1. Introduction
The European directive 2002/49/EC [
1] encouraged agglomerations of people, namely, cities or groups of cities nearby, to create their strategic noise mapping (SNM) sharing the results with citizens. Moreover, the results of these noise maps led to the establishment of noise-reduction action plans where noise exposure protection zones are defined. To create performance reports with the data obtained in the strategic noise map and to define special noise protection areas within the city, data are usually analyzed by descriptive analysis, with basic statistics, such as the average or median of the defined noise indicator obtained for the overall assessment period. In general, using these statistics, two main types of areas are proposed relying on the places where values are higher than a certain recommended sound level, known as special regime areas, and others where their noise exposure is lower than the average, known as quiet areas. However, the acoustic environment of an area is a complex phenomenon that needs to be characterised not only by the noise levels in the area, but also by other properties such as its behavior in different time periods of the day and its long-term variation. Therefore, it would be interesting to explore the application of clustering techniques for the identification of areas with different behavior in relation to the noise environment.
Murphy et al. [
2] analyzed the methodological issues concerning the implementation of the directive across different countries of the European Union (EU), and dealing specifically with noise calculation and noise mapping, highlighting the implications of these issues for cross-country sharing of results. Moreover, a recent research [
3] also summarizes the challenges to be faced by the EU Members and concludes that the opportunity to set up a common database of noise exposure based on common methods should be seized on time, encouraging local administrations to establish common frameworks. In the period 2021–2027, the European Commission will invest in a High Impact Project on European data spaces and federated cloud infrastructures to encourage the establishment of EU-wide common, inter-operable data spaces in strategic sectors, such as mobility and health, and public administrations with data spaces initiatives, such as Gaia-X [
4] and Federated European Infrastructure for Genomics data and Cancer Images data [
5]. In the future, these data spaces can be used to join noise pollution data owned by public administrations to improve the health of citizens by the creation of more accurate predictive models, or obtaining better insights due to the more available data. In line with this trend, the application of unsupervised learning algorithms using federated data are proposed in this work to identify different acoustic environments that can help city managers to define personalized action plans for each behavior and share data in a common framework.
In recent years, large cities are deploying Wireless Acoustic Sensor Networks (WASN), based on Internet of Things (IoT) technologies [
6], to perform continuous monitoring of environmental acoustic parameters at many locations [
7]. The acoustic nodes that compose these networks continuously capture information regarding the sound environment over long periods, generating a large amount of data. These acoustic data, together with further environmental data, such as water quality [
8] or air pollution [
9], are being used by city managers to make decisions and propose improvement actions. Moreover, this smart city system has given rise to the creation of the so-called dynamic noise maps where SNM is more often updated, each day for instance, by integrating data obtained from acoustic sensors and the application of predictive models of sound propagation in cities [
10]. The improvement of SNM has been the goal of researchers, such as Puyana-Romero et al. [
11] who concludes that colors add supplementary and more intuitive information on soundscape to those provided by the acoustic parameters. In this work, acoustic datasets from WASN deployed in Barcelona and Madrid cities, Spain, are used for comparison of several machine learning clustering techniques.
Machine Learning has been used with acoustic data, both audio signal and sound level indexes, to help cities to manage noise in recent literature. On one hand, supervised learning techniques were applied to identify the main noise source of the acoustic environment using Mel-frequency cepstral coefficients as features with Gaussian Mixture Model and Artificial Neural Networks as algorithms [
12]. In reference [
13], Convolutional Neural Networks (CNN) were evaluated to classify urban sound events using local features of short-term sound recording features and with long-term descriptive statistics. Additionally, CNN was implemented to detect anomalous noise source detection to remove unrelated road traffic noise events and then generate a noise map [
14]. Another study using CNN over acoustic signal recordings developed a system to detect the presence of an unmanned aerial vehicle in a complex urban acoustic scenario focusing on cities security [
15]. On the other hand, the unsupervised learning technique Hierarchical Agglomeration was trained to optimize the choice and the number of monitoring sites [
16] for defining a methodology to estimate the mean
and
levels in urban roads with the noise profiles detected in the clustering [
10]. Additionally, the K-means method was trained in reference [
17] to identify sound pressure level patterns.
In this paper, the performance of several data clustering techniques is evaluated for discovering and analyzing different behavior patterns of the sound pressure level. A comparison of clustering techniques is carried out using noise data from two large cities, considering isolated and federated data. After this introduction, datasets, applied techniques, and evaluation metrics are described in the next
Section 2. Then, the results of the comparison together with a discussion and an analysis of these results are presented in
Section 3. Finally, the main conclusions of this work are summarized in
Section 4.
