1. Introduction
Text classification is the basic work of natural language processing tasks, and it is also one of the hot spots in its research field. It mainly uses text classification to manage texts effectively and plays an important role in application fields such as information retrieval, public opinion analysis, topic classification, spam screening, and opinion mining. Traditional text classification models are mainly based on machine learning algorithms, such as Support Vector Machines (SVM) [
1], naive Bayes [
2], etc. These algorithms are relatively mature and have achieved good results. Of course, they also have limitations, such as high-dimensionality, data sparsity and other problems in text classification, insufficient representation of text semantic features, etc. Deep learning methods can extract text features that are richer in semantic information, and it can greatly save the cost of manual intervention. Existing text classification models based on deep neural networks include typical neural network methods (e.g., Convolutional Neural Network (CNN) [
3], Recurrent Neural Network (RNN) [
4], Capsule Network [
5]), and their excellent variants (e.g., Long and Short-Term Memory (LSTM) [
6] Network, Gated Recurrent Unit (GRU) [
7], Convolutional Recurrent Neural Network (CRNN) [
8]), and various models based on attention [
9] (e.g., BERT [
10]), etc. These deep learning models can well capture the semantic and syntactic information in the local continuous word sequence, but most of them may ignore the information with discontinuous semantic words. Moreover, they are limited in their ability to capture the global features of the information [
11]. For example, global word co-occurrence information, global syntactic structure information, etc., and the global dependencies between all words also have a certain guiding role for classification. The Graph Convolutional Neural Network [
12] method has been a research hotspot in recent years. This model performs graph convolution operations on the constructed topological relationship graph to obtain features, thereby realizing text classification. In order to solve the classification problem, many variants of GCN [
13,
14,
15,
16] have been proposed and explored. Although GCN is gradually becoming a good choice for graph-based text classification, the current research still has some shortcomings that cannot be ignored.
In the recent study on text classification, researchers represented text as a graph structure and captured the structural information of the text as well as the discontinuous and long-distance dependencies between words through a Graph Convolutional Network. The most representative work is Graph Convolutional Network (GCN) [
12] and its variant Text GCN [
13]. This method represents words as nodes and aggregates the neighborhood information of the nodes through an adjacency matrix, thus integrating the global context of domain-specific languages to some extent. When the graph convolutional network model builds text graphs, most of them use the co-occurrence relationship of words and the inclusion relationship between documents and words, resulting in a lack of richer relationship information expression between words and words and the insufficient capture of long-distance dependencies of words in sentences. The measure of a word co-occurrence relationship generally uses normalized point-wise mutual information (NPMI) to calculate the weight between two word nodes. However, the calculation of NPMI depends on the corpus. If some words have a low probability of appearing in the corpus, this method may make the calculation result of NPMI very small, resulting in the determination that the similarity of two words is low or not.
