1. Introduction
With an increase in the volume of transmitted information and speed and reliability, the task arises of an effective method for reducing the volume of transmitted data, mainly using lossless data compression methods. Various lossless compression algorithms are widely used in areas such as medicine [
1], industrial [
2], the Internet of Things (IoT) [
3], databases [
4], cloud computing [
5], especially communication networks [
6], and space data system [
7].
Finding an effective data compression algorithm for any application remains relevant [
8]. Modern lossless data compression methods combine entropy coding and general-purpose compression techniques. For example, the main algorithms of universal compressions, such as LZ77/78 (Lempel–Ziv coding 1977/1978), LZW (Lempel–Ziv–Welch), and LZMA (Lempel–Ziv–Markov chain algorithm), are based on a dictionary, zip (LZ77 + Huffman), gzip (LZ77 + Huffman), 7-zip (LZMA + arithmetic coding) and bzip2 (block sorting + Move-to-Front + Huffman) [
9,
10]. Also used is LZSS [
10,
11], which optimizes matching operations in the look-up table to assign fewer bits for compressed data than LZ77 [
12,
13,
14].
One of the main compression methods is the class of statistical compression methods since their implementation requires knowledge only of the probability distribution of compressed messages. They are mainly intended for communication systems and are quite versatile for them. Their main disadvantage is the need for statistical data. In parallel with statistical methods, other compression methods are being developed that, as a rule, are of a special nature and do not require direct statistical tests. One such method is the numbering method, which usually compresses mathematical objects such as permutations or combinations. Their use is applicable in information security and error protection systems. In [
15], for the need to improve health information systems for health monitoring, lossless electroencephalogram (EEG) data compression is applicable [
16], and proposed a lossy EEG compression model based on fractals for network traffic. manifest the advantage of this method. In [
17], a simpler alternative to arithmetic coding is presented. The advantage of this method is its simplicity and the possibility of using it for simultaneous data encryption or as a block of cryptosystems. The disadvantage of this method is that it requires the creation and storage of encoding tables and decoding. In [
18], a mathematical model of the method of compression of equilibrium combinations based on binary binomial numbers and a mathematical model of generalized binomial compression of binary sequences are shown, but this method is not adaptive. Meanwhile, ref. [
19] presents a mathematical model for compressing binary sequences by binomial numbers.
This paper proposes a universal adaptive method for compressing binary sequences of unlimited length n without losing information. The code length of the original binary sequence n will be greater than the length of the number m, which determines the compression effect. Its value is determined by the length difference between the original code length n of the binary sequence and the compressed length m. The more significant this difference, the greater the compression effect. It will take the largest value in the case when the original binary sequence consists of either only zeros (k = 0) or only ones (k = n), and the smallest value when k = n/2. In the first case, the compression effect will be determined only by the number of bits required to transmit the value k, which is always less than n. In this case, the compressed binary sequence number is not transmitted.
Therefore, this case will be the most favorable for compression. In practice, it occurs, for example, in television binary images, where there are empty or completely dark lines. In the second case, when k = n/2, the code length of the number m approximately coincides with the code length of n. Accordingly, when transmitting the values m and n, instead of compressing the binary sequence, its lengthening will be observed due to redundant coding since the transmission of the length of the compressed number m is also added to the transmission of the length of the binary number for the number of units k. In all other cases of compression of binary sequences most often encountered in practice, the inequality n > k > 0 takes place.
This inequality allows the compression to be adapted to its required speed. A restriction is introduced on the value of k, the excess of which prohibits the compression of binary sequences. Changing this value reduces or increases the information transfer rate due to the compression ratio. The possibility of such regulation is the effect of the adaptability of the proposed compression method. When restrictions generally prohibit the compression of a number of binary sequences, it is possible to increase their noise immunity by transmitting only the k value to the receiver during compression.
