
A Blockchain-Based Trust Model for Uploading Illegal Data Identification
Abstract
:1. Introduction
- This paper proposes a trust model for uploading illegal data identification. The identification blockchain identifies the data by decentralized voting. Only when the number of votes exceeds the specified number will the identification blockchain consider the data as illegal data. The identification nodes can obtain benefits through the identification service. In order to obtain a higher income, they must identify the data fairly.
- This paper designs a reputation-based random selection algorithm. The identification blockchain generates identification nodes by the reputation-based random selection algorithm. The algorithm tends to nodes with high reputation values. The seed is hashed by node total reputation value, block height, and timestamp. Each time you select an identification node, the seeds are hashed again. Ensure the randomness and credibility of the identification nodes.
- This paper analyzes the model with game theory and proposes an incentive mechanism based on the results. This paper conducted a game theory analysis among the identification nodes. In order to obtain higher income, the identification nodes must honestly identify the data. According to the analysis, this paper designs an incentive mechanism for identification nodes. The incentive mechanism can punish or reward the identification nodes, which can encourage identification nodes to identify data fairly and impartially, thereby improving the credibility of the model.
2. Related Work
3. Trust Model for Uploading Illegal Data Identification
3.1. Symbols Involved in The Trust Model
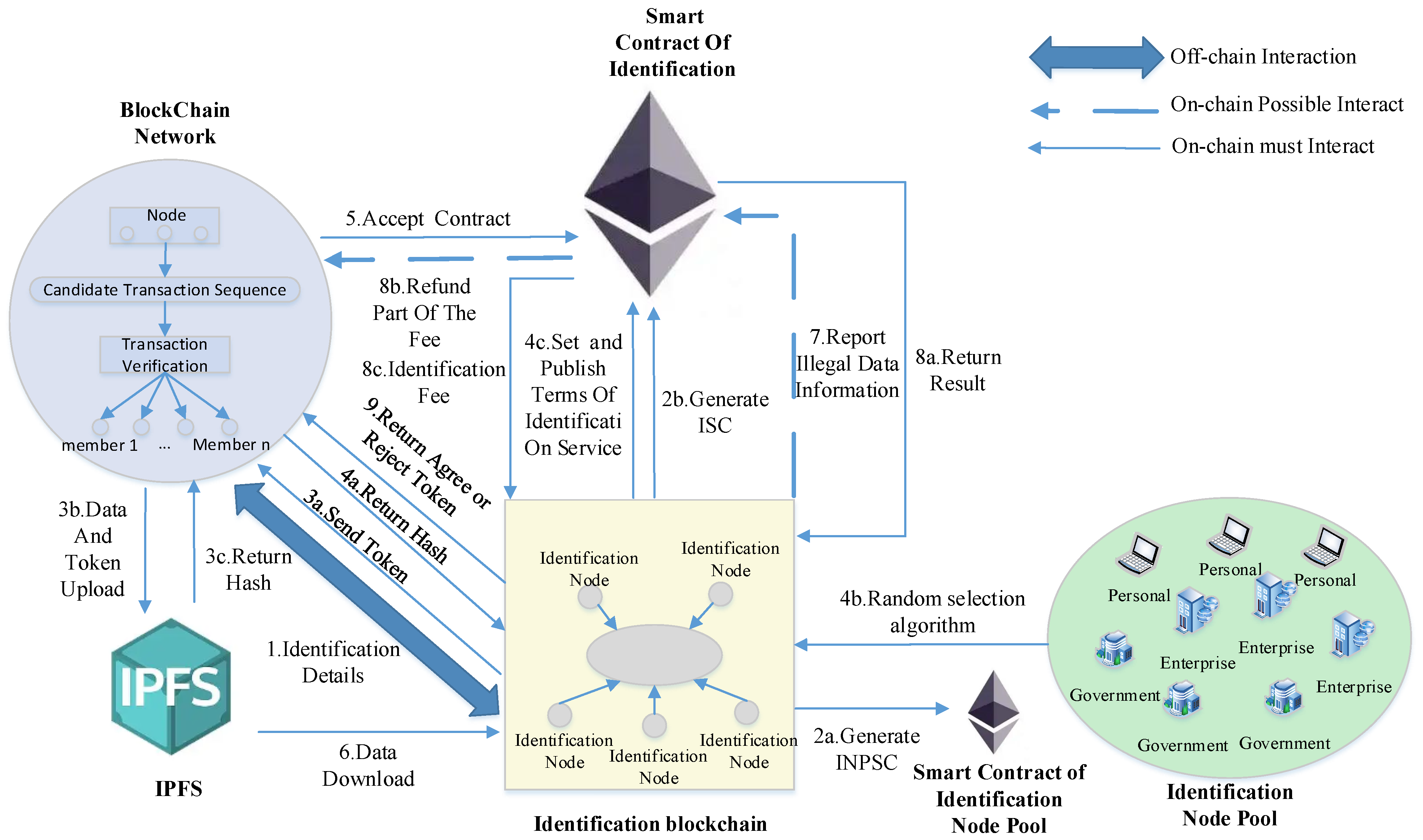
3.2. Scheme Architecture
4. Key Technology
4.1. The Detailed Design of RBRSA
| Algorithm 1 Reputation-Based Random Selection Algorithm() |
| Input: A set of Registered NN, NNAddrs, a list of addresses; Required number, Number, of members in a IN committee; The address of the IDBC; The address of the IBC; Output: Selected Number IN to form a committee, INC; 1: assert (NNAddrs.length > 10*N) & assert (curBlockNum != 0); 2: Seed←0, Trust←0; 3: for i = 0; i<NNAddrs.length && NN.state = WState.online; i++ do Trust += NN.Trust; end for Hash =Hash(Trust, timestamp, height); for node = 0; node < Number; node++ do Seed = Hash % Trust; reputation ← 0; for n = 0; n<NNAddrs.length && NN != IBC && NN != IDBC && NN.state ==WState.online; n++ do if InPool[NNAddrs[n]].state != WState.NNtoIN then reputation = reputation + NN.Trust; if Seed < reputation then NN.state = WState.NNtoIN; NN.confirmDeadline = now+ 5 minutes; NN.IdentificationContract = sender; onlineCounter--; Trust -= NN.Trust; INC←NN; Break; end if end if end for Hash = Hash(Seed, timestamp); end for return INC; |
4.2. Incentive Mechanism and Nash Equilibrium
- , where
- , where
4.3. The Analysis of the INs Uncertainty Behavior
