
Legal Judgment Prediction via Heterogeneous Graphs and Knowledge of Law Articles

Abstract
:1. Introduction
- A novel method for legal judgment prediction is proposed. It can solve the confusion of similar charges and similar law articles.
- We propose a method to fuse different feature information of nodes from different kinds of graphs (graph fusion method).
- This paper incorporates six kinds of graphs to predict case judgment; we achieved excellent results using real-world datasets, outperforming all baseline models.
2. Related Work
3. Our Method
3.1. Problem Formulation
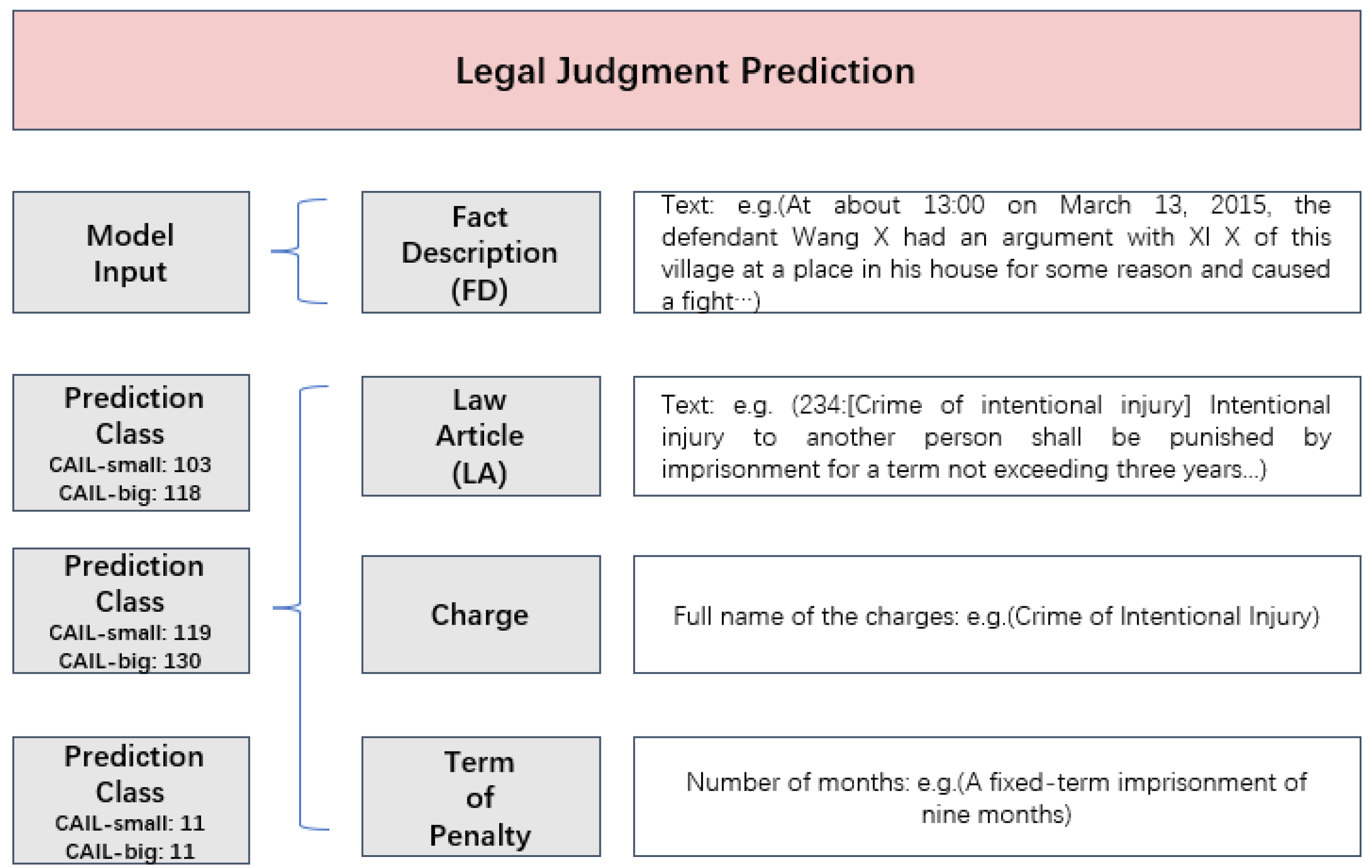
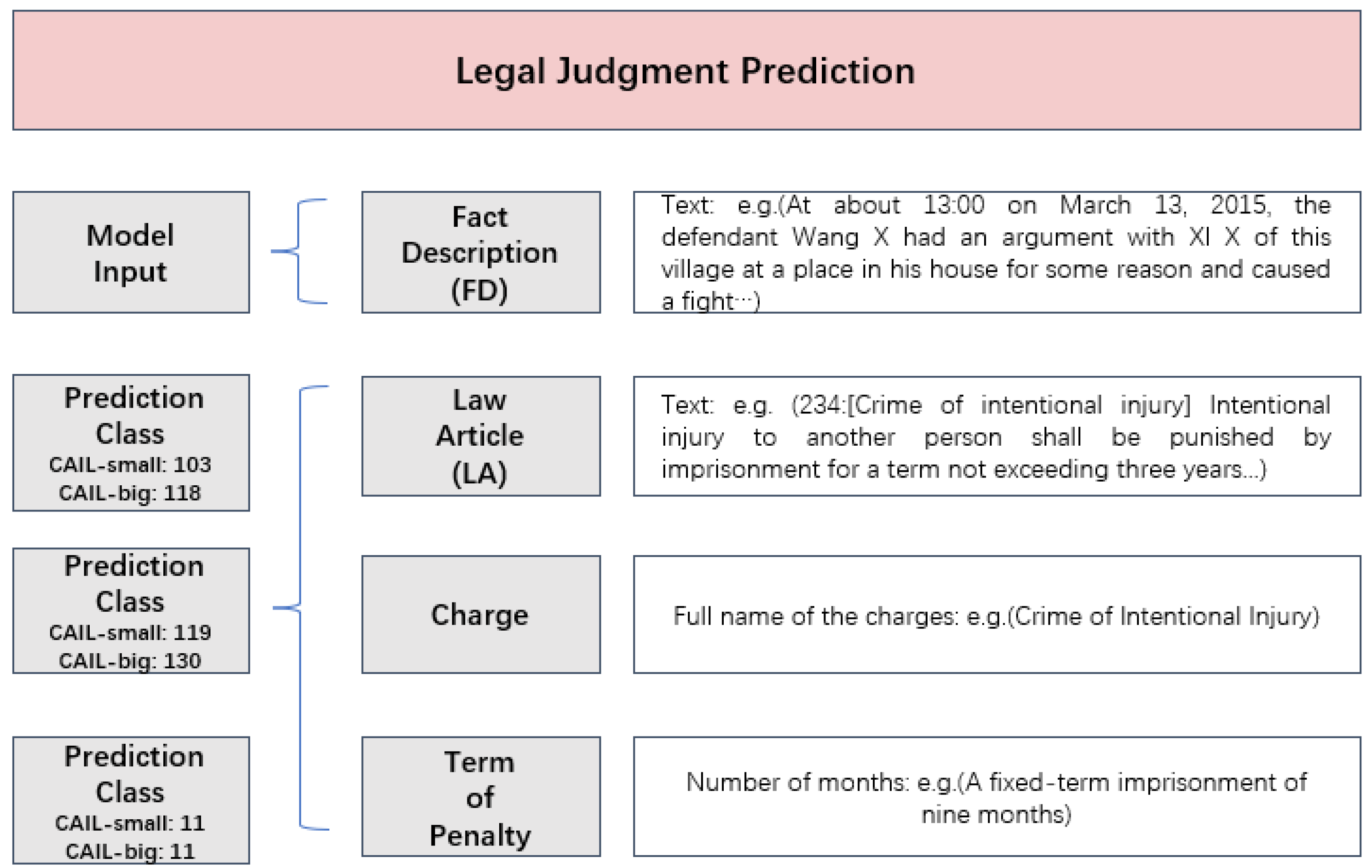
- Fact description: The fact description is a part of an Judicial decision document which mainly describes the time and place of the case, the defendant, what illegal activities were carried out, etc., and is noted as .
- Law article: Law articles are the basis for convictions and each charge has at least one law article. The law articles are noted as . In the dataset used in the paper, the maximum number is 118.
- Charge: The charges are the items that need to be predicted. The maximum number is 130.
- Term of penalty: The terms of penalty are the items that need to be predicted. The maximum number is 11.
- Legal judgment prediction: The LJP task is to obtain the legal judgment based on the fact description of the case and our task is to train a model F to predict the LJP LJP result (applicable law articles, charges and terms of penalty).
