
Train Me If You Can: Decentralized Learning on the Deep Edge




Abstract
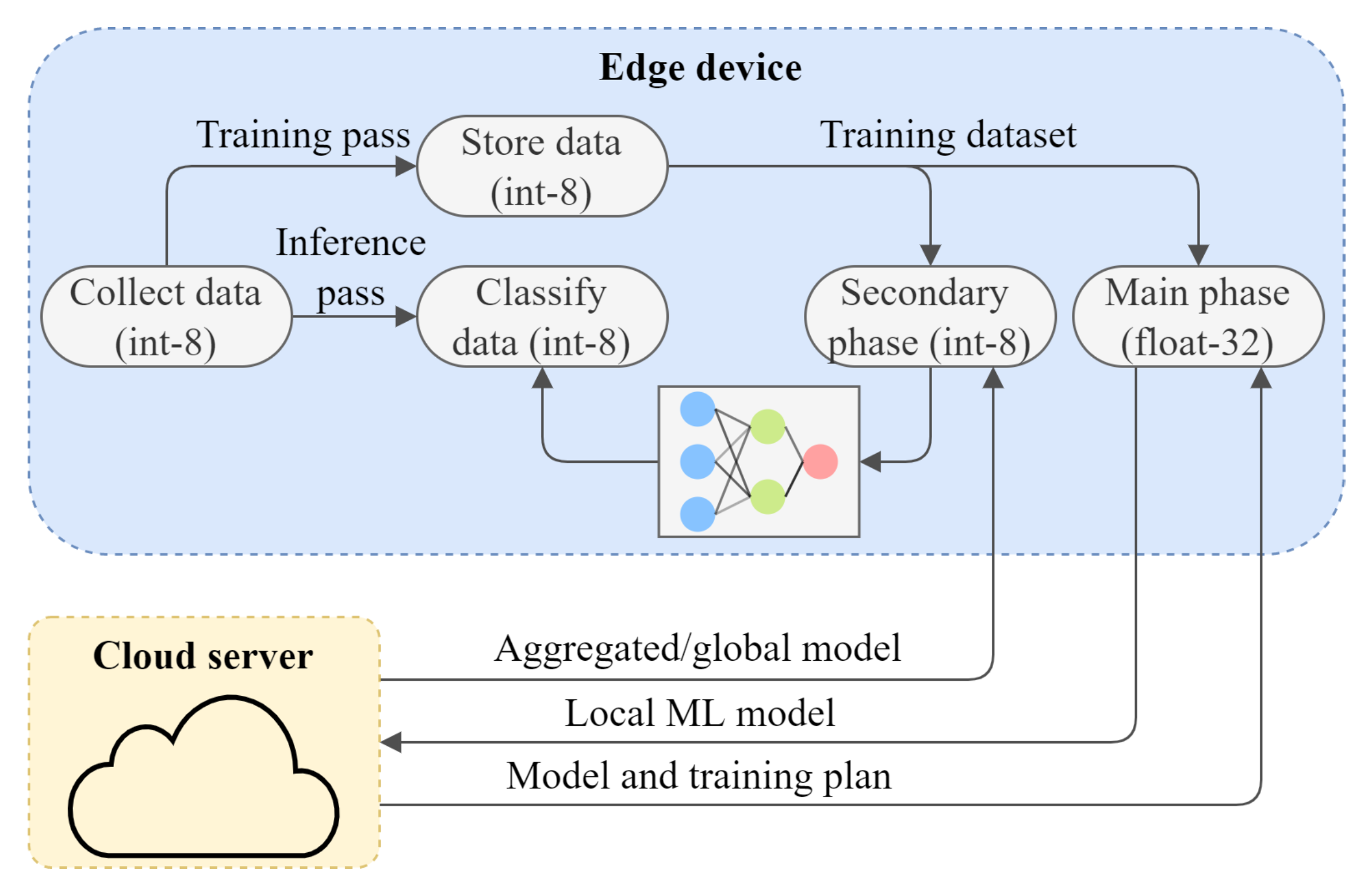
:1. Introduction
- Design and develop an optimization algorithm, tuned for maximum speed and minimum memory footprint, to train an ANN using floating-point gradients;
- Design and develop an optimization algorithm for quantized training of an ANN;
- Evaluate the feasibility of both floating-point and integer-point training on Arm Cortex-M MCUs under an FL scenario.
