1. Introduction
Emotion expression and perception is a very important issue in human interactions and is one of the bases upon which the communication between humans is established. Therefore, the automatic detection of emotions by a computer has become a very attractive topic due to its impact on the effort towards more natural and empathic human–machine interaction systems. Emotions can be expressed in different ways, including facial expression, speech, gestures, etc. In this work, we focus on speech and its ability to provide diverse information.
In addition to the message communicated, speech signals can provide information related to different aspects of the speaker. In fact, speech signals can give insights into the emotional state of the speaker or even their baseline mood, as shown in many studies about this issue [
1,
2]. The probability of suffering from a disease, such as depression, Alzheimer’s disease [
3,
4,
5], or even COVID-19 [
6], can also be extracted from speech. However, speech may also be influenced by several other variables, such as the speaker’s habits, personality, culture, or specific objective [
7,
8].
Human–human interactions take place in specific contexts where, to some extent, people know each other. However, current artificial agents have little capacity to imitate a real user, resulting in shallow interactions [
9]. In fact, users find it hard to interact with agents with rudimentary visual and speech capacities [
10]. The literature suggests that human behavior in human–human interactions is guided by the other human’s behavior and is, thus, reactionary behavior [
11]. However, comparisons between these two scenarios have almost only been carried out at the interaction and dialogue levels [
9,
11]. The emotional exchange in both scenarios is completely different due the rudimentary emotional capacity of the agent, which results in very subtle emotions. This work aims to contrast the similarities and differences for emotions identified in two very different scenarios: human–human interactions on Spanish TV debates (TV Debates) and human–machine interactions with a virtual agent developed by the H2020 EMPATHIC project (
http://www.empathic-project.eu, accessed on 3 February 2022) (Empathic VA), also in Spanish. Thus, we profile the task in each scenario or, more specifically, the speakers involved in each task. Although they are quite different, they both share the spontaneity of speech, as well as the spontaneity of the expression of emotions in real scenarios [
12].
Disfluencies or spontaneous speech events, such as filled pauses or speech repairs, enrich spontaneous communication [
13] with paralinguistic information that depends on the context, on the speaker profile, and on emotional state. In recent years, research on spontaneously expressed emotions in everyday tasks has gained interest in the scientific community [
14,
15]. However, this research has typically been conducted on emotions simulated by professional actors in artificially designed databases such as EMODB [
16] or IEMOCAP [
17]. The six basic emotions defined by Eckman [
