
Non-Parallel Articulatory-to-Acoustic Conversion Using Multiview-Based Time Warping

 ,
,  ,
,  and
and
Abstract
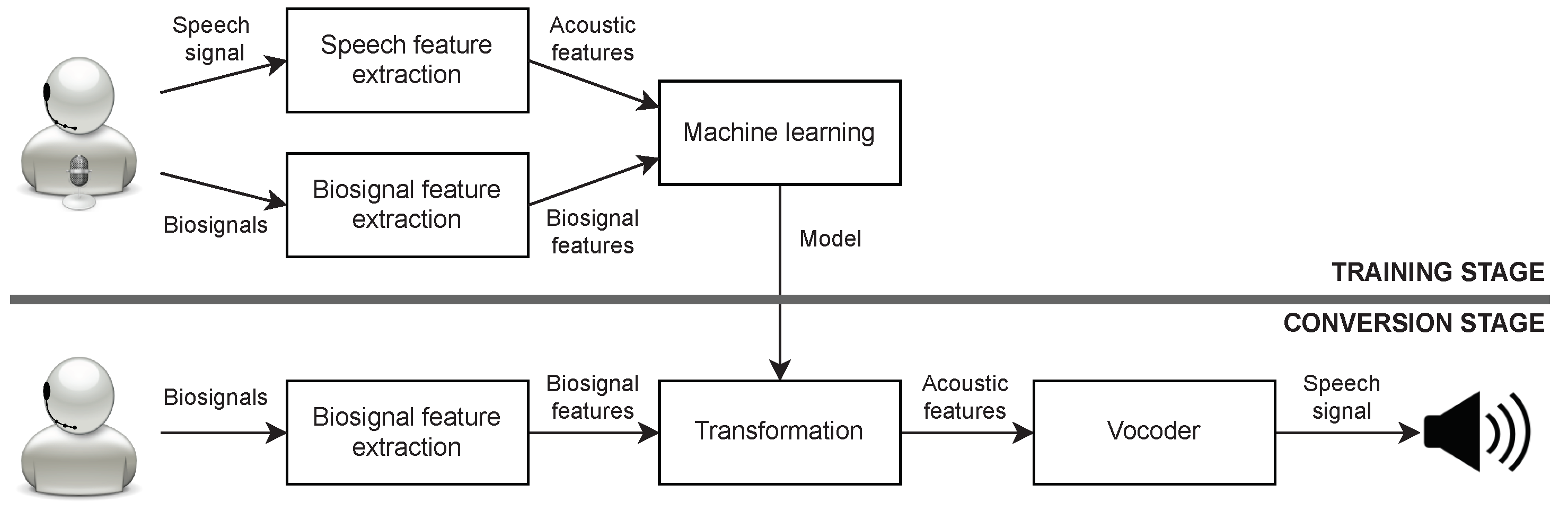
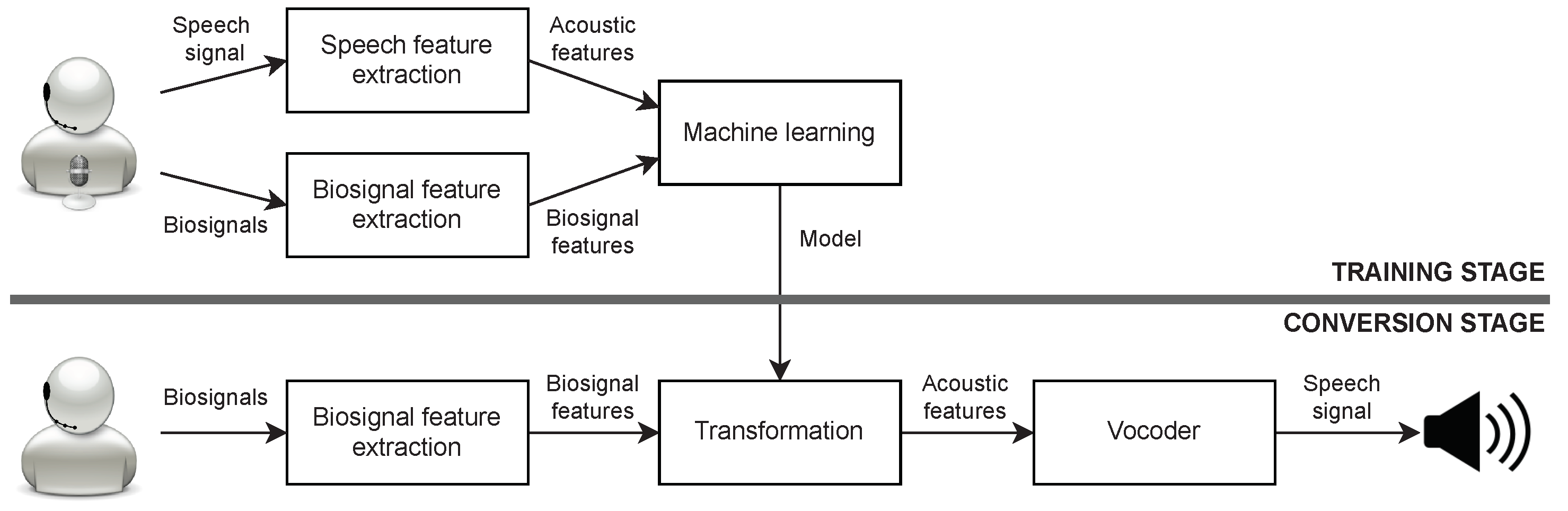
:1. Introduction
2. Related Work
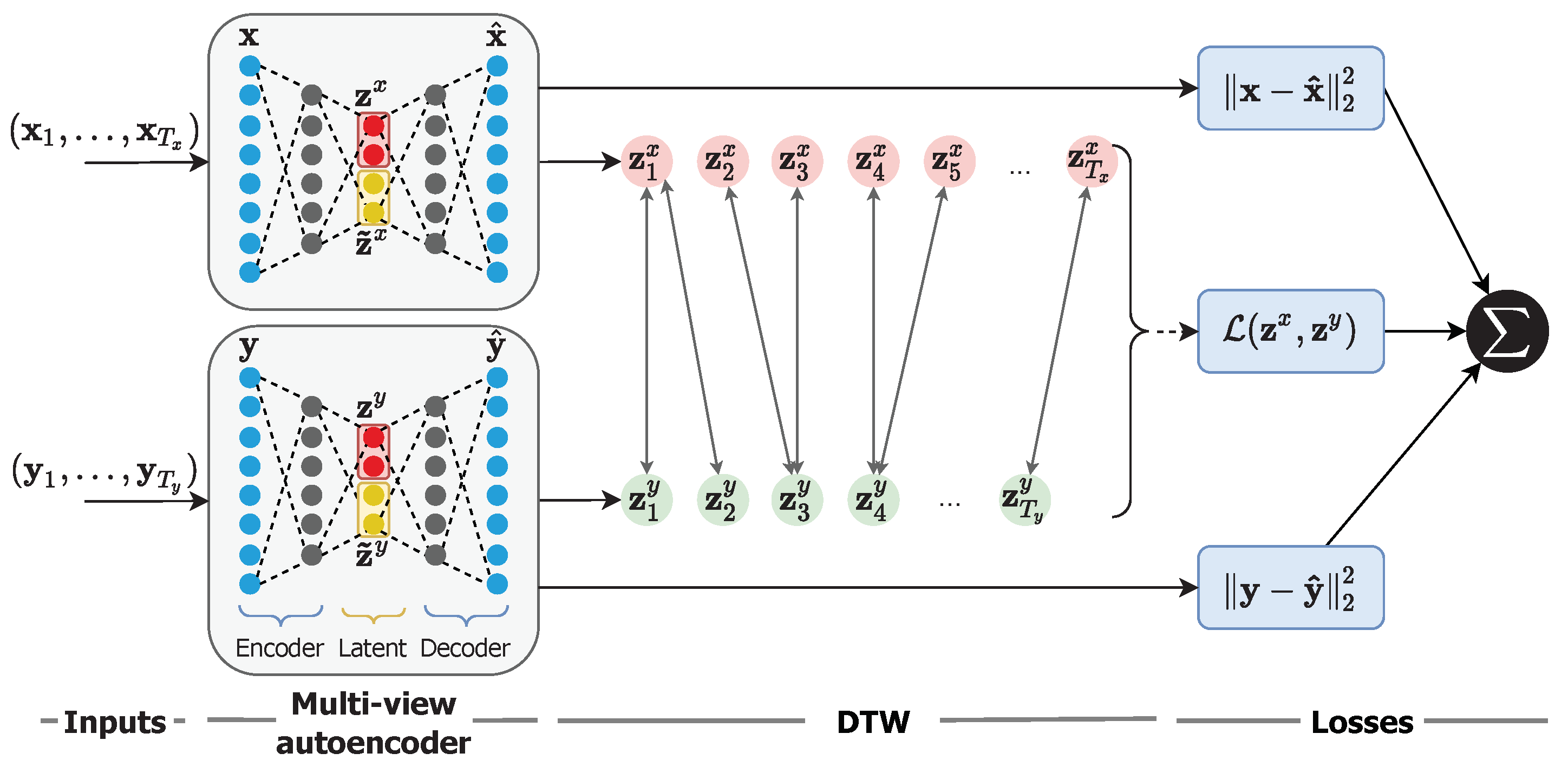
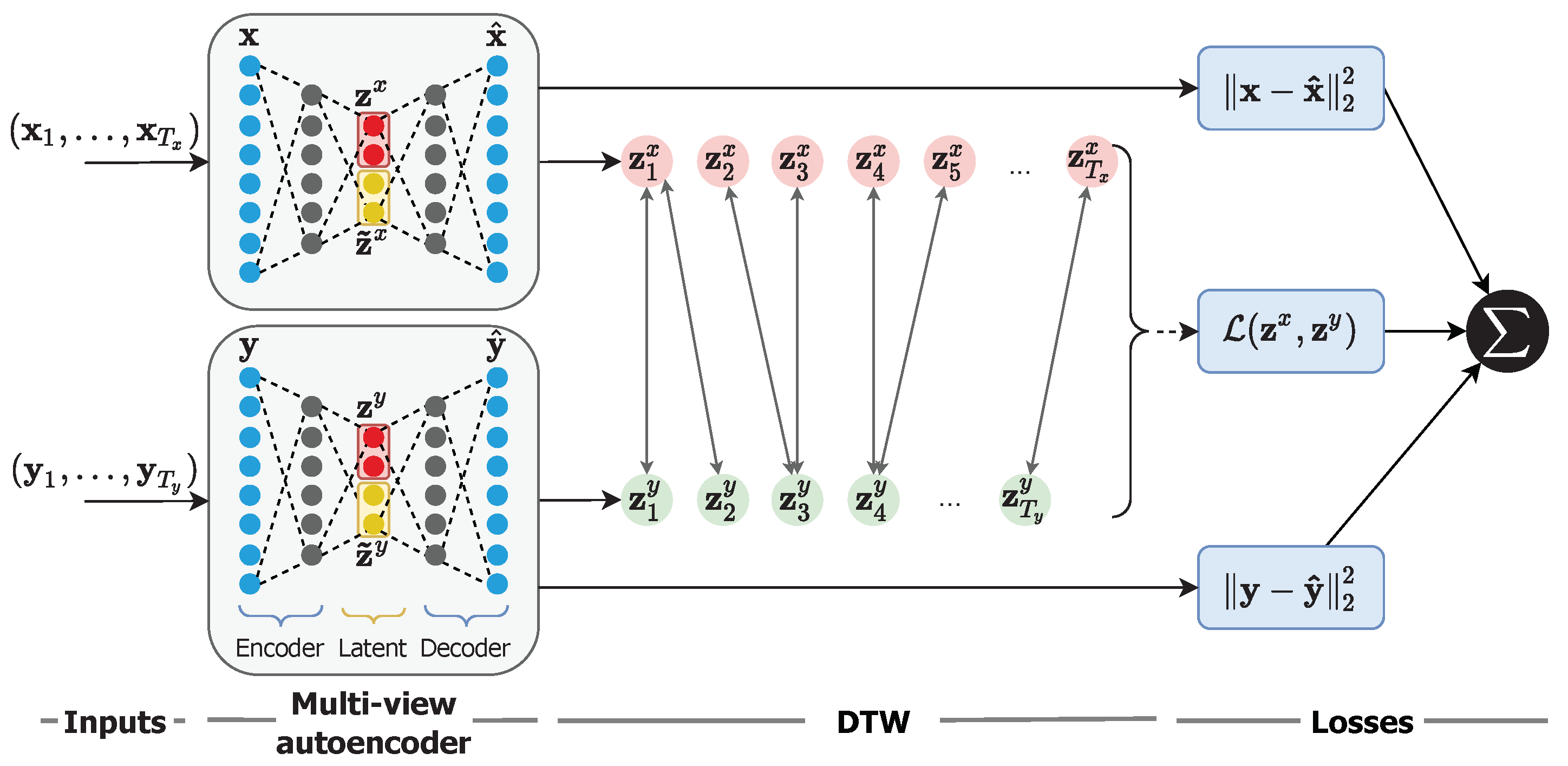
3. Multiview Temporal Alignment
3.1. Latent-Space Similarity Metrics
3.1.1. Canonical Correlation Analysis
3.1.2. Maximum Mutual Information
3.1.3. Contrastive Loss
3.2. Multiview Autoencoder
3.3. Private Latent Variables
4. Experimental Setup
4.1. Dataset
Feature Extraction
4.2. Implementation Details
4.3. PMA-to-Speech System
4.4. Performance Evaluation
5. Results and Discussion
5.1. Objective Evaluation
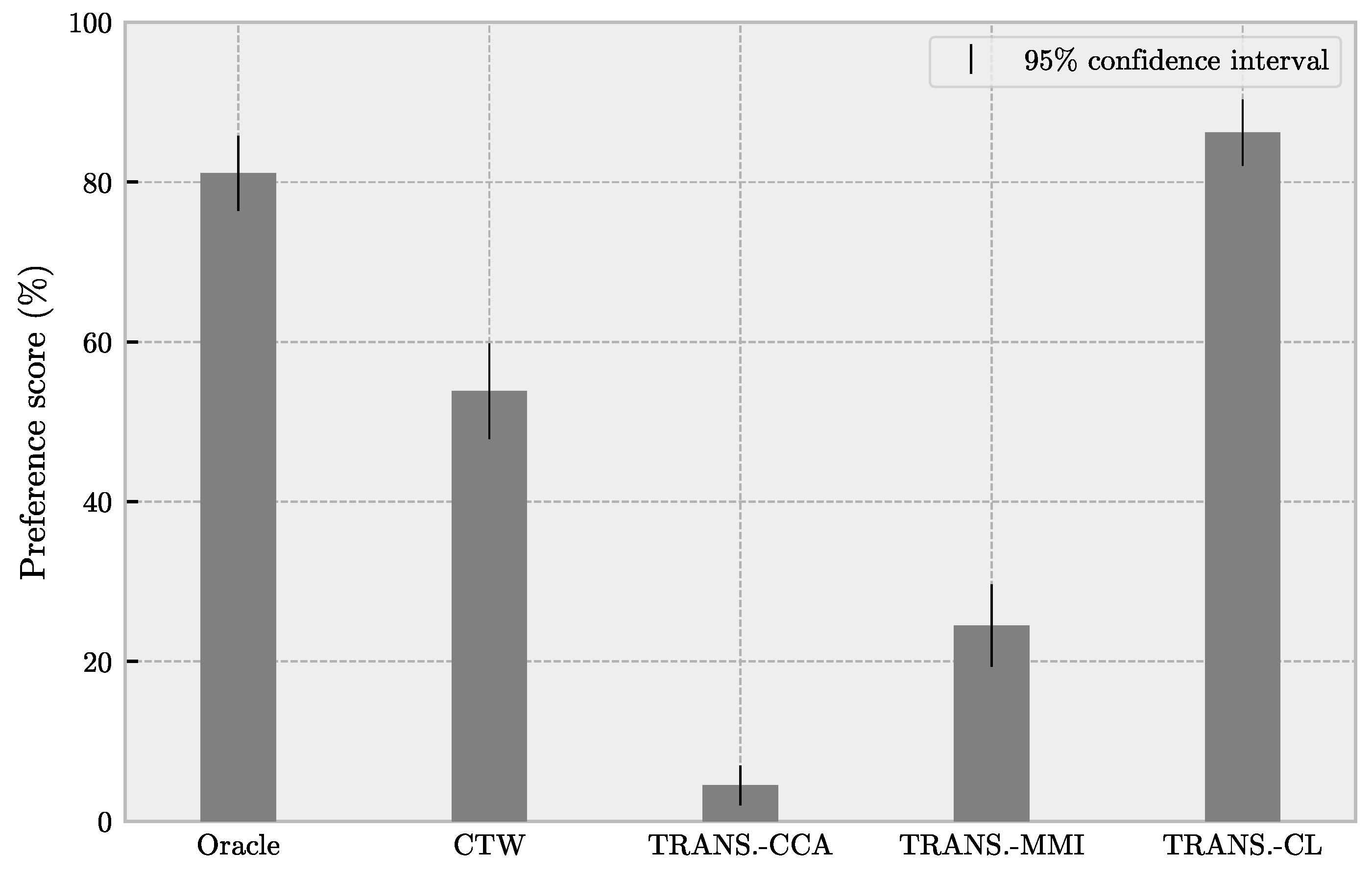
5.2. Subjective Evaluation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| A2A | Articulatory-to-Acoustic |
| AA-CCA | Alignment-Agnostic CCA |
| ASR | Automatic Speech Recognition |
| BAP | Band APeriodicity |
| CCA | Canonical Correlation Analysis |
| CL | Contrastive Loss |
| CTW | Canonical Time Warping |
| DCTW | Deep Canonical Time Warping |
| DNN | Deep Neural Network |
| DTW | Dynamic Time Warping |
| EEG | Electroencephalogram |
| EMG | Electromyography |
| GCTW | Generalyzed Canonical Time Warping |
| KDE | Kernel Density Estimation |
| KL | Kullback-Leibler |
| LReLU | Leaky Rectified Linear Unit |
| MCD | Mel-Cepstral Distortion |
| MGCC | Mel-Generalised Cepstral Coefficient |
| MLPG | Maximum-Likelihood Parameter Generation |
| MMI | Maximum Mutual Information |
