

Prompt Tuning for Multi-Label Text Classification: How to Link Exercises to Knowledge Concepts?

Abstract
:1. Introduction
2. Related Work
2.1. Multi-Label Text Classification
2.2. Prompt Tuning
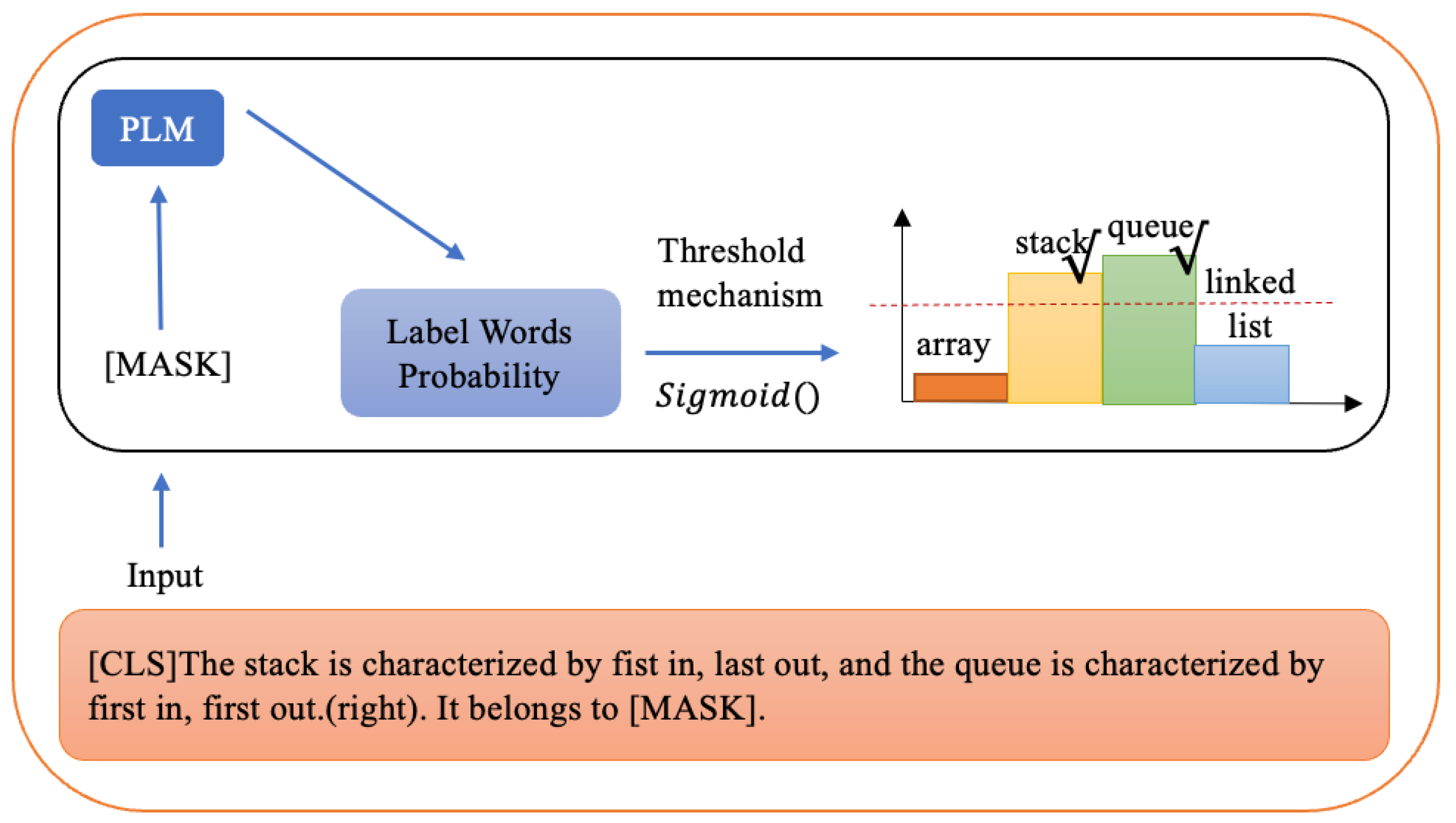
3. Prompt Tuning Method for Multi-Label Text Classification
3.1. Problem Formalization
3.2. Prompt Tuning Method for Multi-Label Text Classification
4. Experiment
4.1. Datasets
4.2. Baselines and Evaluation
4.2.1. Baselines
4.2.2. Evaluation
4.3. Experimental Results
4.3.1. Experiment Settings
4.3.2. Performance Comparison
4.3.3. Ablation Study
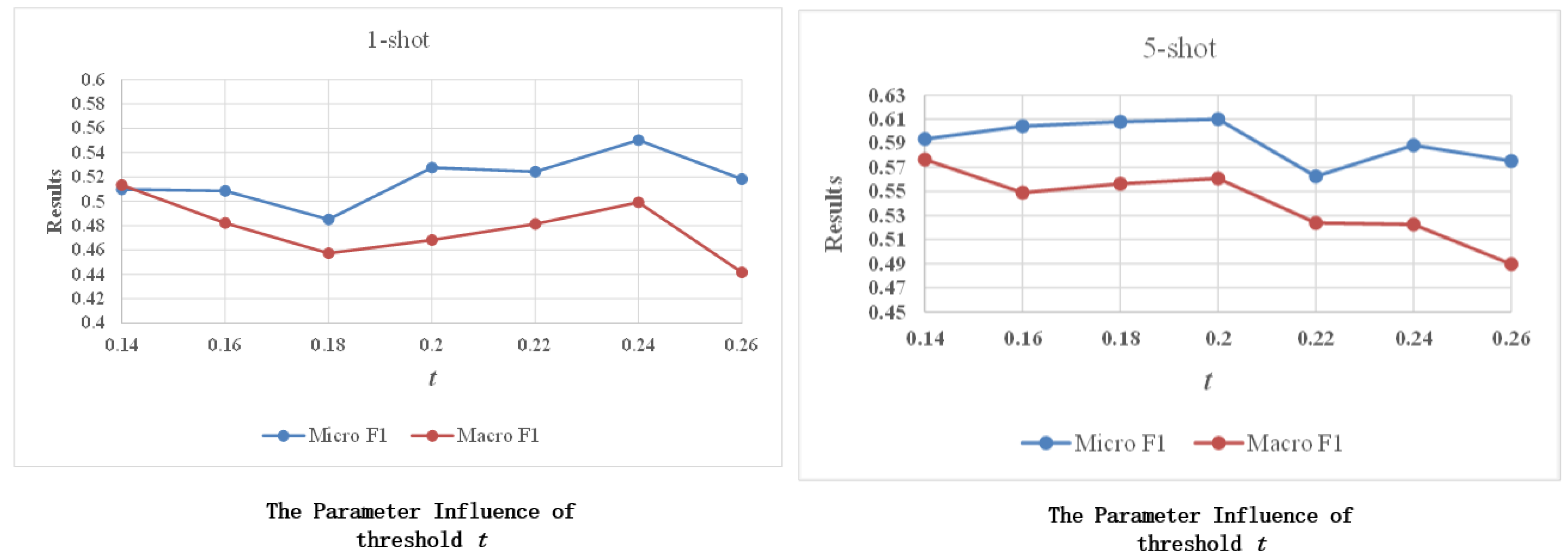
4.3.4. Parameter Sensitivity
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gong, J.; Wang, S.; Wang, J.; Feng, W.; Peng, H.; Tang, J.; Yu, P.S. Attentional graph convolutional networks for knowledge concept recommendation in moocs in a heterogeneous view. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 25–30 July 2020; pp. 79–88. [Google Scholar]
- Chen, S.Y.; Wang, J.H. Individual differences and personalized learning: A review and appraisal. Univers. Access Inf. Soc. 2021, 20, 833–849. [Google Scholar] [CrossRef]
- Khalid, A.; Lundqvist, K.; Yates, A. Recommender systems for moocs: A systematic literature survey (January 1, 2012–July 12, 2019). Int. Rev. Res. Open Distrib. Learn. 2020, 21, 255–291. [Google Scholar]
- Corbett, A.T.; Anderson, J.R. Knowledge tracing: Modeling the acquisition of procedural knowledge. User Model. User-Adapt. Interact. 1994, 4, 253–278. [Google Scholar] [CrossRef]
- He, Z.; Li, W.; Yan, Y. Modeling knowledge proficiency using multi-hierarchical capsule graph neural network. Appl. Intell. 2021, 52, 7230–7247. [Google Scholar] [CrossRef]
