
Comparative Evaluation of NLP-Based Approaches for Linking CAPEC Attack Patterns from CVE Vulnerability Information


 , ,
, , 
 , and
, and
Abstract
1. Introduction
- Even with CWE, it may not be possible to trace the CVE-ID to the associated CAPEC-ID.
- Cybersecurity databases are linked manually. The growing amount of vulnerability information makes manual handling problematic, resulting in more failures.
2. Related Work and Problems
2.1. Related Work
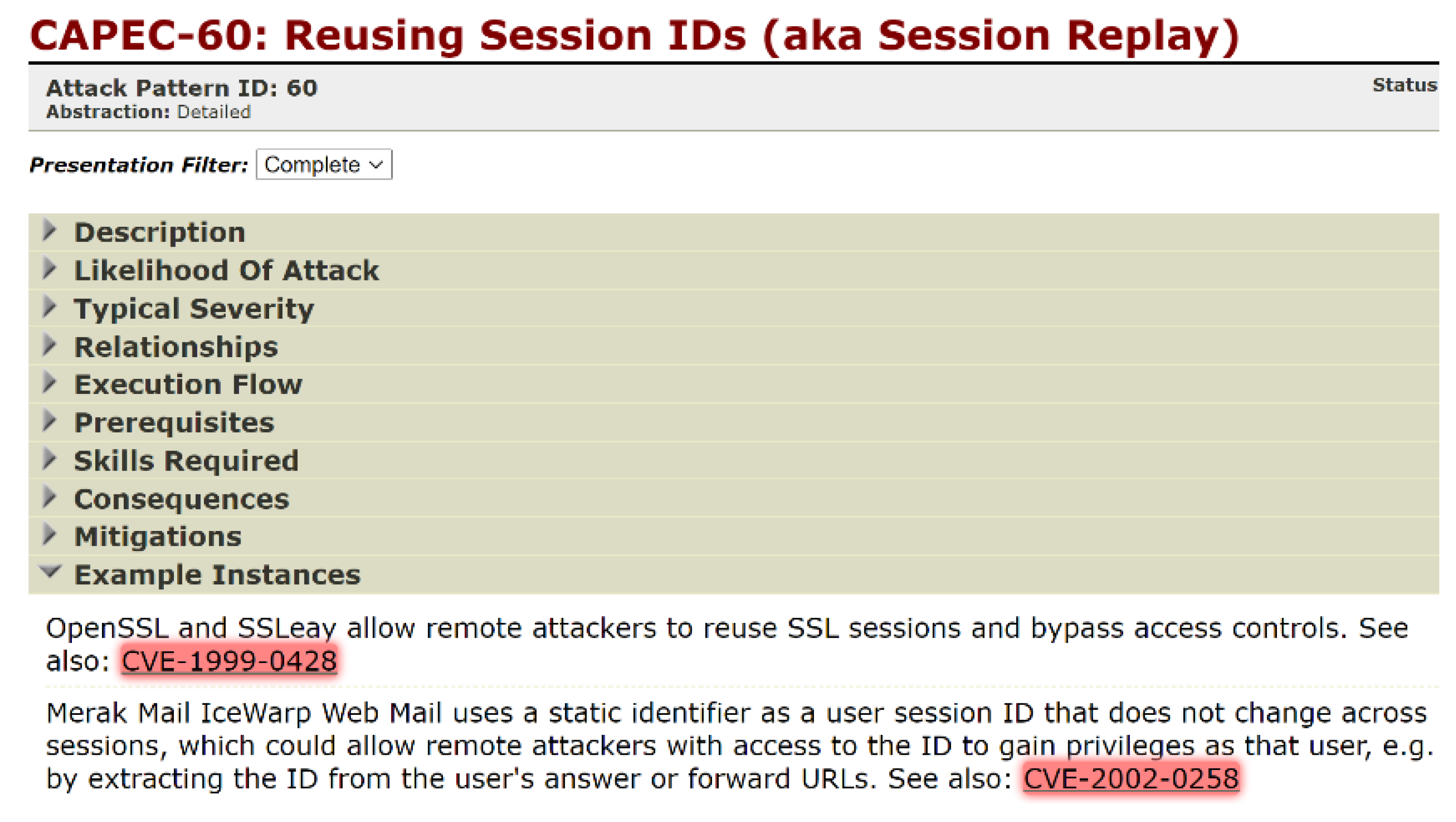
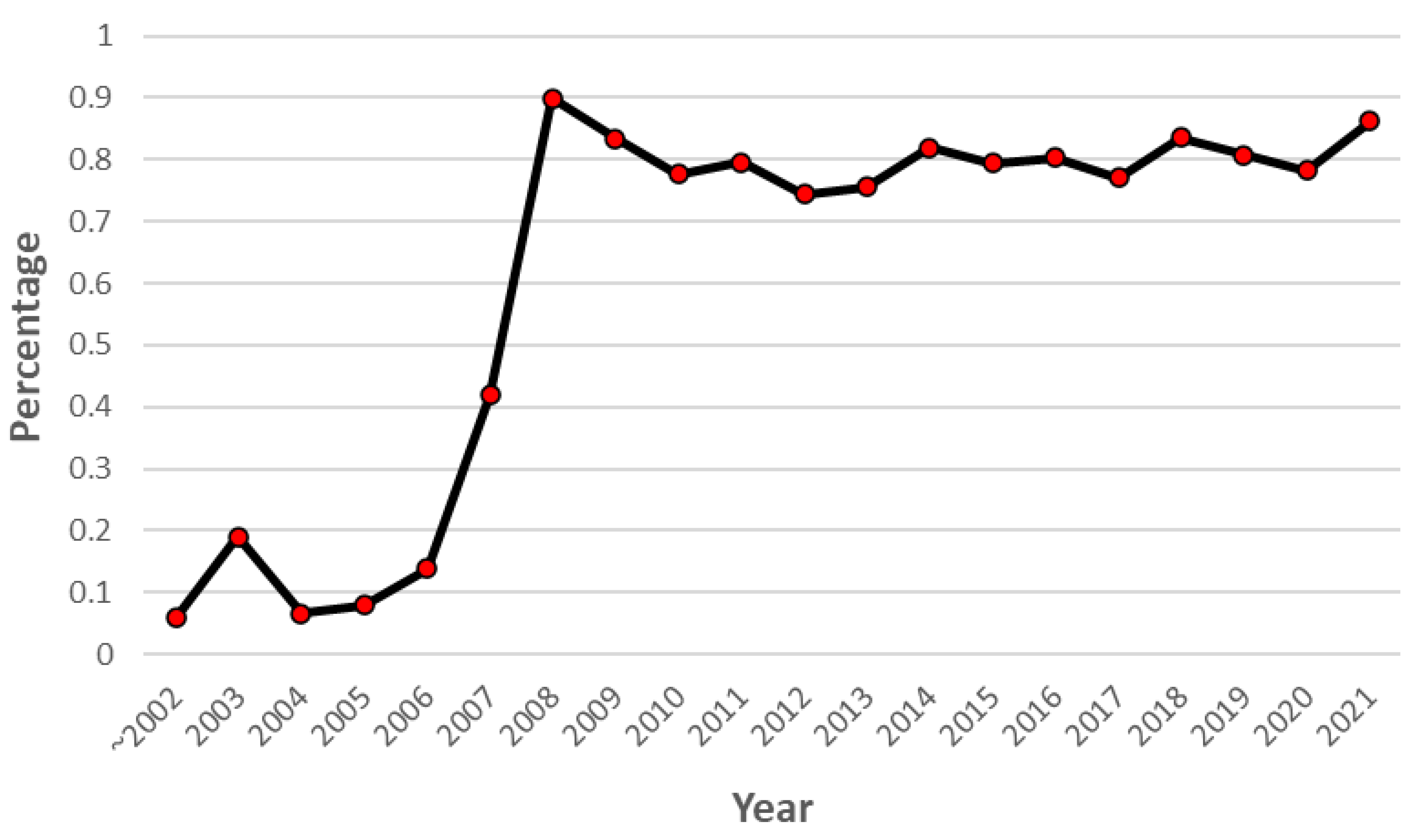
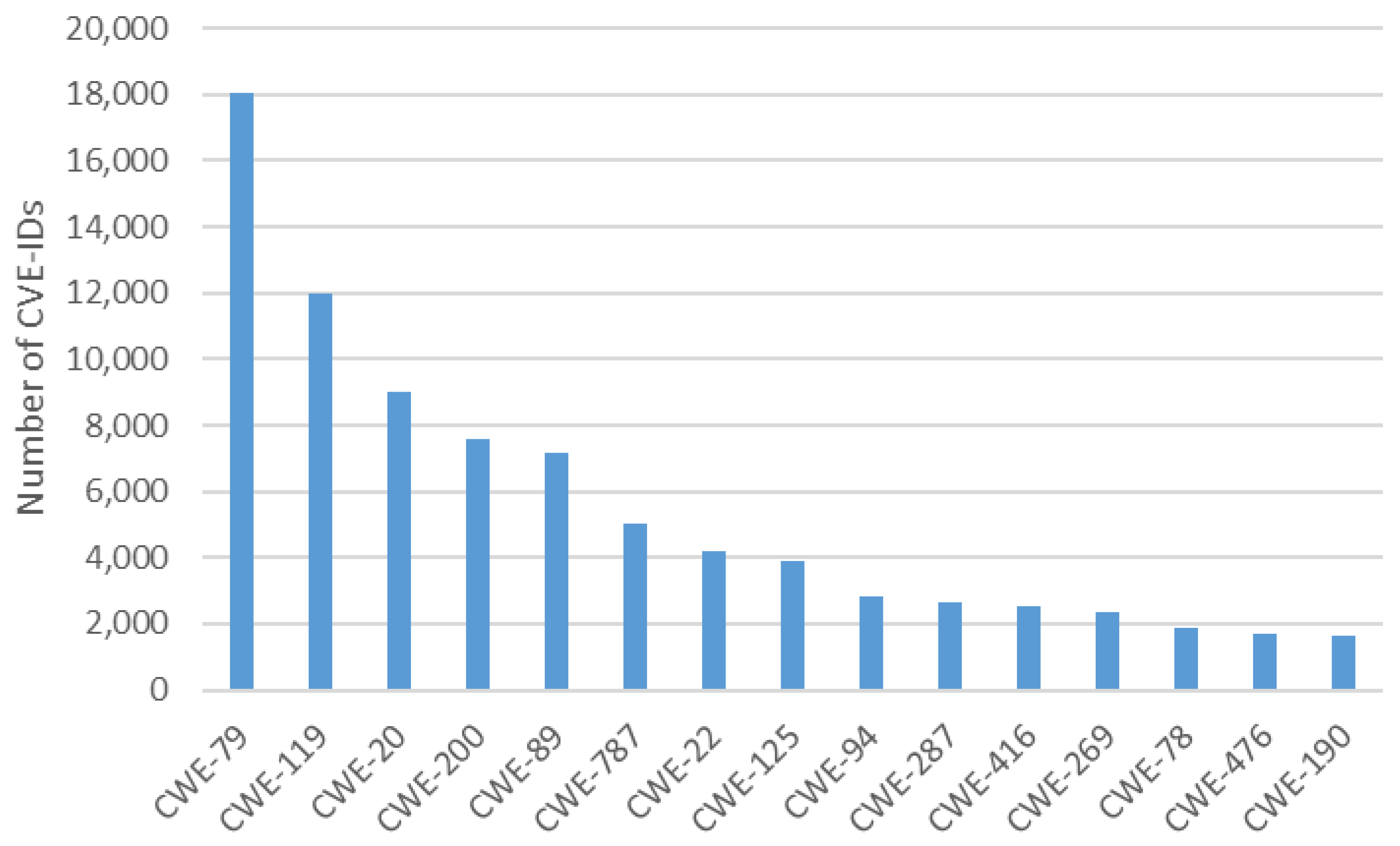
2.2. Motivating Example and Problems
3. Tracing Method from CVE-ID to CAPEC-ID
