

A Lightweight Residual Model for Corrosion Segmentation with Local Contextual Information

Abstract
:1. Introduction
- (1)
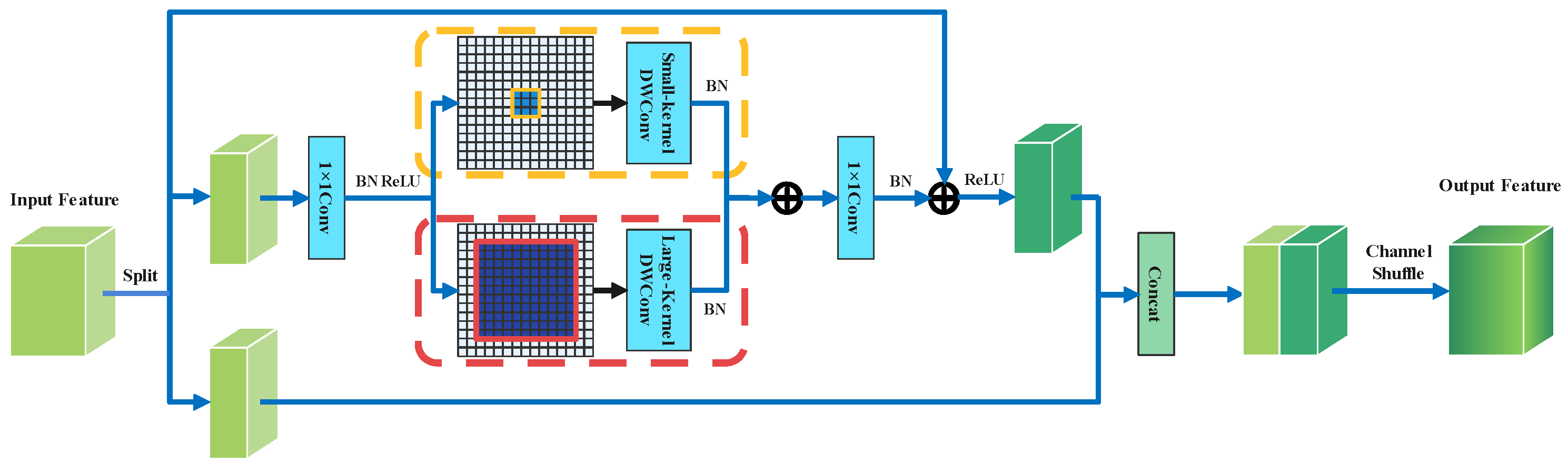
- We present a mixture of large and small kernels to acquire spatial and semantic contextual information and perform superior corrosion segmentation.
- (2)
