Once a within-show speaker annotation has been produced, the resulting speakers are linked to the already existing database of speakers from past shows. After this stage, we do not question the within-show segmentation anymore and only focus on speaker linking between current and past shows.
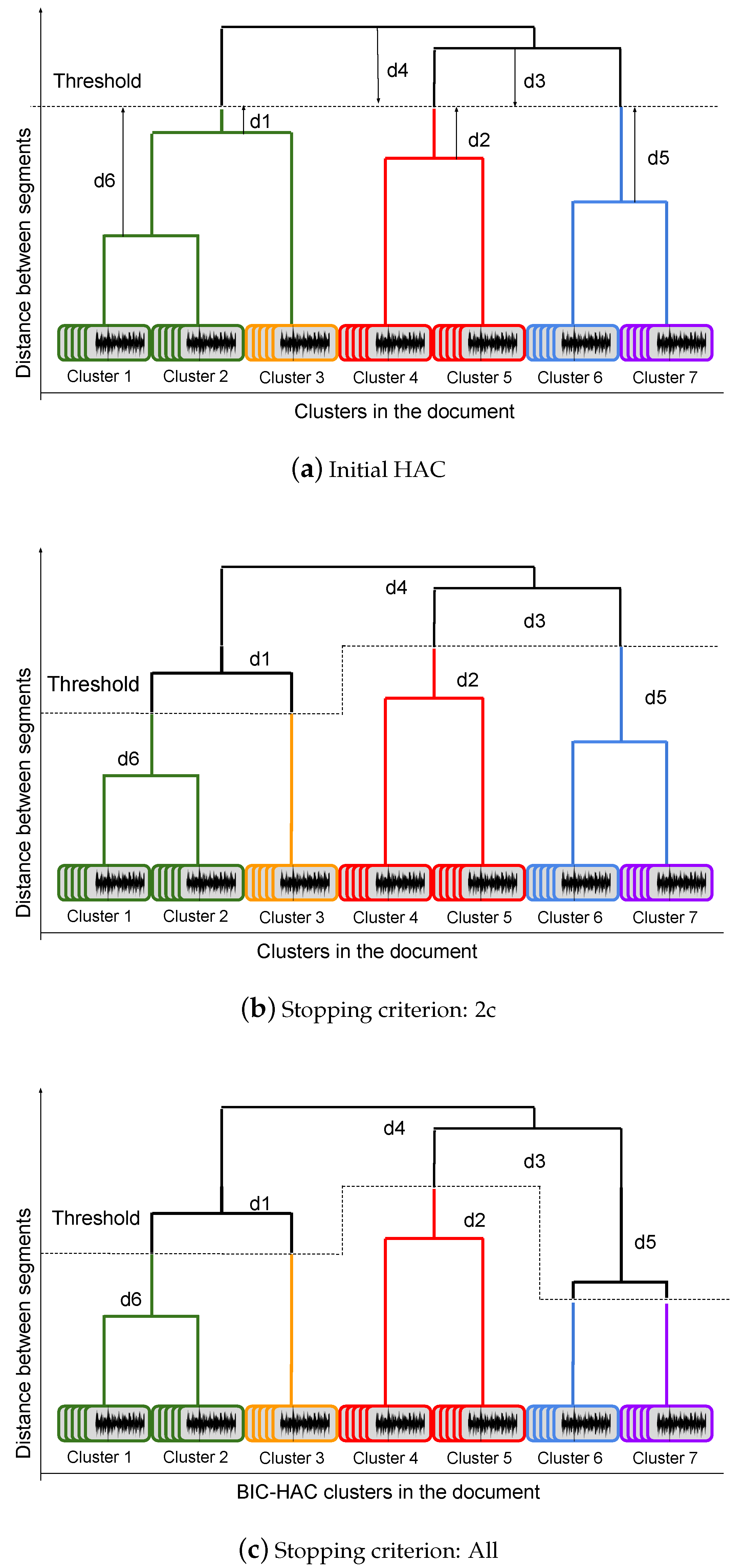
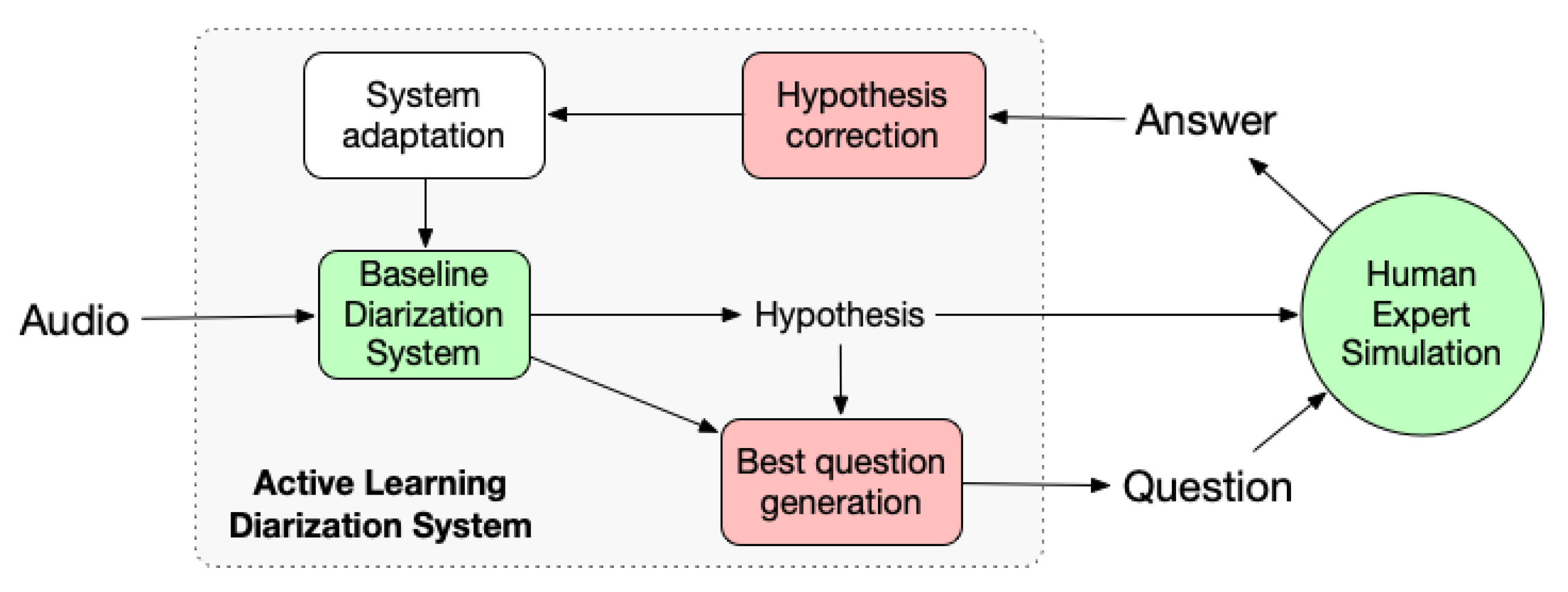
7.1. Cross-Show Question Generation Module
Similarly to the human-assisted within-show speaker diarization, our method only focuses on speaker linking (clustering) and does not modify the segmentation nor the clustering obtained during the stage of within-show diarization. During the incremental cross-show speaker linking process described in
Section 6, the automatic system selects a couple of speakers
where
appeared in the past and
appeared in the current show. The human operator is then asked to listen to one speech sample from each speaker (
and
