
Two-View Mammogram Synthesis from Single-View Data Using Generative Adversarial Networks


Abstract
1. Introduction
- We explore the possibility that CR-GAN can provide two-view mammograms from single-view image data;
- With the aim of higher resolution and superior quality mammogram syntheses, we implement two adaptations of CR-GAN:
- (1)
- Progressive growing technique;
- (2)
- Feature matching loss.
2. Materials and Methods
2.1. Training Networks
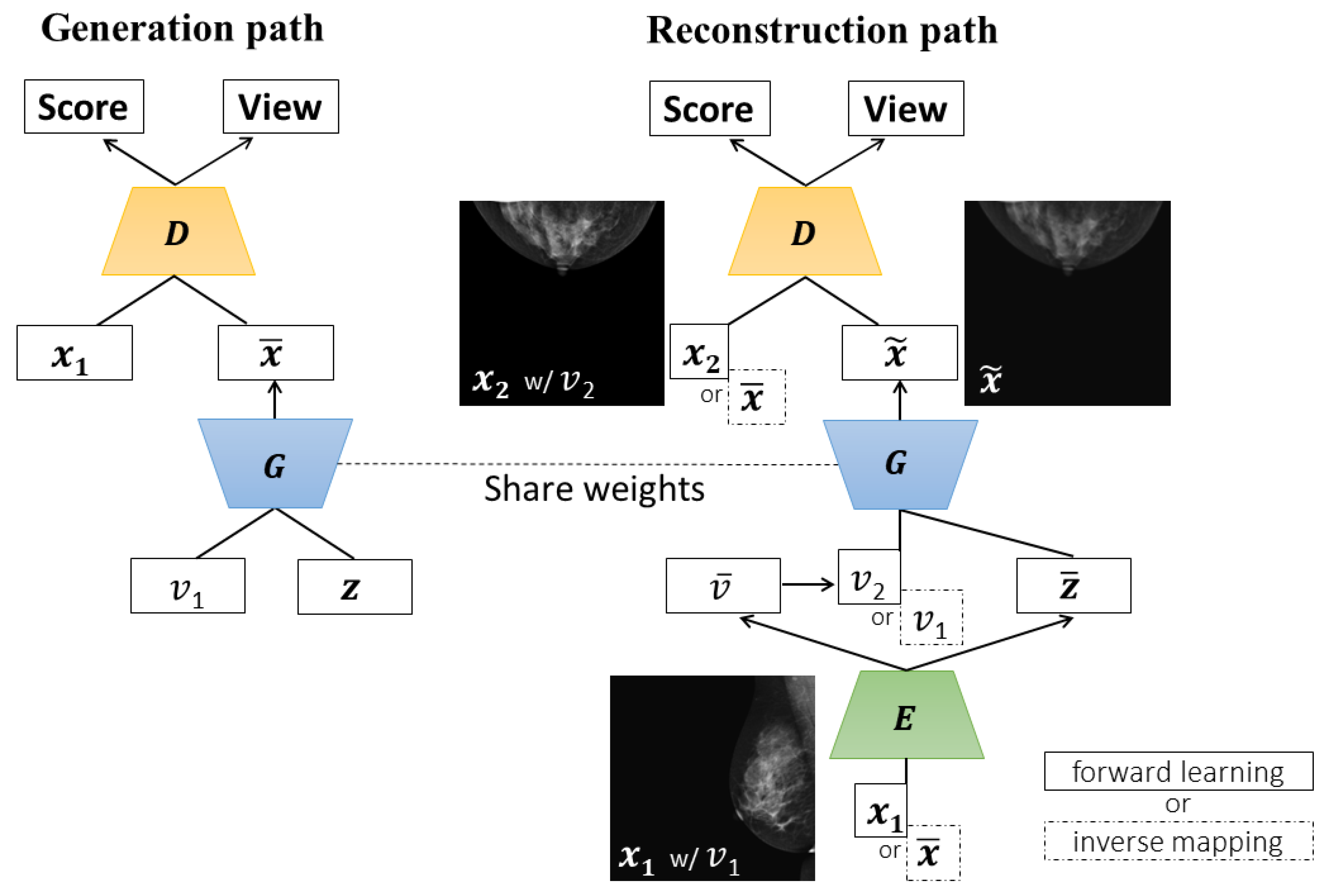
2.1.1. CR-GAN
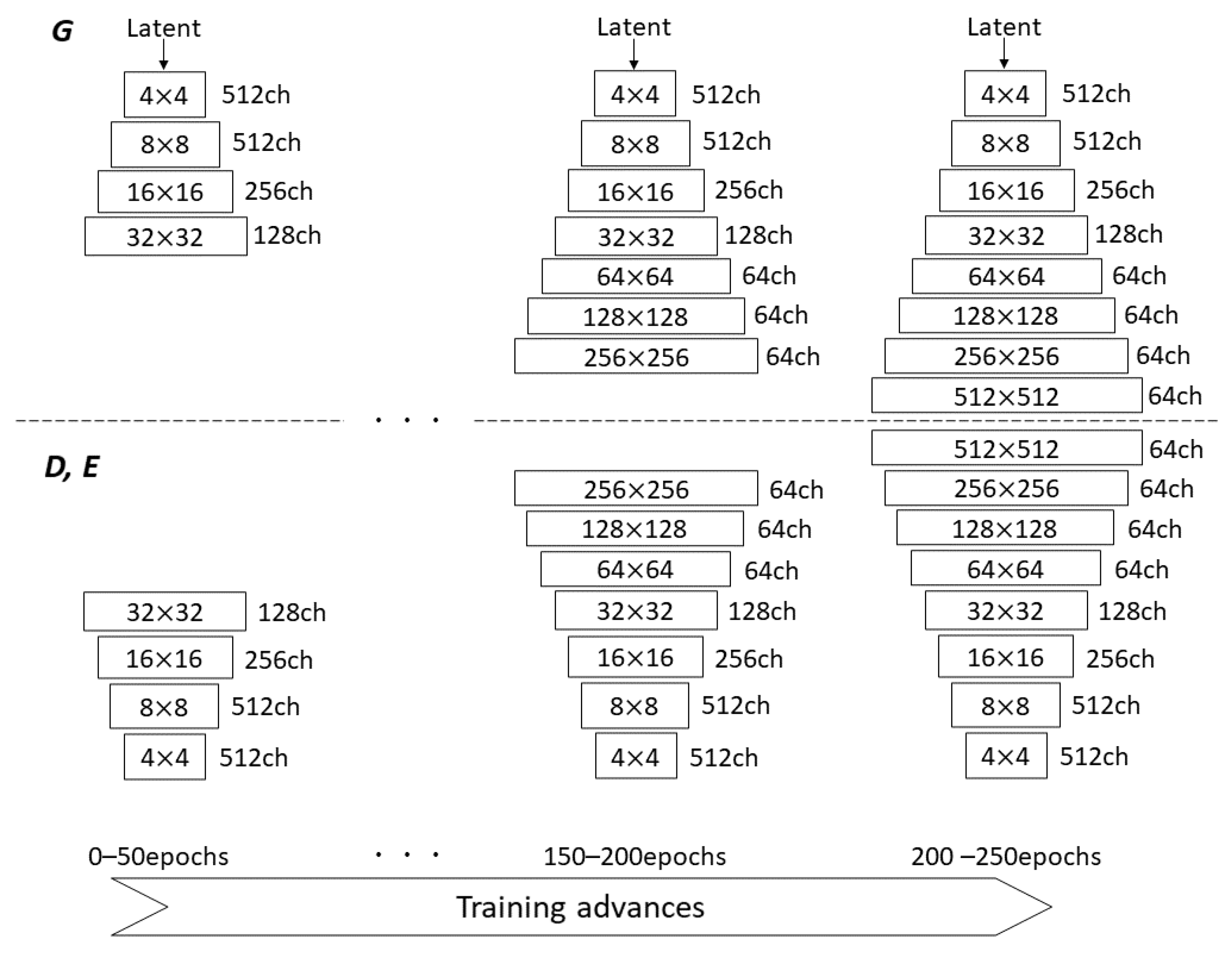
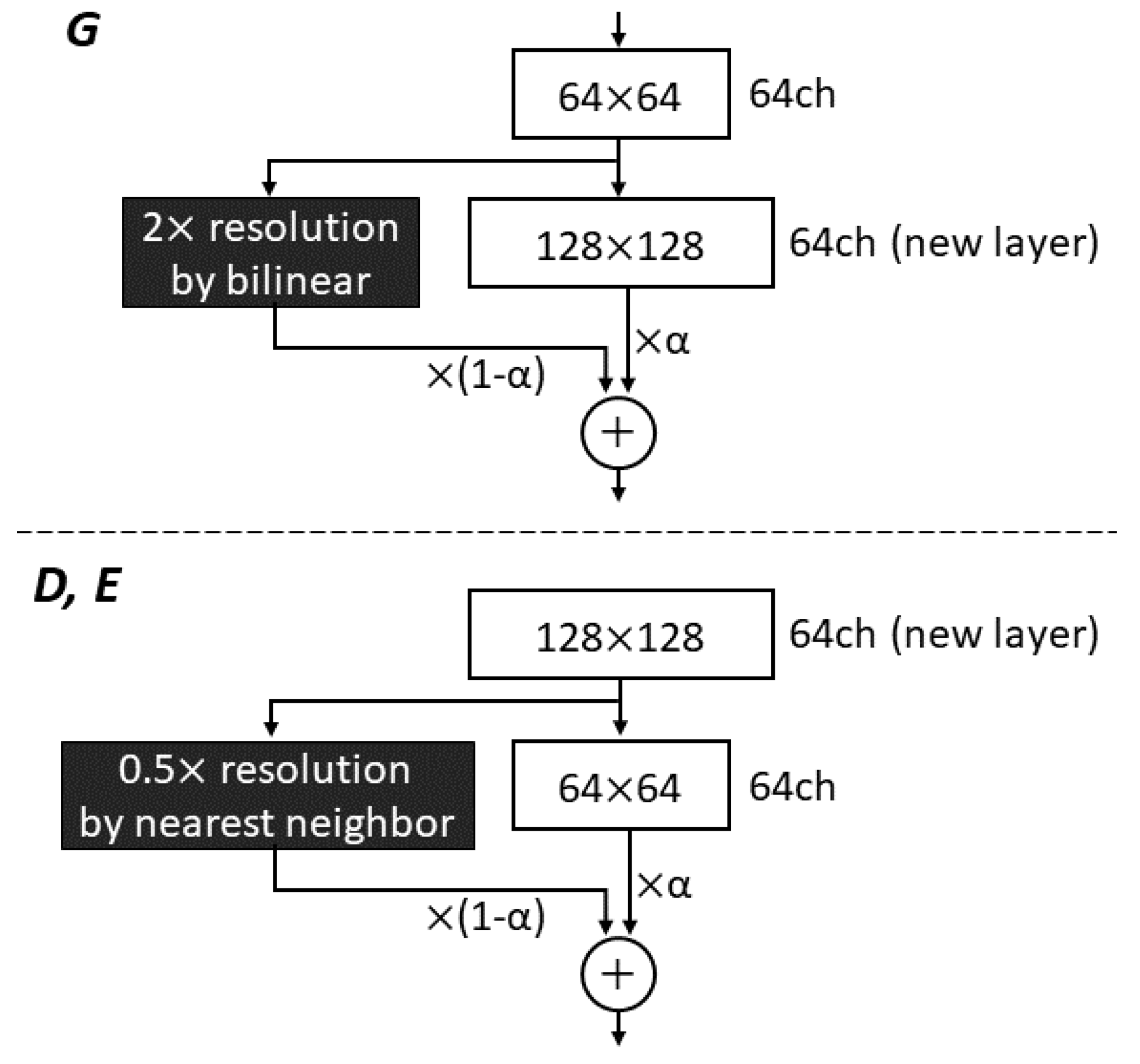
2.1.2. Progressive Growing Technique
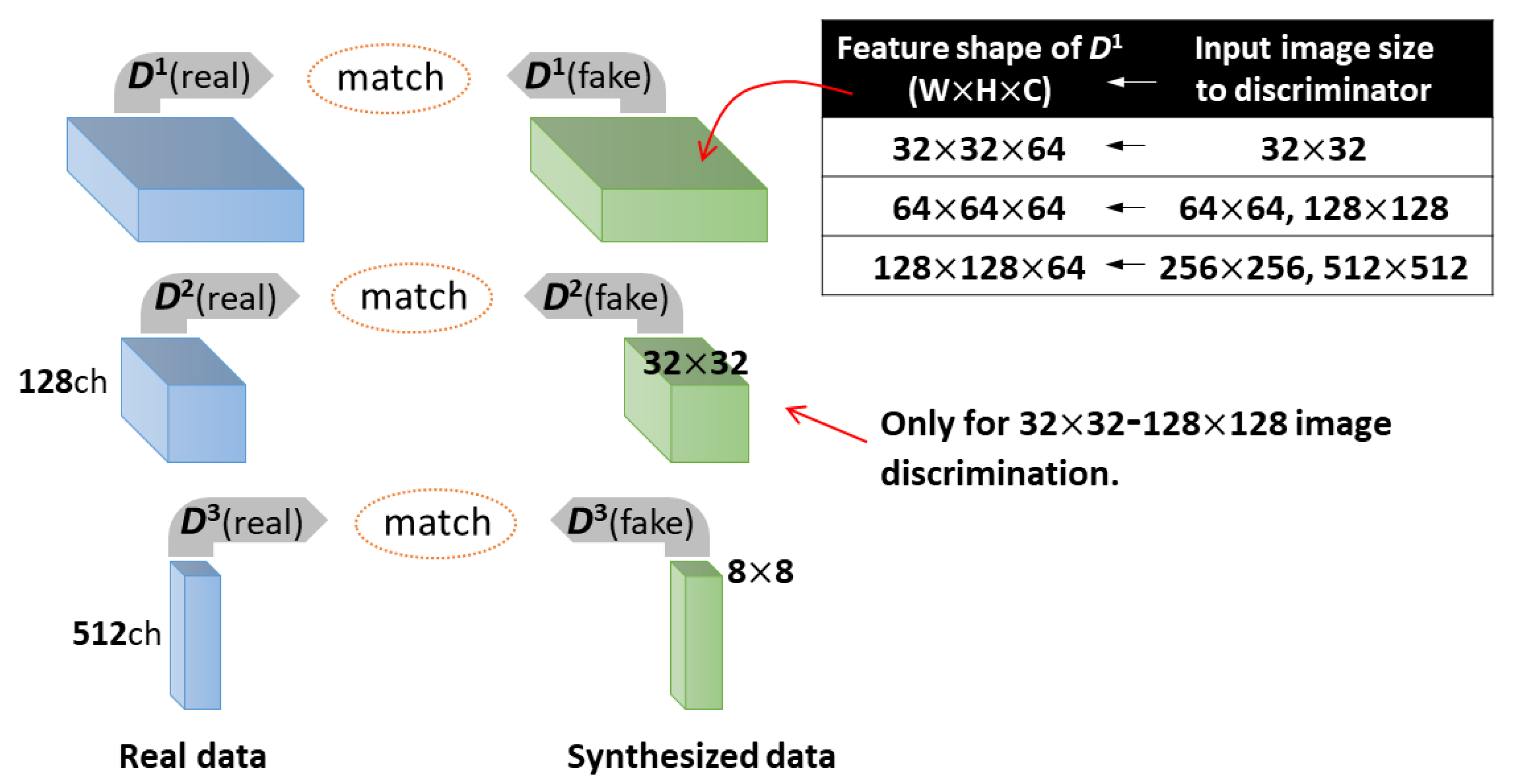
2.1.3. Feature Matching Loss
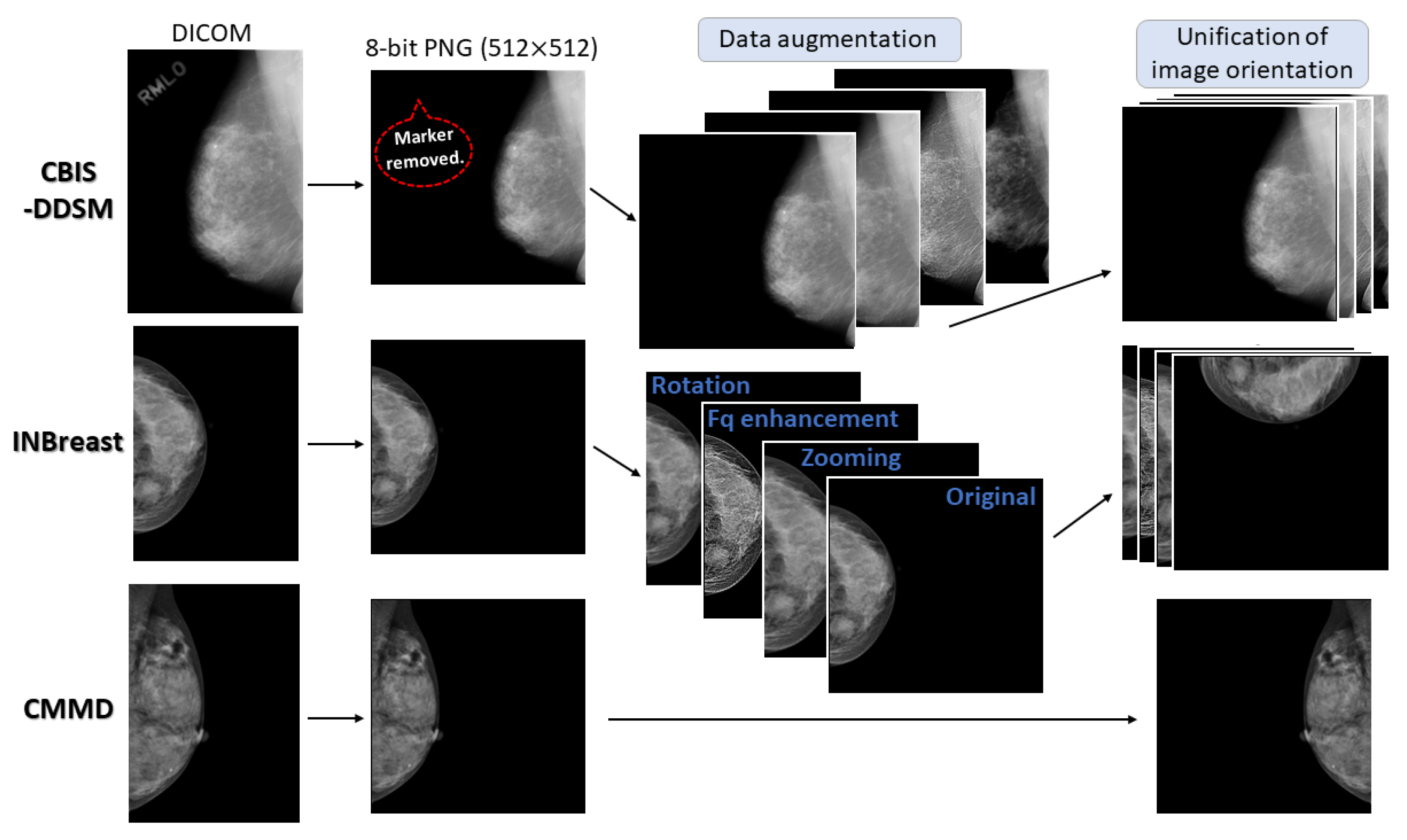
2.2. Data Sets
2.3. Pre-Processing for Training
2.4. Experimental Environment and Parameter Settings
2.5. Performance Evaluation
3. Results
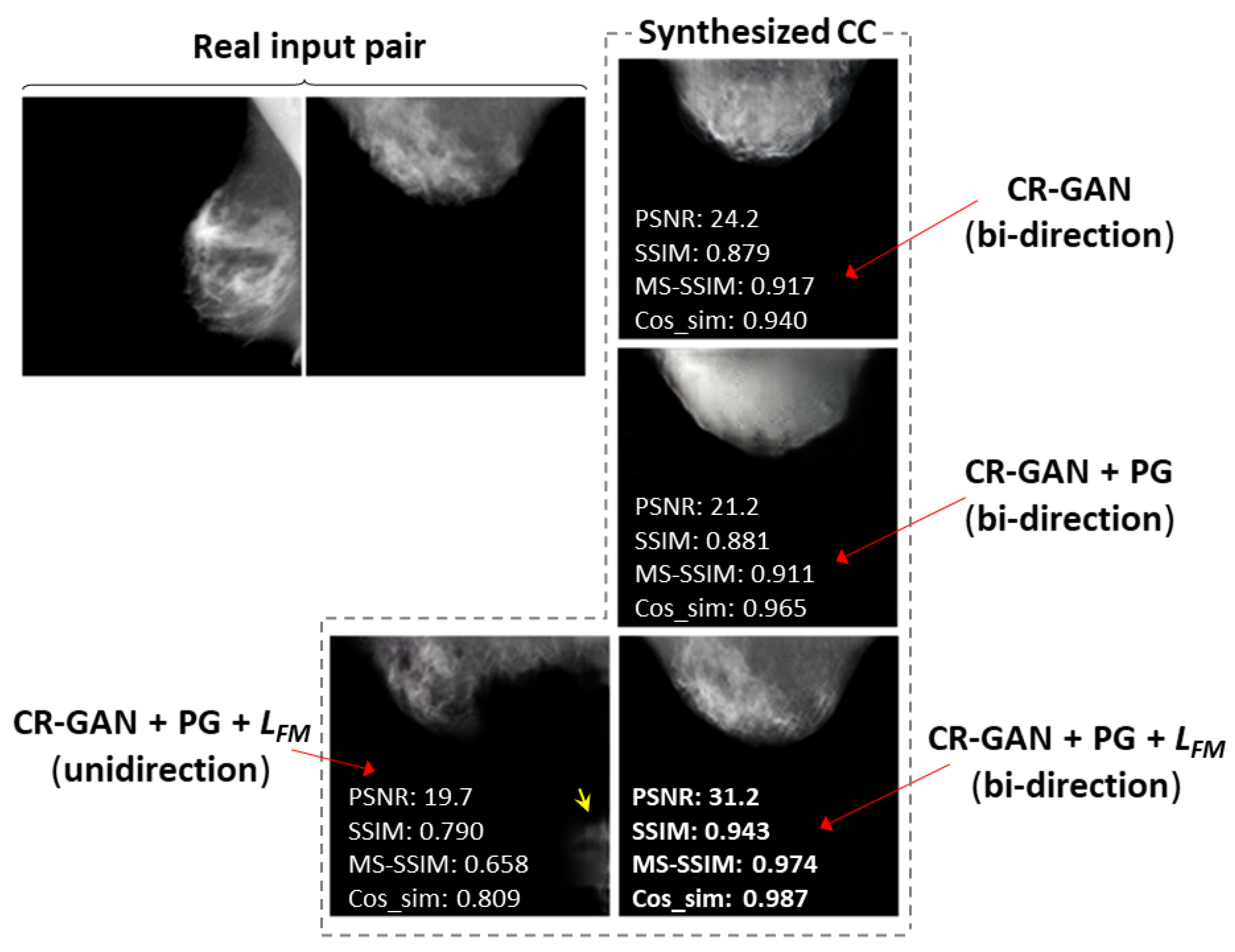
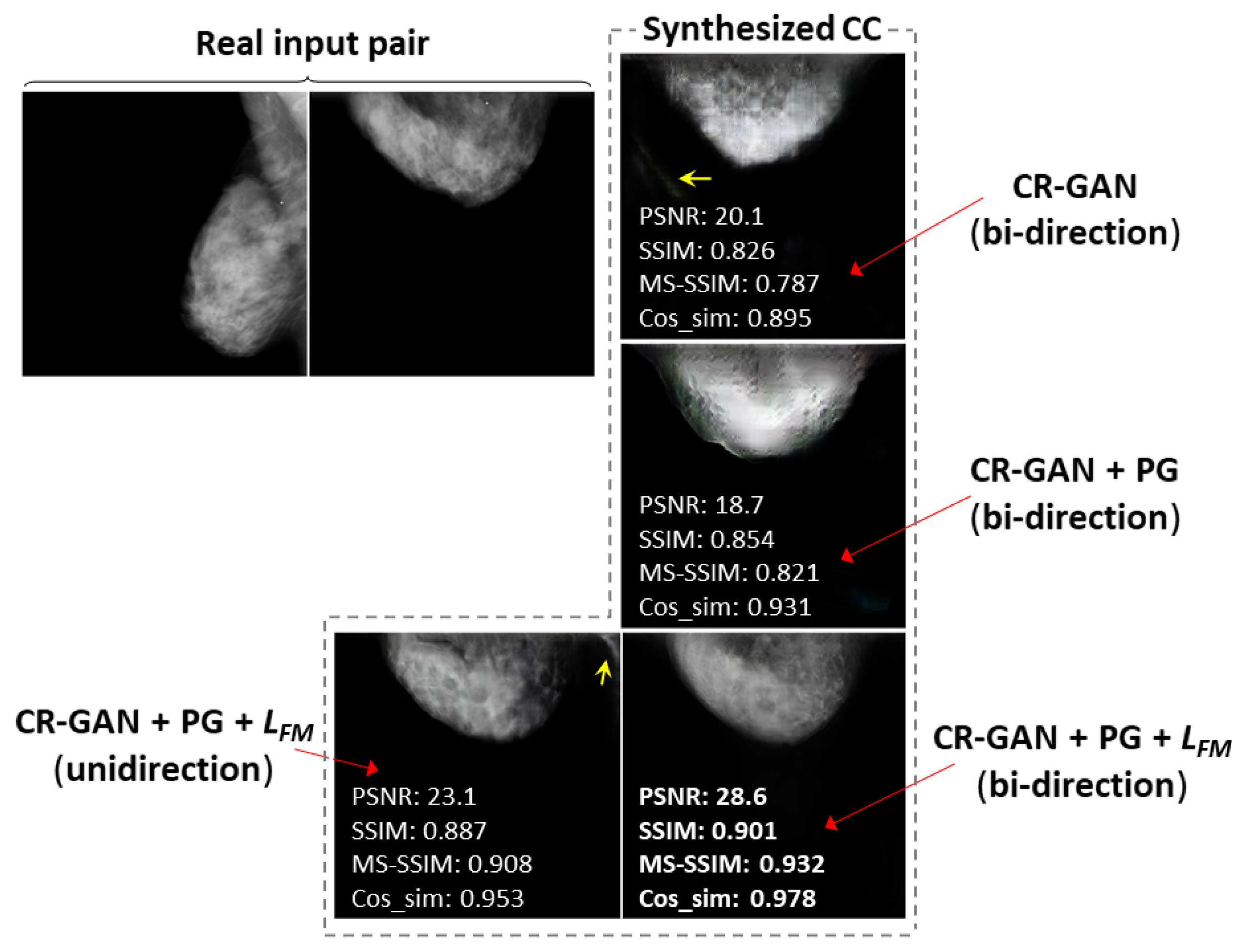
3.1. Comparison of the Similarity Metrics by Training Methods
3.2. Comparison of Images Synthesized by Different Training Methods