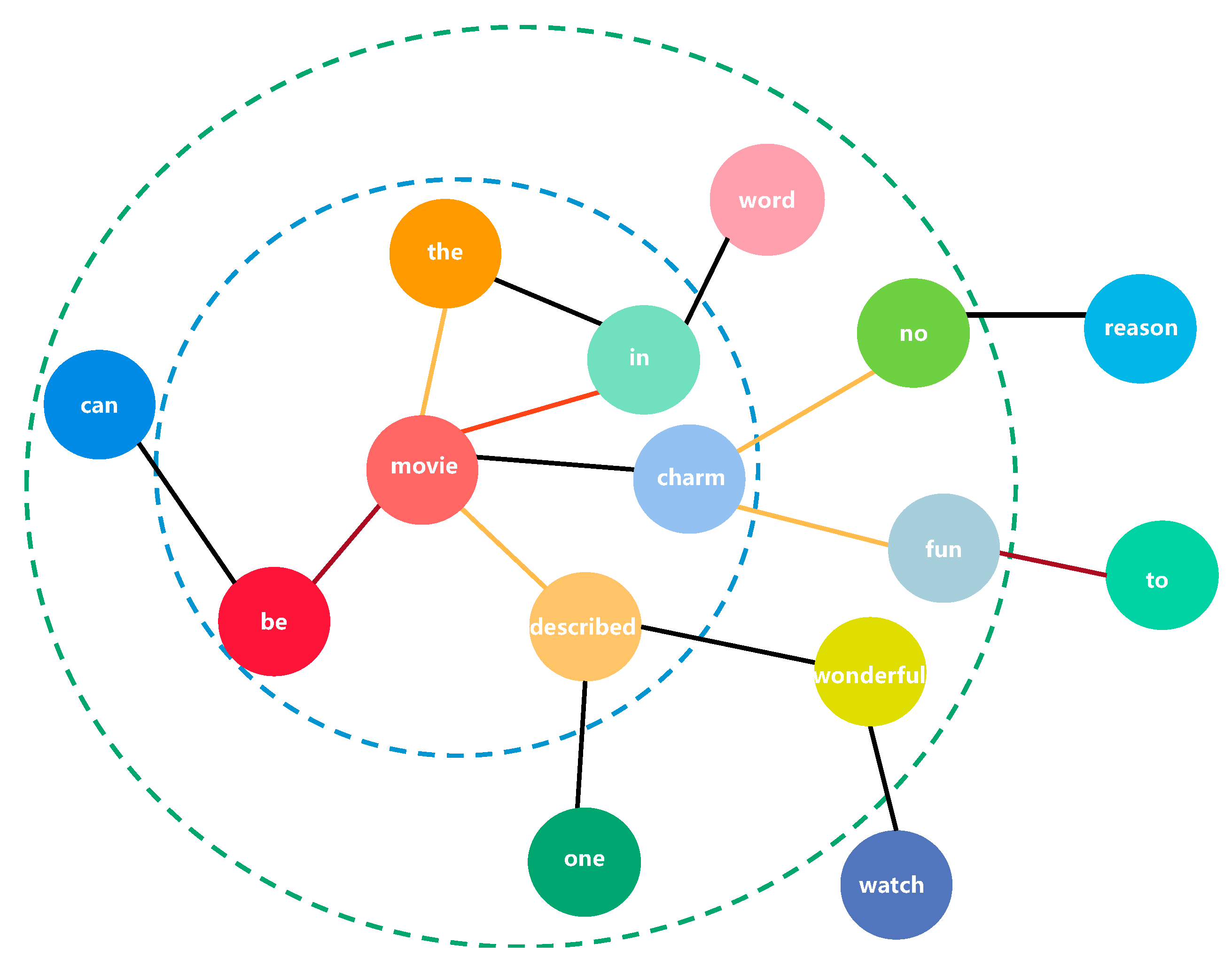
In addition, graph convolution based on word co-occurrence relationships and semantic dictionary composition can only capture the relationship of non-continuous entities in the text and cannot simultaneously capture the short-distance and long-distance dependencies of words in sentences. For example, a text graph is constructed from a corpus of word co-occurrence relations and semantic dictionaries, as shown in
Figure 1. Here “This movie can be described in one word: wonderful.” is a sentence in the corpus. Taking “wonderful” as the center, the blue circle represents the aggregation of one-level neighbor node information, and the green circle represents the aggregation of two-level neighbor node information. Among them, “wonderful” is used to modify “movie” in the sentence, and it is very useful for analyzing the expression of the text as a whole. However, the two word nodes “movie” and “wonderful” in
Figure 1 are not directly related, but there should be a certain dependency between them. Graph Convolutional Network only aggregates direct neighbor node information, so one layer of GCN can only capture short-distance dependencies of words in sentences. Capturing long-range dependencies between words such as “movie” and “wonderful” can be solved by increasing the number of GCN layers. However, current research shows that multi-layer graph convolutional networks for text classification tasks incur high space complexity. At the same time, increasing the number of network layers will also make the local features converge to similar values. To overcome this problem, we introduce dependencies when building the text graph. Dependency syntax is mainly concerned with the relationship between words (sentence components) in a sentence, and it is not affected by the physical location of the components. By introducing dependencies, short-range dependencies and long-range dependencies can be well utilized while also providing syntactic constraints and partially reducing the number of GCN layers.
However, due to the characteristics of the graphs, when learning word features, graph convolutional networks do not effectively capture the word order that is very useful for them, resulting in the loss of contextual semantic information of the text. For example, “You have a lot of hard work.”, “You have to work hard.”, where the word “work” will change meaning depending on its position in the contextual sentence. The graph formed by the words in these two sentences cannot reflect the order between the words, so it cannot represent the characteristics of word order changes. Obviously, this is very important for understanding the meaning of the sentence. In addition, the graph convolutional network cannot distinguish polysemy; for example, “She’s grown into quite an individual.”, “So this individual came up.”, the meaning of the word “individual” expresses different semantics depending on the context. In the first sentence, it is the meaning of “person with personality”, and in the second sentence, it has the meaning of “weird person”. In this case, if not differentiated, it may affect the understanding of the text, thereby affecting the classification effect. Leveraging multilayer multi-head self-attention and positional word embeddings, BERT mainly focuses on local contiguous word sequences that provide local contextual information. By pre-training a large amount of text data in different fields, BERT can well infer the meaning that polysemous words should express in the current context. However, BERT may have difficulty interpreting global information about vocabulary.
