
Prostate Gleason Score Detection by Calibrated Machine Learning Classification through Radiomic Features

 , , , and
, , , and
Abstract
1. Introduction and Related Work
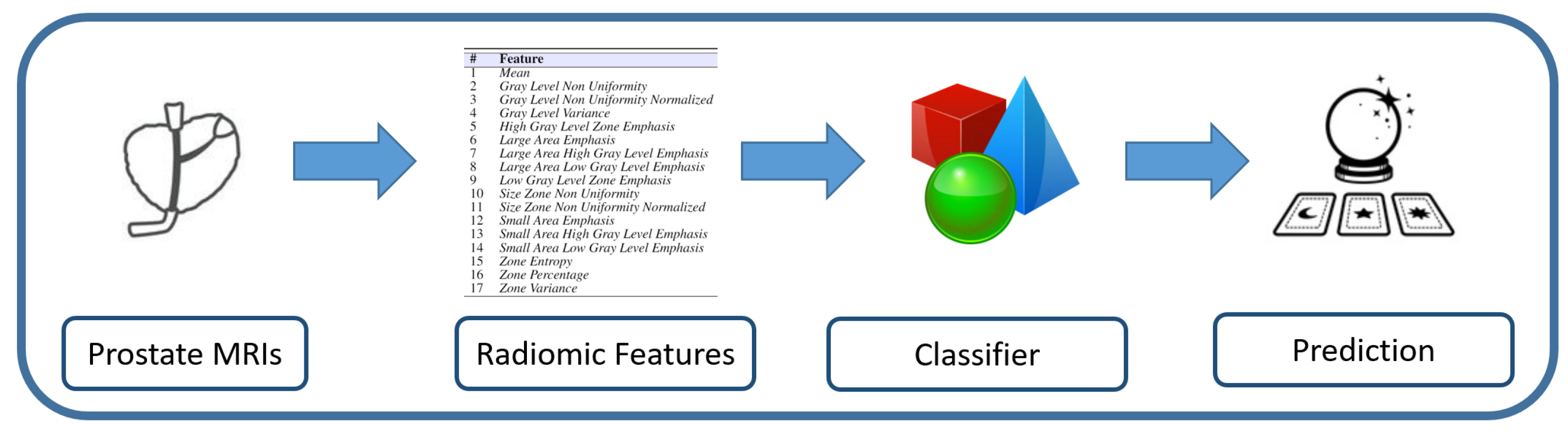
2. Materials and Methods
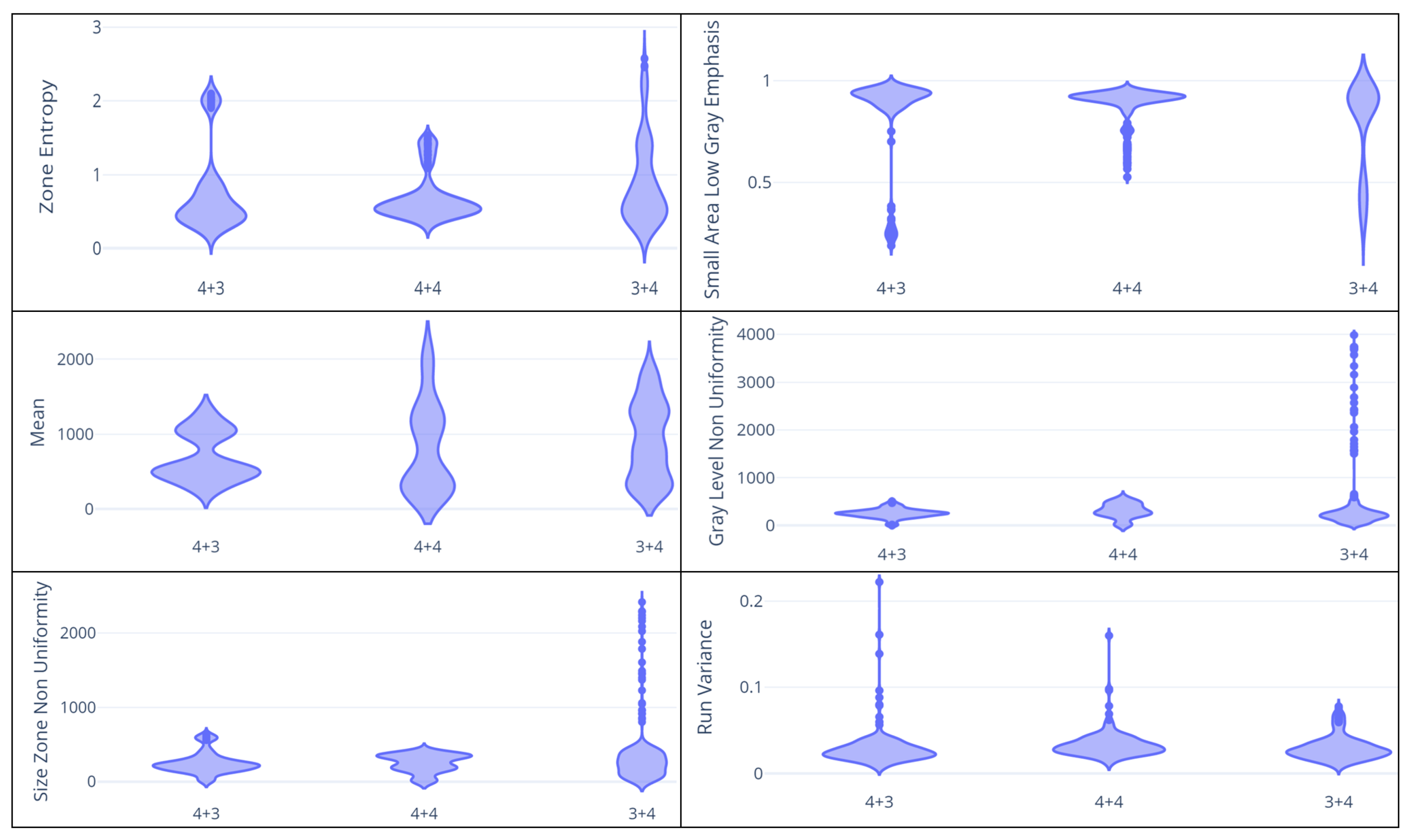
- First Order (FO): this category is related to the voxel distribution of the intensities within the ROI (i.e., the region of interest that in this study is represented by the areas interested by the cancer). We extract 1 feature belonging to the FO category;
- Gray Level Run Length Matrix (GLRLM): the features related to this category consider the grey level run length matrix, aiming to give the size of (homogeneous) runs for each grey level. In addition, in this category, 1 feature is considered;
- Gray Level Size Zone Matrix (GLSZM): the features related to the GLSZM category are aimed at quantifying the gray level zones in a medical image under analysis. With the gray level zone, we refer to a zone defined as the number of (connected) voxels sharing the same gray level intensity. Sixteen different features are considered from this category.
