
Text Mining from Free Unstructured Text: An Experiment of Time Series Retrieval for Volcano Monitoring


 ,
,  ,
,  and
and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data
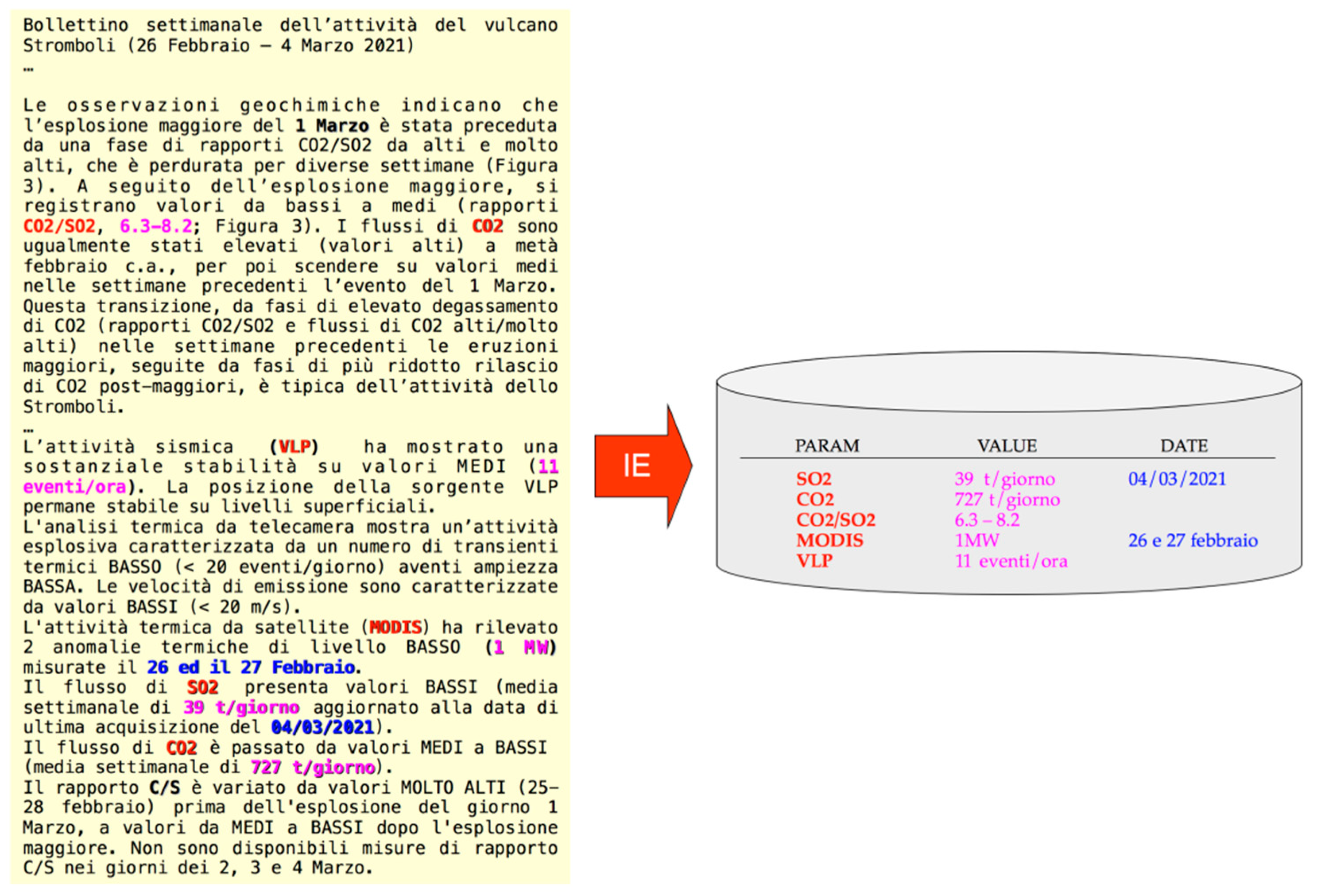
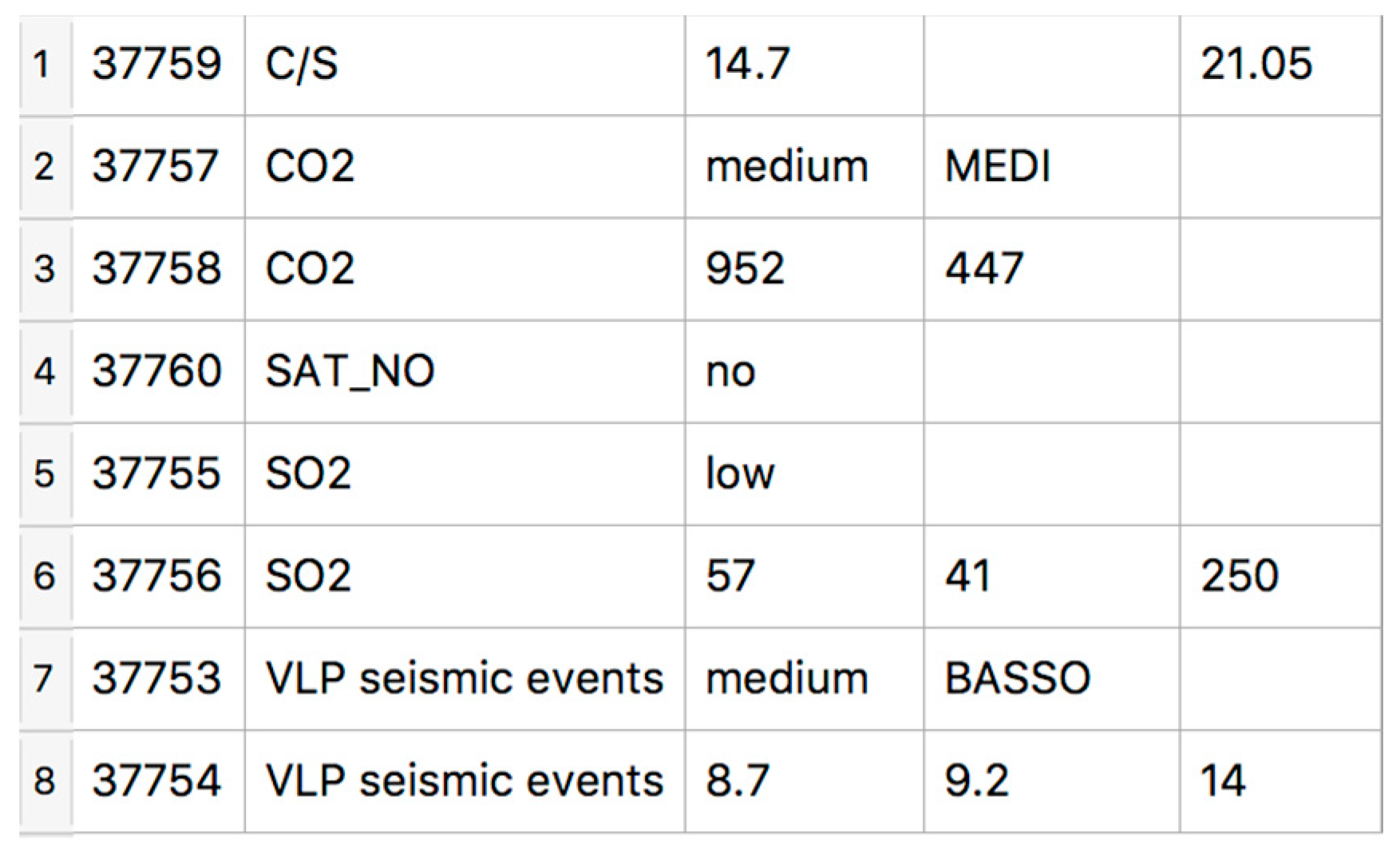
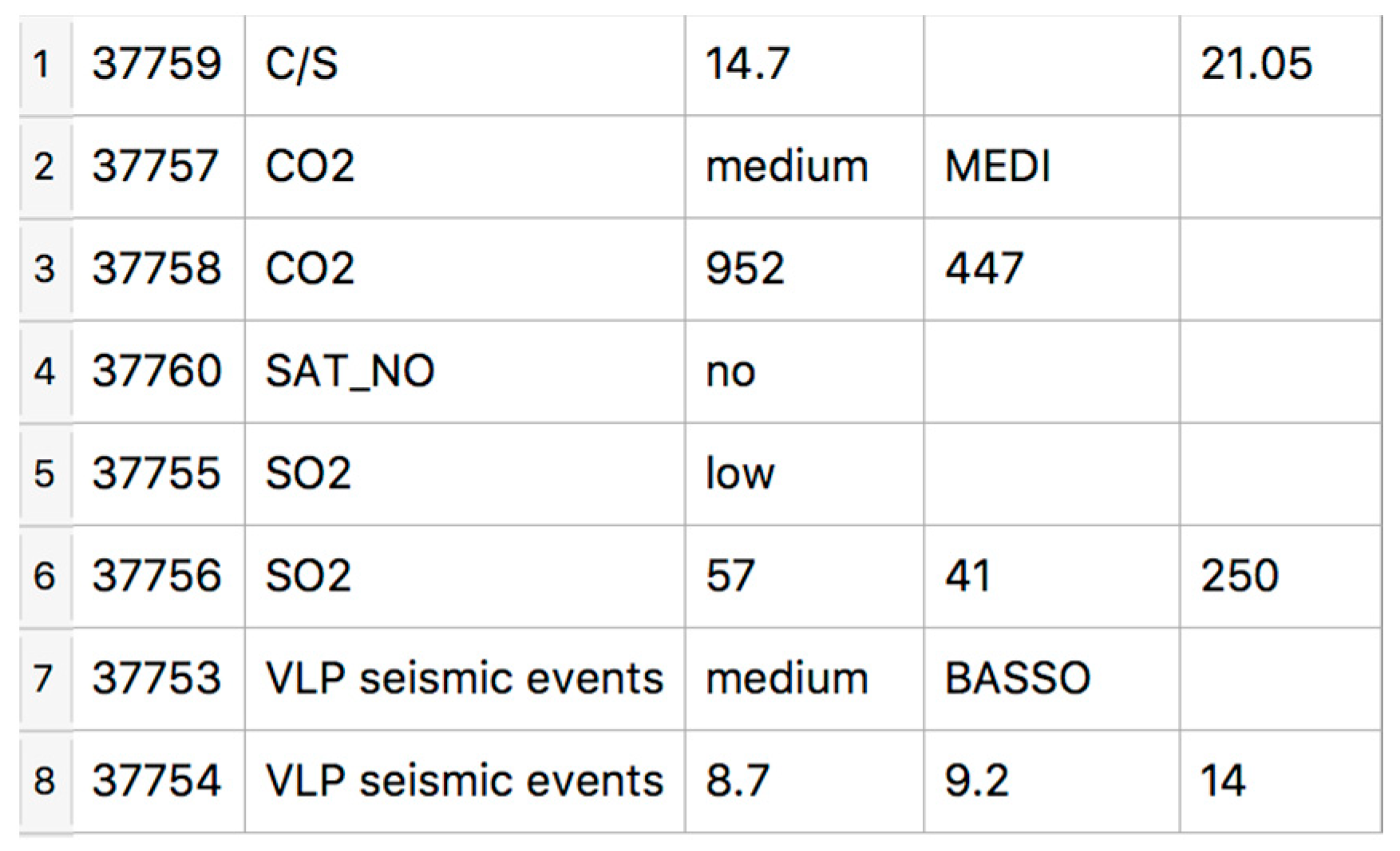