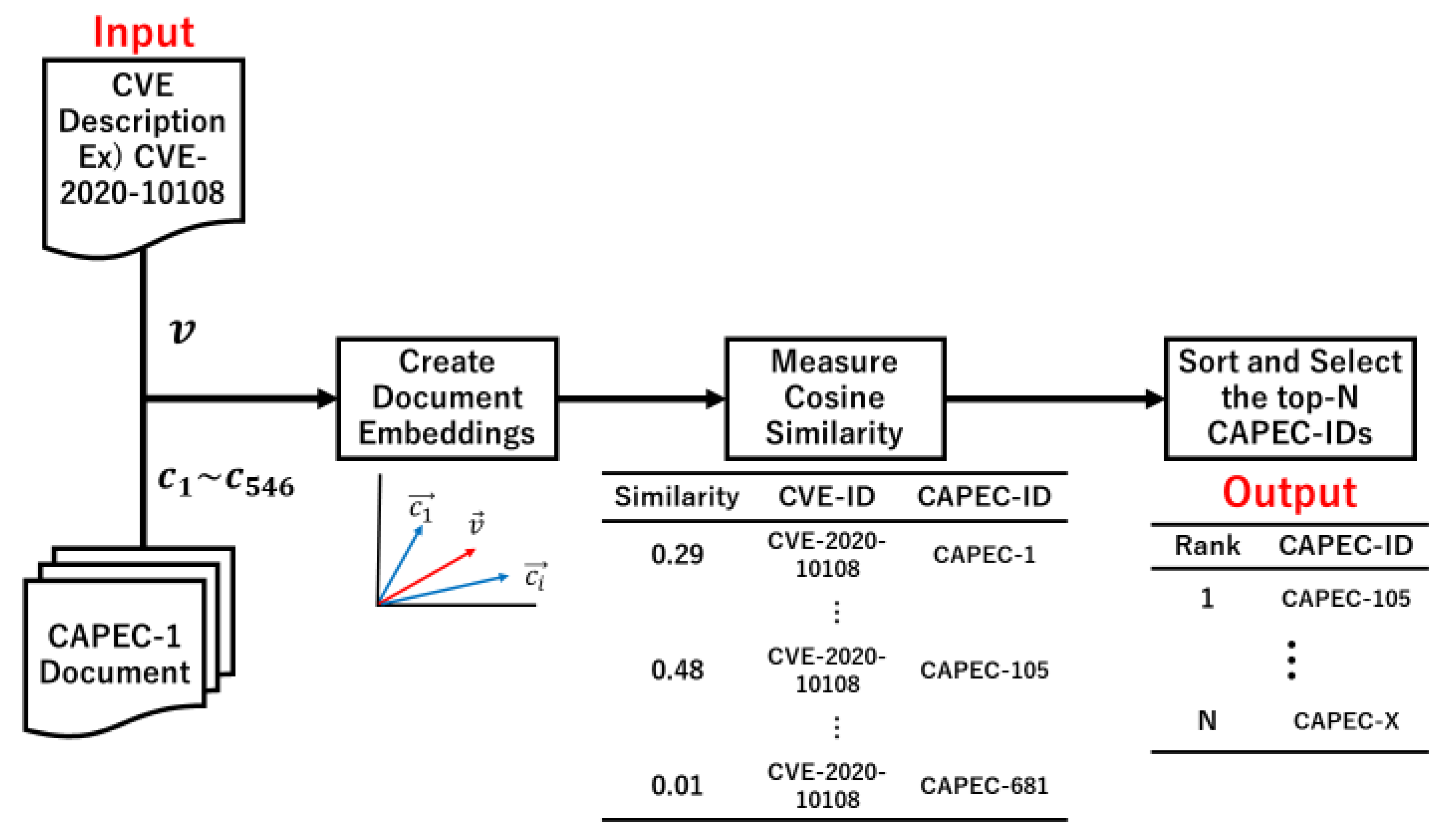
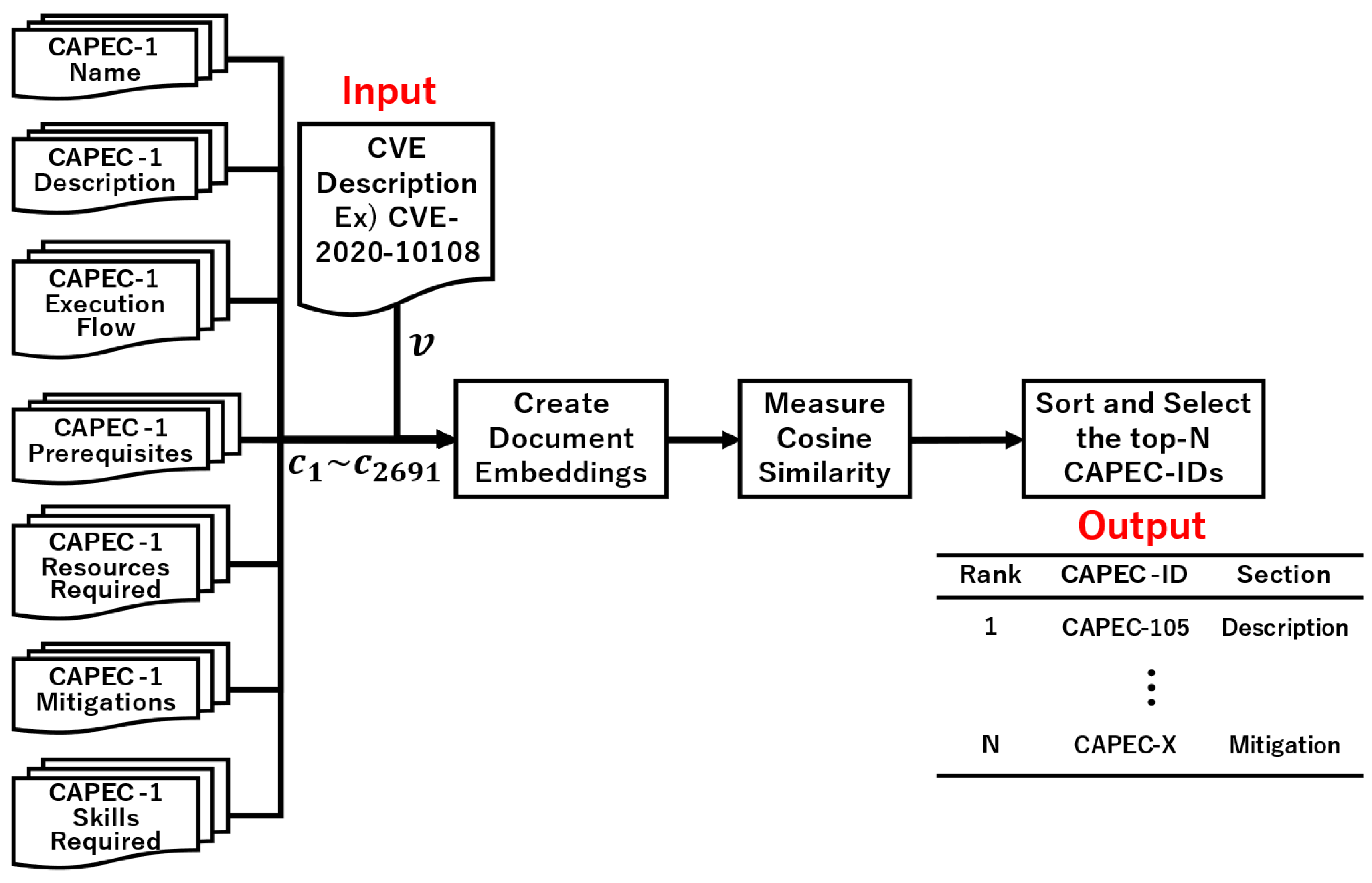
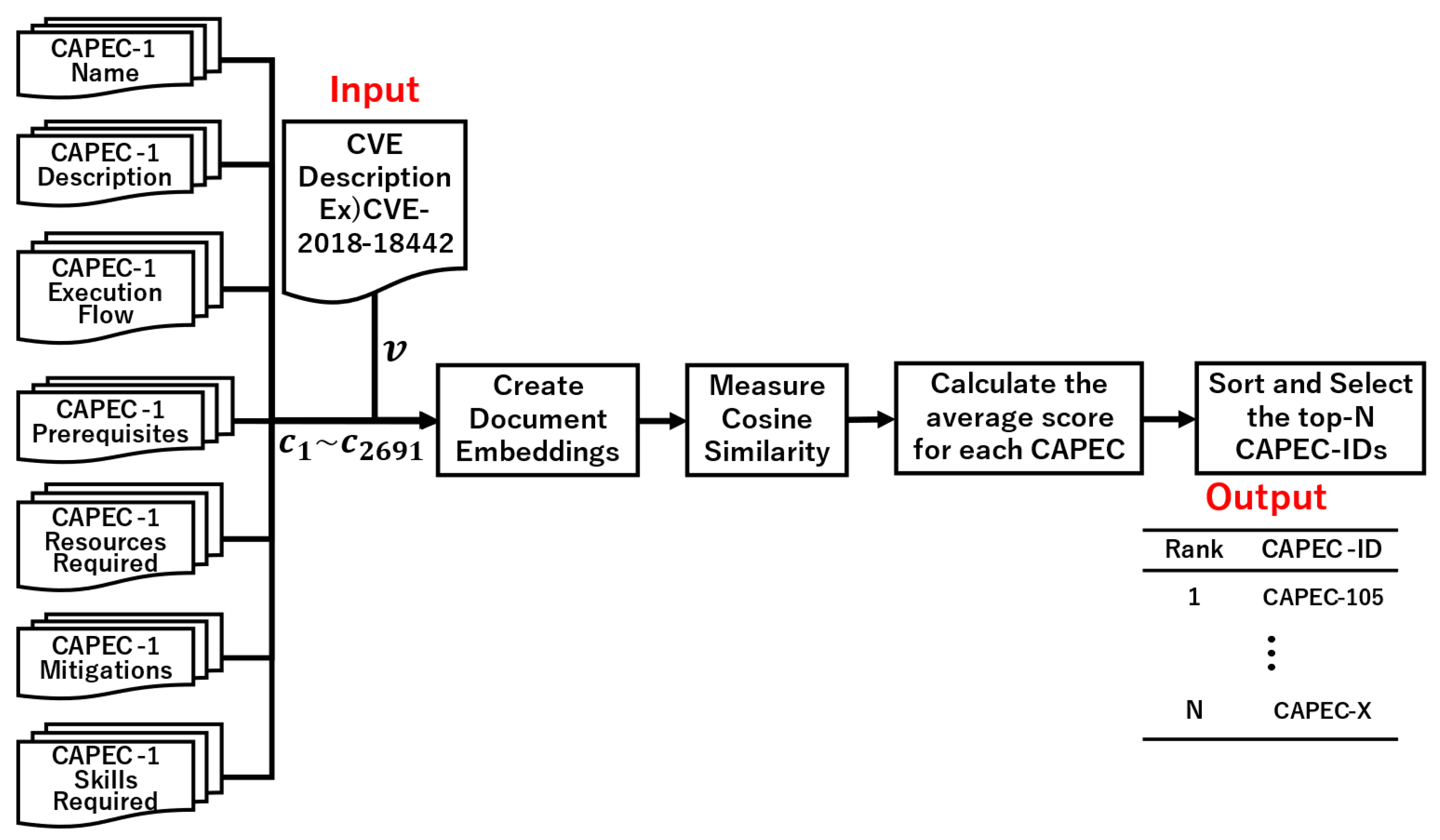
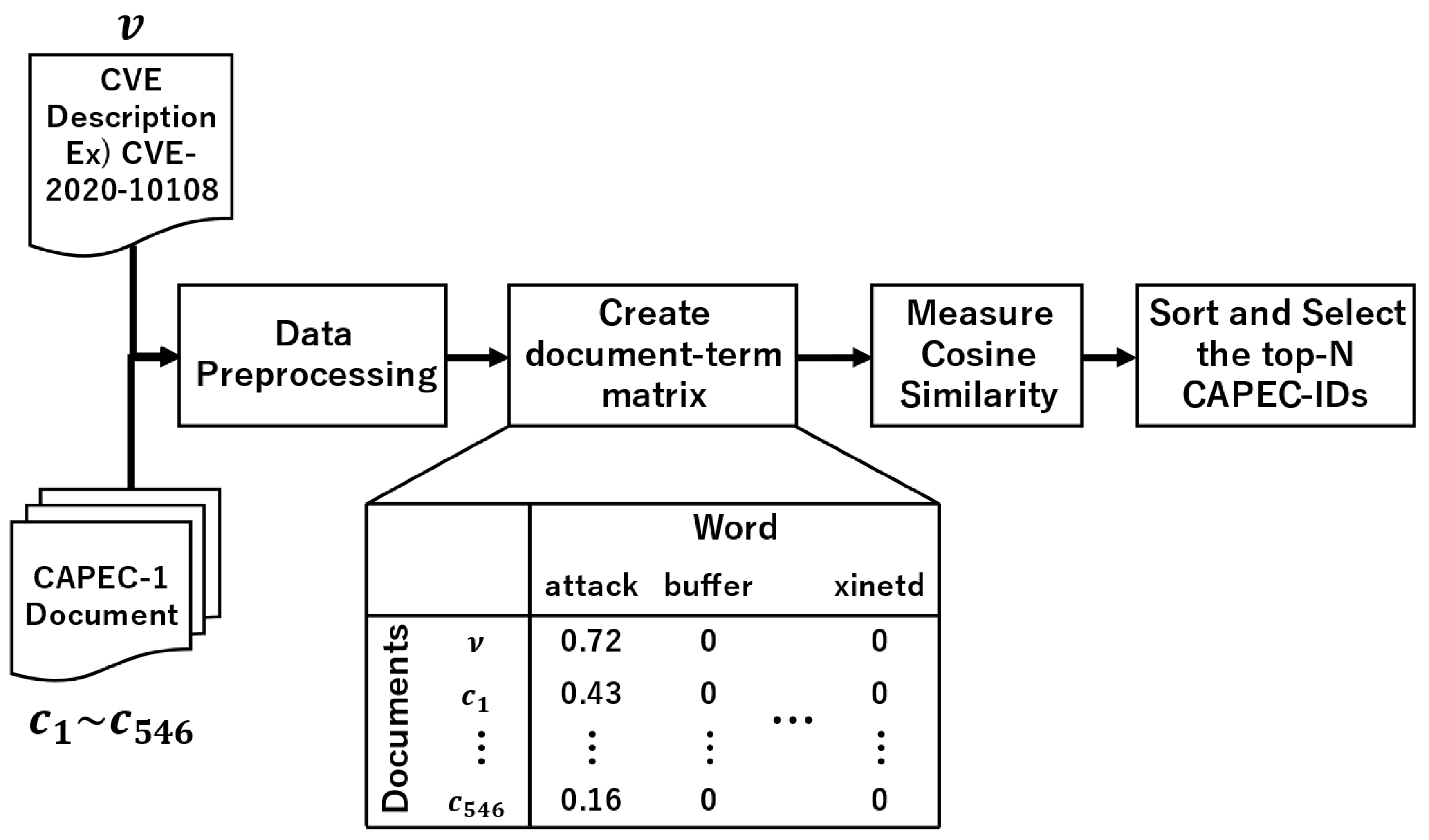
3.1. Tracing Based on TF-IDF
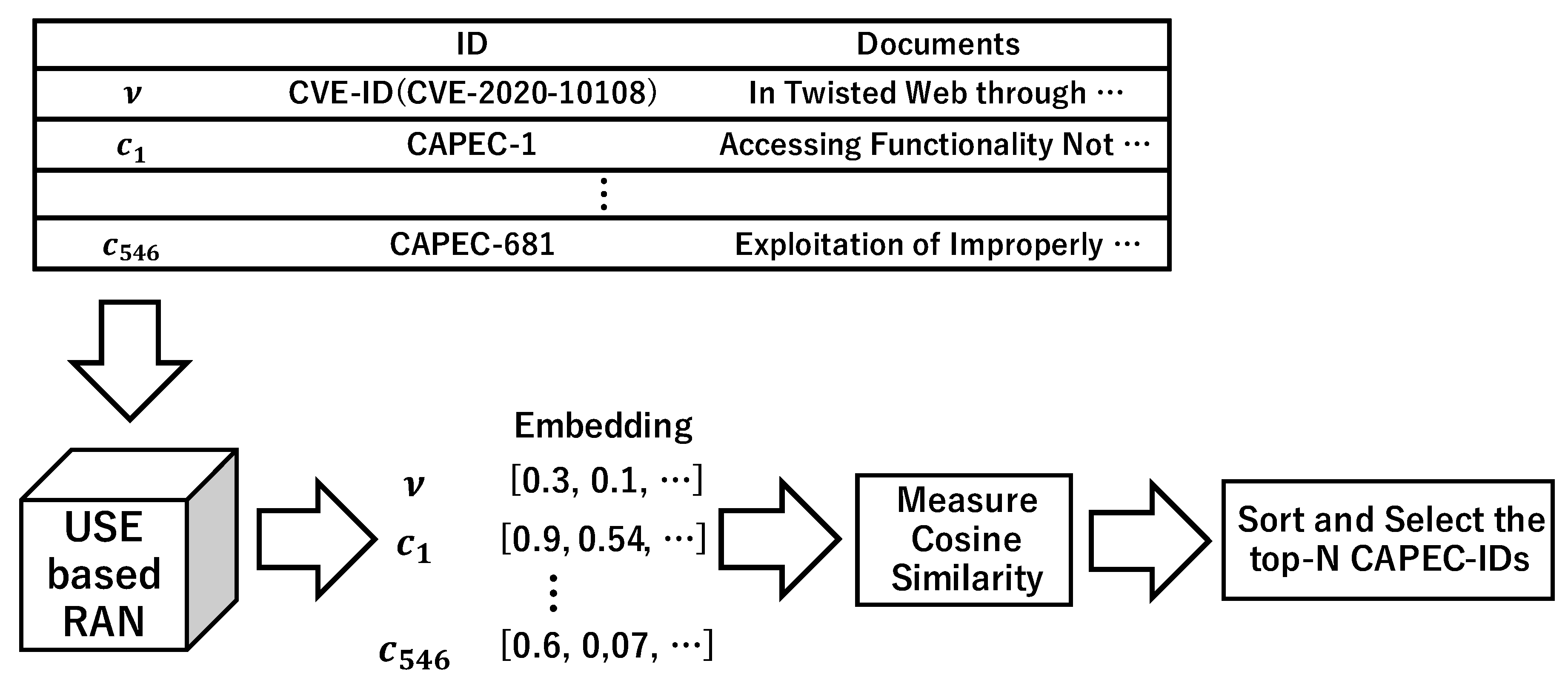
3.2. Tracing Based on USE
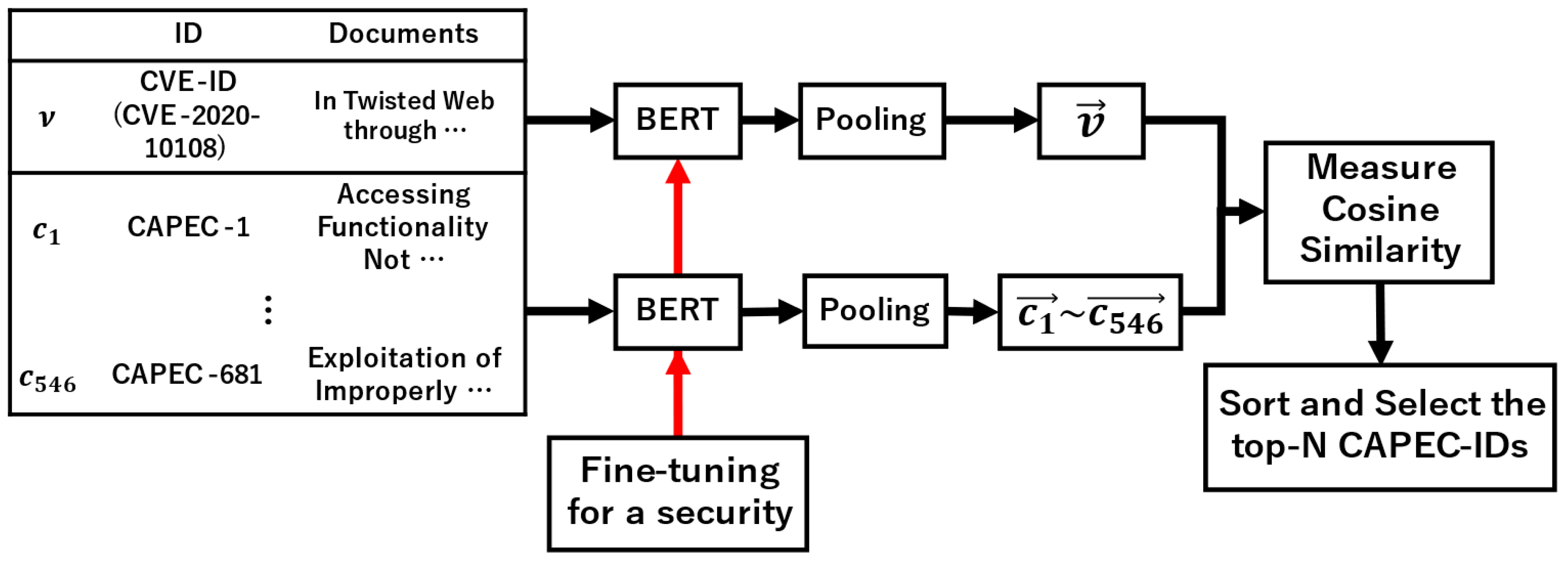
3.3. Tracing Based on SBERT
4. Experiments and Results
4.1. 61 CVE-IDs
4.2. Experimental Patterns
4.3. Metrics
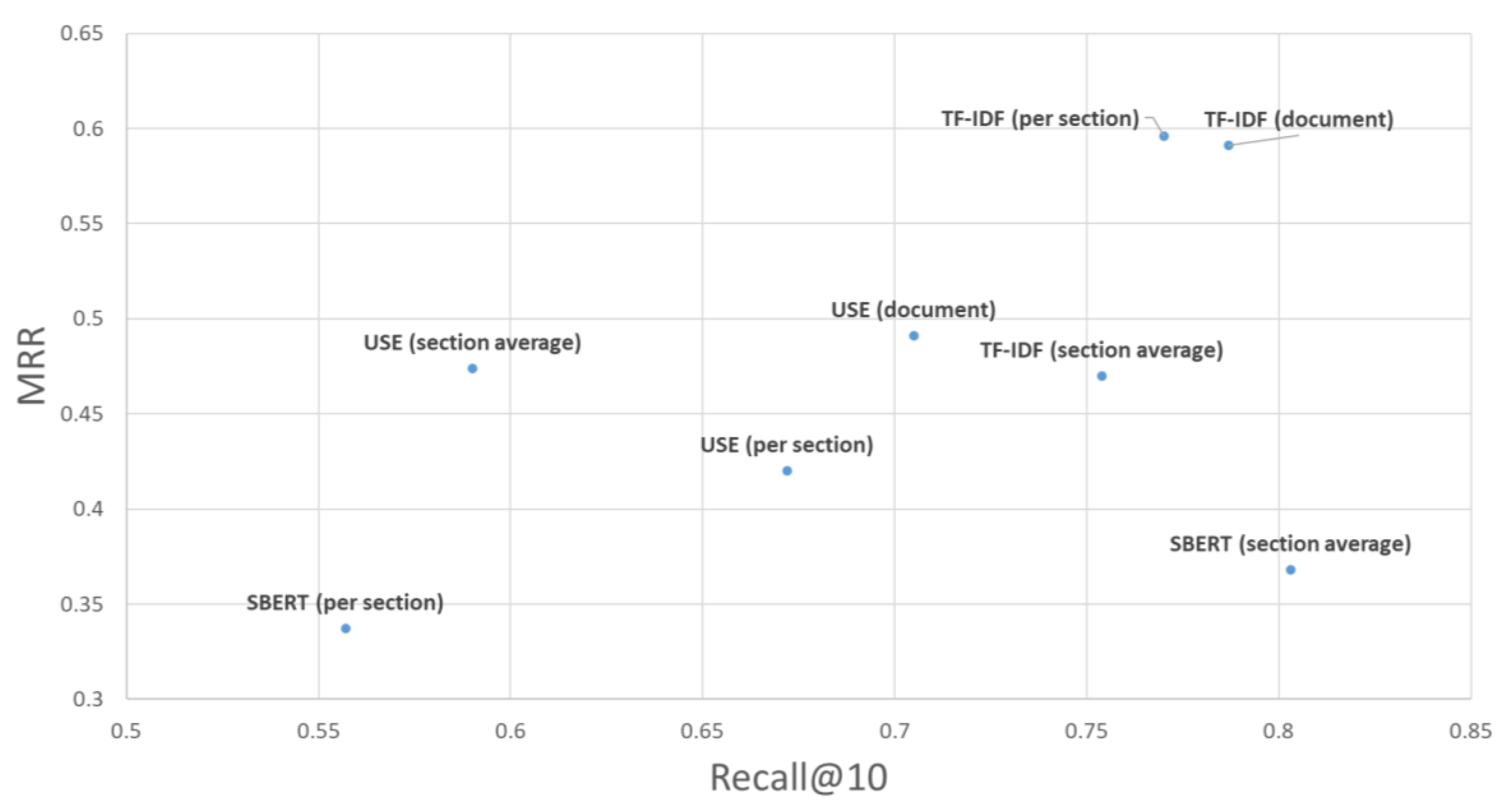
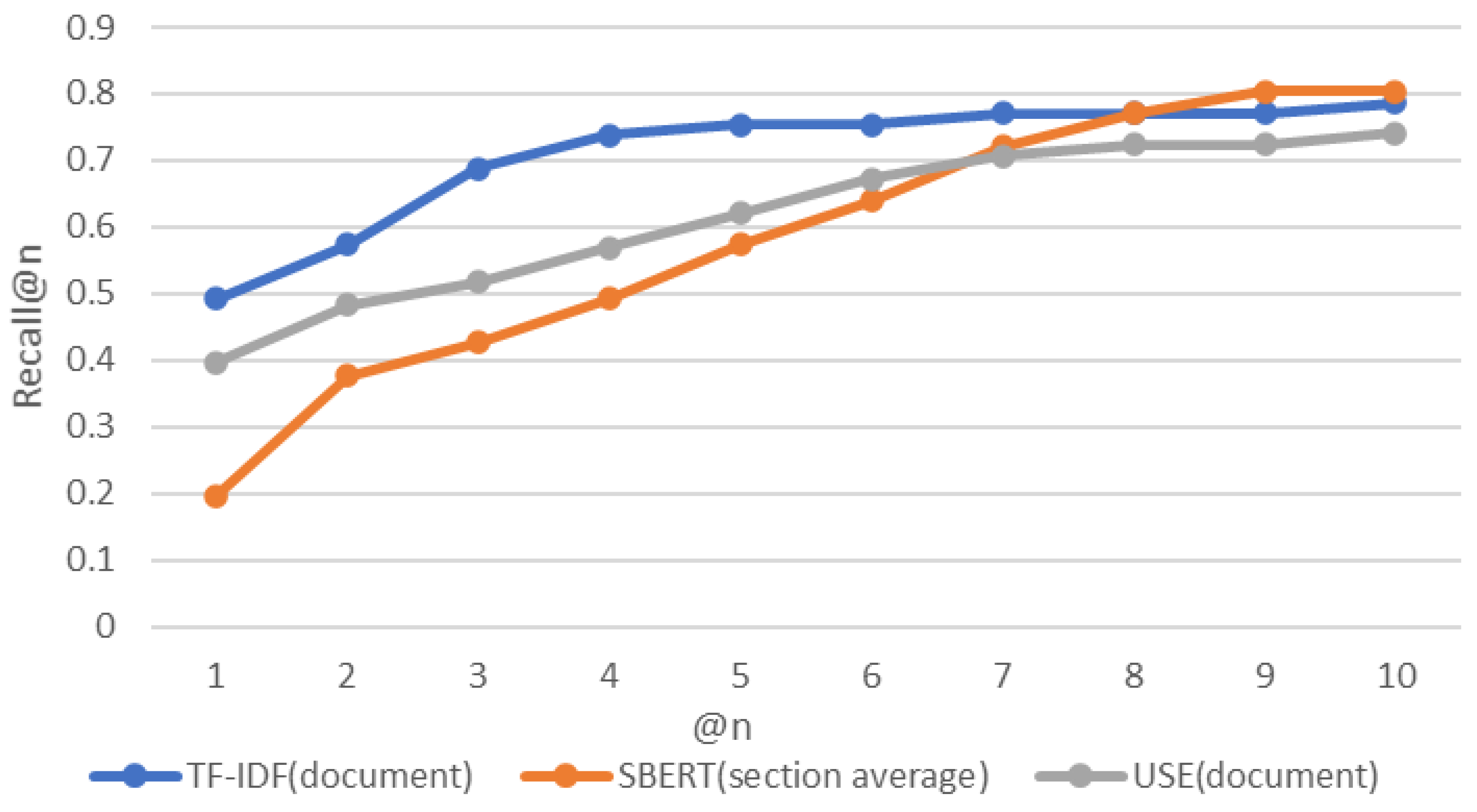
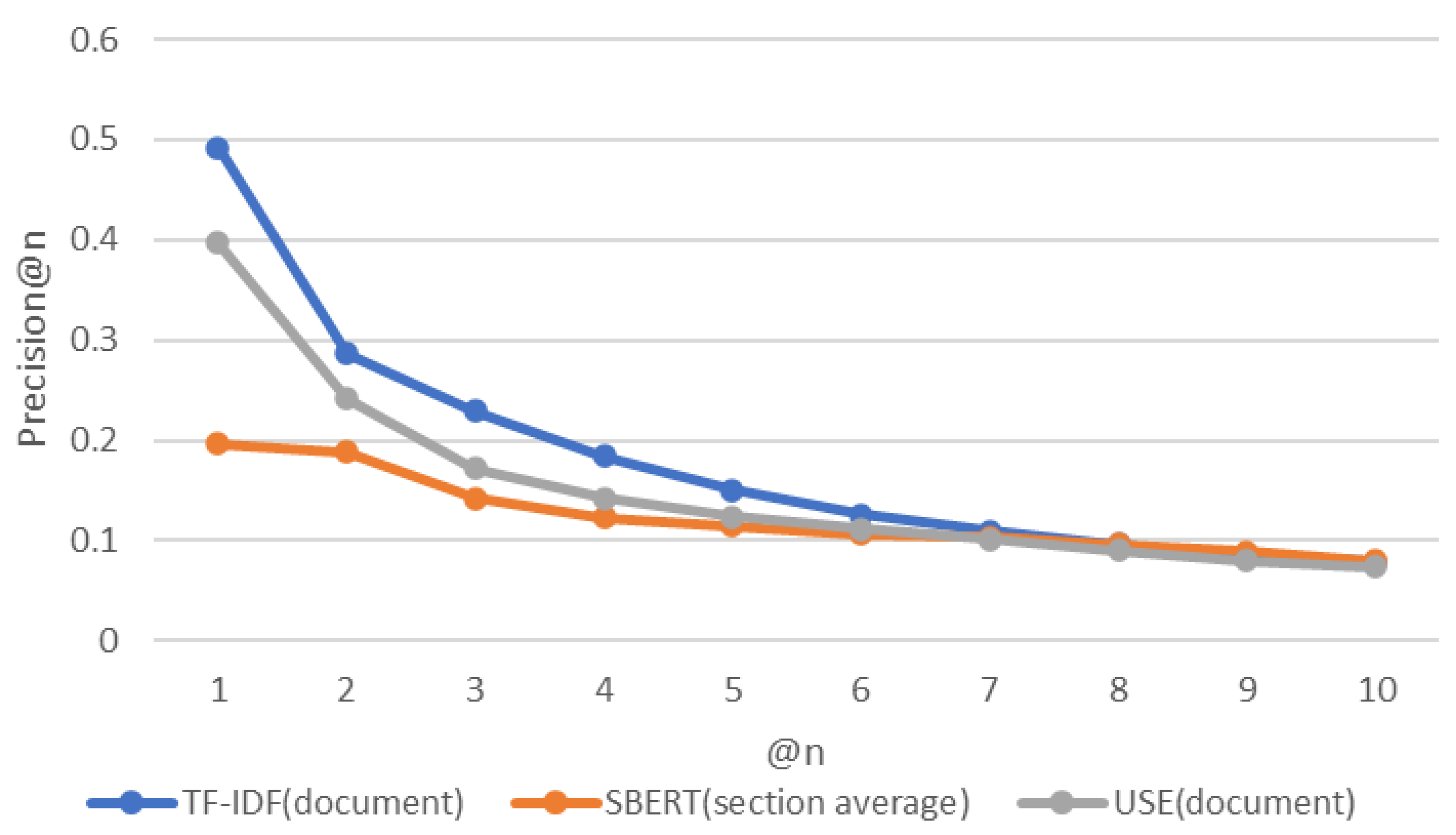
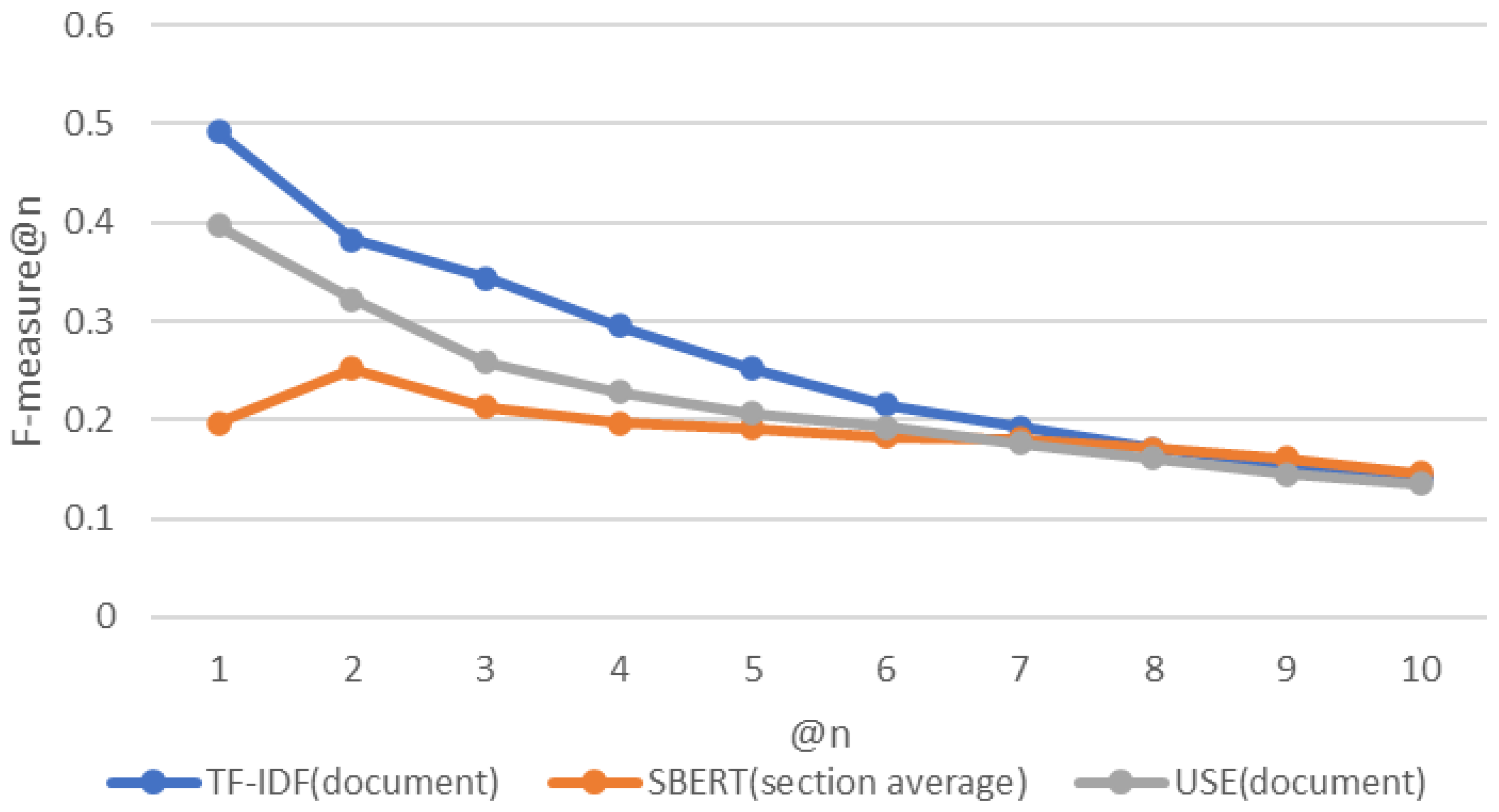
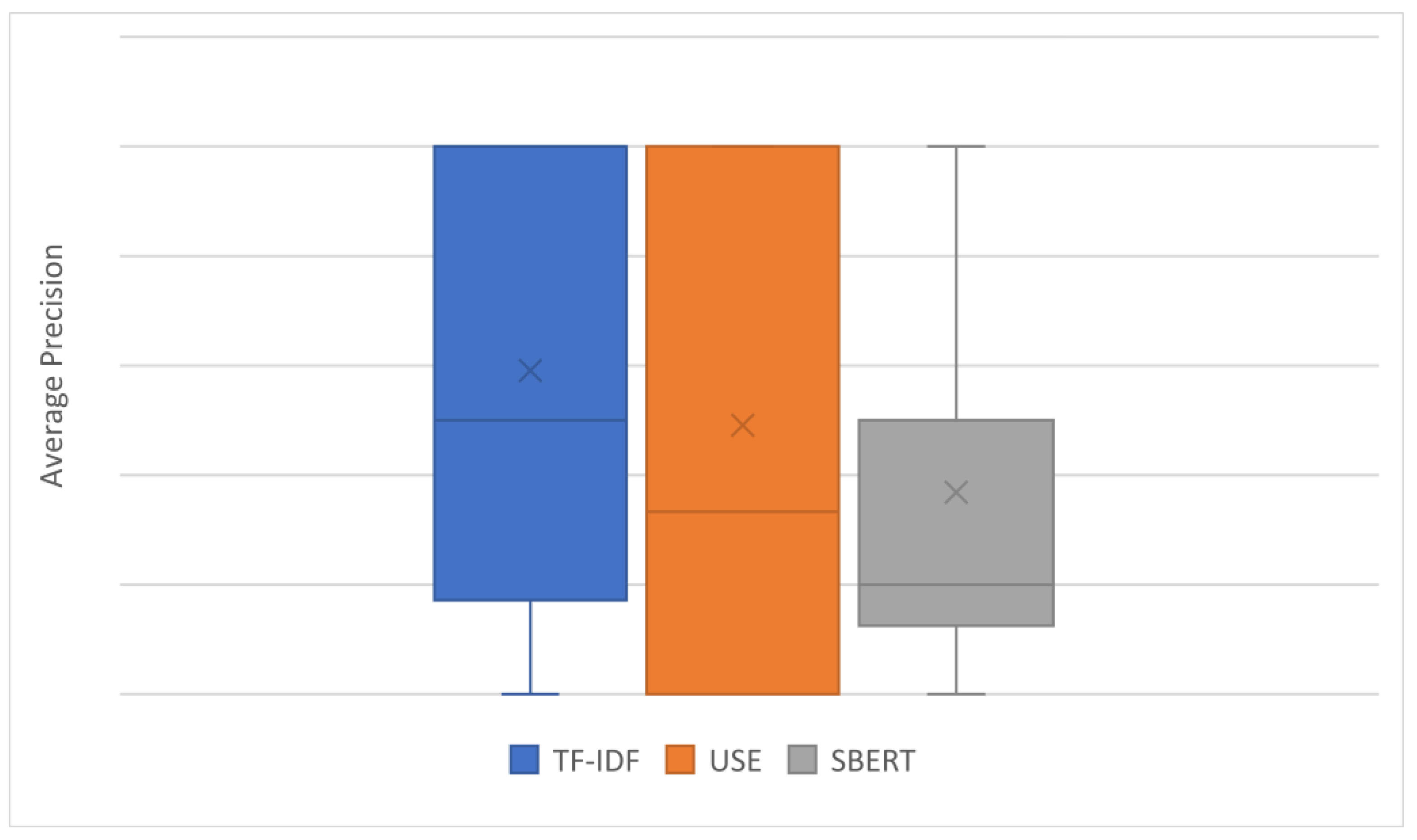
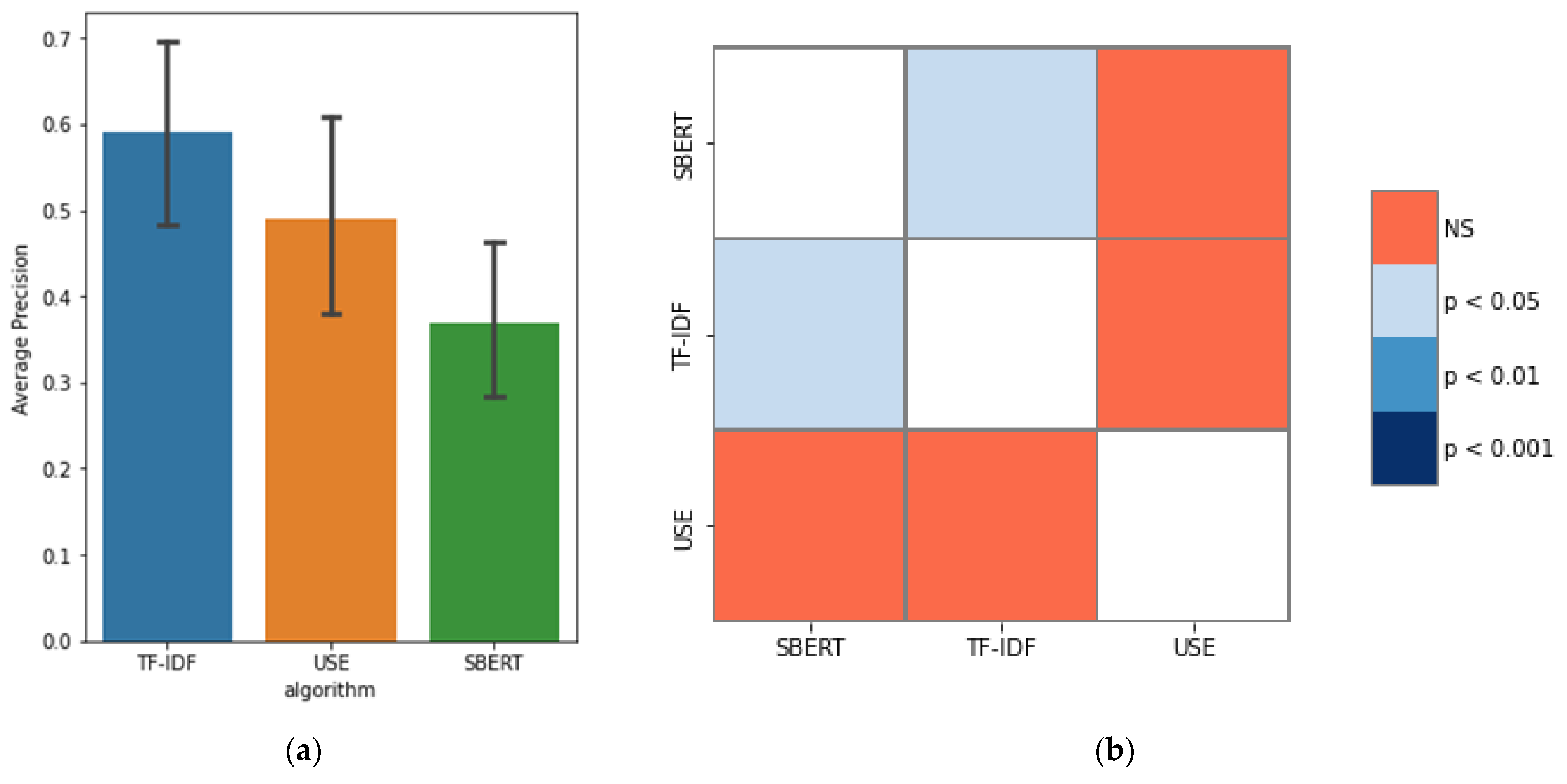
