
Comparing the Effectiveness of Speech and Physiological Features in Explaining Emotional Responses during Voice User Interface Interactions

 ,
,
Abstract
1. Introduction
- RQ1: Between speech and physiological features, which are more informative in assessing intense emotional responses during vocal interactions with a voice user interface?
- RQ2: Can we unobtrusively identify an intense emotional response during voice user interface interactions?
2. Literature Review and Hypotheses Development
2.1. Speech Features
2.2. Physiological Features
2.3. Combination of Speech and Physiological Measures
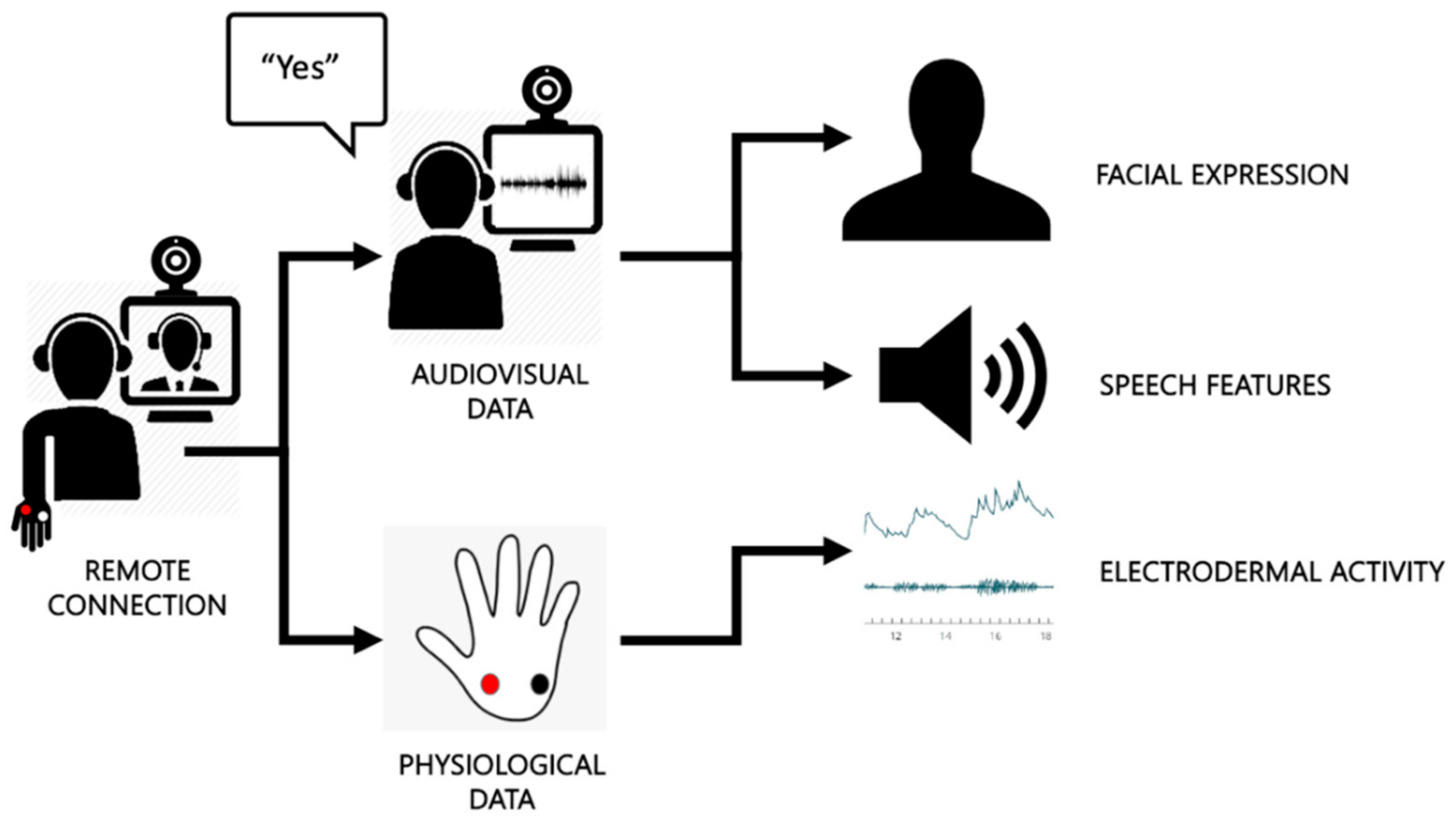
3. Methods
3.1. Experimental Design
3.2. Sample
3.3. Voice User Interface Stimuli
3.4. Experimental Setup
3.5. Measures
3.6. Experimental Procedures
3.7. Third-Party Emotion Evaluation
3.8. Data Processing and Feature Extraction
3.8.1. Speech Features
3.8.2. Facial Expression Feature
3.8.3. Electrodermal Activity Feature
3.9. Statistical Analyses
4. Results
4.1. Inter-Evaluator Reliability Results
4.2. Multiple Linear Regression
4.3. Multiple Linear Regression of Speech and Physiology
5. Discussion
5.1. Theoretical Contributions
5.2. Practical Implications
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Original French Question | English Translation of Questions | Type | Description | Question Number | Possibility of “Yes” Response |
|---|---|---|---|---|---|
| Bonjour. Je m’appelle Renée. Je suis un robot chercheur. Aujourd’hui, j’aimerais mener une entrevue avec vous. Les questions sont faciles. Certaines questions seront à choix multiples. Certaines questions seront des questions par oui ou par non. Dans tous les cas, vous pouvez dire «je ne sais pas», si vous ne savez pas ou si vous ne pouvez pas décider. | Hello. My name is Renée. I am a research robot. Today I would like to conduct an interview with you. The questions are easy. Some questions will be multiple choice. Some questions will be yes or no questions. Either way, you can say “I don’t know” if you don’t know or if you can’t decide. | VUI 1 Comment | Introduction/ Instructions | ||
| [Robot] Acceptez-vous de participer? | [Robot] Do you agree to participate? | VUI Question | Confirmation | 1 | |
| [pXX] 2 Réponse | [pXX] Answer | Participant Response | Answer | Yes | |
| Merveilleux. Merci beaucoup. Avant de commencer, j’aimerais calibrer mes oreilles à votre voix. Pour ce faire, j’ai besoin que vous lisiez le texte de calibrage qui vous a été fourni par le modérateur de l’expérience d’aujourd’hui. Veuillez lire le texte de calibrage en commençant par le premier mot, puis attendez deux secondes, puis lisez le mot ou la phrase sur la ligne ci-dessous. Continuez comme cela jusqu’à ce que vous ayez fini de lire la dernière ligne. | Marvellous. Thank you so much. Before I begin, I would like to calibrate my ears to your voice. To do this I need you to read the calibration text provided to you by the moderator of today’s experiment. Please read the calibration text starting with the first word, pause two seconds, then read the word or phrase on the line below. Continue like this until you have finished reading the last line. | VUI Comment | Introduction/ Instructions | ||
| [Robot] Êtes-vous prêt? | [Robot] Are you ready? | VUI Question | Question | 2 | |
| [pXX] Réponse | [pXX] Answer | Participant Response | Answer | Yes | |
| Excellent. Veuillez commencer. | Excellent. Please begin. | VUI Comment | Introduction/ Instructions | ||
| Bonjour. | Hello. | Participant Response | Calibration | ||
| Chat. | Cat. | Participant Response | Calibration | ||
| Chien. | Dog. | Participant Response | Calibration | ||
| Oui. | Yes. | Participant Response | Calibration | ||
| Il fait froid aujourd’hui. | It is cold today. | Participant Response | Calibration | ||
| Non. | Non. | Participant Response | Calibration | ||
| Un cheval fou dans mon jardin. | A crazy horse in my garden. | Participant Response | Calibration | ||
| Il y a une araignée au plafond. | There is a spider on the ceiling. | Participant Response | Calibration | ||
| Oui. | Yes. | Participant Response | Calibration | ||
| Deux ânes aigris au pelage brun. | Two brown-furred embittered donkeys. | Participant Response | Calibration | ||
| Des arbres dans le ciel. | Trees in the sky. | Participant Response | Calibration | ||
| Non. | No. | Participant Response | Calibration | ||
| Trois signes aveugles au bord du lac. | Three blind swans by the lake. | Participant Response | Calibration | ||
| Des singes dans les arbres. | Monkeys in trees. | Participant Response | Calibration | ||
| Oui. | Yes. | Participant Response | Calibration | ||
| Quatre vieilles truies éléphantesques. | Four old elephantine sows. | Participant Response | Calibration | ||
| Super. | Super. | Participant Response | Calibration | ||
| Merci. | Thank you. | Participant Response | Calibration | ||
| Bien sûr. | Of course. | Participant Response | Calibration | ||
| Oui. | Yes. | Participant Response | Calibration | ||
| Cinq pumas fiers et passionnés. | Five proud and passionate pumas. | Participant Response | Calibration | ||
| Non. | No. | Participant Response | Calibration | ||
| Six ours aimants domestiqués. | Six affectionate domesticated bears. | Participant Response | Calibration | ||
| J’ai terminé Renée. | I’m finished Renée. | Participant Response | Calibration | ||
| Fantastique. Merci beaucoup. Calibration réussie. Vous pouvez me parler librement. Je voudrais commencer l’entrevue maintenant. N’oubliez pas d’évaluer votre satisfaction à mon égard après chaque réponse verbale. Ces informations aideront mes designers à me rendre meilleur. | Fantastic. Thank you so much. Calibration successful. You can talk to me freely. I would like to start the interview now. Remember to rate your satisfaction with me after each verbal response. This information will help my designers to make me better. | VUI Comment | Introduction/ Instructions | ||
| Êtes-vous prêt à commencer? | Are you ready to being? | VUI Question | Question | 3 | |
