
Adaptive Feature Fusion for Small Object Detection

Abstract
1. Introduction
- The small object has few pixels, and the object scale spans large;
- The expression ability of small object features is weak, and the detection accuracy is low;
- The background image of the small object is complex, the background information is highly similar to the small object, and it is easily disturbed by the background.
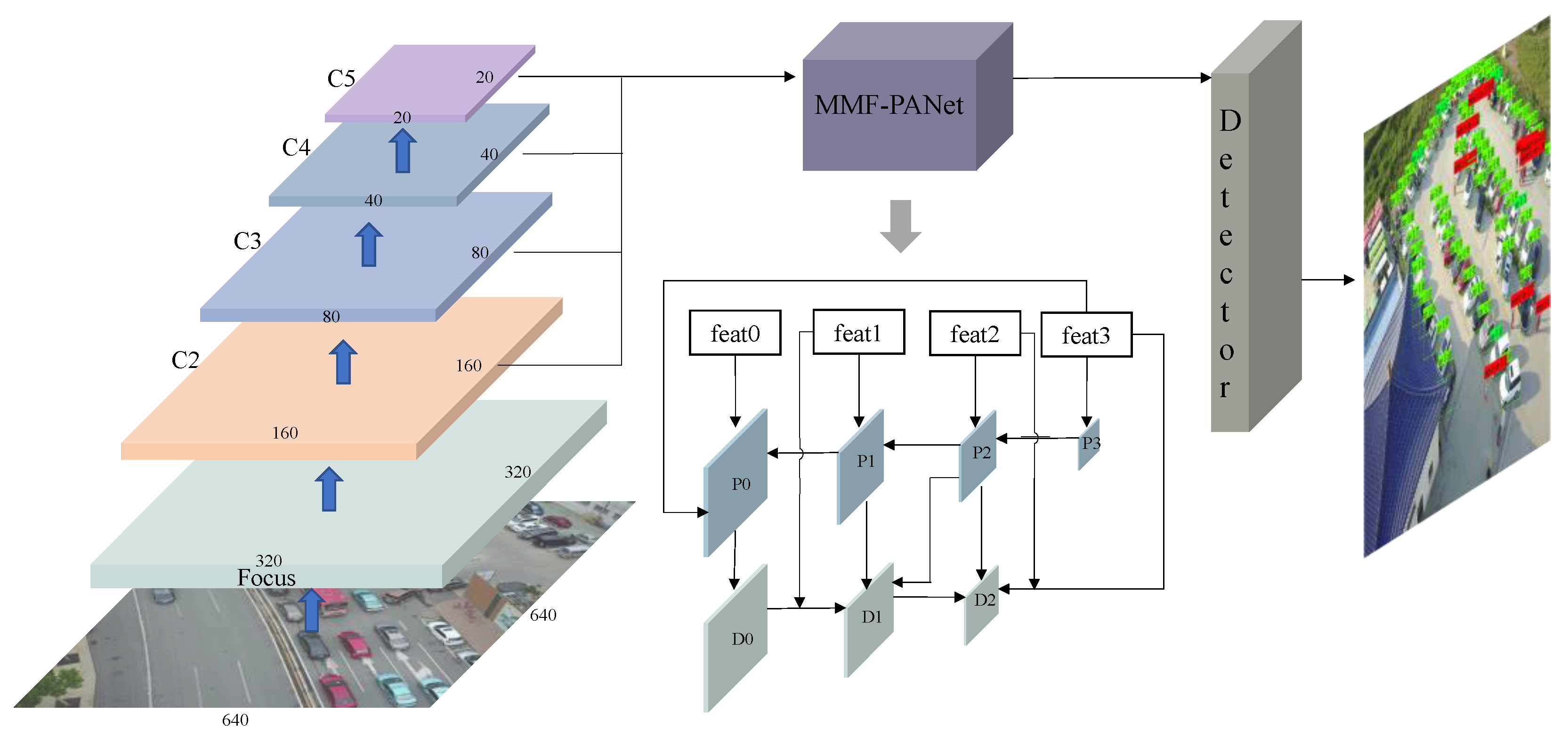
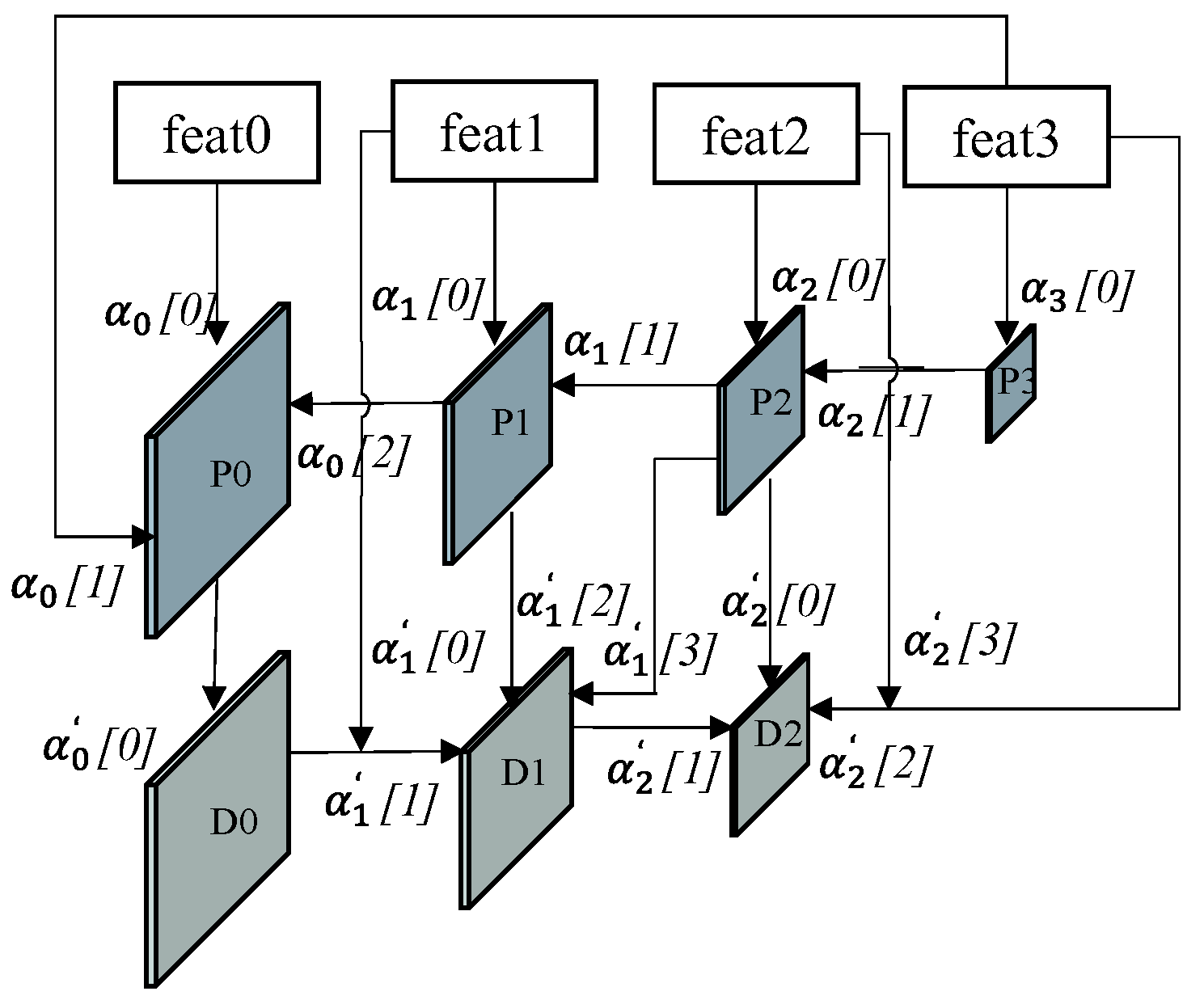
- For the problem of large scale changes of small objects like objects, we designed a