
Ultrasonic Doppler Based Silent Speech Interface Using Perceptual Distance


Abstract
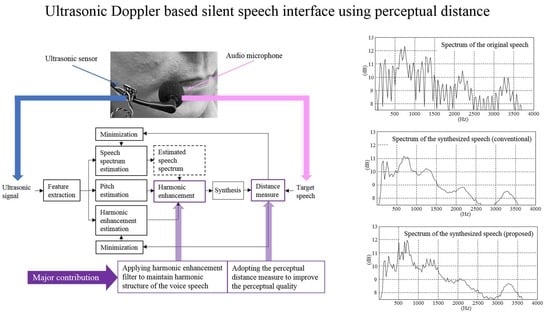
:
1. Introduction
2. Baseline UDS-Based SSI
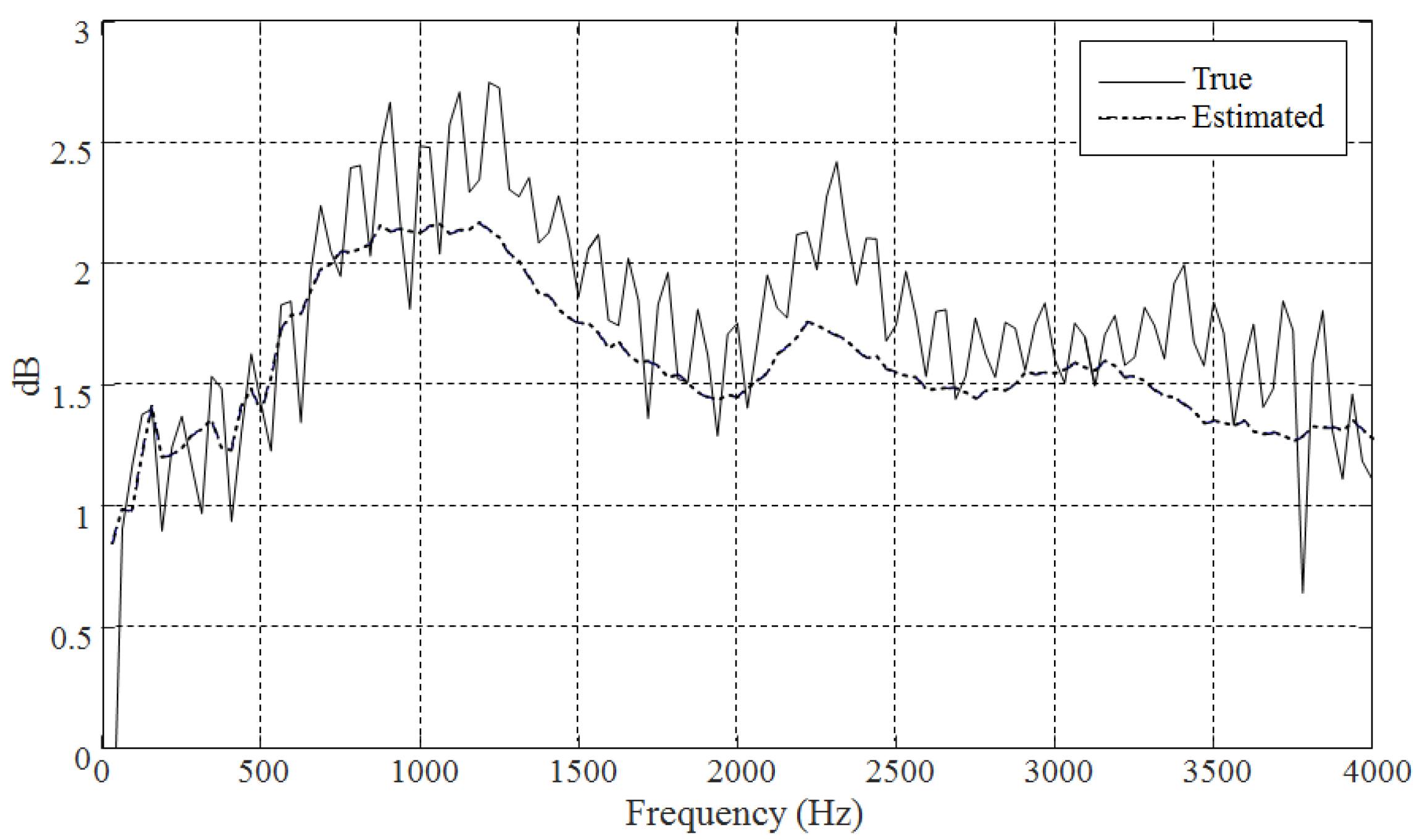
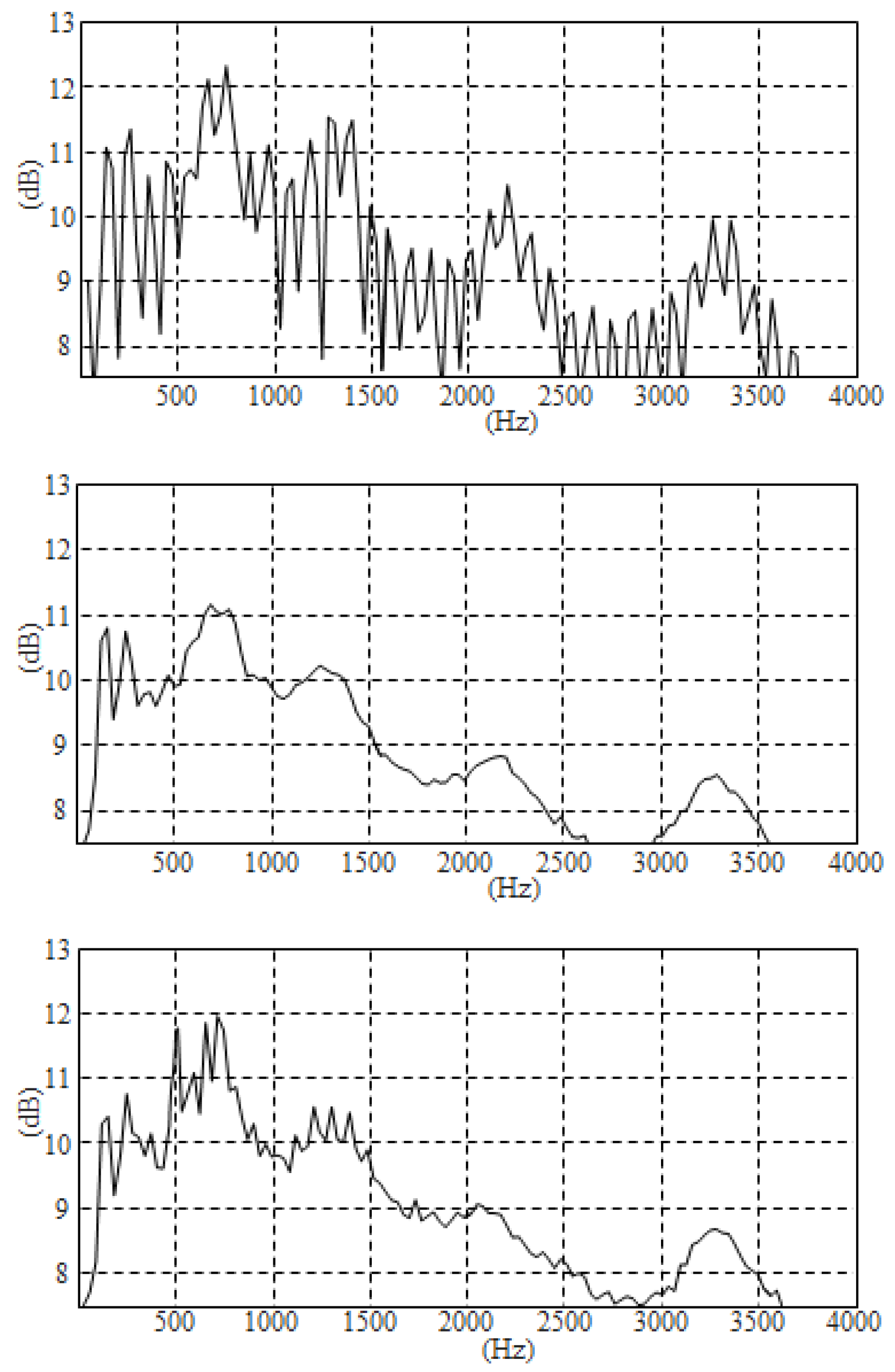
2.1. Estimating the Speech Spectrum
2.2. Harmonic Enhancement
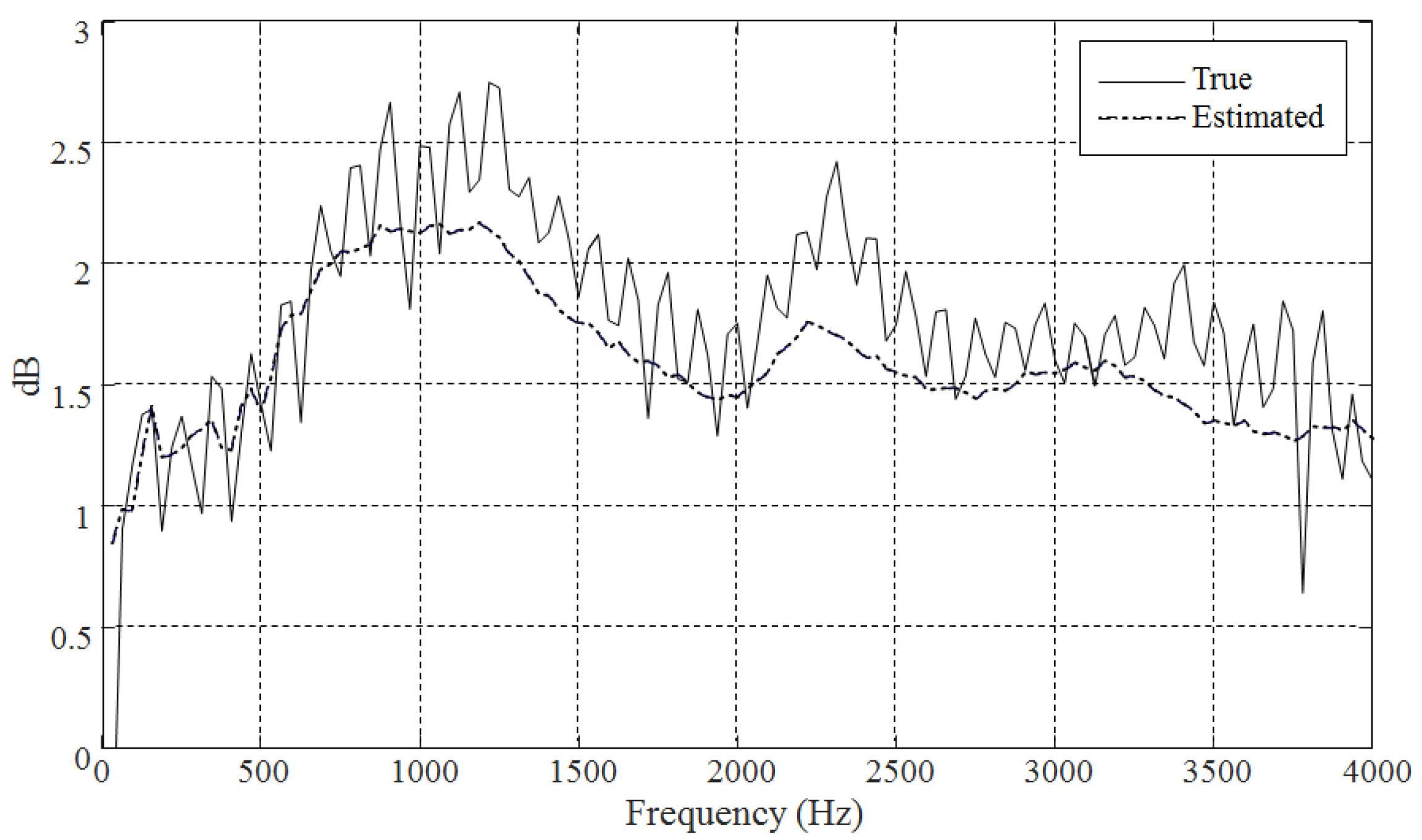
2.3. Performance of Pitch Estimation and V/UV Decisions
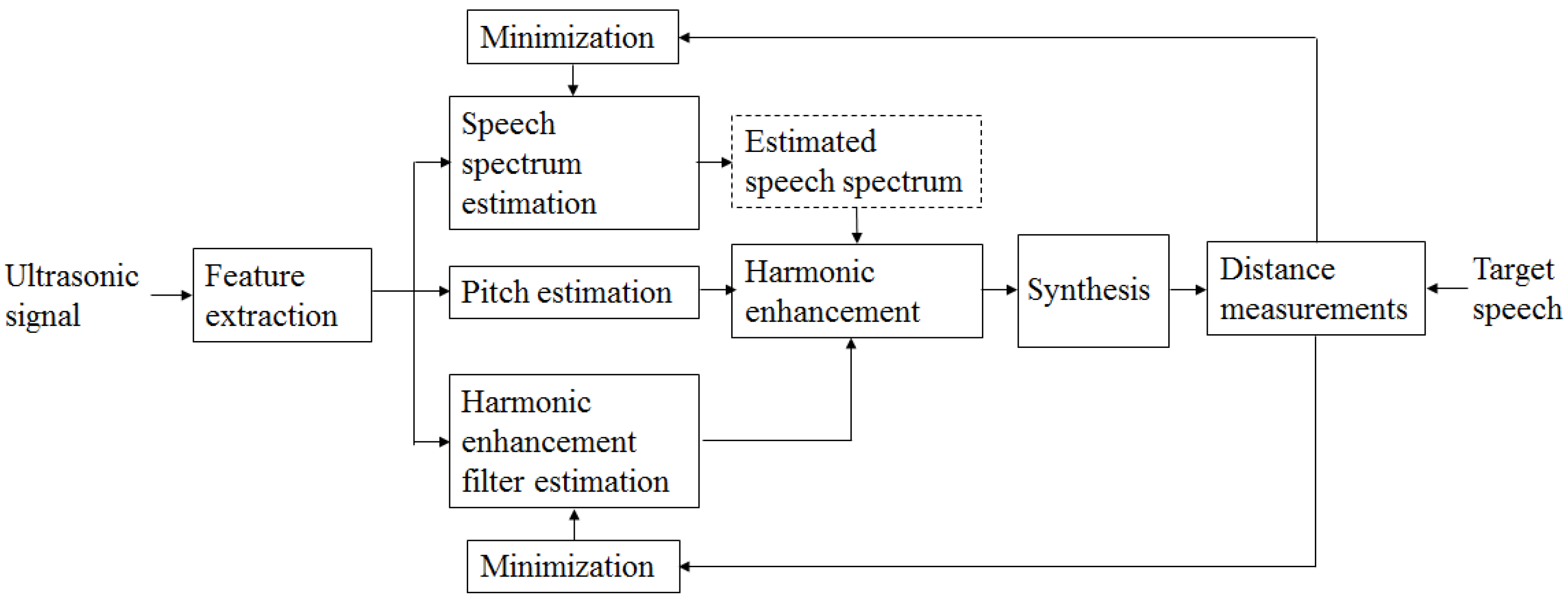
3. Proposed UDS-Based SSI
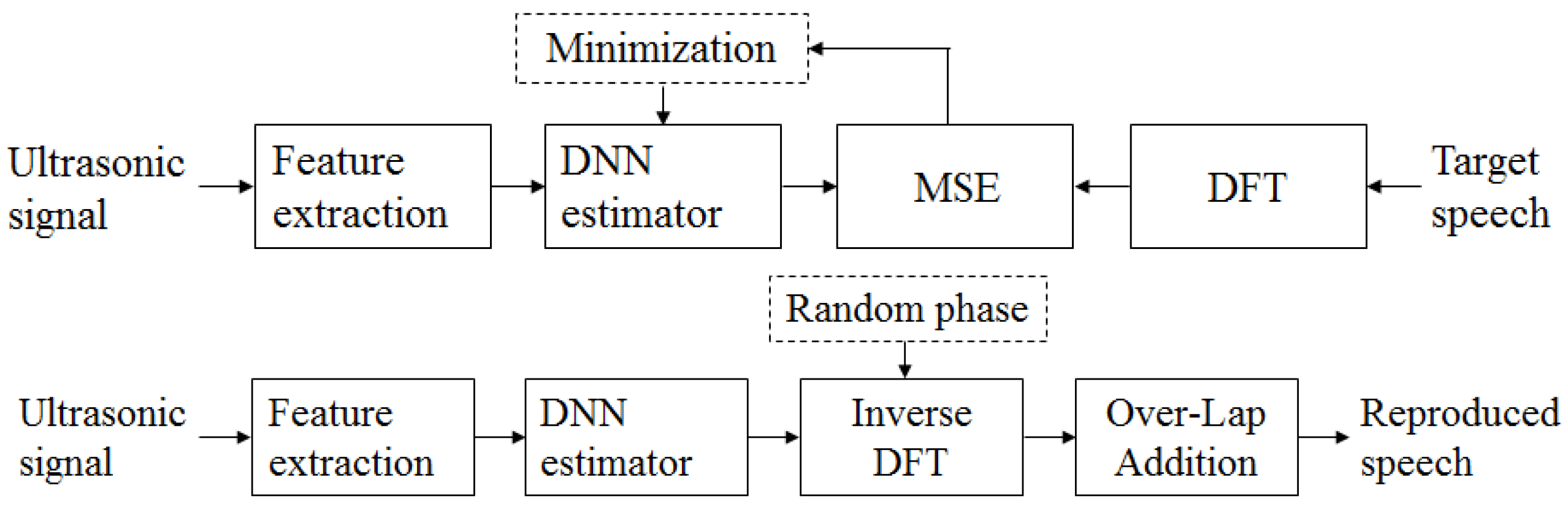
3.1. Joint Minimization Using Iterative Learning
3.2. Perceptual Distance
- (1)
- Perceptual domain transformation: The target and converted loudness spectra and , which are perceptually closer to human listening are obtained as follows,where Q is the number of Bark bands, is a Bark transformation matrix that converts the power spectra , into the Bark spectra and , respectively. is a mapping function that converts each band of the Bark spectrum to a sone loudness scale. A detailed description of this function is found in [34].
- (2)
- Disturbances computation: A center-clipping operator over the absolute difference between the loudness spectra was applied to compute the symmetrical disturbance vector as follows,where is a clipping factor and , , and are applied element-wise. The designation is a zero-filled vector of length Q. The asymmetrical disturbance vector is obtained as , where ⊙ denotes an element-wise multiplication and is a vector of asymmetry