



A Survey of Information Extraction Based on Deep Learning

Abstract
1. Introduction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
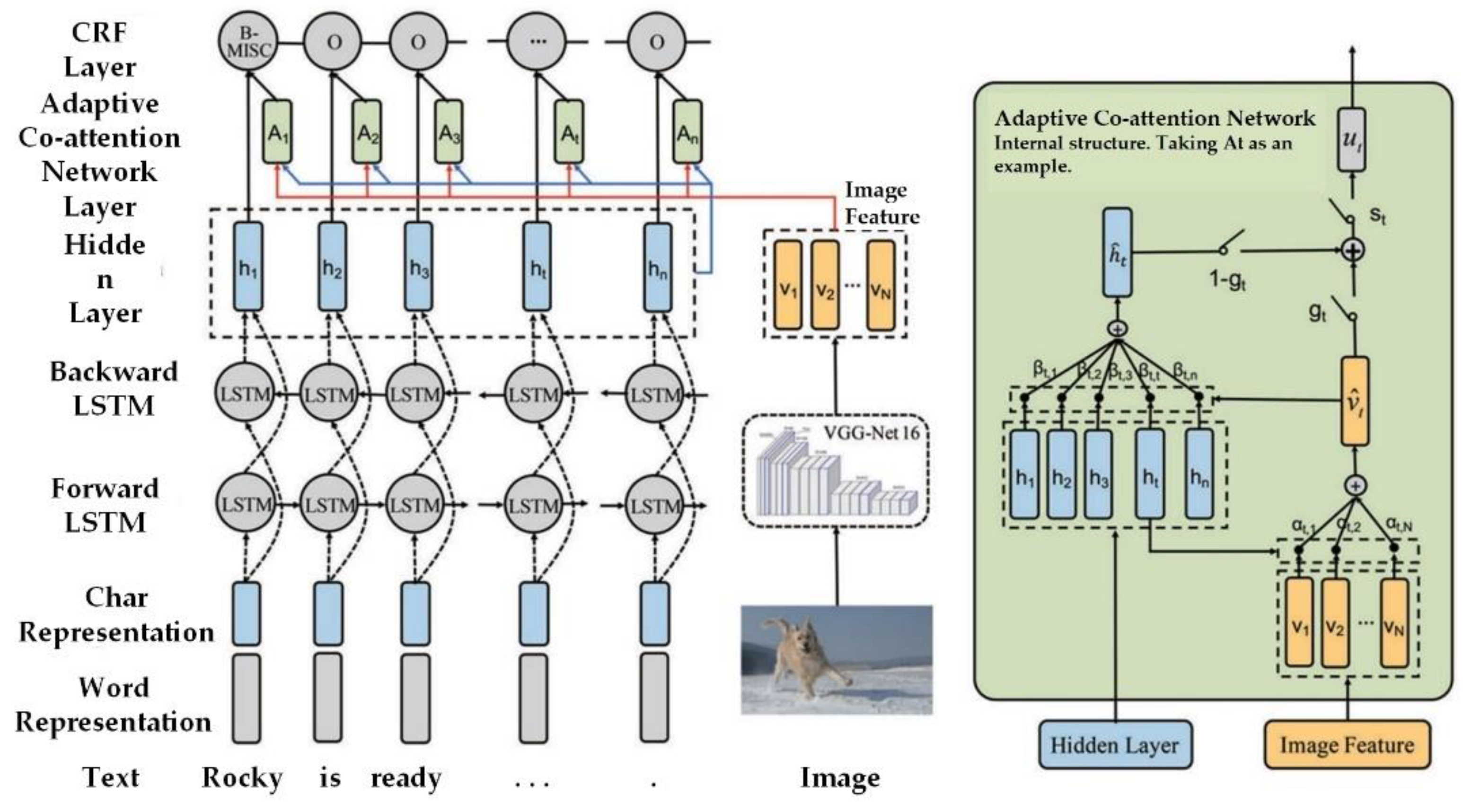{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic | Deep Learning | Classical Machine Learning |
|---|---|---|
| Data requirements | It is suitable for processing big data. With the increase in data volume, its performance will also be improved. Its dependence on prior knowledge of the data is weak. | It is suitable for small- and medium-sized data and has a strong dependence on prior knowledge of the data. |
| Model structure | The model has high complexity, a wide application range, and good expansibility. | It has a simple network structure with poor portability. |
| Feature extraction | Without feature engineering, it can automatically learn feature representations, which makes it easier to find hidden features and improves generalization ability [3]. | Features need to be identified by experts, and then manually coded according to the domain and data type. There are problems on error accumulation and propagation. |
| Solution | Solves problems once and end-to-end, with strong adaptability and easy migration. | Solves the problem in stages and then re-assemble. |
| Execution time | It takes a lot of time to train and there are too many parameters to learn. | Generally, it can be trained well in a few seconds to a few hours. |
| Interpretability | Due to the lack of theoretical basis, the deep-seated network cannot be explained, and the hyperparameters and network design are also a great challenge. | Rules and characteristics are understandable. |
| Hardware dependency | Deep learning algorithm has high requirements on GPU and relies on high-end hardware facilities. | It can work on low-end machines. |
2. Entity Relationship Extraction Based on Deep Learning
2.1. Supervised Learning—Pipeline Extraction
2.1.1. CNNs


2.1.2. RNNs

2.1.3. GNNs
2.1.4. Entity Relationship Extraction Based on Mixed Models
2.1.5. Entity Relational Extraction Based on Knowledge Embedding
2.2. Supervised Learning—Joint Extraction
2.2.1. Joint Extraction Based on Parameter Sharing
2.2.2. Joint Extraction Based on Sequence Annotation
2.2.3. Joint Extraction Based on Knowledge Enhancement
2.2.4. Joint Extraction Based on Graph Structure
2.3. Entity Relational Extraction Based on Distant Supervision
2.4. Summary
3. Event Extraction Based on Deep Learning
3.1. Single-Task or Multitask Event Extraction


| Model | NER | Event Extraction | ||||
|---|---|---|---|---|---|---|
| P/% | R/% | F1/% | PI% | R/% | F1/% | |
| Layered-BiLSTM-CRF | 74.20 | 70.30 | 72.20 | - | - | - |
| GEANN | 77.10 | 73.30 | 75.20 | - | - | - |
| BiFlaG | 75.00 | 75.20 | 75.10 | - | - | - |
| Merge and Label [ELMO] | 79.70 | 78.00 | 78.90 | - | - | - |
| Merge and Label [BERT] | 82.70 | 82.10 | 82.40 | - | - | - |
| JOINTEVENTENTITY | - | - | - | 75.10 | 63.30 | 68.70 |
| DMCNN | - | - | - | 75.60 | 63.60 | 69.10 |
| FN-ANN | - | - | - | 79.50 | 60.70 | 68.80 |
| BDLSTM-TNNs | - | - | - | 75.30 | 63.40 | 68.90 |
| JRNN | - | - | - | 66.00 | 73.00 | 69.30 |
| TD-DMN | - | - | - | 65.80 | 65.90 | 65.60 |
| RNN-AL | - | - | - | 77.40 | 61.30 | 67.80 |
| GAIL | - | - | - | 74.20 | 65.30 | 69.50 |
| Conv-BiLSTM | - | - | - | 74.70 | 64.90 | 69.50 |
| ANN-Gold2 | - | - | - | 81.40 | 66.90 | 73.40 |
| HNN-EE | 84.00 | 82.50 | 83.20 | 74.40 | 67.30 | 70.60 |
| Single task NER (MDL-J3E) | 83.86 | 84.10 | 83.98 | - | - | - |
| Single task ED (MDL-J3E) | - | - | - | 66.67 | 74.25 | 70.25 |
| MDL-J3E | 83.48 | 84.83 | 84.15 | 69.16 | 72.85 | 70.96 |

3.2. Sentence-Level or Chapter-Level Event Extraction


3.3. Summary
4. Multi-Model IE Based on Deep Learning
4.1. Multi-Modal Entity Identification


4.2. Mult-Imodal Relationship Extraction

4.3. Summary
5. Discussions
5.1. Method Level
5.2. Model Level
6. Prospect
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Summary of Characteristics and Applications of Typical Methods
| Typical Model | Characteristic | Application | |
|---|---|---|---|
| Entity relation extraction | RNN (2012) | Handles both internal feedback connections and feed-forward connections between the units. | Suitable for the extraction of timing features. |
| CNN (2014) | The structure is simple, and the neural network is used for feature extraction, which avoids the tedious manual feature extraction of [13]. | Suitable to process data with correlation. | |
| PCNNs (2015) | Regard the remote-supervised relation extraction problem as a multi-instance problem, and a convolution structure with a segmented maximum pool is used to automatically learn related features. | Remote supervised relationship extraction. | |
| CAN (2018) | Produces deep semantic dependency features, introducing attention mechanisms to capture dependency representation [18]. | Chemistry-disease field. | |
| LSTM (2014) | Produces long-term dependencies from the corpus, but the network structure is more complex. | Machine translation, dialogue generation, encoding, and decoding. | |
