
Multimodal Diarization Systems by Training Enrollment Models as Identity Representations †

 , ,
, ,  , and
, and
Abstract
:1. Introduction
2. RTVE 2020 Challenge
3. Face Enrollment Models
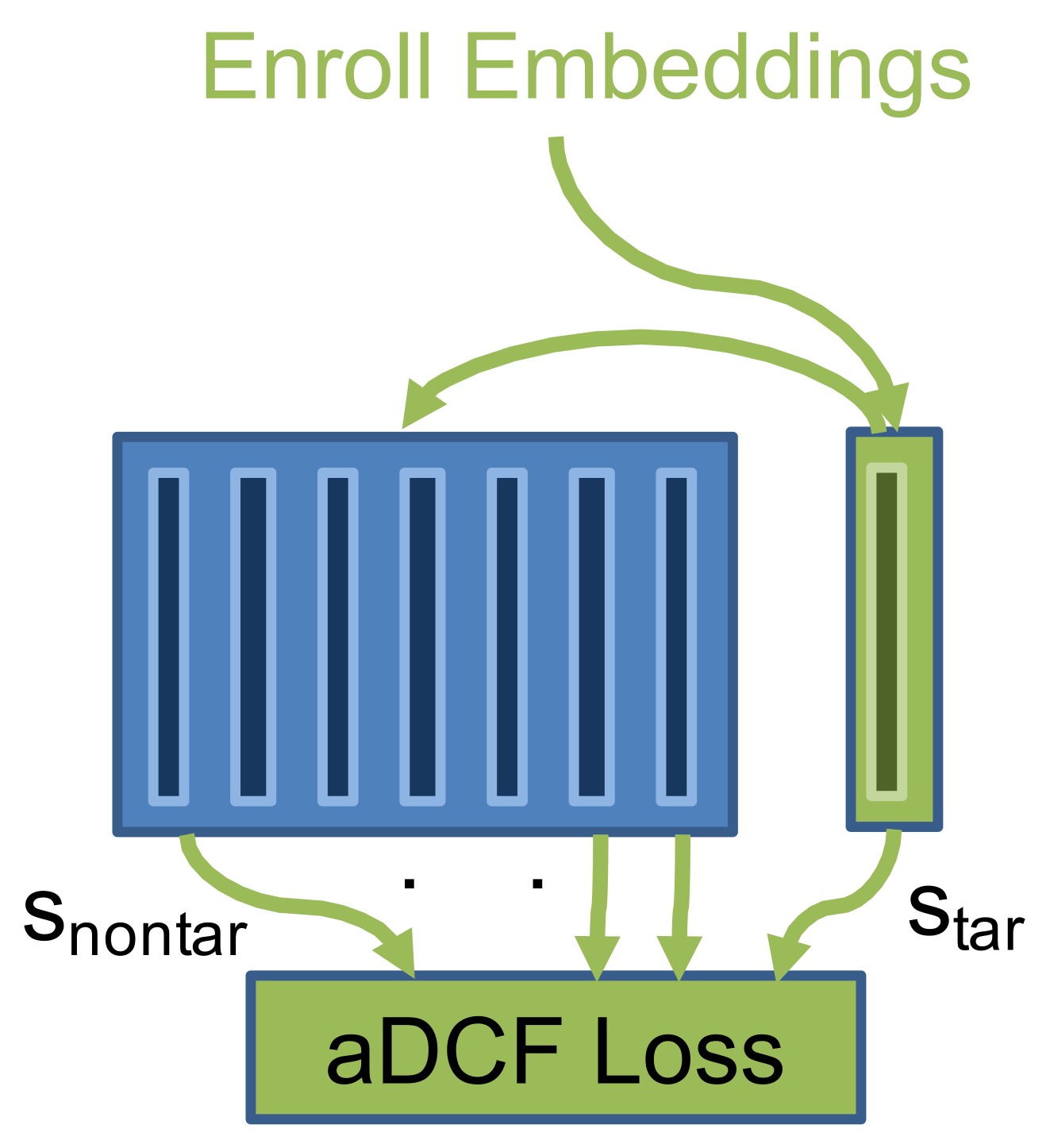
3.1. Approximated Detection Cost Function (aDCF) Loss
3.2. Training Process of Enrollment Models
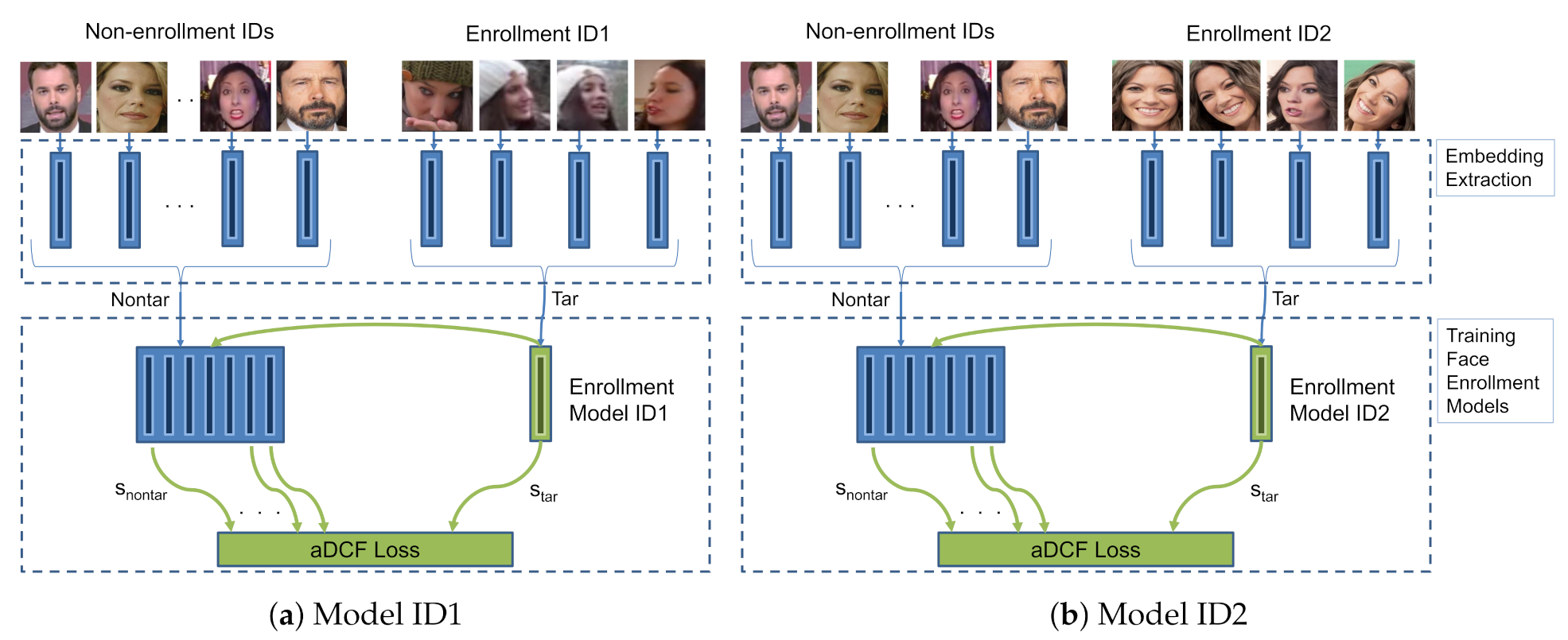
- The target and nontarget embeddings extracted from the pretrained model are employed as positive and negative examples.
- Each enrollment model is trained using the aDCF loss function with all nontarget embeddings and only the target embeddings of the corresponding enrollment identity.
- The trained models are stored to use them in the assignment process.