ratios the components of which are computed from the Bark spectra.For the speech enhancement task, the constants and were set to 50 and 1.2, respectively [34]. In the present study, experiments were performed to optimally determine the two constants, and , minimizing minimize the overall PD. The experimental results show that the same values adopted in [34] also yielded the minimum . The symmetrical and asymmetrical disturbance terms in (12) are given by the weighted sum of each disturbance vector,where the components of the weight vector is proportional to the width of the Bard bands, as explained in [37].
3.3. Estimation of the Prediction Rules
3.4. Speech Synthesis
4. Evaluation
4.1. Experimental Setup
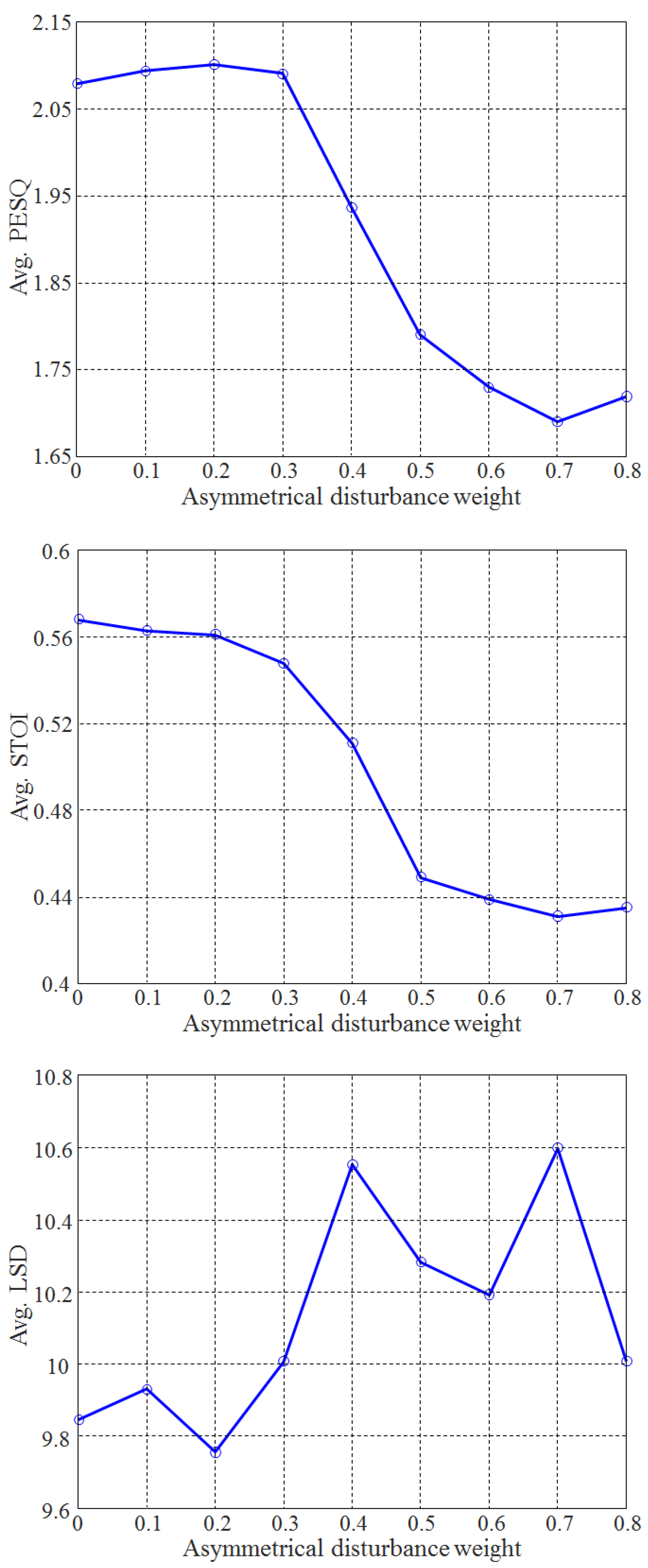
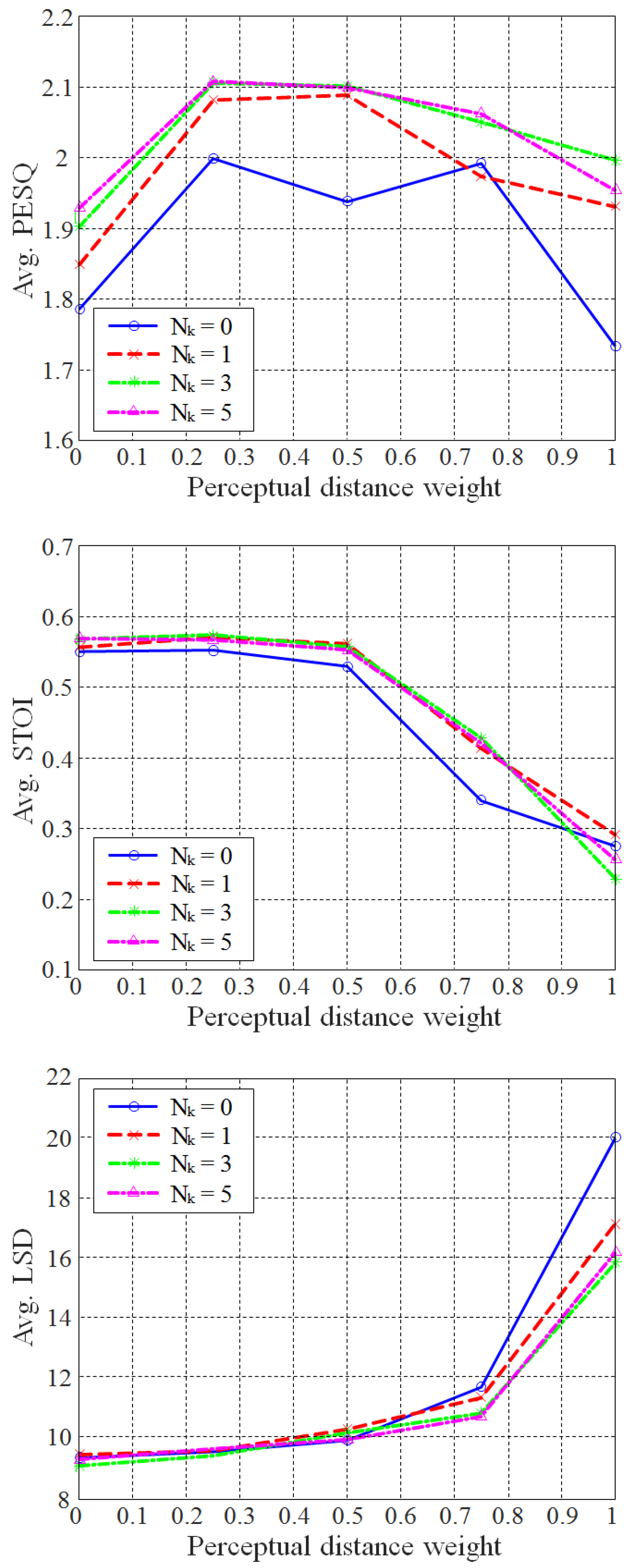
4.2. Determination of the Weights for Each Disturbance
4.3. Objective Evaluation Results According to the PD Weights and the Length of the HE Filter
4.4. Comparison with Other Methods
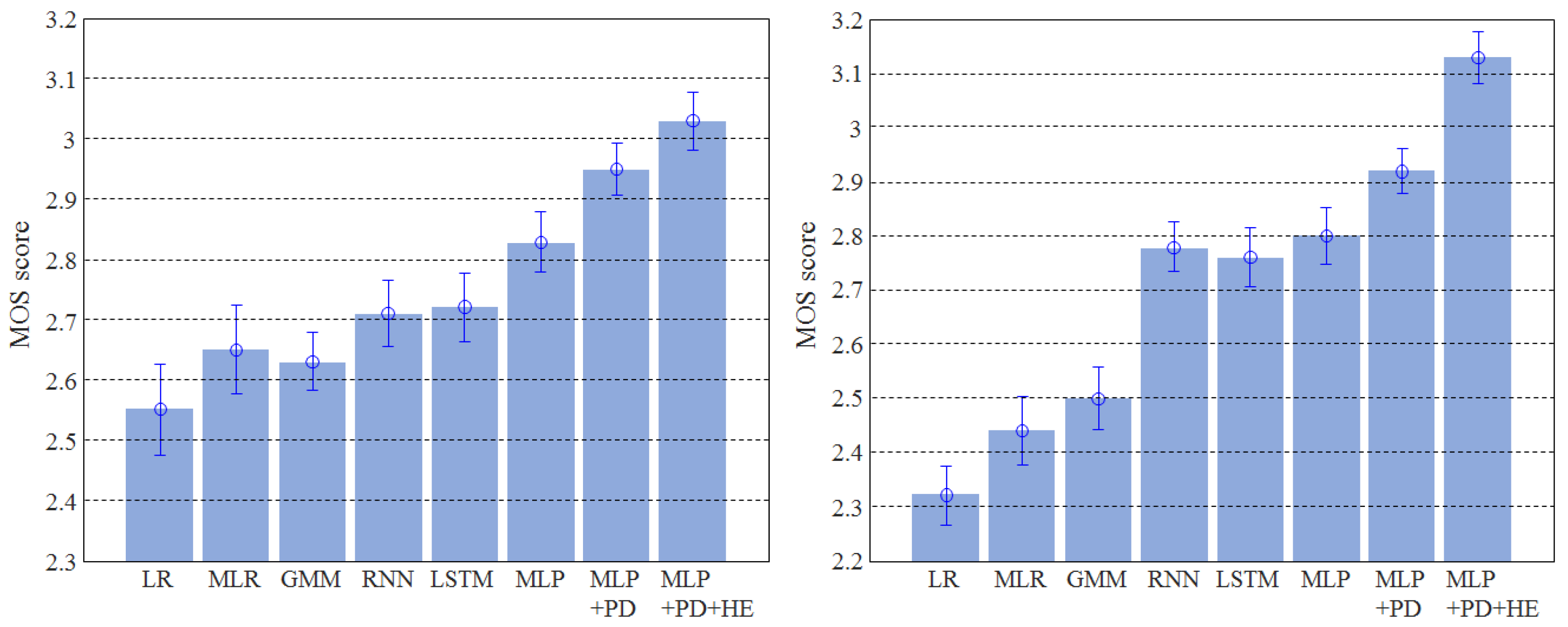
4.5. Subjective Evaluation
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Denby, B.; Schultz, T.; Honda, K.; Hueber, T.; Gilbert, J.M.; Brumberg, J.S. Silent speech interfaces. Speech Commun. 2010, 4, 270–287. [Google Scholar] [CrossRef] [Green Version]
- Schultz, T.; Wand, M.; Hueber, T.; Krusienski, J.; Herff, C.; Brumberg, J. Biosignal-based spoken communication: A survey. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 12, 2257–2271. [Google Scholar] [CrossRef]
