




Long Short-Term Memory-Based Methodology for Predicting Carbonation Models of Reinforced Concrete Slab Bridges: Case Study in South Korea


Abstract
Featured Application
Abstract
1. Introduction
2. Literature Review
2.1. Concrete Carbonation Model
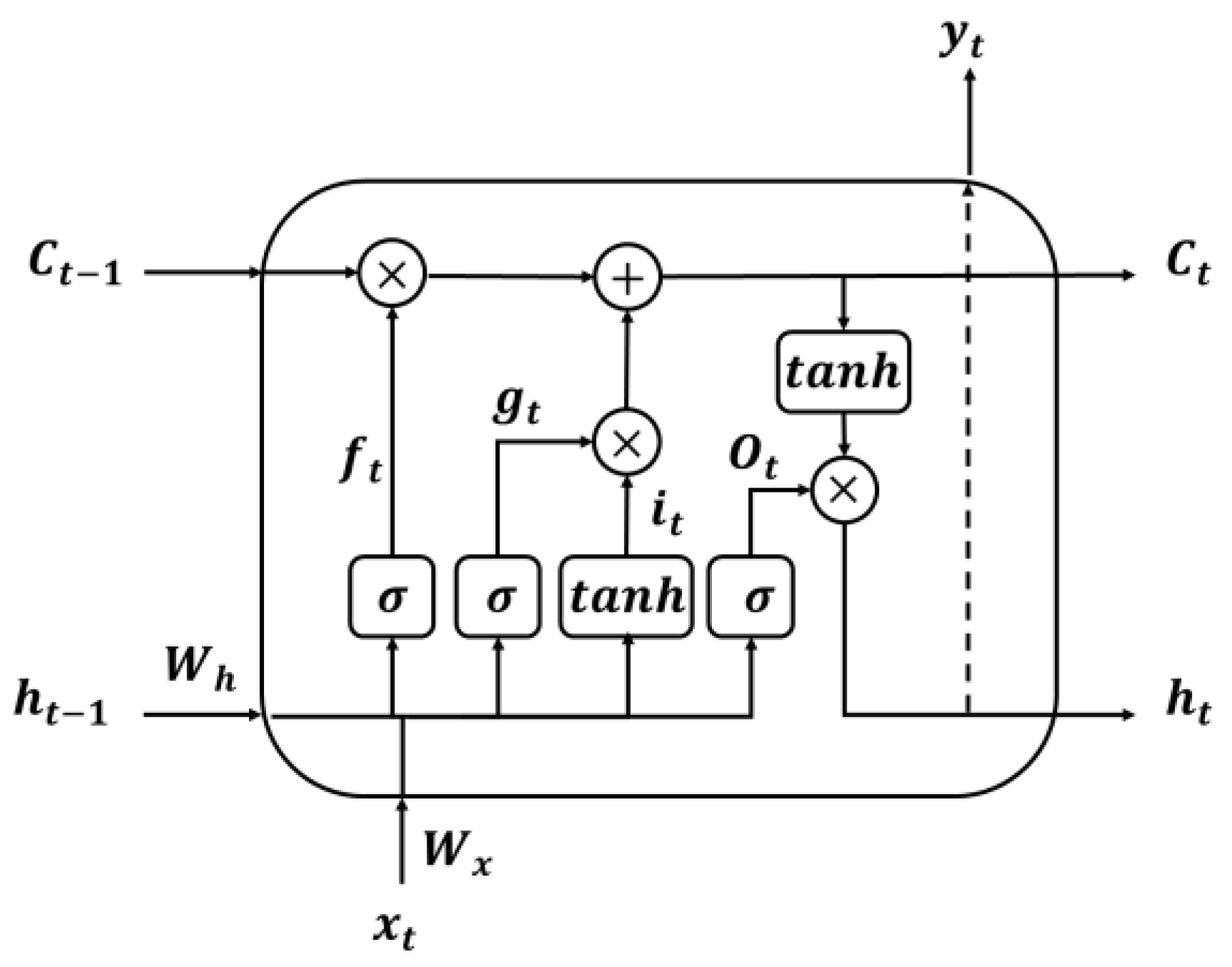
2.2. LSTM
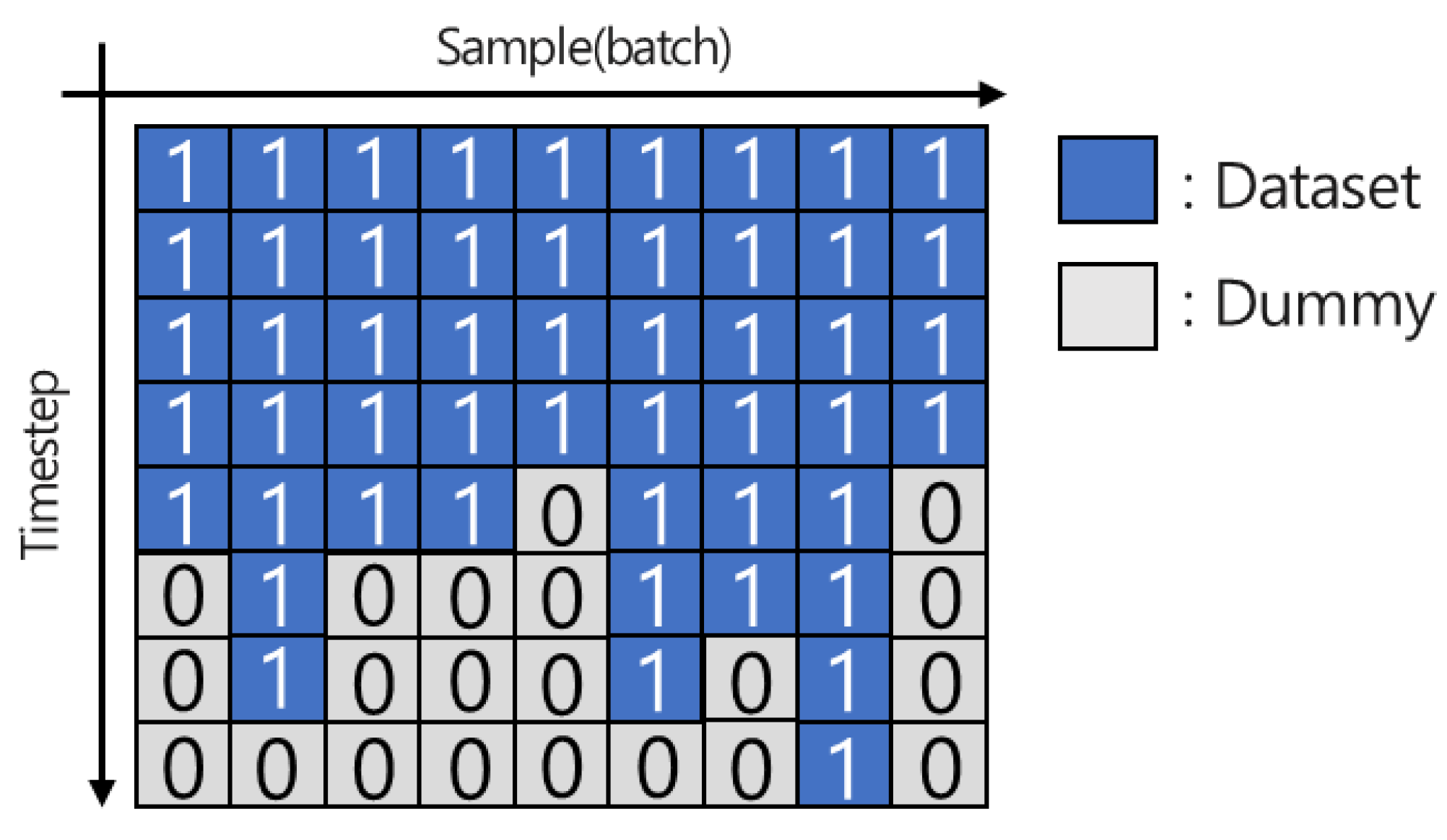
2.3. Padding and Masking Methods
2.4. Evaluation Index of the Carbonation Models
3. Data Collection for the Case Study of Natural Carbonation
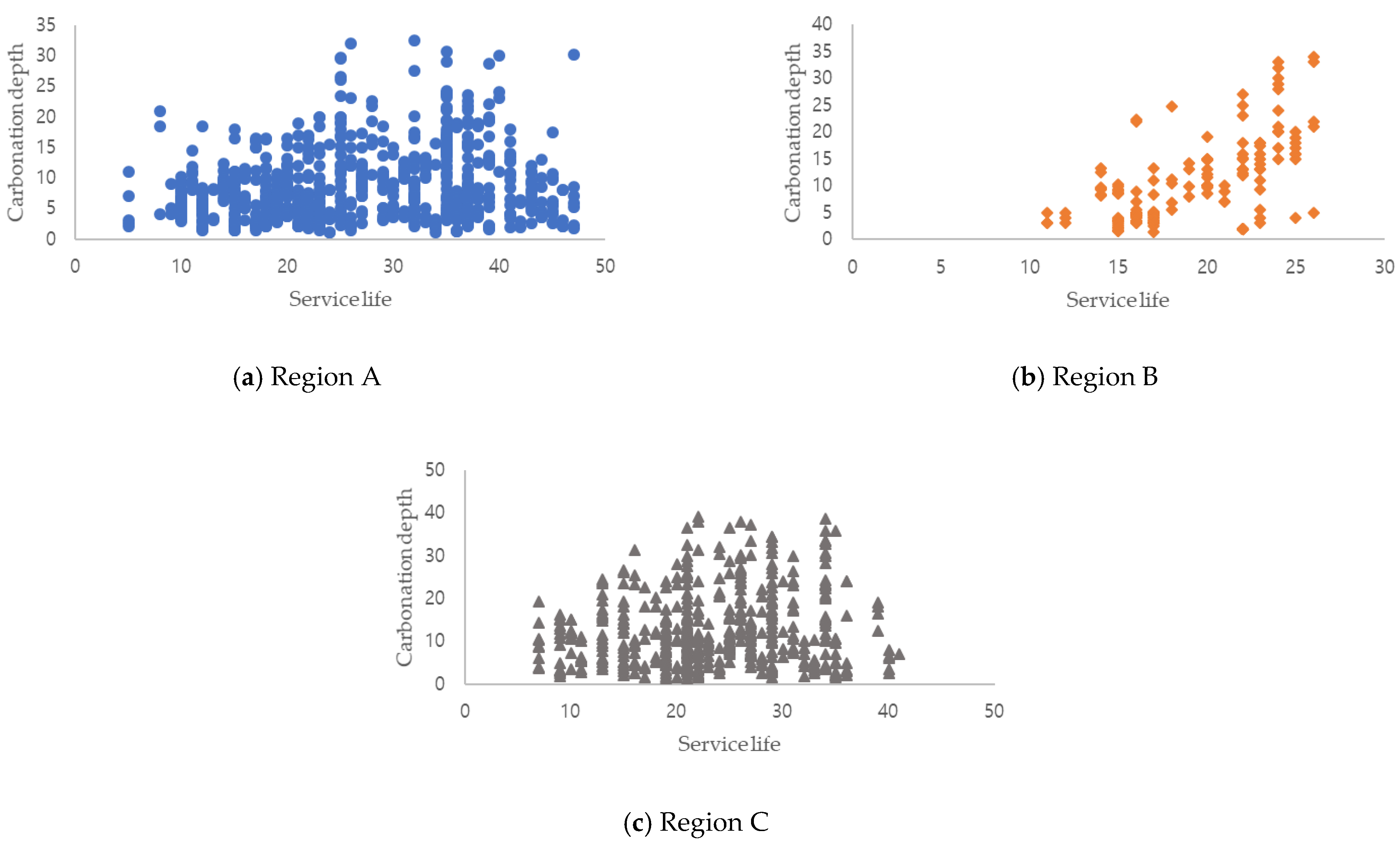
3.1. Data Description of Inspection Reports
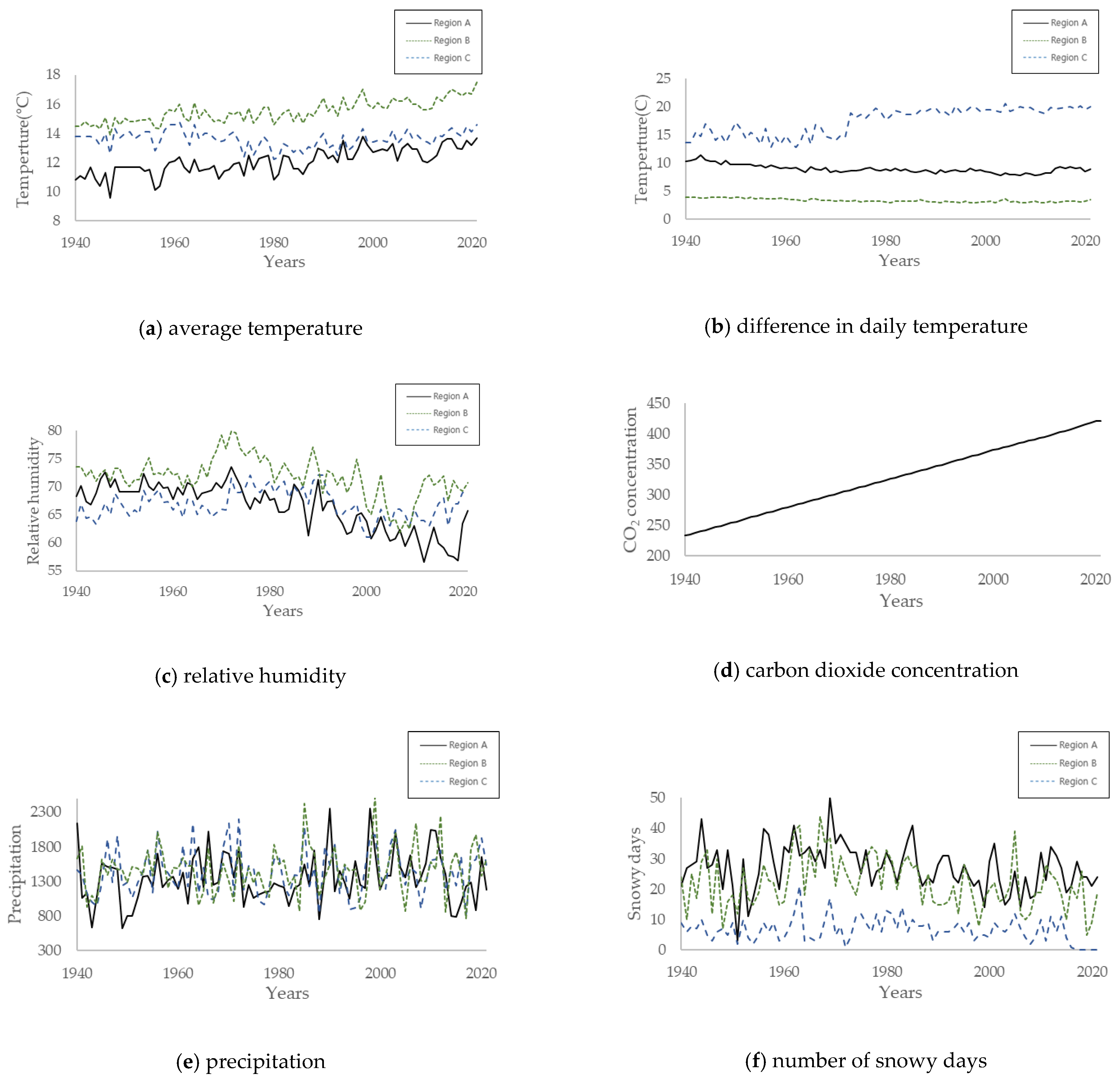
3.2. Data Description of Environmental Conditions
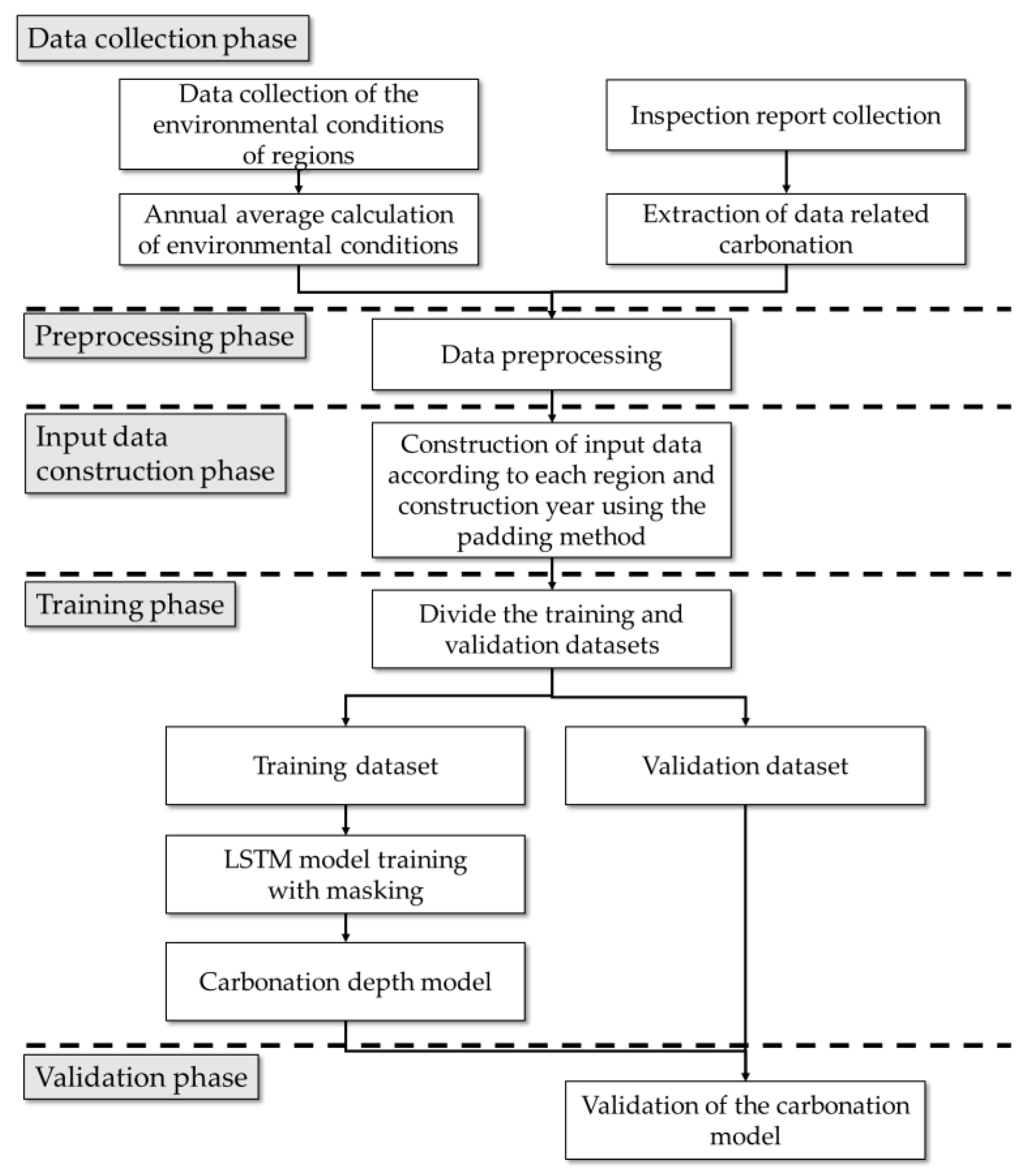
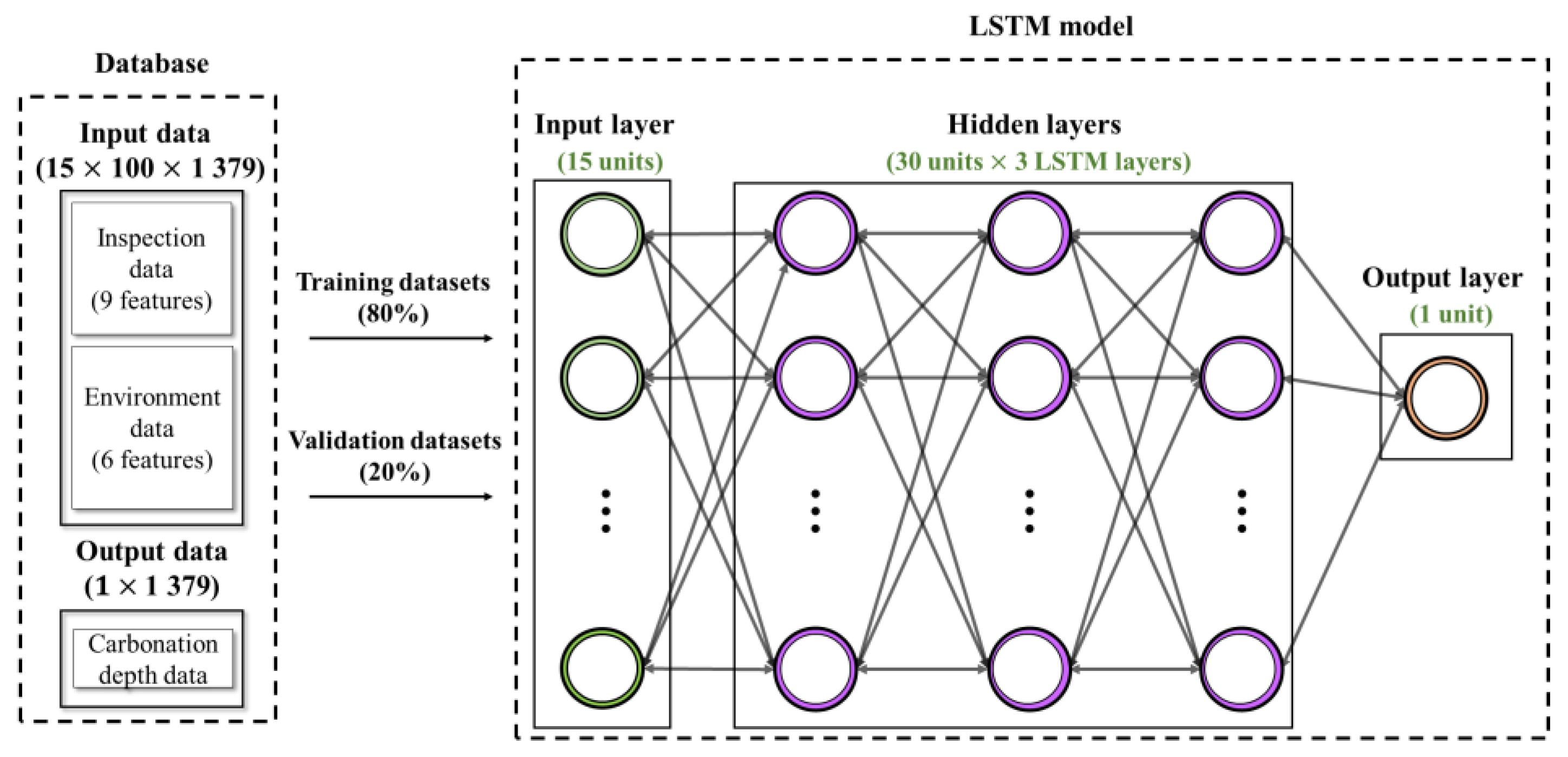
4. LSTM-Based Methodology for Generating the Carbonation Model
5. Experimental Results
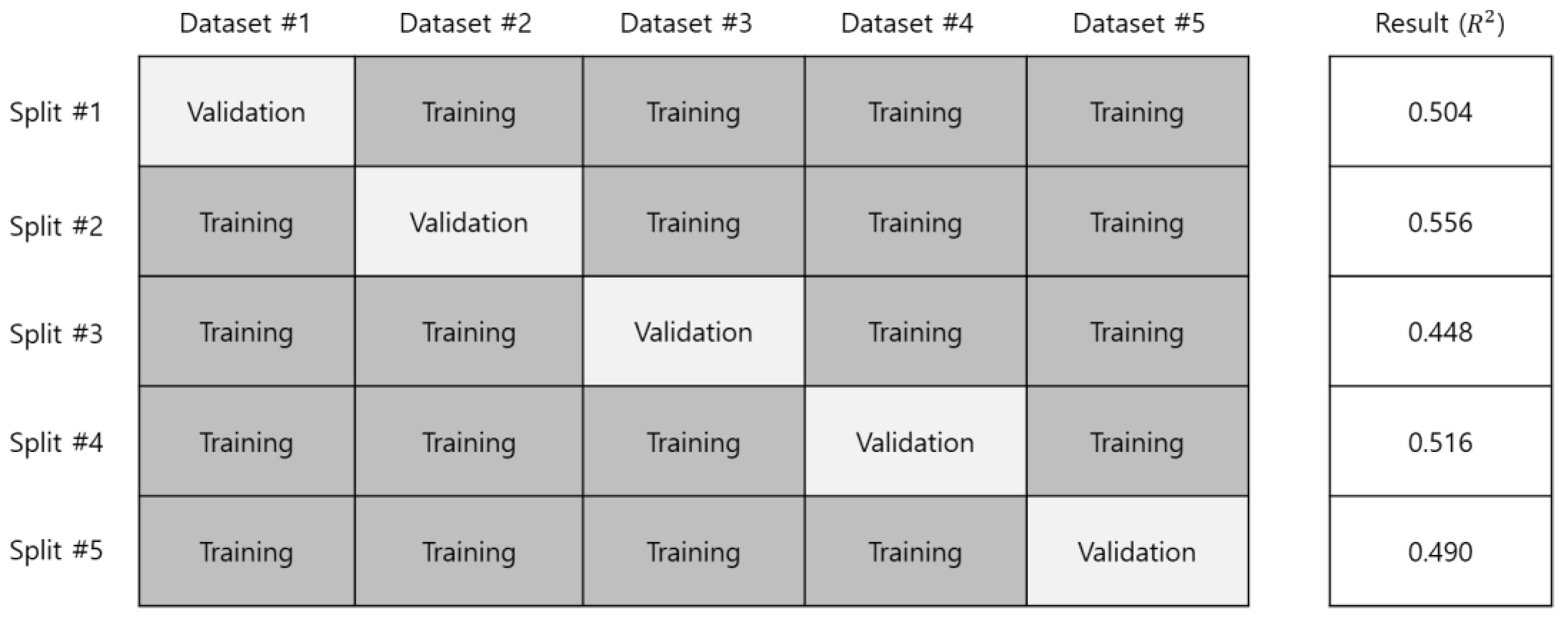
5.1. Experimental Results of the Case Study
5.2. Comparison of the Proposed Methodology with Other Analysis Methods
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Miao, P.; Yokota, H.; Zhang, Y. Deterioration prediction of existing concrete bridges using a LSTM recurrent neural network. Struct. Infrastruct. Eng. 2021, 17, 1–15. [Google Scholar] [CrossRef]
- Rathnarajan, S.; Dhanya, B.; Pillai, R.G.; Gettu, R.; Santhanam, M. Carbonation model for concretes with fly ash, slag, and limestone calcined clay-using accelerated and five-year natural exposure data. Cement Concr. Compos. 2022, 126, 104329. [Google Scholar] [CrossRef]
- Kellouche, Y.; Boukhatem, B.; Ghrici, M.; Tagnit-Hamou, A. Exploring the major factors affecting fly-ash concrete carbonation using artificial neural network. Neural Comput. Appl. 2019, 31, 969–988. [Google Scholar] [CrossRef]
