
Face Recognition Based on Deep Learning and FPGA for Ethnicity Identification

 ,
,  ,
,  ,
, 
 ,
,  ,
,  ,
,  and
and 
Abstract
:1. Introduction
- A network proposal was used to group the human face by its race, specifically from Chinese, Pakistani, and Russian citizens;
- The collected image dataset is a unique one in its kind and is publicly available upon request;
- Several HPC hardware accelerator architectures have been tested, such as FPGAs and GPUs;
- The proposed network was compared against four different pre-trained CNN models: ResNet50, DenseNet, AlexNet, and GoogleNet;
- The experimental results were enriched by reporting the power usage and execution time achieved by the proposed network in order to facilitate its future easy development as a mobile embedded system.
2. Background and Related Work
2.1. Deep CNNs
2.2. Transfer Learning
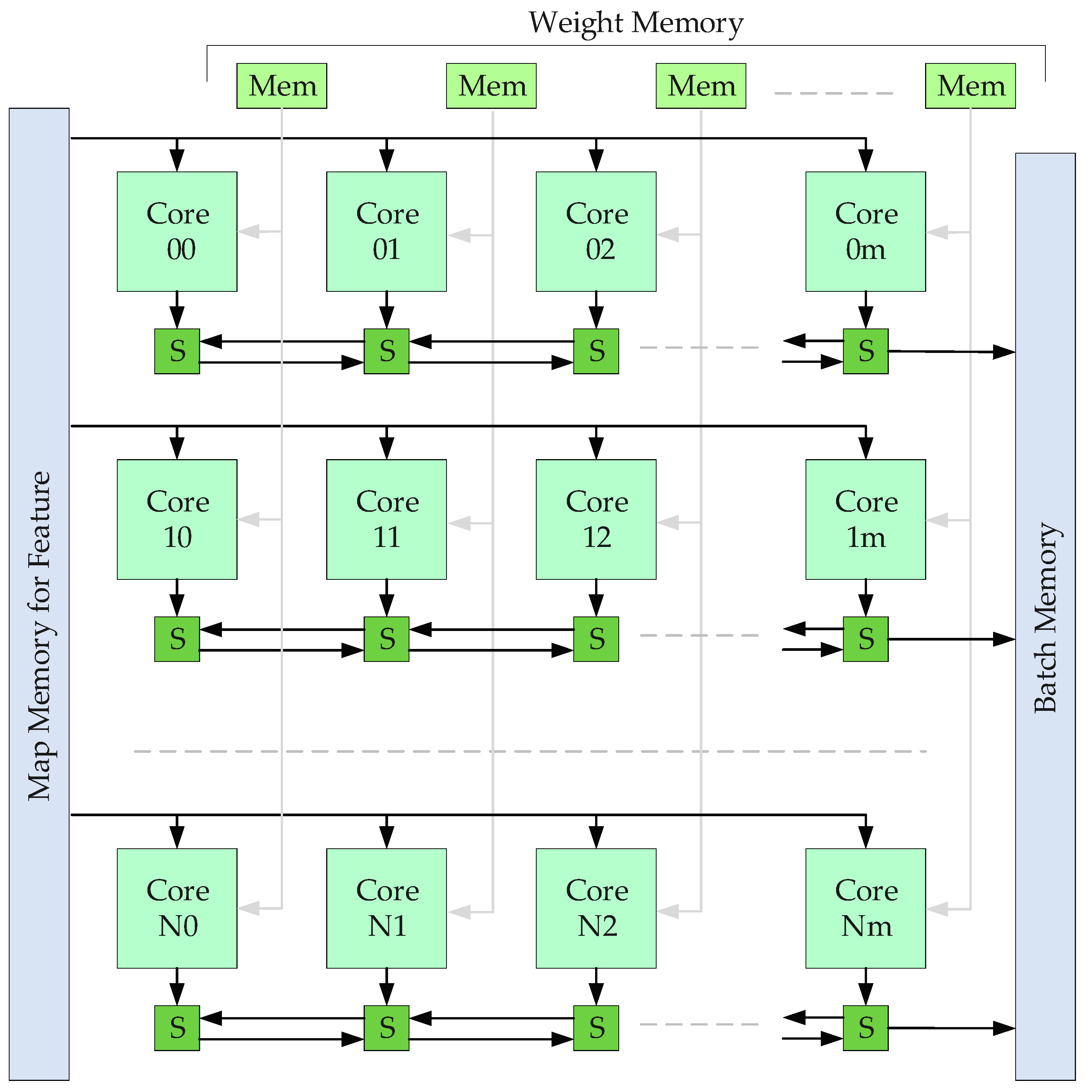
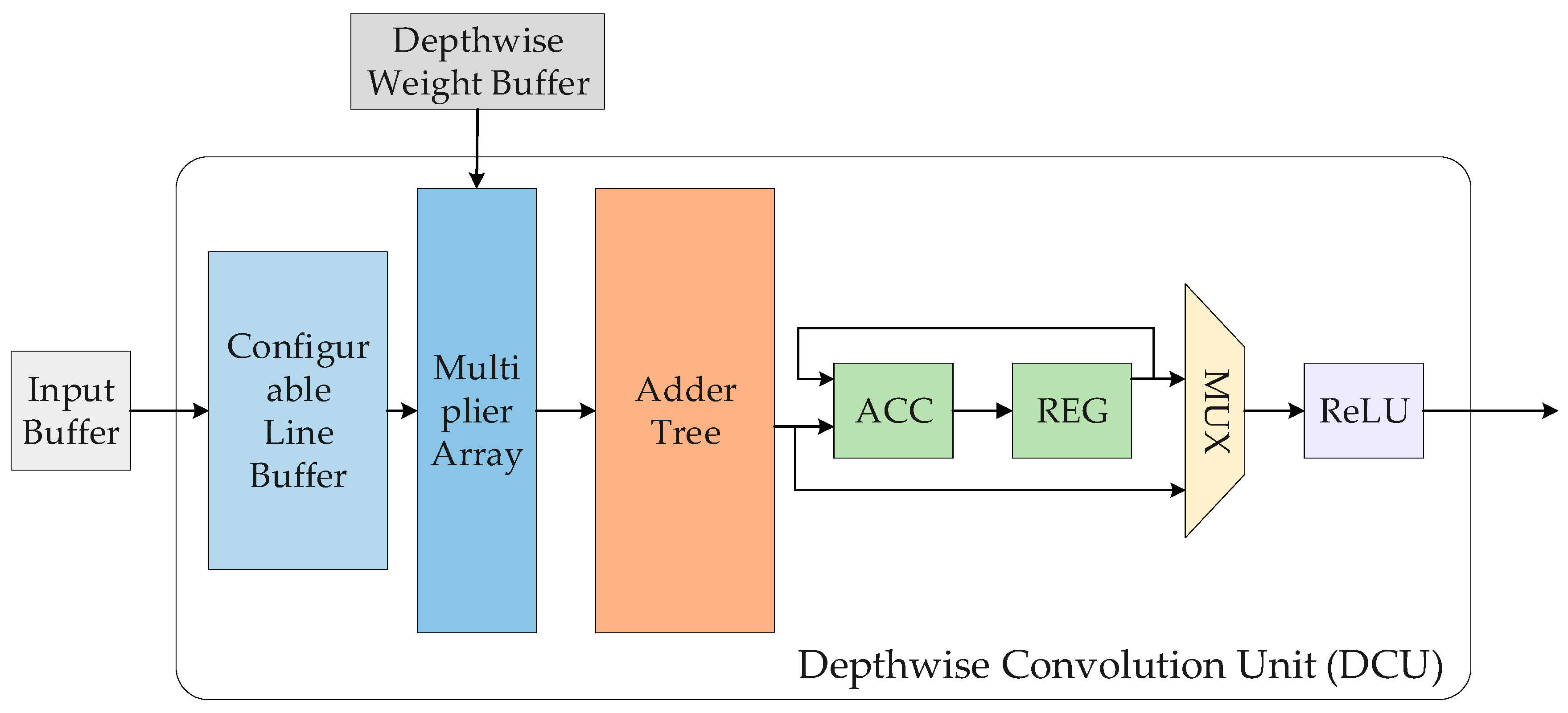
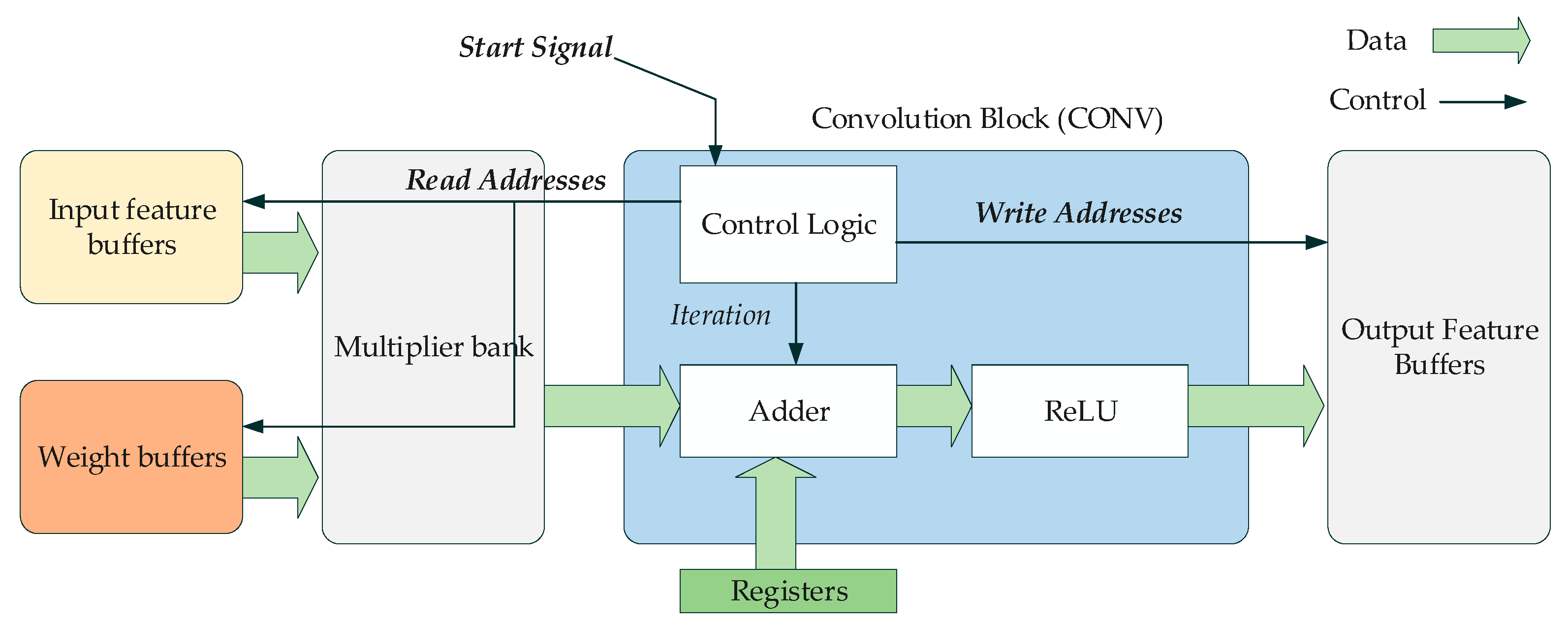
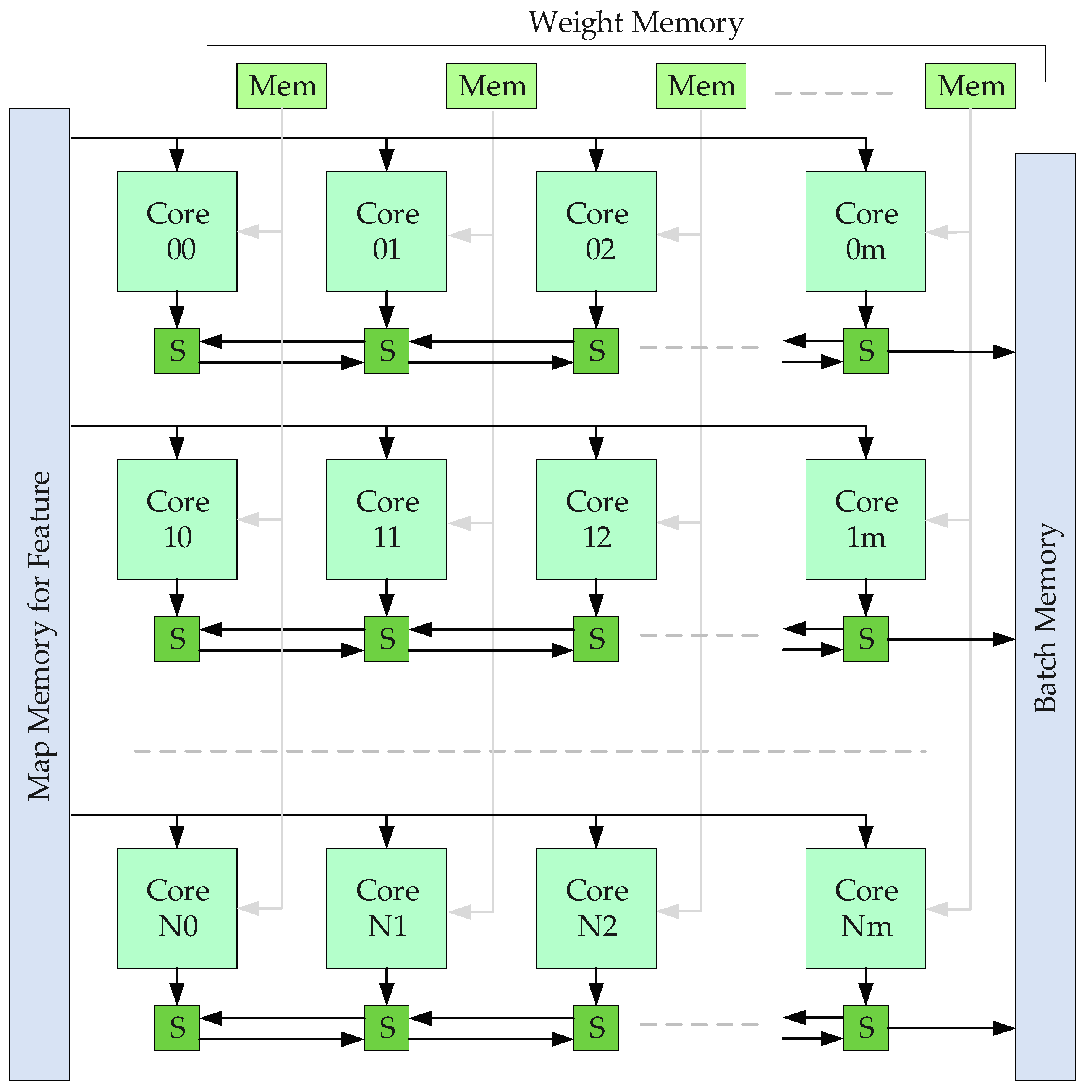
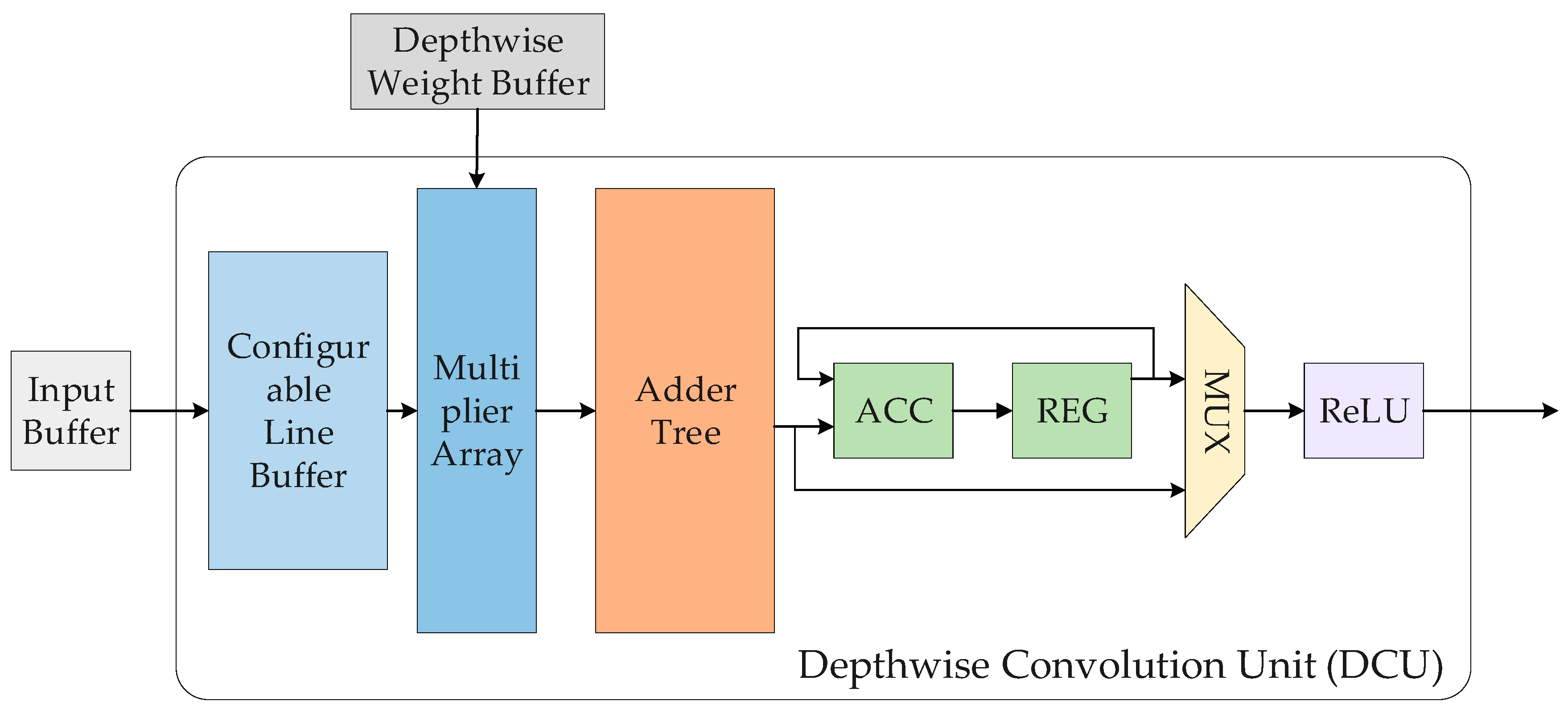
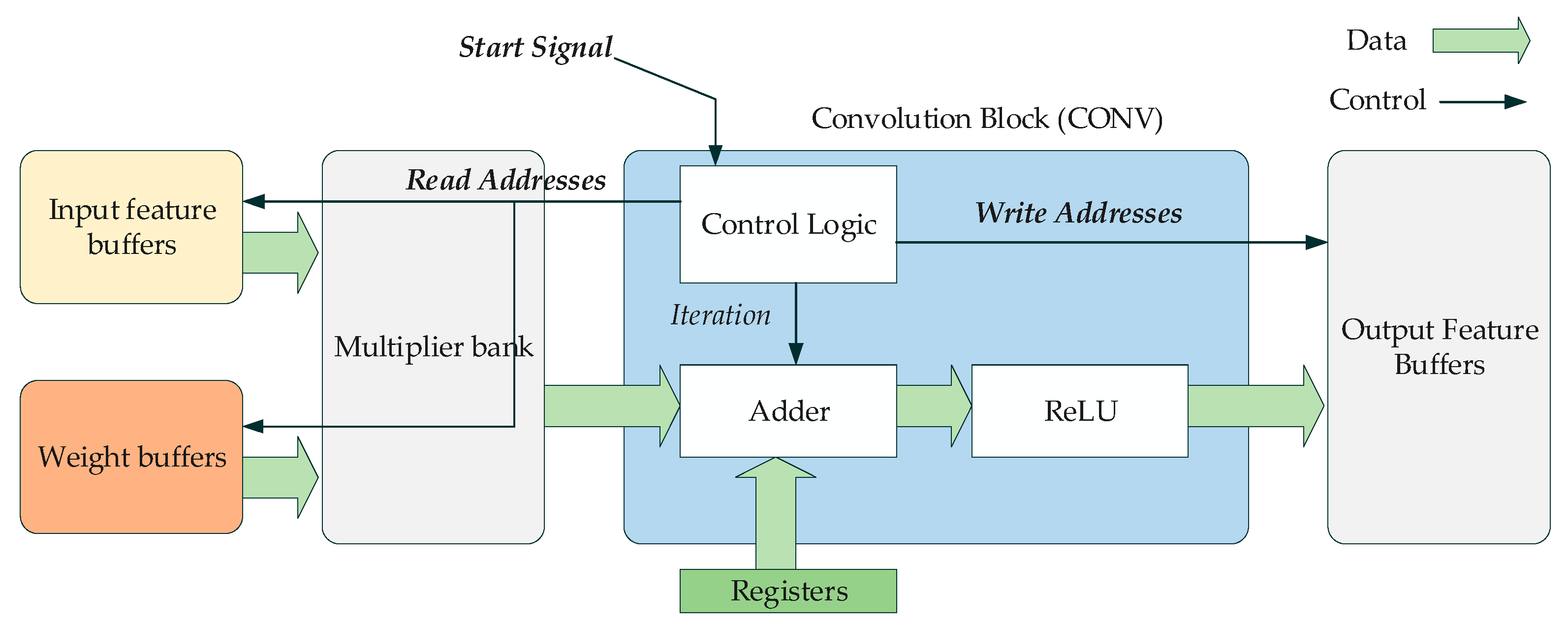
3. Deployment of Deep Learning on FPGAs
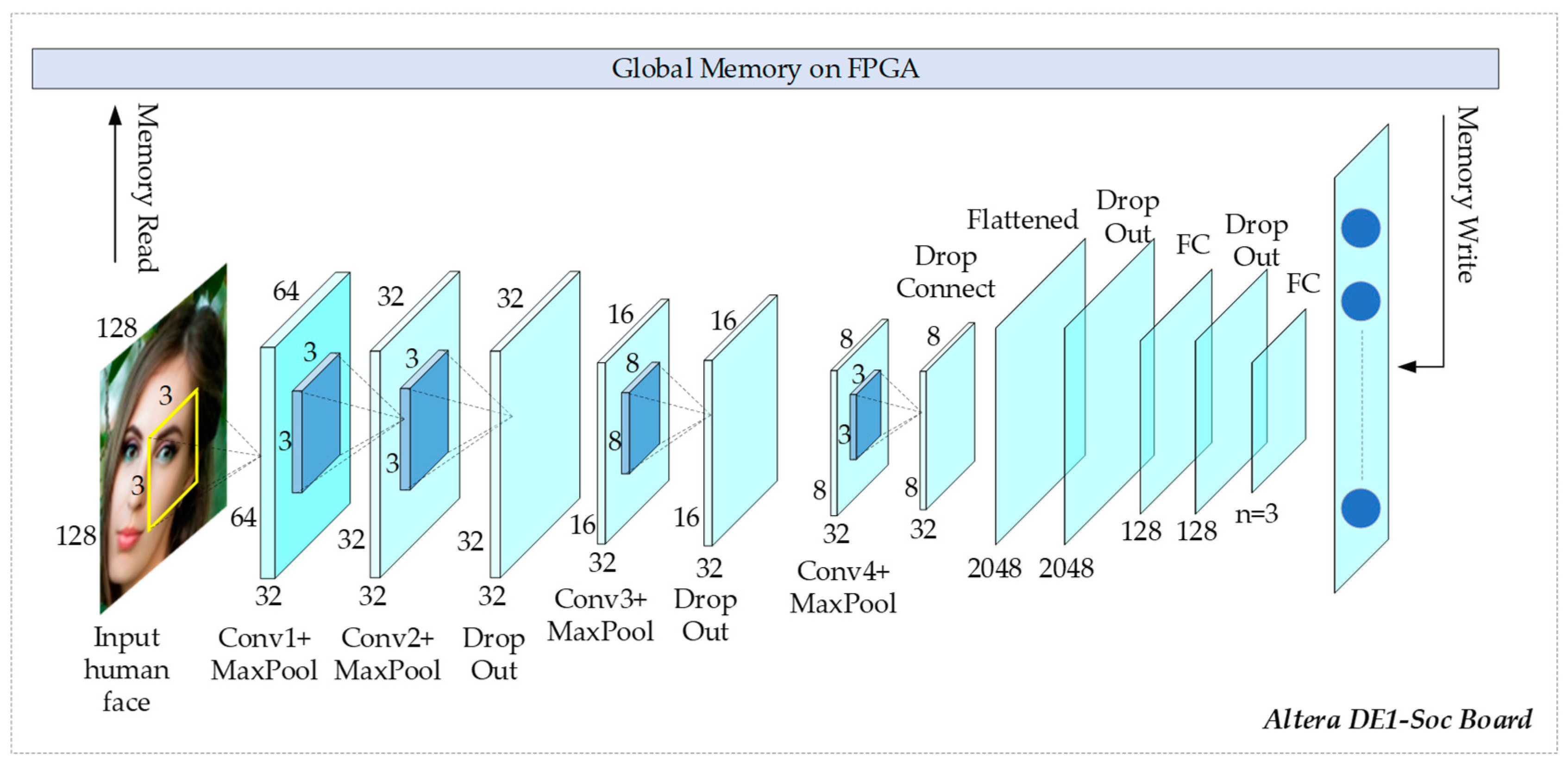
4. The Deep Learning-Based Ethnicity Identification Proposal
4.1. Ethnicity Identification
4.2. Dropout Layer
5. Results
5.1. Training Dataset
5.2. FPGA Hardware Implementations
5.3. A Preliminary Comparitive Analysis
5.4. Comparison for the Pre-Trained CNNs
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gallo, P.; Pongnumkul, S.; Nguyen, U.Q. BlockSee: Blockchain for IoT video surveillance in smart cities. In Proceedings of the 2018 IEEE International Conference on Environment and Electrical Engineering and 2018 IEEE Industrial and Commercial Power Systems Europe (EEEIC/I&CPS Europe), Palermo, Italy, 12–15 June 2018; pp. 1–6. [Google Scholar]
