
Hierarchical Federated Learning for Edge-Aided Unmanned Aerial Vehicle Networks

 , , and
, , and
Abstract
:1. Introduction
1.1. Motivations
1.2. Related Works
1.3. Contributions
- We develop a novel and high-performing FL scheme, namely, the hierarchical FL algorithm, for the edge-aided UAV network that works well in real-world scenarios with non-i.i.d data distributions (i.e., highly skewed feature and label distributions). In this algorithm, we make an innovative idea to employ commonly shared data at the edge servers to effectively solve the divergence issue caused by the non-i.i.d. nature. In practice, this idea is realizable since the commonly shared data can be made or constructed on the edge servers offline by collecting exemplary data samples from the UAVs. We also present an effective method to hierarchically aggregate the local models of both the UAVs and the edge servers for the global model update.
- We present extensive numerical results under various degrees of non-i.i.d data distributions, especially including several extreme situations with label distribution skew in order to demonstrate the superiority and effectiveness of the proposed hierarchical FL algorithm, compared to other baseline FL algorithms. From the numerical results, we also provide useful and insightful guidelines on how the hyperparameters of the hierarchical FL can be set and used in practical UAV networks with edge servers.
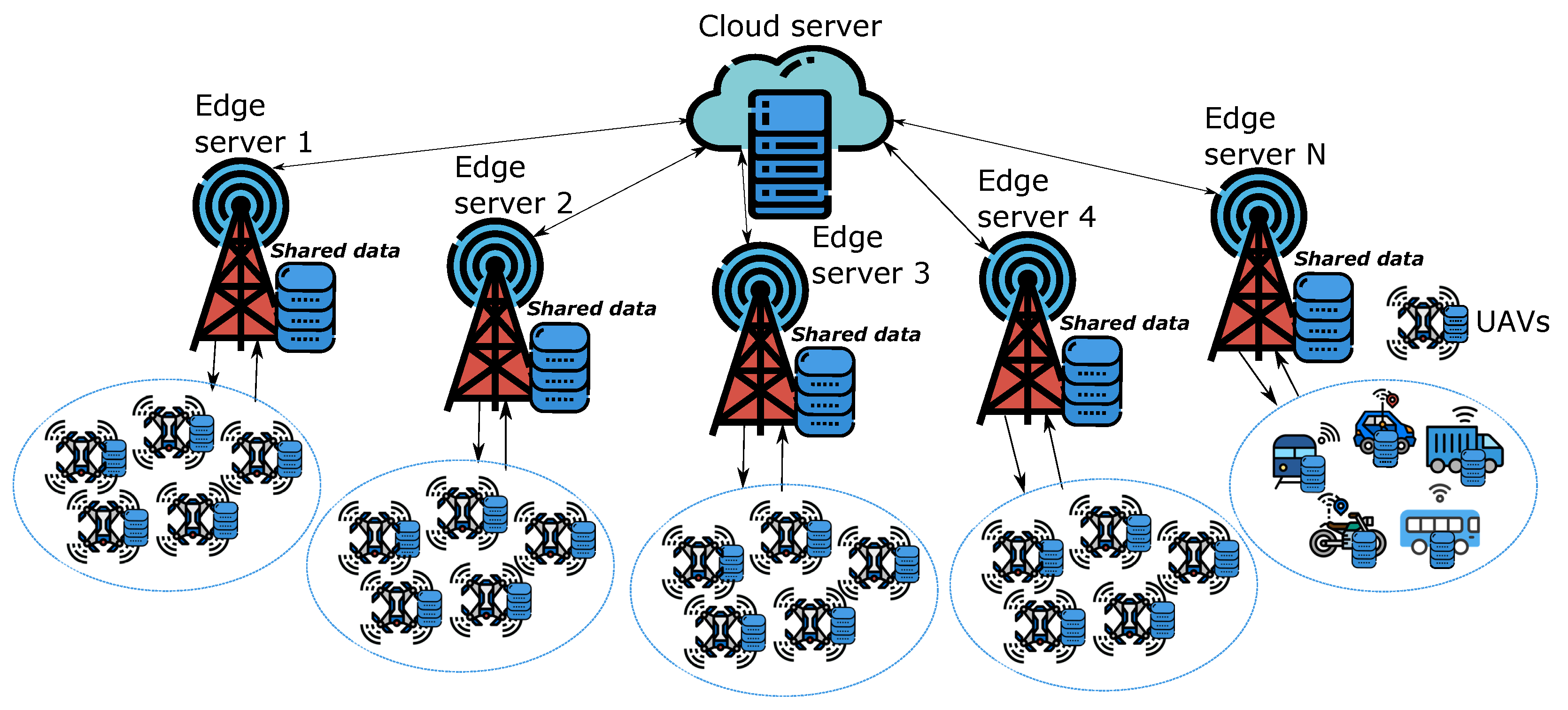
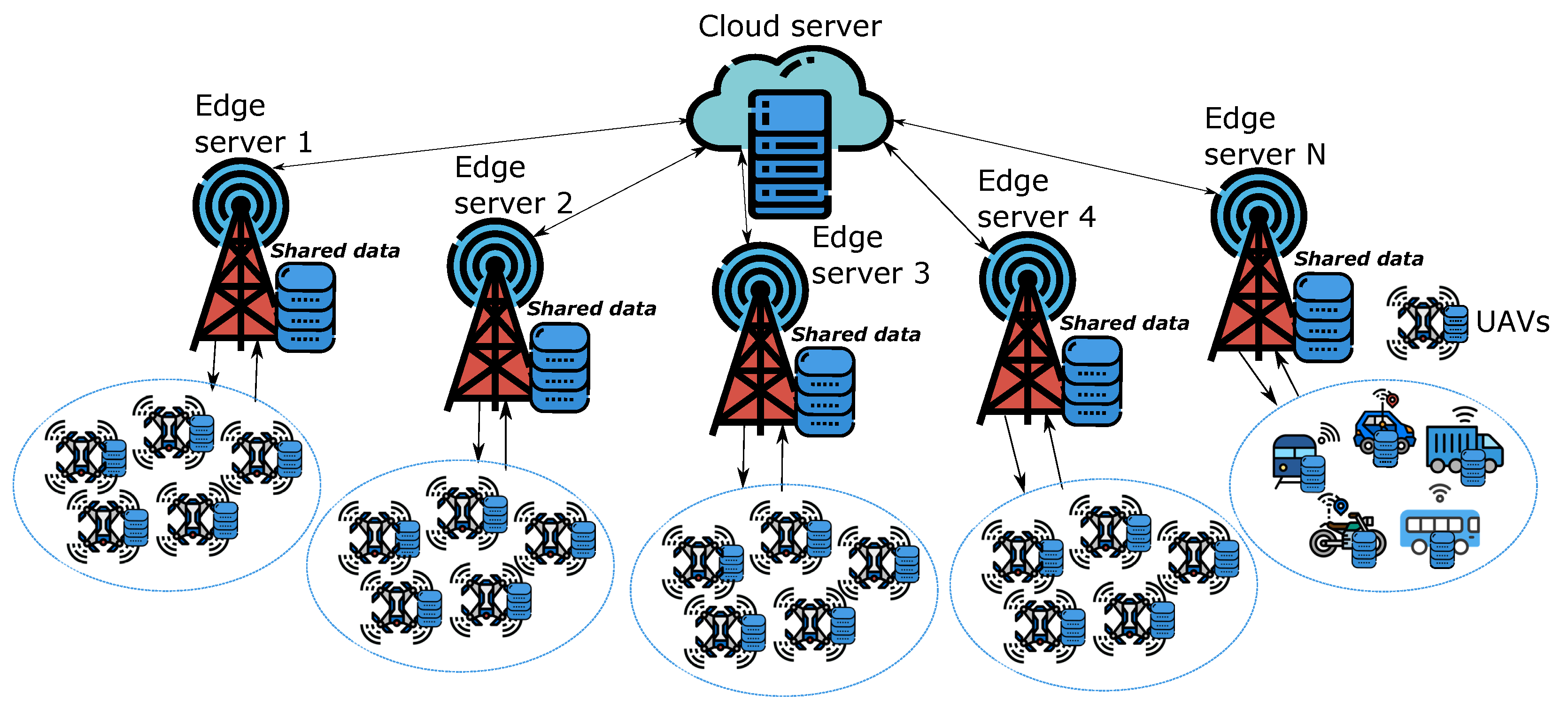
2. System Model and Problem Description
Non-Identical Distributions among UAVs
- Feature distribution skew: The marginal distributions vary among the devices. That means the features of data are different between the devices. For example, the picture of the same object might differ in terms of brightness, occlusion, camera sensor, etc.