- Okpo, J.; Masthoff, J.; Dennis, M.; Beacham, N. Conceptualizing a framework for adaptive exercise selection with personality as a major learner characteristic. In Proceedings of the Adjunct Publication of the 25th Conference on User Modeling, Adaptation and Personalization, Bratislava, Slovakia, 9–12 July 2017; pp. 293–298. [Google Scholar]
- Okpo, J.A.; Masthoff, J.; Dennis, M. Qualitative Evaluation of an Adaptive Exercise Selection Algorithm. In Proceedings of the 29th ACM Conference on User Modeling, Adaptation and Personalization, Utrecht, The Netherlands, 21–25 June 2021; pp. 167–174. [Google Scholar]
- Gao, W.; Liu, Q.; Huang, Z.; Yin, Y.; Bi, H.; Wang, M.C.; Ma, J.; Wang, S.; Su, Y. Rcd: Relation map driven cognitive diagnosis for intelligent education systems. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 11–15 July 2021; pp. 501–510. [Google Scholar]
- Piech, C.; Bassen, J.; Huang, J.; Ganguli, S.; Sahami, M.; Guibas, L.J.; Sohl-Dickstein, J. Deep knowledge tracing. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, USA, 7–12 December 2015; Volume 28. [Google Scholar]
- Zhang, J.; Shi, X.; King, I.; Yeung, D.Y. Dynamic key-value memory networks for knowledge tracing. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 765–774. [Google Scholar]
- Ghosh, A.; Heffernan, N.; Lan, A.S. Context-aware attentive knowledge tracing. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020; pp. 2330–2339. [Google Scholar]
- Liu, J.; Chang, W.C.; Wu, Y.; Yang, Y. Deep learning for extreme multi-label text classification. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 115–124. [Google Scholar]
