
Improved U-Net with Residual Attention Block for Mixed-Defect Wafer Maps



Abstract
:1. Introduction
- Applying an attention-guided U-Net for classification of wafer defects.
- Reducing unnecessary human resources and time by generating the ground truth essential for training the segmentation model with an automatic defect masking technique.
- Performing detection of mixed faults using only a single fault using the training of the proposed model.
2. Related Work
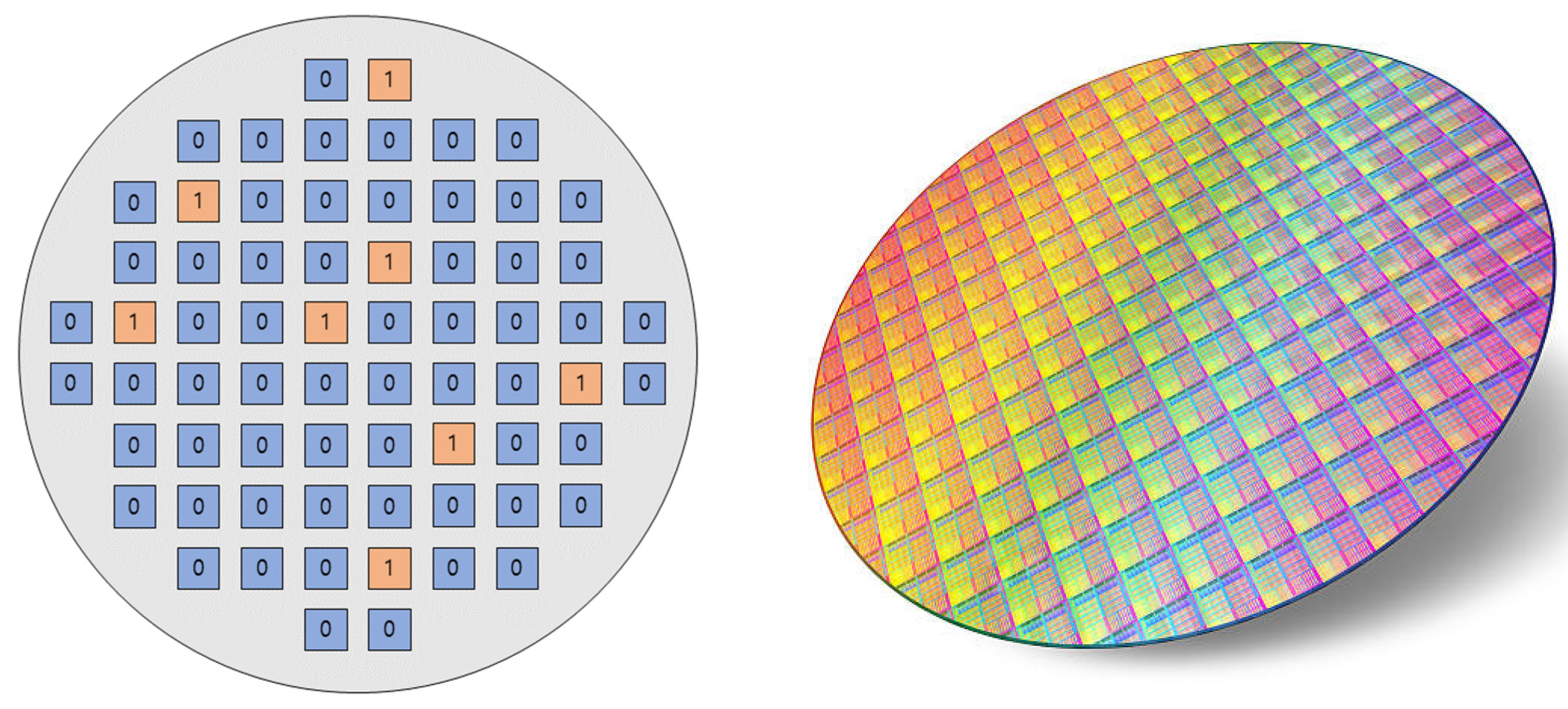
2.1. Semiconductor Wafer Map
2.2. U-Net
2.3. Attention Mechanism
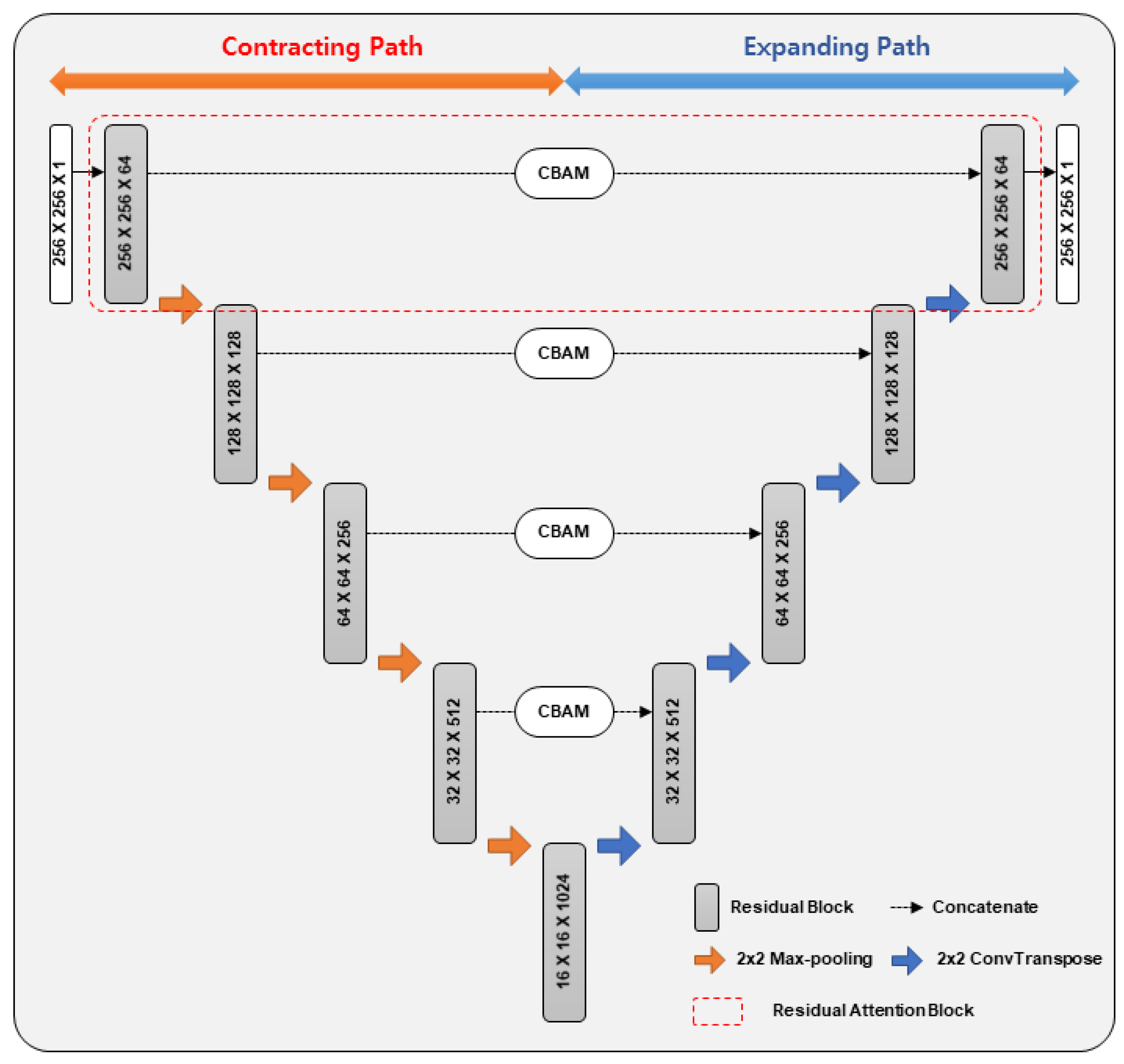
3. Improved U-Net with Residual Attention Block
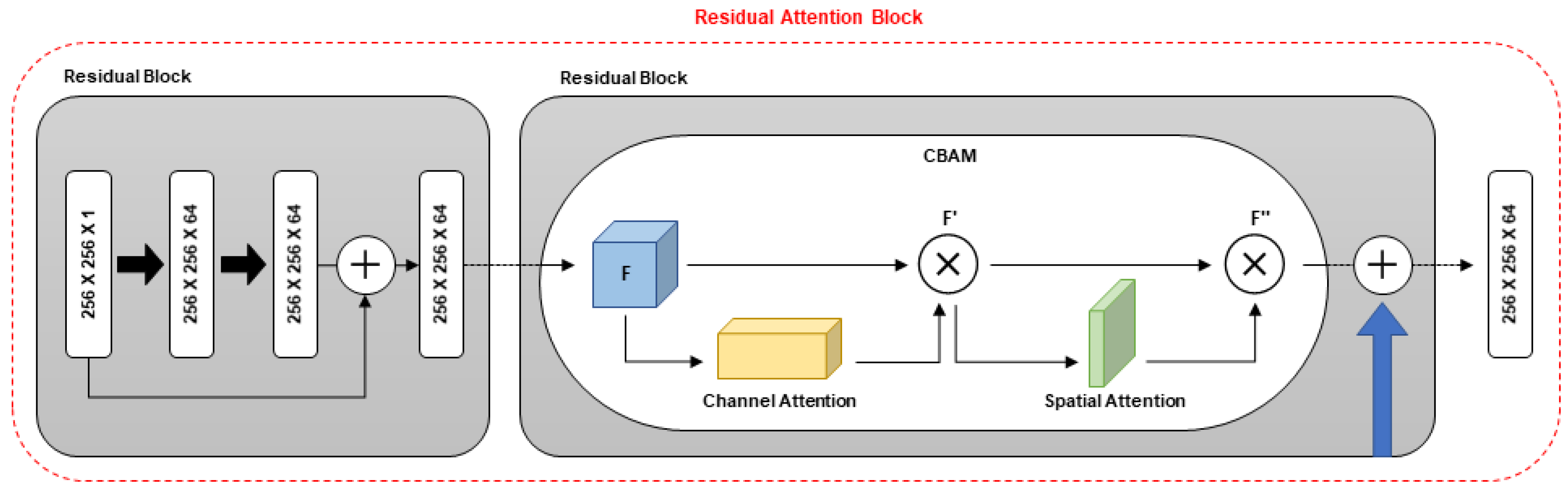
3.1. Network Architecture
3.2. Residual Attention Block