- Label distribution skew: The marginal distributions variance, where devices have access to a small subset of all available labels. For example, each device has access to a couple of images of a certain digit.
- Concept shift (different features, same label): The conditional distributions vary among the devices. This is the case where the same label y might have different features x among devices. In the digit recognition case, digits might be written in drastically different ways, which results in varying underlying features for the same digit.
- Concept shift (same features, different label): The conditional distributions vary among the devices. Here, similar features might be labeled differently across devices. For example, different digits are written in very similar ways, such as 5 and 6, or 3 and 8.
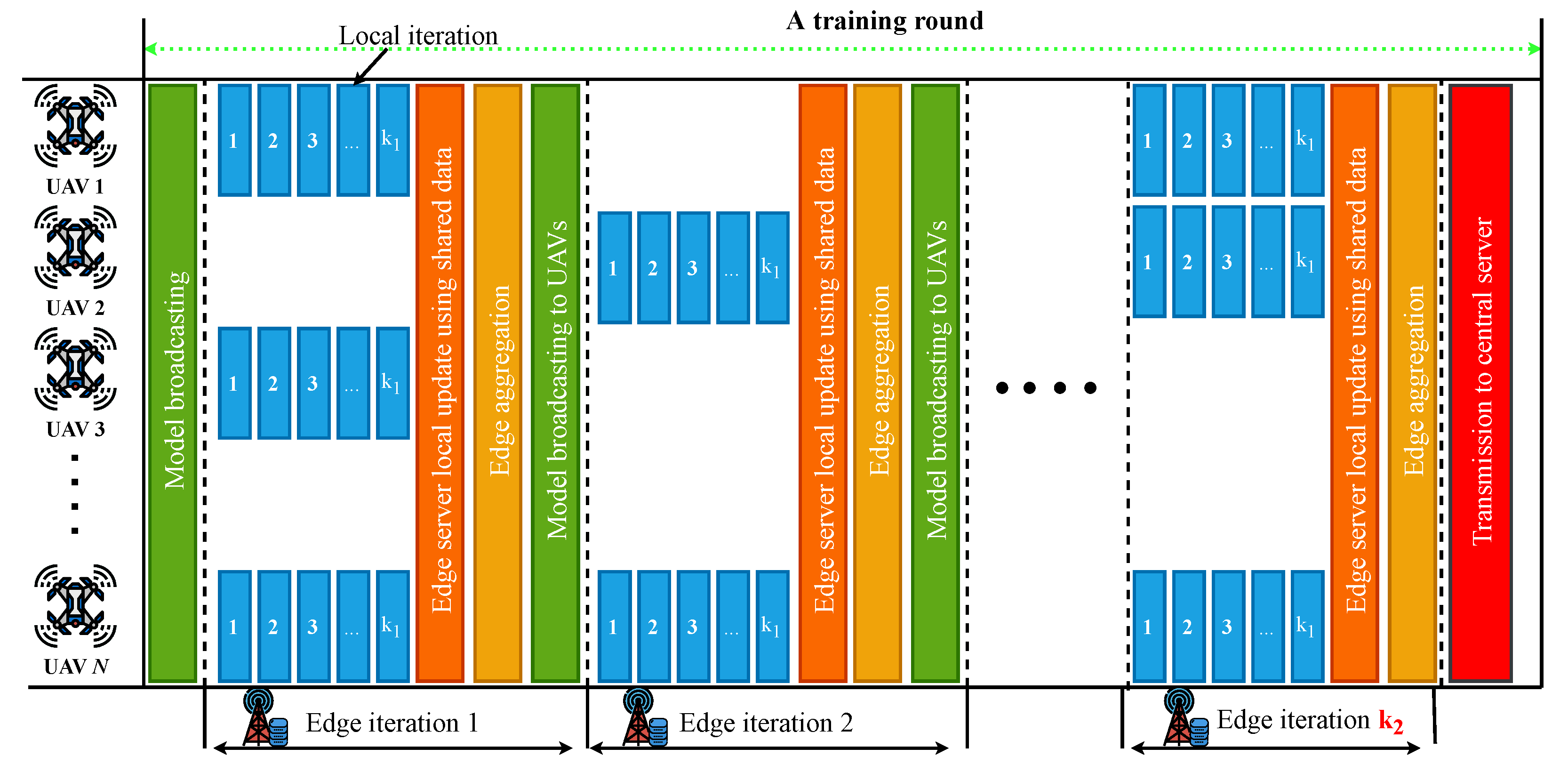
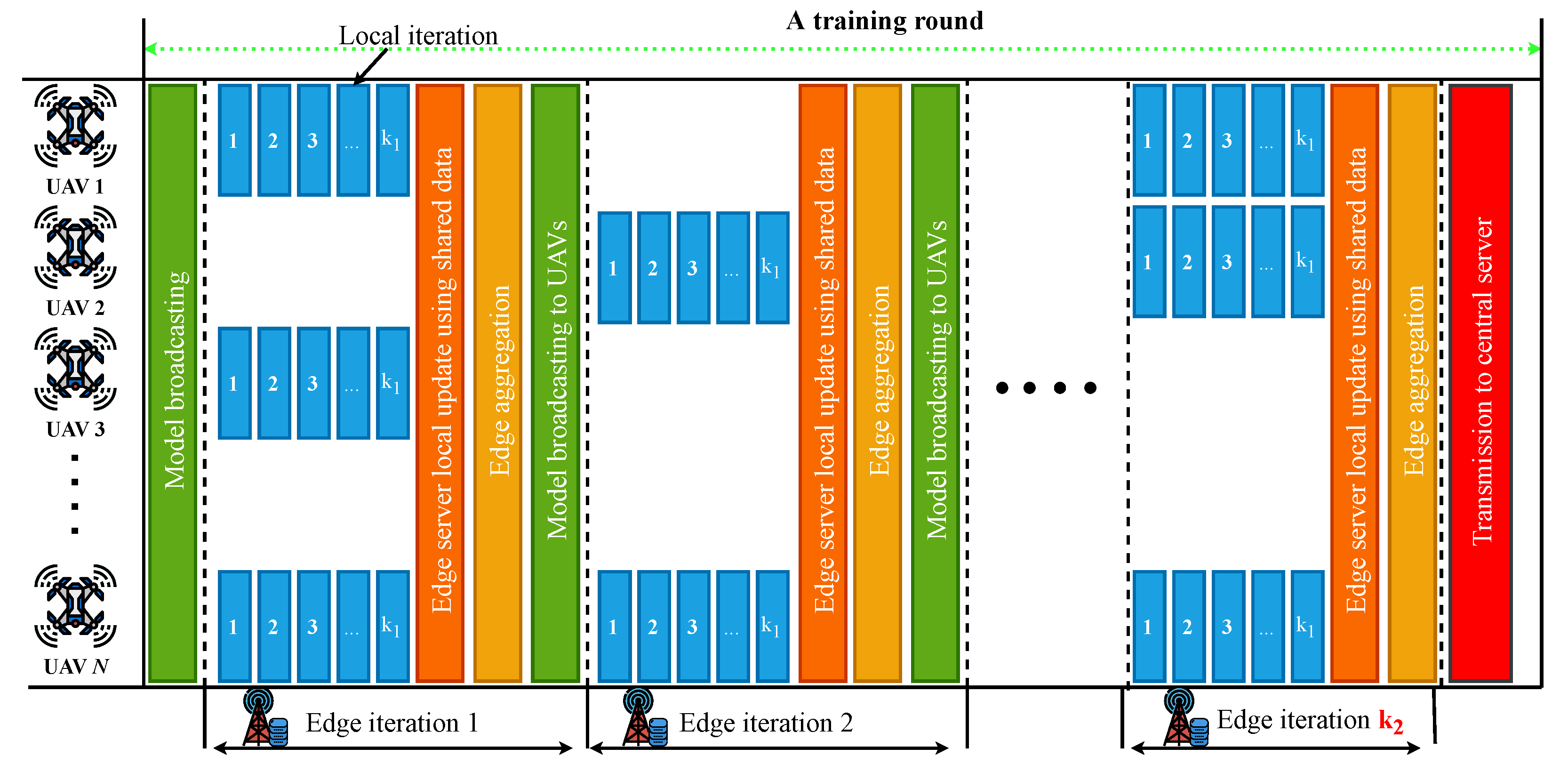
3. Hierarchical FL Algorithm
| Algorithm 1 Proposed hierarchical FL algorithm. |
|
| Algorithm 2 Local update procedure. |
|
| Algorithm 3 Edge aggregation procedure. |
|
| Algorithm 4 Global aggregation procedure. |
|
Complexity Analysis
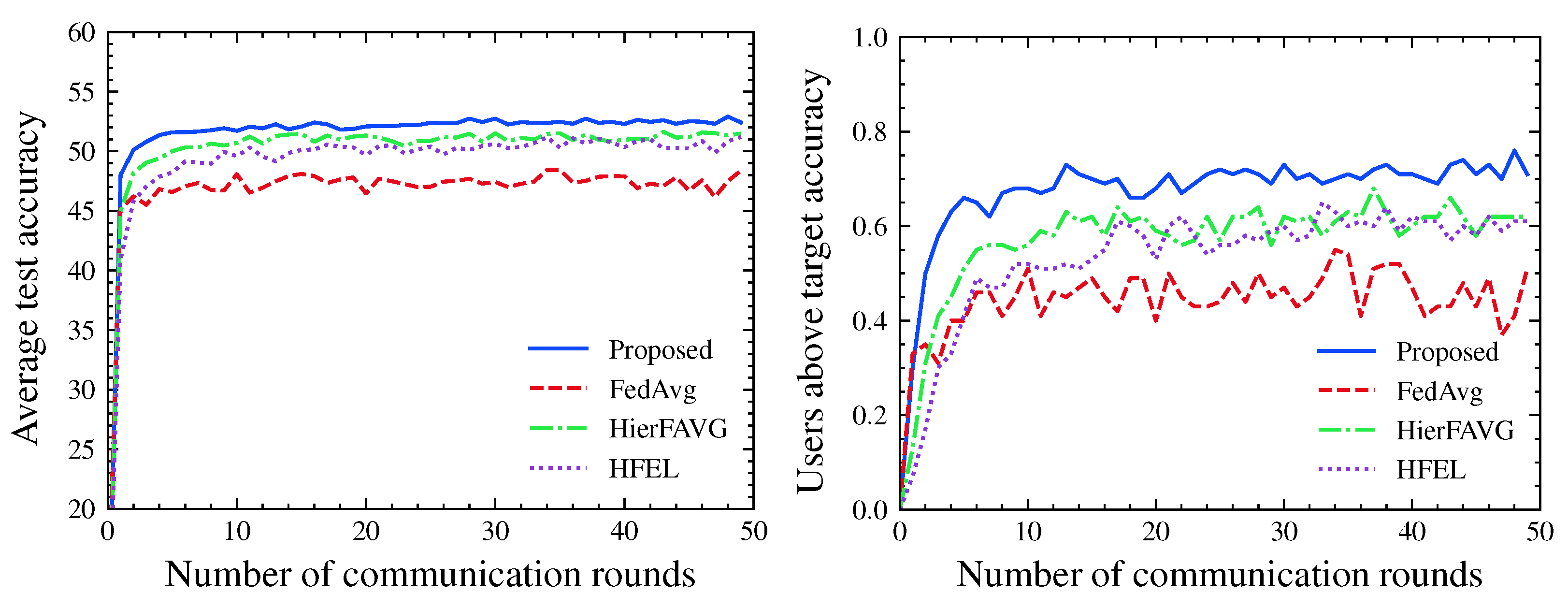
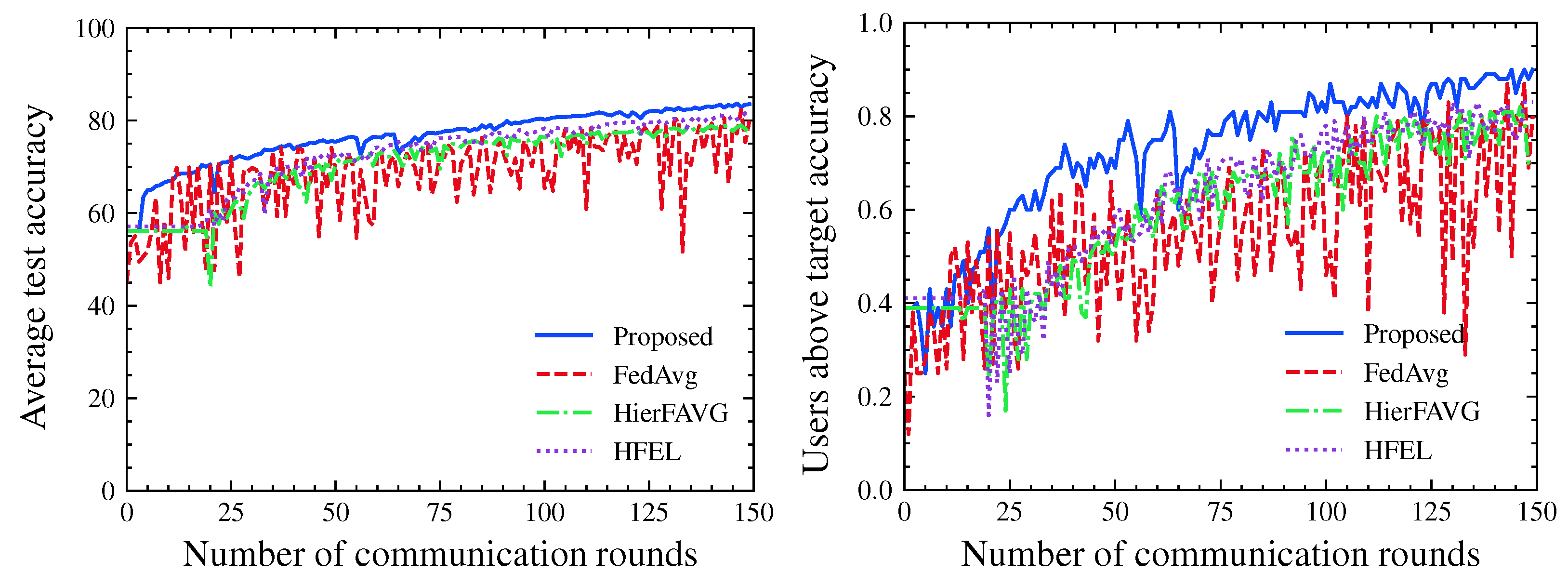
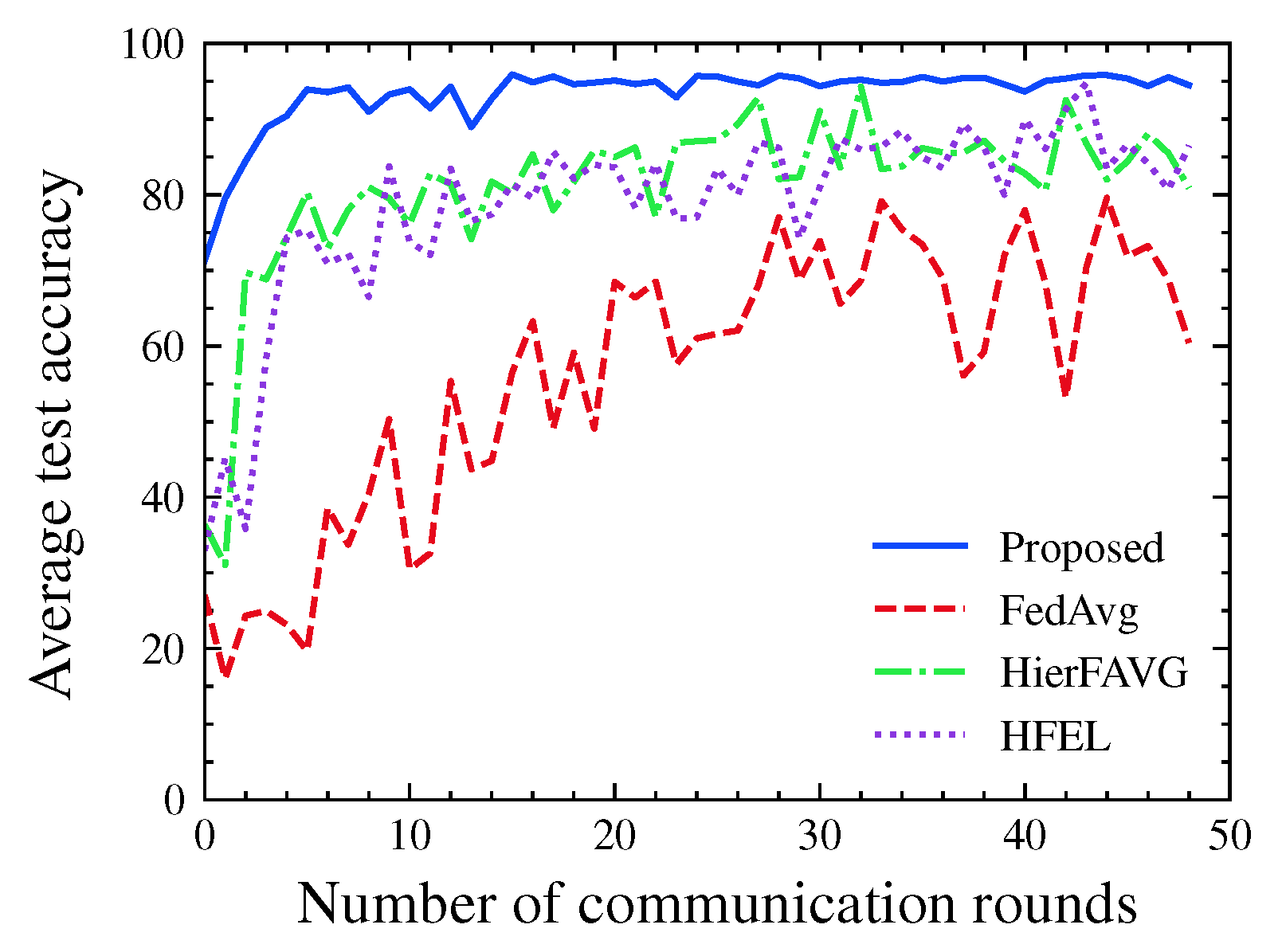
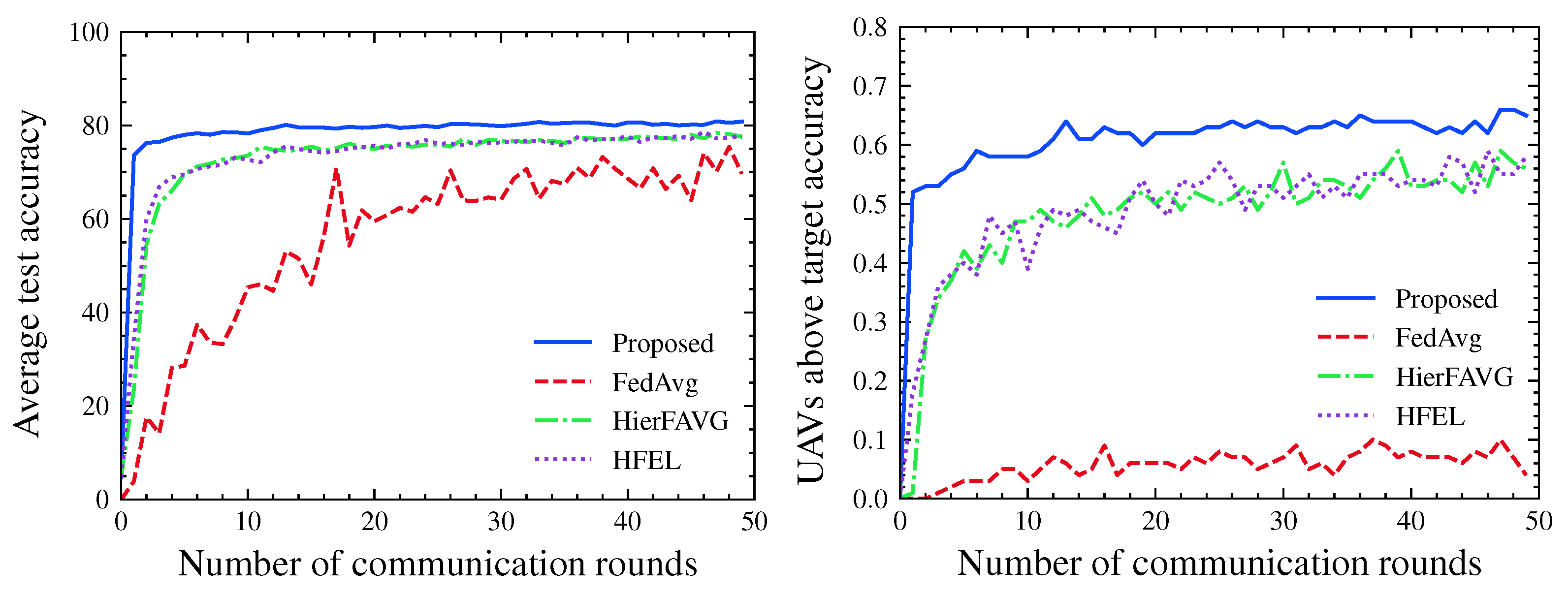
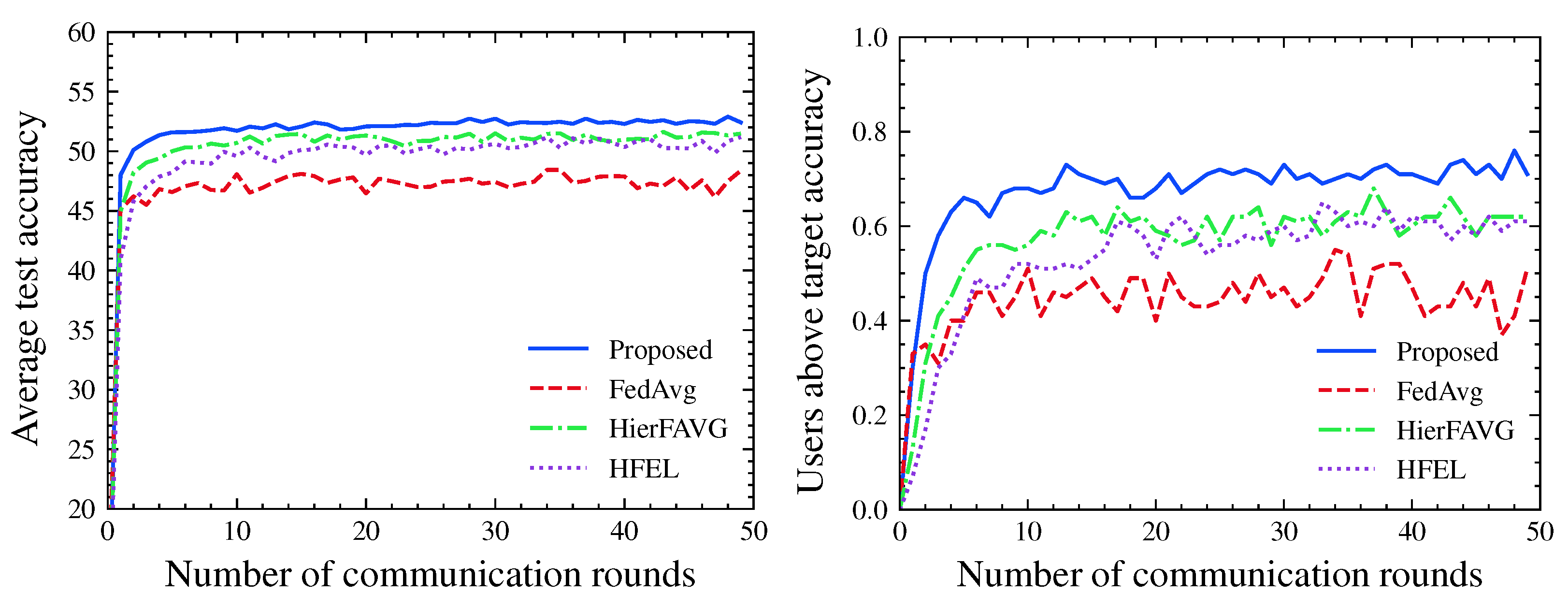
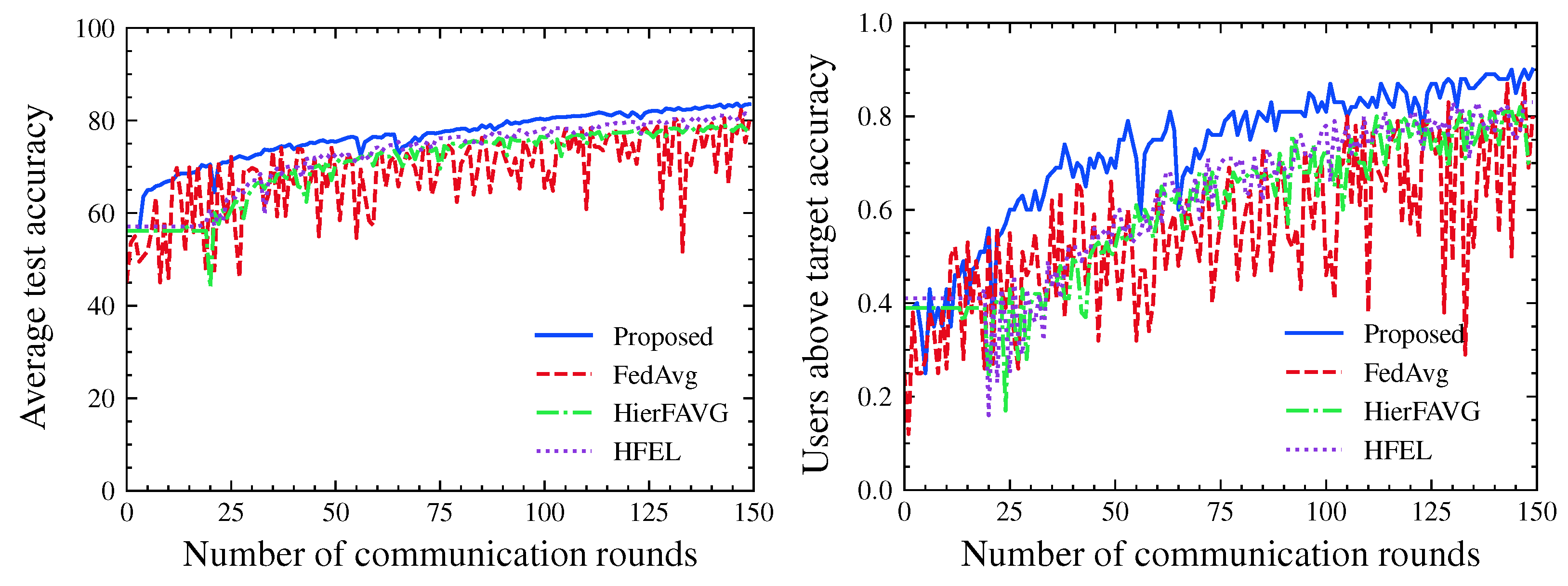
4. Numerical Results