- Gattuso, J.-P.; Magnan, A.; Billé, R.; Cheung, W.W.; Howes, E.L.; Joos, F.; Allemand, D.; Bopp, L.; Cooley, S.R.; Eakin, C.M. Contrasting futures for ocean and society from different anthropogenic CO2 emissions scenarios. Science 2015, 349, aac4722. [Google Scholar] [CrossRef]
- Ekolu, S. A review on effects of curing, sheltering, and CO2 concentration upon natural carbonation of concrete. Construct. Build. Mater. 2016, 127, 306–320. [Google Scholar] [CrossRef]
- Yoon, I.-S.; Chang, C.-H. Time evolution of CO2 diffusivity of carbonated concrete. Appl. Sci. 2020, 10, 8910. [Google Scholar] [CrossRef]
- Kwon, S.-J.; Song, H.-W. Analysis of carbonation behavior in concrete using neural network algorithm and carbonation modeling. Cement Concr. Res. 2010, 40, 119–127. [Google Scholar] [CrossRef]
- Neves, A.C.; Gonzalez, I.; Leander, J.; Karoumi, R. Structural health monitoring of bridges: A model-free ANN-based approach to damage detection. J. Civil Struct. Health Monitor. 2017, 7, 689–702. [Google Scholar] [CrossRef]
- Lin, C.-J.; Wu, N.-J. An ANN model for predicting the compressive strength of concrete. Appl. Sci. 2021, 11, 3798. [Google Scholar] [CrossRef]
- Singh, P.; Bhardwaj, S.; Dixit, S.; Shaw, R.N.; Ghosh, A. Development of prediction models to determine compressive strength and workability of sustainable concrete with ANN. In Innovations in Electrical and Electronic Engineering; Springer: Berlin/Heidelberg, Germany, 2021; pp. 753–769. [Google Scholar]
- Kandiri, A.; Sartipi, F.; Kioumarsi, M. Predicting compressive strength of concrete containing recycled aggregate using modified ANN with different optimization algorithms. Appl. Sci. 2021, 11, 485. [Google Scholar] [CrossRef]