- We follow the ShuffleNetv2 to alleviate the computational overhead caused by large kernels and to embed high-precision models into mobile devices more appropriately.
- (3)
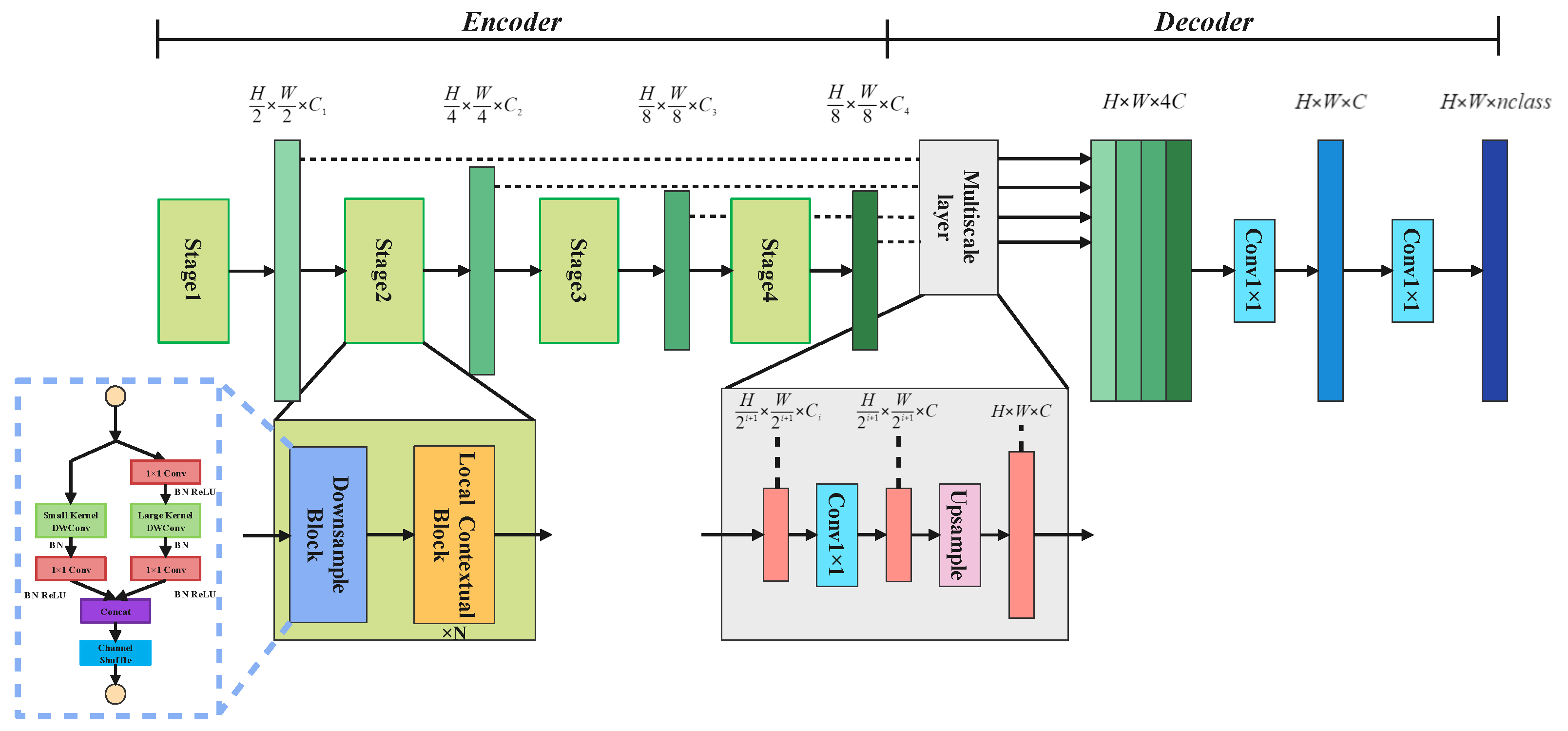
- The creation of a fused multi-scale feature promotes information acquisition under limited resources.
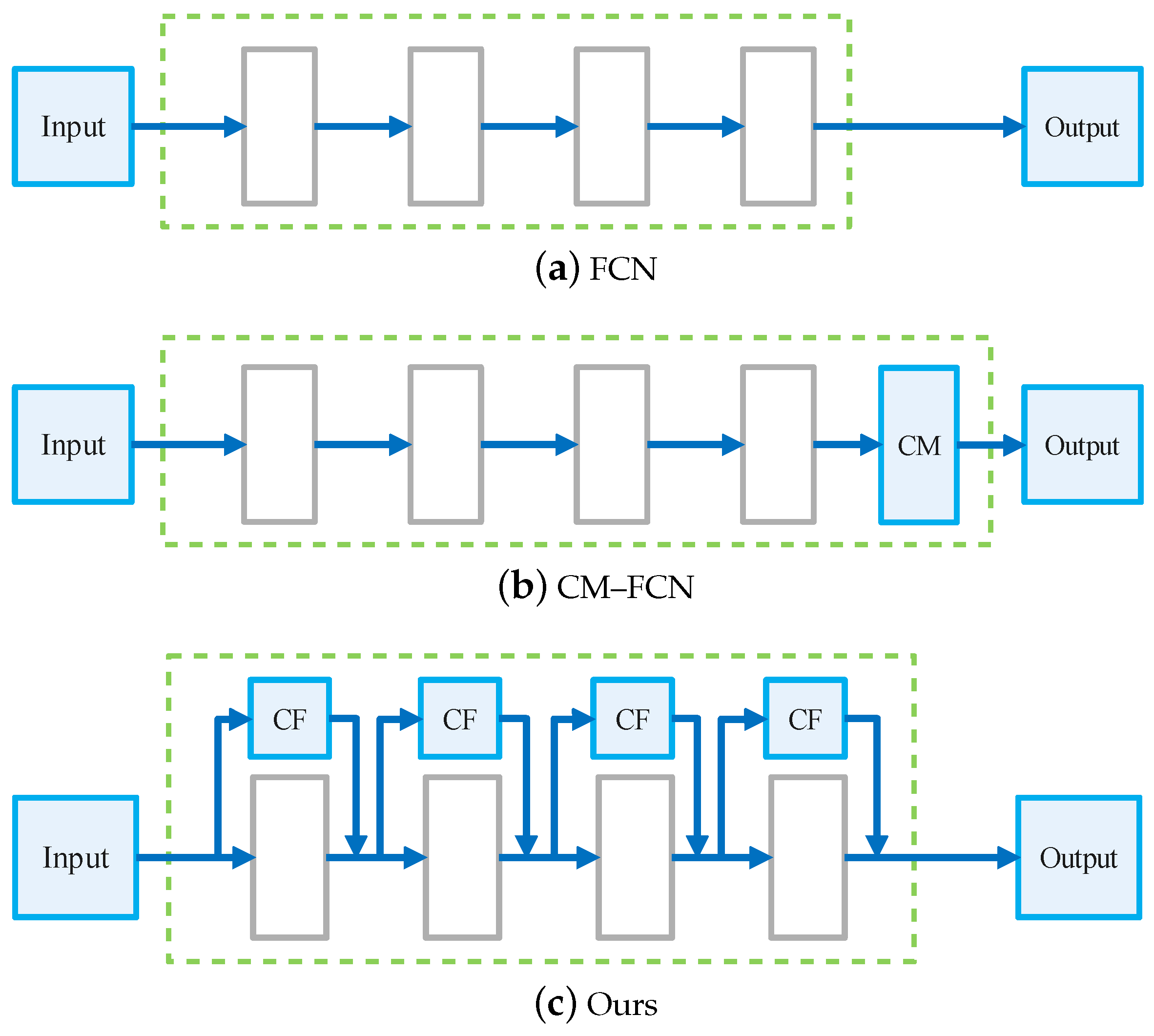