multi-scale, multi-path, and multi-flow feature fusion module, referred to as MMF-Net. Among them, the features of multi-branch fusion have unique fusion factors.
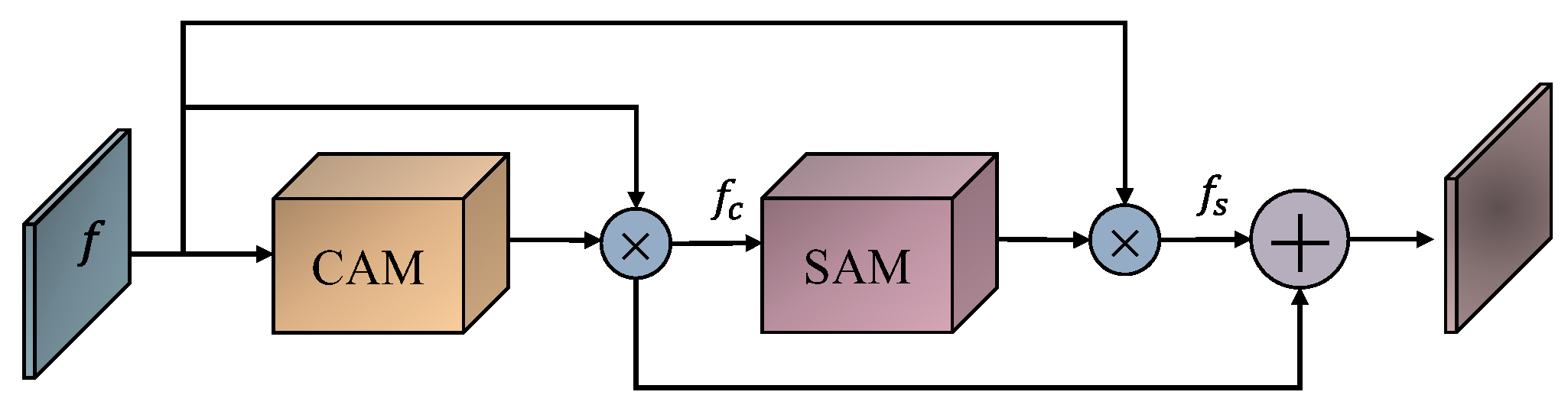
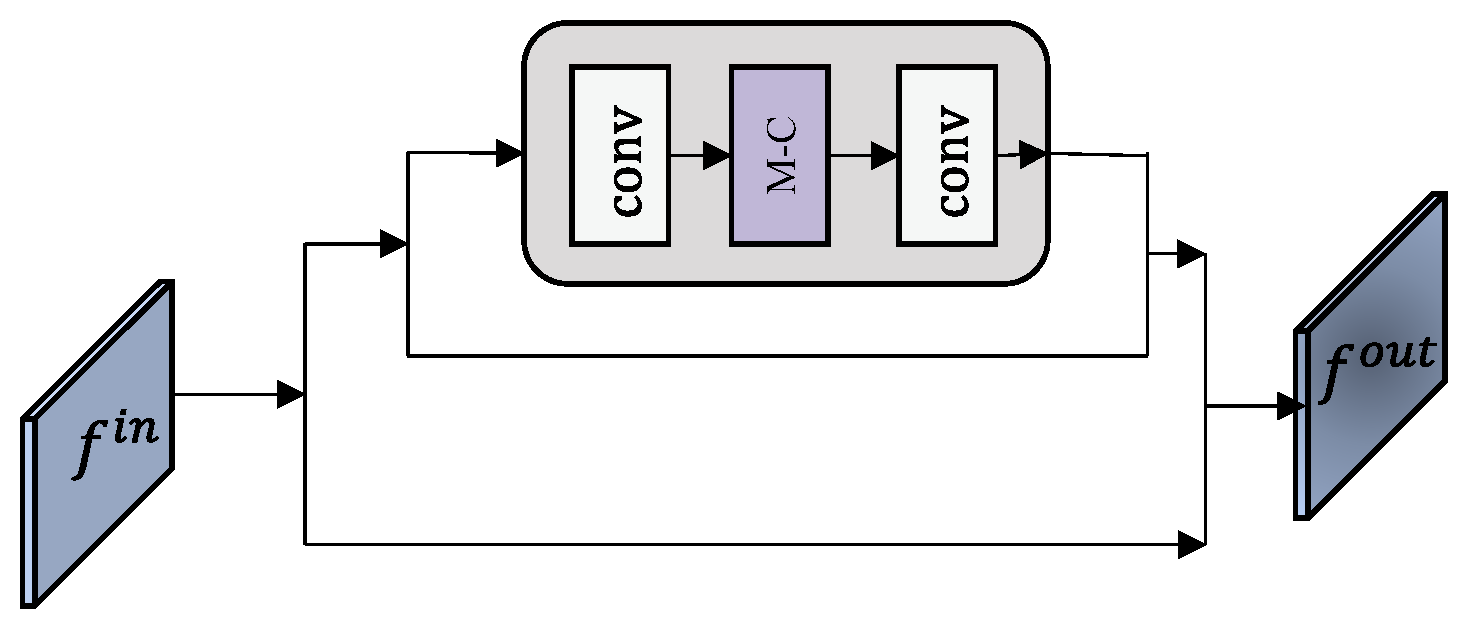
- In order to focus the “gaze” of the network on the representative local object region after convolution and accurately separate the background information from the object information, a new attention mechanism (M-CBAM) was designed, which was added to the feature strengthening extraction to increase attention to the features to be extracted, so that the convolution can pay attention to the feature map with less sample information.
