
Semantic Representation Using Sub-Symbolic Knowledge in Commonsense Reasoning †


Abstract
:1. Introduction
- We demonstrate how to assess pre-trained models on the understanding of the questions and demonstrate the limitations of the language models.
- We propose a new graph representation strategy expanded with an AMR graph and ConceptNet.
- Compared with the baselines, our method shows significant performance improvement in diverse commonsense reasoning-based datasets.
2. Related Work
2.1. Abstract Meaning Representation (AMR)
2.2. ConceptNet
2.3. Commonsense Reasoning
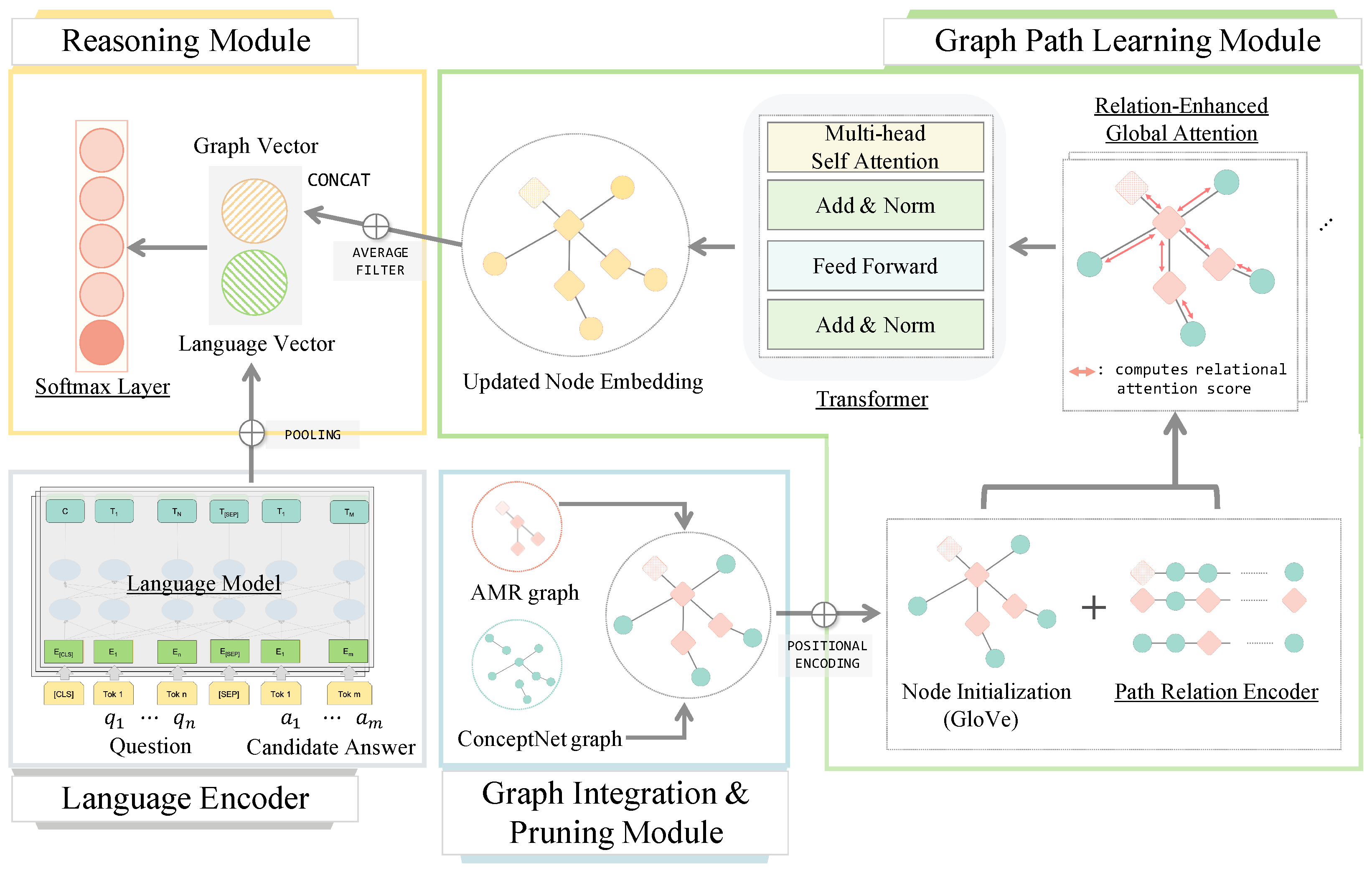
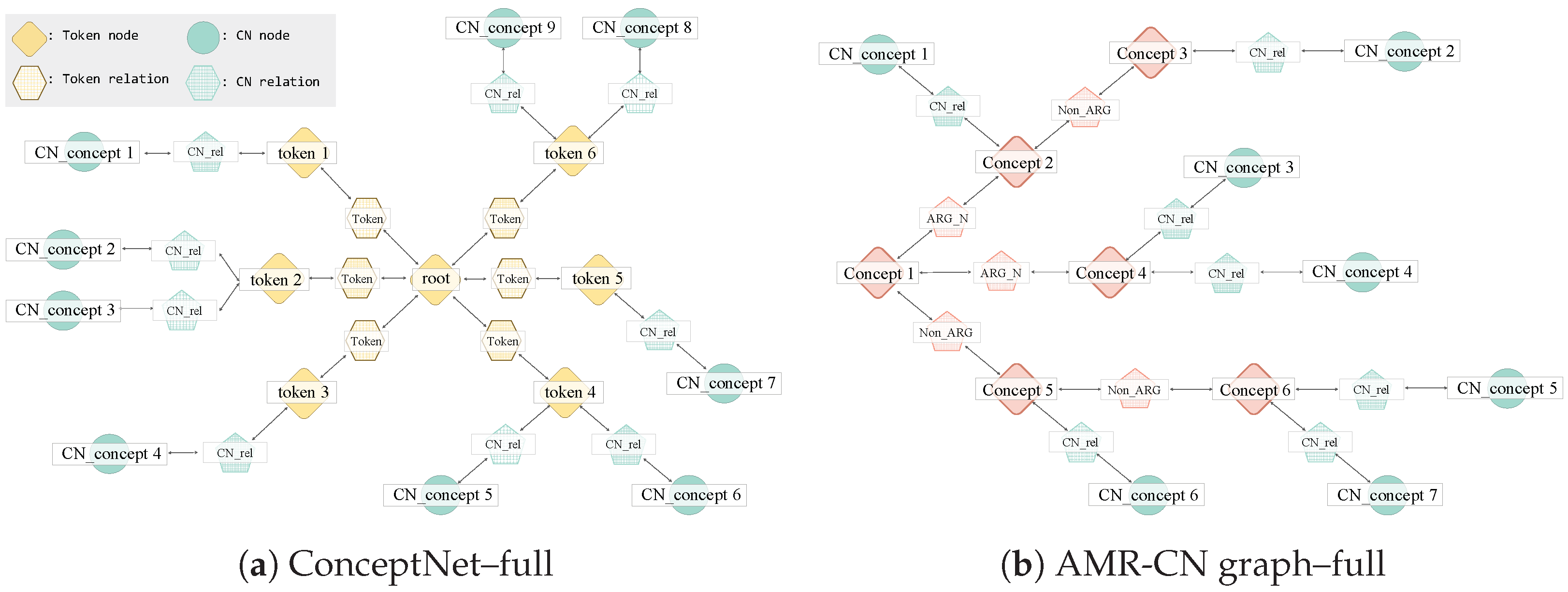
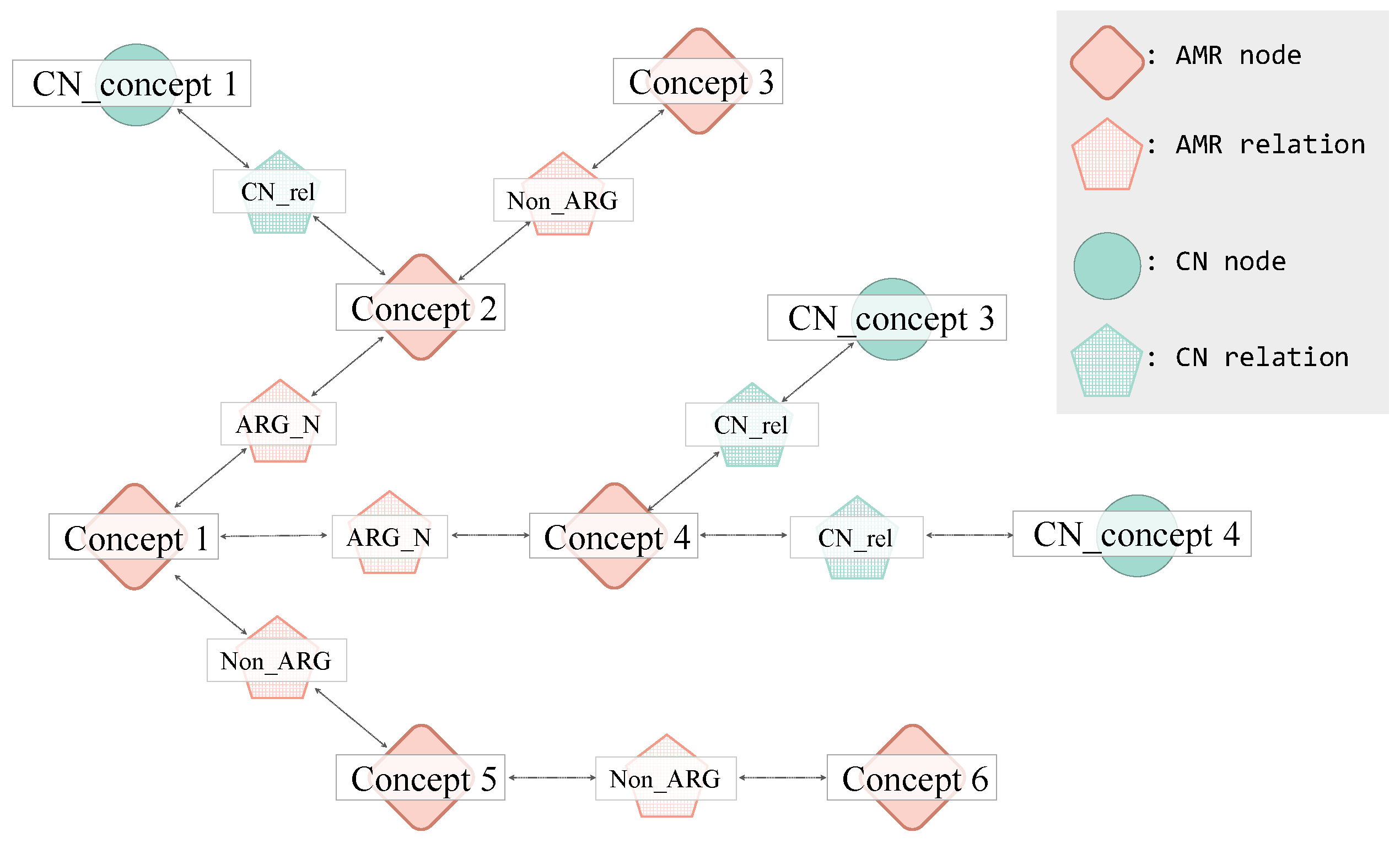
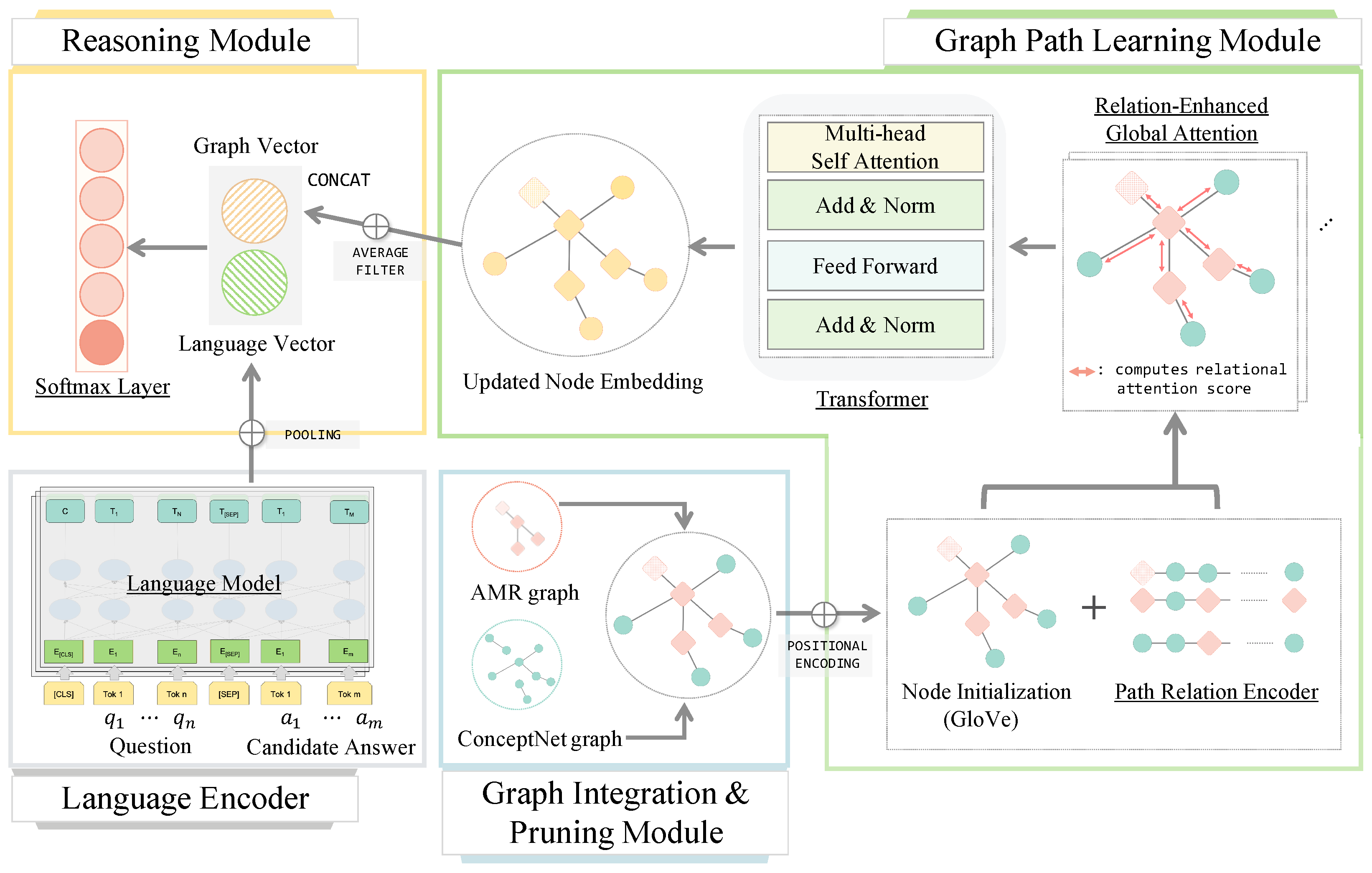
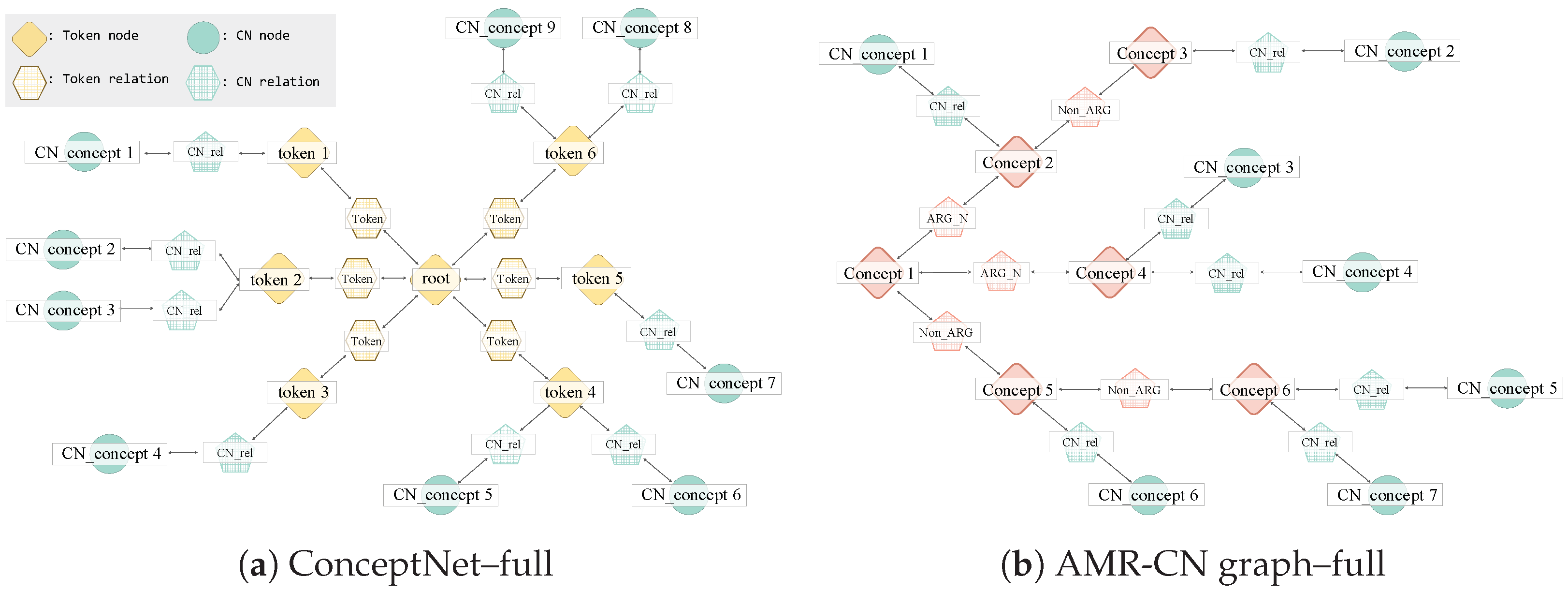
3. Proposed Method
4. Experiments
4.1. Data Setup
4.2. Experimental Details
4.3. Baselines
4.3.1. Pre-Trained Language Models
4.3.2. AMR-CN Reasoning Model
4.3.3. Graph Path Learning Module
4.3.4. Language Encoder
4.3.5. Reasoning Module
4.4. Experimental Results
4.4.1. Diverse Expansion Methods