| <parameter>:= parameter_name: “name-string” parameter_value: “number”* institute: “institute-string” date: “date-expr” detection-site: “site-expr” |
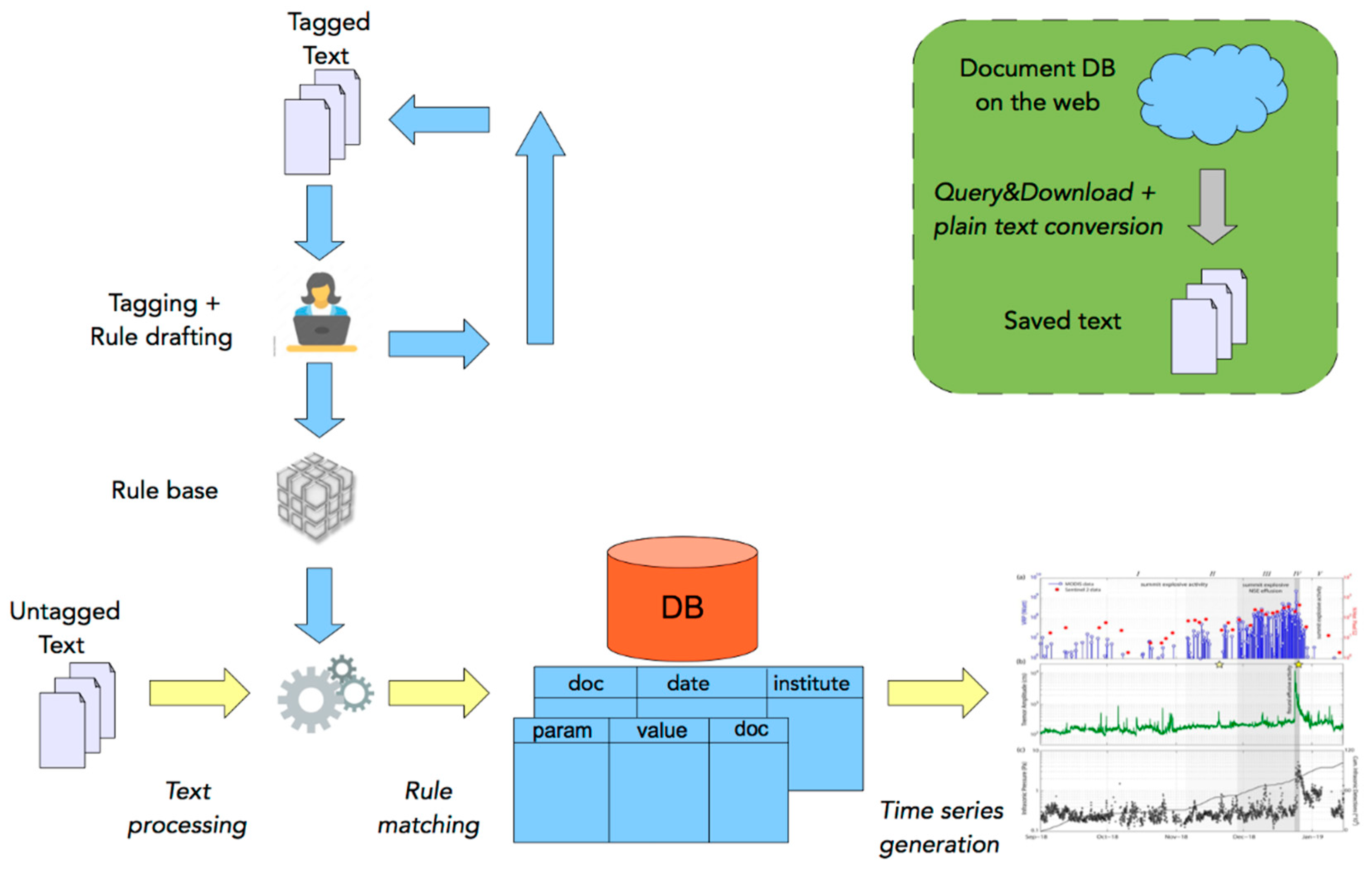
2.2. Method and System
- Corpus download and processing;
- Manual consultation and tagging;
- Automatic tagging and rule base refinement;