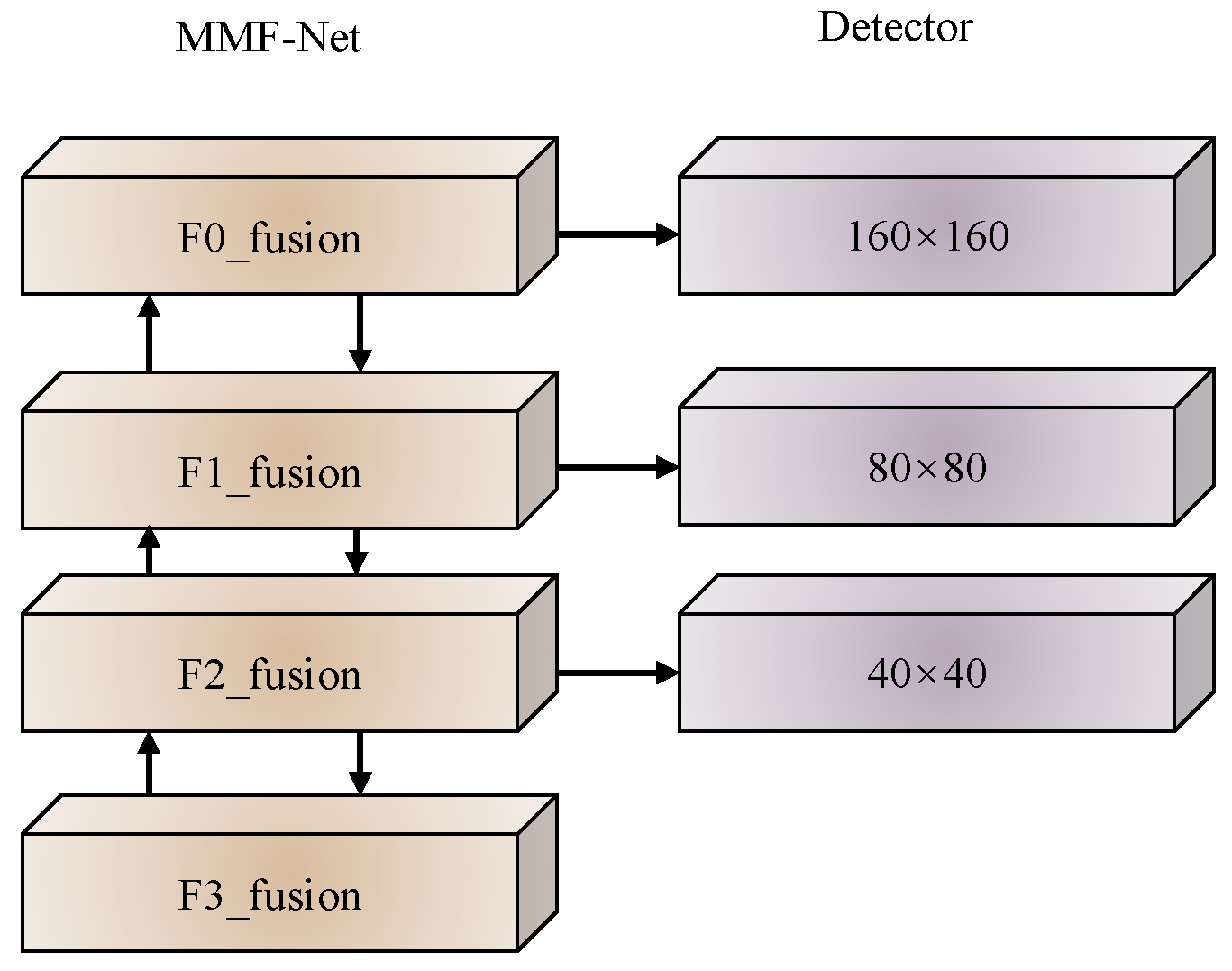
- In order to improve the classification probability and regression coefficient of small objects, a shallow object detector was added for the small size of small objects. Simultaneously, in order to reduce the computational load of the network, the detection head in the deepest layer of the network was discarded. At the same time, in order to ensure the correct detection of larger-sized objects in small objects, shallower and deeper detection heads were reserved.