) and to answer the question: “Are the two speech samples spoken by the same speaker? ”
The human-assisted cross-show diarization correction process differs from the within-show as no clustering tree can be used to define the question. In the cross-show scenario, we decompose the task into two steps:
detection of recurrent speakers, i.e., detect if a given speaker from the current file has been observed in the past;
human-assisted closed-set identification of speakers detected as seen during the first step. Speakers who have not been categorized as seen are simply added to the known speaker database.
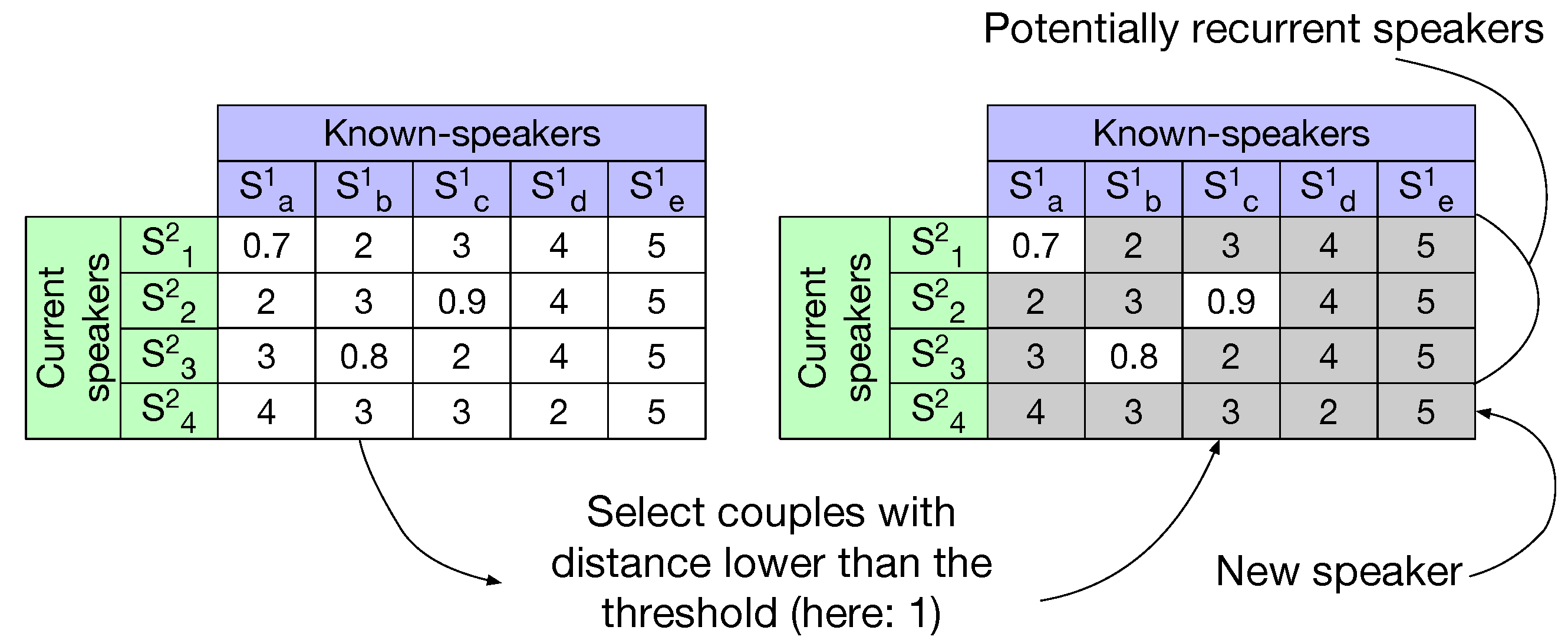
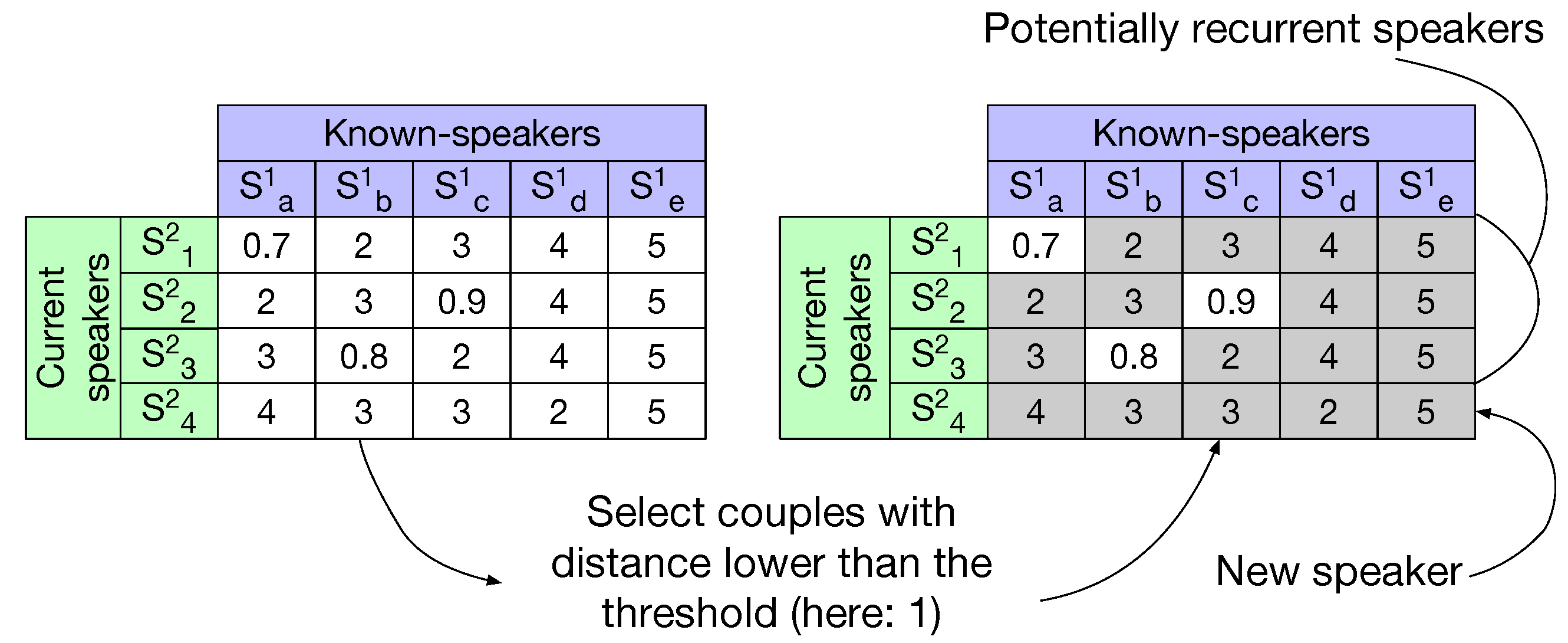
To detect the recurrent speakers we propose to use a pseudo-distance matrix based on the one described in
Section 6.1. The information conveyed in this matrix is the pseudo-distance between couples of
x-vectors, the lower the pseudo-distance, the more likely two speakers are the same. This matrix is depicted in
Figure 4.
This matrix can be computed in different manners depending on the representation chosen for known-speakers. Based on the idea that a known-speaker owns many x-vectors in each show where they appear, we consider here three speaker representations:
The speaker can be represented by the average of her existing x-vectors (corresponding to all segments of this speaker in all already processed shows).
A second representation, referred to as Averaging in the remaining of this study, consists of a set of one x-vector per file in which this speaker appears. The x-vector for a show being the averaged of all x-vector for this speaker in the given show.
Eventually, we could keep, to represent a speaker, the set of all x-vectors belonging to this speaker (one x-vector per segment). We will later on refer to this last approach as No averaging.