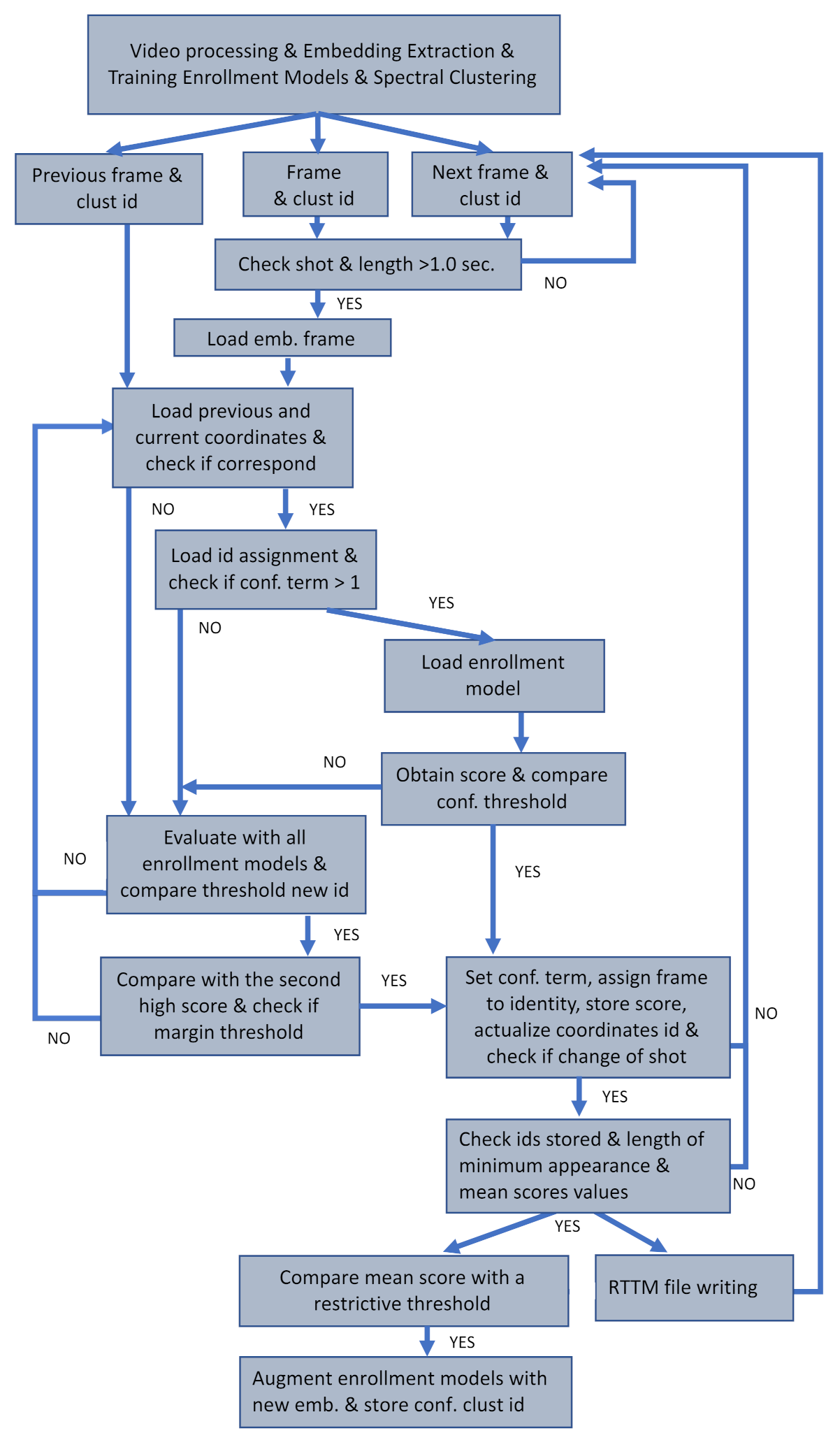
4. Face Subsystem
4.1. Video Processing
4.1.1. Frame Extraction
4.1.2. Face Detection
4.1.3. Change Shot Detection
4.2. Embedding Extraction
4.3. Training Face Enrollment Models
4.4. Clustering
4.5. Tracking and Identity Assignment Scoring
5. Speaker Subsystem
5.1. Audio Processing
5.1.1. Front-End and Speech Activity Detection
5.1.2. Speaker Change Point Detection
5.2. Embedding Extraction
5.3. Clustering
5.4. Identity Assignment Scoring
6. Performance Metrics
- Probability of misses (MISS): Indicates the segments where the target identity is presented but the system does not detect it.
- Probability of false alarm (FA): Illustrates the number of errors due to the assignment of one enrollment identity to a segment without identity known.
- Identity error (ID): Reflects the segments assigned to enrollment identities different from the target identity.