- Pal, A.; Selvakumar, M.; Sankarasubbu, M. Multi-label text classification using attention-based graph neural network. arXiv 2020, arXiv:2003.11644. [Google Scholar]
- Chang, W.C.; Yu, H.F.; Zhong, K.; Yang, Y.; Dhillon, I. X-bert: Extreme multi-label text classification with bert. arXiv 2019, arXiv:1905.02331. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Babbar, R.; Schölkopf, B. Dismec: Distributed sparse machines for extreme multi-label classification. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 721–729. [Google Scholar]
- Yen, I.E.; Huang, X.; Dai, W.; Ravikumar, P.; Dhillon, I.; Xing, E. Ppdsparse: A parallel primal-dual sparse method for extreme classification. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 545–553. [Google Scholar]
- Prabhu, Y.; Kag, A.; Harsola, S.; Agrawal, R.; Varma, M. Parabel: Partitioned label trees for extreme classification with application to dynamic search advertising. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 993–1002. [Google Scholar]
- Jain, H.; Prabhu, Y.; Varma, M. Extreme multi-label loss functions for recommendation, tagging, ranking & other missing label applications. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 935–944. [Google Scholar]
- Akbarnejad, A.H.; Baghshah, M.S. An efficient semi-supervised multi-label classifier capable of handling missing labels. IEEE Trans. Knowl. Data Eng. 2018, 31, 229–242. [Google Scholar] [CrossRef]
- Tagami, Y. Annexml: Approximate nearest neighbor search for extreme multi-label classification. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 455–464. [Google Scholar]
