1. Introduction
Conducting experiments to better understand manufacturing processes is crucial, with real physical experiments being considered the gold standard. However, conducting real physical experiments for each new experimental setting is impractical because of expensive materials, production stoppages and labor hours for monitoring and evaluation. One good alternative is conducting experiments via simulation, where numerical methods–such as Finite Element Method (FEM)–present a well-observed method in the field of structural analysis. However, solving complex problems with FEM is time-consuming and computationally expensive. In order to reduce the computational effort, surrogate modeling may offer a promising solution [
1]. Surrogate models are trained in a supervised manner and are designed to learn the function mapping between inputs and outputs. With a sufficient amount of training data with respect to the observed use case, a customized surrogate model is able to substitute for a FEM simulation up to a certain accuracy. When only specific dimensions with a controlled reduction in accuracy of a simulation result are desired, reduced-order surrogate modeling is an already known technique. Thus, reduced-order surrogate modeling aims to substitute the high-resolution simulation domain with some carefully selected dimensions of importance, e.g., selected displacement measures of a deformed part can be predicted by a reduced-order surrogate modeling with low computational effort, instead of performing a computationally intensive FEM simulation that predicts the displacement of each node representing the deformed part.
Meanwhile, Gaussian process regression (GP) has been successfully used as a surrogate model in the past. In literature, GP regression is also called “kriging” after the statistician and mining engineer Danie G. Krige [
2]. However, for consistency, we use only the term GP regression or plain GP in this paper. Regarding GP regression, one of the biggest advantages is that it predicts a distribution (described by mean and standard deviation) rather than just a point estimate. The predicted standard deviation can be seen as a quality criterion related to the corresponding predicted mean value. In the following, we will refer to that standard deviation of a prediction as epistemic uncertainty, i.e., how certain the model is with respect to its prediction. Considering real manufacturing processes, another source of uncertainty can be observed with regard to the lack of complete control over all influence parameters. These deviations occurring during repeated process iterations under the same conditions are referred to as aleatoric uncertainty.
Recapitulating, we want to shed light on two types of uncertainties in surrogate modeling: (1) epistemic uncertainty referring to the lack of knowledge in respect to a simulation model and can be minimized by adding additional sources of information (with respect to machine learning models, it is mainly increasing the number of training instances at new locations in the feature space) and (2) aleatoric uncertainty referring to deviations of an observed manufacturing process itself, i.e., aleatoric uncertainty cannot be minimized even if more data is generated. Since epistemic and aleatoric uncertainties describe different properties, it seems natural to treat them separately when making predictions or optimization. However, it should be mentioned that in certain circumstances it may be useful to consider uncertainty as a whole rather than dividing it into aleatoric and epistemic uncertainty. In such cases, heteroskedastic GP regression represents a common approach for optimization with surrogate models [
3,
4,
5]. In our problem definition, especially in solving inverse problems, we argue that the distinction of epistemic and aleatoric uncertainty shows clear advantages.
There is a wealth of literature on surrogate models, reduced-order surrogate models, and optimization with GP regression. We present in the following the main related works to our research field organized in (1) GP regression and FEM simulations, (2) GP regression trained with pure sensor data and (3) optimization with GP regression.
In the work of Roberts et al. [
6], they predict damage development in forged brake discs reinforced with Al-SiC particles using damage maps. In addition to Multilayer Perceptron (MLP), Roberts et al. [
6] utilize GP regression as a surrogate model. Loghin and Ismonov [
7] predict the stress intensity factors using GP regression trained with FEM results of a classical bolt-nut assembly use case. Ming et al. [
8] model an electrical discharge machining process with GP regression. Su et al. [
9] utilize GP regression as a surrogate in a structural reliability analysis of a large suspension bridge. In the work of Guo and Hesthaven [
10], GP regression is used as a reduced-order model for nonlinear structural analysis in a 1D and 3D use case, where data generation was performed with active learning. Hu et al. [
11] use GP regression to estimate residual stresses field of machined parts from two-dimensional numerical simulations. Yue et al. [
12] propose two active learning approaches using GP regression for a composite fuselage use case. In the work of Ortali et al. [
13] GP regression is used as a reduced-order surrogate model for fluid dynamics use cases. Venkatraman et al. [
14] use GP regression as a surrogate model of texture in micro-springs. GP regression can also be used on data with multiple fidelity levels, where Lee et al. [
15] investigate GP regression surrogate modeling with uncertain material properties of soft tissues and multi-fidelity data. Brevault et al. [
16] provide an overview of multi-fidelity GP regression techniques in the field of aerospace systems. GP regression can also be extended by methods that stack them or use them in a tree model. Civera et al. [
17] predict imperfections in pultruded glass fiber reinforced polymers with a treed method of GP regression trained with experimental data and FEM simulation results. Abdelfatah et al. [
18] propose a stacked GP regression to integrate different datasets and propagate uncertainties through the stacked model. GP regression can also be used for calibrating simulations, where Mao et al. [
19] use GP regression as a surrogate model in a Bayesian model updating method to calibrate FEM simulation of a long-span suspension bridge.
In addition to the use of FEM data, GP regression also finds application in the use of pure sensor data, which we will discuss in the following. Tapia et al. [
20] use a GP regression based surrogate model of a laser powder-bed fusion process to predict melt pool depth. Yu et al. [
21] utilize–besides other thriving methods–a GP regression to model the relationship between geological variables and the broken rock zone thickness. Lee [
22] uses GP regression trained with experimental data to optimize wire arc additive manufacturing process deposition parameters. Saul et al. [
23] propose chained GP regression models based on non-linear latent function combination. Binois et al. [
24] provide a heteroskedastic GP regression approach and results of two use cases, namely manufacturing and management of epidemics.
In the course of function maximization with GP regression surrogate models, Dai Nguyen et al. [
25] propose a robust optimization approach based on Upper Confidence Bound (UCB) Bayesian Optimization (BO). In another field of optimization, namely solving inverse problems, there is related work found where BO with generalized chi-squared distribution is researched by Huang et al. [
26], and Uhrenholt and Jensen [
27], where besides standard GP regression Uhrenholt and Jensen [
27] utilized warped GP regression from the work of Snelson et al. [
28]. An extension of the standard BO can be found in the work of Plock et al. [
29], where they combine BO with the Levenberg-Marquardt method. While in maximization and minimization problems aleatoric and epistemic uncertainties can often be treated in the same way, in most cases robust results can be obtained by distinguishing between these two sources of uncertainty [
30]. We refer to robust results when mean predictions are associated with low aleatoric uncertainty.
There is already considerable related work in reduced-order surrogate modeling and optimization using GP regression surrogates. However, to the best of our knowledge, we could not identify related work for solving inverse problems in which aleatoric and epistemic uncertainties are treated differently. Optimization approaches for solving inverse problems usually use only epistemic uncertainty. When epistemic and aleatoric uncertainties are taken into account, they are often simply combined, resulting in the potential loss of important information.
To sum up, we identify the following drawbacks:
Related work shows that mainly epistemic uncertainty is used for prediction or optimization with GP regression.
In research using aleatoric and epistemic uncertainties, they are not considered separately when solving inverse problems.
As a response, we present the following main contributions of our research to tackle the identified drawbacks of related work:
We present a GP based surrogate that models (a) the mean result, (b) the aleatoric and (c) the epistemic uncertainty of a manufacturing process outcome.
We utilize aleatoric and epistemic uncertainties in solving inverse problems for robust optimization results.
With the proposed surrogate model and novel multi-objective optimization strategy, we pave the way for surrogate modeling and inverse problem-solving for practical applications that make use of explicit modeling of sources of uncertainties. Our findings are validated on a typical hot metal forming manufacturing process: preforming an Inconel 625 superalloy billet on a forging press.
This paper is structured as follows. In
Section 2, we present the proposed surrogate model, providing an introduction to GP regression in
Section 2.1 and describe the GP based parts of our surrogate model in
Section 2.2 and
Section 2.3. The data generation of aleatoric uncertainty for our surrogate model approach is presented in
Section 2.4.