2. Materials and Methods
This section presents materials and methods applied during this research. Two datasets, described in
Section 2.1, containing sound pressure level indicators for fixed locations during a long period were used. Additionally, a third federated dataset has been created, joining the previous one involving the nodes of both cities together. The list and references for the clustering techniques used in this work can be found in
Section 2.2. Once the models are trained, an evaluation of their performance allows for comparing the different algorithms using three different metrics that analyze the internal structure of the clusters. The definition of the metrics is presented in
Section 2.3. Last, the software and hardware used to perform all the processing and analysis can be found in
Section 2.4.
2.1. Data Sources
This research has considered datasets from two different WASNs deployed in big cities, Barcelona and Madrid, Spain, and collected sound pressure level values.
On one hand, the network of acoustics nodes deployed in Barcelona, denoted in this work by
, by the city council during the last years consists of 86 sound sensors [
18,
19]. The dataset used in this research was collected from 70 of the 86 sound sensors that were chosen for reasons of stability of the data over time and homogeneity in the spatial distribution of the nodes. The data were provided by the Barcelona City Council after a request from the authors. In the Acknowledgments section, the names of the data managers are indicated. As a summary, the data captured using Cesva TA120 [
20] remote sonometers, considering international standards [
21,
22], is aggregated and sent to a data platform called
Plataforma de Sensors i Actuadors de Barcelona [
23]. A detailed explanation about the technological structure of the WASN and the data pipeline process involved can be found in Camps et al. [
18]. A description of the data source, the transformations carried out, the variables created, along with the distribution of the nodes is provided in a previous article of the authors [
17].
On the other hand, the acoustic pollution monitoring network of the city of Madrid has 31 permanent stations, denoted in this work by
, in charge of the control and continuous monitoring of the existing noise levels. Garrido et al. [
24] described Madrid’s WASN in detail showing how sound pressure level measurement dataset of these stations was retrieved from the acoustic pollution sensors and stored in a database management system platform that allows data analysts to work with the data in a structured way. The data are available on the Madrid council’s open data portal [
25]. In particular, data from recent years can be downloaded in the acoustic pollution data repository [
26]. In the current research, only data from 2019 from both cities have been selected to explore a regular year period and avoid the pandemic period. More details regarding descriptive analysis and data processing can be found in previous authors’ studies [
17,
27] for both cities.
Figure 1 shows the location of the chosen nodes in both cities.
These datasets are transformed into a normalized common structure that allows the comparison. The common structure is an structure table where rows represent each node with the following features:
,
,
and
(
). Three first sound pressure level features have been selected considering the recommendations established in Directive 2002/49/EC [
1] and to take into account levels during different time periods of the day. The last feature has been chosen to take into account long-term variation of the main parameter
in Directive 2002/49/EC [
1]. These acoustic parameters are defined below.
ISO 1996-2: 2017 [
22] developed by the technical committee ISO/TC 43/SC 1 Noise describes how sound pressure levels intended as a basis for assessing environmental noise limits or comparison of scenarios in spatial studies can be determined. Determination can be performed by direct measurement and by extrapolation of measurement results through calculation. In this research, the definition, notations, and calculations performed over acoustic data follow the referred ISO [
22]. As the sound pressure
p(
t) is measured continuously over a given time period
for all
, to quantify the sound level on a single value using the equivalent sound pressure level in dB, denoted as
, Equation (
1) is used.
where
is the sound pressure reference value equal to 20
Pa. In particular, deployed nodes compute the A frequency-weighting equivalent sound pressure level of one minute period, denoted as
in dBA unit, applying Equation (
1).
From these one minute period data,
,
and
, defined as the A-weighted long-term average sound pressure level for day, evening and night periods respectively, are calculated using Equation (
2). These features are determined over all the day periods (07:00–19:00 h), evening periods (19:00–23:00 h), and night periods (23:00–07:00 h), respectively, across all the assessment periods.
where
n is the total number of 1-unit time intervals in period
T and
is the equivalent sound pressure level in the interval
i obtained by the sensor applying Equation (
1). For instance, to calculate
, 60 values of
are averaged.
Finally, the daily standard deviation
(
) is computed.
, defined in Equation (
3), refers to the day–evening–night noise indicator obtained for an overall annoyance in the assessment period [
1] for one year.