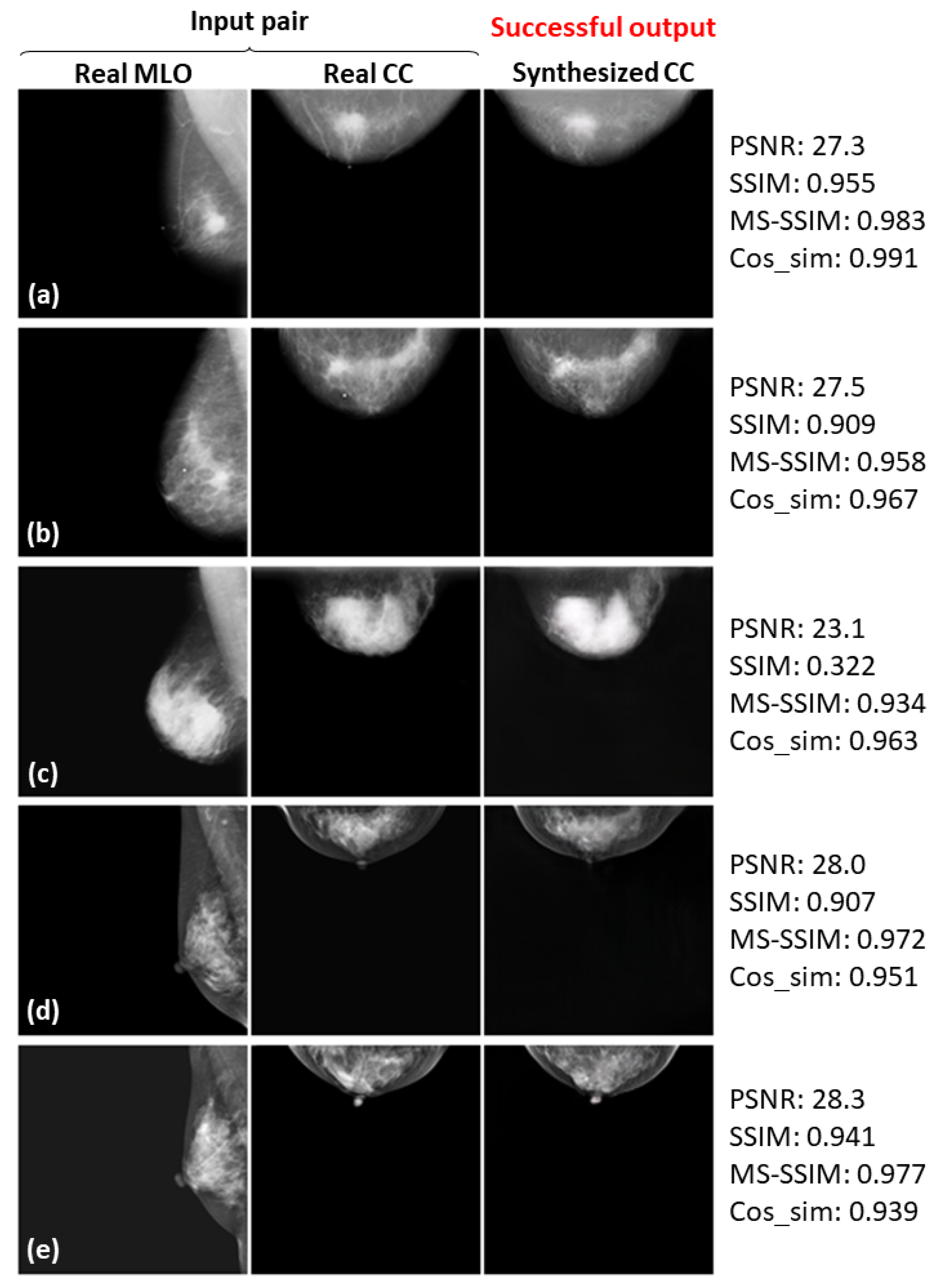
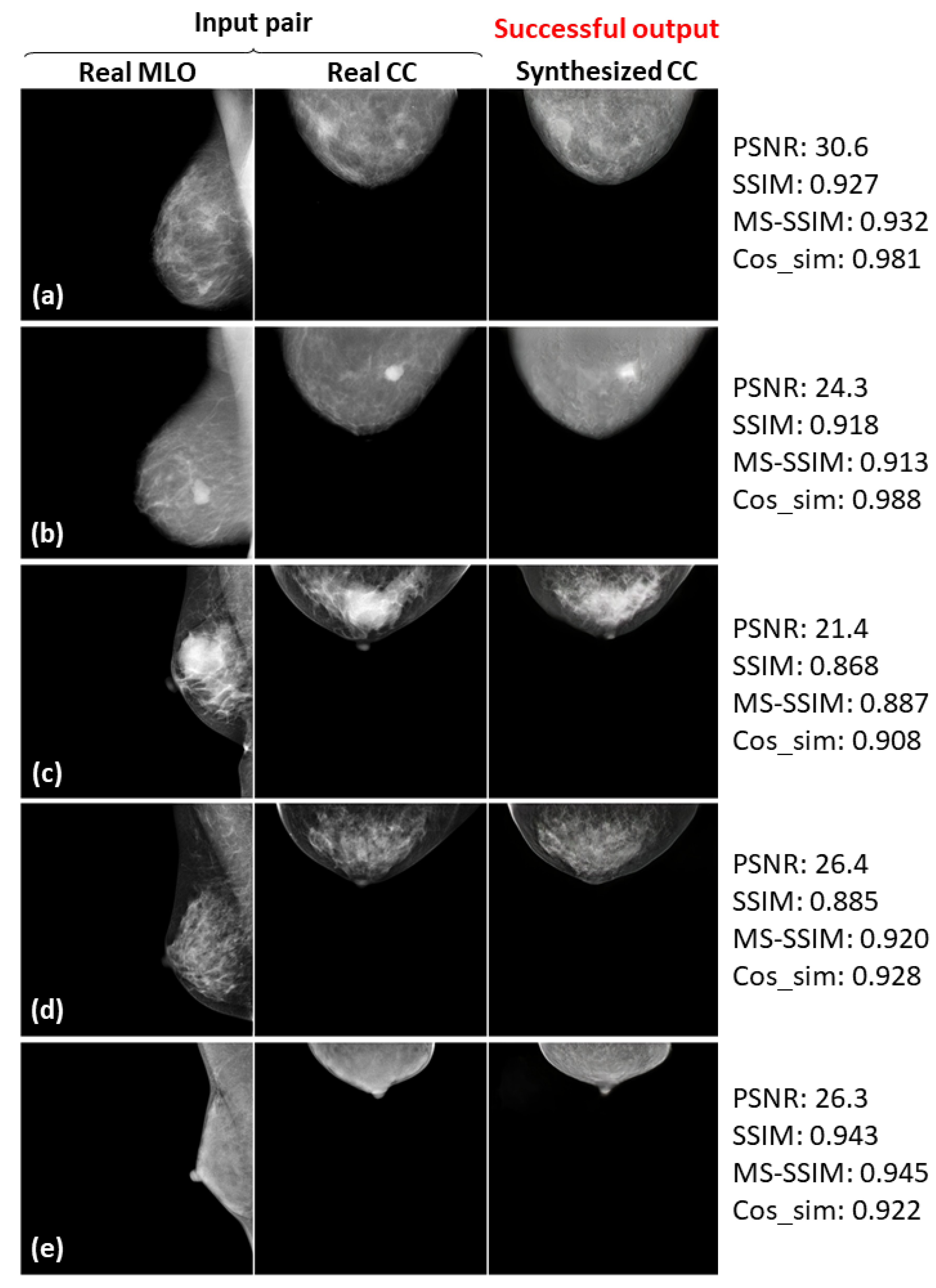
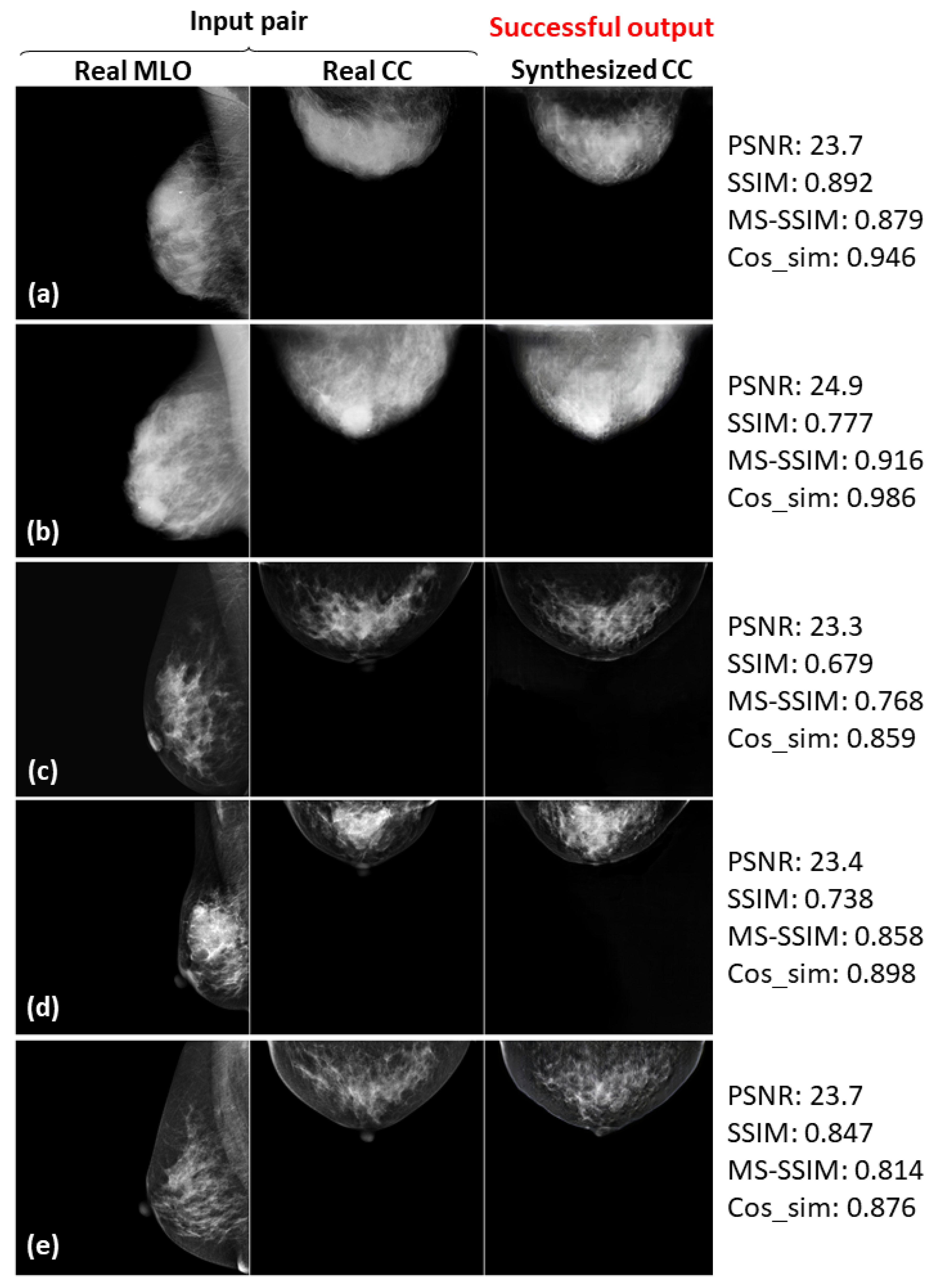
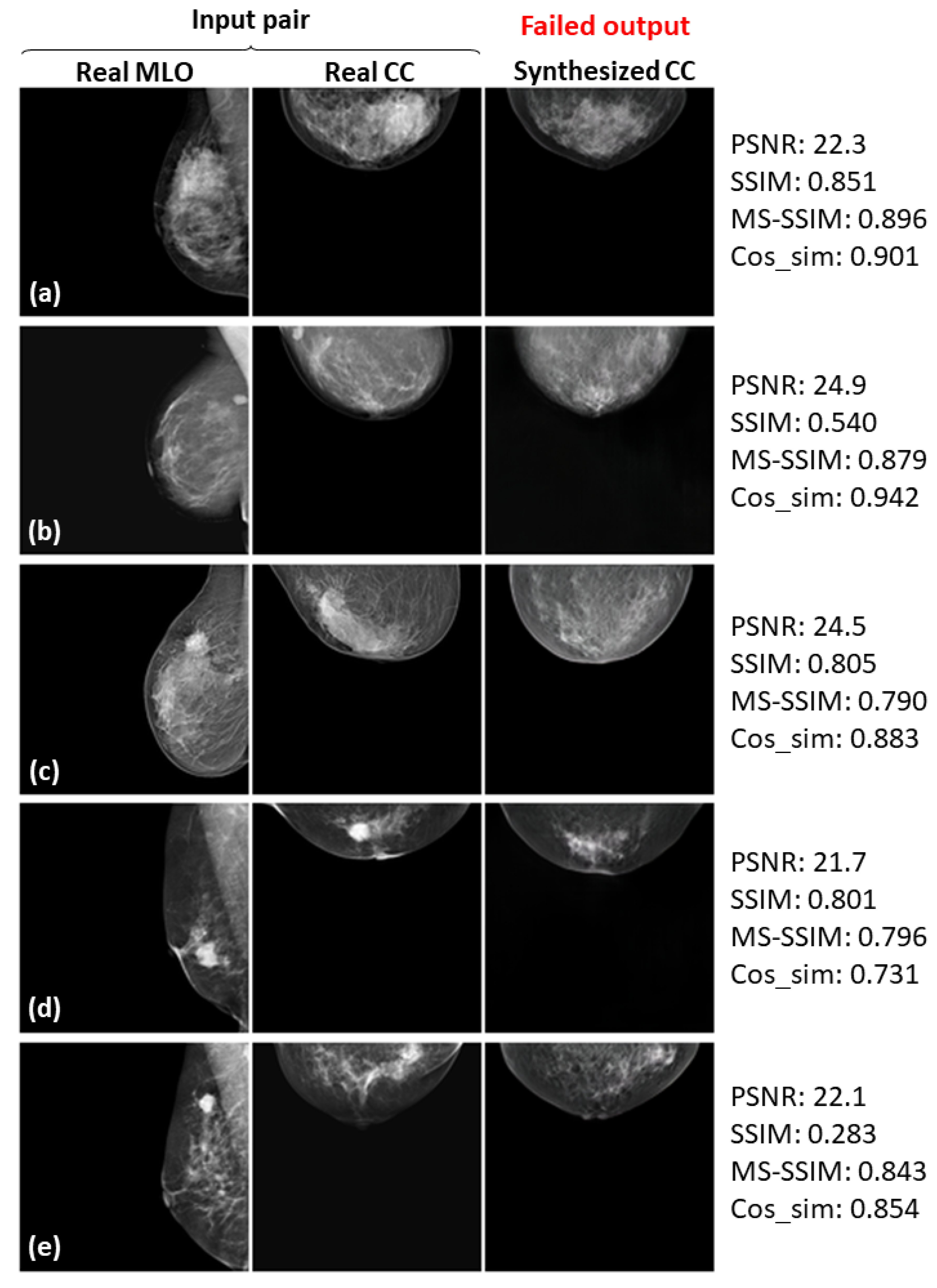
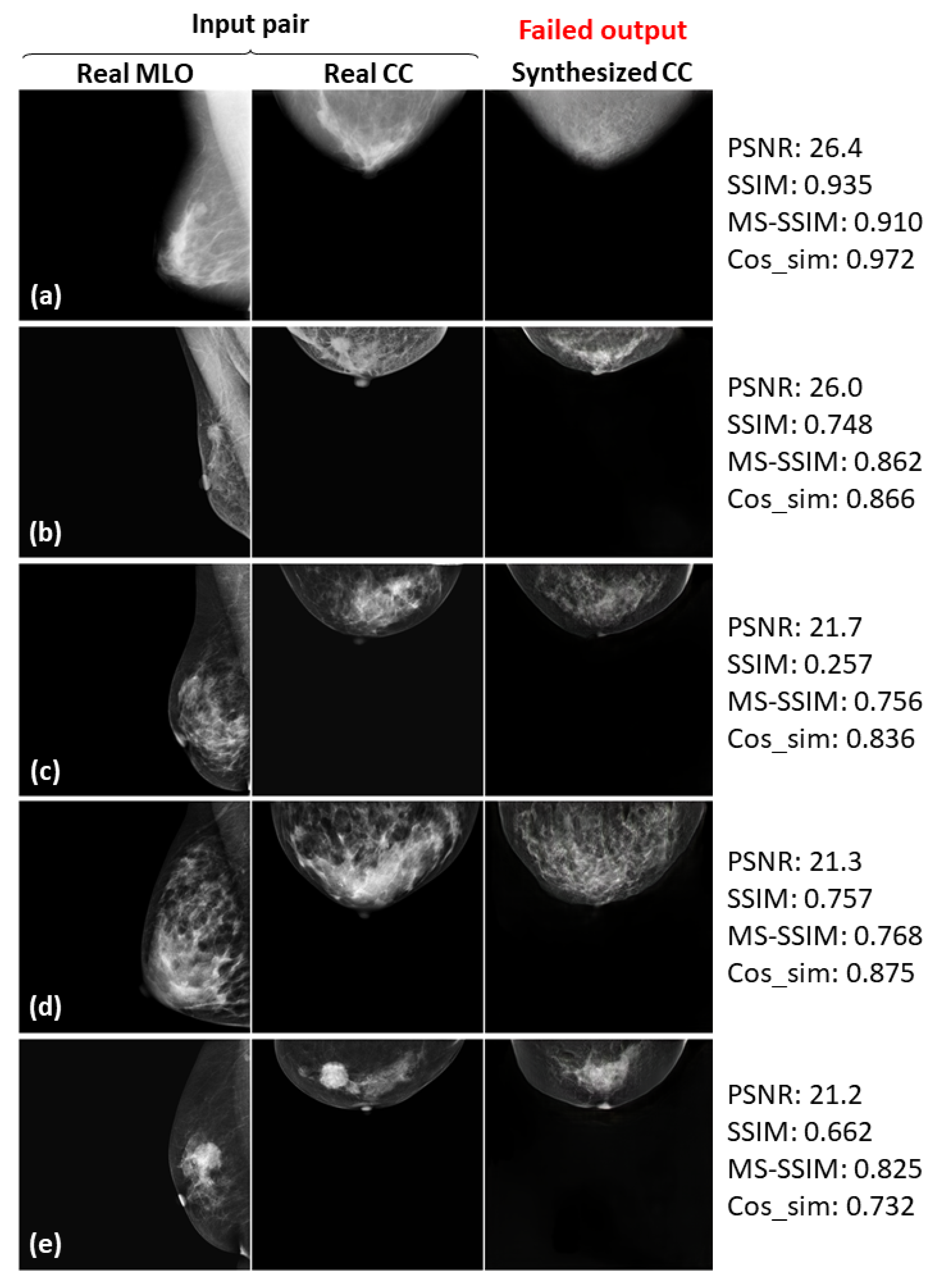
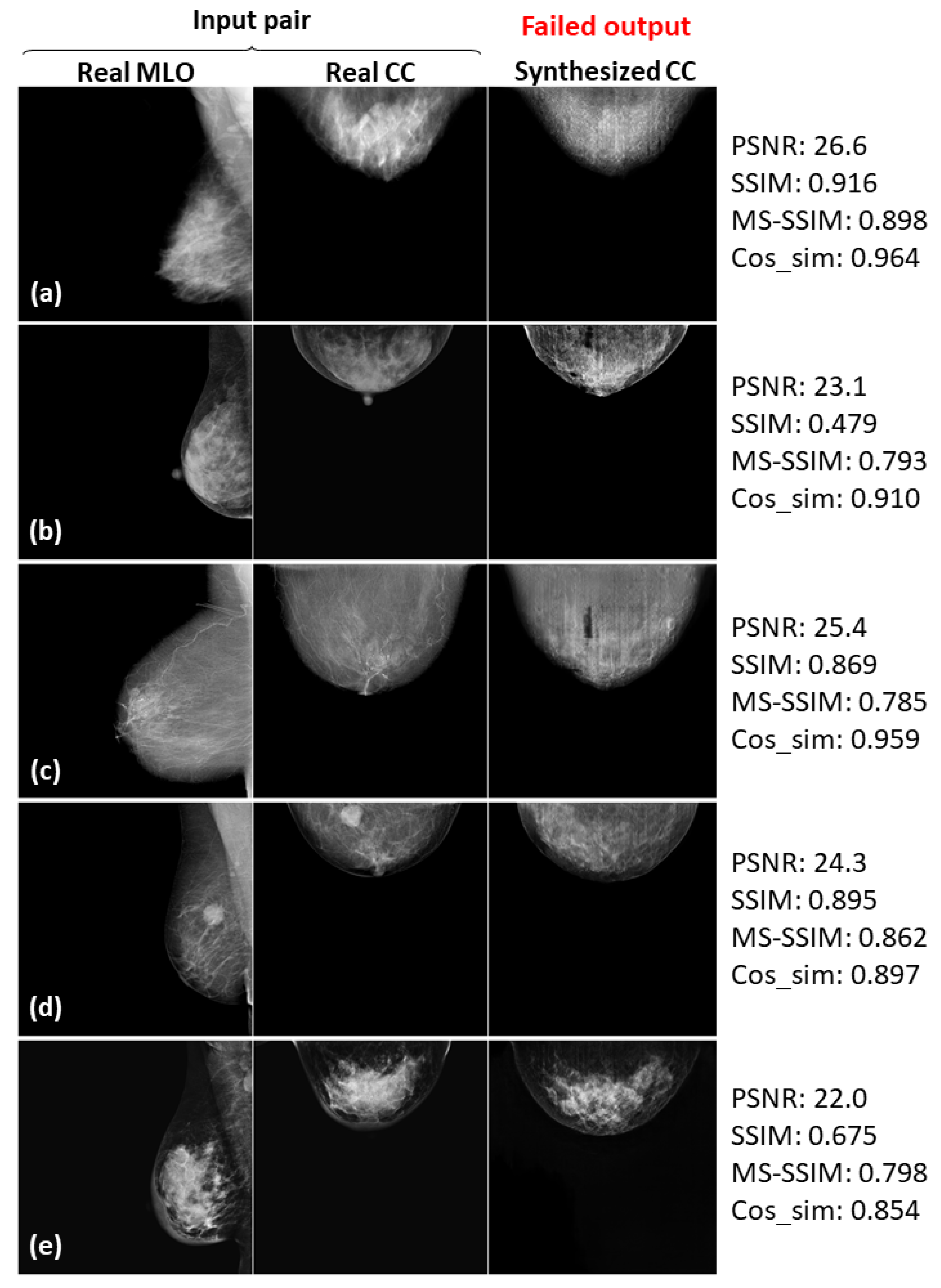
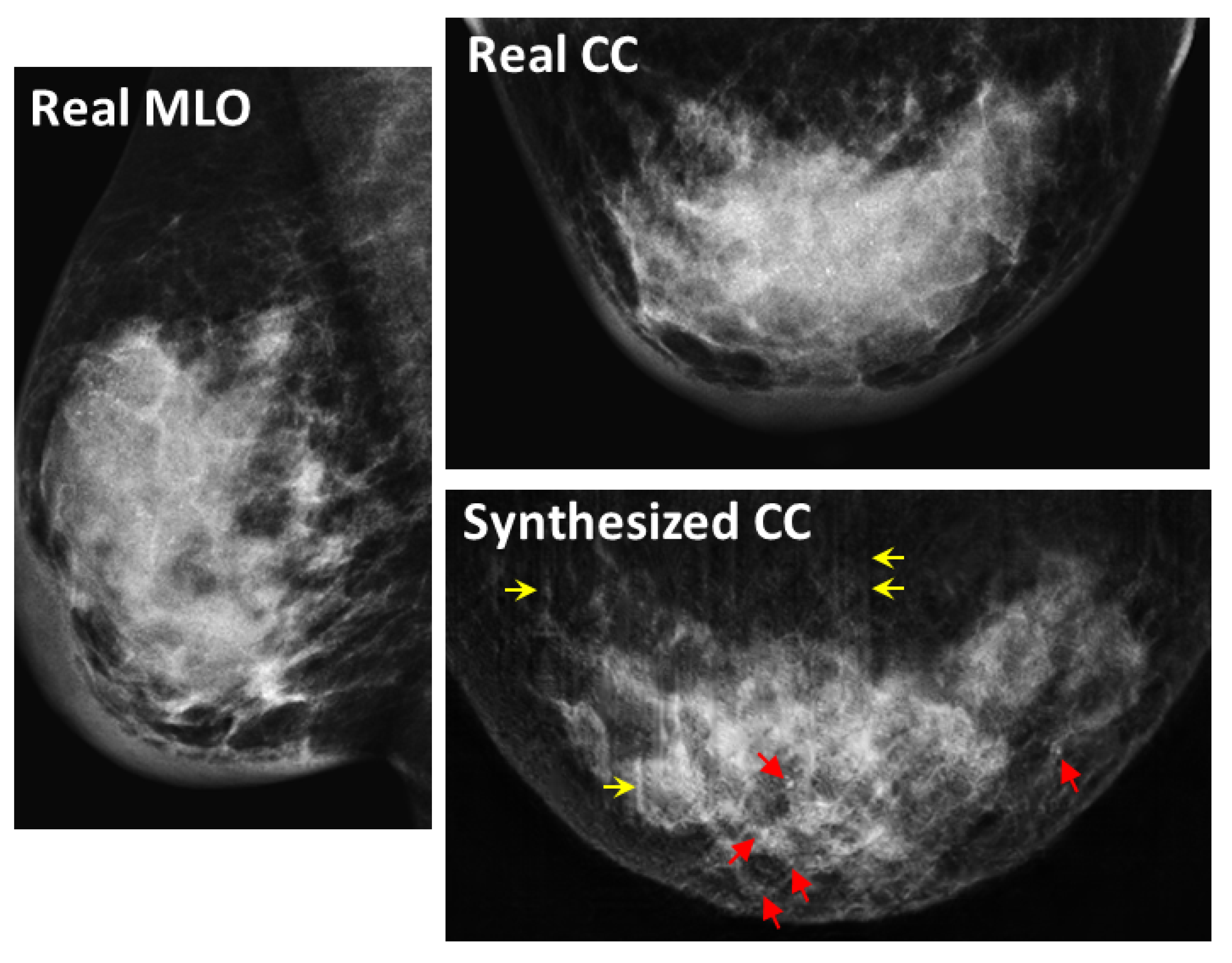
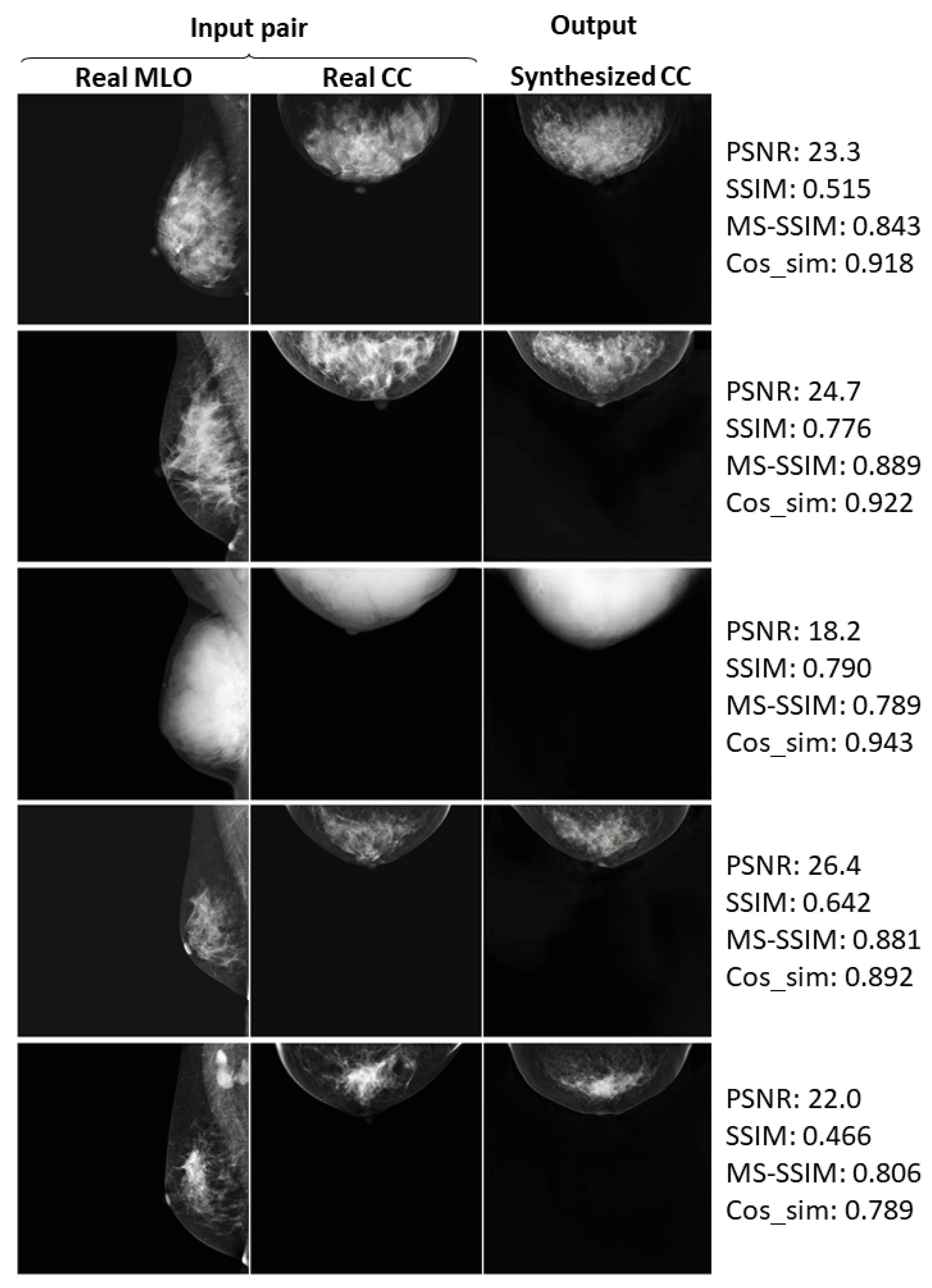
3.3. Successful and Failed Examples
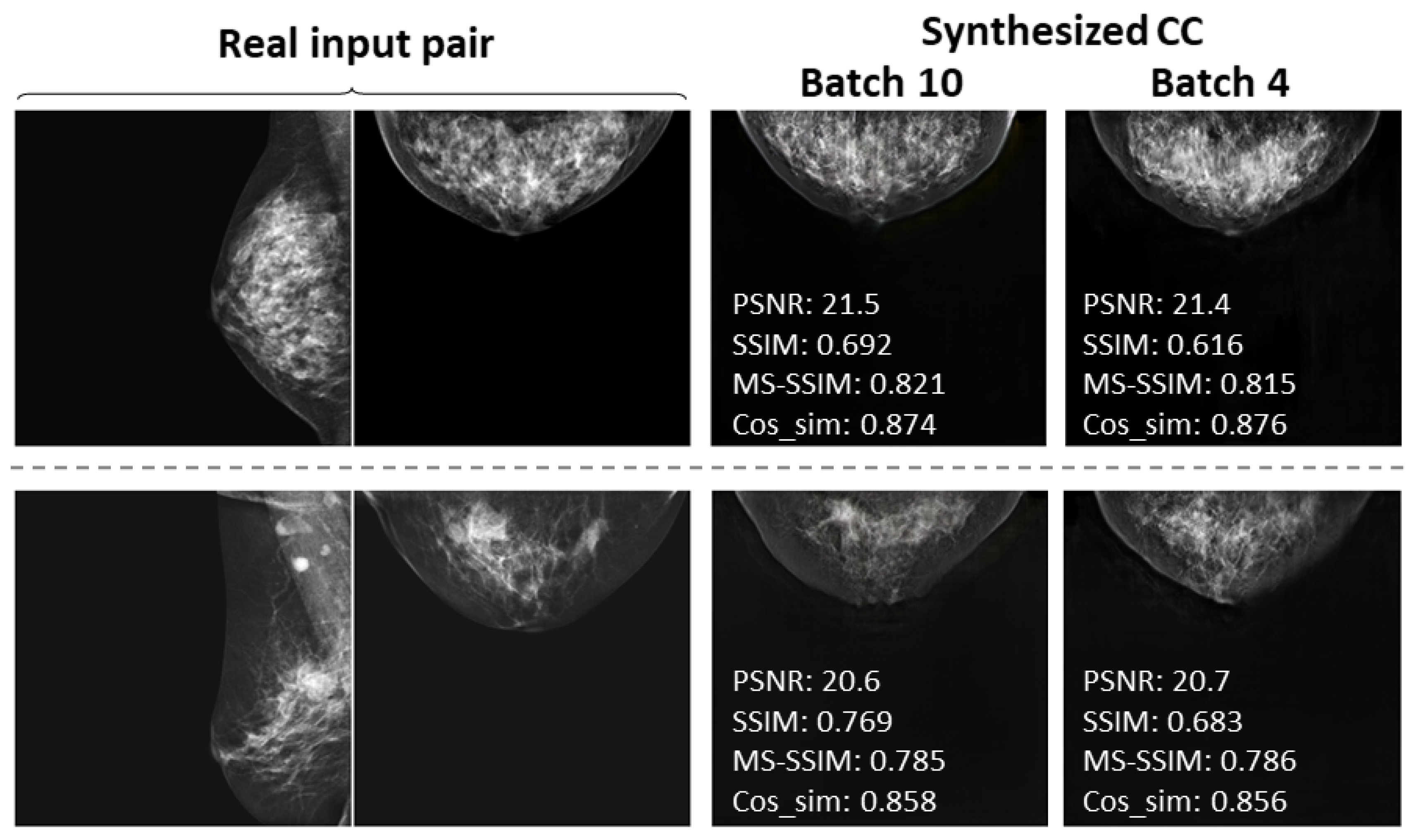
3.4. Comparison by Batch Size
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
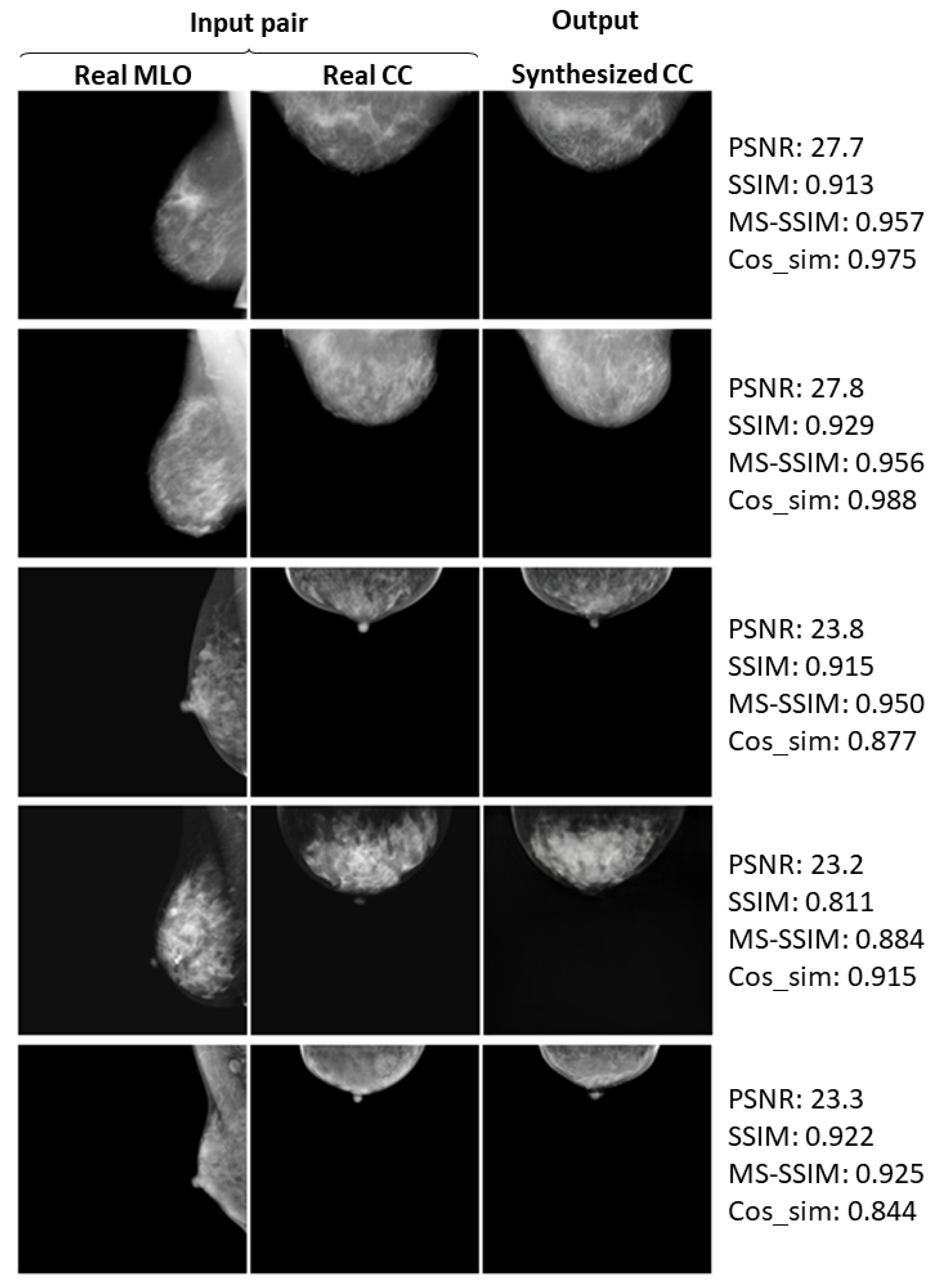
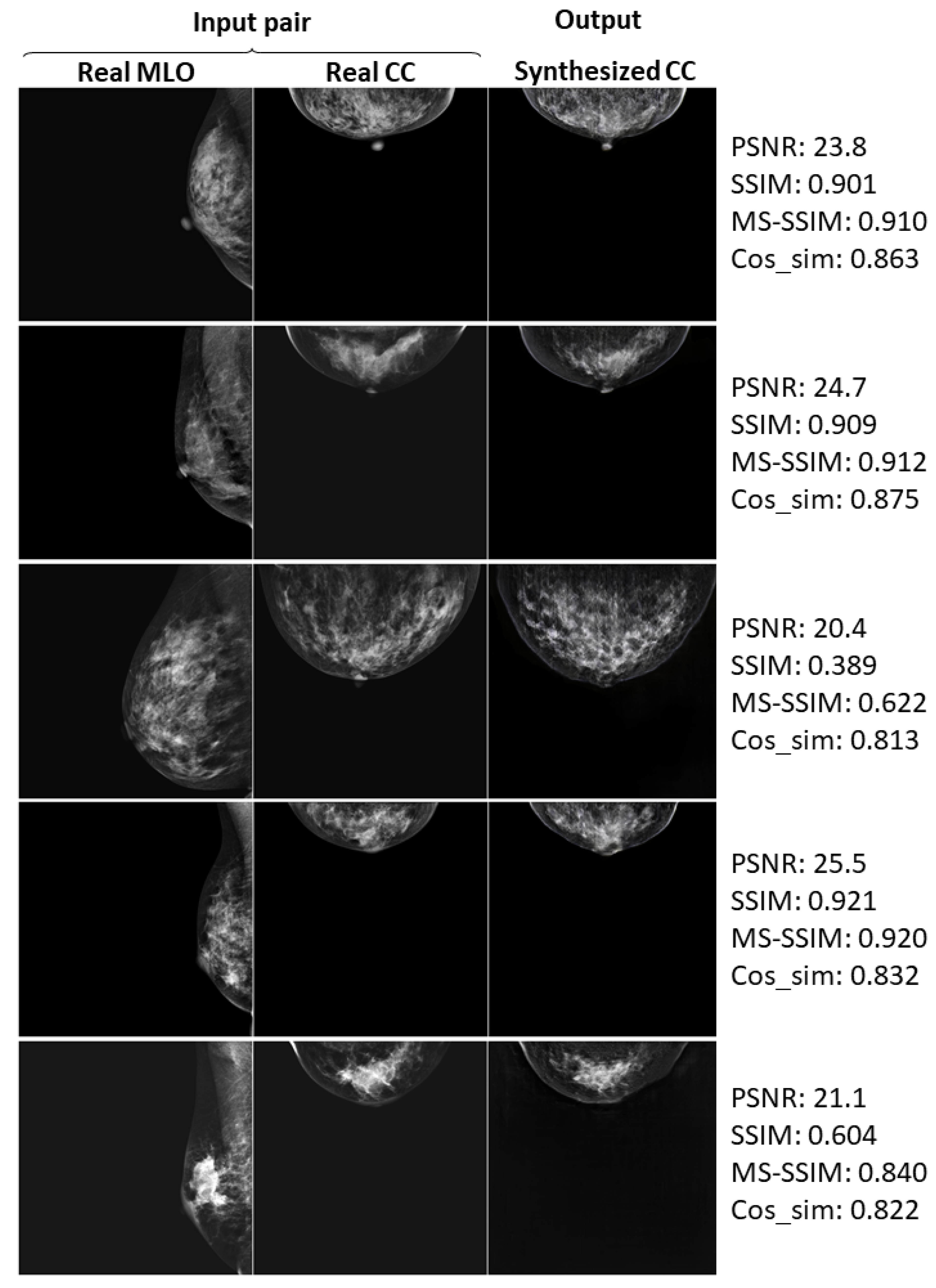
Appendix A. Further Examples



References
- Terrasse, V. Latest global cancer data: Cancer burden rises to 19.3 million new cases and 10.0 million cancer deaths in 2020. In The International Agency for Research on Cancer Press Release 292; IARC: Lyon, France, 2020; pp. 1–3. [Google Scholar]
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global Cancer Statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef] [PubMed]
