



MFFAMM: A Small Object Detection with Multi-Scale Feature Fusion and Attention Mechanism Module


Abstract
:1. Introduction
2. Related Work
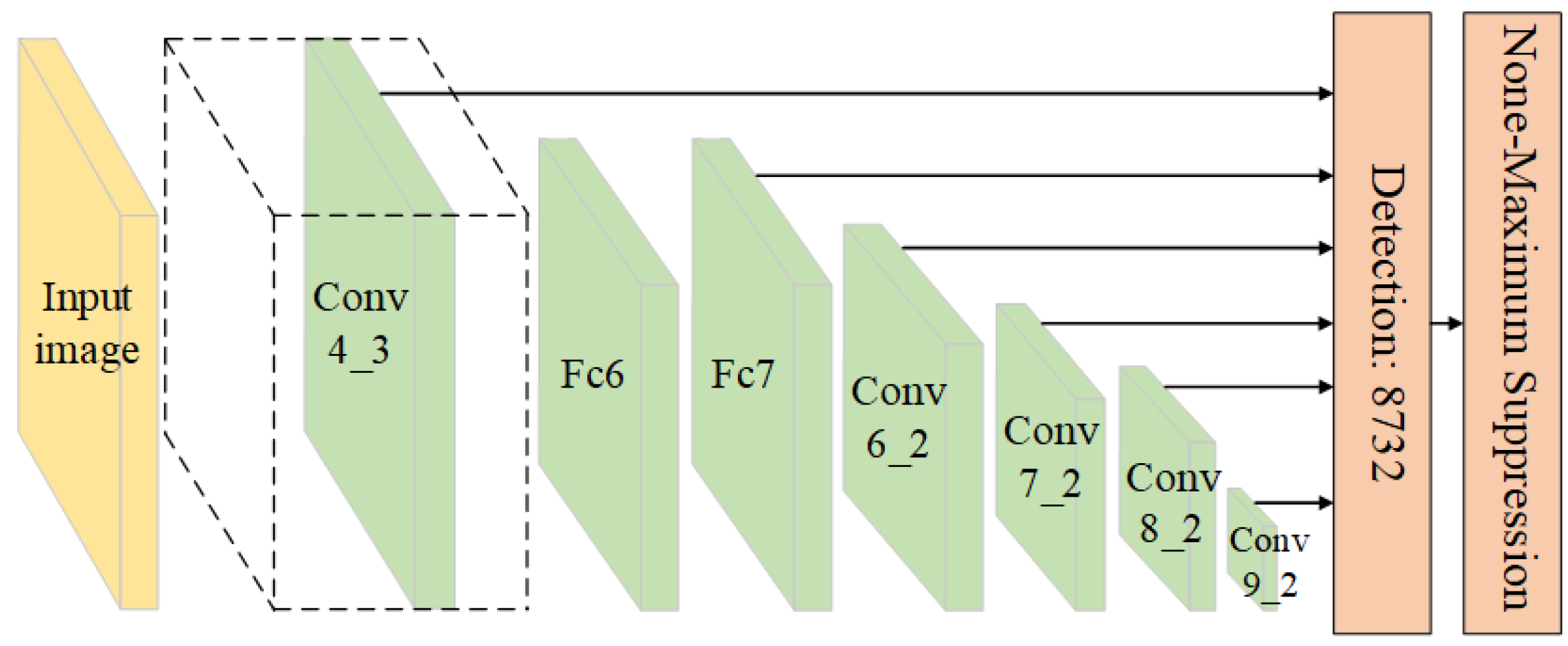
2.1. SSD
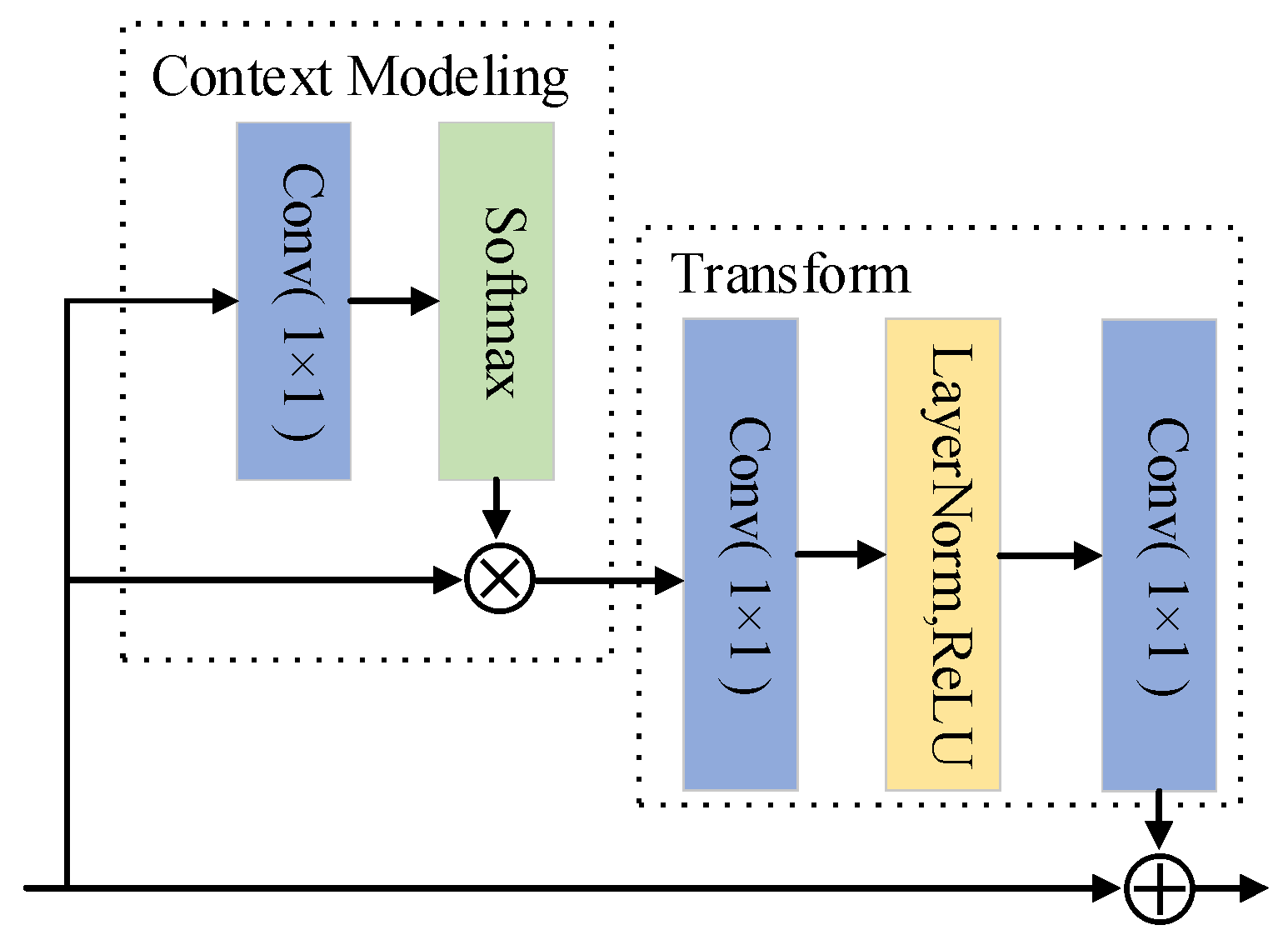
2.2. Attention Mechanism
2.3. Multi-Scale Feature Fusion
2.4. Receptive Field Block
3. The Improved SSD Networks
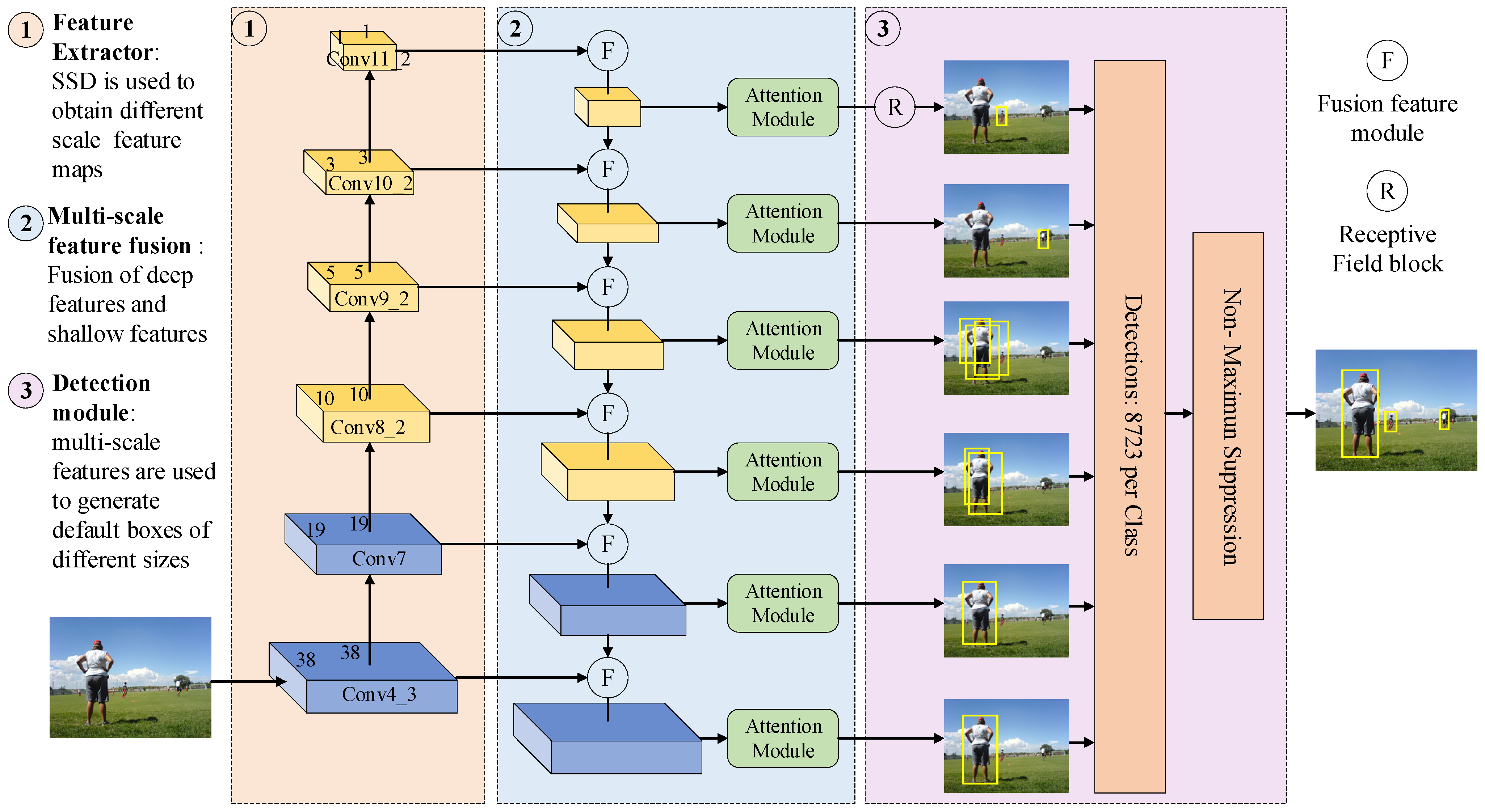
3.1. Network Architecture
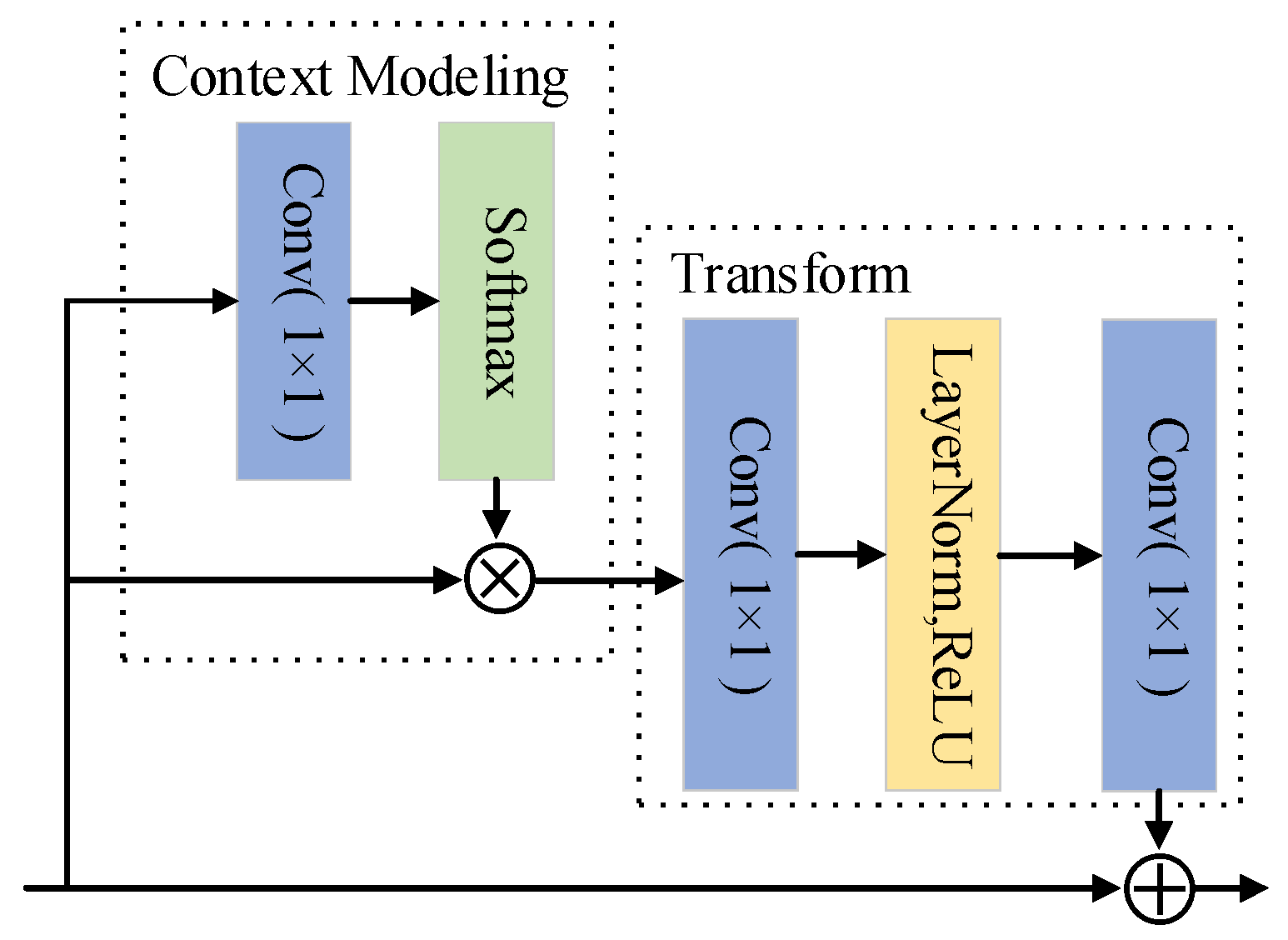
3.2. Backbone with Attention Mechanism
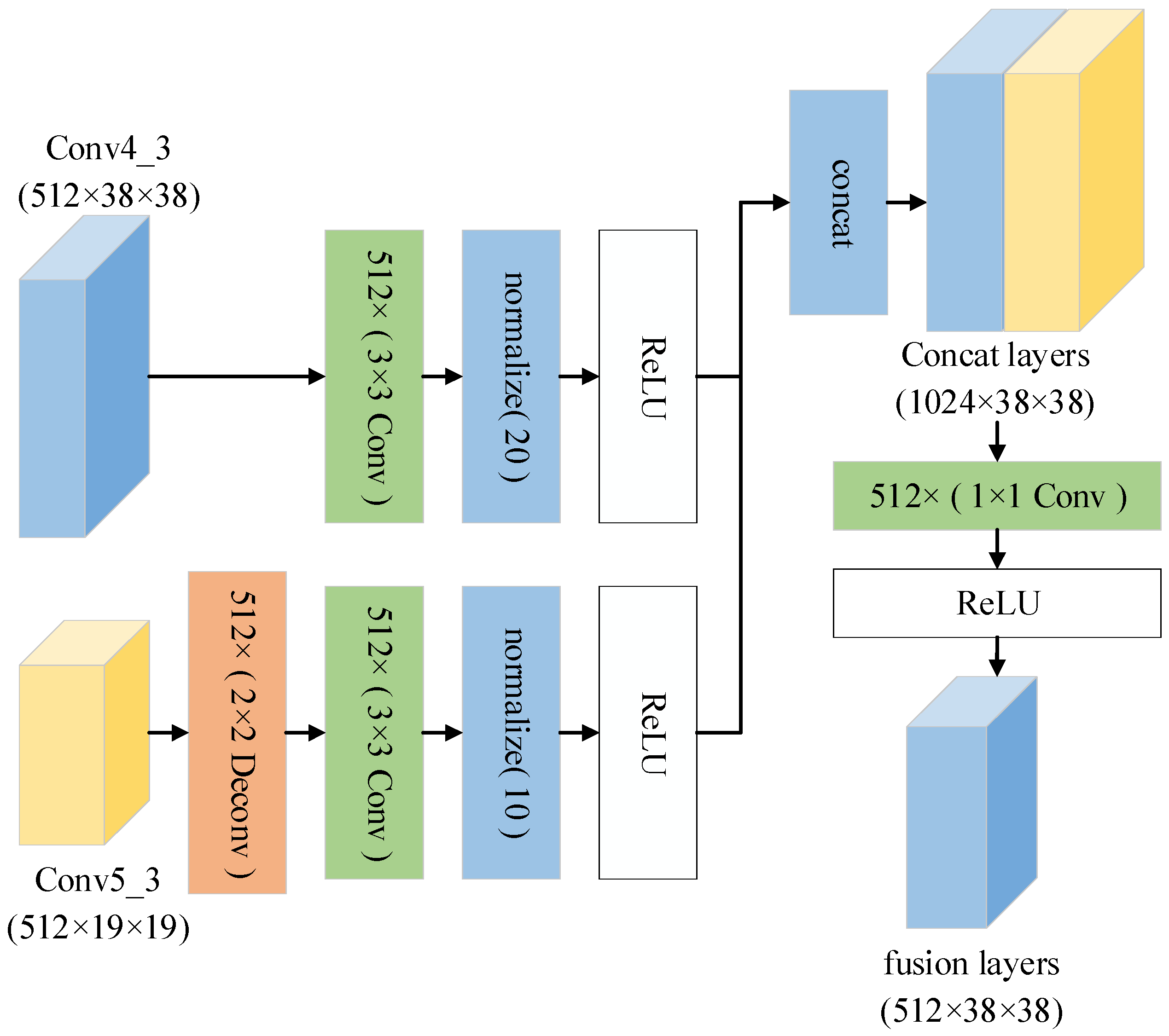
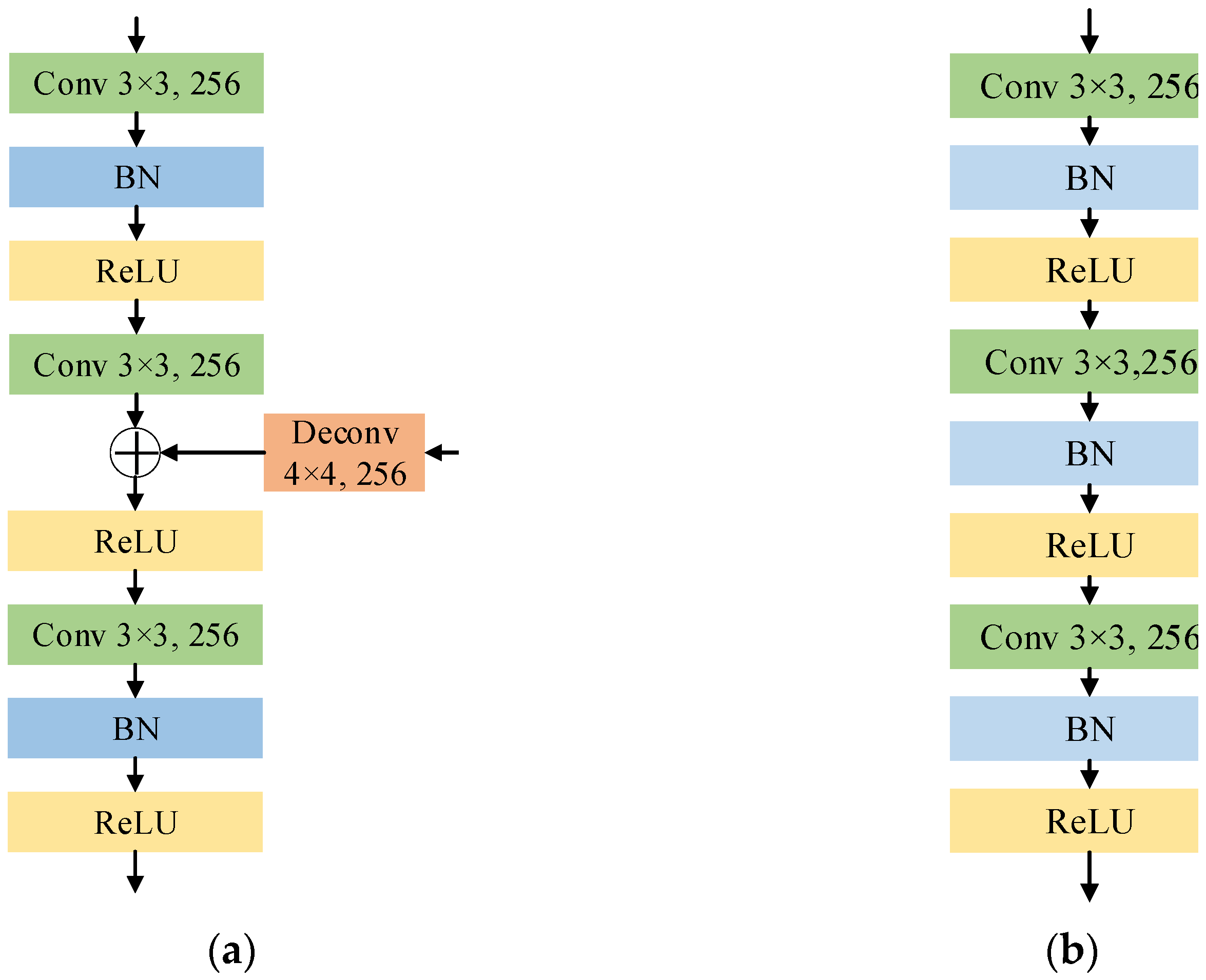
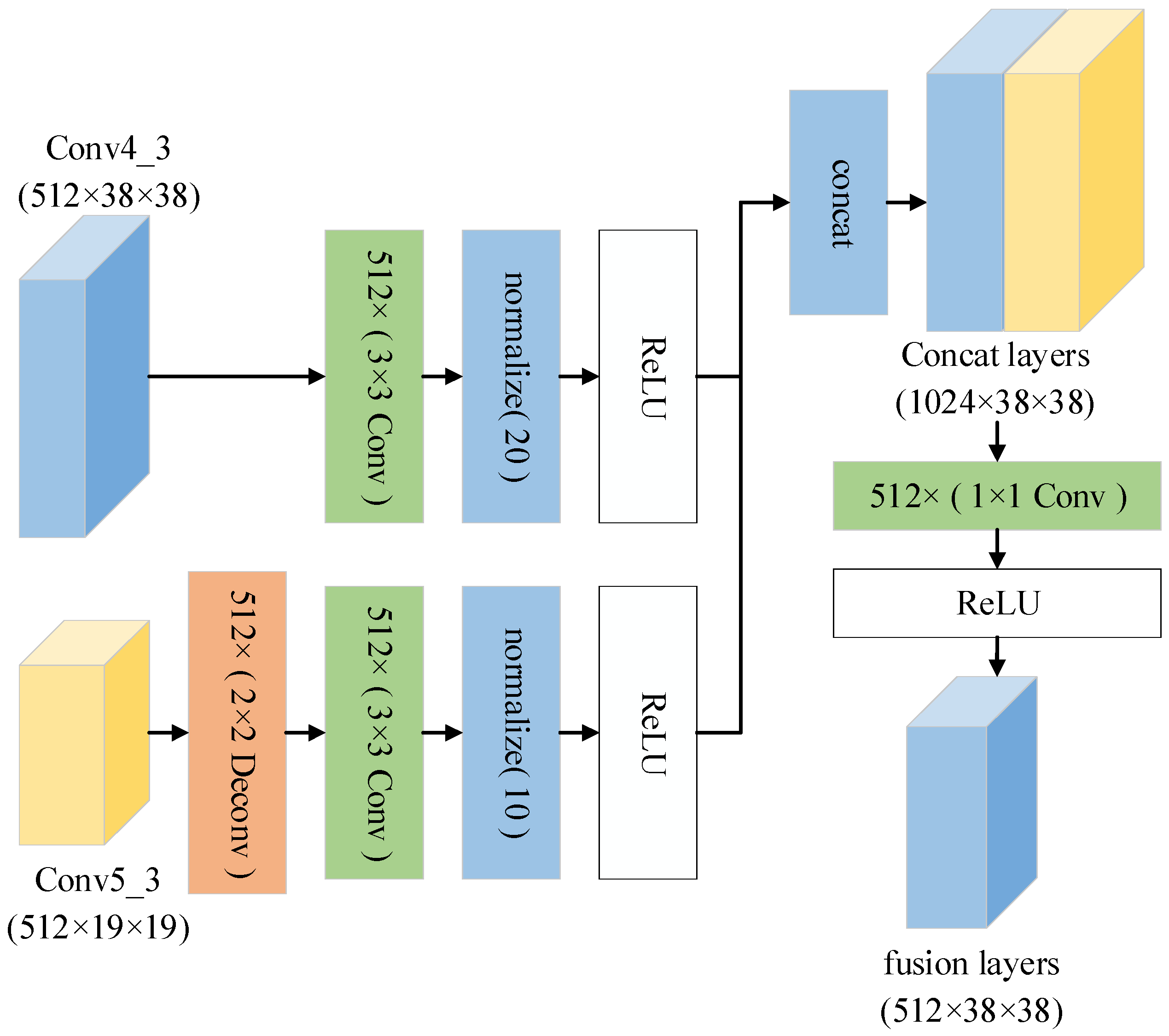
3.3. Feature Fusion
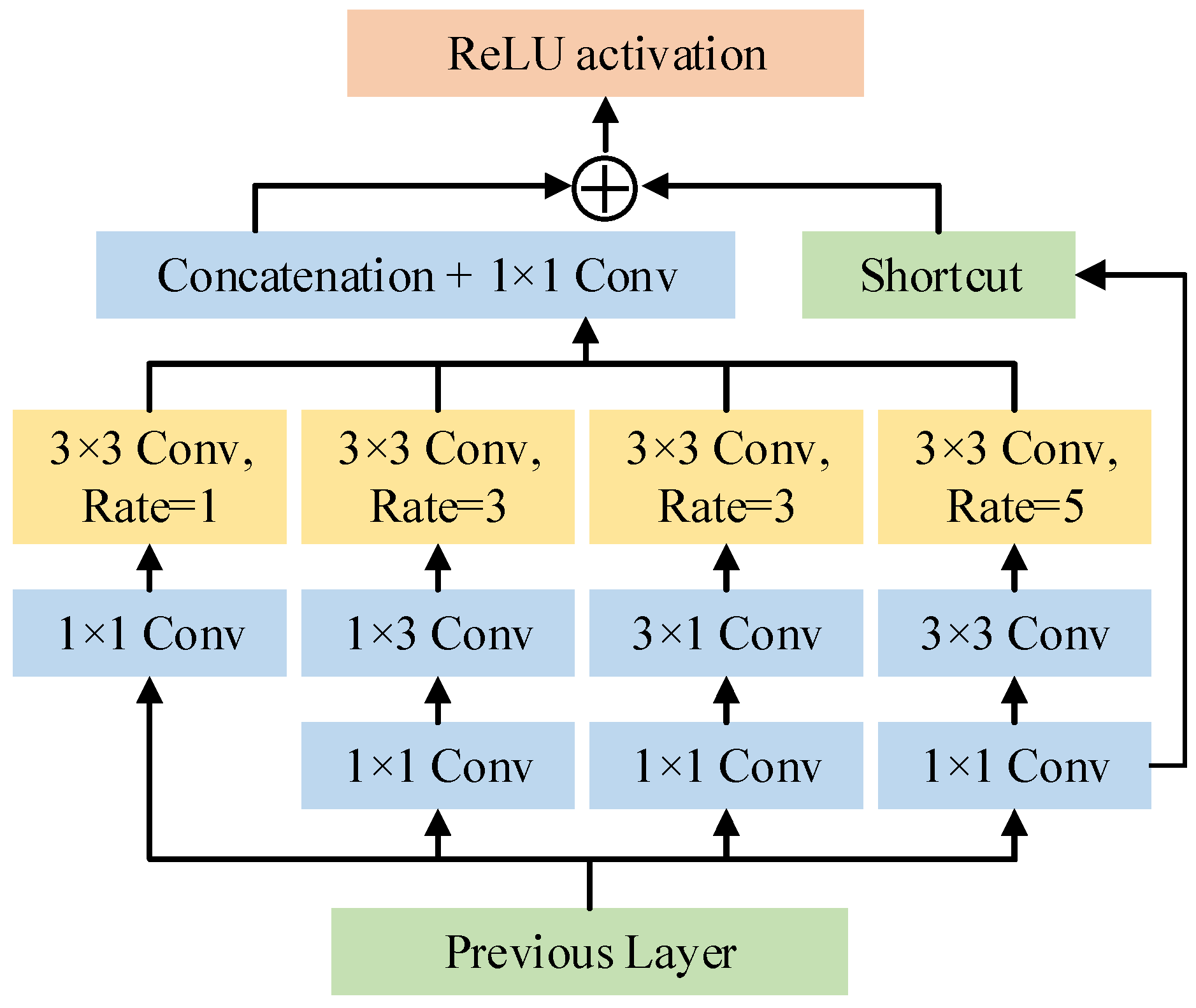
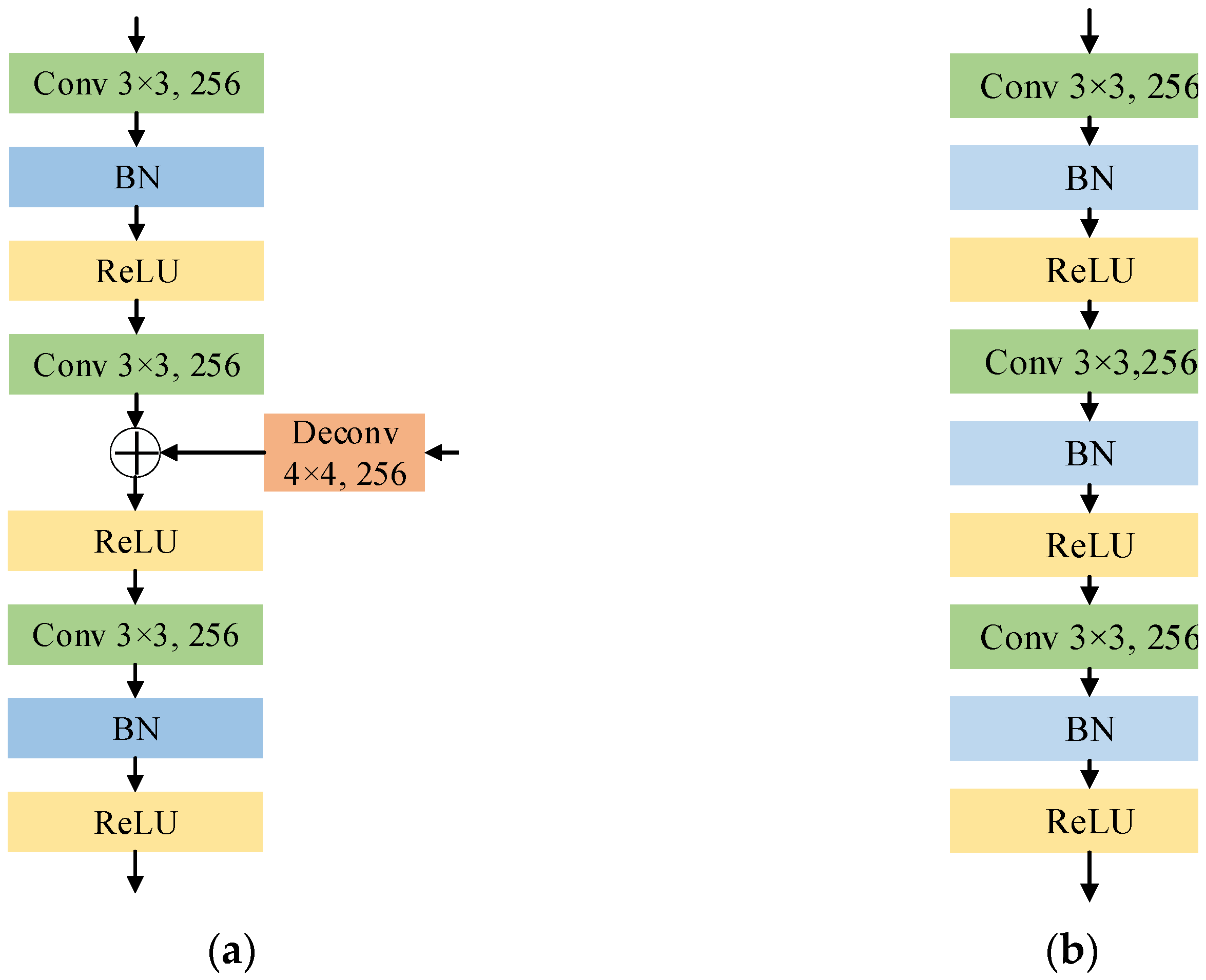
3.4. RFB and Dilated Convolution
3.5. Loss Function
4. Experimental Results and Analysis
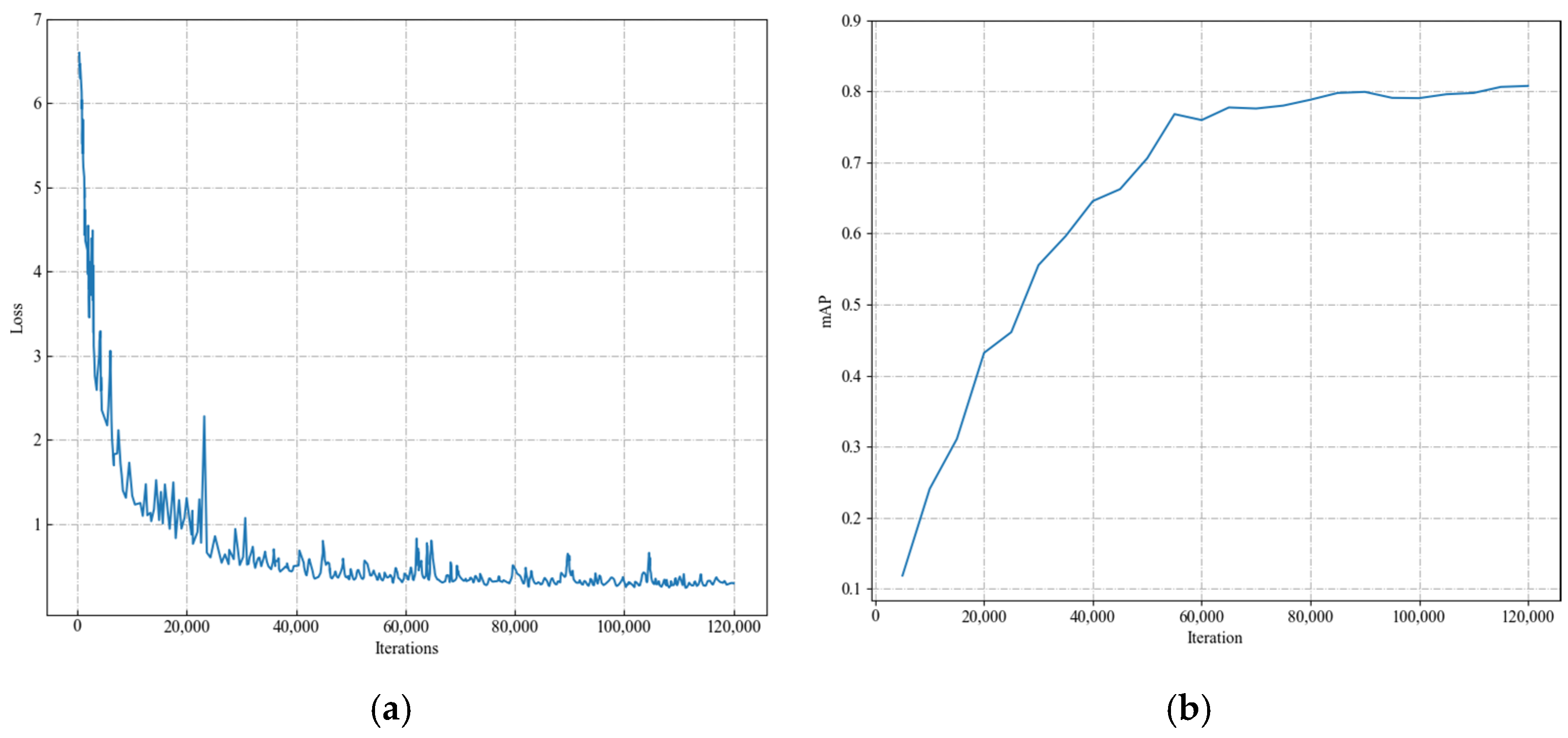