- Al-Yassin, H.; Mousa, J.I.; Fadhel, M.A.; Al-Shamma, O.; Alzubaidi, L. Statistical accuracy analysis of different detecting algorithms for surveillance system in smart city. Indones. J. Electr. Eng. Comput. Sci. 2020, 18, 979–986. [Google Scholar] [CrossRef]
- Kardas, K.; Cicekli, N.K. SVAS: Surveillance Video Analysis System. Expert Syst. Appl. 2017, 89, 343–361. [Google Scholar] [CrossRef]
- Darabant, A.S.; Borza, D.; Danescu, R. Recognizing Human Races through Machine Learning—A Multi-Network, Multi-Features Study. Mathematics 2021, 9, 195. [Google Scholar] [CrossRef]
- Cosar, S.; Donatiello, G.; Bogorny, V.; Garate, C.; Alvares, L.O.; Bremond, F. Toward Abnormal Trajectory and Event Detection in Video Surveillance. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 683–695. [Google Scholar] [CrossRef]
- Vo, T.; Nguyen, T.; Le, T. Race Recognition Using Deep Convolutional Neural Networks. Symmetry 2018, 10, 564. [Google Scholar] [CrossRef] [Green Version]
- Dagnes, N.; Marcolin, F.; Nonis, F.; Tornincasa, S.; Vezzetti, E. 3D geometry-based face recognition in presence of eye and mouth occlusions. Int. J. Interact. Des. Manuf. 2019, 13, 1617–1635. [Google Scholar] [CrossRef]
- Khan, A.; Marwa, M. Considering race a problem of transfer learning. In Proceedings of the IEEE Winter Applications of Computer VisionWorkshops, Waikoloa Village, NI, USA, 7–11 January 2019; pp. 100–106. [Google Scholar]
- Jian-wen, H.A.O.; Lihua, W.; Lilongguang, L.; Shourong, C. Analysis of morphous characteristics of facial reconstruction and the five organs in Chinese north five national minorities crowd. J. Chongqing Med. Univ. 2010, 35, 297–303. [Google Scholar]