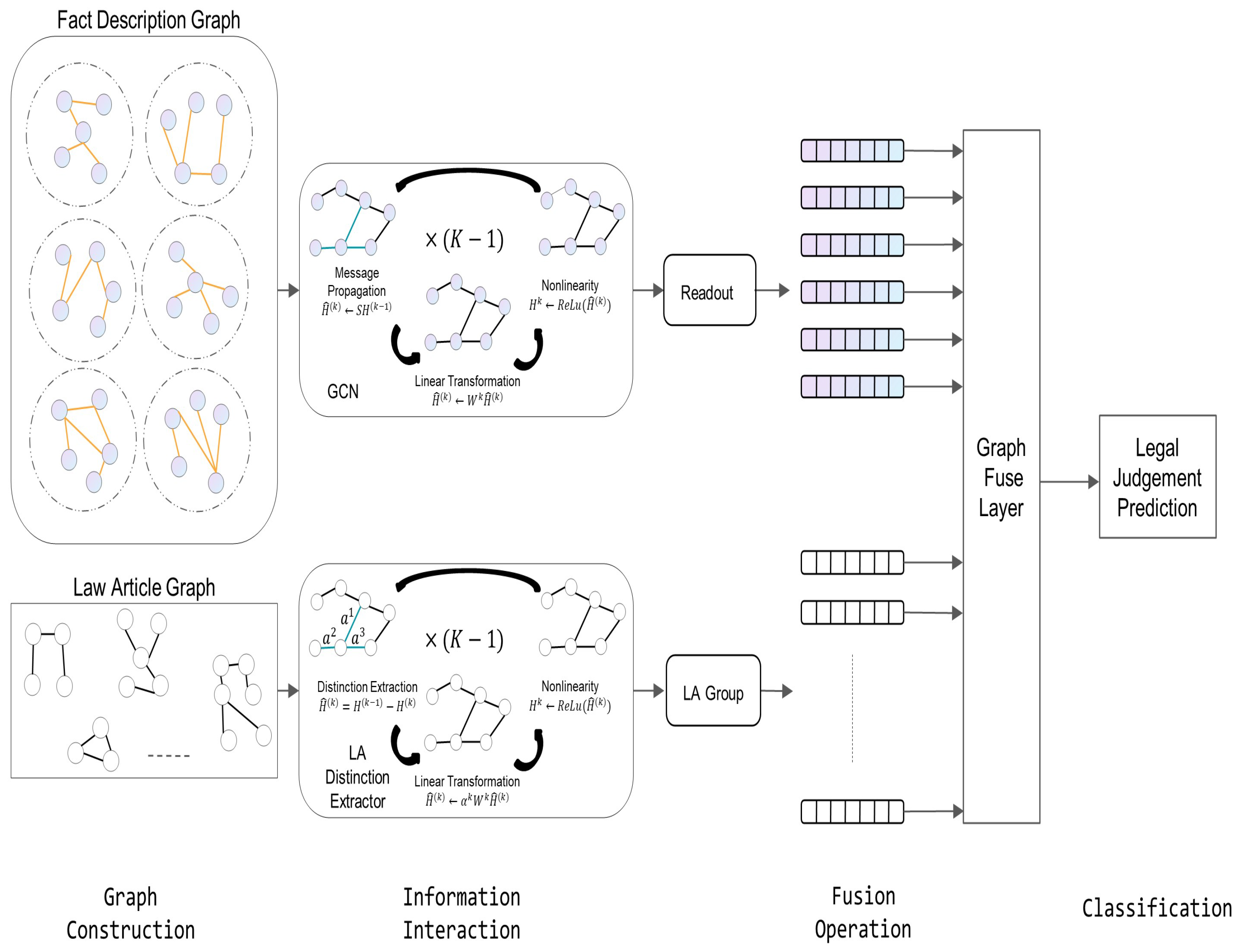
3.2. Graph Construction Based on Legal Text
3.2.1. Co-Occurrence Graph
3.2.2. Point-Wise Mutual Information Graph
3.2.3. Semantic Graph
3.2.4. Build Graph for Each Document
3.3. Law Article Distinction Extractor
3.3.1. Build Law Articles Graph
3.3.2. Law Article Groups’ Distinct Learning Operation
3.4. Fact Description Graph Interaction
3.5. Graph Fusion Layer
3.6. Prediction and Train
4. Experiments
4.1. Datasets
4.2. Baselines
- TFIDF + SVM: This technique uses TF-IDF to make text vectors and SVM [28] as a text classifier.
- CNN [29]: This method uses CNNs containing multiple filters and employs softmax as a classifier.
- RCNN [30]: The approach fuses RNN and CNN to make a new model and exploits the advantages of both models to improve the performance of text classification.
- HARNN [31]: First, the method considers the hierarchical structure of documents; words form sentences and sentences form documents, so the modeling is also performed in these two parts and the attention mechanism is introduced.
- FLA [2]: The method proposes an attention-based neural network framework that can perform the task of charge prediction and relevant law articles extraction and show the importance of law articles in the civil law system for judicial decision making.
