1. Introduction
The vast amount of online content will drown Internet users if online recommendation systems are not in place, and IoT developers will be confused. Therefore, a huge challenge exists in extracting useful information from vast amounts of data [
1,
2]. In order to help users choose what they want or need, recommendation systems have been given plenty of attention.
In order to facilitate content recommendation, researchers have developed several mechanisms. They can be classified into four categories: collaborative filtering (CF)-based (which includes latent factor models or matrix factorization), social network-based, deep learning (DL)-based and variational inference (VI)-based [
3,
4] (see
Table 1).
The first type of recommendation recommends by locating existing users with suitable preferences and offers the content based on their content lists. Collaborative filtering has become the widely-used recommendation approach in recent decades. The probabilistic matrix factorization (PMF) was brought up by Salakhutdinov and Mnih in 2007, for example, in order to predict Netflix user ratings. The Bayesian probabilistic matrix factorization (BPMF) proposed by Salakhutdinov and Mnih [
5] uses the Markov Chain Monte Carlo (MCMC) sampling and can deal with large datasets. Based on item categories and an interesting measure, Wei et al. developed a new item-based CF recommendation algorithm in 2012 [
6]. The algorithm can deal with sparsity and thus demonstrate high accuracy. The Tag-Based Recommendation System that Yin et al. presented in 2016 can output a customized recommendation list for TV users through a tag-based recommendation list [
7]. A new integrated CF recommendation for social cyber physical system (CPS) was released in 2017 by Xu et al. [
8]. In addition to item ratings and user ratings, the proposed algorithm also uses social trust to improve choices. On 15 March 2019, Xu et al. proposed an algorithm for determining the independent degree between different classification sets that is based on Gaussian cores [
9]. In 2020, Meng et al. proposed a security-driven hybrid collaborative recommendation method for a cloud-based IoT service [
10]. Even though a CF-based recommendation is simple to apply, it has a few favorable features, such as high computing costs for large user numbers and low accuracy in the existence of sparsity, as well as difficulty in explaining [
11].
Since the preference of one user is influenced by the preference of another user, a social network-based recommendation is easy to understand. Thus, social network-based recommendations have both advantages and disadvantages. Generally, the recommendations are correct but lack originality and freshness [
12].
The content-based recommendation method creates a user preference file from the user’s rating, viewing, and labeling behavior so that it can recommend the contents most aligned with that preference. In their pioneering paper, Basu et al. developed a recommending algorithm capable of incorporating both user ratings and item knowledge [
13]. Then, Bhagavatula et al. developed the content-based academic paper recommending system [
14], Pablo et al. developed an artwork recommendation based on content [
15], and Sun et al. developed a customized service recommendation system based on content [
16]. An algorithm based on content is obviously better for those with professional knowledge in that field. However, content-based recommendations face the issue of cold starts and overfitting.
Deep learning systems offer superior accuracy to traditional recommendation algorithms because of the computing power enabled by deep neural networks. As part of their research on DL-based recommendation systems for various uses, Song et al. brought up a method that utilizes long-term and short-term user history to boost recommendation accuracy [
17]. Using neural networks to model the client’s penchant for all kinds of online content, Zheng et al. developed a neural autoregressive distribution estimator (NADE) system the following year. An image recommendation system based on DL for large scale online commerce was proposed by Shankar et al. in 2017 [
18]. This process computes how similar the visual characteristics of different items are to each other and makes recommendations based on that information. An algorithm integrating DL and CF was proposed by Deng et al. [
19] in 2019. Then, Fang and colleagues exploited DNN’s sequentiality to enhance recommending performance by capturing Internet users’ preferences in real time [
20]. A second DLTSR-based system was developed by Bai et al. [
21] in 2020. Since, in practical terms, deep neural network (DNN) models are only suitable for some scenarios that contain visual elements and for which only word searching is not sufficient, such as garment recommendation. Thus, we need other recommendation algorithms to complement the DL-based method.