2.2. Unsupervised Learning Algorithms
There are a large number of algorithms in the literature dedicated to data clustering. In this research, several representative algorithms from three unsupervised learning approaches, in particular, hierarchical, partitional, and model-based techniques have been considered to evaluate which one performs better over acoustic data. As it is mentioned in
Section 1, Hierarchical Agglomeration and K-means have been previously applied to acoustic data. In this paper, other clustering algorithms, together with the mentioned above, were trained to fit the data:
- 1.
HC: Hierarchical Agglomeration [
28];
- 2.
DIANA: a divisive hierarchical algorithm [
29];
- 3.
- 4.
PAM: Partitioning Around Medoids [
31];
- 5.
CLARA: the sampling-based algorithm [
29];
- 6.
SOM: Kohonen Self-Organizing Maps [
32];
- 7.
SOTA: the Self-Organizing Tree Algorithm [
33];
- 8.
GAUSS: Expectation Maximization (EM) algorithm over a finite mixture of Gaussian distributions [
34].
Hierarchical Agglomeration [
28] and DIANA [
29] methods, belonging to hierarchical clustering methods, create the clusters grouping the elements in hierarchical steps. K-means [
30], PAM [
31] and CLARA [
29] methods, belonging to partitional clustering methods, are based on centroids and they iterative the algorithm until convergence. Moreover, SOM [
32] technique applies an unsupervised neural network, and SOTA [
33] is an evolution of the SOM algorithm which included a binary tree topology, both belonging to model-based methods, in this case in machine learning algorithms. Finally, GAUSS [
34] technique is based on the maximization of the likelihood for a statistical distribution, belonging to model-based methods, in this case in statistical normal distributions.
In reference [
35], a revision of different approaches for grouping similar objects into different groups is presented with an analysis of the advantages and disadvantages of every algorithm family. The features for the clustering algorithms chosen for this work are summarized in
Table 1.
2.3. Evaluation Metrics
For the evaluation and comparison of the clustering algorithms, Berry et al. [
36] proposed two criteria for clustering evaluation and selection of an optimal clustering scheme: compactness and separation. Later, Hand et al. [
37] introduce a new criteria: connectedness. In this article, these three internal characteristics are chosen to be calculated and analyzed.
Connectedness is related to what extent observations are placed in the same cluster as their nearest neighbors in the data space. To measure that connectivity [
38], Equation (
4) is applied. For each element
i, the
represents the
j-th nearest neighbor of
i using a distance (often euclidean distance) and
is a boolean function that takes value
when
i and
are not in the same cluster and zero otherwise. This metric is called the Connectivity metric.
where
N is the number of elements to group into
K clusters and
M is a parameter that determines the number of neighbors that contribute to the Connectivity measure, fixed to ten in this research as established in [
39]. The Connectivity metric is equal to or higher than zero and the lower the value the better the clustering trained so must be minimized.
Compactness is related to cluster cohesion or homogeneity, measuring how close are the objects within the same cluster, usually by looking at the intra-cluster or within-cluster variance. A lower within-cluster variation is an indicator of good compactness, and, hence, a good clustering. So compactness must be minimized. The different indices for evaluating the compactness of clusters are based on distance measures, such as the cluster-wise within average/median distances between observations.
Separation measures how well-separated a cluster is from other clusters quantifying the degree of separation between clusters, usually by measuring the minimum distance between cluster centroids or the pairwise minimum distances between objects in different clusters. Therefore, separation must be maximized.
When the number of clusters increases, by definition compactness and separation used decrease. To manage this trade-off, some methods combine the two measures into a single score. The Dunn index [
40] and Silhouette width [
41] are both examples of non-linear combinations of compactness and separation.
The Dunn index aims to identify dense and well-separated clusters. It is defined as the ratio between the minimal inter-cluster distance to maximal intra-cluster distance. Equation (
5) shows how to calculate the Dunn index for clustering with
K partitions.
where
d(
i,
j) is the distance between cluster
i and
j (measuring separation) and
is the intra-cluster distance of cluster k (measuring compactness). As separation should be maximized and compactness minimized, it results in that Dunn index must be maximized.
Silhouette width estimates the average distance between clusters considering how well an observation is clustered, in particular, how close each element in one cluster is to elements in the neighboring clusters. To calculate Silhouette width, it is necessary to first calculate the average dissimilarity
between the element
i and all other elements of the cluster
k to which
i belongs (
) using Equation (
6).
representing the compactness of an element to the cluster to which belongs.
