2. Methodological Issues
2.1. Eye-Tracking Technology Applied in VR
To establish the common ground in all video-based eye-tracking technology, whether VR or otherwise, the similarities in the hardware and software of most eye-trackers must first be examined.
The commonalities in the hardware include the type of technology used and the metrics for sampling rate, field of view, accuracy, and precision. Given the limited space of the interior of a VR headset, the eye-trackers used in VR employ tiny cameras that implement infrared PCCR, which is the most used eye-tracking technology today. The sampling rate, accuracy, and precision of all non-stationary eye-trackers, whether VR or mobile, is limited by the size, layout, and performance constraints of the hardware, resulting in worse parameters than stationary eye-trackers (eye-trackers used in VR sample at 75–120 Hz, at about 3–5 degrees of accuracy, whereas stationary eye-trackers are superior, sampling at, for example, 2000 Hz at 0.15 degrees of accuracy [
39]). Most VR headsets use an LED display behind an optical lens to cover a visual field of 100–110 degrees to accommodate most of the clearly perceived human vision; the range covered by eye-trackers used in VR has greater limits due to the optical limits of the system [
40].
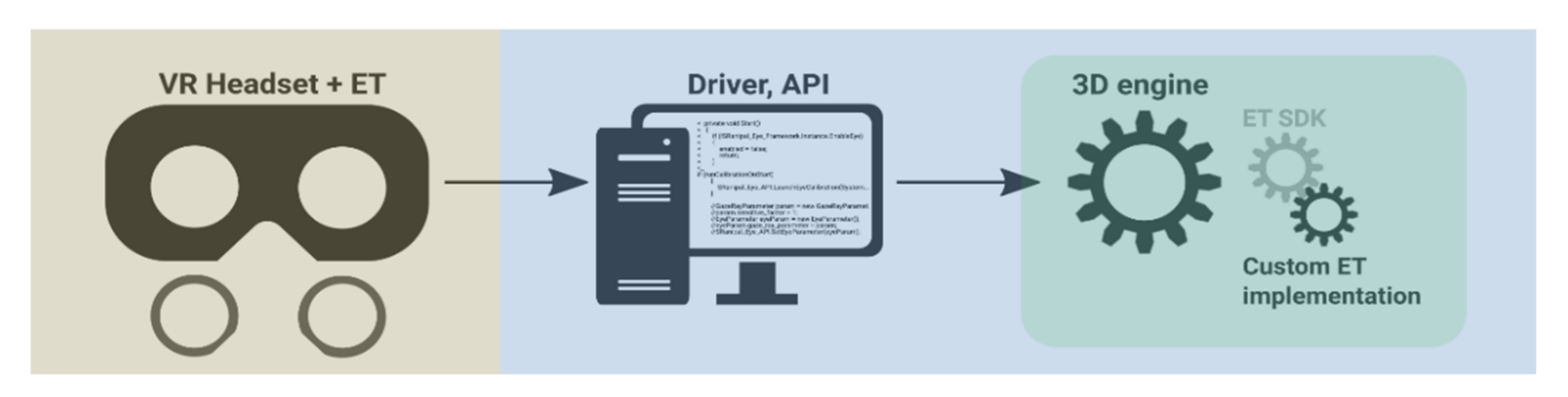
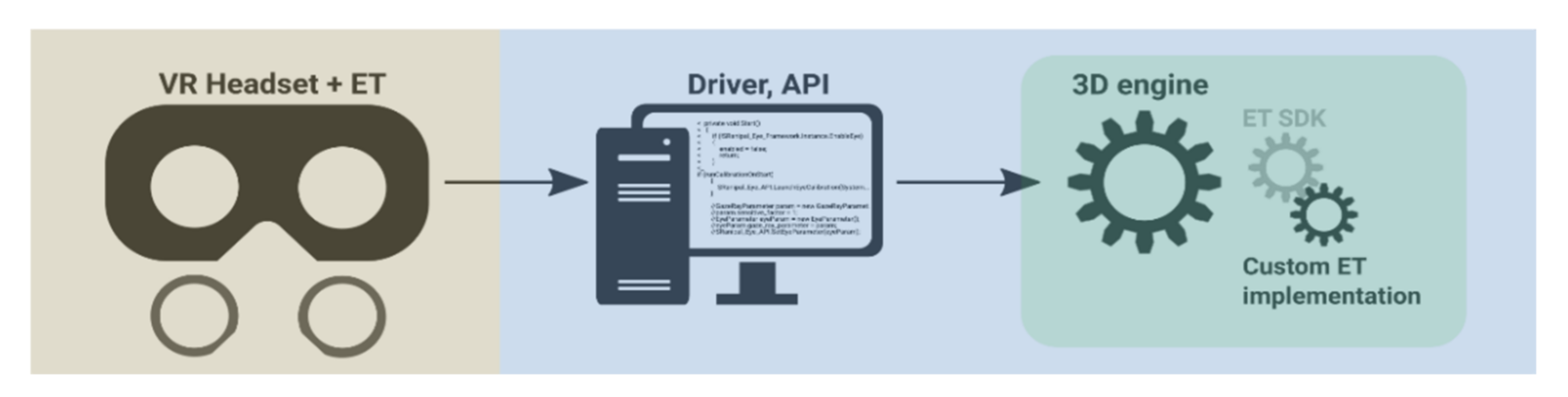
Eye-tracking software for VR (APIs, calibration procedures, and 3D engine extensions) is tailored to the virtual 3D world. The captured data contain two levels: the raw X/Y coordinate data, as captured through the eye-tracking cameras, and the transformed 3D data, as projected into the virtual world. Whether the raw data are accessible or correctible, and how it interfaces with third-party applications such as 3D engines, depends on the implementation of an eye-tracker API for VR or a 3D engine-specific software development kit (SDK) that draws functionality from the API. At the level of the 3D engine, it would be beneficial if the VR eye-tracking vendor provided an engine-specific SDK or a preconfigured extension (plugin) so that the API link between the eye-tracker and the engine would be well established, out of the box, with official support. This would allow the hardware-capable features to be utilized in the engine without the need for deep understanding of hardware and low-level programming to access the functionality. All Tobii XR eye-trackers (HTC Vive Pro Eye, Pico Neo 2/3 Eye, HP Reverb G2 Omnicept Edition) [
31] and enterprise solutions such as VRgineers [
41] and Varjo [
42] provide engine-specific plugins for eye-tracking in VR. Behavioral data inputs, such as eye-tracking gaze, fixations, dwell time, and object-to-object transitions, can thus be both logged and used as a means of interacting with the objects in a virtual world. Custom programming functionality in 3D engines can expand on the eye-tracker’s extensions and functionality. All this, as depicted in
Figure 1, provides a full picture of how an eye-tracking solution integrates with a 3D engine and a virtual world. The industry is even showing an inclination to develop standardized eye-tracking interfaces for VR [
31] and SDKs [
43].
2.2. Levels of Interpretation
Traditional 2D eye-tracking has two distinct levels of interpretation, one through eye-tracking coordinates (point of regard) and the other through defined areas of interest (AoI). As with eye-tracking in 2D, eye-tracking in 3D VR can observe coordinates in virtual 3D space (point of fixation (PoF)—a positional vector coordinate) and virtual 3D objects (as visually defined by 3D meshes). The informational value obtained from eye-tracking in 3D is similar to its 2D counterparts; although, differences exist because of the three-dimensionality of the virtual coordinates and the predefined surface area of the in-engine 3D meshes. Since the virtual 3D space is defined in exact mathematical coordinates, this allows for executing spatial algorithms on top of it.
A virtual 3D world is composed of virtual objects (3D objects and 3D meshes, depending on the terminology and technology of the 3D engine). The eye-trackable 3D objects have physics boundaries (collision geometry) attached to them. At a detailed interpretation level, the 3D gaze coordinate can be obtained when the user’s eye-tracking raycast hits the object collision geometry at a particular positional vector. At the simplified interpretation level, the information that a user is looking at the object, is aggregated.
The problem with 3D coordinate tracking is that the subsequent data filtering and analysis is demanding on the required implementation, algorithmization, and processing time. Similarly, the problem with 3D object tracking is loss in measurement accuracy and the inherent issues of object-based geometry, for example, the non-uniform sizes and scales of objects, their frequently illogical segmentation/separation, or their partial visibility in a scene.
Nevertheless, processing eye-tracking data from 3D VR at either the coordinate level or object level does not need to be antagonistic. One approach can complement the other, and hybrids can be implemented. This is discussed in the implementation section (e.g., fixation magnetism, distance-based object segmentation, and fixation algorithms).
2.3. The Complex World behind the Projection
The virtual world presented to a user through the VR headset display does not have any physical dimensionality. It is instead rendered onto the two-dimensional plane of a VR LED display. Depth perception of a virtual 3D world is maintained by simulating some of the visual cues present in the real world. Monocular visual cues that can be applied in 3D graphics include perspective, 3D lighting, and postprocessing filters for recomputing light occlusion and atmospheric perspective [
44]. At this level,
pseudo 3D level of depth perception is produced (e.g., as achieved by 3D graphics projected onto an LCD screen). By adding the binocular disparity visual cue, i.e., by shifting near object positions to the side for left/right display (as would be naturally perceived by the left/right eye in physical space),
real 3D depth perception is attained.
Regardless of whether eye-tracking is stationary, mobile, or VR, or whether the stimulus is presented in 2D, pseudo 3D, or real 3D, eye-tracking device will always internally capture eye coordinates as 2D X/Y coordinates of the normalized projection plane where the capture commences (point of regard, PoR). The VR headset display is one such projection plane, and it serves as a portal between the real and the virtual world:
Head movement is tracked by the VR headset (or a motion capture setup for whole body movement). Unless otherwise limited, its six degrees of freedom (6DoF) [
45] allows direct rotation (3DoF) and movement (3DoF) in real space. User kinetic movement is translated directly into the virtual space, altering the camera’s rotation and position.