18] (anger, surprise, disgust, enjoyment, fear, and sadness) can be represented by facial expressions that typically characterize these emotions and thus can be used in the automatic identification of emotions on a face [
19]. However, spontaneous emotions are more varied and complex. Furthermore, emotions expressed during acting or during a real-life scenario show significant differences [
20]. In fact, only a small set of complex and compound emotions [
21] can be found in real scenarios [
2,
15,
22], and this subset is strongly dependent on the situation. Therefore, a set of categories including the emotions that arise in each specific task has to be defined. To this end, some perception experiments have to be conducted to specify the set of emotions of interest. However, this process is expensive; time consuming; and sometimes, not viable. Alternatively, and assuming that ordinary communication involves a variety of complex feelings that cannot be characterized by a reduced set of categories, a number of researchers [
23,
24] proposed a dimensional representation [
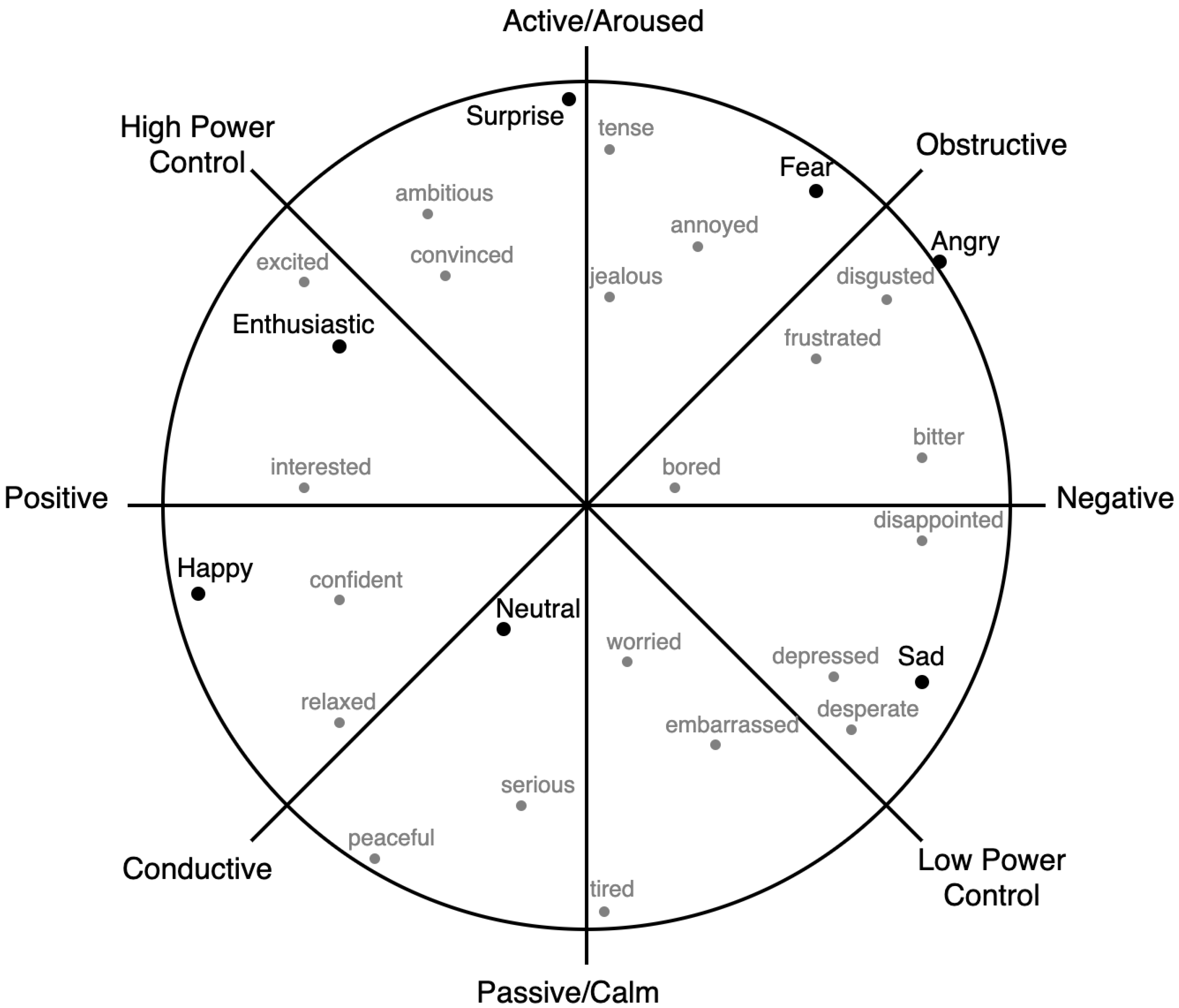
25] of the emotional space. Thus, each affective state is represented by a point in a two-dimensional space, namely valence and arousal, which space some authors extend to three dimensions by also considering dominance (also known as the VAD model). This work employs both approaches to analyze emotional information.
Additionally, spontaneous emotions cannot be unambiguously perceived, not even by experts. In fact, the emotional label assigned by a speaker to their own utterances might differ from those assigned by a listener, with the former being, of course, more accurate [
26]. In this work, we draw from some works dealing with the annotation of a virtual agent [
22,
27] that provide insights into the problems associated with this kind of annotation. The intrinsic subjectivity of this task makes obtaining a ground truth for emotional states associated with an audio signal using either the categorical or the dimensional model difficult. According to some work, such as the one presented in [
28], this subjectivity cannot be properly gathered when experts label emotions; therefore, a more useful representation based on the interpretation of emotions across a crowd should be used. In this work, crowd annotations, using a crowdsourcing platform [
29], was carried out to obtain emotional labels for both the VAD and categorical models. This methodology led to two corpora for each task: (a) TV debates labeled in terms of discrete categories, (b) TV debates labeled in terms of the VAD model, (c) empathic VAs labeled in terms of discrete categories, and (d) empathic VAs labeled in terms of the VAD model.
In the context of interactions, annotations are usually carried at the turn or dialogue levels [
9]. However, the debate on the minimum temporal length of the audio for which the emotions can be extracted reliably remain open. This length has usually been set in tuning experiments for a particular situation [
26]. In contrast, in this work, we propose utterances compatible with clauses as segments to be annotated and develop an algorithm to obtain them from speech signal.