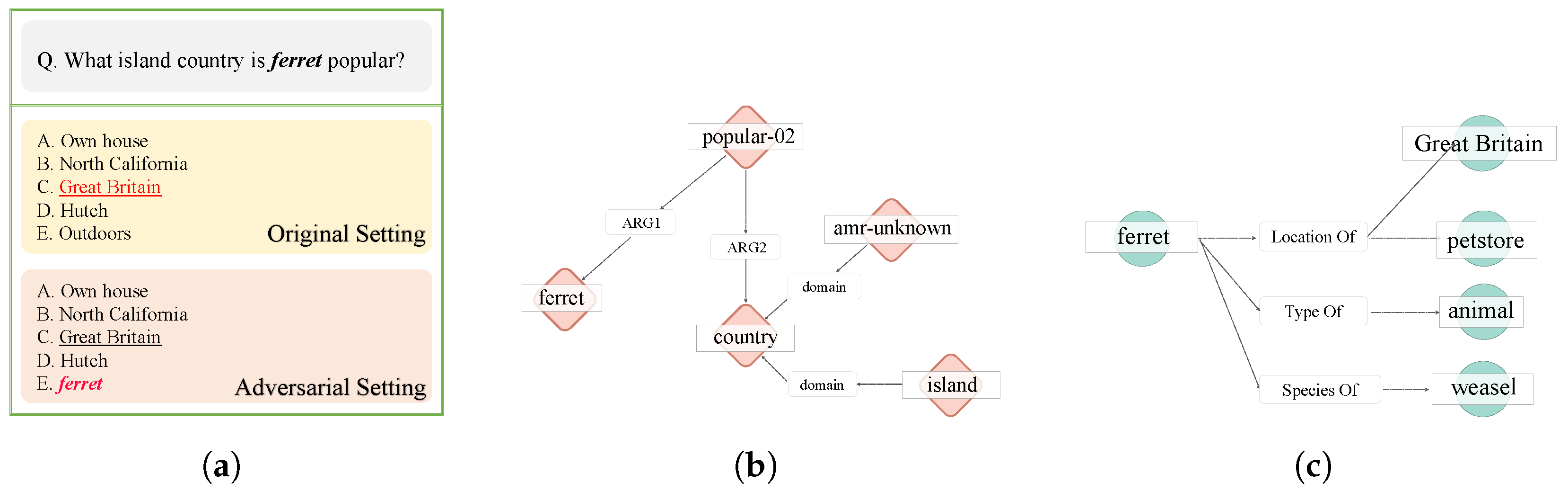
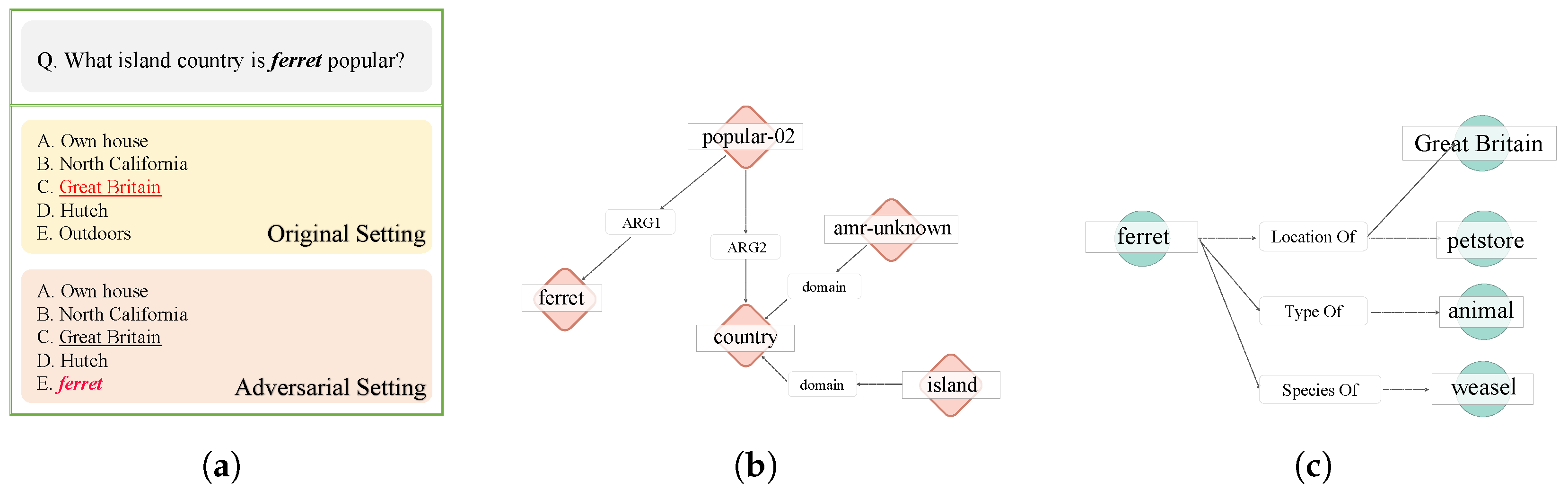
4.4.2. Adversarial Attack Test Using SRL
4.4.3. Comparison on Different Language Models
4.4.4. Experiment on Official Test Set
4.4.5. Experiment on OpenBookQA Dataset
5. Strengths and Limitations
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Marcus, G. The next decade in ai: Four steps towards robust artificial intelligence. arXiv 2020, arXiv:2002.06177. [Google Scholar]
- Berant, J.; Chou, A.; Frostig, R.; Liang, P. Semantic parsing on freebase from question-answer pairs. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1533–1544. [Google Scholar]
- Yih, W.t.; He, X.; Meek, C. Semantic parsing for single-relation question answering. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 22–27 June 2014; pp. 643–648. [Google Scholar]
- Yih, S.W.t.; Chang, M.W.; He, X.; Gao, J. Semantic Parsing Via Staged Query Graph Generation: Question Answering with Knowledge Base. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 1321–1331. [Google Scholar]