- Prabhu, Y.; Varma, M. Fastxml: A fast, accurate and stable tree-classifier for extreme multi-label learning. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 263–272. [Google Scholar]
- Qiang, J.; Chen, P.; Ding, W.; Wang, T.; Xie, F.; Wu, X. Heterogeneous-length text topic modeling for reader-aware multi-document summarization. ACM Trans. Knowl. Discov. Data (TKDD) 2019, 13, 1–21. [Google Scholar] [CrossRef]
- Qiang, J.; Wu, X. Unsupervised statistical text simplification. IEEE Trans. Knowl. Data Eng. 2021, 33, 1802–1806. [Google Scholar] [CrossRef]
- Xiao, Y.; Li, Y.; Yuan, J.; Guo, S.; Xiao, Y.; Li, Z. History-based attention in Seq2Seq model for multi-label text classification. Knowl-Based Syst. 2021, 224, 107094. [Google Scholar] [CrossRef]
- Ma, Y.; Liu, X.; Zhao, L.; Liang, Y.; Zhang, P.; Jin, B. Hybrid embedding-based text representation for hierarchical multi-label text classification. Expert Syst. Appl. 2022, 187, 115905. [Google Scholar] [CrossRef]
- Chen, G.; Ye, D.; Xing, Z.; Chen, J.; Cambria, E. Ensemble application of convolutional and recurrent neural networks for multi-label text categorization. In Proceedings of the 2017 IEEE International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 2377–2383. [Google Scholar]
- Yang, P.; Sun, X.; Li, W.; Ma, S.; Wu, W.; Wang, H. SGM: Sequence generation model for multi-label classification. arXiv 2018, arXiv:1806.04822. [Google Scholar]
- Xun, G.; Jha, K.; Sun, J.; Zhang, A. Correlation networks for extreme multi-label text classification. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020; pp. 1074–1082. [Google Scholar]
- Ding, N.; Hu, S.; Zhao, W.; Chen, Y.; Liu, Z.; Zheng, H.T.; Sun, M. Openprompt: An open-source framework for prompt-learning. arXiv 2021, arXiv:2111.01998. [Google Scholar]