| K-CNN (2019) | Contains two collaborative channels: the knowledge-oriented channel and data-oriented channel and combines the information obtained from the two channels [19]. | Causal relationship extraction. | |
| CRN (2020) | Extracts non-superordinate relationships from the unstructured text [20]. | Food field. | |
| 2ATT-BiGRU (2020) | Uses the character-level and sentence-level attention mechanisms, finds the words that have a significant impact on the output, and gives them a higher weight to better obtain their semantic information [25]. | Medical domain. | |
| FastText-BiGRU-Dual Attention (2021) | Focuses on words with decisive influence on sentence relationship extraction, creates word-level low-dimensional entity vectors at the embedding layer, and feeds the word embedding and position embedding results to the BiGRU layer to obtain high-level features [11]. | Forestry field. | |
| GREG (2020) | The two modules of the model are synchronized during training, and each of the model’s modules is designed to deal with local relationships and global relationships separately [26]. | Overall relationship extraction. | |
| SKEoG (2021) | Takes full advantage of the document structure and external knowledge of [9]. | Medical relationship extraction at the document level. | |
| AGCN (2020) | Uses context and structural knowledge, combines GCN and a recurrent network-based encoder, and employs a new attention-based pruning strategy [30]. | Drug-drug interaction extraction. | |
| FC-GCN (2021) | Creates the un-directed graphs based on the combined features, uses the atomic features as the nodes, constructs the edges between the nodes according to the combination rules, and considers the prior knowledge and avoids the error caused by the resolution [31]. | Better analysis of the sentence structure. | |
| IPR-DCGAT (2021) | A dense connectivity graph attention network is used to update the representation of nodes and a two-step iterative algorithm to update the representation of edges [34]. | Document-level relationship extraction. | |
| BioGraphSAGE (2021) | Biological semantic and positional features are combined to improve the identification of long-distance entity relationships [35]. | Biological entity relationship extraction. | |
| KERE (2020) | Extracting knowledge information from the knowledge graph to generate knowledge-oriented word embeddings can enhance the effectiveness of the word embedding and using lexical features as supplementary information for semantic understanding can reduce semantic ambiguity and manually annotate [41]. | Biomedical relationship extraction. | |
| NAM (2019) | [43] demonstrates combining contextual information and knowledge representation with an attention mechanism. | Chemical-disease relation extraction. | |
| ATLOP (2021) | Adaptive thresholds replace global thresholds, and the local context pool shifts attention from the pre-trained language model to the localization-relevant context, alleviating multi-label and multi-entity problems [45]. | Document-level relationship extraction in biomedical fields. | |
| HDP (2019) | Converts the multi-pair-triplet extraction into a sequence generation task; generates a hybrid binary-pointer sequence extraction to alleviate the entity overlap problem [53]. | Multi-relationship triples were extracted. | |
| KSBERT (2021) | Integrates domain-specific external lexical and syntactic knowledge into end-to-end neural networks to solve the overlap problem [54]. | Military entities and relationship extraction. | |
| KEWE-BERT (2021) | Overlays the token embeddings and knowledge embeddings of BERT and TransR output with [55]. | Construction of the manufacturing domain knowledge map. | |
| Gated-K-BERT (2021) | Combines knowledge-aware attention representations with BERT; entities and their relations are jointly extracted using a gating fusion sharing mechanism [56]. | Study of the associations between depression and cannabis use. | |
| GraphRel (2019) | Combining the RNN and GCN, extracting the sequence features and region-dependent features of each word, considering the recessive features between word pairs, and considering the interaction between named entities and relationships through the relationship-weighted GCN [57]. | Joint entity and relationship extraction; alleviate overlap problems. | |
| A2DSRE (2021) | Advanced graph neural network GeniePath is introduced in DSRE to incorporate additional supervised information from the knowledge graph through the margin between the representation of the retraction package and the pre-trained knowledge graph embeddings [67]. | Reduce noise and remote supervision relationship extraction. | |
| REIF (2022) | Bridges the gap of realizing the influence of sub-sampling in deep learning. | Solve the problem of high noise interference. | |
| Event extraction | DMCNN (2015) | Vocabulary and sentence-level features can be automatically extracted from plain text without complex NLP preprocessing; using dynamic multi-pooling layers to store more valuable information based on event triggers and event arguments [71]. | Single-task event extraction. |