Section 3 deals with optimization, where we outline active learning in
Section 3.1 and solving inverse problems in
Section 3.2. In
Section 4 we present the studied use case, preforming an Inconel 625 superalloy billet on a forging press, where we give insights on the design of the forging aggregate characteristics in
Section 4.1 and all information regarding the corresponding FEM simulation in
Section 4.2.
Section 5 shows the results, which are discussed in
Section 6. In
Section 7, we present the conclusion of our work and an outlook for the future.
2. GP based Surrogate Model
In this section, we first introduce briefly the general idea behind our surrogate modeling approach. We familiarize in
Section 2.1 the reader with the general functionality of GP regression to provide an appropriate foundation for the content that follows. In
Section 2.2 and
Section 2.3 we provide more detailed descriptions of each individual GP of our surrogate model. After describing our surrogate model, we move on to uncertainty propagation analysis with FEM simulation in
Section 2.4, where we present the procedure for obtaining aleatoric uncertainties.
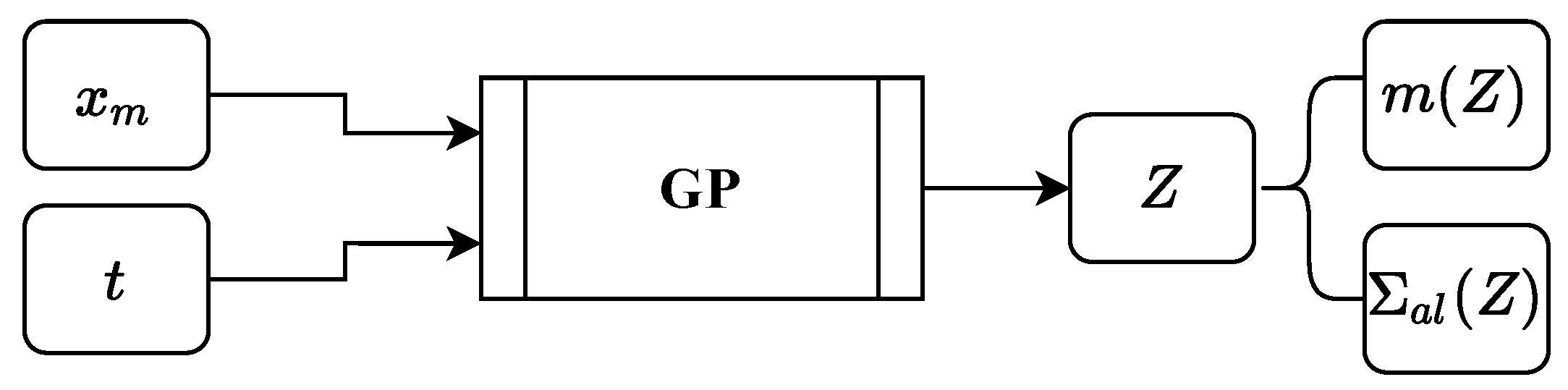
GP regression is already well researched for surrogate modeling, replacing expensive target labellers (e.g., numerical simulations, expensive manually labelling, conducting real physical experiments, etc.). One reason is their ability to work with low-dimensional data. Another big advantage of using GP regression is that predictions are made in a probabilistic way, i.e., a prediction is represented by a posterior distribution. Thus, a prediction of GP regression is described by a mean and a covariance. The covariance of a prediction can be used as a metric of prediction confidence, i.e., epistemic uncertainty. We specify that outputs of GP regression describe a distribution with mean m and epistemic uncertainty .
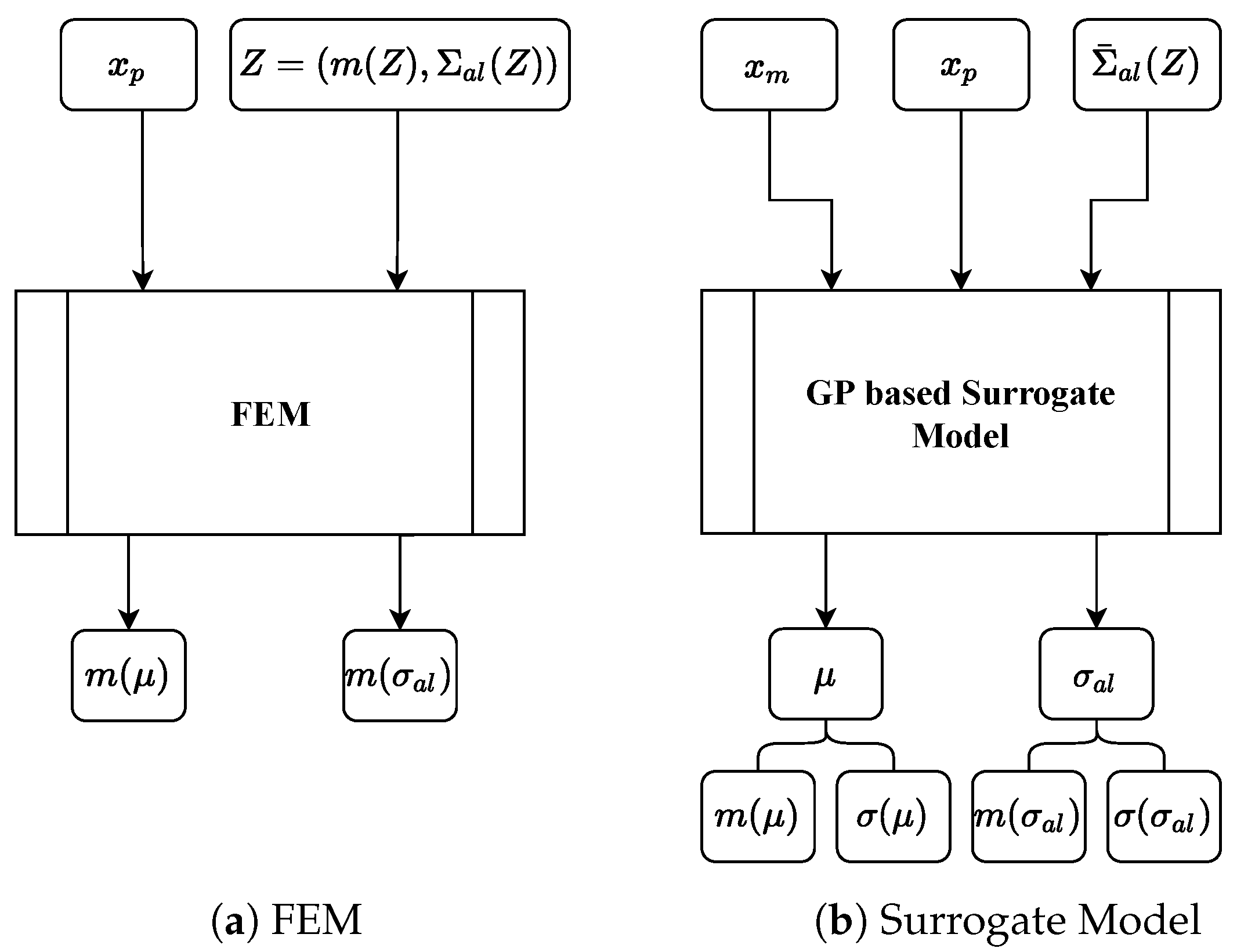
The proposed surrogate model consists of two individual GPs and takes manufacturing process-specific parameters
, part-specific parameters
and aleatoric process uncertainty
as input and predicts the mean manufacturing result
and aleatoric uncertainty
of the manufacturing result, see
Figure 1b,
Figure 2 and
Figure 3. A similar simulation approach using FEM is shown in
Figure 1a. We define
Z as a parameter that describes the manufacturing process characteristics, e.g., velocity profile of a forming tool. Our model assumes that
can be efficiently obtained for every
. This assumption is justified in our running example, where we focus on the first of two directly successive forging strokes. That means that measurements of the manufacturing process are available (i.e., velocity profile of the forging tool), but measurements in respect to the forged part are not possible due to the short time span between the first and second stroke.