- TOPJUDGE [32]: The approach unifies multiple subtasks of LJP into a single learning framework, builds dependencies between LJP subtasks into a DAG form and enhances trial predictions using prior knowledge. The model can handle any DAG-dependent subtasks.
- GCN [12]: This method uses text to construct a graph and then a graph convolutional network to extract node features for classification.
- MPBFN-WCA [2]: The approach designs a multi-view forward prediction and backward verification framework to efficiently exploit the dependencies between multiple subtasks. The word matching features of fact descriptions are integrated into the network through an attention mechanism to distinguish cases with similar descriptions but different penalties.
- LADAN [8]: The model effectively solves the problem of confusing charges (law articles) in the LJP task. The method takes into account not only the positive effect of the textual definitions of charges (law articles) on the semantic extraction of case fact descriptions but also the negative effect of interrelationships (e.g., similarity relations) between the definitions of charges (law articles) on the semantic extraction.
4.3. Experimental Settings
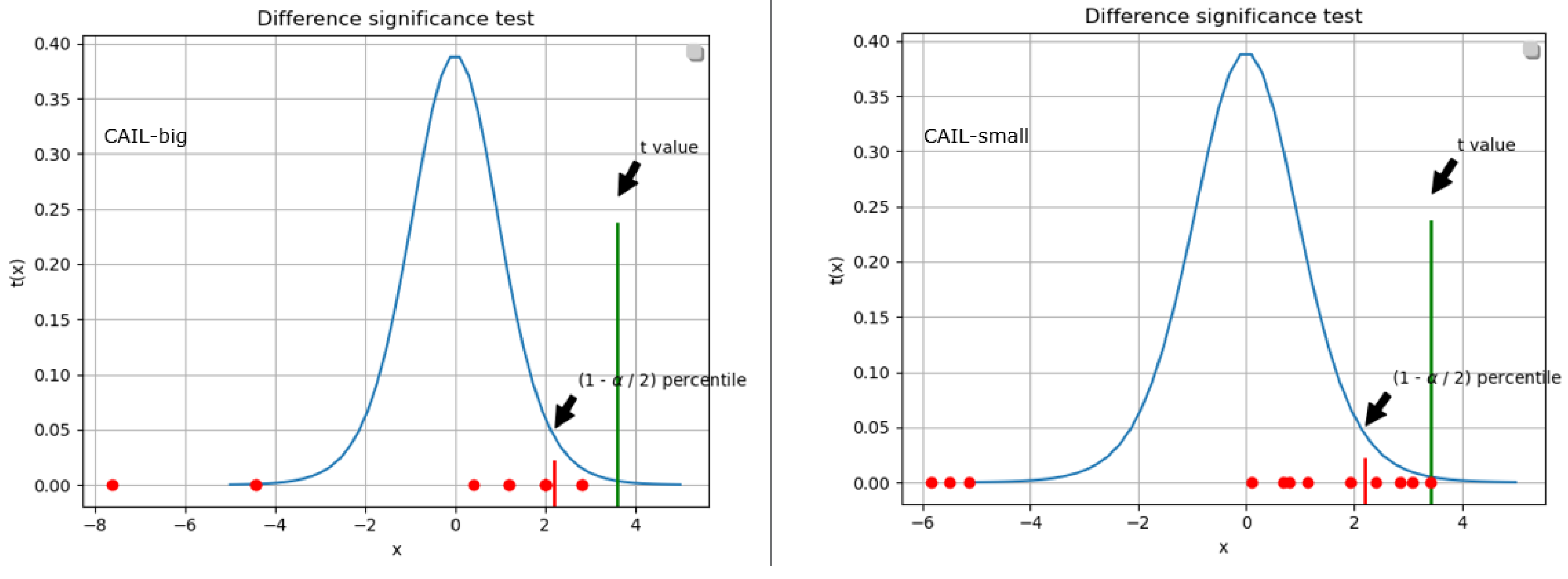
4.4. Experimental Results
4.5. Ablation Experiments
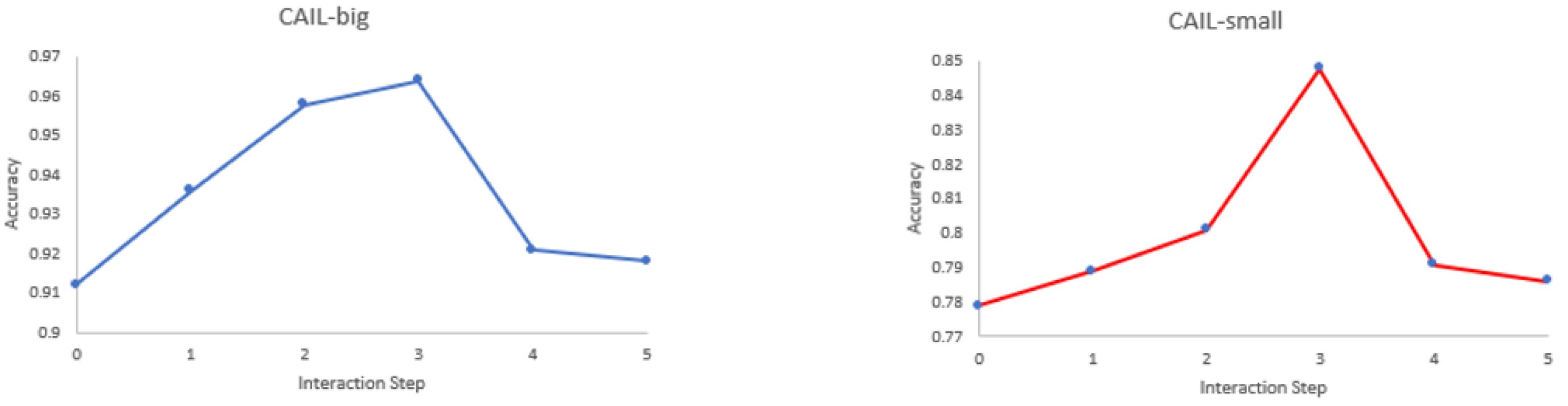
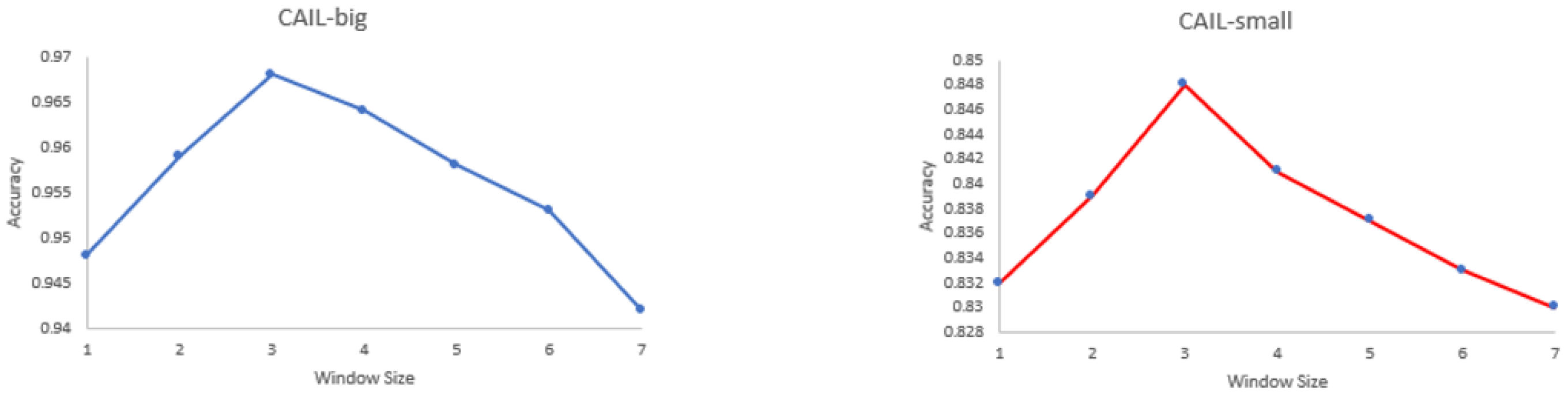
4.6. Parameter Sensitivity
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhong, H.; Xiao, C.; Tu, C.; Zhang, T.; Liu, Z.; Sun, M. How Does NLP Benefit Legal System: A Summary of Legal Artificial Intelligence. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 5218–5230. [Google Scholar]
- Yang, W.M.; Jia, W.J.; Zhou, X.J.; Luo, Y.T. Legal Judgment Prediction via Multi-Perspective Bi-Feedback Network. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 4085–4091. [Google Scholar]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The long-document transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar]
- Kitaev, N.; Kaiser, L.; Levskaya, A. Reformer: The Efficient Transformer. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019; pp. 1–10. [Google Scholar]
- Wang, S.; Li, B.Z.; Khabsa, M.; Fang, H.; Ma, H. Linformer: Self-attention with linear complexity. arXiv 2020, arXiv:2006.04768. [Google Scholar]
- Choromanski, K.M.; Likhosherstov, V.; Dohan, D.; Song, X.; Gane, A.; Sarlos, T.; Hawkins, P.; Davis, J.Q.; Mohiuddin, A.; Kaiser, L.; et al. Rethinking Attention with Performers. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April–2 May 2020; pp. 1–9. [Google Scholar]