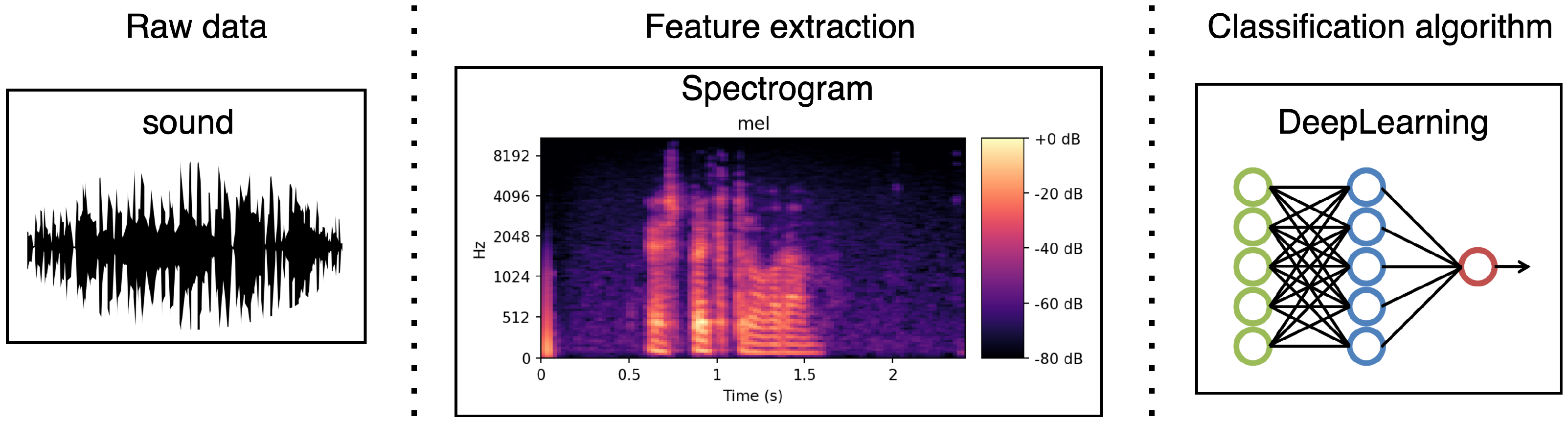
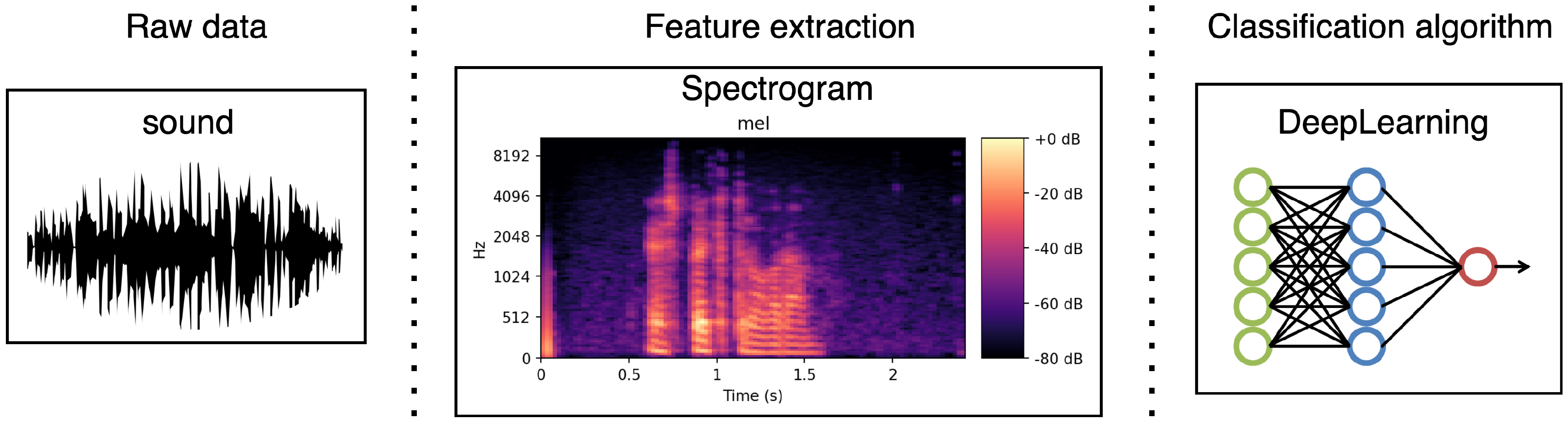
Once a labeled corpus is designed, a machine learning-based system can be built to carry out automatic emotion detection. One of the first steps in creating such a system is to identify which acoustic features are the most suitable for detecting emotions. In recent years, promoted by challenges such as the INTERSPEECH Computational Paralinguistic Challenge [
30], several attempts have been made to obtain such a set, such as the minimalist set of GeMAPS speech features proposed in [
31]. However, several studies [
32,
33] suggested that no universal acoustic features that extract emotional content and work well in all contexts exist. Low-level descriptors (LLD) [
33,
34] based on characteristics related to prosody (pitch, formants, energy, jitter, and shimmer) or to the spectrum (centroid, flux, and entropy), and its functionals (mean, std, quartiles 