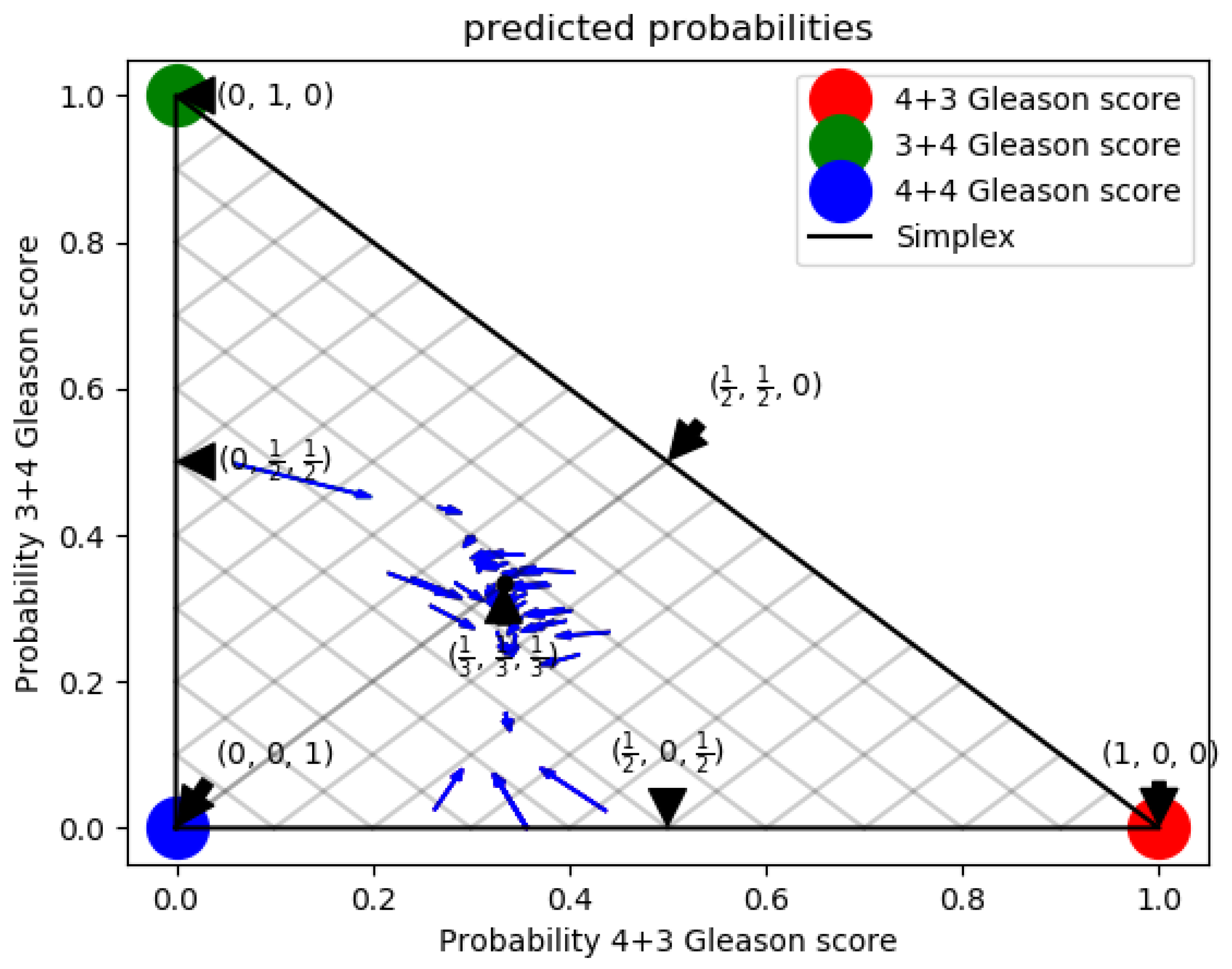
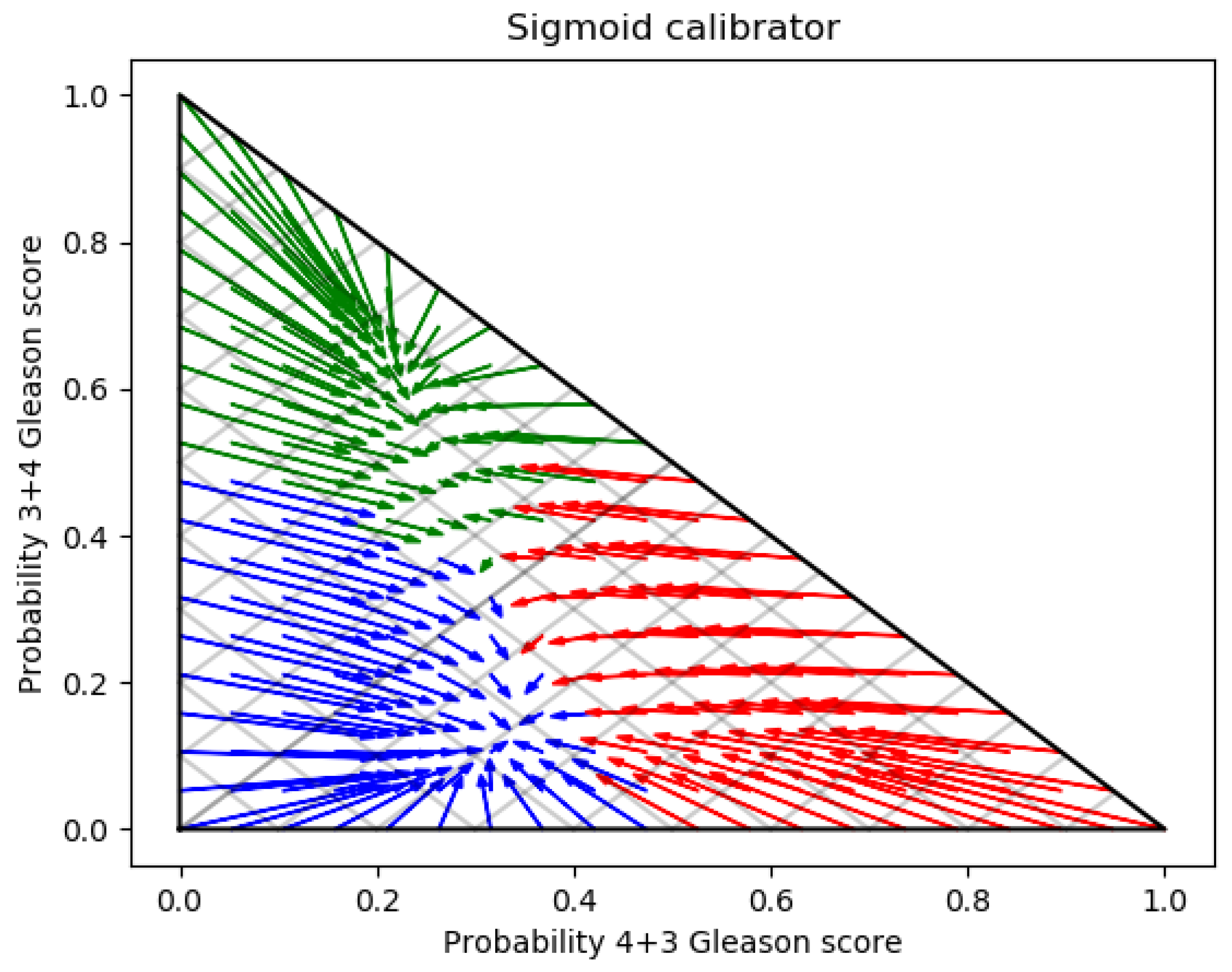
3. Experimental Results
4. Conclusions and Future Work
Author Contributions
Funding
Informed Consent Statement
Conflicts of Interest
References
- Bray, F.; Ferlay, J.; Soerjomataram, I.; Siegel, R.L.; Torre, L.A.; Jemal, A. Global cancer statistics 2018: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 2018, 68, 394–424. [Google Scholar] [CrossRef]
- Ferlay, J.; Steliarova-Foucher, E.; Lortet-Tieulent, J.; Rosso, S.; Coebergh, J.; Comber, H.; Forman, D.; Bray, F. Cancer incidence and mortality patterns in Europe: Estimates for 40 countries in 2012. Eur. J. Cancer 2013, 49, 1374–1403. [Google Scholar] [CrossRef]
- Siegel, R.L.; Miller, K.D.; Fuchs, H.E.; Jemal, A. Cancer Statistics, 2021. CA Cancer J. Clin. 2021, 71, 7–33. [Google Scholar] [CrossRef]