| MSE | Mean Squared Error |
| PCA | Principal Component Analysis |
| Probability Density Function | |
| PMA | Permanent Magnet Articulography |
| ReLU | Rectified Linear Unit |
| RMSE | Root Mean Squared Error |
| seq2seq | Sequence-to-Sequence |
| SSI | Silent Speech Interface |
| TRANSIENCE | multiview Temporal Alignment by Dependence |
| Maximisation in the Latent Space |
References
- Denby, B.; Schultz, T.; Honda, K.; Hueber, T.; Gilbert, J.M.; Brumberg, J.S. Silent speech interfaces. Speech Commun. 2010, 52, 270–287. [Google Scholar] [CrossRef] [Green Version]
- Schultz, T.; Wand, M.; Hueber, T.; Krusienski, D.J.; Herff, C.; Brumberg, J.S. Biosignal-Based Spoken Communication: A Survey. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 2257–2271. [Google Scholar] [CrossRef]
- Gonzalez-Lopez, J.A.; Gomez-Alanis, A.; Martín-Doñas, J.M.; Pérez-Córdoba, J.L.; Gomez, A.M. Silent speech interfaces for speech restoration: A review. IEEE Access 2020, 8, 177995–178021. [Google Scholar] [CrossRef]
- Guenther, F.H.; Brumberg, J.S.; Wright, E.J.; Nieto-Castanon, A.; Tourville, J.A.; Panko, M.; Law, R.; Siebert, S.A.; Bartels, J.L.; Andreasen, D.S.; et al. A wireless brain-machine interface for real-time speech synthesis. PLoS ONE 2009, 4, e8218. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Akbari, H.; Khalighinejad, B.; Herrero, J.L.; Mehta, A.D.; Mesgarani, N. Towards reconstructing intelligible speech from the human auditory cortex. Sci. Rep. 2019, 9, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Anumanchipalli, G.K.; Chartier, J.; Chang, E.F. Speech synthesis from neural decoding of spoken sentences. Nature 2019, 568, 493–498. [Google Scholar] [CrossRef]