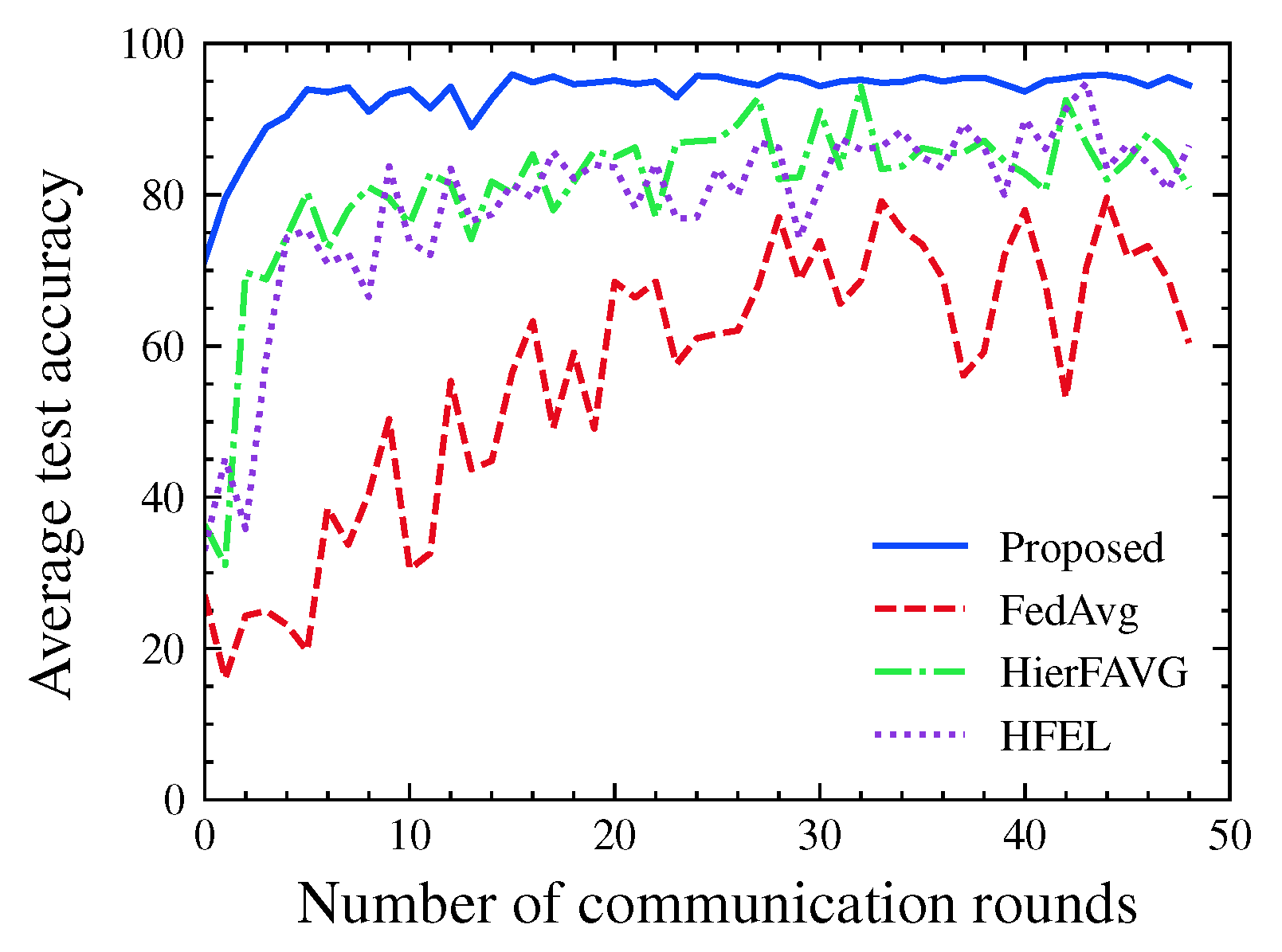
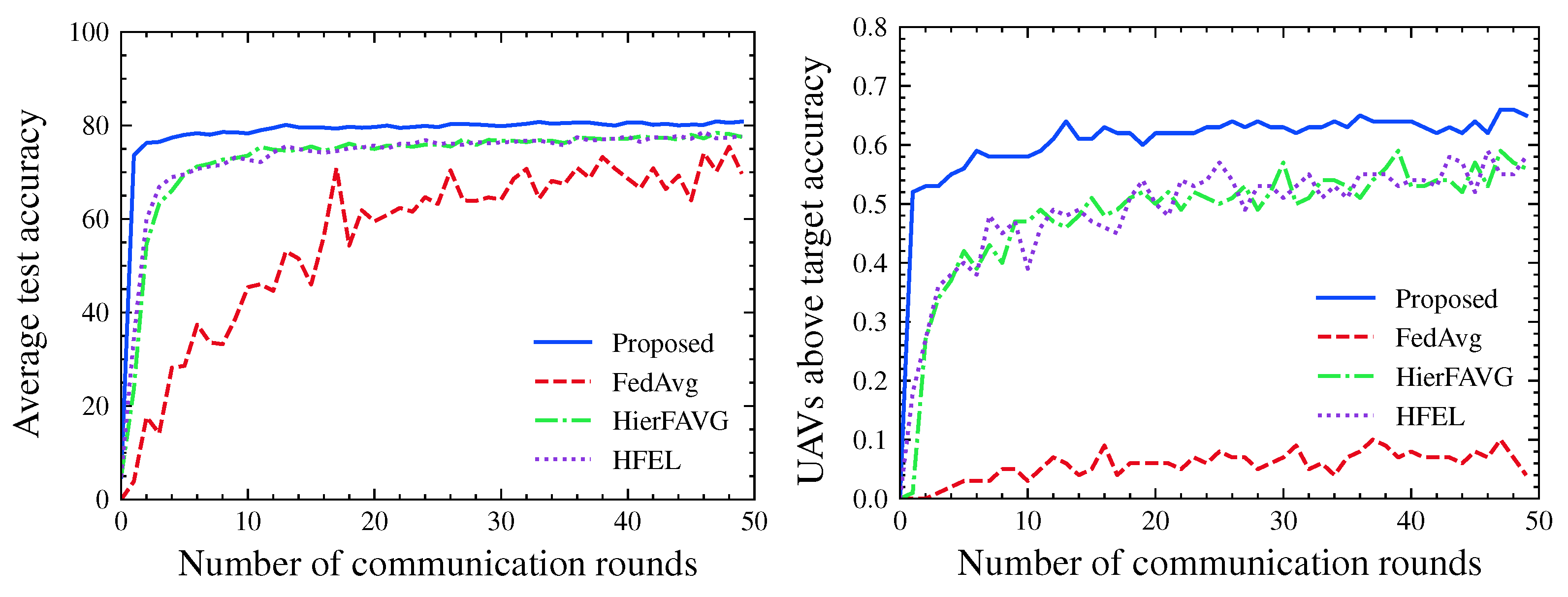
4.1. Evaluation Metrics
4.2. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Song, H.; Bai, J.; Yi, Y.; Wu, J.; Liu, L. Artificial intelligence enabled Internet of Things: Network architecture and spectrum access. IEEE Comput. Intell. Mag. 2020, 15, 44–51. [Google Scholar] [CrossRef]
- Senthilnath, J.; Varia, N.; Dokania, A.; Anand, G.; Benediktsson, J.A. Deep TEC: Deep transfer learning with ensemble classifier for road extraction from UAV imagery. Remote Sens. 2020, 12, 245. [Google Scholar] [CrossRef] [Green Version]
- Samir Labib, N.; Danoy, G.; Musial, J.; Brust, M.R.; Bouvry, P. Internet of unmanned aerial vehicles—A multilayer low-altitude airspace model for distributed UAV traffic management. Sensors 2019, 19, 4779. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brik, B.; Ksentini, A.; Bouaziz, M. Federated learning for UAVs-enabled wireless networks: Use cases, challenges, and open problems. IEEE Access 2020, 8, 53841–53849. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Artificial Intelligence and Statistics; PMLR: Fort Lauderdale, FL, USA, 2017; pp. 1273–1282. [Google Scholar]
- Singh, A.; Vepakomma, P.; Gupta, O.; Raskar, R. Detailed comparison of communication efficiency of split learning and federated learning. arXiv 2019, arXiv:1909.09145. [Google Scholar]
