1. Introduction
Semantic dependency parsing (SDP) attempts to identify semantic relationships between words in a sentence by representing the sentence as a labeled directed acyclic graph (DAG), also known as the semantic dependency graph (SDG). In an SDG, not only can semantic predicates have multiple or zero arguments, but also words from the sentence can be attached as arguments to more than one head word (predicate), or they can be outside the SDG (being neither a predicate nor an argument). SDP has been successfully applied in many downstream tasks of natural language processing, including named entity recognition [
1], information extraction [
2], machine translation [
3], sentiment analysis [
4], question generation [
5], question answering [
6], etc. SDP originates from syntactic dependency parsing which aims to represent the syntactic structure of a sentence by means of a labeled tree.
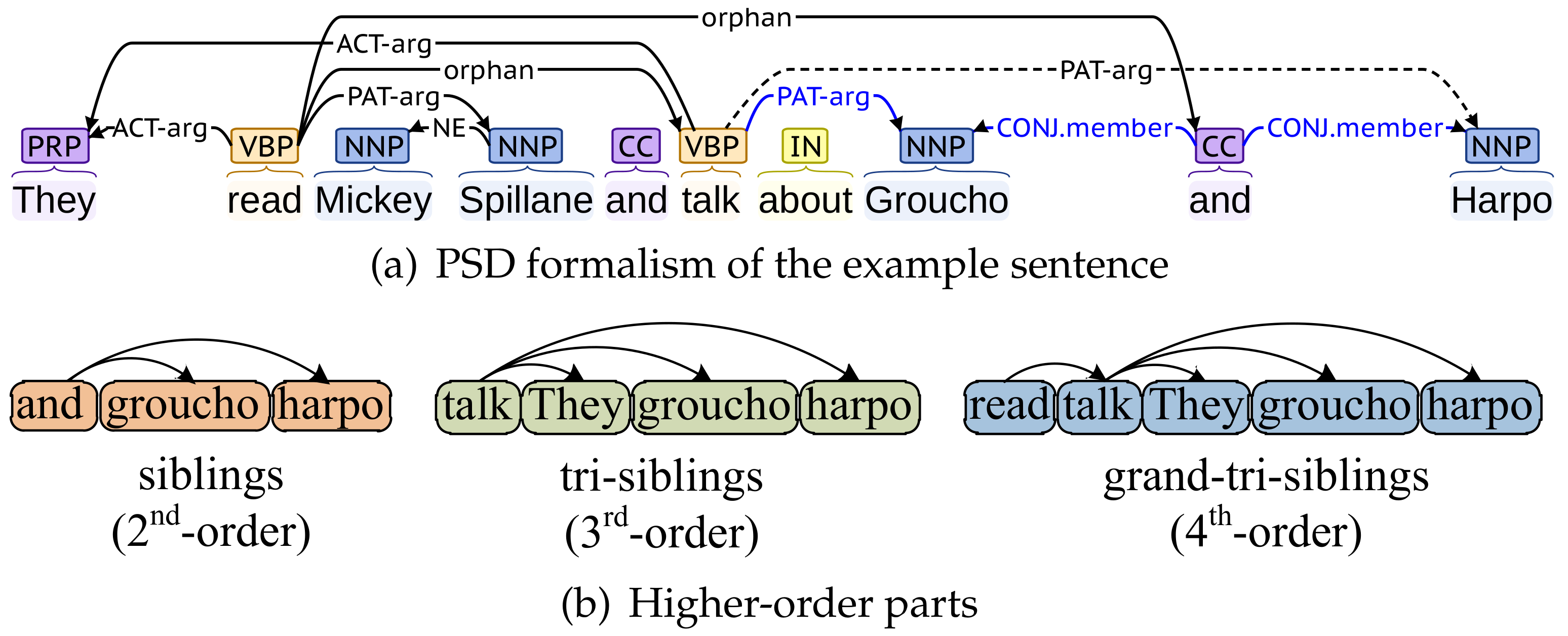
Higher-order information is generally helpful for improving the performance of syntactic and semantic dependency parsing [
7,
8,
9] because it contains not only the information about the head and modifier tokens but also the information about higher-order parts (head tokens, modifier tokens, and other tokens linked to them together form the higher-order parts). Here is a straightforward example (as in
Figure 1). For the sentence
“They read Mickey Spillane and talk about Groucho and Harpo”, its semantic dependency representation is shown in
Figure 1a; the higher-order parts that appear in this sentence are shown in
Figure 1b. When considering the semantic dependency relationship between
talk and
Harpo (dotted edge), if we know (1)
Groucho and
Harpo are included in the second-order part (
siblings) and (2) there is a dependency edge labeled
PAT-arg between
talk and
Groucho (blue edges), it is obvious that there is also a dependency edge labeled
PAT-arg between
talk and
Harpo.