Locomotion user interfaces allow translating movement into the virtual world—be it through abstraction, movement metaphors, or actual movement tracking. Up to six degrees of freedom are also possible, depending on the complexity and usability of the physical user interface (e.g., keyboard and mouse vs. a VR controller, treadmill, or other (experimental) devices [
46]). There is a trade-off between the complexity of a locomotion user interface and the quality of sensory input it offers (e.g., keyboard facilitates on/off movement along one axis at a constant pace—it is a simple interface, but the lack of bodily kinesthetic feedback makes it susceptible to motion sickness [
26]; a complex interface such as full-body motion capture allows for realistic, precise movement sensation—at a cost of setting up the interface, physical space demands, and significant purchasing costs). Locomotion user interfaces influence users’ perceived ease of movement and distance estimation [
47]; they can even facilitate new ways of working with digital content [
48,
49]. They may also influence viewing behavior—this, however, has not been addressed in any research to date.
Eye gaze coordinates are transformed into raycasts, which extend into the virtual world, i.e., by using the point of regard eye coordinate and camera position/rotation in the virtual world. As the ray is cast, it lands onto a spatial coordinate in the virtual world (point of fixation, PoF), provided something is in the ray’s path to land on (3D objects or surfaces).
In geometry and 3D engine terminology, a raycast is a beam with a positional vector origin and a directional vector angle [
50]. In eye-tracking in VR, the origin is the virtual camera’s position and rotation as aligned by real-world user movement or the locomotion user interface, and the directional vector is the eye-tracking coordinate angle relative to the camera’s position/rotation. The specificity of processing and evaluating eye-tracking in 3D VR is dependent on the applied device(s), algorithm(s), and virtual environment(s). The transition to a virtual world is an extra calculation that traditional 2D eye-trackers need not be concerned about.
The validity and feasibility of eye-tracking analysis in 3D VR therefore becomes complicated (a greater number of measured and intervening variables, and variable transition rules). This complexity has various degrees, however, and was first described by Lappi [
37]: while a stationary eye-tracker needs only to observe eye movements, such movements in VR may be occurring in addition to or counter to the user’s head or body movements (performed either directly, kinesthetically, or indirectly through a user interface), hand movements, user controller movements, interactions with other objects/users/entities in dynamic virtual scenes, and so on.
A stationary eye-tracker with a chinrest only tracks the user’s eyeballs, which move along two axes and have a limited angular range of rotation and can only be projected against a fixed observed plane. Mobile eye-trackers may have to account for changing surroundings while the user moves about. Beyond the physical dimension, if a subject is rendered in VR, the projection must be converted, for example, by translation of the virtual coordinates into seemingly physical ones. Some stationary VR experiences have limited or no degrees of freedom, for example, 360 video or driving simulators [
51]. Many VR devices, however, make full use of the mobility aspect to utilize the full potential of VR as a medium [
52]. Eye-tracking in VR scenarios is therefore interpretation-heavy. Below is a description of the interpretation complexity in scenes when considering two control variables:
Static camera, static scene. The VR user observes the virtual world through a stationary, immovable virtual camera with zero degrees of freedom, and the only registered physical movement is eye movement. The user’s eye movements have no dynamic or interactive function attached, effectively equating this interpretation level to that of traditional 2D eye-tracking with static stimuli and the user resting on a chinrest. This is the simplest eye-tracking interpretation level, as the point of regard is the only relevant variable. The point of fixation transition is unnecessary since all the virtual coordinates seen on the screen are the only coordinates there are. Even if the presented scene is a 3D visualization with varying depth, the point of regard data set will always be transformed to the same point of fixation data set, with 1:1 projection. The acquired data can therefore be reduced to point of regard or worked with as if the stimulus were a static 2D image.
Level of interpretation complexity: eye coordinates over time.
Static camera, dynamic scene. The user has no control over the virtual camera position or rotation, giving them no possibility to change the perspective from which the presented stimuli are seen. The experimental scene can, however, dynamically change in front of the user’s eyes. In 3D, this would involve a predefined animation or other actors (AI, or other users with dynamic movement enabled). In classic eye-tracking studies, this can be equated to presenting a video. The majority of experimental control is still retained, i.e., the camera’s rotation/position is shown through the virtual camera, but knowing which content is shown, and the order in which it is shown, depends on whether the dynamics are deterministic (e.g., predefined animation vs. another user with dynamic controls). Regardless, this type of scene must be evaluated frame-by-frame. In these types of continuous scene, the positions of objects and their AoI coordinates change in time.
Level of interpretation complexity: eye coordinates over time with scene movement.
Dynamic camera, static scene. All interaction occurring in this type of scene is movement interaction [
52], i.e., the user manipulates the virtual camera. The degree of complexity in recording and evaluating such movement increases significantly since the researcher abdicates control of the camera to the user, and thereby loses control of what is shown to the user, when it is shown, the order in which it is shown, from what angle and distance it is shown, and the overall scene composition. The user’s ability to navigate through the virtual scene depends on the physical controller and how the physical controller translates into the virtual scene (in-engine character controller [
53]), and how many degrees of freedom such a controller provides, i.e., whether the camera can be rotated and moved and the extent of this movement. Even with simple camera dynamics, the three-dimensionality of a scene, i.e., the virtual space coordinates at and from which the user looks, and the distance between the user camera and the
point of regard, must be considered for eye-tracking evaluation purposes. Free movement of the camera may cause 3D objects to occlude other objects, creating difficulties in interpretation [
54]. Given the rather low precision of VR eye-trackers, measurement artifacts can originate at the border of multiple neighboring objects. The depth irregularity of a 3D scene and the potential measurement error is also projected irregularly onto objects in the 3D scene (objects at greater/varying distances accumulate more absolute-distance measurement errors than near objects of similar size since the eye-tracking precision error is based on angles, and the absolute distances between angle-based raycasts increase with depth). This level of eye-tracking complexity in 3D VR has no parallel in traditional eye-tracking in 2D.
Level of interpretation complexity: eye movements over time with user movement and scene movement (synchronously).
Dynamic camera, dynamic scene. All the interpretation issues mentioned above apply to this classification. In this case, other actors besides the user can also manipulate the projection and composition of the scene. At the user interaction level, these may be other (concurrent) user interfaces, controllers, or interaction metaphors, which allow selection, manipulation, systemic control, or symbolic input. Scene manipulation may occur at the level of individual objects, groups of objects [
52], or the entire virtual scene [
55]. At the execution level, events happening in the scene may be user-driven (interaction) or autonomous (AI or script-based), with or without feedback (visible, audible, or unregistrable), with or without affordances [
56], (communicating or not communicating to the user that events or objects are potentially (inter)actible). Other users (multiplayer), AI, or interactive scripts may also instill changes within the scene. All these factors raise a new set of computational and visualization questions in the interpretation and visualization of a series of
point of regard coordinates that target moving objects (especially when the user is concurrently moving in a different direction, or using a different controller).
Level of interpretation complexity: eye movements over time with user movement and scene movement (asynchronously or a multitude of concurrent movements).
The examples as described above of a static, fixed user and a dynamic, moving user who observes a complex virtual scene, are depicted below in
Figure 2, sourced from Lappi [
37]. These examples do not consider the dynamics of the stimulus, regardless of whether it is a flat 2D video or an interactive multi-actor 3D scene. The movement diagram depicted by Lappi does not include other devices (e.g., motion controllers) with their own fields of reference.
Beyond research interests and theoretical approaches, the potential and limitations of eye-tracking in VR are also applicable in practical implementation, i.e., in algorithms and the optimization, evaluation, and visualization of VR eye-tracking data in virtual 3D scenarios. Previous studies and implementations have considered this only to an extent. The present paper regards implementation as its principal contribution. A discussion and demonstration are given in the following sections.
2.4. The State of Other Implementations
Other studies and implementations of eye-tracking in VR should also be considered to determine their links with the theory described above, and whether they are able to solve the aforementioned issues. Unfortunately, only a few solutions exist for comparison, and we are reluctant to apply these existing implementations because they interpret eye-tracking data at a rather shallow level or in specific, easy-to-interpret scenarios, only.
A 2018 study [
57] employs eye-tracking in VR but reduces all evaluated eye-tracking data to those observed on a flat orthogonal wall in front of a user (effectively staying in the realm of traditional 2D eye-tracking). A 2019 study [
37] goes further by visualizing the raycastHit.hit coordinate returned by a basic projection function in the Unity engine API. This is the 3D coordinate where the raycast hits an object collision geometry. The authors visualized this with a sphere, and then colored the sphere according to the distance from which it was gazed upon (the raycastHit.distance numeric value according to the Unity API). The remainder of the article discussed working with this basic eye-tracking data using external statistics, visualization software, and user movement parameters. The in-engine eye-tracking data itself were not processed or corrected into derived variables, and therefore the specifics of eye-tracking methodology in VR, such as data filtering, scene complexity, or fixation processing, remained unaddressed.
The Tobii XR SDK, which is an extension of the SRanipal API used by some VR eye-trackers, implements some eye-tracking logging and visualization functionality [
58], such as standard object-level data logging metrics (first dwell time, dwell time, and dwell count) and heatmap-based visualization projected onto supported objects using a dynamic graphics shader [
59] to draw the gaze heatmap as an additive texture over already fixated objects/textures. While the solution behind this implementation does provide some value and ingenuity, it is only applicable to qualitative scenes with a low complexity in the 3D geometric variance, such as gazing at a static car object situated in the simple scene of a showroom. If eye-tracking is performed in an environment where, for example, a vast, dynamic cityscape with varying distances and overlapping vistas is present, using a heatmap-based eye-tracking visualization would not be practical or acceptable. Similar issues would arise when qualitative evaluation of the acquired eye-tracking data is intended.
The Vizard virtual reality software extension for researchers from WorldViz, SightLab VR [
60] offers features similar to the aforementioned solutions (gaze intersections, fixations, fixations per object, average time of fixation, etc.), which are automatically logged to a text file. It also features a record function that lets the user replay certain sessions with graphical overlays of the gaze paths, fixations, fixation spheres, heatmaps, or intersect points. Vizard and SightLab VR, however, are developed as proprietary software, and hence the functions in the free version of Vizard are strictly limited, or in case of the SightLab VR, must be purchased.