- Kwon, T.H.; Park, S.H.; Park, S.I.; Lee, S.-H. Building information modeling-based bridge health monitoring for anomaly detection under complex loading conditions using artificial neural networks. J. Civil Struct. Health Monit. 2021, 11, 1301–1319. [Google Scholar] [CrossRef]
- Cavaleri, L.; Barkhordari, M.S.; Repapis, C.C.; Armaghani, D.J.; Ulrikh, D.V.; Asteris, P.G. Convolution-based ensemble learning algorithms to estimate the bond strength of the corroded reinforced concrete. Construct. Build. Mater. 2022, 359, 129504. [Google Scholar] [CrossRef]
- Lu, C.; Liu, R. Predicting carbonation depth of prestressed concrete under different stress states using artificial neural network. Adv. Artif. Neural Syst. 2009, 2009, 193139. [Google Scholar] [CrossRef]
- Liu, K.; Alam, M.S.; Zhu, J.; Zheng, J.; Chi, L. Prediction of carbonation depth for recycled aggregate concrete using ANN hybridized with swarm intelligence algorithms. Construct. Build. Mater. 2021, 301, 124382. [Google Scholar] [CrossRef]
- Felix, E.F.; Carrazedo, R.; Possan, E. Carbonation model for fly ash concrete based on artificial neural network: Development and parametric analysis. Construct. Build. Mater. 2021, 266, 121050. [Google Scholar] [CrossRef]
- Felix, E.F.; Possan, E.; Carrazedo, R. Analysis of training parameters in the ANN learning process to mapping the concrete carbonation depth. J. Build. Pathol. Rehabilit. 2019, 4, 16. [Google Scholar] [CrossRef]
- Kellouche, Y.; Boukhatem, B.; Ghrici, M.; Rebouh, R.; Zidol, A. Neural network model for predicting the carbonation depth of slag concrete. Asian J. Civ. Eng. 2021, 22, 1401–1414. [Google Scholar] [CrossRef]
- Wu, N.-J. Predicting the compressive strength of concrete using an RBF-ANN model. Appl. Sci. 2021, 11, 6382. [Google Scholar] [CrossRef]
