
Unsupervised Adaptation of Deep Speech Activity Detection Models to Unseen Domains



Abstract
:1. Introduction
2. Domain Adaptation
2.1. Problem Formulation
2.2. Approaches to Domain Adaptation
- Discrepancy-based: this family of solutions works under the assumption that fine-tuning a model using labelled or unlabelled data can reduce the shift between source and target domain. Under this idea, several criteria can be used to perform domain adaptation: some authors use class information to transfer knowledge between two domains [35]. The authors of [36,37] seek to align the statistical distribution shift between source and target domain. Other approaches also aim to improve generalisation by adjusting the architectures of DNNs, such as the work presented in [38].
- Adversarial-based: in this case, a domain discriminator tries to identify whether a data point belongs to the source or the target domain. This is used to encourage domain confusion through an adversarial objective that minimises the distance between source and target domain distributions. Two main groups can be observed when implementing this idea: those relying on generative models such as generative adversarial networks (GAN) [39], or those that rely on non-generative models that aim to obtain domain invariant representation through a domain confusion loss [40].
- Reconstruction-based: This approach is based on the idea that data reconstruction of the source or target samples may be helpful in order to improve the domain adaptation process. This way the reconstructor is able to ensure both specificity of intra-domain representations and indistinguishability of inter-domain representations. Some examples of these methods can be cited, such as the use of an encoder-decoder reconstruction process [41], or an adversarial reconstruction obtained via a cycle GAN model [42].
2.3. Unsupervised Domain Adaptation Techniques
2.3.1. Pseudo-Labelling
- Train source model: first, an initial model is trained in a supervised way on the source domain.
- Predict target labels: the initial model is then used to predict speech presence or absence for the unlabelled target domain.
- Adapt using predicted labels: finally, the initial model is retrained in a supervised way using the pseudo-labels as if they were true labels.
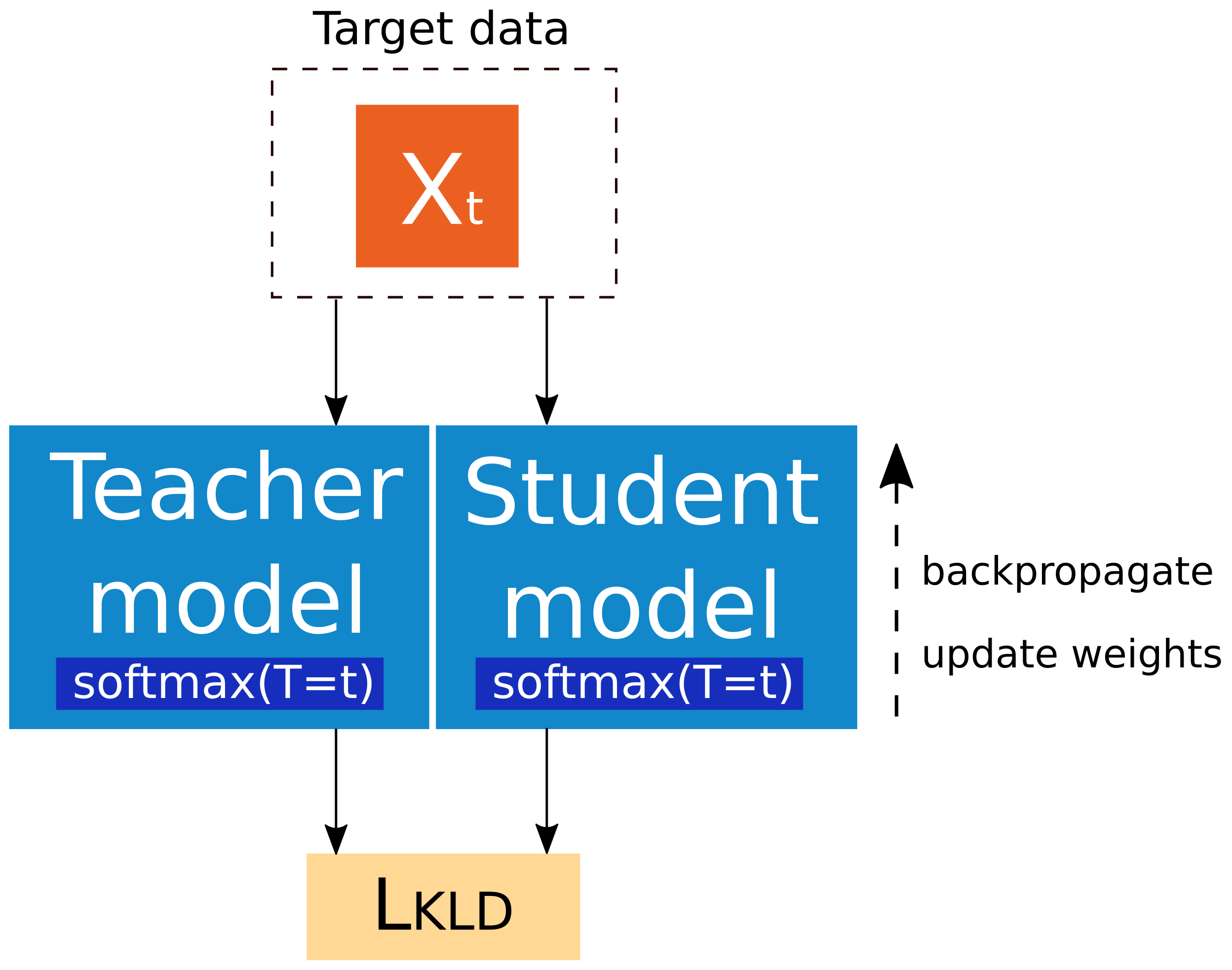
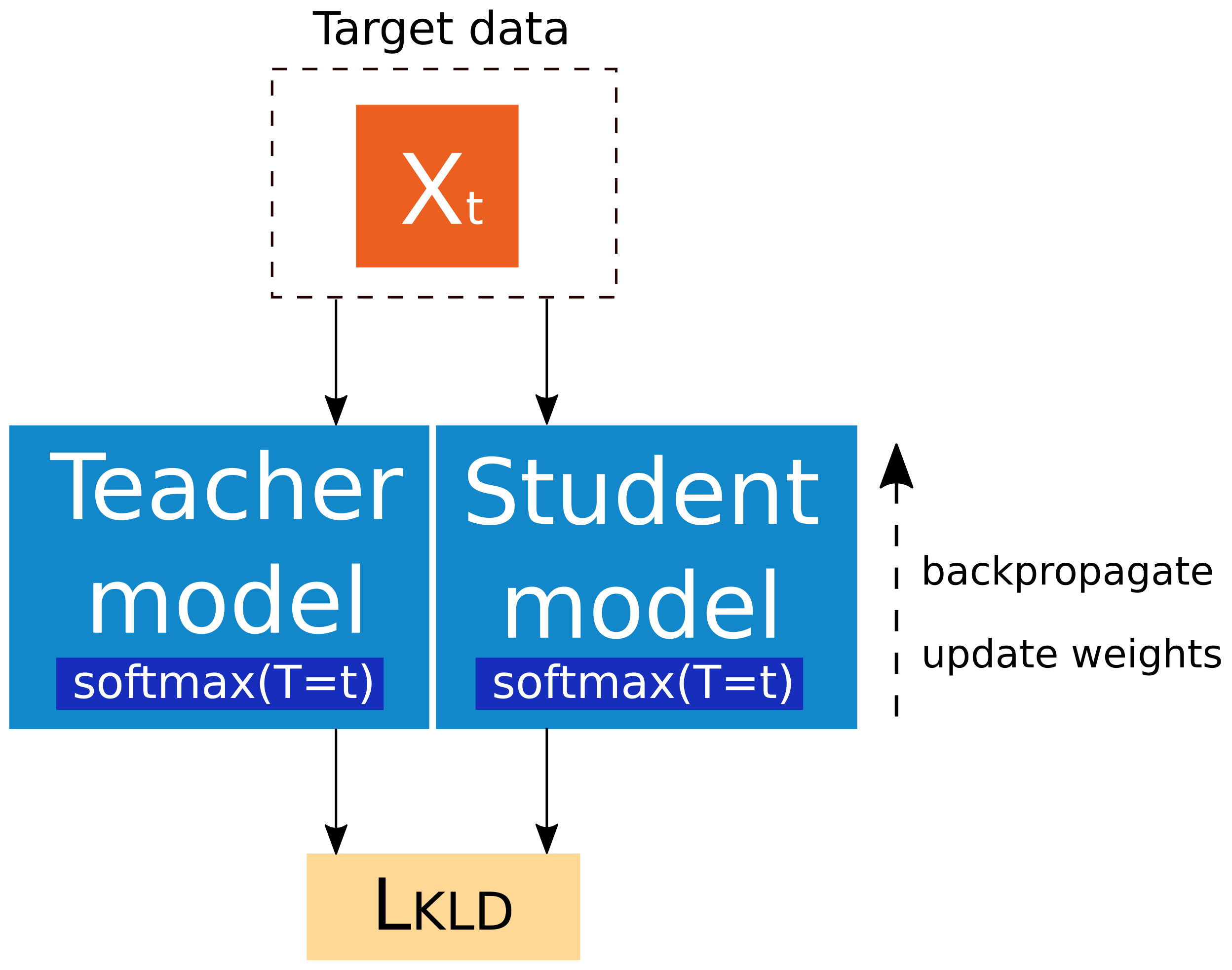
2.3.2. Knowledge Distillation
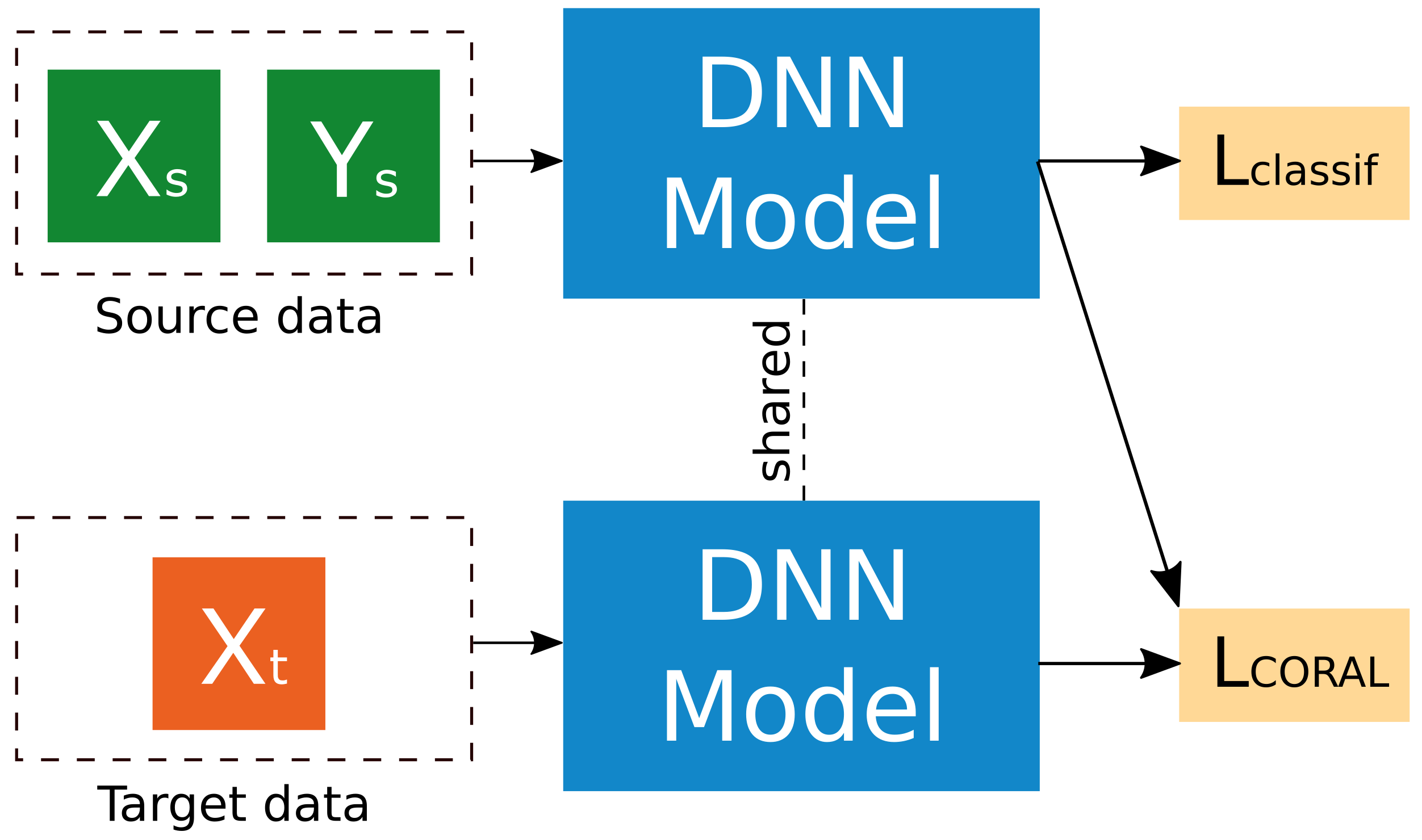
2.3.3. Deep CORAL
3. Experimental Setup
3.1. Data Description
- Train: Training subset is made of 125 files of approximately 30 min duration each. This makes a total of approximately 62.5 h of audio. Despite the ground truth labels for this partition are available, in the experiments we consider the target domain unlabelled, so we make no use of those labels in our systems. The audio is used then as target data in order to adapt SAD models to this new unseen domain.