The aim of the present paper is therefore to develop algorithms for eye-tracking in VR that facilitate data logging, filtering, correction, analysis, and visualization. This solution is to function with scenarios of high complexity, providing better methods of managing eye-tracking data in complex scenes, all while respecting the methodology.
3. Implementation
To give some context to VR eye-tracking algorithms that aid in dealing with the interpretative difficulties of virtual 3D environments, their unifying technological foundations should first be explained. This section therefore describes the technology we worked with, the software architecture and design of the proposed implementation, the process of obtaining and working with eye-tracking data, and the desired 3D scene setup for use in an eye-tracking experiment. Based on this foundation, the algorithms that can eliminate some of the issues with 3D VR eye-tracking data are described and implemented. Together with visualizations of the processed data, the solution is able to offer clearer interpretative value.
Partial software implementation of the VR eye-tracking solutions mentioned throughout this section are available at the following GitHub repository:
https://github.com/VGE-lab-MUNI/vr-et, accessed on 16 January 2022. This is a demonstration implementation for the Unity engine version 2019 LTS and newer, using the HTC Vive Pro Eye VR headset and SRanipal API (the technology is explained in
Section 3.1).
3.1. The Technology That Is Available and the Technology That Is Used
The technology applied in eye-tracking and VR forms a layered architecture consisting of VR and eye-tracking hardware and low-level drivers (firmware) to facilitate the hardware’s basic functionality. This translates into an operating system level driver and API used in a 3D engine. Additional work over the API can be tailored into a premade 3D engine extension to cut implementation costs for the users of the engine. In the end, a set of eye-tracking-related in-engine functions are made available for use.
Due to the current market fragmentation (many vendors of VR headsets, many third party vendors of VR eye-trackers, and multiple 3D engines), the future will likely include a standard for extended/virtual/mixed/augmented reality devices, i.e., multiple APIs under a single SDK [
43] that interconnects the hardware with 3D engines and other applications. Standardization of eye-tracking for VR is also expected [
61].
The inter-compatibility of devices under a single SDK is significant because it eliminates researcher dependence on a single hardware vendor or device. This is relevant, as hardware dependence could become an issue in ongoing research. For example, in long-term research design, the original vendor-centric hardware could become obsolete or unusable over time (lack of support, feature-breaking update, or hardware error). API/SDK standardization also enables designing and programming of eye-tracking evaluation scripts in a manner that allows their re-use, either immediately or with minor tweaks only, with different VR eye-trackers (within the constraints of the programming language of the selected 3D engine).
The present paper demonstrates an implementation and interpretation of eye-tracking for VR in a virtual indoor evacuation behavior experiment (to observe user decision-making and navigation strategies based on locomotion and eye-tracking). The experiment employed an HTC Vive Pro Eye headset with an integrated eye-tracker (Tobii). VR and eye-tracking functionality was enabled in the engine with the SteamVR application (as required for all HTC or Valve headsets) and applied with the SRanipal API for Tobii eye-trackers [
62]. Upon importing the SRanipal API into Unity, the 3D engine of our choice, basic eye-tracking functionality, such as positional tracking and a calibration procedure, was available out of the box. The remainder was implemented using algorithms of our own design.
The currently most used 3D engines are Unreal engine [
63] and Unity [
64]. We selected Unity for the experiment. The criteria to determine the suitability of an engine to one’s (experimental) needs include the programming language and the range of functionality of the provided programming API, the customizability, scalability and extensibility of the engine and its scene editor, available extensions, supported 3D formats and available 3D model repositories, platform compatibility, and graphics fidelity. In other words, a 3D engine is a middleware with various functionalities and quality of life additions, and the end-product software (whether a research application or otherwise) should make the best use of the 3D engine’s features to reduce the potential implementation costs (man-hours, budget, workflows, or technical knowledge). Unity provides a C# programming language API, along with its own repository,
Asset Store (to obtain editor extensions and 3D models). Comprehensive documentation is available, and it has the support of a strong community. However, the level of its graphics fidelity is lacking, in direct contrast with Unreal engine, which is written in C++, has a less widespread community, yet state-of-the-art graphics. It is noteworthy that Unreal engine has been driving advances in the 3D industry by providing feature additions and improvements such as a photogrammetric 3D object library [
65], virtualized geometry [
66], and a visual scripting language [
67]. As such, the engine is well-established for excellence in the future.
Although we used Unity throughout the implementation phase of our paper, the examples are described in a manner so that they can be applied or implemented in other 3D engines.
3.2. The Program Architecture
The core of the proposed solution, as implemented partially in the Unity engine and partially by applying external scripts and applications (data log file processing and statistical analysis), is straightforward and in accordance with the intended program architecture. Most of the provided programming language classes are instantiated in engine run-time either as single instances (singletons) or script components attached to 3D objects existing in the virtual world. This is acceptable, since only one eye-tracking raycaster script, one data logger script, one data processing script, one data visualization script, etc., are required at a time. This also enables extensibility and interchangeability in the provided algorithms, and if the need arises, their reimplementation in other 3D engines.
The complexity of the implementation is evident from the eye-tracking algorithms. These must be optimized for efficiency, i.e., reasonable processing time and memory allocation. This applies especially to algorithms executed in real time, i.e., with a severely limited processing budget (a few milliseconds). Each algorithm must also follow the eye-tracking methodology and apply workarounds to its (and the engine’s) limitations.
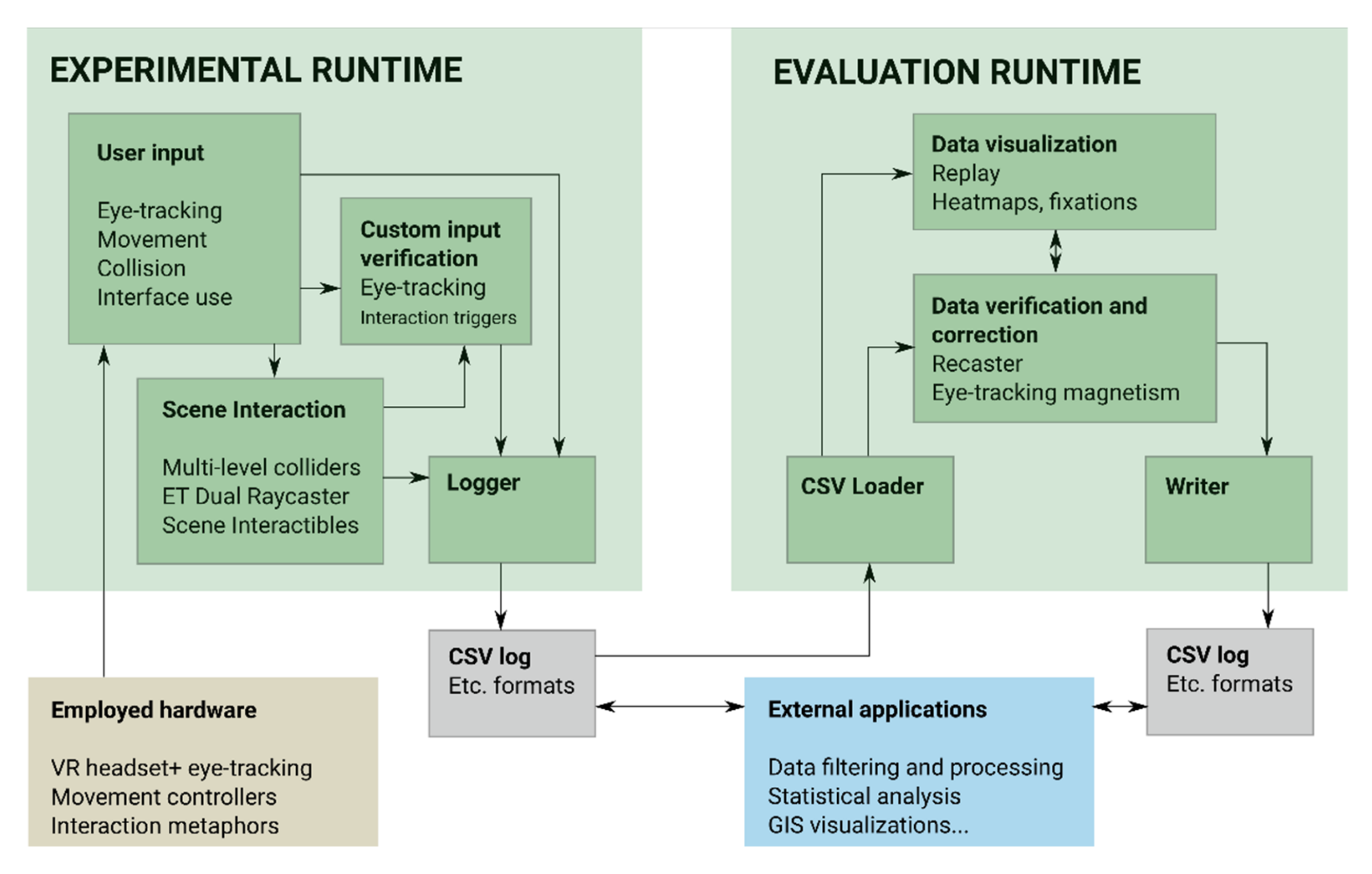
Figure 3 illustrates the proposed program logic:
experimental runtime and
evaluation runtime. The program architecture of the proposed solution follows this logic because the two runtimes frequently apply algorithms that are oftentimes mutually exclusive.
Experimental runtime should be included in any experimental scenario purposed for data acquisition. The scenario should contain fully realized visuals in the virtual scene, a user controller logic allowing users to move around the environment or interact with their surroundings as intended, and a data logger script that produces the desired data outputs. The user experience here is critical: the user should perceive the experimental scenario as it was intended. Scene interactivity scripts and data logging should therefore be performed in the background, without disrupting the flow of the experience.
Evaluation runtime is an ex-post set of tools for researchers: i.e., for processing, visualizing, and verifying the movement, interaction, and eye-tracking data produced by the user. The runtime still contains the virtual experimental scenario (allowing the researchers to move through it), but data logging or user experience is not the intent. The user behavior data produced in experimental runtime are then loaded by the evaluation runtime for visualization or processing into aggregated values (then visualized or sent for statistical analysis). In addition, algorithms that are either inefficient for implementation in the experimental phase, too visually intrusive, non-relevant, or experiment-tampering, are applied and used here. These include eye-tracking fixation calculations in 3D space, eye-tracking correction algorithms, visualizations and projections of user behavior, visualization filtration, and user behavior replays.