- Houst, Y.F.; Wittmann, F.H. Influence of porosity and water content on the diffusivity of CO2 and O2 through hydrated cement paste. Cement Concr. Res. 1994, 24, 1165–1176. [Google Scholar] [CrossRef]
- Sanjuán, M.Á.; Andrade, C.; Mora, P.; Zaragoza, A. Carbon dioxide uptake by cement-based materials: A Spanish case study. Appl. Sci. 2020, 10, 339. [Google Scholar] [CrossRef]
- Yoon, I.-S.; Çopuroğlu, O.; Park, K.-B. Effect of global climatic change on carbonation progress of concrete. Atmos. Environ. 2007, 41, 7274–7285. [Google Scholar] [CrossRef]
- Vu, Q.H.; Pham, G.; Chonier, A.; Brouard, E.; Rathnarajan, S.; Pillai, R.; Gettu, R.; Santhanam, M.; Aguayo, F.; Folliard, K.J. Impact of different climates on the resistance of concrete to natural carbonation. Construct. Build. Mater. 2019, 216, 450–467. [Google Scholar] [CrossRef]
- Sagues, A.A.; Moreno, E.; Morris, W.; Andrade, C. Carbonation in Concrete and Effect on Steel Corrosion; University of South Florida: Tampa, FL, USA, 1997. [Google Scholar]
- Kobayashi, K.; Uno, Y. Mechanism of carbonation of concrete. Concr. Libr. JSCE 1990, 16, 139–151. [Google Scholar]
- Parrott, L.J. A Review of Carbonation in Reinforced Concrete; Cement and Concrete Association: London, UK, 1987. [Google Scholar]
- Jiang, L.; Lin, B.; Cai, Y. A model for predicting carbonation of high-volume fly ash concrete. Cement Concr. Res. 2000, 30, 699–702. [Google Scholar] [CrossRef]
- Papadakis, V.G.; Vayenas, C.G.; Fardis, M.N. Experimental investigation and mathematical modeling of the concrete carbonation problem. Chem. Eng. Sci. 1991, 46, 1333–1338. [Google Scholar] [CrossRef]