Due to a high cross-show variability, we found that the first option is not optimal, probably because TV and radio shows have high acoustic variability for which a single average x-vector computed on all of them would not be a good representative of the speaker; for this reason we only focus in this article on two methods: Averaging of x-vectors per show and No averaging, where all possible x-vectors are kept for comparison.
The pseudo-distance matrix is computed by comparing each speaker single
x-vector from the current show to all past-speakers
Averaging and
No averaging representations. A threshold, set empirically on the development set, is then applied on the pseudo-distances. If a speaker from the current show has no distance below the threshold (see
Figure 4) it is categorized as new (never seen in the past). Other speakers are categorized as possibly recurrent and selected for the following closed-set speaker identification phase.
In a second step, human-assisted closed-set identification is applied for all speakers categorized as possibly recurrent. For each possibly recurrent speaker, x-vectors from all known-speakers (i.e., Averaging or No averaging representations of those speakers) are sorted by increasing pseudo-distance (Note that the number of those x-vectors depends on the chosen representation: averaging or no averaging). By increasing pseudo-distance, a binary question is asked to the human operator to compare the couples of speakers. This question makes use of one single audio segment selected for each speaker. Similarly to the within-show human-assisted process, the human operator is offered two audio segments (one belongs to the current speaker and one belongs to a known-speaker) to listen to: the longest for each speaker. Based on those two segments, the question asked to the human expert is: “Is the speaker from this segment (a known-speaker) the same as the one speaking in this current segment?”.
If the operator answers “Yes”, the two speakers are linked and the selected known-speaker is not proposed anymore to link with any other current speaker. If the operator answers “No”, the next x-vector per order of pseudo-distance is considered. For one current speaker, the process ends either when linked with a known-speaker or after a number of questions chosen empirically; in the latest case, the current speaker is added to the known speaker database.
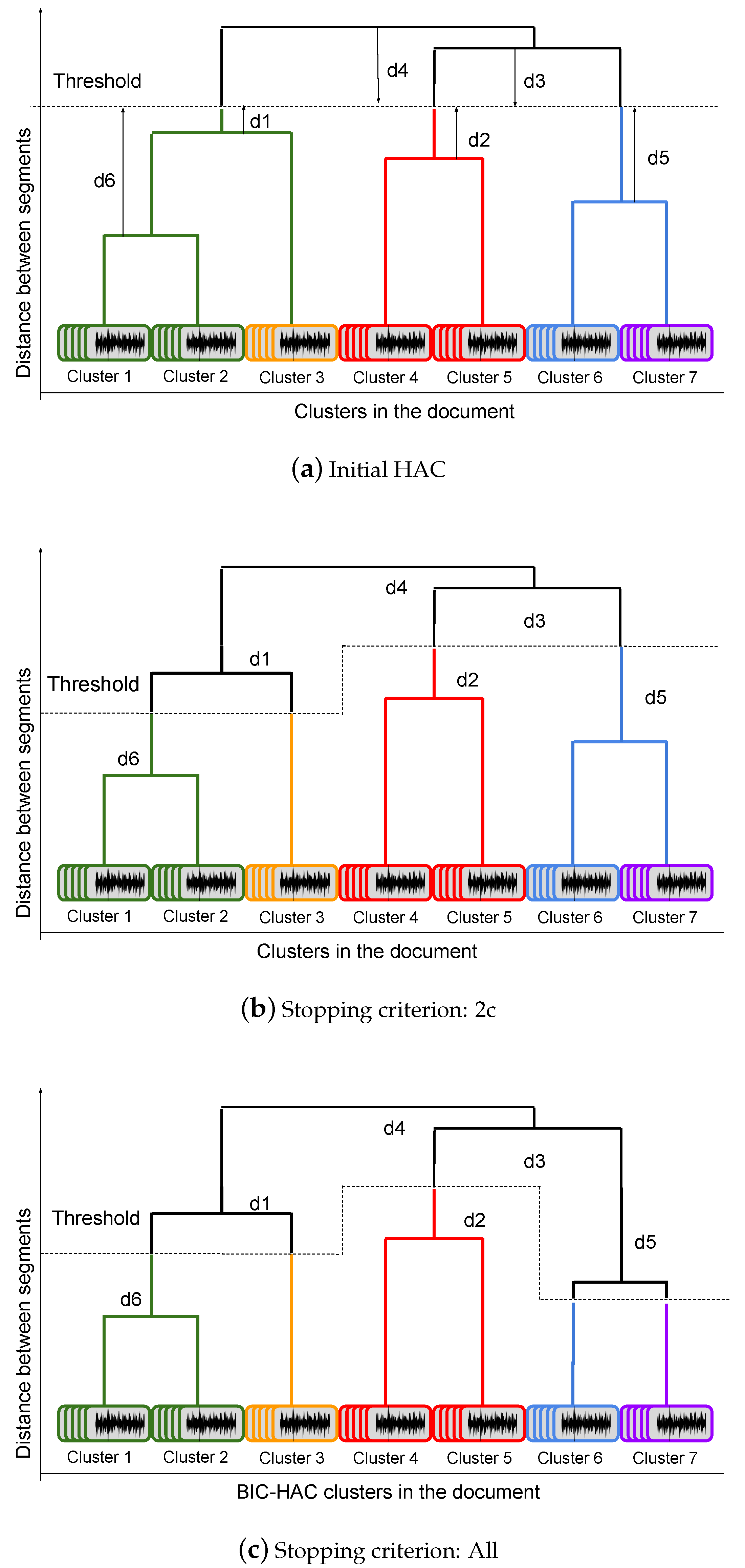
Cross-show acoustic variability can pollute x-vectors and cause errors in their pseudo-distance sorting. In other words, two segments with a higher acoustic mismatch can have lower pseudo-distance, which misleads the close-set speaker identification. We assume here that the shows are homogeneous enough so that if the current speaker has appeared in past show (so that actually is the same as ), then pseudo-distance to must be lower than other speakers in the current show. This assumption motives us to keep only the most similar speaker (the one with lower pseudo-distance) in each past show to include in the checking list. In order to find the best match of speakers cross-show (a speaker from current show and a speaker from past shows), two strategies are proposed: (i) Nearest speaker per show: in which one single speaker per show is included in the list (with respect to the pseudo-distance order) as candidate for matching with the current speaker. (ii) All: in which all speakers for all shows are ranked with respect to their pseudo-distance to the current speaker without limiting of number of speaker per show.