3.3. Levels of Working with Eye-Tracking Data
Eye-tracking data can be acquired and reprocessed (recomputed and aggregated). This can be performed either non-destructively, by retaining the full information provided by the eye-tracker hardware, or destructively, by reducing the information resolution. This relies on obtaining data from the eye-tracking hardware, the ability to access the data through the eye-tracking API, and the in-engine implementation and virtual scene definition (explained in the following subsections).
What is the minimum required level of distinction in the acquired data for it to be fully useful for evaluation? That depends on the degrees of freedom of the provided VR hardware (the headset and controllers, if any). Generally, it requires:
Eye-tracking calibration data (success/failure, or more detailed accuracy value);
Timestamp for each log entry (time, up to milliseconds);
User coordinates (positional Vector3 in the virtual world);
User camera rotation (rotational Vector3 in the virtual world);
Eye-tracking rotation relative to the user camera rotation or the point of fixation (Vector3).
This could be considered the bare minimum set of variables to be acquired during experimental runtime. Other derived variables may also be obtained. The question is whether it is better to acquire the derived variables during runtime (for convenience) or to recompute them later, outside experimental runtime (to conserve computational power during the runtime). At a minimum, these derived variables include:
Eye-tracking rotation relative to the user camera rotation and point of fixation—both;
Gazed 3D object name (object.name value);
Gaze distance from the user camera to the point of fixation (in meters);
Data loss metric, i.e., a check for missing eye inputs;
Fixation metric, i.e., a check for whether eye-tracking fixation is occurring, based on the eye-tracker movement velocity and its near-time history, all relative to camera movement;
Other potential physiological measurements of the eyes, if supported by the API (e.g., pupil dilation size or measurement accuracy);
Other potential derived variables.
Beyond eye-tracking, experimental runtime can also process other algorithms. To measure user behavior, other logs can be produced, such as user movement logs, interface usage logs, interaction logs, etc. Such interaction logs (event logs) are important, as their execution (based on a temporal event, spatial event, etc.) allows segmentation of the eye-tracking data. An event log is a demarcation that states that from this event here until another event there, an experimental phase occurs, and, therefore, this eye-tracking data section is suitable for further extraction and processing.
3.4. Setting Up the 3D Environment for Eye-Tracking
Depending on the hardware, software, visual art direction/stylization, and intended scene use, various types of scenes can originate from a number of graphics pipelines and workflows [
68]. A graphics pipeline takes into consideration the available rendering technology, for example, the rendering library, 3D modeling software, external sources like photogrammetry, AI-assisted pattern generation, and 3D engine scripting extensions. A graphics workflow is a set of agreed rules and best practices of working with the 3D sources and technologies in the context of a specific project, incorporating the 3D content into a scene in a (semi) streamlined fashion. Namely, a scene can be generated fully from the author’s imagination, while the opposite approach is the generation of a virtual scene strictly based on existing geometry (e.g., a replica of an existing real environment). An example of an approach situated between these two is the use of pre-generated 3D objects acquired from real geometry to produce layouts of new spatial compositions. Given the possibilities in graphics shaders and graphics post-processing [
69], it is possible to visualize a scene in various styles, for example, realistic, semi-realistic, surrealistic, simplistic, and cartoonish. Depending on the artistic or research intentions of the creator, all these approaches and stylizations have some merit.
For the present paper, we created a digital substitute of an existing building based on its floor plan. The scene was then digitized into a 3D standard used in the construction industry, followed by porting into a 3D engine. The scene was originally created to serve as a digital copy of a real environment with the intent that an experiment could be run simultaneously in VR/real counterparts.
The virtual scene was created based on BIM (Building Information Modeling) documentation presented in the IFC data format. BIM is a commonly used digital representation of the physical and functional characteristics of a building’s entire life cycle, with a focus on large-scale details that are relevant in architecture, civil engineering, construction, and project management [
70,
71]. At the level of implementation, BIM is a container for five-dimensional data, which describes space, material type, and building changes through time. For 3D engine use, the format is excessive and requires simplification.
Because we initiated the conversion process from BIM to the Unity engine, the building’s model was converted from the IFC format to the Unity compatible DAE format using the Tridify Convert service [
72]. The Unity editor was extended with the Tridify BIM Tools extension [
73], which allowed conversion of the DAE data into standard 3D objects native to the Unity ecosystem. However, the imported 3D objects of the building did not satisfy the requirements for graphics fidelity, model organization, and model optimization. Many more manual optimizations were required before the 3D scene was usable in the subsequent eye-tracking experiment.
To objectively recreate the environment in high fidelity, we visited the physical site and acquired reference photos, textures and a 360° spherical video for modeling and texturing the building’s environment (a four-story interior with an exterior entry) accordingly. We focused on capturing the physical and visual characteristics (e.g., approximate dimensions, shapes, materials, and colors) and the overall layout of indoor objects so that we could suitably recreate them. The overall physical dimensions (without the textures and optimizations) had already been incorporated in the imported BIM data. Small, decorative objects not included in the BIM data (e.g., furniture and indoor plants) were created from scratch. The general steps in producing a realistic visualization (from establishing dimensions, to detailing and texturing geometry, to lighting) is depicted in
Figure 4.
The imported BIM objects required extensive rework and optimization. The hierarchical structure and naming convention of the individual floor objects and construction elements were in disarray after importing, and required rearrangement into a more orderly, logical structure in which objects were grouped according to their affiliation to a certain floor and object type. Not only did this aid in working with the structures of the virtual environment in the Unity editor, it also assisted in the subsequent eye-tracking evaluation (i.e., having unique, structured object names as AoIs that could later be interpreted according to the acquired eye-tracking gaze log). For easier interpretation, the interior space was also partitioned into logical spatial polygons (as shown in
Figure 5). An object naming convention (e.g.,
4A_Plant_3) thus developed; the example mentioned, representing the third small plant object contained in the “A” spatial polygon on the fourth floor.
Many of the pre-existing objects and construction elements imported from the BIM model contained erroneous or somewhat complex geometry (consisting of too many polygons or individual parts). These had to be remodeled since they would cause performance issues in real-time 3D rendering (
Figure 6). Other objects that were redundant in the final solution were discarded. Remodeling of unsuitable objects was performed either directly in Unity, using the ProBuilder extension [
74] or externally, using the Blender modeling software [
75]. ProBuilder’s integration with the Unity engine was useful in remodeling the building’s construction elements, whereas Blender was superior in maintaining good practices in creating 3D model topology (i.e., detailed objects). Some 3D models were created with two levels of detail (LoD) [
76] to reduce the rendering load on the GPU. The result was a reasonable polycount (i.e., the total number of triangles present in the user viewport of the scene at any one time), which ensured stable performance with no visual frame drops (given the performance of the GPU). Frame drops would adversely affect the user’s overall perception of the scene. A high level of in-scene object detail (i.e., high polycount) also reaches a point of diminishing return (there is a significant difference in visual fidelity in observing a 3D model of a detailed object composed of a hundred polygons versus the same object composed of a thousand polygons; the visual difference between a thousand polygons and ten thousand polygons is nowhere as prominent, yet the increased rendering demands are much more significant).
Regarding the suitability of the final virtual scene for eye-tracking, the important components are not the models and 3D meshes themselves, but rather their physical collision (interaction) with the user’s gaze. These physical collisions between objects are mediated by colliders, which are invisible, simplified representations of the actual 3D models. Correct definition of such colliders is important for two reasons: (i) to register the user’s eye-tracking gaze (since colliders are the 3D equivalents of eye-tracking AoIs); (ii) to block the user from walking through objects that were not intended to be walked through (e.g., walls or furniture). Inspecting and testing the 3D scene at this point in development is crucial, because we want to ensure the virtual 3D scene retains the features of a controlled experiment with no unexpected issues. We check whether eye-tracking registers object colliders as intended, and that users can only move around within the bounds of a defined area while experiencing no walk-through glitches, fall-through glitches, or other, incorrect 3D geometry-related visual/interaction glitches (gaps or holes in 3D object models, flickering textures, objects defying reality by hanging in space or being unnaturally crammed together, etc.).
Implementing custom scripts into a virtual 3D scene (to provide user interactivity with objects and their surroundings, facilitate events, visuals, or animations, etc., between interactable actors in a scene) has its own challenges. While this paper focuses mainly on scripts related to eye-tracking, some comments about scripting in general should be offered.
Any 3D engine should have an analytics tool for logging and reporting the performance of a 3D scene, i.e., for both visual rendering and script execution. A badly written script that slows down the entire scene can therefore be discovered. In the case of Unity, analytics is provided through the Unity Profiler [
77]. There are two kinds of scripts according to their execution time: on-event or loop-based. An on-event script is generally not a problem since the script is executed only once or sporadically (e.g., upon user-object collision). A loop-based script is executed frequently, up to once per every rendered frame. A heavy, poorly programmed script such as this can degrade the performance of the entire application. General script optimization recommendations [
77] suggest (re)implementing as many scripts into the on-event category as possible and refraining from using execution-time heavy functions, such as hard drive read/write operations. While some scripts are execution-heavy by design (e.g., continuous user eye-tracking and other activity logging), there are still good and bad ways of implementing them. This is discussed in the next section. The overall performance budget of real-time rendering is always limited: if VR scene visualization and eye-tracking data renders and processes on a common VR device at 90 frames per second, it means we have a real time budget of 11 ms for each frame (1000 ms/90 = 11 ms). The scene geometry rendering and script processing must be performed below this time budget to ensure a smooth, continuous experience and valid data logging.
Because visuals, scripting implementations, and analytics are all combined, a standardized and automated performance test can verify the performance targets of the scene (as in software integration testing). To test the performance demands of a 3D scene, a user camera can be animated to fly through the scene. When the frame rate is logged during the fly-through, weak areas in the scene with frame rate drops can be discovered. The weak points can then be fixed by adjusting the 3D model polycount and then verified using the same camera fly-through. Standardized performance testing is achieved in this manner.