- Development: There are available 30 files of 30 min length for development purposes, resulting in around 15 h of audio. In this work, this subset is used to evaluate our systems, in terms of the particular metrics introduced.
3.2. Feature Extraction
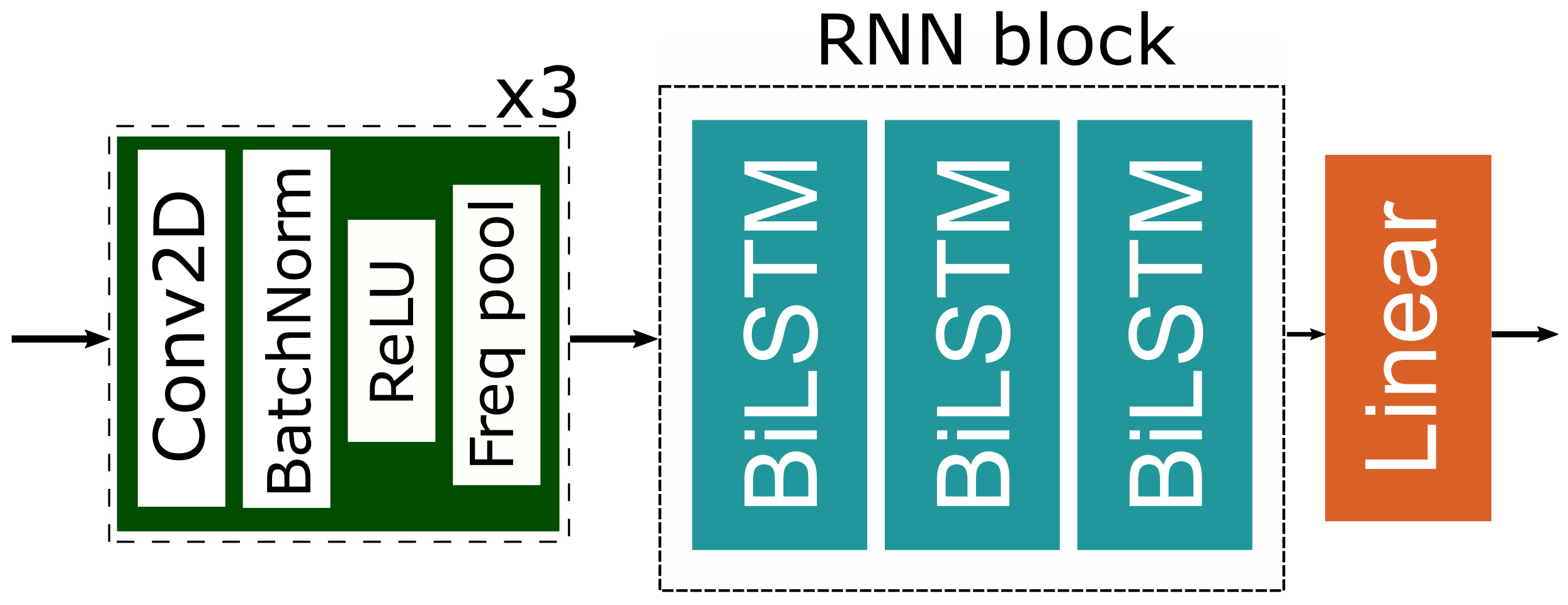
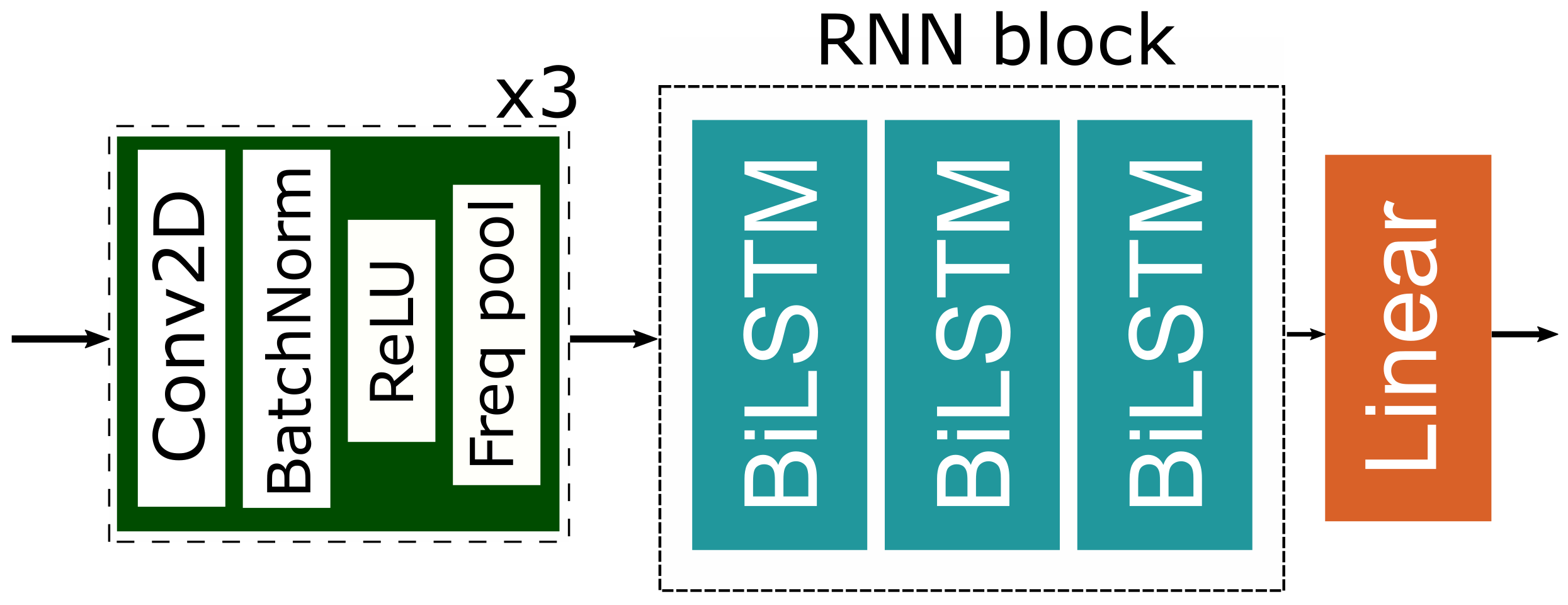
3.3. Neural Network Model
3.4. Evaluation Metrics
4. Results
4.1. Baseline System
4.2. Pseudo-Label Domain Adaptation
4.3. Knowledge Distillation Domain Adaptation
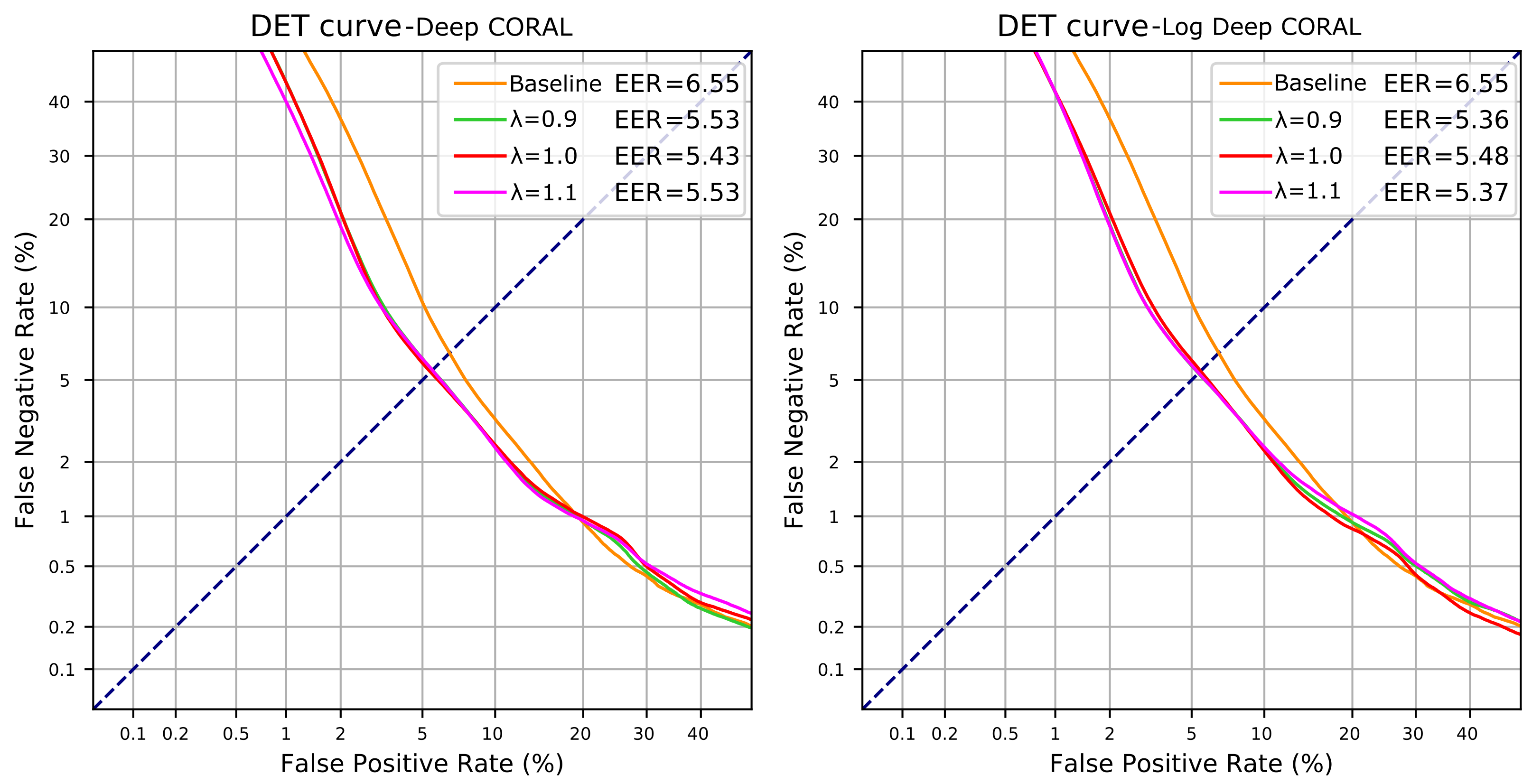
4.4. Deep CORAL Domain Adaptation
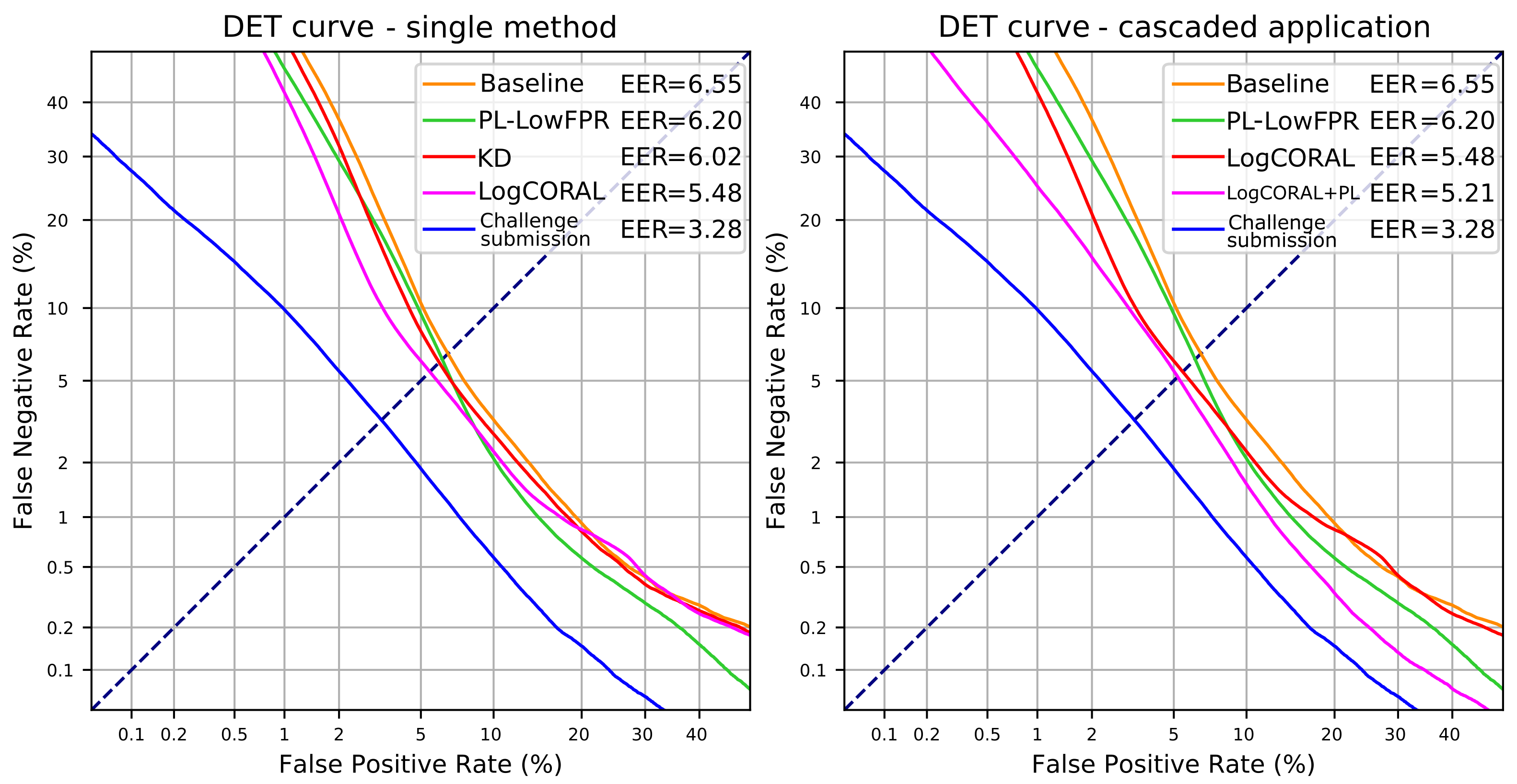
4.5. Cascaded Application of Domain Adaptation Methods
4.6. Discussion
5. Conclusions and Future Lines
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ASR | Automatic Speech Recognition |
| AUC | Area Under the ROC Curve |
| CRNN | Convolutional Recurrent Neural Network |
| CORAL | Correlation Alignment |
| DCF | Detection Cost Function |
| DET | Detection Error Trade-off |
| DNN | Deep Neural Network |
| EER | Equal Error Rate |
| FNR | False Negative Rate |
| FPR | False Positive Rate |
| FS | Fearless Steps |
| GAN | Generative Adversarial Networks |
| GPU | Graphics Processing Unit |
| KD | Knowledge Distillation |
| KLD | Kullback–Leibler Divergence |
| LDC | Language Data Consortium |
| LSTM | Long Short-Term Memory |
| MGB | Multi-Genre Broadcast |
| NIST | National Institute of Standard and Technology |
| PL | Pseudo-labelling |
| ReLU | Rectified Linear Unit |
| RNN | Recurrent Neural Network |
| ROC | Receiver operating characteristics |
| RT | Rich Transcription |
| SAD | Speech Activity Detection |
| SRE | Speaker Recognition Evaluation |
References
- Gerven, S.V.; Xie, F. A comparative study of speech detection methods. In Proceedings of the Fifth European Conference on Speech Communication and Technology, Rhodes, Greece, 22–25 September 1997. [Google Scholar]
- Junqua, J.C.; Mak, B.; Reaves, B. A robust algorithm for word boundary detection in the presence of noise. IEEE Trans. Speech Audio Process. 1994, 2, 406–412. [Google Scholar] [CrossRef]
- Chang, J.H.; Kim, N.S.; Mitra, S.K. Voice activity detection based on multiple statistical models. IEEE Trans. Signal Process. 2006, 54, 1965–1976. [Google Scholar] [CrossRef]
- Ng, T.; Zhang, B.; Nguyen, L.; Matsoukas, S.; Zhou, X.; Mesgarani, N.; Veselỳ, K.; Matějka, P. Developing a Speech Activity Detection system for the DARPA RATS program. In Proceedings of the Interspeech, Portland, OR, USA, 9–13 September 2012; pp. 1969–1972. [Google Scholar]
- Woo, K.H.; Yang, T.Y.; Park, K.J.; Lee, C. Robust voice activity detection algorithm for estimating noise spectrum. Electron. Lett. 2000, 36, 180–181. [Google Scholar] [CrossRef]