Several semantic dependency parsers have been presented in recent years. Most of them are first-order parsers that utilize the information about first-order parts [
10,
11,
12,
13,
14]; the rest are second-order parsers that utilize the information about second-order parts [
8,
15,
16]. They have demonstrated that second-order information could bring significant accuracy gains in SDP. However, the second-order parts used in these second-order parsers are limited to specific types, including
siblings,
grandparent, and
co-parents. Utilizing more types of higher-order parts (e.g.
tri-siblings, great-grandparents, grand-tri-siblings, etc.) in SDP still remains under-explored. The reason for this issue is that modeling higher-order parts is non-trivial [
8]. Higher-order parts have been exploited in syntactic dependency parsing [
7,
9,
17,
18,
19]. However, algorithms for higher-order syntactic dependency parsing aim to generate a dependency tree rather than a dependency graph, therefore they are not applicable to SDP.
Graph neural networks (GNNs) have been demonstrated to be an effective tool for encoding higher-order information in many graph learning tasks [
7,
20]. GNNs aggregate higher-order information in a similar incremental manner: One GNN layer encodes information about immediate neighbors and
K layers encode
K-order neighborhoods (i.e., information about nodes at most
K hops away).
This study aims to exploit GNNs’ powerful ability of representation learning in SDP. Inspired by the success of GNNs, we investigate using GNNs to encode higher-order information to improve the accuracy of SDP. Instead of encoding higher-order information of specific types of higher-order parts extracted from intermediate parsing graphs, we aggregate higher-order information by stacking multiple GNN layers. We extend the biaffine parser [
12] and employ it as the vanilla parser to produce an initial adjacency matrix (close to gold) since there is no graph structure available during testing. Two GNN variants, Graph Convolutional Network (GCN) [
21] and Graph Attention Network (GAT) [
22], have been investigated in our model (GNNSDP:
GNN-based
Semantic
Dependency
Parser).
GNNSDP has been evaluated on the SemEval 2015 Task 18 dataset which covers three languages (Chinese, English, and Czech) and contains three semantic dependency formalisms (DM, PAS, and PSD). Compared to the previous best one, our parser yields 0.3% and 2.2% improvement in average labeled F1-score on English in-domain (ID) and out-of-domain (OOD) test sets, 2.6% improvement on Chinese ID test set, and 2.0% and 1.8% improvement on Czech ID and OOD test sets. Experimental results show that GNNSDP outperforms the previous state-of-the-art parser in three languages. In addition, GNNSDP shows greater advantage over the baseline in the longer sentence and PSD formalism (appearing linguistically most fine grained). To the best of our knowledge, this work is the first study to apply GNNs in semantic dependency parsing. Our code is publicly available at
https://github.com/LiBinNLP/GNNSDP (accessed on 16 April 2022).
3. GNN-Based Semantic Dependency Parser
GNNSDP is a parser that extends the biaffine parser [
12]. An overview of GNNSDP is shown in
Figure 2. Given sentence
s with
n words
, there are three steps to parse it as an SDG. Firstly, the sentence will be parsed with a vanilla SDP parser, producing an initial SDG. Secondly, the contextualized word representations output by long short-term memory (BiLSTM) and adjacency matrix obtained from the initial SDG will be fed into the GNN encoder to obtain node representations which contain higher-order information. Finally, Multi-Layer Perceptron (MLP) will be used to get the hidden state representation, and then decoded by the biaffine classifier to predict edge and label.