4.4. Results
4.5. RQ1 How Accurately Can a CVE-ID Be Traced to Its Associated CAPEC-ID following a Link between Cybersecurity Databases?
4.6. RQ2 How Accurate Is the Tracing of CVE-IDs to the Associated CAPEC-IDs When Using the Proposed Approach?
4.7. RQ3 Which Algorithm Provides the Most Suitable Tracing?
4.7.1. TF-IDF
4.7.2. SBERT
4.8. Findings
4.9. Threats to Validity
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Common Vulnerabilities and Exploits. Available online: https://cve.mitre.org/ (accessed on 16 June 2021).
- Common Attack Pattern Enumeration and Classification. Available online: https://capec.mitre.org/ (accessed on 16 June 2021).
- Common Weakness Enumeration. Available online: https://cwe.mitre.org/ (accessed on 16 June 2021).
- National Vulnerability Database. Available online: https://nvd.nist.gov/ (accessed on 10 February 2022).
- Kanakogi, K.; Washizaki, H.; Fukazawa, Y.; Ogata, S.; Okubo, T.; Kato, T.; Kanuka, H.; Hazeyama, A.; Yoshioka, N. Tracing CAPEC Attack Patterns from CVE Vulnerability Information using Natural Language Processing Technique. In Proceedings of the 54th Hawaii International Conference on System Sciences, Kauai, HI, USA, 4–8 January 2021; pp. 6996–7004. [Google Scholar]