The compression effect of the proposed method depends on the probabilities of the distribution of the number of units in the compressed binary code sequences. The greater the likelihood of sequences with a number of ones different from k = n/2, the greater this effect will be. However, it cannot exceed the bounds given by Shannon’s equation for the entropy of binary sequences. Therefore, this method is comparable in terms of compression efficiency with existing lossless information compression methods. Its main advantage over them is the ability to change the compression efficiency depending on the requirements for its performance. Another essential property of this binomial compression method is it increases the noise immunity of a part of transmitted binary messages. In addition, using the binomial number system in this compression method makes it possible to effectively implement it in hardware while increasing data compressions speed, reliability, and noise immunity.
A distinctive feature of the proposed method for compressing binary sequences of finite length n is their numbering using the binomial number system (BNS). In addition, the method allows the compression ratio K to be adapted to its required speed and error detection. Adaptation manifests itself in the fact that for each compressed sequence, the compression coefficient K is preliminarily determined, and, depending on its value and the requirements for speed and error detection, a decision is made whether or not to perform the compression operation. As a result, only those sequences are compressed for which the compression coefficients K are more significant than the specified value. The remaining possible sequences are transmitted or stored in their original form. Using the binomial number system and binomial numbers in the method makes it possible to implement it in hardware. The availability of keys for each compressed sequence can be used in systems to protect information from unauthorized access.
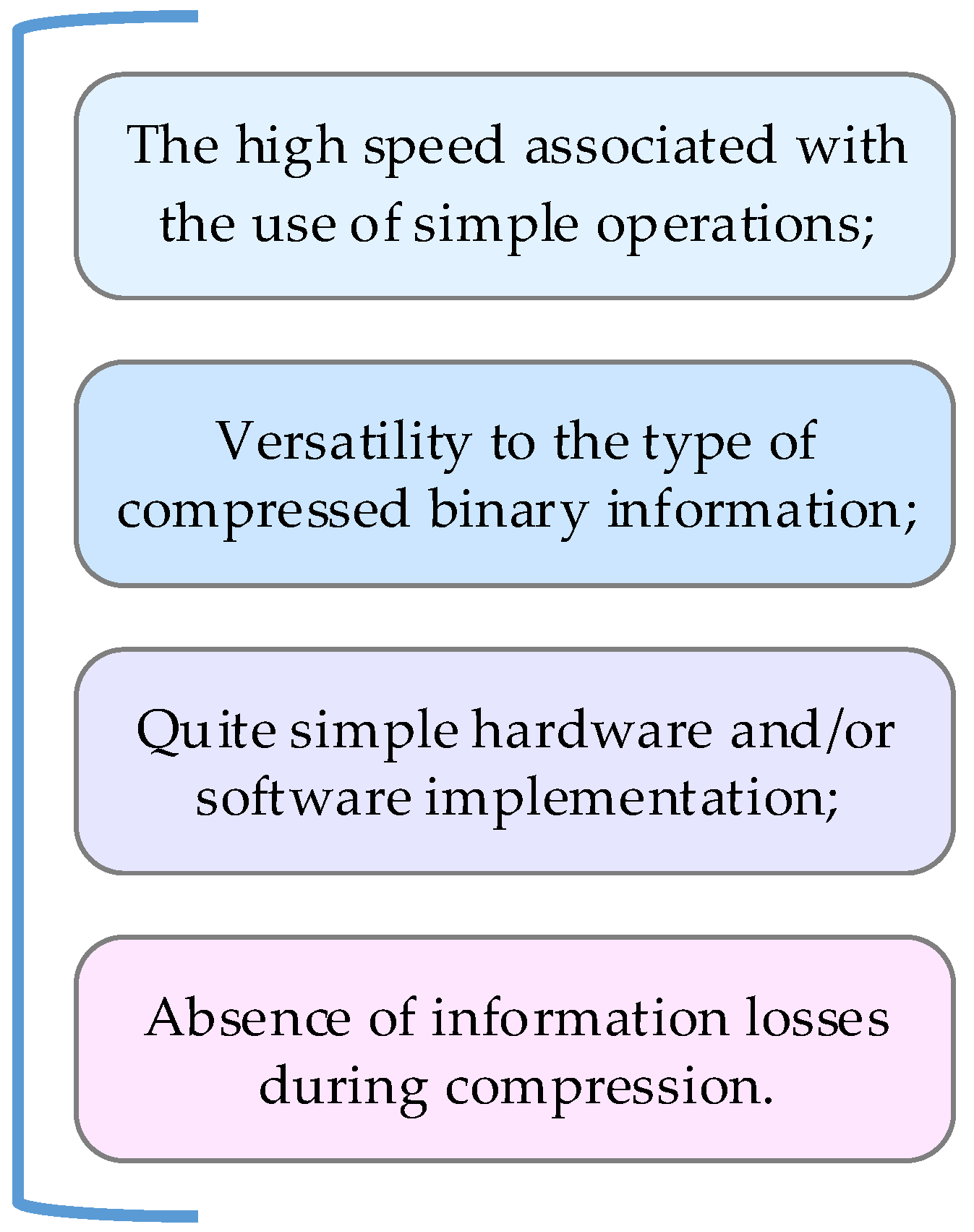
The rationale for developing methods for compressing information based on binary binomial numbers generated by binomial number systems is:
(1) The non-uniformity of binomial numbers whose length r is less than the length n of the original compressible code combinations, which provides a compression coefficient more significant than one;
(2) The functionality of correspondences between sets of binary binomial numbers and combination codes and provides one-to-one coding and decoding;