2.1. Gaussian Process
A GP is a generalization of the Gaussian distribution. The Gaussian distribution describes random variables or random vectors, while a GP describes functions
. In general, a GP is completely specified by its mean function
and covariance function
, also called kernel. If the function
under consideration is modeled by a GP, we have
for all
x and
. Where
x refers to training and
to test data. Thus, we can define the GP by
We use the following notation for explanatory purposes only in this section. Matrix
contains the training data with input data matrix
and output data matrix
, and test data matrix
contains the test data with
as input and
as output. We define that they are jointly Gaussian and have zero mean with consideration of the prior distribution, further, we assume an additive independent identically distributed Gaussian noise with variance
and identity matrix
I for noisy observations:
The GP predicts the function values
at positions
in a probabilistic way, where, the posterior distribution can be fully described by the mean and the covariance.
Resulting in mean
covariance
and epistemic standard deviation
where the diagonal of the covariance matrix
is extracted as a vector and the square root is calculated for each element to determine the epistemic standard deviation
. It can be observed that the selection or design of the covariance function is the main ingredient when using GP regression. In the following, we describe the two covariance functions we use in our approach: the popular Radial Basis Function (RBF) (also called squared exponential covariance function)
with characteristic length-scale parameter
l and
denoting the Euclidean distance and the Matérn covariance function
with gamma function
, modified Bessel function
and parameter
that controls the smoothness of the resulting function. For more information on GP regression and covariance functions, we refer the reader to the book of Williams and Rasmussen [
31].
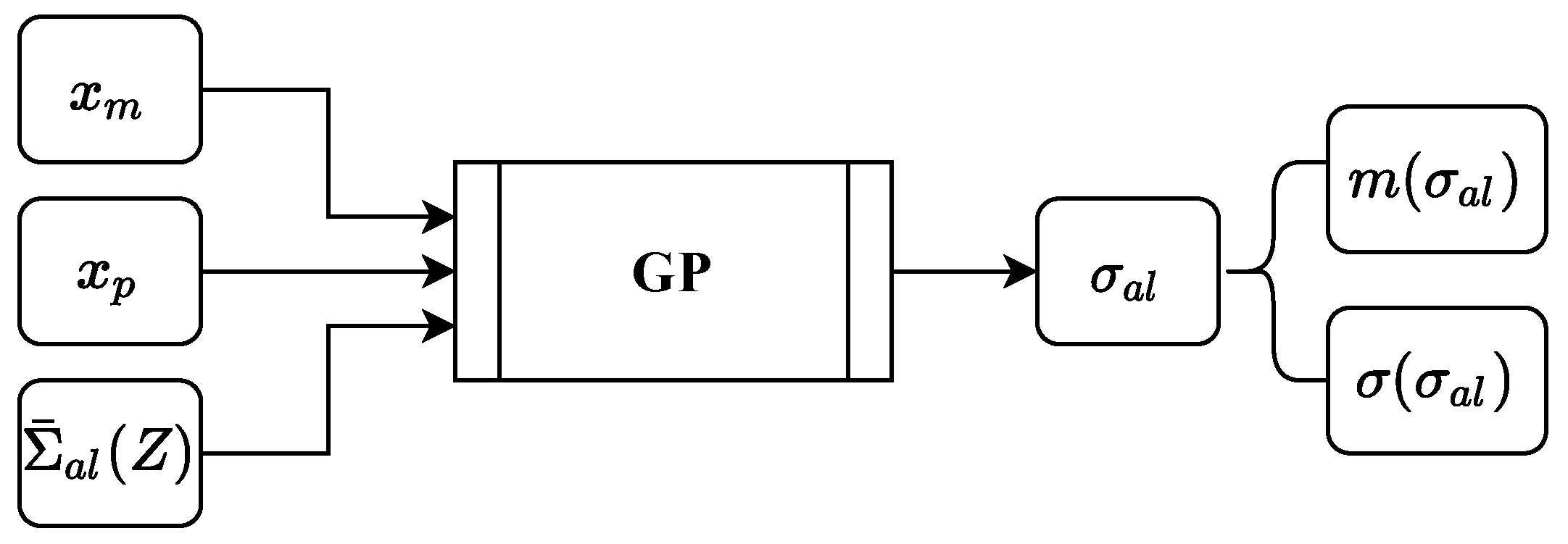
2.2. Aleatoric Uncertainty GP
A GP is used to predict a manufacturing process related aleatoric uncertainty
of the manufactured part. Aleatoric uncertainty data are generated by uncertainty propagation analysis with FEM simulation. The inputs are the setting parameters from a real physical manufacturing process
, properties of the part to be manufactured
and aleatoric manufacturing process uncertainty
obtained from, e.g., sensor data of the real physical manufacturing process, see
Figure 2. Here,
Z describes a characteristic of the manufacturing process, e.g., the velocity profile of a forming tool. The output
is predicted by a GP regression, such that
with mean
and covariance function
.
Of course, a wide variety of manufacturing process characteristics can be implemented, e.g., rolling speeds, cutting forces, heating times etc. As a running example, we choose as a manufacturing process hot metal forming on a friction screwpress, where
contains different input features which control the forging aggregate (clutch pressure between flywheels and rotation speed of the electric motor),
describes the part to be forged by different dimensions and part temperature and
Z is a resulting velocity profile of the forging tool over time for a given input
, where
represents aggregated aleatoric deviations in respect to forging velocity.
then describes the deviations of the final forged part, i.e., deviations from important final part geometries. All relevant details of our running example can be found in
Section 4.
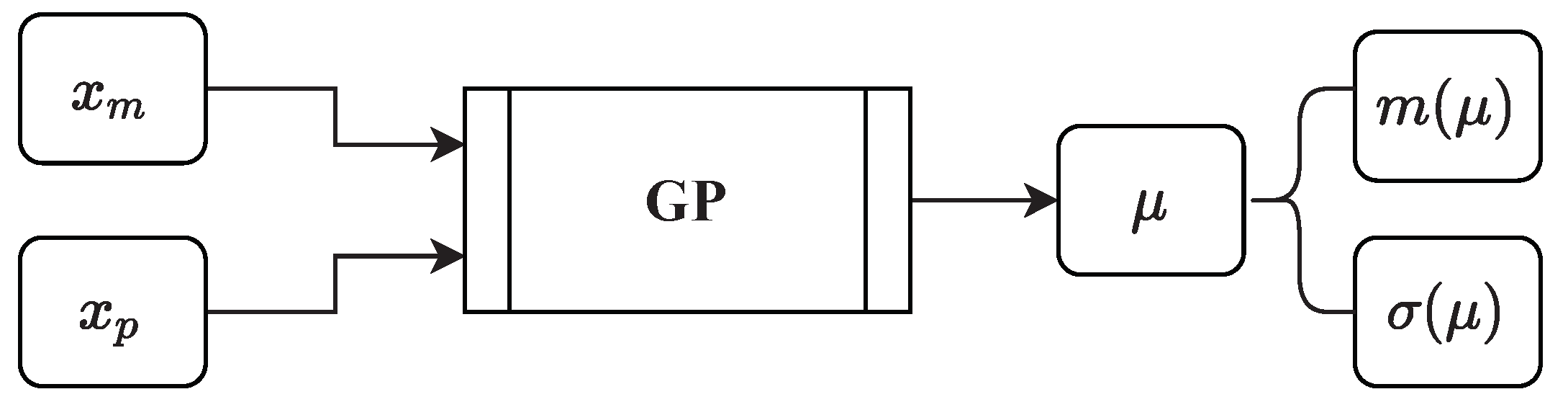
2.3. Mean Result GP
Besides the GP that predicts the aleatoric uncertainty of a manufactured part, a second GP is used to predict the mean result of the manufactured part. The inputs for the second GP are the setting parameters from the real physical manufacturing process and properties of the to be manufactured part . The output is predicted by the GP regression, such that . In respect to our running example, describes the final forged part by important final part geometries.