- Ramırez, J.; Segura, J.C.; Benıtez, C.; De La Torre, A.; Rubio, A. Efficient voice activity detection algorithms using long-term speech information. Speech Commun. 2004, 42, 271–287. [Google Scholar] [CrossRef]
- Liu, B.; Wang, Z.; Guo, S.; Yu, H.; Gong, Y.; Yang, J.; Shi, L. An energy-efficient voice activity detector using deep neural networks and approximate computing. Microelectron. J. 2019, 87, 12–21. [Google Scholar] [CrossRef]
- Vesperini, F.; Vecchiotti, P.; Principi, E.; Squartini, S.; Piazza, F. Deep neural networks for multi-room voice activity detection: Advancements and comparative evaluation. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 3391–3398. [Google Scholar]
- Fan, Z.C.; Bai, Z.; Zhang, X.L.; Rahardja, S.; Chen, J. AUC Optimization for Deep Learning Based Voice Activity Detection. In Proceedings of the IEEE ICASSP, Brighton, UK, 12–17 May 2019; pp. 6760–6764. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Kim, J.; Kim, J.; Lee, S.; Park, J.; Hahn, M. Vowel based voice activity detection with LSTM recurrent neural network. In Proceedings of the 8th International Conference on Signal Processing Systems, Auckland, New Zealand, 21–24 November 2016; pp. 134–137. [Google Scholar]
- de Benito-Gorron, D.; Lozano-Diez, A.; Toledano, D.T.; Gonzalez-Rodriguez, J. Exploring convolutional, recurrent, and hybrid deep neural networks for speech and music detection in a large audio dataset. EURASIP J. Audio Speech Music Process. 2019, 2019, 9. [Google Scholar] [CrossRef] [Green Version]
- Viñals, I.; Gimeno, P.; Ortega, A.; Miguel, A.; Lleida, E. Estimation of the Number of Speakers with Variational Bayesian PLDA in the DIHARD Diarization Challenge. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 2803–2807. [Google Scholar]
- Vinals, I.; Gimeno, P.; Ortega, A.; Miguel, A.; Lleida, E. In-domain Adaptation Solutions for the RTVE 2018 Diarization Challenge. In Proceedings of the IberSPEECH, Barcelona, Spain, 21–23 November 2018; pp. 220–223. [Google Scholar]
- Sainath, T.N.; Vinyals, O.; Senior, A.; Sak, H. Convolutional, long short-term memory, fully connected deep neural networks. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 4580–4584. [Google Scholar]
- Huang, X.; Qiao, L.; Yu, W.; Li, J.; Ma, Y. End-to-end sequence labeling via convolutional recurrent neural network with a connectionist temporal classification layer. Int. J. Comput. Intell. Syst. 2020, 13, 341–351. [Google Scholar] [CrossRef] [Green Version]
- Vafeiadis, A.; Fanioudakis, E.; Potamitis, I.; Votis, K.; Giakoumis, D.; Tzovaras, D.; Chen, L.; Hamzaoui, R. Two-Dimensional Convolutional Recurrent Neural Networks for Speech Activity Detection. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 2045–2049. [Google Scholar] [CrossRef] [Green Version]