(3) The prefix of binary binomial numbers, which allows, without additional hardware (and/or software) and time costs for separators, compression coding, and restoration of binary sequences;
(4) Prevalence of code combinations based on binomial numbers (for example, equilibrium and quasi-equilibrium codes, combinations with restrictions on mutual arrangement of zeros and units, etc.) for data presentation in information-control systems.
The method of compressing data based on binary binomial numbers has properties shown in
Figure 1:
In addition, an essential advantage of the method is that compressed sequences are endowed with numerical characteristics that are expressed by their corresponding binomial numbers. Thus, information is compressed without loss, adapting to speed and error detection.
The paper is structured as follows.
Section 2 describes the general analysis of the binomial adaptive compression method.
Section 2.1 describes the binomial decomposition of information sources, while
Section 2.2 describes the analysis of the proposed compression method.
Section 3 describes the lossless adaptive data compression method based on the binomial number system (BNS).
Section 3.1 describes the data compression method with BNS, and
Section 3.2 describes the methods for converting binomial code to binary.
Section 3.3 describes the methods for converting binary sequences to binomial code and vice versa. Theoretical aspects of the lossless adaptive binomial data compression method are described in
Section 4. Finally, we conclude this paper in
Section 5.
2. General Analysis of the Binomial Adaptive Compression Method
2.1. The Binomial Decomposition of Information Sources
The lossless binomial adaptive compression of binary sequences of length
n proposed by the authors is based on the binomial information compression they developed based on the theorem on the decomposition of Bernoulli sources of information [
20]. The theorem proves that the Bernoulli source of probabilistic binary sequences
A* decomposes into two sources, one of which is a combinatorial source
A with conditional entropy
, generating equally probable binary sequences of different code lengths, and another probabilistic source of information
B with entropy
, generating quantities of
k number of units 0, 1, …,
n in these sequences.
Probabilities determine the probabilities of occurrence of these quantities. It is proved that the sum of the entropies (entropy of the union) of the sources A and B are equal to the entropy original source of binary sequences A*, where —source generation probability A* of jth binary code combination.