- Schultz, T.; Wand, M. Modeling coarticulation in EMG-based continuous speech recognition. Speech Commun. 2010, 52, 341–353. [Google Scholar] [CrossRef] [Green Version]
- Wand, M.; Janke, M.; Schultz, T. Tackling speaking mode varieties in EMG-based speech recognition. IEEE Trans. Biomed. Eng. 2014, 61, 2515–2526. [Google Scholar] [CrossRef]
- Janke, M.; Diener, L. EMG-to-speech: Direct generation of speech from facial electromyographic signals. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 2375–2385. [Google Scholar] [CrossRef] [Green Version]
- Hueber, T.; Benaroya, E.L.; Chollet, G.; Denby, B.; Dreyfus, G.; Stone, M. Development of a silent speech interface driven by ultrasound and optical images of the tongue and lips. Speech Commun. 2010, 52, 288–300. [Google Scholar] [CrossRef] [Green Version]
- Schönle, P.W.; Gräbe, K.; Wenig, P.; Höhne, J.; Schrader, J.; Conrad, B. Electromagnetic articulography: Use of alternating magnetic fields for tracking movements of multiple points inside and outside the vocal tract. Brain Lang. 1987, 31, 26–35. [Google Scholar] [CrossRef]
- Fagan, M.J.; Ell, S.R.; Gilbert, J.M.; Sarrazin, E.; Chapman, P.M. Development of a (silent) speech recognition system for patients following laryngectomy. Med. Eng. Phys. 2008, 30, 419–425. [Google Scholar] [CrossRef] [PubMed]
