1. Introduction
Object detection is one of the core problems in the field of computer vision research. With the development of the convolutional neural network [
1], many advanced detectors based on deep learning have appeared in recent years. At present, there are two types of mainstream object detection algorithms. One is the two-stage object detection based on the candidate box represented by R-CNN [
2] and its variants, such as Fast R-CNN [
3], Faster R-CNN [
4], Mask R-CNN [
5], etc. The two-stage object detection is developing rapidly, and the detection accuracy is constantly improving, but the problem of its architecture leads to high network computing costs and slow detection speed, which cannot meet the real-time requirements. The other type of mainstream object detection algorithm is the one-stage object detection based on regression analysis represented by SSD [
6], YOLOv1 [
7] and its variants [
8,
9,
10], RetinaNet [
11], EfficientDet [
12], etc. The one-stage object detection algorithm directly predicts the target coordinates and categories after extracting the input image features through CNN, which greatly improves the detection efficiency, but the most important deficiency is that the detection accuracy needs to be further improved.
How to improve the accuracy of one-stage object detection has attracted the attention of many researchers. DSSD [
13] adds a deconvolution model to SSD [
6]. FSSD [
14] reconstructs the pyramid feature map and integrates the features of different scales. YOLOv3 [
9] solves the multi-scale problem through the residual network. RefineDet [
15] combines the idea of a two-stage and one-stage target detector, adopts the regression idea from coarse to fine, and introduces the feature fusion operation similar to FPN [
16]. Using the idea of a thermodynamic diagram for reference, CornerNet [
17] predicts the target by predicting a group of corners. EfficientDet [
12] uses a weighted bidirectional feature pyramid network for feature fusion and scales the model through a composite feature pyramid network. All of the above improve the object detection effect in varying degrees, but it also inevitably leads to problems such as high model complexity, difficult convergence, and slow detection speed.
One of the one-stage detectors, RetinaNet [
11], introduces focal loss to solve the problem of sample imbalance and achieves comparable accuracy to the two-stage object detection framework while ensuring real-time performance; however, small targets have always been a difficult point in target detection. Due to the small coverage area of small targets, low resolution, and lack of diversity in locations, various target detection methods cannot achieve the same accuracy as large targets for the detection of small targets. In particular, RetinaNet is ideal for detecting large-sized objects, but it is not effective for detecting small objects smaller than 32 × 32 pixels [
18].
By analyzing the network structure of RetinaNet, this paper found that the main reason for the low detection accuracy of small objects is the limited utilization of high-resolution information. It is mainly manifested in two aspects. First, the standard RetinaNet does not make full use of the lower feature layer C2 containing high-resolution features. The shallow layer C2 of the backbone network contains rich location information that is conducive to small target recognition. In the bottom-up path, in order to expand the receptive field of the backbone network, the feature map in the network will continue to shrink, and the value of the stride is likely to be larger than the size of the small target, resulting in the loss of the feature information of the small target during the convolution process. If the shallow information cannot be fully utilized, the small object features will be lost. Second, the standard RetinaNet uses the FPN structure, upsampling the high-level feature map, and then adding and merging with the shallow-level features to obtain a new feature map with stronger expressive ability. Feature maps fused with multi-scale features have better robustness when detecting objects of different sizes; however, in the bottom-up backbone network, the path from the low-level features to the top-level features is long (such as Resnet50 and ResNet101 [
19]), and some high-resolution information is lost in the process of upsampling, which increases the difficulty of obtaining accurate positioning information.
In view of the above two reasons for the low utilization of low-level high-resolution information, this paper makes the following improvements to the standard RetinaNet:
First, to supplement and improve the utilization of high-resolution features, inspired by PANet [
20], this paper introduces a bidirectional feature pyramid structure, which fully combines deep and shallow information for feature extraction, thereby improving the expression of target semantic information by the shallow feature network. Based on the standard RetinaNet, this paper adds a bottom-up enhancement path, which greatly shortens the propagation path of low-level information and improves the utilization of low-level information. The semantic and contextual information of small and medium-scale objects is enhanced by bottom-up branching. In addition, the bidirectional feature fusion also fully integrates multi-scale information, which is beneficial to the target detection effect.
Second, to make full use of the high-resolution information, this paper reuses the low-level feature C2 of the backbone network. At the same time, in order to solve the shortcomings of the limited receptive field of low-level features and weak semantic information, and inspired by DetNet [
21], this paper uses dilated convolution to expand the receptive field and connect it laterally with P3 from the top-down path. In addition, to enhance the feature fusion between the features extracted from different receptive fields, inspired by AC-FPN [
22] and DenseNet [
23], this paper connects dilated convolutions with different dilation rates in a residual connection.
Third, to reduce the loss of high-level semantic features caused by the bidirectional feature pyramid structure, this paper designs high-level features C6 directly from the backbone network and supplemented by low-level high-resolution features. It does not need to go through a top-down fusion path and fuses information from lower layers to obtain rich localization information while minimizing the loss of semantic information.