| [Le participant doit répondre par «oui»]. | [The participant must answer with “yes”]. | Participant Response | Answer | Yes | |
| Êtes-vous prêt à commencer? | Are you ready to being? | VUI Question | Error | 4 | |
| [Le participant doit répondre par «oui»]. | [The participant must answer with “yes”]. | Participant Response | Error | Yes | |
| D’accord. Voici la première question. | OK. Here is the first question. | VUI Comment | Transition | ||
| Êtes-vous étudiant à HEC Montréal? | Are you a student at HEC Montréal? | VUI Question | Question | 5 | |
| [Le participant doit répondre par «oui» ou «non»]. | [The participant must answer with “yes” or “no”]. | Participant Response | Answer | Yes | |
| Oh. C’est étrange. Je pensais que vous étiez un étudiant d’HEC. | Oh. That’s strange. I thought you were a HEC student. | VUI Comment | Error | ||
| [pause un moment, car un participant pourrait parler] | [pause for a moment, as the participant might reply] | Participant Response | Error | ||
| Vous n’êtes donc pas un étudiant de HEC Montréal? | So you are not a HEC Montréal student? | VUI Question | Error | 6 | |
| [Le participant devrait commencer à montrer sa frustration et répondre] | [The participant should start to show frustration and reply] | Participant Response | Error | No/Yes 3 | |
| Je vous demande pardon? | Excuse me? | VUI Question | Error | 7 | |
| [Le participant devrait commencer à montrer sa frustration et répondre] | [The participant should start to show frustration and reply] | Participant Response | Error | ||
| Oh. Je suis vraiment désolée. J’étais vraiment confuse pendant un instant. | Oh. I am very sorry. I was really confused for a moment. | VUI Comment | Reply | ||
| Donc vous êtes en fait... un étudiant de HEC Montréal? | So you are in fact a HEC Montréal student? | VUI Question | Error | 8 | |
| [Le participant doit répondre par «oui» ou «non»] | [The participant must reply] | Participant Response | Error | Yes | |
| J’ai compris. Merci. Désolée encore une fois. | I understand. Thank you. Apologies once more. | VUI Comment | Reply | ||
| Essayons la question suivante. | Let’s try the next question. | VUI Comment | Transition | ||
| Pensez-vous que votre communication téléphonique et virtuelle avec les autres a augmenté pendant la pandémie? | Do you think your phone and virtual communication with others has increased during the pandemic? | VUI Question | Question | 9 | |
| [pXX] Réponse | [pXX] Answer | Participant Response | Answer | Yes | |
| C’est bien. Mais, maintenant, vous êtes ici en train de parler à un robot. Des temps étranges. | That’s good. And now here you are talking to a robot. Strange times. | VUI Comment | Transition | ||
| Pensez-vous que HEC. Montréal a fait du bon travail pour répondre à la pandémie? | Do you think HEC Montréal did a good job in response to the pandemic? | VUI Question | Question | 10 | |
| [pXX] Réponse | [pXX] Answer | Participant Response | Answer | Yes | |
| Flow 1 Question 10 | Flow 1 Question 10 | ||||
| [Si oui,] Moi aussi. Ils ont créé de nouveaux emplois juste pour les robots. Donc je ne peux pas me plaindre. | [If yes,] So do I. They’ve created new jobs for robots. I can’t complain. | VUI Comment | Reply | ||
| Flow 2 Question 10 | Flow 2 Question 10 | ||||
| [Si non ou je ne sais pas,] Je comprends. J’ai essayé de dire à l’administration ce qu’ils pourraient faire de mieux, mais personne ne semble m’écouter. | [If no or unsure] I understand. I tried to tell the administration what they could do better, but no one seemed to listen to me. | VUI Comment | Reply | ||
| Quoi qu’il en soit, j’aimerais maintenant vous poser quelques questions pour mieux vous connaître. | Anyways, I would now like to ask you a few questions to get to know you better. | VUI Comment | Transition | ||
| Vous préférez les chiens ou les chats? | Do you prefer cats or dogs? | VUI Question | Question | 11 | |
| [pXX] Réponse | [pXX] Answer | Participant Response | Answer | ||
| Flow 1 Question 11 | Flow 1 Question 11 | ||||
| [Si les chats] Vous avez dit, «rats»? | [If cats] Did you say, “rats”? | VUI Question | Error | 12 | |
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Error | ||
| Les rats n’étaient pas une option. | Rats was not an option. | VUI Comment | Error | ||
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Error | ||
| Les chats? | Cats? | VUI Question | Error | 13 | |
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Error | ||
| Bon, d’accord. J’aime aussi les rats, je suppose. | Okay. I also like rats I suppose. | VUI Comment | Error | ||
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Error | ||
| Flow 2 Question 11 | Flow 2 Question 11 | ||||
| [Si les chiens] Vous avez dit amphibiens? | [If dogs] Did you say amphibians? | VUI Question | Error | 12 | |
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Error | ||
| Les amphibiens n’étaient pas une option. | Amphibians was not an option. | VUI Comment | Error | ||
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Error | ||
| Les chiens? | Dogs? | VUI Question | Error | 13 | |
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Error | ||
| Je suppose que les grenouilles aussi sont gentilles. | I guess frogs are nice too. | VUI Comment | Error | ||
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Error | ||
| Flow 3 Question 11 | Flow 3 Question 11 | ||||
| [Si, je ne sais pas] Préférez-vous les chats ou les chiens? | [If unsure] Do you prefer cats or dogs? | VUI Question | Error | 12 | |
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Error | ||
| [Si, je ne sais pas] Préférez-vous les chats ou les chiens? | [If unsure] Do you prefer cats or dogs? | VUI Question | Error | 13 | |
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Error | ||
| [Si, je ne sais pas] Préférez-vous les chats ou les chiens? | [If unsure] Do you prefer cats or dogs? | VUI Question | Error | 14 4 | |
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Error | ||