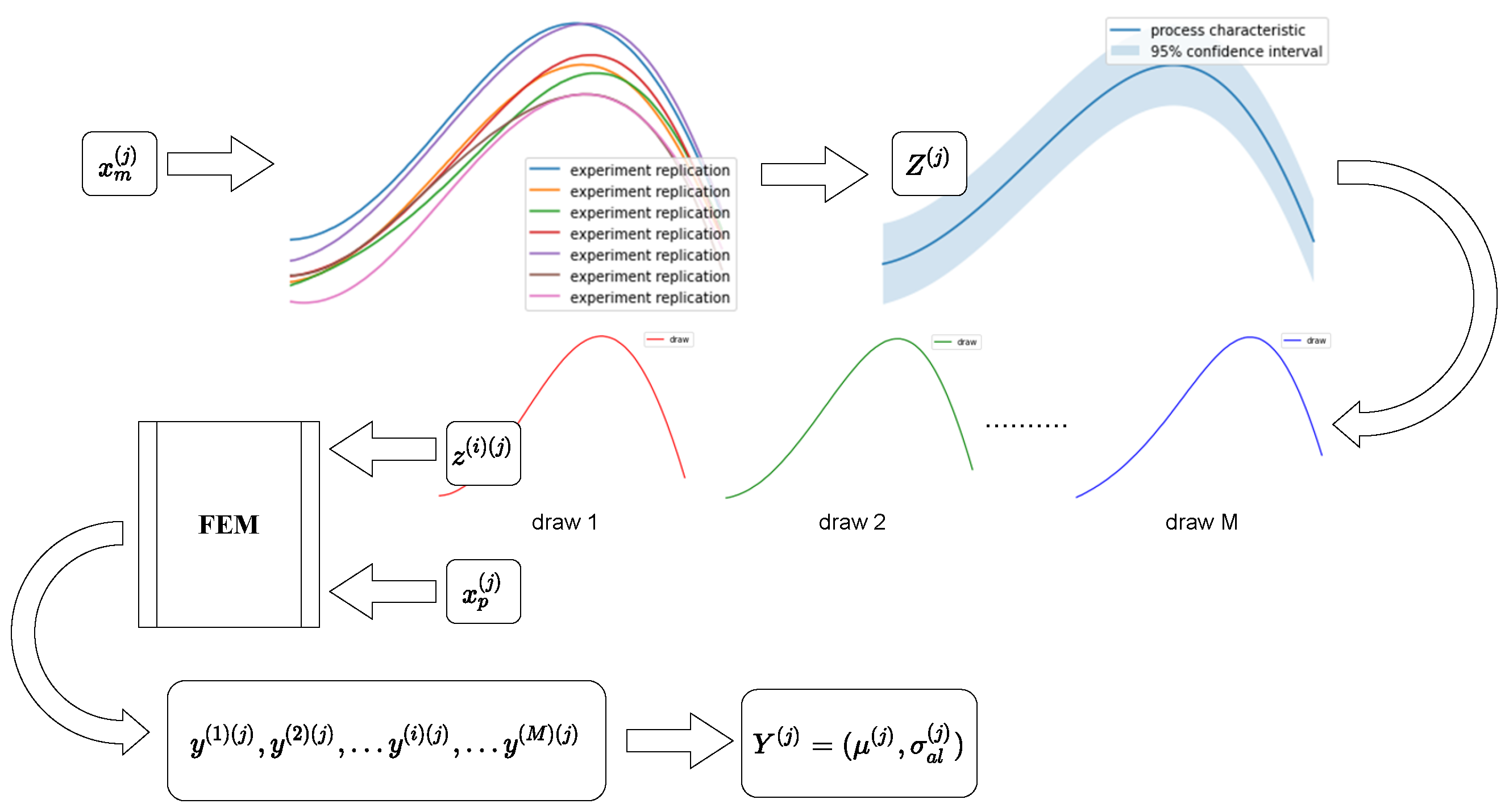
2.4. Uncertainty Propagation Analysis
In uncertainty propagation analysis, the effect of uncertainties related to an input on uncertainties of the corresponding output is investigated. In our case, refers to the aleatoric deviations of a manufacturing process characteristics (i.e., deviations in velocity profile data) due to different input settings. We refer to uncertainties with respect to a manufacturing process output obtained by uncertainty propagation analysis as aleatoric uncertainty .
We vary input values with where N is the number of different input setting scenarios. For each case of process-specific input parameters , we obtain a process-specific characteristic that is a distribution with mean and standard deviation . Such distributions occur because, with identical input parameters, process characteristics in reality can show deviations when repeated. We simulate that behavior with a separate GP, thus, a random variable is assumed to be Normally distributed, such that . From the posterior, we randomly draw M predictions with (i.e., different curves characterizing the manufacturing process) and with each and we execute FEM simulations to obtain targets . We collect the individual targets , such that we obtain for each input setting j a distribution with mean and aleatoric standard deviation (i.e., aleatoric uncertainty) . With that, we are able to describe each target by its distribution.
Thus, we obtain a dataset where each datapoint can then be separated into input and output . Here is an aggregated manufacturing process uncertainty obtained from data. We model each output with a GP regression, thus the outputs are described again by a distribution with mean m and epistemic standard deviation (i.e., epistemic uncertainty), such that and .
4. Case Study on Forging Superalloys
We evaluate the proposed surrogate model and novel optimization method with a classic use case from the field of hot metal forming, preforming an Inconel 625 superalloy billet on an artificially designed forging press. First, we design the forging press characteristics with a parameterized curve and a GP and second, we design the forming process itself in a FEM simulation environment where we provide all the relevant information so that it is possible for researchers to link directly to our work.
4.1. Forging Aggregate Characteristic
We calculate the mean forming velocity values of an artificially designed forging process on the example of a forging screwpress by a self-designed parameterized curve in (
15) that models the die velocity
in mm/s as a function of the process timestep
t in
, clutch pressure
in
and rotation speed of the electric motor
in rpm, such that
. Where,
and
are two process-specific setting parameters, i.e.
.
where
mm
/kg and
mm
/kgs are constants. We utilize a designed forging press specific GP with data generated by using (
15) to model the mean and input dependent deviations in respect to the manufacturing process characteristic
Z (i.e.,
Z represents the velocity profile of the forging die
).
Z is defined by a distribution with mean
and aleatoric standard deviation
. With respect to our use case, the forging press specific GP with output
is at the very beginning of the uncertainty propagation analysis, see
Figure 4. The inputs for the forging press GP are
and time increments
, where
T represents the duration of the manufacturing process. The output of the forging press GP is
Z, such that
with mean
and covariance function
. Thus, we obtain for each time increment a distribution describing the velocity at time
t. The principle GP design for the forging press can be seen in
Figure 5. As covariance function,
k we found out that an RBF kernel is appropriate.
We utilize (
15) and different input parameter combinations to generate training data for the forging press GP, see
Table 1. In terms of time step size
t, we assume that each forging stroke lasts one second, and we model each stroke with a resolution of 100 time steps.
To obtain different deviations connected to different
and
combinations, we use the underlying inference properties of GP regression and vary inter- and extrapolation tasks in respect to the input values for forging process representation, see
Table 2.
We define interpolation such that a value is within the training range (i.e., equals 14 or 18 and equals 55 or 65) and extrapolation such that a value is out of the training range (i.e., equals 10 or 22 and equals 45 or 75).
Exemplary forging press characteristics can be seen in
Figure 6, where
Figure 6a shows low deviation because
and
are both lie within the range of training data,
Figure 6b,c show moderate deviation because one of the process parameters is within and the other is outside the range of the training data and
Figure 6d shows the highest deviation because both of the process-parameters lie outside the range of training data. Thus, our forging press GP represents a forging aggregate characteristics with uncertainties dependent on the inputs. In our approach, we intentionally generate deviations depending on input parameters and assume that uncertainty is aleatoric to approximate reality, i.e., we abuse epistemic uncertainty and assume that it is aleatoric. When working with sensor data coming from a real manufacturing process, it is obvious that deviations, i.e., aleatoric process uncertainties
, can be directly measured from data.
