
MCA-YOLOV5-Light: A Faster, Stronger and Lighter Algorithm for Helmet-Wearing Detection
Abstract
:Featured Application
Abstract
1. Introduction
2. Related Work
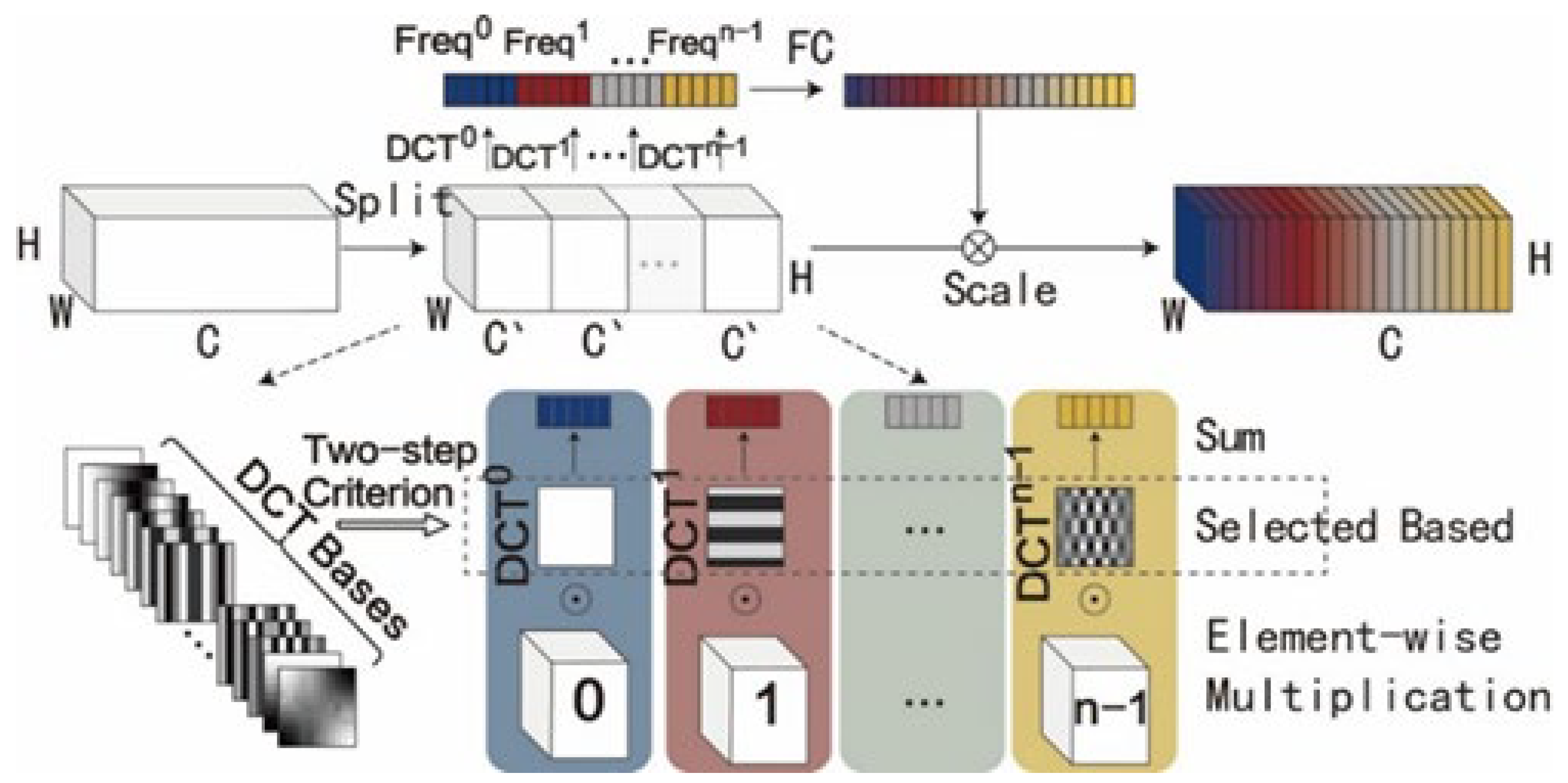
2.1. Attention Machine
2.2. Model Puring
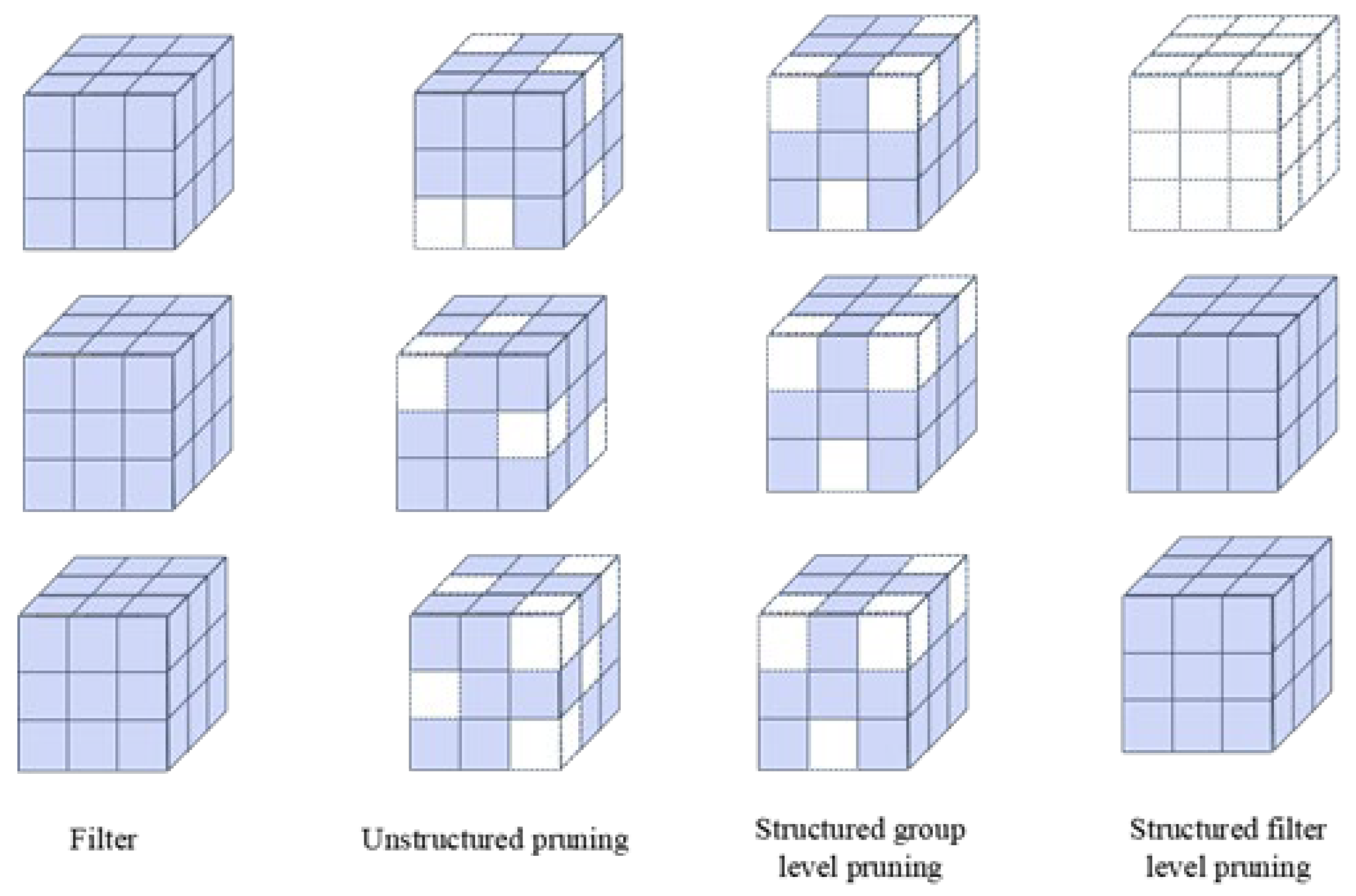
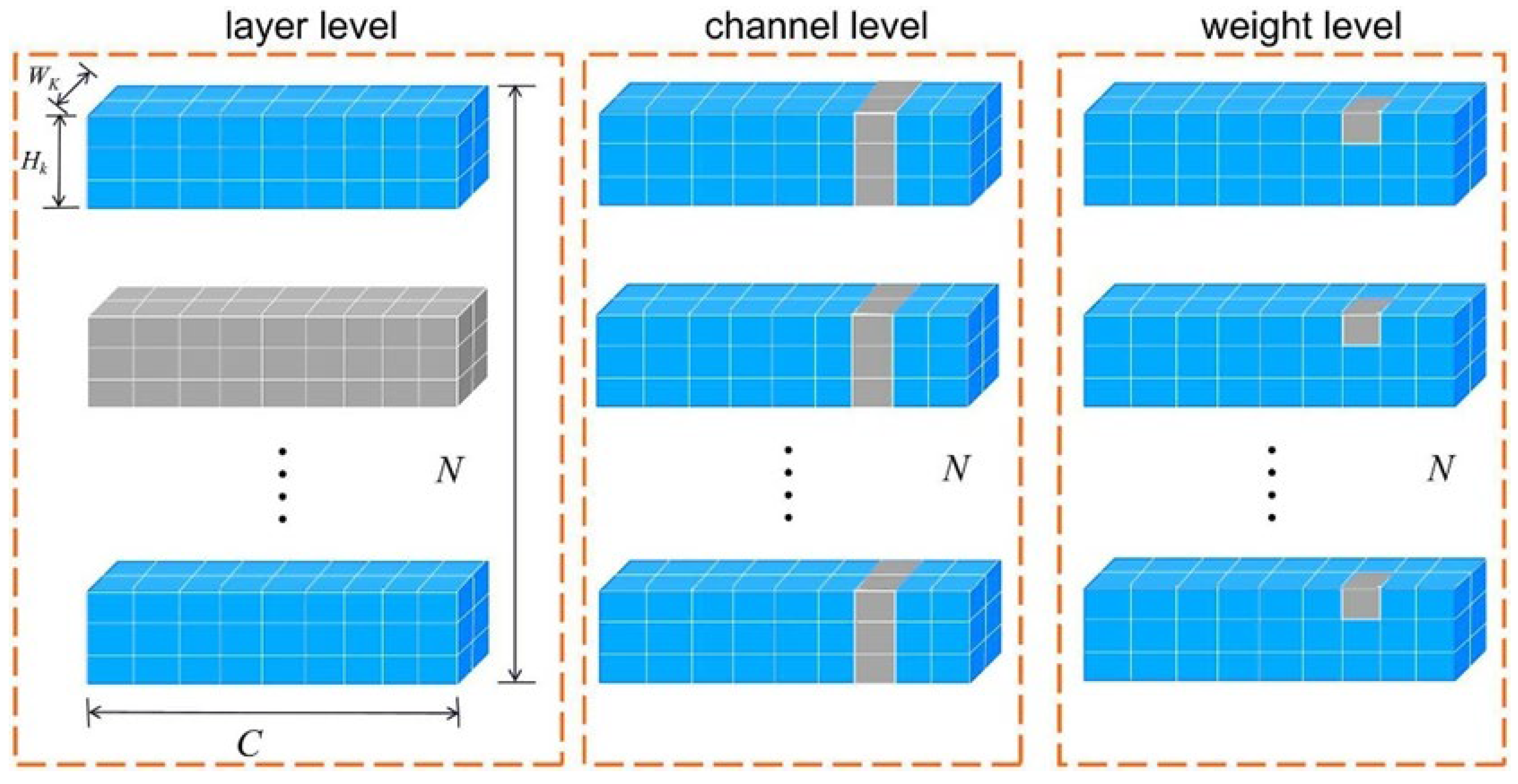
2.2.1. Structured Pruning
2.2.2. Unstructured Pruning
3. Method
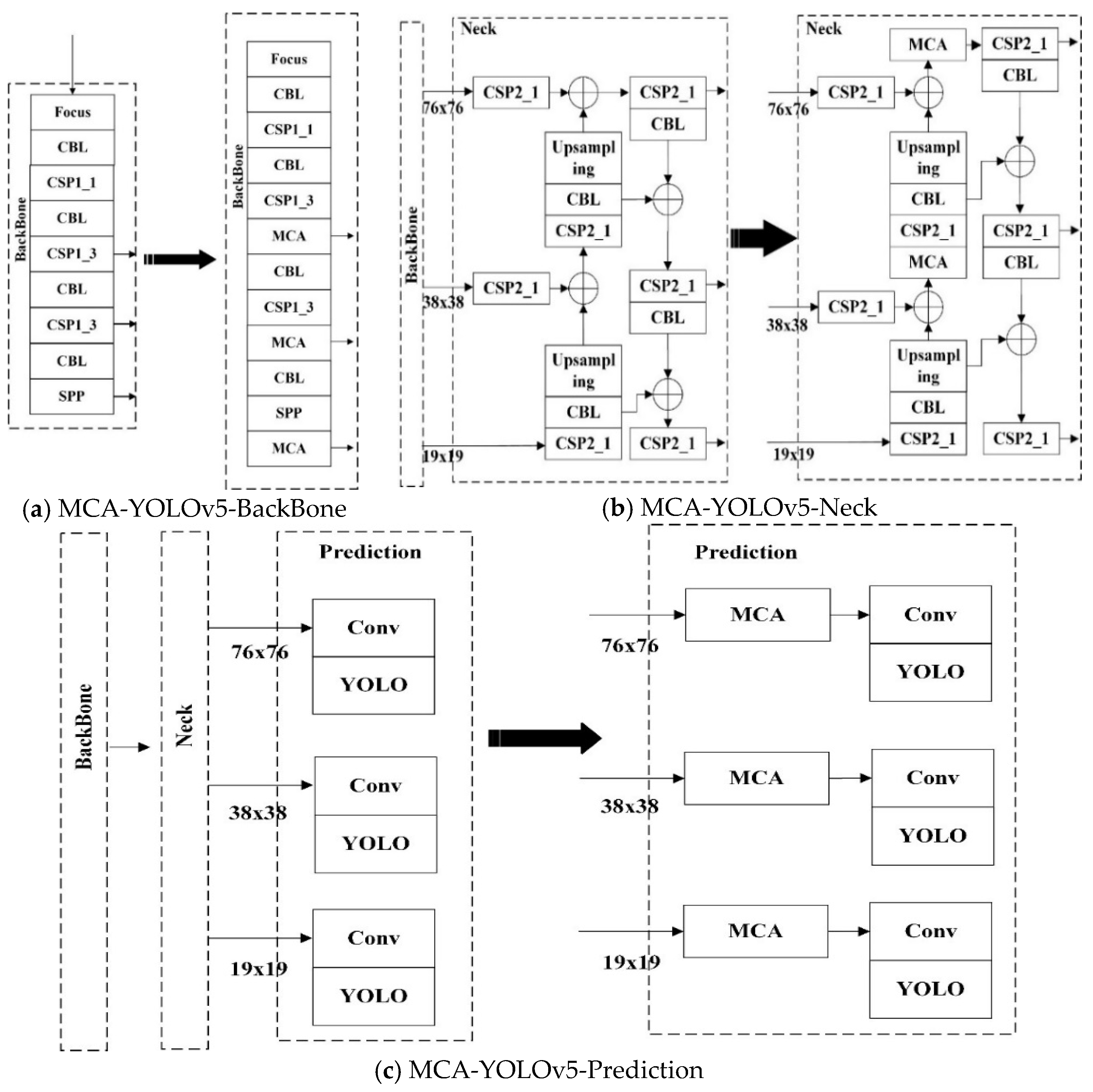
3.1. MCA-YOLOv5
3.1.1. MCA-YOLOv5 Safety Helmet Wearing Detection Algorithm