- Quatieri, T.F.; Brady, K.; Messing, D.; Campbell, J.P.; Campbell, W.M.; Brandstein, M.S.; Weinstein, C.J.; Tardelli, J.D.; Gatewood, P.D. Exploiting nonacoustic sensors for speech encoding. IEEE Trans. Audio Speech Lang. Process. 2006, 2, 533–544. [Google Scholar] [CrossRef]
- Jiao, M.; Lu, G.; Jing, X.; Li, S.; Li, Y.; Wang, J. A novel radar sensor for the non-contact detection of speech signals. Sensors 2010, 10, 4622–4633. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, S.; Wang, J.-Q.; Niu, M.; Liu, T.; Jing, X.-J. The enhancement of millimeter wave conduct speech based on perceptual weighting. Prog. Electromagn. Res. B 2008, 9, 199–214. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Tian, Y.; Lu, G.; Zhang, Y.; Lv, H.; Yu, X.; Xue, H.; Zhang, H.; Wang, J.; Jing, X. A 94-GHz milimeter-wave sensor for speech signal acquisition. Sensors 2013, 13, 14248–14260. [Google Scholar] [CrossRef]
- Li, S.; Tian, Y.; Lu, G.; Zhang, Y.; Xue, H.; Wang, J.; Jing, X. A new kind of non-acoustic speech acquisition method based on millimeter wave radar. Prog. Electromagn. Res. B 2012, 130, 17–40. [Google Scholar] [CrossRef] [Green Version]
- Lin, C.-S.; Chang, S.-F.; Chang, C.-C.; Lin, C.-C. Microwave human vocal vibration signal detection based on Doppler radar technology. IEEE Trans. Microw. Theory Technol. 2010, 8, 2299–2306. [Google Scholar] [CrossRef]