2. Background
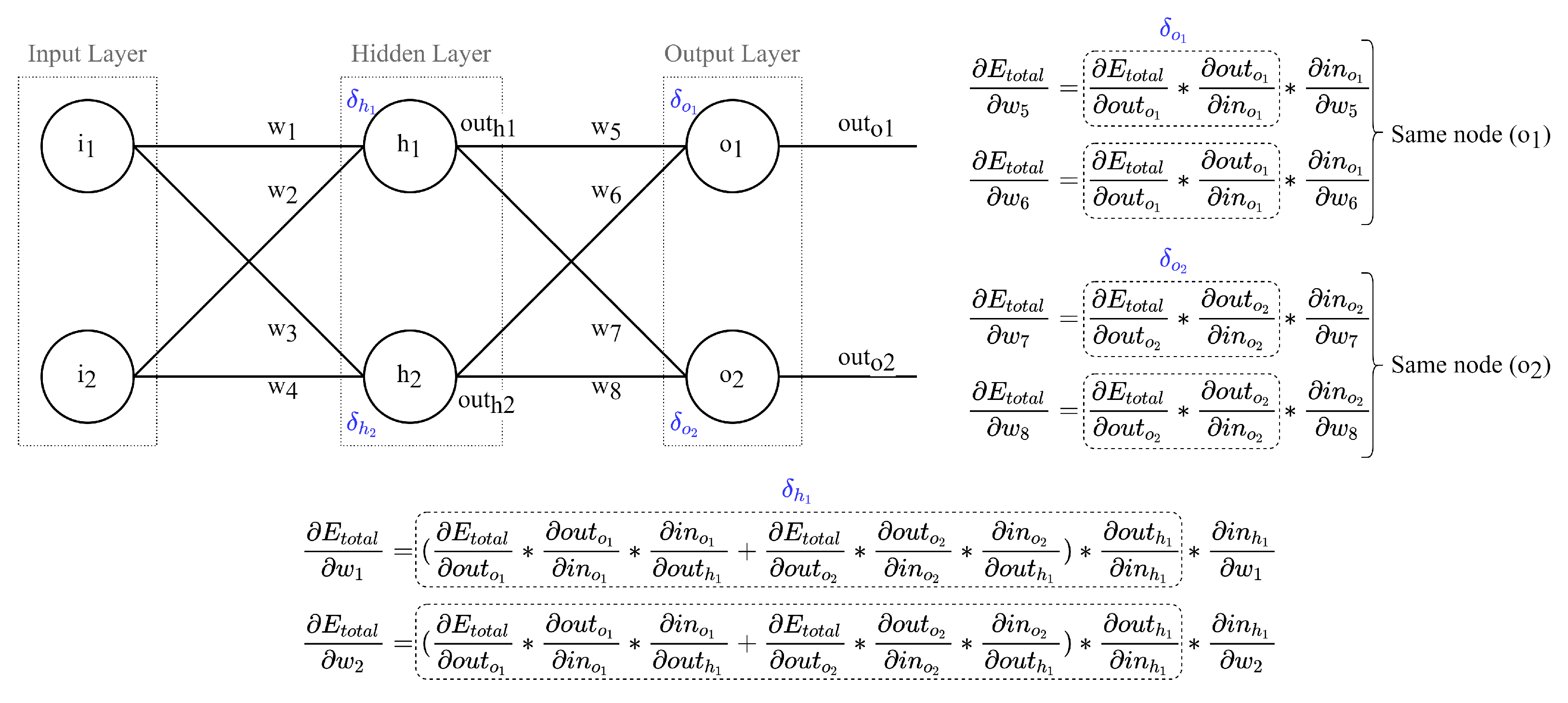
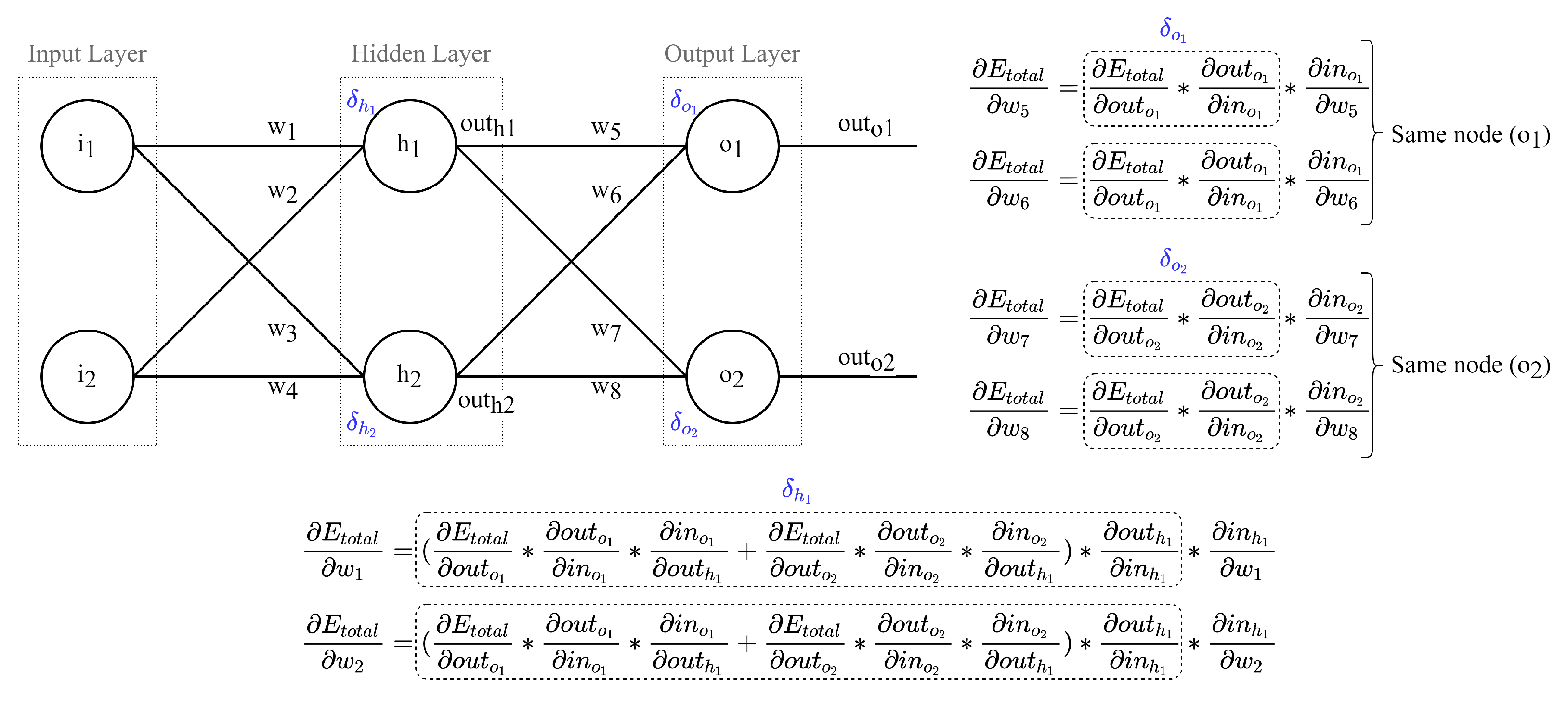
2.1. Stochastic Gradient Descent (SGD)
2.2. Quantization
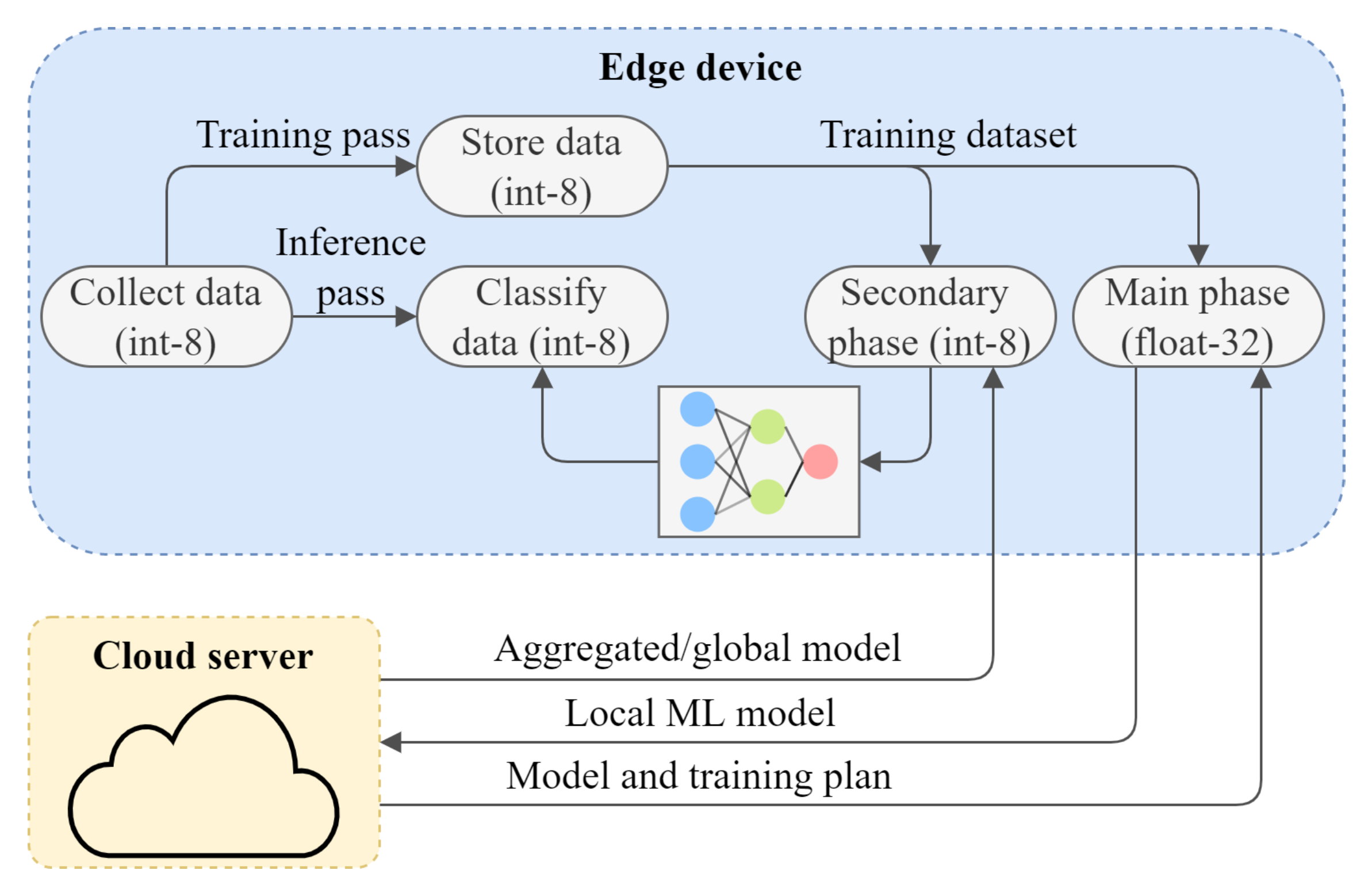
2.3. Federated Learning
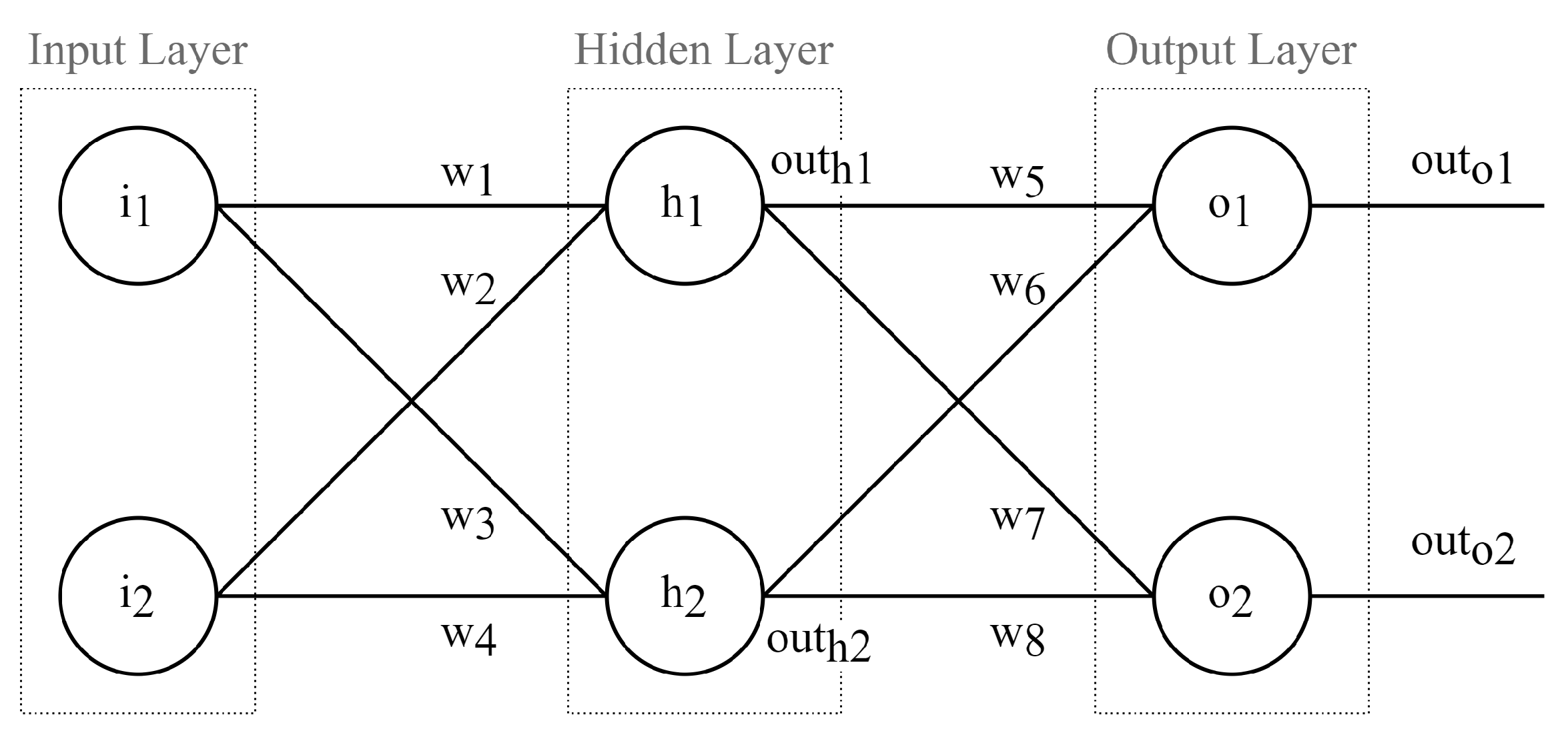
3. Lightweight SGD (L-SGD)
3.1. Node Delta Optimization
| Algorithm 1 Baseline implementation of SGD. |
|
| Algorithm 2 Implementation of L-SGD. |
|
3.2. Node Delta Calculus
3.3. Quantized Training—L-SGD (int-8)
4. L-SGD in Federated Learning
5. Results
5.1. SGD vs. L-SGD