1–3, delta, etc.) have been widely used. Alternatively, some authors avoided LLD features and let a neural network extract the emotional features in the first layers using other speech representations, such as a spectrogram [
35,
36,
37] or a raw audio signal [
38]. Moreover, the rise in the self-supervised learning paradigm and the recently proposed transformer architecture [
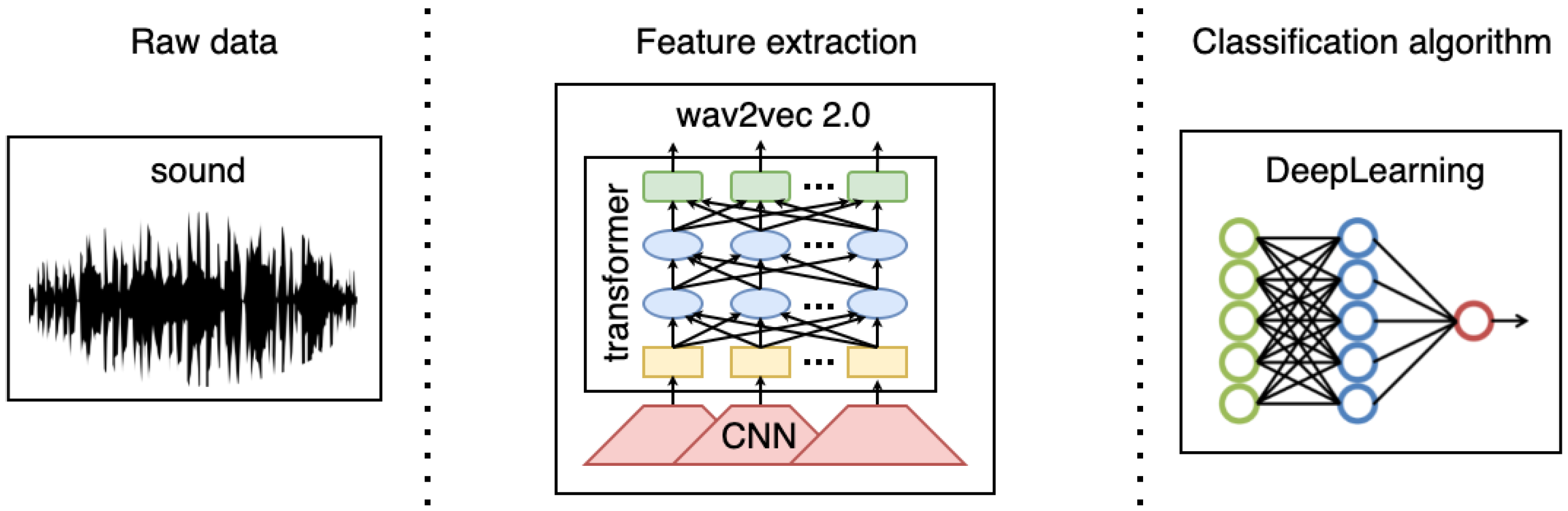
39], have led to novel speech representations, such as wav2vec [
40,
41] or HuBERT [
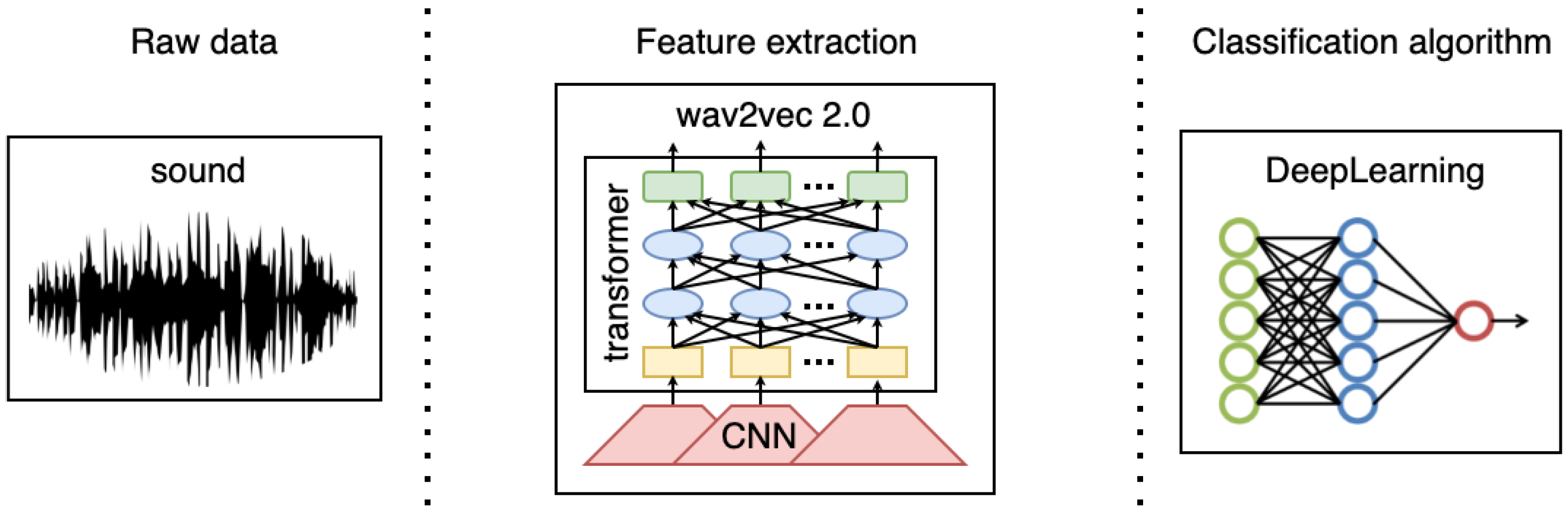
42]. These representations were extracted from raw audio and can be used to feed a neural network. In this work, we primarily design and build a deep neural network architecture fed with a spectrogram. Furthermore, we also provide some preliminary experiments for which the network is fed with the wav2vec model to obtain preliminary insights into such an approach to working with the tasks tackled in this work.