Combining the above analysis and strategies, the detection method proposed in this paper has the following advantages:
(1) To shorten the propagation path of high-resolution information and improve the utilization of high-resolution features, this paper introduces a bidirectional feature pyramid structure.
(2) To take full advantage of the low-level features, this paper designs the Dilated Feature Enhancement structure to extract the high-resolution information of the low-level features through the dilated convolution of residual connections.
(3) To compensate for the high-resolution information lost during the long propagation process of the backbone network, this paper designs the High-level Guided Model, which is guided by high-level features to extract high-resolution information in lower layers.
3. Method
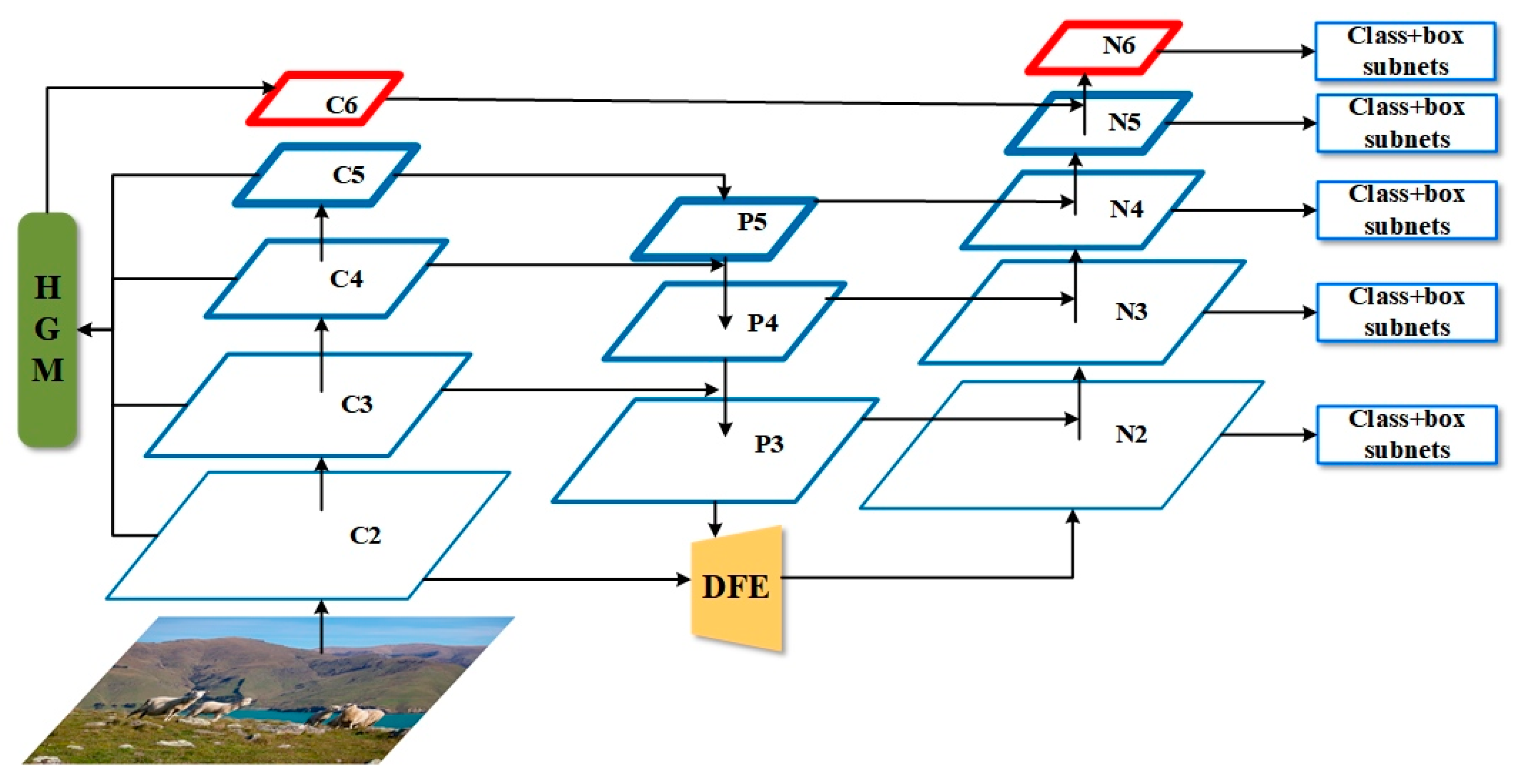
This section introduces the overall architecture of our proposed model BFE-Net (
Figure 1). This paper replaces the feature pyramid structure of the standard RetinaNet with a bidirectional feature pyramid structure, which can better achieve multi-scale feature fusion. It consists of a High-level Guided model (HGM) and Dilated Feature Enhancement (DFE).
3.1. Overall Architecture
In the process of feature extraction, the shallow feature map contains location information with high resolution, which can be used to improve the accuracy of bounding box regression; however, due to less convolution, it has lower semantics and more noise. Although a deep feature map contains strong semantic information, its resolution is low and its detail expression ability is poor.