- Schick, T.; Schütze, H. Exploiting cloze questions for few shot text classification and natural language inference. arXiv 2020, arXiv:2001.07676. [Google Scholar]
- Zhang, N.; Li, L.; Chen, X.; Deng, S.; Bi, Z.; Tan, C.; Huang, F.; Chen, H. Differentiable prompt makes pre-trained language models better few-shot learners. arXiv 2021, arXiv:2108.13161. [Google Scholar]
- Floridi, L.; Chiriatti, M. GPT-3: Its nature, scope, limits, and consequences. Minds Mach. 2020, 30, 681–694. [Google Scholar] [CrossRef]
- Hu, S.; Ding, N.; Wang, H.; Liu, Z.; Li, J.; Sun, M. Knowledgeable prompt-tuning: Incorporating knowledge into prompt verbalizer for text classification. arXiv 2021, arXiv:2108.02035. [Google Scholar]
- Chen, X.; Zhang, N.; Xie, X.; Deng, S.; Yao, Y.; Tan, C.; Huang, F.; Si, L.; Chen, H. Knowprompt: Knowledge-aware prompt-tuning with synergistic optimization for relation extraction. arXiv 2021, arXiv:2104.07650. [Google Scholar]
- Ma, Y.; Wang, Z.; Cao, Y.; Li, M.; Chen, M.; Wang, K.; Shao, J. Prompt for Extraction? PAIE: Prompting Argument Interaction for Event Argument Extraction. arXiv 2022, arXiv:2202.12109. [Google Scholar]
- Cui, L.; Wu, Y.; Liu, J.; Yang, S.; Zhang, Y. Template-based named entity recognition using BART. arXiv 2021, arXiv:2106.01760. [Google Scholar]
- Li, X.L.; Liang, P. Prefix-tuning: Optimizing continuous prompts for generation. arXiv 2021, arXiv:2101.00190. [Google Scholar]
- Scao, T.L.; Rush, A.M. How many data points is a prompt worth? arXiv 2021, arXiv:2103.08493. [Google Scholar]
- Hambardzumyan, K.; Khachatrian, H.; May, J. Warp: Word-level adversarial reprogramming. arXiv 2021, arXiv:2101.00121. [Google Scholar]