Within this framework in which the perception, modeling, and detection of emotions constitute a challenge, the main contributions of this work can be summarized as follows:
An in depth analysis of the emotions arising in two different scenarios as a way of profiling the speakers associated with a task using both the categorical and the VAD model to represent the emotional state.
Two Spanish corpora are emotionally labeled by the crowd, where spontaneous emotions can be found instead of acted ones.
An emotion-detection system based on deep learning is specifically designed to the tasks considered. In this framework, this paper discusses the issues derived from the detection of realistic emotions in Spanish tasks as an attempt to progress research on emotion detection.
The preliminary experiments aimed to evaluate the convenience of the recent wav2vec representation of speech for the automatic detection of spontaneous emotions in Spanish Language.
This paper is structured as follows:
Section 2 describes the tasks and the associated corpora tackled in this work (
Section 2.1) and provides insights into the annotation procedure (
Section 2.2) as well as insights into the design of the automatic detection system including the neural network architecture (
Section 2.3). In
Section 3, the results obtained in terms of both an analysis of emotions (
Section 3.1) and the classification performance (
Section 3.2) are given. Finally,
Section 4 provides a discussion of the results.
3. Analysis of Emotions and Classification Results
For this section, we conducted an analysis of the emotions perceived by the annotators in the different tasks, and then, different series of classification experiments were carried out.
3.1. Analysis of Emotions
First, the categorical model annotation was analyzed.
Table 5 shows the list of categories for each task along with the percentage of samples in each category in descending order. A minimum agreement of 0.6 (3/5) was requested to consider a sample to be valid, as mentioned above. Moreover, a minimum number of samples (1% of the total) was required in each class. These requirements led to a reduction in the valid samples, resulting in a set of 1266 samples for the TV Debates dataset and 4023 for the Empathic VA dataset when considering the categorical model. This table shows that different categories are predominant in each of the corpora. Some of them could be considered equivalent, such as calm/indifferent and calm/bored/tired, which are the most frequent categories in both sets. However, annoyed/tense, for instance, is the second most frequent class in the TV Debates dataset but was almost last in the Empathic VA dataset. In the same way, puzzled is almost absent (included in others) in the list for the TV Debates dataset.
Table 5 also shows that both datasets are imbalanced, with the calm category being the majority class, with more than 70% of the samples. This reflects the spontaneous nature of the data, showing that, most of the time, people do not show extreme emotions. Moreover, more positive emotions, such as happy/amused, appear in the Empathic VA annotations and more negative emotions, such as annoyed/tense, appear in the TV Debates set. This difference comes from the specific nature of the tasks. During political debates (human–human interactions), people try to convince or even impose their opinions on other interlocutors. However, during coaching sessions (human–machine interaction), speakers are quiet and pay attention to the virtual agent while preparing their next exchange.
As mentioned above, all of the samples were considered for the VAD model.