- Parameter validation;
- Visual exploration of time series.
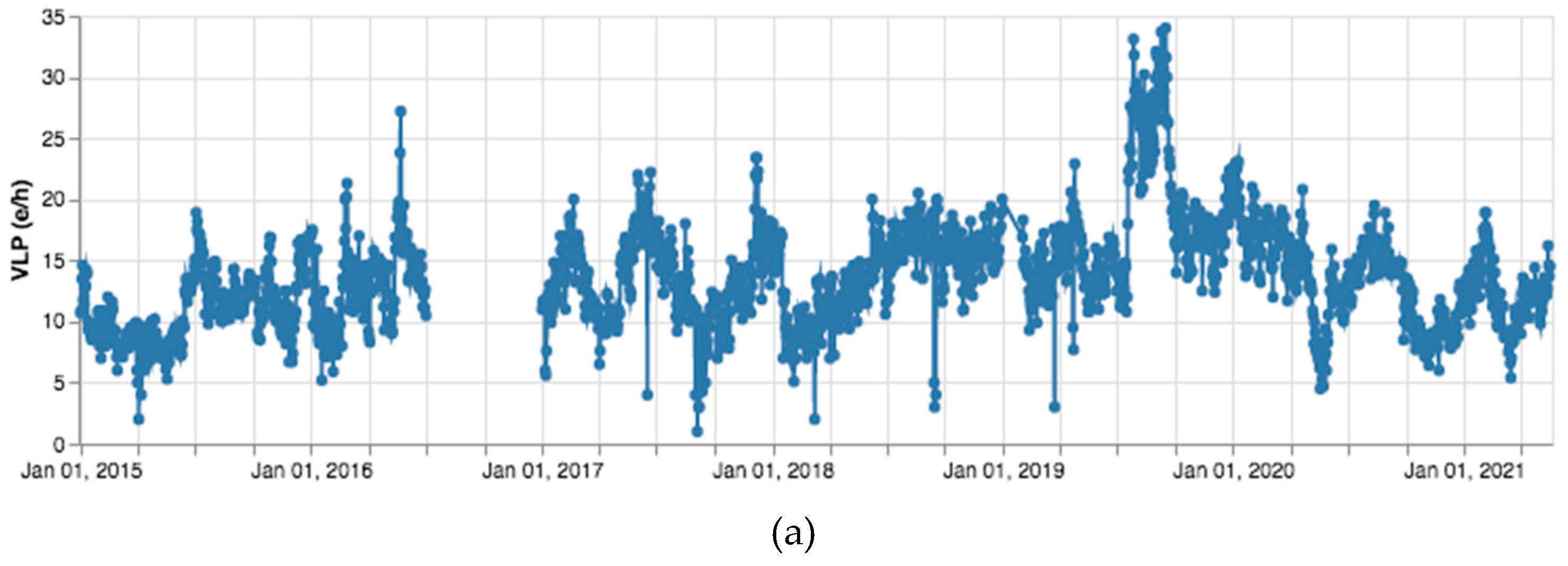
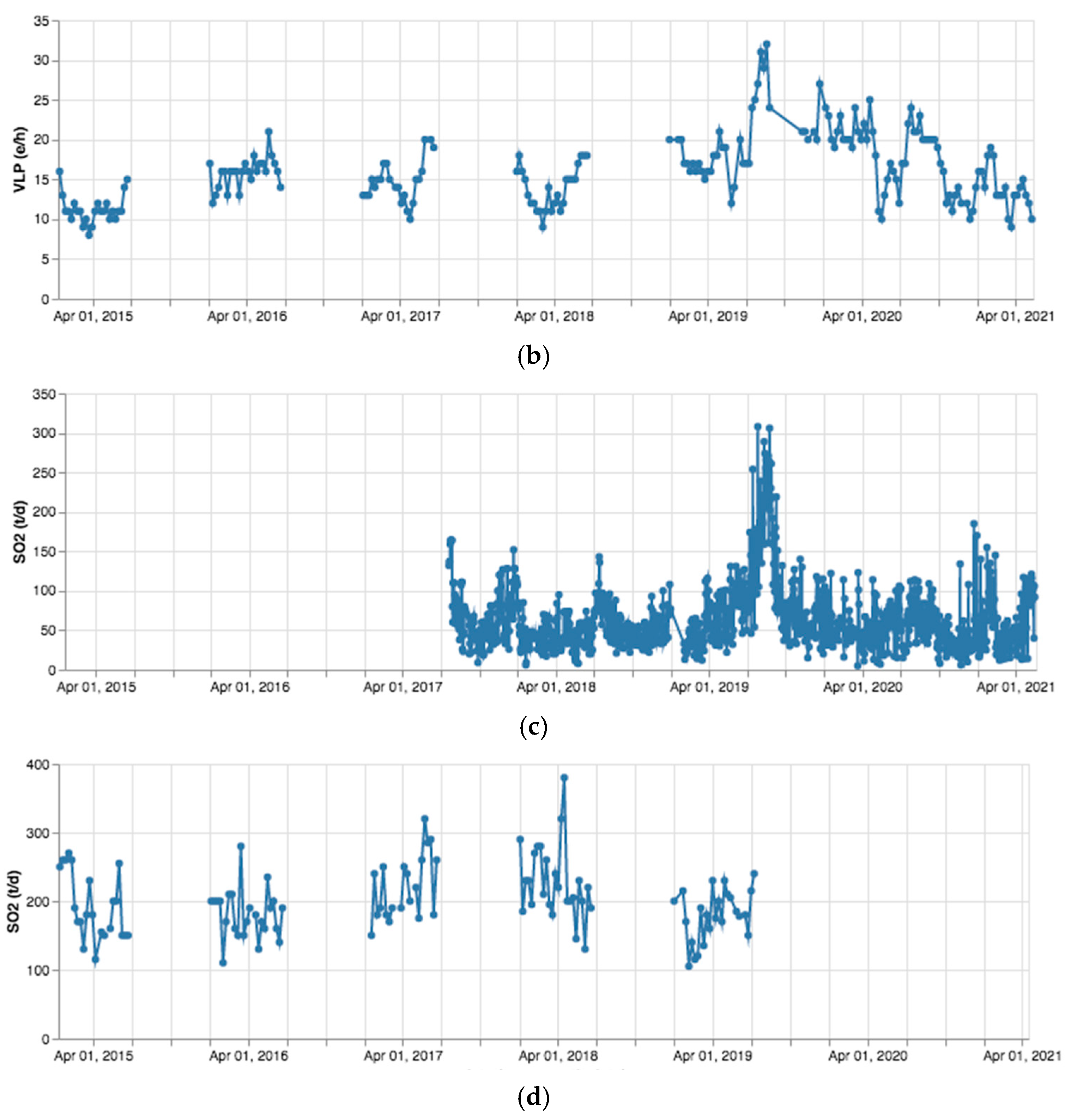
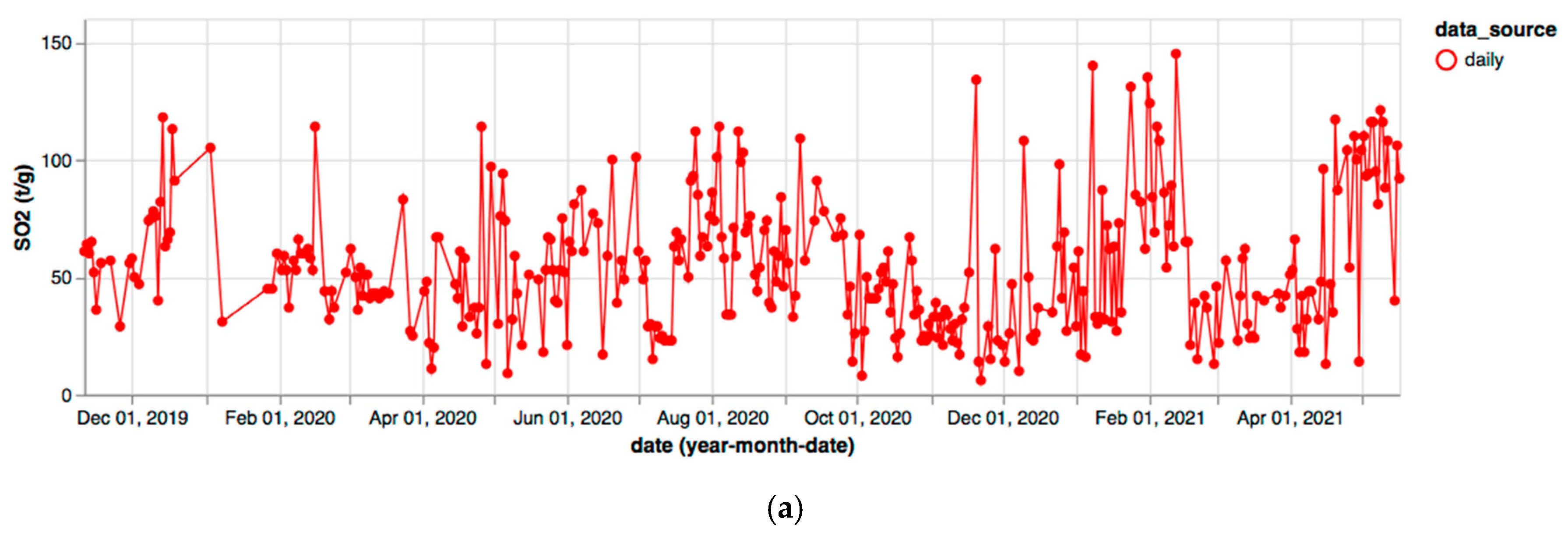
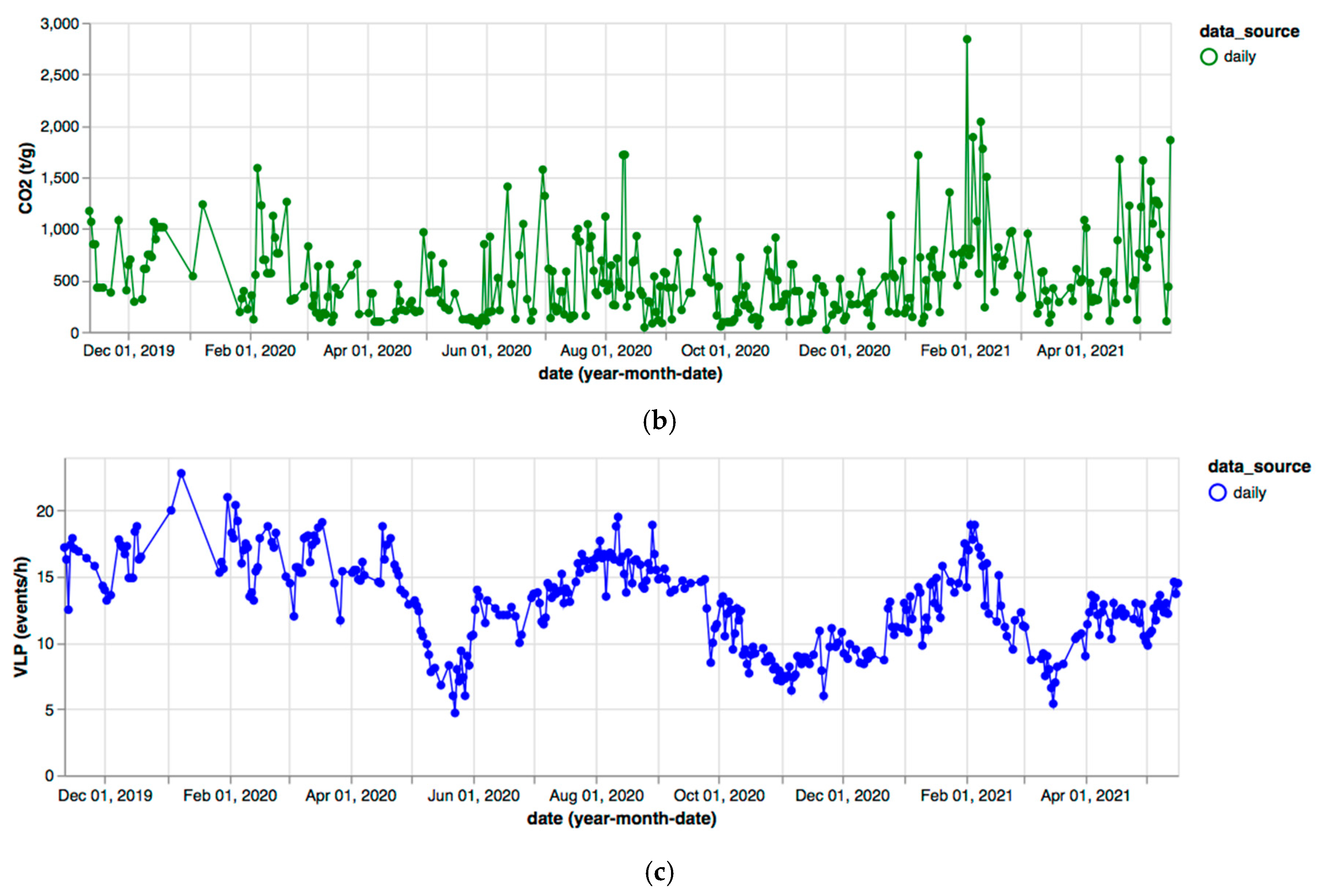
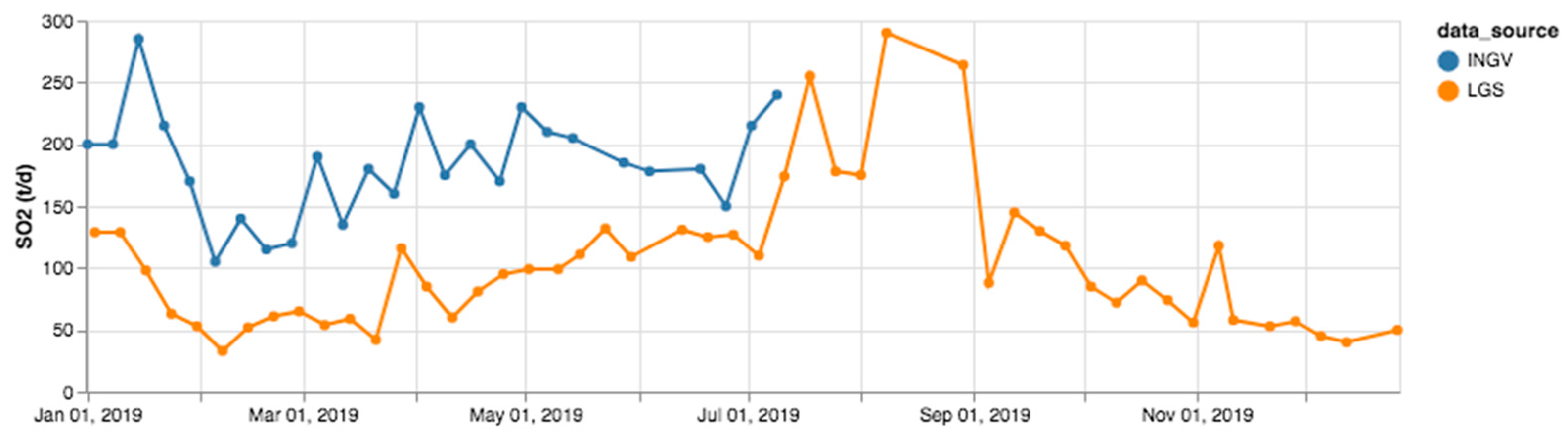
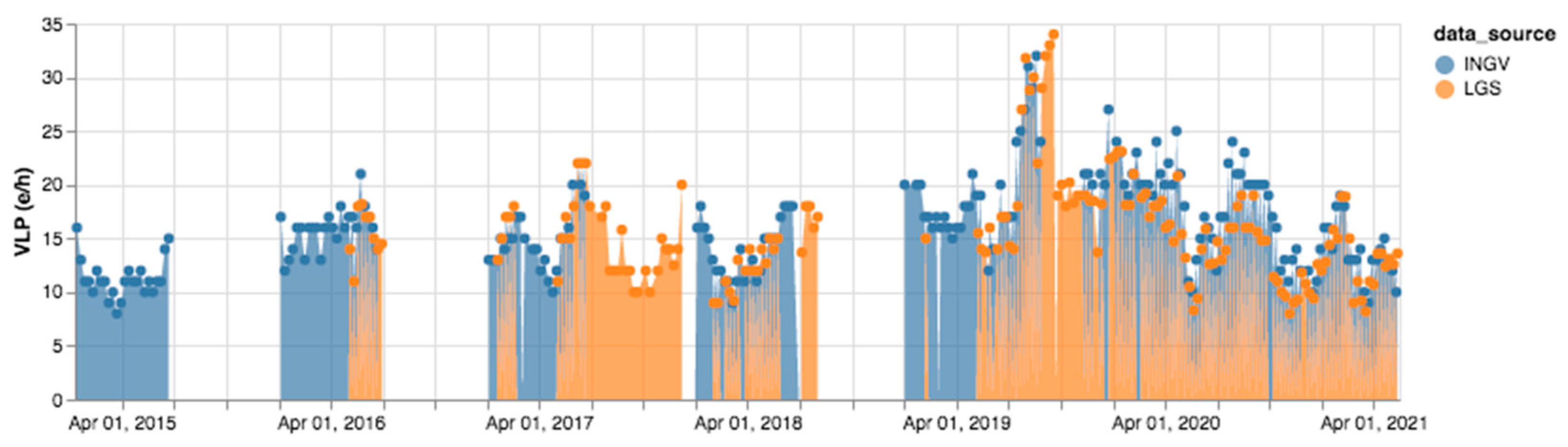
