


A Classification Feature Optimization Method for Remote Sensing Imagery Based on Fisher Score and mRMR

 ,
, 

Abstract
:1. Introduction
2. The Study Area and the Data Source
2.1. Study Area
2.2. Data Source and Preprocessing
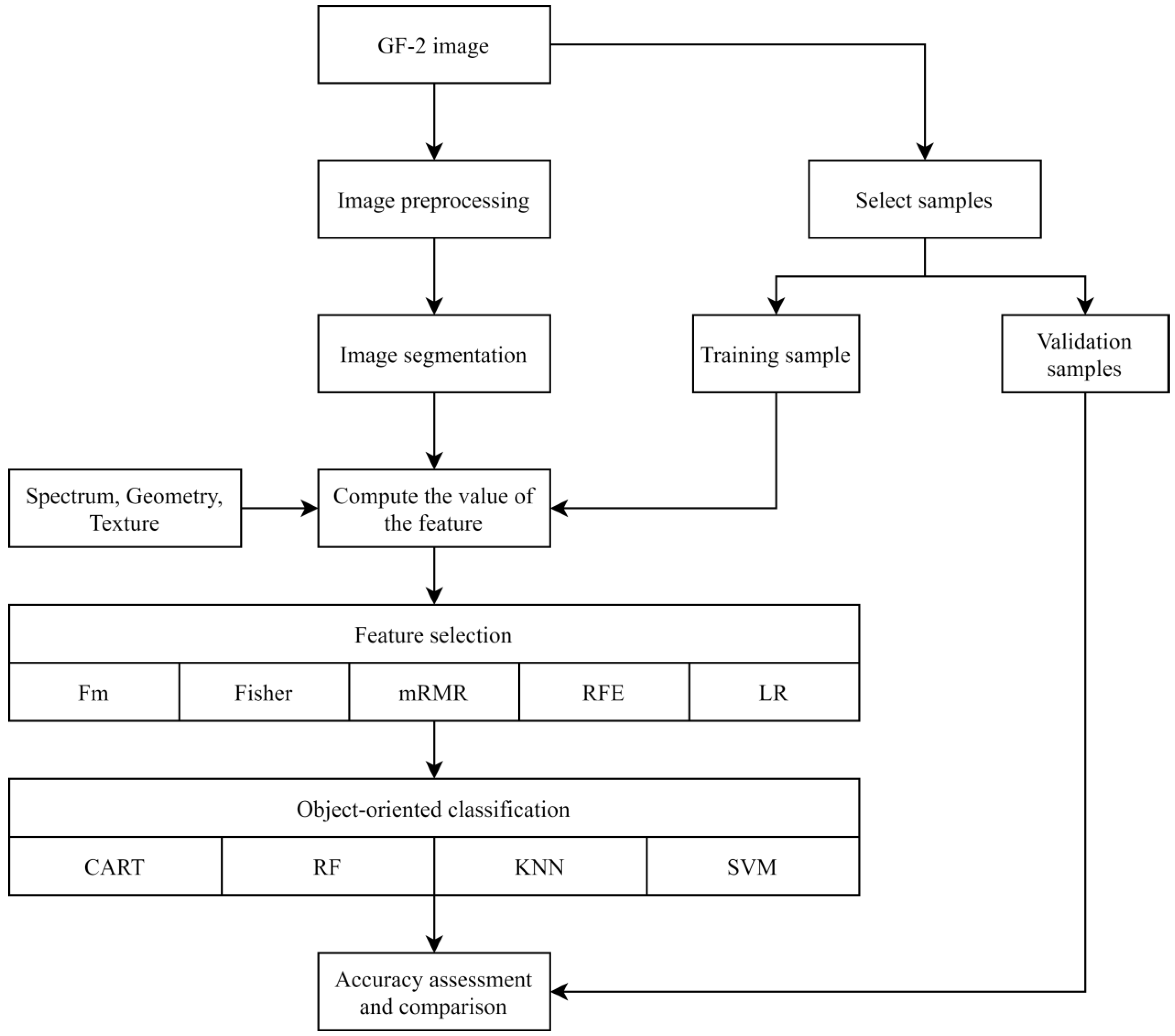
3. Research Methods
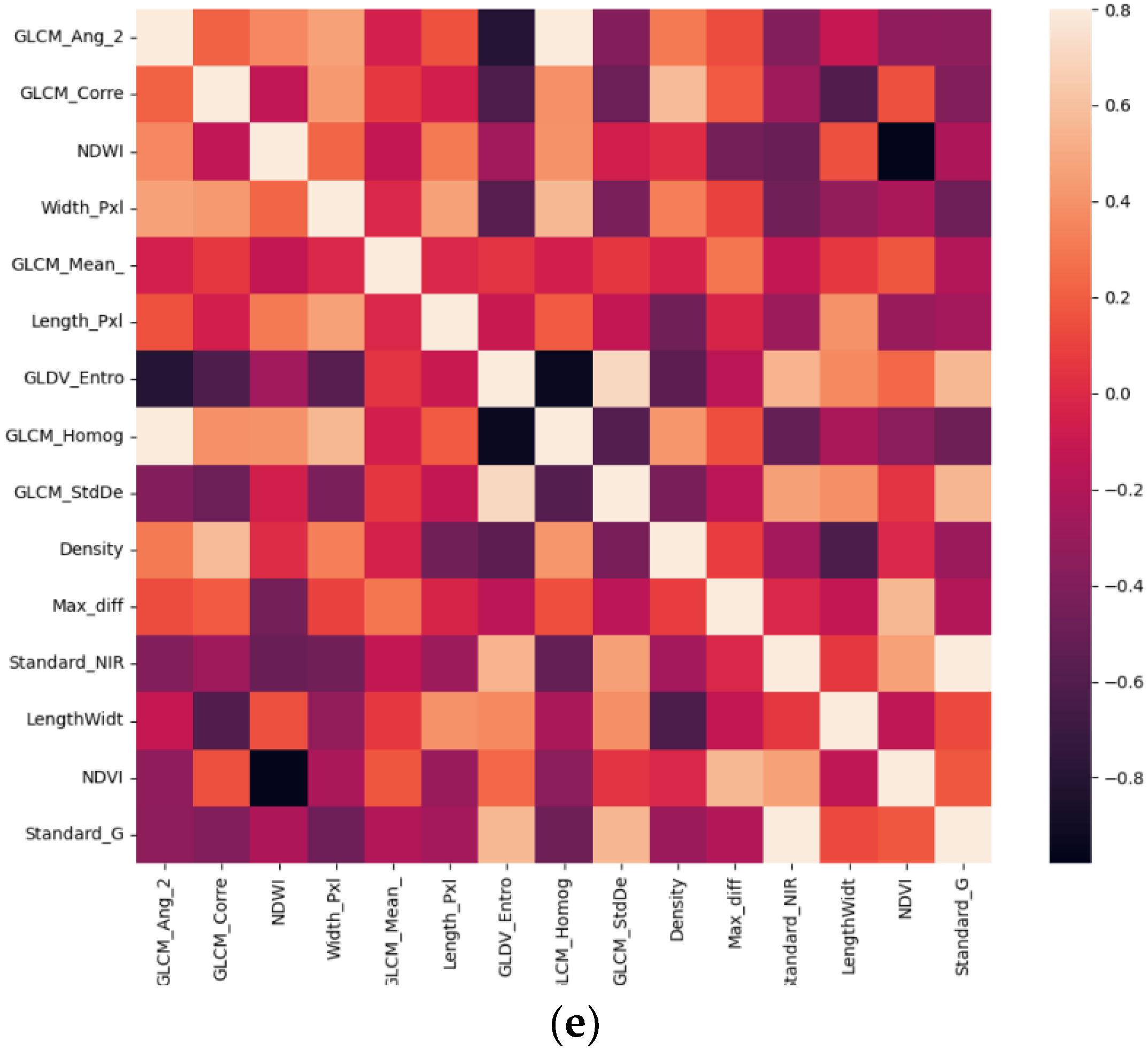
3.1. Build the Feature Space
3.2. Feature Selection
3.3. Image Classification
4. Object-Oriented Classification Process
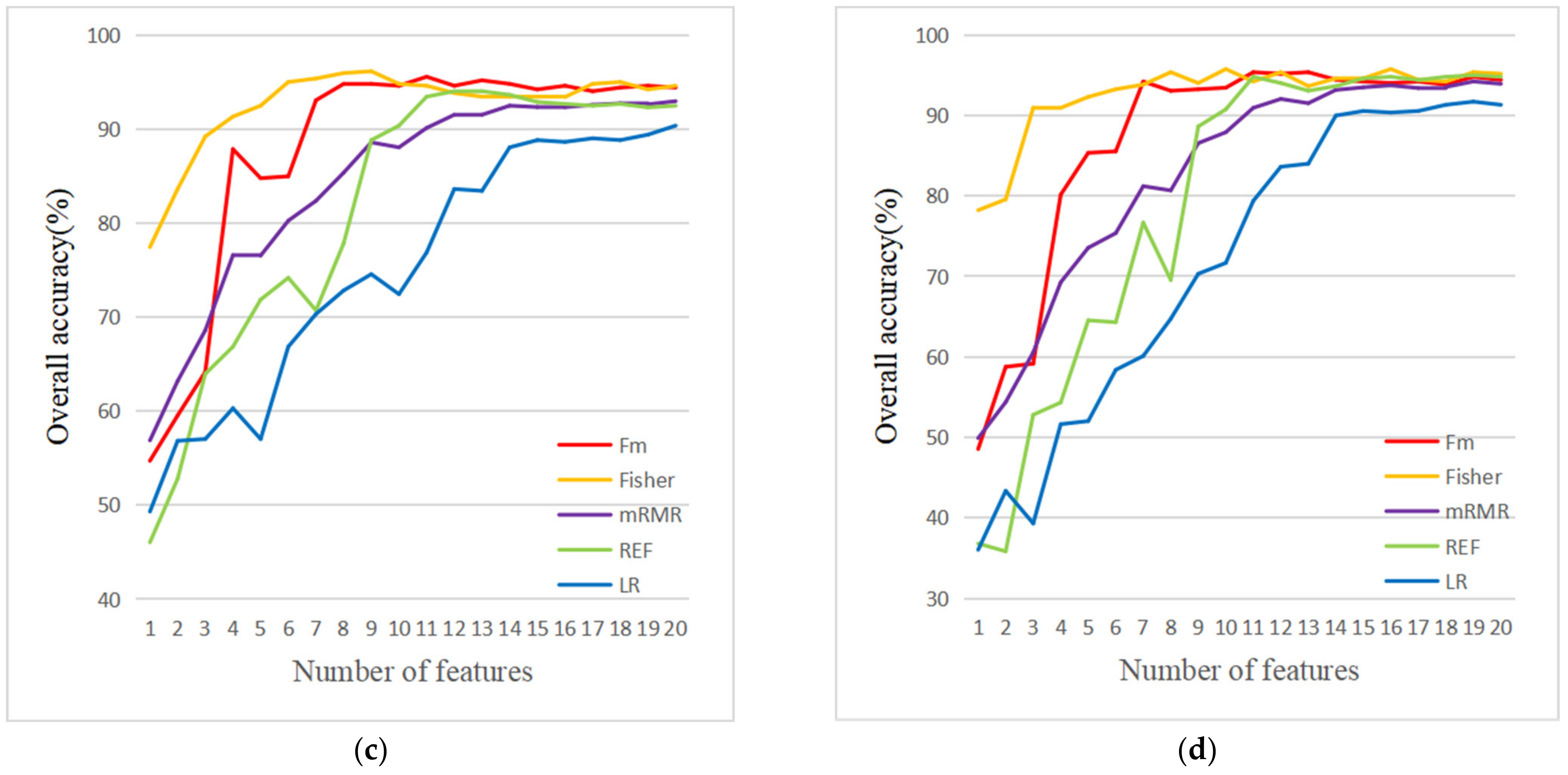
4.1. Feature Selection Results
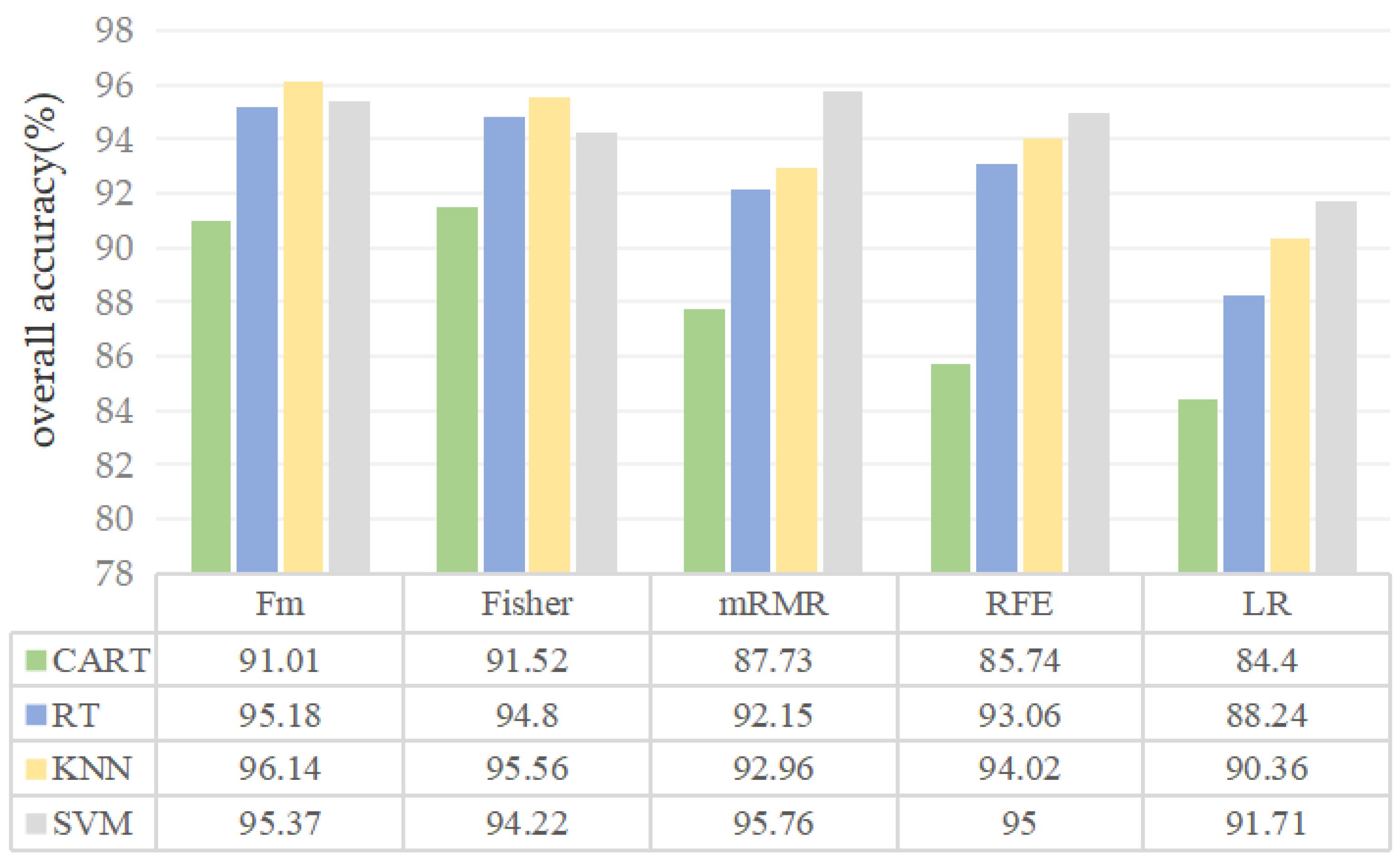
4.2. Comparison of Classification Results
4.3. Classification Results
4.4. Validation of the Fm Method
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Muzirafuti, A.; Cascio, M.; Lanza, S.; Randazzo, G. UAV Photogrammetry-based Mapping of the Pocket Beaches of Isola Bella Bay, Taormina (Eastern Sicily). In Proceedings of the 2021 International Workshop on Metrology for the Sea; Learning to Measure Sea Health Parameters (MetroSea), Reggio Calabria, Italy, 4–6 October 2021; pp. 418–422. [Google Scholar]
- Randazzo, G.; Italiano, F.; Micallef, A.; Tomasello, A.; Cassetti, F.P.; Zammit, A.; D’Amico, S.; Saliba, O.; Cascio, M.; Cavallaro, F.; et al. WebGIS Implementation for Dynamic Mapping and Visualization of Coastal Geospatial Data: A Case Study of BESS Project. Appl. Sci. 2021, 11, 8233. [Google Scholar] [CrossRef]
- Hong, L.; Feng, Y.F.; Peng, H.Y.; Chu, S.S. Classification of high spatial resolution remote sensing imagery based on object-oriented multi-scale weighted sparse representation. Acta Geod. Cartogr. Sin. 2022, 51, 224–237. [Google Scholar] [CrossRef]