- Gonzalez, J.A.; Cheah, L.A.; Gilbert, J.M.; Bai, J.; Ell, S.R.; Green, P.D.; Moore, R.K. A silent speech system based on permanent magnet articulography and direct synthesis. Comput. Speech. Lang. 2016, 39, 67–87. [Google Scholar] [CrossRef] [Green Version]
- Gonzalez, J.A.; Cheah, L.A.; Gomez, A.M.; Green, P.D.; Gilbert, J.M.; Ell, S.R.; Moore, R.K.; Holdsworth, E. Direct speech reconstruction from articulatory sensor data by machine learning. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 2362–2374. [Google Scholar] [CrossRef] [Green Version]
- Kain, A.; Macon, M. Spectral voice conversion for text-to-speech synthesis. In Proceedings of the 1998 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 1998), Seattle, WA, USA, 15 May 1998; Volume 1, pp. 285–288. [Google Scholar] [CrossRef]
- Stylianou, Y.; Cappe, O.; Moulines, E. Continuous probabilistic transform for voice conversion. IEEE Trans. Audio Speech Lang. Process. 1998, 6, 131–142. [Google Scholar] [CrossRef] [Green Version]
- Mohammadi, S.H.; Kain, A. An overview of voice conversion systems. Speech Commun. 2017, 88, 65–82. [Google Scholar] [CrossRef]
- Rabiner, L.R.; Juang, B.H. Fundamentals of Speech Recognition; Prentice-Hall: Upper Saddle River, NJ, USA, 1993. [Google Scholar]
- Andrew, G.; Arora, R.; Bilmes, J.; Livescu, K. Deep canonical correlation analysis. In Proceedings of the International Conference on Machine Learning (ICML 2013), Atlanta, GA, USA, 16–21 June 2013; pp. 1247–1255. [Google Scholar]
- Wang, W.; Arora, R.; Livescu, K.; Bilmes, J. On deep multiview representation learning. In Proceedings of the International Conference on Machine Learning (ICML 2015), Lille, France, 6–11 July 2015; pp. 1083–1092. [Google Scholar]