| JRNN (2016) | Based on the bi-directional RNN, introducing the memory matrix can effectively capture the dependencies between the argument element-roles and the trigger sub-types [73]. | Multi-event information extraction. | |
| DCFEE (2018) | Remote monitoring automatically tags event reference annotation triggers and arguments throughout the document, which includes sentence-level event extraction and document-level event extraction [87]. | Online event extraction of financial news and Chinese financial texts. | |
| HNN-EE (2019) | In the entity extraction module, the BiLSTM is used to capture the long-distance dependence information; in the event extraction module, the self-attention layer captures the internal structure of the sequence, and the gated convolution layer extracts the higher-level feature [86]. | Joint entity and event extraction. | |
| CNN-BiGRU (2021) | The word vector and position vectors are stitched as input, and word-level features are extracted using CNN and sentence-level features [85] using BiGRU. | Event-trigger word extraction. | |
| DEGREE (2022) | A data-efficient model that formulates event extraction as a conditional generation problem. | Focus on low-resource end-to-end event extraction. | |
| UIE (2022) | Structured extraction languages operate to uniformly encode different extraction structures, adaptively generate target draws, and capture the common IE capability [80] through large-scale pre-trained “text-to-structure” models. | Unified extraction of entities, relationships, and events in general fields. | |
| Multimodal information extraction | IKRL (2017) | Considers the visual information in solid images and constructs representations for all images of entities using a neural image encoder, which are integrated into the aggregated image-based representations of [101] via an attention-based approach. | Triplet classification, knowledge map construction. |
| Rp-BERT (2021) | Expands vanilla BERT to a multi-task framework of text-image relationship classification and visual-language learning; and better utilize visual information according to the relationship between text and image [97]. | Better use of visual information for multi-modal named entity recognition. | |
| UMGF (2021) | Uses unified multi-modal graphs and represents input sentences and images to capture various semantic relationships between multi-modal semantic units (words and visual objects); stacks multiple graph-based multi-modal fusion layers and iteratively performs semantic interactions to learn node representation [99]. | Explore the multi-modal graph neural networks of MNER for multi-modal named entity identification. | |
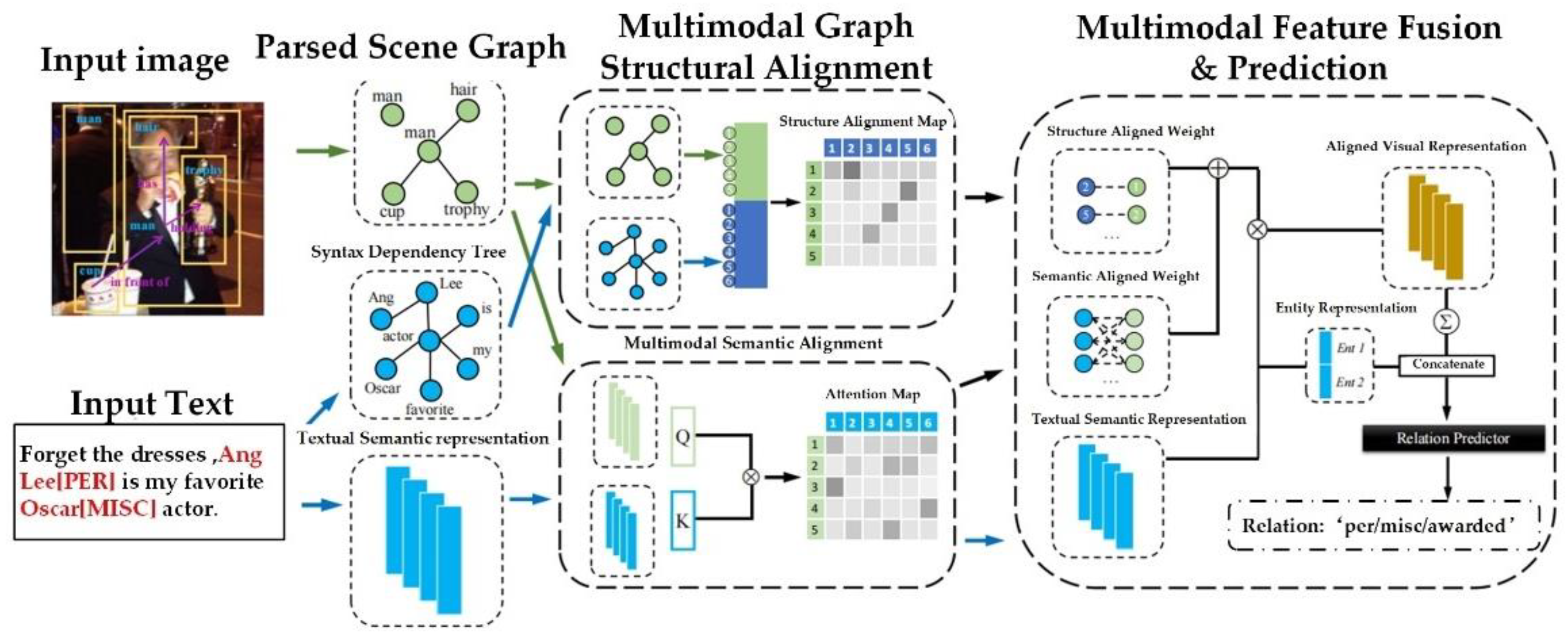
| MEGA (2021) | Generates scene maps from the image rich in visual information, treats the object features in the extracted scene map as visual semantic features, aligns the structure and semantic information of multi-modal features respectively, and then merges the alignment results [104]. | Social media relationship extraction. | |
| CAT-MNER (2022) | Proposed to refine the cross-modal attention by identifying and highlighting some task-salient features. The saliency of each feature is measured according to its correlation with the expanded entity label words derived from external knowledge bases. | To solve the problem that existing MNER methods are vulnerable to some implicit interactions and are prone to overlook the involved significant features. | |
| HVPNeT (2022) | Regards visual representation as a pluggable visual prefix to guide the textual representation for error-insensitive forecasting decisions. | To solve the problem that existing approaches for MNER and MRE usually suffer from error sensitivity when irrelevant object images incorporated in texts. |
References
- Hinton, G.E.; Osindero, S.; The, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Ji, Z.Y.; Tong, C.; Liang, G.; Yang, X.; Zhao, Z.; Wang, X. Named entity recognition based on deep learning. Comput. Integr. Manuf. Syst. 2022, 28, 1603–1615. [Google Scholar]
- Xu, Y.L.; Li, W.F.; Zhou, C.J. A survey of deep learning based natural language processing. In Proceedings of the 22nd Annual Conference on New Network Technologies and Applications of Network Application Branch of China Computer Users Association in 2018, SuZhou, China, 24–28 October 2018. [Google Scholar]
- Luo, X. A survey of natural language processing based on Deep learning. Intell. Comput. Appl. 2020, 4, 133–137. [Google Scholar]
- Jiang, Y.Y.; Jin, B.; Zhang, B.C. Research Progress of Natural Language Processing Based on Deep Learning. Comput. Eng. Appl. 2021, 22, 1–14. [Google Scholar]
- Liu, J.W.; Ding, X.H.; Luo, X.L. Survey of multimodal deep learning. Appl. Res. Comput. 2020, 37, 1601–1614. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Martinez-Gonzalez, P.; Garcia-Rodriguez, J. A survey on deep learning techniques for image and video semantic segmentation. Appl. Soft Comput. 2018, 70, 41–65. [Google Scholar] [CrossRef]