- Wang, H.; Wang, C.B.; Wu, H.G. Using GF-2 Imagery and the Conditional Random Field Model for Urban Forest Cover Mapping. Remote Sens. Lett. 2016, 7, 378–387. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Feng, X.Z.; Jiang, H. Feature set optimization in object-oriented methodology. J. Remote Sens. 2009, 13, 664–669. [Google Scholar] [CrossRef]
- Stefanos, G.; Tais, G.; Sabine, V.; Morutz, S.; Stamatis, K.; Eleonore, W. Less is more: Optimizing classification performance through feature selection in a very-high-resolution remote sensing object-based urban application. GISci. Remote Sens. 2018, 55, 221–242. [Google Scholar]
- Xue, B.; Zhang, M.; Browne, W.N.; Yao, X. A Survey on Evolutionary Computation Approaches to Feature Selection. IEEE Trans. Evol. Comput. 2016, 20, 606–626. [Google Scholar] [CrossRef]
- Li, J.; Cheng, K.; Wang, S.; Morstatter, F.; Trevino, R.P.; Tang, J.; Liu, H. Feature Selection: A Data Perspective. ACM Comput. Surv. (CSUR) 2017, 50, 1–45. [Google Scholar] [CrossRef]
- Dokeroglu, T.; Deniz, A.; Kiziloz, H.E. A Comprehensive Survey on Recent Metaheuristics for Feature Selection. Neurocomputing 2022, 494, 269–296. [Google Scholar] [CrossRef]
- Saúl, S.F.; Carrasco-Ochoa, J.A.; José, M.T. A new hybrid filter-wrapper feature selection method for clustering based on ranking. Neurocomputing 2016, 214, 866–880. [Google Scholar]
- Zhao, L.; Gong, J.X.; Huang, D.R.; Hu, C. Fault feature selection method of gearbox based on Fisher Score and maximum information coefficient. Control. Decis. 2021, 36, 2234–2240. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhang, R.; Wang, S.X.; Wang, F.T. Feature Selection Method Based on High-Resolution Remote Sensing Images and the Effect of Sensitive Features on Classification Accuracy. Sensors 2018, 18, 2013. [Google Scholar] [CrossRef]
- Liu, W.; Wang, J.Y. Recursive elimination–election algorithms for wrapper feature selection. Appl. Soft Comput. J. 2021, 113, 107956. [Google Scholar] [CrossRef]