4.1. Experiments on PASCAL VOC
4.2. Category Accuracy
4.3. Comparison of Fusion Methods
4.4. Experiments on COCO
4.5. Ablation Study
4.6. Experimental Effect Display
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, J.; Liang, X.; Shen, S.; Xu, T.; Feng, J.; Yan, S. Scale-aware Fast R-CNN for Pedestrian Detection. IEEE Trans. Multimedia 2017, 20, 985–996. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, J.; Wang, X.; Dolan, J.M. Road-segmentation based curb detection method for self-driving via a 3d-lidar sensor. IEEE Trans. Intell. Transp. Syst. 2018, 19, 3981–3991. [Google Scholar] [CrossRef]
- Haller, P.; Genge, B.; Duka, A. On the practical integration of anomaly detection techniques in industrial control applications. Int. J. Crit. Infrastruct. Prot. 2019, 24, 48–68. [Google Scholar] [CrossRef]
- Qu, Z.; Cao, C.; Liu, L.; Zhou, D.-Y. A Deeply Supervised Convolutional Neural Network for Pavement Crack Detection With Multiscale Feature Fusion. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 4890–4899. [Google Scholar] [CrossRef] [PubMed]
- Qu, Z.; Li, J.; Bao, K.-H.; Si, Z.-C. An Unordered Image Stitching Method Based on Binary Tree and Estimated Overlapping Area. IEEE Trans. Image Process. 2020, 29, 6734–6744. [Google Scholar] [CrossRef] [PubMed]
- Azimi, S.M.; Fischer, P.; Korner, M.; Reinartz, P. Aerial lanenet: Lane-marking semantic segmentation in aerial imagery using wavelet enhanced cost-sensitive symmetric fully convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2920–2938. [Google Scholar] [CrossRef]
- Chabanne, H.; Danger, J.; Guiga, L.; Kühne, U. Side channel attacks for architecture extraction of neural networks. CAAI Trans. Intell. Technol. 2021, 6, 3–16. [Google Scholar] [CrossRef]