- Denby, B.; Stone, M. Speech synthesis from real time ultrasound images of the tongue. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Montreal, QC, Canada, 17–21 May 2004; pp. 685–688. [Google Scholar]
- Denby, B.; Qussar, Y.; Dreyfus, G.; Stone, M. Prospects for a silent speech interface using ultrasound imaging. In Proceedings of the IEEE International Conference on Acoustic Speech Signal Processing, Toulouse, France, 14–19 May 2006; pp. 365–368. [Google Scholar]
- Hueber, T.; Aversano, G.; Chollet, G.; Stone, M. Eigentongue feature extraction for an ultrasound-based silent speech interface. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Honolulu, HI, USA, 15–20 April 2007; pp. 1245–1248. [Google Scholar]
- Cornu, T.L.; Milner, B. Generating intelligible audio speech from visual speech. IEEE Trans. Audio Speech Lang. Process. 2017, 9, 1447–1457. [Google Scholar] [CrossRef] [Green Version]
- Deligne, S.; Potamianos, G.C.; Neti, C. Audio-visual speech enhancement with AVCDCN (Audio-Visual Codebook Dependent Cepstral Normalization). In Proceedings of the International Conference on Spoken Language Processing, Denver, CO, USA, 16–20 September 2002; pp. 1449–1452. [Google Scholar]
- Girin, L.; Varin, L.; Feng, G.; Schwartz, J.L. Audiovisual speech enhancement: New advances using multi-layer perceptrons. In Proceedings of the IEEE 2nd Workshop on Multimedia Signal Processing, Redondo Beach, CA, USA, 7–9 December 1998; pp. 77–82. [Google Scholar]