- Byers, F.; Byers, F.; Sadjadi, O. 2017 Pilot Open Speech Analytic Technologies Evaluation (2017 NIST Pilot OpenSAT): Post Evaluation Summary; US Department of Commerce, National Institute of Standards and Technology: Gaithersburg, MD, USA, 2019.
- Hansen, J.H.; Joglekar, A.; Shekhar, M.C.; Kothapally, V.; Yu, C.; Kaushik, L.; Sangwan, A. The 2019 Inaugural Fearless Steps Challenge: A Giant Leap for Naturalistic Audio. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019; pp. 1851–1855. [Google Scholar]
- Hansen, J.H.; Sangwan, A.; Joglekar, A.; Bulut, A.E.; Kaushik, L.; Yu, C. Fearless Steps: Apollo-11 Corpus Advancements for Speech Technologies from Earth to the Moon. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 2758–2762. [Google Scholar]
- Mezza, A.I.; Habets, E.A.; Müller, M.; Sarti, A. Unsupervised domain adaptation for acoustic scene classification using band-wise statistics matching. In Proceedings of the 2020 28th European Signal Processing Conference (EUSIPCO), Virtual, 18–22 January 2021; pp. 11–15. [Google Scholar]
- Anoop, C.; Prathosh, A.; Ramakrishnan, A. Unsupervised domain adaptation schemes for building ASR in low-resource languages. In Proceedings of the Workshop on Automatic Speech Recognition and Understanding, ASRU, Cartagena, Colombia, 15–17 December 2021. [Google Scholar]
- Gimeno, P.; Ribas, D.; Ortega, A.; Miguel, A.; Lleida, E. Convolutional recurrent neural networks for Speech Activity Detection in naturalistic audio from apollo missions. Proc. IberSPEECH 2021, 2021, 26–30. [Google Scholar]
- Gimeno, P.; Ortega, A.; Miguel, A.; Lleida, E. Unsupervised Representation Learning for Speech Activity Detection in the Fearless Steps Challenge 2021. In Interspeech 2021; ISCA: Singapore, 2021; pp. 4359–4363. [Google Scholar]
- Zhang, X.L. Unsupervised domain adaptation for deep neural network based voice activity detection. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 6864–6868. [Google Scholar]
- Luo, Y.; Zheng, L.; Guan, T.; Yu, J.; Yang, Y. Taking a closer look at domain shift: Category-level adversaries for semantics consistent domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2507–2516. [Google Scholar]
- Chu, C.; Wang, R. A survey of domain adaptation for neural machine translation. arXiv 2018, arXiv:1806.00258. [Google Scholar]
- Wilson, G.; Cook, D.J. A survey of unsupervised deep domain adaptation. ACM Trans. Intell.Syst. Technol. 2020, 11, 1–46. [Google Scholar] [CrossRef] [PubMed]
- Sun, S.; Zhang, B.; Xie, L.; Zhang, Y. An unsupervised deep domain adaptation approach for robust speech recognition. Neurocomputing 2017, 257, 79–87. [Google Scholar] [CrossRef]
- Wang, Q.; Rao, W.; Sun, S.; Xie, L.; Chng, E.S.; Li, H. Unsupervised domain adaptation via domain adversarial training for speaker recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4889–4893. [Google Scholar]