- Mayor, S. Survival of women treated for early breast cancer detected by screening is same as in general population, audit shows. BML 2008, 336, 1398–1399. [Google Scholar] [CrossRef] [PubMed]
- Duffy, S.W.; Vulkan, D.; Cuckle, H.; Parmar, D.; Sheikh, S.; Smith, R.A.; Evans, A.; Blyuss, O.; Johns, L.; Ellis, I.O.; et al. Effect of mammographic screening from age 40 years on breast cancer mortality (UK Age trial): Final results of a randomised, controlled trial. Lancet Oncol. 2020, 21, 1165–1172. [Google Scholar] [CrossRef] [PubMed]
- Hamashima, C.; Ohta, K.; Kasahara, Y.; Katayama, T.; Nakayama, T.; Honjo, S.; Ohnuki, K. A meta-analysis of mammographic screening with and without clinical breast examination. Cancer Sci. 2015, 106, 812–818. [Google Scholar] [CrossRef]
- van den Ende, C.; Oordt-Speets, A.M.; Vroling, H.; van Agt, M.E. Benefits and harms of breast cancer screening with mammography in women aged 40–49 years: A systematic review. Int. J. Cancer 2017, 141, 1295–1306. [Google Scholar] [CrossRef]
- Christiansen, S.R.; Autier, P.; Støvring, H. Change in effectiveness of mammography screening with decreasing breast cancer mortality: A population-based study. Eur. J. Public Health. 2022, 32, 630–635. [Google Scholar] [CrossRef]