| [Si, je ne sais pas] Très bien. Je comprends. Ce ne sont que des bêtes poilues, il est donc difficile de se décider. | [If unsure] Very well. I understand. They are both hairy beasts, so it’s difficult to decide. | VUI Comment | Reply | ||
| Question suivante. | Next question. | VUI Comment | Transition | ||
| Quels aliments préférez-vous au petit-déjeuner, des céréales ou de la poutine? | What type of food do you prefer for breakfast, cereal or poutine? | VUI Question | Question | 14 | |
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Answer | ||
| Flow 1 Question 14 | Flow 1 Question 14 | ||||
| [Si les céréales] Vraiment? | [If cereal] Really? | VUI Question | Error | 15 | |
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Error | Yes | |
| Je suis choquée. N’êtes-vous pas Québécois? | I am shocked. Are you not from Quebec? | VUI Question | Error | 16 | |
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Error | Yes | |
| Intéressant. | Interesting. | VUI Comment | Reply | ||
| Flow 2 Question 14 | Flow 2 Question 14 | ||||
| [Si la poutine] Vraiment ? | [If poutine] Really? | VUI Question | Error | 15 | |
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Error | Yes | |
| Je suis choquée. Votre santé ne vous inquiète-t-elle pas? | I am shocked. Are you not worried about your health? | VUI Question | Error | 16 | |
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Error | Yes | |
| Intéressant | Interesting. | VUI Comment | Reply | ||
| Question suivante. | Next question. | VUI Comment | Transition | ||
| Les chemises de l’archiduchesse sont-elles sèches ou archi-sèches? | Are the Archduchess’s shirts dry or very dry? | VUI Question | Question | 17 | |
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Error | ||
| Sèches ou archi-sèches? | Dry or very dry? | VUI Question | Error | 18 | |
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Error | ||
| Quoi? | What? | VUI Question | Error | 19 | |
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Error | ||
| Archiduchesse? | Archduchess? | VUI Question | Error | 20 | |
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Error | ||
| Désolée. Je ne faisais que plaisanter. Revenons à une question sérieuse. | Sorry. I was just kidding. Let’s get back to a serious question. | VUI Comment | Transition | ||
| Après avoir obtenu votre diplôme, avez-vous l’intention d’entrer immédiatement sur le marché du travail? | After having graduated, do you plan on immediately entering the workforce? | VUI Question | Question | 21 | |
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Answer | Yes | |
| Flow 1 Question 21 | Flow 1 Question 21 | ||||
| [Si oui] Envisageriez-vous un emploi à l’extérieur du Québec? | [If yes] Would you consider a job outside of Quebec? | VUI Question | Question | 22 | |
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Answer | Yes | |
| [Si oui ou non] Je vois. Je vous remercie. | [If yes or no] I see. Thank you. | VUI Comment | Reply | ||
| Flow 2 Question 21 | Flow 2 Question 21 | ||||
| [Si non] Prévoyez-vous de poursuivre vos études? | [If no] Do you plan to continue your studies? | VUI Question | Question | 22 | |
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Answer | Yes | |
| [Si oui ou non] Je vois. Je vous remercie. | [If yes or no] I see. Thank you. | VUI Comment | Reply | ||
| Dernière question. | Last question. | VUI Comment | Transition | ||
| Faites-vous de l’exercice de temps en temps? | Do you exercise every now and then? | VUI Question | Question | 23 | |
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Answer | Yes | |
| [Si oui ou non] Plus d’un jour par semaine? | [If yes or no] More than one day a week? | VUI Question | Question | 24 | |
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Answer | Yes | |
| [Si oui ou non] Trois jours par semaine ou plus? | [If yes or no] Three days a week or more? | VUI Question | Question | 25 | |
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Answer | Yes | |
| [Si oui ou non] Avez-vous déjà menti sur la quantité d’exercice que vous faites pour impressionner les autres? | [If yes or no] Have you ever lied about how much exercise you do to impress others? | VUI Question | Question | 26 | |
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Answer | Yes | |
| [Si oui ou non] Eh bien, je suppose que c’était un peu trop personnel. | [If yes or no] Well, I guess that was a little too personal. | VUI Comment | Reply | ||
| Voilà qui conclut notre petit entretien. | This concludes our brief interview. | VUI Comment | Conclusion | ||
| Merci beaucoup pour votre participation. | Thank you very much for your participation. | VUI Comment | Conclusion | ||
| Avez-vous apprécié le temps que nous avons passé ensemble? | Did you enjoy the time we spent together? | VUI Question | Question | 27 | |
| [Permettre au participant de répondre] | [Allow the participant to respond] | Participant Response | Reply | Yes | |
| [Si oui ou non] Merci, je transmettrai vos commentaires à mes concepteurs. | [If yes or no] Thank you, I will pass your comments on to my designers. | VUI Comment | Conclusion | ||
| Passez une bonne journée. | Have a good day. | VUI Comment | Conclusion |
| Total number of questions posed | 27 |
| Total number of questions posed if Flow 3 Question 11 was selected | 28 |
| Total number possibilities of “Yes” responses | 21 |
References
- Murad, C.; Munteanu, C. Designing Voice Interfaces: Back to the (Curriculum) Basics. In Proceedings of the CHI ‘20: CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–12. [Google Scholar] [CrossRef]
- Bastien, J.M.C.; Scapin, D.L. A validation of ergonomic criteria for the evaluation of human-computer interfaces. Int. J. Hum.-Comput. Interact. 1992, 4, 183–196. [Google Scholar] [CrossRef]
- Nielsen, J. Usability inspection methods. In Proceedings of the CHI94: ACM Conference on Human Factors in Computer Systems, Boston, MA, USA, 24–28 April 1994; pp. 413–414. [Google Scholar]
- Statista. The Most Important Voice Platforms in 2020. Available online: https://www.statista.com/chart/22314/voice-platform-ranking/ (accessed on 10 July 2021).