3.1.2. MCA Attention Mechanism
3.2. MCA-YOLOv5-Light Safety Hat Wearing Detection Model
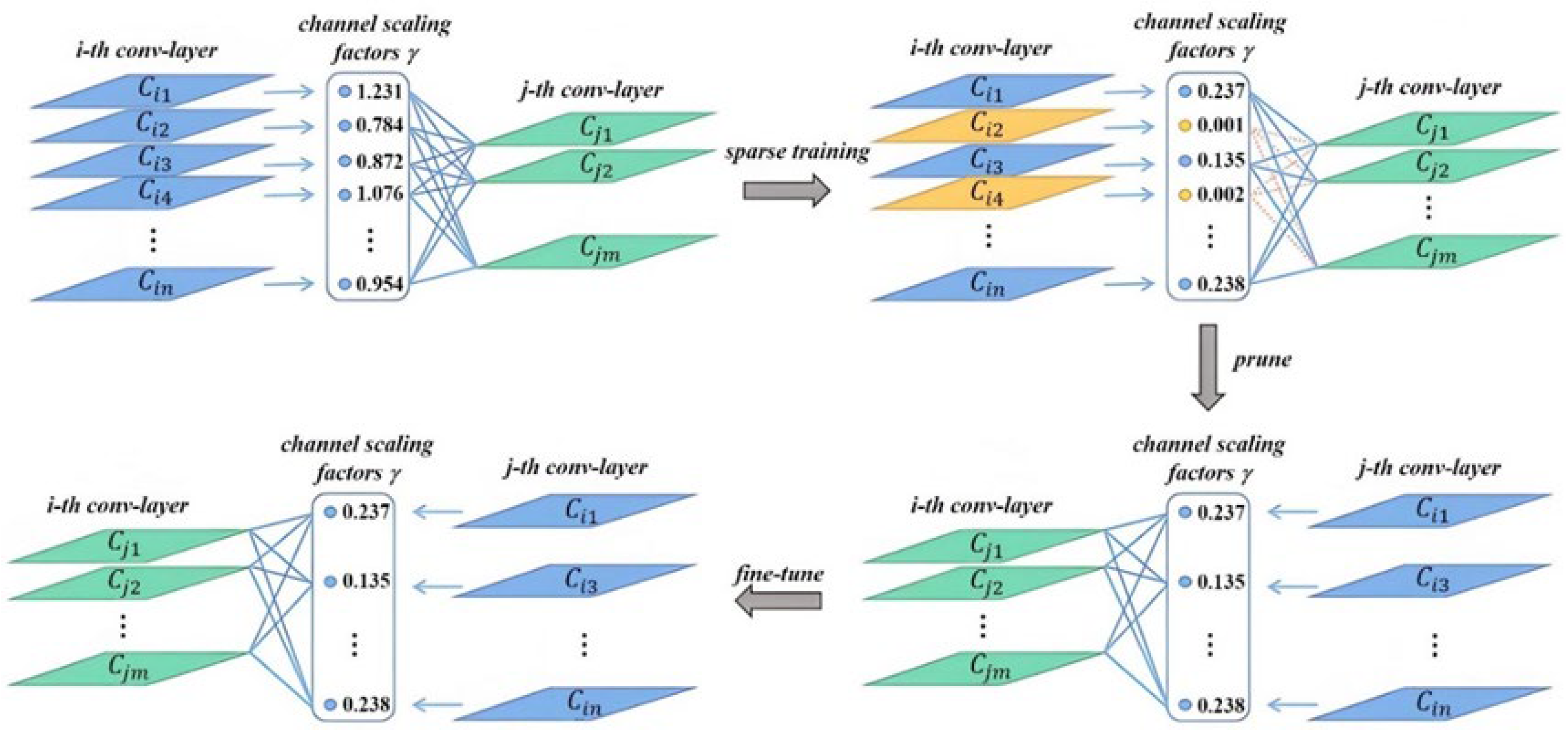
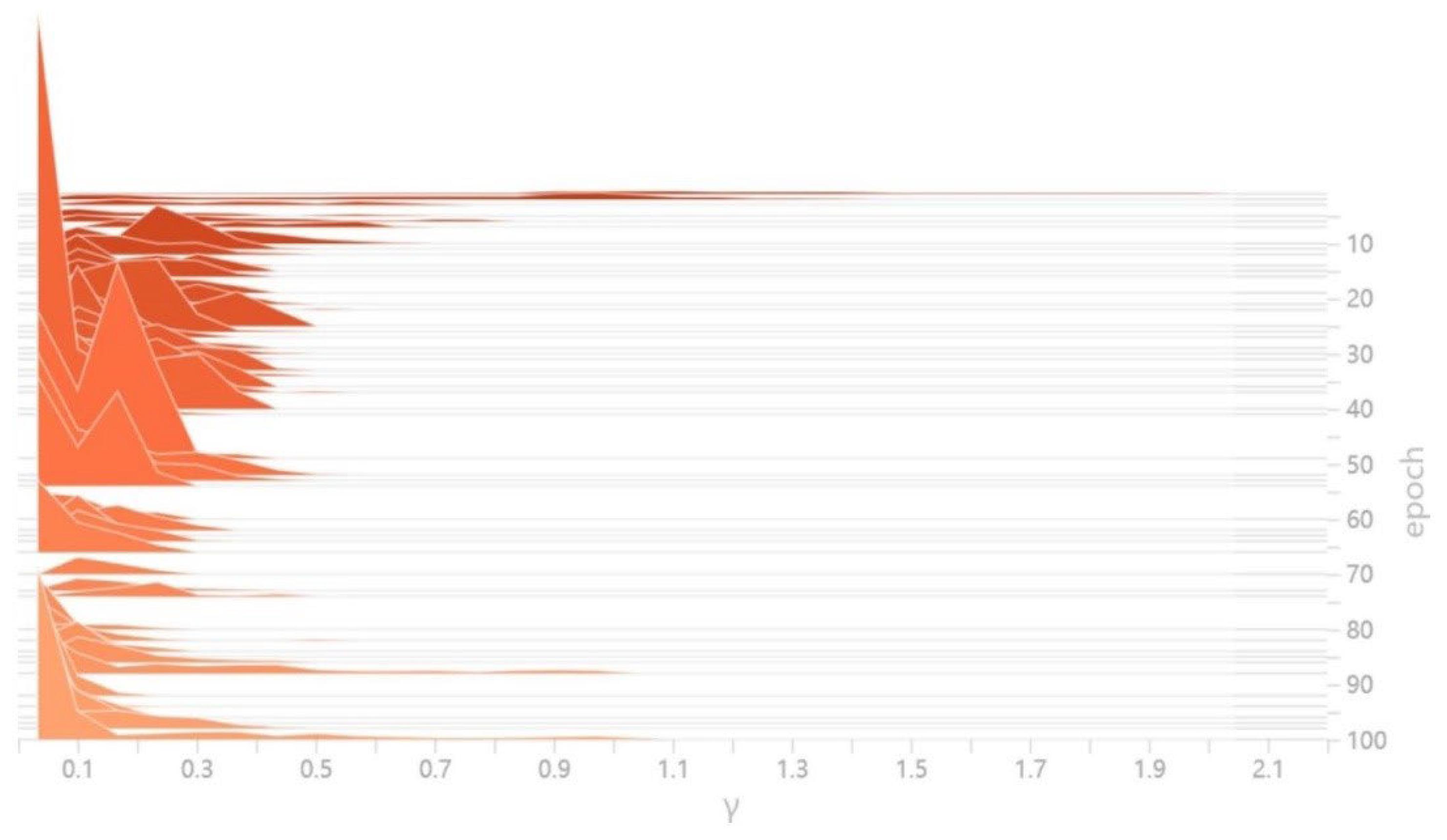
3.2.1. Sparsity Training of the Safety-Helmet-Wearing Detection Model
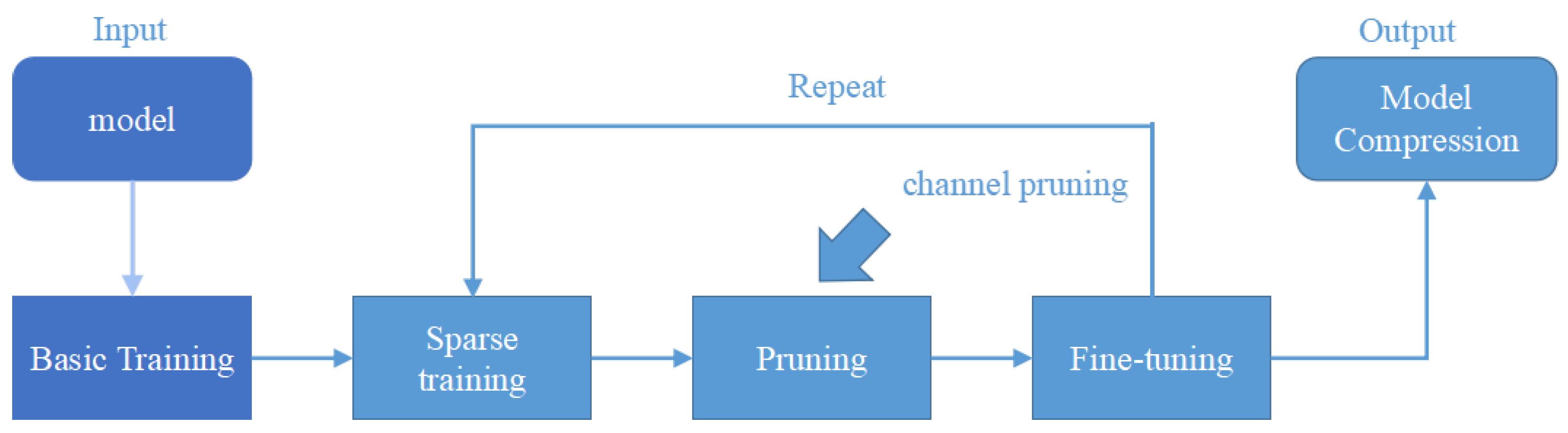
3.2.2. Channel Pruning and Fine-Tuning of the Safety-Helmet-Wearing Detection Model
| Algorithm 1 A channel pruning algorithm based on the scaling factor |