2. Materials and Methods
2.1. Materials
2.1.1. Small Object Detection
2.1.2. Feature Fusion
2.2. Methods
2.2.1. MMF-YOLO Algorithm
2.2.2. MMF-PANet Feature Fusion Module
2.2.3. Improvements to the Attention Mechanism
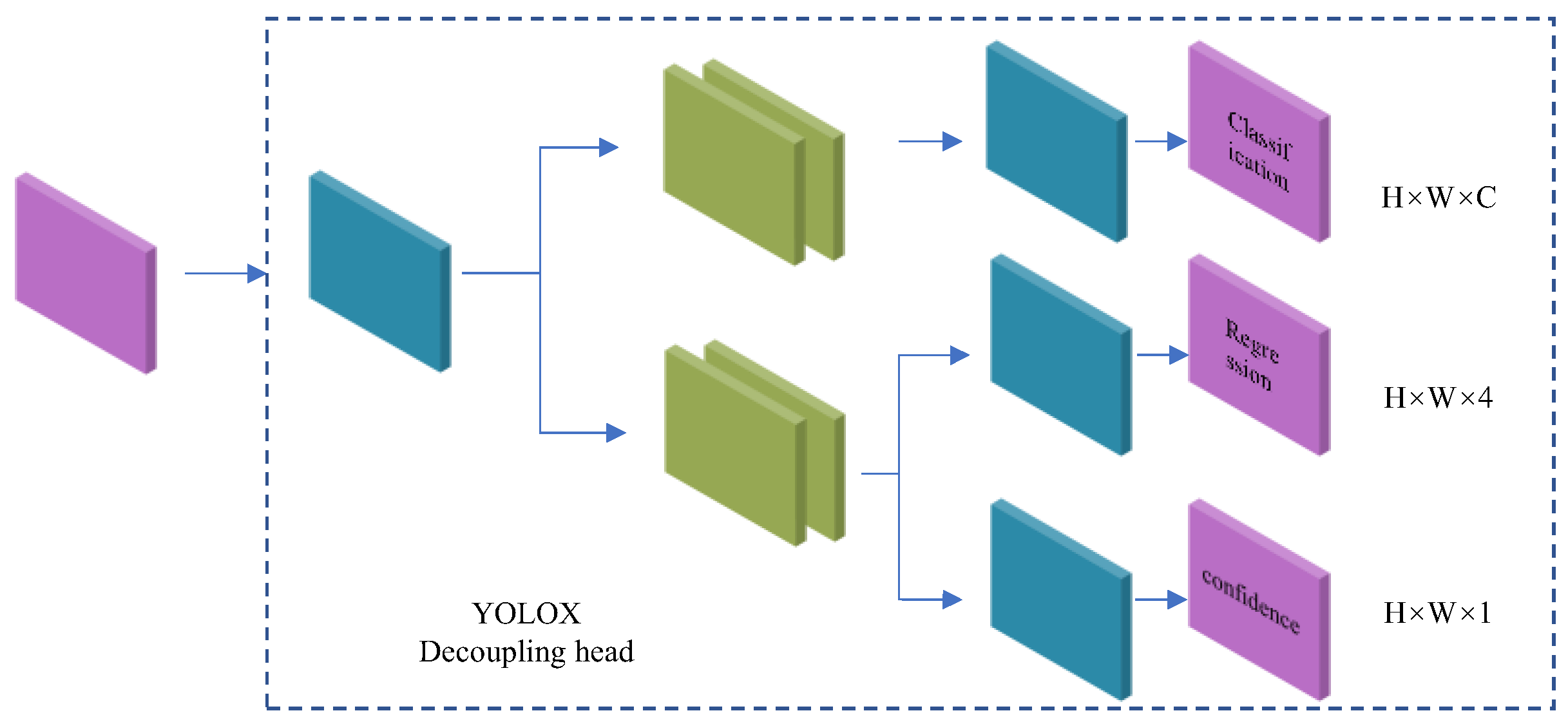
2.2.4. Feature Enhancement Extraction and Object Detection Head
3. Experiment
3.1. Experiment Platform
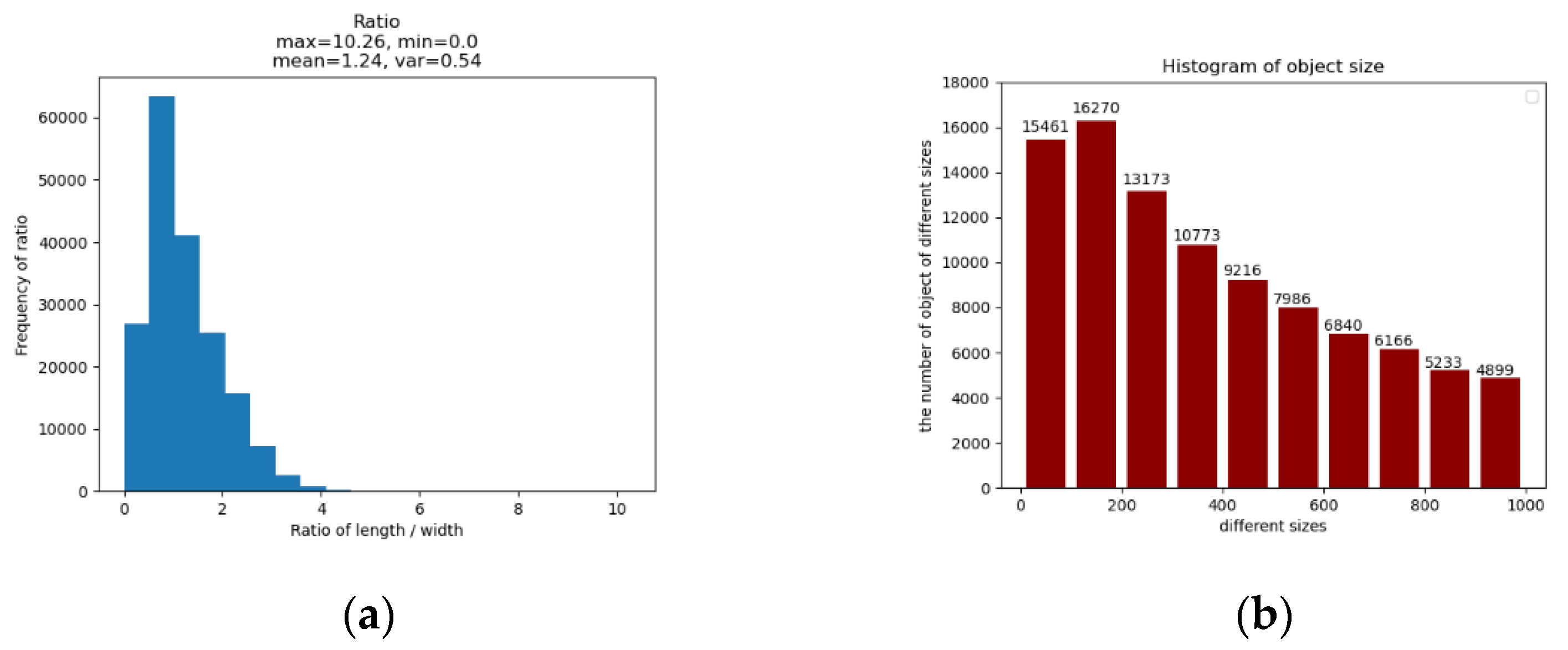
3.2. Introduction to the Dataset VisDrone
3.3. Model Training and Evaluation Metrics
4. Analysis of Experimental Results
4.1. Ablation Experiment Results
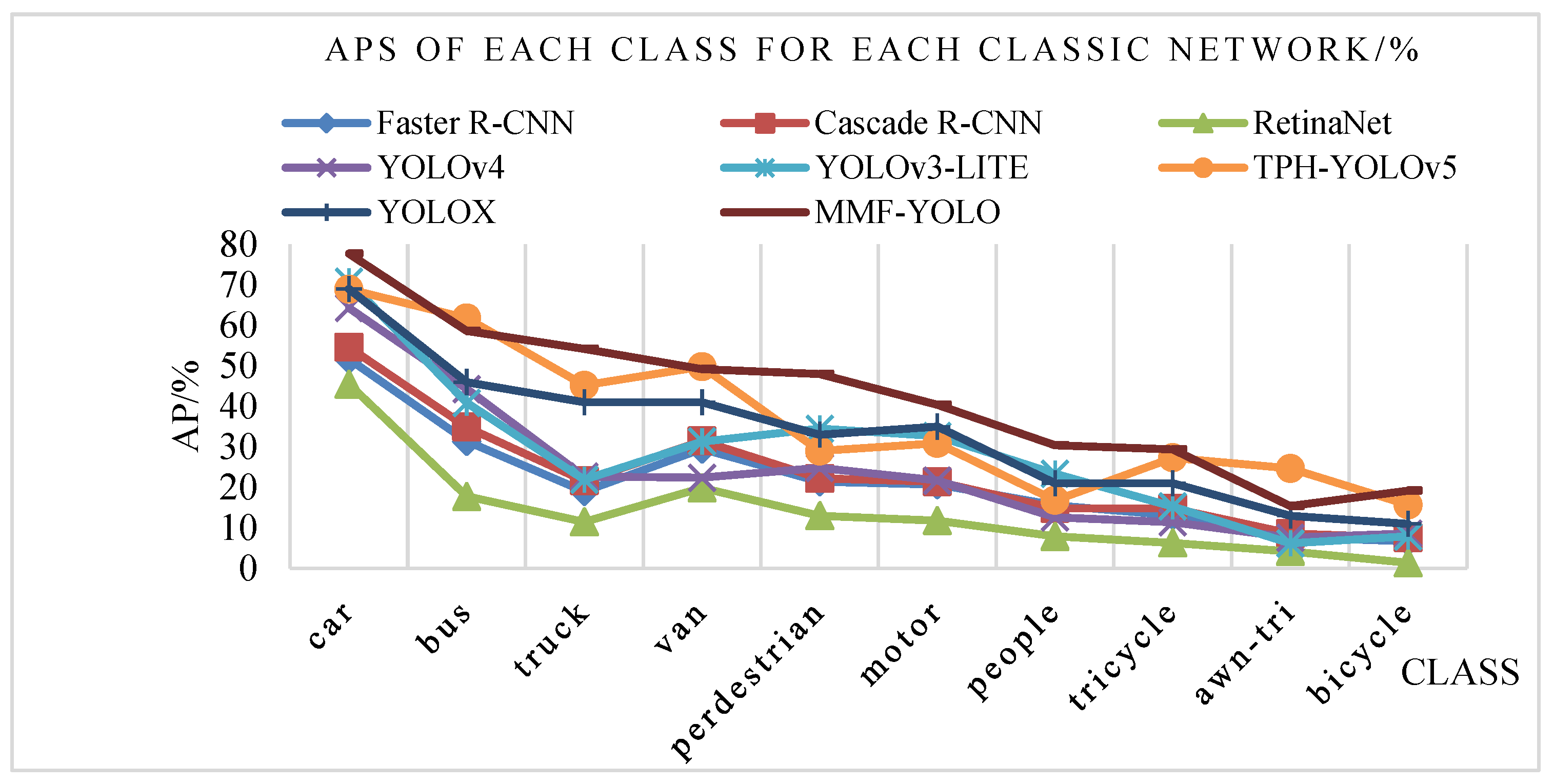
4.2. Comparative Experiments
4.3. Visualize the Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, F.; Ding, Q.; Hui, B.; Chang, Z.; Liu, Y. Multi-scale kernel correlation filter algorithm for visual tracking based on the fusion of adaptive features. Acta Optics 2020, 40, 109–120. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; p. 28. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 21–26 July 2017, Honolulu, HI, USA; IEEE: New York, NY, USA, 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision, IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Xinbo, G.; Mengjingcheng, M.; Haitao, W.; Jiaxu, L. Research progress of small target detection. Data Acquis. Process. 2021, 36, 391–417. [Google Scholar] [CrossRef]
- Lin, T.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Computer Vision–ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; Volume 8693, pp. 740–755. [Google Scholar]
- Hongguang, L.; Ruonan, Y.; Wenrui, D. Research progress of small target detection based on deep learning. J. Aviat. 2021, 42, 107–125. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA., 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 936–944. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Pang, J.; Li, C.; Shi, X.Z.; Feng, H. R2 -CNN: Fast Tiny Object Detection in Large-Scale Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5512–5524. [Google Scholar] [CrossRef]
- Yin, Z.; Guiyi, Z.; Tianjun, S.; Kun, Z.; Junhua, Y. Small object detection in remote sensing images based on feature fusion and attention. J. Opt. 2022, 1–17. Available online: http://kns.cnki.net/kcms/detail/31.1252.O4.20220714.1843.456.html (accessed on 26 October 2022).
- Jinkai, W.; Xijin, S. Review of Applied Research on Computer Vision Technology. Comput. Age 2022, 1–4+8. [Google Scholar] [CrossRef]