- Li, M.; Kamili, M. Research on Feature Selection Methods and Algorithms. Comput. Technol. Dev. 2013, 23, 16–21. [Google Scholar] [CrossRef]
- Wu, D.; Guo, S.C. An improved Fisher Score feature selection method and its application. J. Liaoning Tech. Univ. (Nat. Sci.) 2019, 38, 472–479. [Google Scholar]
- Gu, Q.Q.; Li, Z.H.; Han, J.W. Generalized Fisher Score for Feature Selection. arXiv 2012, arXiv:1202.3725. [Google Scholar]
- Cheng, X.M.; Shen, Z.F.; Xing, T.Y.; Xia, L.G.; Wu, T.J. Efficiency and accuracy analysis of multi-spectral remote sensing image classification based on mRMR feature optimization algorithm. J. Geo-Inf. Sci. 2016, 18, 815–823. [Google Scholar] [CrossRef]
- Chen, S.L.; Gao, X.X.; Liao, Y.F.; Deng, J.B.; Zhou, B. Wetland classification method of Dongting Lake district based on CART using GF-2 image. Bull. Surv. Map. 2021, 6, 12–15. [Google Scholar] [CrossRef]
- Gómez, C.; Wulder, M.A.; Montes, F.; Delgado, J.A. Modeling Forest Structural Parameters in the Mediterranean Pines of Central Spain using QuickBird-2 Imagery and Classification and Regression Tree Analysis (CART). Remote Sens. 2012, 4, 135–159. [Google Scholar] [CrossRef]
- Gu, H.Y.; Yan, L.; Li, H.T.; Jia, Y. An Object-based Automatic Interpretation Method for Geographic Features Based on Random Forest Machine Learning. Geomat. Inf. Sci. Wuhan Univ. 2016, 41, 228–234. [Google Scholar] [CrossRef]
- Dennis, C.D.; Steven, E.F.; Monique, G.D. A comparison of pixel-based and object-based image analysis with selected machine learning algorithms for the classification of agricultural landscapes using SPOT-5 HRG imagery. Remote Sens. Environ. 2012, 118, 259–272. [Google Scholar]