- Malicious Behavior: Because nodes are selfish, some INs may engage in malicious behavior for their benefit. INs incorrectly identify data when facing benefits, leading to a decrease in the credibility of the model.
- Credible Behavior: Because nodes are subjective, some INs still engage in credible behavior when facing benefits. The incentive mechanism in the trust model will reward the nodes that exhibit credible behaviors. The incentive mechanism will improve the reputation of nodes. Nodes with a high reputation will have a higher probability of participating in the identification service, so the nodes will obtain more income.
- Alliance Behavior: Some INs make the same wrong decision together, thus affecting the results of identification. The trust model has an anonymity and selection mechanism. On the one hand, anonymity can ensure that nodes cannot know the identity of other nodes. On the other hand, the nodes selected by RBRSA are random, and the nodes cannot control the results of the selection. Therefore, the model can ensure that the INs are independent.
- Lazy Behavior: The behavior of INs does not actively work, because some INs are lazy when faced with these incentives. Regardless of whether the data information is illegal, INs do not report the data information to IBC. In this way, INs can obtain a low income.
5. Results and Discussion
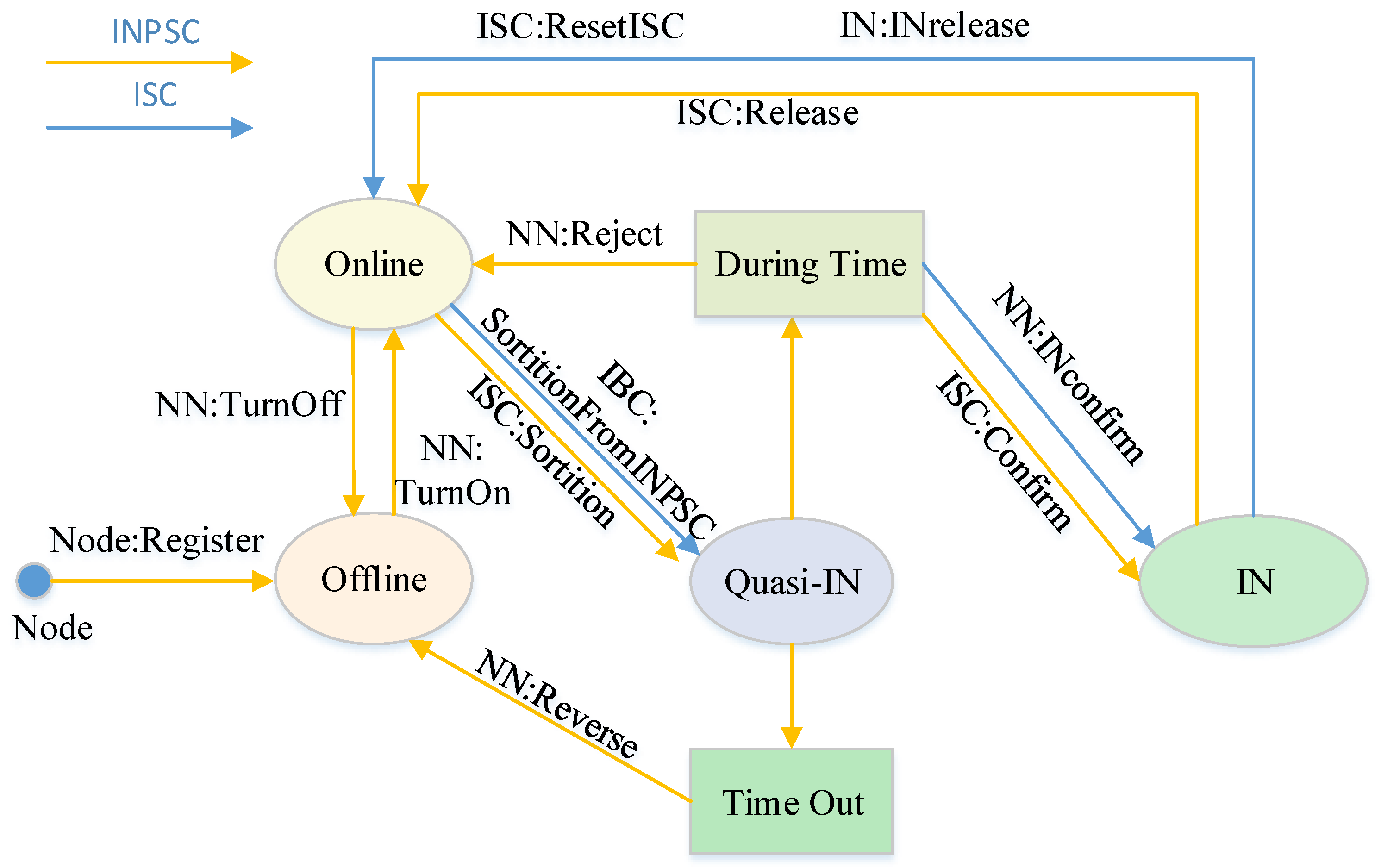
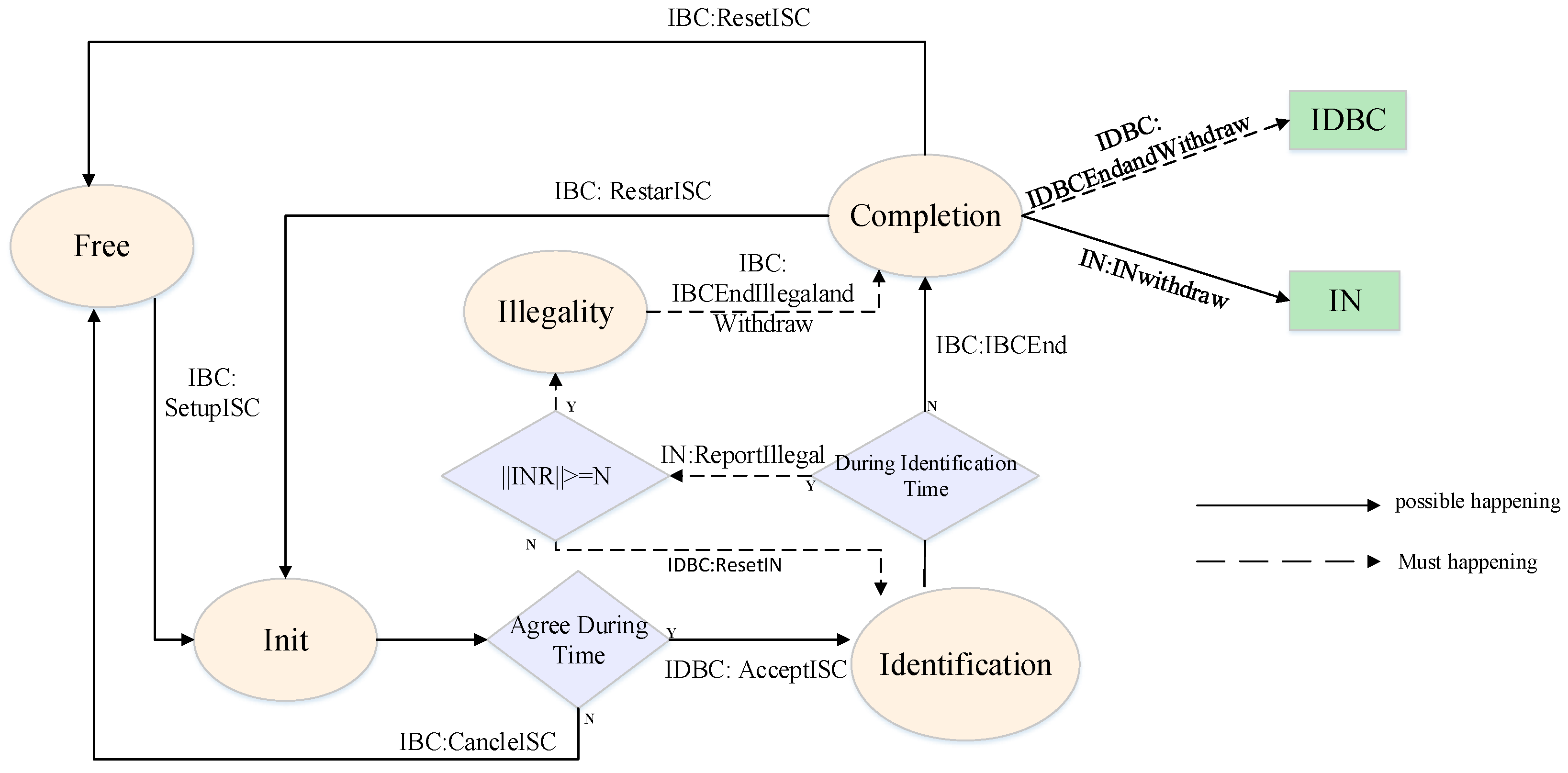
5.1. Implementation of INPSC
5.2. Implementation of ISC
5.3. Trust Model Results and Analysis
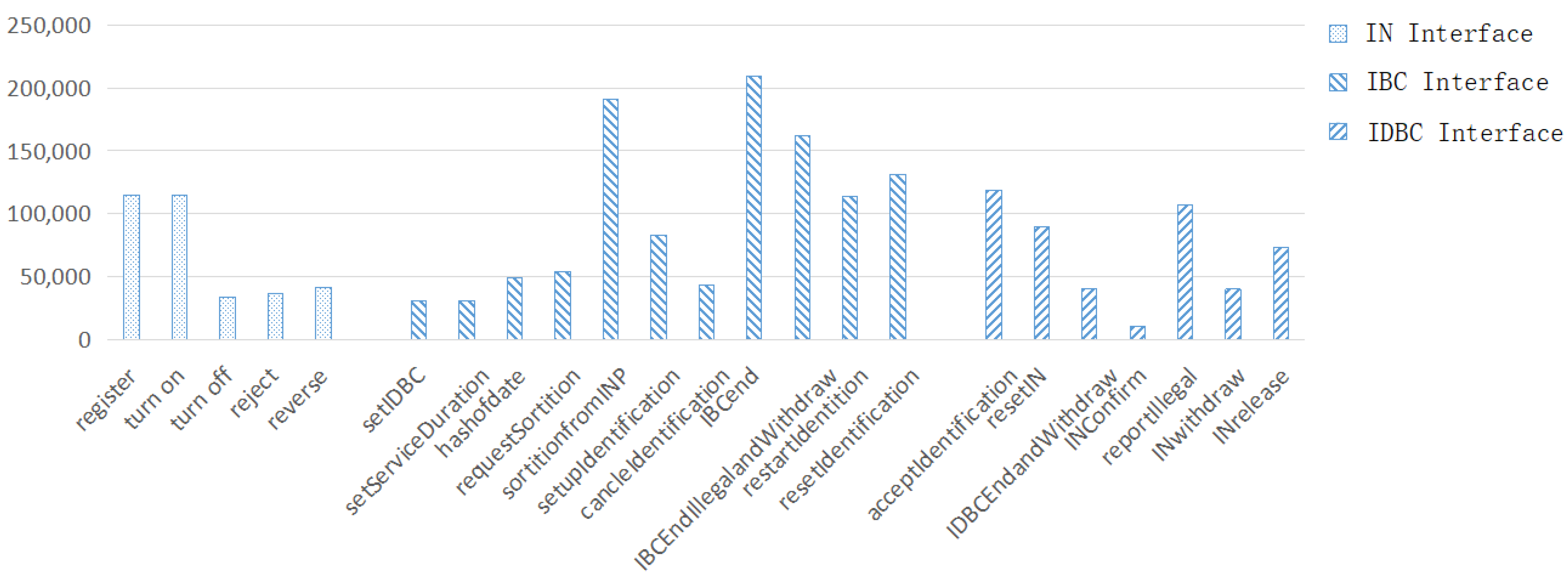
