. Early detection and classification of breast cancer subtypes are crucial in deciding the best treatment plan and mitigating the risk of death. According to the World Health Organization (WHO), increasing the survival rates of patients with breast cancer significantly requires early and precise diagnosis of malignancy [
4]. There are two kinds of growth in breast tissue, non-harmful (benign) and malignant, with subtypes occurring in each category. Non-harmful (benign) growth patterns include adenosis (A), fibroadenoma (FA), phyllodes tumor (PT), and tubular adenoma (TA), and dangerous (malignant or cancerous) growth patterns include ductal carcinoma (DC), lobular carcinoma (LB), mucinous carcinoma (MC), and papillary carcinoma (PC). These subtypes of BC have distinct biological features, leading to different response patterns to various treatment modalities and thus have varied clinical outcomes. Consequently, to ensure that sufferers receive lifesaving, patient-tailored treatment early, it is very important to accurately distinguish dangerous malignant subtypes of tumors from benign harmless subtypes [
5] during patient assessments. Global gene expression profiling (GEP) [
6] studies have shown that survival is associated with the classification of distinct biological classes.
As a result of limited knowledge and availability of experts, between 10% and 30% of BCs go undetected during regular screenings. The accuracy of manual BC screening varies according to the pathologist’s experience and knowledge, and diagnoses can be incorrect due to human error. Automated