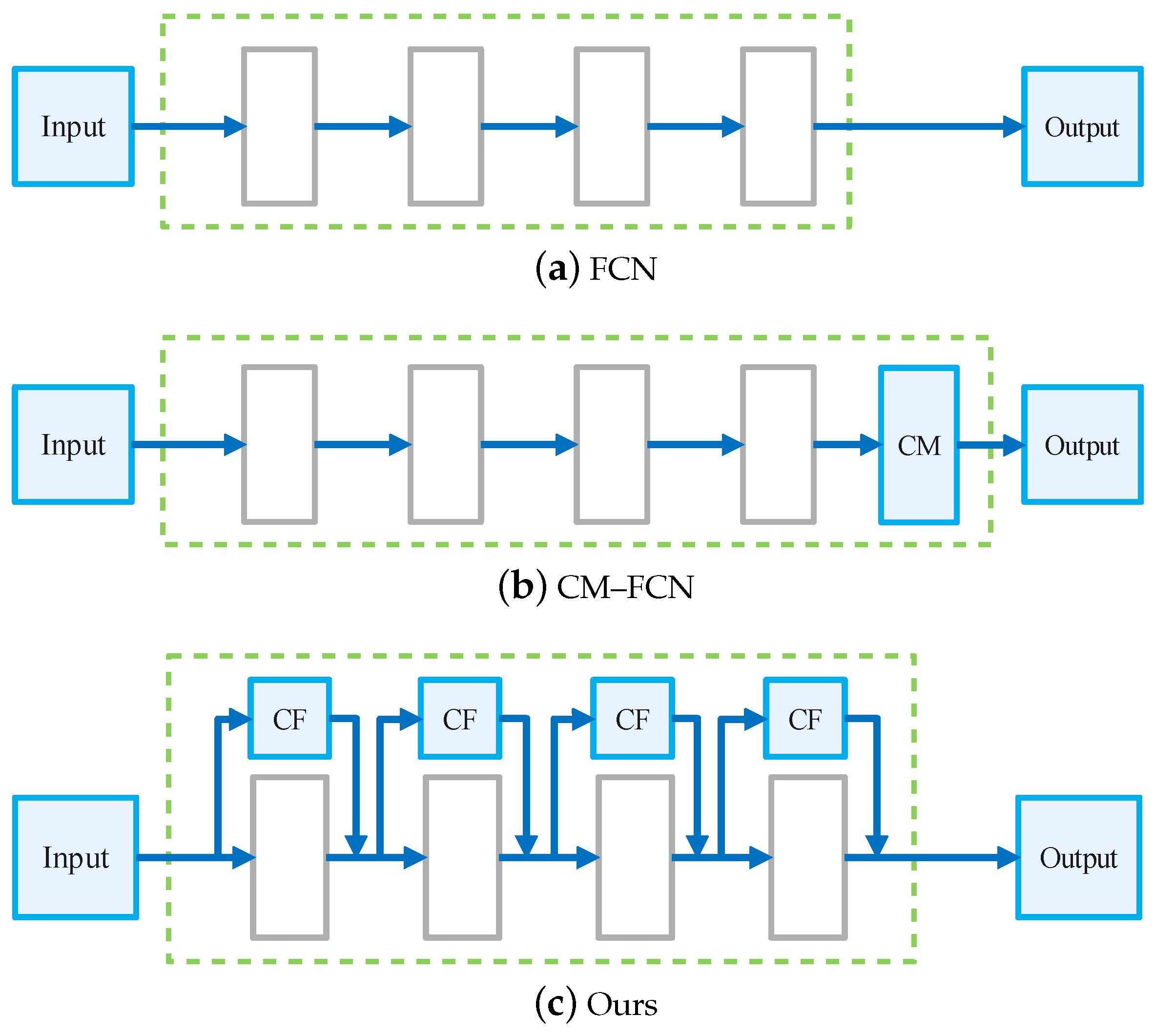
- The design of large and small convolution kernels at all stages in the encoder to capture the long-distance dependencies between pixels and local detailed information and the design of a novel, simple decoder structure to fuse multi-scale information to improve model accuracy in an end-to-end residual deep-learning framework.