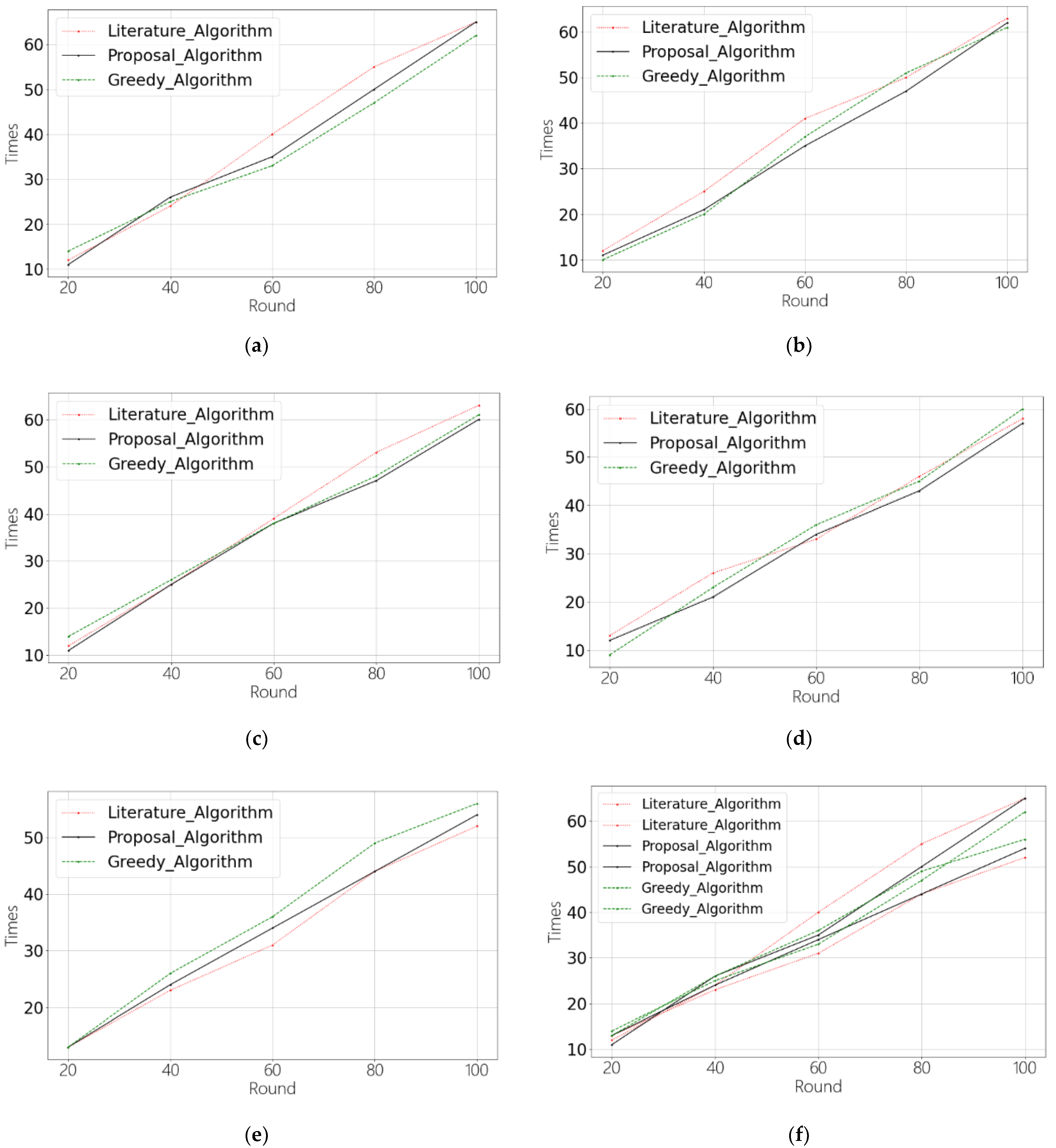
5.4. Algorithm Results and Analysis
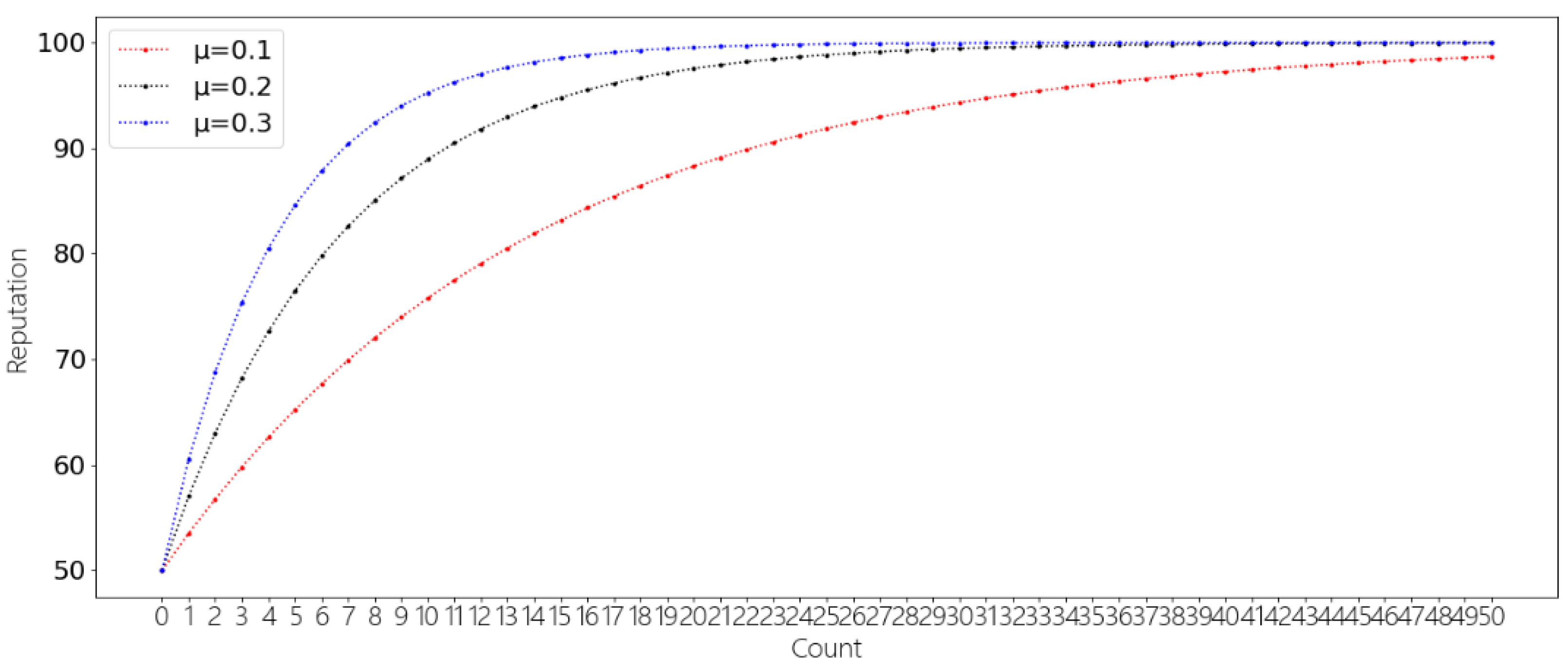
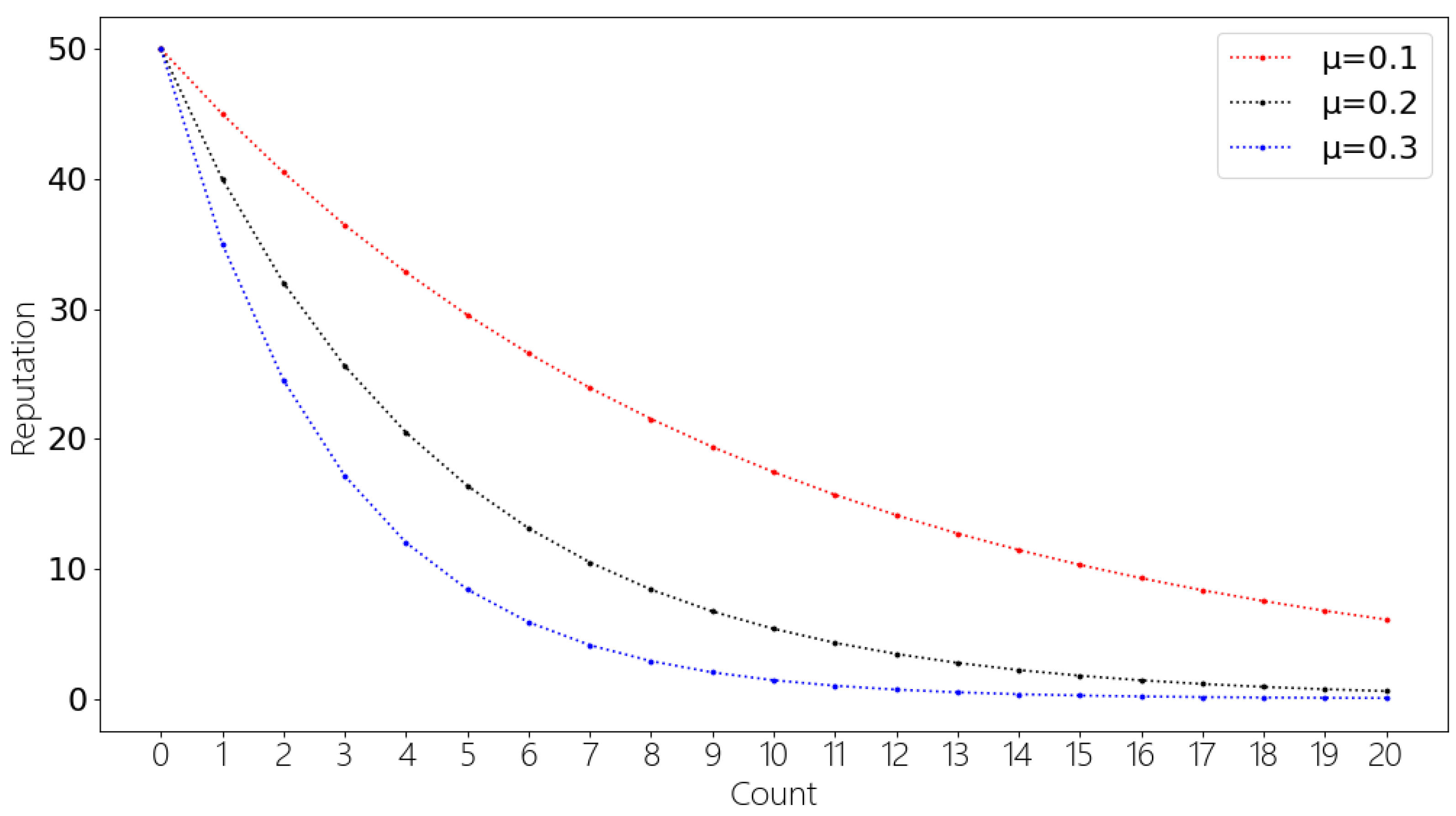
5.5. Incentive Mechanism Results and Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ren, Y.; Guan, H.P.; Zhao, Q.X.; Yi, Z.X. Blockchain-Based Proof of Retrievability Scheme. Secur. Commun. Netw. 2022, 2022, 3186112. [Google Scholar] [CrossRef]
- Mendi, A.F. Blockchain for Food Tracking. Electronics 2022, 11, 2491. [Google Scholar] [CrossRef]
- Hewa, T.; Ylianttila, M.; Liyanage, M. Survey on blockchain based smart contracts: Applications, opportunities and challenges. J. Netw. Comput. Appl. 2021, 177, 102857. [Google Scholar] [CrossRef]
- Lone, A.H.; Naaz, R. Applicability of Blockchain smart contracts in securing Internet and IoT: A systematic literature review. Comput. Sci. Rev. 2021, 39, 100360. [Google Scholar] [CrossRef]
- Kumar, R.L.; Khan, F.; Kadry, S.; Rho, S. A Survey on blockchain for industrial Internet of Things. Alex. Eng. J. 2022, 61, 6001–6022. [Google Scholar] [CrossRef]
- Guo, H.Q.; Yu, X.J. A Survey on Blockchain Technology and its security. Blockchain Res. Appl. 2022, 3, 100067. [Google Scholar] [CrossRef]
- Wang, Y.; Gou, G.P.; Liu, C. Survey of security supervision on blockchain from the perspective of technology. J. Inf. Secur. Appl. 2021, 60, 102859. [Google Scholar] [CrossRef]