7.2. Performance and Analyses of Cross-Show Human Assisted Diarization
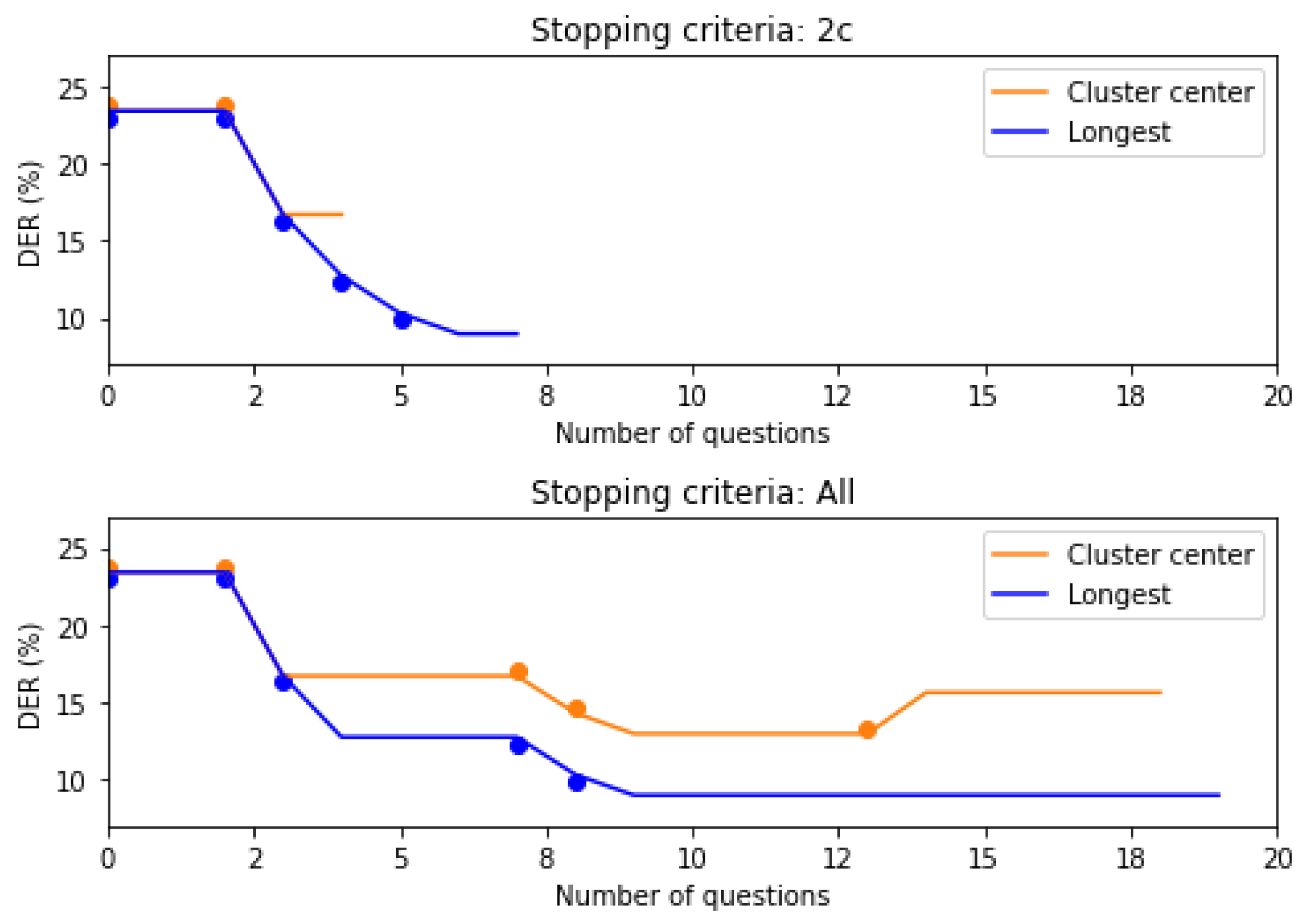
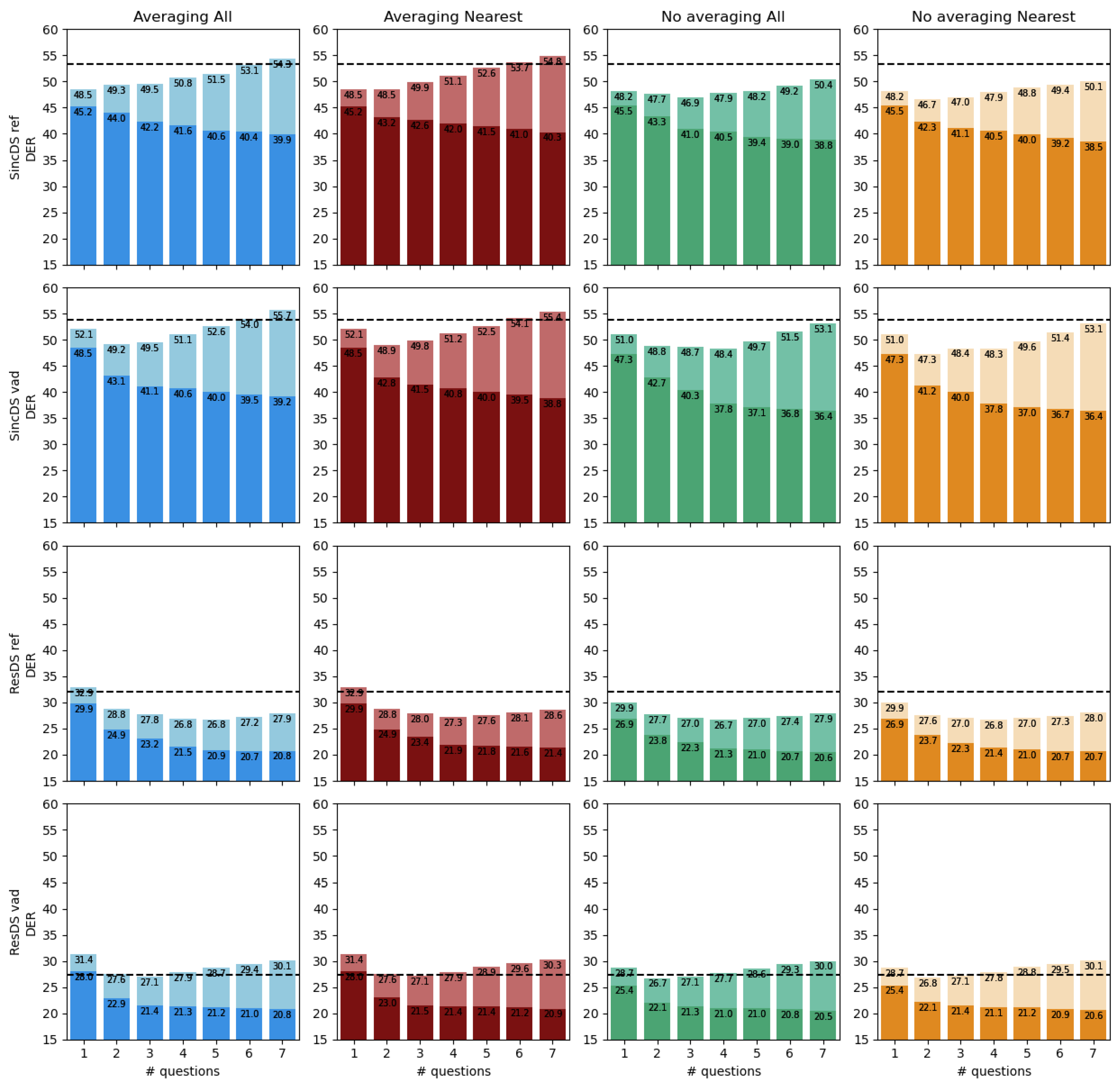
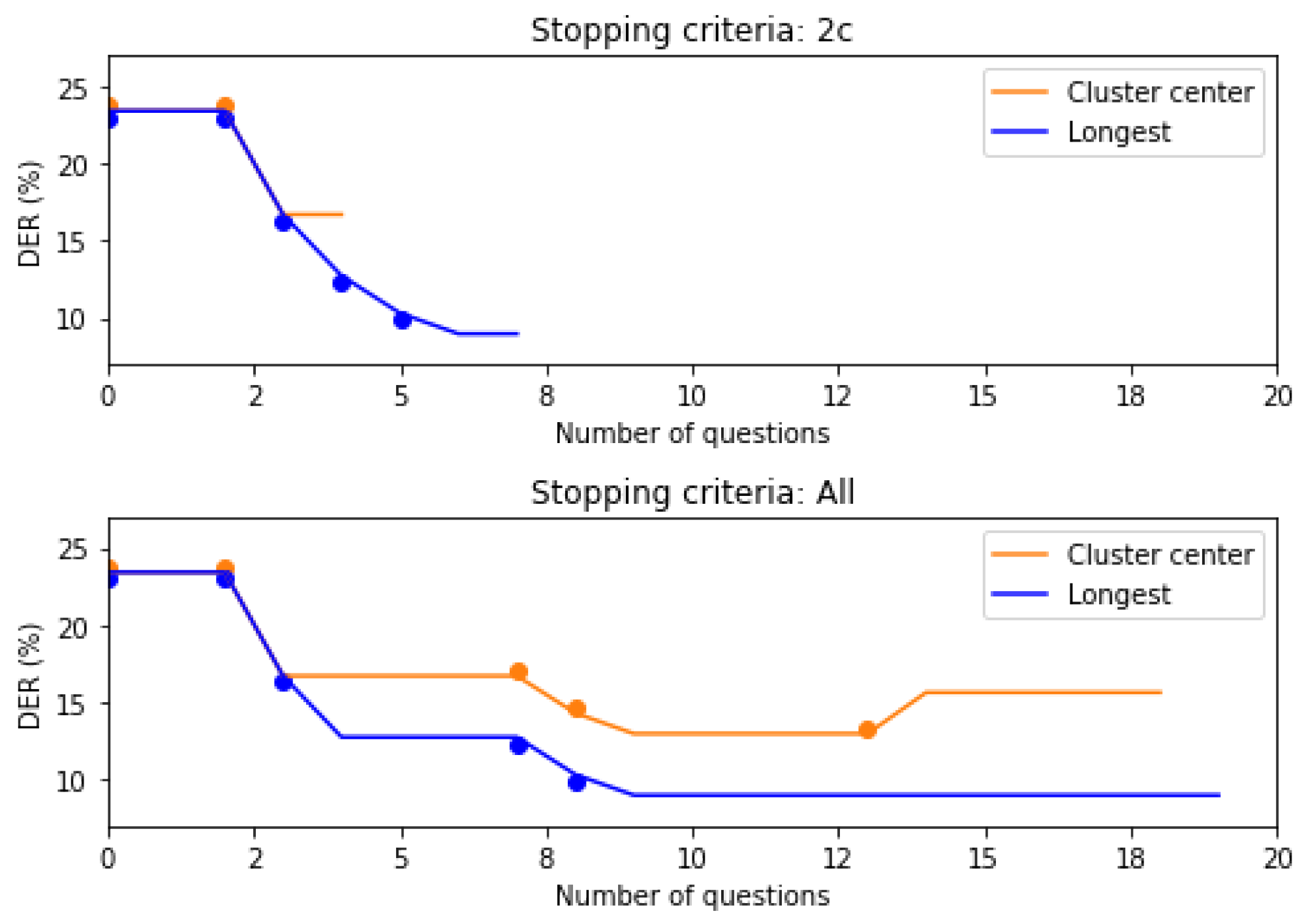
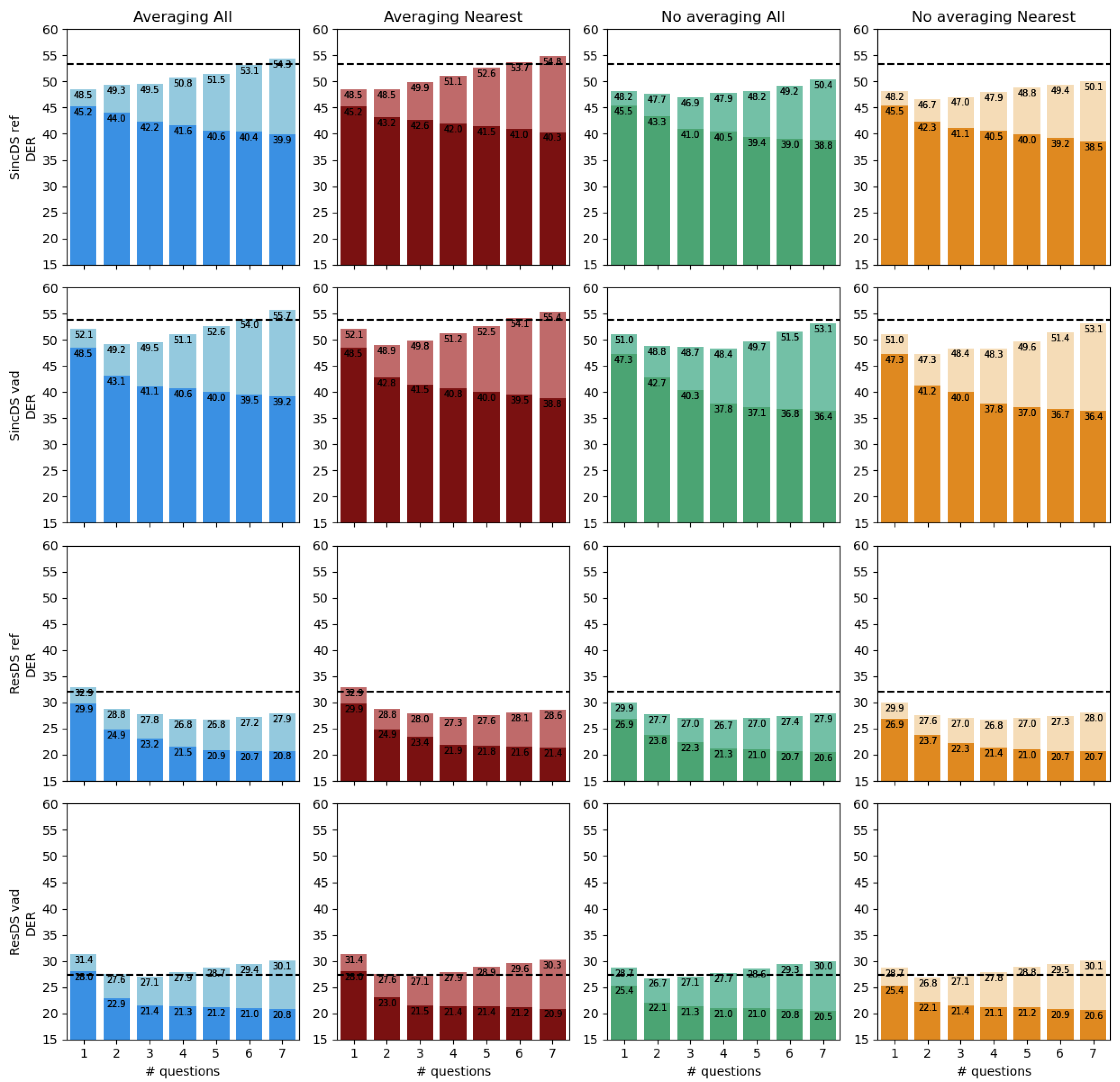
This section reports the performance of our human-assisted cross-show speaker linking for the two baseline systems (SincDS and ResDS) and the combination of both Averaging and No averaging speaker representations considering the ranking of All speakers or only the Nearest speaker per show.
All results are given in
Figure 5. A first look at the Figure confirms that the
ResDS system strongly outperforms the
SincDS system due to the quality of the produced embeddings. We then observe that all four systems benefit from asking more questions to the human operator (improving final DER), and this for all speaker representations and when considering the entire list of speakers or only the nearest per show. According to the penalized DER (lightest bars), the benefit obtained when using the proposed active correc-tion method is higher than the cost of active correction (except for some cases in the
