
Robotic Peg-in-Hole Assembly Strategy Research Based on Reinforcement Learning Algorithm

Abstract
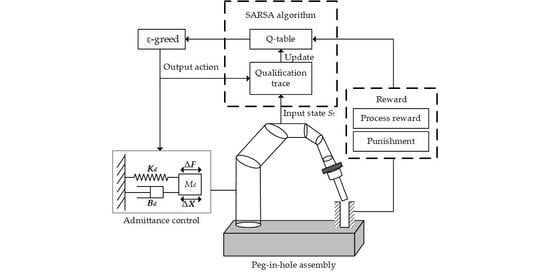
1. Introduction
2. Materials and Methods
2.1. Mechanism Analysis of Compliance Assembly
2.1.1. Peg-in-Hole Assembly Task
2.1.2. Admittance Model
2.2. Variable Admittance Control Based on RL Algorithm
2.2.1. MDP Model for Variable Admittance Control
2.2.2. Admittance Parameter Identification via SARSA
2.2.3. Admittance Parameter Identification via DDPG
3. Results and Discussion
3.1. Experiment Setup
3.2. Assembly Experiment using Position Control
3.3. Compliance Assembly Experiment Using Fuzzy Control
3.4. Compliance Assembly Experiment Using SARSA
3.5. Compliance Assembly Experiment Using DDPG
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yang, X.T.; Wang, Z.Y.; Li, F.M.; Song, R. Robot phased guided assembly based on process modeling. Comput. Inregrated Manuf. Syst. 2021, 27, 2321–2330. [Google Scholar]
- Liu, K.X. Research on Robotic Assembly Theory of Circular-Rectangular Compound Peg in Hole; Harbin Institute of Technology: Harbin, China, 2021. [Google Scholar]
- Beltran-Hernandez, C.C.; Petit, D.; Ramirez-Alpizar, I.G.; Harada, K. Variable Compliance Control for Robotic Peg-in-Hole Assembly: A Deep-Reinforcement-Learning Approach. Appl. Sci. 2020, 10, 6923. [Google Scholar] [CrossRef]
- Kilikevicius, S.; Baksys, B. Dynamic analysis of vibratory insertion process. Assem. Autom. 2011, 31, 275–283. [Google Scholar] [CrossRef]
- Kim, Y.L.; Song, H.C.; Song, J.B. Hole detection algorithm for chamferless square peg-in-hole based on shape recognition using F/T sensor. Int. J. Precis. Eng. Manuf. 2014, 15, 425–432. [Google Scholar] [CrossRef]
- Shimizu, M.; Kosuge, K. Designing robot admittance for polyhedral parts assembly taking into account grasping uncertainty. In Proceedings of the 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Edmonton, AB, Canada, 2–6 August 2005. [Google Scholar]
- Shimizu, M.; Kosuge, K. An admittance design approach to dynamic assembly of polyhedral parts with uncertainty. In Proceedings of the 2006 IEEE International Conference on Robotics and Automation (ICRA), Orlando, FL, USA, 15–19 May 2006. [Google Scholar]
- Mol, N.; Smisek, J.; Babuska, R.; Schiele, A. Nested compliant admittance control for robotic mechanical assembly of misaligned and tightly toleranced parts. In Proceedings of the 2016 IEEE International Conference on Systems Man and Cybernetics (SMC), Budapest, Hungary, 9–12 October 2016. [Google Scholar]
- Wu, H.; Li, M. Iterative Learning Algorithm Design for Variable Admittance Control Tuning of a Robotic Lift Assistant System. SAE Int. J. Engines 2017, 10, 203–208. [Google Scholar] [CrossRef]
- Wu, C.; Shen, Y.; Li, G.; Li, P.; Tian, W. Compliance Auxiliary Assembly of Large Aircraft Components Based on Variable Admittance Control. In Proceedings of the International Conference on Intelligent Robotics and Applications, Yantai, China, 22–25 October 2021; Springer: Cham, Switzerland, 2021; pp. 469–479. [Google Scholar]
- Tsumugiwa, T.; Yokogawa, R.; Hara, K. Variable impedance control with virtual stiffness for human-robot cooperative peg-in-hole task. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Lausanne, Switzerland, 30 September–4 October 2002. [Google Scholar]
- Kober, J.; Bagnell, J.A.; Peters, J. Reinforcement learning in robotics: A survey. Int. J. Robot. Res. 2013, 32, 1238–1274. [Google Scholar] [CrossRef]