- The reduction of the model size by borrowing the core idea of ShuffleNetv2. The depthwise separable convolution and channel split operations reduce the computational overhead from large kernels, and the channel shuffle further improves feature representation capability.
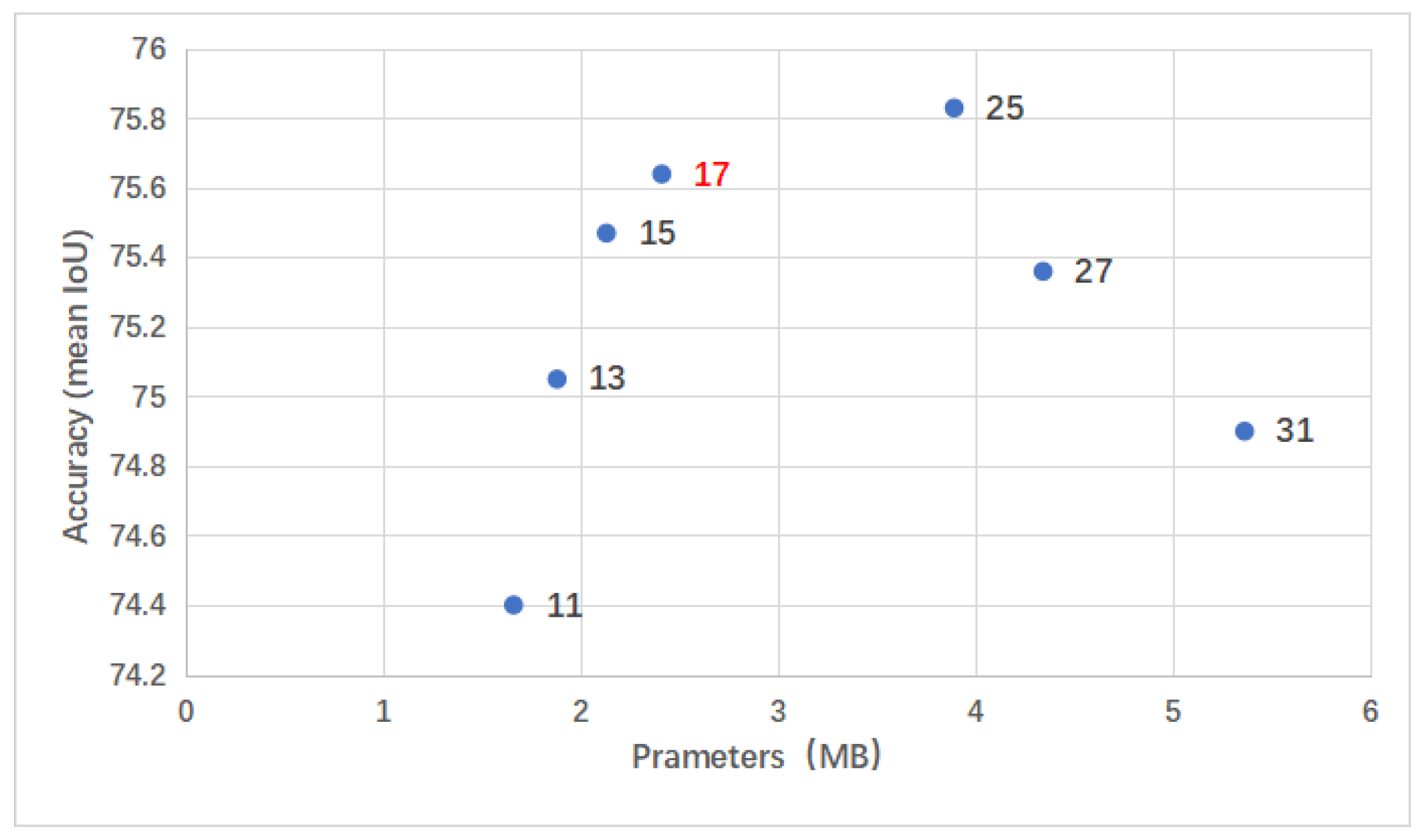
- The design of two differently sized models to accommodate a variety of application scenarios. Extensive experimental results on a benchmark dataset showed that both models outperformed the state-of-the-art methods in model size and in accuracy trade-off for corrosion segmentation and degree evaluation.