- Mavaddaty, S.; Ahadi, S.M.; Seyedin, S. A novel speech enhancement method by learnable sparse and low-rank decomposition and domain adaptation. Speech Commun. 2016, 76, 42–60. [Google Scholar] [CrossRef]
- Wang, M.; Deng, W. Deep visual domain adaptation: A survey. Neurocomputing 2018, 312, 135–153. [Google Scholar] [CrossRef] [Green Version]
- Tan, B.; Zhang, Y.; Pan, S.; Yang, Q. Distant domain transfer learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Csurka, G. Domain adaptation for visual applications: A comprehensive survey. arXiv 2017, arXiv:1702.05374. [Google Scholar]
- Hu, J.; Lu, J.; Tan, Y.P. Deep transfer metric learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 1–7 June 2015; pp. 325–333. [Google Scholar]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Unsupervised domain adaptation with residual transfer networks. arXiv 2016, arXiv:1602.04433. [Google Scholar]
- Sun, B.; Feng, J.; Saenko, K. Return of frustratingly easy domain adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Li, Y.; Wang, N.; Shi, J.; Liu, J.; Hou, X. Revisiting batch normalization for practical domain adaptation. arXiv 2016, arXiv:1603.04779. [Google Scholar]
- Liu, M.Y.; Tuzel, O. Coupled generative adversarial networks. Adv. Neural Inf. Process. Syst. 2016, 29, 469–477. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 2030–2096. [Google Scholar]
- Zhuang, F.; Cheng, X.; Luo, P.; Pan, S.J.; He, Q. Supervised representation learning: Transfer learning with deep autoencoders. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Lee, D.H. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. Workshop Chall. Represent. Learn. ICML 2013, 3, 896. [Google Scholar]
- Iscen, A.; Tolias, G.; Avrithis, Y.; Chum, O. Label propagation for deep semi-supervised learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5070–5079. [Google Scholar]
- Shi, W.; Gong, Y.; Ding, C.; Tao, Z.M.; Zheng, N. Transductive semi-supervised deep learning using min-max features. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 299–315. [Google Scholar]
- Wang, G.H.; Wu, J. Repetitive reprediction deep decipher for semi-supervised learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 6170–6177. [Google Scholar]
- Rizve, M.N.; Duarte, K.; Rawat, Y.S.; Shah, M. In defense of pseudo-labeling: An uncertainty-aware pseudo-label selection framework for semi-supervised learning. arXiv 2021, arXiv:2101.06329. [Google Scholar]
- Zhong, M.; LeBien, J.; Campos-Cerqueira, M.; Dodhia, R.; Ferres, J.L.; Velev, J.P.; Aide, T.M. Multispecies bioacoustic classification using transfer learning of deep convolutional neural networks with pseudo-labeling. Appl. Acoust. 2020, 166, 107375. [Google Scholar] [CrossRef]
- Takashima, Y.; Fujita, Y.; Horiguchi, S.; Watanabe, S.; García, P.; Nagamatsu, K. Semi-Supervised Training with Pseudo-Labeling for End-to-End Neural Diarization. arXiv 2021, arXiv:2106.04764. [Google Scholar]