4.2. FEM Simulation
The considered use case, preforming an Inconel 625 superalloy billet on a forging press machine, is observed by utilizing a corresponding FEM simulation. Manufacturing process related FEM inputs
, i.e., different velocity profiles of the upper die over time, are modeled by the forging press GP. Inputs for the forging press GP are
,
and
t, such that
. All 16 possible combinations for manufacturing process related FEM inputs are shown in
Table 2. Billet related inputs
that are shared with our proposed surrogate model and FEM simulation are diameter, height and temperature, such that
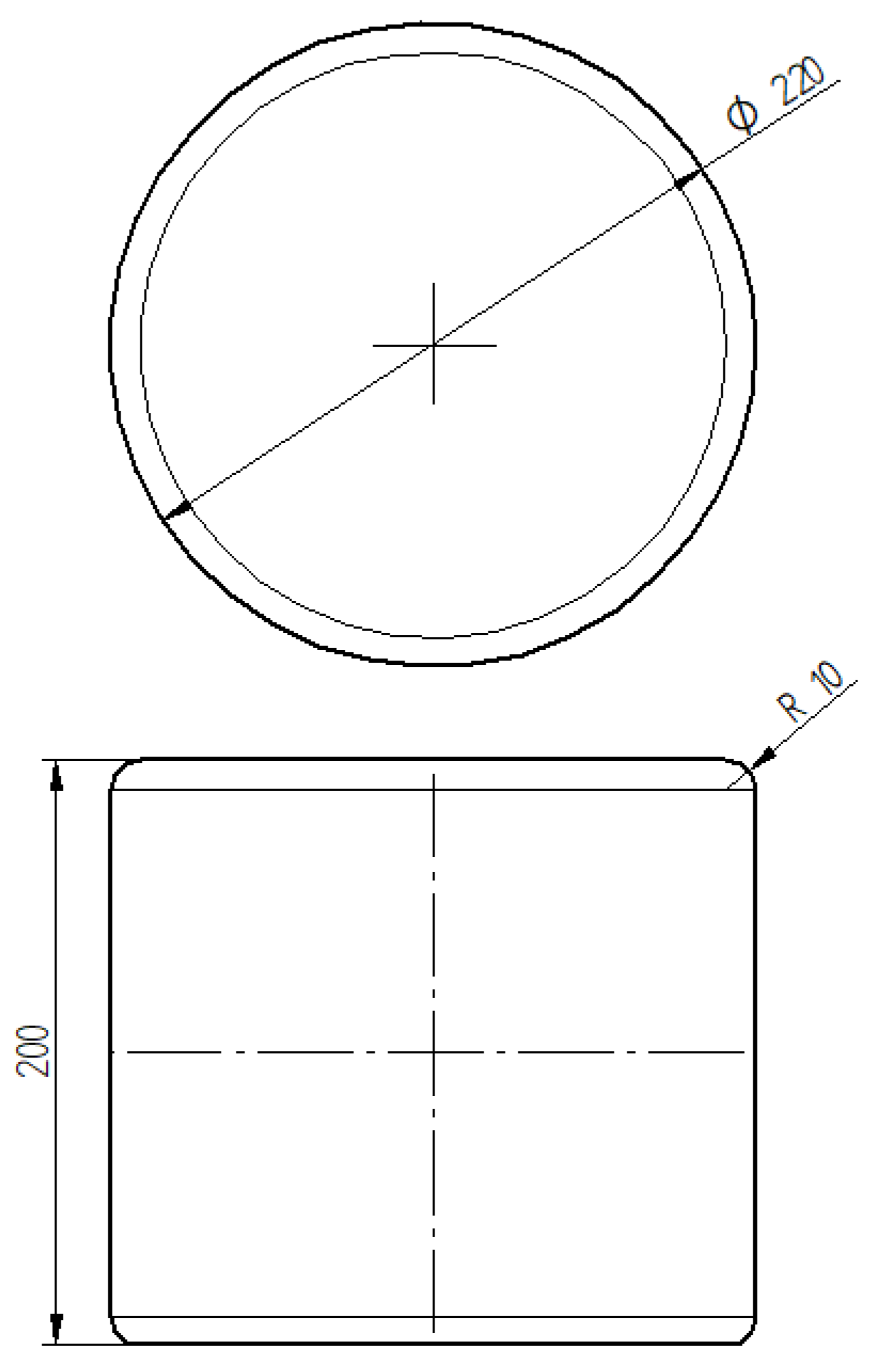
. One possible billet configuration is shown in
Figure 7 and possible billet parameters for different configurations are shown in
Table 3. We define the radius of the rounded edges to be constant 10 mm across all configurations.
We observe in total 27 different billets. Connecting manufacturing process related combinations with different billets, we obtain 432 combinations, i.e., . For evaluation of the uncertainty propagation, we randomly draw with from each distribution , i.e., 20 FEM simulations are performed for each input setting. Thus, a total of 8640 FEM simulation results are generated for our experiments. Selected FEM output variables for our surrogate model are the final diameter and height of the preformed billet, such that and . In respect to the final diameter , we calculate the empiric mean by and aleatoric standard deviation by . The calculations are analogous with respect to . Thus, we obtain a dataset with 432 instances described by six input features and four output features. For our running example, input features are clutch pressure, rotation speed, initial billet diameter, initial billet height, initial billet temperature and aggregated manufacturing process uncertainties obtained from data, i.e., the aggregated output of the forging press GP . Output features are the mean of the final billet diameter, the mean of the final billet height, the aleatoric uncertainty of the final billet diameter and the aleatoric uncertainty of the final billet height.
The problem is defined as a 2D axisymmetric simulation task to utilize symmetries and make efficient use of computational resources. We utilize isotropic elasto-plastic Inconel 625 material behavior from literature. The Young’s modulus is temperature-dependent and the yield stress depends on plastic strain, strain-rate and temperature. We set contact properties to tangential behavior with isotropic directionality and a friction coefficient of 0.3 between the billet and upper and lower forging tool, which means that we assume lubricated hot forging conditions. The lower tool is encastred and the upper tool’s boundary conditions are set so that the vertical movement
is drawn from distribution
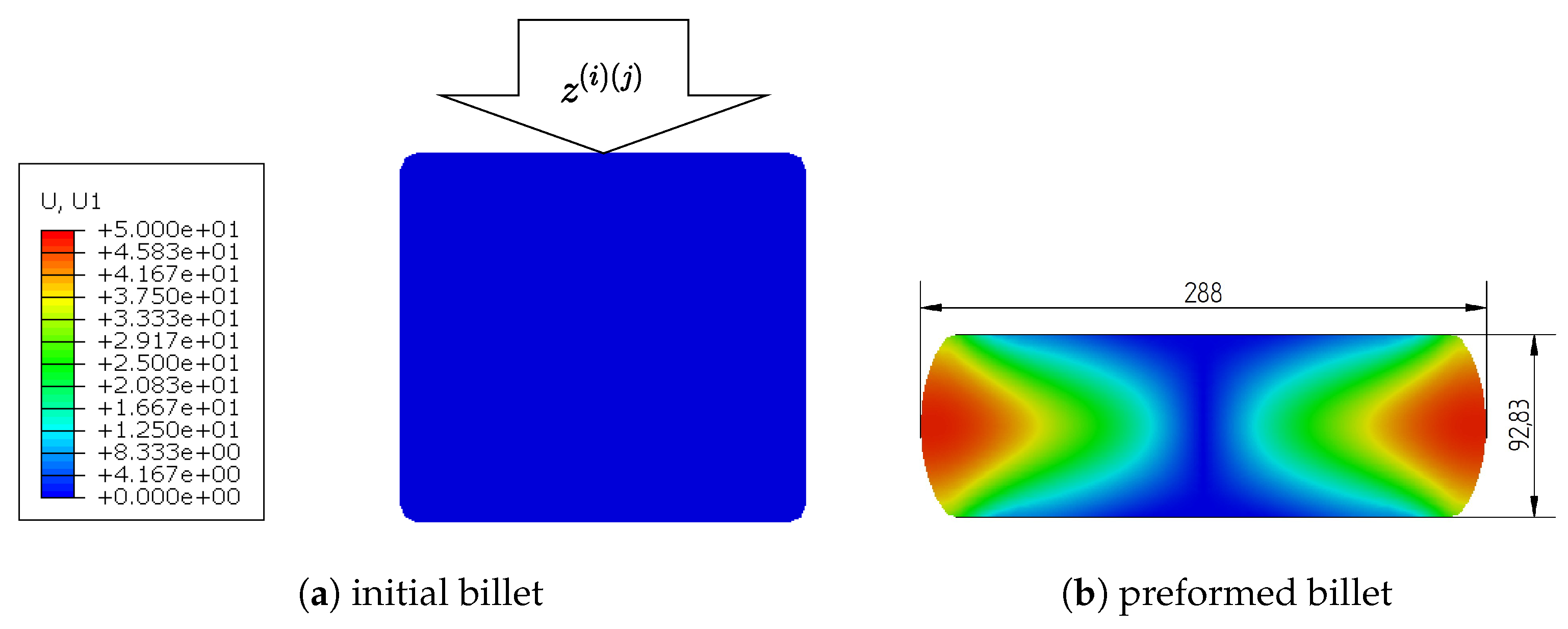
and there is no horizontal movement. An exemplary simulation definition can be seen in
Figure 8, where (a) shows the initial state of the billet loaded with a randomly drawn screwpress velocity profile
and (b) the end result of the simulation with selected FEM output variables
, i.e., the final diameter of 288 mm and the final height of 92.83 mm.