- Yang, J.; Xing, D.; Hu, Z.; Yao, T. A two-branch network with pyramid-based local and spatial attention global feature learning for vehicle re-identification. CAAI Trans. Intell. Technol. 2021, 6, 46–54. [Google Scholar] [CrossRef]
- Qu, Z.; Shang, X.; Xia, S.; Yi, T.; Zhou, D. A method of single-shot target detection with multi-scale feature fusion and feature enhancement. IET Image Process. 2022, 16, 1752–1763. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 142–158. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–15 June 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.K.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–15 June 2015; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Fu, C.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 958–969. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Li, Z.; Zhou, F. Fssd: Feature fusion single shot multibox detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 752–762. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolo9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolo v3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lin, T.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; pp. 936–944. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seoul, Korea, 27 October–2 November 2019; pp. 1971–1980. [Google Scholar]
- Fan, J.; Bocus, J.; Hosking, B.; Wu, R.; Liu, Y.; Vityazev, S.; Fan, R. Multi-Scale Feature Fusion: Learning Better Semantic Segmentation for Road Pothole Detection. In Proceedings of the 2021 IEEE International Conference on Autonomous Systems (ICAS), Montréal, QC, Canada, 11–13 August 2021. [Google Scholar]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 354–370. [Google Scholar]
- Huang, L.; Chen, C.; Yun, J.; Sun, Y.; Tian, J.; Hao, Z.; Yu, H.; Ma, H. Multi-Scale Feature Fusion Convolutional Neural Network for Indoor Small Target Detection. Front. Neurorobot. 2022, 16, 881021. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D.; Wang, Y. Receptive Field Block Net for Accurate and Fast Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar]
- Shao, Z.; Cai, J. Remote sensing image fusion with deep convolutional neural network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1656–1669. [Google Scholar] [CrossRef]
- Zhang, M.; Li, W.; Du, Q.; Gao, L.; Zhang, B. Feature Extraction for Classification of Hyperspectral and LiDAR Data Using Patch-to-Patch CNN. IEEE Trans. Cybern. 2018, 50, 100–111. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Xiao, T.; Jiang, Y.; Shao, S.; Sun, J.; Shen, C. Repulsion loss: Detecting pedestrians in a crowd. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7774–7783. [Google Scholar]
- Qu, Z.; Gao, L.-Y.; Wang, S.-Y.; Yin, H.-N.; Yi, T.-M. An improved YOLOv5 method for large objects detection with multi-scale feature cross-layer fusion network. Image Vis. Comput. 2022, 125, 104518. [Google Scholar] [CrossRef]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region based fully convolutional networks. In Proceedings of the Advances Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Hong-yuan, M.L. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.09460. [Google Scholar]
- Jocher, G. Yolov5. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 26 June 2020).