The Bernoulli information source entropy equation is decomposed into two entropies. They provide the basis for new compression methods, one of which is discussed in this article. The entropy decomposition equations show that the Shannon–Fano and Huffman statistical methods of optimal coding can be effectively replaced by numerical coding methods that do not require preliminary statistical tests for their implementation. In this case, the compression efficiency in practice is not less than in statistical methods of optimal coding. With that compression occurring with zero errors in statistics, it is even higher. This idea underlies the compression method [
20] previously presented by the authors, which was carried out using binomial numbers [
21,
22,
23]. However, compression occurs for different binary sequences with different efficiencies. The difference here depends on the probability distribution of generating compressible sequences.
To eliminate the time spent on compression, it was proposed to abandon the compression of inefficiently compressible sequences. As a result, practically without reducing the compression efficiency, it was possible to reduce the compression time several times while increasing its noise immunity. However, this process requires the authors’ dynamic control system called adaptive coding. The solution to the problem of improving efficiency proposed by the authors formed the basis of this paper. The binomial compression method itself, without adaptation, has long been studied by the authors and has shown its practical performance. This adaptive compression method development has been proposed for the first time for publication. The authors also developed a program that confirms the practical performance of the adaptive compression method. In any case, the efficiency of the proposed adaptive compression method is higher than without adaptation.
2.2. Analysis of the Proposed Compression Method
The considered compression method belongs to the class of numbering compression methods and does not require preliminary statistical tests, which is its advantage. Compared with other numbering compression methods, it is versatile and dynamic, expressed in adaptation to the source of information, reducing the compression time. As a result, the compression ratio increases, and the cost of the equipment implementing the method becomes cheaper. In addition, the method allows for detecting errors, thereby improving the noise immunity of compression. The method also includes the ability to protect information from unauthorized access.
The compression methods proposed above in the introduction, which have a high compression ratio and speed, are primarily specialized. Universal methods, especially those requiring statistical studies, are less fast. At the same time, both methods, during compression, reduce the noise immunity of the compressed information by eliminating redundancy. It is possible to eliminate the shortcomings of existing compression methods by solving the task of the optimal adaptive control of the values of their compression ratios, noise immunity, and compression time. The proposed adaptive method is based on the method developed for the universal compression of binary sequences based on binomial numbers. The universality of the proposed method of adaptive binomial compression is explained by the fact that it compresses binary sequences. Moving from binary sequences to processing symbolic, graphic, and more complex information is relatively easy. In addition, many messages and images themselves are represented as binary sequences. These include television binary images, graphics, and symbols.
However, the binomial compression method compressed all binary sequences without exception, significantly increasing the compression time since many of the binary sequences gave almost zero compression ratio or even negative. In this paper, we propose to solve this task using adaptive selective compression of binary sequences, in which inefficient sequences are not compressed. Accordingly, the task of this paper is to develop a universal binomial information compression method that does not require preliminary statistical tests, adaptively optimally regulating the value of the compression ratio, time, and noise immunity. This paper is research; therefore, it does not provide information on the practical application of results. The reliability of the obtained scientific results was verified experimentally on computer models and in separate works on the theoretical study of the method. It is easy to check it for specific examples in manual mode without additional calculations by the method proposed in the paper.
Practical applications of the proposed adaptive binomial compression method are most effective in mobile communication systems operating under interference. This method also can compress texts, graphics, and images. In this case, the longer the compressed binary block, the more efficient the compression. This method can be especially effective in hardware implementation. In terms of speed, compression ratio, and noise immunity, the method, under certain conditions, can significantly surpass the known compression methods. The peculiarity of the method is its adaptability, which means obtaining maximum efficiency under the conditions of changing probabilities of generated binary sequences. It can give a gain in performance and a loss in the compression ratio and vice versa, giving the most significant overall effect. Therefore, its comparison with conventional compression methods is not correct. To date, adaptive binomial methods in compression systems were first proposed by the authors.
The disadvantage of the method is the complexity of implementation and lack of universality. Changing the probabilities requires changing the adaptive properties of the method, which complicates its structure. Many compression problems do not obey the binomial probability distribution and have forbidden sequences and other restrictions. The inability to take them into account in the method under consideration reduces the degree of compression and the versatility of its application. Additionally, converting binomial numbers to binary numbers and vice versa is a time-consuming procedure that requires a reduction in conversion time.