- Potamianos, G.; Neti, C.; Gravier, G.; Garg, A.; Senior, A.W. Recent advances in the automatic recognition of audiovisual speech. Proc. IEEE 2003, 9, 1306–1326. [Google Scholar] [CrossRef]
- Almajai, T.B.; Milner, B. Visually derived Wiener filters for speech enhancement. IEEE Trans. Audio Speech Lang. Process. 2011, 6, 1642–1651. [Google Scholar] [CrossRef]
- Kalgaonkar, K.; Raj, B. Ultrasonic doppler sensor for speaker recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Las Vegas, NA, USA, 30 March–4 April 2008; pp. 4865–4868. [Google Scholar]
- Lee, K.-S. Speech enhancement using ultrasonic doppler sonar. Speech Commun. 2019, 110, 21–32. [Google Scholar] [CrossRef]
- Lee, K.-S. Silent speech interface using Doppler sonar. IEICE Trans. Inf. Syst. 2020, 8, 1875–1887. [Google Scholar] [CrossRef]
- Raj, B.; Kalgaonkar, K.; Harrison, C.; Dietz, P. Ultrasonic doppler sensing in HCI. IEEE Pervasive Comput. 2012, 2, 24–29. [Google Scholar] [CrossRef]
- Toth, A.R.; Raj, B.; Kalgaonkar, K.; Ezzat, T. Synthesizing speech from doppler signals. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010; pp. 4638–4641. [Google Scholar]
- Toda, T.; Shikano, K. NAM-to-Speech conversion with Gaussian Mixture Models. In Proceedings of the Interspeech, Lisbon, Portugal, 4–8 September 2005; pp. 1957–1960. [Google Scholar]
- Toda, T.; Nakagiri, M.; Shikano, K. Statistical voice conversion techniques for body-conducted unvoiced speech enhancement. IEEE Trans. Audio Speech Lang. Process. 2012, 9, 2505–2517. [Google Scholar] [CrossRef]