3.3. Contracting Path
3.4. Expanding Path
3.5. Loss Function
4. Experiments and Results
4.1. Experiment Environment
4.2. Dataset
4.2.1. Single Defect
4.2.2. Mixed-Type Defects
4.3. Data Pre-Processing
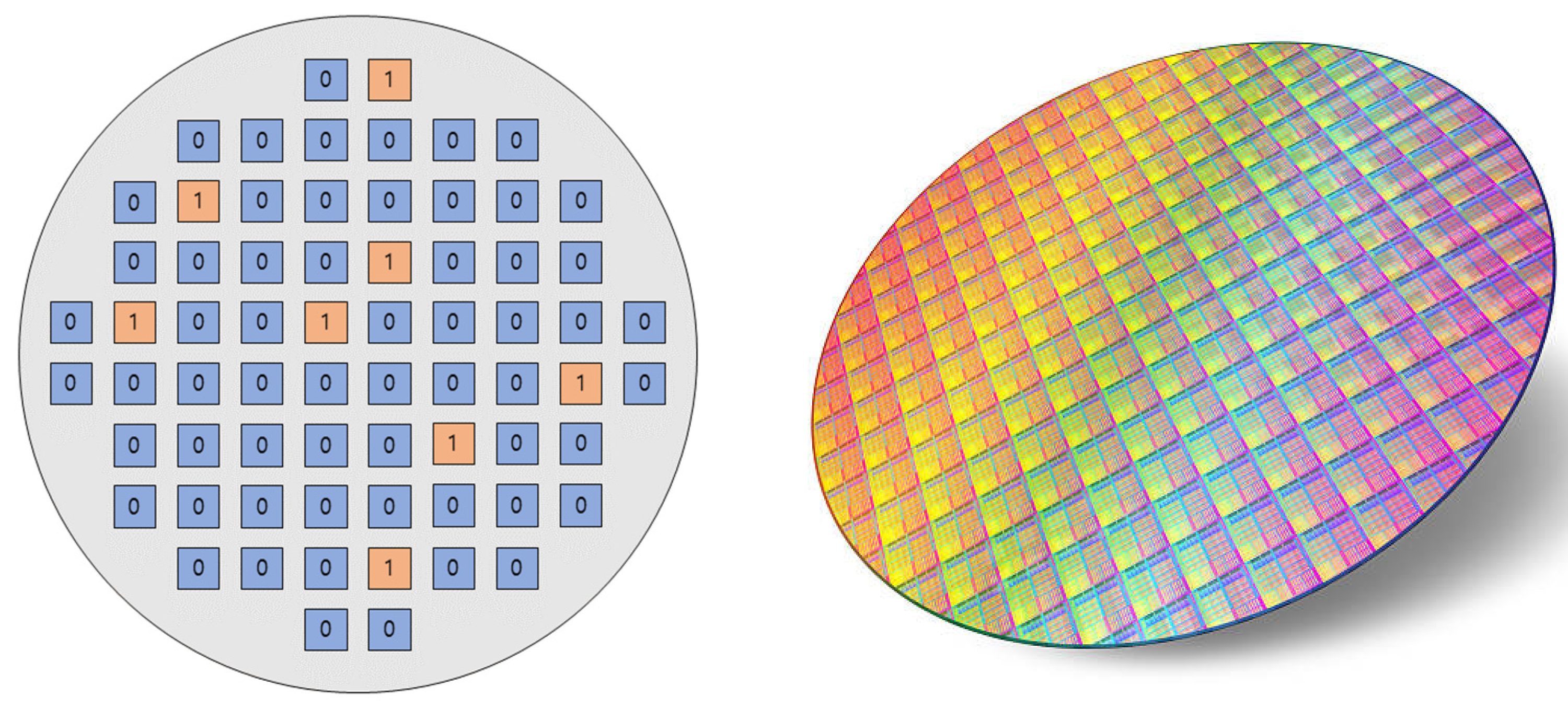
4.3.1. Defect Masking
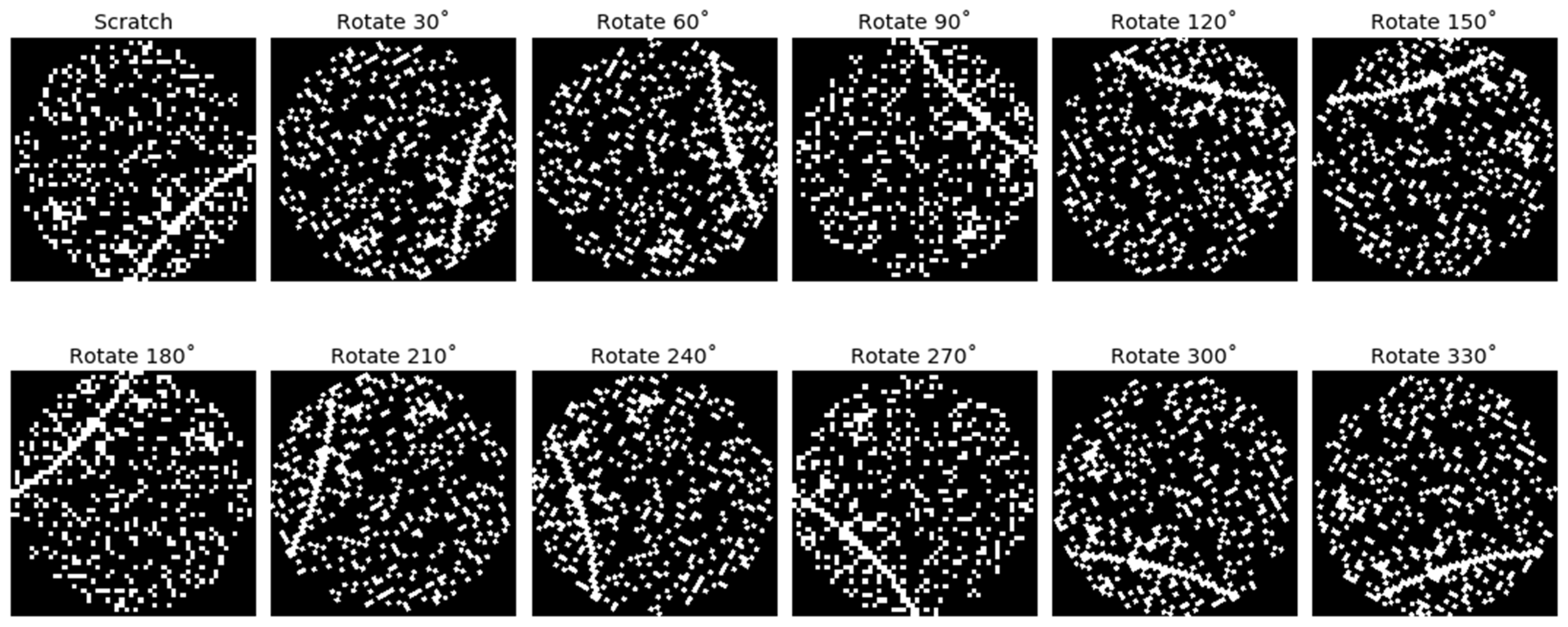
4.3.2. Data Augmentation
4.4. Evaluation Metrics
4.5. Results
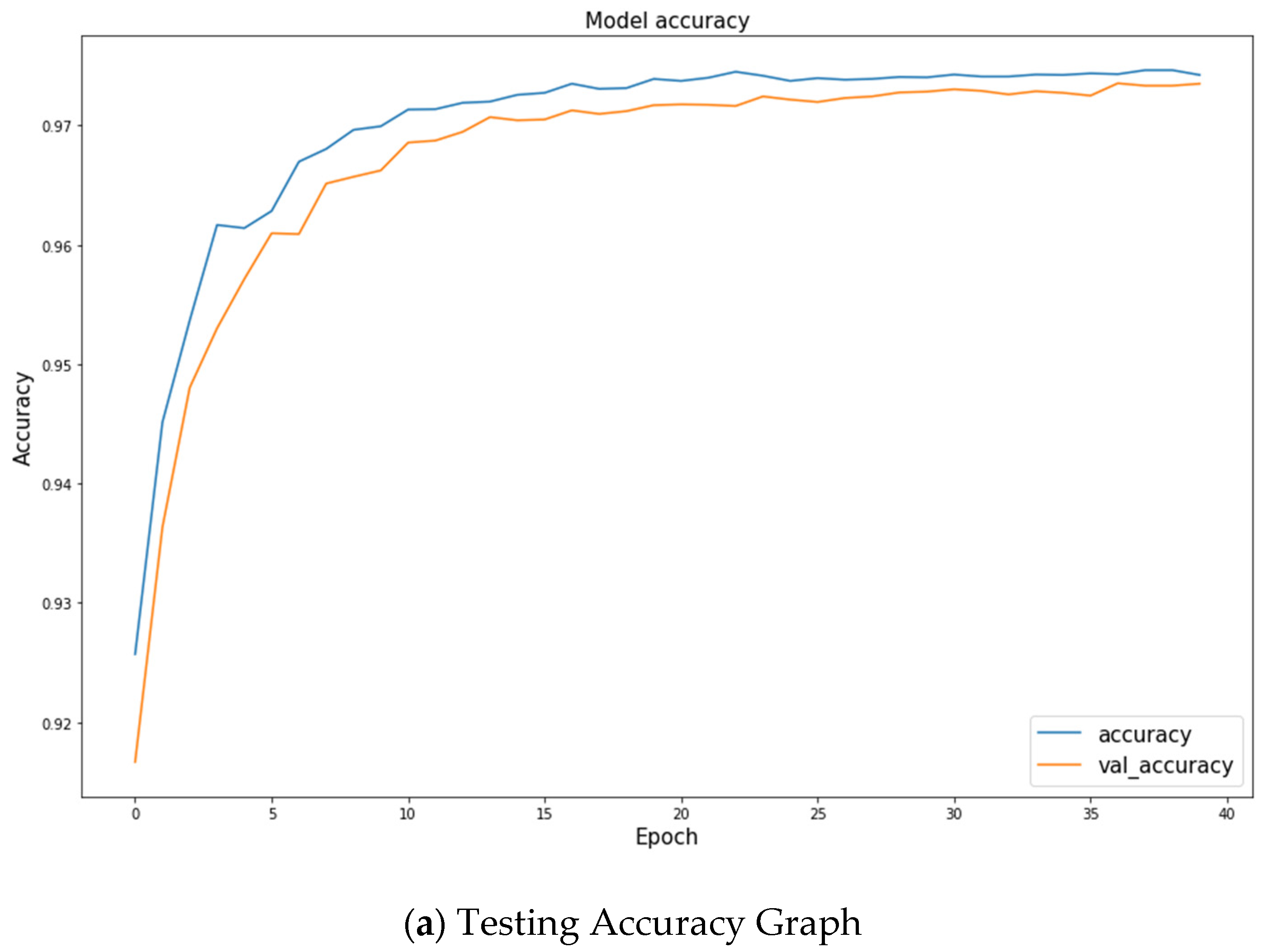
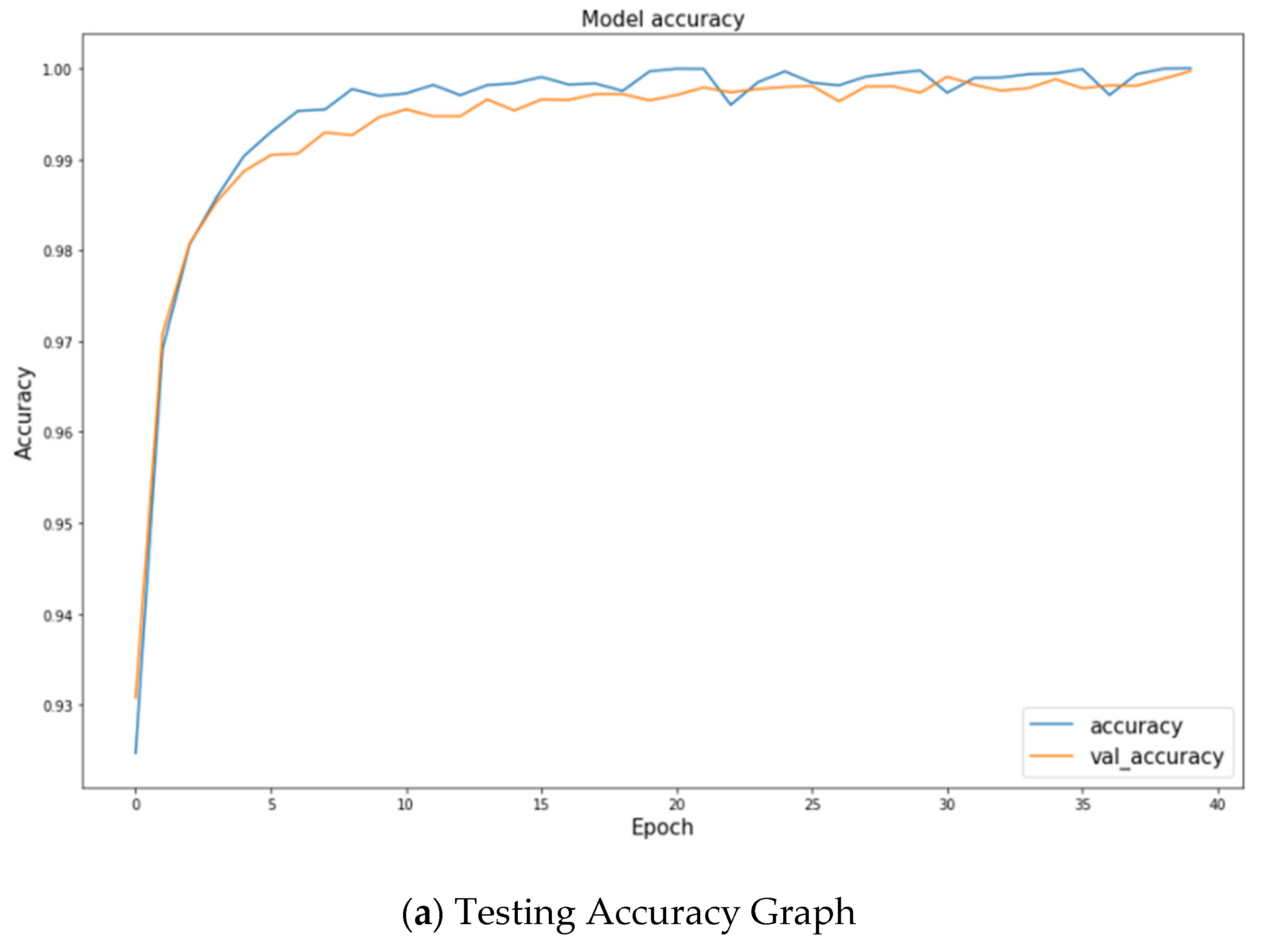
4.5.1. Training Model
4.5.2. Single-Defect Result
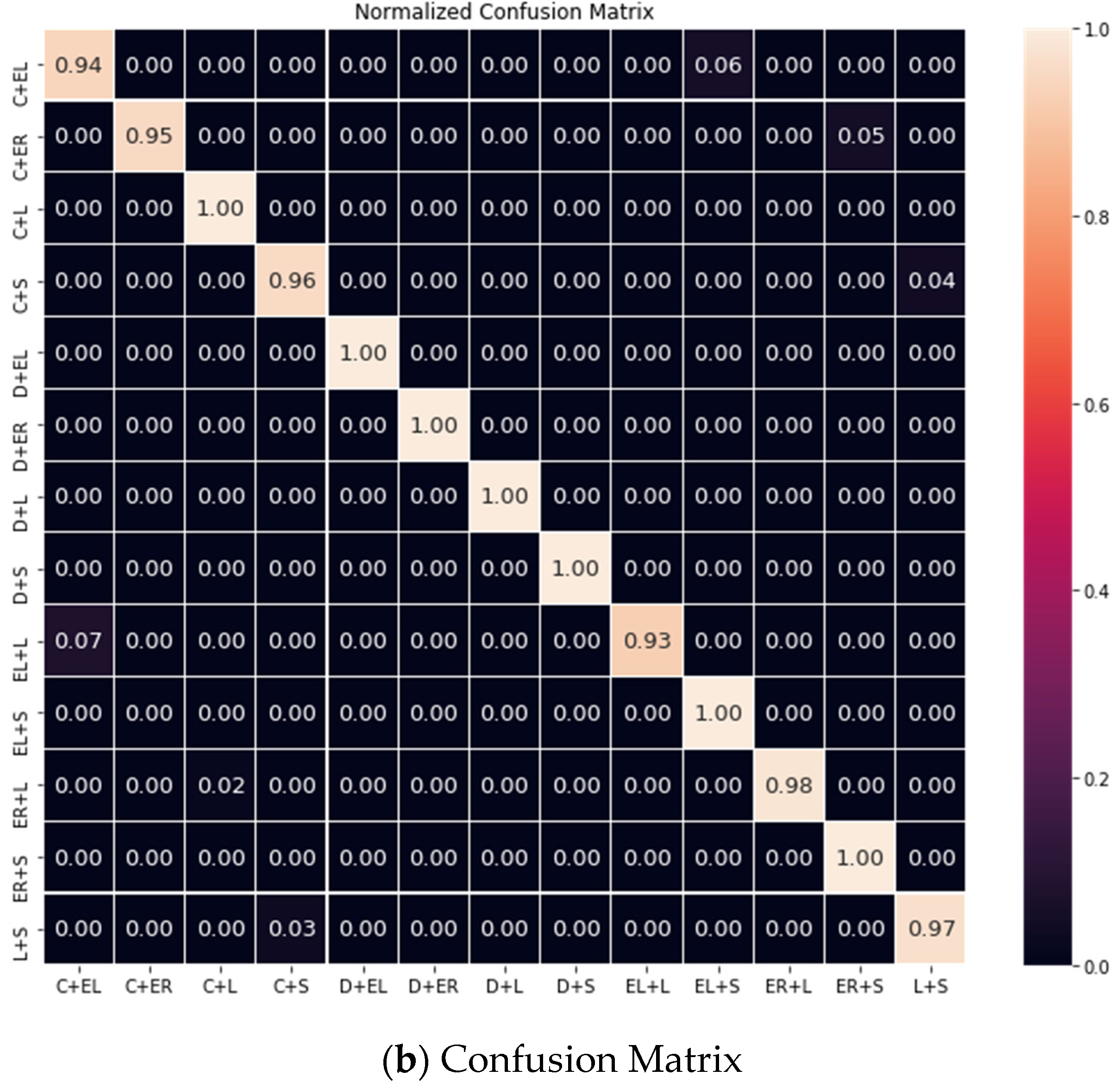
4.5.3. Mixed-Type Defect Result
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fan, S.K.S.; Hsu, C.Y.; Tsai, D.M.; He, F.; Cheng, C.C. Data-driven approach for fault detection and diagnostic in semiconductor manufacturing. IEEE Trans. Autom. Sci. Eng. 2020, 17, 1925–1936. [Google Scholar] [CrossRef]