- Yuan, X.; Shi, J.; Gu, L. A review of deep learning methods for semantic segmentation of remote sensing imagery. Expert Syst. Appl. 2021, 169, 114417. [Google Scholar] [CrossRef]
- Raghunandan, A.; Mohana; Raghav, P.; Ravish Aradhya, H.V. Object Detection Algorithms for Video Surveillance Applications. In Proceedings of the 2018 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 3–5 April 2018. [Google Scholar]
- Kermany, D.S.; Goldbaum, M.; Cai, W.; Valentim, C.C.S.; Liang, H.; Baxter, S.L.; McKeown, A.; Yang, G.; Wu, X.; Yan, F.; et al. Identifying medical diagnoses and treatable diseases by image-based deep learning. Cell 2018, 172, 1122–1131.e9. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Cai, T.; Tang, X.; Zhang, Y.; Wang, C. Visual recognition of traffic signs in natural scenes based on improved RetinaNet. Entropy 2022, 24, 112. [Google Scholar] [CrossRef] [PubMed]
- Sun, X.; Wang, P.; Wang, C.; Liu, Y.; Fu, K. PBNet: Part-based convolutional neural network for complex composite object detection in remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 173, 50–65. [Google Scholar] [CrossRef]
- Li, Y.; Zhao, J.; Lv, Z.; Li, J. Medical image fusion method by deep learning. Int. J. Cogn. Comput. Eng. 2021, 2, 21–29. [Google Scholar] [CrossRef]
- Yu, X.; Gong, Y.; Jiang, N.; Ye, Q.; Han, Z. Scale Match for Tiny Person Detection. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass, CO, USA, 1–5 March 2020; pp. 1246–1254. [Google Scholar] [CrossRef]
- Singh, B.; Davis, L.S. An analysis of scale invariance in object detection snip. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3578–3587. [Google Scholar]
- Singh, B.; Najibi, M.; Davis, L.S. Sniper: Efficient multi-scale training. Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2018; p. 31. [Google Scholar]
- Deng, C.; Wang, M.; Liu, L.; Liu, Y.; Jiang, Y. Extended feature pyramid network for small object detection. IEEE Trans. Multimed. 2021, 24, 1968–1979. [Google Scholar] [CrossRef]
- Noh, J.; Bae, W.; Lee, W.; Seo, J.; Kim, G. Better to follow, follow to be better: Towards precise supervision of feature super-resolution for small object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9725–9734. [Google Scholar]
- Chen, Y.; Zhang, P.; Li, Z.; Li, Y. Stitcher: Feedback-driven data provider for object detection. arXiv 2020, arXiv:2004.12432. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-aware trident networks for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6054–6063. [Google Scholar]