- Diener, L.; Janke, M.; Schultz, T. Direct conversion from facial myoelectric signals to speech using deep neural networks. In Proceedings of the International Joint Conference on Neural Networks, Killarney, Ireland, 12–17 July 2015; pp. 1–7. [Google Scholar]
- Hueber, T.; Bailly, G. Statistical conversion of silent articulation into audible speech using full-covariance HMM. Comput. Speech Lang. 2016, 36, 274–293. [Google Scholar] [CrossRef]
- Janke, M.; Wand, M.; Nakamura, K.; Schultz, T. Further investigations on EMG-to-speech conversion. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Kyoto, Japan, 25–30 March 2012; pp. 365–368. [Google Scholar]
- Janke, M.; Diener, D. EMG-to-Speech: Direct generation of speech from facial electromyographic signals. IEEE Trans. Audio Speech Lang. Process. 2017, 12, 2375–2385. [Google Scholar] [CrossRef] [Green Version]
- Lee, K.-S. EMG-based speech recognition using Hidden Markov Models with global control variables. IEEE Trans. Biomed. Eng. 2008, 3, 930–940. [Google Scholar] [CrossRef]
- Lee, K.-S. Prediction of acoustic feature parameters using myoelectric signals. IEEE Trans. Biomed. Eng. 2010, 7, 1587–1595. [Google Scholar]
- Toth, A.R.; Wand, M.; Schultz, T. Synthesizing speech from electromyography using voice transformation techniques. In Proceedings of the Interspeech, Brighton, UK, 6–10 September 2009; pp. 652–655. [Google Scholar]
- Wand, M.; Janke, M.; Schultz, T. Tackling speaking mode varieties in EMG-based speech recognition. IEEE Trans. Biomed. Eng. 2014, 10, 2515–2526. [Google Scholar] [CrossRef]