- Mitra, A.; Baral, C. Addressing a question answering challenge by combining statistical methods with inductive rule learning and reasoning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2779–2785. [Google Scholar]
- Talmor, A.; Herzig, J.; Lourie, N.; Berant, J. COMMONSENSEQA: A Question Answering Challenge Targeting Commonsense Knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4149–4158. [Google Scholar]
- Mihaylov, T.; Clark, P.; Khot, T.; Sabharwal, A. Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2381–2391. [Google Scholar]
- Singh, P.; Lin, T.; Mueller, E.T.; Lim, G.; Perkins, T.; Zhu, W.L. Open mind common sense: Knowledge acquisition from the general public. In Proceedings of the OTM Confederated International Conferences, Rhodes, Greece, 21–25 October 2002; pp. 1223–1237. [Google Scholar]
- Lin, B.Y.; Chen, X.; Chen, J.; Ren, X. KagNet: Knowledge-Aware Graph Networks for Commonsense Reasoning. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 2822–2832. [Google Scholar]
- Lv, S.; Guo, D.; Xu, J.; Tang, D.; Duan, N.; Gong, M.; Shou, L.; Jiang, D.; Cao, G.; Hu, S. Graph-based reasoning over heterogeneous external knowledge for commonsense question answering. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8449–8456. [Google Scholar]
- Ma, K.; Francis, J.; Lu, Q.; Nyberg, E.; Oltramari, A. Towards generalizable neuro-symbolic systems for commonsense question answering. arXiv 2019, arXiv:1910.14087. [Google Scholar]
- Speer, R.; Chin, J.; Havasi, C. Conceptnet 5.5: An open multilingual graph of general knowledge. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Banarescu, L.; Bonial, C.; Cai, S.; Georgescu, M.; Griffitt, K.; Hermjakob, U.; Knight, K.; Koehn, P.; Palmer, M.; Schneider, N. Abstract meaning representation for sembanking. In Proceedings of the 7th Linguistic Annotation Workshop and Interoperability with Discourse, Sofia, Bulgaria, 8–9 August 2013; pp. 178–186. [Google Scholar]
- Gross, J.L.; Yellen, J.; Zhang, P. Handbook of Graph Theory; CRC Press: Boca Raton, FL, USA, 2013; p. 1192. [Google Scholar]
- Cai, D.; Lam, W. Graph transformer for graph-to-sequence learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 7464–7471. [Google Scholar]