- Pinsky, P.F.; Prorok, P.C.; Kramer, B.S. Prostate Cancer Screening—A Perspective on the Current State of the Evidence. N. Engl. J. Med. 2017, 376, 1285–1289. [Google Scholar] [CrossRef]
- Young, R.H. (Ed.) Tumors of the Prostate Gland, Seminal Vesicles, Male Urethra, and Penis; Number Series 3; Fasc. 28 in Atlas of Tumor Pathology/Prepared at the Armed Forces Institute of Pathology; Armed Forces Int. of Pathology: Washington, DC, USA, 2000. [Google Scholar]
- Brunese, L.; Mercaldo, F.; Reginelli, A.; Santone, A. Prostate gleason score detection and cancer treatment through real-time formal verification. IEEE Access 2019, 7, 186236–186246. [Google Scholar] [CrossRef]
- Humphrey, P.A.; Moch, H.; Cubilla, A.L.; Ulbright, T.M.; Reuter, V.E. The 2016 WHO Classification of Tumours of the Urinary System and Male Genital Organs—Part B: Prostate and Bladder Tumours. Eur. Urol. 2016, 70, 106–119. [Google Scholar] [CrossRef] [PubMed]
- Yegnasubramanian, S.; De Marzo, A.M.; Nelson, W.G. Prostate Cancer Epigenetics: From Basic Mechanisms to Clinical Implications. Cold Spring Harb. Perspect. Med. 2019, 9, a030445. [Google Scholar] [CrossRef]
