
An Efficient Person Search Method Using Spatio-Temporal Features for Surveillance Videos †



Abstract
:1. Introduction
2. Related Work
2.1. Person Re-Identification Method
2.2. Person Search Method
3. The Proposed Method
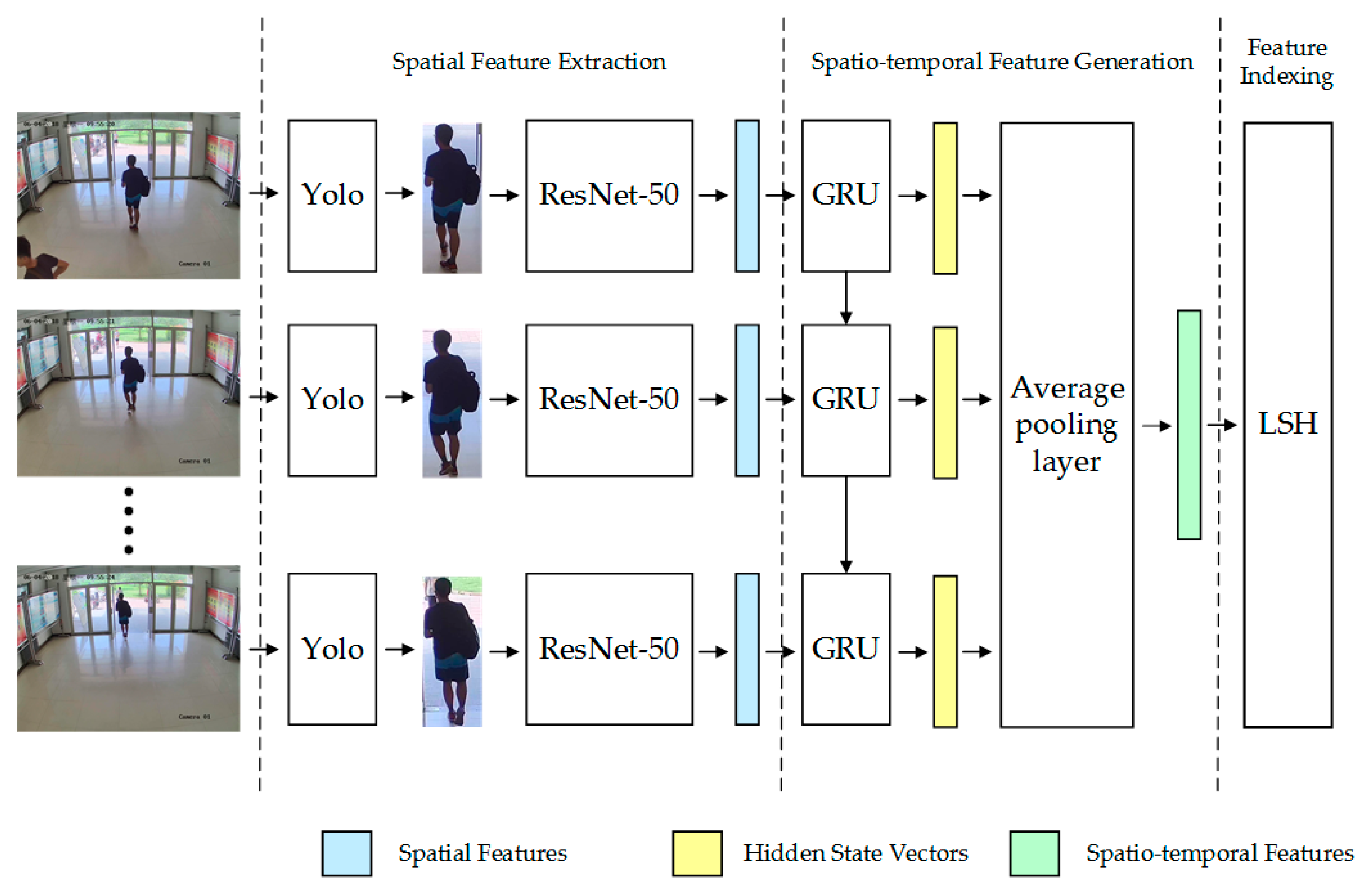