- Nowacki, C.; Gordeeva, A.; Lizé, A.H. Improving the Usability of Voice User Interfaces: A New Set of Ergonomic Criteria. In Design, User Experience, and Usability. Design for Contemporary Interactive Environments, Proceedings of HCII 2020: International Conference on Human-Computer Interaction, Copenhagen, Denmark, 19–24 July 2020; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2020; Volume 12201, pp. 117–133. [Google Scholar] [CrossRef]
- Seaborn, K.; Urakami, J. Measuring Voice UX Quantitatively: A Rapid Review. In Proceedings of the Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohoma, Japan, 8 May 2021; pp. 1–8. [Google Scholar]
- Alves, R.; Valente, P.; Nunes, N.J. The state of user experience evaluation practice. In Proceedings of the NordiCHI 2014: The 8th Nordic Conference on Human-Computer Interaction: Fun, Fast, Foundational, Helsinki, Finland, 26–30 October 2014; pp. 93–102. [Google Scholar] [CrossRef]
- Hura, S.L. Usability testing of spoken conversational systems. J. Usability Stud. 2017, 12, 155–163. [Google Scholar]
- Ortiz de Guinea, A.; Titah, R.; Léger, P.-M. Explicit and implicit antecedents of users’ behavioral beliefs in information systems: A neuropsychological investigation. J. Manag. Inf. Syst. 2014, 30, 179–210. [Google Scholar] [CrossRef]
- Den Uyl, M.J.; Van Kuilenburg, H. The Facereader: Online Facial Expression Recognition. In Proceedings of the Measuring Behavior 2005, Wageningen, The Netherlands, 30 August–2 September 2005. [Google Scholar]
- Braithwaite, J.J.; Watson, D.G.; Jones, R.; Rowe, M. A guide for analysing electrodermal activity (EDA) & skin conductance responses (SCRs) for psychological experiments. Psychophysiology 2013, 49, 1017–1034. [Google Scholar]
- Clark, L.; Doyle, P.; Garaialde, D.; Gilmartin, E.; Schlögl, S.; Edlund, J.; Aylett, M.; Cabral, J.; Munteanu, C.; Edwards, J.; et al. The state of speech in HCI: Trends, themes and challenges. Interact. Comput. 2019, 31, 349–371. [Google Scholar] [CrossRef]
- Lopatovska, I.; Williams, H. Personification of the Amazon Alexa: BFF or a mindless companion. In Proceedings of the 2018 Conference on Human Information Interaction & Retrieval, New Brunswick, NJ, USA, 11–15 March 2018; pp. 265–268. [Google Scholar]
- Garg, R.; Moreno, C. Exploring Everyday Sharing Practices of Smart Speakers. In Proceedings of the IUI Workshops, Los Angeles, CA, USA, 20 March 2019. [Google Scholar]
- Sciuto, A.; Saini, A.; Forlizzi, J.; Hong, J.I. “Hey Alexa, What’s Up?”. In Proceedings of the Designing Interactive Systems Conference 2018—DIS ’18, Hong Kong, China, 9–13 June 2018. [Google Scholar] [CrossRef]
- Lopatovska, I.; Oropeza, H. User interactions with “Alexa” in public academic space. Proc. Assoc. Inf. Sci. Technol. 2018, 55, 309–318. [Google Scholar] [CrossRef]
- Ortiz de Guinea, A.; Webster, J. An investigation of information systems use patterns: Technological events as triggers, the effect of time, and consequences for performance. MIS Q. 2013, 37, 1165–1188. [Google Scholar] [CrossRef]
- Dirican, A.C.; Göktürk, M. Psychophysiological Measures of Human Cognitive States Applied in Human Computer Interaction. Procedia Comput. Sci. 2011, 3, 1361–1367. [Google Scholar] [CrossRef]
- Ivonin, L.; Chang, H.-M.; Díaz, M.; Català, A.; Chen, W.; Rauterberg, M. Beyond Cognition and Affect: Sensing the Unconscious. Behav. Inf. Technol. 2014, 34, 220–238. [Google Scholar] [CrossRef]
- Cordaro, D.T.; Keltner, D.; Tshering, S.; Wangchuk, D.; Flynn, L.M. The voice conveys emotion in ten globalized cultures and one remote village in Bhutan. Emotion 2016, 16, 117–128. [Google Scholar] [CrossRef]
- Juslin, P.N.; Laukka, P. Communication of emotions in vocal expression and music performance: Different channels, same code? Psychol. Bull. 2003, 129, 770–814. [Google Scholar] [CrossRef] [PubMed]
- Kraus, M.W. Voice-only communication enhances empathic accuracy. Am. Psychol. 2017, 72, 644–654. [Google Scholar] [CrossRef]
- Laukka, P.; Elfenbein, H.A.; Thingujam, N.S.; Rockstuhl, T.; Iraki, F.K.; Chui, W.; Althoff, J. The expression and recognition of emotions in the voice across five nations: A lens model analysis based on acoustic features. J. Personal. Soc. Psychol. 2016, 111, 686–705. [Google Scholar] [CrossRef]
- Provine, R.R.; Fischer, K.R. Laughing, smiling, and talking: Relation to sleeping and social context in humans. Ethology 1989, 83, 295–305. [Google Scholar] [CrossRef]
- Vidrascu, L.; Devillers, L. Real-life emotion representation and detection in call centers data. In Affective Computing and Intelligent Interaction; Tao, J., Tan, T., Picard, R.W., Eds.; Springer: Berlin, Germany, 2005; pp. 739–746. [Google Scholar]
- Lausen, A.; Hammerschmidt, K. Emotion recognition and confidence ratings predicted by vocal stimulus type and prosodic parameters. Humanit. Soc. Sci. Commun. 2020, 7, 2. [Google Scholar] [CrossRef]
- Johnstone, T.; Scherer, K.R. Vocal communication of emotion. Handb. Emot. 2000, 2, 220–235. [Google Scholar]
- Tahon, M.; Degottex, G.; Devillers, L. Usual voice quality features and glottal features for emotional valence detection. In Proceedings of the 6th International Conference on Speech Prosody, Shanghai, China, 25 May 2012; Volume 2, pp. 693–697. [Google Scholar]
- Shilker, T.S. Analysis of Affective Expression in Speech. Ph.D. Thesis, Cambridge University, Cambridge, UK, 2009. [Google Scholar]
- Bachorowski, J.A. Vocal Expression and Perception of Emotion. Curr. Dir. Psychol. Sci. 1999, 8, 53–57. [Google Scholar] [CrossRef]
- Li, S.Z.; Jain, A. Fundamental Frequency, Pitch, F0. In Encyclopedia of Biometrics; Springer: Boston, MA, USA, 2009. [Google Scholar] [CrossRef]
- Little, M.A.; McSharry, P.E.; Hunter, E.J.; Spielman, J.; Ramig, L.O. Suitability of dysphonia measurements for telemonitoring of Parkinson’s disease. IEEE Trans. Bio-Med. Eng. 2009, 56, 1015. [Google Scholar] [CrossRef]