ResDS system using VAD). Compared to the baseline systems, asking seven questions per current speaker allows to reduce the incremental cross-show DER by a relative 24% for the
ResDS system using a VAD segmentation and all
x-vectors from the
Averaging representation of past speakers and can be reduced by up to 35% for the case of
ResDS system using the reference segmentation with the
Averaging representation of the Nearest speaker per file.
Now comparing the two speaker representations—Averaging of No-averaging—we find that the No-averaging representation always perform (at least slightly) better the Averaging representation. This might be explained by the fact that averaging all x-vectors from a speaker per show merges robust x-vectors extracted from long clean segments with other x-vectors extracted from noisy and short segments that degrade the speaker representations. This effect is more clear for the SincDS system which embedding’s quality is lower than for the ResDS system. Reducing the set of x-vectors to the nearest speaker per show does not provide any clear benefit.
This experiment also shows that when using
ResDS system, active correction of the clustering is highly dependent on the quality of the segmentation, which is less the case for SincDS. For
ResDS, by comparing the performance of active correction when using reference segmentation or an automatic one (the difference of dash line and bars in two below line of
Figure 5), it can be observed that the proposed active correction process is more efficient with the reference segmentation. Indeed, when using an automatic segmentation, allowing more questions per speaker leads to an increase of
that ends to be higher than the baseline one. The benefit of active human correction does not compensate for its cost. Remember that the number of questions from 1 to 7 is an upper limit but in many practical cases this number is not reached. Future work will focus on active correction for segmentation.
One could be surprised by the fact that the DER obtained by the ResDS system on the Development set is lower when using an automatic segmentation than when using the reference. A first analysis shows that an automatic segmentation using this system generates a higher number of speakers in the within show hypothesis. Each of these speakers having thus a shorter speech duration, the clustering errors that occur during the cross-show diarization affect less the final DER when a speaker is misclassified. The same effect not being observed with the SincDS system underline the fact that side effects of within show diarization errors on the cross-show diarization are complex and will be studied in further studies.
After analysing the results obtained on the Development set, we set the optimal configuration for each system using both reference or automatic segmentation, we also set a maximum number of questions per speaker in the current file for each system and perform the corresponding experiment. Results are given in
Table 8.
The results obtained on the Evaluation set and provided in
Table 8 confirm observations from the Dev set. The quality of the segmentation is essential for the efficiency of the human assisted correction process. We also note that when using the reference segmentation, enabling more questions per speaker during the incremental process leads to better performance even in terms of penalized DER. This means that theoretically allowing more questions might be beneficial without necessarily leading to a higher number of questions actually asked (the automatic system does not need to ask all possible questions).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}