| Input: Original model Output: Lightweight compression model 1 bn_weights = γ1, γ2, γ3,…… γn, Initialize Epochs = 200 2//Turn on the sparse training session 3 while epoch ≤ Epochs 4 5 objective function 6 Output of the BN 7 Update γ1, γ2, γ3,……γn 8 bn_weightsγ1, γ2, γ3,……γn 9 end 10 Initialize prune_ratio = 0.9 11 To γ1, γ2, γ3,……γn Sort by channel number 12 if c1, c2, c3,……, cn channel_id < len(channels) prune_ratio× 13 Trim the channel c1, c2, c3,……, ci 14 end 15 Fine-tuning of the pruning network |
4. Experimental Analysis and Analysis
4.1. Experimental Environment, as well as the Dataset
4.2. Experimental Results and Analysis
4.2.1. MCA-YOLOV5s Fusion Analysis
4.2.2. Sparse Training Process
4.2.3. Analysis of the Model Pruning Results
Model Pruning Comparison
Model Comparison Experiment
5. Conclusions
6. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wójcik, B.; Żarski, M.; Książek, K.; Miszczak, J.A.; Skibniewski, M.J. Hard hat wearing detection based on head keypoint localization. arXiv 2021, arXiv:2106.10944. [Google Scholar]
- Bruno, L.T.; Low, C.T.; Idiake, J. Compliance with the use of personal protective equipment (PPE) on construction sites in Johor, Malaysia. Int. J. Real Estate Stud. 2020, 14, 123–138. [Google Scholar]
- Sharma, B.; Nowrouzi-Kia, B.; Mollayeva, T.; Kontos, P.; Grigorovich, A.; Liss, G.; Gibson, B.; Mantis, S.; Lewko, J.; Colantonio, A. Work-Related traumatic brain injury: A brief report on workers perspective on job and health and safety training, supervision, and injury preventability. Work 2019, 62, 319–325. [Google Scholar] [CrossRef] [PubMed]
- Brolin, K.; Lanner, D.; Halldin, P. Work-related traumatic brain injury in the construction industry in Sweden and Germany. Saf. Sci. 2021, 136, 105147. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Venice, Italy, 22–29 October 2017; IEEE: Honolulu, HI, USA, 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G. Yolov5[EB/OL]. Available online: https://github.com/ultralytics/yolov5 (accessed on 1 December 2020).