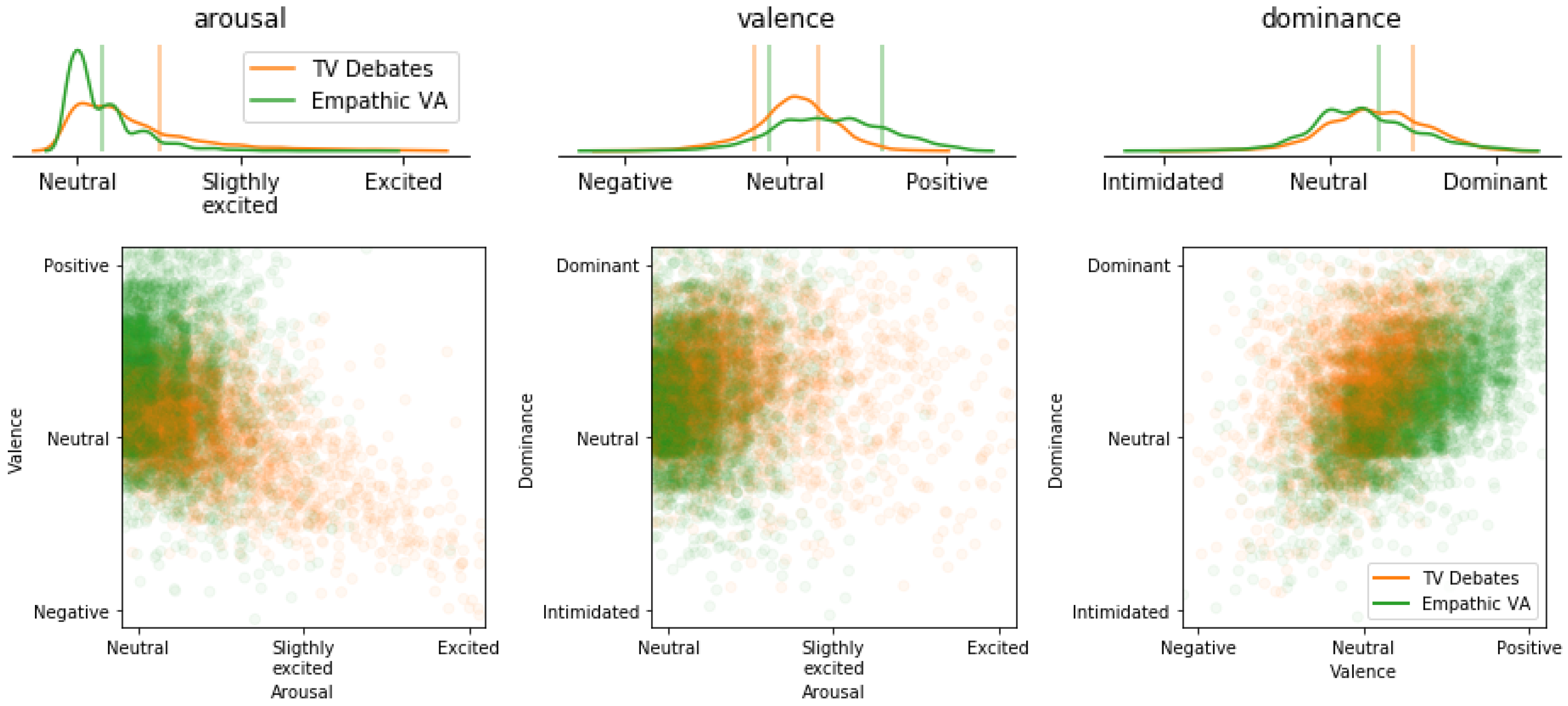
Figure 6 shows the probability density function of each variable (valence, arousal, and dominance) that was obtained by a Gaussian kernel density estimator (upper row).
Figure 6 also shows different 2D projections of the sample distribution in the 3D space (row below), representing each scenario in a different color. When regarding arousal, the Empathic VA dataset works in a very neutral scenario, where excitement is almost absent. In TV debates, although neutrality is also predominant, some excitement is perceived due to the nature of debates. The distribution of valence also shows a clear deviation towards positive values for the Empathic VA scenario, which is an indicator of the good acceptance of the system among users, whereas in TV debates, neutrality is predominant, with only a slight nuance towards positiveness. On the contrary, dominance is shifted towards dominant values in TV debates but remains neutral when users interact with the Empathic VA case. These results correlate well with the types of audio we deal with in the two scenarios. In the TV debates, people express themselves without becoming angry (low levels of excitement) but in a very assertive way (quite high dominance levels). Additionally, they appear to be neutral when communicating their opinions (valence tends to be neutral or slightly positive). In the Empathic VA scenario, the users are volunteers with a good predisposition and seem to be pleased with the system (positive valence values). They are relaxed while talking to the agent (levels of excitement tend toward neutrality) and are not intimidated (dominance values are around neutrality, with a slight shift to the right). The differences between human–human and human–machine interactions are also noticeable in the specific tasks we are dealing with. Human–human communication appears to be more intense and emotional, with higher arousal and dominance values. During communication with a machine, on the contrary, people are not confident and they tend to be expectant, which might be translated into low values of arousal/dominance and higher values of valence.