- Li, T.; Xiong, Y.; Wang, X.; Chen, Q.; Tang, B. Document-level medical relation extraction via edge-oriented graph neural network based on document structure and external knowledge. BMC Med. Inform. Decis. Mak. 2021, 21 (Suppl. 7), 1–10. [Google Scholar] [CrossRef] [PubMed]
- Tang, M.; Li, T.; Wang, W.; Zhu, R.; Ma, Z.; Tang, Y. Software Knowledge Entity Relation Extraction with Entity-Aware and Syntactic Dependency Structure Information. Sci. Program. 2021, 2021, 7466114. [Google Scholar] [CrossRef]
- Yue, Q.; Li, X.; Li, D. Chinese Relation Extraction on Forestry Knowledge Graph Construction. Comput. Syst. Sci. Eng. 2021, 37, 423–442. [Google Scholar] [CrossRef]
- Ling, D.M.; Zhang, Y.; Liu, D.Y.; Li, D.Q. Review of Entity Relation Extraction Methods. J. Comput. Res. Dev. 2020, 57, 1424–1448. [Google Scholar]
- Zeng, D.J.; Liu, K.; Lai, S.W.; Zhou, G.Y.; Zhao, J. Relation Classification via Convolutional Deep Neural Network. In Proceedings of the COLING 2014, the 25th International Conference on Computational Linguistics, Dublin, Ireland, 23–29 August 2014. [Google Scholar]
- Liu, C.; Sun, W.; Chao, W.; Che, W. Convolution Neural Network for Relation Extraction. In International Conference on Advanced Data Mining and Applications; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Lavin, A.; Gray, S. Fast Algorithms for Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016. [Google Scholar]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- Gu, J.; Wang, G.; Cai, J.; Chen, T. An Empirical Study of Language CNN for Image Captioning. In Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhou, H.; Ning, S.; Yang, Y.; Liu, Z.; Lang, C.; Lin, Y. Chemical-induced disease relation extraction with dependency information and prior knowledge. J. Biomed. Inform. 2018, 84, 171–178. [Google Scholar] [CrossRef] [PubMed]
- Li, P.; Mao, K. Knowledge-oriented convolutional neural network for causal relation extraction from natural language texts. Expert Syst. Appl. 2019, 115, 512–523. [Google Scholar] [CrossRef]
- Li, J.; Huang, G.; Chen, J.; Wang, Y. Dual CNN for Relation Extraction with Knowledge-Based Attention and Word Embeddings. Comput. Intell. Neurosci. 2019, 2019, 6789520. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.; Li, H.; Mao, D.; Cai, Q. A relationship extraction method for domain knowledge graph construction. World Wide Web-Internet Web Inf. Syst. 2020, 23, 735–753. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Yang, J.; Gou, X.; Qi, X. Recurrent neural networks with segment attention and entity description for relation extraction from clinical texts. Artif. Intell. Med. 2019, 97, 9–18. [Google Scholar] [CrossRef]
- Lin, C.; Miller, T.; Dligach, D.; Amiri, H.; Bethard, S.; Savova, G. Self-training improves Recurrent Neural Networks performance for Temporal Relation Extraction. In Proceedings of the 9th International Workshop on Health Text Mining and Information Analysis, LOUHI 2018, Brussels, Belgium, 31 October–1 November 2018. [Google Scholar]
- Zhang, Y.; Li, X.; Zhang, Z. Disease-Pertinent Knowledge Extraction in Online Health Communities Using GRU Based on a Double Attention Mechanism. IEEE Access 2020, 8, 95947–95955. [Google Scholar] [CrossRef]
- Kim, K.; Hur, Y.; Kim, G.; Lim, H. GREG: A Global Level Relation Extraction with Knowledge Graph Embedding. Appl. Sci. 2020, 10, 1181. [Google Scholar] [CrossRef]
- Bianchini, M.; Dimitri, G.M.; Maggini, M.; Scarselli, F. Deep neural networks for structured data. In Computational Intelligence for Pattern Recognition; Springer: Cham, Switzerland, 2018; pp. 29–51. [Google Scholar]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. arXiv 2018, arXiv:1812.08434. [Google Scholar] [CrossRef]
- Wu, T.; Kong, F. Document-Level Relation Extraction Based on Graph Attention Convolutional Neural Network. J. Chin. Inf. Process. 2021, 35, 73–80. [Google Scholar]
- Park, C.; Park, J.; Park, S. AGCN: Attention-based graph convolutional networks for drug-drug interaction extraction. Expert Syst. Appl. 2020, 159, 113538. [Google Scholar] [CrossRef]
- Xu, J.; Chen, Y.; Qin, Y.; Huang, R.; Zheng, Q. A Feature Combination-Based Graph Convolutional Neural Network Model for Relation Extraction. Symmetry 2021, 13, 1458. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Alalwan, N.; Abozeid, A.; ElHabshy, A.A.; Alzahrani, A. Efficient 3D Deep Learning Model for Medical Image Semantic Segmentation. Alex. Eng. J. 2020, 60, 1231–1239. [Google Scholar] [CrossRef]
- Zhang, H.Y.; Huang, Z.; Li, Z.; Li, D.; Liu, F. Densely Connected Graph Attention Network Based on Iterative Path Reasoning for Document-Level Relation Extraction. In Proceedings of the 25th Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD), Online, 11–14 May 2021. [Google Scholar]
- Guo, S.; Huang, L.; Yao, G.; Wang, Y.; Guan, H.; Bai, T. Extracting Biomedical Entity Relations using Biological Interaction Knowledge. Interdiscip. Sci.-Comput. Life Sci. 2021, 13, 312–320. [Google Scholar] [CrossRef]