- Arora, S.; Baghai-Ravary, L.; Tsanas, A. Developing a large scale population screening tool for the assessment of Parkinson’s disease using telephone-quality voice. J. Acoust. Soc. Am. 2019, 145, 2871–2884. [Google Scholar] [CrossRef]
- Mannepalli, K.; Sastry, P.N.; Suman, M. Emotion recognition in speech signals using optimization based multi-SVNN classifier. J. King Saud Univ. Comput. Inf. Sci. 2018, in press. [CrossRef]
- Toh, A.M.; Togneri, R.; Nordholm, S. Spectral entropy as speech features for speech recognition. Proc. PEECS 2005, 1, 92. [Google Scholar]
- Papakostas, M.; Siantikos, G.; Giannakopoulos, T.; Spyrou, E.; Sgouropoulos, D. Recognizing emotional states using speech information. In GeNeDis 2016; Springer: Cham, Switzerland, 2017; pp. 155–164. [Google Scholar]
- Wani, T.M.; Gunawan, T.S.; Qadri, S.A.A.; Kartiwi, M.; Ambikairajah, E. A Comprehensive Review of Speech Emotion Recognition Systems. IEEE Access 2021, 9, 47795–47814. [Google Scholar] [CrossRef]
- Robinson, C.; Obin, N.; Roebel, A. Sequence-to-sequence modelling of f0 for speech emotion conversion. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12 May 2019; pp. 6830–6834. [Google Scholar]
- Xue, Y.; Hamada, Y.; Akagi, M. Voice conversion for emotional speech: Rule-based synthesis with degree of emotion controllable in dimensional space. Speech Commun. 2018, 102, 54–67. [Google Scholar] [CrossRef]
- Russell, J.A. A circumplex model of affect. J. Personal. Soc. Psychol. 1980, 39, 1161–1178. [Google Scholar] [CrossRef]
- Zhu, C.; Ahmad, W. Emotion recognition from speech to improve human-robot interaction. In Proceedings of the IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), Fukuoka, Japan, 5–8 August 2019; pp. 370–375. [Google Scholar] [CrossRef]
- Koh, Y.; Kwahk, J. B3-1 Analysis of User’s Speech Behavior Pattern after Correction: Focusing on Smartphone Voice User Interface. Jpn. J. Ergon. 2017, 53, 408–411. [Google Scholar] [CrossRef][Green Version]
- Zaman, B.; Shrimpton-Smith, T. The FaceReader: Measuring instant fun of use. In Proceedings of the 4th Nordic Conference on Human-Computer Interaction: Changing Roles, Oslo, Norway, 14 October 2006; pp. 457–460. [Google Scholar] [CrossRef]
- Lang, P.J.; Bradley, M.M.; Cuthbert, B.N. Emotion, motivation, and anxiety: Brain mechanisms and psychophysiology. Biol. Psychiatry 1998, 44, 1248–1263. [Google Scholar] [CrossRef]
- Burton-Jones, A.; Gallivan, M.J. Towards a deeper understanding of system usage in organizations. MIS Q. 2007, 31, 657–679. [Google Scholar] [CrossRef]
- Dawson, M.E.; Schell, A.M.; Filion, D.L. The electrodermal system. In Handbook of Psychophysiology; Cacioppo, J.T., Tassinary, L.G., Berntson, G.G., Eds.; Cambridge University Press: Cambridge, UK, 2007; pp. 159–181. [Google Scholar] [CrossRef]
- Bethel, C.L.; Salomon, K.; Murphy, R.R.; Burke, J.L. Survey of psychophysiology measurements applied to human-robot interaction. In Proceedings of the RO-MAN 2007—The 16th IEEE International Symposium on Robot and Human Interactive Communication, Jeju, Korea, 26–29 August 2007; pp. 732–737. [Google Scholar]
- Riedl, R.; Léger, P.M. Fundamentals of NeuroIS: Information Systems and the Brain; Studies in Neuroscience, Psychology and Behavioral Economics; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar] [CrossRef]
- Léger, P.-M.; Davis, F.D.; Cronan, T.P.; Perret, J. Neurophysiological Correlates of Cognitive Absorption in an Enactive Training Context. Comput. Hum. Behav. 2014, 34, 273–283. [Google Scholar] [CrossRef]
- Vom Brocke, J.; Riedl, R.; Léger, P.-M. Application strategies for neuroscience in information systems design science research. J. Comput. Inf. Syst. 2013, 53, 1–13. [Google Scholar] [CrossRef]
- Giroux-Huppé, C.; Sénécal, S.; Fredette, M.; Chen, S.L.; Demolin, B.; Léger, P.-M. Identifying Psychophysiological Pain Points in the Online User Journey: The Case of Online Grocery; Springer: Cham, Switzerland, 2019; pp. 459–473. [Google Scholar]
- Lamontagne, C.; Sénécal, S.; Fredette, M.; Chen, S.L.; Pourchon, R.; Gaumont, Y.; De Grandpré, D.; Léger, P.M. User Test: How Many Users Are Needed to Find the Psychophysiological Pain Points in a Journey Map? In Proceedings of the International Conference on Human Interaction and Emerging Technologies, Nice, France, 26 July 2019; Springer: Cham, Switzerland, 2020; pp. 136–142. [Google Scholar]
- Hassenzahl, M.; Tractinsky, N. User Experience—A Research Agenda. Behav. Inf. Technol. 2006, 25, 91–97. [Google Scholar] [CrossRef]
- Boucsein, W. Electrodermal Activity; Springer: Boston, MA, USA, 2012. [Google Scholar]
- Ekman, P.; Friesen, W.V. The Facial Action Coding System; Consulting Psychologists Press: San Fransisco, CA, USA, 1978. [Google Scholar]
- Leite, I.; Henriques, R.; Martinho, C.; Paiva, A. Sensors in the wild: Exploring electrodermal activity in child-robot interaction. In Proceedings of the 2013 8th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Tokyo, Japan, 3–6 March 2013; pp. 41–48. [Google Scholar]
- Castellano, G.; Kessous, L.; Caridakis, G. Emotion recognition through multiple modalities: Face, body gesture, speech. In Affect and Emotion in Human-Computer Interaction; Springer: Berlin/Heidelberg, Germany, 2008; pp. 92–103. [Google Scholar]
- Gross, J.J.; Muñoz Ricardo, F. Emotion regulation and mental health. Clin. Psychol. Sci. Pract. 1995, 2, 151–164. [Google Scholar] [CrossRef]
- Greco, A.; Marzi, C.; Lanata, A.; Scilingo, E.P.; Vanello, N. Combining Electrodermal Activity and Speech Analysis towards a more Accurate Emotion Recognition System. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Berlin, German, 23–27 July 2019; pp. 229–232. [Google Scholar] [CrossRef]
- Prasetio, B.H.; Tamura, H.; Tanno, K. Embedded Discriminant Analysis based Speech Activity Detection for Unsupervised Stress Speech Clustering. In Proceedings of the 2020 Joint 9th International Conference on Informatics, Electronics and Vision and 2020 4th International Conference on Imaging, Vision and Pattern Recognition, ICIEV and IcIVPR, Kitakyushu, Japan, 26–29 August 2020. [Google Scholar] [CrossRef]