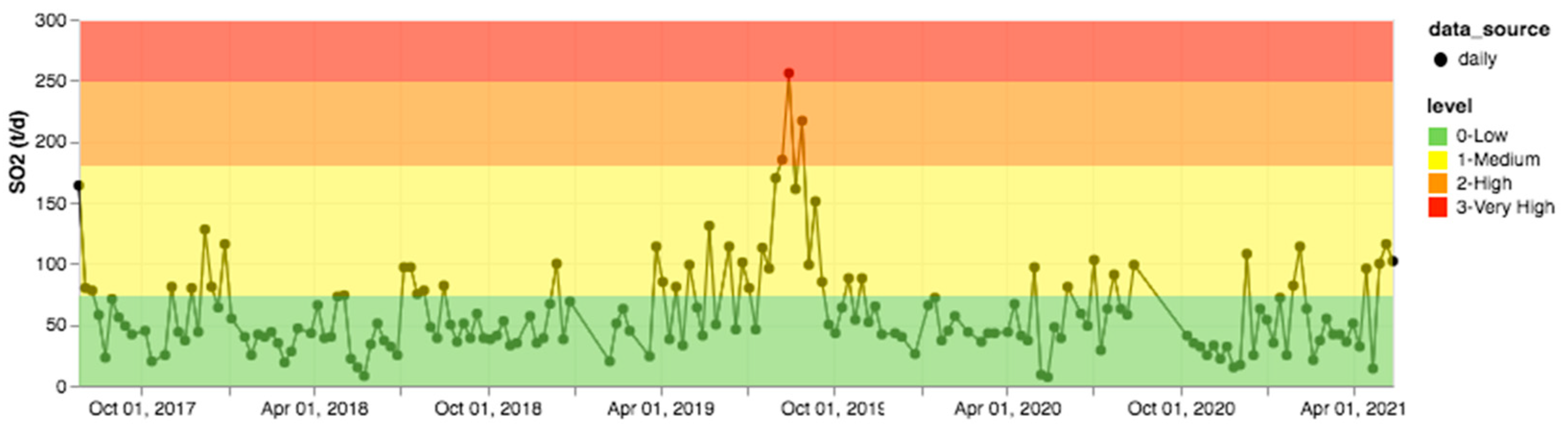
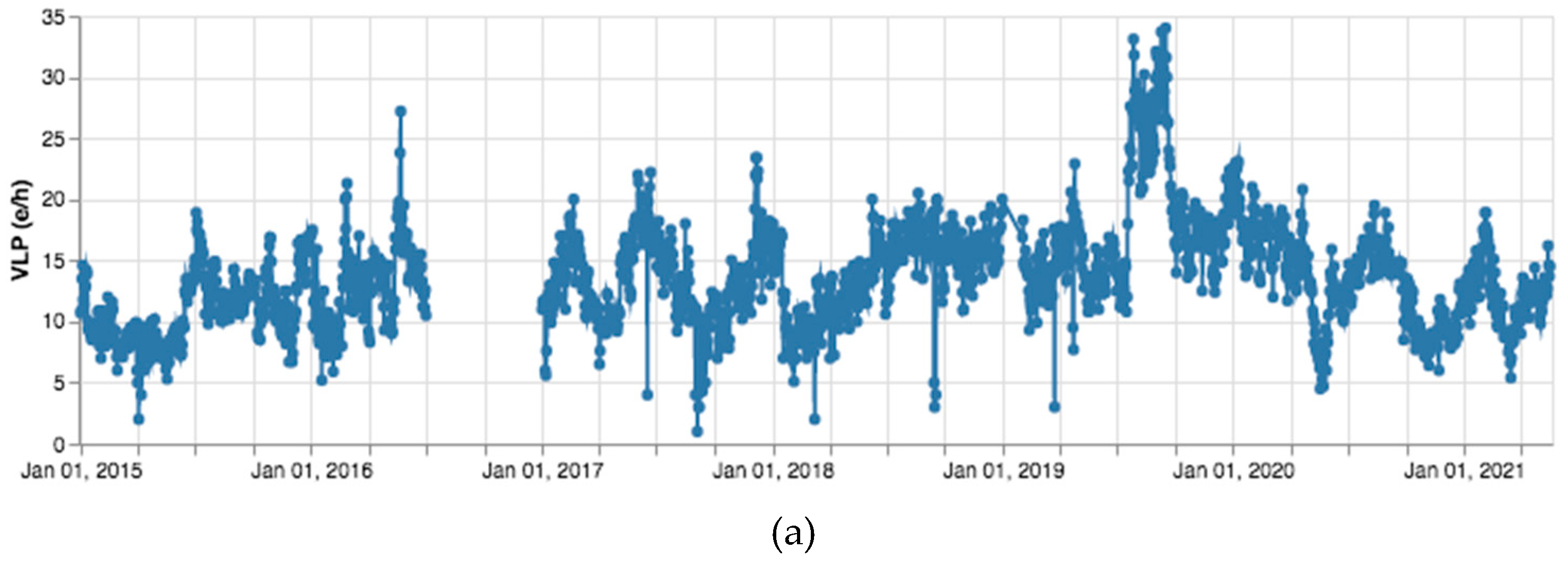
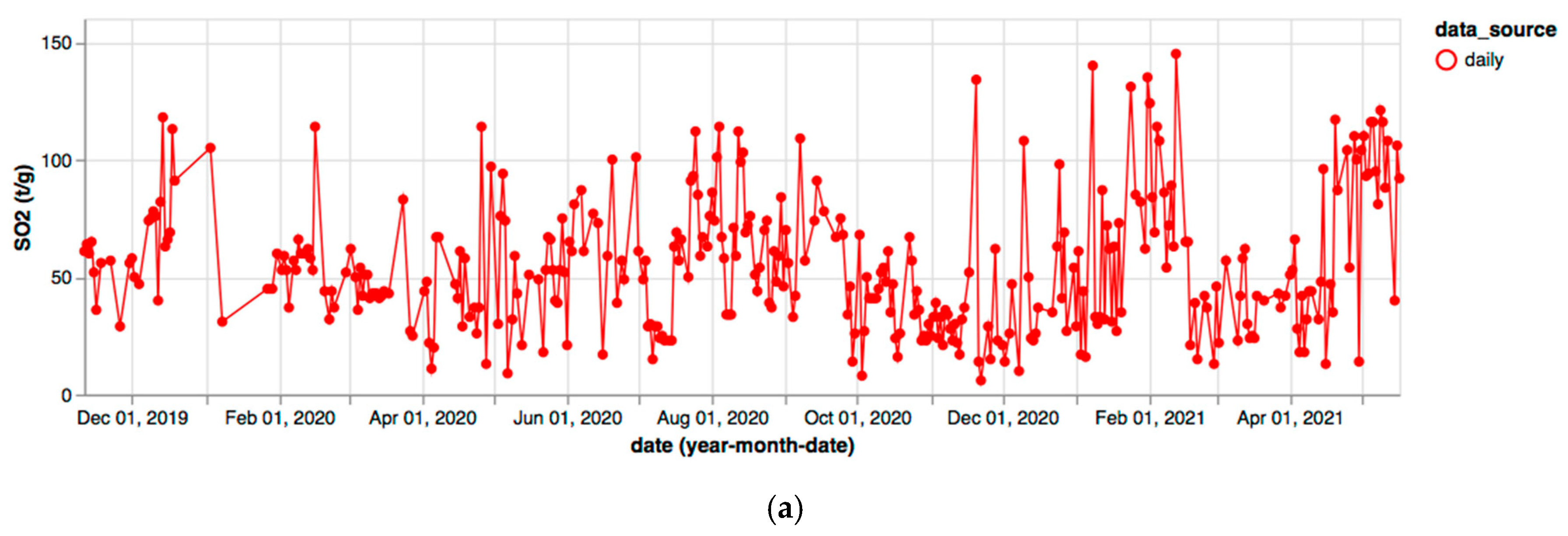
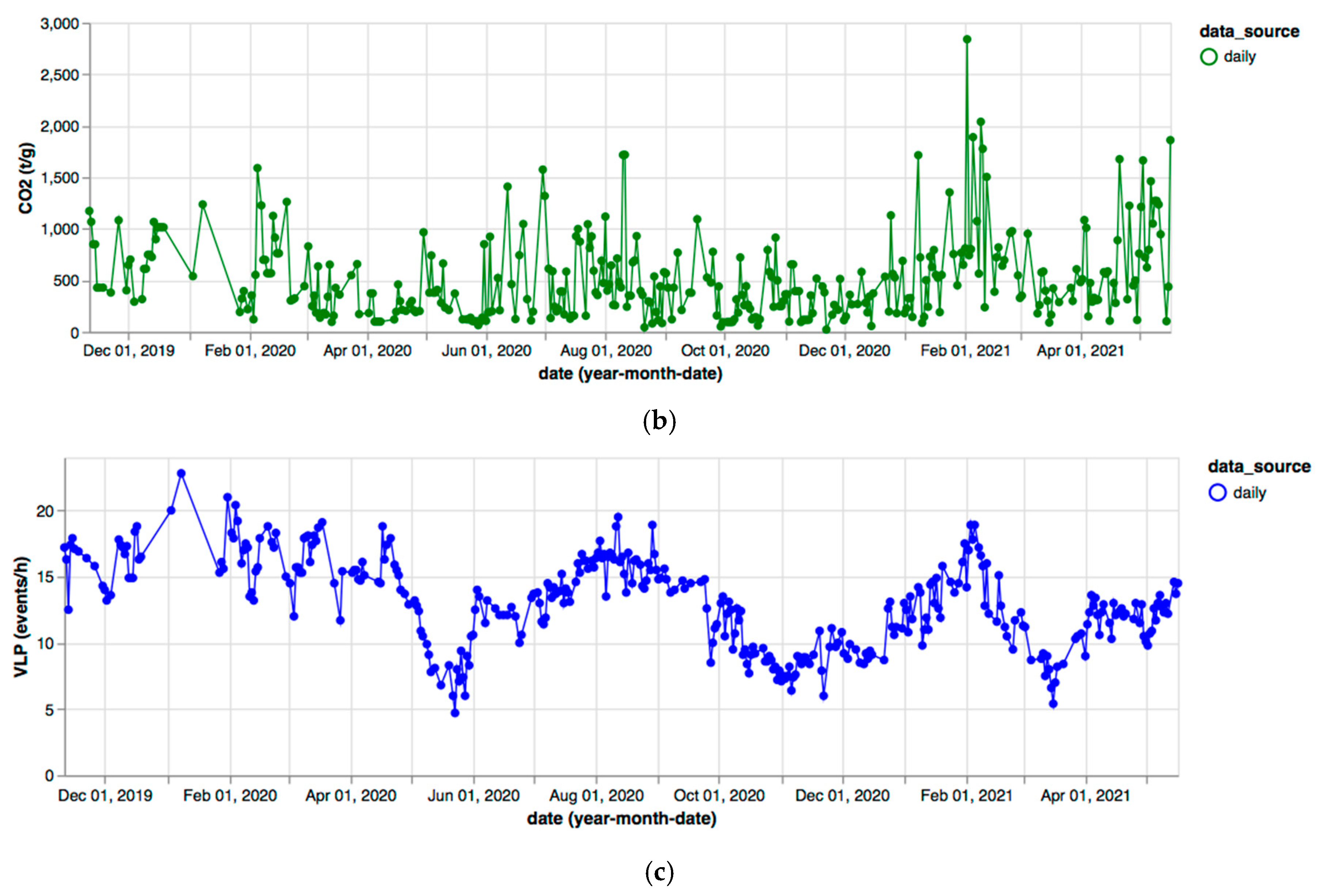
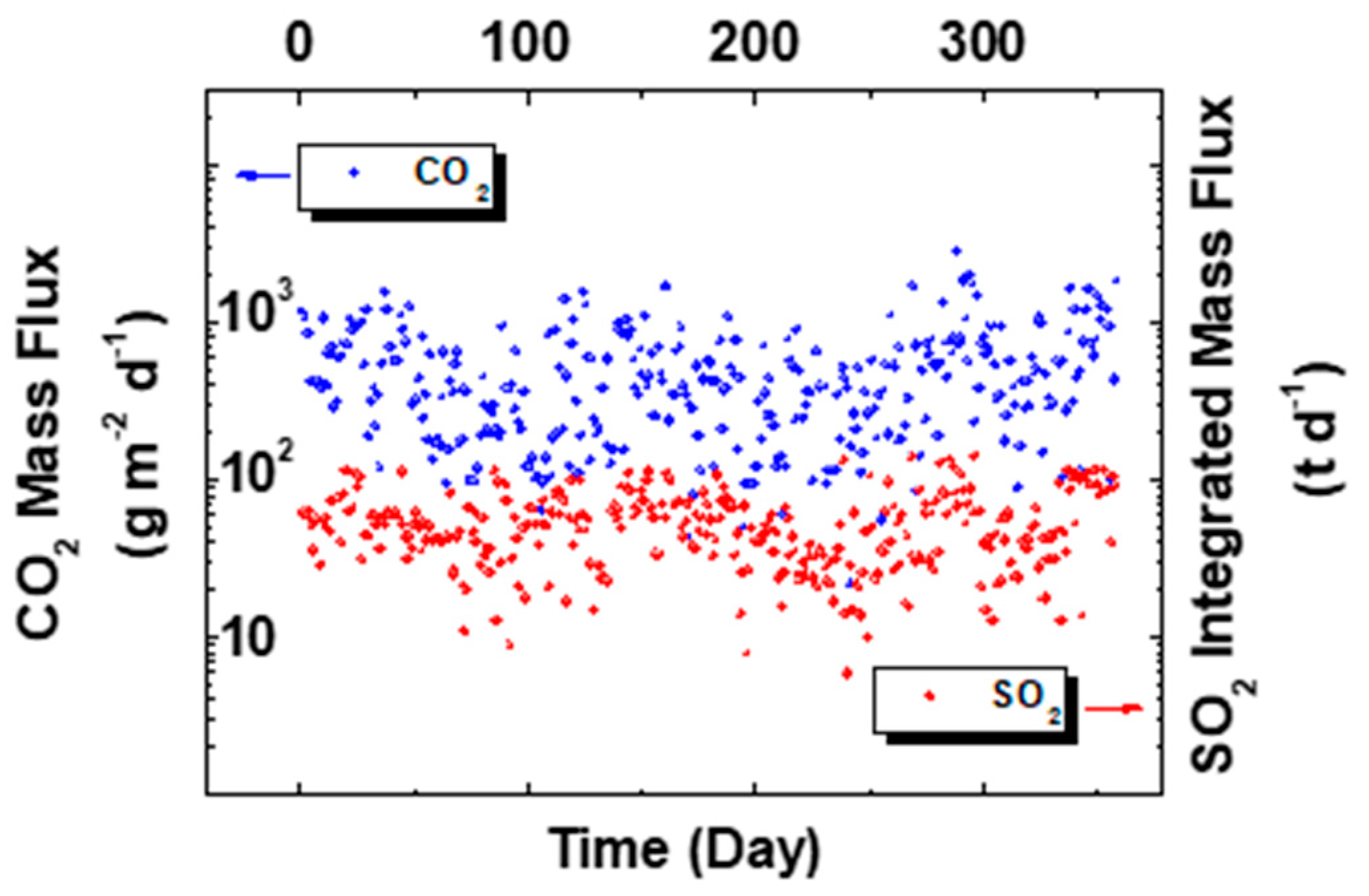
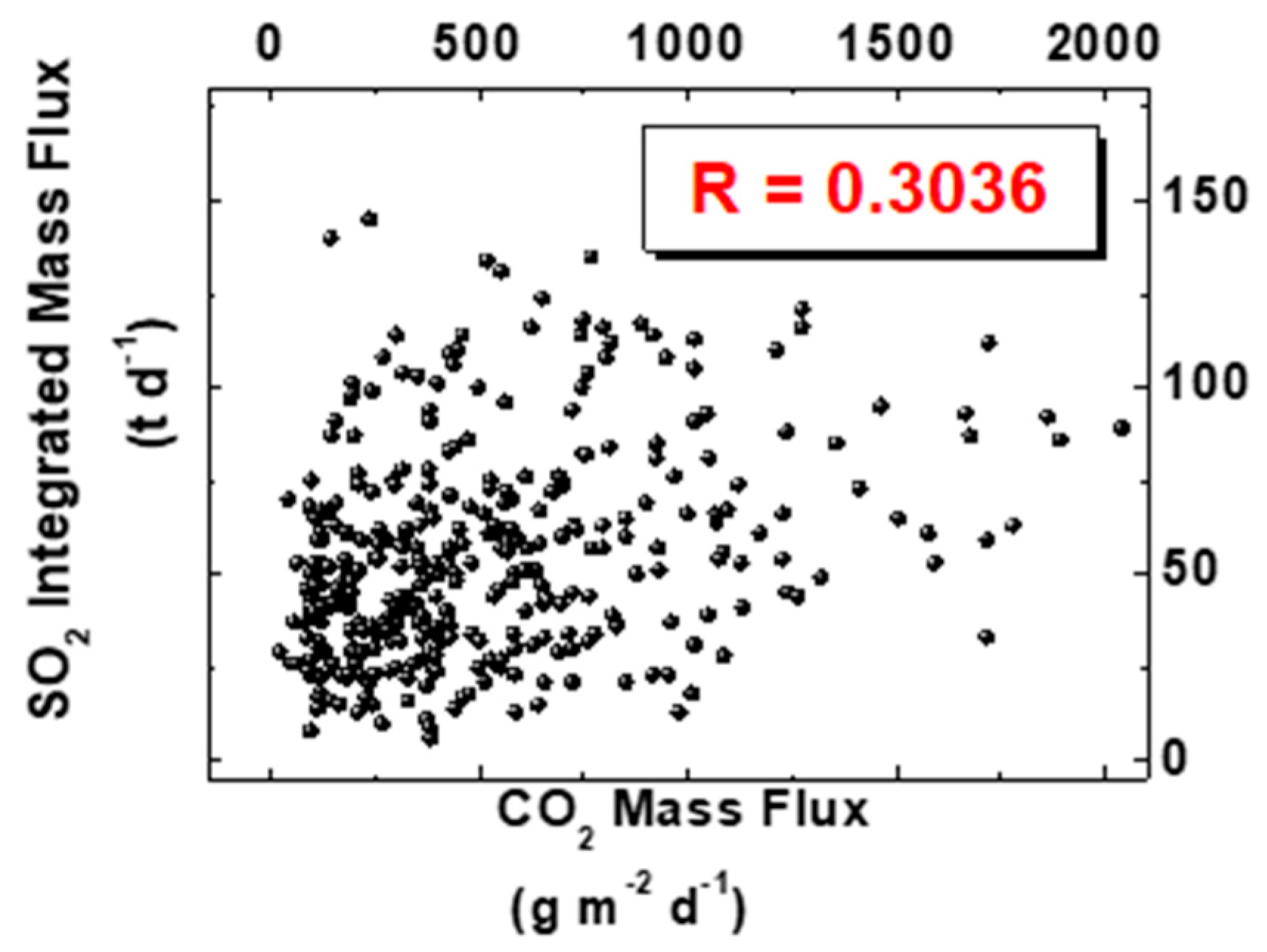
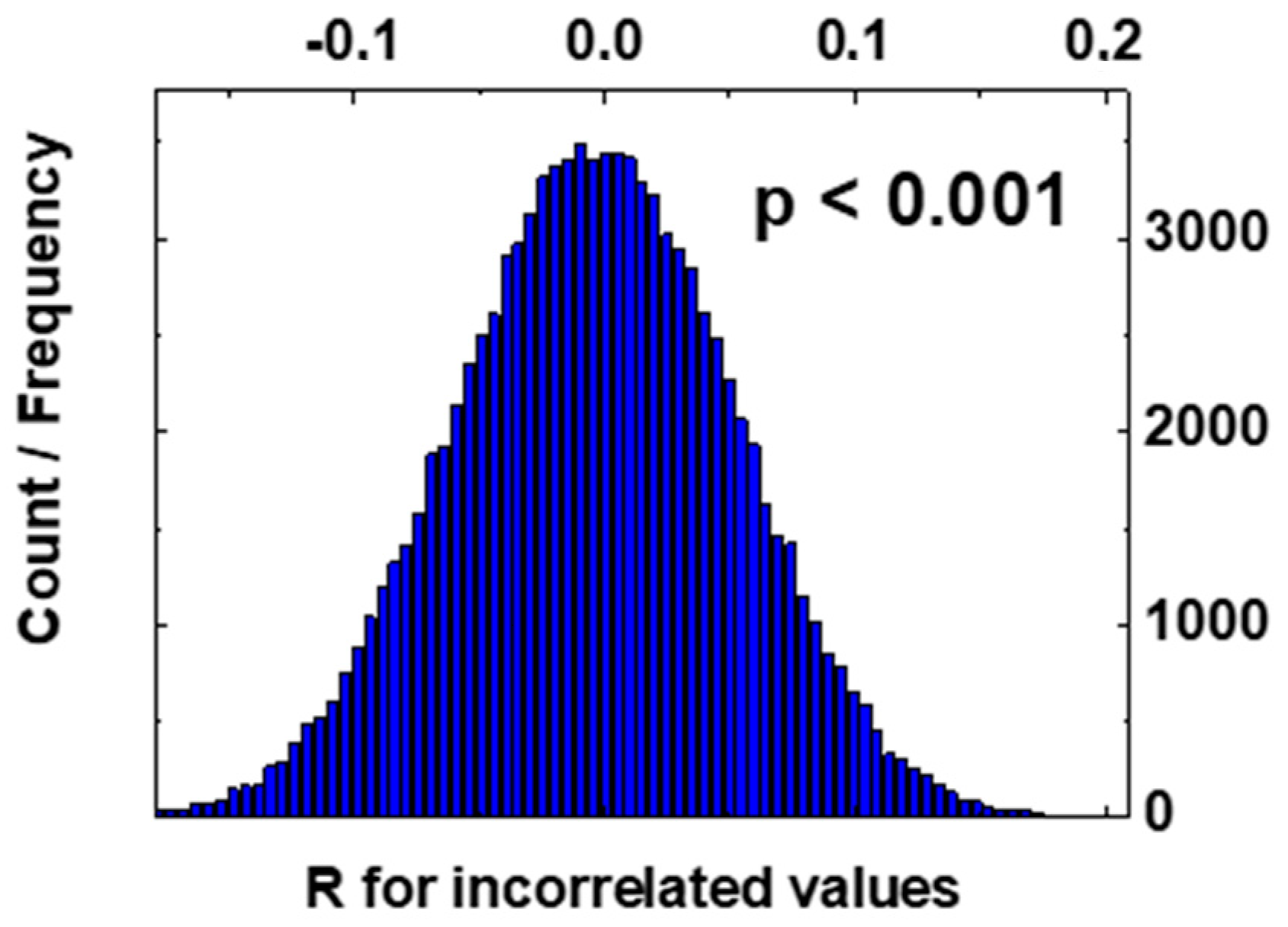
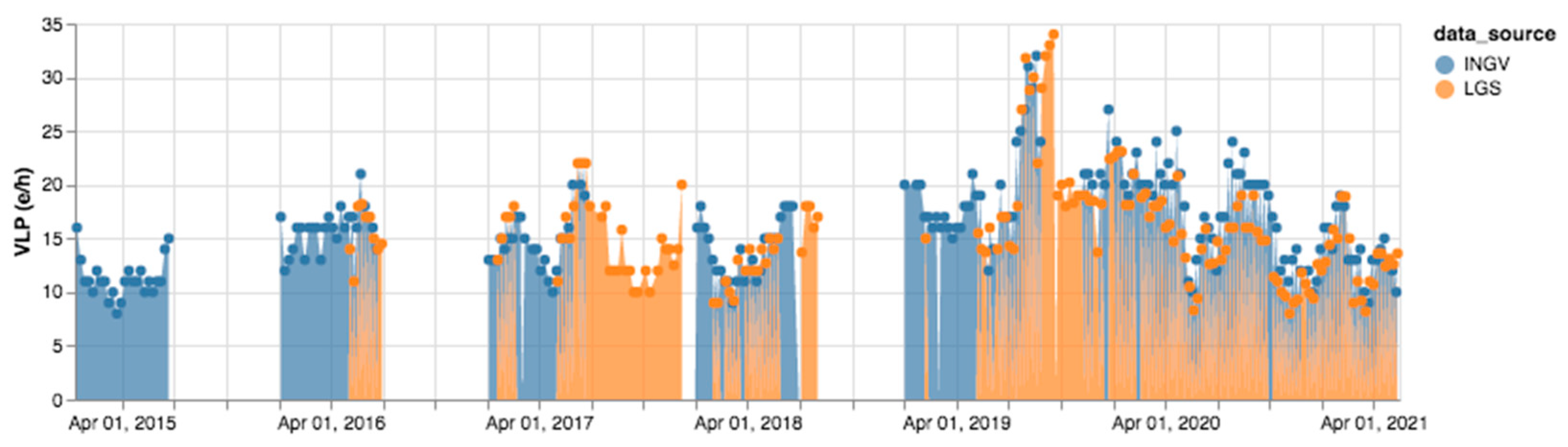