2. Related Works
2.1. Corrosion Segmentation
2.2. Image Semantic Segmentation
3. Method
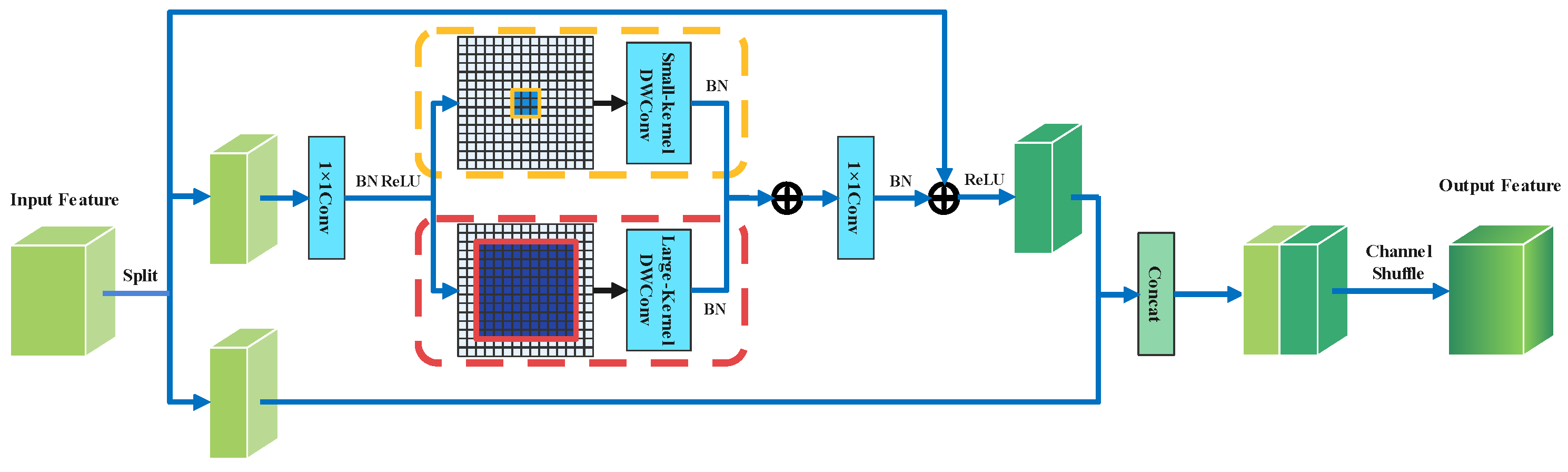
3.1. Local Contextual Block
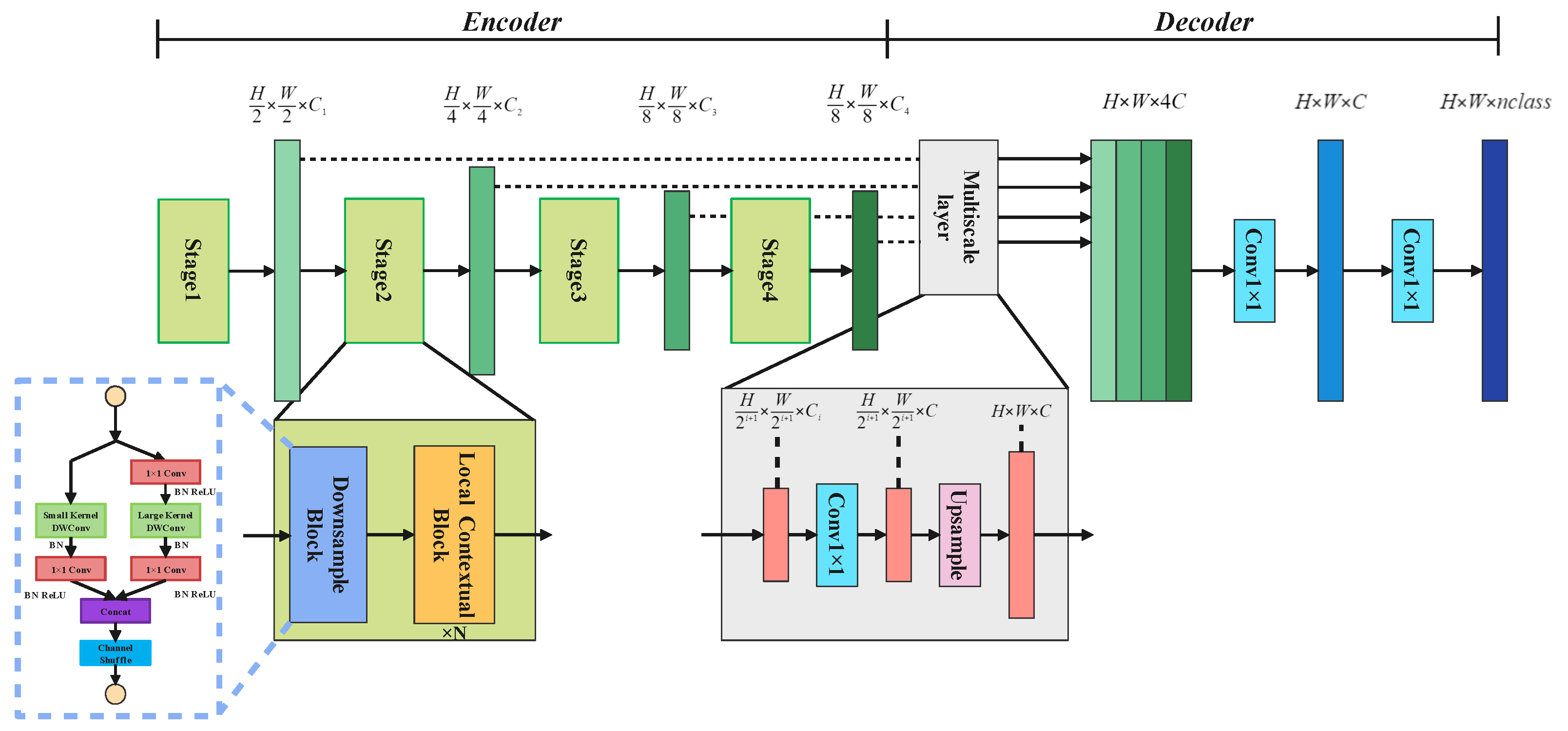
3.2. Encoder–Decoder Architecture
4. Experiment
4.1. Experiment Settings
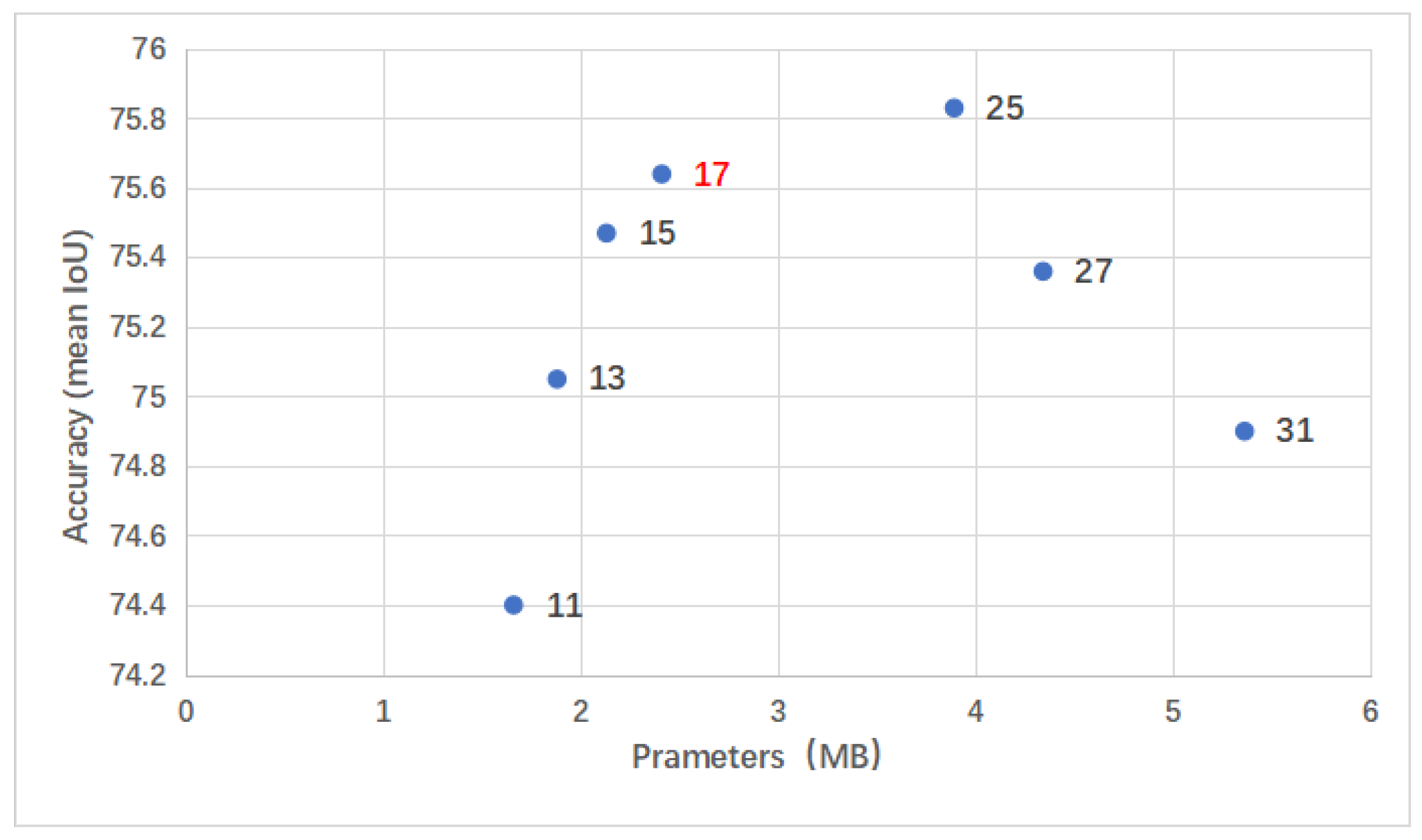
4.2. Comparison with Similar Methods
4.3. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mazumder, M.A.J. Global impact of corrosion: Occurrence, cost and mitigation. Glob. J. Eng. Sci 2020, 5, 4. [Google Scholar] [CrossRef]
- Zhang, C.; Patras, P.; Haddadi, H. Deep learning in mobile and wireless networking: A survey. IEEE Commun. Surv. Tutor. 2019, 21, 2224–2287. [Google Scholar] [CrossRef]
- Luo, D.; Cai, Y.; Yang, Z.; Zhang, Z.; Zhou, Y.; Bai, X. Survey on industrial defect detection with deep learning. J. Sci. Sin. Inf. 2022, 52, 1002–1039. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Takos, G. A survey on deep learning methods for semantic image segmentation in real-time. arXiv 2020, arXiv:2009.12942. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Morizet, N.; Godin, N.; Tang, J.; Maillet, E.; Fregonese, M.; Normand, B. Classification of acoustic emission signals using wavelets and Random Forests: Application to localized corrosion. Mech. Syst. Signal Process. 2016, 70, 1026–1037. [Google Scholar] [CrossRef]
- Hoang, N.D. Image processing-based pitting corrosion detection using metaheuristic optimized multilevel image thresholding and machine-learning approaches. Math. Probl. Eng. 2020, 2020, 6765274. [Google Scholar] [CrossRef]
- Zou, Z.; Ma, L.; Fan, Q.; Gan, X.; Qiao, L. Feature recognition of metal salt spray corrosion based on color spaces statistics analysis. In Proceedings of the SPIE Optical Engineering + Applications, San Diego, CA, USA, 6–10 August 2017; Volume 10396, pp. 562–569. [Google Scholar]
- Atha, D.J.; Jahanshahi, M.R. Evaluation of deep learning approaches based on convolutional neural networks for corrosion detection. Struct. Health Monit. 2018, 17, 1110–1128. [Google Scholar] [CrossRef]