- Spagnuolo, M.; Maggi, F.; Zanero, S. Bitiodine: Extracting intelligence from the bitcoin network. In International Conference on Financial Cryptography and Data Security; Springer: Berlin/Heidelberg, Germany, 2014; pp. 457–468. [Google Scholar]
- Matzutt, R.; Hohlfeld, O.; Henze, M.; Rawiel, R.; Ziegeldorf, J.H. Poster: I don’t want that content! on the risks of exploiting bitcoin’s blockchain as a content store. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; Association for Computing Machinery, ACM: New York, NY, USA, 2016; pp. 1769–1771. [Google Scholar]
- Matzutt, R.; Hiller, J.; Henze, M.; Ziegeldorf, J.H.; Mullmann, D.; Hohlfeld, D.; Wehrle, K. A quantitative analysis of the impact of arbitrary blockchain content on bitcoin. In International Conference on Financial Cryptography and Data Security; Springer: Berlin/Heidelberg, Germany, 2018; pp. 420–438. [Google Scholar]
- Goldsmith, D.; Grauer, K.; Shmalo, Y. Analyzing hack subnetworks in the bitcoin transaction graph. Appl. Netw. Sci. 2020, 5, 1–20. [Google Scholar] [CrossRef]
- Reijers, W.; Wuisman, I.; Mannan, M.; Filippi, P.D.; Raelooi, V.; Velez, A.C.; Orgad, L. Now the code runs itself: On-chain and off-chain governance of blockchain technologies. Topoi 2021, 40, 821–831. [Google Scholar] [CrossRef]
- Bitcoin Improvement Proposals. 2021. Available online: https://github.com/bitcoin/bips (accessed on 13 March 2022).
- Ethereum Improvement Proposals. 2021. Available online: https://eips.ethereum.org (accessed on 13 February 2022).
- Subramanian, H. Decentralized blockchain-based electronic marketplaces. Commun. ACM 2017, 61, 78–84. [Google Scholar] [CrossRef]