To improve the above-mentioned problems, this paper proposes an improved model (IMGCN) for text classification. On the basis of Vocabulary Graph Convolution (VGCN) [
15], a semantic dictionary (WordNet) and dependencies are introduced, and the features of GCN and BERT are further learned through residual bi-layer BiLSTM with an attention mechanism [
17]. By building dependencies, GCNs can be made to capture long-range dependencies of words in sentences more efficiently. WordNet was introduced to provide more useful connections between words. At the same time, the BERT model is used to extract the local feature information of a text. The global vocabulary information obtained by GCN is combined with the context information obtained by pre-trained BERT. Considering that the text has a hierarchical structure of word-sentence-document, in order to obtain more comprehensive text features, we use hierarchical BiLSTM to extract the combined features hierarchically to capture word, sentence, and document feature information, respectively. In the process of word-to-sentence feature extraction, the attention mechanism is used to generate sentence embeddings, which solves the problem that keyword features cannot be paid attention to in text classification. We changed the initialization method of the context vector in the attention mechanism and combined the bidirectional word hidden features as the initial value of the context vector to guide the learning of the attention mechanism. By introducing residual connections, the neural network degradation problem that occurs when stacking multi-layer network models can be alleviated, and the model can learn residuals to better obtain new features.
We call the proposed model IMGCN. Experiments on four benchmarking datasets demonstrate that IMGCN can effectively improve the results in current GCN-based methods and achieve better results. The main contributions of this paper are as follows:
The dependency and semantic dictionary are fully integrated into IMGCN. They can enrich the connections between words and capture the long-range dependencies of words in sentences while providing syntactic constraints and partially reducing the number of GCN layers.
Combining graph features and sequence features, using hierarchical BiLSTM to extract input features hierarchically, capturing word and sentence feature information, respectively, so as to obtain more comprehensive text features.
2. Related Work
Traditional text classification methods are mainly based on feature engineering. Feature engineering includes the bag-of-words model [
18] and n-grams, etc. Later, there was research [
19,
20] that converted text into graphics and performed feature engineering on graphics. However, these methods cannot automatically learn the embedding representation of nodes. Compared with traditional methods, deep learning-based methods can automatically acquire features, and they can learn the deep semantic information of the text. In terms of deep learning models, Kim 2014 [
3] uses a simple convolutional neural network (CNN) for text classification. Tang et al. 2015 [
21] proposed a gated recurrent neural network. Yang et al. 2016 [
17] proposed the use of hierarchical attention networks to model and classify documents. Wang et al. 2016 [
22] introduced the attention mechanism into LSTM. Dong et al., 2020 [
23] introduce the Bidirectional Encoder Representation from Transformers (BERT) [
10] and the self-interaction attention mechanism. Most attention-based deep neural networks mainly focus on local continuous word sequences, which provide local context information. However, the ability to capture the global characteristics of the relevant information may not be sufficient.
In recent years, many studies have tried to apply convolution operations to graph data. Kipf and Welling 2017 [
12] proposed Graph Convolutional Networks (GCNs), and the model has achieved good results on node classification tasks. Velickovic et al. 2018 [
24] proposed a Graph Attention Network (GAT), which uses the attention mechanism [
25] to assign weights to the neighborhood information of nodes. Compared with the GCN without adding weights, it has a better promotion. Later, Yao et al. 2019 [
13] proposed the TextGCN model, which introduced the Graph Convolutional Network to text classification for the first time. By modeling the text into a graph, the nodes in the graph are composed of words and documents, and a good effect is finally obtained. Cavallari et al. 2019 [
26] introduced a new setting for graph embedding, which considers embedding communities instead of individual nodes.
Now, many studies try to combine GCN with other models. Ye et al. 2020 [
14] input the word and document nodes trained by GCN and BERT’s word vector into the BiLSTM classification model, where the input vector of GCN is a one-hot vector. Lu et al. 2020 [
15] integrated the vocabulary graph embedding module with BERT and achieved good results in many public datasets, where GCN uses BERT’s word vector. In contrast to this, in our method, GCN uses BERT’s word vectors and uses dependencies when building the text graph. One graph focuses on extracting dependencies between words, and the other graph focuses on word co-occurrences. We use a two-layer BiLSTM with attention combined with GCN and BERT; one layer is used to focus on the word sequence, the other layer focuses on the sentence sequence, and a residual operation is added after BiLSTM to learn the residual.