- Fu, S.; He, H.; Hou, Z.-G. Learning Race from Face: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2483–2509. [Google Scholar] [CrossRef] [Green Version]
- Alzubaidi, L.; Fadhel, M.A.; Al-Shamma, O.; Zhang, J.; Santamaría, J.; Duan, Y. Robust application of new deep learning tools: An experimental study in medical imaging. Multimedia Tools Appl. 2021, 1–29. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Duan, Y.; Al-Dujaili, A.; Ibraheem, I.K.; Alkenani, A.H.; Santamaría, J.; Fadhel, M.A.; Al-Shamma, O.; Zhang, J. Deepening into the suitability of using pre-trained models of ImageNet against a lightweight convolutional neural network in medical imaging: An experimental study. PeerJ Comput. Sci. 2021, 7, e715. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Fadhel, M.; Al-Shamma, O.; Zhang, J.; Santamaría, J.; Duan, Y.; Oleiwi, S. Towards a Better Understanding of Transfer Learning for Medical Imaging: A Case Study. Appl. Sci. 2020, 10, 4523. [Google Scholar] [CrossRef]
- Nasser, A.R.; Hasan, A.M.; Humaidi, A.J.; Alkhayyat, A.; Alzubaidi, L.; Fadhel, M.A.; Santamaría, J.; Duan, Y. IoT and Cloud Computing in Health-Care: A New Wearable Device and Cloud-Based Deep Learning Algorithm for Monitoring of Diabetes. Electronics 2021, 10, 2719. [Google Scholar] [CrossRef]
- Arias-Vergara, T.; Klumpp, P.; Vasquez-Correa, J.C.; Noeth, E.; Orozco-Arroyave, J.R.; Schuster, M. Multi-channel spectrograms for speech processing applications using deep learning methods. Pattern Anal. Appl. 2021, 24, 423–431. [Google Scholar] [CrossRef]
- Lauriola, I.; Lavelli, A.; Aiolli, F. An Introduction to Deep Learning in Natural Language Processing: Models, Techniques, and Tools. Neurocomputing 2021, 470, 443–456. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Al-Amidie, M.; Al-Asadi, A.; Humaidi, A.J.; Al-Shamma, O.; Fadhel, M.A.; Zhang, J.; Santamaría, J.; Duan, Y. Novel Transfer Learning Approach for Medical Imaging with Limited Labeled Data. Cancers 2021, 13, 1590. [Google Scholar] [CrossRef] [PubMed]