- Cao, R.; Bajgiran, A.M.; Mirak, S.A.; Shakeri, S.; Zhong, X.; Enzmann, D.; Raman, S.; Sung, K. Joint Prostate Cancer Detection and Gleason Score Prediction in mp-MRI via FocalNet. IEEE Trans. Med. Imaging 2019, 38, 2496–2506. [Google Scholar] [CrossRef]
- Epstein, J.I.; Amin, M.B.; Fine, S.W.; Algaba, F.; Aron, M.; Baydar, D.E.; Beltran, A.L.; Brimo, F.; Cheville, J.C.; Colecchia, M.; et al. The 2019 Genitourinary Pathology Society (GUPS) White Paper on Contemporary Grading of Prostate Cancer. Arch. Pathol. Lab. Med. 2021, 145, 461–493. [Google Scholar] [CrossRef] [PubMed]
- Maggi, M.; Panebianco, V.; Mosca, A.; Salciccia, S.; Gentilucci, A.; Di Pierro, G.; Busetto, G.M.; Barchetti, G.; Campa, R.; Sperduti, I.; et al. Prostate Imaging Reporting and Data System 3 Category Cases at Multiparametric Magnetic Resonance for Prostate Cancer: A Systematic Review and Meta-analysis. Eur. Urol. Focus 2020, 6, 463–478. [Google Scholar] [CrossRef] [PubMed]