- Xu, Q.; Likhomanenko, T.; Kahn, J.; Hannun, A.; Synnaeve, G.; Collobert, R. Iterative pseudo-labeling for speech recognition. arXiv 2020, arXiv:2005.09267. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Shen, P.; Lu, X.; Li, S.; Kawai, H. Feature Representation of Short Utterances Based on Knowledge Distillation for Spoken Language Identification. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 1813–1817. [Google Scholar]
- Li, J.; Zhao, R.; Chen, Z.; Liu, C.; Xiao, X.; Ye, G.; Gong, Y. Developing far-field speaker system via teacher-student learning. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5699–5703. [Google Scholar]
- Korattikara, A.; Rathod, V.; Murphy, K.; Welling, M. Bayesian dark knowledge. arXiv 2015, arXiv:1506.04416. [Google Scholar]
- Asami, T.; Masumura, R.; Yamaguchi, Y.; Masataki, H.; Aono, Y. Domain adaptation of dnn acoustic models using knowledge distillation. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5185–5189. [Google Scholar]
- Li, J.; Seltzer, M.L.; Wang, X.; Zhao, R.; Gong, Y. Large-scale domain adaptation via teacher-student learning. arXiv 2017, arXiv:1708.05466. [Google Scholar]
- Luckenbaugh, J.; Abplanalp, S.; Gonzalez, R.; Fulford, D.; Gard, D.; Busso, C. Voice Activity Detection with Teacher-Student Domain Emulation. Proc. Interspeech 2021, 2021, 4374–4378. [Google Scholar]
- Dinkel, H.; Wang, S.; Xu, X.; Wu, M.; Yu, K. Voice activity detection in the wild: A data-driven approach using teacher-student training. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1542–1555. [Google Scholar] [CrossRef]
- Sun, B.; Saenko, K. Deep coral: Correlation alignment for deep domain adaptation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 443–450. [Google Scholar]
- Morerio, P.; Murino, V. Correlation alignment by riemannian metric for domain adaptation. arXiv 2017, arXiv:1705.08180. [Google Scholar]
- Huang, Z.; Gool, L.V. A Riemannian Network for SPD Matrix Learning. arXiv 2016, arXiv:1608.04233. [Google Scholar]
- MacDuffee, C.C. The Theory of Matrices; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 5. [Google Scholar]
- Butko, T.; Nadeu, C. Audio segmentation of broadcast news in the Albayzin-2010 evaluation: Overview, results, and discussion. EURASIP J. Audio Speech Music Process. 2011, 2011, 1. [Google Scholar] [CrossRef] [Green Version]
- McCowan, I.; Carletta, J.; Kraaij, W.; Ashby, S.; Bourban, S.; Flynn, M.; Guillemot, M.; Hain, T.; Kadlec, J.; Karaiskos, V.; et al. The AMI meeting corpus. In Proceedings of the 5th International Conference on Methods and Techniques in Behavioral Research, Wageningen, The Netherlands, 30 August–2 September 2005; Volume 88, p. 100. [Google Scholar]