3. Proposed Method
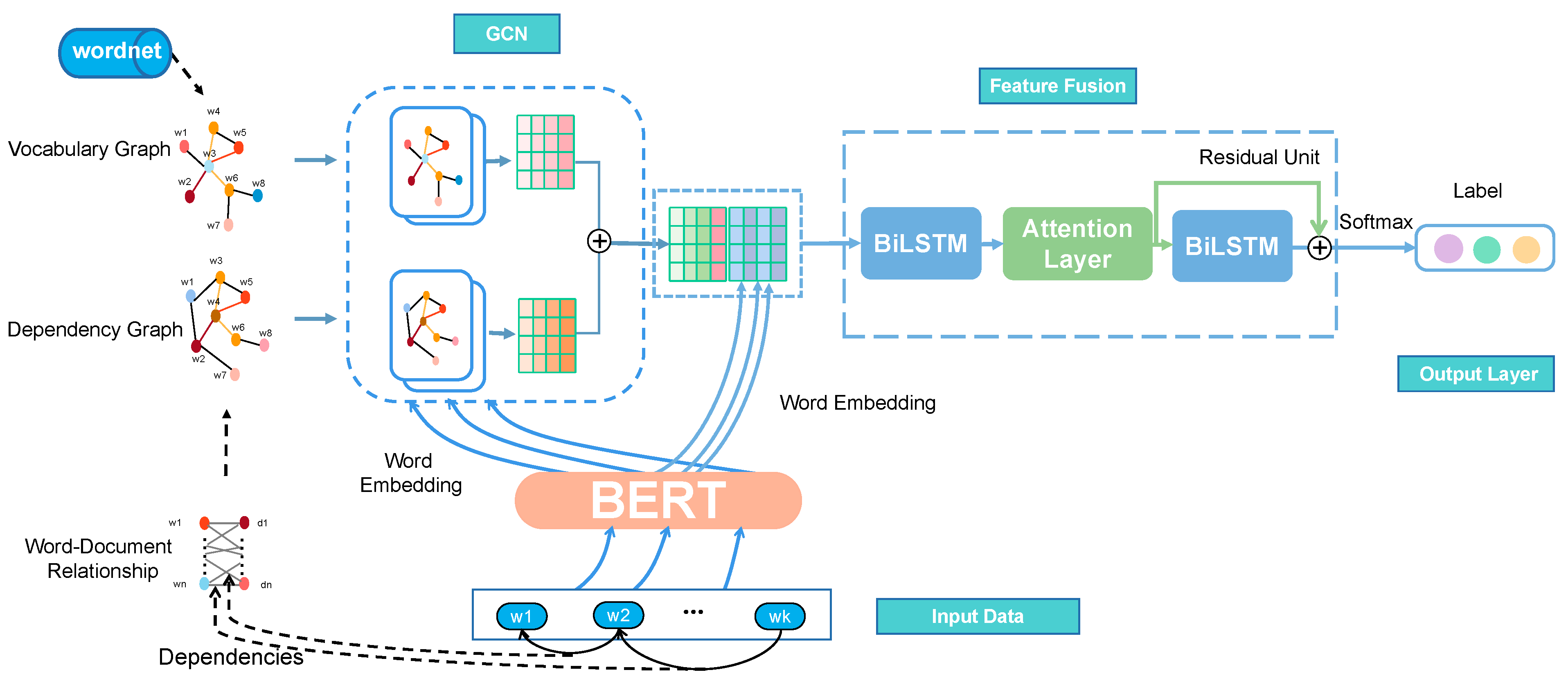
Following in-depth research on text classification based on neural networks, this paper proposes IMGCN. The whole process of IMGCN can be divided into the steps of text composition, graph convolutional network, feature fusion, and final prediction. The architecture of IMGCN is shown in
Figure 2. The colored continuous line in the IMGCN architecture is the output of each single model, and the intermittent line represents the modules composed of a single model. We construct two text graphs by establishing edges between word nodes. Build a vocabulary graph from word co-occurrence relations and semantic lexicon. Build a dependency graph from the inclusion and dependencies of documents and words. We use point-wise mutual information (NPMI) [
27] and a semantic dictionary to assign association weights to edges between words to jointly build a text graph. Then, the dependency-based TF-IDF method is used to assign association weights to the edges between words and documents and use a matrix transformation to map them to the relations between words and words, thereby constructing another text graph. Then the word embedding of BERT is used as the input vector required by the graph convolutional network, and the two text graphs are respectively used as the adjacency matrix required by the graph convolutional network. Subsequently, they are separately fed into a two-layer graph convolutional network for training, and the two hidden output vectors are then summed. Next, the added word vector is fused with the feature vector of the pre-trained BERT and input to the first-layer BiLSTM model to extract the semantic dependency information between words within a single sentence. To further distinguish the importance of words, we add an attention mechanism to the first layer of BiLSTM to distinguish the importance of words by assigning different word weights. The word weights and the output of the first layer of BiLSTM are weighted and summed to form an overall representation of the current sentence. Here, the bidirectional word hidden features are combined as the context vector of the attention mechanism to guide the learning of the attention mechanism. The obtained sentence feature representation is then input to the second layer of the BiLSTM to extract semantic dependency information between sentences within the text. The learned sentence feature representation and the feature obtained by the context attention layer are subjected to residual operation to form an overall text representation. Finally, the overall text representation is input to the Softmax classification layer to obtain the final category of the text.