The VI-based approach has become popular among researchers because it helps reduce overfitting and efficiently solves hyperparameters. A variational Bayesian matrix factorizations-based movie recommendation algorithm developed by Koenigstein et al. in 2013 is one example. Using variational Bayesian methods, Lim et al. developed a method for predicting TV program feedback. A 2015 paper by Sedhain and his colleagues [
22] described an approach that utilizes autoencoders (a VI approach) with CF-based recommendation systems. In a study by Zhang et al. on deep optimization of sparse data using variational matrix factorization, they propose an algorithm for making recommendations based on a large scale sparse rating matrix [
23]. Then, in 2019, Shen et al. [
24] developed a recommendation system that uses both deep learning, VI, and matrix factorization, called deep variational matrix factorization (DVMF). However, the accuracy and complexity of VI depend in large part on how complex the target density is, and without full knowledge, it is difficult to construct general VI models. Thus, to use a VI model in different scenarios, we have to construct VI algorithms that improve generality [
25]. Recently, Stein’s method, another class of VI method, is a general tool to obtain bounds on distances between distributions, offering a powerful density approximation solution [
26].
In this paper, inspired by the generalization and low-complexity of Stein’s method, we offer a Stein Variational Recommendation System that reduces overfitting, incorporates large volumes of data, and has lower MAE and RMSE. In this paper, we develop and analyze an SVRS algorithm both theoretically and experimentally in terms of accuracy and complexity. We also provide justifications and characteristics of our SVRS in the appendix.
We discuss the concept of SVRS in
Section 2, and we provide a detailed explanation of SVRS in
Section 3. In
Section 4, we simulate experimental comparisons of SVRS with others. In the end, the paper is concluded in
Section 6.
2. Preliminaries
First, we introduce Stein’s identity, the core of SVRS. We define
as the feature of user
i,
that of IoT service
j, the density to be obtained, and
and
, the approximate distribution or functions of
and
. Stein’s discrepancy, a general measure of how different two distributions, is the basis of Stein’s identity, which means that, for any regular
, the following equality stands:
in which
is the Stein operator, and ∇ is the derivation operator. In this way, we can solve
u and
v at the same time, since
.
As noted before, Stein discrepancy
is the divergence of one distribution from another Gaussian distribution [
25,