- Alzubaidi, L.; Abbood, A.A.; Fadhel, M.A.; AL-Shamma, O.M.R.A.N.; Zhang, J. Comparison of hybrid convolutional neural networks models for diabetic foot ulcer classification. J. Eng. Sci. Technol. 2021, 16, 2001–2017. [Google Scholar]
- Cust, E.E.; Sweeting, A.J.; Ball, K.; Robertson, S. Machine and deep learning for sport-specific movement recognition: A systematic review of model development and performance. J. Sports Sci. 2018, 37, 568–600. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Al-Shamma, O.; Fadhel, M.A.; Hameed, R.A.; Alzubaidi, L.; Zhang, J. Boosting convolutional neural networks performance based on FPGA accelerator. In International Conference on Intelligent Systems Design and Applications; Springer: Cham, Switzerland, 2018; pp. 509–517. [Google Scholar]
- Frasser, C.F.; de Benito, C.; Skibinsky-Gitlin, E.S.; Canals, V.; Font-Rosselló, J.; Roca, M.; Ballester, P.J.; Rosselló, J.L. Using Stochastic Computing for Virtual Screening Acceleration. Electronics 2021, 10, 2981. [Google Scholar] [CrossRef]
- Coe, J.; Atay, M. Evaluating Impact of Race in Facial Recognition across Machine Learning and Deep Learning Algorithms. Computers 2021, 10, 113. [Google Scholar] [CrossRef]
- Nassih, B.; Amine, A.; Ngadi, M.; Azdoud, Y.; Naji, D.; Hmina, N. An efficient three-dimensional face recognition system based random forest and geodesic curves. Comput. Geom. 2021, 97, 101758. [Google Scholar] [CrossRef]
- Klare, B.; Jain, A.K. On a taxonomy of facial features. In Proceedings of the 2010 Fourth IEEE International Conference on Biometrics: Theory, Applications and Systems (BTAS), Washington, DC, USA, 27–29 September 2010; pp. 1–8. [Google Scholar]