3.1. Text Graph
3.1.1. Vocabulary Graph
In this paper, we first use a semantic dictionary (Wordnet) and Normalized Pointwise Mutual Information (NPMI) to construct a text graph. For constructing text graphs using word co-occurrence relationships, normalized pointwise mutual information (NPMI) is generally used to calculate edge weights between two word nodes, which is a common measure of word association. However, the calculation of NPMI depends on the corpus. If the probability of some words appearing in the corpus is low, this method may lead to a small calculation result of NPMI, and the similarity of two words is judged to be low or not. For example, the word “abundant” has a very low probability of appearing in the corpus. Let P (word and other words) be the co-occurrence probability between words. When calculating the co-occurrence probability of “abundant” and other words, the values of P (abundant and other words) and P (abundant) are very small; even if it is 0, it will result in a very small value of NPMI, so in the end, “abundant” and other words may be judged as having little or no semantic relevance.
In addition, there are a lot of connections between words, and the most direct connection is the synonymous relationship that exists between certain words. For example, the words “abundant” and “plentiful” have very similar meanings and can be used interchangeably in most cases. If two words are synonymous, then only constructing a text graph through word co-occurrence relationship may lack this part of word relationship information. If this synonymous relationship can be used, the relationship information of words can be enriched, thereby improving the accuracy of the calculation. The semantic dictionary describes the different semantic relations between words. Therefore, we jointly construct a text graph using word co-occurrence relations and semantic lexicon.
For the selection of the semantic dictionary, we use WordNet. WordNet describes a network of semantic relationships between words. For every content word in the language, it gives all possible word meanings. WordNet organizes words in a dictionary using semantic and lexical relations, where semantic relations represent the degree of association between the semantic items of two words. Nouns, verbs, adverbs, and adjectives are each organized into a network of synonyms, each set of synonyms representing a basic semantic concept, and these sets are also connected by various relationships. Since a word can have multiple meanings, it is necessary to compare the meanings between the two words. Therefore, we first use WordNet to expand synonyms and then use the WordNet-based Wup method to calculate the semantic similarity between words in the two synonym sets and calculate the average of all similarity scores. This value is the final similarity score of the two words. The larger the calculated value, the higher the semantic similarity between them. Among them, the “Wup” method [
28] is a similarity measurement method based on the path structure proposed by Wu and Palmer. The similarity is calculated according to the similarity of the meaning of the words and the position of the synonym sets in the hypernym tree relative to each other.
Therefore, for two words i and j, we first calculate the edge weights between two words using the NPMI method. If the calculated NPMI value is small, the WordNet-based method is used for calculation, which can minimize the problems caused by the low frequency of some words in the corpus, and at the same time, add more word relationship information. Formally, the edge weight between node i and node j is defined as:
The NPMI value of a pair of words i, j is calculated as:
where
,
,
is the number of all sliding windows containing word i,
is the number of all sliding windows containing word i and word j, and
is the total number of sliding windows. We set the window larger to gain long-term dependence. The value range of NPMI is
. A positive NPMI value indicates that the semantic relevance between words is high, while a negative NPMI value indicates that there is little or no semantic relevance. Therefore, we only create an edge between word pairs with positive NPMI values.
When the NPMI value of a pair of words i, j is calculated to be negative, their semantic similarity is calculated as:
where
represents the semantic similarity of two words in the synonym lexicon, Let
be the deepest parent concept of
and
,
is the number of nodes on the path from
to
,
is the number of nodes on the path from
to
, and
is the root of the concept hierarchy tree from
the number of nodes on the path of the node. Let
be the synonym word set of word i,
be the number of words in
,
be the synonym word set of word j,
be the number of words in
, and a is the number of word pairs with 0 semantic similarity in the word set. The value range of
is
. If the
values of the two words are within a certain range, we create an edge between the two words. Experiments show that the performance is better when
is between 0.5 and 1.
3.1.2. Dependency Graph
Based on the above two relational compositions, graph convolutional networks can capture short-range dependencies of words in sentences but cannot capture long-range dependencies at the same time. Therefore, we introduce dependencies to construct another text graph to overcome the above problems. In addition, in order to obtain the inclusion relationship between documents and words while introducing the dependencies between words, we combine the two relationships. The edge weights between general document nodes and word nodes are calculated using the TF-IDF algorithm. TF-IDF is the word frequency-inverse text frequency index. The term frequency (TF) is the number of times a word appears in the document, and the inverse text frequency (IDF) reflects the general importance of the feature word in the corpus. However, the TF-IDF method lacks the combination of textual semantics, which is useful for understanding textual content. To overcome this problem, we refer to [
29], introduce dependencies, and use an improved edge weight calculation method to understand and optimize text features.