- Gossner, J. Digital mammography in young women: Is a single view sufficient? J. Clin. Diagn. Res. 2016, 10, TC10–TC12. [Google Scholar] [CrossRef]
- Rubin, D. Guidance on Screening and Symptomatic Breast Imaging, 4th ed.; The Royal College of Radiologists: London, UK, 2019; pp. 1–27. [Google Scholar]
- Sickles, E.A.; Weber, W.N.; Galvin, H.B.; Ominsky, S.H.; Sollitto, R.A. Baseline screening mammography: One vs two views per breast. Am. J. Roentgenol. 1986, 147, 1149–1155. [Google Scholar] [CrossRef]
- Feig, S.A. Screening mammography: A successful public health initiative. Pan. Am. J. Public Health 2006, 20, 125–133. [Google Scholar] [CrossRef]
- Ray, K.M.; Joe, B.N.; Freimanis, R.I.; Sickles, E.A.; Hendrick, R.E. Screening mammographyin women 40-49 years old: Current evidence. Am. J. Roentgenol. 2018, 210, 264–270. [Google Scholar] [CrossRef]
- Kasumi, F. Problems in breast cancer screening. Jpn. Med. Assoc. J. 2005, 48, 301–309. [Google Scholar]
- Tsuchida, J.; Nagahashi, M.; Rashid, O.M.; Takabe, K.; Wakai, T. At what age should screening mammography be recommended for Asian women? Cancer Med. 2015, 4, 1136–1144. [Google Scholar] [CrossRef]
- Helme, S.; Perry, N.; Mokbel, K. Screening mammography in women aged 40–49: Is it time to change? Int. Semin. Surg. Oncol. 2006, 3, 1–4. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Giess, C.S.; Frost, E.P.; Birdwell, R.L. Interpreting one-view mammographic findings: Minimizing callbacks while maximizing cancer detection. RadioGraphics. 2014, 34, 928–940. [Google Scholar] [CrossRef] [PubMed]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.W.M.; van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar]
- Bakator, M.; Radosav, D. Deep learning and medical diagnosis: A review of literature. Multimodal Technol. Interact. 2018, 2, 47. [Google Scholar] [CrossRef]
- Sahiner, B.; Pezeshk, A.; Hadjiiski, L.M.; Wang, X.; Drukker, K.; Cha, K.H.; Summers, R.M.; Giger, M.L. Deep learning in medical imaging and radiation therapy. Med. Phys. 2019, 46, e1–e36. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems (NIPS 2014); NeurIPS: San Diego, CA, USA, 2014; pp. 2672–2680. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. In Proceedings of the Sixth International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–26. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of StyleGAN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8107–8116. [Google Scholar]
- Lee, J.; Nishikawa, R.M. Identifying women with mammographically- occult breast cancer leveraging GAN- simulated mammograms. IEEE Trans. Med. Imaging 2022, 41, 225–236. [Google Scholar] [CrossRef]
- Korkinof, D.; Rijken, T.; O’Neill, M.; Yearsley, J.; Harvey, H.; Glocker, B. High-resolution mammogram synthesis using progressive generative adversarial networks. arXiv 2018, arXiv:1807.03401. [Google Scholar]
- Oyelade, O.N.; Ezugwu, A.E.; Almutairi, M.S.; Saha, A.K.; Abualigah, L.; Chiroma, H. A generative adversarial network for synthetization of regions of interest based on digital mammograms. Sci. Rep. 2022, 12, 6166. [Google Scholar] [CrossRef]
- Tran, L.; Yin, X.; Liu, X. Disentangled representation learning GAN for pose-invariant face recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1283–1292. [Google Scholar]
- Zhao, B.; Wu, X.; Cheng, Z.; Liu, H.; Jie, Z.; Feng, J. Multi-view image generation from a single-view. arXiv 2018, arXiv:1704.04886. [Google Scholar]
- Heo, Y.; Kim, B.; Roy, P.P. Frontal face generation algorithm from multi-view images based on generative adversarial network. J. Multimed. Inf. Syst. 2021, 8, 85–92, ISSN: 2383–7632. [Google Scholar] [CrossRef]
- Zou, H.; Ak, K.E.; Kassim, A.A. Edge-Gan: Edge conditioned multi-view face image generation. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 2401–2405. [Google Scholar]
- Tian, Y.; Peng, X.; Zhao, L.; Zhang, S.; Metaxas, D.N. CR-GAN: Learning complete representations for multi-view generation. arXiv 2018, arXiv:1806.11191. [Google Scholar]
- Jahanian, A.; Puig, X.; Tian, Y.; Isola, P. Generative models as a data source for multiview representation learning. arXiv 2021, arXiv:2106.05258. [Google Scholar]
- bluer555/CR-GAN. Available online: https://github.com/bluer555/CR-GAN (accessed on 31 October 2022).