- Li, X.; Wu, L.; Zhao, R.; Lu, W.S.; Xue, F. Two-layer Adaptive Blockchain-based Supervision model for off-site modular housing production. Comput. Ind. 2021, 128, 103437. [Google Scholar] [CrossRef]
- Yong, B.B.; Shen, J.; Liu, X.; Li, F.C.; Chen, H.M.; Zhou, Q.G. An intelligent blockchain-based system for safe vaccine supply and supervision. Int. J. Inf. Manag. 2020, 52, 102024. [Google Scholar] [CrossRef]
- Omar, I.A.; Debe, M.; Jayaraman, R.; Salah, K.; Omar, M.; Arshad, J. Blockchain-based Supply Chain Traceability for COVID-19 personal protective equipment. Comput. Ind. Eng. 2022, 167, 107995. [Google Scholar] [CrossRef] [PubMed]
- Zhu, P.; Hu, J.; Zhang, Y.; Li, X.T. Enhancing Traceability of Infectious Diseases: A Blockchain-Based Approach. Inf. Process. Manag. 2021, 58, 102570. [Google Scholar] [CrossRef] [PubMed]
- Zhou, H.; Ouyang, X.; Ren, Z.J.; Su, J.S.; Laat, C.D.; Zhao, Z.M. A blockchain based witness model for trustworthy cloud service level agreement enforcement. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1567–1575. [Google Scholar]
- Dursun, T.; Ustundag, B.B. A novel framework for policy based on-chain governance of blockchain networks. Inf. Process. Manag. 2021, 58, 102556. [Google Scholar] [CrossRef]
- Bao, Z.S.; Wang, K.X.; Zhang, W.B. An Auditable and Secure Model for Permissioned Blockchain. In Proceedings of the 2019 International Electronics Communication Conference, Okinawa, Japan, 7–9 July 2019; ACM: New York, NY, USA, 2019. [Google Scholar]