The two models, categorical and VAD, were also considered together. Each category was represented in the 3D VAD space for comparison purposes. Specifically, the average of the valence, arousal, and dominance values of all of the audios labeled within a specific category was computed, and the resulting value was represented as a point in the 3D space.
Figure 7 shows a 2D projection of the resulting representation. If we focus on the TV Debates dataset, we notice that interested and worried, the least representative categories, according to
Table 5, are very close to the category with the highest number of samples, calm/indifferent, in all of the 2D projections (the purple, orange, and deep-blue points), so they were merged into only one category. The same happens with enthusiastic and satisfied (light-blue and green points). Overall, three different categories were finally considered for the TV Debates dataset. With regard to the Empathic VA scenario, puzzled and sad were merged into a single category because they are extremely close in all three projections, as shown in
Figure 7. Thus, the final set of categories used for the classification experiments reported in this work are shown in
Table 6.
The distribution of categories is quite different for both sets due to the nature of the scenarios (see
Table 6). For instance, annoyed/tense, although present in both tasks, has a very different significance in the TV Debates dataset (almost 15%) and in the Empathic VA dataset (less than 3%). Puzzled was not considered in the TV Debates dataset due to the low number of samples labeled with that emotion, but it entails 3% of the samples in the Empathic VA dataset. Moreover, the final category, puzzled + sad, represented by the union of brown and purple points (low levels of valence and dominance) is not represented in the TV Debates dataset and is slightly separated from the other categories in the Empathic VA scenario. Moreover,
Figure 7 shows that the location of annoyed/tense (red point, which is in fact quite separated from the other categories) is closer to neutrality in the Empathic VA scenario (lower excitement levels and lower negative values of valence) than in the TV Debates dataset, meaning that this negative feeling is softer when interacting with the machine and within this specific scenario.
This correlates well with the idea that people interacting with the Empathic VA scenario are not angry with the system, and if they experience any anger, their feelings are more related to annoyance, which is quite common during debates. Furthermore, speakers in debates do not usually show that they are in an unexpected situation (puzzled), since this emotion can be interpreted as weakness, while it is often shown in interactions with machines. In fact, puzzled was detected in the Empathic VA scenario. Categories such as calm also had a similar location in both scenarios, but with higher values of valence for the Empathic VA interactions; what the annotators perceived as calm tend to be more positive in the Empathic VA scenario than in the TV Debates scenario. The same occurs with enthusiastic + satisfied from the TV Debates scenario and with happy/pleased from the Empathic VA scenario, which although are very close in location in both scenarios (with very similar meanings), happy/pleased seems to have more positive valence values than enthusiastic + satisfied but a bit lower dominance and arousal values.
3.2. Classification Results
Some classification experiments were carried out for the tasks described in
Section 2.1. In the TV Debates dataset, 1266 chunks were selected and distributed into the three categories mentioned above (CALM, ANN, and ENT), and for the Empathic VA, 4023 samples were selected and divided into four categories (CALM, HAPPY, ANN, and PUZZ).
When using the dimensional model, previous studies showed that trying to predict a specific value in 3D space (as a regression problem) leads to very poor results [
2,
15] due to the scarcity of data and the tendency toward neutrality. To solve this problem, a discretization of each dimension was carried out and the regression problem was converted into a classification one. The discrete levels were selected according to the distributions of the annotated data in
Figure 6, with orange lines as selected frontiers for the TV Debates dataset and green lines selected for the Empathic VA dataset.
According to the top row displayed in
Figure 6, arousal can be approximated by a log-normal distribution with a longer tail towards higher values of excitement. Thus, we decided to discern between only two values: neutral and excited. The thresholds (0.25 for TV Debates and 0.075 for Empathic VA) were selected to keep the classes as balanced as possible without distorting the limits imposed by the density function form.
In the case of valence, three categories were kept because of their similarity to a Gaussian distribution. The decisions related to these thresholds also avoided the imbalance problem. In the TV Debates set, since many of the samples are neutral, the values outside the limits [0.4, 0.6] were considered negative or positive samples respectively. The Empathic VA corpus was slightly more positive, and as a consequence, the limits were shifted towards the more positive values 0.45 and 0.8, respectively.
Finally, the dominance distribution was similar to a Gaussian distribution. However, it shifted towards dominant values; intimidated samples were almost absent. Consequently, only two categories were considered: dominant and neutral. The cutoff limit between neutral samples and dominant ones was set to 0.75 for the TV Debates dataset and to 0.65 for the Empathic VA dataset, which was the less dominant corpus.
Once the aforementioned discretization was applied, the distribution of samples in the different classes remained, as
Table 7 shows.