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved training of Wasserstein GANs. In NeurIPS Proceedings; NeurIPS: San Diego, CA, USA, 2017; pp. 5769–5779. [Google Scholar]
- Wang, T.; Liu, M.; Zhu, J.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; pp. 694–711. [Google Scholar]
- Donahue, J.; Krähenbühl, P.; Darrell, T. Adversarial feature learning. arXiv 2016, arXiv:1605.09782. [Google Scholar]
- Lee, R.S.; Gimenez, F.; Hoogi, A.; Miyake, K.K.; Gorovoy, M.; Rubin, D.L. A curated mammography data set for use in computer-aided detection and diagnosis research. Sci. Data. 2017, 4, 170177. [Google Scholar] [CrossRef]
- Inês, C.M.; Igor, A.; Hoogi, A.; Inês, D.; António, C.; Maria, J.C.; Jaime, S.C. INbreast: Toward a full-field digital mammographic database. Acad. Radiol. 2012, 19, 236–248. [Google Scholar]
- The Chinese Mammography Database (CMMD). Available online: https://wiki.cancerimagingarchive.net/pages/viewpage.action?pageId=70230508 (accessed on 31 October 2022).
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs trained by a two time-scale update rule converge to a local nash equilibrium. In Advances in Neural Information Processing Systems (NIPS 2017); NeurIPS: San Diego, CA, USA, 2017; pp. 6626–6637. [Google Scholar]
- Borji, A. Pros and cons of GAN evaluation measures. arXiv 2018, arXiv:1802.03446. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error measurement to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the 37th IEEE Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; Volume 2, pp. 1398–1402. [Google Scholar]
- Jaiswal, A.; Babu, A.R.; Zadeh, M.Z.; Banerjee, D. A survey on contrastive self-supervised learning. arXiv 2021, arXiv:2011.00362. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. arXiv 2020, arXiv:2002.05709. [Google Scholar]
- Gross, R.; Matthews, I.; Cohn, J.; Kanade, T.; Baker, S. Multi-PIE. Image Vis. Comput. 2010, 25, 807–813. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Umme, S.; Morium, A.; Mohammad, S.U. Image quality assessment through FSIM, SSIM, MSE and PSNR—A comparative study. J. Comput. Commun. 2019, 7, 8–18. [Google Scholar]
- Pambrun, J.-F.; Noumeir, R. Limitations of the SSIM quality metric in the context of diagnostic imaging. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 2960–2963. [Google Scholar]
- Mudeng, V.; Kim, M.; Choe, S. Prospects of structual similarity index for medical image analysis. Appl. Sci. 2022, 12, 3754. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Description of Type | Norm 1 | Activation | Input Shape 2 | Output Shape 2 | |
|---|---|---|---|---|---|---|
| Input projection | FC 3 | Linear transformation | – | – | 256 | 4 × 4 × 512 |
| Layer 1 | Convolution1 | {Upsample→Conv2d(3,1,1)} +{BN→ReLU→Upsample →BN→ReLU→Conv2d(3,1,1)} | 4 × 4 × 512 | 8 × 8 × 512 | ||
| Layer 2 | 8 × 8 × 512 | 16 × 16 × 256 | ||||
| Layer 3 | 16 × 16 × 256 | 32 × 32 × 128 | ||||
| Layer 4 | 32 × 32 × 128 | 64 × 64 × 64 | ||||
| Layer 5 | 64 × 64 × 64 | 128 × 128 × 64 | ||||
| Layer 6 | BN | ReLU | 128 × 128 × 64 | 256 × 256 × 64 | ||
| Layer 7 | Convolution2 | Conv2d(3,1,1) | – | Tanh | 256 × 256 × 64 | 256 × 256 × 3 |
| Type | Description of Type | Activation | Input Shape | Output Shape | |
|---|---|---|---|---|---|
| Layer 1 | Convolution1 | Conv2d(3,1,1) | – | 256 × 256 × 3 | 256 × 256 × 64 |
| Layer 2 | Convolution2 | {Conv2d(3,1,1)→AvgPool2d} +{ReLU→Conv2d(3,1,1)→ReLU →Conv2d(3,1,1)→AvgPool2d} | ReLU | 256 × 256 × 64 | 128 × 128 × 64 |
| Layer 3 | 128 × 128 × 64 | 64 × 64 × 64 | |||
| Layer 4 | 64 × 64 × 64 | 32 × 32 × 128 | |||
| Layer 5 | 32 × 32 × 128 | 16 × 16 × 256 | |||
| Layer 6 | 16 × 16 × 256 | 8 × 8 × 512 | |||
| Layer 7 | 8 × 8 × 512 | 4 × 4 × 512 | |||
| Layer 8-1 | FC | Linear transformation | Softmax | 4 × 4 × 512 | 2 |
| Layer 8-2 | – | 4 × 4 × 512 | 1 |
| Resolution | Batch Size | Model | Training Direction | PSNR | SSIM | MS-SSIM | Cos_sim | Time (h) |
|---|---|---|---|---|---|---|---|---|
| 128 × 128 | 20 | CR-GAN | Bi-directional | 21.9 | 0.746 | 0.842 | 0.817 | 16.8 |
| CR-GAN+PG | 23.0 | 0.742 | 0.858 | 0.877 | 21.8 | |||
| CR-GAN+PG | 23.9 | 0.754 | 0.883 | 0.889 | 23.0 | |||
| CR-GAN+PG | Unidirectional | 22.0 | 0.705 | 0.838 | 0.829 | 10.6 | ||
| 256 × 256 | 10 | CR-GAN | Bi-directional | 21.3 | 0.727 | 0.812 | 0.845 | 87.9 |
| CR-GAN+PG | 20.2 | 0.736 | 0.827 | 0.871 | 36.4 | |||
| CR-GAN+PG | 23.9 | 0.767 | 0.857 | 0.890 | 38.2 | |||
| CR-GAN+PG | Unidirectional | 21.2 | 0.730 | 0.821 | 0.799 | 30.1 | ||
| 4 | CR-GAN | Bi-directional | NA 1 | NA | NA | NA | NA | |
| CR-GAN+PG | ||||||||
| CR-GAN+PG | 23.1 | 0.766 | 0.852 | 0.876 | 72.8 | |||
| 512 × 512 | 4 | CR-GAN+PG | Bi-directional | NA | NA | NA | NA | NA |
| CR-GAN+PG | 22.7 | 0.766 | 0.831 | 0.868 | 112.4 | |||
| CR-GAN+PG | Unidirectional | NA | NA | NA | NA | NA |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yamazaki, A.; Ishida, T. Two-View Mammogram Synthesis from Single-View Data Using Generative Adversarial Networks. Appl. Sci. 2022, 12, 12206. https://doi.org/10.3390/app122312206
Yamazaki A, Ishida T. Two-View Mammogram Synthesis from Single-View Data Using Generative Adversarial Networks. Applied Sciences. 2022; 12(23):12206. https://doi.org/10.3390/app122312206
Chicago/Turabian StyleYamazaki, Asumi, and Takayuki Ishida. 2022. "Two-View Mammogram Synthesis from Single-View Data Using Generative Adversarial Networks" Applied Sciences 12, no. 23: 12206. https://doi.org/10.3390/app122312206
APA StyleYamazaki, A., & Ishida, T. (2022). Two-View Mammogram Synthesis from Single-View Data Using Generative Adversarial Networks. Applied Sciences, 12(23), 12206. https://doi.org/10.3390/app122312206