- Voisin, A.; Krylov, V.A.; Moser, G.; Serpico, S.B.; Zerubia, J. Supervised Classification of Multisensor and Multiresolution Remote Sensing Images with a Hierarchical Copula-Based Approach. IEEE Trans. Geosci. Remote Sens. 2014, 52, 3346–3358. [Google Scholar] [CrossRef]
- Paradis, E. Probabilistic unsupervised classification for large-scale analysis of spectral imaging data. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 102675. [Google Scholar] [CrossRef]
- Liu, S.; Jiang, Q.G.; Ma, Y.; Xiao, Y.; Li, Y.H.; Cui, C. Object-oriented Wetland Classification Based on Hybrid Feature Selection Method Combining with Relief F/Mult-objective Genetic. Trans. Chin. Soc. Agric. Mach. 2017, 48, 119–127. [Google Scholar] [CrossRef]
- Zhang, W.Q.; Li, X.R.; Zhao, L.Y. Discovering the Representative Subset with Low Redundancy for Hyperspectral Feature Selection. Remote Sens. 2019, 11, 1341. [Google Scholar] [CrossRef]
- Wang, L.; Gong, G.H. Multiple features remote sensing image classification based on combining ReliefF and mRMR. Chin. J. Stereol. Image 2014, 19, 250–257. [Google Scholar] [CrossRef]
- Wu, Q.; Zhong, R.F.; Zhao, W.J.; Song, K.; Du, L.M. Land-cover classification using GF-2 images and airborne lidar data based on Random Forest. Int. J. Remote Sens. 2019, 40, 2410–2426. [Google Scholar] [CrossRef]
- Shao, L.Y.; Zhou, Y. Application of improved oversampling algorithm in class-imbalance credit scoring. Appl. Res. Comput. 2019, 36, 1683–1687. [Google Scholar] [CrossRef]
- Zhu, J.F.; Li, F.; Lu, B.X. Comparative Study of Fisher and KNN Discriminant Classification Algorithms Based on Clustering Improvement. J. Anhui Agric. Sci. 2019, 47, 250–252, 257. [Google Scholar]
- Xu, X.Y.; Zhao, L.Z.; Chen, X.Y.; He, Z.C. Design of Convolutional Neural Network Based on Improved Fisher Discriminant Criterion. Comput. Eng. 2020, 46, 255–260, 266. [Google Scholar] [CrossRef]