- Heijne, E.H. Future semiconductor detectors using advanced microelectronics with post-processing, hybridization and packaging technology. Nucl. Instrum. Methods Phys. Res. Sect. A: Accel. Spectrometers Detect. Assoc. Equip. 2020, 541, 274–285. [Google Scholar] [CrossRef] [Green Version]
- Chang, C.H.; Paul, B.K.; Remcho, V.T.; Atre, S.; Hutchison, J.E. Synthesis and post-processing of nanomaterials using microreaction technology. J. Nanoparticle Res. 2008, 10, 965–980. [Google Scholar] [CrossRef]
- Grybos, P. Front-End Electronics for Multichannel Semiconductor Detector Systems; Institute of Electronic Systems, Warsaw University of Technology: Warsaw, Poland, 2020; pp. 132–135. [Google Scholar]
- Sneh, O.; Clark-Phelps, R.B.; Londergan, A.R.; Winkler, J.; Seidel, T.E. Thin film atomic layer deposition equipment for semiconductor processing. Thin Solid Film. 2020, 402, 248–261. [Google Scholar] [CrossRef]
- Qin, S.J.; Cherry, G.; Good, R.; Wang, J.; Harrison, C.A. Semiconductor manufacturing process control and monitoring: A fab-wide framework. J. Process Control 2006, 16, 179–191. [Google Scholar] [CrossRef]
- Kang, S.; Cho, S.; An, D.; Rim, J. Using wafer map features to better predict die-level failures in final test. IEEE Trans. Semicond. Manuf. 2015, 28, 431–437. [Google Scholar] [CrossRef]
- Piao, M.; Jin, C.H.; Lee, J.Y.; Byun, J.Y. Decision tree ensemble-based wafer map failure pattern recognition based on radon transform-based features. IEEE Trans. Semicond. Manuf. 2018, 31, 250–257. [Google Scholar] [CrossRef]