- Zhang, Y.; Zhang, E.; Chen, W. Deep neural network for halftone image classification based on sparse auto-encoder. Eng. Appl. Artif. Intell. 2016, 50, 245–255. [Google Scholar] [CrossRef]
- Wei, Y.; Xia, W.; Lin, M.; Huang, J.; Ni, B.; Dong, J.; Zhao, Y.; Yan, S. HCP: A Flexible CNN Framework for Multi-Label Image Classification. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 1901–1907. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dagnes, N.; Marcolin, F.; Vezzetti, E.; Sarhan, F.R.; Dakpé, S.; Marin, F.; Nonis, F.; Mansour, K.B. Optimal marker set assessment for motion capture of 3D mimic facial movements. J. Biomech. 2019, 93, 86–93. [Google Scholar] [CrossRef]
- Gogić, I.; Ahlberg, J.; Pandžić, I.S. Regression-based methods for face alignment: A survey. Signal Process. 2020, 178, 107755. [Google Scholar] [CrossRef]
- Li, X.; Lai, S.; Qian, X. DBCFace: Towards Pure Convolutional Neural Network Face Detection. IEEE Trans. Circuits Syst. Video Technol. 2021. [Google Scholar] [CrossRef]
- Li, H.; Lin, Z.; Shen, X.; Brandt, J.; Hua, G. A convolutional neural network cascade for face detection. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5325–5334. [Google Scholar]
- Parka, B.H.; Oha, S.Y.; Kim, I.J. Face alignment using a deep neural network with local feature learning and recurrent regression. Expert Syst. Appl. 2017, 89, 66–80. [Google Scholar] [CrossRef]
- Chen, J.; Ou, Q.; Chi, Z.; Fu, H. Smile detection in the wild with deep convolutional neural networks. Mach. Vis. Appl. 2016, 28, 173–183. [Google Scholar] [CrossRef]
- Ahmed, E.; Jones, M.J.; Marks, T.K. An improved deep learning architecture for person re-identification. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3908–3916. [Google Scholar]