7. Results
7.1. Analysis of Training Enrollment Models for Face Subsystem
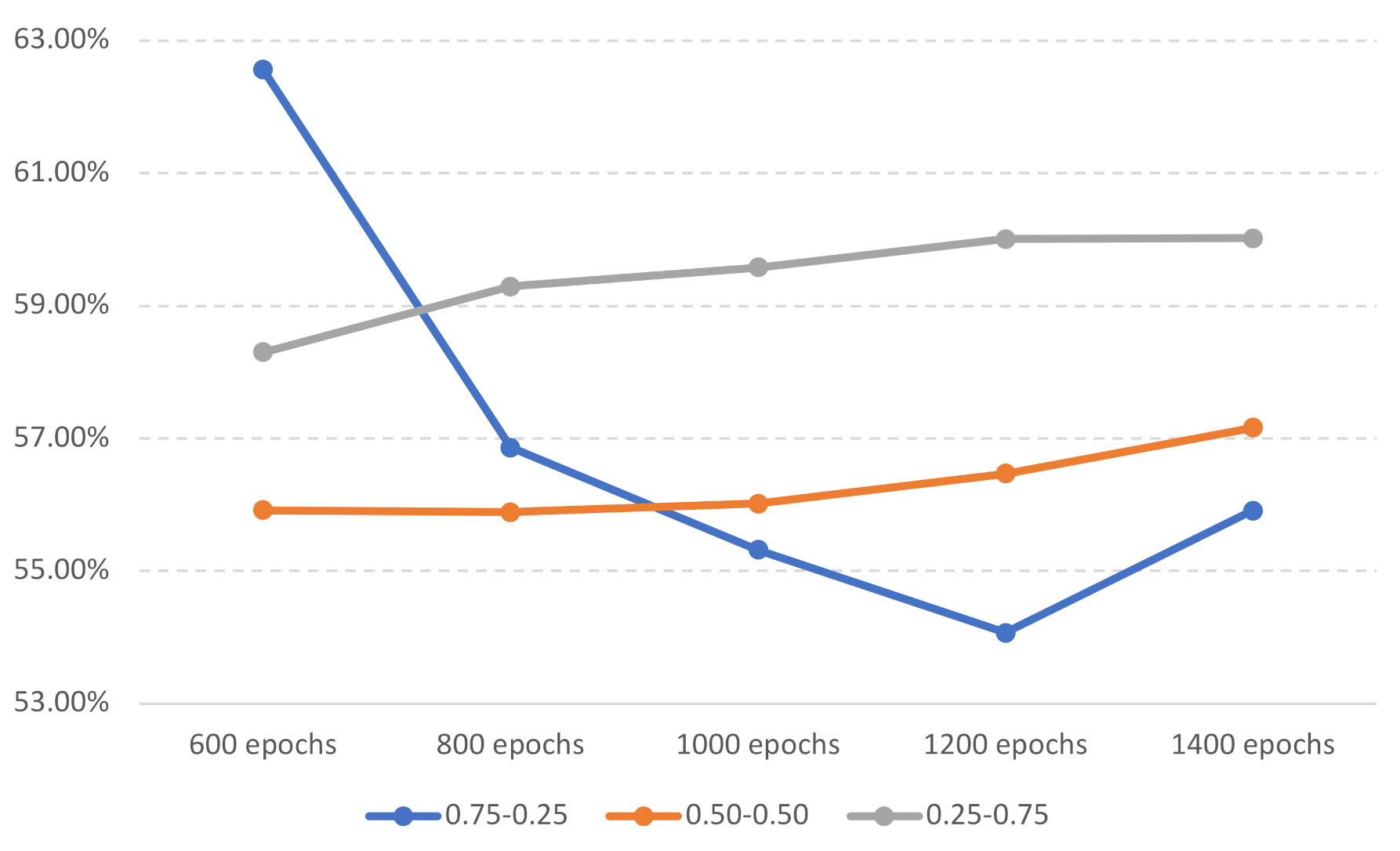
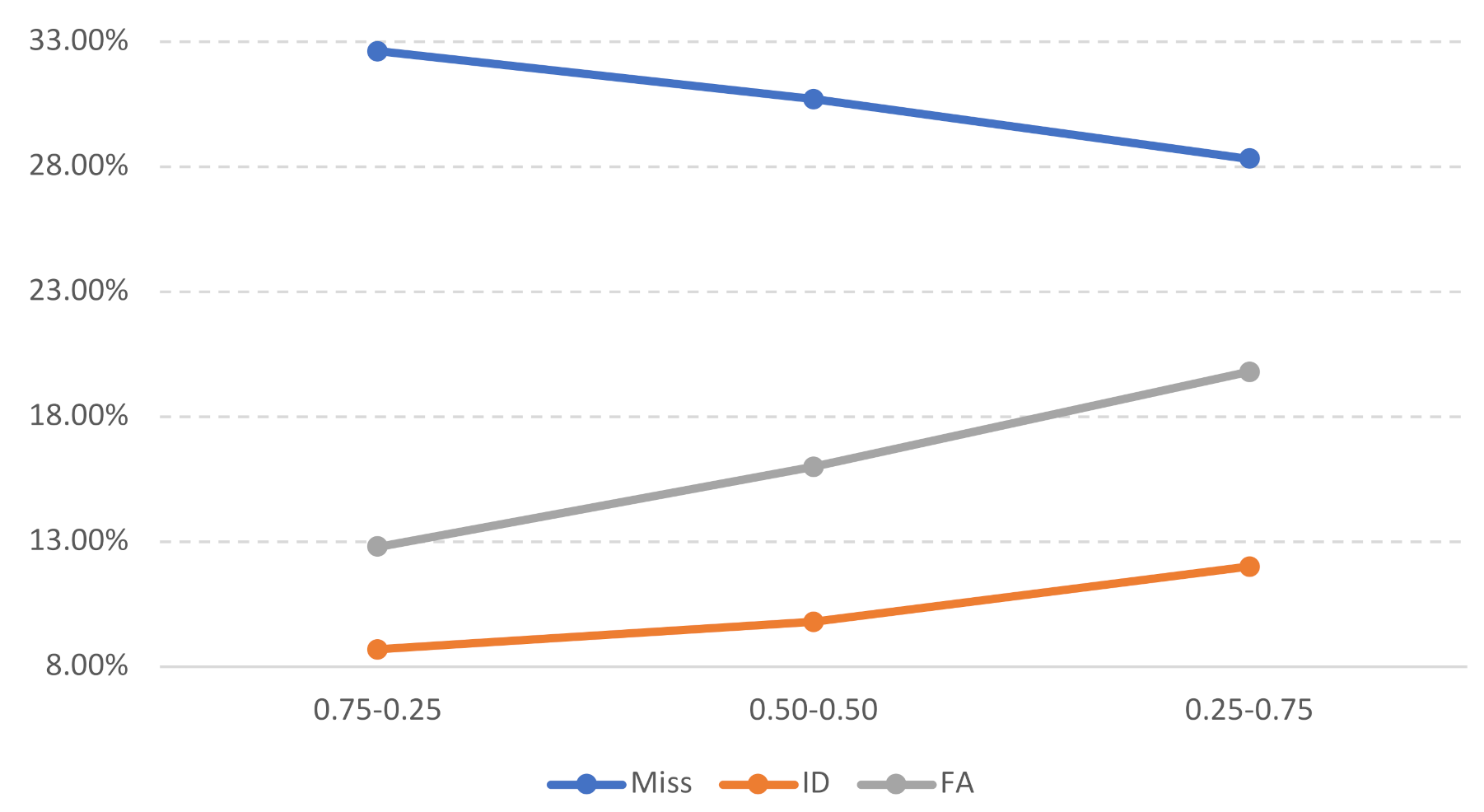
7.2. Effect of aDCF Parameters , for Training Face Enrollment Models
7.3. Summary of Face and Speaker Results
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Poignant, J.; Bredin, H.; Barras, C. Multimodal Person Discovery in Broadcast tv at Mediaeval 2015. MediaEval 2015 Working Notes Proceedings. 2015. Available online: CEUR-WS.org (accessed on 23 December 2021).
- Bredin, H.; Barras, C.; Guinaudeau, C. Multimodal Person Discovery in Broadcast TV at MediaEval 2016. MediaEval 2016 Working Notes Proceedings. 2016. Available online: CEUR-WS.org (accessed on 23 December 2021).