- Khunthongkeaw, J.; Tangtermsirikul, S.; Leelawat, T. A study on carbonation depth prediction for fly ash concrete. Construct. Build. Mater. 2006, 20, 744–753. [Google Scholar] [CrossRef]
- Londhe, S.; Kulkarni, P.; Dixit, P.; Silva, A.; Neves, R.; de Brito, J. Tree based approaches for predicting concrete carbonation coefficient. Appl. Sci. 2022, 12, 3874. [Google Scholar] [CrossRef]
- Niu, D.; Dong, Z.; Pu, J. Random model of predicting the carbonated concrete depth. Ind. Construct. 1999, 29, 41–45. [Google Scholar]
- Chang, C.-F.; Chen, J.-W. The experimental investigation of concrete carbonation depth. Cement Concr. Res. 2006, 36, 1760–1767. [Google Scholar] [CrossRef]
- Sisomphon, K.; Franke, L. Carbonation rates of concretes containing high volume of pozzolanic materials. Cement Concr. Res. 2007, 37, 1647–1653. [Google Scholar] [CrossRef]
- Dhir, R.; Hewlett, P.; Chan, Y. Near-surface characteristics of concrete: Prediction of carbonation resistance. Mag. Concr. Res. 1989, 41, 137–143. [Google Scholar] [CrossRef]
- Roy, S.; Beng, P.K.; Northwood, D. The carbonation of concrete structures in the tropical environment of Singapore and a comparison with published data for temperate climates. Mag. Concr. Res. 1996, 48, 293–300. [Google Scholar] [CrossRef]
- Guiglia, M.; Taliano, M. Comparison of carbonation depths measured on in-field exposed existing RC structures with predictions made using fib-Model Code 2010. Cement Concr. Compos. 2013, 38, 92–108. [Google Scholar] [CrossRef]
- Walraven, J.C. Model Code 2010-Final Draft: Volume 1; FIB—Fédération Internationale du Béton: Lausanne, Switzerland, 2012; Volume 65. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Cernocký, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the Interspeech, Chiba, Japan, 26–30 September 2010; pp. 1045–1048. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Dou, Z.; Sun, Y.; Zhang, Y.; Wang, T.; Wu, C.; Fan, S. Regional manufacturing industry demand forecasting: A deep learning approach. Appl. Sci. 2021, 11, 6199. [Google Scholar] [CrossRef]