3.1. Vanilla Parser
We use the biaffine parser [
12] as the vanilla parser. Sentence
s will be parsed by the vanilla parser to obtain the initial adjacency matrix.
where
is the initial adjacency matrix;
is the initial SDG;
W denotes
n words and
F denotes features of words.
3.2. Embeddings
Word embeddings and feature embeddings are used to represent the embedding of each token in GNNSDP.
3.2.1. Word Embeddings
Pretrained word embeddings of three languages are downloaded from the internet:
For English, the 100-dimension English word embeddings from GloVe [
32] are used.
For Chinese, the 300-dimension Chinese word embeddings from SGNS [
33] are used.
For Czech, the 300-dimension Czech word embeddings from fasttext [
34] are used.
3.2.2. Feature Embeddings
Four types of features are used in GNNSDP. The dimension of each feature embedding is denoted as d ():
Part-of-speech (POS) tag embeddings: POS tag embeddings are randomly generated. , where n is the number of POS tags.
Lemma embeddings: A lemma is the base form of a word; lemma embeddings are also randomly generated. , where l is the number of lemmas. Lemmas that occurred seven times or more are included in the lemma embedding matrix.
Character embeddings: Character embeddings summarize the information of characters in each token, which are generated using a one-layer unidirectional LSTM (CharLSTM) that convolves over three character embeddings at a time, whose end state is linearly transformed to be d-dimensional.
Bidirectional Encoder Representation from Transformer (BERT) embeddings: BERT embeddings are extracted from the pretrained BERT model.
3.3. Encoder
We concatenate word embeddings and feature embeddings, and feed them into a BiLSTM to obtain contextualized representations.
Specifically, BiLSTM is a sequence processing model that consists of two reversed unidirectional LSTM networks: One taking the input in a forward direction to capture forward information, and another in a backward direction to capture backward information. BiLSTM can integrate both forward and backward information by concatenating bidirectional information.
where
is the concatenation (⊕) of the word embeddings and feature embeddings of word
,
X represents
.
is the contextualized representations of sequence
X.
Then we employ
K-layer GNNs to capture higher-order information by aggregating the representation of
K-order neighborhoods. The node embedding matrix
in the
kth-layer is computed as Equation (
6):
When the
GNNLayer is implemented in the
GCN, the representation
of node
i in the
kth layer is computed as Equation (
7)
where
W and
B are parameter matrices;
are neighbors of node
i;
is the active function (ReLU is used);
.
When
GNNLayer is implemented in
GAT,
is computed as Equation (
8):
where
is the attention coefficient of node
i to its neighbour
j in attention head
m at the
th layer.
While higher-order information is important, GNNs would suffer from the over-smoothing problem when the number of layer is excessive. Therefore we stack three layers with the past experience.
3.4. Decoder
The decoder has two modules: The edge existence prediction module and the edge label prediction module. For each of the two modules, we use MLP to split the final node representation
into two parts—a head representation, and a dependent representation, as shown in Equations (
9)–(
12):
We can then use two biaffine classifiers (as Equation (
13)), which are generalizations of linear classifiers to include multiplicative interactions between two vectors—to predict edges and labels, as Equations (
14) and (
15):
where
and
are scores of edge existence and edge label between words
and
.
U,
W, and
b are learned parameters of the biaffine classifier. For the edge existence prediction module,
U will be
-dimensional, so that the
will be a scalar. For edge label prediction, if the parser is unlabeled,
U will be
-dimensional, so that the
will be a scalar. If the parser is labeled,
U will be
-dimensional, where
c is the number of labels, so that the
is a vector that represents the probability distributions of each label.
The unlabeled parser scores each edge between pairs of words in the sentence—these scores can be decoded into a graph by keeping only edges that received a positive score. The labeled parser scores every label for each pair of words, so we simply assign each predicted edge its highest-scoring label and discard the rest.