- Petrillo, A.; Fusco, R.; Setola, S.V.; Ronza, F.M.; Granata, V.; Petrillo, M.; Carone, G.; Sansone, M.; Franco, R.; Fulciniti, F.; et al. Multiparametric MRI for prostate cancer detection: Performance in patients with prostate-specific antigen values between 2.5 and 10 ng/mL: Multiparametric MRI for Prostate Cancer Detection. J. Magn. Reson. Imaging 2014, 39, 1206–1212. [Google Scholar] [CrossRef] [PubMed]
- Brunese, L.; Brunese, M.C.; Carbone, M.; Ciccone, V.; Mercaldo, F.; Santone, A. Automatic PI-RADS assignment by means of formal methods. La Radiol. Medica 2022, 127, 83–89. [Google Scholar] [CrossRef]
- Oderda, M.; Albisinni, S.; Benamran, D.; Calleris, G.; Ciccariello, M.; Dematteis, A.; Diamand, R.; Descotes, J.; Fiard, G.; Forte, V.; et al. Accuracy of elastic fusion biopsy: Comparing prostate cancer detection between targeted and systematic biopsy. Prostate 2022, pros.24449. Available online: https://onlinelibrary.wiley.com/doi/abs/10.1002/pros.24449 (accessed on 13 September 2022).