computer screening systems for breast cancer classification and identification have been proposed to automatically diagnose malignancy, improving the accuracy and consistency of differentiating the normal vs. abnormal classes of breast tissues by about 10% [
7]. Computer aided diagnosis (CAD) systems are accessible, fast, and reliable [
8]. Machine learning using handcrafted image features was used in previous image-based breast cancer classification studies [
9,
10,
11]. Recently, due to their demonstrated impressive performance, deep convolutional neural networks (DCNNs) have become increasingly popular for medical image analysis, segmentation, classification, and ailment prediction [
12]. Breast cancer can be detected by automated therapeutic imaging techniques such as histopathological imaging, computed tomography, breast X-rays, sonograms, and magnetic resonance imaging [
13]. Currently, histopathological images are considered the best diagnostic images for cancer diagnosis [
14]. Several top-down and bottom-up image analyses rely on automated and exact classification of histopathological images, such as classifying nuclei, detecting mitosis, and segmenting glands [
15]. Tumor classification, however, is the most critical step in histopathological image examination. A wide range of image analysis tasks can be performed with convolutional neural networks (CNNs), including image classification, disease detection, localization, segmentation [
16], and the analyses of histopathological images [
12].
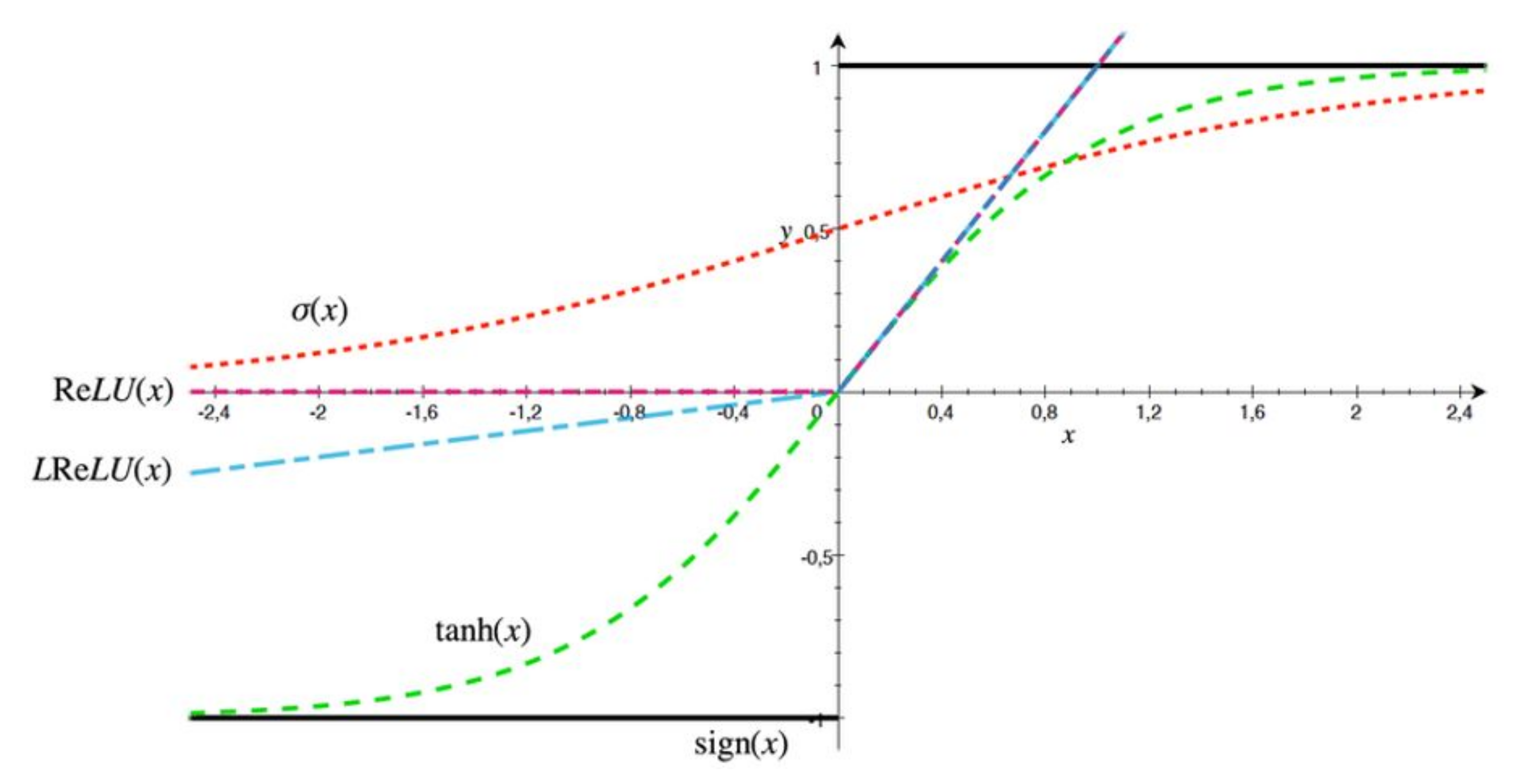