The classification results for the TV Debates and Empathic VA datasets are given in
Table 8. The experiments were carried out by considering the categorical and VAD models in an independent way. In both series, the spectrogram represented the speech signal. Different evaluation metrics were given to provide better insight into the capabilities of the neural network in predicting: the accuracy (ACC), precision (P), recall (R), and
-score (
). Since we dealt with a multi-class classification problem, weighted and macro averages were considered. Macro
is the average of the
-scores for all classes; thus, it penalizes imbalanced datasets, which was the case in this work. It was computed as shown in Equation (
1):
where
is the number of classes and
is the
-score computed assuming that the
i-th class is the positive one and that the negative one is composed by the remaining classes.
In weighted
(
) (Equation (
2)) instead, the
-scores were calculated for each label, and then, their average is weighted with the number of true instances for each label.
where
is the number of samples in
class and
n is the total number of samples in the test set.
Note that, hereafter, macro averages are denoted as P, R, and , whereas weighted averages are denoted as , , and .
In the results associated with the TV Debates experiments, a macro
-score of 0.56 was achieved in the categorical model. Interestingly, all of the evaluation metrics (P, R, and
) provided results in the same range and were quite compensated for. Weighted
(
) provided better results (about 0.65) than macro
due to the imbalance that could be appreciated in the dataset (the minority class comprises only 8% of the corpus, as seen in
Table 6). If we focus on the specific categories, the best results were achieved for the most frequent one (CALM), but the
scores for the rest were still acceptable. Focusing on the VAD model, we notice that arousal provideds a much better
-score, reaching 0.7; the
-score dropped again for valence (0.47) and, then, increased a bit for dominance (0.58). Let us note that three different labels were provided for valence, which made the classification task more difficult, while only two were provided for arousal and dominance. Dominance was the most difficult dimension to perceive for the annotators and the most ambiguous one. Nevertheless, in this dataset, dominance had a significant presence and was efficiently perceived and classified.
The experiments in the Empathic VA task resulted in lower performances. The categorical model provided a much lower
-score when compared with those obtained in the TV Debates dataset, which may be due to the imbalance being even higher in this dataset. The minority class comprised 2.8% of the whole corpus, which was lower than that found in the TV Debates dataset (8%), as shown in
Table 6. In fact, looking at the independent categories, the evaluation metrics were very low for less-frequent classes, such as PUZZ or ANN. Moreover, in this set, the number of labels was higher (four instead of three), which also leads, in general, to more confusion and lower performance. The VAD model followed the same tendency observed in the TV Debates dataset, with the highest performance for arousal and lower values for valence and dominance. However, in this case, the results achieved in the previous corpus were not reached, either, because it was a more neutral dataset and little emotional information could be learned.
Preliminary Classification Results Using wav2vec Model
Some preliminary experiments were also carried out using the wav2vec model, as shown in
Table 9. The performance achieved was significantly lower. Minority categories, such as HAPPY and PUZZ, were almost never recognized. However, the same tendency observed with the spectrogram was also perceived, here: the VAD model performed better than the categorical one, where arousal was the best recognized dimension and weighted averages provided better results due to the imbalanced nature of these scenarios. Thus, the results achieved were promising, considering the pretrained nature of the model and the specific datasets employed in the training process. These datasets were based on speech that is quite far from the conversational nature of the scenarios we deal with in this work. Their contents were mostly neutral, and Spanish was scarcely included. A fine-tuning process would be needed, in this case, to adapt the model to specific features of the task and language. However, the aforementioned corpora might not be large enough to robustly perform such an adaptation, which, currently, makes the use of pretrained representations of the speech signal to model emotions in Spanish really difficult.
5. Conclusions
This work analyzed the emotional features found in two very different spontaneous speech scenarios: human interactions during TV debates and human–machine conversations with a virtual agent. In both scenarios, a very reduced set of emotions was perceived by a large number of annotators. Moreover, the emotional information had a high tendency to be neutral, with the rest of the emotions being of a clear minority. This fact raised a difficult pattern recognition problem, which was the imbalance in the data. Overall, the automatic identification of spontaneous speech and related emotional content is still a difficult problem to address. However, this work also showed that human interactions could be more emotional and, thus, easier to tackle than human–machine interactions. Thus, the design of human–machine conversational systems, aimed at integrating a user’s emotional state, are still challenging tasks.
In this framework, the VAD model was demonstrated to be more adequate in representing emotional information. The dimensional VAD space, in fact, could be better managed than categories in terms of annotation and automatic identification. The classification experiments carried out in this work showed that deep learning approaches are useful for detecting speakers’ emotional information, reaching a -score for arousal. The preliminary experiments with the novel wav2vec2.0 representation of speech signals seem to be promising. However, this representation needs large sets of spontaneous emotional speech in the target language, i.e., Spanish, which are not currently found.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}