- Zhu, R.; Zhang, S.; Wang, X.; Wen, L.; Mei, T. Scratchdet: Training single-shot object detectors from scratch. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2263–2272. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Doll’ar, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | Train | Input Size | mAP (%) | FPS |
|---|---|---|---|---|---|
| Faster RCNN [13] | ResNet-101 | VOC 2007 + 2012 | 600 × 1000 | 76.4 | 5 |
| R-FCN [35] | ResNet-101 | VOC 2007 + 2012 | 600 × 1000 | 80.5 | 9 |
| YOLO [14] | GoogleNet-9 | VOC 2007 + 2012 | 448 × 448 | 63.4 | 45 |
| YOLOv2 [19] | Darknet-19 | VOC 2007 + 2012 | 544 × 544 | 78.6 | 40 |
| YOLOv3 [20] | Darknet-53 | VOC 2007 + 2012 | 640 × 640 | 78.3 | - |
| YOLOv4 [36] | Darknet-53 | VOC 2007 + 2012 | 640 × 640 | 84.3 | - |
| YOLOv5_S [37] | Darknet-53 | VOC 2007 + 2012 | 640 × 640 | 81.9 | - |
| SSD300 [15] | VGGNet-16 | VOC 2007 + 2012 | 300 × 300 | 77.2 | 46 |
| DSSD321 [16] | ResNet-101 | VOC 2007 + 2012 | 321 × 321 | 78.6 | 9.5 |
| FSSD300 [18] | VGGNet-16 | VOC 2007 + 2012 | 300 × 300 | 78.8 | - |
| ScratchDet300 [38] | Root-ResNet-34 | VOC 2007 + 2012 | 300 × 300 | 80.4 | 17.8 |
| OURS | VGGNet-16 | VOC 2007 + 2012 | 300 × 300 | 80.7 | 26 |
| Method | SSD | Faster RCNN | DSSD | YOLO | Proposed |
|---|---|---|---|---|---|
| model | VGG16 | ResNet | ResNet | GoogleNet-9 | VGG16 |
| mAP (%) | 77.5 | 76.4 | 78.6 | 63.4 | 80.7 |
| aero | 79.5 | 79.8 | 81.9 | 79 | 89.4 |
| bike | 83.9 | 80.7 | 84.9 | 74.3 | 86.7 |
| bird | 76.0 | 76.2 | 80.5 | 62.5 | 81.7 |
| boat | 69.6 | 68.3 | 68.4 | 42.6 | 72.9 |
| bottle | 50.5 | 55.9 | 53.9 | 42.5 | 65.3 |
| bus | 87.0 | 85.1 | 85.6 | 68.3 | 87.2 |
| car | 85.7 | 85.3 | 86.2 | 62.1 | 88.2 |
| cat | 88.1 | 89.8 | 88.9 | 81.4 | 91.1 |
| chair | 60.3 | 56.7 | 61.1 | 42.3 | 62.5 |
| person | 79.4 | 78.4 | 79.7 | 63.5 | 87.7 |
| plant | 52.3 | 41.7 | 51.7 | 41.6 | 55.2 |
| sheep | 77.9 | 78.6 | 78.0 | 65.2 | 78.7 |
| sofa | 79.5 | 79.8 | 80.9 | 54.8 | 78.9 |
| train | 87.6 | 85.3 | 87.2 | 74.9 | 88.2 |
| tv | 76.8 | 72.0 | 79.4 | 62.5 | 79.2 |
| Layers | Fusion Method | mAP (%) |
|---|---|---|
| Conv4_3 | concatenate | 79.3 |
| Conv4_3 + Conv3_3 | concatenate | 79.5 |
| Conv4_3 + Conv6 | concatenate | 80.3 |
| Conv3_3 + Conv4_3 + Conv5_3 | concatenate | 80.4 |
| Conv4_3 + Conv5_3 | concatenate | 80.7 |
| Conv4_3 + Conv5_3 | elementsum | 80.5 |
| Method | Backbone | Train Data | Test Data | mAP@0.5 (%) | FPS |
|---|---|---|---|---|---|
| Faster RCNN [13] | ResNet-101-FPN | COCO 2017 trainval | COCO 2017 test-dev | 58.0 | - |
| SSD300 [15] | VGGNet-16 | COCO 2017 trainval | COCO 2017 test-dev | 41.2 | 46 |
| SSD512 [15] | VGGNet-16 | COCO 2017 trainval | COCO 2017 test-dev | 50.4 | 8 |
| DSSD321 [16] | ResNet-101 | COCO 2017 trainval | COCO 2017 test-dev | 46.1 | 12 |
| RetinaNet [39] | ResNet-101 | COCO 2017 trainval | COCO 2017 test-dev | 49.5 | 11.6 |
| OURS | VGGNet-16 | COCO 2017 trainval | COCO 2017 test-dev | 50.8 | 23 |
| Method | Backbone | Fusion | GC Block | RFB | mAP (%) |
|---|---|---|---|---|---|
| SSD | VGG16 | 77.5 | |||
| SSD | VGG16 | √ | 78.6 | ||
| SSD | VGG16 | √ | 80.1 | ||
| SSD | VGG16 | √ | 79.2 | ||
| SSD | VGG16 | √ | √ | √ | 80.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qu, Z.; Han, T.; Yi, T. MFFAMM: A Small Object Detection with Multi-Scale Feature Fusion and Attention Mechanism Module. Appl. Sci. 2022, 12, 8940. https://doi.org/10.3390/app12188940
Qu Z, Han T, Yi T. MFFAMM: A Small Object Detection with Multi-Scale Feature Fusion and Attention Mechanism Module. Applied Sciences. 2022; 12(18):8940. https://doi.org/10.3390/app12188940
Chicago/Turabian StyleQu, Zhong, Tongqiang Han, and Tuming Yi. 2022. "MFFAMM: A Small Object Detection with Multi-Scale Feature Fusion and Attention Mechanism Module" Applied Sciences 12, no. 18: 8940. https://doi.org/10.3390/app12188940
APA StyleQu, Z., Han, T., & Yi, T. (2022). MFFAMM: A Small Object Detection with Multi-Scale Feature Fusion and Attention Mechanism Module. Applied Sciences, 12(18), 8940. https://doi.org/10.3390/app12188940