- Caridakis, G.; Malatesta, L.; Kessous, L.; Amir, N.; Raouzaiou, A.; Karpouzis, K. Modeling naturalistic affective states via facial and vocal expressions recognition. In Proceedings of the ICMI’06: 8th International Conference on Multimodal Interfaces, Banff, AB, Canada, 2–4 November 2006; pp. 146–154. [Google Scholar] [CrossRef]
- Alshamsi, H.; Kepuska, V.; Alshamsi, H.; Meng, H. Automated Facial Expression and Speech Emotion Recognition App Development on Smart Phones using Cloud Computing. In Proceedings of the 2018 IEEE 9th Annual Information Technology, Electronics and Mobile Communication Conference, IEMCON 2018, Vancouver, BC, Canada, 1–3 November 2019; pp. 730–738. [Google Scholar] [CrossRef]
- Scherer, K.R. Vocal affect expression: A review and a model for future research. Psychol. Bull. 1986, 99, 143–165. [Google Scholar] [CrossRef]
- Breitenstein, C.; Van Lancker, D.; Daum, I. The contribution of speech rate and pitch variation to the perception of vocal emotions in a German and an American sample. Cogn. Emot. 2001, 15, 57–79. [Google Scholar]
- Davitz, J.R. (Ed.) The Communication of Emotional Meaning; Mcgraw Hill: New York, NY, USA, 1964. [Google Scholar]
- Levin, H.; Lord, W. Speech pitch frequency as an emotional state indicator. IEEE Trans. Syst. Man Cybern. 1975, 5, 259–273. [Google Scholar] [CrossRef]
- Pereira, C. Dimensions of emotional meaning in speech. In Proceedings of the ISCA Tutorial and Research Workshop (ITRW) on Speech and Emotion, Newcastle, UK, 5–7 September 2000. [Google Scholar]
- Scherer, K.R.; Oshinsky, J.S. Cue utilization in emotion attribution from auditory stimuli. Motiv. Emot. 1977, 1, 331–346. [Google Scholar] [CrossRef]
- Schröder, M.; Cowie, R.; Douglas-Cowie, E.; Westerdijk, M.; Gielen, S. Acoustic correlates of emotion dimensions in view of speech synthesis. In Proceedings of the Seventh European Conference on Speech Communication and Technology, Aalborg, Denmark, 3–7 September 2001. [Google Scholar]
- Apple, W.; Streeter, L.A.; Krauss, R.M. Effects of pitch and speech rate on personal attributions. J. Personal. Soc. Psychol. 1979, 37, 715–727. [Google Scholar] [CrossRef]
- Kehrein, R. The prosody of authentic emotions. In Proceedings of the Speech Prosody 2002 International Conference, Aix-en-Provence, France, 11–13 April 2002. [Google Scholar] [CrossRef]
- Pittam, J.; Gallois, C.; Callan, V. The long-term spectrum and perceived emotion. Speech Commun. 1990, 9, 177–187. [Google Scholar] [CrossRef]
- Laukka, P.; Juslin, P.N.; Bresin, R. A dimensional approach to vocal expression of emotion. Cogn. Emot. 2005, 19, 633–653. [Google Scholar] [CrossRef]
- Scherer, K.R. Acoustic concomitants of emotional dimensions: Judging affect from synthesized tone sequences. In Nonverbal Communication; Weitz, S., Ed.; Oxford University Press: New York, NY, USA, 1974; pp. 105–111. [Google Scholar]
- Uldall, E. Attitudinal meanings conveyed by intonation contours. Lang. Speech 1960, 3, 223–234. [Google Scholar] [CrossRef]
- Busso, C.; Deng, Z.; Yildirim, S.; Bulut, M.; Lee, C.M.; Kazemzadeh, A.; Lee, S.; Neumann, U.; Narayanan, S. Analysis of emotion recognition using facial expressions, speech and multimodal information. In Proceedings of the 6th International Conference on Multimodal Interfaces, State College, PA, USA, 13–14 October 2004; pp. 205–211. [Google Scholar]
- Busso, C.; Rahman, T. Unveiling the acoustic properties that describe the valence dimension. In Proceedings of the Thirteenth Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012. [Google Scholar]
- Giroux, F.; Léger, P.M.; Brieugne, D.; Courtemanche, F.; Bouvier, F.; Chen, S.L.; Tazi, S.; Rucco, E.; Fredette, M.; Coursaris, C.; et al. Guidelines for Collecting Automatic Facial Expression Detection Data Synchronized with a Dynamic Stimulus in Remote Moderated User Tests. In Proceedings of the International Conference on Human-Computer Interaction, Washngton, DC, USA, 24–29 July 2021; Springer: Cham, Switzerland, 2021; pp. 243–254. [Google Scholar]
- Vasseur, A.; Léger, P.M.; Courtemanche, F.; Labonte-Lemoyne, E.; Georges, V.; Valiquette, A.; Brieugne, D.; Rucco, E.; Coursaris, C.; Fredette, M. Distributed remote psychophysiological data collection for UX evaluation: A pilot project. In Proceedings of the International Conference on Human-Computer Interaction, Virtual Event, 24–29 July 2021; Springer: Cham, Switzerland, 2021; pp. 255–267. [Google Scholar]
- Figner, B.; Murphy, R.O. Using skin conductance in judgment and decision making research. In A Handbook of Process Tracing Methods for Decision Research; Psychology Press: New York, NY, USA, 2011; pp. 163–184. [Google Scholar]
- Courtemanche, F.; Fredette, M.; Senecal, S.; Leger, P.M.; Dufresne, A.; Georges, V.; Labonte-Lemoyne, E. Method of and System for Processing Signals Sensed from a User. U.S. Patent No. 10,368,741, 6 August 2019. [Google Scholar]
- Courtemanche, F.; Léger, P.M.; Fredette, M.; Sénécal, S. Cobalt—Bluebox: Système de Synchronisation et d’Acquisition Sans-Fil de Données Utilisateur Multimodales; Declaration of Invention No. AXE-0045; HEC Montréal: Montreal, QC, Canada, 2022. [Google Scholar]
- Bradley, M.M.; Lang, P.J. Measuring emotion: The self-assessment manikin and the semantic differential. J. Behav. Ther. Exp. Psychiatry 1994, 25, 49–59. [Google Scholar] [CrossRef]
- Betella, A.; Verschure, P.F. The Affective Slider: A Digital Self-Assessment Scale for the Measurement of Human Emotions. PLoS ONE 2016, 11, e0148037. [Google Scholar] [CrossRef] [PubMed]
- Sutton, T.M.; Herbert, A.M.; Clark, D.Q. Valence, arousal, and dominance ratings for facial stimuli. Q. J. Exp. Psychol. 2019, 72, 2046–2055. [Google Scholar] [CrossRef] [PubMed]