- Guo, Z.; Zhang, Y.; Teng, Z.; Lu, W. Densely connected graph convolutional networks for graph-to-sequence learning. Trans. Assoc. Comput. Linguist. 2019, 7, 297–312. [Google Scholar] [CrossRef]
- Vlachos, A. Guided neural language generation for abstractive summarization using Abstract Meaning Representation. arXiv 2018, arXiv:1808.09160. [Google Scholar]
- Liao, K.; Lebanoff, L.; Liu, F. Abstract Meaning Representation for Multi-Document Summarization. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 1178–1190. [Google Scholar]
- Bonial, C.; Donatelli, L.; Lukin, S.; Tratz, S.; Artstein, R.; Traum, D.; Voss, C. Augmenting Abstract Meaning Representation for Human-Robot Dialogue. In Proceedings of the First International Workshop on Designing Meaning Representations, Florence, Italy, 1 August 2019; pp. 199–210. [Google Scholar]
- Issa, F.; Damonte, M.; Cohen, S.B.; Yan, X.; Chang, Y. Abstract meaning representation for paraphrase detection. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 5–6 June 2018; pp. 442–452. [Google Scholar]
- Wang, Y.; Liu, S.; Rastegar-Mojarad, M.; Wang, L.; Shen, F.; Liu, F.; Liu, H. Dependency and AMR embeddings for drug-drug interaction extraction from biomedical literature. In Proceedings of the 8th ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics, Northbrook, IL, USA, 7–10 August 2017; pp. 36–43. [Google Scholar]
- Garg, S.; Galstyan, A.; Hermjakob, U.; Marcu, D. Extracting biomolecular interactions using semantic parsing of biomedical text. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Bonial, C.; Hwang, J.; Bonn, J.; Conger, K.; Babko-Malaya, O.; Palmer, M. English propbank annotation guidelines. In Proceedings of the Center for Computational Language and Education Research Institute of Cognitive Science University of Colorado, Boulder, CO, USA, 14 July 2015; Volume 48. [Google Scholar]
- Meyer, C.M.; Gurevych, I. Wiktionary: A New Rival for Expert-Built Lexicons? Exploring the Possibilities of Collaborative Lexicography. Linguistics. November 2012. Available online: https://academic.oup.com/book/27204/chapter-abstract/196665268?redirectedFrom=fulltext (accessed on 1 April 2021).
- Miller, G.A. WordNet: A lexical database for English. Proc. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. Dbpedia: A nucleus for a web of open data. In Proceedings of the Semantic Web, Busan, Korea, 11–15 November 2007; pp. 722–735. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 5754–5764. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. Electra: Pre-training text encoders as discriminators rather than generators. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Cai, D.; Lam, W. AMR Parsing via Graph-Sequence Iterative Inference. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 1290–1301. [Google Scholar]
- Shi, P.; Lin, J. Simple BERT Models for Relation Extraction and Semantic Role Labeling. arXiv 2019, arXiv:1904.05255. [Google Scholar]
- Lim, J.; Oh, D.; Jang, Y.; Yang, K.; Lim, H.S. I Know What You Asked: Graph Path Learning using AMR for Commonsense Reasoning. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 2459–2471. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October; pp. 1724–1734.