5.2. L-SGD (Float-32) vs. L-SGD (int-8)
6. Related Work
Gap Analysis
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ANN | Artificial Neural Network |
| ASIC | Application-Specific Integrated Circuit |
| FL | Federated Learning |
| FPU | Floating-Point Unit |
| GDPR | General Data Protection Regulation |
| GD | Gradient Descent |
| SGD | Stochastic Gradient Descent |
| GPU | Graphics Processing Unit |
| ISA | Instruction Set Architectures |
| L-SGD | Lightweight Stochastic Gradient Descent |
| MCU | Microcontroller Unit |
| ML | Machine Learning |
| SGD | Stochastic Gradient Descent |
| SIMD | Single Instruction Multiple Data |
References
- Sparks, P. The Route to a Trillion Devices. White Paper. ARM. 2017. Available online: https://www.google.com.hk/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&ved=2ahUKEwit7uqT_8f3AhVCmuYKHWnlAB0QFnoECA0QAQ&url=https%3A%2F%2Fcommunity.arm.com%2Fcfs-file%2F__key%2Ftelligent-evolution-components-attachments%2F01-1996-00-00-00-01-30-09%2FArm-_2D00_-The-route-to-a-trillion-devices-_2D00_-June-2017.pdf&usg=AOvVaw0u3rfw99tKfKFI-1COOBkz (accessed on 20 April 2022).