4. Theoretical Aspects of the Lossless Adaptive Binomial Data Compression Method
Following the above-explained compression method, any binary sequence for which the number of units
k is known is converted into a combination of an equilibrium code with
combinations. Since
k can vary from 0 to
n, the number of possible equilibrium codes will equal
n + 1, and each of them will have the same value of the number of units in their combinations
k = 0, 1, 2, …,
n. Accordingly, the number of equilibrium combinations is equal to
. Together they form a binary code with a total number of combinations of code length
n equal to:
If we assume that compressible sequences are equally probable, then the equilibrium combinations corresponding to them will be the same in length. Then the average amount of information transmitted by one equilibrium combination is
It is impossible to compress information without losing it in such a case. For binary messages to be compressed, different probabilities must characterize them
. Then, the amount of data transmitted by one binary sequence from the information source is determined by the Shannon equation:
The difference
determines the information redundancy of this source and, accordingly, the maximum possible compression ratio of the information transmitted:
Obviously, in the case of compression, only a part of the possible sequences from the number 2n the compression ratio K decreases. Still, this decrease will be insignificant if only sequences with a value of k close to n/2 are excluded from the compression procedure. However, the overall compression speed will increase significantly. Thus, it becomes possible to adjust it adaptively by changing the compression ratio. Since k must be determined for all sequences, its presence makes it possible to increase the noise immunity of uncompressed sequences and, accordingly, to detect errors in them. This means that changing the compression ratio makes it possible to optimally adjust the compression rate and the noise immunity of the compressed sequences.
This compression method requires prior knowledge of the statistics of transmitted messages, unlike, for example, the Shannon-Fano or Huffman statistical compression method, since it is automatically determined during the compression process, and with the highest possible accuracy, by analyzing the value of
k for each compressible sequence. The same
k also determines the compression ratio (10), taken for each binary sequence
Expression
is the amount of information in bits contained in the compressed sequence number with
k ones. This information should be supplemented with information
about the value of
k. Then the amount of data after compression equal to
Accordingly, the compression ratio of the compressed sequence:
For
k = 0 and
k =
n—compression ratio
reaches its maximum.
The most significant value of the compression ratio is observed. So, for example, with the compression ratio and with , . At the same time, the compression coefficient reaches its minimum since the binomial coefficient takes the highest value in this case. Therefore, in such a case, the compression of the equilibrium combination should be eliminated by transmitting it in its original form, which increases its average transmission compression speed. At the same time, q value information can be used k to improve the noise immunity of the transmitted equilibrium combination. In this case, comparing k with the number of units in the transmitted equilibrium combination determines its correctness.
Table 4 shows examples of compression ratios
K for various
k. The coefficient
k is 1, 2, 16, 32, and 64.
The presence of information about the number of units k, transmitted separately from the compressed binary sequence, allows it to be used as a key, without which it is impossible to restore the original sequence. Therefore, it can be used to protect a compressed sequence. The key k can, in principle, be obtained by iterating its values, changing them from 0 to n. However, this overkill still requires the expenditure of computing power and the corresponding program. Therefore, such a search can be used to protect confidential information that is not of particular importance or is rapidly losing its value.
However, embedding this compression method into an information protection system from unauthorized access can significantly increase its resistance since the general enumeration of the protection system keys becomes more complicated. For each possible key from k of the compression system, the possible keys of the security system are sorted out, and only after that, in the absence of decryption, does the transition to a new possible key from k occur.
In the worst case, the result is manifested in the need to enumerate the product of all possible keys k by the number of possible keys of the protected system. The use of binomial adaptive compression makes it possible to protect particular sequences from opening, and not all, as with conventional compression, which makes it possible to find the optimal ratio of protected and unprotected sequences from the point of view of the compression rate criterion.




 ,
, 




{kind=link}
{kind=link}
{kind=link}