All billets are meshed with an approximate global element size of 7 mm, using 4-node bilinear axisymmetric quadrilateral elements with reduced integration and hourglass control. We obtain our FEM simulation results in the context of general static simulations. Details of the simulation steps are shown in
Table 4. Simulation control parameters that are not listed are left at default values.
6. Discussion
Evaluation of the individual GPs with 10-fold cross-validation shows promising R2-Scores (lowest: 0.8146, mean: 0.89355, highest: 0.9586), i.e., hyperparameters appear to be appropriate for further evaluations. Observation of generated manufacturing process uncertainties, i.e., shows a diverse data landscape, thus, we assume that further uncertainty propagation analysis is meaningful.
We observe the distributions obtained from uncertainty propagation analysis by calculating Pearson kurtosis and Fisher-Pearson coefficient of skewness (A Pearson kurtosis of and Fisher-Pearson coefficient of skewness of describe a normal distribution). Regarding kurtosis, results shows that distributions are near to Normal distributions, where the distribution of is slightly platykurtic (), i.e., it is less peaked than a Normal distribution and the distribution of is little leptokurtic (), i.e., the distribution is more peaked compared to a Normal distribution. In terms of skewness, the distribution of is more skewed compared to , however, both values are less than 0.5 so that approximate symmetry can be assumed.
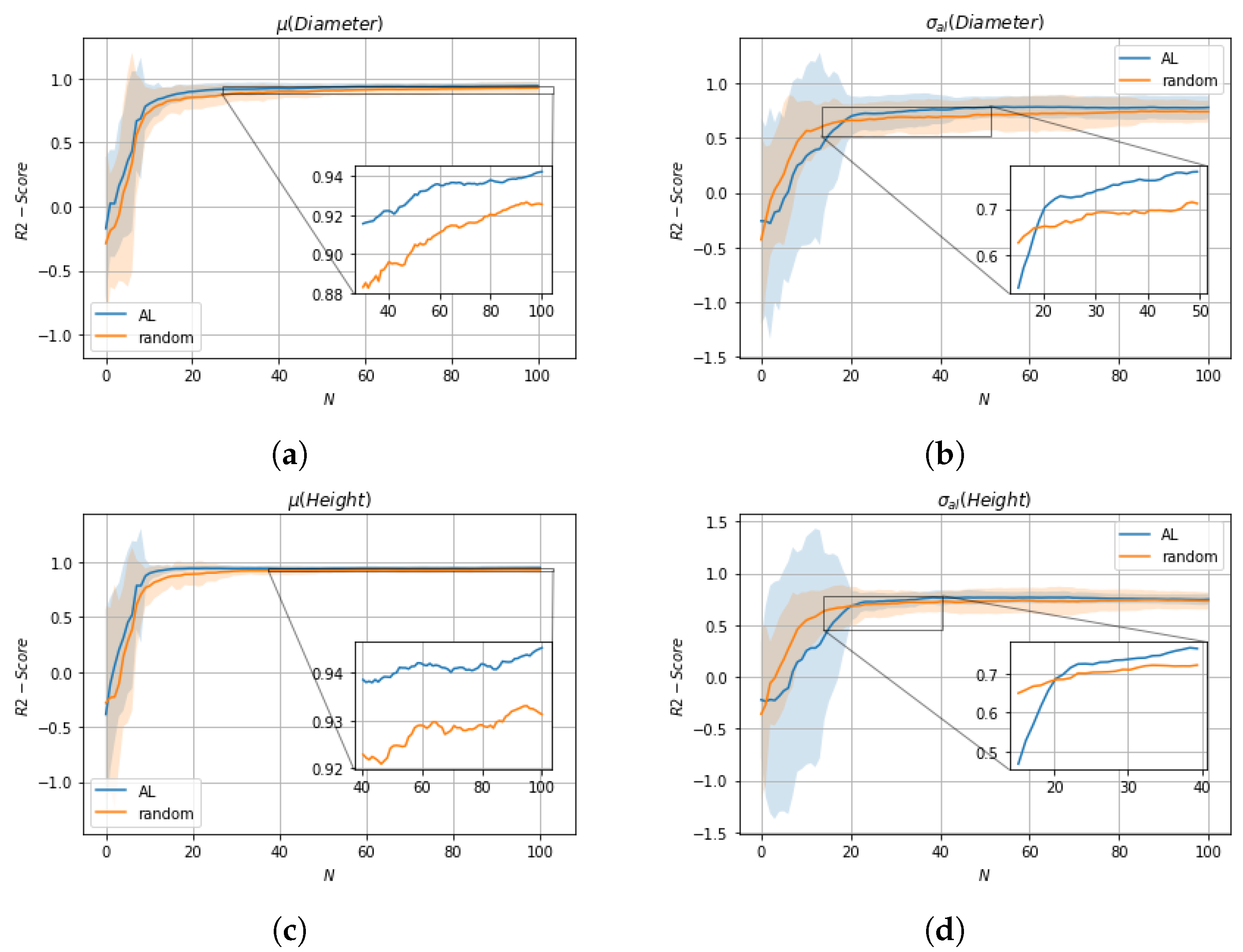
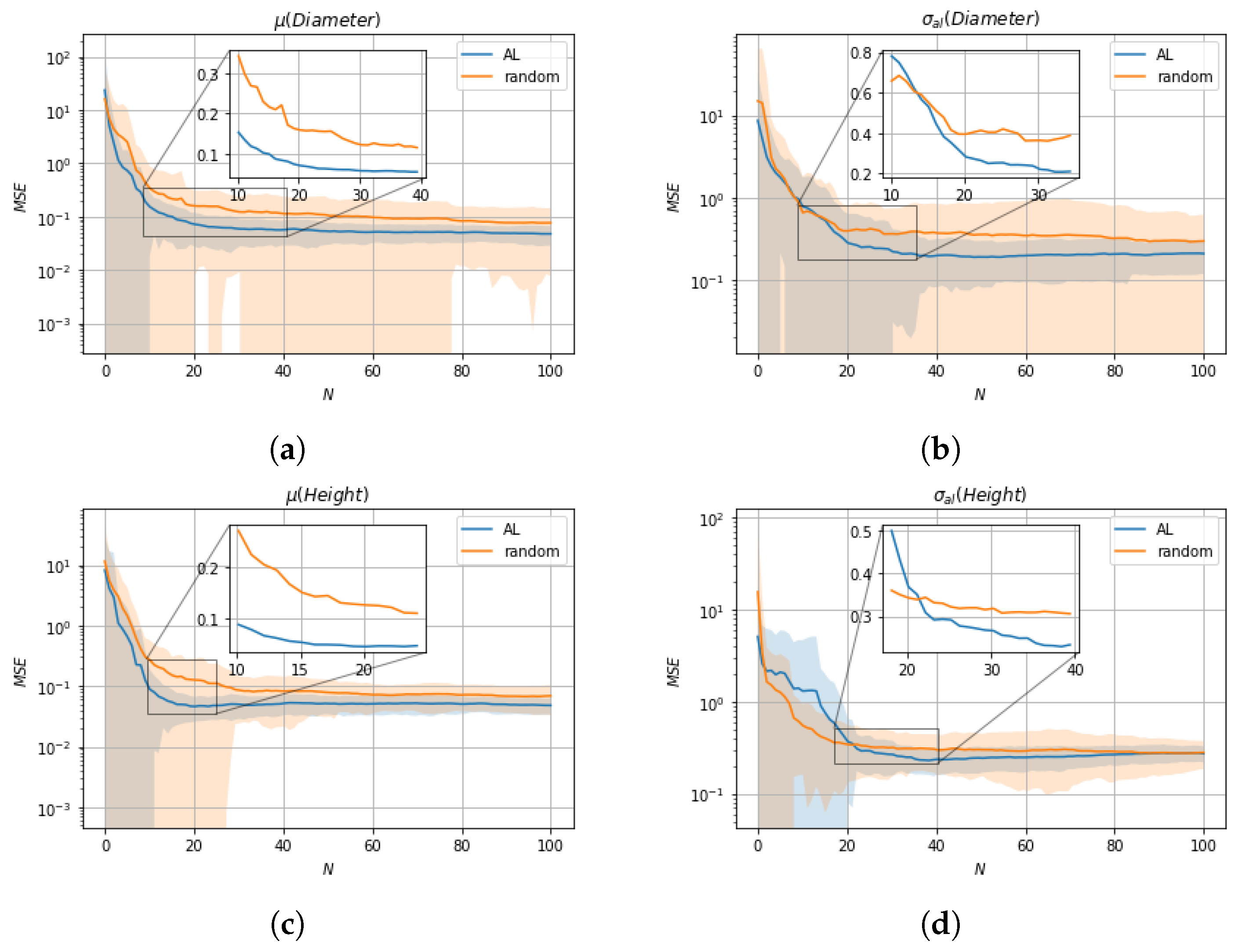
We evaluate the impact of data selection for model training using two metrics, R2-Score and MSE, with a 10-fold cross-validation comparing active learning with random sample selection. With respect to mean values , active learning shows overall an improvement compared to random sample selection. In terms of aleatoric uncertainties , random sample selection is superior to active learning up to the selection of about 20 samples, but after that active learning shows superior performance compared to random sample selection. The initially worse performance of active learning with respect to is due to a trade-off in the active learning cost function between and with the influence of dominating. A possible solution for this would be the introduction of appropriate tuning parameters that regulate the influence of the respective epistemic uncertainties and . Moreover, it should be noted that random sample selection shows only better performance at a stage where the tuning of parameters is far from complete, so the better performance is not applicable in practice.