- Zhang, G.J.; Lu, S.J.; Zhang, W. CAD-Net: A context-aware detection network for objects in remote sensing imagery. IEEE Trans Geosci Remote Sens 2019, 57, 10015–10024. [Google Scholar] [CrossRef]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2Det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 8–12 October 2019; Volume 33, pp. 9259–9266. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of The IEEE/CVF Conference on Computer Vision And Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Gong, Y.; Yu, X.; Ding, Y.; Peng, X.; Zhao, J.; Han, Z. Effective fusion factor in FPN for tiny object detection. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, Virtual Conference, 5–9 January 2021; pp. 1160–1168. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Hou, Q.; Zhou, D.F. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhu, P.F.; Wen, L.; Du, D.; Bian, X.; Ling, H.; Hu, Q.; Nie, Q.; Cheng, H.; Liu, C.; Liu, X.; et al. VisDrone-DET2019: The vision meets drone object detection in image challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Yu, W.P.; Yang TJ, N.; Chen, C. Towards Resolving the Challenge of Long-tail Distribution in UAV Images for Object Detection. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Virtual, 5–9 January 2021; IEEE Press: Waikoloa, HI, USA, 2021; pp. 3257–3266. [Google Scholar]
- Xiaojun, L.; Wei, X.; Yunpeng, L. Small target detection algorithm for UAV aerial imagery based on enhanced underlying features. Comput. Appl. Res. 2021, 38, 1567–1571. [Google Scholar] [CrossRef]
- Ali, S.; Siddique, A.; Ateş, H.F.; Güntürk, B.K. Improved YOLOv4 for aerial object detection. In Proceedings of the 2021 29th Signal Processing and Communications Applications Conference (SIU), Istanbul, Turkye, 9–11 June 2021. [Google Scholar]
- Zhao, H.; Zhou, Y.; Zhang, L.; Peng, Y.; Hu, X.; Peng, H.; Cai, X. Mixed YOLOv3-LITE: A Lightweight Real-Time Object Detection Method. Sensors 2020, 20, 1861. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Chronological | Algorithm | Backbone | Method |
|---|---|---|---|
| 2015 | Faster R-CNN [3] | ResNet-50 | It improves the fully connected layer and implements the stitching of multi-task loss functions. |
| 2016 | YOLOv1 [5] | GoogLeNet | It takes the entire graph as input to the network, regressing the location and category of the BBox directly at the output layer. |