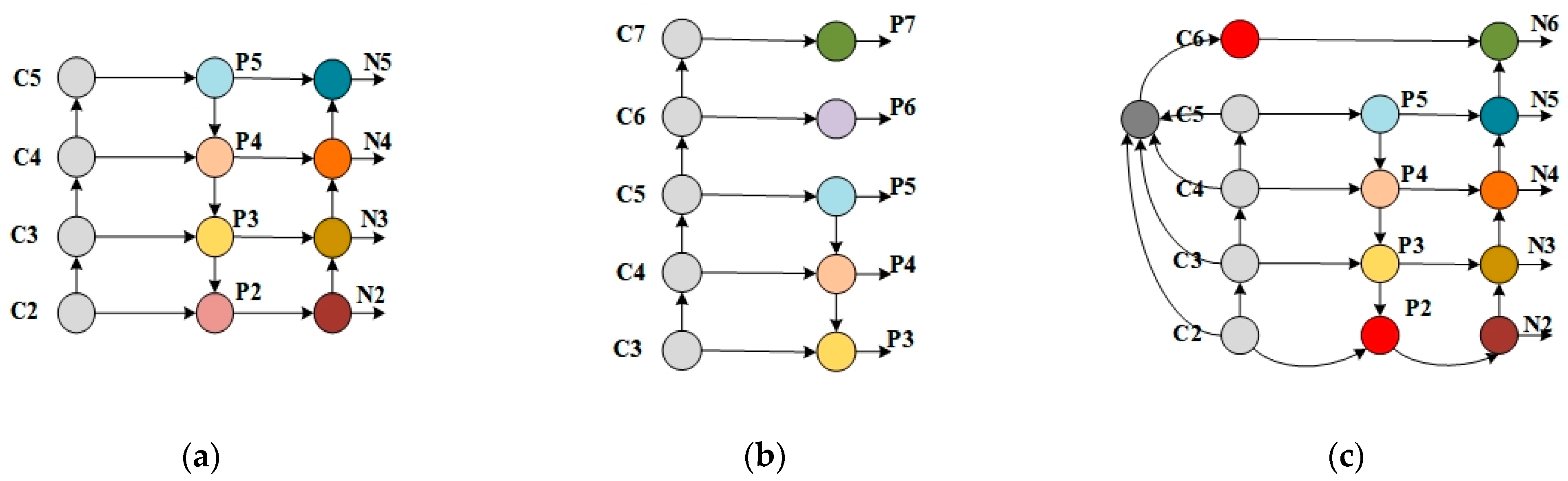
Multi-scale fusion is an important method to improve the accuracy of small target detection. The feature pyramid network (FPN) [
16] uses the feature expression structure of each network layer for the same scale image in different dimensions from the bottom to the top and refers to the feature information of the multi-scale feature map while taking into account the strong semantic features and location features, which is conducive to the detection of small objects. The standard RetinaNet [
11] uses the feature pyramid network (FPN) in [
16] as the backbone network. At the same time, in order to obtain richer semantic features and better detection results for large targets, the standard RetinaNet innovates the generation layers C6 and C7 in the bottom-up backbone network (
Figure 2b). To further shorten the information transmission path and make full use of high-resolution information, PANet creates a bottom-up path enhancement based on the standard FPN (
Figure 2a). Inspired by PANet, this work designs a bidirectional feature pyramid structure (
Figure 2c) with levels N2 through N6, all pyramid levels in this structure have C = 256 channels.