3.5. Data Acquisition and Related Algorithms
These implementations occur in experimental runtime and involve the capture of mainly raw eye-tracking data. While corrective eye-tracking measures can be employed (described in the following sections), it is economical to acquire the best possible measurements immediately from the experiment as opposed to correcting them later, provided the measurements can be corrected at that point.
An in-engine eye-tracking data acquisition script must execute continuously, producing a stream of dozens of entries per second. The frame rate for logging eye-tracking can be set according to either the VR headset display refresh rate or the sampling rate of the eye-tracker’s hardware. Logging eye-tracking in VR with a sampling rate that differs from the VR display refresh rate may need to be handled separately. In Unity, this is solved by the
update and
fixedUpdate functions. The
update function executes scripts at the speed of the framerate (i.e., while visuals are rendered), and the
fixedUpdate function can be used to process physics, engine program logic, and script extensions at a different rate [
78]. With different display/eye-tracker frequencies, it is prudent to employ the
fixedUpdate function. When this function is used, however, a new visual frame does not always render each time an eye-tracking measurement is taken (or vice versa). This is a minor problem for visual cognition, as these logging/rendering frequencies are sufficiently high to begin with [
79]. Regardless, for the ease of the methodology, implementation, and data evaluation, it is preferable to use hardware in which the display/eye-tracker frequencies match and synchronize.
Implementation of user behavior logging is based on a generic logging script with public functions (i.e., functions accessible by any other script). This generic logging functionality can then be used by specific scripts, for example, eye-tracking logging scripts, user movement logging scripts, custom event logging scripts, etc. Once a VR application is launched, the generic logging script waits for other scripts to subscribe to it and specify their own logging formats, i.e., the VR eye-tracking logger calls the generic logger to create a dedicated CSV data file for the eye-tracking log output, along with specifying the log header (the variables). When the VR application is running, the subscribed scripts can pass their own data to the generic logging script whenever required. In the case of VR eye-tracking, this occurs at a pre-specified rate in the fixedUpdate loop. The generic logging script handles writing of the passed-on data into CSV files, along with implementing a writing cache for each of the subscribed loggers to reduce the overall demand on hard drive write performance.
This is the basis behind single-user logging. Implementations with multiple users in a scene (see
Section 2.3,
dynamic camera,
dynamic scene variable level), may require an extra network layer to ensure correct logging functionality, i.e., the generic logging script must be implemented on a server, and all the user logging scripts of all involved users (separate devices—clients) must subscribe to the server. This ensures synchronization of all the user logs under a single, server-side time. A stable, low-latency and low packet loss local network is also a critical requirement, especially if eye-tracking is logged. For a related issue, refer to
Section 3.7 discussing implementation challenges of a robust
replay script.
For a solid, operationalized understanding of where a user’s eye-tracking gaze dwells in uncertain situations in real time during the experimental runtime, we propose two algorithmic workarounds: dual raycaster and multi-level collider segmentation.
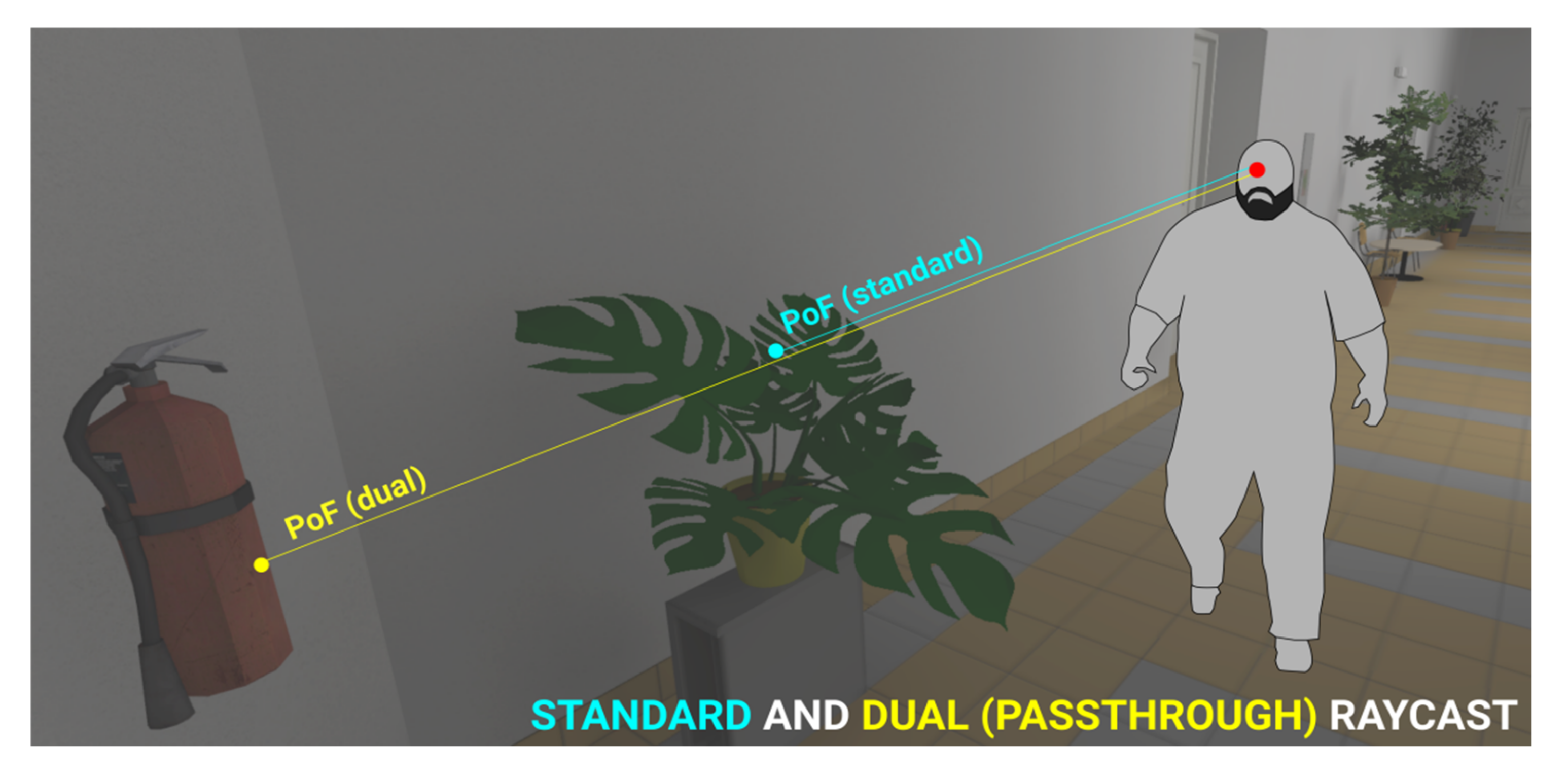
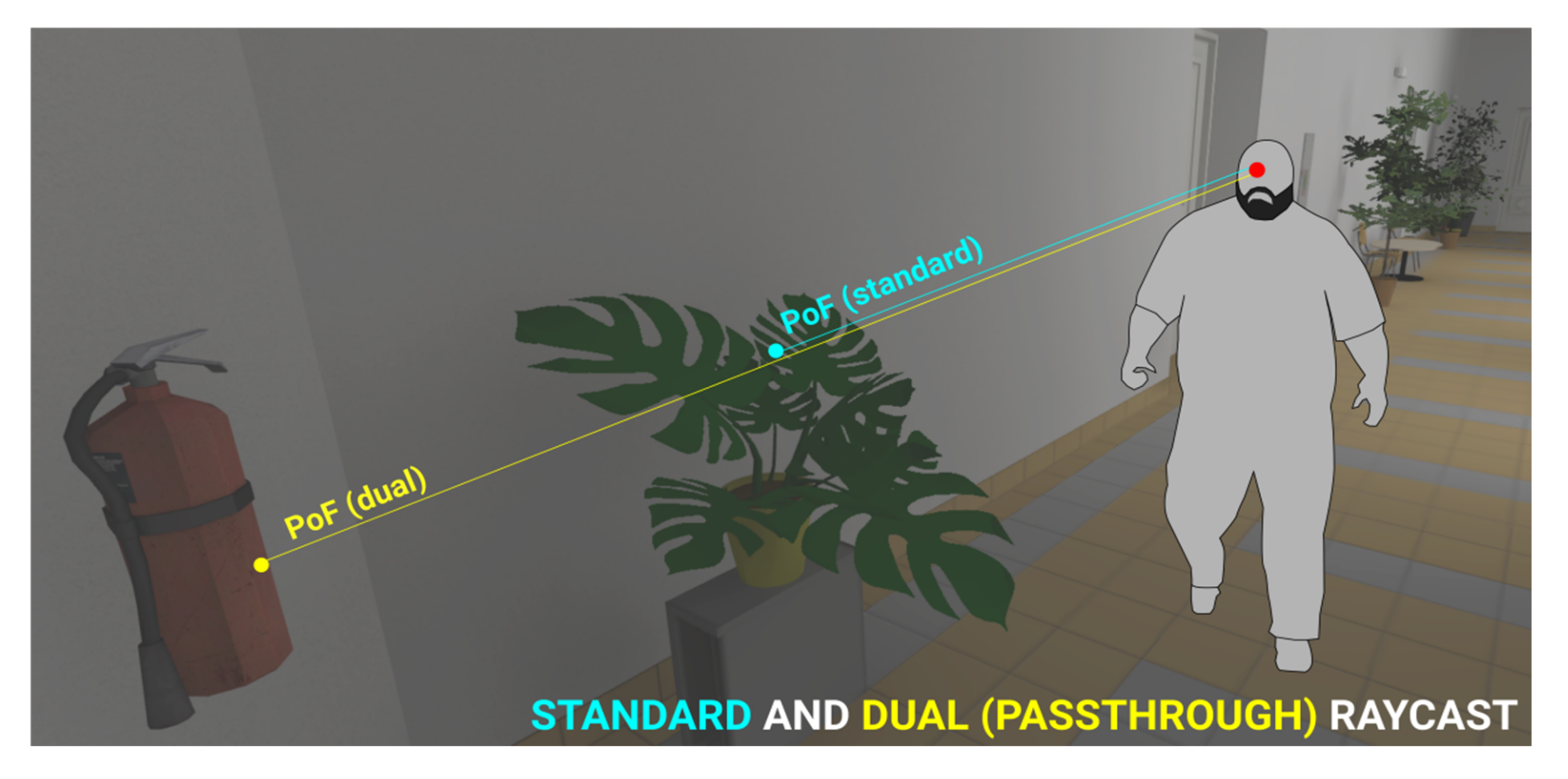
Dual raycaster—Regarding the fidelity of graphics in modern 3D rendering, an issue with transparent objects arises.