- Fusco, R.; Sansone, M.; Granata, V.; Setola, S.V.; Petrillo, A. A systematic review on multiparametric MR imaging in prostate cancer detection. Infect. Agents Cancer 2017, 12, 57. [Google Scholar] [CrossRef] [PubMed]
- Hatt, M.; Tixier, F.; Pierce, L.; Kinahan, P.E.; Le Rest, C.C.; Visvikis, D. Characterization of PET/CT images using texture analysis: The past, the present… any future? Eur. J. Nucl. Med. Mol. Imaging 2017, 44, 151–165. [Google Scholar] [CrossRef] [PubMed]
- Santone, A.; Brunese, M.C.; Donnarumma, F.; Guerriero, P.; Mercaldo, F.; Reginelli, A.; Miele, V.; Giovagnoni, A.; Brunese, L. Radiomic features for prostate cancer grade detection through formal verification. La Radiol. Medica 2021, 126, 688–697. [Google Scholar] [CrossRef] [PubMed]
- Wang, P.; Li, Y.; Reddy, C.K. Machine learning for survival analysis: A survey. ACM Comput. Surv. (CSUR) 2019, 51, 110. [Google Scholar] [CrossRef]
- Huang, F.; Ing, N.; Eric, M.; Salemi, H.; Lewis, M.; Garraway, I.; Gertych, A.; Knudsen, B. Abstract B094: Quantitative digital image analysis and machine learning for staging of prostate cancer at diagnosis. Cancer Res. 2018, 78 (Suppl. 16), B094. [Google Scholar] [CrossRef]
- Tan, A.C.; Gilbert, D. Ensemble machine learning on gene expression data for cancer classification. In Proceedings of the New Zealand Bioinformatics Conference, Wellington, New Zealand, 13–14 February 2003. [Google Scholar]
- Van Griethuysen, J.J.; Fedorov, A.; Parmar, C.; Hosny, A.; Aucoin, N.; Narayan, V.; Beets-Tan, R.G.; Fillion-Robin, J.C.; Pieper, S.; Aerts, H.J. Computational radiomics system to decode the radiographic phenotype. Cancer Res. 2017, 77, e104–e107. [Google Scholar] [CrossRef]
- Niculescu-Mizil, A.; Caruana, R. Predicting good probabilities with supervised learning. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; ACM: New York, NY, USA, 2005; pp. 625–632. [Google Scholar]
- Kortum, X.; Grigull, L.; Muecke, U.; Lechner, W.; Klawonn, F. Improving the Decision Support in Diagnostic Systems Using Classifier Probability Calibration. In Proceedings of the International Conference on Intelligent Data Engineering and Automated Learning, Madrid, Spain, 21–23 November 2018; Springer: Cham, Switzerland, 2018; pp. 419–428. [Google Scholar]
- Quinlan, R. C4.5: Programs for Machine Learning; Morgan Kaufmann Publishers: San Mateo, CA, USA, 1993. [Google Scholar]
- Jin, C.; De-Lin, L.; Fen-Xiang, M. An improved ID3 decision tree algorithm. In Proceedings of the 4th International Conference on Computer Science & Education (ICCSE’09), Nanning, China, 25–28 July 2009; pp. 127–130. [Google Scholar]
- Webb, G. Decision Tree Grafting from the All-Tests-But-One Partition; Morgan Kaufmann: San Francisco, CA, USA, 1999. [Google Scholar]
- Friedman, J.; Hastie, T.; Tibshirani, R. The Elements of Statistical Learning; Springer series in statistics; Springer: New York, NY, USA, 2001; Volume 1. [Google Scholar]
- Pérez, J.M.; Muguerza, J.; Arbelaitz, O.; Gurrutxaga, I.; Martín, J.I. Combining multiple class distribution modified subsamples in a single tree. Pattern Recognit. Lett. 2007, 28, 414–422. [Google Scholar] [CrossRef]
- MacKay, D.J. Introduction to Gaussian processes. NATO ASI Ser. F Comput. Syst. Sci. 1998, 168, 133–166. [Google Scholar]
- Barandiaran, I. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- Naeini, M.P.; Cooper, G.F. Binary classifier calibration using an ensemble of piecewise linear regression models. Knowl. Inf. Syst. 2018, 54, 151–170. [Google Scholar] [PubMed]
- Zadrozny, B.; Elkan, C. Obtaining calibrated probability estimates from decision trees and naive Bayesian classifiers. Icml 2001, 1, 609–616. [Google Scholar]