3.5. Learning
We can train the model by summing the losses from the two modules, back propagating the error to the parser. The cross entropy function is used as as the loss function, which is computed as Equation (
18):
The loss functions of the edge existence prediction module and the edge label prediction module are defined as:
where
and
are the parameters of two modules.
Then the adaptive moment estimation (Adam) method is used to optimize the summed loss function
:
where
is a tunable interpolation constant
.
5. Experimental Analysis
In this section, we analyse the experimental results from three perspectives, including performance on different sentence length, ablation study, and case study.
5.1. Performance on Different Sentence Length
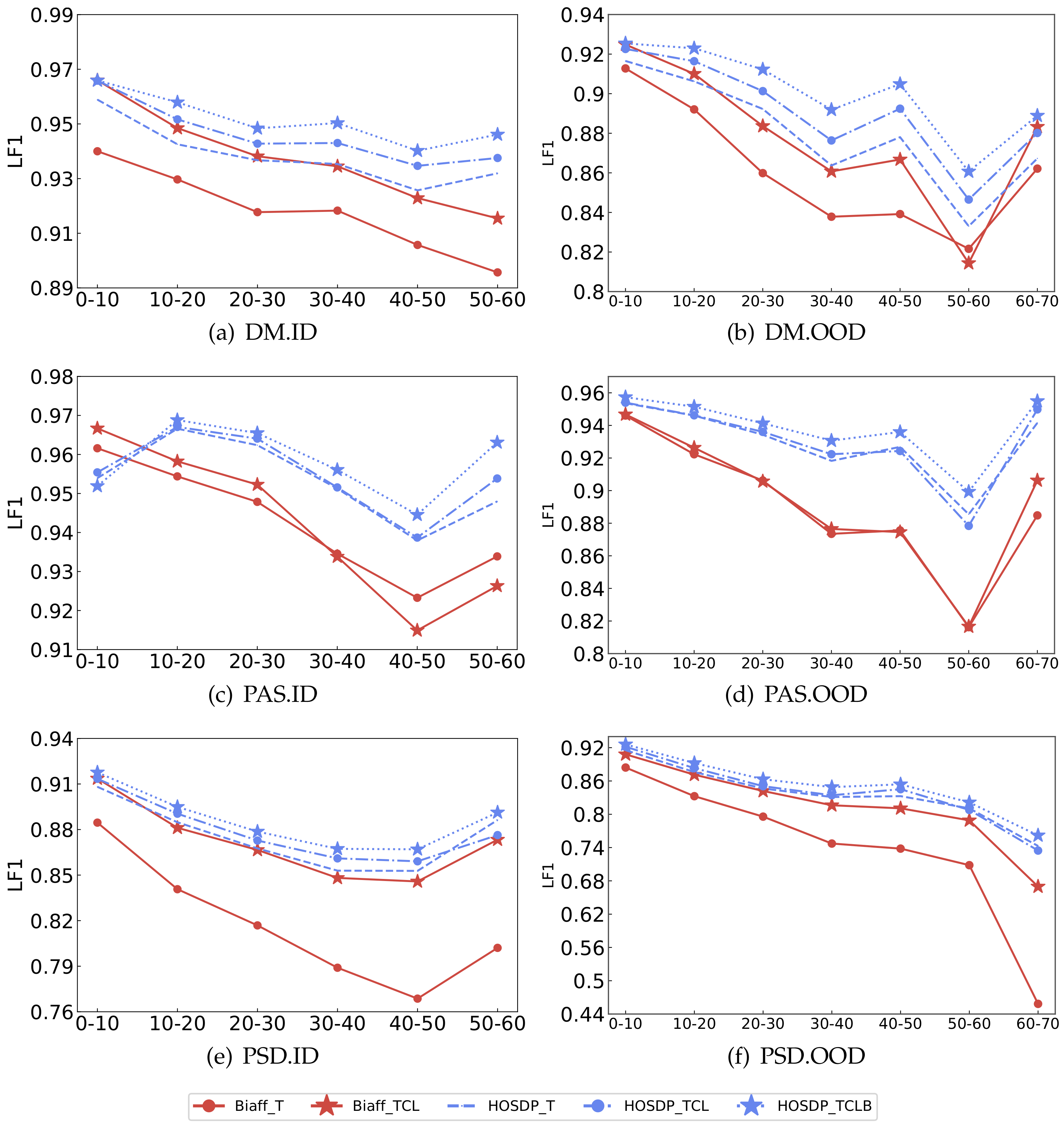
We want to study the impact of sentence lengths. The ID and OOD test sets of the three formalisms are split with 10 tokens range. The ID test set has six groups and OOD has seven groups. GNNSDP(GCN) and biaffine parser are evaluated on them. The results for different groups are shown in
Figure 3.