- Zhang, Y.; Lin, H.; Yang, Z.; Wang, J.; Zhang, S.; Sun, Y.; Yang, L. A hybrid model based on neural networks for biomedical relation extraction. J. Biomed. Inform. 2018, 81, 83–92. [Google Scholar] [CrossRef] [PubMed]
- Peng, Y.; Rios, A.; Kavuluru, R.; Lu, Z. Extracting chemical–protein relations with ensembles of SVM and deep learning models. Database 2018, 2018, bay073. [Google Scholar] [CrossRef] [PubMed]
- Sun, C.; Yang, Z.; Su, L.; Wang, L.; Zhang, Y.; Lin, H.; Wang, J. Chemical-protein interaction extraction via Gaussian probability distribution and external biomedical knowledge. Bioinformatics 2020, 36, 4323–4330. [Google Scholar] [CrossRef]
- Ristoski, P.; Gentile, A.L.; Alba, A.; Gruhl, D.; Welch, S. Large-scale relation extraction from web documents and knowledge graphs with human-in-the-loop. J. Web Semant. 2019, 60, 100546. [Google Scholar] [CrossRef]
- Fossati, M.; Dorigatti, E.; Giuliano, C. N-ary relation extraction for simultaneous T-Box and A-Box knowledge base augmentation. Semant. Web 2018, 9, 413–439. [Google Scholar] [CrossRef]
- Zhao, Q.; Li, J.; Xu, C.; Yang, J.; Zhao, L. Knowledge-Enhanced Relation Extraction for Chinese EMRs. It Prof. 2020, 22, 57–62. [Google Scholar] [CrossRef]
- Weinzierl, M.A.; Maldonado, R.; Harabagiu, S.M. The impact of learning Unified Medical Language System knowledge embeddings in relation extraction from biomedical texts. J. Am. Med. Inform. Assoc. 2020, 27, 1556–1567. [Google Scholar] [CrossRef] [PubMed]
- Zhou, H.; Yang, Y.; Ning, S.; Liu, Z.; Lang, C.; Lin, Y.; Huang, D. Combining Context and Knowledge Representations for Chemical-Disease Relation Extraction. IEEE-ACM Trans. Comput. Biol. Bioinform. 2019, 16, 1879–1889. [Google Scholar] [CrossRef]
- Zhao, D.; Wang, J.; Zhang, Y.; Wang, X.; Lin, H.; Yang, Z. Incorporating representation learning and multihead attention to improve biomedical cross-sentence n-ary relation extraction. BMC Bioinform. 2020, 21, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Zhou, W.; Huang, K.; Ma, T.; Huang, J. Document-Level Relation Extraction with Adaptive Thresholding and Localized Context Pooling. In Proceedings of the 35th AAAI Conference on Artificial Intelligence/33rd Conference on Innovative Applications of Artificial Intelligence/11th Symposium on Educational Advances in Artificial Intelligence, Electr Network, Online, 2–9 February 2021. [Google Scholar]
- Yang, S.; Yoo, S.; Jeong, O. DeNERT-KG: Named Entity and Relation Extraction Model Using DQN, Knowledge Graph, and BERT. Appl. Sci. 2020, 10, 6429. [Google Scholar] [CrossRef]
- Qi, T.; Qiu, S.; Shen, X.; Chen, H.; Yang, S.; Wen, H.; Zhang, Y.; Wu, Y.; Huang, Y. KeMRE: Knowledge-enhanced medical relation extraction for Chinese medicine instructions. J. Biomed. Inform. 2021, 120, 103834. [Google Scholar] [CrossRef]
- Dehghani, M.; Gouws, S.; Vinyals, O.; Uszkoreit, J.; Kaiser, Ł. Universal transformers. arXiv 2018, arXiv:1807.03819. [Google Scholar]
- Hao, J.; Wang, X.; Yang, B.; Wang, L.; Zhang, J.; Tu, Z. Modeling recurrence for transformer. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 1198–1207. [Google Scholar]
- Pham, H.; Guan, M.Y.; Zoph, B.; Le, Q.V.; Dean, J. Efficient neural architecture search via parameter sharing. arXiv 2018, arXiv:1802.03268. [Google Scholar]
- Zheng, S.; Hao, Y.; Lu, D.; Bao, H.; Xu, J.; Hao, H.; Xu, B. Joint entity and relation extraction based on a hybrid neural network. Neurocomputing 2017, 257, 59–66. [Google Scholar] [CrossRef]
- Zheng, S.; Wang, F.; Bao, H.; Hao, Y.; Zhou, P.; Xu, B. Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme. In Proceedings of the 55th Annual Meeting of the Association-for-Computational-Linguistics (ACL), Vancouver, BC, Canada, 30 June–4 August 2017. [Google Scholar]
- Pang, Y.; Liu, J.; Liu, L.; Yu, Z.; Zhang, K. A Deep Neural Network Model for Joint Entity and Relation Extraction. IEEE Access 2019, 7, 179143–179150. [Google Scholar] [CrossRef]
- Ding, K.; Liu, S.; Zhang, Y.; Zhang, H.; Zhang, X.; Wu, T.; Zhou, X. A Knowledge-Enriched and Span-Based Network for Joint Entity and Relation Extraction. Comput. Mater. Contin. 2021, 68, 377–389. [Google Scholar] [CrossRef]
- Dong, J.; Wang, J.; Chen, S. Knowledge graph construction based on knowledge enhanced word embedding model in manufacturing domain. J. Intell. Fuzzy Syst. 2021, 41, 3603–3613. [Google Scholar] [CrossRef]
- Yadav, S.; Lokala, U.; Daniulaityte, R.; Thirunarayan, K.; Lamy, F.; Sheth, A. When they say weed causes depression, but it’s your fav antidepressant: Knowledge-aware attention framework for relationship extraction. PLoS ONE 2021, 16, e0248299. [Google Scholar] [CrossRef] [PubMed]
- Fu, T.-J.; Li, P.-H.; Ma, W.-Y. GraphRel: Modeling Text as Relational Graphs for Joint Entity and Relation Extraction. In Proceedings of the 57th Annual Meeting of the Association-for-Computational-Linguistics (ACL), Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Miao, L.; Zhang, Y.J.; Xie, B.H.; Li, Y. Joint entity relation extraction based on graph neural network. Appl. Res. Comput. 2022, 39, 424–431. [Google Scholar]