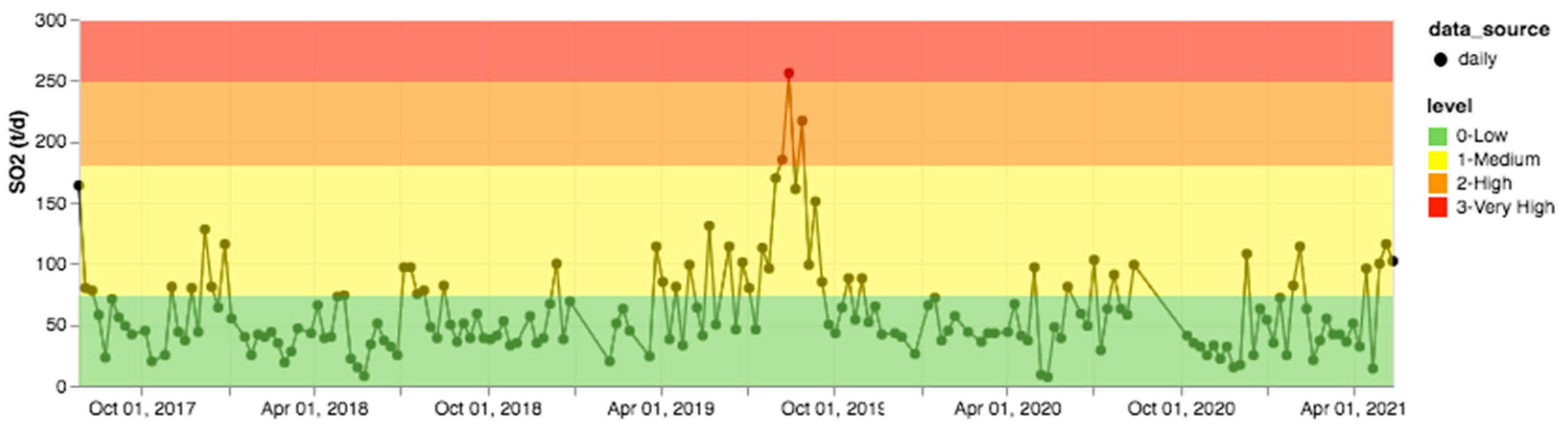
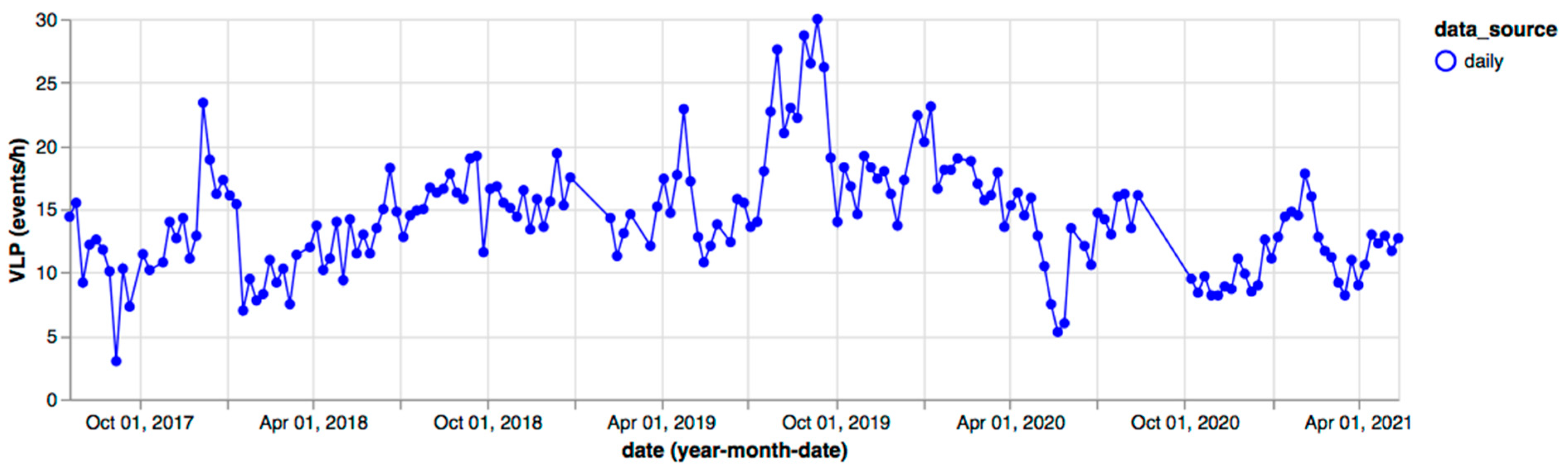
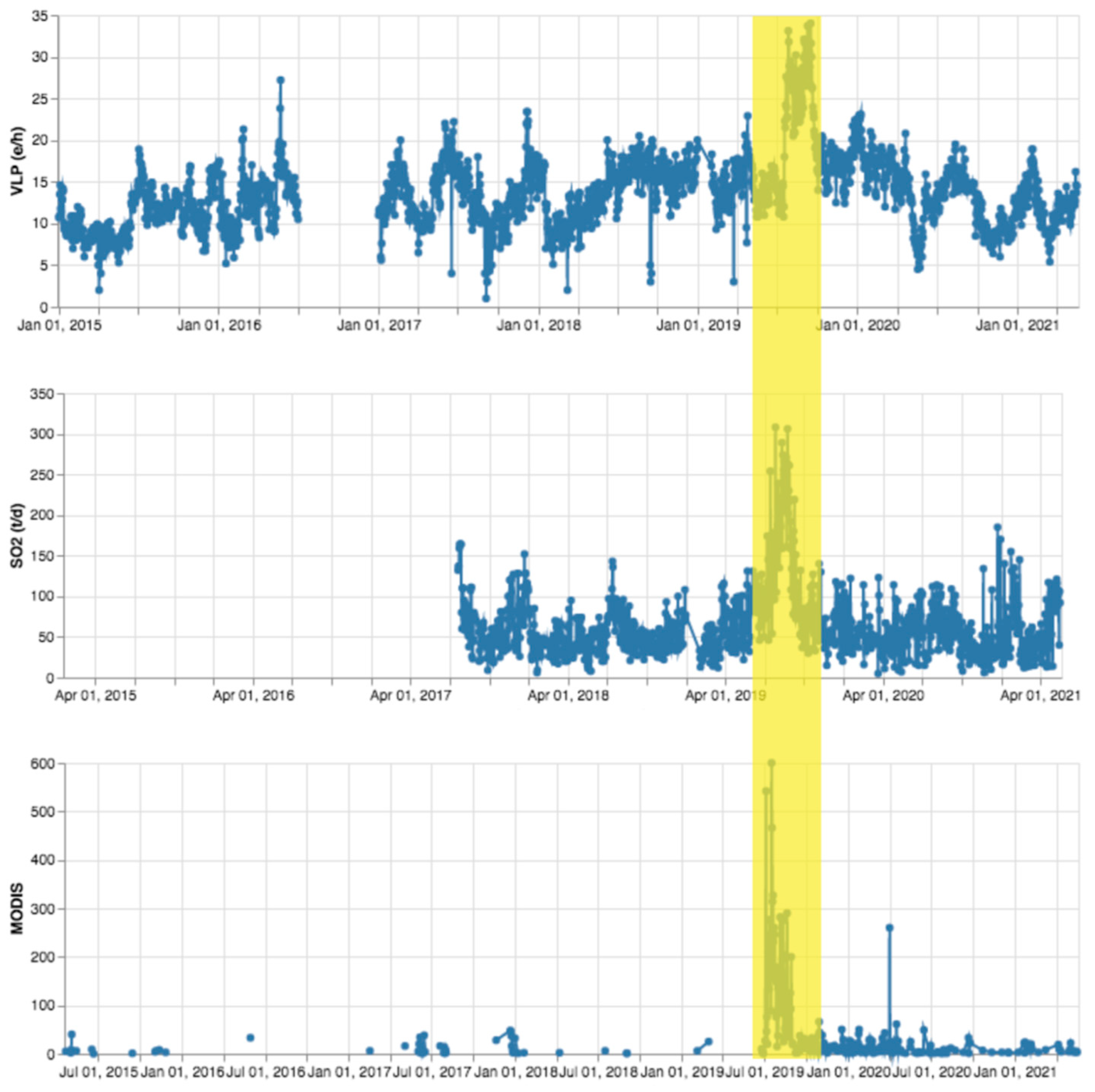
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Di Traglia, F.; Calvari, S.; D’Auria, L.; Nolesini, T.; Bonaccorso, A.; Fornaciai, A.; Esposito, A.; Cristaldi, A.; Favalli, M.; Casagli, N. The 2014 effusive eruption at Stromboli: New insights from in situ and remote-sensing measurements. Remote Sens. 2018, 10, 2035. [Google Scholar] [CrossRef] [Green Version]
- Valade, S.; Ley, A.; Massimetti, F.; D’Hondt, O.; Laiolo, M.; Coppola, D.; Loibl, D.; Hellwich, O.; Walter, T.R. Towards Global Volcano Monitoring Using Multisensor Sentinel Missions and Artificial Intelligence: The MOUNTS Monitoring System. Remote Sens. 2019, 11, 1528. [Google Scholar] [CrossRef] [Green Version]
- Elsevier. Elsevier Developers-Text Mining. Available online: https://dev.elsevier.com/tecdoc_text_mining.html (accessed on 12 June 2021).