Secondly, for each element
i, the average dissimilarity
d(
i,
C) of
i to all elements of
C are calculated and the minimum is computed, as enunciated in the following Equation (
7).
where
K in the number of clusters. This metric represents the separation of an element from the rest of the clusters.
Lastly, using results from Equations (
6) and (
7), the Silhouette width for an element
i is calculated applying Equation (
8).
It is important to note that, the Silhouette coefficient of clustering is the mean of the Silhouette width of all the elements. Therefore, the objective is to maximize this index.
There are other internal validation metrics available to be used in the validation of an unsupervised learning algorithm [
42,
43,
44,
45,
46,
47] that could be alternatives to the selected ones. However, the chosen measures cover the three clustering criteria in order to evaluate and compare the trained clustering models [
37].
2.4. Software and Hardware
The preparation, transformation, analysis, and modeling of the data have been performed using the Statistical Programming Language R [
48] with the configuration presented in
Table 2 for two environments, on-premise and cloud. The latter one has been used to parallelize some tasks.
To ensure the reproducibility of the research, in every task that includes a random step, the seed using the R function set.seed() has been fixed. Due to changes in random numbers generation in R version 4.0.0, the way to generate them to be sure that the analysis will be reproducible in every R version has also been defined.
3. Results and Discussion
In this section, the results of the performance of the different unsupervised learning algorithms are shown to evaluate and compare them with the three metrics explained in
Section 2.3. Moreover, a selection of the best clustering algorithm to work with acoustic data to identify behavior patterns is completed. Additionally, a more detailed discussion of the resulting clustering is presented. This discussion is carried out by comparing cluster outputs from both federated data, that is, dataset containing data from both cities, and non-federated data, that is, dataset containing data from only one city.
For each normalized dataset, clustering algorithms listed in
Section 2.2 are trained several times, increasing the number of clusters from 3 to 12, to fit the three different datasets presented in
Section 2. For the interest of the research, the case
k = 2 is avoided because it uses to separate the nodes in one group of high sound pressure level values and another of low sound pressure level values, not adding value since that is what city managers usually do. This particular case has been enunciated in previous literature [
16,
27] that would not help to discover new knowledge.
Firstly,
Table 3 shows the results for the Connectivity metric of the different techniques.
A first comparison of the resulting values offers that the best algorithm for the Connectivity metric, the optimum algorithms are Hierarchical Agglomeration and K-means. Note that values are highlighted in
Table 3. From these results an important insight could be extrapolated, that the number of optimal clusters for the Connectivity metric holds in three.
Now, in
Table 4 the Dunn index obtained for all the algorithms and 3 to 12 clusters are shown.
It is observed that this metric aims to create a higher amount of clusters, prioritizing separation from compactness. Again, note that the highest values are highlighted. For the Dunn index, Hierarchical Agglomeration and K-means algorithms are also the top performers.
Finally,
Table 5 shows the Silhouette Width for all the clustering techniques and for the same number of clusters and the datasets previous indicated.
Hierarchical Agglomeration and K-means algorithms also maximize the Silhouette Width.
For this metric, it is shown in
Table 5 that the Barcelona dataset and the federated dataset are recommended to be split into 4 clusters, but for the Madrid dataset, the recommendation is 3 clusters. However, a hypothesis could be that Madrid only has three of the four behaviors identified in the full dataset.
As a summary, regarding the federated dataset, see
Table 3 for details, the Connectivity metric is minimized with the Hierarchical Agglomeration algorithm for
k = 3 clusters. It is important to note that, when the amount of elements to group is small, an increase in the number of clusters will increase Connectivity, thus this metric tends to select low values for the number of clusters. Then, the Dunn index selects K-means and Hierarchical Agglomeration clustering with
k = 12 clusters as can be seen in
Table 4. Finally, the Hierarchical Agglomeration algorithm for
has been selected by the Silhouette Width metric, see
Table 5, showing that the Hierarchical Agglomeration method has a good equilibrium between the three clustering characteristics presented in
Section 2.3.