The results show that GNNSDP outperforms the biaffine parser on different groups with the same embedding settings, except for being slightly lower on the first group (0–10 tokens) on ID test set of PAS formalism. Furthermore, GNNSDP that only uses POS tag embeddings outperforms the biaffine parser that uses POS tag, character-level, and lemma embeddings when sentences get longer, especially when sentences are longer than 30. It turns out that higher-order information is favorable for longer sentences since higher-order dependency relationships are more prevalent in longer sentences.
5.2. Ablation Study
We investigate how the number of GNN layers affects the performance of our parser. We train and test the GNNSDP(GCN) in PSD formalism datasets of English and Czech. The number of GCN layers increases from 1 to 3.
Table 7 shows the results of GNNSDP(GCN) with different numbers of GCN layers in basic embedding settings. From the results, we can see that:
GNNSDP(GCN) with only one GCN layer still performs better than the biaffine parser, demonstrating that higher-order information is beneficial for improving SDP.
The performance of GNNSDP(GCN) is gradually improved when the number of GCN layers is increased, demonstrating that stacking more GNN layers is able to capture better higher-order information.
5.3. Case Study
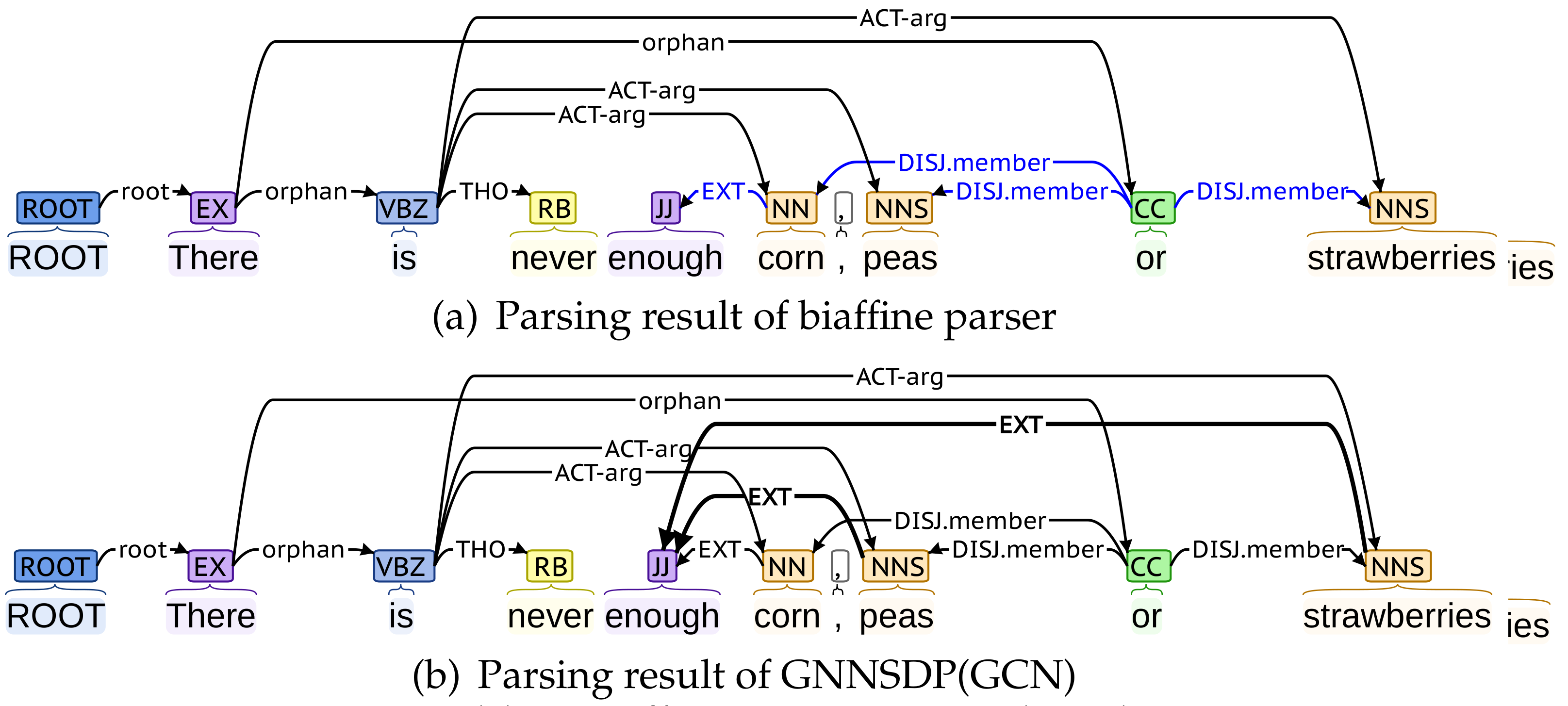
We provide a parsing example to show why GNNSDP benefits from higher-order information.
Figure 4 shows the parsing results of the biaffine parser (
Figure 4a) and GNNSDP(GCN) (
Figure 4b) for the English sentence (sent_id = 40504035, in OOD of PSD formalism)
“There is never enough corn, peas or strawberries”. Both parsers are trained in the basic embedding settings.
In the gold annotation, three words corn, peas, and strawberries are three members of the disjunctive word or. In addition, the word enough has three dependency edges labeled EXT with them. In the results of the biaffine parser, only the dependency edge between enough and corn is identified; the remaining two are not. In GNNSDP(GCN), given the initial SDG predicted by the biaffine parser, the words corn, peas, and