3.1. Framework
3.2. Spatial Feature Extraction
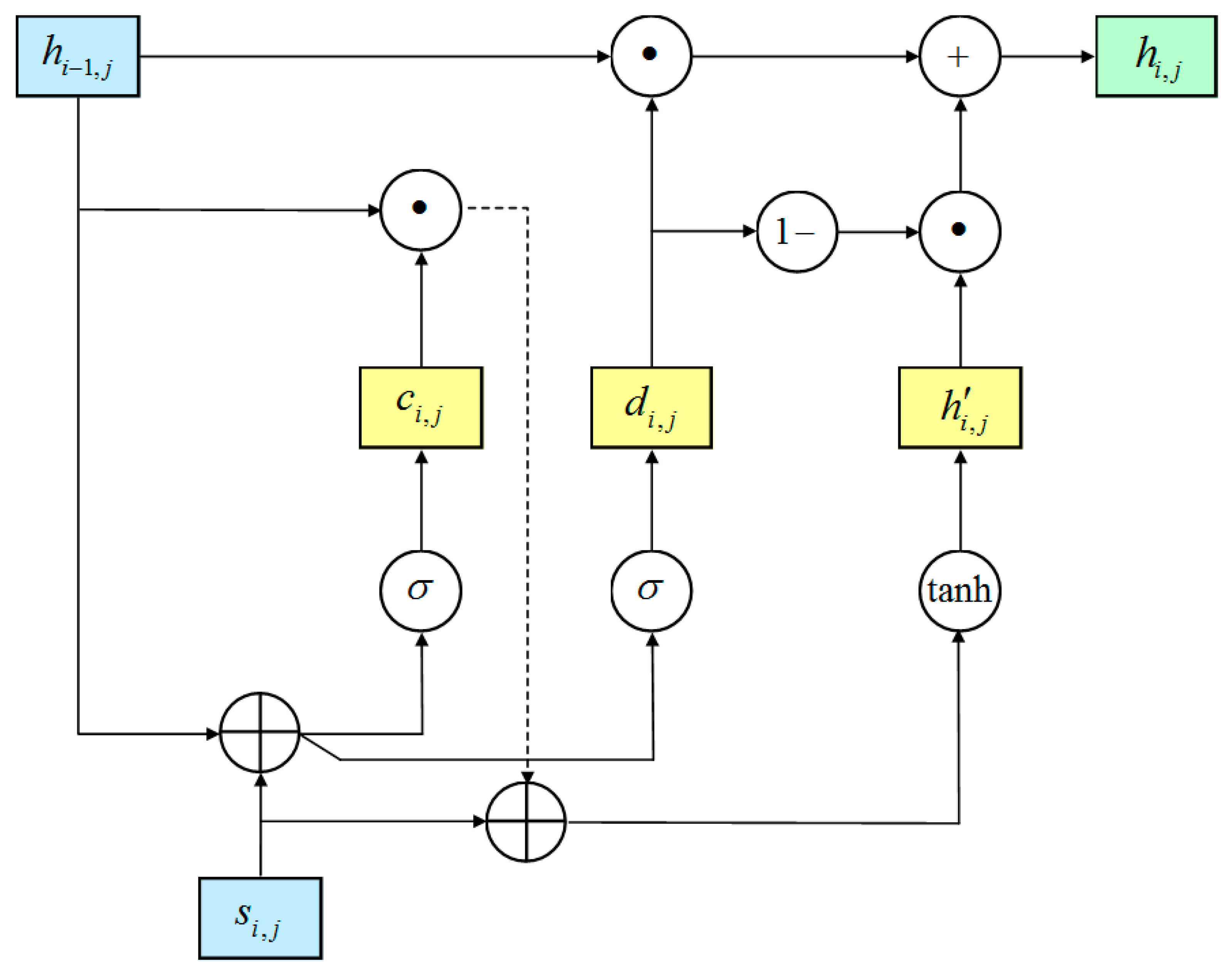
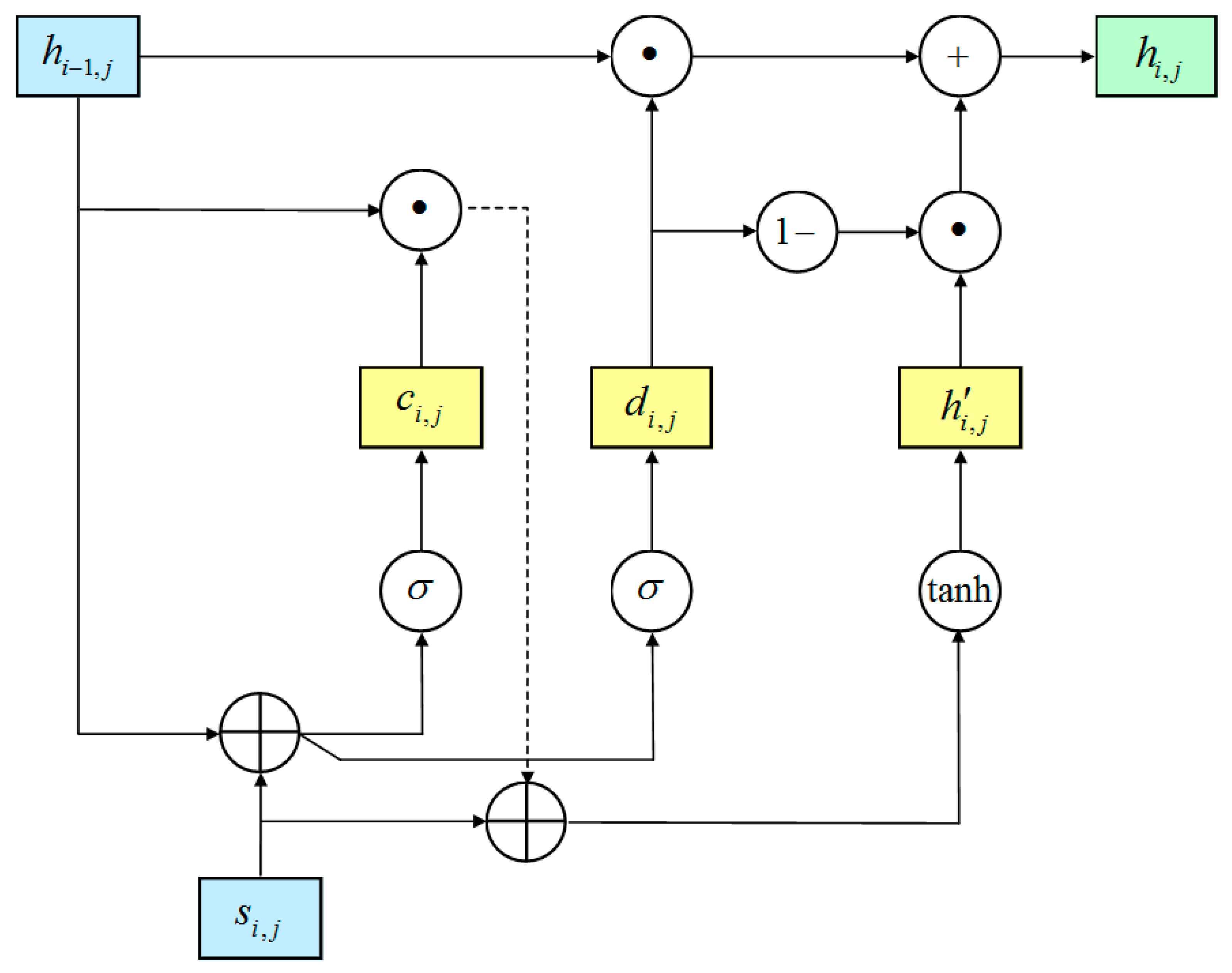