- Lim, W.Y.B.; Luong, N.C.; Hoang, D.T.; Jiao, Y.; Liang, Y.C.; Yang, Q.; Niyato, D.; Miao, C. Federated learning in mobile edge networks: A comprehensive survey. IEEE Commun. Surv. Tutorials 2020, 22, 2031–2063. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Liu, B.; Huang, H.; Guo, S.; Zheng, Z. When UAV swarm meets edge-cloud computing: The QoS perspective. IEEE Netw. 2019, 33, 36–43. [Google Scholar] [CrossRef]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A survey on mobile edge computing: The communication perspective. IEEE Commun. Surv. Tutorials 2017, 19, 2322–2358. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Su, Z.; Zhang, N.; Benslimane, A. Learning in the air: Secure federated learning for UAV-assisted crowdsensing. IEEE Trans. Netw. Sci. Eng. 2020, 8, 1055–1069. [Google Scholar] [CrossRef]
- Zhang, H.; Hanzo, L. Federated learning assisted multi-UAV networks. IEEE Trans. Veh. Technol. 2020, 69, 14104–14109. [Google Scholar] [CrossRef]
- Yu, Y.; Bu, X.; Yang, K.; Yang, H.; Gao, X.; Han, Z. UAV-Aided Low Latency Multi-Access Edge Computing. IEEE Trans. Veh. Technol. 2021, 70, 4955–4967. [Google Scholar] [CrossRef]
- Lim, W.Y.B.; Huang, J.; Xiong, Z.; Kang, J.; Niyato, D.; Hua, X.S.; Leung, C.; Miao, C. Towards federated learning in uav-enabled internet of vehicles: A multi-dimensional contract-matching approach. IEEE Trans. Intell. Transp. Syst. 2021, 22, 5140–5154. [Google Scholar] [CrossRef]