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra r-cnn: Towards balanced learning for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 821–830. [Google Scholar]
- Lu, X.; Li, B.; Yue, Y.; Li, Q.; Yan, J. Grid r-cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 7363–7372. [Google Scholar]
- Rao, C.; Zheng, Z.; Wang, Z. Multi-Scale Safety Helmet Detection Based on SAS-YOLOv3-Tiny. Appl. Sci. 2021, 11, 3652. [Google Scholar]
- Yan, D.; Wang, L. Improved YOLOv3 Helmet Detection Algorithm. In Proceedings of the 2021 4th International Conference on Robotics, Control and Automation Engineering (RCAE), Wuhan, China, 4–6 November 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 6–11. [Google Scholar]
- Fan, Z.; Peng, C.; Dai, L.; Cao, F.; Qi, J.; Hua, W. A deep learning-based ensemble method for helmet-wearing detection. PeerJ Comput. Sci. 2020, 6, e311. [Google Scholar] [CrossRef]
- Mozaffari, M.H.; Lee, W.S. Semantic Segmentation with Peripheral Vision. In Advances in Visual Computing, Proceedings of the 15th International Symposium, ISVC 2020, San Diego, CA, USA, 5–7 October 2020; Springer: Cham, Switzerland, 2020; pp. 421–429. [Google Scholar]
- Lee, Y.; Hwang, J.-W.; Lee, S.; Bae, Y.; Park, J. An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 752–760. [Google Scholar] [CrossRef]
- Stojnić, V.; Risojević, V.; Muštra, M.; Jovanović, V.; Filipi, J.; Kezić, N.; Babić, Z. A Method for Detection of Small Moving Objects in UAV Videos. Remote Sens. 2021, 13, 653. [Google Scholar] [CrossRef]
- Cao, G.; Xie, X.; Yang, W.; Liao, Q.; Shi, G.; Wu, J. Feature-fused SSD: Fast detection for small objects. Proc. SPIE 2018, 10615, 106151E. [Google Scholar] [CrossRef]
- Tian, S.; Zhang, J.; Shu, X.; Chen, L.; Niu, X.; Wang, Y. A Novel Evaluation Strategy to Artificial Neural Network Model Based on Bionics. J. Bionic Eng. 2022, 19, 224–239. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Wei, X.; Zhang, S.; Niu, X.; Li, G.; Tian, T. Research on Network Model of Dentate Gyrus Based on Bionics. J. Healthc. Eng. 2021, 2021, 4609741. [Google Scholar] [CrossRef] [PubMed]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Con-ference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 7132–7141. [Google Scholar]
- Yang, Z.; Zhu, L.; Wu, Y.; Yang, Y. Gated channel transformation for visual recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 11794–11803. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 11534–11542. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 783–792. [Google Scholar]
- Guo, M.H.; Liu, Z.N.; Mu, T.J.; Hu, S.M. Beyond self-attention: External attention using two linear layers for visual tasks. arXiv 2021, arXiv:2105.02358. [Google Scholar]
- Yang, L.; Zhang, R.Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. PMLR 2021, 139, 11863–11874. [Google Scholar]
- Misra, D.; Nalamada, T.; Arasanipalai, A.U.; Hou, Q. Rotate to attend: Convolutional triplet attention module. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 3139–3148. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 13713–13722. [Google Scholar]
- Deng, L.; Li, G.; Han, S.; Shi, L.; Xie, Y. Model compression and hardware acceleration for neural networks: A comprehensive survey. Proc. IEEE 2020, 108, 485–532. [Google Scholar] [CrossRef]
- Liang, T.; Glossner, J.; Wang, L.; Shi, S.; Zhang, X. Pruning and quantization for deep neural network acceleration: A survey. Neurocomputing 2021, 461, 370–403. [Google Scholar] [CrossRef]