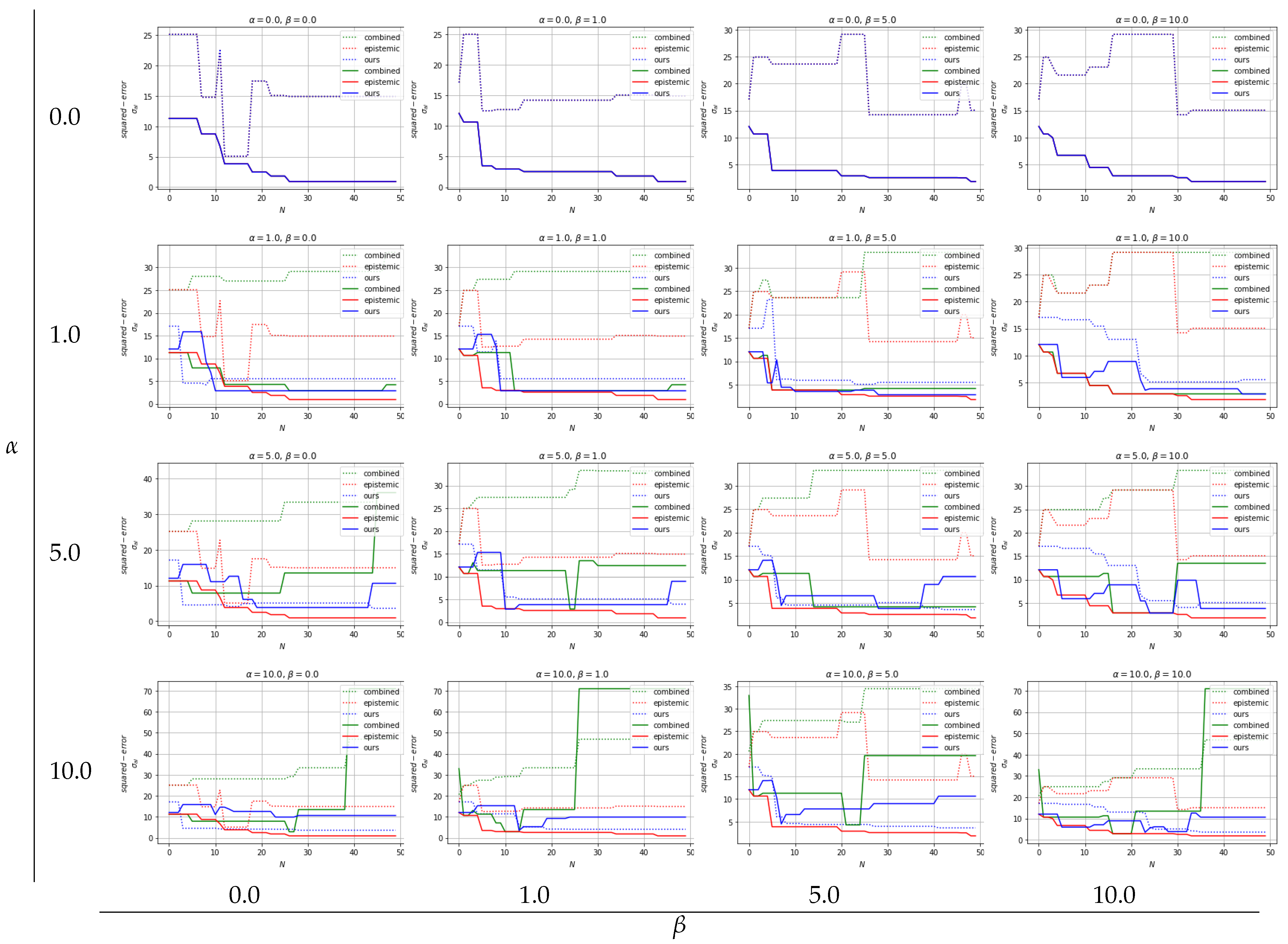
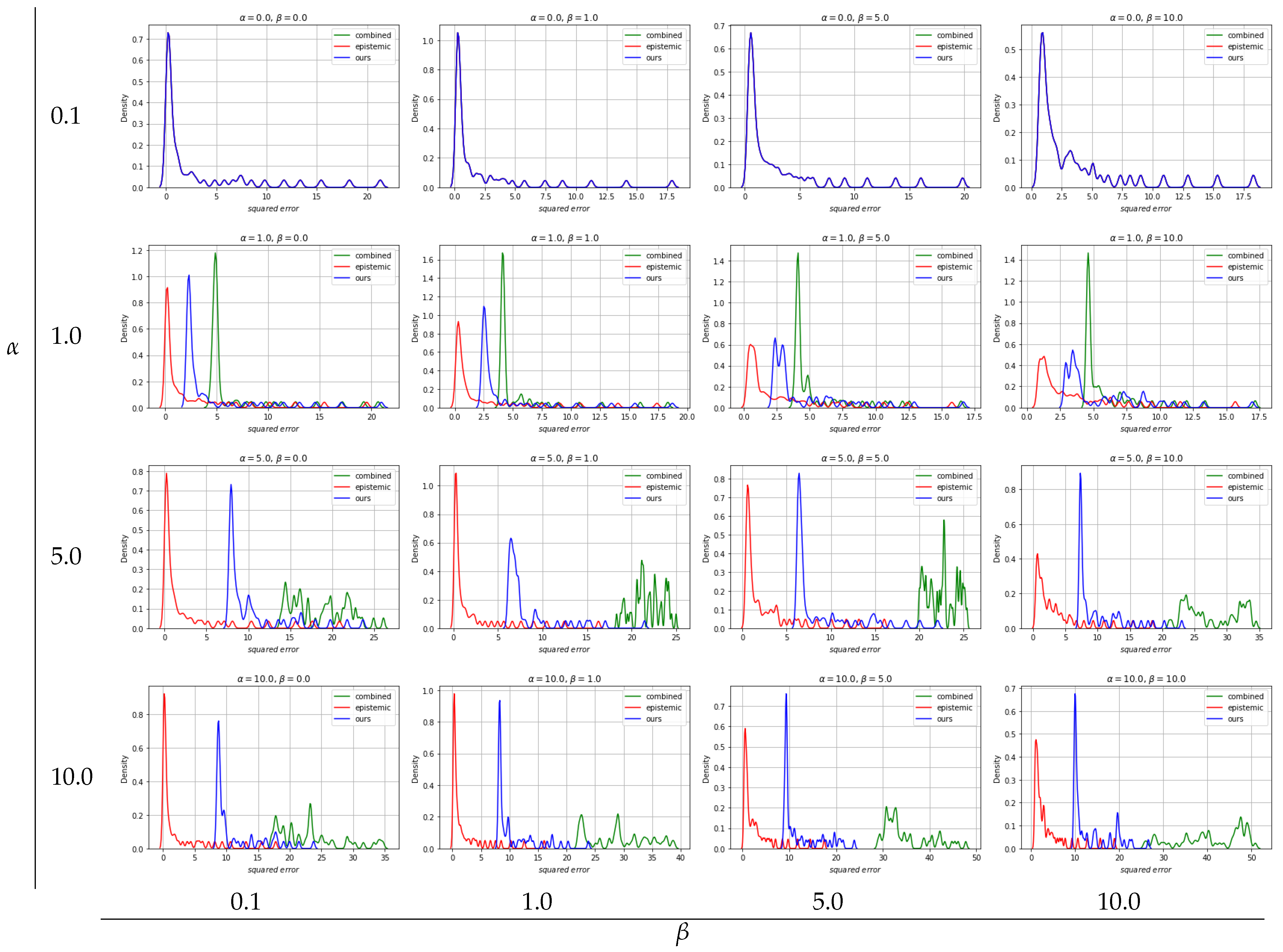
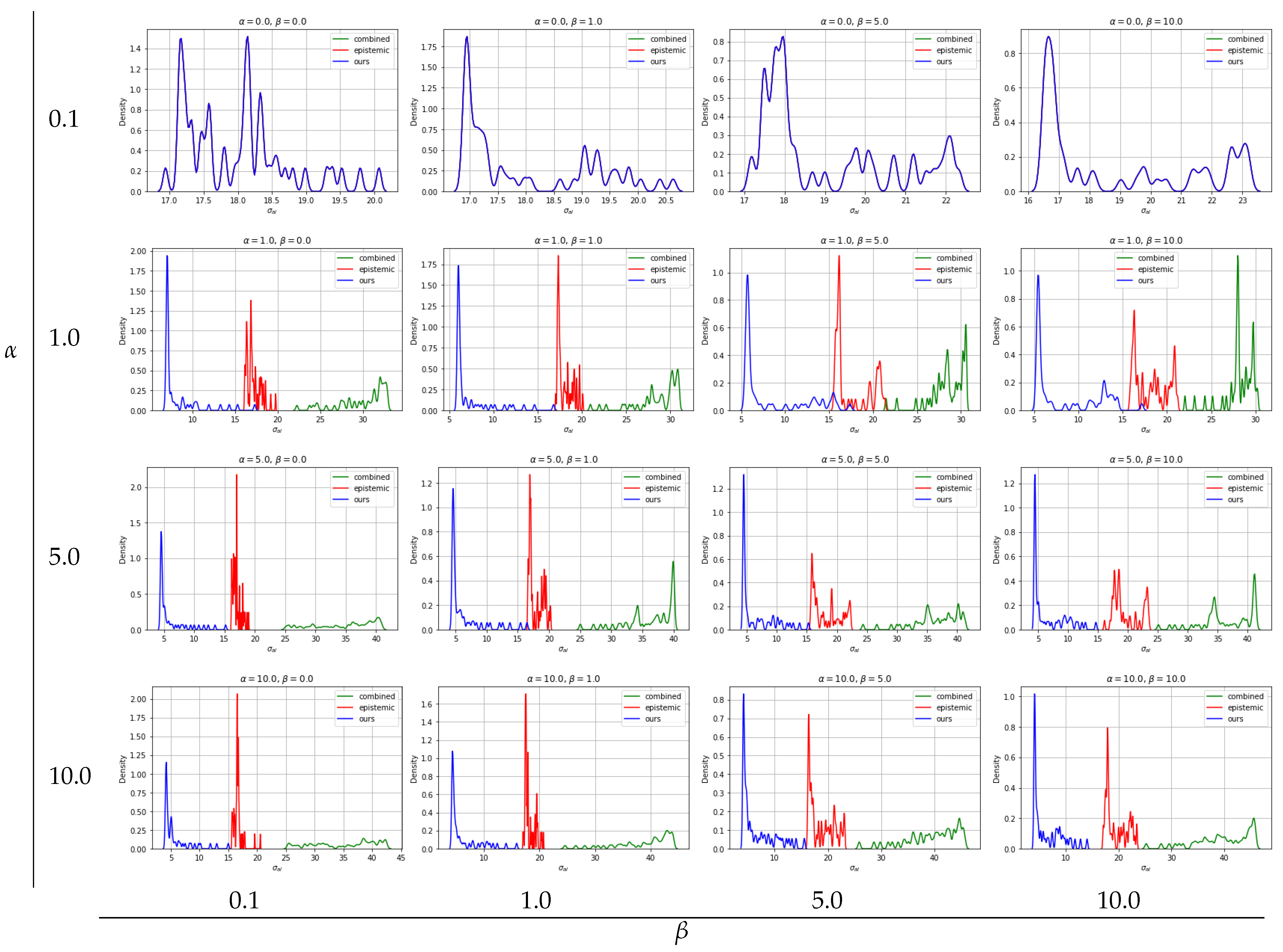
With regard to solving inverse problems, we compare our novel robust UCB based BO multi-objective optimization algorithm with two baselines: (1) combined: no distinction of uncertainties in UCB based BO and (2) epistemic: neglecting aleatoric uncertainty in UCB based BO. We show that over different values of tuning parameters and there are clear tendencies of the different approaches. By disabling the influence of aleatoric uncertainty (), all three approaches show the same results as expected: low squared errors and neglected aleatoric uncertainty. For all approaches, slight differences can be seen over different values while , regulating the exploration vs. exploitation trade-off.
Due to the fundamentals of the epistemic approach, there are no differences in the optimization result when
values are changed for constant
values, see
Figure 11. Differences in kernel density estimate plots over varying
values are from random target vector selection. Overall, the epistemic approach yields the best optimization results in terms of squared errors, see
Figure 11 and
Figure 12, however, as expected, aleatoric uncertainty is ignored and thus high, see
Figure 13. The combined approach, where aleatoric and epistemic uncertainties are simply added and handled as quasi-epistemic, shows the overall worst results. At low
values, the squared errors are acceptable, but the aleatoric uncertainty is high due to inappropriate handling of information, see
Figure 11,
Figure 12 and
Figure 13. To arrive at our approach, once aleatoric uncertainty is considered, i.e.,
results for the inverse problem show low squared errors and low aleatoric uncertainty which we recognize as robust results. Moreover, by increasing
one can see that our approach leads to results where lowering aleatoric uncertainty
is more preferred than lowering squared errors, see
Figure 11 and
. Kernel density estimate plots generated from 10-fold cross-validation results confirm those findings, where clear tendencies of optimization results in respect to tuning parameters
and
can be seen. While an approach considering only epistemic uncertainties delivers overall best results in respect to squared errors, aleatoric uncertainties are out of scope, thus, optimization results lead to less robust outcomes. An approach considering aleatoric and epistemic uncertainties combined by summing them up shows overall worst results and can not compete with the remaining. Our approach, where aleatoric and epistemic uncertainties are considered to deliver different information, depicts that overall good results are achieved with respect to squared errors while keeping aleatoric uncertainty low, thus robust solutions for solving multi-objective inverse problems are provided.
Moreover, our model is directly applicable in an industrial framework where the forging press characteristics are represented by measured sensor data of the aggregate (e.g., velocity over time, forging force over time, forging force over the forming path, etc.), which can be used in an appropriately designed FEM simulation for uncertainty propagation analysis and, moreover, for surrogate model training.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}