- Zou, P.; Zhu, Q.; Wu, J.; Xiong, R. Learning-based Optimization Algorithms Combining Force Control Strategies for Peg-in-Hole Assembly. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021. [Google Scholar]
- Chen, J.P.; Zheng, M.H. A Survey of Robot Manipulation Behavior Research Based on Deep Reinforcement Learning. Robot 2022, 44, 236–256. [Google Scholar]
- Kozlovsky, S.; Newman, E.; Zacksenhouse, M. Reinforcement Learning of Impedance Policies for Peg-in-Hole Tasks: Role of Asymmetric Matrices. IEEE Robot. Autom. Lett. 2022, 7, 10898–10905. [Google Scholar] [CrossRef]
- Wu, X.P.; Zhang, D.P.; Qin, F.B.; Xu, D. Deep Reinforcement Learning of Robotic Precision Insertion Skill Accelerated by Demonstrations. In Proceedings of the 15th IEEE International Conference on Automation Science and Engineering (IEEE CASE), Vancouver, BC, Canada, 22–26 August 2019. [Google Scholar]
- Hou, Z.M.; Dong, H.M.; Zhang, K.G.; Gao, Q.; Chen, K.; Xu, J. Knowledge-Driven Deep Deterministic Policy Gradient for Robotic Multiple Peg-in-Hole Assembly Tasks. In Proceedings of the IEEE International Conference on Robotics and Biomimetics (ROBIO), Kuala Lumpur, Malaysia, 12–15 December 2018. [Google Scholar]
- Martín-Martín, R.; Lee, M.A.; Gardner, R.; Savarese, S.; Bohg, J.; Garg, A. Variable impedance control in end-effector space: An action space for reinforcement learning in contact-rich tasks. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2019, Macau, China, 3–8 November 2019. [Google Scholar]
- Beltran-Hernandez, C.C.; Petit, D.; Ramirez-Alpizar, I.G.; Nishi, T.; Kikuchi, S.; Matsubara, T.; Harada, K. Learning force control for contact-rich manipulation tasks with rigid position-controlled robots. IEEE Robot. Autom. Lett. 2020, 5, 5709–5716. [Google Scholar] [CrossRef]
- Zhang, X.; Sun, L.; Kuang, Z.; Tomizuka, M. Learning variable impedance control via inverse reinforcement learning for force-related tasks. IEEE Robot. Autom. Lett. 2021, 6, 2225–2232. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Name | Value |
|---|---|
| Virtual inertia | 0.0001 |
| Virtual damping | 0.02 |
| Virtual stiffness | 1 |
| Learning rate α | 0.95 |
| Discount factor γ | 0.95 |
| Probability factor ε | 0.05 |
| Degradation factor λ | 0.95 |
| Max step | 100 |
| Parameter Name | Value |
|---|---|
| Actor learning rate | 0.005 |
| Critic learning rate | 0.005 |
| Target update rate | 1 |
| Batch size | 50 |
| Memory pool size | 300 |
| Reward discount | 0.95 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Yuan, X.; Niu, J. Robotic Peg-in-Hole Assembly Strategy Research Based on Reinforcement Learning Algorithm. Appl. Sci. 2022, 12, 11149. https://doi.org/10.3390/app122111149
Li S, Yuan X, Niu J. Robotic Peg-in-Hole Assembly Strategy Research Based on Reinforcement Learning Algorithm. Applied Sciences. 2022; 12(21):11149. https://doi.org/10.3390/app122111149
Chicago/Turabian StyleLi, Shaodong, Xiaogang Yuan, and Jie Niu. 2022. "Robotic Peg-in-Hole Assembly Strategy Research Based on Reinforcement Learning Algorithm" Applied Sciences 12, no. 21: 11149. https://doi.org/10.3390/app122111149
APA StyleLi, S., Yuan, X., & Niu, J. (2022). Robotic Peg-in-Hole Assembly Strategy Research Based on Reinforcement Learning Algorithm. Applied Sciences, 12(21), 11149. https://doi.org/10.3390/app122111149