- Marvasti-Zadeh, S.M.; Cheng, L.; Ghanei-Yakhdan, H.; Kasaei, S. Deep learning for visual tracking: A comprehensive survey. IEEE Trans. Intell. Transp. Syst. 2021. [Google Scholar] [CrossRef]
- Ronao, C.A.; Cho, S.-B. Human activity recognition with smartphone sensors using deep learning neural networks. Expert Syst. Appl. 2016, 59, 235–244. [Google Scholar] [CrossRef]
- Paul, R.; Hawkins, S.; Balagurunathan, Y.; Schabath, M.; Gillies, R.; Hall, L.; Goldgof, D. Deep Feature Transfer Learning in Combination with Traditional Features Predicts Survival among Patients with Lung Adenocarcinoma. Tomography 2016, 2, 388–395. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Shin, H.C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sze, V.; Chen, Y.-H.; Yang, T.-J.; Emer, J.S. Efficient Processing of Deep Neural Networks: A Tutorial and Survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef] [Green Version]
- Véstias, M.P. A Survey of Convolutional Neural Networks on Edge with Reconfigurable Computing. Algorithms 2019, 12, 154. [Google Scholar] [CrossRef] [Green Version]
- Umuroglu, Y.; Fraser, N.J.; Gambardella, G.; Blott, M.; Leong, P.; Jahre, M.; Vissers, K. Finn: A framework for fast, scalable binarized neural network inference. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, New York, NY, USA, 22–24 February 2017; pp. 65–74. [Google Scholar]
- Seng, K.P.; Lee, P.J.; Ang, L.M. Embedded Intelligence on FPGA: Survey, Applications and Challenges. Electronics 2021, 10, 895. [Google Scholar] [CrossRef]
- Laith, A.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 1–74. [Google Scholar]