- Qiao, Y.P.; Yu, Y.X.; Liu, S.Y.; Wang, Z.T.; Xia, Z.F.; Qiao, J.Q. Graph Convolution-Enhanced Joint Entity and Relation Extraction Model by Multi-Channel Decoding. J. Comput. Res. Dev. 2022, 1–14. [Google Scholar]
- Kim, E.-K.; Choi, K.-S. Improving Distantly Supervised Relation Extraction by Knowledge Base-Driven Zero Subject Resolution. IEICE Trans. Inf. Syst. 2018, E101.D, 2551–2558. [Google Scholar] [CrossRef]
- Zeng, D.; Liu, K.; Chen, Y.; Zhao, J. Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks. In Proceedings of the EMNLP, Lisbon, Portugal, 17–21 September 2015. [Google Scholar]
- Deng, K.; Zhang, X.; Ye, S.; Liu, J. Knowledge-embodied attention for distantly supervised relation extraction. Intell. Data Anal. 2020, 24, 445–457. [Google Scholar] [CrossRef]
- Huang, H.; Lei, M.; Feng, C. Graph-based reasoning model for multiple relation extraction. Neurocomputing 2020, 420, 162–170. [Google Scholar] [CrossRef]
- Augenstein, I.; Maynard, D.; Ciravegna, F. Distantly supervised Web relation extraction for knowledge base population. Semant. Web 2016, 7, 335–349. [Google Scholar] [CrossRef]
- Lin, Y.; Li, Y.; Lu, K.; Ma, C.; Zhao, P.; Gao, D.; Fan, Z.; Cheng, Z.; Wang, Z.; Yu, S. Long-distance disorder-disorder relation extraction with bootstrapped noisy data. J. Biomed. Inform. 2020, 109, 103529. [Google Scholar] [CrossRef] [PubMed]
- Huang, W.; Mao, Y.; Yang, L.; Yang, Z.; Long, J. Local-to-global GCN with knowledge-aware representation for distantly supervised relation extraction. Knowl.-Based Syst. 2021, 234, 107565. [Google Scholar] [CrossRef]
- Shi, Y.; Xiao, Y.; Quan, P.; Lei, M.; Niu, L. Distant Supervision Relation Extraction via adaptive dependency-path and additional knowledge graph supervision. Neural Netw. 2021, 134, 42–53. [Google Scholar] [CrossRef] [PubMed]
- Mao, N.; Huang, W.; Zhong, H. KGGCN: Knowledge-Guided Graph Convolutional Networks for Distantly Supervised Relation Extraction. Appl. Sci. 2021, 11, 7734. [Google Scholar] [CrossRef]
- Wang, Z.; Wen, R.; Chen, X.; Huang, S.; Zhang, N.; Zheng, Y. Finding Influential Instances for Distantly Supervised Relation Extraction. In Proceedings of the COLING, Gyeongju, Korea, 12–17 October 2022. [Google Scholar]
- Li, X.H.; Cheng, W.; Tang, X.Y.; Yu, T.; Chen, Z.; Qian, T.Y. A Joint Extraction Method of Financial Events Based on Multi-Layer Convolutional Neural Networks. Libr. Inf. Serv. 2021, 65, 89–99. [Google Scholar]
- Chen, Y.; Xu, L.; Liu, K.; Zeng, D.; Zhao, J. Event Extraction via Dynamic Multi-Pooling Convolutional Neural Networks. In Proceedings of the ACL, Austin, TX, USA, 2–22 October 2015. [Google Scholar]
- Liu, S.; Chen, Y.; Liu, K.; Zhao, J. Exploiting argument information to improve event detection via supervised attention mechanisms. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1. Association for Computational Linguistics, Vancouver, BC, USA, 30 July–4 August 2017; pp. 1789–1798. [Google Scholar]
- Nguyen, T.H.; Cho, K.; Grishman, R. Joint Event Extraction via Recurrent Neural Networks. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 300–309. [Google Scholar]
- Yu, C.M.; Lin, H.J.; Zhang, Z.G. Joint Extraction Model for Entities and Events with Multi-task Deep Learning. Data Anal. Knowl. Discov. 2022, 6, 117–128. [Google Scholar]
- Kruengkrai, C.; Nguyen, T.H.; Aljunied, S.M.; Bing, L. Improving LowResource Named Entity Recognition Using Joint Sentence and Token Labeling. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 5898–5905. [Google Scholar]
- Martins, P.H.; Marinho, Z.; Martins, A.F.T. Joint Learning of Named Entity Recognition and Entity Linking. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: Student Research Workshop, Florence, Italy, 28 July–2 August 2019; pp. 190–196. [Google Scholar]
- He, R.; Duan, S. Joint Chinese Event Extraction Based Multi-Task Learning. J. Softw. 2019, 30, 1015–1030. [Google Scholar]
- Lin, Y.; Yang, S.Q.; Stoyanov, V.; Ji, H. A Multi-lingual Multi-task Architecture for Low-resource Sequence Labeling. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 799–809. [Google Scholar]
- Wang, J.; Kulkarni, M.; Preotiuc-Pietro, D. Multi-domain Named Entity Recognition with Genre-aware and Agnostic Inference. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 8476–8488. [Google Scholar]
- Lu, Y.; Liu, Q.; Dai, D.; Xiao, X.; Lin, H.; Han, X.; Sun, L.; Wu, H. Unified Structure Generation for Universal Information Extraction. arXiv 2022, arXiv:2203.12277. [Google Scholar]
- Gao, S.; Tao, H.; Jiang, Y.Z.; Jia, Q.; Zhang, D.Z.; Xie, Y.H. Sentence-level Joint Event Extraction of Traditional Chinese Medical Literature. Technol. Intell. Eng. 2021, 7, 15–29. [Google Scholar]
- Yu, X.H.; He, L.; Xu, J. Extracting Events from Ancient Books Based on RoBERTaCRF. Data Anal. Knowl. Discov. 2021, 5, 26–35. [Google Scholar]
- Hsu, I.-H.; Huang, K.-H.; Boschee, E.; Miller, S.; Natarajan, P.; Chang, K.-W.; Peng, N. DEGREE: A Data-Efficient Generation-Based Event Extraction Model. In Proceedings of the NAACL, Seattle, WA, USA, 10–15 July 2022. [Google Scholar]