- Zhang, L.; Ansari, N. Optimizing the Operation Cost for UAV-aided Mobile Edge Computing. IEEE Trans. Veh. Technol. 2021, 70, 6085–6093. [Google Scholar] [CrossRef]
- Imteaj, A.; Thakker, U.; Wang, S.; Li, J.; Amini, M.H. A survey on federated learning for resource-constrained IoT devices. IEEE Internet Things J. 2021, 9, 1–24. [Google Scholar] [CrossRef]
- Gutierrez-Torre, A.; Bahadori, K.; Iqbal, W.; Vardanega, T.; Berral, J.L.; Carrera, D. Automatic Distributed Deep Learning Using Resource-constrained Edge Devices. IEEE Internet Things J. 2021. [Google Scholar] [CrossRef]
- Zhao, Z.; Barijough, K.M.; Gerstlauer, A. Deepthings: Distributed adaptive deep learning inference on resource-constrained iot edge clusters. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2018, 37, 2348–2359. [Google Scholar] [CrossRef]
- Imteaj, A.; Khan, I.; Khazaei, J.; Amini, M.H. FedResilience: A Federated Learning Application to Improve Resilience of Resource-Constrained Critical Infrastructures. Electronics 2021, 10, 1917. [Google Scholar] [CrossRef]
- Briggs, C.; Fan, Z.; Andras, P. Federated learning with hierarchical clustering of local updates to improve training on non-IID data. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–9. [Google Scholar]
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated learning with non-iid data. arXiv 2018, arXiv:1806.00582. [Google Scholar] [CrossRef]