3.3. Spatio-Temporal Feature Generation
3.4. Feature Indexing
3.5. Computational Complexity Analysis
4. Experiments and Results
4.1. Datasets
4.2. Evaluation Criteria
4.3. Experimental Design
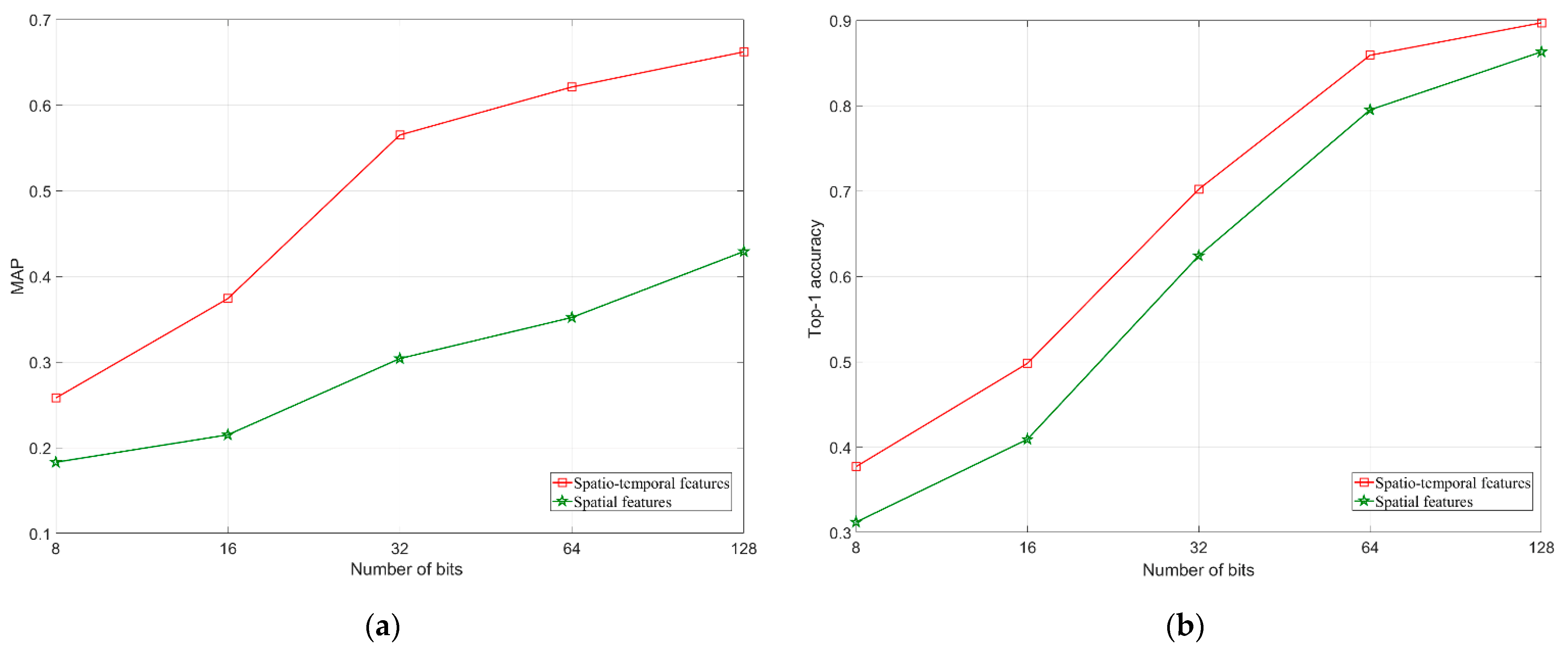