- Huang, L.S.; Ruan, C.; Huang, W.J.; Shi, Y.; Peng, D.L.; Ding, W.J. Wheat Powdery mildew monitoring based on GF-1 remote sensing image and relief-mRMR-GASVM model. Trans. Chin. Soc. Agric. Eng. 2018, 34, 167–175, 314. [Google Scholar] [CrossRef]
- Özyurt, F. A fused CNN model for WBC detection with MRMR feature selection and extreme learning machine. Soft Comput. 2020, 24, 163–8172. [Google Scholar] [CrossRef]
- Huang, L.; Xiang, Z.J.; Chu, H. Remote sensing image classification algorithm based on mRMR selection and IFCM clustering. Bull. Surv. Map. 2019, 4, 32–37. [Google Scholar] [CrossRef]
- Zhang, X.L.; Zhang, F.; Zhou, N.; Zhang, J.J.; Liu, W.F.; Zhang, S.; Yang, X.J. Near-Infrared Spectral Feature Selection of Water-Bearing Rocks Based on Mutual Information. Spectrosc. Spectr. Anal. 2021, 41, 2028–2035. [Google Scholar] [CrossRef]
- Wu, C.W.; Liang, J.H.; Wang, W.; Li, C.S. Random Forest Algorithm Based on Recursive Feature Elimination. Stat. Decis. 2017, 21, 60–63. [Google Scholar] [CrossRef]
- Fan, T.C.; Jia, Y.F.; Li, Y.F.; Zhao, J.L. Prediction of Gully Distribution Probability in Yanhe Basin Based on Remote Sensing lmage and Logistic Regression Model. Res. Soil Water Conserv. 2022, 29, 316–321. [Google Scholar] [CrossRef]
- Luo, H.X.; Li, M.F.; Dai, S.P.; Li, H.L.; Li, Y.P.; Hu, Y.Y.; Zheng, Q.; Yu, X.; Fang, J.H. Combinations of Feature Selection and Machine Learning Algorithms for Object-Oriented Betel Palms and Mango Plantations Classification Based on Gaofen-2 Imagery. Remote Sens. 2022, 14, 1757. [Google Scholar] [CrossRef]
- Lu, L.Z.; Tao, Y.; Di, L.P. Object-Based Plastic-Mulched Landcover Extraction Using Integrated Sentinel-1 and Sentinel-2 Data. Remote Sens. 2018, 10, 1820. [Google Scholar] [CrossRef]