- Reynolds, L.; McDonell, K. Prompt programming for large language models: Beyond the few-shot paradigm. In Proceedings of the Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; pp. 1–7. [Google Scholar]
- Xu, G.; Lee, H.; Koo, M.W.; Seo, J. Convolutional neural network using a threshold predictor for multi-label speech act classification. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju, Korea, 13–16 February 2017; pp. 126–130. [Google Scholar]
- Hou, Y.; Lai, Y.; Wu, Y.; Che, W.; Liu, T. Few-shot learning for multi-label intent detection. arXiv 2020, arXiv:2010.05256. [Google Scholar]
- Yu, J.; Luo, G.; Xiao, T.; Zhong, Q.; Wang, Y.; Feng, W.; Luo, J.; Wang, C.; Hou, L.; Li, J.; et al. MOOCCube: A large-scale data repository for NLP applications in MOOCs. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5 July 2020; pp. 3135–3142. [Google Scholar]
- Chen, Y. Convolutional Neural Network for Sentence Classification. Master’s Thesis, University of Waterloo, Waterloo, ON, Canada, 2015. [Google Scholar]
- Khezrian, N.; Habibi, J.; Annamoradnejad, I. Tag recommendation for online Q&A communities based on BERT pre-training technique. arXiv 2020, arXiv:2010.04971. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
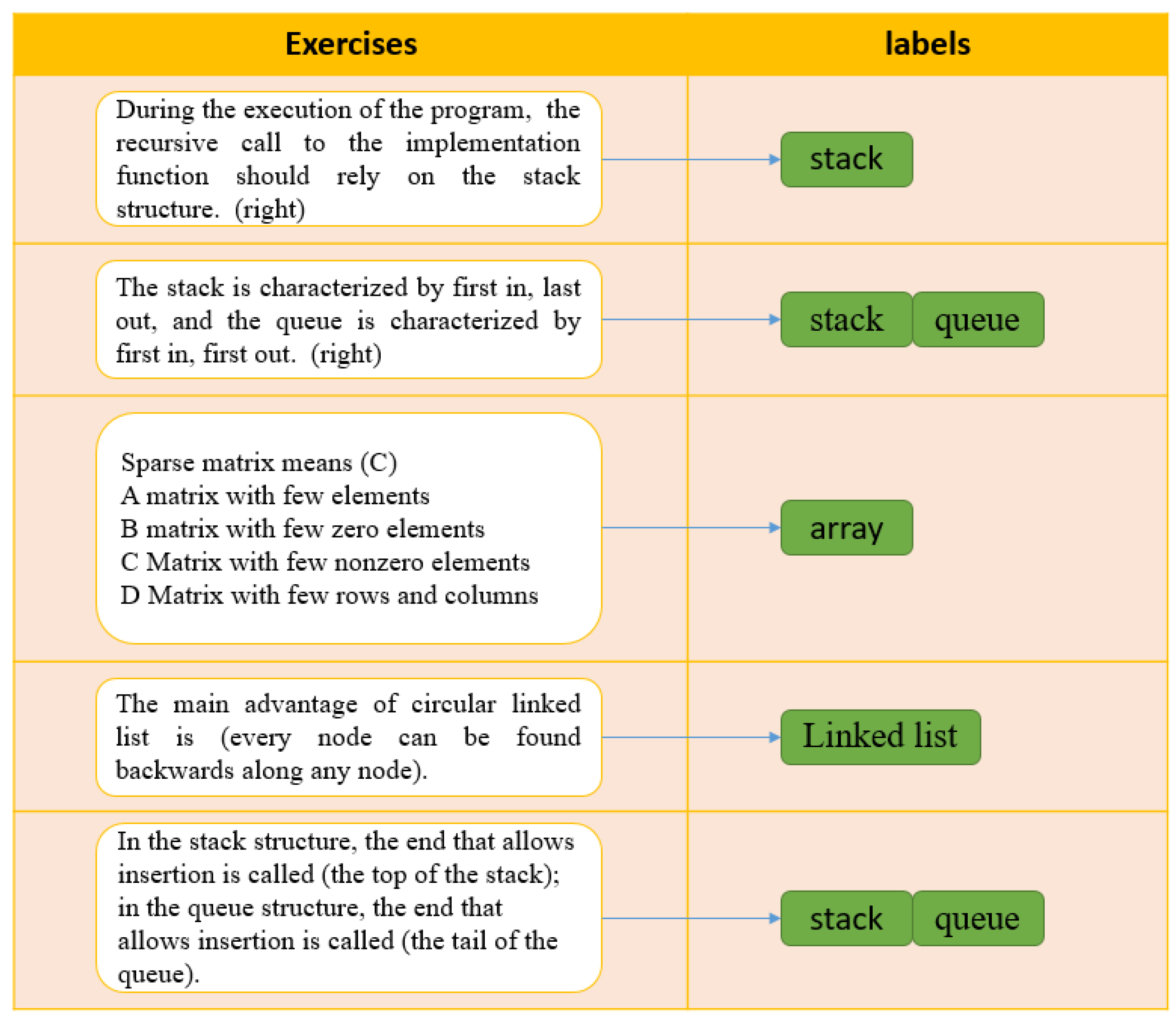



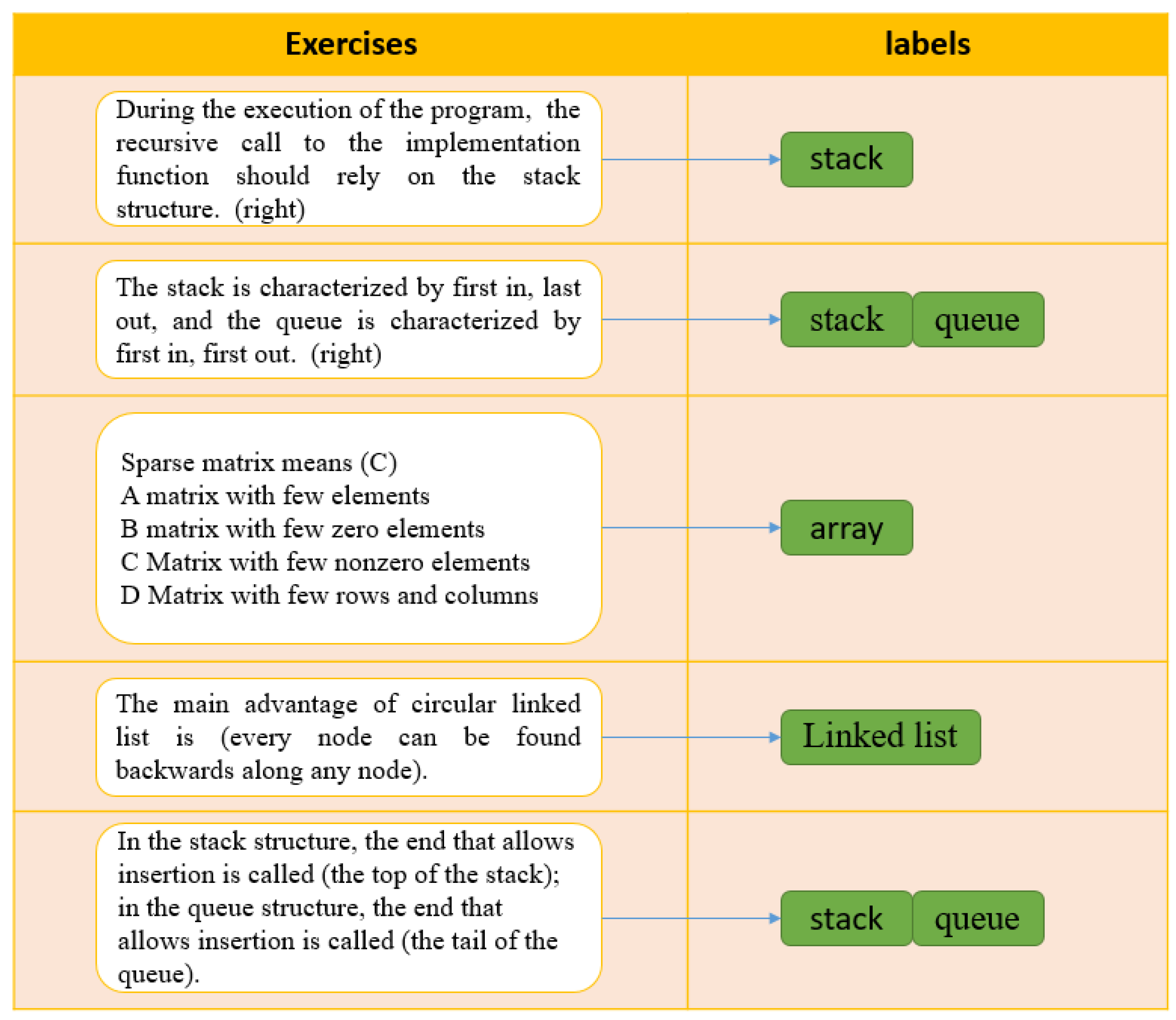{kind=link}
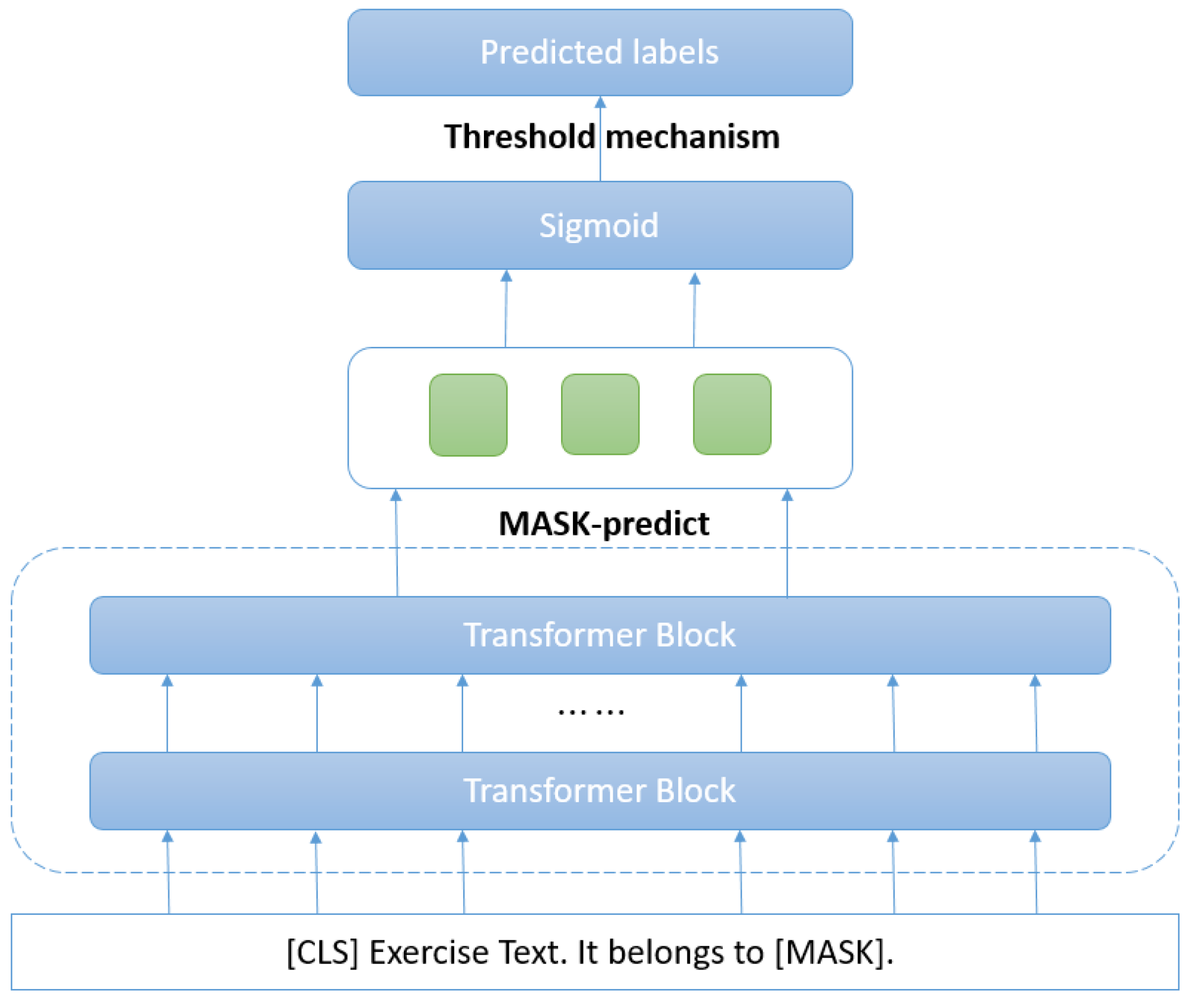
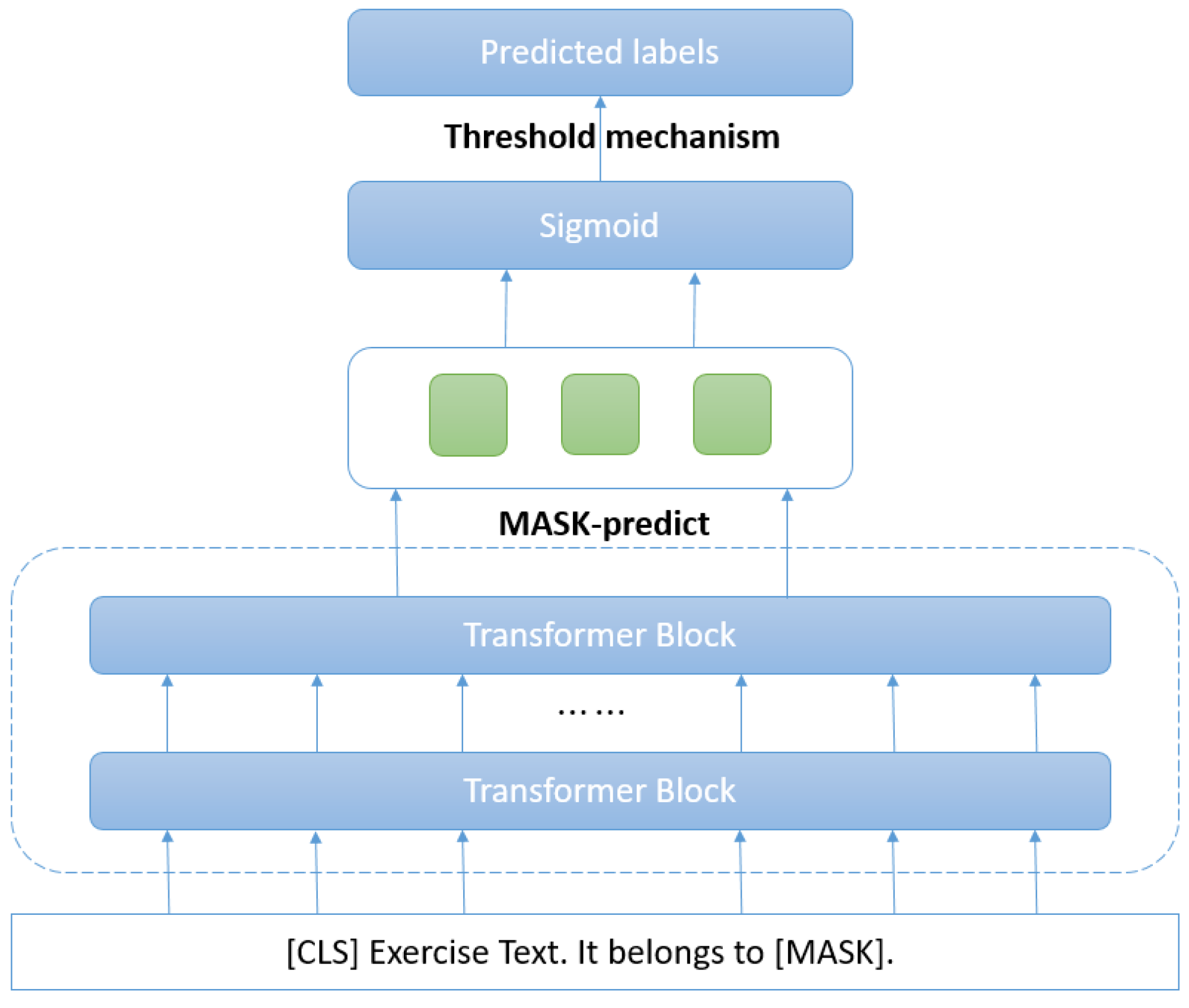{kind=link}
{kind=link}
{kind=link}
| C | N | C | N | C | N | C | N |
|---|---|---|---|---|---|---|---|
| Array | 36 | Sequential List | 46 | Bubble Sort | 41 | Binary Search | 48 |
| Logical Structure | 48 | Linked Storage Structure | 48 | Time Complexity | 91 | Generalized table | 35 |