- Fang, F.; Yamagishi, J.; Echizen, I.; Lorenzo-Trueba, J. High-quality nonparallel voice conversion based on cycle-consistent adversarial network. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5279–5283. [Google Scholar]
- Gilbert, J.M.; Rybchenko, S.I.; Hofe, R.; Ell, S.R.; Fagan, M.J.; Moore, R.K.; Green, P. Isolated word recognition of silent speech using magnetic implants and sensors. Med. Eng. Phys. 2010, 32, 1189–1197. [Google Scholar] [CrossRef]
- Trigeorgis, G.; Nicolaou, M.A.; Schuller, B.W.; Zafeiriou, S. Deep canonical time warping for simultaneous alignment and representation learning of sequences. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1128–1138. [Google Scholar] [CrossRef] [Green Version]
- Hotelling, H. Relations between two sets of variates. Biometrika 1936, 28, 321–377. [Google Scholar] [CrossRef]
- Wang, W.; Yan, X.; Lee, H.; Livescu, K. Deep variational canonical correlation analysis. arXiv 2016, arXiv:1610.03454. [Google Scholar]
- Zhou, F.; De la Torre, F. Generalized canonical time warping. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 279–294. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sahbi, H. Learning CCA Representations for Misaligned Data. In Proceedings of the European Conference on Computer Vision, ECCV—Workshop, Munich, Germany, 8–14 September 2018; Springer: Munich, Germany, 2018; Volume Voume 11132, pp. 468–485. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Parzen, E. On Estimation of a Probability Density Function and Mode. Ann. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- Hermann, K.M.; Blunsom, P. Multilingual models for compositional distributed semantics. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 22–27 June 2014; pp. 58–68. [Google Scholar] [CrossRef]
- Kominek, J.; Black, A.W. The CMU Arctic speech databases. In Proceedings of the 5th ISCA Workshop on Speech Synthesis, Pittsburgh, PA, USA, 14–16 June 2004; pp. 223–224. [Google Scholar]
- Morise, M.; Yokomuri, F.; Ozawa, K. WORLD: A vocoder-based high-quality speech synthesis system for real-time applications. IEICE Trans. Inf. Syst. 2016, 99, 1877–1884. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Gonzalez, J.A.; Cheah, L.A.; Green, P.D.; Gilbert, J.M.; Ell, S.R.; Moore, R.K.; Holdsworth, E. Evaluation of a silent speech interface based on magnetic sensing and deep learning for a phonetically rich vocabulary. In Proceedings of the Annual Conference of the International Speech Communication Association, Interspeech, Stockholm, Sweden, 20–24 August 2017; pp. 3986–3990. [Google Scholar]
- Tokuda, K.; Yoshimura, T.; Masuko, T.; Kobayashi, T.; Kitamura, T. Speech parameter generation algorithms for HMM-based speech synthesis. In Proceedings of the 2000 IEEE International Conference on Acoustics, Speech, and Signal Processing, Istanbul, Turkey, 5–9 June 2000; pp. 1315–1318. [Google Scholar] [CrossRef]
- Toda, T.; Black, A.W.; Tokuda, K. Voice conversion based on maximum-likelihood estimation of spectral parameter trajectory. IEEE Trans. Audio Speech Lang. Process. 2007, 15, 2222–2235. [Google Scholar] [CrossRef]