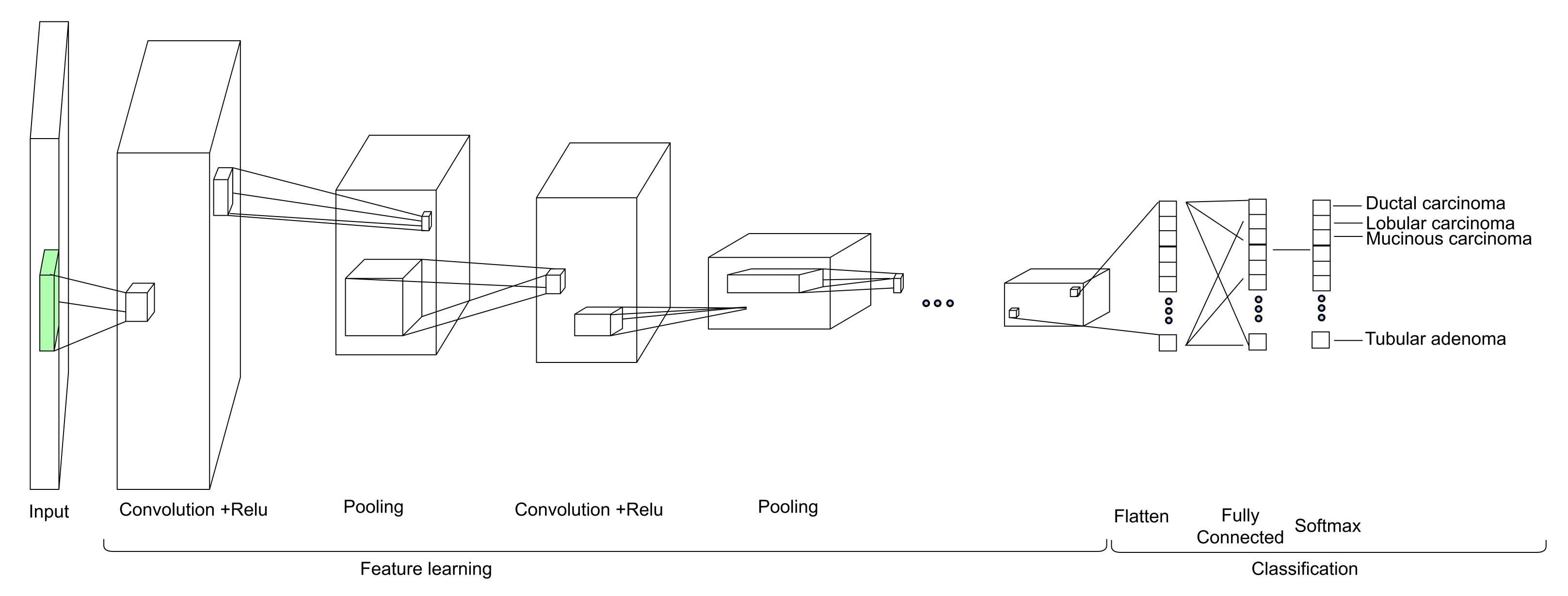
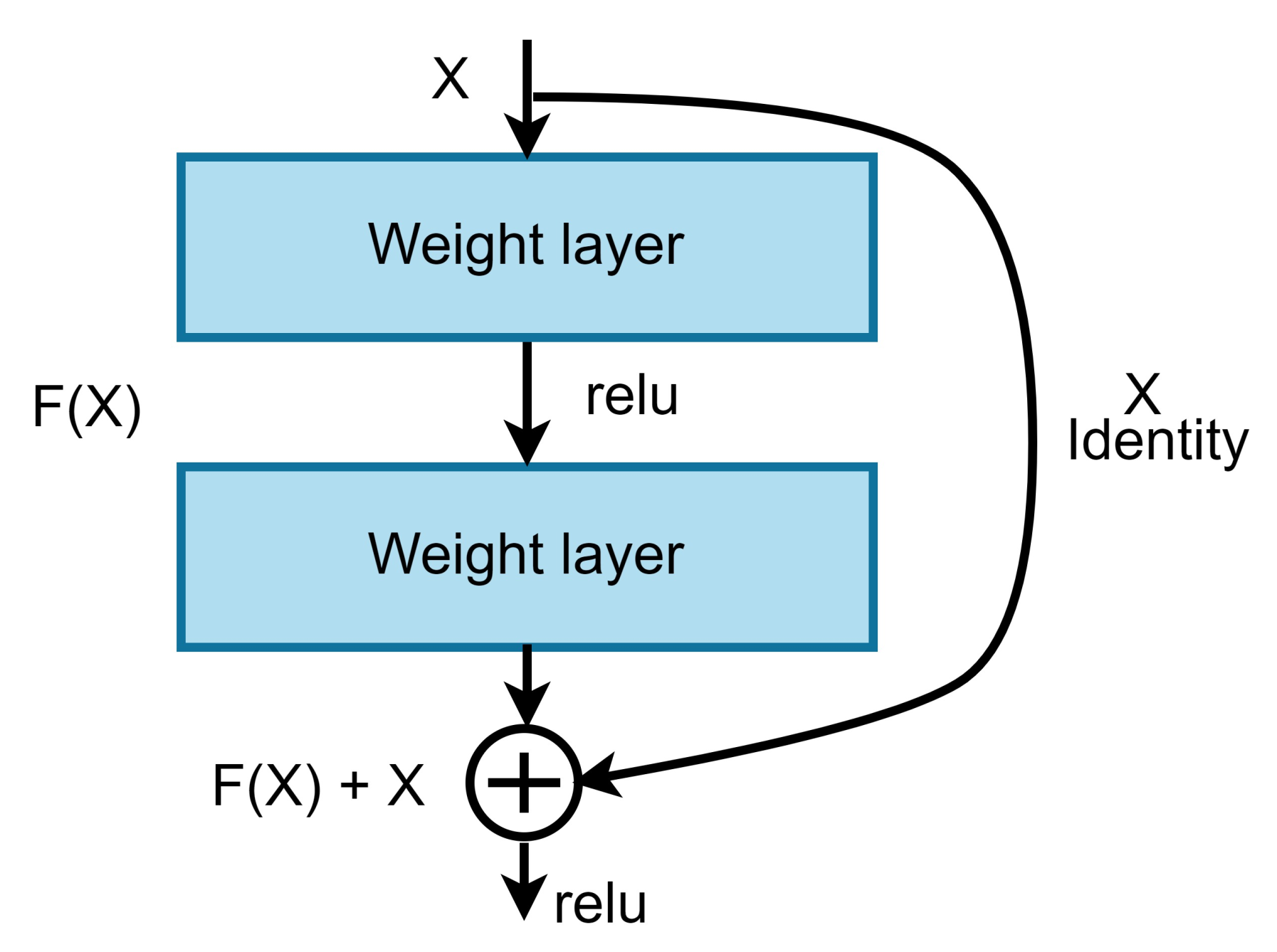
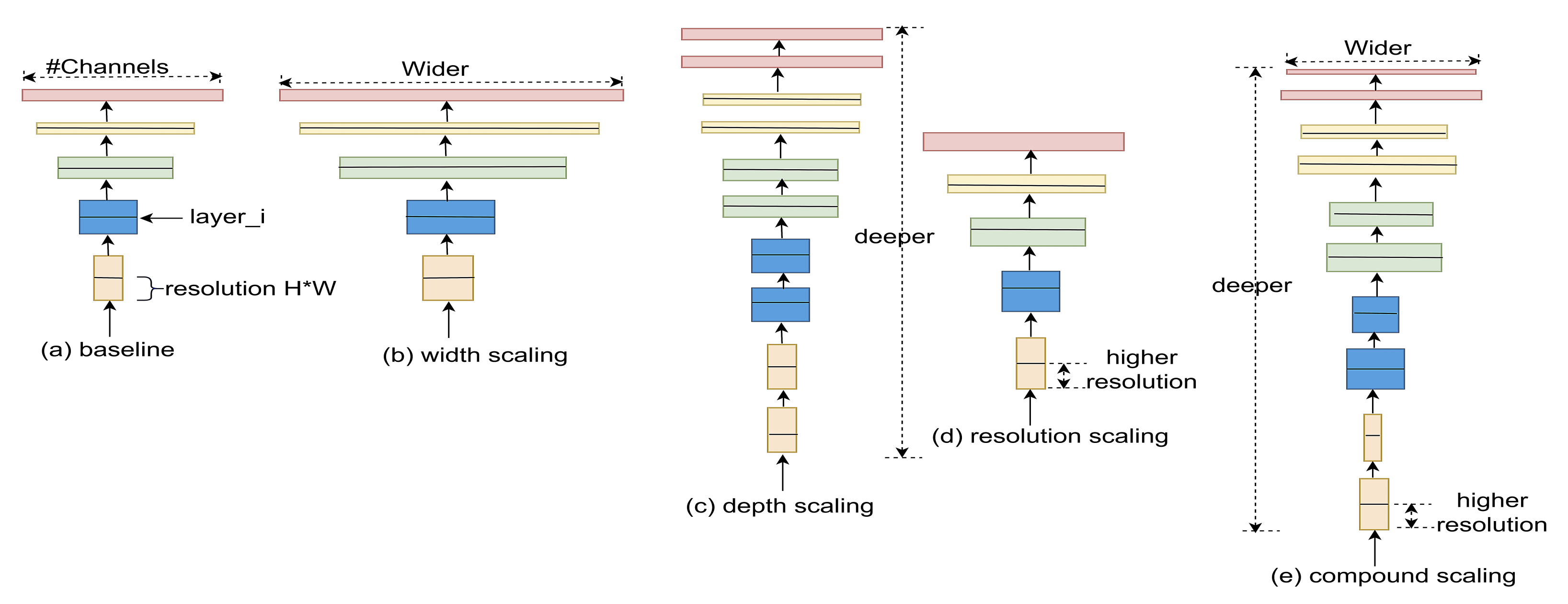
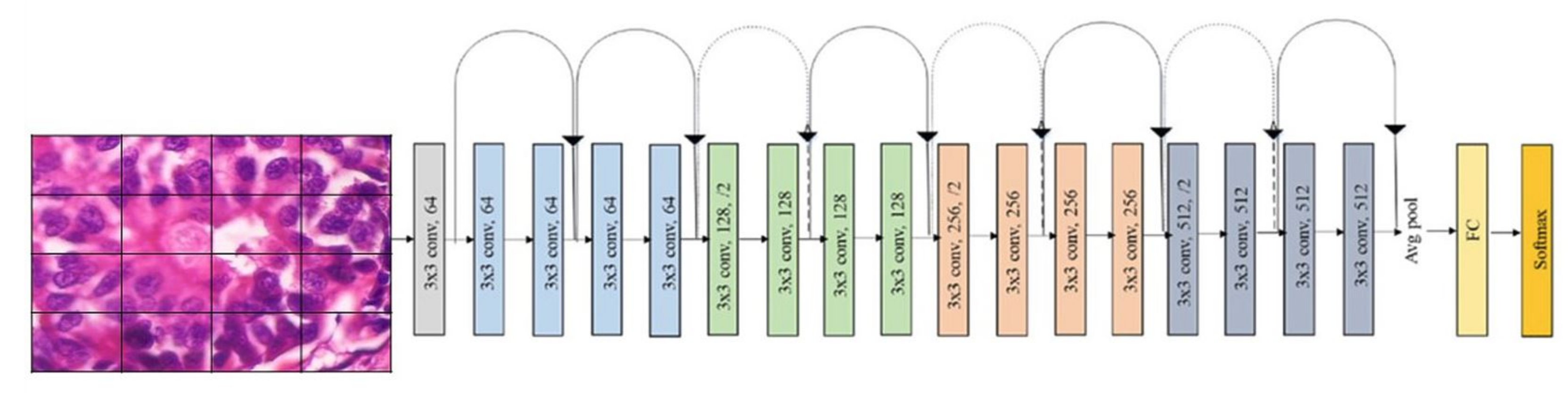
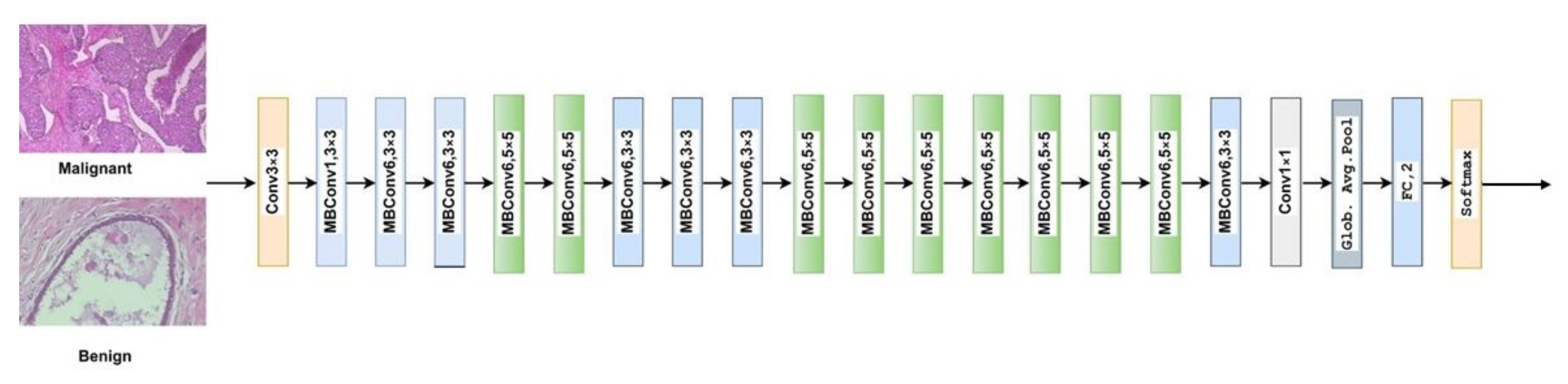
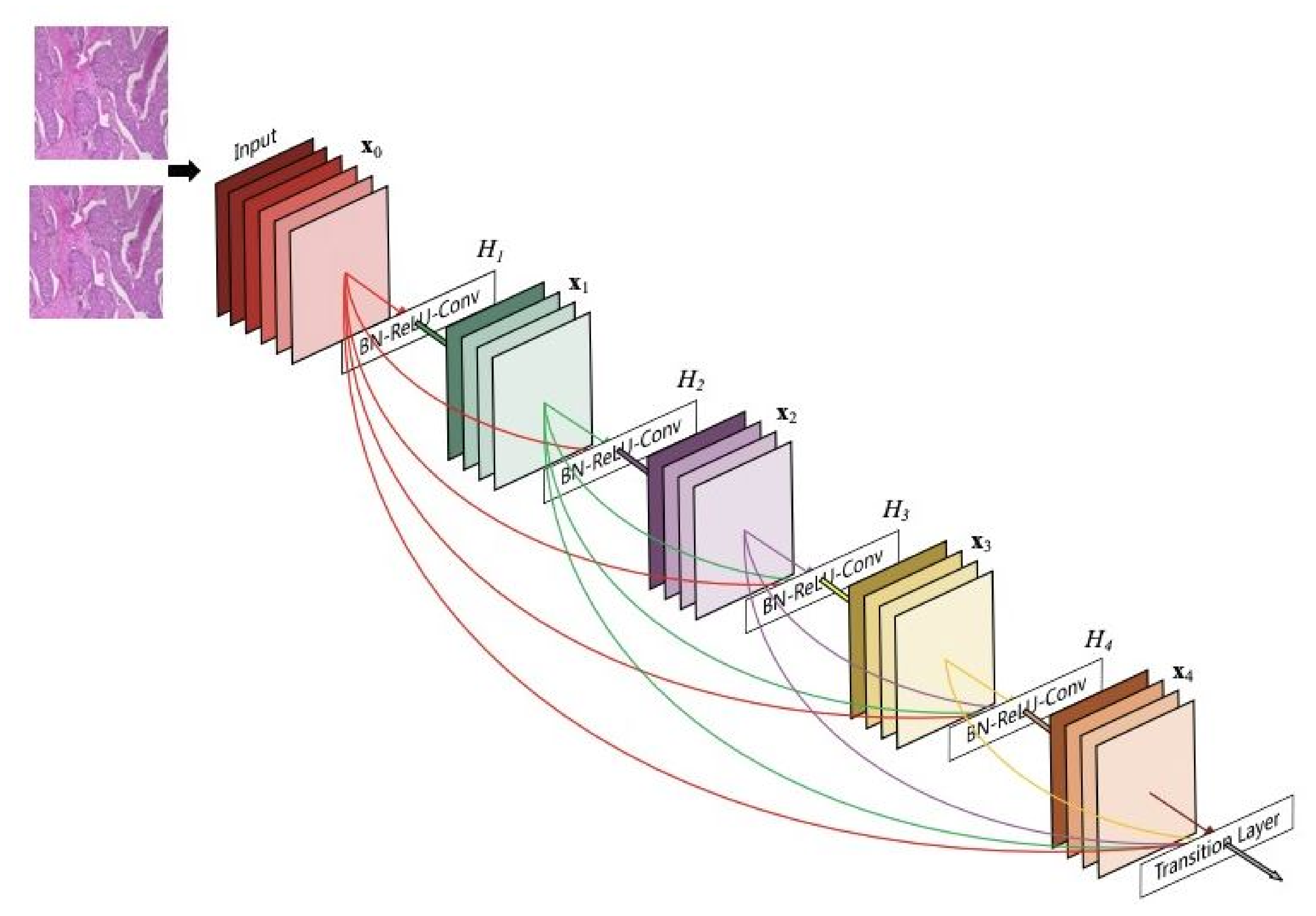
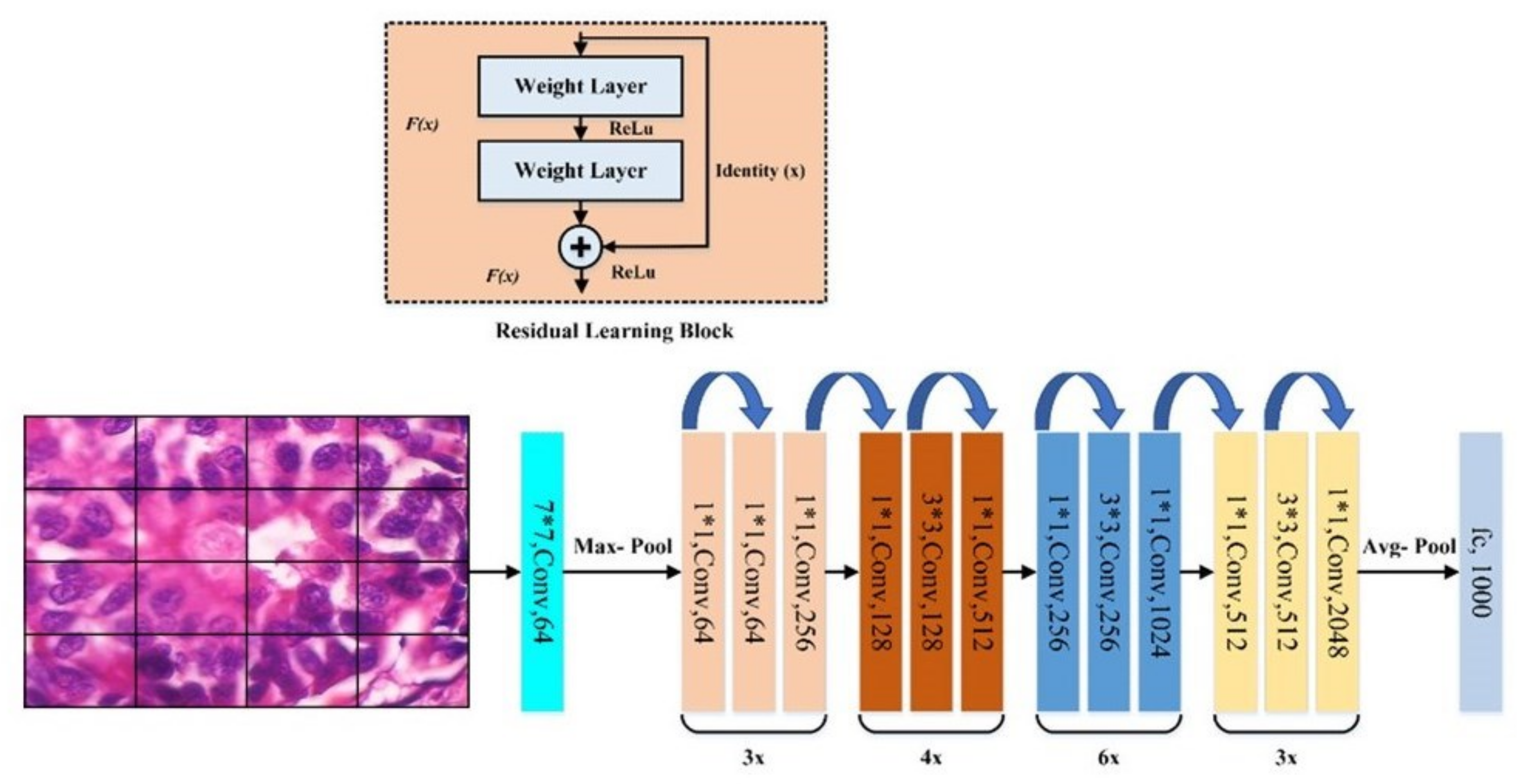
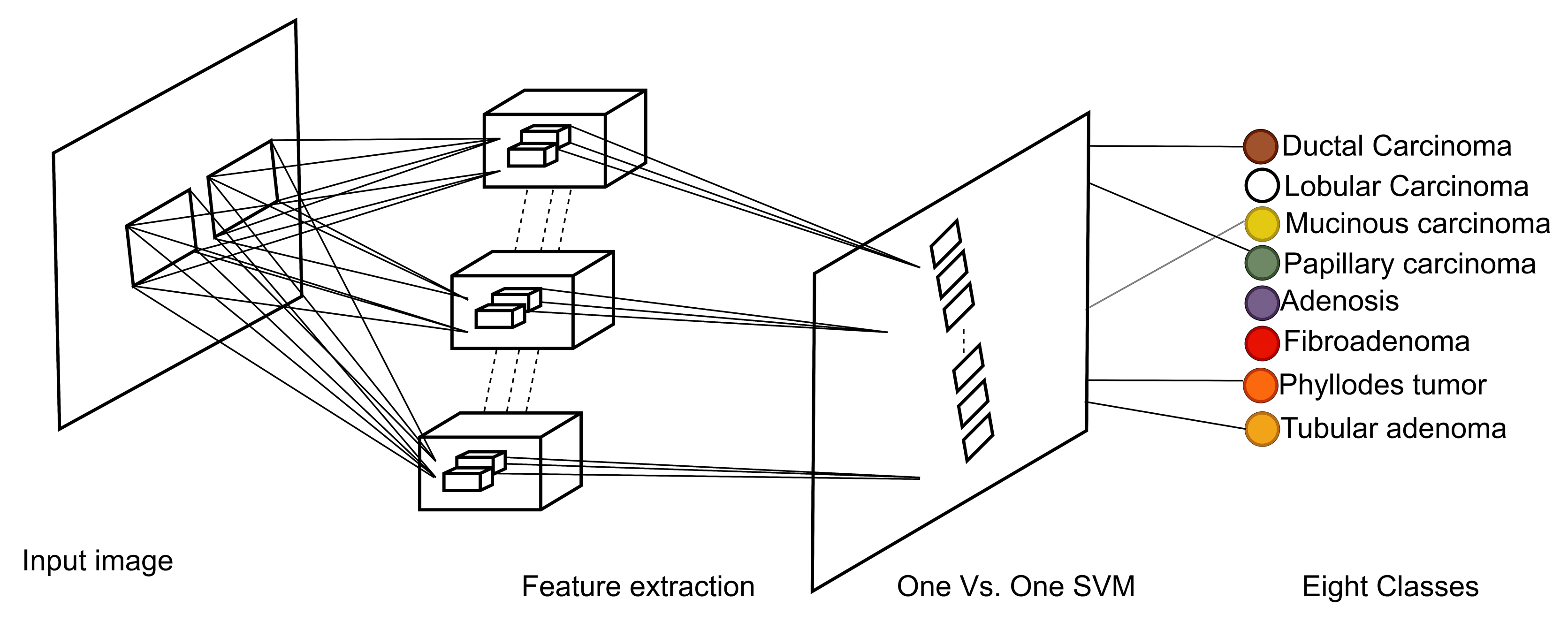
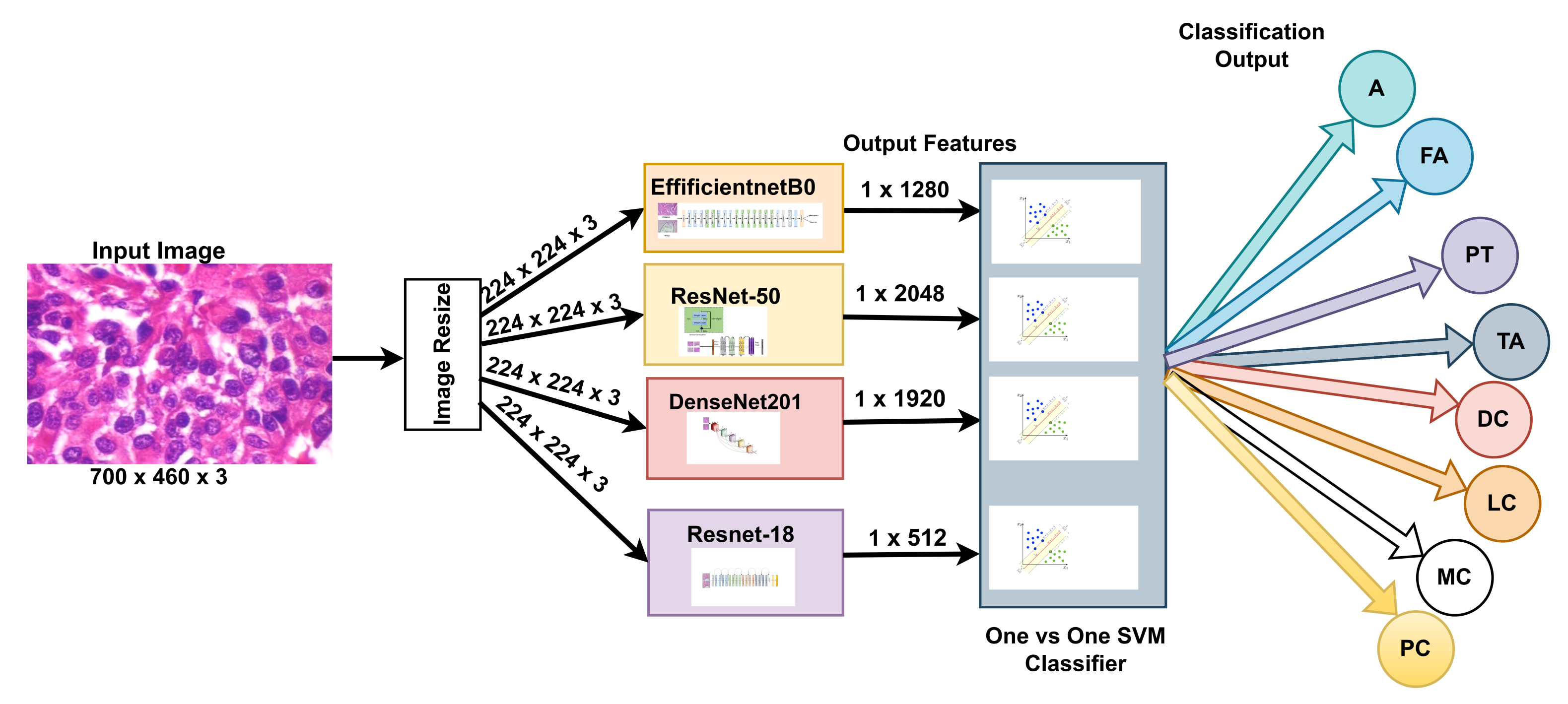
Our approach: In this study, a method for multiclass classification of breast cancer using an ensemble of pre-trained deep convolutional neural network (DCNN) and SVM, is proposed. First, four state-of-the-art DCNN backbone models (1) ResNet50 [
17], (2) ResNet18 [
17], (3) DenseNet201 [
18], and (4) EfficientNetb0 [
19] were used for feature extraction. The models were used to extract rich multi-resolution features from four resolutions (40×, 100×, 200×, and 400×) of histopathological breast cancer images. The rich multiresolution features were then pooled using global average pooling to create an array of deep multiresolution convolutional features, SVM classifier performs multiclassification (8sub-types) of malignant and benign tumors. SVM algorithms always converge at a global minimum when provided with a suitable feature set irrespective of the dimensionality of the inputs. The target malignant breast cancer classes are ductal carcinoma in situ, lobular carcinoma, mucinous carcinoma, and papillary carcinoma subtypes, and the benign breast cancer target classes are adenosis, fibroadenoma, phyllodes tumor, and tubular adenoma subtypes. Methods for extracting image features fall into three main categories [