- Feng, X.; Qin, B.; Liu, T.A. Language-Independent Neural Network for Event Detection. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 66–71. [Google Scholar]
- Miao, J.; Duan, Y.; Zhang, Y.; Zhang, Z. Method for extracting event trigger words based on the CNNBiGRU model. Comput. Eng. 2021, 47, 69–74+83. [Google Scholar]
- Wu, W.T.; Li, P.F.; Zhu, Q.M. Joint Extraction of Entities and Events by Hybrid Neural Network. J. Chin. Inf. Process. 2019, 33, 77–83. [Google Scholar]
- Yang, H.; Chen, Y.B.; Liu, K.; Xiao, Y.; Zhao, J. DCFEE: A Document-level Chinese Financial Event Extraction System based on Automatically Labeled Training Data. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics-System Demonstrations, Dublin, Ireland, 22–27 May 2018; pp. 50–55. [Google Scholar]
- Zhong, W.F.; Yang, H.; Chen, Y.B.; Liu, K.; Zhao, J. Document-level Event Extraction Based on Joint Labeling and Global Reasoning. J. Chin. Inf. Process. 2019, 33, 88–95. [Google Scholar]
- Zheng, S.; Cao, W.; Xu, W.; Bian, J. Doc2EDAG: An end-to-end document-level framework for Chinese financial event extraction. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 337–346. [Google Scholar]
- Guo, X.; Gao, C.X.; Chen, Q.; Wang, S.G.; Wang, X.J. Three-stage Document-level Event Extraction for COVID-19 News. Comput. Eng. Appl. 2021, 1–12. [Google Scholar]
- Yang, B.S.; Mitchell, T.M. Joint Extraction of Events and Entities within a Document Context. arXiv 2016, arXiv:1609.03632. [Google Scholar]
- Liu, J.; Chen, Y.; Liu, K.; Bi, W.; Liu, X. Event Extraction as Machine Reading Comprehension. In Proceedings of the Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Online, 16–20 December 2020. [Google Scholar]
- Liu, Z.Y.; Yu, W.H.; Hong, Z.Y.; Ke, G.Z.; Tan, R.J. Chinese Event Extraction Using Question Answering. Comput. Eng. Appl. 2022, 1–8. [Google Scholar]
- Chen, Y.; Zhou, G.; Lu, J.C. Survey on construction and application research for multi-modal knowledge graphs. Appl. Res. Comput. 2021, 38, 3535–3543. [Google Scholar]
- Liu, X.; Gao, F.; Zhang, Q.; Zhao, H. Graph Convolution for Multimodal Information Extraction from Visually Rich Documents. In Proceedings of the NAACL, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Wang, M.; Wang, H.F.; Li, B.H.; Zhao, X.; Wang, X. Survey of Key Technologies of New Generation Knowledge Graph. J. Comput. Res. Dev. 2022, 1–18. [Google Scholar]
- Sun, L.; Wang, J.Q.; Zhang, K.; Su, Y.D.; Weng, F.S. RpBERT: A Text-image Relation Propagation-based BERT Model for Multimodal NER. In Proceedings of the 35th AAAI Conference on Artificial Intelligence/33rd Conference on Innovative Applications of Artificial Intelligence/11th Symposium on Educational Advances in Artificial Intelligence, Electr Network, Online, 2–9 February 2021. [Google Scholar]
- Zhang, Q.; Fu, J.; Liu, X.; Huang, X. Adaptive Co-Attention Network for Named Entity Recognition in Tweets. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence/30th Innovative Applications of Artificial Intelligence Conference/8th AAAI Symposium on Educational Advances in Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Zhang, D.; Wei, S.; Li, S.; Wu, H.; Zhu, Q.; Zhou, G. Multi-modal Graph Fusion for Named Entity Recognition with Targeted Visual Guidance. In Proceedings of the 35th AAAI Conference on Artificial Intelligence/33rd Conference on Innovative Applications of Artificial Intelligence/11th Symposium on Educational Advances in Artificial Intelligence, Electr Network, Online, 2–9 February 2021. [Google Scholar]
- Sui, D.; Tian, Z.; Chen, Y.; Liu, K.; Zhao, Y. A Large-Scale Chinese Multimodal NER Dataset with Speech Clues. In Proceedings of the Joint Conference of 59th Annual Meeting of the Association-for-Computational-Linguistics (ACL)/11th International Joint Conference on Natural Language Processing (IJCNLP)/6th Workshop on Representation Learning for NLP (RepL4NLP), Electr Network, Online, 1–6 August 2021. [Google Scholar]
- Xie, R.B.; Liu, Z.; Luan, H.; Sun, M. Image-embodied Knowledge Representation Learning. In Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI), Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Sergieh, H.M.; Botschen, T.; Gurevych, I.; Roth, S. A Multimodal Translation-Based Approach for Knowledge Graph Representation Learning. In Proceedings of the *SEMEVAL, New Orleans, LA, USA, 5–6 June 2018. [Google Scholar]
- Zheng, C.; Wu, Z.; Feng, J.; Fu, Z.; Cai, Y. MNRE: A Challenge Multimodal Dataset for Neural Relation Extraction with Visual Evidence in Social Media Posts. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021. [Google Scholar]
- Zheng, C.; Feng, J.; Fu, Z.; Cai, Y.; Li, Q.; Wang, T. Multimodal Relation Extraction with Efficient Graph Alignment. In Proceedings of the 29th ACM International Conference on Multimedia, Online, 20–24 October 2021. [Google Scholar]
- Oral, B.; Emekligil, E.; Arslan, S.; Eryiǧit, G. Information Extraction from Text Intensive and Visually Rich Banking Documents. Inf. Process. Manag. 2020, 57, 102361. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, N.; Li, L.; Yao, Y.; Deng, S.; Tan, C.; Huang, F.; Si, L.; Chen, H. Good Visual Guidance Makes A Better Extractor: Hierarchical Visual Prefix for Multimodal Entity and Relation Extraction. In Proceedings of the NAACL, Seattle, WA, USA, 10–15 July 2022. [Google Scholar]