- Ortiz, A.; Bonnin-Pascual, F.; Garcia-Fidalgo, E.; Company-Corcoles, J.P. Vision-based corrosion detection assisted by a micro-aerial vehicle in a vessel inspection application. Sensors 2016, 16, 2118. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Deng, X.; Lu, Y.; Hong, S.; Kong, Z.; Peng, Y.; Luo, Y. A channel attention based deep neural network for automatic metallic corrosion detection. J. Build. Eng. 2021, 42, 103046. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xu, X.; Wang, Y.; Wu, J.; Wang, Y. Intelligent corrosion detection and rating based on faster region-based convolutional neural network. In Proceedings of the 2020 Global Reliability and Prognostics and Health Management (PHM-Shanghai), Shanghai, China, 16–18 October 2020; pp. 1–5. [Google Scholar]
- Hou, S.; Dong, B.; Wang, H.; Wu, G. Inspection of surface defects on stay cables using a robot and transfer learning. Autom. Constr. 2020, 119, 103382. [Google Scholar] [CrossRef]
- Fondevik, S.K.; Stahl, A.; Transeth, A.A.; Knudsen, O. Image Segmentation of Corrosion Damages in Industrial Inspections. In Proceedings of the 2020 IEEE 32nd International Conference on Tools with Artificial Intelligence (ICTAI), Baltimore, MD, USA, 9–11 November 2020; pp. 787–792. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. Denseaspp for semantic segmentation in street scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3684–3692. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. Enet: A deep neural network architecture for real-time semantic segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. Icnet for real-time semantic segmentation on high-resolution images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 405–420. [Google Scholar]
- Mehta, S.; Rastegari, M.; Caspi, A.; Shapiro, L.; Hajishirzi, H. Espnet: Efficient spatial pyramid of dilated convolutions for semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 552–568. [Google Scholar]
- Chaurasia, A.; Culurciello, E. Linknet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Romera, E.; Alvarez, J.M.; Bergasa, L.M.; Arroyo, R. Erfnet: Efficient residual factorized convnet for real-time semantic segmentation. IEEE Trans. Intell. Transp. Syst. 2017, 19, 263–272. [Google Scholar] [CrossRef]
- Wu, T.; Tang, S.; Zhang, R.; Cao, J.; Zhang, Y. Cgnet: A light-weight context guided network for semantic segmentation. IEEE Trans. Image Process. 2020, 30, 1169–1179. [Google Scholar] [CrossRef] [PubMed]