This structure uses feature pyramid levels P2 to P6, where P3 to P5 are obtained from the corresponding ResNet residual stages (C3 through C5) using top-down and lateral connections as in RetinaNet [
11]. P6 is obtained through HGM, P2 is obtained by using DFE to enhance the C2 feature and then connecting it laterally with P3, which is different from [
11]. N2 to N5 are obtained from the corresponding P2 to P5 via lateral connections and bottom-up paths, as in PANet [
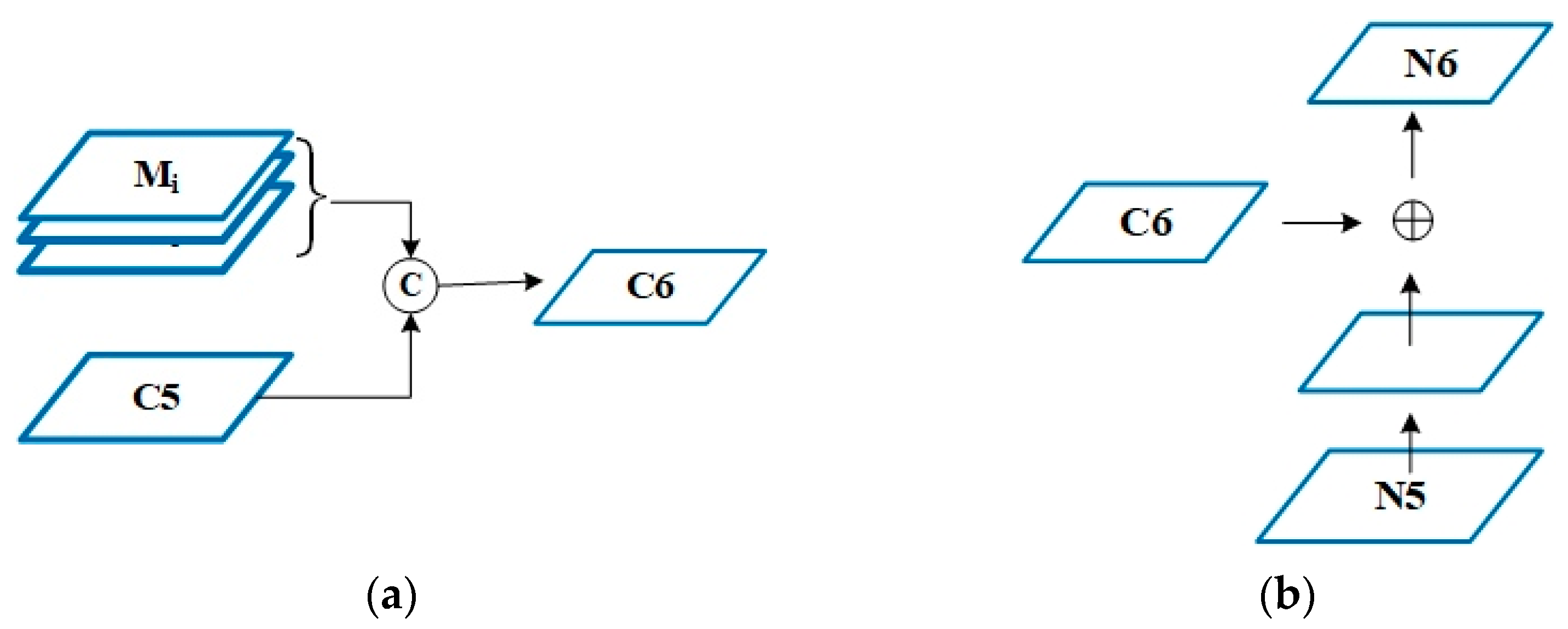
20]. N6 is obtained by lateral connections with C6 by stride convolution instead of down sampling (
Figure 3a), which is different from [
20].
HGM obtains C6 by using C5 as a guide to extract lower-level feature information, which supplements the high-resolution information lost during bottom-up long-path propagation by standard backbone networks. DFE is used to increase the receptive field size of the convolution kernel by expanding the convolution, extract richer contextual information in the lower layers, and obtain richer low-level localization features. We introduce them in detail below.
3.2. Dilated Feature Enhancement
The standard RetinaNet discards use the high-resolution pyramid level P2 computed from the output of the corresponding ResNet residual stage C2. The shallow feature C2 in the backbone network contains rich feature location information with higher resolution, which will be beneficial to the localization of small targets. We can employ effective strategies to make full use of the high-resolution features from C2.
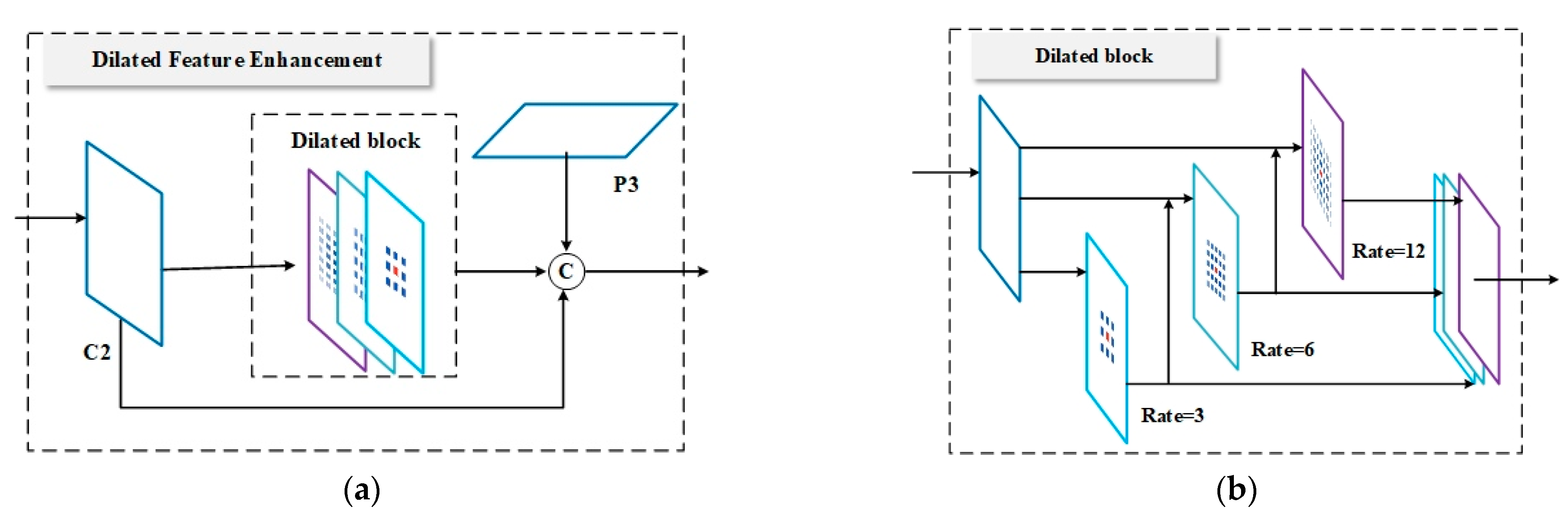
In this paper, we present the Dilated Feature Enhancement (
Figure 4a), which combines the feature enhanced high-resolution feature C2 with P3 in the top-down path to obtain P2 as the input of the enhanced bottom-up structure. The structure consists of Dilated block (
Figure 4b) and a lateral connection by 1 × 1 conv just as in [
16]. The dilated convolution is used to increase the receptive field size of the convolution kernel, extract richer context information, and obtain richer low-level localization features without significantly increasing the computational load. This operation can be constructed as:
where
D(·) is the Dilated block operation, which is described in detail below, and the detailed description is given in Equation (4). N2 represents the input of the bottom-up augmentation path.