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-Attention with Relative Position Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; pp. 464–468. [Google Scholar]
- Salton, G.; Ross, R.; Kelleher, J. Attentive language models. In Proceedings of the Eighth International Joint Conference on Natural Language Processing, Taipei, China, 27 November–1 December 2017; pp. 441–450. [Google Scholar]
- Palmer, M.; Gildea, D.; Xue, N. Semantic role labeling. Proc. Synth. Lect. Hum. Lang. Technol. 2010, 3, 1–103. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Relation | Ntrain | Ndev | Ntest |
|---|---|---|---|
| ARG0 | 17,300 (22.70%) | 2547 (22.73%) | 2477 (23.09%) |
| ARG1 | 24,673 (32.38%) | 3566 (31.83%) | 3521 (32.82%) |
| ARG2 | 6001 (7.88%) | 864 (7.71%) | 829 (7.73%) |
| ARG3 | 286 (0.38%) | 37 (0.33%) | 51 (0.48%) |
| ARG4 | 587 (0.77%) | 92 (0.82%) | 59 (0.55%) |
| Total relations | 76,203 | 11,204 | 10,727 |
| Language Model | Graph Type | Ndev-Acc(%) | Ntest-Acc(%) | Avg |
|---|---|---|---|---|
| BERT-base-cased | - | 51.81 | 51.59 | 52.70 |
| CN-Full | 53.48 | 53.10 | 53.29 | |
| AMR-CN-Full (ACF) | 53.81 | 52.38 | 53.10 | |
| AMR-CN-Pruned-ARG0,1 (ACP-ARG-mini) | 53.89 | 52.54 | 53.22 | |
| AMR-CN-Pruned-nonARG (ACP-nonARG) | 53.15 | 50.77 | 51.96 | |
| AMR-CN-Pruned-ARGN(ACP-ARG) | 54.38 | 53.51 | 53.95 |
| Language Model | Setting | Odev-Acc(%) |
|---|---|---|
| BERT-base-cased | Original | 51.81 |
| BERT-base-cased with ACP-ARG | Original | 54.38 |
| BERT-base-cased | SRL-C | 46.03 (−5.78%p) |
| BERT-base-cased with ACP-ARG | SRL-C | 53.32 (−1.06%p) |
| Language Model | Ndev-Acc(%) | Ntest-Acc(%) | Avg |
|---|---|---|---|
| BERT-base | 51.81 | 51.59 | 51.70 |
| ELECTRA-base | 71.25 | 70.19 | 70.72 |
| BERT-base with ACP-ARG-mini [16,34] | 53.97 | 53.58 | 53.78 |
| ELECTRA-base with ACP-ARG-mini [16,34] | 71.99 | 70.91 | 71.45 |
| BERT-base with ACP-ARG | 54.38 | 53.51 | 53.95 |
| ELECTRA-base with ACP-ARG | 73.63 | 71.72 | 72.68 |
| Models | Odev-Acc(%) | Otest-Acc(%) | Avg |
|---|---|---|---|
| ELECTRA-large with ACP-ARG-mini [16,34] | 82.15 | 75.43 | 78.79 |
| ELECTRA-large with ACP-ARG | 83.04 | 75.79 | 79.42 |
| Language Model | Otest-Acc(%) |
|---|---|
| BERT-base-cased | 47.20 |
| BERT-large-cased | 56.40 |
| ELECTRA-base | 63.20 |
| ELECTRA-large | 77.60 |
| BERT-base-cased with ACP-ARG | 56.00 |
| BERT-large-cased with ACP-ARG | 60.00 |
| ELECTRA-base with ACP-ARG | 64.20 |
| ELECTRA-large with ACP-ARG | 82.40 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oh, D.; Lim, J.; Park, K.; Lim, H. Semantic Representation Using Sub-Symbolic Knowledge in Commonsense Reasoning. Appl. Sci. 2022, 12, 9202. https://doi.org/10.3390/app12189202
Oh D, Lim J, Park K, Lim H. Semantic Representation Using Sub-Symbolic Knowledge in Commonsense Reasoning. Applied Sciences. 2022; 12(18):9202. https://doi.org/10.3390/app12189202
Chicago/Turabian StyleOh, Dongsuk, Jungwoo Lim, Kinam Park, and Heuiseok Lim. 2022. "Semantic Representation Using Sub-Symbolic Knowledge in Commonsense Reasoning" Applied Sciences 12, no. 18: 9202. https://doi.org/10.3390/app12189202
APA StyleOh, D., Lim, J., Park, K., & Lim, H. (2022). Semantic Representation Using Sub-Symbolic Knowledge in Commonsense Reasoning. Applied Sciences, 12(18), 9202. https://doi.org/10.3390/app12189202