After this first discussion, more details for
k = 3 and
k = 4 clusters cases are explained below. Applying the Hierarchical Agglomeration algorithm using
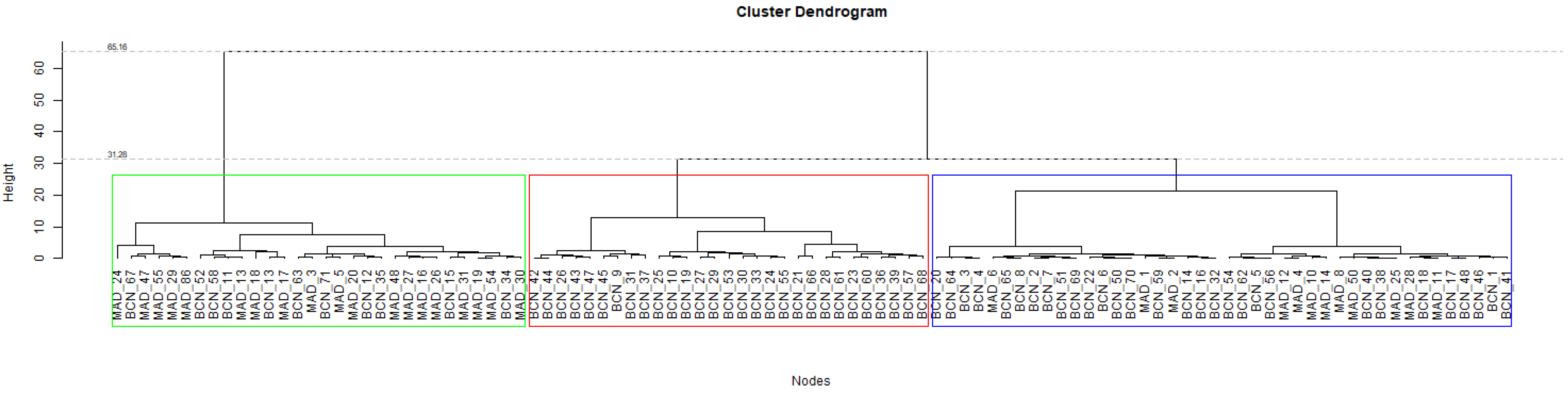
k = 3, the data are divided into different groups, as it is graphed in a Dendogram in
Figure 2. This
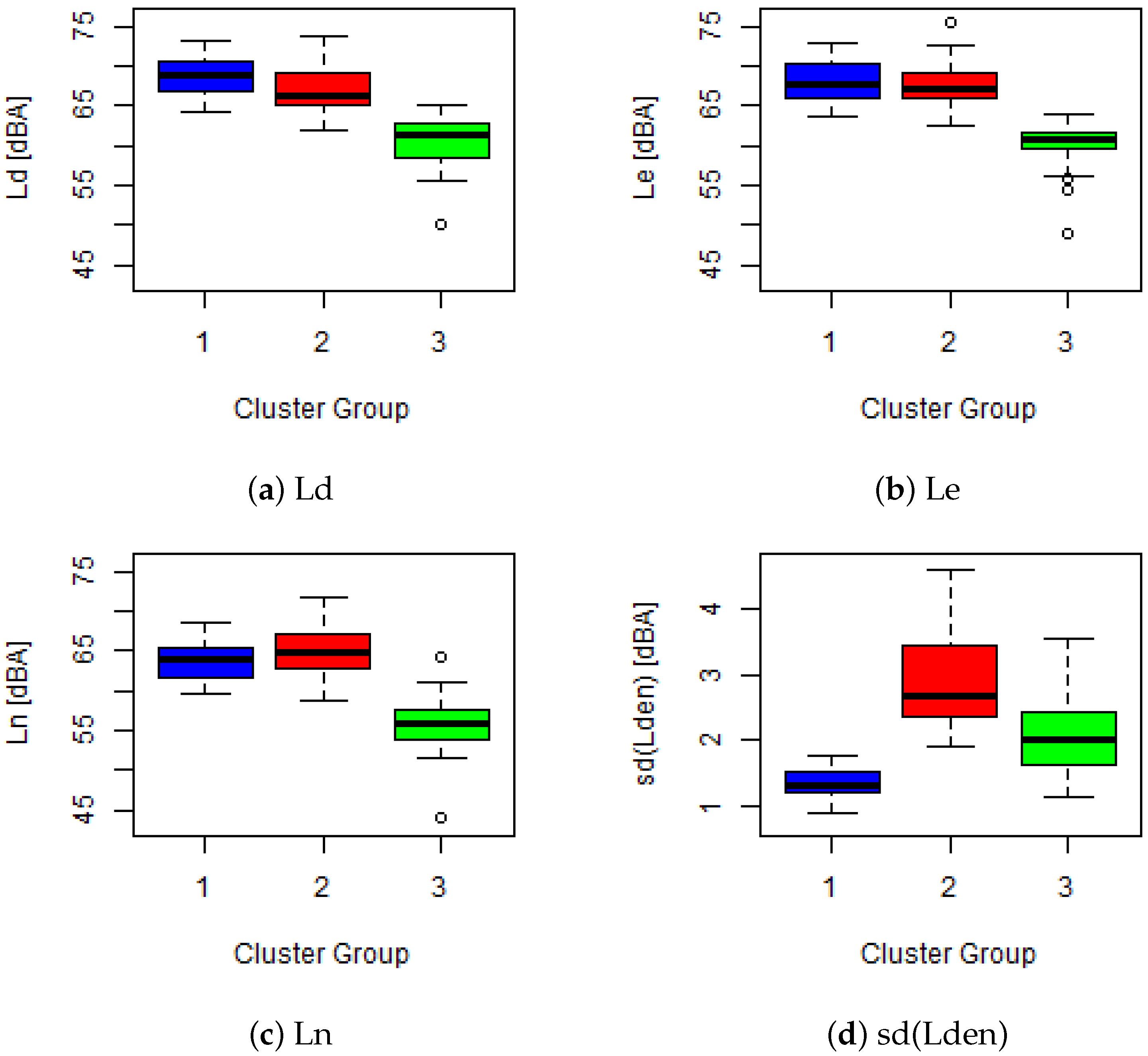
Figure 2 shows the three main patterns that the algorithm has identified. To study the behavior of these three clusters, four box-plots graphs are shown in
Figure 3, corresponding to the parameters used for the training phase,
,
,
and
(
). It can be observed in
Figure 3 that, the first cluster is related to the nodes with high sound pressure levels during the day and evening period, medium sound pressure levels during the night, and the lowest standard deviation of the three clusters, to sum up, there are 42 nodes with a stable and high noise level. The second cluster includes 29 nodes, and presents high sound pressure levels during the three periods reaching