- Kubichek, R. Mel-cepstral distance measure for objective speech quality assessment. In Proceedings of the IEEE Pacific Rim Conference on Communications, Computers and Signal Processing, Victoria, BC, Canada, 19–21 May 1993; pp. 125–128. [Google Scholar]
- Zhou, F.; Torre, F. Canonical time warping for alignment of human behavior. In Proceedings of the International Conference Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; Volume 22, pp. 2286–2294. [Google Scholar]
- Kraft, S.; Zölzer, U. BeaqleJS: HTML5 and JavaScript based framework for the subjective evaluation of audio quality. In Proceedings of the Linux Audio Conference, Karlsruhe, Germany, 1–4 May 2014. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Gomez-Alanis, A.; Gonzalez-Lopez, J.A.; Peinado, A.M. A kernel density estimation based loss function and its application to asv-spoofing detection. IEEE Access 2020, 8, 108530–108543. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| # Of Sentences | |||
|---|---|---|---|
| Condition | Training Set | Evaluation Set | |
| Intra-subject | F → F | 103 (11.3 min) | 20 (1.2 min) |
| M → M | 134 (8.4 min) | 20 (1.1 min) | |
| Cross-subject | F → F | 99 (6.0 min) | 18 (0.9 min) |
| F → M | 332 (18.7 min) | 20 (1.0 min) | |
| M → F | 332 (21.9 min) | 20 (1.2 min) | |
| M → M | 414 (27.9 min) | 20 (1.2 min) | |
| MGCC | BAP | Voicing | ||
|---|---|---|---|---|
| Method | MCD (dB) | RMSE (dB) | RMSE (Hz) | Err. Rate (%) |
| Oracle | 7.81 | 0.43 | 14.75 | 23.79 |