- Lleida, E.; Ortega, A.; Miguel, A.; Bazán-Gil, V.; Pérez, C.; Gómez, M.; De Prada, A. Albayzin 2018 evaluation: The iberspeech-rtve challenge on speech technologies for spanish broadcast media. Appl. Sci. 2019, 9, 5412. [Google Scholar] [CrossRef] [Green Version]
- Janin, A.; Baron, D.; Edwards, J.; Ellis, D.; Gelbart, D.; Morgan, N.; Peskin, B.; Pfau, T.; Shriberg, E.; Stolcke, A.; et al. The ICSI meeting corpus. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, Proceedings (ICASSP’03), Hong Kong, China, 6–10 April 2003; Volume 1, p. I. [Google Scholar]
- Bell, P.; Gales, M.J.; Hain, T.; Kilgour, J.; Lanchantin, P.; Liu, X.; McParland, A.; Renals, S.; Saz, O.; Wester, M.; et al. The MGB challenge: Evaluating multi-genre broadcast media recognition. In Proceedings of the 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Scottsdale, AZ, USA, 13–17 December 2015; pp. 687–693. [Google Scholar]
- Ortega, A.; Miguel, A.; Lleida, E.; Bazán, V.; Pérez, C.; Gómez, M.; de Prada, A. Albayzin Evaluation: IberSPEECH-RTVE 2020 Speaker Diarization and Identity Assignment. 2020. Available online: http://catedrartve.unizar.es/reto2020/EvalPlan-SD-2020-v1.pdf (accessed on 7 February 2022).
- Canavan, A.; Graff, D.; Zipperlen, G. Callhome American English Speech; Linguistic Data Consortium: Philadelphia, PA, USA, 1997. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Joglekar, A.; Hansen, J.H.; Shekar, M.C.; Sangwan, A. Fearless Steps Challenge (fs-2): Supervised learning with massive naturalistic apollo data. arXiv 2020, arXiv:2008.06764. [Google Scholar]
- Chen, C.; Fu, Z.; Chen, Z.; Jin, S.; Cheng, Z.; Jin, X.; Hua, X.S. HoMM: Higher-order moment matching for unsupervised domain adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 3422–3429. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Domain | |||
|---|---|---|---|
| Broadcast | Telephonic | Meetings | |
| Train data | Albayzín 2010—TV3 [63] | SRE08 Summed | AMI [64] |
| Albayzín 2018—RTVE [65] | ICSI Meetings [66] | ||
| MGB [67] | |||
| Test data | Albayzín 2020—RTVE [68] | CALLHOME [69] | RT09 |
| Model | Train Domain | Test Domain | Dataset | AUC (%) | EER (%) |
|---|---|---|---|---|---|
| Baseline | Broad. + Tele. + Meet. | Broadcast | Albayzín 2020 | 98.12 | 6.68 |
| Telephonic | CALLHOME | 96.70 | 7.62 | ||
| Meetings | RT09 | 97.07 | 6.98 | ||
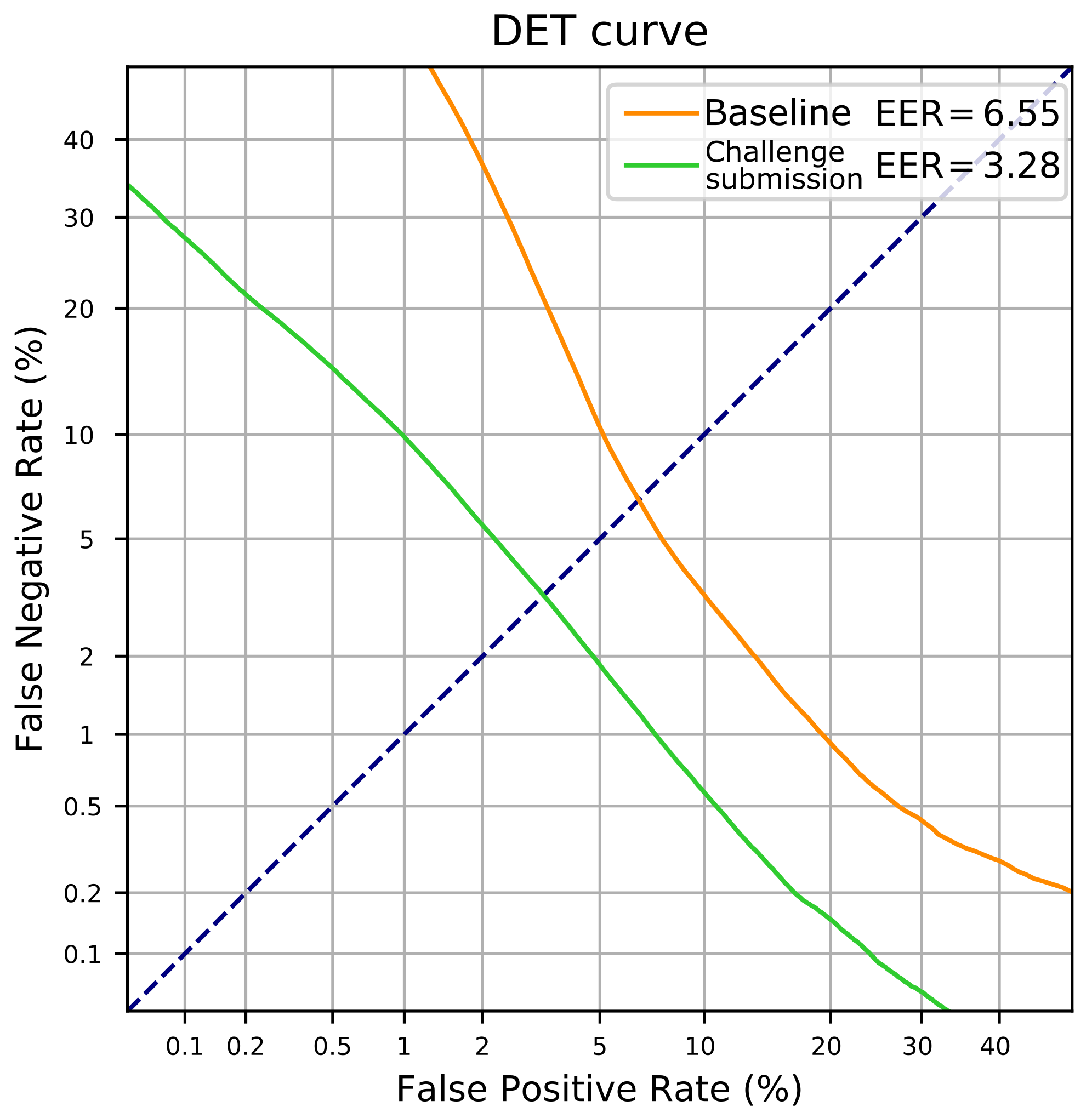
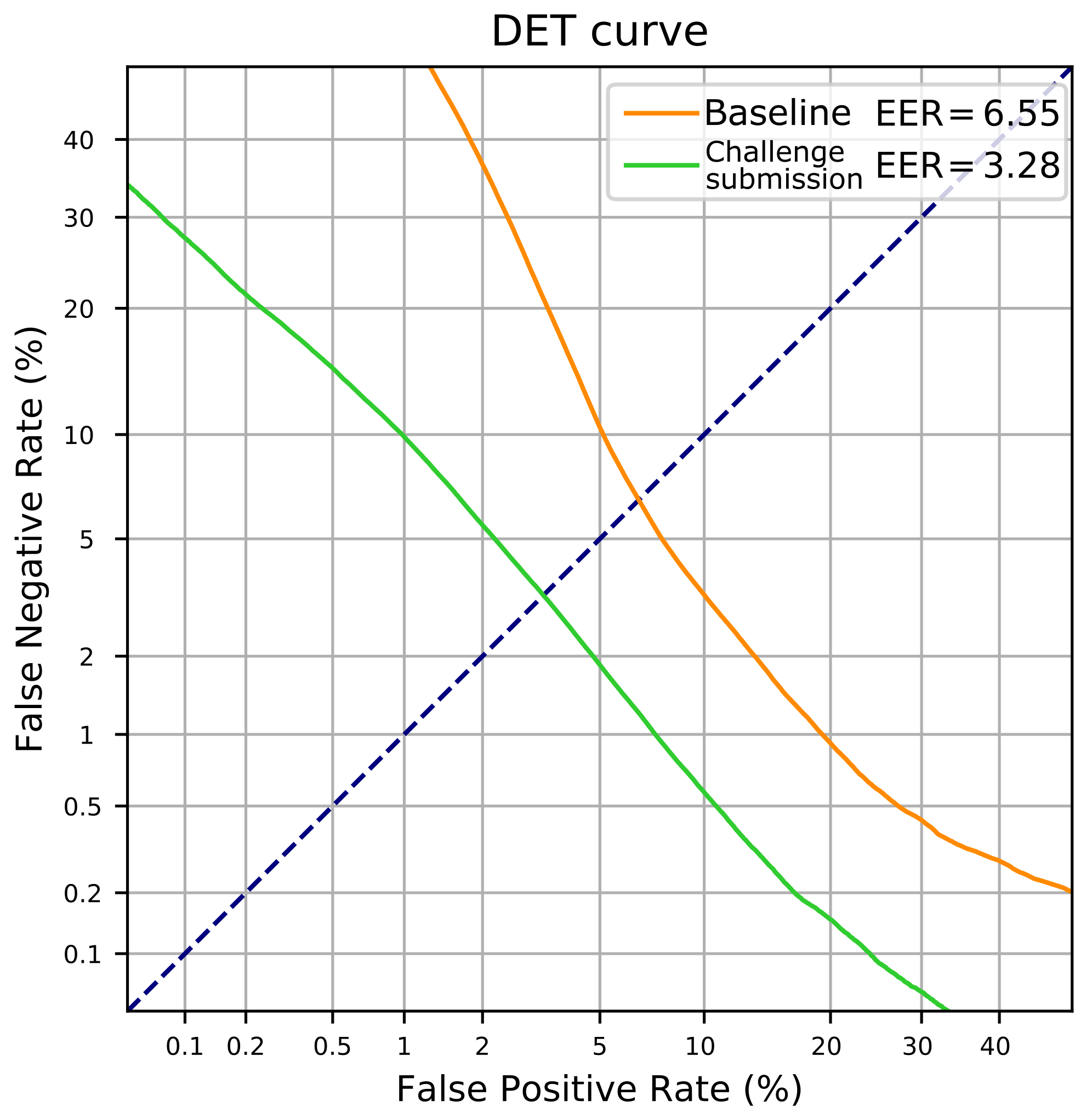
| Baseline | Broad. + Tele. + Meet. | Apollo missions | FS02-Dev | 97.57 | 6.55 |
| Challenge submission | Apollo missions | Apollo missions | 99.56 | 3.28 |
| Dataset | AUC (%) | EER (%) | Operating Point | FPR (%) | FNR (%) |
|---|---|---|---|---|---|
| FS02–Train | 97.36 | 7.28 | Low FPR | 5.78 | 10.00 |
| Balanced | 7.37 | 7.15 | |||
| Low FNR | 11.04 | 3.56 |
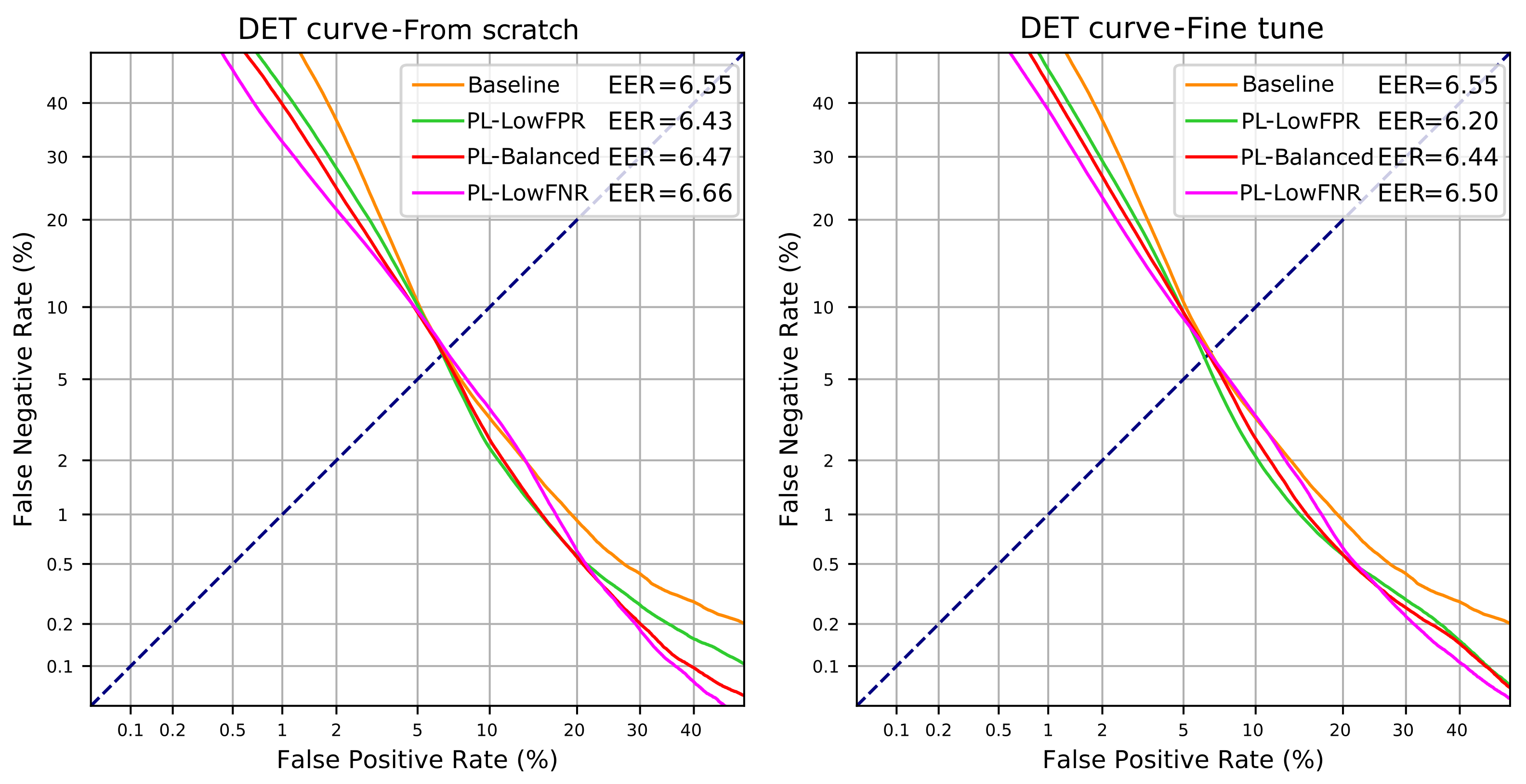
| Pseudo-Labels | From Scratch | Fine Tuning | ||