Dependency syntax is mainly concerned with the relationship between the various words in a sentence, and it is not affected by the physical location of the components [
30]. Since the importance and relevance of various dependencies in a sentence are not the same, first, the importance of words to sentences, texts, and even categories is determined according to the different dependencies between words and predicates in terms of word meaning. Then, according to the importance of different components to the sentence, the sentence composition is divided into eight levels.
The results of dependency analysis are usually represented by a labeled directed graph. For example, as shown in
Figure 3, “root” represents the central word “has”. Examples of the relationship between the performance head word and its subsidiary words are “has” and “performances”. The result of dependency analysis shows that the relationship between these two words is a direct object (dobj, direct object) relationship.
After classifying the text features in the data set according to the dependency relationship, this paper uses the following dependency-based TFIDF weight calculation method [
29]. The specific steps are as follows:
For the word i, we calculate the number of times that the word i appears in the text and set it as n. Then, according to the result of the dependency syntax analysis implemented by Stanford Parser, it is obtained that the word i belongs to the m-th
sentence component in the text. Furthermore, according to paper [
29], classify the m-th occurrence of word i in the text into
level, and assign weight
to it. The calculation process is shown in Formula (4):
Then the improved frequency with the weight of word i in the text is calculated by Formula (5). For word i, the improved weight based on the dependency relationship is as shown in Formula (6). Where s represents the total number of words in the text where the word i is located, pi represents the number of texts containing the word i, and D represents the total number of texts in the dataset. Where λ is a parameter, which is used to adjust the weight gap between feature levels, and the range is [0,1].
Calculate the weight of the edge between the word node and the document node according to the above method, and obtain the adjacency matrix A, as shown in Formula (7). Then, the relationship between the words and documents is mapped to the relationship between words and words containing document information and dependencies through matrix transformation so as to construct another text graph
.
where
, n is the number of document nodes and m is the number of word nodes.
3.2. Vocabulary GCN
A general graph convolutional network is a multi-layer (usually two-layer) neural network that performs convolution directly on the graph and updates a node’s embedding vector based on the information of its neighbor nodes. The graph nodes of a graph convolutional network are “task entities”, such as documents that need to be classified. It requires all entities, including those from training, validation, and test sets, to be displayed in the graph, so that node representations are not missing from downstream tasks. This limits the application of graph convolutional networks to many prediction tasks where test data are not seen during training. Therefore, we use Vocabulary Graph Convolution (VGCN), whose graph is constructed on the vocabulary without using the training set to obtain entities, mainly convolving related words. Then for a single document, the single-layer graph convolution is shown in Formula (8):
where
represents the vocabulary graph.
to extract part of vocabulary related to the input matrix
, combining the words in the input sentence with the relevant words in the vocabulary. W hold hidden state vector of a weight of a single document, dimension is
.
The corresponding two-level GCN with LeakyReLU function is:
where m is the mini-batch size, v is the vocabulary size, h is the hidden layer size, and c is the class size or sentence embedding size. W holds the weight of the hidden state vector of a single document. Each row of
is a vector containing document features, which is the word embedding of BERT. Then a two-layer convolution is performed to combine the words in the input sentence with the related words in the vocabulary.
Specifically, we perform two layers of graph convolution for the two text graphs generated in the previous section, then add the two generated hidden layer vectors.