- Song, L.; Liu, J.; Cui, C.; Yu, Z.; Fan, Z.; Hou, J. Carbonation process of reinforced concrete beams under the combined effects of fatigue damage and environmental factors. Appl. Sci. 2020, 10, 3981. [Google Scholar] [CrossRef]
- Shi, X.; Yao, Y.; Wang, L.; Zhang, C.; Ahmad, I. A modified numerical model for predicting carbonation depth of concrete with stress damage. Construct. Build. Mater. 2021, 304, 124389. [Google Scholar] [CrossRef]
- Duan, K.; Cao, S. Data-driven parameter selection and modeling for concrete carbonation. Materials 2022, 15, 3351. [Google Scholar] [CrossRef]
- Korea Meteorological Administration. National Climate Data Center. Available online: https://data.kma.go.kr/resources/html/en/ncdci.html (accessed on 16 November 2022).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Region | Number of Reports | Characteristics | |
|---|---|---|---|
| Region A | 137 | High-densely downtown area | 600 |
| Region B | 22 | Low-density coastal area | 1850 |
| Region C | 166 | Low-density island | 10,550 |
| Classification | Factors | Average | Min | Max |
|---|---|---|---|---|
| Carbonation-related factors | Service life | 24.79 | 5 | 47 |
| Year of construction | 1989.65 | 1969 | 2010 | |
| Concrete strength | 23.42 | 18 | 35 | |
| Indirect factors | Length | 83.19 | 5.2 | 261 |
| Maximum span length | 17.70 | 5 | 55 | |
| Width | 18.87 | 4 | 61.48 | |
| Height | 6.67 | 2 | 29.5 | |
| Loading condition for design | 22.08 | 13.5 | 24 | |