27] (only Gaussian distribution can obtain a Stein’s identity), which is
of which
is differentiable everywhere. Many ground truth inference problems have been solved using Stein’s identity. As stated earlier, we intend to compute a posterior density of
p in our paper.
Stein’s identity is similar to but differs from the KL divergence in that it can be used to describe the distance between different distributions in a more general sense. The Stein discrepancy is equal to zero if and only if . Therefore, we use q, the variational distribution, to replace p, and then try to minimize the Stein discrepancy between p and q.
However, another question arises when doing so, i.e., selecting the right kind of
to simplify the computation process of minimizing Stein discrepancy. Therefore, we restrict
to a unit hyperspace of reproducing kernel Hilbert space (RKHS) [
25], which is
Furthermore, the kernel method is used to reduce the computational complexity due to its simple and elegant features—of which the reproducing kernel is a promising type. We use
to denote the positive kernel. Therefore, the optimum of (3) is
[
27], which can also be written as
and therefore
can be reached using U-statistics [
27]
and also
3. SVRS
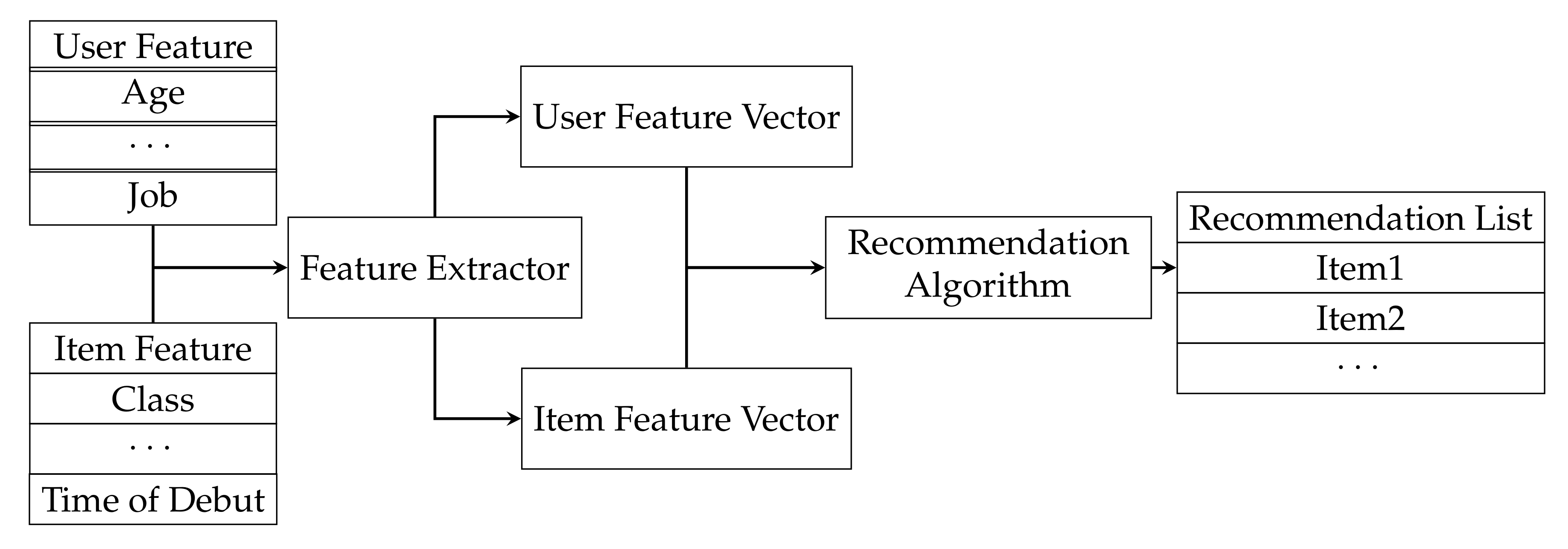
The standard procedure of the recommendation system can be seen in
Figure 1. To begin with, we pre-train a set of user-item scores. Define
to be the feature vector of user
i, the value of which is in
; then,
the feature vector of item
j, the value of which is in
. The number of users is
, and the number of items is
. Denote the rating matrix as
L. Therefore, we reach the fundamental objective, i.e., to calculate
. Note that the matrix factorization way decomposes
L to obtain
. After this, we use
U and
I, the ground truth of user and item feature, to further predict ratings that users have not given. Specifically, the objective of SVRS is to obtain the
U and
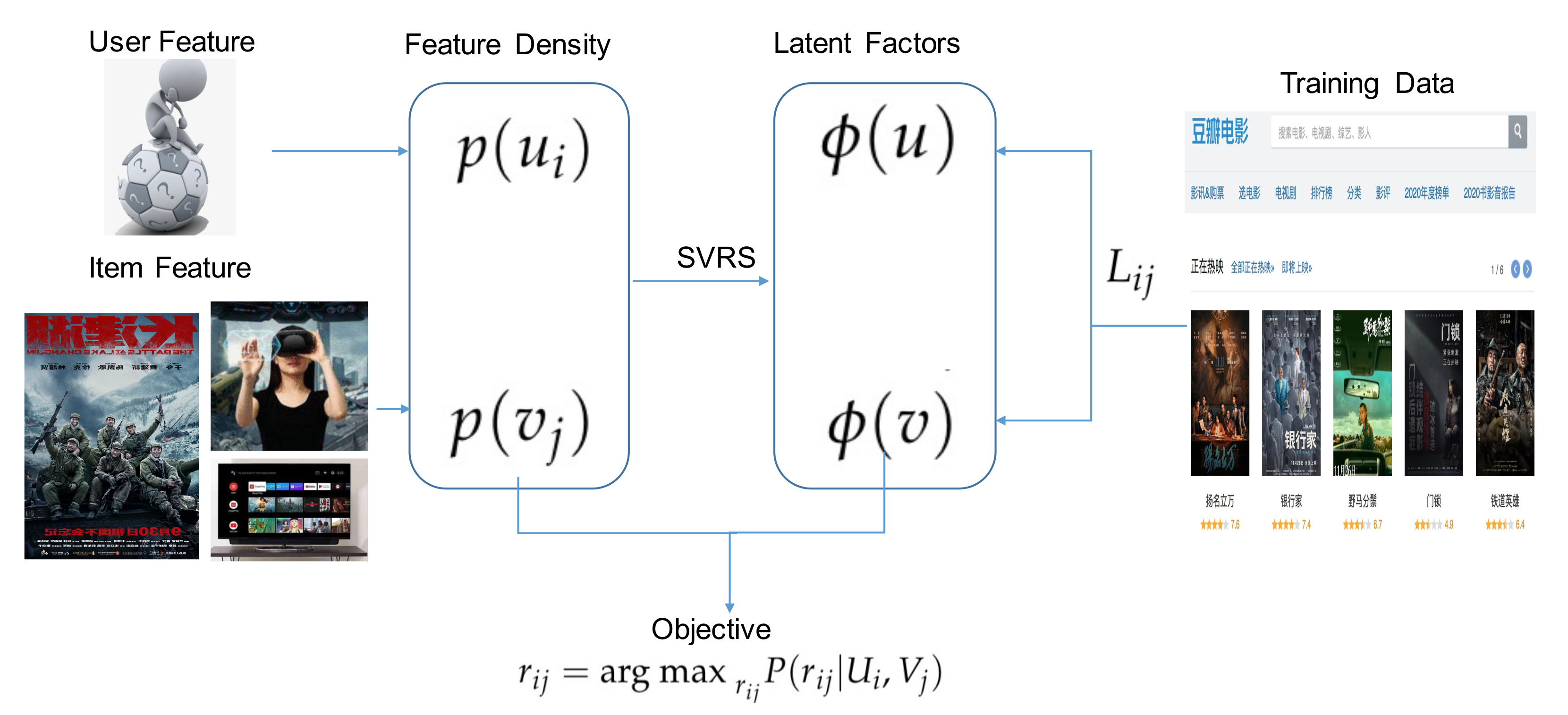
V that can maximize the likelihood, or minimize the Stein discrepancy. The user feature density is
of which
.
is the normalization. Notice that
U and
V are calculated alternatively, and that, in order to save space, we may skip the derivation of
V (see
Figure 2 for the procedure of SVRS).
Traditionally,
is maximized by maximizing the function that has the same monotonicity with joint probability, a highly-demanding process to apply directly in VI. To calculate the log joint density, we can instead compute the evidence lower bound (ELBO), or the metrics that measure the difference (or distance) of
with
—of which
is the approximate variational distribution [
28]:
where
,
.