- Sadjadi, O.; Greenberg, C.; Singer, E.; Reynolds, D.; Mason, L.; Hernandez-Cordero, J. The 2019 NIST Audio-Visual Speaker Recognition Evaluation. In Proceedings of the Odyssey 2020 The Speaker and Language Recognition Workshop, Tokyo, Japan, 1–5 November 2020; pp. 259–265. [Google Scholar]
- Das, R.K.; Tao, R.; Yang, J.; Rao, W.; Yu, C.; Li, H. HLT-NUS Submission for NIST 2019 Multimedia Speaker Recognition Evaluation. arXiv 2020, arXiv:2010.03905. [Google Scholar]
- Garcia-Romero, D.; Snyder, D.; Sell, G.; Povey, D.; McCree, A. Speaker diarization using deep neural network embeddings. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 4930–4934. [Google Scholar]
- Viñals, I.; Gimeno, P.; Ortega, A.; Miguel, A.; Lleida, E. In-domain Adaptation Solutions for the RTVE 2018 Diarization Challenge. In Proceedings of the Iberspeech 2018, Barcelona, Spain, 21–23 November 2018; pp. 220–223. [Google Scholar]
- Khoury, E.; Gay, P.; Odobez, J.M. Fusing matching and biometric similarity measures for face diarization in video. In Proceedings of the 3rd ACM Conference on International Conference on Multimedia Retrieval, Dallas, Texas, USA, 16–19 April 2013; pp. 97–104. [Google Scholar]
- Le, N.; Heili, A.; Wu, D.; Odobez, J.M. Efficient and Accurate Tracking for Face Diarization via Periodical Detection. In Proceedings of the International Conference on Pattern Recognition, Cancun, Mexico, 4–8 December 2016. [Google Scholar]
- Ortega, A.; Miguel, A.; Lleida, E.; Bazán, V.; Pérez, C.; Gómez, M.; de Prada, A. Albayzin evaluation: IberSPEECH-RTVE 2020 Speaker Diarization and Identity Assignment. Available online: http://catedrartve.unizar.es/reto2020/EvalPlan-SD-2020-v1.pdf (accessed on 23 December 2021).
- Lleida, E.; Ortega, A.; Miguel, A.; Bazán, V.; Pérez, C.; Gómez, M.; de Prada, A. Albayzin evaluation: IberSPEECH-RTVE 2020 Multimodal Diarization and Scene Description Challenge. Available online: http://catedrartve.unizar.es/reto2018/EvalPlan-Multimodal-v1.3.pdf (accessed on 23 December 2021).
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar] [CrossRef] [Green Version]
- Jung, J.; Heo, H.; Kim, J.; Shim, H.; Yu, H. RawNet: Advanced End-to-End Deep Neural Network Using Raw Waveforms for Text-Independent Speaker Verification. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 1268–1272. [Google Scholar]
- Mingote, V.; Miguel, A.; Ortega, A.; Lleida, E. Training Speaker Enrollment Models by Network Optimization. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 October 2020; pp. 3810–3814. [Google Scholar]
- Mingote, V.; Miguel, A.; Ribas, D.; Ortega, A.; Lleida, E. Optimization of False Acceptance/Rejection Rates and Decision Threshold for End-to-End Text-Dependent Speaker Verification Systems. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 2903–2907. [Google Scholar]
- Lleida, E.; Ortega, A.; Miguel, A.; Bazán-Gil, V.; Pérez, C.; Gómez, M.; de Prada, A. Albayzin 2018 evaluation: The iberspeech-RTVE challenge on speech technologies for spanish broadcast media. Appl. Sci. 2019, 9, 5412. [Google Scholar] [CrossRef] [Green Version]
- Mingote, V.; Miguel, A.; Ortega, A.; Lleida, E. Optimization of the area under the ROC curve using neural network supervectors for text-dependent speaker verification. Comput. Speech Lang. 2020, 63, 101078. [Google Scholar] [CrossRef] [Green Version]
- Mingote, V.; Castan, D.; McLaren, M.; Nandwana, M.K.; Ortega, A.; Lleida, E.; Miguel, A. Language Recognition Using Triplet Neural Networks. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 4025–4029. [Google Scholar]
- Bai, Z.; Zhang, X.; Chen, J. Partial AUC Optimization Based Deep Speaker Embeddings with Class-Center Learning for Text-Independent Speaker Verification. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6819–6823. [Google Scholar]