- Sattler, F.; Müller, K.R.; Samek, W. Clustered federated learning: Model-agnostic distributed multitask optimization under privacy constraints. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 3710–3722. [Google Scholar] [CrossRef]
- Liu, L.; Zhang, J.; Song, S.; Letaief, K.B. Client-edge-cloud hierarchical federated learning. In Proceedings of the ICC 2020–2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Luo, S.; Chen, X.; Wu, Q.; Zhou, Z.; Yu, S. Hfel: Joint edge association and resource allocation for cost-efficient hierarchical federated edge learning. IEEE Trans. Wirel. Commun. 2020, 19, 6535–6548. [Google Scholar] [CrossRef]
- Callegaro, D.; Levorato, M. Optimal edge computing for infrastructure-assisted uav systems. IEEE Trans. Veh. Technol. 2021, 70, 1782–1792. [Google Scholar] [CrossRef]
- Ren, J.; Yu, G.; Ding, G. Accelerating DNN training in wireless federated edge learning systems. IEEE J. Sel. Areas Commun. 2020, 39, 219–232. [Google Scholar] [CrossRef]
- Lin, C.; Han, G.; Qi, X.; Guizani, M.; Shu, L. A distributed mobile fog computing scheme for mobile delay-sensitive applications in SDN-enabled vehicular networks. IEEE Trans. Veh. Technol. 2020, 69, 5481–5493. [Google Scholar] [CrossRef]
- Mowla, N.I.; Tran, N.H.; Doh, I.; Chae, K. Federated learning-based cognitive detection of jamming attack in flying ad-hoc network. IEEE Access 2019, 8, 4338–4350. [Google Scholar] [CrossRef]