- Zaheer, M.; Guruganesh, G.; Dubey, K.A.; Ainslie, J.; Alberti, C.; Ontanon, S.; Pham, P.; Ravula, A.; Wang, Q.; Yang, L.; et al. Big bird: Transformers for longer sequences. Adv. Neural Inf. Process. Syst. 2020, 33, 83–97. [Google Scholar]
- Tay, Y.; Dehghani, M.; Abnar, S.; Shen, Y.; Bahri, D.; Pham, P.; Rao, J.; Yang, L.; Ruder, S.; Metzler, D. Long Range Arena: A Benchmark for Efficient Transformers. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April–2 May 2020; pp. 10–17. [Google Scholar]
- Niklaus, J.; Chalkidis, I.; Stürmer, M. Swiss-Judgment-Prediction: A Multilingual Legal Judgment Prediction Benchmark. arXiv 2021, arXiv:2110.00806. [Google Scholar]
- Chalkidis, I.; Jana, A.; Hartung, D.; Bommarito, M.; Androutsopoulos, I.; Katz, D.M.; Aletras, N. LexGLUE: A Benchmark Dataset for Legal Language Understanding in English. arXiv 2021, arXiv:2110.00976. [Google Scholar] [CrossRef]
- Xiao, C.; Hu, X.; Liu, Z.; Tu, C.; Sun, M. Lawformer: A pre-trained language model for chinese legal long documents. AI Open 2021, 1, 79–84. [Google Scholar] [CrossRef]
- Luo, B.; Feng, Y.; Xu, J.; Zhang, X.; Zhao, D. Learning to predict charges for criminal cases with legal basis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 2727–2736. [Google Scholar]
- Hu, Z.; Li, X.; Tu, C.; Liu, Z.; Sun, M. Few-shot charge prediction with discriminative legal attributes. In Proceedings of the 27th Conference on Computational Linguistics and Speech Processing, Santa Fe, NM, USA, 20–26 August 2018; pp. 487–498. [Google Scholar]
- Xu, N.; Wang, P.; Chen, L. Distinguish Confusing Law Articles for Legal Judgment Prediction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3086–3095. [Google Scholar]
- Kipf, T.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the 2017 International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–14. [Google Scholar]
- Kort, F. Predicting supreme court decisions mathematically: A quantitative analysis of the right to counsel cases. Am. Political Sci. Rev. 1957, 51, 1–12. [Google Scholar] [CrossRef]
- Wang, H.; He, T.; Zou, Z.; Shen, S.; Li, Y. Using case facts to predict accusation based on deep learning. In Proceedings of the QRS-C, Sofia, Bulgaria, 22–26 April 2019; pp. 133–137. [Google Scholar]
- Liu, Z.; Tu, C.; Sun, M. Legal cause prediction with inner descriptions and outer hierarchies. In Proceedings of the Chinese Computational Linguistics, Beijing, China, 17–20 October 2019; pp. 573–586. [Google Scholar]