- Gimeno, P.; Mingote, V.; Ortega, A.; Miguel, A.; Lleida, E. Partial AUC Optimisation Using Recurrent Neural Networks for Music Detection with Limited Training Data. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 October 2020; pp. 3067–3071. [Google Scholar]
- Gimeno, P.; Mingote, V.; Ortega, A.; Miguel, A.; Lleida, E. Generalising AUC Optimisation to Multiclass Classification for Audio Segmentation with Limited Training Data. IEEE Signal Process. Lett. 2021, 28, 1135–1139. [Google Scholar] [CrossRef]
- Martin, A.; Przybocki, M. The NIST 1999 speaker recognition evaluation—An overview. Digit. Signal Process. 2000, 10, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- Yi, D.; Lei, Z.; Liao, S.; Li, S.Z. Learning face representation from scratch. arXiv 2014, arXiv:1411.7923. [Google Scholar]
- Huang, G.B.; Mattar, M.; Berg, T.; Learned-Miller, E. Labeled faces in the wild: A database forstudying face recognition in unconstrained environments. In Proceedings of the Workshop on Faces in ‘Real-Life’ Images: Detection, Alignment, and Recognition, Marseille, France, 12–18 October 2008. [Google Scholar]
- Huang, G.; Mattar, M.; Lee, H.; Learned-Miller, E.G. Learning to align from scratch. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 764–772. [Google Scholar]
- Shi, J.; Malik, J. Normalized Cuts and Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Ramos-Muguerza, E.; Docío-Fernández, L.; Alba-Castro, J.L. The GTM-UVIGO System for Audiovisual Diarization. In Proceedings of the Iberspeech 2018, Barcelona, Spain, 21–23 November 2018; pp. 204–207. [Google Scholar]
- Viñals, I.; Ortega, A.; Miguel, A.; Lleida, E. The Domain Mismatch Problem in the Broadcast Speaker Attribution Task. Appl. Sci. 2021, 11, 8521. [Google Scholar] [CrossRef]
- Davis, S.; Mermelstein, P. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 357–366. [Google Scholar] [CrossRef] [Green Version]
- Gimeno, P.; Ribas, D.; Ortega, A.; Miguel, A.; Lleida, E. Convolutional recurrent neural networks for speech activity detection in naturalistic audio from apollo missions. In Proceedings of the IberSPEECH 2021, Valladolid, Spain, 24–25 March 2021; pp. 26–30. [Google Scholar]
- Viñals, I.; Gimeno, P.; Ortega, A.; Miguel, A.; Lleida, E. Estimation of the Number of Speakers with Variational Bayesian PLDA in the DIHARD Diarization Challenge. In Proceedings of the Interspeech 2018, Hyderabad, India, 2–6 September 2018; pp. 2803–2807. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Alam, M.J.; Ouellet, P.; Kenny, P.; O’Shaughnessy, D. Comparative evaluation of feature normalization techniques for speaker verification. In Proceedings of the International Conference on Nonlinear Speech Processing, Las Palmas de Grancanaria, Spain, 7–9 November 2011; pp. 246–253. [Google Scholar]
- Chen, S.; Gopalakrishnan, P. Speaker, environment and channel change detection and clustering via the bayesian information criterion. In Proceedings of the DARPA Broadcast News Transcription and Understanding Workshop, Landsdowne, VA, USA, 8–11 February 1998; Volume 8, pp. 127–132. [Google Scholar]
- Snyder, D.; Ghahremani, P.; Povey, D.; Garcia-Romero, D.; Carmiel, Y.; Khudanpur, S. Deep neural network-based speaker embeddings for end-to-end speaker verification. In Proceedings of the 2016 IEEE Spoken Language Technology Workshop (SLT), San Diego, CA, USA, 13–16 December 2016; pp. 165–170. [Google Scholar]
- Villalba, J.; Chen, N.; Snyder, D.; Garcia-Romero, D.; McCree, A.; Sell, G.; Borgstrom, J.; Richardson, F.; Shon, S.; Grondin, F.; et al. State-of-the-Art Speaker Recognition for Telephone and Video Speech: The JHU-MIT Submission for NIST SRE18. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 1488–1492. [Google Scholar]
- Waibel, A.; Hanazawa, T.; Hinton, G.; Shikano, K.; Lang, K.J. Phoneme recognition using time-delay neural networks. IEEE Trans. Acoust. Speech Signal Process. 1989, 37, 328–339. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Nagrani, A.; Chung, J.S.; Zisserman, A. VoxCeleb: A Large-Scale Speaker Identification Dataset. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 2616–2620. [Google Scholar]