- Kanakogi, K.; Washizaki, H.; Fukazawa, Y.; Ogata, S.; Okubo, T.; Kato, T.; Kanuka, H.; Hazeyama, A.; Yoshioka, N. Tracing CVE Vulnerability Information to CAPEC Attack Patterns Using Natural Language Processing Techniques. J. Inf. 2021, 12, 298. [Google Scholar] [CrossRef]
- Miller, D.; Leek, T.; Schwartz, R. A hidden Markov model information retrieval system. In Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, New York, NY, USA, 15–19 August 1999; pp. 214–221. [Google Scholar] [CrossRef]
- Cer, D.; Yang, Y.; Kong, S.Y.; Hua, N.; Limtiaco, N.; St. John, R.; Constant, N.; Guajardo-Cespedes, M.; Yuan, S.; Tar, C.; et al. Universal sentence encoder for English. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Brussels, Belgium, 31 October–4 November 2018; pp. 169–174. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 3982–3992. [Google Scholar]
- Dang, Q.; François, J. Utilizing attack enumerations to study SDN/NFV vulnerabilities. In Proceedings of the 2018 4th IEEE Conference on Network Softwarization and Workshops (NetSoft), Montreal, QC, Canada, 25–29 June 2018; pp. 356–361. [Google Scholar] [CrossRef]
- Navarro, J.; Legrand, V.; Lagraa, S.; Francois, J.; Lahmadi, A.; Santis, G.D.; Festor, O.; Lammari, N.; Hamdi, F.; Deruyver, A.; et al. HuMa: A multi-layer framework for threat analysis in a heterogeneous log environment. In Proceedings of the 10th International Symposium on Foundations & Practice of Security, Nancy, France, 23–25 October 2017; pp. 144–159. [Google Scholar] [CrossRef]
- Scarabeo, N.; Fung, B.C.M.; Khokhar, R.H. Mining known attack patterns from security-related events. PeerJ Comput. Sci. 2015, 1, e25. [Google Scholar] [CrossRef][Green Version]
- Ma, X.; Davoodi, E.; Kosseim, L.; Scarabeo, N. Semantic Mapping of Security Events to Known Attack Patterns. In Proceedings of the 23rd International Conference on Natural Language and Information Systems, Paris, France, 13–15 June 2018; Volume 10859, pp. 91–98. [Google Scholar]
- MITRE ATT&CK. Available online: https://attack.mitre.org (accessed on 10 February 2022).