- Jin, C.H.; Na, H.J.; Piao, M.; Pok, G.; Ryu, K.H. A novel DBSCAN-based defect pattern detection and classification framework for wafer bin map. IEEE Trans. Semicond. Manuf. 2019, 32, 286–292. [Google Scholar] [CrossRef]
- Lee, H.; Kim, H. Semi-supervised multi-label learning for classification of wafer bin maps with mixed-type defect patterns. IEEE Trans. Semicond. Manuf. 2020, 33, 653–662. [Google Scholar] [CrossRef]
- Kyeong, K.; Kim, H. Classification of mixed-type defect patterns in wafer bin maps using convolutional neural networks. IEEE Trans. Semicond. Manuf. 2018, 31, 395–402. [Google Scholar] [CrossRef]
- Wang, J.; Xu, C.; Yang, Z.; Zhang, J.; Li, X. Deformable convolutional networks for efficient mixed-type wafer defect pattern recognition. IEEE Trans. Semicond. Manuf. 2020, 33, 587–596. [Google Scholar] [CrossRef]
- Kim, J.; Lee, Y.; Kim, H. Detection and clustering of mixed-type defect patterns in wafer bin maps. IISE Trans. 2018, 50, 99–111. [Google Scholar] [CrossRef]
- Chiu, M.C.; Chen, T.M. Applying Data Augmentation and Mask R-CNN-Based Instance Segmentation Method for Mixed-Type Wafer Maps Defect Patterns Classification. IEEE Trans. Semicond. Manuf. 2021, 34, 455–463. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Chen, X.; Yao, L.; Zhang, Y. Residual attention u-net for automated multi-class segmentation of COVID-19 chest ct images. arXiv 2020, arXiv:2004.05645. [Google Scholar]
- Liu, Y.C.; Shahid, M.; Sarapugdi, W.; Lin, Y.X.; Chen, J.C.; Hua, K.L. Cascaded atrous dual attention U-Net for tumor segmentation. Multimed. Tools Appl. 2021, 80, 30007–30031. [Google Scholar] [CrossRef]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Pathak, A.R.; Pandey, M.; Rautaray, S. Application of deep learning for object detection. Procedia Comput. Sci. 2018, 132, 1706–1717. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional Networks for Biomedical Image Segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Mikołajczyk, A; Grochowski, M. Data augmentation for improving deep learning in image classification problem. In Proceedings of the 2018 international interdisciplinary PhD workshop (IIPhDW), Swinoujscie, Poland, 9–12 May 2018; pp. 117–122.