20]: (1) Automatic feature extraction using deep learning, (2) handcrafted features, and (3) unsupervised feature learning. Manual feature extraction is tedious and error-prone. EffficientNetb0 is the baseline model for EfficientNet, which uses compound scaling, a novel scaling method, to scale the model’s dimensions uniformly to increase performance. With ResNet-50, deep residual networks are constructed with 50 layers of residual blocks, which mitigates the vanishing gradient descent problem to maintain accuracy as the depth of the network increases. In contrast to the previously described neural networks, ResNet18 is a gateless or open-gated variant of the highway-net, the first working very deep feedforward neural network. Some layers can be jumped over by using skip connections. In typical implementations, it includes double- or triple-layer skips with nonlinearities and batch normalizations. DenseNet-201 is a convolutional neural network that is 201 layers deep. It utilizes dense connections between layers through dense blocks, where all layers are connected directly. Each layer receives additional inputs from all preceding layers and passes its feature maps to all subsequent layers to preserve the feed-forward nature. The feature extraction step is fundamental to the analysis of medical images using machine learning, and a variety of extraction strategies have been proposed in the past for the classification of various diseases using images [
21,
22,
23,
24].
In summary, the proposed method utilizes the power of pre-trained, state-of-the-art DCNN models to extract a multi-scale pooled image feature representation (MPIFR) from four resolutions (40×, 100×, 200×, and 400×) of BC images. The proposed MPIFR is a highly predictive auto-learned representation that is then classified using SVM. In rigorous evaluation, the proposed MPIFR achieved an average accuracy of 97.77%, with 97.48% sensitivity, and 98.45% precision on the BreaKHis dataset [
25]. The proposed ensemble approach outperforms a comprehensive set of state-of-the-art CNN baselines and the prior state-of-the-art for classifying multiresolution (40×, 100×, 200×, and 400×) histopathological breast cancer images including ResNet18, InceptionV3, DenseNet201, EfficientNetb0, SqueezeNet, and ShuffleNet. Our evaluation demonstrates that every component of MPIFR contributes non-trivially to its superior performance, including transfer learning (pre-training and fine-tuning), deep feature extraction at multiple resolutions into a powerful feature representation and classification using one-versus-one SVM.
Challenges: Firstly, due to the heterogeneous visual texture patterns in breast histopathological images, DCNNs are challenged to reliably classify tumor malignancy, which negatively impacts their performance. Secondly, the most predictive features that discriminate malignant and benign breast cancers in histopathological images may appear at different resolutions, which differ for various BC cases. The proposed MPIFR approach innovatively addresses these two challenges, making it particularly appropriate for discriminating between BC tumor malignancies.