- Yang, H.B.; Li, F.; Wang, W.; Yu, K. Estimating Above-Ground Biomass of Potato Using Random Forest and Optimized Hyperspectral Indices. Remote Sens. 2021, 13, 2339. [Google Scholar] [CrossRef]
- Wang, G.Z.; Jin, H.L.; Gu, X.H.; Yang, G.J.; Feng, H.K.; Sun, Q. Remote Sensing Classification of Autumn Crops Based on Hybrid Feature Selection Model Combining with Relief F and Improved Separability and Thresholds. Trans. Chin. Soc. Agric. Mach. 2021, 52, 199–210. [Google Scholar] [CrossRef]
- Garg, R.; Kumar, A.; Prateek, M.; Pandey, K.; Kumar, S. Land Cover Classification of Spaceborne Multifrequency SAR and Optical Multispectral Data using Machine Learning. Adv. Space Res. 2021, 69, 1726–1742. [Google Scholar] [CrossRef]
- Zhang, S.; Huang, H.; Huang, Y.; Cheng, D.; Huang, J. A GA and SVM Classification Model for Pine Wilt Disease Detection Using UAV-Based Hyperspectral Imagery. Appl. Sci. 2022, 12, 6676. [Google Scholar] [CrossRef]
- Hu, J.M.; Dong, Z.Y.; Yang, X.Z. Object-oriented High-resolution Remote Sensing Image lnformation Extraction Method. Geospat. Inf. 2021, 19, 10–13, 18, 157. [Google Scholar] [CrossRef]
- Hao, S.; Cui, Y.; Wang, J. Segmentation Scale Effect Analysis in the Object-Oriented Method of High-Spatial-Resolution Image Classification. Sensors 2021, 21, 7935. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Type | Feature Name | Number of Features |
|---|---|---|
| Spectrum | Mean value of bands 1–4, Standard deviation of bands 1–4, Brightness, Max. diff, NDVI, NDWI | 12 |
| Geometry | Area, Length, Width, Length/Width, Density, Compactness, Border length, Number of pixels | 8 |
| Texture | Homogeneity, Contrast, Dissimilarity, Ang. 2nd moment, Entropy, Correlation, StdDev, Mean | 12 |
| Fm | Fisher | mRMR | REF | LR |