- Springer. Text and Data Mining at Springer Nature. Available online: https://www.springernature.com/gp/researchers/text-and-data-mining (accessed on 3 July 2021).
- Aggarwal, C.C.; Zhai, C.X. Mining Text Data, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Mullins, M. Information Extraction in Text Mining. Available online: https://cedar.wwu.edu/cgi/viewcontent.cgi?article=1003&context=computerscience_stupubs (accessed on 31 October 2021).
- Feldman, R.; Sanger, J. VI chapter “Information Extraction”. In The Text Mining Handbook. Advanced Approaches in Analyzing Unstructured Data; Cambridge University Press: Cambridge, UK, 2006; pp. 94–130. [Google Scholar] [CrossRef]
- Grishman, R.; Sundheim, B. Message Understanding Conference-6: A Brief History. COLING 1996, 96, 466–471. [Google Scholar]
- Schmitt, X.; Kubler, S.; Robert, J.; Papadakis, M.; LeTraon, Y. A Replicable Comparison Study of NER Software: StanfordNLP, NLTK, OpenNLP, SpaCy, Gate. In Proceedings of the 2019 Sixth International Conference on Social Networks Analysis, Management and Security (SNAMS), Granada, Spain, 22–25 October 2019; pp. 338–343. [Google Scholar] [CrossRef]
- Peters, S.E.; Zhang, C.; Livny, M.; Ré, C. A Machine Reading System for Assembling Synthetic Paleontological Databases. PLoS ONE 2014, 9, e113523. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Peters, S.E.; Husson, J.M.; Wilcots, J. The rise and fall of stromatolites in shallow marine environments. Geology 2017, 45, 487–490. [Google Scholar] [CrossRef]
- Wang, C.; Ma, X.; Chen, J.; Chen, J. Information extraction and knowledge graph construction from geoscience literature. Comput. Geosci. 2018, 112, 112–120. [Google Scholar] [CrossRef]
- Shi, L.; Jianping, C.; Jie, X. Prospecting Information Extraction by Text Mining Based on Convolutional Neural Networks–A Case Study of the Lala Copper Deposit, China. IEEE Access 2018, 6, 52286–52297. [Google Scholar] [CrossRef]
- Holden, E.-J.; Liu, W.; Horrocks, T.; Wang, R.; Wedge, D.; Duuring, P.; Beardsmore, T. GeoDocA—Fast Analysis of Geological Content in Mineral Exploration Reports: A Text Mining Approach. Ore Geol. Rev. 2019, 111, 102919. [Google Scholar] [CrossRef]
- Qiu, Q.; Xie, Z.; Wu, L.; Tao, L. GNER: A Generative Model for Geological Named Entity Recognition without Labeled Data Using Deep Learning. Earth Space Sci. 2019, 6, 931–946. [Google Scholar] [CrossRef] [Green Version]
- INGV Bollettini Multidisciplinari. Available online: https://www.ct.ingv.it/index.php/monitoraggio-e-sorveglianza/prodotti-del-monitoraggio/bollettini-settimanali-multidisciplinari (accessed on 3 May 2020).
- UNIFI LGS, Laboratory of Experimental Geophysics. Available online: http://lgs.geo.unifi.it/index.php (accessed on 3 May 2020).
- Vega & Vega-Lite. Available online: https://vega.github.io/ (accessed on 18 November 2020).
- Salerno, G.; Burton, M.; Oppenheimer, C.; Caltabiano, T.; Tsanev, V.I.; Bruno, N. Novel retrieval of volcanic SO2 abundance from ultraviolet spectra. J. Volcanol. Geotherm. Res. 2009, 181, 141–153. [Google Scholar] [CrossRef]
- Delle Donne, D.; Tamburello, G.; Aiuppa, A.; Bitetto, M.; Lacanna, G.; D’Aleo, R.; Ripepe, M. Exploring the explosive-effusive transition using permanent ultraviolet cameras. J. Geophys. Res. Solid Earth 2017, 122, 4377–4394. [Google Scholar] [CrossRef]
- Bevilacqua, A.; Bertagnini, A.; Pompilio, M.; Landi, P.; Del Carlo, P.; Di Roberto, A.; Aspinall, W.; Neri, A. Major explosions and paroxysms at Stromboli (Italy): A new historical catalog and temporal models of occurrence with uncertainty quantification. Sci. Rep. 2020, 10, 17357. [Google Scholar] [CrossRef] [PubMed]
- Cofano, A.; Cigna, F.; Santamaria Amato, L.; Siciliani de Cumis, M.; Tapete, D. Exploiting Sentinel-5P TROPOMI and Ground Sensor Data for the Detection of Volcanic SO2 Plumes and Activity in 2018–2021 at Stromboli, Italy. Sensors 2021, 21, 6991. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Daily | Weekly |
|---|---|---|
| 2015 | 365 | 51 |
| 2016 | 335 | 42 |
| 2017 | 358 | 48 |
| 2018 | 363 | 51 |
| 2019 | 332 | 45 |
| 2020 | 364 | 52 |
| 2021 | 137 | 19 |
| Year | Daily | Weekly |
|---|---|---|
| 2015 | 0 | 24 |
| 2016 | 0 | 25 |
| 2017 | 0 | 24 |
| 2018 | 0 | 25 |
| 2019 | 69 | 39 |
| 2020 | 0 | 52 |
| 2021 | 0 | 19 |
| Parameter | Value |
|---|---|
| VLP | 11 events/h |
| SO2 | 39 t/d |
| CO2 | MEDIUM |
| CO2 | 727 t/d |
| MODIS | 1 MW |
| Year | SO2 (t/d) | CO2 (t/d) | C/S | VLP (Events/h) | MODIS (MW) |
|---|---|---|---|---|---|
| 2015 | 0 | 0 | 0 | 358 | 22 |
| 2016 | 0 | 0 | 0 | 180 | 3 |
| 2017 | 176 | 0 | 0 | 390 | 43 |
| 2018 | 396 | 0 | 0 | 383 | 34 |
| 2019 | 366 | 45 | 34 | 365 | 160 |
| 2020 | 383 | 291 | 259 | 415 | 145 |
| 2021 | 149 | 123 | 103 | 156 | 38 |
| Year | SO2 (t/d) | CO2 (t/d) | C/S | VLP (Events/h) | MODIS (MW) |
|---|---|---|---|---|---|
| 2015 | 23 | 21 | 1 | 24 | 0 |
| 2016 | 25 | 25 | 1 | 25 | 0 |
| 2017 | 23 | 23 | 4 | 23 | 0 |
| 2018 | 25 | 25 | 0 | 25 | 0 |
| 2019 | 52 | 18 | 2 | 37 | 46 |
| 2020 | 51 | 0 | 9 | 51 | 52 |
| 2021 | 15 | 0 | 9 | 19 | 5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Berardi, M.; Santamaria Amato, L.; Cigna, F.; Tapete, D.; Siciliani de Cumis, M. Text Mining from Free Unstructured Text: An Experiment of Time Series Retrieval for Volcano Monitoring. Appl. Sci. 2022, 12, 3503. https://doi.org/10.3390/app12073503
Berardi M, Santamaria Amato L, Cigna F, Tapete D, Siciliani de Cumis M. Text Mining from Free Unstructured Text: An Experiment of Time Series Retrieval for Volcano Monitoring. Applied Sciences. 2022; 12(7):3503. https://doi.org/10.3390/app12073503
Chicago/Turabian StyleBerardi, Margherita, Luigi Santamaria Amato, Francesca Cigna, Deodato Tapete, and Mario Siciliani de Cumis. 2022. "Text Mining from Free Unstructured Text: An Experiment of Time Series Retrieval for Volcano Monitoring" Applied Sciences 12, no. 7: 3503. https://doi.org/10.3390/app12073503
APA StyleBerardi, M., Santamaria Amato, L., Cigna, F., Tapete, D., & Siciliani de Cumis, M. (2022). Text Mining from Free Unstructured Text: An Experiment of Time Series Retrieval for Volcano Monitoring. Applied Sciences, 12(7), 3503. https://doi.org/10.3390/app12073503