- Li, S.; Zhang, H.; Ye, L.; Guo, X.; Fang, B. Mann: A multichannel attentive neural network for legal judgment prediction. IEEE Access 2019, 7, 151144–151155. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, P.; Zhang, L.; Shou, L.; Xu, W. A recurrent attention network for judgment prediction. In Proceedings of the International Conference on Artificial Neural Networks, Munich, Germany, 17–19 September 2019; pp. 253–266. [Google Scholar]
- Ma, L.; Zhang, Y.; Wang, T.; Liu, X.; Ye, W.; Sun, C.; Zhang, S. Legal Judgment Prediction with Multi-Stage Case Representation Learning in the Real Court Setting. In Proceedings of the ACM SIGIR, Online, 11–15 July 2021; pp. 993–1002. [Google Scholar]
- Chen, H.; Cai, D.; Dai, W.; Dai, Z.; Ding, Y. Charge-Based Prison Term Prediction with Deep Gating Network. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 6361–6366. [Google Scholar]
- Pan, S.; Lu, T.; Gu, N.; Zhang, H.; Xu, C. Charge prediction for multidefendant cases with multi-scale attention. In Proceedings of the CCF Conference on Computer Supported Cooperative Work and Social Computing, Kunming, China, 16–18 August 2019; pp. 766–777. [Google Scholar]
- Kang, L.; Liu, J.; Liu, L.; Shi, Q.; Ye, D. Creating auxiliary representations from charge definitions for criminal charge prediction. arXiv 2019, arXiv:1911.05202. [Google Scholar]
- Xiao, C.; Zhong, H.; Guo, Z.; Tu, C.; Liu, Z.; Sun, M.; Feng, Y.; Han, X.; Hu, Z.; Wang, H.; et al. Cail2018: A large-scale legal dataset for judgment prediction. arXiv 2018, arXiv:1807.02478. [Google Scholar]
- Jafar, O.; Ramakrishnan, S. A Study of Bio-inspired Algorithm to Data Clustering using Different Distance Measures. Int. J. Comput. Appl. 2013, 66, 33–44. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Li, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, QC, Canada, 30 April–3 May 2018. [Google Scholar]
- Suykens, J.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Yoon, K. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Lai, S.; Xu, L.; Liu, K. Recurrent convolutional neural networks for text classification. In Proceedings of the 29th National Conference on Artificial Intelligence, Austin, TX, USA, 25–29 January 2015; pp. 2267–2273. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C. Hierarchical Attention Networks for Document Classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Zhong, H.; Guo, Z.; Tu, C.; Liu, Z.; Sun, M. Legal Judgment Prediction via Topological Learning. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31–4 November 2018; pp. 3540–3549. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | CAIL-Small | CAIL-Big |