- Kim, K.; Hong, C.S. Optimal task-UAV-edge matching for computation offloading in UAV assisted mobile edge computing. In Proceedings of the 2019 20th Asia-Pacific Network Operations and Management Symposium (APNOMS), Matsue, Japan, 18–20 September 2019; pp. 1–4. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Caldas, S.; Duddu, S.M.K.; Wu, P.; Li, T.; Konečnỳ, J.; McMahan, H.B.; Smith, V.; Talwalkar, A. Leaf: A benchmark for federated settings. arXiv 2018, arXiv:1812.01097. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario I | Scenario II | Scenario III | ||||
|---|---|---|---|---|---|---|
| Accuracy | % UAVs | Accuracy | % UAVs | Accuracy | % UAVs | |
| Proposed | 98.3% | 66% | 80.8% | 65% | 78.51% | 55% |
| FedAvg | 62% | 6% | 69.7% | 7.2% | 62.3% | 3.4% |
| HierFAVG | 84.3% | 26% | 77.5% | 55.6% | 74.1% | 45.3% |
| HFEL | 85.7% | 28% | 77.7% | 57.8% | 73.8% | 43.2% |
| Scenario I | Scenario II | |||||
|---|---|---|---|---|---|---|
| Accuracy | % UAVs | Accuracy | % UAVs | |||
| 1 | 1 | 98.1 | 46 | 74.4 | 48.8 | |
| 5 | 1 | 98.2 | 54 | 76.6 | 57.8 | |
| 0.1 | 5 | 5 | 98.4 | 60 | 80.1 | 64.4 |
| 10 | 5 | 98.7 | 62 | 79.1 | 60 | |
| 30 | 10 | 98.6 | 62 | 76.9 | 56.1 | |
| 1 | 1 | 97.8 | 42 | 77.2 | 54.4 | |
| 5 | 1 | 97.9 | 44 | 78.7 | 58.3 | |
| 0.2 | 5 | 5 | 98.6 | 60 | 80.8 | 64.4 |
| 10 | 5 | 98.6 | 68 | 80.5 | 62.2 | |