- Han, W.; Zhang, Z.; Zhang, Y.; Yu, J.; Chiu, C.C.; Qin, J.; Gulati, A.; Pang, R.; Wu, Y. Contextnet: Improving convolutional neural networks for automatic speech recognition with global context. arXiv 2020, arXiv:2005.03191. [Google Scholar]
- Lo, S.Y.; Hang, H.M.; Chan, S.W.; Lin, J.J. Efficient dense modules of asymmetric convolution for real-time semantic segmentation. In Proceedings of the ACM Multimedia Asia, Beijing, China, 16–18 December 2019; pp. 1–6. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling up your kernels to 31 × 31: Revisiting large kernel design in cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 11963–11975. [Google Scholar]
- Zheng, S.; Jayasumana, S.; Romera-Paredes, B.; Vineet, V.; Su, Z.; Du, D.; Huang, C.; Torr, P.H. Conditional random fields as recurrent neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1529–1537. [Google Scholar]
- Li, X.; Zhong, Z.; Wu, J.; Yang, Y.; Lin, Z.; Liu, H. Expectation-maximization attention networks for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9167–9176. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 603–612. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Bianchi, E.; Hebdon, M. Corrosion Condition State Semantic Segmentation Dataset; University Libraries, Virginia Tech: Blacksburg, VA, USA, 2021. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Li, G.; Yun, I.; Kim, J.; Kim, J. Dabnet: Depth-wise asymmetric bottleneck for real-time semantic segmentation. arXiv 2019, arXiv:1907.11357. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Kernel Size | Stride | Repeat | Output Channels | |
|---|---|---|---|---|---|
| Small | Large | ||||
| Image | 3 | 3 | |||
| Stage 1 | 3 × 3 | 2 | 1 | 32 | 72 |
| 3 × 3 (DW) | 1 | 1 | 32 | 72 | |
| 1 × 1 | 1 | 1 | 32 | 72 | |
| Stage 2 | 2 | 1 | 32 | 72 | |
| 1 | 3 | 64 | 144 | ||
| Stage 3 | 2 | 1 | 64 | 144 | |
| 1 | 7 | 128 | 288 | ||
| Stage 4 | 1 | 1 | 128 | 288 | |
| 1 | 3 | 256 | 576 | ||
| Params | 2.41 MB | 8.25 MB | |||
| Model | Params (MB) | mIoU (%) | mPA (%) | F1-Score | FPS |
|---|---|---|---|---|---|
| ENet [27] | 1.36 | 67.79 | 80.64 | 0.766 | 43.55 |