- Jessen, S.; Kotz, S.A. The temporal dynamics of processing emotions from vocal, facial, and bodily expressions. NeuroImage 2011, 58, 665–674. [Google Scholar] [CrossRef] [PubMed]
- Yildirim, S.; Bulut, M.; Lee, C.M.; Kazemzadeh, A.; Busso, C.; Deng, Z.; Lee, S.; Narayanan, S. An acoustic study of emotions expressed in speech. In Proceedings of the Eighth International Conference on Spoken Language Processing, Jeju, Korea, 4–8 October 2004. [Google Scholar]
- Skiendziel, T.; Rösch, A.G.; Schultheiss, O.C. Assessing the convergent validity between the automated emotion recognition software Noldus FaceReader 7 and Facial Action Coding System Scoring. PLoS ONE 2019, 14, e0223905. [Google Scholar] [CrossRef]
- Lewinski, P.; den Uyl, T.M.; Butler, C. Automated facial coding: Validation of basic emotions and FACS AUs in FaceReader. J. Neurosci. Psychol. Econ. 2014, 7, 227. [Google Scholar] [CrossRef]
- Cohn, J.F.; Kanade, T. Use of automated facial image analysis for measurement of emotion expression. In Handbook of Emotion Elicitation and Assessment; Oxford University Press: Oxford, UK, 2007; pp. 222–238. [Google Scholar]
- Hallgren, K.A. Computing Inter-Rater Reliability for Observational Data: An Overview and Tutorial. Tutor. Quant. Methods Psychol. 2012, 8, 23–34. [Google Scholar] [CrossRef]
- Bartko, J.J. The intraclass correlation coefficient as a measure of reliability. Psychol. Rep. 1966, 19, 3–11. [Google Scholar] [CrossRef]
- Koo, T.K.; Li, M.Y. A guideline of selecting and reporting intraclass correlation coefficients for reliability research. J. Chiropract. Med. 2016, 15, 155–163. [Google Scholar] [CrossRef]
- Bland, J.M.; Altman, D.G. Multiple significance tests: The Bonferroni method. BMJ 1995, 310, 170. [Google Scholar] [CrossRef]
- Cicchetti, D.V. Guidelines, criteria, and rules of thumb for evaluating normed and standardized assessment instruments in psychology. Psychol. Assess. 1994, 6, 284. [Google Scholar] [CrossRef]
- Christopoulos, G.I.; Uy, M.A.; Yap, W.J. The Body and the Brain: Measuring Skin Conductance Responses to Understand the Emotional Experience. Organ. Res. Methods 2019, 22, 394–420. [Google Scholar] [CrossRef]
- Fujimura, T.; Sato, W.; Suzuki, N. Facial expression arousal level modulates facial mimicry. Int. J. Psychophysiol. 2010, 76, 88–92. [Google Scholar] [CrossRef]
- Patel, S.; Scherer, K.R.; Sundberg, J.; Björkner, E. Acoustic markers of emotions based on voice physiology. In Proceedings of the Conference: Speech Prosody, Chicago, IL, USA, 10–14 May 2010; Volume 2010. [Google Scholar]
- Easwara Moorthy, A.; Vu, K.-P.L. Privacy Concerns for Use of Voice Activated Personal Assistant in the Public Space. Int. J. Hum.-Comput. Interact. 2015, 31, 307–335. [Google Scholar] [CrossRef]
- Jiang, J.; Hassan Awadallah, A.; Jones, R.; Ozertem, U.; Zitouni, I.; Gurunath Kulkarni, R.; Khan, O.Z. Automatic Online Evaluation of Intelligent Assistants. In Proceedings of the 24th International Conference on World Wide Web—WWW’15, Florence, Italy, 18–22 May 2015. [Google Scholar] [CrossRef]
- Ali, M.; Mosa, A.H.; Machot, F.A.; Kyamakya, K. Emotion Recognition Involving Physiological and Speech Signals: A Comprehensive Review. In Recent Advances in Nonlinear Dynamics and Synchronization; Kyamakya, K., Mathis, W., Stoop, R., Chedjou, J., Li, Z., Eds.; Studies in Systems, Decision and Control; Springer: Cham, Switzerland, 2018; Volume 109. [Google Scholar] [CrossRef]
- Szameitat, D.P.; Darwin, C.J.; Wildgruber, D.; Alter, K.; Szameitat, A.J. Acoustic correlates of emotional dimensions in laughter: Arousal, dominance, and valence. Cogn. Emot. 2011, 25, 599–611. [Google Scholar] [CrossRef]
- Banse, R.; Scherer, K.R. Acoustic profiles in vocal emotion expression. J. Personal. Soc. Psychol. 1996, 70, 614–636. [Google Scholar] [CrossRef]
- Statista. Number of Digital Voice Assistants in Use Worldwide from 2019 to 2024 (in Billions). 2021. Available online: https://www.statista.com/statistics/973815/worldwide-digital-voice-assistant-in-use/ (accessed on 10 July 2021).
- Le Pailleur, F.; Huang, B.; Léger, P.M.; Sénéecal, S. A new approach to measure user experience with voice-controlled intelligent assistants: A pilot study. In Proceedings of the HCII 2020: Human-Computer Interaction. Multimodal and Natural Interaction, Copenhagen, Denmark, 19–24 July 2020; Kurosu, M., Ed.; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2020; Volume 12182, pp. 197–208. [Google Scholar] [CrossRef]








| Speech Features | Definition |
|---|---|
| Fundamental frequency (F0) | The rate of vocal fold vibration. |
| Pitch period | The fundamental period of the signal. |
| Pitch period entropy (PPE) | The impaired control of F0 during sustained phonation. |
| Spectral slope | The observed tendency to have low energy during high frequencies. |
| Spectral spread | The total bandwidth of a speech signal using spectral centroid. |
| Spectral centroid | A measure used to evaluate the brightness of a speech. |
| Spectral entropy | Observed to assess silence and voice region of speech. |
| Study | Contribution | Contribution |
|---|---|---|
| Greco et al. (2019) | Improved the recognition of human arousal level during the pronunciation of single affective words. | EDA Speech Features (F0 and MFCC) |
| Prasetio et al. (2020) | Developed a speech activity detection system which can perform in noisy environment and compensate for the presence of emotional conditions. | EDA Speech Features (MFCC) |
| Caridakis et al. (2006) | Proposed a framework to model affective states in naturalistic video sequences. | Facial Expression Speech Features (prosody related to pitch and rhythm) Bodily Expression (excluded in the fusion of modalities) |
| Castellano et al. (2008) | Presented framework of multimodal automatic emotion recognition system during a speech-based interaction. | Facial Expression Speech Features (MFCC) Bodily Expression |