Fconcat represents the features that are fused in the concatenate method.
Dilated Block: In most network structures with FPN, feature maps corresponding to different receptive fields are simply merged by element-wise addition in the top-down path. Merging the feature maps corresponding to different receptive fields through element addition cannot make the information captured by different receptive fields interact effectively, resulting in limited utilization of extracted information.
As shown in
Figure 4b, to merge multi-scale information with different receptive fields elaborately, this paper employs residual connection in the Dilated block, where the output of each dilated layer is concatenated with the original input feature maps and then fed into the next dilated layer. At the same time, each dilated layer is given a separate output feature as a part of the output of the Dilated block. Finally, in order to maintain the coarse-grained information of the initial inputs, this paper concatenates the outputs of all dilated layers and feeds them into a 1 × 1 convolutional layer to fuse the coarse-and-fine grained features.
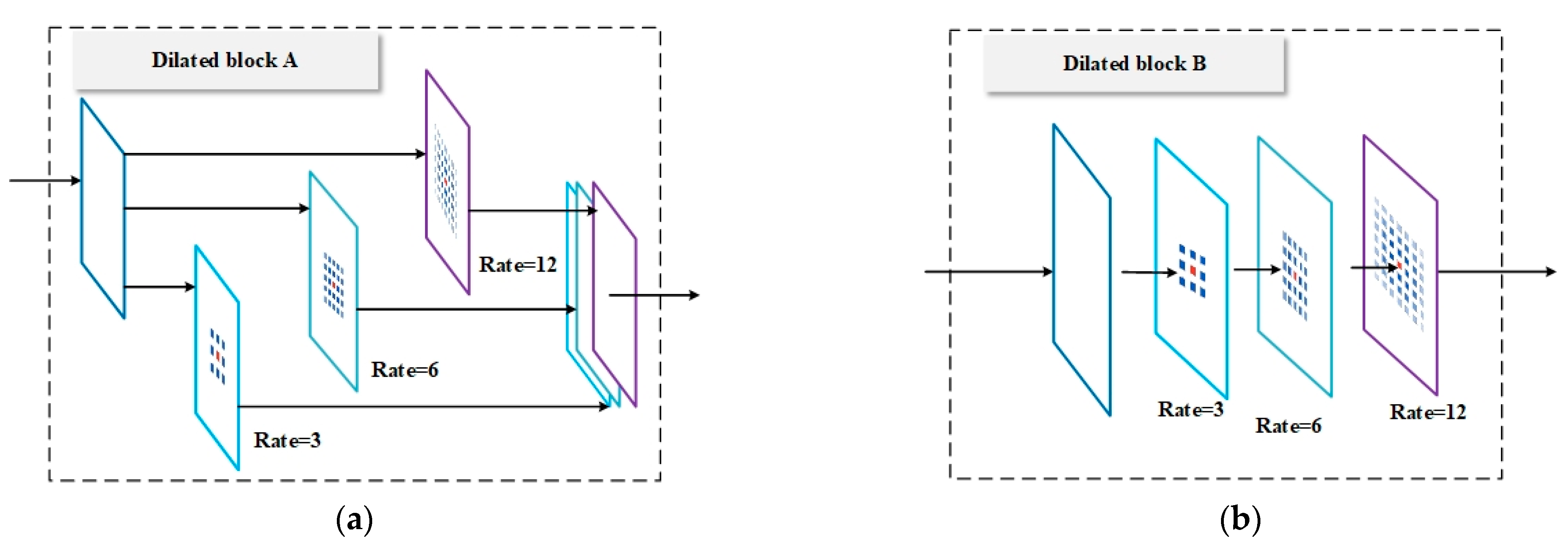
In this model, we have designed two other feature extraction methods. As shown in
Figure 5, Dilated block A (
Figure 5a) uses the parallel method in Inception to extract features on the input feature map using dilated convolutions with different expansion rates. Finally, the extracted features are fused in a concatenated manner. Dilated block B (
Figure 5b) uses the general feature extraction method to extract features in series and finally obtains only one feature layer. We analyze the effects of different structures in the experimental results in
Section 4.4.