| CGNet [32] | 1.88 | 73.32 | 85.09 | 0.820 | 12.77 |
| EDANet [34] | 2.60 | 67.49 | 80.49 | 0.761 | 21.79 |
| DABNet [48] | 2.87 | 68.89 | 79.95 | 0.779 | 46.30 |
| ContextNet [33] | 3.34 | 69.17 | 81.35 | 0.828 | 104.78 |
| ESPNetv2 [29] | 4.75 | 72.13 | 83.34 | 0.798 | 38.61 |
| ERFNet [31] | 7.87 | 69.10 | 81.12 | 0.794 | 41.43 |
| Ours–small | 2.41 | 75.64 | 86.07 | 0.838 | 16.87 |
| Deeplabv3+ [10] | 22.18 | 77.67 | 88.96 | 0.879 | 25.58 |
| LinkNet [30] | 44.00 | 67.58 | 77.82 | 0.820 | 48.22 |
| SegNet [44] | 112.32 | 58.37 | 70.89 | 0.778 | 12.89 |
| CCNet [38] | 200.69 | 78.47 | 86.58 | 0.899 | 7.42 |
| Ours–large | 8.25 | 79.06 | 88.07 | 0.891 | 11.60 |
| Small Kernel | Large Kernel | Params | mIoU | mPA | F1-Score |
|---|---|---|---|---|---|
| w/o | w | 2.36 MB | 75.30% | 85.64% | 0.824 |
| w | w/o | 1.38 MB | 71.38% | 82.95% | 0.793 |
| w | w | 2.41 MB | 75.64% | 86.07% | 0.838 |
| Residual | Params | mIoU | mPA | F1-Score |
|---|---|---|---|---|
| w/o | 2.41 MB | 74.67% | 85.55% | 0.821 |
| w | 2.41 MB | 75.64% | 86.07% | 0.838 |
| IRB | LCB | Params | mIoU | mPA | F1-Score |
|---|---|---|---|---|---|
| w | w/o | 2.04 MB | 74.53% | 85.31% | 0.813 |
| w/o | w | 2.41 MB | 75.64% | 86.07% | 0.838 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, J.; Liu, Q.; Xiang, L.; Li, G.; Zhang, Y.; Chen, W. A Lightweight Residual Model for Corrosion Segmentation with Local Contextual Information. Appl. Sci. 2022, 12, 9095. https://doi.org/10.3390/app12189095
Huang J, Liu Q, Xiang L, Li G, Zhang Y, Chen W. A Lightweight Residual Model for Corrosion Segmentation with Local Contextual Information. Applied Sciences. 2022; 12(18):9095. https://doi.org/10.3390/app12189095
Chicago/Turabian StyleHuang, Jingxu, Qiong Liu, Lang Xiang, Guangrui Li, Yiqing Zhang, and Wenbai Chen. 2022. "A Lightweight Residual Model for Corrosion Segmentation with Local Contextual Information" Applied Sciences 12, no. 18: 9095. https://doi.org/10.3390/app12189095
APA StyleHuang, J., Liu, Q., Xiang, L., Li, G., Zhang, Y., & Chen, W. (2022). A Lightweight Residual Model for Corrosion Segmentation with Local Contextual Information. Applied Sciences, 12(18), 9095. https://doi.org/10.3390/app12189095