Thus, two methods can be used to obtain the target distribution that can maximize the log likelihood of L, maximizing ELBO or minimizing . We choose the second one. In order to minimize the KL divergence, we need to differentiate it with respect to . This is not easy. Thus, we have to set to simple forms, or use MCMC sampling instead. In this work, we choose the first popular way.
SVRS requires some assumptions before we can proceed. To begin with, we assume the rating noise is Gaussian,
Since we use
and
to replace
, we need to first define which form of
/
is best-suited. Clearly, the optimal
and
have the smallest divergence with
. Thus, the best
and
have the following form:
of which
is
’s space, and
is
’s space. Intuitively, the best
possesses the feature of accuracy and tractability. Therefore, it is rational to choose linear
that is continuous and differentiable (in another perspective described in other papers, this is the trick of reparameterization) [
29].
In this way, using
we can simplify the computing and differentiating process.
denotes the step-size, and
is selected simple density. If we take Equation (12) as the updating function, then
will be the updating direction.
T can be viewed as a map that is invertible and monotone [
30]. It is our goal to output data points to model the posterior distribution. Therefore, we initially produce some data points and then update
instead gradually in order to obtain the final optimal data sets. Notice that there is always a measurable map
T if
q and
p are atom-less density.
Based on Liu et al.’s work [
25], there is a close connection between KL divergence and Stein’s identity, and we obtain the following conclusion:
Theorem 1. Letting and , one can obtainwhere is the Stein operator. Proof. Seen from Equation (13) with (2), one can obtain that iteratively reduces the KL-divergence. □
Thus, we can obtain by solving the maximum of , which is computed according to Theorem 1.
Theorem 2. The Stein’s variational direction is the steepest updating direction in an RKHS with dimension d, which is:in which . This indicates that the negative gradient direction of Equation (12) is also the derivative of the KL-divergence w.r.t. , which is also equal to ’s Stein discrepancy.
Thus, we obtain the updating equation
where
. In this way, we have converted the problem of calculating the user density
into a Stein VI optimization that calculates data points of
. Thus, SVRS can be summed up in Algorithm 1.
| Algorithm 1 SVRS. |
Input Output: U,V, for each label do where where end for until convergence Output: Compute: MAE, RMSE. |
A detailed analysis of the appendix shows that SVRS is unbiased and converging, and that it is closely related to the popular PMF and CF models.