where
Fdilated(
i) represents the dilated convolution operation function with residual structure. The symbol ⊕ denotes feature fusion by addition.
Dconv3×3(·) represents a dilated convolution with a convolution kernel of 3 × 3 and expansion rates of 3, 6, and 12, respectively. Then, the three output feature maps containing multi-scale context information are fused in using the concatenate method.
3.3. High-Level Guided Model
In order to extract richer abstract features, the current general backbone networks such as ResNet [
19] and VGG [
31] have a deeper network structure; however, in the detection process, with the increase in depth, through continuous down sampling and feature extraction, the position information of the deep feature map is weakened, which is not conducive to target detection and localization.
In the standard RetinaNet [
11], in order to obtain more abstract features, P6 is obtained via a 3 × 3 stride-2 conv on C5; P7 is computed by applying ReLU followed by a 3 × 3 stride-2 conv on P6. This operation not only obtains rich semantic information but also loses a lot of location information. In order to make up for the loss of high-resolution information caused by too deep network layers in the standard RetinaNet, the High-level Guided Model was designed. Inspired by [
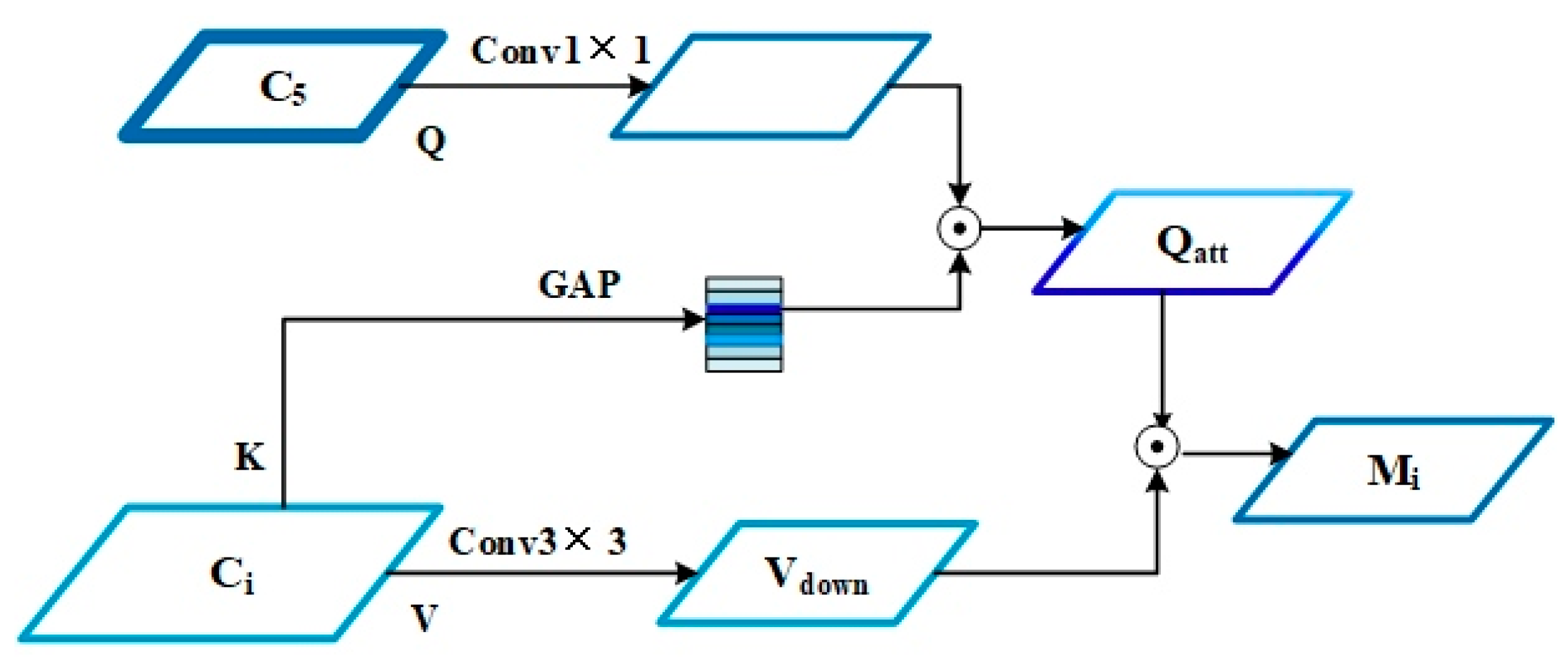
30], this model uses the highest-level output feature of the backbone network as Query, and then uses the lower-level features as both Key and Value, respectively, and integrates the higher-resolution lower-level information into the highest-level features using the visual attributes of low-level pixels to render high-level concepts to achieve high-level and bottom-level feature fusion.