| Element position (superstructure and substructure) | - | 0 (superstructure) | 1 (substructure) | |
| Carbonation | Carbonation depth | 10.510 | 2 | 40 |
| Classification | Factors | Region | Average | Min | Max |
|---|---|---|---|---|---|
| Temperature (°C) | Average temperature | A | 12.1 | 9.6 | 13.8 |
| B | 13.6 | 12.2 | 14.8 | ||
| C | 15.5 | 13.9 | 17.5 | ||
| Daily temperature difference | A | 9.0 | 7.8 | 11.4 | |
| B | 17.5 | 12.8 | 20.5 | ||
| C | 3.4 | 2.9 | 4 | ||
| Humidity | Relative humidity | A | 66.4 | 56.6 | 73.6 |
| B | 66.8 | 61 | 72 | ||
| C | 71.7 | 61.8 | 79.8 | ||
| Carbon dioxide | Carbon dioxide concentration | A | 327.5 | 233.5 | 421.4 |
| B | |||||
| C | |||||
| Precipitation | Precipitation | A | 1344.9 | 623.5 | 2355.5 |
| B | 1431.7 | 819.3 | 2195.5 | ||
| C | 1465.9 | 773.3 | 2526 | ||
| Chloride penetration | Number of snowy days | A | 27.1 | 3 | 50 |
| B | 6.6 | 0 | 21 | ||
| C | 22.0 | 5 | 44 |
| Number | Layer Name | Hidden Unit | Activation Function | Number of Parameters |
|---|---|---|---|---|
| 1 | LSTM | 30 | tanh | 5400 |
| - | Dropout | - | - | |
| 2 | LSTM | 30 | ReLU | 7320 |
| - | Dropout | - | - | |
| 3 | LSTM | 30 | tanh | 7320 |
| - | Dropout | - | - | |
| 4 | Dense | 1 | Linear | 31 |
| Performance Indicator | Value |
|---|---|
| Training dataset | 0.638 |
| Training dataset RMSE | 4.572 |
| Validation dataset | 0.504 |
| Validation dataset RMSE | 5.057 |
| Region | Methodology | RMSE | |
|---|---|---|---|
| A | Proposed model | 0.426 | 4.970 |
| Fick’s second law equation | 0.035 | 6.411 | |
| B | Proposed model | 0.542 | 5.556 |
| Fick’s second law equation | 0.129 | 7.377 | |
| C | Proposed model | 0.677 | 5.132 |
| Fick’s second law equation | 0.016 | 8.793 |
| Regression Analysis Method | Validation Dataset | ||