3.1. Convergence Proof
Defining the bounded Lipschitz metric as the maximum difference of their mean values on a continuous text function,
where, according to Liu et al. [
26], we have:
Theorem 3. Assuming is bounded Lipschitz on with a limited norm, then, for any two probability measures , we have In addition, furthermore, we have:
Theorem 4. Let be the empirical measure of at the tth iteration of SVRS, and assumethen, for , we have This suggests that, as long as the initial data points converge, the final result’s probability measure will surely converge, which means that SVRS will introduce no further divergence during iteration. Furthermore, from the property of RKHS, and treating the data points obtained from each iteration, the density represented by the data points can be treated as a convergent sequence, which is unique for map T. Therefore, the theoretical final measure reached by a sequence of T is a fixed point. We therefore can show that SVRS has good convergence property.
Unbiasedness and Variance
Assuming that the final variational distribution we obtained is , then the gradient of with respect to is . Since the SVRS algorithm produces a sequence of particles that construct the objective distribution (and . We can say that . If f is continuous at the value space of , and is the unbiased samples of , we can see that is also the unbiased estimation of .
In addition, the Fisher information [
31] of
is
. Since the updating direction of
is also connected to the updating direction of
, we can see that the Stein discrepancy is closely related to the Fisher divergence, which is
. According to the Cramer–Rao bound, we have
Therefore, we have the lower variance bound for SVRS. The reason is that the second part of Equation (14) acts as a repulsive force to drive the particles away from the sink value, i.e., the mean value of the target distribution, causing the variance to increase. Interested readers can refer to Oates et al. [
32] for variance reduction methods.
3.2. Connection with CF-Based Recommendation
SVRS can be treated as a kind of model-based CF algorithm. A typical model-based CF algorithm first develops a model of user ratings, and then uses the probability approach to compute the expected prediction of user ratings on other items. From the perspective of Equation (10), computing the expected prediction is an intermediate step in SVRS, and, in a general sense, SVRS can be called a CF-based recommendation algorithm. However, a traditional CF-based algorithm computes the similarity between users or items, and then recommends a list of items according to the similarities, and in this sense, CF is just a kind of classification or cluster algorithm that produces the feature distance between users and items, and cannot scale or deal with sparsity.
3.3. Connection with PMF Models