- Fan, X.X.; Chai, Q.; Zhong, Z. Multav: A multi-chain token backed voting framework for decentralized blockchain governance. In International Conference on Blockchain; Springer: Cham, Switzerland, 2020; pp. 33–47. [Google Scholar]
- Liu, Y.; Yao, R.; Jia, S.; Wang, F.; Wang, R.; Ma, R.; Qi, L. A label noise filtering and label missing supplement framework based on game theory. Digit. Commun. Netw. 2022; in press. [Google Scholar] [CrossRef]
- Mohamed, M.A.; Mirjalili, S.; Dampage, U.; Salmen, S.H.; Obaid, S.A.; Annuk, A. A Cost-Efficient-Based Cooperative Allocation of Mining Devices and Renewable Resources Enhancing Blockchain Architecture. Sustainability 2021, 13, 10382. [Google Scholar] [CrossRef]
- Almalaq, A.; Albadran, S.; Mohamed, M.A. Deep Machine Learning Model-Based Cyber-Attacks Detection in Smart Power Systems. Mathematics 2022, 10, 2574. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| [(+,+),(+,+),(+,+), (+,+),(+,+)] | [(+,+),(+,+),(+,+), (+,+),(-,0)] | [(+,+),(+,+),(+,+), (-,0),(+,+)] | [(+,+),(+,+),(+,+), (-,0),(-,0)] | |||
| [(+,+),(+,+),(-,0), (+,+),(+,+)] | [(+,+),(+,+),(-,0), (+,+),(-,0)] | [(+,+),(+,+),(-,0), (-,0),(+,+)] | [(-,-),(-,-),(+,+), (+,+),(+,+)] | |||
| [(+,+),(-,0),(+,+), (+,+),(+,+)] | [(+,+),(-,0),(+,+), (+,+),(-,0)] | [(+,+),(-,0),(+,+), (-,0),(+,+)] | [(-,-),(+,+),(-,-), (+,+),(+,+)] | |||
| [(+,+),(-,0),(-,0), (+,+),(+,+)] | [(-,-),(-,-),(+,+), (+,+),(+,+)] | [(-,-),(+,+),(+,+), (+,+),(-,-)] | [(-,-),(+,+),(+,+), (+,+),(+,+)] | |||