- Costa, M.; Oliveira, D.; Pinto, S.; Tavares, A. Detecting Driver’s Fatigue, Distraction and Activity Using a Non-Intrusive Ai-Based Monitoring System. J. Artif. Intell. Soft Comput. Res. 2019, 9, 247–266. [Google Scholar]
- Grigorescu, S.; Trasnea, B.; Cocias, T.; Macesanu, G. A survey of deep learning techniques for autonomous driving. J. Field Robot. 2020, 37, 362–386. [Google Scholar] [CrossRef]
- Feng, C.; Wu, S.; Liu, N. A user-centric machine learning framework for cyber security operations center. In Proceedings of the 2017 IEEE International Conference on Intelligence and Security Informatics (ISI), Beijing, China, 22–24 July 2017; pp. 173–175. [Google Scholar] [CrossRef]
- Alimi, O.A.; Ouahada, K.; Abu-Mahfouz, A.M. A Review of Machine Learning Approaches to Power System Security and Stability. IEEE Access 2020, 8, 113512–113531. [Google Scholar] [CrossRef]
- Shailaja, K.; Seetharamulu, B.; Jabbar, M.A. Machine Learning in Healthcare: A Review. In Proceedings of the 2018 Second International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 29–31 March 2018; pp. 910–914. [Google Scholar] [CrossRef]
- Ahamed, F.; Farid, F. Applying Internet of Things and Machine-Learning for Personalized Healthcare: Issues and Challenges. In Proceedings of the 2018 International Conference on Machine Learning and Data Engineering (iCMLDE), Sydney, Australia, 3–7 December 2018; pp. 19–21. [Google Scholar] [CrossRef]
- Polat, Ç.; Karaman, O.; Karaman, C.; Korkmaz, G.; Balcı, M.C.; Kelek, S.E. COVID-19 diagnosis from chest X-ray images using transfer learning: Enhanced performance by debiasing dataloader. J. X-ray Sci. Technol. 2021, 29, 19–36. [Google Scholar]
- Alhudhaif, A.; Polat, K.; Karaman, O. Determination of COVID-19 pneumonia based on generalized convolutional neural network model from chest X-ray images. Expert Syst. Appl. 2021, 180, 115141. [Google Scholar] [CrossRef]
- Karaman, O.; Alhudhaif, A.; Polat, K. Development of smart camera systems based on artificial intelligence network for social distance detection to fight against COVID-19. Appl. Soft Comput. 2021, 110, 107610. [Google Scholar]
- Karaman, O.; Çakın, H.; Alhudhaif, A.; Polat, K. Robust automated Parkinson disease detection based on voice signals with transfer learning. Expert Syst. Appl. 2021, 178, 115013. [Google Scholar] [CrossRef]
- Nurvitadhi, E.; Sim, J.; Sheffield, D.; Mishra, A.; Krishnan, S.; Marr, D. Accelerating recurrent neural networks in analytics servers: Comparison of FPGA, CPU, GPU, and ASIC. In Proceedings of the 2016 26th International Conference on Field Programmable Logic and Applications (FPL), Lausanne, Switzerland, 29 August–2 September 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Ukidave, Y.; Li, X.; Kaeli, D. Mystic: Predictive Scheduling for GPU Based Cloud Servers Using Machine Learning. In Proceedings of the 2016 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Chicago, IL, USA, 23–27 May 2016; pp. 353–362. [Google Scholar] [CrossRef]
- Wang, J.B.; Wang, J.; Wu, Y.; Wang, J.Y.; Zhu, H.; Lin, M.; Wang, J. A machine learning framework for resource allocation assisted by cloud computing. IEEE Netw. 2018, 32, 144–151. [Google Scholar]
- DeBenedictis, E.P. It’s time to redefine Moore’s law again. Computer 2017, 50, 72–75. [Google Scholar]
- Jiang, J.; Hu, L.; Hu, C.; Liu, J.; Wang, Z. BACombo—Bandwidth-aware decentralized federated learning. Electronics 2020, 9, 440. [Google Scholar]
- Lai, L.; Suda, N.; Chandra, V. Cmsis-nn: Efficient neural network kernels for arm cortex-m cpus. arXiv 2018, arXiv:1801.06601. [Google Scholar]
- Truong, N.; Sun, K.; Wang, S.; Guitton, F.; Guo, Y. Privacy preservation in federated learning: An insightful survey from the GDPR perspective. Comput. Secur. 2021, 110, 102402. [Google Scholar]
- Ghimire, B.; Rawat, D.B. Recent Advances on Federated Learning for Cybersecurity and Cybersecurity for Federated Learning for Internet of Things. IEEE Internet Things J. 2022, 1. [Google Scholar] [CrossRef]
- Zhao, S.; Bharati, R.; Borcea, C.; Chen, Y. Privacy-Aware Federated Learning for Page Recommendation. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 1071–1080. [Google Scholar] [CrossRef]
- Oliveira, D.; Costa, M.; Pinto, S.; Gomes, T. The future of low-end motes in the Internet of Things: A prospective paper. Electronics 2020, 9, 111. [Google Scholar]
- Du, W.; Atallah, M.J. Privacy-preserving cooperative statistical analysis. In Proceedings of the Seventeenth Annual Computer Security Applications Conference, New Orleans, LA, USA, 10–14 December 2001; pp. 102–110. [Google Scholar]
- Li, Q.; Wen, Z.; He, B. A Survey on Federated Learning Systems: Vision, Hype and Reality for Data Privacy and Protection. IEEE Trans. Knowl. Data Eng. 2021. [Google Scholar] [CrossRef]
- Sattler, F.; Wiedemann, S.; Müller, K.R.; Samek, W. Robust and communication-efficient federated learning from non-iid data. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 3400–3413. [Google Scholar]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical Secure Aggregation for Privacy-Preserving Machine Learning. Available online: https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&ved=2ahUKEwi_p8DN_8f3AhV2_rsIHfOfA8oQFnoECAYQAQ&url=https%3A%2F%2Feprint.iacr.org%2F2017%2F281.pdf&usg=AOvVaw2-ff5sUXAo7J-mpZmek81h (accessed on 20 April 2022).