|---|---|---|---|
| RMSE | |||
| Linear regression | Linear | 0.1322 | 7.260 |
| Interaction linear | 0.2203 | 6.898 | |
| Robust linear | 0.1302 | 7.373 | |
| Stepwise linear | 0.2102 | 6.928 | |
| Tree | Complex tree | 0.3877 | 6.157 |
| Medium tree | 0.3367 | 6.363 | |
| Simple tree | 0.2161 | 6.932 | |
| Support vector machine | Linear | 0.1259 | 7.537 |
| Quadratic | 0.2457 | 6.868 | |
| Cubic | 0.2229 | 7.182 | |
| Fine Gaussian | 0.3756 | 6.220 | |
| Gaussian process regression | Squared exponential | 0.4220 | 5.964 |
| Matern 5/2 | 0.4235 | 5.955 | |
| Rational quadratic | 0.4310 | 5.910 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kwon, T.H.; Kim, J.; Park, K.-T.; Jung, K.-S. Long Short-Term Memory-Based Methodology for Predicting Carbonation Models of Reinforced Concrete Slab Bridges: Case Study in South Korea. Appl. Sci. 2022, 12, 12470. https://doi.org/10.3390/app122312470
Kwon TH, Kim J, Park K-T, Jung K-S. Long Short-Term Memory-Based Methodology for Predicting Carbonation Models of Reinforced Concrete Slab Bridges: Case Study in South Korea. Applied Sciences. 2022; 12(23):12470. https://doi.org/10.3390/app122312470
Chicago/Turabian StyleKwon, Tae Ho, Jaehwan Kim, Ki-Tae Park, and Kyu-San Jung. 2022. "Long Short-Term Memory-Based Methodology for Predicting Carbonation Models of Reinforced Concrete Slab Bridges: Case Study in South Korea" Applied Sciences 12, no. 23: 12470. https://doi.org/10.3390/app122312470
APA StyleKwon, T. H., Kim, J., Park, K.-T., & Jung, K.-S. (2022). Long Short-Term Memory-Based Methodology for Predicting Carbonation Models of Reinforced Concrete Slab Bridges: Case Study in South Korea. Applied Sciences, 12(23), 12470. https://doi.org/10.3390/app122312470