| [(-,0),(+,+),(+,+), (+,+),(+,+)] | [(-,0),(+,+),(+,+), (+,+),(-,0)] | [(-,0),(+,+),(+,+), (-,0),(+,+)] | [(+,+),(-,-),(-,-), (+,+),(+,+)] | |||
| [(-,0),(+,+),(-,0), (+,+),(+,+)] | [(+,+),(-,-),(+,+), (-,-),(+,+)] | [(+,+),(-,-),(+,+), (+,+),(-,-)] | [(+,+),(-,-),(+,+), (+,+),(+,+)] | |||
| [(-,0),(-,0),(+,+), (+,+),(+,+)] | [(+,+),(+,+),(-,-), (-,-),(+,+)] | [(+,+),(+,+),(-,-), (+,+),(-,-)] | [(+,+),(+,+),(-,-), (+,+),(+,+)] | |||
| [(+,+),(+,+),(+,+), (-,-),(-,-)] | [(+,+),(+,+),(+,+), (-,-),(+,+)] | [(+,+),(+,+),(+,+), (+,+),(-,-)] | [(+,+),(+,+),(+,+), (+,+),(+,+)] | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, J.; Li, Y.; Yuan, Y.; Zhang, B.; Xu, X. A Blockchain-Based Trust Model for Uploading Illegal Data Identification. Appl. Sci. 2022, 12, 9657. https://doi.org/10.3390/app12199657
Cheng J, Li Y, Yuan Y, Zhang B, Xu X. A Blockchain-Based Trust Model for Uploading Illegal Data Identification. Applied Sciences. 2022; 12(19):9657. https://doi.org/10.3390/app12199657
Chicago/Turabian StyleCheng, Jieren, Yuanshen Li, Yuming Yuan, Bo Zhang, and Xinbin Xu. 2022. "A Blockchain-Based Trust Model for Uploading Illegal Data Identification" Applied Sciences 12, no. 19: 9657. https://doi.org/10.3390/app12199657
APA StyleCheng, J., Li, Y., Yuan, Y., Zhang, B., & Xu, X. (2022). A Blockchain-Based Trust Model for Uploading Illegal Data Identification. Applied Sciences, 12(19), 9657. https://doi.org/10.3390/app12199657