- Choi, H.; Cho, K.; Bengio, Y. Fine-grained attention mechanism for neural machine translation. Neurocomputing 2018, 284, 171–176. [Google Scholar] [CrossRef] [Green Version]
- Tian, C.; Xu, Y.; Li, Z.; Zuo, W.; Fei, L.; Liu, H. Attention-guided CNN for image denoising. Neural Netw. 2020, 124, 117–129. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Xu, X.; Pang, Y.; Han, J. Multi-layer attention based CNN for target-dependent sentiment classification. Neural Processing Lett. 2020, 51, 2089–2103. [Google Scholar] [CrossRef]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hui, L.; Belkin, M. Evaluation of neural architectures trained with square loss vs cross-entropy in classification tasks. arXiv 2020, arXiv:2006.07322. [Google Scholar]
- Yu, J.; Zheng, X.; Liu, J. Stacked convolutional sparse denoising auto-encoder for identification of defect patterns in semiconductor wafer map. Comput. Ind. 2019, 109, 121–133. [Google Scholar] [CrossRef]
- Seliya, N.; Khoshgoftaar, T.M.; Van Hulse, J. A study on the relationships of classifier performance metrics. In Proceedings of the 2009 21st IEEE International Conference on Tools with Artificial Intelligence, Newark, NJ, USA, 2–4 November 2009; pp. 59–66. [Google Scholar]
- Rácz, A.; Bajusz, D.; Héberger, K. Multi-level comparison of machine learning classifiers and their performance metrics. Molecules 2019, 24, 2811. [Google Scholar] [CrossRef] [Green Version]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hardware Environment | Software Environment |
|---|---|
| CPU: Intel Core i7-8700k, 3.7 Ghz, Six-core twelve threads 16 GB GPU: Geforce GTX 1080Ti | Window Tensorflow 2.0 Python 3.7 |
| Defect Type | Accuracy | F1-Score | IoU |
|---|---|---|---|
| Center | 1.000 | 0.987 | 0.742 |
| Donut | 1.000 | 1.000 | 0.721 |
| Edge-Loc | 1.000 | 0.974 | 0.650 |
| Edge-Ring | 1.000 | 1.000 | 0.686 |
| Loc | 0.995 | 0.976 | 0.712 |
| Scratch | 0.987 | 0.982 | 0.720 |
| Defect Type | Accuracy | F1-Score | IoU |
|---|---|---|---|
| Two-types Mixed | 0.979 | 0.982 | 0.645 |
| Three-types Mixed | 0.962 | 0.953 | 0.582 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cha, J.; Jeong, J. Improved U-Net with Residual Attention Block for Mixed-Defect Wafer Maps. Appl. Sci. 2022, 12, 2209. https://doi.org/10.3390/app12042209
Cha J, Jeong J. Improved U-Net with Residual Attention Block for Mixed-Defect Wafer Maps. Applied Sciences. 2022; 12(4):2209. https://doi.org/10.3390/app12042209
Chicago/Turabian StyleCha, Jaegyeong, and Jongpil Jeong. 2022. "Improved U-Net with Residual Attention Block for Mixed-Defect Wafer Maps" Applied Sciences 12, no. 4: 2209. https://doi.org/10.3390/app12042209
APA StyleCha, J., & Jeong, J. (2022). Improved U-Net with Residual Attention Block for Mixed-Defect Wafer Maps. Applied Sciences, 12(4), 2209. https://doi.org/10.3390/app12042209