PMF is a popular recommendation algorithm that has slightly better performance than others. However, PMF is only a very primitive form of loss optimization framework. Its main computing technique is the same as VI, or SVRS, formulating the user/item feature parameter into a posterior inference problem, and then solving the optimum by setting the derivatives with respect to the target parameter to 0. The differences are that the PMF is not general, which requires a specific assumption of the prediction distribution, and it does not treat the recommendation problem as a general variational optimization framework.
6. Conclusions
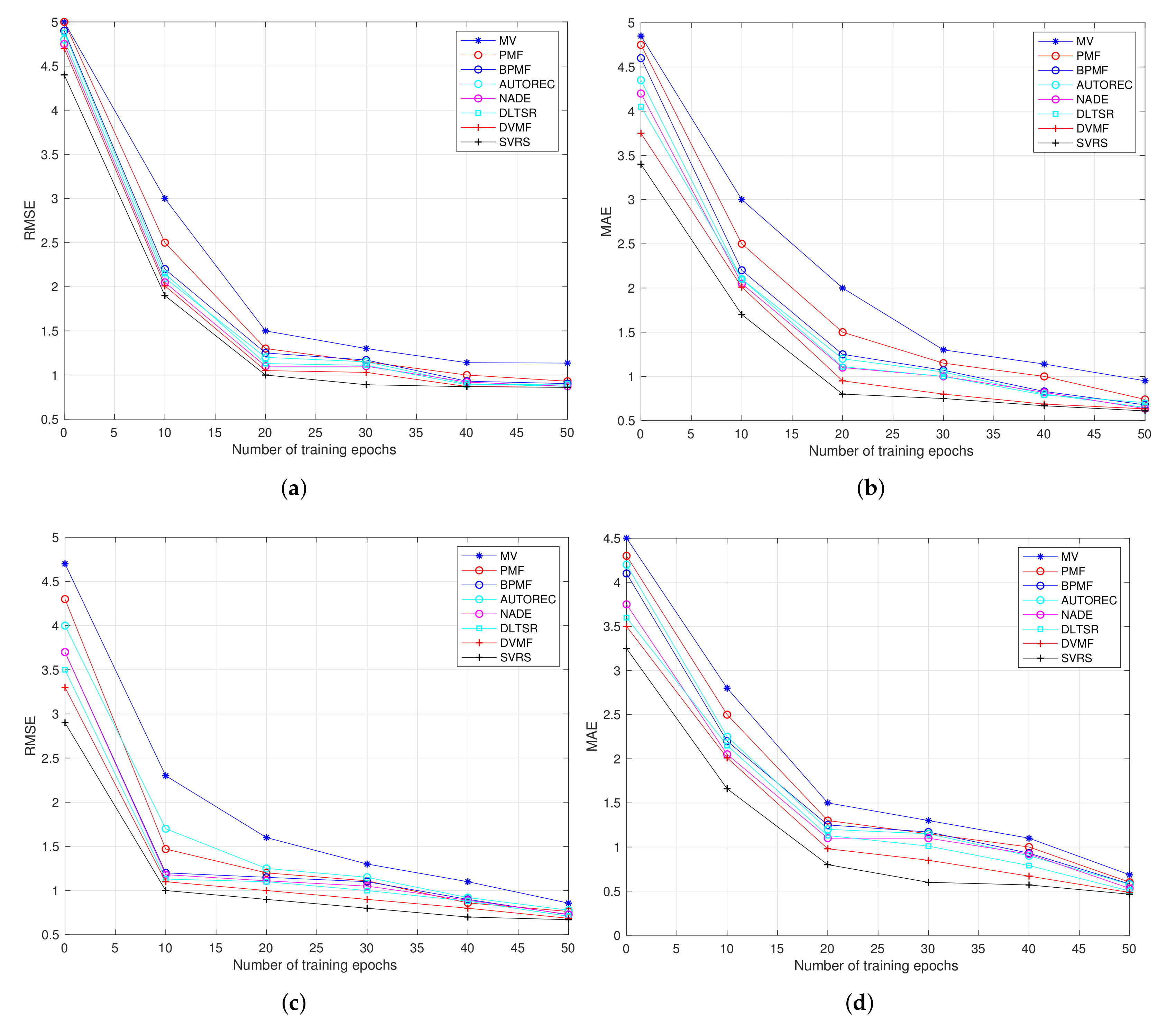
Providing convenient and useful IoT services requires solving the problems facing the online recommendation systems. The target of this paper is to propose and verify a novel Stein variational inference based recommendation algorithm—SVRS that infers the ground truth density of latent variables and predicts the ratings of items they might give. Users who have not viewed a particular piece of content can also be predicted via this algorithm. We offer insights into how user ratings are formed in our SVRS, and we can extend its capabilities to incorporate more dimensions. SVRS performs better than existing algorithms by simulations.
In the future, we will try to apply SVRS to more applications to solve the most prominent problems in the industry and continue to study the most accurate and practical ground truth analysis methods. Specifically, there are four promising areas that can be explored. The first is how to identify the factors or parameters that can influence the performances of SVRS. In the current literature, most authors compare their models’ best performance with others to verify them. However, any model’s performance is not fixed, all subject to the change of settings, data quality, model dimension and model complexity. It is urgent to build a unified platform that can show readers and researchers the advantages and disadvantages of SVRS for their information. The second is how to build SVRS based recommendation models that can adapt to complex network structures. In the existing literature, most Stein variational recommendation-based models use a different simplification method to deal with networks with complex structures. Therefore, it is necessary to develop recommendation models that require less simplification and adapt to complex models. The third is how to unify SVRS with different kinds of recommendation models. As we have seen in the above discussions, SVRS has a close relationship with other recommendation models, such as CF and PMF. There is no doubt that all those methods share some common methodology inherently. However, how to unify them together, or if they have differences that cannot be reconciled, the exact differences between them remain unexplored in the literature. The last is how to apply SVRS in the fields where there is no satisfying solution for recommendation or prediction. Since SVRS is a rather new tool in the literature, many fields lack the application of the Stein Variational-based method to solve the most prominent problems. Therefore, the wide application of the Stein variational recommendation-based method can not only promote the theoretical understanding of itself but also contribute to the research of other fields.



.png)

{kind=link}
{kind=link}
{kind=link}
{kind=link}