|---|---|---|---|---|
| Standard_G | NDVI | Standard_R | GLCM_Entropy | GLCM_Ang_2nd moment |
| Density | NDWI | NDVI | Compactness | GLCM_Correlation |
| Standard_R | Mean_NIR | Length/Width | Standard_B | NDWI |
| Mean_B | Mean_B | GLCM_StdDev | Standard_R | Width |
| Width_Pxl | Area_Pxl | Standard_G | LengthWidt | GLCM_Mean |
| Border_length | Standard_B | Density | GLCM_StdDev | length |
| NDVI | Standard_NIR | Compactness | GLCM_Dissimilarity | GLDV_Entropy |
| Max_diff | Max_diff | GLCM_Correlation | GLCM_Mean_ | GLCM_Homogeneity |
| GLDV_Entropy | Mean_R | GLCM_Dissimilarity | Mean_B | GLCM_StdDev |
| Standard_B | Width | Mean_B | Mean_G | Density |
| NDWI | Mean_G | Width_Pxl | Mean_NIR | max_diff |
| Mean_NIR | GLCM_Homogeneity | NDWI | Mean_R | Standard_NIR |
| GLDV_Ang_2nd moment | Standard_G | Number_of_ | Standard_G | Length/Width |
| Mean_R | GLCM_Ang_2nd moment | Standard_B | GLDV_Entropy | NDVI |
| GLCM_Homogeneity | Brightness | GLCM_Mean | Standard_NIR | Standard_G |
| Feature Selection Method | Feature Description | Spectral | Geometric | Texture |
|---|---|---|---|---|
| Fm | Number of features | 9 | 3 | 3 |
| Top 15 feature ratios | 60.00% | 20.00% | 20.00% | |
| Fisher | Number of features | 11 | 2 | 2 |
| Top 16 feature ratios | 73.33% | 13.33% | 13.33% | |
| mRMR | Number of features | 7 | 5 | 4 |
| Top 17 feature ratios | 46.67% | 33.33% | 26.67% | |
| REF | Number of features | 8 | 2 | 5 |
| Top 18 feature ratios | 53.33% | 13.33% | 33.33% | |
| LR | Number of features | 5 | 4 | 6 |
| Top 19 feature ratios | 33.33% | 26.67% | 40.00% |
| Fisher-CART | Fm-RF | Fm-KNN | mRMR-SVM | |||||
|---|---|---|---|---|---|---|---|---|
| Producer’s accuracy | User’s accuracy | Producer’s accuracy | User’s accuracy | Producer’s accuracy | User’s accuracy | Producer’s accuracy | User’s accuracy | |