Is the user looking at the transparent object or is the user looking through it and focusing on something more distant? In any 3D scene, this type of ambiguity in interpretation can arise in two forms: the object is either area-transparent, i.e., not convex, containing gaps/holes (e.g., plants, segmented mesh structures, etc.), or the object is surface-transparent, i.e., see-through texture (glass, liquids, etc.). While it can be difficult to nearly impossible to determine the actual object a user is looking at from a purely algorithmic decision (since the physical cue of eye accommodation present in perceiving near/far objects in the real world is non-existent in VR), it can at least be beneficial to log both cases of the ambiguity, i.e., simultaneously register both the transparent object and what is behind it (
Figure 7). This is solved by assigning all transparent objects/colliders into a separate semi-pass-through object layer, followed by implementing a dual eye-tracking raycaster: one raycast is permitted to pass through the transparent layer while the other is not, and both are logged simultaneously.
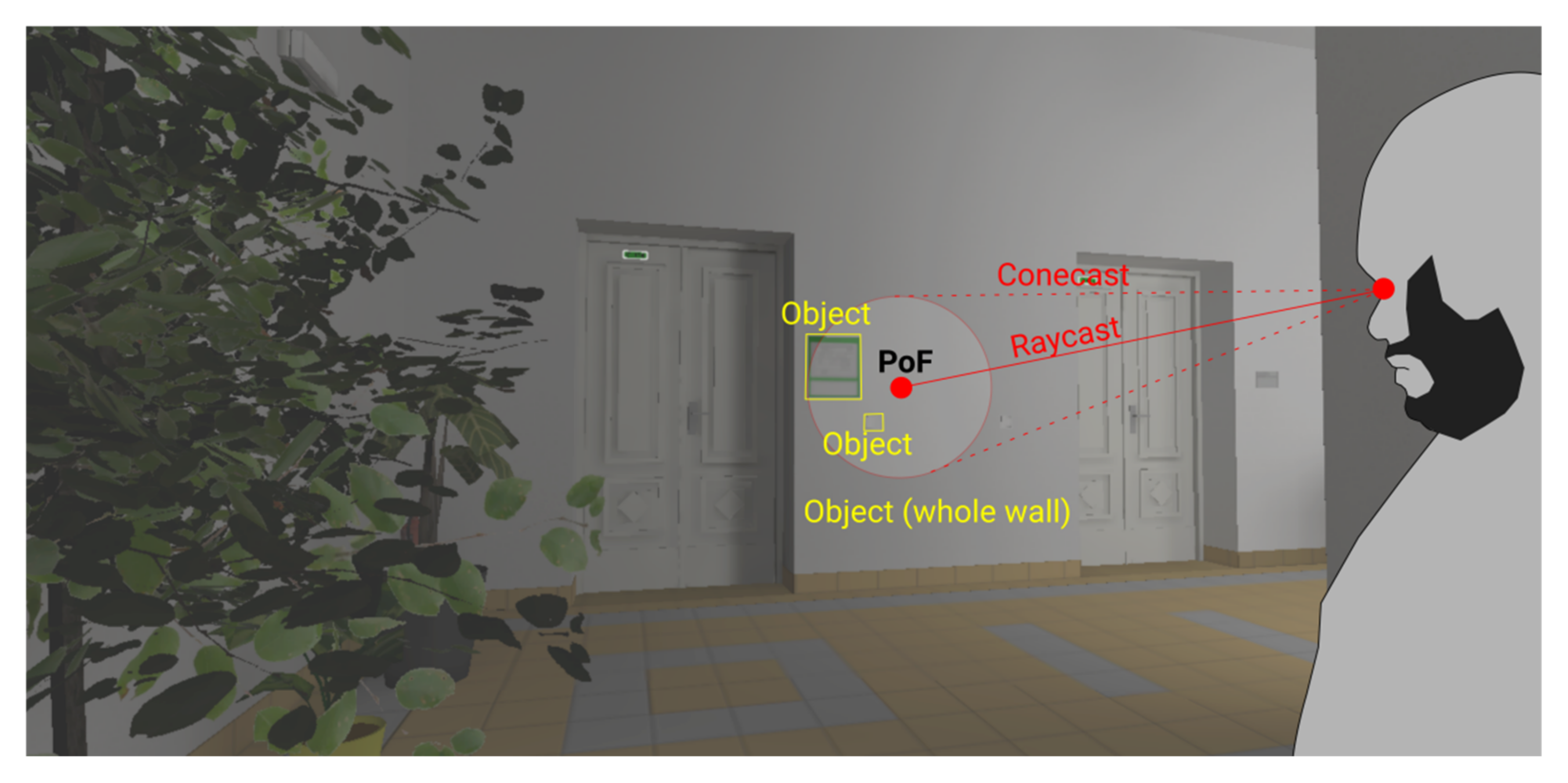
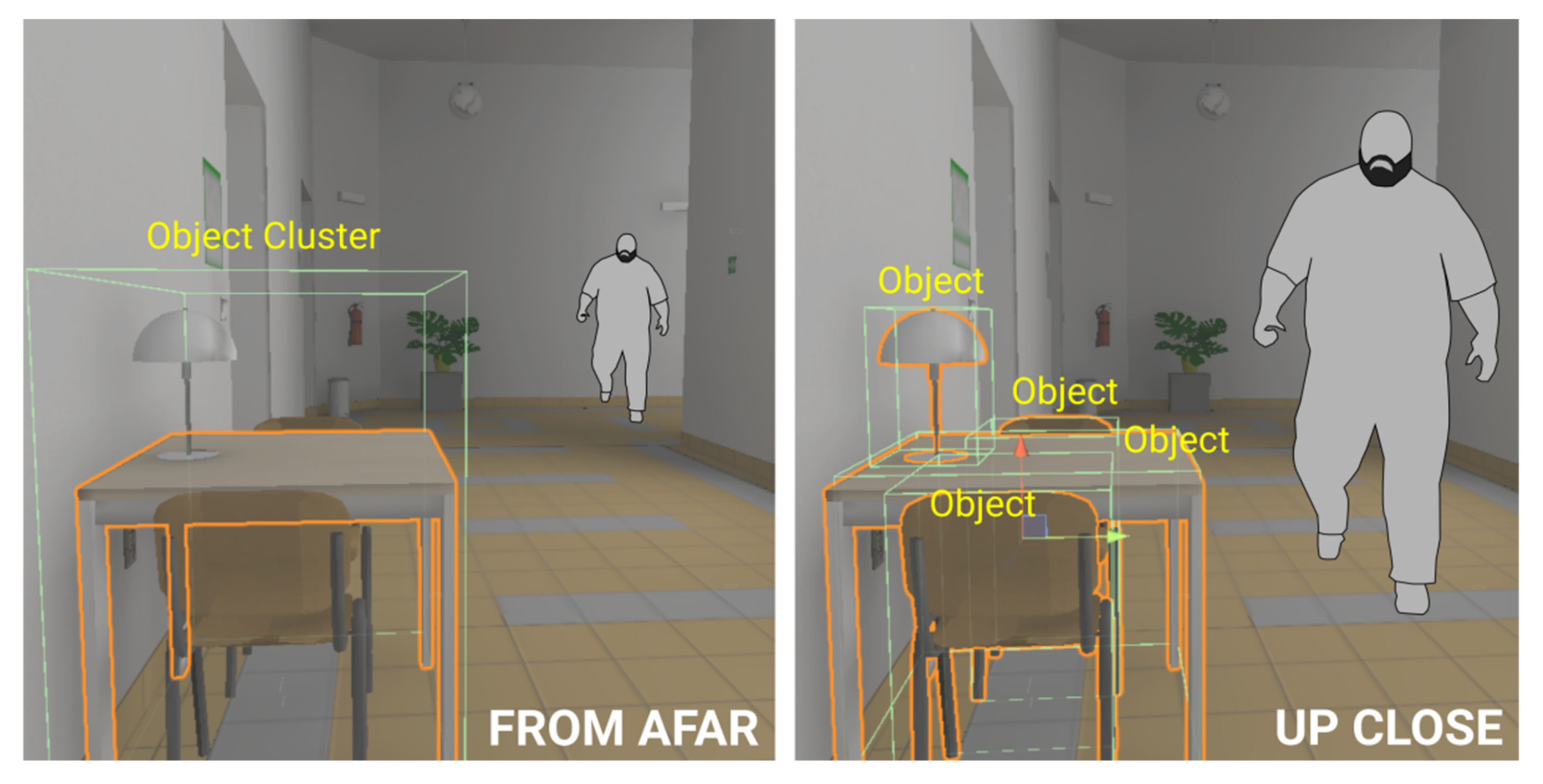
Multi-level collider segmentation—The interpretation of dwelling on distant objects can be challenging. The resolution of even the most advanced VR headsets of 2021 is noticeably less than the resolution provided by the fovea of the eye [
23], and therefore distant and sufficiently small objects or a combination of these (i.e., objects of a low relative size) will be represented by just a few pixels when the virtual image is rendered. The issue may concern entire objects or only subsections of objects, provided the division of objects into segments is desired. A researcher interpreting such problematic data may ask whether they represent a valid eye-tracking gaze upon a relatively small object or just noise in the data. The inherent inaccuracy in all current eye-tracking technology also represents a problem in interpretation. A superior method of handling this is operationalization, i.e., defining the distances from which an object is relevant as a potential gaze target. At a global level, this can be defined by a maximum permitted eye-tracking raycast distance (calculated as the distance of a straight line from the user’s virtual camera position to the potential
point of fixation on a 3D object). The global maximum raycast distance does not, however, take into account relative object size. Any 3D object in a scene relevant to eye-tracking can therefore be segmented according to a custom-distance multi-level collider distinction; for example,
non-registered distance (sufficiently far-away to be disregarded by the eye-tracker),
standard distance (standard eye-tracking collider (AoI) registration),
detailed distance(s) (sufficiently close for the single object collider to be broken into segmented parts). Established in this manner according to each relevant object of interest in the scene, the setup checks for user-object distance, and upon crossing a threshold distance, the colliders assigned to the object are interchanged or enabled/disabled (
Figure 8). This can be implemented in two ways: the simple implementation works with predefined threshold distances (specified manually for each object), whereas the advanced implementation uses algorithmic detection of relative object size, as seen by the user, to set/disable object colliders dynamically.