strawberries aggregate the higher-order information of or and is (first-order), there (second-order), and ROOT (third-order). The word enough aggregates the higher-order information of the corn (first-order), is and or (second-order), there (third-order), and ROOT (fourth-order). The dependent word enough and three head words corn, peas, and strawberries aggregate information of four common words (ROOT, There, is and or). Therefore, the representations of them with higher-order information bring more evidence into decoders’ final decisions. As a result, it is effortless for GNNSDP to identify that there are also two dependency edges labeled EXT between the dependent word enough and the head words peas and strawberries.
6. Conclusions
This paper aims to exploit GNNs’ powerful ability of representation learning in SDP. GNNs are utilized to encode higher-order information to improve the accuracy of semantic dependency parsing. Experiments are conducted on the SemEval 2015 Task 18 dataset in three languages (Chinese, English, and Czech). Compared to the previous state-of-the-art parser, our parser yields 0.3% and 2.2% improvement in the average labeled F1-score on English in-domain (ID) and out-of-domain (OOD) test sets, 2.6% improvement on Chinese ID test set, and 2.0% and 1.8% improvement on the Czech ID and OOD test sets. Experimental results show that our parser outperforms the previous best one on the SemEval 2015 Task 18 dataset in three languages. In addition, our parser shows greater advantage in longer sentence and complex semantic formalism. Outstanding performances of our parser demonstrates that higher-order information encoded by GNNs is exceedingly beneficial for improving SDP.
Despite that significant improvement has been made, the initial graph structure output by the vanilla parser may be noisy, resulting in a performance penalty to some extent. In the future, we would like to apply graph structure learning models to jointly learn graph structure and graph representation, rather than depending on the initial dependency graph output by the vanilla parser.








{kind=link}
{kind=link}
{kind=link}
{kind=link}