- Hamm, J.; Champion, A.C.; Chen, G.; Belkin, M.; Xuan, D. Crowd-ML: A privacy-preserving learning framework for a crowd of smart devices. In Proceedings of the 2015 IEEE 35th International Conference on Distributed Computing Systems, Columbus, OH, USA, 29 June–2 July 2015; pp. 11–20. [Google Scholar]
- Wang, S.; Tuor, T.; Salonidis, T.; Leung, K.K.; Makaya, C.; He, T.; Chan, K. When edge meets learning: Adaptive control for resource-constrained distributed machine learning. In Proceedings of the IEEE INFOCOM 2018-IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 63–71. [Google Scholar]
- Zantalis, F.; Koulouras, G.; Karabetsos, S.; Kandris, D. A Review of Machine Learning and IoT in Smart Transportation. Future Internet 2019, 11, 94. [Google Scholar] [CrossRef] [Green Version]
- Lim, W.Y.B.; Luong, N.C.; Hoang, D.T.; Jiao, Y.; Liang, Y.C.; Yang, Q.; Niyato, D.; Miao, C. Federated Learning in Mobile Edge Networks: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2020, 22, 2031–2063. [Google Scholar] [CrossRef] [Green Version]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Deng, S.; Zhao, H.; Fang, W.; Yin, J.; Dustdar, S.; Zomaya, A.Y. Edge intelligence: The confluence of edge computing and artificial intelligence. IEEE Internet Things J. 2020, 7, 7457–7469. [Google Scholar]
- Wang, S.; Tuor, T.; Salonidis, T.; Leung, K.K.; Makaya, C.; He, T.; Chan, K. Adaptive federated learning in resource constrained edge computing systems. IEEE J. Sel. Areas Commun. 2019, 37, 1205–1221. [Google Scholar]
- Rizk, E.; Vlaski, S.; Sayed, A.H. Dynamic Federated Learning. In Proceedings of the 2020 IEEE 21st International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Atlanta, GA, USA, 26–29 May 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Chen, Y.T.; Chuang, Y.C.; Wu, A.Y. Online extreme learning machine design for the application of federated learning. In Proceedings of the 2020 2nd IEEE International Conference on Artificial Intelligence Circuits and Systems (AICAS), Genova, Italy, 31 August–2 September 2020; pp. 188–192. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar]
- Wang, H.; Yurochkin, M.; Sun, Y.; Papailiopoulos, D.; Khazaeni, Y. Federated learning with matched averaging. arXiv 2020, arXiv:2002.06440. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. arXiv 2018, arXiv:1812.06127. [Google Scholar]
- Fallah, A.; Mokhtari, A.; Ozdaglar, A. Personalized federated learning: A meta-learning approach. arXiv 2020, arXiv:2002.07948. [Google Scholar]
- Sprague, M.R.; Jalalirad, A.; Scavuzzo, M.; Capota, C.; Neun, M.; Do, L.; Kopp, M. Asynchronous federated learning for geospatial applications. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2018; pp. 21–28. [Google Scholar]
- Ek, S.; Portet, F.; Lalanda, P.; Vega, G. Evaluation of federated learning aggregation algorithms: Application to human activity recognition. In Proceedings of the 2020 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2020 ACM International Symposium on Wearable Computers, Virtual Event, 12–17 September 2020; pp. 638–643. [Google Scholar]
- Bonawitz, K.; Eichner, H.; Grieskamp, W.; Huba, D.; Ingerman, A.; Ivanov, V.; Kiddon, C.; Konečnỳ, J.; Mazzocchi, S.; McMahan, H.B.; et al. Towards federated learning at scale: System design. arXiv 2019, arXiv:1902.01046. [Google Scholar]
- Suda, N.; Loh, D. Machine Learning on Arm Cortex-M Microcontrollers; Arm Ltd.: Cambridge, UK, 2019. [Google Scholar]
- Banbury, C.R.; Reddi, V.J.; Lam, M.; Fu, W.; Fazel, A.; Holleman, J.; Huang, X.; Hurtado, R.; Kanter, D.; Lokhmotov, A.; et al. Benchmarking TinyML Systems: Challenges and Direction. arXiv 2020, arXiv:2003.04821. [Google Scholar]
- Costa, M.; Costa, D.; Gomes, T.; Pinto, S. Shifting Capsule Networks from the Cloud to the Deep Edge. arXiv 2021, arXiv:2110.02911. [Google Scholar]
- Yang, J.; Shen, X.; Xing, J.; Tian, X.; Li, H.; Deng, B.; Huang, J.; Hua, X. Quantization networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 7308–7316. [Google Scholar]