- Kaufmann, S.; Russo, G.I.; Bamberg, F.; Löwe, L.; Morgia, G.; Nikolaou, K.; Stenzl, A.; Kruck, S.; Bedke, J. Prostate cancer detection in patients with prior negative biopsy undergoing cognitive-, robotic- or in-bore MRI target biopsy. World J. Urol. 2018, 36, 761–768. [Google Scholar] [CrossRef]
- Santone, A.; Vaglini, G.; Villani, M.L. Incremental construction of systems: An efficient characterization of the lacking sub-system. Sci. Comput. Program. 2013, 78, 1346–1367. [Google Scholar] [CrossRef]
- De Francesco, N.; Lettieri, G.; Santone, A.; Vaglini, G. GreASE: A tool for efficient “Nonequivalence” checking. ACM Trans. Softw. Eng. Methodol. 2014, 23, 1–26. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Radiomic Feature | Category |
|---|---|---|
| Mean | FO | |
| Run Variance | GLRLM | |
| Gray Level Non Uniformity | GLSZM | |
| Gray Level Non Uniformity Normalized | GLSZM | |
| Gray Level Variance | GLSZM | |
| High Gray Level Zone Emphasis | GLSZM | |
| Large Area Emphasis | GLSZM | |
| Large Area High Gray Level Emphasis | GLSZM | |
| Large Area Low Gray Level Emphasis | GLSZM | |
| Low Gray Level Zone Emphasis | GLSZM | |
| Size Zone Non Uniformity | GLSZM | |
| Size Zone Non Uniformity Normalized | GLSZM | |
| Small Area Emphasis | GLSZM | |
| Small Area High Gray Level Emphasis | GLSZM | |
| Small Area Low Gray Level Emphasis | GLSZM | |
| Zone Entropy | GLSZM | |
| Zone Percentage | GLSZM | |
| Zone Variance | GLSZM |
| # Radiomic Feature | Wald–Wolfowitz | Mann–Whitney | Test Result |
|---|---|---|---|
| p < 0.001 | p < 0.001 | passed | |
| p > 0.10 | p < 0.001 | not passed | |
| p < 0.001 | p < 0.001 | passed | |
| p > 0.10 | p < 0.001 | not passed |
| Algorithm | FP Rate | Precision | Recall | F-Measure | Roc Area | Gleason |
|---|---|---|---|---|---|---|
| 0.035 | 0.848 | 0.740 | 0.790 | 0.908 | 3 + 4 | |
| C 4.5 | 0.103 | 0.852 | 0.852 | 0.852 | 0.912 | 4 + 3 |
| 0.027 | 0.885 | 0.874 | 0.880 | 0.932 | 4 + 4 | |
| 0.018 | 0.727 | 0.185 | 0.295 | 0.583 | 3 + 4 | |
| SVM | 0.835 | 0.448 | 0.976 | 0.615 | 0.570 | 4 + 3 |
| 0.008 | 0.844 | 0.170 | 0.283 | 0.581 | 4 + 4 | |
| 0.728 | 0.460 | 0.893 | 0.608 | 0.673 | 3 + 4 | |
| Gaussian | 0.049 | 0.508 | 0.191 | 0.277 | 0.702 | 4 + 3 |
| 0.006 | 0.692 | 0.057 | 0.105 | 0.739 | 4 + 4 | |
| 0.080 | 0.886 | 0.899 | 0.893 | 0.918 | 3 + 4 | |
| RandomForest | 0.057 | 0.803 | 0.873 | 0.837 | 0.924 | 4 + 3 |
| 0.021 | 0.888 | 0.879 | 0.942 | 0.944 | 4 + 4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mercaldo, F.; Brunese, M.C.; Merolla, F.; Rocca, A.; Zappia, M.; Santone, A. Prostate Gleason Score Detection by Calibrated Machine Learning Classification through Radiomic Features. Appl. Sci. 2022, 12, 11900. https://doi.org/10.3390/app122311900
Mercaldo F, Brunese MC, Merolla F, Rocca A, Zappia M, Santone A. Prostate Gleason Score Detection by Calibrated Machine Learning Classification through Radiomic Features. Applied Sciences. 2022; 12(23):11900. https://doi.org/10.3390/app122311900
Chicago/Turabian StyleMercaldo, Francesco, Maria Chiara Brunese, Francesco Merolla, Aldo Rocca, Marcello Zappia, and Antonella Santone. 2022. "Prostate Gleason Score Detection by Calibrated Machine Learning Classification through Radiomic Features" Applied Sciences 12, no. 23: 11900. https://doi.org/10.3390/app122311900
APA StyleMercaldo, F., Brunese, M. C., Merolla, F., Rocca, A., Zappia, M., & Santone, A. (2022). Prostate Gleason Score Detection by Calibrated Machine Learning Classification through Radiomic Features. Applied Sciences, 12(23), 11900. https://doi.org/10.3390/app122311900