- LeCun, Y.; Denker, J.; Solla, S. Optimal brain damage. Adv. Neural Inf. Process. Syst. 1990, 2, 598–605. [Google Scholar]
- Alqahtani, A.; Xie, X.; Jones, M.W.; Essa, E. Pruning CNN filters via quantifying the importance of deep visual representations. Comput. Vis. Image Underst. 2021, 208, 103220. [Google Scholar] [CrossRef]
- Tasoulas, Z.G.; Zervakis, G.; Anagnostopoulos, I.; Amrouch, H.; Henkel, J. Weight-oriented approximation for energy-efficient neural network inference accelerators. IEEE Trans. Circuits Syst. I Regul. Pap. 2020, 67, 4670–4683. [Google Scholar] [CrossRef]
- Kwon, S.J.; Lee, D.; Kim, B.; Kapoor, P.; Park, B.; Wei, G.Y. Structured compression by weight encryption for unstructured pruning and quantization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1909–1918. [Google Scholar]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2736–2744. [Google Scholar]
- Data. Available online: https://github.com/Shiso-Q/Safety-helmet-detection/ (accessed on 1 December 2021).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Itemize | Edition |
|---|---|---|
| Hardware configuration | system | Ubuntu 18.04 |
| Graphics card | GeForce RTX 2080 Ti | |
| Software configuration | CPU | AMD Ryzen 7 3800X 8-Core |
| Python Version | 3.8 | |
| Deep learning framework | Pytorch | |
| CUDA | 10.0 |
| Network Model | Small Object | Medium Object | Large Object | P/% | R/% | mAP/% |
|---|---|---|---|---|---|---|
| YOLOv5 | 83.0 | 97.9 | 99.3 | 76.4 | 92.5 | 92.7 |
| MCA-YOLOv5-BackBone | 90.4 | 98.6 | 99.6 | 82.2 | 95.4 | 96.0 |
| MCA-YOLOv5-Neck | 78.3 | 96.4 | 99.1 | 70.9 | 93.7 | 91.6 |
| MCA-YOLOv5-Prediction | 82.7 | 97.1 | 99.2 | 72.5 | 92.8 | 92.4 |
| Cut Branch Ratio | mAP/% | Parameters/106 | Reference Time/ms | Model Size/MB |
|---|---|---|---|---|
| base (0.00) | 96.0 | 7.30 | 37 | 15.2 |
| 0.80 | 89.5 | 0.93 | 17.2 | 2.1 |
| 0.70 | 93.2 | 1.67 | 18.5 | 3.6 |
| 0.60 | 93.9 | 2.39 | 19.3 | 5.0 |
| 0.50 | 94.6 | 2.96 | 20.3 | 6.1 |
| Detection Model | Hat | Person | mAP/% | FLOPS | Parameters/106 | Reference Time/ms | Model Size/MB |
|---|---|---|---|---|---|---|---|
| Faster R-CNN | 80.8 | 42.2 | 61.5 | 181.12 | 186 | 291 | 182.1 |
| SSD | 78.8 | 68.2 | 73.5 | 31.75 | 23.75 | 126 | 188 |
| YOLOv3 | 89.12 | 80.7 | 84.9 | 65.86 | 61.9 | 69 | 236 |
| YOLOv3+SPP | 90.5 | 86.3 | 88.41 | 141.45 | 63.0 | 70 | 237.4 |
| YOLOv5s | 93.3 | 91.7 | 92.7 | 17.0 | 7.26 | 36 | 14.8 |
| MCA-YOLOv5 | 96.7 | 95.2 | 96.0 | 21.75 | 7.30 | 37 | 15.2 |
| MCA-YOLOv5-Light | 95.7 | 94.6 | 95.1 | 2.74 | 0.93 | 17.2 | 2.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, C.; Zhang, S.; Qu, P.; Wu, X.; Feng, P.; Tao, Z.; Zhang, J.; Wang, Y. MCA-YOLOV5-Light: A Faster, Stronger and Lighter Algorithm for Helmet-Wearing Detection. Appl. Sci. 2022, 12, 9697. https://doi.org/10.3390/app12199697
Sun C, Zhang S, Qu P, Wu X, Feng P, Tao Z, Zhang J, Wang Y. MCA-YOLOV5-Light: A Faster, Stronger and Lighter Algorithm for Helmet-Wearing Detection. Applied Sciences. 2022; 12(19):9697. https://doi.org/10.3390/app12199697
Chicago/Turabian StyleSun, Cheng, Shiwen Zhang, Peiqi Qu, Xingjin Wu, Peng Feng, Zhanya Tao, Jin Zhang, and Ying Wang. 2022. "MCA-YOLOV5-Light: A Faster, Stronger and Lighter Algorithm for Helmet-Wearing Detection" Applied Sciences 12, no. 19: 9697. https://doi.org/10.3390/app12199697
APA StyleSun, C., Zhang, S., Qu, P., Wu, X., Feng, P., Tao, Z., Zhang, J., & Wang, Y. (2022). MCA-YOLOV5-Light: A Faster, Stronger and Lighter Algorithm for Helmet-Wearing Detection. Applied Sciences, 12(19), 9697. https://doi.org/10.3390/app12199697