- Rabiner, L.R.; Juang, B.-H. Auditory-based spectral analysis models. In Fundamentals of Speech Recognition; Prentice Hall: Englewood Cliffs, NJ, USA, 1993; pp. 132–139. [Google Scholar]
- Cernak, M.; Asaei, A.; Hyafil, A. Cognitive Speech Coding: Examining the Impact of Cognitive Speech Processing on Speech Compression. IEEE Signal Process. Mag. 2018, 3, 97–109. [Google Scholar] [CrossRef]
- Martin, J.M.; Gomez, A.M.; Gonzalez, J.A.; Peinado, A.M. A deep learning loss function based on the perceptual evaluation of the speech quality. IEEE Signal Process. 2018, 11, 1680–1684. [Google Scholar] [CrossRef]
- Moritz, N.; Anemu¨ller, J.B.; Kollmeier, B. An Auditory Inspired Amplitude Modulation Filter Bank for Robust Feature Extraction in Automatic Speech Recognition. IEEE Trans. Audio Speech Lang. Process. 2015, 11, 1926–1937. [Google Scholar] [CrossRef]
- Tachibana, K.; Toda, T.; Shiga, Y.; Kawai, H. An Investigation of Noise Shaping with Perceptual Weighting for Wavenet-Based Speech Generation. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Calgary, AB, Canada, 15–20 April 2018; pp. 5664–5668. [Google Scholar]
- ITU-T, Rec. P. 862; Perceptual Evaluation of Speech Quality (PESQ): An Objective Method for End-to-End Speech Quality Assessment of Narrow Band Telephone Networks and Speech Codecs. International Telecommunication Union-Telecommunication Standardisation Sector: Geneva, Switzerland, 2001.