In the training process of the original GCN, ReLU is used as the activation function of the GCN. In this paper, the non-linear function LeakyReLU is selected as the activation function of GCN, which overcomes the problem of gradient disappearance and speeds up training. In addition, L2 regularization is also used to reduce overfitting. The LeakyReLU function is as follows:
3.3. Feature Fusion and Classification
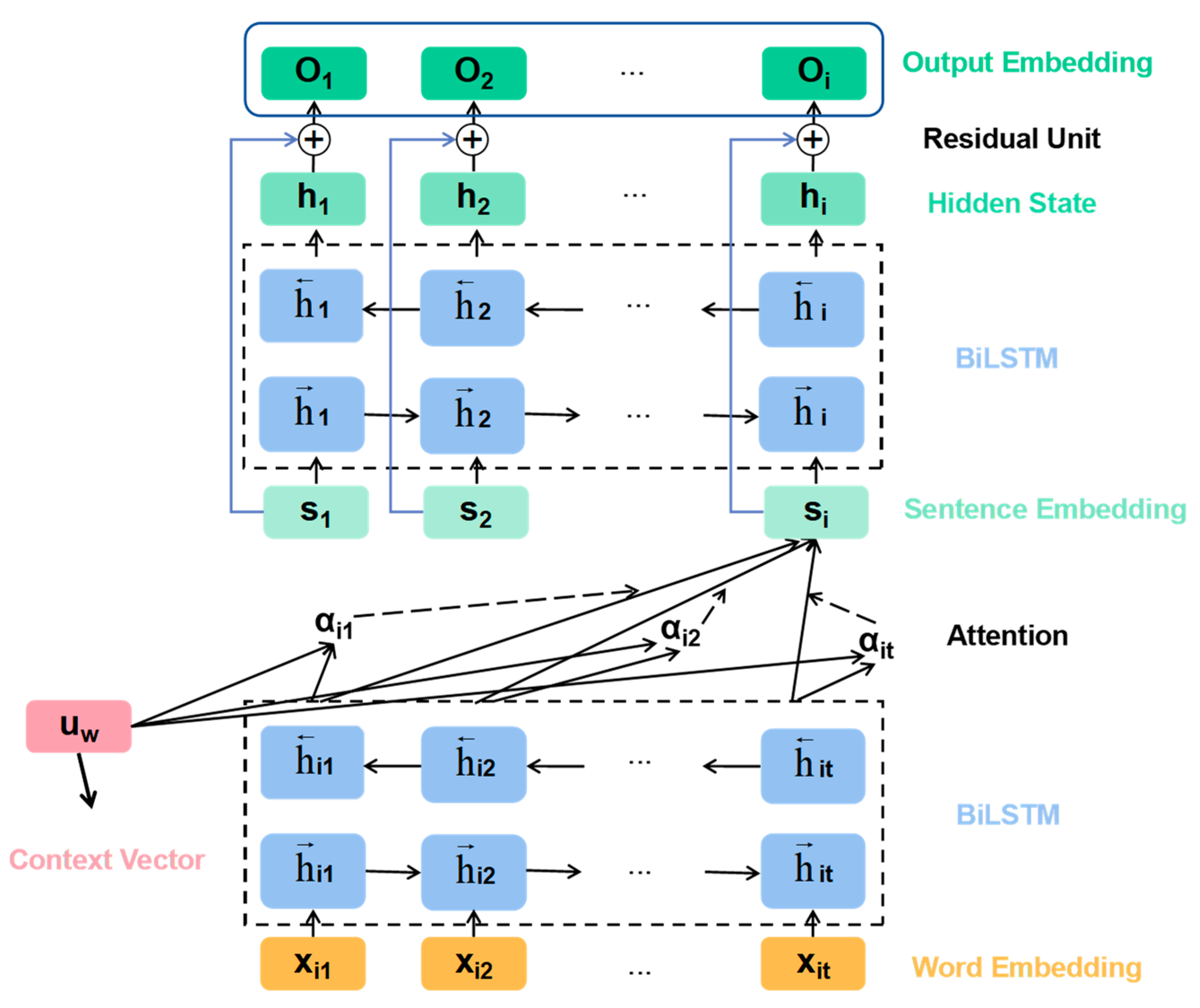
Since words are represented as nodes, the neighborhood information of nodes is aggregated through an adjacency matrix, ignoring the order structure of a text, resulting in the loss of contextual semantic information of a text. Therefore, we combine the global vocabulary information obtained by GCN with the context information obtained by the pre-trained BERT. While using the global vocabulary information, we can also take into account the order of words to capture contextual information. In order to dig deeper into the semantics, the sequence model LSTM can be used to fuse the two parts of information, but it can only capture features in a single direction, from front to back or from back to front. The mode of human reading text is to use the foregoing and the following to jointly infer the meaning of a word when encountering a word. Therefore, BiLSTM models that can capture features in both front-to-back and back-to-front directions are more in line with this pattern. Considering that text has a hierarchical structure, the text is composed of sentences, and sentences are composed of words. Therefore, we use a two-layer BiLSTM to learn word features and sentence features, respectively. Since the feature words have different importance to the text, and the output vector of BiLSTM does not distinguish the importance of words, we add an attention mechanism to its hidden output. We changed the initialization method of the context vector in the attention mechanism and combined the bidirectional word hidden features as the initial value of the context vector to guide the learning of the attention mechanism. At the same time, in order to prevent the deepening of the model layers from affecting the classification results, we introduced the residual operation. The specific structure of the model feature fusion module is shown in
Figure 4.
The module consists of a semantic feature splicing layer, word-level feature extraction layer, contextual attention layer, and a sentence-level feature extraction layer. First, the GCN and the pre-trained BERT model convert the text word sequence into two different word vector representations. Secondly, the corresponding fusion of the obtained two different word vector representations is input into the first-layer BiLSTM model to extract the semantic dependency information between words within a single sentence, and a layer of attention mechanism is added to the first-layer BiLSTM, constructs an overall representation of the current sentence. Here, the bidirectional word hidden features are combined as the context vector of the attention mechanism. Then the obtained sentence feature representation is input to the second layer BiLSTM to extract semantic dependency information between sentences within the text. The learned sentence feature representation and the sentence feature representation obtained by the context attention layer are subjected to residual operation to form an overall text representation. Finally, the overall text representation is input to the Softmax classification layer to obtain the final category of the text.