maximum noise level values, in addition to the highest standard deviation, in other words, the variation over the mean is high. Finally, the third cluster includes 30 nodes with the lowest sound pressure level during all periods. Moreover, its standard deviation is at an intermediate value between the two other clusters.
A summary of the three discovered clusters obtained with federated data is presented in
Table 6 in which the number of nodes per city is broken down together with the centroid of each acoustics parameter.
It is remarkable that, as can be seen in
Table 6, cluster number 2 only contains nodes belonging to Barcelona city, suggesting that this type of behavior is specific to this city. Moreover, the relative proportion of Madrid’s nodes in cluster number 1 is lower than in cluster number 3, showing that Madrid has nodes with lower sound pressure levels on average than Barcelona.
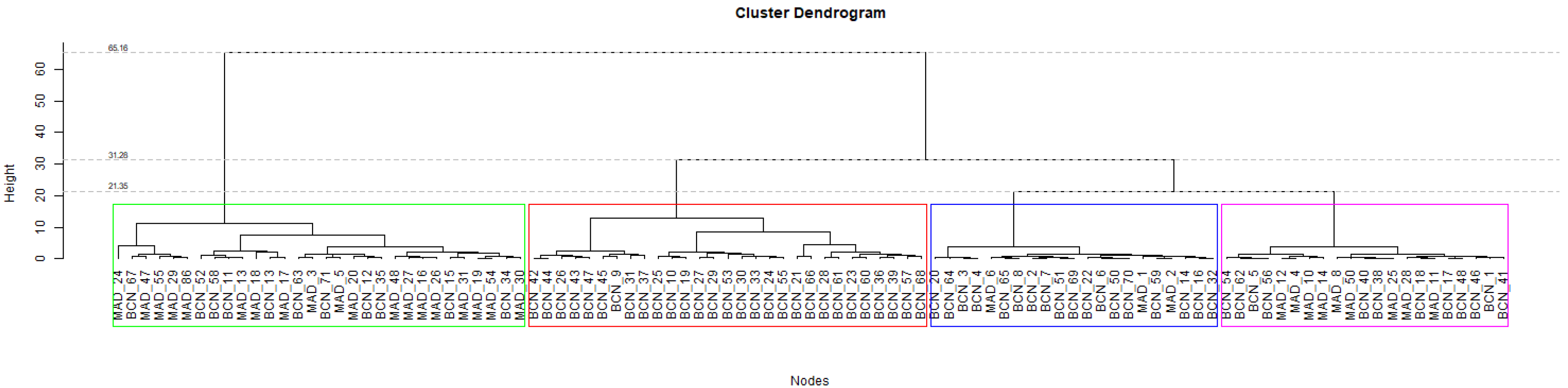
Now, Hierarchical Agglomeration is applied for
k = 4 clusters.