| 30 | 10 | 98.3 | 56 | 77.7 | 59.4 | |
| 1 | 1 | 98 | 40 | 77.6 | 54.4 | |
| 5 | 1 | 98.4 | 56 | 79.4 | 59.4 | |
| 0.4 | 5 | 5 | 98.7 | 72 | 80.7 | 65.5 |
| 10 | 5 | 98.7 | 68 | 80.4 | 61.7 | |
| 30 | 10 | 98.6 | 62 | 77.7 | 56.7 | |
| 1 | 1 | 98.2 | 54 | 78.5 | 58.8 | |
| 5 | 1 | 98.7 | 62 | 79.02 | 60.5 | |
| 0.6 | 5 | 5 | 98.8 | 64 | 81.5 | 68.3 |
| 10 | 5 | 98.7 | 64 | 80.9 | 65.5 | |
| 30 | 10 | 98.9 | 72 | 79.01 | 61.1 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tursunboev, J.; Kang, Y.-S.; Huh, S.-B.; Lim, D.-W.; Kang, J.-M.; Jung, H. Hierarchical Federated Learning for Edge-Aided Unmanned Aerial Vehicle Networks. Appl. Sci. 2022, 12, 670. https://doi.org/10.3390/app12020670
Tursunboev J, Kang Y-S, Huh S-B, Lim D-W, Kang J-M, Jung H. Hierarchical Federated Learning for Edge-Aided Unmanned Aerial Vehicle Networks. Applied Sciences. 2022; 12(2):670. https://doi.org/10.3390/app12020670
Chicago/Turabian StyleTursunboev, Jamshid, Yong-Sung Kang, Sung-Bum Huh, Dong-Woo Lim, Jae-Mo Kang, and Heechul Jung. 2022. "Hierarchical Federated Learning for Edge-Aided Unmanned Aerial Vehicle Networks" Applied Sciences 12, no. 2: 670. https://doi.org/10.3390/app12020670
APA StyleTursunboev, J., Kang, Y.-S., Huh, S.-B., Lim, D.-W., Kang, J.-M., & Jung, H. (2022). Hierarchical Federated Learning for Edge-Aided Unmanned Aerial Vehicle Networks. Applied Sciences, 12(2), 670. https://doi.org/10.3390/app12020670