| 2016 | SSD [6] | VGG16 | The use of multi-feature mapping can be comparable to FasterRCNN in some scenarios, and the network optimization is simple. |
| 2017 | Mask R-CNN [4] | VGG16/Resnet | It redesigned the backbone network structure and replaced RoI Pooling with RoI Align. |
| 2017 | YOLOv2 [7] | Darknet19 | It proposes a joint training method of object detection and classification using a new multi-scale training method. |
| 2018 | YOLOv3 [8] | Darknet53 | It proposes multi-scale predictions. |
| 2019 | Trident [31] | ResNet | It designed the Trident parallel network to increase the width of the network and proposed the concept of parallel network. |
| 2019 | M2Det [33] | VGG-16/ ResNet-101 | It proposed a multi-layer feature pyramid network. |
| 2020 | EfficientFet [34] | MobileNet | It proposed a two-way pyramid network, BiFPN. |
| 2020 | YOLOv4 [37] | CSPDarkent | It adopted various training skills and improved the loss function and maximum suppression method. |
| 2021 | EFPN [28] | Feature texture transfer (FTT) and foreground-background balance loss functions were designed to mitigate the area imbalance of the foreground and background. | |
| 2021 | TPH-YOLOv5 [9] | CSPDarknet | It integrated transformer prediction heads (TPH) and CBAM into YOLOv5. |
| 2021 | YOLOX [38] | CSPDarknet | It decoupled the detection head and used dynamic sample matching. |
| Attention Mechanism | mAP/% |
|---|---|
| CA_v1 | 32.63 |
| CBAM_v1 | 32.95 |
| CA_v2 | 33.10 |
| CBAM_v2 | 33.27 |
| Attention Mechanism | mAP/% |
|---|---|
| - | 33.10 |
| CBAM | 33.27 |
| M-CBAM | 33.53 |
| Order | MMF-Net | M-CBAM | Head | mAP | Paras/MB | |
|---|---|---|---|---|---|---|
| ➀ | √ | 35.73 | 38.12 | |||
| ➁ | √ | 35.32 | 38.12 | |||
| ➂ | √ | √ | 41.21 | 29.3 | ||
| ➃ | √ | √ | 38.01 | 29.3 | ||
| ➄ | √ | 33.53 | 34.27 | |||
| ➅ | √ | √ | 39.94 | 27.75 | ||
| ➆ | √ | 36.51 | 27.67 | |||
| ➇ | √ | √ | √ | 41.69 | 29.37 | |
| ➈ | √ | √ | √ | 42.23 | 29.33 | |
| ➉ | 33.10 | 34.11 | ||||
| 40 Epoch/mAP (%) | 80 Epoch/mAP (%) | 120 Epoch/mAP (%) | |||
|---|---|---|---|---|---|
| YOLOX | MMF_YOLO | YOLOX | MMF_YOLO | YOLOX | MMF_YOLO |
| 11.57 | 13.68 | 31.84 | 40.35 | 33.23 | 41.45 |
| Order | Model | Backbone | Input Resolution | mAP/% | Paras/MB |
|---|---|---|---|---|---|
| ➀ | YOLOv5-L [9] | CSPDarknet | 1920 × 1920 | 28.88 | |