|---|---|---|
| Training Set Cases | 101,690 | 1,588,768 |
| Test Set Cases | 20,338 | 185,212 |
| Law Articles | 103 | 118 |
| Charges | 119 | 130 |
| Terms of Penalty | 11 | 11 |
| Hardware Name | Parameter Description | Quantity |
|---|---|---|
| CPU | Intel Core i7-10700K | 2 |
| GPU | NVIDIA Tesla V100 32 G | 1 |
| Memory | Lenovo 16 G | 2 |
| SSD | SAMSUNG 512 G | 1 |
| Hard Disk | Seagate 1 TB | 2 |
| Software Name | Parameter Description |
|---|---|
| Ubuntu 16.04 | |
| Pycharm 2020 | |
| 3.8 | |
| 1.7.0 | |
| 0.3 |
| Law Articles | Charges | Term of Penalty | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc. | MP | MR | F1 | Acc. | MP | MR | F1 | Acc. | MP | MR | F1 | |
| TFIDF + SVM | 89.93 | 68.56 | 60.58 | 61.25 | 85.81 | 69.76 | 61.92 | 63.51 | 54.13 | 39.15 | 37.62 | 39.14 |
| FLA | 93.22 | 72.81 | 64.27 | 66.57 | 92.48 | 76.21 | 68.12 | 69.97 | 57.66 | 49.01 | 44.87 | 46.62 |
| CNN | 95.79 | 82.79 | 75.15 | 76.62 | 95.23 | 86.57 | 78.93 | 81.02 | 55.41 | 45.23 | 38.73 | 39.96 |
| RCNN | 95.98 | 82.93 | 75.26 | 77.13 | 95.50 | 87.89 | 79.03 | 81.65 | 55.62 | 45.43 | 38.88 | 40.17 |
| HARNN | 96.01 | 82.99 | 75.58 | 77.38 | 95.62 | 87.93 | 79.27 | 81.79 | 56.11 | 44.21 | 40.57 | 41.87 |
| TOPJUDGE | 95.81 | 84.41 | 74.36 | 76.67 | 95.73 | 87.99 | 79.49 | 81.93 | 57.29 | 47.35 | 42.61 | 44.03 |
| GCN | 95.69 | 84.24 | 74.22 | 76.58 | 95.60 | 87.89 | 79.28 | 81.82 | 57.2 | 47.17 | 42.53 | 43.91 |
| MPBFN | 96.01 | 84.83 | 74.64 | 77.48 | 95.93 | 89.25 | 80.82 | 83.06 | 58.04 | 45.95 | 39.01 | 41.49 |
| LADAN | 96.49 | 85.71 | 80.21 | 81.35 | 96.32 | 88.03 | 82.98 | 84.54 | 59.52 | 51.83 | 45.2 | 46.96 |
| GFDN | 96.51 | 85.74 | 80.23 | 81.39 | 96.42 | 88.05 | 83.12 | 84.64 | 59.54 | 51.84 | 45.21 | 46.99 |
| Law Articles | Charges | Term of Penalty | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc. | MP | MR | F1 | Acc. | MP | MR | F1 | Acc. | MP | MR | F1 | |
| TFIDF + SVM | 76.52 | 43.21 | 40.12 | 39.68 | 79.81 | 45.86 | 42.72 | 42.77 | 33.32 | 27.66 | 24.99 | 24.64 |
| FLA | 77.72 | 75.21 | 74.12 | 72.78 | 80.98 | 79.11 | 77.92 | 76.77 | 36.32 | 30.81 | 28.22 | 27.83 |
| CNN | 78.61 | 75.86 | 74.6 | 73.59 | 82.23 | 81.57 | 79.73 | 78.82 | 35.2 | 32.96 | 29.09 | 29.68 |
| RCNN | 79.12 | 76.58 | 75.13 | 74.15 | 82.50 | 81.89 | 79.72 | 79.05 | 35.52 | 33.76 | 30.41 | 30.27 |
| HARNN | 79.73 | 75.05 | 76.54 | 74.67 | 83.41 | 82.23 | 82.27 | 80.79 | 35.95 | 34.5 | 31.04 | 31.18 |