- Garofalo, A.; Rusci, M.; Conti, F.; Rossi, D.; Benini, L. PULP-NN: Accelerating quantized neural networks on parallel ultra-low-power RISC-V processors. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2020, 378, 20190155. [Google Scholar] [CrossRef] [Green Version]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics. PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Wei, K.; Li, J.; Ma, C.; Ding, M.; Chen, C.; Jin, S.; Han, Z.; Poor, H.V. Low-Latency Federated Learning Over Wireless Channels With Differential Privacy. IEEE J. Sel. Areas Commun. 2022, 40, 290–307. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated Learning: Challenges, Methods, and Future Directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Kleinberg, B.; Li, Y.; Yuan, Y. An Alternative View: When Does SGD Escape Local Minima? In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 2698–2707. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Bäckström, K.; Walulya, I.; Papatriantafilou, M.; Tsigas, P. Consistent Lock-free Parallel Stochastic Gradient Descent for Fast and Stable Convergence. In Proceedings of the 2021 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Portland, OR, USA, 17–21 May 2021; pp. 423–432. [Google Scholar]
- Deng, L. The mnist database of handwritten digit images for machine learning research. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar]
- Bengio, Y.; LeCun, Y. Scaling learning algorithms towards AI. Large-Scale Kernel Mach. 2007, 34, 1–41. [Google Scholar]
- Bhavsar, H.; Ganatra, A. A comparative study of training algorithms for supervised machine learning. Int. J. Soft Comput. Eng. 2012, 2, 2231–2307. [Google Scholar]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Nielsen, M.A. Neural Networks and Deep Learning; Determination Press: San Francisco, CA, USA, 2015; Volume 25. [Google Scholar]
- Kim, G.; Hwang, C.S.; Jeong, D.S. Stochastic Learning with Back Propagation. In Proceedings of the 2019 IEEE International Symposium on Circuits and Systems (ISCAS), Sapporo, Japan, 26–29 May 2019; pp. 1–5. [Google Scholar]
- Wilamowski, B.M. Neural network architectures and learning algorithms. IEEE Ind. Electron. Mag. 2009, 3, 56–63. [Google Scholar]
- Zhang, A.; Lipton, Z.C.; Li, M.; Smola, A.J. Dive into deep learning. arXiv 2021, arXiv:2106.11342. [Google Scholar]
- O’Connor, D. A Historical Note on Shuffle Algorithms. Retrieved Maret 2014, 4, 2018. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Lin, D.; Talathi, S.; Annapureddy, S. Fixed point quantization of deep convolutional networks. In Proceedings of the International Conference on Machine Learning. PMLR, New York, NY, USA, 20–22 June 2016; pp. 2849–2858. [Google Scholar]
- Lai, L.; Suda, N.; Chandra, V. Deep convolutional neural network inference with floating-point weights and fixed-point activations. arXiv 2017, arXiv:1703.03073. [Google Scholar]
- Gholami, A.; Kim, S.; Dong, Z.; Yao, Z.; Mahoney, M.W.; Keutzer, K. A Survey of Quantization Methods for Efficient Neural Network Inference. arXiv 2021, arXiv:2103.13630, 2021. [Google Scholar]
- Novac, P.E.; Boukli Hacene, G.; Pegatoquet, A.; Miramond, B.; Gripon, V. Quantization and Deployment of Deep Neural Networks on Microcontrollers. Sensors 2021, 21, 2984. [Google Scholar] [CrossRef] [PubMed]
- Wang, P.; Chen, Q.; He, X.; Cheng, J. Towards Accurate Post-training Network Quantization via Bit-Split and Stitching. In Proceedings of the 37th International Conference on Machine Learning, Virtual Event, 13–18 July 2020; Volume 119, pp. 9847–9856. [Google Scholar]
- Imteaj, A.; Hadi Amini, M. FedAR: Activity and Resource-Aware Federated Learning Model for Distributed Mobile Robots. In Proceedings of the 2020 19th IEEE International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 14–17 December 2020; pp. 1153–1160. [Google Scholar] [CrossRef]
- Qu, X.; Wang, J.; Xiao, J. Quantization and Knowledge Distillation for Efficient Federated Learning on Edge Devices. In Proceedings of the 2020 IEEE 22nd International Conference on High Performance Computing and Communications; IEEE 18th International Conference on Smart City; IEEE 6th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Yanuca Island, Cuvu, Fiji, 14–16 December 2020; pp. 967–972. [Google Scholar] [CrossRef]
- Korkmaz, C.; Kocas, H.E.; Uysal, A.; Masry, A.; Ozkasap, O.; Akgun, B. Chain FL: Decentralized Federated Machine Learning via Blockchain. In Proceedings of the 2020 Second International Conference on Blockchain Computing and Applications (BCCA), Antalya, Turkey, 2–5 November 2020; pp. 140–146. [Google Scholar]
- Konečnỳ, J.; McMahan, H.B.; Ramage, D.; Richtárik, P. Federated optimization: Distributed machine learning for on-device intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar]