- Chung, J.S.; Nagrani, A.; Zisserman, A. VoxCeleb2: Deep Speaker Recognition. In Proceedings of the Interspeech 2018, Hyderabad, India, 2–6 September 2018; pp. 1086–1090. [Google Scholar]
- Bell, P.; Gales, M.J.; Hain, T.; Kilgour, J.; Lanchantin, P.; Liu, X.; McParland, A.; Renals, S.; Saz, O.; Wester, M.; et al. The MGB challenge: Evaluating multi-genre broadcast media recognition. In Proceedings of the 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Scottsdale, AZ, USA, 13–17 December 2015; pp. 687–693. [Google Scholar]
- Garcia-Romero, D.; Espy-Wilson, C.Y. Analysis of i-vector length normalization in speaker recognition systems. In Proceedings of the Twelfth Annual Conference of the International Speech Communication Association, Florence, Italy, 27–31 August 2011. [Google Scholar]
- Viñals, I.; Gimeno, P.; Ortega, A.; Miguel, A.; Lleida, E. ViVoLAB Speaker Diarization System for the DIHARD 2019 Challenge. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 988–992. [Google Scholar]
- Viterbi, A. Error bounds for convolutional codes and an asymptotically optimum decoding algorithm. IEEE Trans. Inf. Theory 1967, 13, 260–269. [Google Scholar] [CrossRef] [Green Version]
- Brümmer, N.; Strasheim, A. Agnitio’s speaker recognition system for evalita 2009. In Proceedings of the 11th Conference of the Italian Association for Artificial Intelligence, Reggio Emilia, Italy, 9–12 December 2009. [Google Scholar]
- Mingote, V.; Vinals, I.; Gimeno, P.; Miguel, A.; Ortega, A.; Lleida, E. ViVoLAB Multimodal Diarization System for RTVE 2020 Challenge. In Proceedings of the IberSPEECH 2021, Valladolid, Spain, 24–25 March 2021; pp. 76–80. [Google Scholar]
- Porta-Lorenzo, M.; Alba-Castro, J.L.; Docío-Fernández, L. The GTM-UVIGO System for Audiovisual Diarization 2020. In Proceedings of the IberSPEECH 2021, Valladolid, Spain, 24–25 March 2021; pp. 81–85. [Google Scholar]
- Luna-Jiménez, C.; Kleinlein, R.; Fernández-Martınez, F.; Manuel, J.; Pardo-Munoz, J.M.M.F. GTH-UPM System for Albayzin Multimodal Diarization Challenge 2020. In Proceedings of the IberSPEECH 2021, Valladolid, Spain, 24–25 March 2021; pp. 71–75. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Back-End | Nontarget Examples | DER% |
|---|---|---|
| Average Embedding | − | |
| Enrollment Models | 57 | |
| 3302 | 56.86% |
| 600 Epochs | 800 Epochs | 1000 Epochs | 1200 Epochs | 1400 Epochs | ||
|---|---|---|---|---|---|---|
| 55.32% | 54.07% | 55.91% | ||||
| 55.92% | 55.89% | |||||
| MISS | FA | ID | DER | ||
|---|---|---|---|---|---|
| 12.80% | 8.70% | 54.07% | |||
| 28.30% |
| Subset | Modality | DER% | DER% Ours [46] | DER% [47] | DER% [48] |
|---|---|---|---|---|---|
| − | − | ||||
| − | − | ||||
| − | − | ||||
| Modality | Subset | MISS | FA | ID |
|---|---|---|---|---|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mingote, V.; Viñals, I.; Gimeno, P.; Miguel, A.; Ortega, A.; Lleida, E. Multimodal Diarization Systems by Training Enrollment Models as Identity Representations. Appl. Sci. 2022, 12, 1141. https://doi.org/10.3390/app12031141
Mingote V, Viñals I, Gimeno P, Miguel A, Ortega A, Lleida E. Multimodal Diarization Systems by Training Enrollment Models as Identity Representations. Applied Sciences. 2022; 12(3):1141. https://doi.org/10.3390/app12031141
Chicago/Turabian StyleMingote, Victoria, Ignacio Viñals, Pablo Gimeno, Antonio Miguel, Alfonso Ortega, and Eduardo Lleida. 2022. "Multimodal Diarization Systems by Training Enrollment Models as Identity Representations" Applied Sciences 12, no. 3: 1141. https://doi.org/10.3390/app12031141
APA StyleMingote, V., Viñals, I., Gimeno, P., Miguel, A., Ortega, A., & Lleida, E. (2022). Multimodal Diarization Systems by Training Enrollment Models as Identity Representations. Applied Sciences, 12(3), 1141. https://doi.org/10.3390/app12031141