| CTW | 8.55 | 0.59 | 15.98 | 23.08 |
| +autoenc. | 9.20 | 0.88 | 16.70 | 25.30 |
| +priv. vars. | 8.83 | 0.58 | 15.74 | 21.47 |
| TRANSIENCE-CCA | 9.37 | 0.85 | 16.40 | 27.95 |
| +autoenc. | 10.02 | 1.46 | 15.95 | 34.08 |
| +priv. vars. | 10.48 | 1.24 | 15.79 | 31.88 |
| TRANSIENCE-MMI | 9.74 | 0.69 | 16.43 | 22.25 |
| +autoenc. | 9.97 | 1.09 | 16.92 | 23.72 |
| +priv. vars. | 9.86 | 1.70 | 16.41 | 21.75 |
| TRANSIENCE-CL | 7.65 | 0.12 | 15.28 | 24.10 |
| +autoenc. | 7.76 | 0.20 | 14.98 | 24.06 |
| +priv. vars. | 7.82 | 0.30 | 14.58 | 23.68 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gonzalez-Lopez, J.A.; Gomez-Alanis, A.; Pérez-Córdoba, J.L.; Green, P.D. Non-Parallel Articulatory-to-Acoustic Conversion Using Multiview-Based Time Warping. Appl. Sci. 2022, 12, 1167. https://doi.org/10.3390/app12031167
Gonzalez-Lopez JA, Gomez-Alanis A, Pérez-Córdoba JL, Green PD. Non-Parallel Articulatory-to-Acoustic Conversion Using Multiview-Based Time Warping. Applied Sciences. 2022; 12(3):1167. https://doi.org/10.3390/app12031167
Chicago/Turabian StyleGonzalez-Lopez, Jose A., Alejandro Gomez-Alanis, José L. Pérez-Córdoba, and Phil D. Green. 2022. "Non-Parallel Articulatory-to-Acoustic Conversion Using Multiview-Based Time Warping" Applied Sciences 12, no. 3: 1167. https://doi.org/10.3390/app12031167
APA StyleGonzalez-Lopez, J. A., Gomez-Alanis, A., Pérez-Córdoba, J. L., & Green, P. D. (2022). Non-Parallel Articulatory-to-Acoustic Conversion Using Multiview-Based Time Warping. Applied Sciences, 12(3), 1167. https://doi.org/10.3390/app12031167