- Li, Q.; Wen, Z.; He, B. Practical federated gradient boosting decision trees. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 4642–4649. [Google Scholar]
- Saha, S.; Ahmad, T. Federated Transfer Learning: Concept and applications. Intell. Artif. 2021, 15, 35–44. [Google Scholar]
- Nwankpa, C.; Ijomah, W.; Gachagan, A.; Marshall, S. Activation functions: Comparison of trends in practice and research for deep learning. arXiv 2018, arXiv:1811.03378. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and Open Problems in Federated Learning. Found. Trends® Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Fang, M.; Cao, X.; Jia, J.; Gong, N.Z. Local Model Poisoning Attacks to Byzantine-Robust Federated Learning. In Proceedings of the 29th USENIX Conference on Security Symposium, Berkeley, CA, USA, 12–14 August 2020. [Google Scholar]
- Li, T.; Sanjabi, M.; Beirami, A.; Smith, V. Fair resource allocation in federated learning. arXiv 2019, arXiv:1905.10497. [Google Scholar]
- Lyu, L.; Yu, J.; Nandakumar, K.; Li, Y.; Ma, X.; Jin, J.; Yu, H.; Ng, K.S. Towards Fair and Privacy-Preserving Federated Deep Models. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 2524–2541. [Google Scholar] [CrossRef]
- Mahesh, B. Machine Learning Algorithms—A Review. Int. J. Sci. Res. 2020, 9, 381–386. [Google Scholar]
- Sun, S.; Cao, Z.; Zhu, H.; Zhao, J. A Survey of Optimization Methods From a Machine Learning Perspective. IEEE Trans. Cybern. 2020, 50, 3668–3681. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bharath, B.; Borkar, V.S. Stochastic approximation algorithms: Overview and recent trends. Sādhanā 1999, 24, 425–452. [Google Scholar] [CrossRef] [Green Version]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2704–2713. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Neurons Output | Weight Errors | Node Delta Layer l | Node Delta Layer | |
|---|---|---|---|---|
| SGD | X | X | - | - |
| L-SGD | X | - | X | X |
| Loss Function | Equation |
|---|---|
| Binary cross entropy (BCE) | |
| BCE partial derivative | |
| Cross entropy (CE) | |
| CE partial derivative |
| Activation Function | Equation |
|---|---|
| ReLU | |
| ReLU partial derivative | |
| Sigmoid | |
| Sigmoid partial derivative | |
| TanH | |
| TanH partial derivative |
| Operation (A, B) = O | Format | Constraints | Procedure | ||
|---|---|---|---|---|---|
| A | B | O | |||
| Multiply | N.A | val = x * y shifts = x + y − z out = val | |||
| Divide | N.A | val = x * y shifts = z − ( x − y) out = val <<shifts | |||
| Add | O = A + B | ||||
| MNIST | CogDist | |
|---|---|---|
| Input layer | 784 | 6 |
| Fully connected 0 | 40 | 40 |
| Activation 0 | TanH | TanH |
| Fully connected 1 | 32 | 32 |
| Activation 2 | TanH | TanH |
| Fully connected 3 | 10 | 1 |
| Activation 3 | Sigmoid | Sigmoid |
| MNIST | CogDist | |||
|---|---|---|---|---|
| SGD | L-SGD | SGD | L-SGD | |
| Accuracy (%) | 92.45 | 93.54 | 83.51 | 82.18 |
| Memory footprint (Bytes) | 135,632 | 3784 | 6816 | 636 |
| Latency (ms/sample) | 75.09 | 17.84 | 8.90 | 8.51 |
| MNIST | CogDist | |||
|---|---|---|---|---|
|
L-SGD (Float-32) |
L-SGD (int-8) |
L-SGD (Float-32) |
L-SGD (int-8) | |
| Accuracy (%) | 92.54 | 92.83 | 91.95 | 92.79 |
| Memory footprint (Bytes) | 3784 | 1026 | 636 | 239 |
| Latency (ms/sample) | 17.84 | 7.17 | 8.51 | 4.49 |
| Optimizer | Computational Complexity | Memory Footprint | Vulnerable to Local Minima Effect | Automatic Learning Rate Decay | Latency |
|---|---|---|---|---|---|
| GD [81] | Low | High | Yes | No | Slow |
| SGD [82] | Moderated | Moderated | Yes | No | Slow |
| AdaGrad [83] | High | Moderated | No | Yes | Moderated |
| Adam [84] | High | Moderated | No | Yes | Fast |
| L-SGD | Low | Low | Yes | No | Moderated |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Costa, D.; Costa, M.; Pinto, S. Train Me If You Can: Decentralized Learning on the Deep Edge. Appl. Sci. 2022, 12, 4653. https://doi.org/10.3390/app12094653
Costa D, Costa M, Pinto S. Train Me If You Can: Decentralized Learning on the Deep Edge. Applied Sciences. 2022; 12(9):4653. https://doi.org/10.3390/app12094653
Chicago/Turabian StyleCosta, Diogo, Miguel Costa, and Sandro Pinto. 2022. "Train Me If You Can: Decentralized Learning on the Deep Edge" Applied Sciences 12, no. 9: 4653. https://doi.org/10.3390/app12094653
APA StyleCosta, D., Costa, M., & Pinto, S. (2022). Train Me If You Can: Decentralized Learning on the Deep Edge. Applied Sciences, 12(9), 4653. https://doi.org/10.3390/app12094653