| Roads | 95.00% | 76.61% | 97.00% | 93.26% | 93.00% | 95.87% | 97.00% | 89.81% |
| Buildings | 74.00% | 91.02% | 85.00% | 91.40% | 92.00% | 91.08% | 85.00% | 94.44% |
| Water | 92.93% | 97.87% | 93.94% | 97.90% | 96.96% | 98.96% | 97.98% | 98.97% |
| Bare land | 97.14% | 94.44% | 100% | 90.90% | 98.57% | 94.52% | 98.57% | 97.18% |
| Vegetation | 99.33% | 98.68% | 99.33% | 99.33% | 99.33% | 98.67% | 99.33% | 98.03% |
| Overall accuracy | 91.52% | 95.18% | 96.14% | 95.76% | ||||
| Kappa | 0.8923 | 0.939 | 0.951 | 0.9461 | ||||
| CART | RF | KNN | SVM | |
|---|---|---|---|---|
| Overall accuracy | 88.67% | 92.04% | 91.08% | 88.68% |
| Kappa | 0.8545 | 0.8979 | 0.8852 | 0.8546 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lv, C.; Lu, Y.; Lu, M.; Feng, X.; Fan, H.; Xu, C.; Xu, L. A Classification Feature Optimization Method for Remote Sensing Imagery Based on Fisher Score and mRMR. Appl. Sci. 2022, 12, 8845. https://doi.org/10.3390/app12178845
Lv C, Lu Y, Lu M, Feng X, Fan H, Xu C, Xu L. A Classification Feature Optimization Method for Remote Sensing Imagery Based on Fisher Score and mRMR. Applied Sciences. 2022; 12(17):8845. https://doi.org/10.3390/app12178845
Chicago/Turabian StyleLv, Chengzhe, Yuefeng Lu, Miao Lu, Xinyi Feng, Huadan Fan, Changqing Xu, and Lei Xu. 2022. "A Classification Feature Optimization Method for Remote Sensing Imagery Based on Fisher Score and mRMR" Applied Sciences 12, no. 17: 8845. https://doi.org/10.3390/app12178845
APA StyleLv, C., Lu, Y., Lu, M., Feng, X., Fan, H., Xu, C., & Xu, L. (2022). A Classification Feature Optimization Method for Remote Sensing Imagery Based on Fisher Score and mRMR. Applied Sciences, 12(17), 8845. https://doi.org/10.3390/app12178845