- He, K.; Wang, Y.; Hopcroft, J. A powerful generative model using random weights for the deep image representation. arXiv 2016, arXiv:1606.04801. [Google Scholar]
- Albdairi, A.J.A.; Xiao, Z.; Alghaili, M. Identifying Ethnics of People through Face Recognition: A Deep CNN Approach. Sci. Program. 2020, 2020, 6385281. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Dataset | Number of Images | Groups | Accuracy | Hardware Platform |
|---|---|---|---|---|---|
| [4] | Internet images | over 175,000 | Asian, Afro, Caucasian, and Indian | 96.64% | GPU |
| [6] | VNFaces | 6100 | Vietnamese and others | 88.87% | Not mention |
| [8] | Celeb-A | over 200,000 | predominately Western celebrities | 91% | Not mention |
| [23] | Private | 22 | WD, RBAL and BD | 96% | GPU |
| Our | Private | 3141 | Chinese, Pakistani, and Russian | 96.9 | GPU and FPGA |
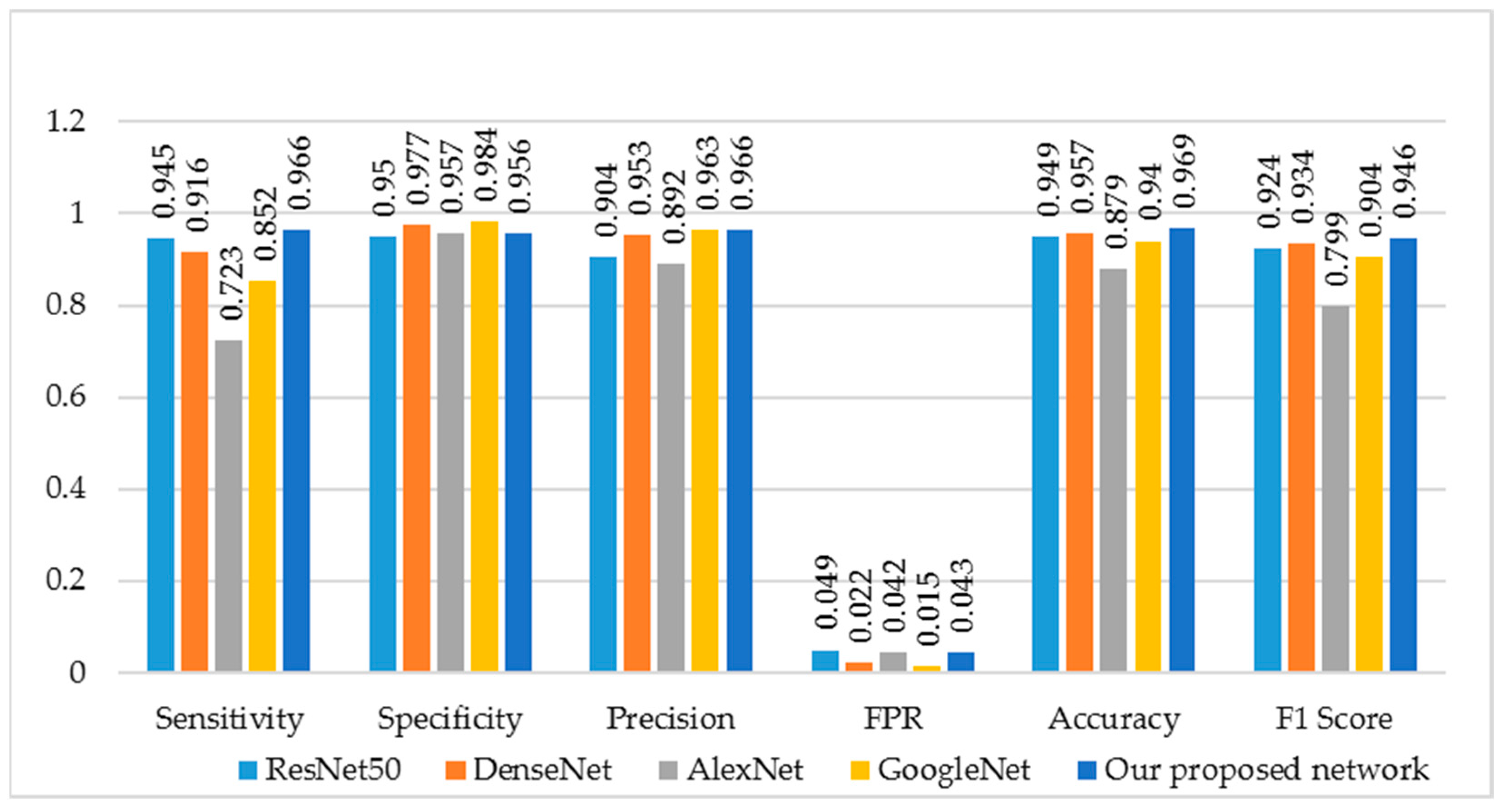
| Measure | ResNet50 | DenseNet | AlexNet | GoogleNet | Our Proposed Network | Derivations |
|---|---|---|---|---|---|---|
| Sensitivity | 0.945 | 0.916 | 0.723 | 0.852 | 0.966 | TPR = TP/(TP + FN) |
| Specificity | 0.950 | 0.977 | 0.957 | 0.984 | 0.956 | TNR = TN/(FP + TN) |
| Precision | 0.904 | 0.953 | 0.892 | 0.963 | 0.966 | PPV = TP/(TP + FP) |
| False Positive Rate | 0.049 | 0.022 | 0.042 | 0.015 | 0.043 | FPR = FP/(FP + TN) |
| Accuracy | 0.949 | 0.957 | 0.879 | 0.940 | 0.969 | ACC = (TP + TN)/(P + N) |
| F1 Score | 0.924 | 0.934 | 0.799 | 0.904 | 0.946 | F1 = 2TP/(2TP + FP + FN) |
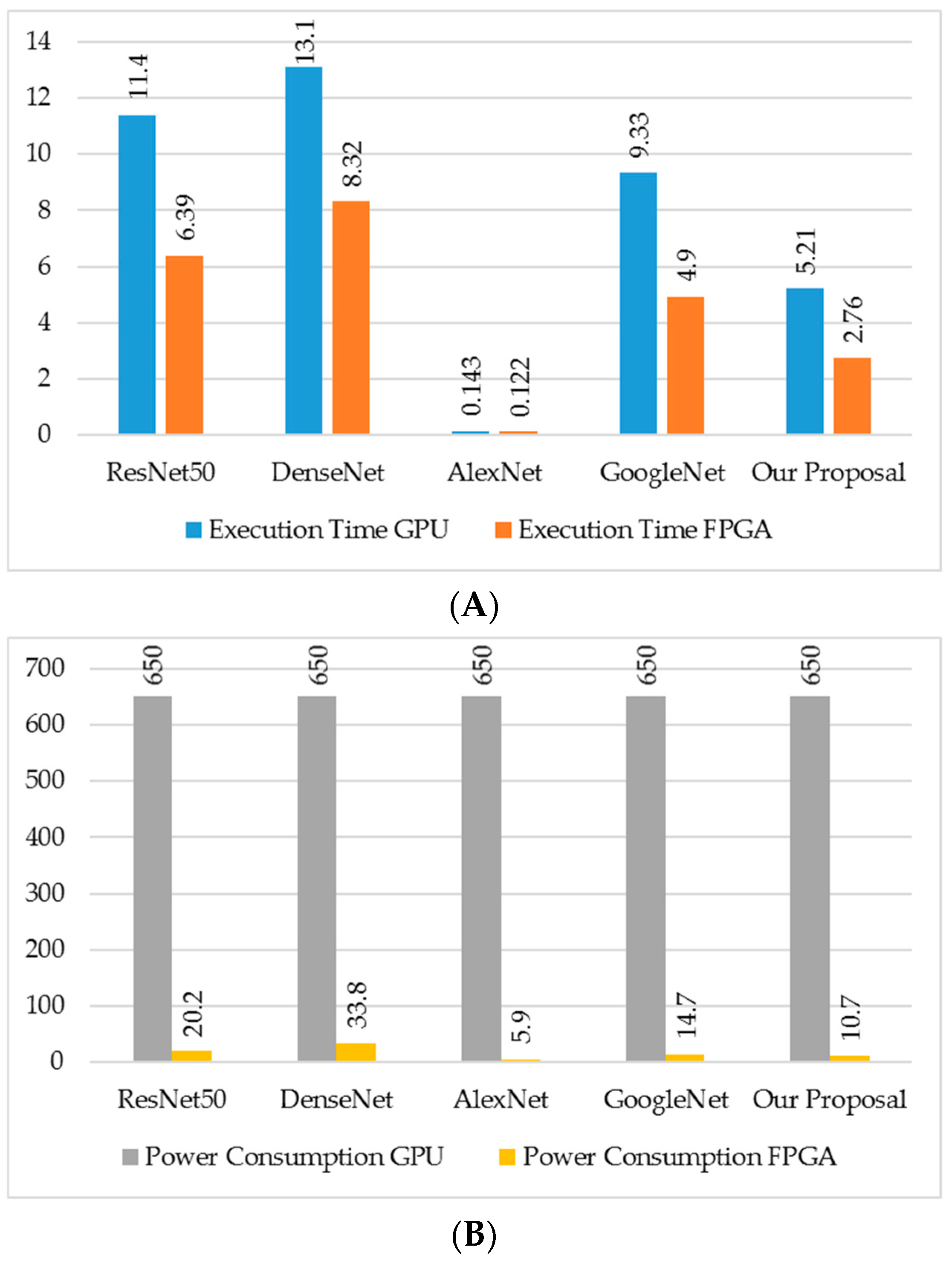
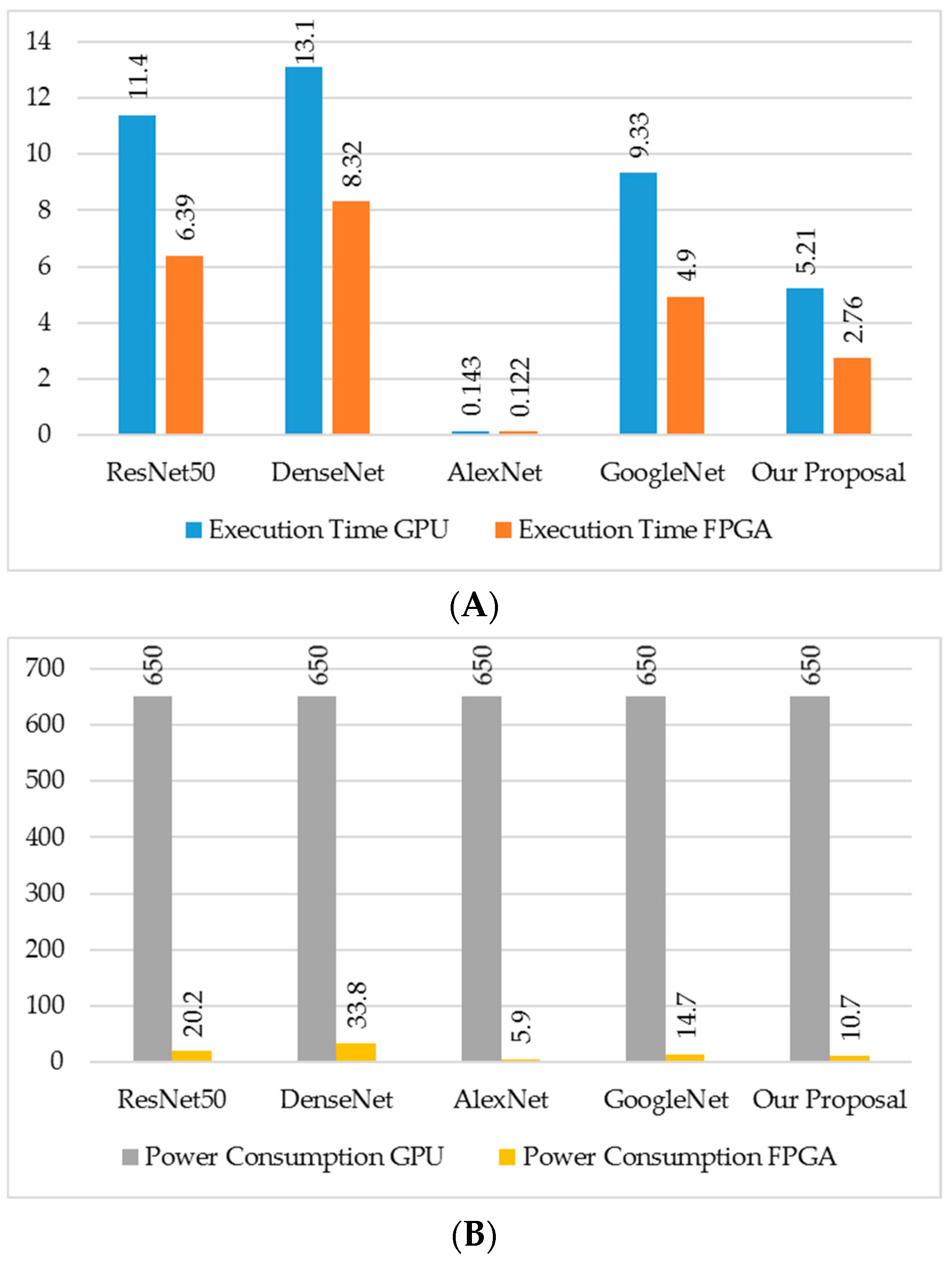
| ResNet50 | DenseNet | AlexNet | GoogleNet | Our Proposal | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| GPU | FPGA | GPU | FPGA | GPU | FPGA | GPU | FPGA | GPU | FPGA | |
| Execution Time | 11.4 s | 6.39 s | 13.1 s | 8.32 s | 143 ms | 122 ms | 9.33 s | 4.90 s | 5.21 s | 2.76 s |