|---|---|---|---|---|
| AUC (%) | EER (%) | AUC (%) | EER (%) | |
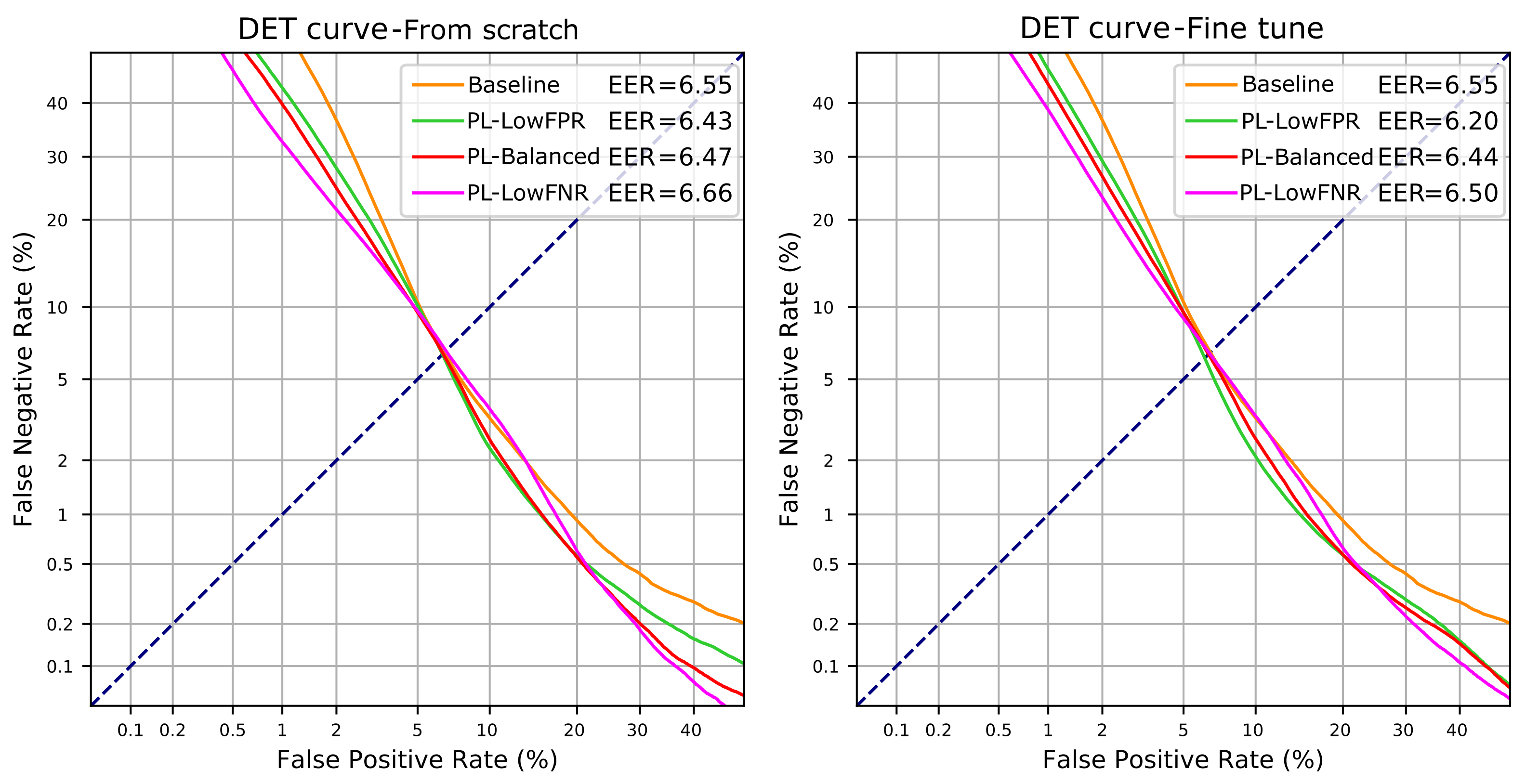
| Low FPR | 98.06 | 6.43 | 98.03 | 6.20 |
| Balanced | 98.21 | 6.47 | 98.09 | 6.44 |
| Low FNR | 98.26 | 6.66 | 98.19 | 6.50 |
| Softmax Temperature | AUC (%) | EER (%) |
|---|---|---|
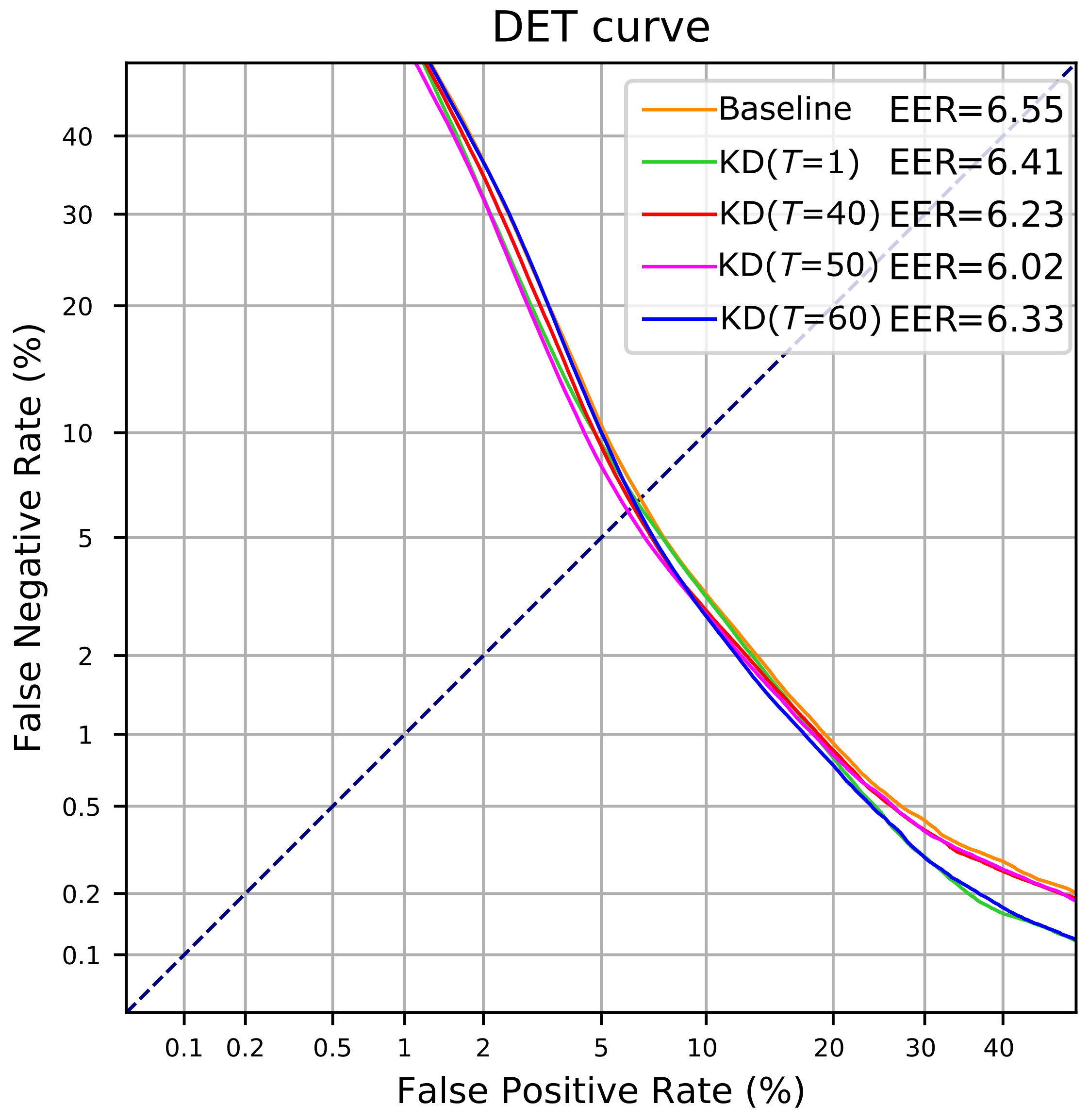
| 97.79 | 6.41 | |
| 97.72 | 6.32 | |
| 97.80 | 6.27 | |
| 97.80 | 6.25 | |
| 97.72 | 6.23 | |
| 97.86 | 6.02 | |
| 97.70 | 6.33 |
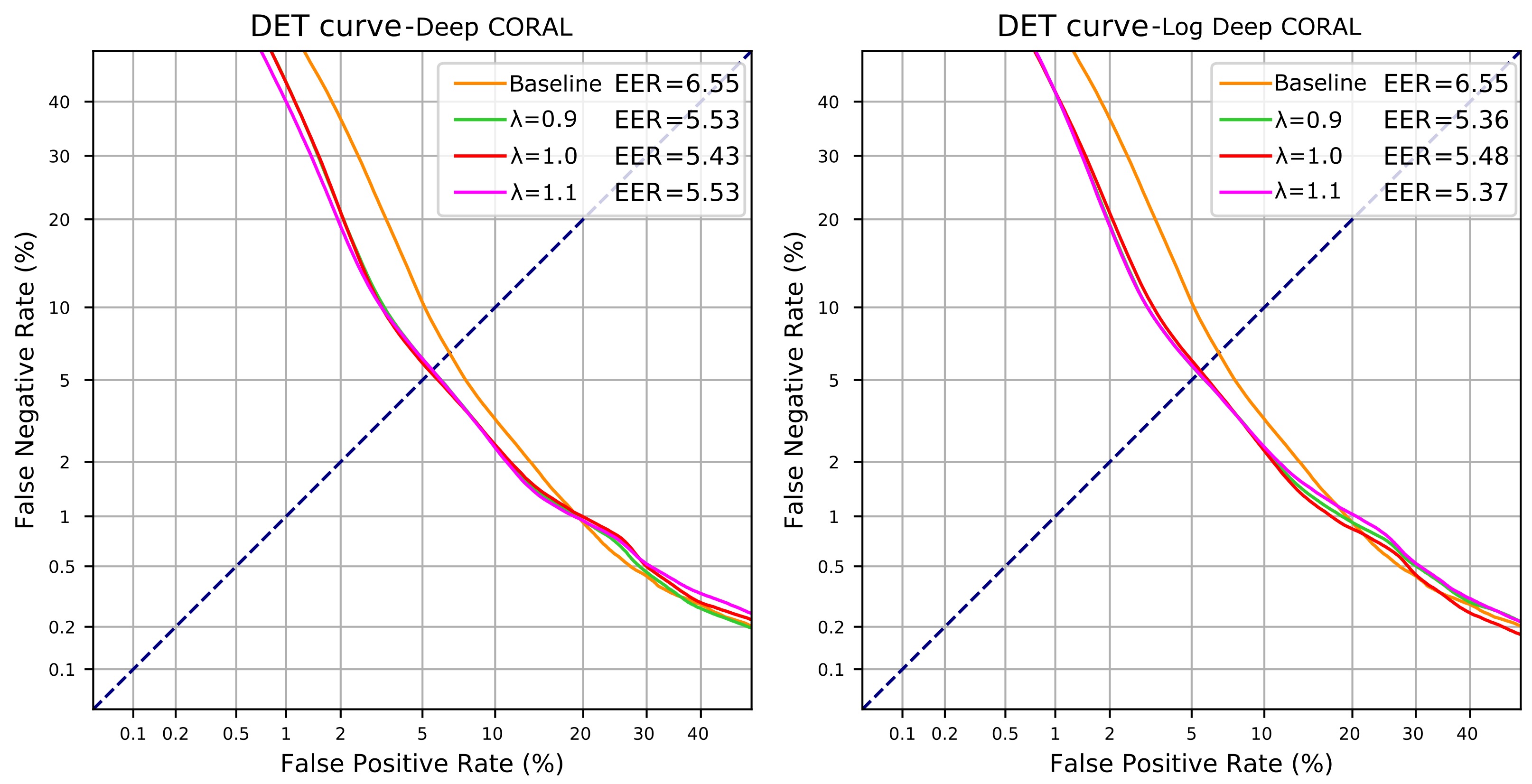
| Method | CORAL Weight | AUC (%) | EER (%) |
|---|---|---|---|
| Deep CORAL | 98.19 | 5.53 | |
| 98.18 | 5.43 | ||
| 98.25 | 5.53 | ||
| Log Deep CORAL | 98.26 | 5.36 | |
| 98.26 | 5.48 | ||
| 98.24 | 5.37 |
| Dataset | AUC (%) | EER (%) | Operating Point | FPR (%) | FNR (%) |
|---|---|---|---|---|---|
| FS02–Train | 98.26 | 5.63 | Low FPR | 4.55 | 7.55 |
| Balanced | 5.70 | 5.54 | |||
| Low FNR | 7.27 | 3.78 |
| Pseudo-Labels | From Scratch | Fine Tuning | ||
|---|---|---|---|---|
| AUC (%) | EER (%) | AUC (%) | EER (%) | |
| Low FPR | 98.86 | 5.21 | 98.85 | 5.34 |
| Balanced | 98.81 | 5.50 | 98.83 | 5.49 |
| Low FNR | 98.75 | 5.67 | 98.85 | 5.51 |
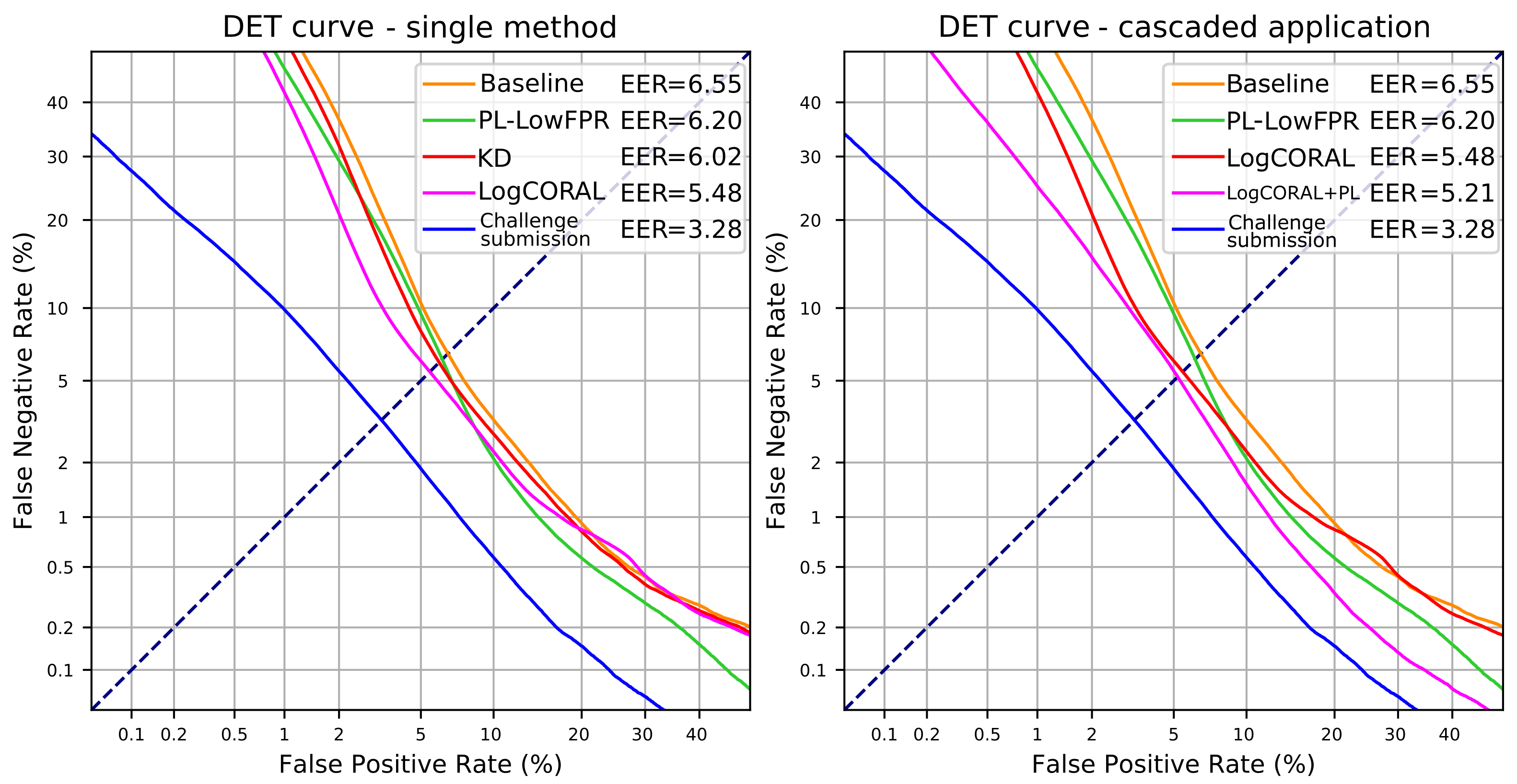
| Model | AUC (%) | EER (%) | DCF (%) | Rel. Improv. (%) |
|---|---|---|---|---|
| Baseline | 97.57 | 6.55 | 4.84 | - |
| Pseudo-labels (fine tune) | 98.03 | 6.20 | 4.25 | 12.19 |
| Pseudo-labels (scratch) | 98.21 | 6.46 | 4.31 | 10.95 |
| Knowledge distillation () | 97.79 | 6.41 | 4.78 | 1.24 |
| Knowledge distillation () | 97.86 | 6.02 | 4.56 | 5.79 |
| Deep CORAL () | 98.25 | 5.53 | 4.26 | 11.98 |
| Log Deep CORAL () | 98.25 | 5.48 | 4.20 | 13.23 |
| Log CORAL + PL (fine tune) | 98.85 | 5.34 | 3.67 | 24.17 |
| Log CORAL + PL (scratch) | 98.86 | 5.21 | 3.65 | 24.59 |
| Challenge baseline | - | - | 12.50 | - |
| Challenge submission | 99.56 | 3.28 | 2.56 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gimeno, P.; Ribas, D.; Ortega, A.; Miguel, A.; Lleida, E. Unsupervised Adaptation of Deep Speech Activity Detection Models to Unseen Domains. Appl. Sci. 2022, 12, 1832. https://doi.org/10.3390/app12041832
Gimeno P, Ribas D, Ortega A, Miguel A, Lleida E. Unsupervised Adaptation of Deep Speech Activity Detection Models to Unseen Domains. Applied Sciences. 2022; 12(4):1832. https://doi.org/10.3390/app12041832
Chicago/Turabian StyleGimeno, Pablo, Dayana Ribas, Alfonso Ortega, Antonio Miguel, and Eduardo Lleida. 2022. "Unsupervised Adaptation of Deep Speech Activity Detection Models to Unseen Domains" Applied Sciences 12, no. 4: 1832. https://doi.org/10.3390/app12041832
APA StyleGimeno, P., Ribas, D., Ortega, A., Miguel, A., & Lleida, E. (2022). Unsupervised Adaptation of Deep Speech Activity Detection Models to Unseen Domains. Applied Sciences, 12(4), 1832. https://doi.org/10.3390/app12041832