High-level Guided Model (HGM) can be categorized as a low-level information enhancement transformer, which utilizes high-level features with rich category information for the weighted selection of low-level information. By selecting precise resolution details, the structure makes up for the high-resolution information lost in the propagation process and enriches the highest-level information.
We denote the output of the convolutional layer in each scale as {C2, C3, C4, C5} according to the settings in [
16]. Specifically, the highest-level C5 in the backbone network is defined as
Q, {C2, C3, C4} are used as
K and
V at the same time, respectively. We take C5 as
Q and C4 as
K and
V as an example to describe the feature fusion process, as shown in
Figure 6.
First,
K uses global average pooling (GAP) to obtain the weighted value
W and
V uses a 3 × 3 convolution kernel with step size
S for down sampling to obtain
Vdown, so that the size of a is the same as
Q. Second,
Q uses the 1 × 1 convolutional layer for dimension reduction according to the dimensions of
K. Then
W weights
Q to obtain
Qatt. Finally,
Qatt and
V perform element-wise addition to obtain M
4. In particular, we formulate this procedure as follows.
where the symbol ⊗ denotes feature fusion by matrix multiplication.
Sconv3×3 is a 3 × 3 stride-2 conv to reduce the size of
V.
We perform the above with C2, C3 as
K and
V, and we obtain {M
2, M
3}. Then, we perform the concatenate operation on {M
2, M
3, M
4} to obtain M.
M and C5 are fused via the concatenate method, and then by 3 × 3 stride-2 conv for down sampling, and finally, C6 is obtained after dimensionality reduction by a 1 × 1 conv, as shown in
Figure 3a.
4. Experiments
4.1. Dataset and Evaluation Metrics
This paper performs all experiments on the MS COCO detection dataset with 80 categories. We train our model on MS-COCO 2017, which consists of 115 k training images and 5k validation images (minival). We also report the results on a set of 20 k test images (test-dev). The COCO-style Average Precision (AP) is chosen as the evaluation metrics, which averages AP across IoU thresholds from 0.5 to 0.95 with an interval of 0.05. Objects with a ground truth area smaller than 32 × 32 are regarded as small objects, objects larger than 32 × 32 and smaller than 96 × 96 are regarded as medium objects, and objects larger than 96 × 96 are regarded as large objects. The target proportion of small size is 41.43%, the target proportion of medium size is 34.32%, and the target proportion of large size is 24.24%. The small object accuracy rate is regarded as APS, the medium object accuracy rate is regarded as APM, and the large object accuracy rate is regarded as APL.
4.2. Implementation Details
To demonstrate the effectiveness of the BFE-Net proposed in this paper, we conducted a series of experiments on the MS COCO dataset for verification. For all experiments in this section, we used the SGD optimizer to train our models on a machine whose CPU is Intel i7-9700k, 32 RAM, 1 NVIDIA GeForce GTX TITAN X GPUs, deep learning framework is Pytorch 1.7.1, and the CUDA version is 10.1. The momentum is set as 0.9 and the weight decay is 0.0001. The batch size is set to 32 to prevent model overfitting and model convergence. We initialize the learning rate as 0.01 and decrease it to 0.001 and 0.0001 at 8th epoch and 11th epoch. The classical networks ResNet-50 and ResNet-101 were adopted as backbones for comparative experiments.
4.3. Main Results
In this section, we evaluate the BFE-Net on the COCO test-dev and compare it with other state-of-the-art one-stage and two-stage detectors. Original settings of RetinaNet, such as hyper-parameters for anchors and focal loss, were implemented to ensure a fair comparison. For all studies, we used an image scale of 500 pixels unless noted for training and testing. All the results are shown in
Table 1.
By analyzing the experimental results, it can be found that when ResNet101 is used as the backbone network with an image short size of 500 pixels, the standard RetinaNet [
11] achieves excellent results in detecting large targets, with an AP
L of 49.1%; however, when detecting small targets, it is different from the two-stage target detection method, with an AP
S of 14.7%. Compared with Faster R-CNN w FPN, it is 3.5% lower, and the detection results are not very ideal. In particular, the BFE-Net proposed in this paper has the same effect as detecting large targets when detecting small targets, and the AP
S reaches 17.9%, with a 3.2% improvement compared to the standard RetinaNet. At the same time, its detection accuracy is equally competitive with some two-stage object detection results. Compared with the standard RetinaNet, BFE-Net achieves higher AP of various sizes, which shows the effectiveness of the model proposed in this paper, especially for small object detection.