Related work that utilized deep learning and CNNs for breast cancer tumor multiclassification are summarized in
Table 1. The deep multiresolution feature representation for 8-classes, which we propose, has not been explored previously for breast cancer classification using neural networks and SVM. Omar et al. in [
26] performed multi-class breast cancer classification from histopathology images using 6B-Net deep CNN model, with feature fusion and selection mechanism. The method achieved a multi-class average accuracy of 94.20% for 4-class and 90.00% for 8-class, respectively, on histopathological images. Wei et al. proposed a breast cancer multiclassification from histopathological images with a structured deep learning model [
27], the model achieved an accuracy of 93.2%. Murtaza et al. [
28] utilized GoogleNet architecture [
29] to classify histopathology images into subtypes using majority voting. MUDeRN investigated using ResNet [
17] to classify breast cancer images into malignant or benign and further categorized each to its subsequent subtypes using two modules M and B [
30]. Ameh Joseph et al. in [
31] used handcrafted features extracted to train the DNN classifiers with four dense layers and the SoftMax layer. Xie et al. in [
32] performed 4-class classification based on magnification factor, using some deep learning models.
Related work that used CNNs to extract deep features from medical images Wichakam et al. proposed an automated mammographic image detection system using a CNN for feature extraction and SVM for classification but did not explore multi-resolution extraction and pooling [
35]. Devnath et al. [
36] used CNN models to detect pneumoconiosis in X-ray images by extracting deep multi-level features. Devnath et al. [
37] present a systematic review of computer-aided diagnosis of coal workers’ pneumoconiosis in chest X-rays using machine learning, which included approaches that used CNNs. Devnath et al. [
38] used CheXNet-model as part of an ensemble of multi-dimensional deep feature extractors from chest X-rays to detect and visualize pneumoconiosis. To convert the output of the model into one-dimensional vectors, the last layer close to the output layer was removed, then a global average pooling layer was added. Huynh 162 et al. [
39] used computer-aided diagnosis (CADx) systems, to examine the optimal point for extracting features from pre-trained CNNs. Zhang et al. [
40] proposed ensemble learners for pulmonary nodule classification by combining deep CNNs. Other related research includes work by Yang et al. [
41] who previously used adaptive boosting (AdaBoost), an ensemble method, to combine multiple weak classifiers into a single classifier. Using k-means with K = 4000, each tissue image generated 4000-Teton histograms as features. An accuracy of 80% was achieved for multi-class classification (three target classes: I, II, and benign). Al-Haija and Adebanjo [
33] proposed a binary classifier using a transfer learning model ResNet-50 CNN and achieved a performance accuracy of 99% using histopathological images. Filipczuk et al. [
42] and George et al. [
20] previously extracted nuclei feature from fine needle biopsies. First, the circular Hough transform was utilized for detecting nuclei candidates and false-positive reduction, followed by machine learning and Otsu thresholding.
Novelty: Our work is novel because while some prior work has utilized CNNs for 2- and 4-class breast cancer classification, they did not explore using a multi-scale pooled image feature representation (MPIFR) to classify histopathological images into eight (8) BC classes. Specifically, some prior work utilized CNNs for the classification of four (4) BC classes using 6B-Net with deep feature fusion and achieved an accuracy of 94.2%. Innovatively, the proposed ensemble approach leverages several key insights. First, pre-training state-of-the-art DCNNs on huge repositories such as the 14 million image ImageNet repository provides them with the intelligence to learn low-level features such as edges and corners from images of histological breast cancer. Secondly, by extracting features from multiple resolutions of histopathological images, classification accuracy is improved due to the fact that specific visual characteristics may be more visible at different resolutions. Thirdly, the extraction of multiresolution breast cancer features creates a powerful set of features that can be classified using SVM for highly accurate multi-class classification of histopathological images of breast cancer.
5. Results