- Aghaei, E.; Shaer, E.A. ThreatZoom: Neural Network for Automated Vulnerability Mitigation. In Proceedings of the 6th Annual Symposium on Hot Topics in the Science of Security, New York, NY, USA, 1–3 April 2019; pp. 1–3. [Google Scholar] [CrossRef]
- Ampel, B.; Sagar Samtani, S.; Ullman, S.; Chen, H. Linking Common Vulnerabilities and Exposures to the MITRE ATT&CK Framework: A Self-Distillation Approach. In Proceedings of the 2021 ACM Conference Knowledge Discovery and Data Mining (KDD’ 21) Workshop on AI-enabled Cybersecurity Analytics, Singapore, 14–18 August 2021; pp. 1–5. [Google Scholar]
- Kuppa, A.; Aouad, L.; Le-Khac, N. Linking CVE’s to MITRE ATT&CK Techniques. In Proceedings of the 16th International Conference on Availability, Reliability and Security, New York, NY, USA, 17–20 August 2021; pp. 1–12. [Google Scholar] [CrossRef]
- Ouchn, J.N. Method and System for Automated Computer Vulnerability Tracking. U.S. Patent 9,871,815, 16 January 2018. [Google Scholar]
- Adams, S.; Carter, B.; Fleming, C.; Beling, P.A. Selecting system specific cybersecurity attack patterns using topic modeling. In Proceedings of the 17th IEEE International Conference on Trust, Security and Privacy in Computing and Communications, New York, NY, USA, 31 July 2018–3 August 2018; pp. 490–497. [Google Scholar] [CrossRef]
- Bezdan, T.; Stoean, C.; Naamany, A.A.; Bacanin, N.; Rashid, T.A.; Zivkovic, M.; Venkatachalam, K. Hybrid Fruit-Fly Optimization Algorithm with K-Means for Text Document Clustering. Mathematics 2021, 9, 1929. [Google Scholar] [CrossRef]
- Mounika, V.; Yuan, X.; Bandaru, K. Analyzing CVE Database Using Unsupervised Topic Modelling. In Proceedings of the 6th Annual Conference on Computational Science and Computational Intelligence, Las Vegas, NV, USA, 5–7 December 2019; pp. 72–77. [Google Scholar] [CrossRef]
- Ou, S.; Kim, H. Unsupervised Citation Sentence Identification Based on Similarity Measurement. In Proceedings of the 13th International Conference on Transforming Digital Worlds, Sheffield, UK, 25–28 March 2018; pp. 384–394. [Google Scholar] [CrossRef]
- Kim, D.; Seo, D.; Cho, S.; Kang, P. Multi-co-training for document classification using various document representations: TF–IDF, LDA, and Doc2Vec. J. Inf. Sci. 2019, 477, 15–29. [Google Scholar] [CrossRef]
- Zhu, L.; Zhang, Z.; Xia, G.; Jiang, C. Research on Vulnerability Ontology Model. In Proceedings of the 2019 IEEE 8th Joint International Information Technology and Artificial Intelligence Conference, Chongqing, China, 24–26 May 2019; pp. 657–661. [Google Scholar] [CrossRef]
- Gao, J.B.; Zhang, B.W.; Chen, X.H.; Luo, Z. Ontology-based model of network and computer attacks for security assessment. J. Shanghai Jiaotong Univ. Sci. 2013, 18, 554–562. [Google Scholar] [CrossRef]
- Ansarinia, M.; Asghari, S.A.; Souzani, A.; Ghaznavi, A. Ontology-based modeling of DDoS attacks for attack plan detection. In Proceedings of the 6th International Symposium on Telecommunications, Tehran, Iran, 6–8 November 2012; pp. 993–998. [Google Scholar] [CrossRef]
- Wang, J.A.; Wang, H.; Guo, M.; Zhou, L.; Camargo, J. Ranking attacks based on vulnerability analysis. In Proceedings of the 43rd Hawaii International Conference on System Sciences, Kauai, HI, USA, 5–8 January 2010; pp. 1–10. [Google Scholar] [CrossRef]
- Wita, R.; Jiamnapanon, N.; Teng-Amnuay, Y. An ontology for vulnerability lifecycle. In Proceedings of the 2010 Third International Symposium on Intelligent Information Technology and Security Informatics, Jinggangshan, China, 2–4 April 2010; pp. 553–557. [Google Scholar] [CrossRef]
- Lee, Y.; Woo, S.; Song, Y.; Lee, J.; Lee, D.H. Practical Vulnerability-Information-Sharing Architecture for Automotive Security-Risk Analysis. IEEE Access 2020, 8, 120009–120018. [Google Scholar] [CrossRef]
- Stellios, I.; Kotzanikolaou, P.; Grigoriadis, C. Assessing IoT enabled cyber-physical attack paths against critical system. J. Comput. Secur. 2021, 107, 102316. [Google Scholar] [CrossRef]
- Rostami, S.; Kleszcz, A.; Dimanov, D.; Katos, V. A Machine Learning Approach to Dataset Imputation for Software Vulnerabilities. In Proceedings of the 10th International Conference on Multimedia Communications, Services and Security, Krakow, Poland, 8–9 October 2020; pp. 25–36. [Google Scholar] [CrossRef]
- Sion, L.; Tuma, K.; Scandariato, R.; Yskout, K.; Joosen, W. Towards Automated Security Design Flaw Detection. In Proceedings of the 2019 34th IEEE/ACM International Conference on Automated Software Engineering Workshops, San Diego, CA, USA, 10–15 November 2019; pp. 49–56. [Google Scholar] [CrossRef]
- Almorsy, M.; Grundy, J.; Ibrahim, A.S. Collaboration-based cloud computing security management framework. In Proceedings of the 2011 IEEE 4th International Conference on Cloud Computing, Washington, DC, USA, 4–9 July 2011; pp. 364–371. [Google Scholar] [CrossRef]
- Kotenko, I.; Doynikova, E. The CAPEC based generator of attack scenarios for network security evaluation. In Proceedings of the 2015 IEEE 8th International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications, Warsaw, Poland, 24–26 September 2015; pp. 436–441. [Google Scholar] [CrossRef]
- Xianghui, Z.; Yong, P.; Zan, Z.; Yi, J.; Yuangang, Y. Research on parallel vulnerabilities discovery based on open source database and text mining. In Proceedings of the 2015 International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Adelaide, Australia, 23–25 September 2015; pp. 327–332. [Google Scholar] [CrossRef]
- Ruohonen, J.; Leppanen, V. Toward Validation of Textual Information Retrieval Techniques for Software Weaknesses. Commun. Comput. Inf. Sci. 2018, 903, 265–277. [Google Scholar] [CrossRef]
- Guo, M.; Wang, J.A. An ontology-based approach to model common vulnerabilities and exposures in information security. In Proceedings of the ASEE 2009 Southest Section Conference, Marietta, GA, USA, 5–7 April 2009. [Google Scholar]
- CVE. Available online: https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-10108 (accessed on 10 February 2022).
- Scikit-Learn. Available online: https://scikit-learn.org/stable/ (accessed on 10 February 2022).
- Tensorflow Hub. Available online: https://tfhub.dev/ (accessed on 10 February 2022).
- Sentence Transformers Documentation. Available online: https://www.sbert.net/ (accessed on 10 February 2022).
- CWE. Available online: https://cwe.mitre.org/data/definitions/20.html (accessed on 10 February 2022).
- CVE. Available online: https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-0601 (accessed on 10 February 2022).
- CVE. Available online: https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2004-0629 (accessed on 10 February 2022).
- CVE. Available online: https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2006-4705 (accessed on 10 February 2022).
- Xia, P.; Zhang, L.; Li, F. Learning similarity with cosine similarity ensemble. Inf. Sci. 2015, 307, 39–52. [Google Scholar] [CrossRef]
- Hafiz, M.; Adamczyk, P.; Johnson, R. Growing a pattern language (for security). In Proceedings of the ACM International Symposium on New Ideas, New Paradigms, and Reflections on Programming and Software, Tucson, AZ, USA, 19–26 October 2012; pp. 139–158. [Google Scholar] [CrossRef]
- Biswas, B.; Mukhopadhyay, A.; Gupta, G. “Leadership in Action: How Top Hackers Behave” A Big-Data Approach with Text-Mining and Sentiment Analysis. In Proceedings of the 51st Hawaii International Conference on System Sciences, Honolulu, HI, USA, 2–6 January 2018; pp. 1752–1761. [Google Scholar] [CrossRef]
- Samtani, S.; Chinn, R.; Chen, H.; Nunamaker, J.F., Jr. Exploring emerging hacker assets and key hackers for proactive cyber threat intelligence. J. Manag. Inf. Syst. 2017, 34, 1023–1053. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Document | Per Section | Section Average | |
|---|---|---|---|
| TF-IDF | ○ | ○ | ○ |
| USE | ○ | ○ | ○ |
| SBERT | ✕ | ○ | ○ |
| Recall@10 | MRR | |
|---|---|---|
| TF-IDF (document) | 0.787 | 0.591 |
| SBERT (section average) | 0.803 | 0.368 |
| TF-IDF (per section) | 0.770 | 0.596 |
| TF-IDF (section average) | 0.754 | 0.470 |
| USE (document) | 0.705 | 0.491 |
| USE (per section) | 0.672 | 0.420 |
| USE (section average) | 0.590 | 0.474 |
| SBERT (per section) | 0.557 | 0.337 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kanakogi, K.; Washizaki, H.; Fukazawa, Y.; Ogata, S.; Okubo, T.; Kato, T.; Kanuka, H.; Hazeyama, A.; Yoshioka, N. Comparative Evaluation of NLP-Based Approaches for Linking CAPEC Attack Patterns from CVE Vulnerability Information. Appl. Sci. 2022, 12, 3400. https://doi.org/10.3390/app12073400
Kanakogi K, Washizaki H, Fukazawa Y, Ogata S, Okubo T, Kato T, Kanuka H, Hazeyama A, Yoshioka N. Comparative Evaluation of NLP-Based Approaches for Linking CAPEC Attack Patterns from CVE Vulnerability Information. Applied Sciences. 2022; 12(7):3400. https://doi.org/10.3390/app12073400
Chicago/Turabian StyleKanakogi, Kenta, Hironori Washizaki, Yoshiaki Fukazawa, Shinpei Ogata, Takao Okubo, Takehisa Kato, Hideyuki Kanuka, Atsuo Hazeyama, and Nobukazu Yoshioka. 2022. "Comparative Evaluation of NLP-Based Approaches for Linking CAPEC Attack Patterns from CVE Vulnerability Information" Applied Sciences 12, no. 7: 3400. https://doi.org/10.3390/app12073400
APA StyleKanakogi, K., Washizaki, H., Fukazawa, Y., Ogata, S., Okubo, T., Kato, T., Kanuka, H., Hazeyama, A., & Yoshioka, N. (2022). Comparative Evaluation of NLP-Based Approaches for Linking CAPEC Attack Patterns from CVE Vulnerability Information. Applied Sciences, 12(7), 3400. https://doi.org/10.3390/app12073400