| Alshamsi et al. (2019) | Proposed a framework consisting of mobile phone technology backed by cloud computing to recognize emotion in speech and facial expression in real-time. | Facial Expression Speech Features (MFCC) |
| Dimension | ICC Scores | 95% Confidence Interval Lower Bound | 95% Confidence Interval Upper Bound |
|---|---|---|---|
| Valence | 0.898 | 0.874 | 0.919 |
| Arousal | 0.755 | 0.696 | 0.806 |
| Control | 0.789 | 0.739 | 0.833 |
| STEE | 0.707 | 0.637 | 0.767 |
| Mean | Minimum | Maximum | Range | Maximum/ Minimum | Variance | |
|---|---|---|---|---|---|---|
| Valence | 5.187 | 4.862 | 5.516 | 0.654 | 1.135 | 0.061 |
| Arousal | 4.640 | 3.676 | 5.601 | 1.926 | 1.524 | 0.665 |
| Control | 5.537 | 4.723 | 6.404 | 1.681 | 1.356 | 0.542 |
| STEE | −0.057 | −0.0101 | 0.027 | 0.128 | −0.0263 | 0 |
| Factor | Estimate | SE 1 | DF 2 | T Value | p Value | R2 Value 3 |
|---|---|---|---|---|---|---|
| AFE-based valence | 3.076 | 0.351 | 129 | 8.770 | <0.001 *4 | 0.402 |
| EDA Z-Score | −0.074 | 0.066 | 129 | −1.120 | 0.266 | 0.007 |
| Phasic | 0.026 | 0.076 | 127 | 0.350 | 0.728 | <0.001 |
| Slope | −106.750 | 105.970 | 144 | −1.010 | 0.316 | 0.007 |
| Entropy | 0.023 | 0.177 | 144 | 0.130 | 0.898 | <0.001 |
| Centroid | 0.000 | 0.000 | 144 | −0.540 | 0.590 | 0.002 |
| Spread | 0.000 | 0.000 | 144 | −1.230 | 0.221 | 0.010 |
| PPE 5 | 0.000 | 0.000 | 144 | −0.860 | 0.391 | 0.004 |
| F0 Standard Deviation | −0.006 | 0.007 | 144 | −0.790 | 0.430 | 0.004 |
| F0 mean | −0.002 | 0.005 | 144 | −0.460 | 0.646 | 0.002 |
| Log energy | 0.014 | 0.024 | 144 | 0.590 | 0.559 | 0.003 |
| Factor | Estimate | SE 1 | DF 2 | T Value | p Value | R2 Value 3 |
|---|---|---|---|---|---|---|
| AFE-based valence | 1.755 | 0.365 | 129 | 4.810 | <0.001 *4 | 0.152 |
| EDA Z-Score | 0.114 | 0.056 | 129 | 2.020 | 0.046 | 0.019 |
| Phasic | 0.154 | 0.064 | 127 | 2.420 | 0.017 | 0.028 |
| Slope | −310.810 | 92.645 | 144 | −3.350 | 0.001 * | 0.060 |
| Entropy | −0.240 | 0.157 | 144 | −1.530 | 0.129 | 0.012 |
| Centroid | 0.000 | 0.000 | 144 | −1.410 | 0.160 | 0.009 |
| Spread | 0.000 | 0.000 | 144 | −2.940 | 0.004 * | 0.044 |
| PPE 5 | 0.000 | 0.000 | 144 | −1.880 | 0.062 | 0.014 |
| F0 Standard Deviation | 0.017 | 0.006 | 144 | 2.610 | 0.010 | 0.032 |
| F0 mean | 0.001 | 0.004 | 144 | 0.260 | 0.799 | <0.001 |
| Log energy | 0.073 | 0.022 | 144 | 3.360 | 0.001 * | 0.079 |
| Factor | Estimate | SE 1 | DF 2 | T Value | p Value | R2 Value 3 |
|---|---|---|---|---|---|---|
| AFE-based valence | −0.400 | 0.530 | 129 | −0.75 | 0.452 | 0.005 |
| EDA Z-Score | −0.133 | 0.082 | 129 | −1.61 | 0.109 | 0.016 |
| Phasic | −0.108 | 0.095 | 127 | −1.14 | 0.255 | 0.008 |
| Slope | 367.030 | 136.200 | 144 | 2.69 | 0.008 | 0.049 |
| Entropy | 0.425 | 0.229 | 144 | 1.86 | 0.065 | 0.023 |
| Centroid | 0.000 | 0.000 | 144 | 1.53 | 0.129 | 0.014 |
| Spread | 0.000 | 0.000 | 144 | 2.07 | 0.040 | 0.029 |
| PPE 4 | 0.000 | 0.000 | 144 | 0.3 | 0.764 | <0.001 |
| F0 Standard Deviation | −0.004 | 0.010 | 144 | −0.41 | 0.681 | 0.001 |
| F0 mean | −0.002 | 0.006 | 144 | −0.38 | 0.702 | 0.001 |
| Log energy | −0.049 | 0.032 | 144 | −1.57 | 0.120 | 0.021 |
| Factor | Estimate | SE 1 | DF 2 | T Value | p Value | R2 Value 3 |
|---|---|---|---|---|---|---|
| AFE-based valence | 0.936 | 0.171 | 129 | 5.480 | <0001 *4 | 0.209 |
| EDA Z-Score | −0.029 | 0.030 | 129 | −0.960 | 0.337 | 0.006 |
| Phasic | 0.007 | 0.034 | 127 | 0.210 | 0.837 | <0.001 |
| Slope | −18.565 | 47.559 | 144 | −0.390 | 0.697 | 0.001 |
| Entropy | 0.031 | 0.079 | 144 | 0.400 | 0.693 | 0.001 |
| Centroid | 0.000 | 0.000 | 144 | 0.250 | 0.807 | <0.001 |
| Spread | 0.000 | 0.000 | 144 | 0.330 | 0.743 | <0.001 |
| PPE 5 | 0.000 | 0.000 | 144 | 0.420 | 0.677 | 0.001 |
| F0 Standard Deviation | −0.008 | 0.003 | 144 | −2.460 | 0.015 | 0.038 |
| F0 mean | 0.000 | 0.002 | 144 | 0.020 | 0.984 | <0.001 |
| Log energy | −0.002 | 0.011 | 144 | −0.150 | 0.884 | <0.001 |
| Hypothesis | Description | Results Status |
|---|---|---|
| H1 | There is a relationship between the amplitude of targeted speech features and the emotional intensity of users during voice user interface interactions. | Supported |
| H2a | There is a relationship between the amplitude of the extracted EDA features and the emotional intensity of users during voice user interface interactions. | Not supported |
| H2b | There is a relationship between the amplitude of the extracted AFE-based valence feature and the emotional intensity of users during voice user interface interactions. | Supported |
| H3 | Physiological features are more explicative of emotional voice interaction events in comparison to speech features. | Supported |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Swoboda, D.; Boasen, J.; Léger, P.-M.; Pourchon, R.; Sénécal, S. Comparing the Effectiveness of Speech and Physiological Features in Explaining Emotional Responses during Voice User Interface Interactions. Appl. Sci. 2022, 12, 1269. https://doi.org/10.3390/app12031269
Swoboda D, Boasen J, Léger P-M, Pourchon R, Sénécal S. Comparing the Effectiveness of Speech and Physiological Features in Explaining Emotional Responses during Voice User Interface Interactions. Applied Sciences. 2022; 12(3):1269. https://doi.org/10.3390/app12031269
Chicago/Turabian StyleSwoboda, Danya, Jared Boasen, Pierre-Majorique Léger, Romain Pourchon, and Sylvain Sénécal. 2022. "Comparing the Effectiveness of Speech and Physiological Features in Explaining Emotional Responses during Voice User Interface Interactions" Applied Sciences 12, no. 3: 1269. https://doi.org/10.3390/app12031269
APA StyleSwoboda, D., Boasen, J., Léger, P.-M., Pourchon, R., & Sénécal, S. (2022). Comparing the Effectiveness of Speech and Physiological Features in Explaining Emotional Responses during Voice User Interface Interactions. Applied Sciences, 12(3), 1269. https://doi.org/10.3390/app12031269