Figure 4 shows that previous cluster 1 (blue) with 42 nodes, obtained with
k = 3, is split into two groups with 21 nodes each (blue and magenta).
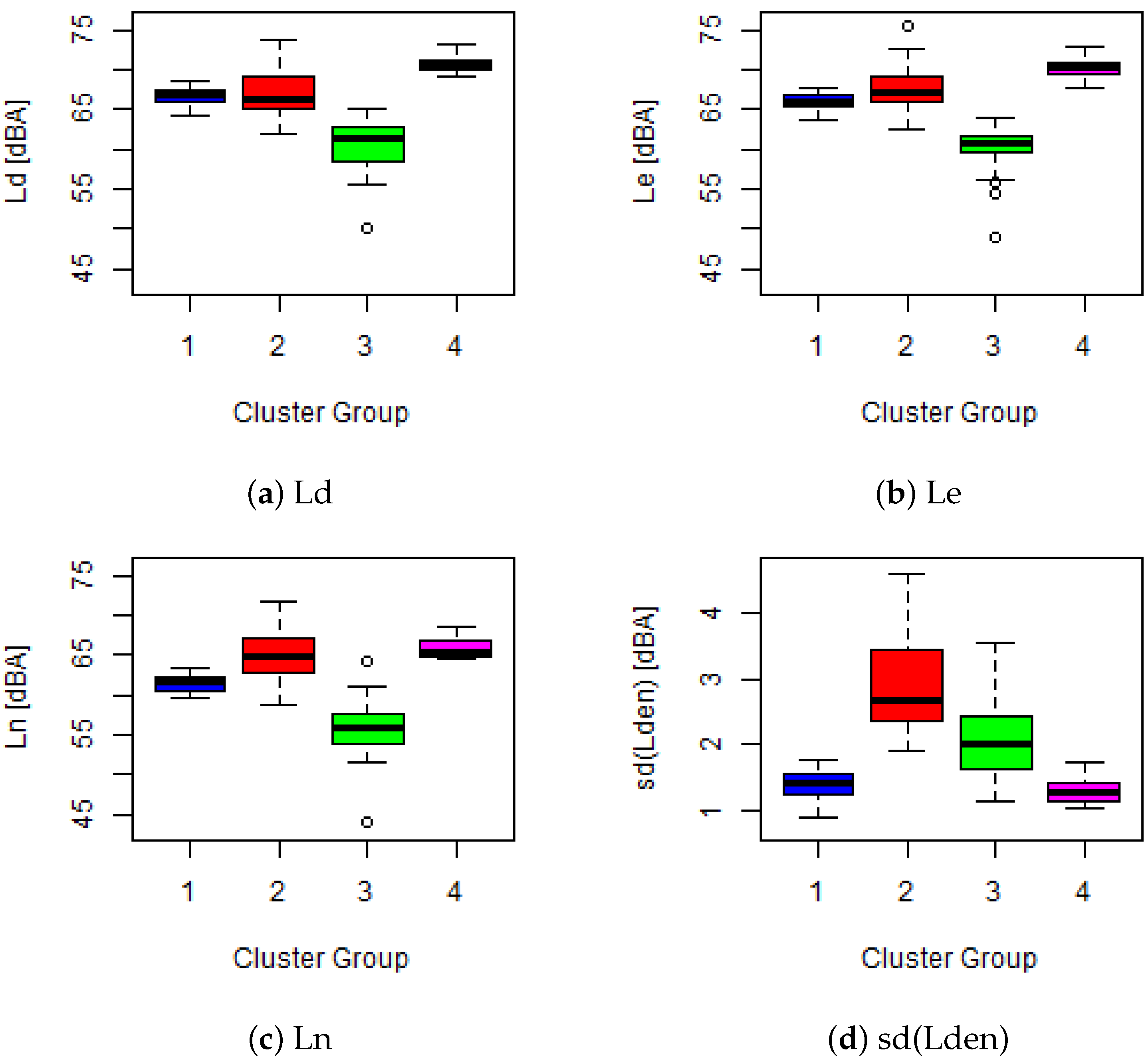
As it can be observed in the boxplots in
Figure 5, the new blue cluster presents a lower sound pressure level than magenta and red, with a significant reduction in level during the night period. However, the new magenta cluster is the one with the highest sound pressure level and the lowest variance of the 4 clusters. In this case, the red cluster has the highest standard deviation.
Table 7 summarizes the clusters showing distribution and centroids. As in the previous case, Madrid only presents three of four behaviors, explaining the outputs of the Silhouette Width metric of
k = 3 for Madrid data, and
for both Barcelona and federated data, see details in
Section 3.