We present the results of various experiments we have conducted in this study. To evaluate the performance of our proposed ensemble architecture, individual baseline models were trained first that would serve as a basis for comparison of our eventual method and also to discover which DCNN architectures performed best. Out of the eight models, the four best-performing baseline models were selected to evaluate the performance of our ensemble architecture.
Table 7 shows the performance of the baseline models.
Only baseline models with accuracy above 90% were selected, which include ResNet50, ResNet18, DenseNet201, and EfficientNetb0. The selected models were pre-trained models using the hyperparameter values presented in
Table 8. We trained the MPIFR by first combining the selected baseline models in pairs, in threes, and all four selected models.
The result of combining the selected baseline models are presented in
Table 9. The result shows significant improvement from a combined pair of baseline models in comparison to all four selected baseline models. However, model training takes more time when a large number of models are combined as indicated by the training time in hours presented in
Table 9. The ensemble model took more than two (2) days to train because the final training time was that combined training time for all four models utilized in our MPIFR method. Further, we note that while the MPIFR model training time is large in some cases, training time is incurred once during model development. Test time is typically faster and is more important when the model is deployed and operationalized. We believe that it is reasonable to trade off higher training time to achieve higher performance.
The ensemble model in
Table 9 combines the four selected baseline models namely ResNet50, DenseNet201, ResNet18, and EfficientNetb0. The resulting performance is the best of the state-of-the-art multi-class models of the histopathological breast cancer classification based on BreakHis images.
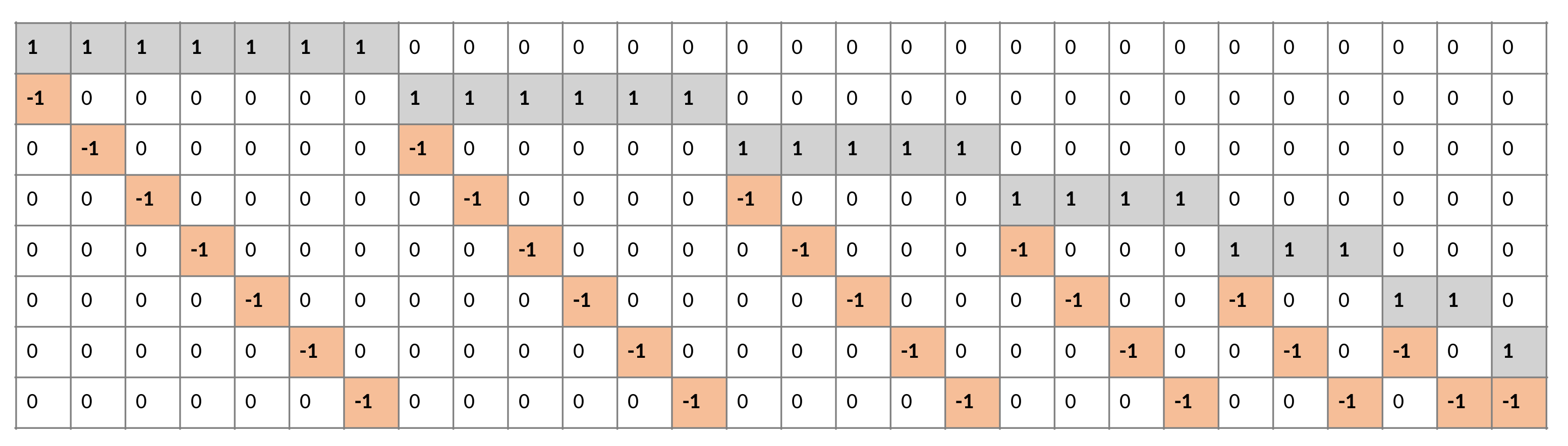
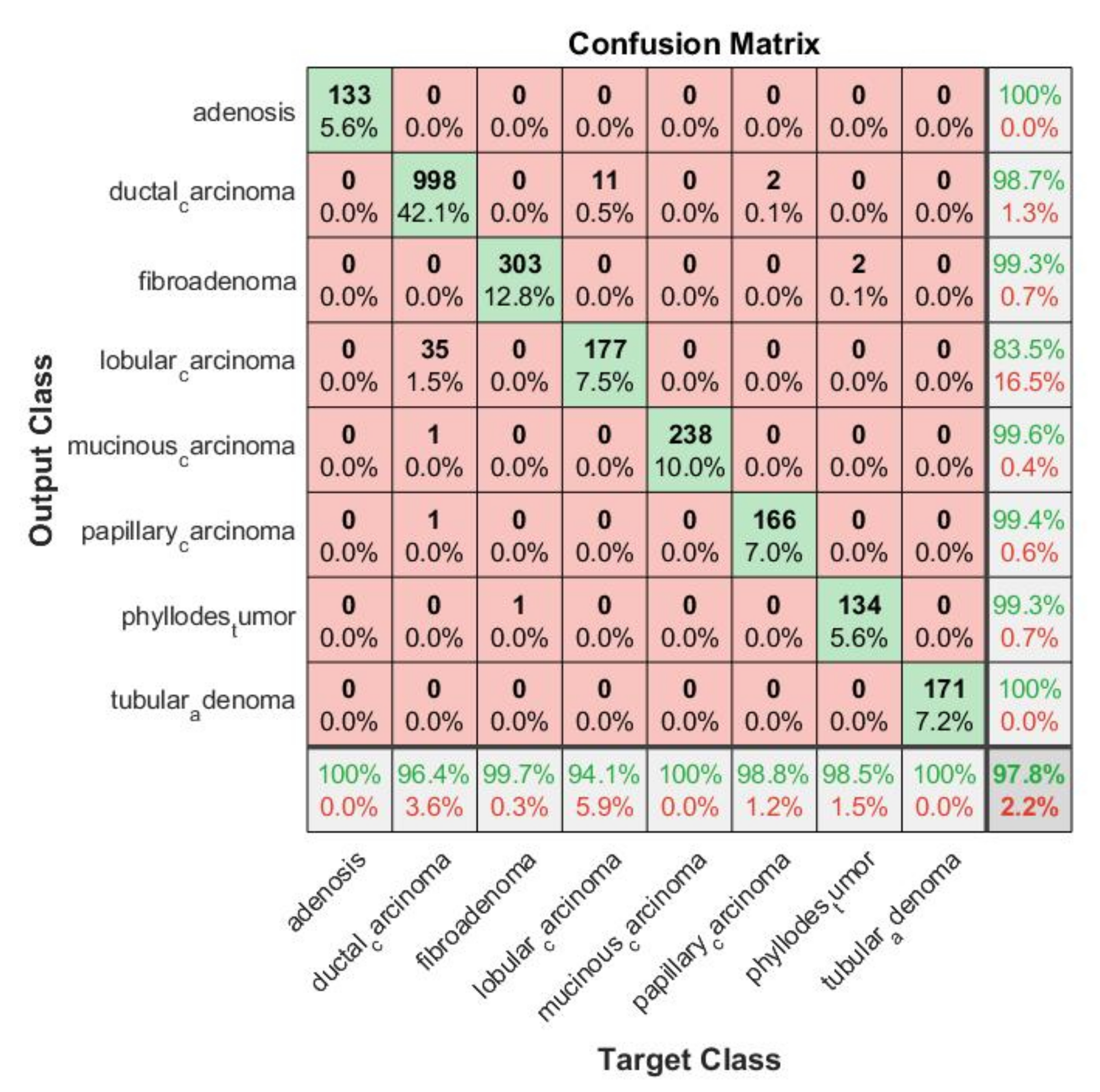
Confusion Matrix: In order to determine which classes were confounded by other classes, we analyzed the confusion matrix.
Figure 17 shows the confusion matrix of the top-performing technique. Columns correspond to targeted classes and rows to output classes. Diagonal cells correspond to correctly classified observations. Off-diagonal cells are referred to as incorrect classifications. There is also a percentage of the overall number of observations and a number of observations for each cell. On the extreme right, you can see the proportion of incorrectly predicted classifications (red color) and correctly predicted classifications (green color). In statistics, these metrics are called false discovery rate and positive predictive value. The lowest row indicates the percentage of incorrectly classified and correctly classified results, referred to as false negative rate (FNR) and true positive rate (TPR). In the bottom-most right cell, you can see the general precision. Column-normalized column summaries show the percentage of correctly classified observations for every predicted class. Using row-standardized row summaries, you can see how many observations are incorrectly classified and how many are correctly classified. As can be seen in the confusion matrix, the majority of results fall on the leading diagonal with very few off the diagonal, demonstrating that the proposed approach did not confuse benign and malignant cells.
The MPIFR model classified all eight cancer subtypes with 97.77% accuracy and 99.57% specificity on average. This means that for a specific subtype, the individual classifier in our proposed model has a high ability to discriminate one class of BC subtype from another. The classifier SVM performance was evaluated with ten-fold cross-validation with a cross-validation error of 0.0432. This is a good indication of the significance and consistency of the results of classifiers of the corresponding individual cancer subtypes. Further, to demonstrate that the difference in performance between the MPIFR and other ensemble baselines was statistically significant, the Nemenyi post hoc test [
55] was performed. At a confidence level of a = 0.05, the critical distance (CD) is 1.2536. Our model F1-score is 97.92%. The F1-score is the harmonic average of precision and sensitivity. While precision measures the extent of the error caused by false positives and sensitivity measures the extent of the error caused by the false negative.
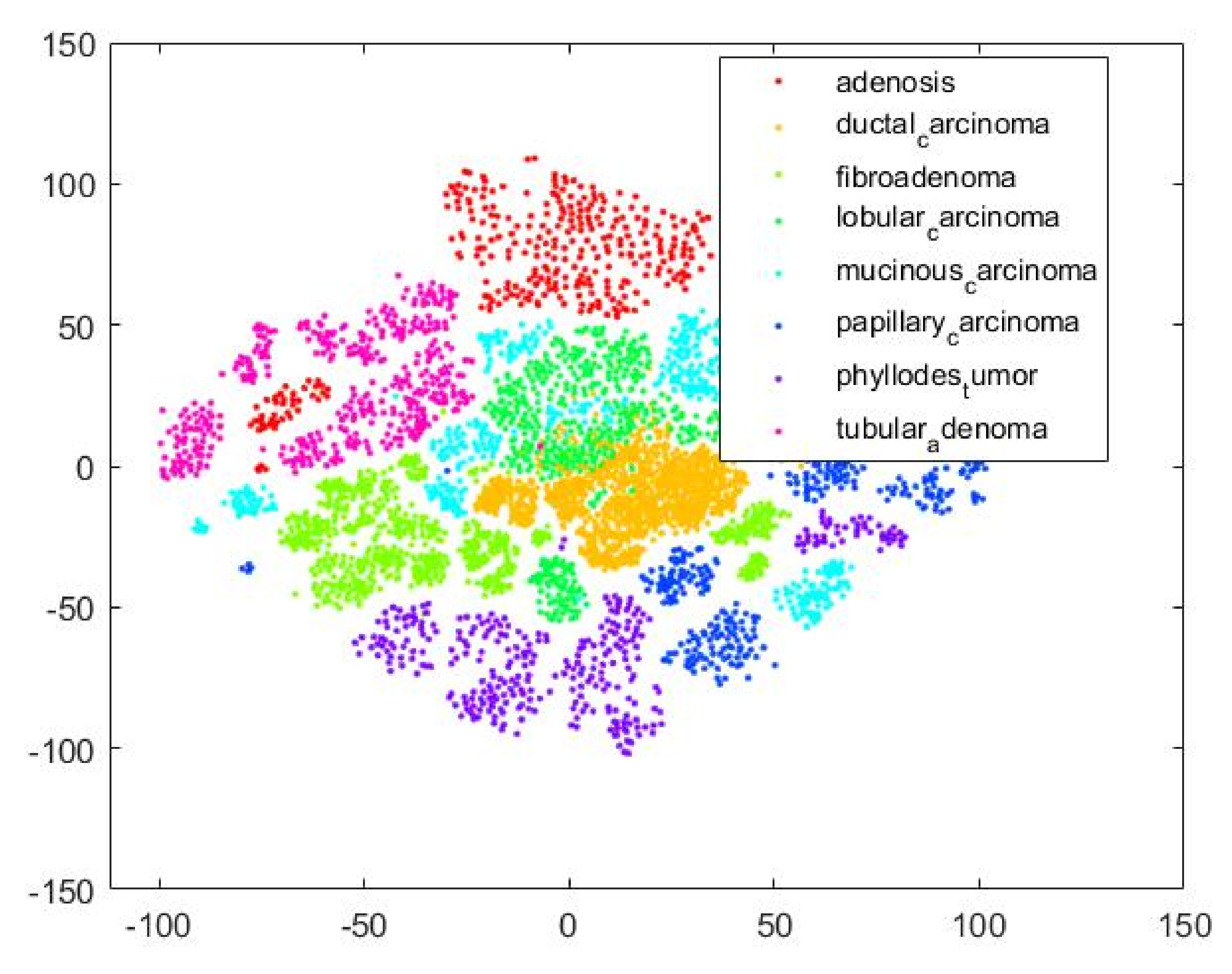
Figure 18 is a T-SNE plot that illustrates that our proposed MPIFR method adequately discriminates between the eight target BC classes in feature space.