A specialized collider adjustment scenario arises when objects of significance are tracked in a scene where the surrounding objects can be disregarded. In this type of scenario, the collider can be enlarged or shrunk continuously and linearly (as opposed to the aforementioned discrete collider level transitions) to adjust to the user distance and eye-tracker accuracy threshold. This, however, is a computationally intensive operation, one that should be used only for a select few objects, if at all.
Both the dual raycaster and multi-level collider algorithms require some manual input and testing from the researcher before application in a 3D eye-tracking experimental scene. The algorithms can, however, contribute to more intelligible data output. A hybrid of the two algorithms can also be implemented, incorporating a dual raycaster solution in which objects of a virtual environment are tracked in higher/lower detail/segmentation simultaneously. This approach can offer multiple levels of interpretation.
3.6. Data Cleaning, Curation, and Related Algorithms
The data obtained in experimental runtime may contain some inaccuracies introduced either by user physiology (brief sudden eye-movements and data loss caused by blinking, or miscalibration) or the eye-tracker (inaccuracy). Some of these inaccuracies can be corrected, while some should be discarded. The algorithms proposed for this purpose adopt two possible data curation paths: (i) clean the data and send them to an external application for statistical processing; (ii) clean/correct the data and reload them into the 3D engine for more processing or visualization (i.e., evaluation runtime).
Some eye-tracker APIs inherently report data loss, i.e., moments when no eye-tracking pupil or corneal signal could be registered. If reported by the API, it is best to implement this into the logger so that the data loss value (Boolean true/false) is included in the log. If data loss is already present, the data cleaning process may simply erase the data entries flagged for data loss. If, however, no data loss is present in the log (whether due to a missing implementation or API feature), data loss events can be recomputed using an external data processing script. A data loss event may manifest as the eye-tracking raycast angle not moving relative to the user camera rotation. In this case, detection and removal of the data loss is accomplished by computing the difference between the user’s camera angle and the user’s eye-tracking raycast angle. If the difference remains static across a time period (i.e., subsequent logs), this can be considered data loss and removed.
A similar data cleaning procedure entails identifying eye-tracking artifacts (eye saccade movements so unnatural that they would be physically impossible to perform), for example, a measurement error caused by blinking, in which the eye-tracker measures an incorrect eye-position while the eyelid is partially closed and in motion and where the assumed eye coordinate is projected into a radically different direction in a very short period of time (this would be physiologically impossible). Such incorrectly measured data can be erased simply by computing the differences in angles between subsequent logs and removing the instances that contain large, outlier numbers.
These types of correction are rather primitive since they rely on deleting incorrect data. However, corrective approaches can also be considered and implemented by repairing, interpolating, or reinterpreting data. This is often feasible, as one of the advantages of eye-tracking in VR is that the virtual world is geometrically defined and therefore fully measurable and computable using linear algebra [
80].
Recaster loads an existing eye-tracking log acquired in experimental runtime into the 3D engine and once again raycasts the data onto the environment, i.e., by accessing each subsequent eye-tracking log entry, user camera position (raycast origin) and raycast angle to reproduce each raycast hit or point of fixation. This is useful when the naming convention or atomicity of the objects in the scene is redefined after data collection, for example, to obtain more accurate data resolution or for corrective reasons. Recasting the raycast does not alter the time, user position, head rotation, or eye-tracking gaze angle data in the eye-tracking log, only the information concerning the raycast-hit object’s name. Coordinate and distance may also be overwritten if objects or colliders in a scene are altered. However, it must be emphasized that while redefining invisible object colliders or their names seems logical, the act of significantly rearranging the visual layout of the 3D models that constitute the scene would be scientifically incorrect, producing either skewed data, or representing a process similar to statistical data tampering.
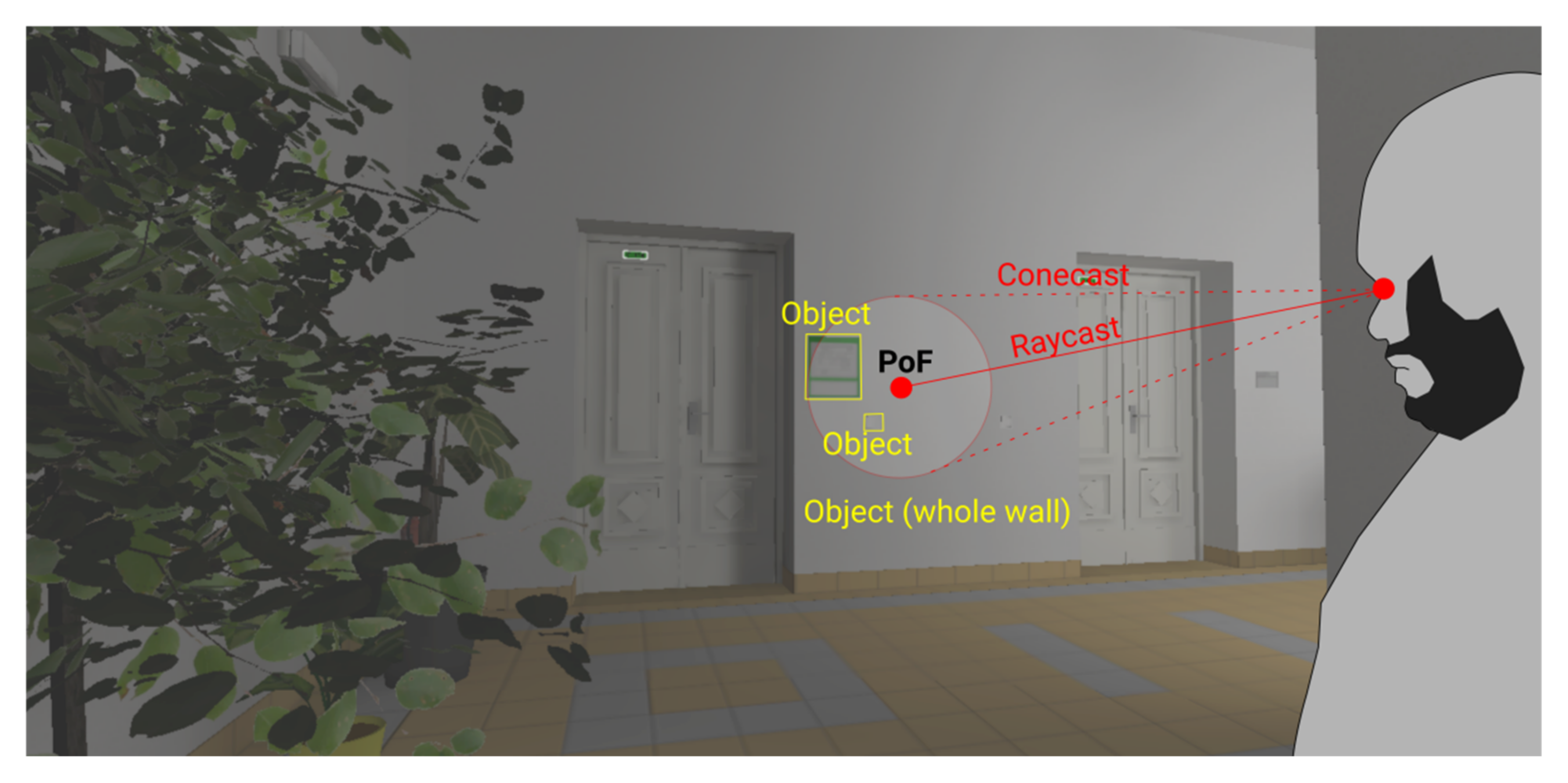
Eye-tracking magnetism is an implementation for correcting eye-tracker inaccuracies based on machine-estimation of the importance of objects in the focal area. It takes into account a predefined level of potential inaccuracy, depending on the hardware and user eyesight (often a circular spread of five to ten degrees is considered a potential focal area [
81]). Then, instead of only a raycast, the algorithm considers a conecast (a conical projection with a diameter equivalent to the specified range). On initialization, the script loads user data that have already been collected, as with the recaster implementation, but now the raycast angle is the central point of the conecast. The algorithm then considers all the objects captured within the cone’s diameter (
Figure 9). Depending on the setup and the algorithm, the magnetism feature can estimate and attempt to correct what the user is looking at.
The magnetism principle specifies that if a user’s gaze dwells on an insignificant area near a significant object, the algorithm will snap-correct the gaze onto the important object. However, what determines an object’s importance is a matter of context and manual setting-up. For example, if the conecast catches the user gazing at a bland-looking white wall with a sufficiently nearby contextual object of importance (e.g., a navigation sign), the algorithm will assume this is a measurement error and snap-correct the gaze onto the object of importance. The object, however, must be manually pre-set as important (or a complex prediction algorithm capable of spontaneously determining the object’s importance can be employed).
Nevertheless, correcting the user’s gaze onto a single important object in close vicinity is a simple example. The eye-tracking magnetism evaluation process becomes more complicated as multiple objects of importance are captured within the conecast. When this occurs, the question arises as to what type of heuristic the algorithm should employ. Does it consider the object whose prominence is closest to the cone’s center? Does it consider the object with the highest percentage of its volume within the conecast? Does it consider the object with the highest significance rating (as defined by the object’s shape and texture, relative to its surroundings)? Or does it consider a combination of all these factors, and if so, what significance do individual factors play in this combination? As seen from this line of thought, the conecast algorithm is only a proof-of-concept at this point, with full implementation depending on other algorithms or heuristic processing.