| Heapsort | 46 | Physical Structure | 35 | Linked List | 10 | Matrix | 35 |
| Adjacency Matrix | 35 | Linear List | 48 | BT-Preorder Traversal | 37 | Tree-Degree | 40 |
| Algorithm | 56 | String | 35 | BT-Postorder Traversal | 35 | Tree-Depth | 45 |
| Queue | 35 | Tree | 24 | Minimum Spanning Tree | 53 | Graph | 18 |
| Recursion | 39 | Binary Tree (BT) | 23 | Topological Sort | 45 | Circular Queue | 35 |
| Complete Binary Tree | 42 | Binary Sort Tree | 35 | Depth First Search | 5 | Binary Tree-Threaded BinaryTree | 35 |
| Balanced BinaryTree | 50 | Huffman Tree | 35 | Breadth First Search | 48 | Shell’s Sort | 60 |
| Search | 136 | Data Structure | 35 | Connected Graph | 47 | Binary Tree-Inorder Traversal | 13 |
| Sequential Search | 53 | Sequential Storage Structure | 35 | Quick Sort | 68 | Merge Sort | 35 |
| Critical Path | 60 | Stack | 35 | Full Binary Tree | 48 | Space Complexity | 35 |
| Selection Sort | 35 | Strongly Connected Graph | 57 | Graph-Degree | 35 | Selection Sort | 35 |
| HashSearch | 35 | Muitl-way Search Tree | 35 | Adjacency List | 37 | Sort | 28 |
| Shortest Path | 35 | Binary Tree-Order Traversal | 56 | Doubly Linked List | 35 | Straight Insertion Sort | 44 |
| Cycle Chain | 14 | Undirected Graph | 27 | Oriented graph | 36 | Data | 12 |
| Double Circle List | 8 |
| Method | 1-Shot | |
|---|---|---|
| Micro F1 | Macro F1 | |
| TextCNN | 6.60 ± 1.23 | 5.70 ± 0.89 |
| TagBert | 9.83 ± 0.77 | 6.05 ± 2.16 |
| BertFGM | 6.65 ± 2.47 | 2.11 ± 2.13 |
| PTMLTC | 53.86 ± 3.16 | 49.04 ± 3.42 |
| Method | 5-Shot | |
|---|---|---|
| Micro_F1 | Macro_F1 | |
| TextCNN | 29.49 ± 0.62 | 29.84 ± 2.67 |