| ➁ | TPH-YOLOv5 [9] | CSPDarknet | 1536 × 1536 | 39.18 | |
| ➂ | Faster R-CNN [42] | ResNet-50 | 1000 × 600 | 21.7 | |
| ➃ | Cascade R-CNN [42] | ResNet-50 | 1000 × 600 | 23.2 | |
| ➄ | RetinaNet [42] | ResNet-50 | 1000 × 600 | 13.9 | 36.53 |
| ➅ | YOLOv3 [43] | Darknet53 | 800 × 1333 | 22.46 | 234.9 |
| ➆ | SSD [43] | VGG16 | 800 × 1333 | 21.10 | 95.17 |
| ➇ | YOLOv4 [44] | CSPDarknet | 1000 × 600 | 30.7 | 244.11 |
| ➈ | YOLOX | CSPDarknet | 640 × 640 | 33.10 | 34.11 |
| ➉ | MMF-YOLO | CSPDarknet | 640 × 640 | 42.23 | 29.33 |
| Order | Model | Paras/MB | FLOPs |
|---|---|---|---|
| ➀ | YOLOv5-L | 178.09 | 114.413 G |
| ➁ | Faster R-CNN | 522.21 | 402.159 G |
| ➂ | RetinaNet | 36.53 | 166.711 G |
| ➃ | YOLOv3 | 234.9 | 155.249 G |
| ➄ | SSD | 95.17 | 277.8 G |
| ➅ | YOLOv4 | 244.11 | |
| ➆ | YOLOX | 34.11 | 26.657 G |
| ➇ | MMF-YOLO | 29.33 | 63.562 G |
| Model | Car /% | Bus /% | Truck /% | Van /% | Pedestrian /% | Motor /% | People /% | Tricycle /% | Awn-Tri /% | Bicycle /% |
|---|---|---|---|---|---|---|---|---|---|---|
| TPH-YOLOv5 [9] | 68.9 | 61.8 | 45.2 | 49.8 | 29.0 | 30.9 | 16.8 | 27.3 | 24.7 | 15.7 |
| Faster R-CNN [42] | 51.7 | 31.4 | 19.0 | 29.5 | 21.4 | 20.7 | 15.6 | 13.1 | 7.7 | 6.7 |
| Cas R-CNN [42], * | 54.6 | 34.9 | 21.6 | 31.5 | 22.2 | 21.4 | 14.8 | 14.8 | 8.6 | 7.6 |
| RetinaNet [42] | 45.5 | 17.8 | 11.5 | 19.9 | 13.0 | 11.8 | 7.9 | 6.3 | 4.2 | 1.4 |
| YOLOv4 [44] | 64.3 | 44.3 | 22.7 | 22.4 | 24.8 | 21.7 | 12.6 | 11.4 | 7.6 | 8.6 |
| YOLOv3-LITE [45] | 70.8 | 40.9 | 21.9 | 31.3 | 34.5 | 32.7 | 23.4 | 15.3 | 6.2 | 7.9 |
| YOLOX | 69.4 | 46.6 | 42.3 | 40.2 | 33.0 | 34.7 | 22.1 | 22.5 | 12.4 | 11.3 |
| MMF-YOLO | 77.7 | 58.6 | 54.19 | 49.12 | 47.97 | 40.4 | 30.4 | 29.4 | 15.39 | 19.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Q.; Zhang, H.; Lu, X. Adaptive Feature Fusion for Small Object Detection. Appl. Sci. 2022, 12, 11854. https://doi.org/10.3390/app122211854
Zhang Q, Zhang H, Lu X. Adaptive Feature Fusion for Small Object Detection. Applied Sciences. 2022; 12(22):11854. https://doi.org/10.3390/app122211854
Chicago/Turabian StyleZhang, Qi, Hongying Zhang, and Xiuwen Lu. 2022. "Adaptive Feature Fusion for Small Object Detection" Applied Sciences 12, no. 22: 11854. https://doi.org/10.3390/app122211854
APA StyleZhang, Q., Zhang, H., & Lu, X. (2022). Adaptive Feature Fusion for Small Object Detection. Applied Sciences, 12(22), 11854. https://doi.org/10.3390/app122211854