3.7. Data Visualization and Related Algorithms
Reimporting CSV data logs into a 3D engine for visualization purposes can be achieved by programming language data structures that efficiently load and work with database-like logs (e.g., List, Dictionary, and HashTable). A challenge is the amount of data that are loaded and the engine’s capacity to process and visualize these data. A 3D engine is ill-equipped to deal with thousands of atomic log entries, each represented as a single coordinate object, a point of fixation (as acquired according to the eye-tracker’s logging rate). Additionally, visualizing raw data brings about less clairvoyant interpretative value compared to the value processed data offers. Some analytics may therefore require pre-computing the raw CSV data by using external or in-engine scripts (which apply spatial computations).
Regardless, processing the data in evaluation runtime implies that some evaluation slowdowns are acceptable (since a substantial loss in framerate or an algorithm-induced lag due to instantiating and handling thousands of small objects is a likelihood). It is therefore acceptable to first instantiate all the data log entries in the engine, process them while considering the existing 3D geometry, and cut out and simplify them afterwards, provided sufficient computer memory is available to manage all the log entries and computations.
Before algorithmic data processing commences, another method of comparing the data is useful, for example, manual verification facilitated by dynamic replay functionality. For this purpose, a replay script can be implemented. This contains two perspectives for consideration: the programmer’s perspective (i.e., the format of the input data, and what the script can do with such data), and the user’s perspective (i.e., the user interface, presentation of the data in a comprehensible manner, researcher control, and convenience of the data and related visualizations, and the utility of this).
Given the list of minimum content required in eye-tracking data logs (
Section 3.3), a data source such as this is sufficient. The replay script should, however, be designed and implemented so that different data logs (if produced by different eye-tracking logging scripts) can be loaded, i.e., the replay script should not rely on hard-coded, unspecifiable naming of variables. Ideally, it should also include algorithms for recomputing a missing variable from an included variable, in which the former can be derived from the latter.
In the user interface, the basic implementation is a temporal one: the replay script takes control of the user’s camera and uses the loaded CSV positional and rotational data to replay the user’s movements, and gazes exactly as the user moved about in the experimental environment. Visualization of the eye-tracking data can also be added to the replay. The eye-tracking coordinate is visualized as a small object (e.g., a sphere) and rendered at the point of fixation coordinates that were acquired at a specific time, according to the existing CSV log entries.
Beyond the basics, the replay script’s functionality and presented visual information can also be extended. To glimpse the cognitive processes behind the user who is observing the environment, a trailing fade-out of the last few previous eye-tracking coordinates can be rendered. The replay functionality can be slowed down, accelerated, rewound, or paused. To control this feature, basic GUI (graphics user interface) or keyboard shortcuts can be implemented. The GUI can also display a spontaneous overview of eye-tracking information, which includes the name of the currently fixated object, the amount of time spent dwelling on the currently fixated object, etc.
A robust replay script can also visualize multiple inputs from various perspectives, i.e., if data are collected during a multi-user (multiplayer) experiment, multiple sources of simultaneous user behavior will be available. Similarly, interactable or autonomous objects present in the virtual scene would need data logs of their own, as they may move about, change their properties or states, or be acted upon by a user. If such an enormous amount of interaction occurs in the experimental scene, replay functionality implemented by manipulating a single user’s camera would not suffice. It would then be necessary to supplement the replay GUI/shortcuts with another, free-to-move observer camera that the researcher can use to observe multiple users/objects from their own perspective or projection. Such a robust multi-actor replay script, however, is beyond the scope of this paper, but having such a utility developed and available would lead to further advancements in the research capability of VR interaction.
Eye-tracking data can be rendered as a static visualization. Upon loading a CSV eye-tracking data file into the 3D engine, the data are then portrayed in the scene. It can be portrayed either fully (raw, unprocessed data), or further processed by an external script or an in-engine eye-tracking aggregation algorithm. Other related eye-tracking data (e.g., user movement, interaction) can also be visualized.
When the individual log entries are loaded and instantiated into the 3D engine as 3D objects, it is good practice to attach a data container to each object. While a data container merely copies or recomputes the data in the CSV log entry from which the 3D object is created (e.g., log id, log time, and raycast distance), this procedure serves optimization purposes. Instead of searching the log table data structure for each 3D computation of the log-originated 3D objects, the data can now be accessed directly from each individual 3D object according to its spatial dimension. This also aids in linking the instantiated eye-tracking objects with other instantiated objects (e.g., eye-tracking coordinates to movement coordinates).
Another key aspect of processing static eye-tracking data is optimization of the algorithm. A comparison of the entire data set of coordinates, entry-to-entry, constitutes an exponentially growing computational difficulty (factorial). Some demanding algorithms may therefore encounter a limit in available memory or in the sheer computational time required for processing. Implementing spatial algorithm optimizations, such as spatial partitioning [
82], or at least a basic form of data prefiltering to disregard the irrelevant entries, is recommended.
Heatmap algorithms (absolute distance) are a basic form of visualizing spatial attention. While the interpretative value of this method is already limited in traditional eye-tracking due to a lack of the temporal factor [
83], the situation is worse with 3D eye-tracking, especially with differentiating depth in a highly varied 3D environment. The standard heatmap algorithm considers the absolute distance of all the eye-tracking
point of fixation coordinates and determines how closely they are lumped together. Differences in spatial depth, however, introduce differences in absolute point-to-point distances. The standard heatmap algorithm is therefore not suitable since it must be corrected for relative distance and (optionally) also the temporal factor. We mention this algorithm because it serves as the basis for all other static visualization algorithms in eye-tracking. The algorithm checks for the distances of other points and how close they are to the
point of fixation currently being processed. Based on the number or proximity of neighboring points deemed close enough to the current point, the current point is assigned a heatmap index value. Then, as all the individual points are processed, they are colored with a color gradient according to their assigned values (e.g., gray/invisible = below the threshold of consideration; light gray = minimum amount of gaze concentration; red = maximum amount of gaze concentration).
The heatmap visualization can take the form of colored geometric primitives (e.g., a small sphere for each
point of fixation, as depicted in
Figure 10), which is a simple, albeit crude implementation. A more challenging implementation entails visualizing the heatmap as an overlay texture or as a custom graphics shader (i.e., decal system or decal shader [
84]). This, however, requires a complex and constrained implementation, because most 3D scenes are composed of multiple objects that contain multiple overlapping textures, some of which use complex texture shaders (the object heatmap overlay is a shader that can interfere with other shaders). Since designing a 3D scene for use with a heatmap overlay texture requires adapting the scene creation process to the heatmap’s constraints and involves increasing implementation costs, the present paper disregards the use of overlay heatmap textures.
Corrected heatmap algorithms (relative distance) are more suitable for obtaining spatial information in VR eye-tracking data with user movement in the virtual space. This is a valid correction in which point-to-point distances are determined according to an observed angular distance rather than an absolute metric distance.
Interpreting absolute point-to-point distances projected onto varying spatial depth in a non-corrected heatmap algorithm can be alleviated, to an extent, by a simple implementation of cut-out distances. Computing an absolute-distance, uncorrected heatmap while including only the points of fixation that were observed within a specified distance interval will discard the remainder of the points from processing and visualization. While this procedure is simple, it does not solve the root cause of the problem—the need to interpret sequences of
PoF data with a high variety of absolute distances (e.g., just like looking down the corridor in
Figure 10). Thus, environments with high spatial variance (or with user-induced movement causing such variance) are not fit to be interpreted by the uncorrected (absolute distance) algorithm.
The corrected heatmap works well for all distances since it uses conecast. Cone projection from the user’s position covers the eye-tracking point of fixation coordinate and its surroundings. The angular width of this conecast can be specified according to the algorithm’s parameters. Only the surrounding points captured within the cone are then considered for the corrected heatmap computation (this also helps tremendously with the issue of optimizing the otherwise exponentially rising difficulty for the algorithm, where each point would require measurement of its distance from all the other points). However, because the points are compared to each other in relative distances, it implies that the difference in user movement will lead to different results. For example, comparing points A–B may determine that they are within a sufficiently close distance, whereas comparing points B–A may yield the opposite, especially when the gaze produced to generate log entry B was taken from a shorter distance, where the cone’s angular distance would not protrude sufficiently far from point B to include point A. Another issue is that of occlusion, in which a varying camera angle/position conecast may not register some points previously looked at. Hence, this may introduce variation in the heatmap’s visualization intensity/coloring, which can be either kept as is, or the algorithm can be expanded to smoothen such A–B/B–A differences.
Corrected fixation algorithms (relative distance–time) are an extension of the previous algorithm, with the ability to compute eye-tracking fixations in virtual 3D space. The angular distances between subsequent points can effectively distinguish between eye-tracking fixations and saccades; the minimum or maximum duration of a fixation can be set and visualized (the algorithm is now a sequential pass-through on the eye-tracking data log). Similar algorithm (including discussing suitable time and angle thresholds) is proposed and experimentally verified by an existing study [
85].
Depicting eye-tracking fixations, saccades, and scan paths is also a visualization issue. The output visualization can produce many fixations that overlay each other, as a user may observe a virtual 3D object of interest from many different angles and distances (we can argue that not only do 3D visual stimuli offer more information than their 2D counterparts [
86], they also require more cognitive processing [
87], i.e., dwell time). It is also relevant that the user moves about in the 3D environment. Subsequently, the following must be visualized: eye-tracking scan path with fixations, user movement path, and associated eye positions at any given time. While this is easily implementable in a 3D engine (using a series of geometric primitives to depict the
points of fixation and basic geometric lines (e.g., Unity’s
LineRenderer class) to connect the subsequent points into a path), the comprehensibility of the resulting visualization may be worth further consideration, filtering, or simplification, etc., especially for cases of prolonged interaction or multi-user visualizations.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}