The extra layers this work adds to the model, such as low-level feature C2 and bidirectional feature pyramid structure, introduce additional overhead, which makes our proposed model not as fast as the standard RetinaNet [
11]. To compare the speed of the improved model, this work used an image scale of 500 pixels on the MS COCO dataset to compare with other object detection models. As shown in
Table 2, compared with the standard RetinaNet [
11], EfficientDet-D0 [
12] has similar speed and accuracy, and the BFE-Net proposed in this paper has better accuracy but slightly slower speed; however, compared with Faster R-CNN w FPN [
16], BFE-Net achieves competitive results in both AP
S and AP, and is also much faster than Faster R-CNN w FPN [
16]. Compared with the one-stage object detection models SSD513 [
6] and DSSD513 [
13], BFE-Net also has obvious advantages in speed and accuracy. The BFE-Net proposed in this paper achieves state-of-the-art accuracy compared to the standard RetinaNet, while maintaining reasonable speed compared to other models.
4.4. Ablation Study
In this section, we conduct extensive ablation experiments to analyze the effects of individual components in our proposed method. This paper also analyzes the effect of each proposed component of BFE-Net on COCO val2017. The purpose of this study is as follows.
To analyze the importance of each component in BFE-Net, we gradually apply a bidirectional feature pyramid network, High-level Guided Model, and Dilated Feature Enhancement to the model to verify its effectiveness. Meanwhile, the improvements brought by the combination of different components are also presented to demonstrate that these components complement each other. The baseline method for all ablation studies is ResNet50. All results are shown in
Table 3.
From the experimental data in the table, it can be seen that the three structures proposed in this paper have different degrees of improvement in the accuracy of the standard RetinaNet. Combining the improved strategies in this paper can effectively improve the detection performance of the detection algorithm for small targets. After adding the bidirectional feature pyramid structure, the accuracy rate has increased by 1.1%, and the accuracy of small targets (APS) has reached 15.1%, with an improvement of 1.2%. In addition, after adding HGM and DFE, the accuracy of small targets (APS) is increased by 0.4% and 0.8%, respectively, which also shows that AGH is of great help to the recognition of small-scale targets by fully extracting shallow features. The accuracy of target detection of other sizes is also improved to varying degrees. The overall accuracy rate has increased from 32.5% to 34.6%, and the accuracy rate of small targets has achieved a very meaningful improvement, from 13.9% to 16.7%, a 2.8% increase.
To verify the effectiveness of HGM, the following ablation experiments were performed. R-C6 represents that C5 directly obtains C6 through a 3 × 3 convolutional layer with stride 2, which is the same as in RetinaNet [
11]. H-C6 represents C6 obtained by means of HGM. The results are shown in
Table 4.
By analyzing the experimental data, it can be found that the accuracy of small target detection (APS) using H-C6 is 0.3% higher than that of R-C6. At the same time, R-C6 also achieved the best results in the recognition of large targets and medium-sized targets. This result shows that the high-resolution features guided by C5 can supplement the lost high-resolution information in the bottom-up propagation process, which is very helpful for object detection at different scales.
To verify the effectiveness of connecting dilated convolutions with different dilation rates in a residual manner in DFE, the following ablation experiments were performed. Feature extraction is performed in the following three ways: P-Dilated (
Figure 4a) represents three dilated convolution layers for feature extraction in parallel connection; S-Dilated (
Figure 4b) represents three dilated convolution layers in series for feature extraction; R-Dilated (
Figure 3b) represents the feature extraction that is finally used in this paper in a residual manner. The results are shown in
Table 5.
By analyzing the experimental results, it can be found that the use of the R-dilated method has achieved the best effect, with an average accuracy (AP) of 34.6% and an improvement of 0.6%. In particular, the accuracy of small targets (APS) has increased from 15.1% to 16.7%, and the improvement effect is as high as one percentage point. In addition, the effect of P-Dilated is better than that of S-Dilated, especially in small target recognition. We analyze that the reason for this phenomenon may be serial connection expansion convolution. Due to the large expansion rate, information will be lost during the convolution process, and the extracted features will be incoherent.
4.5. Visualization of Results
In order to more intuitively show the actual effect of the model proposed in this paper, we compared the qualitative results between BFE-Net and the standard RetinaNet in object detection at COCO val2017, and the results are shown in
Figure 7. The first column represents the original image in the MS COCO dataset, the second column represents the detection result using RetinaNet, and the third column represents the detection result using the improved model BFE-Net in this paper.
By analyzing the detection results in the comparison graphs, it can be found that in the first set of graphs, the standard RetinaNet missed the detection of distant horses, while it was successfully detected in BFE-Net. The same phenomenon exists in the second and third sets of detection results; the BFE-Net is able to detect more birds with small object sizes than RetinaNet. In the last set of pictures, RetinaNet mistakenly identified distant people as birds and missed the boat, while BFE-Net successfully detected people and boats. These experimental results show that the improved model in this paper can further enhance the representation ability of the model and can greatly improve the missed detection and false detection of small targets.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}