| TOPJUDGE | 79.79 | 79.52 | 73.39 | 73.33 | 82.03 | 83.14 | 79.33 | 79.03 | 36.05 | 34.54 | 32.49 | 29.19 |
| GCN | 79.81 | 79.65 | 73.42 | 73.37 | 82.33 | 83.19 | 79.20 | 78.97 | 35.97 | 34.66 | 32.54 | 29.23 |
| MPBFN | 79.14 | 76.03 | 71.1 | 72.21 | 82.16 | 83.15 | 80.82 | 80.06 | 35.76 | 31.72 | 28.31 | 29.56 |
| LADAN | 81.17 | 77.92 | 72.43 | 73.79 | 84.02 | 83.18 | 82.08 | 81.04 | 38.05 | 35.97 | 32.15 | 32.33 |
| GFDN | 81.37 | 78.01 | 72.43 | 73.82 | 84.83 | 83.96 | 82.37 | 81.79 | 38.28 | 36.02 | 32.28 | 32.57 |
| Accuracy | Precision | Recall | F1 | |||||
|---|---|---|---|---|---|---|---|---|
| Max | Min | Max | Min | Max | Min | Max | Min | |
| 96.53 ↑ | 96.50↑ | 85.77↑ | 85.73↑ | 80.25↑ | 80.21- | 81.43↑ | 81.37↑ | |
| 81.50 ↑ | 81.21 ↑ | 78.12 ↑ | 77.95 ↑ | 72.52 ↑ | 72.41 ↓ | 73.85 ↑ | 73.80 ↑ | |
| 96.46↑ | 96.39↑ | 88.08↑ | 88.04↑ | 83.19↑ | 83.06↑ | 84.78↑ | 84.59↑ | |
| 85.12↑ | 84.61↑ | 84.27↑ | 83.36↑ | 82.48↑ | 82.15↑ | 81.92↑ | 81.35↑ | |
| 59.57↑ | 59.52- | 51.87↑ | 51.83- | 45.23↑ | 45.19↓ | 47.03↑ | 46.96- | |
| 38.35↑ | 38.19↑ | 36.12↑ | 35.98↑ | 32.37↑ | 32.21↑ | 32.68↑ | 32.46↑ | |
| Metrics | Acc | MR | MR | F1 |
|---|---|---|---|---|
| GFDN | 84.83 | 83.96 | 82.37 | 81.79 |
| 82.35 | 83.27 | 79.37 | 79.91 | |
| 82.40 | 83.19 | 80.28 | 80.52 | |
| 82.58 | 83.29 | 80.37 | 80.83 | |
| 82.69 | 83.35 | 80.51 | 80.91 | |
| 82.67 | 83.30 | 80.77 | 80.93 | |
| 82.69 | 83.38 | 80.55 | 80.96 |
| Metrics | Acc | MR | MR | F1 |
|---|---|---|---|---|
| GFDN | 84.83 | 83.96 | 82.37 | 81.79 |
| 81.96 | 80.38 | 79.11 | 79.32 | |
| 80.67 | 79.96 | 80.13 | 79.06 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Q.; Gao, T.; Zhou, S.; Li, D.; Wen, Y. Legal Judgment Prediction via Heterogeneous Graphs and Knowledge of Law Articles. Appl. Sci. 2022, 12, 2531. https://doi.org/10.3390/app12052531
Zhao Q, Gao T, Zhou S, Li D, Wen Y. Legal Judgment Prediction via Heterogeneous Graphs and Knowledge of Law Articles. Applied Sciences. 2022; 12(5):2531. https://doi.org/10.3390/app12052531
Chicago/Turabian StyleZhao, Qihui, Tianhan Gao, Song Zhou, Dapeng Li, and Yingyou Wen. 2022. "Legal Judgment Prediction via Heterogeneous Graphs and Knowledge of Law Articles" Applied Sciences 12, no. 5: 2531. https://doi.org/10.3390/app12052531
APA StyleZhao, Q., Gao, T., Zhou, S., Li, D., & Wen, Y. (2022). Legal Judgment Prediction via Heterogeneous Graphs and Knowledge of Law Articles. Applied Sciences, 12(5), 2531. https://doi.org/10.3390/app12052531