| TagBert | 47.06 ± 0.18 | 41.50 ± 6.90 |
| BertFGM | 34.72 ± 0.99 | 26.66 ± 3.12 |
| PTMLTC | 62.37 ± 0.43 | 58.84 ± 0.84 |
| Method | Micro F1 | Macro F1 | ||
|---|---|---|---|---|
| 1-Shot | 5-Shot | 1-Shot | 5-Shot | |
| PTMLTC_Bert | 50.74 ± 1.53 | 58.56 ± 1.50 | 46.11 ± 2.68 | 54.28 ± 1.47 |
| PTMLTC_Roberta | 53.86 ± 3.16 | 62.37 ± 0.43 | 49.04 ± 3.42 | 58.84 ± 0.84 |
| Templates | 1-Shot | 5-Shot | ||
|---|---|---|---|---|
| Micro F1 | Micro F1 | Micro F1 | Micro F1 | |
| It belongs to [MASK]. | 53.86 ± 2.74 | 49.04 ± 3.12 | 62.37 ± 1.05 | 58.84 ± 0.89 |
| The concept is [MASK]. | 50.98 ± 2.92 | 51.35 ± 2.15 | 58.44 ± 0.77 | 54.28 ± 1.15 |
| The concept belongs to [MASK]. | 52.76 ± 3.13 | 46.83 ± 2.47 | 60.99 ± 0.37 | 53.85 ± 0.62 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, L.; Li, Y.; Zhu, Y.; Li, B.; Zhang, L. Prompt Tuning for Multi-Label Text Classification: How to Link Exercises to Knowledge Concepts? Appl. Sci. 2022, 12, 10363. https://doi.org/10.3390/app122010363
Wei L, Li Y, Zhu Y, Li B, Zhang L. Prompt Tuning for Multi-Label Text Classification: How to Link Exercises to Knowledge Concepts? Applied Sciences. 2022; 12(20):10363. https://doi.org/10.3390/app122010363
Chicago/Turabian StyleWei, Liting, Yun Li, Yi Zhu, Bin Li, and Lejun Zhang. 2022. "Prompt Tuning for Multi-Label Text Classification: How to Link Exercises to Knowledge Concepts?" Applied Sciences 12, no. 20: 10363. https://doi.org/10.3390/app122010363
APA StyleWei, L., Li, Y., Zhu, Y., Li, B., & Zhang, L. (2022). Prompt Tuning for Multi-Label Text Classification: How to Link Exercises to Knowledge Concepts? Applied Sciences, 12(20), 10363. https://doi.org/10.3390/app122010363