- Nakamura, K.; Janke, M.; Wand, M.; Schultz, T. Estimation of fundamental frequency from surface electromyographic data:EMG-to-F0. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Prague, Czech Republic, 22–27 May 2011; pp. 573–576. [Google Scholar]
- Xu, Y.; Du, J.; Dai, L.-R.; Lee, C.-H. A regression approach to speech enhancement based on deep neural networks. IEEE Trans. Audio Speech Lang. Process. 2015, 1, 7–19. [Google Scholar] [CrossRef]
- Jin, W.; Liu, X.; Scordilis, M.S.; Han, L. Speech enhancement using harmonic emphasis and adaptive comb filtering. IEEE Trans. Audio Speech Lang. Process. 2010, 2, 356–368. [Google Scholar] [CrossRef]
- Han, K.; Wang, D. Neural network based pitch tracking in very noisy speech. IEEE Trans. Audio Speech Lang. Process. 2014, 12, 2158–2168. [Google Scholar] [CrossRef]
- Kato, A.; Kinnunen, T.H. Statistical Regression Models for Noise Robust F0 Estimation Using Recurrent Deep Neural Networks. IEEE/ACM Trans. Audio Speech Lang. Process 2019, 12, 2336–2349. [Google Scholar] [CrossRef]
- Griffin, D.W.; Lim, J.S. Signal estimation from the modified short-time fourier transform. IEEE Trans. Acoust. Speech Signal Process. 1984, 32, 236–243. [Google Scholar] [CrossRef]
- Hinton, G.E. Training products of experts by minimizing contrastive divergence. Neural Comput. 2002, 8, 1711–1800. [Google Scholar] [CrossRef]
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. An algorithm for intelligibility prediction of time-frequency weighted noisy speech. IEEE/ACM Trans. Audio Speech Lang. Process. 2011, 7, 2125–2136. [Google Scholar] [CrossRef]
- Yadav, R.; Sardana, A.; Namboodiri, V.P.; Hegde, R.M. Speech prediction in silent videos using variational autoencoders. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Totonto, ON, Canada, 6–11 June 2021; pp. 7048–7052. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modality | FPE [Hz] | FPR [Hz] | GPE Rate (%) |
|---|---|---|---|
| Vision | 48.82 | 39.95 | 73.6 |
| EMG | 60.19 | 34.13 | 88.5 |
| e UDS | 27.39 | 39.33 | 45.6 |
| Modality | Voiced Frames (%) | Unvoiced Frames (%) | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | Accuracy | Precision | Recall | Accuracy | |
| Vision | 84.7 | 95.4 | 90.1 | 74.6 | 43.7 | 59.2 |
| EMG | 78.8 | 99.9 | 89.4 | 17.0 | 0.01 | 8.5 |
| UDS | 87.7 | 88.5 | 88.1 | 76.4 | 74.9 | 75.7 |
| Property | Value |
|---|---|
| Average number of utterances (per subject) | 1062 |
| Average duration of utterances (s) | 6.44 |
| Standard deviation of duration (s) | 1.33 |
| Maximum duration of utterance (s) | 12.26 |
| Minimum duration of utterance (s) | 3.23 |
| Average number of phonemes (per subject) | 69,982 |
| Method | Avg. PESQ | Avg. STOI | Avg. LSD | Avg. R |
|---|---|---|---|---|
| Linear regression (LR) | 1.515 | 0.424 | 9.700 | 0.114 |
| Multivariate linear regression (MLR) | 1.551 | 0.469 | 9.105 | 0.135 |
| Gaussian mixture model (GMM) | 1.535 | 0.472 | 9.484 | 0.109 |
| Recurrent neural networks (RNN) | 1.648 | 0.538 | 8.306 | 0.133 |
| Long short term memory (LSTM) | 1.684 | 0.556 | 8.063 | 0.159 |
| Multi-layer perceptron (MLP) | 1.786 | 0.551 | 9.300 | 0.160 |
| Multi-layer perceptron (MLP) with PD | 1.999 | 0.553 | 9.503 | 0.211 |
| Multi-layer perceptron (MLP) with PD + HE | 2.108 | 0.567 | 9.590 | 0.402 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, K.-S. Ultrasonic Doppler Based Silent Speech Interface Using Perceptual Distance. Appl. Sci. 2022, 12, 827. https://doi.org/10.3390/app12020827
Lee K-S. Ultrasonic Doppler Based Silent Speech Interface Using Perceptual Distance. Applied Sciences. 2022; 12(2):827. https://doi.org/10.3390/app12020827
Chicago/Turabian StyleLee, Ki-Seung. 2022. "Ultrasonic Doppler Based Silent Speech Interface Using Perceptual Distance" Applied Sciences 12, no. 2: 827. https://doi.org/10.3390/app12020827
APA StyleLee, K.-S. (2022). Ultrasonic Doppler Based Silent Speech Interface Using Perceptual Distance. Applied Sciences, 12(2), 827. https://doi.org/10.3390/app12020827