Regarding the selection based on the Dunn index, from a noise pollution management perspective, it is neither useful nor easy to handle 12 clusters with only 2.6 nodes on average in Madrid and 5.8 nodes on average in Barcelona. This requires establishing 12 strategies with their associated action plans, therefore K-means for k = 12 is discarded from this analysis.
Another way to compare the results is using an external clustering validity index. If federated data clusters are considered the ground truth partition of the nodes, external evaluation metrics can select the more appropriate clustering completed in isolation. The Chi index is an external clustering validity index based on the chi-squared statistical test, very competitive that, on average, beats other external evaluation metrics [
49]. The Chi index takes a value in [0, 2], where 0 is given by the worst clustering solution, and 2 is the best value that the Chi index can achieve. Chi index results are clear to read, require no further interpretation, and help to select the optimal number of clusters based on the ground truth class.
Table 8 shows results in cross tables a comparison between the
k = 3 Hierarchical Agglomeration clustering considering the federated dataset, in rows, and the optimal cluster models trained considering isolated datasets, which are
k = 3 and
k = 4 K-means for Barcelona dataset, upper-left and lower-left, respectively, and
k = 3 K-means and
k = 2. Hierarchical for Madrid dataset, upper-right and lower-right, respectively. For instance, the upper-left cross table shows the distribution of the Barcelona nodes considering
k = 3 K-means using federated data in rows and
K-means Barcelona data in columns, so the number 9 in the second row and third columns represents the number of Barcelona nodes belonging to cluster number 2 in
k = 3 K-means model using federated data and belonging to cluster number 3 in
k = 3 K-means model using Barcelona data.
For Barcelona city, the federated dataset improves the result of the clustering compared with the Barcelona isolation data (1.104 maximum Chi index). So k = 4 K-means clustering is the best algorithm for Barcelona city based on the federated dataset clusters (chi index 1.104 versus Chi index 0.759 for k = 3 K-means algorithm). For Madrid city, the k = 3 K-means clustering is the best algorithm with a Chi index of 1.777 (compare to k = 2 Hierarchical Agglomeration with 0.714 Chi index). In this case, a smaller improvement has been made with the federated dataset (0.223 = 2 − 1.777), concluding that the clustering created with Madrid data in isolation gives almost the same information that the one created with the federated dataset.
4. Conclusions
Noise pollution is a major concern in cities around the world and wireless acoustic sensor networks are being deployed to acquire information about sound pressure level in many locations and during long-term. Sharing data between administrations in a big data infrastructure, as the EU commission is promoting, can help to obtain better insights and create a common framework. Machine Learning techniques are being applied to learn and analyze these datasets.
In this work, several machine learning clustering techniques have been applied to identify different acoustic environment patterns from sound pressure level datasets. A comparison of clustering techniques for modeling acoustic data from wireless acoustic sensor networks of the cities of Barcelona and Madrid (Spain) has been made. This evaluation has been performed using isolated data and federated data and three parameters as metrics: Connectivity, Dunn index, and Silhouette Width.
From the results, it is observed that both Hierarchical Agglomeration clustering and K-means have the best performance, in both federated and non-federated data. Therefore, they are the more suitable algorithms to fit environmental acoustics parameters, such as sound pressure levels during different periods of the day.
In general, the Connectivity and Silhouette indexes tend to select a low amount of clusters, whereas the Dunn index suggests a large number of groups. Regarding the use case of noise monitoring and management of the noise plans, a small amount of clusters is recommended, therefore the Connectivity or Silhouette index has been used to select the optimal clustering algorithm.
An external clustering validity index, the Chi index, has been also calculated, obtaining insight into the relevance of using federated data to do the clustering. More datasets will be incorporated in future works to further analyze the benefits of using federated datasets instead of isolated datasets.
It has been shown that these techniques can help the local administrations to dynamically detect different patterns of sound pressure level behavior and update the definition of acoustic zones. Moreover, this information can be publicly shared with citizens to know about the acoustic typology of the area in which they live or are planning to buy a house, allowing them better decisions.
Possible future work can continue this research along the following lines:
- 1.
Design a methodology for monitoring the evolution of the acoustic zones to be able to measure the effect of the actions carried out by the consistories included in their action plans.
- 2.
Create an acoustic open data spaces for federated data to identify common clusters.
- 3.
Develop an algorithm to identify the cluster in which belongs to a city spot considering only a small sample of data.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}