AUC is an effective way to summarize the overall accuracy of the test. In general, an AUC of 0.5 suggests no discrimination (i.e., the ability to diagnose patients with or without the BC based on the test), 0.7 to 0.8 is considered acceptable, 0.8 to 0.9 is considered excellent, and more than 0.9 is considered outstanding. The MPIFR has an AUC of 0.99 (99%).
Table 10 presents detailed results of the performance of the ensemble model.
6. Discussion
As shown in
Table 10, in rigorous evaluation experiments, the proposed MPIFR outperformed a comprehensive set of baseline models and also previous state-of-the-art techniques for both binary and multiclassification (
Table 1) of histopathological images. Our results also demonstrate that all key components of our approach contribute non-trivially to its superior results, including:
Transfer learning by pre-training on a large image repository (ImageNet) with fine-tuning on the BreakHis breast cancer image dataset: that enables the CNN feature extractors models to learn a robust image representation from the large image repository. Fine-tuning on the BreakHis breast cancer dataset transfers the learned intelligence to the task of analyzing and classifying breast cancer. This conclusion is evident in
Table 9.
Using an ensemble of DCNNs for deep feature extractors: This step also facilitates downstream classification with traditional machine learning algorithms such as SVM. Deep MPIFRs are a powerful representation, which had the best performance for all combinations of the DCNN model explored in this study as shown in
Table 7. The proposed technique of using MPIFR features, combined and classified using SVM outperformed single DCNN models approaches in
Table 6. Compared with a single pre-trained CNN, it achieves superior performance for feature extraction (see
Table 6 and
Table 8). While SVM is utilized for final classification, pre-trained CNNs were utilized for feature extraction. SVM, a classic machine learning algorithm was utilized for classification because the features extracted by the CNN are relatively small for each of the target classes. We also show in
Table 8 that the four state-of-the-art CNN models (ResNet50, ResNet18, DenseNet201, and EfficientNetb0), which were discovered through extensive experimentation and employed to extract features, outperform other CNN combinations and ensembles. The features extracted by each DCNN are slightly different intuitively. Multi-CNN feature extraction produces a superset of features that outperforms single-CNN feature extraction.
One-versus-one SVM effectively performs 8-class Bc classification: was used as a heuristic technique such as a one-versus-one binary classification model for multi-class classification. With eight target classes for the breast cancer BreakHis dataset, a total of 28 SVM classifiers are modeled based on the
formula, where
k is the number of classes. The result of the one-vs-one technique is presented in
Figure 17.
Our proposed MPIFR method outperforms the state-of-the-art for 8-class BC classification: as shown in
Table 1 in which various proposed BC image classification models are compared in terms of the proposed method, classification type, accuracy, F1-score, specificity, and AUC. All models in the table utilize the BreakHis breast cancer image datasets. As seen in
Table 1, the proposed MPIFR model built for 8-class classification performed better than the other state-of-the-art multi-class models. Multiclassification of breast cancer images into eight (8) subtypes of malignant and benign are much more challenging [
39]. It can be the basis of a computer-aided grading diagnosis system for BC histopathology. Compared to Murtaza et al. [
28], Gandomkar et al. [
30] etc., the proposed ensemble model outperformed (97.77%) the other state-of-the-art multi-class BC classifiers.
Besides that, our study and that of Han et al. are the only ones to perform eight (8) class classifications. The other studies performed four (4) class classifications. Han et al., in their study, used the structured deep learning model, and did not perform feature extraction using pre-trained DCNNs, achieving an accuracy of 93.2% on histopathological images. However, the proposed ensemble model in this study extract features from four pre-trained models and trains SVM classifiers in a one-vs-one approach. The trained model classifies test subset BreakHis images irrespective of the difference in magnification factor. Hypothetically this means that the proposed ensemble model will classify the image with high accuracy regardless of the difference in magnification of the input image. In addition, despite ensemble architecture consisting of multiple baseline models and multiple classifiers, the built model is a single model with reduced generalization error of the prediction. Except for Murtaza et al. [
28], the existing models reported only performance accuracy. Other relevant metrics such as precision, sensitivity, and specificity measures are missing. They are crucial to deciding the consistency and significance of an AI-based BC medical screening and grading system.
We present criteria for selecting machine learning techniques to support the decision of classifying BC from histopathological images in
Table 10. One of the objectives of using an AI-based application is to assist medical specialists with rapid screening for disease by assessing medical images and deciding on the presence or absence of a specific medical condition. A more complex AI-based application can further assess medical images and diagnose the extent or grade of a specified medical condition. The former is an AI-based screening system, and the latter is AI-based grading system. Deep learning is a state-of-the-art machine learning (ML) technique, which has been highly successful in various computer vision and image analysis tasks, substantially outperforming all clinical image analysis techniques [
25]. Although deep learning models outperform other traditional clinical image analysis techniques, they are still susceptible to false positive and false negative rates. For these reasons, some criteria should be considered when selecting a deep learning model as an AI-based medical system.
Table 11 presents criteria for selecting machine learning techniques to support the decision of BC classification from histopathological images.
A deep learning algorithm trained to model BC classification should only be adopted for an AI-based screening or grading system after it has passed a prospective study test. The prospective study is carried out when both a licensed specialist and an AI-based system independently examine BC histopathological images from the same person/patient. The prospective study will compare the diagnostic capability of an AI-based model with respect to actual oncologists evaluating the histopathological image in real-time. In the case of selecting an AI-based model for BC screening in low-incidence regions, in addition to the prospective study, a deep learning model will have high accuracy, sensitivity, and specificity scores with a benchmark histopathological image. It should take a few seconds to run and generate a report and should be lightweight. Such a model should be robust enough to accommodate images of different magnification factors. Lastly, deep learning for grading should score high in all of the selection criteria as indicated in
Table 11.
Limitations of this work and potential future work: Some limitations can be addressed in future work. Before deploying classifiers in hospitals, more images with more magnifications could be included in the dataset for more robust classification. Secondly, the MPIFR was based on four existing models. Future performance could be improved by fusing more deeper models. We would also like to validate our results on other histopathological breast cancer datasets. Lastly, mobile devices can be a promising platform for our methods to be implemented.



 ,
, 



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}