- Wang, X.; Ye, J.; Li, Z.; Tian, J.; Jiang, Y.; Yan, M.; Zhang, J.; Xiao, Y. CAT-MNER: Multimodal Named Entity Recognition with Knowledge-Refined Cross-Modal Attention. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 11–15 July 2022. [Google Scholar]


| IE Methods | Main Ideas | Characteristics |
|---|---|---|
| Methods based on rule and dictionary | Rule based methods: by summarizing the rules, experts construct a large number of rule templates, and extract information based on the templates. Dictionary based methods: to establish a dictionary of recognition objects; the process of information extraction is the process of searching in the dictionary or professional domain knowledge database. | The method based on manual rules can achieve high accuracy on small data sets, but it has no adaptability to a large number of data sets or new fields. The establishment of new rule bases and dictionaries requires a lot of time and manpower. These rules often depend on specific languages, and it is difficult to cover all languages. |
| Methods based on statistical machine learning | Supervised training is carried out by using the manually labelled corpus, and then the prediction is realized by using the trained machine learning model. Common methods include HMM, MEM, SVM, ME, CRF, etc. | Although the method based on statistical machine learning has significantly improved results compared with the previous methods, it also requires a lot of manual annotation by people with professional field knowledge, and the cost of labor and time is very high. |
| Methods based on deep learning | The complex pattern recognition problems are solved by automatically identifying information features and internal laws through complex network structures. Common methods include CNN, RNN, etc. | It is applicable of big data processing and automatically learns sentence features without complex feature engineering. |
| Task | Classification | Pros | Cons |
|---|---|---|---|
| Entity relationship extraction | Supervised learning—pipeline extraction | Solves problems in stages and steps, with high flexibility of the model. | There are problems, such as error accumulation, ignoring the internal relationship and dependence between the two, and information redundancy; the problems of entity overlap, relationship overlap, and data noise cannot be solved. |
| Supervised learning—joint learning | Makes full use of the relationship between entities and relationships to alleviate the problems of error accumulation and information redundancy. | The problem of entity overlap and relationship overlap cannot be solved. | |
| Distance supervised learning | Saves time and cost without a lot of manual labeling. | The problems of information noise and feature extraction error propagation need to be further solved. | |
| Event extraction | Single task | Solves problems in stages and steps, with high flexibility of the model. | Unable to get the relationship between events. |
| Multitasking | Trigger words and argument information promote each other, improves the extraction effect, and effectively alleviates the problem of data sparsity. | The model structure design is complex and often needs to be completed with multiple models. | |
| Sentence level | High recognition accuracy. | Incomplete extraction of event information. | |
| Chapter level | Effectively extracts comprehensive information of events. | The recognition accuracy is low, and the information fusion needs to be strengthened. | |
| Multi-modal information extraction | Multi-modal entity recognition | Improves the effect of named entity recognition for modal information, and multi-modal entity linking technology helps entity alignment. | Modal fusion needs to be improved, and the distinction between entities that are easy to be confused needs to be strengthened |
| Multi-modal relation extraction | Reduces the loss of data information. | The information between different modes is repetitive and noisy. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Wu, Z.; Yang, Y.; Lian, S.; Guo, F.; Wang, Z. A Survey of Information Extraction Based on Deep Learning. Appl. Sci. 2022, 12, 9691. https://doi.org/10.3390/app12199691
Yang Y, Wu Z, Yang Y, Lian S, Guo F, Wang Z. A Survey of Information Extraction Based on Deep Learning. Applied Sciences. 2022; 12(19):9691. https://doi.org/10.3390/app12199691
Chicago/Turabian StyleYang, Yang, Zhilei Wu, Yuexiang Yang, Shuangshuang Lian, Fengjie Guo, and Zhiwei Wang. 2022. "A Survey of Information Extraction Based on Deep Learning" Applied Sciences 12, no. 19: 9691. https://doi.org/10.3390/app12199691
APA StyleYang, Y., Wu, Z., Yang, Y., Lian, S., Guo, F., & Wang, Z. (2022). A Survey of Information Extraction Based on Deep Learning. Applied Sciences, 12(19), 9691. https://doi.org/10.3390/app12199691