3.3.1. Semantic Feature Connection Layer
We do not directly classify the output features of GCN but use the generated hidden feature representation
for subsequent learning. Since
does not adequately capture contextual information and does not discriminate word vector representations of polysemy, pre-trained BERT is introduced. The BERT model uses a bidirectional transformer structure for encoding, which can characterize the specific semantics of each word in the context and distinguish multiple semantics according to the semantic relationship of the context. Each word obtains the word vector representation W of the text through the pre-trained BERT model, as shown in Formula (11):
where
represents the vector matrix of the i-th text,
represents the feature vector of the j-th word in the i-th text, and n represents the maximum sentence length.
Then, the embedded representation
output after the second layer graph convolution operation in the GCN model is spliced with the word vector W generated by the pre-trained BERT to obtain a multi-feature vector X, as shown in Formula (12):
3.3.2. Word-Level Feature Extraction Layer
After the semantic feature connection layer is the word-level feature layer BiLSTM model, which is used to extract semantic dependency information between words within a single sentence. The BiLSTM model corresponds to the forward and backward LSTM models. The sequence information and contextual features are captured by LSTMs in two directions, and the combination of the two output layers generated by the two directions can provide past contextual information and future contextual information. The input of this layer of BiLSTM is the result X after semantic feature concatenation.
Suppose a text has L sentences
, where
, and each sentence contains
words.
represents the word vector of the t-th word in the i-th sentence, where
. In the forward LSTM layer, read sentence s
from
x to
y and perform forward calculation to obtain the hidden state
h; in the backward LSTM layer, read sentence
s from
y to
x and perform reverse calculation to obtain the hidden state
m, as shown in Equations (13) and (14):
Finally, the hidden state
obtained by the forward LSTM layer is spliced with the hidden state
obtained by the backward LSTM layer to obtain the final hidden layer state
of the bidirectional LSTM, as shown in Formula (15):
3.3.3. Contextual Attention Layer
Considering that the words in a sentence contribute differently to the meaning expression of the sentence, the attention mechanism can focus on important information from a large amount of information while ignoring unimportant information. Therefore, an improved attention mechanism is used to focus on important information, and these word representations are aggregated to form sentence feature representations. The hidden output result
of the word-level feature layer is used as the input of the context attention layer, and the calculation process of assigning attention weights is shown in Equations (16) and (17):
where
is the weight matrix,
is the bias term, and
is the normalized importance weight.
is the attention context vector, which contains useful information for the text to guide the attention model to locate informative words from the input sequence, and thus plays an important role in the attention mechanism. Prior work either ignores the context vector or initializes it randomly, which greatly weakens the role of context. Therefore, we use the combination of word hidden features learned by LSTM in two directions as the context vector of the attention mechanism, that is,
. It contains contextual information of words in sentences to guide the learning of the attention mechanism.
Next, the word importance weight calculated by Formula (17) and the hidden output result
of the word-level feature layer are weighted and summed. The word-level feature vectors are aggregated into sentence-level feature vectors
to form an overall representation of the current sentence, as shown in Formula (18):
3.3.4. Sentence Level Feature Extraction Layer
Since a text contains multiple sentences, there are semantic dependencies between each sentence. Therefore, the main task of the sentence-level feature extraction layer is to extract the semantic dependency information between sentences within the text in units of sentences. The sentence vector
obtained by the contextual attention layer is input into a layer of BiLSTM for sentence sequence learning. Where
is the hidden state obtained by the forward LSTM layer through the forward input,
is the hidden state obtained by the backward LSTM layer through the reverse input, and finally, the two hidden states are spliced to obtain
.
The deepening of the number of network layers can improve the accuracy of the model, but there are problems with the disappearance of the gradient of the deep network and the degradation of the network. When the depth reaches a certain level, the accuracy of the model begins to decline again, and the fitting ability becomes worse. In the deep neural network, the residual network can effectively inhibit the network degradation phenomenon and avoid the problem of sub-optimal solutions in deeper networks. Therefore, we introduce a residual connection between two adjacent layers and perform a residual operation on the sentence feature representation learned by the sentence-level feature extraction layer and the sentence feature representation output by the context attention layer. Let the model learn the residual to obtain a higher-level feature representation to achieve a better classification effect, as shown in Formula (22):
Finally, the result is input to the Softmax layer for classification, and the final category of the text can be obtained.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}