| Power Consumption | 650 w | 20.2 w | 650 w | 33.8 w | 650 w | 5.9 w | 650 w | 14.7 w | 650 w | 10.7 w |
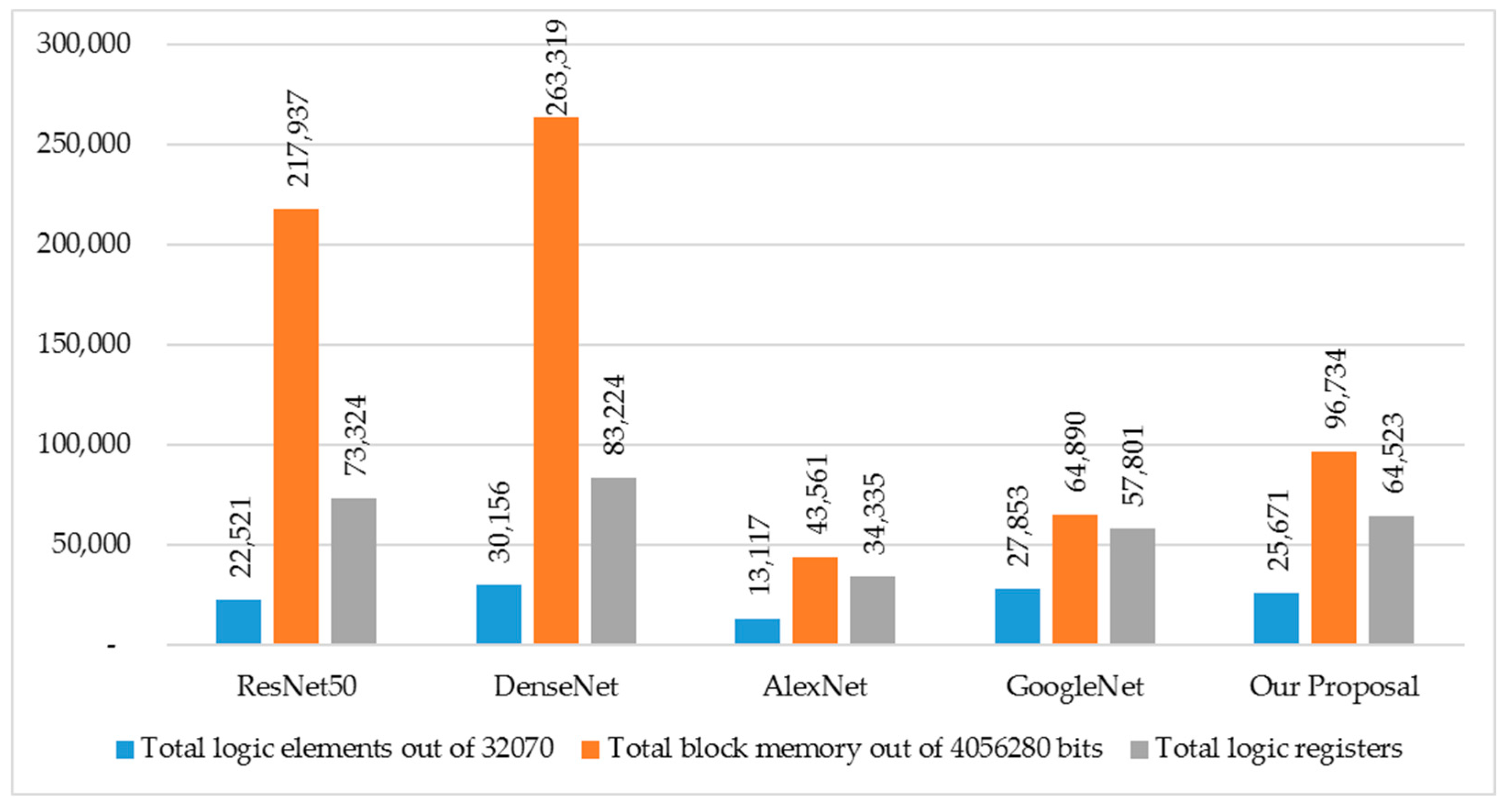
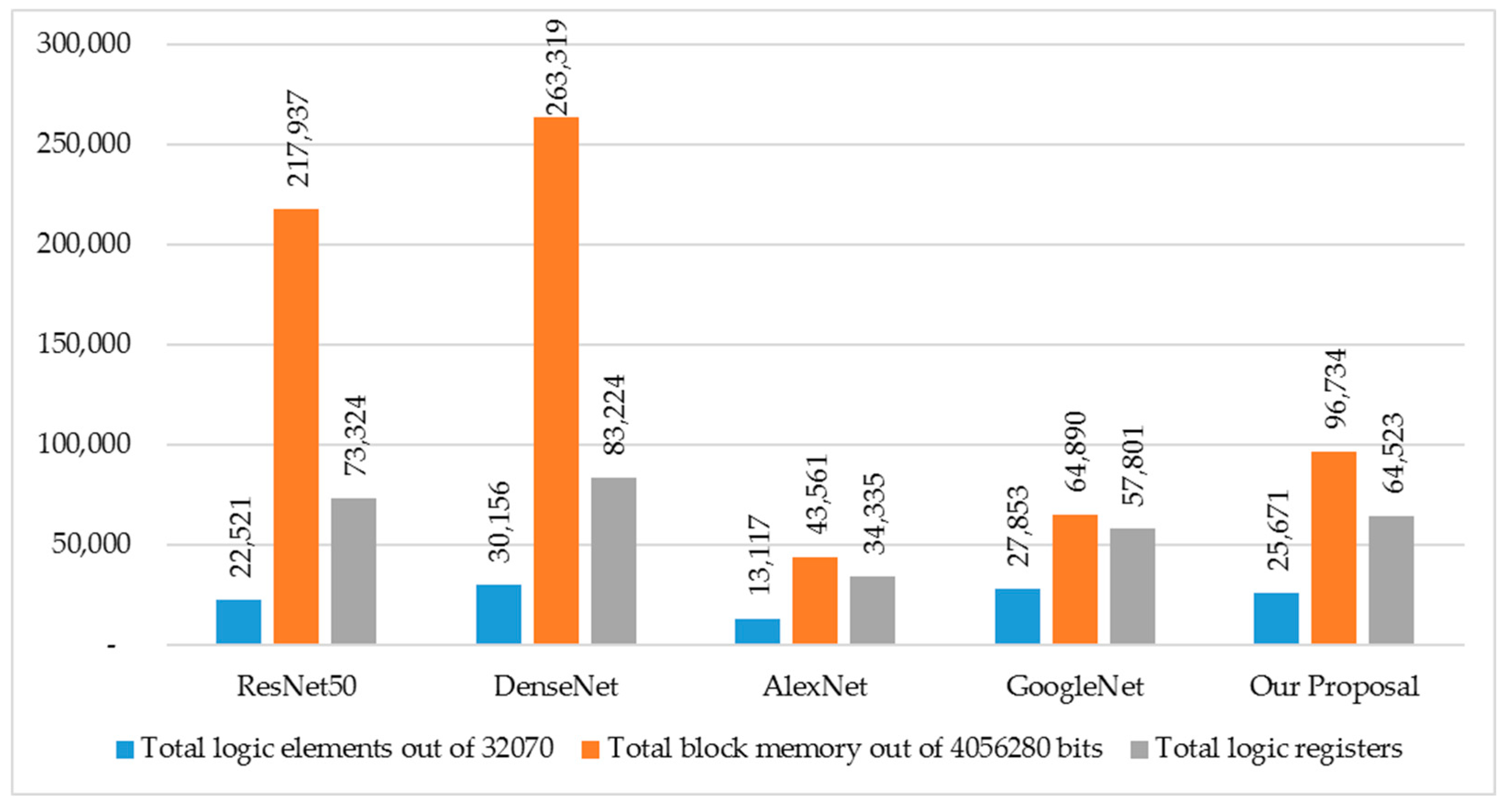
| Measure | ResNet50 | DenseNet | AlexNet | GoogleNet | Our Proposal |
|---|---|---|---|---|---|
| Total logic elements out of 32,070 | 22,521 | 30,156 | 13,117 | 27,853 | 25,671 |
| Total block memory out of 4,056,280 bits | 217,937 | 263,319 | 43,561 | 64,890 | 96,734 |
| Total logic registers | 73,324 | 83,224 | 34,335 | 57,801 | 64,523 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
AlBdairi, A.J.A.; Xiao, Z.; Alkhayyat, A.; Humaidi, A.J.; Fadhel, M.A.; Taher, B.H.; Alzubaidi, L.; Santamaría, J.; Al-Shamma, O. Face Recognition Based on Deep Learning and FPGA for Ethnicity Identification. Appl. Sci. 2022, 12, 2605. https://doi.org/10.3390/app12052605
AlBdairi AJA, Xiao Z, Alkhayyat A, Humaidi AJ, Fadhel MA, Taher BH, Alzubaidi L, Santamaría J, Al-Shamma O. Face Recognition Based on Deep Learning and FPGA for Ethnicity Identification. Applied Sciences. 2022; 12(5):2605. https://doi.org/10.3390/app12052605
Chicago/Turabian StyleAlBdairi, Ahmed Jawad A., Zhu Xiao, Ahmed Alkhayyat, Amjad J. Humaidi, Mohammed A. Fadhel, Bahaa Hussein Taher, Laith Alzubaidi, José Santamaría, and Omran Al-Shamma. 2022. "Face Recognition Based on Deep Learning and FPGA for Ethnicity Identification" Applied Sciences 12, no. 5: 2605. https://doi.org/10.3390/app12052605
APA StyleAlBdairi, A. J. A., Xiao, Z., Alkhayyat, A., Humaidi, A. J., Fadhel, M. A., Taher, B. H., Alzubaidi, L., Santamaría, J., & Al-Shamma, O. (2022). Face Recognition Based on Deep Learning and FPGA for Ethnicity Identification. Applied Sciences, 12(5), 2605. https://doi.org/10.3390/app12052605