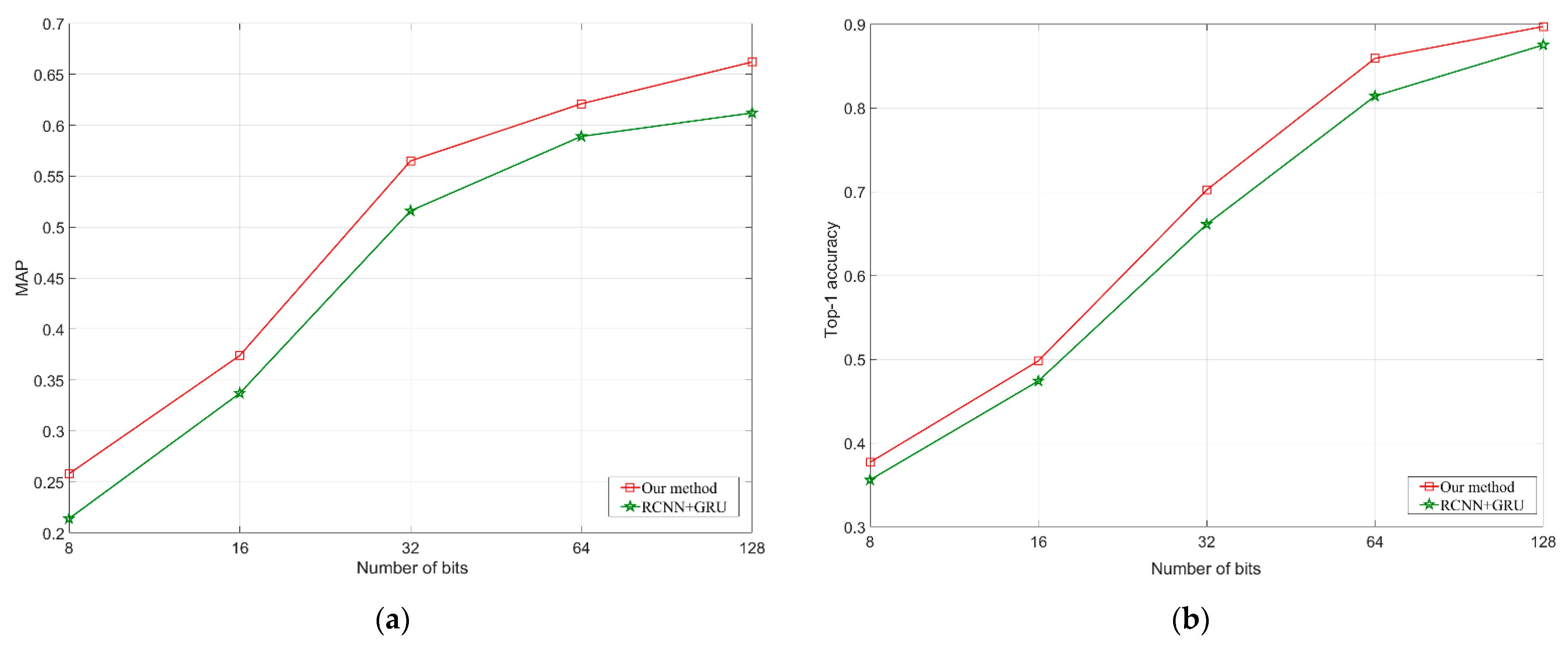
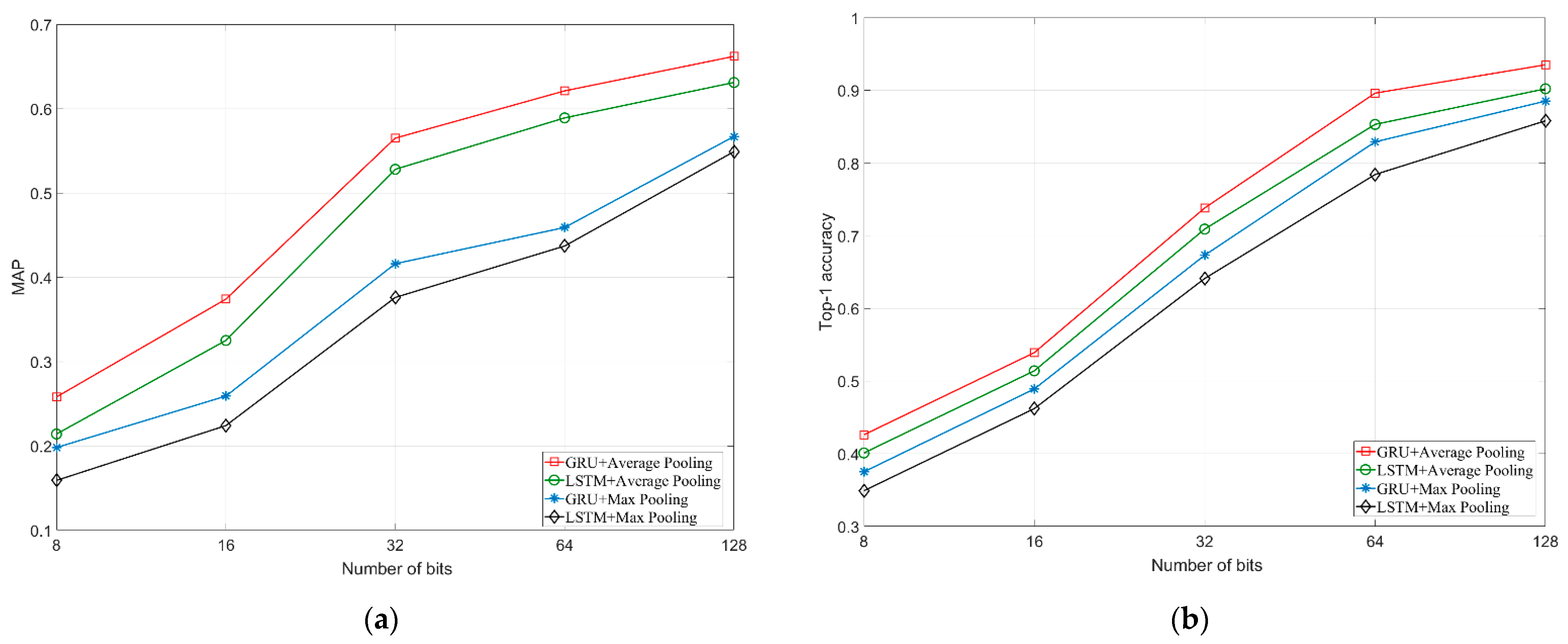
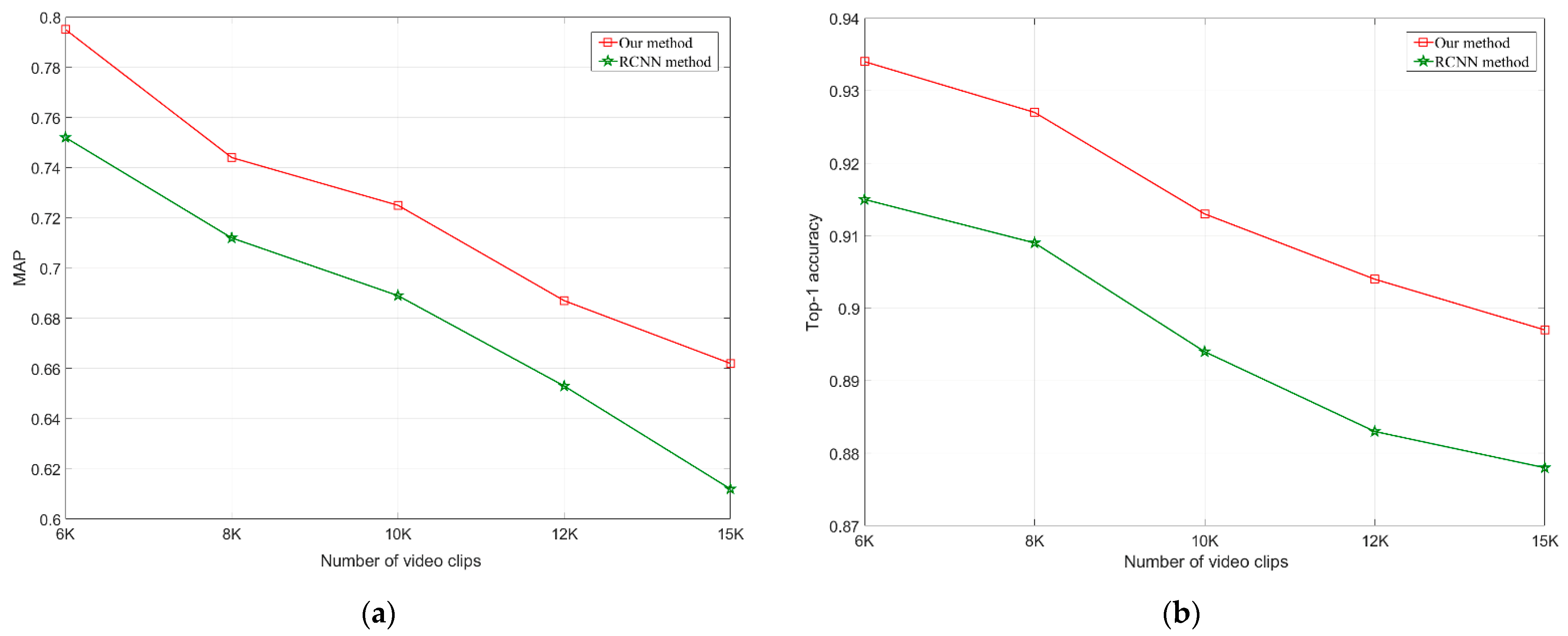
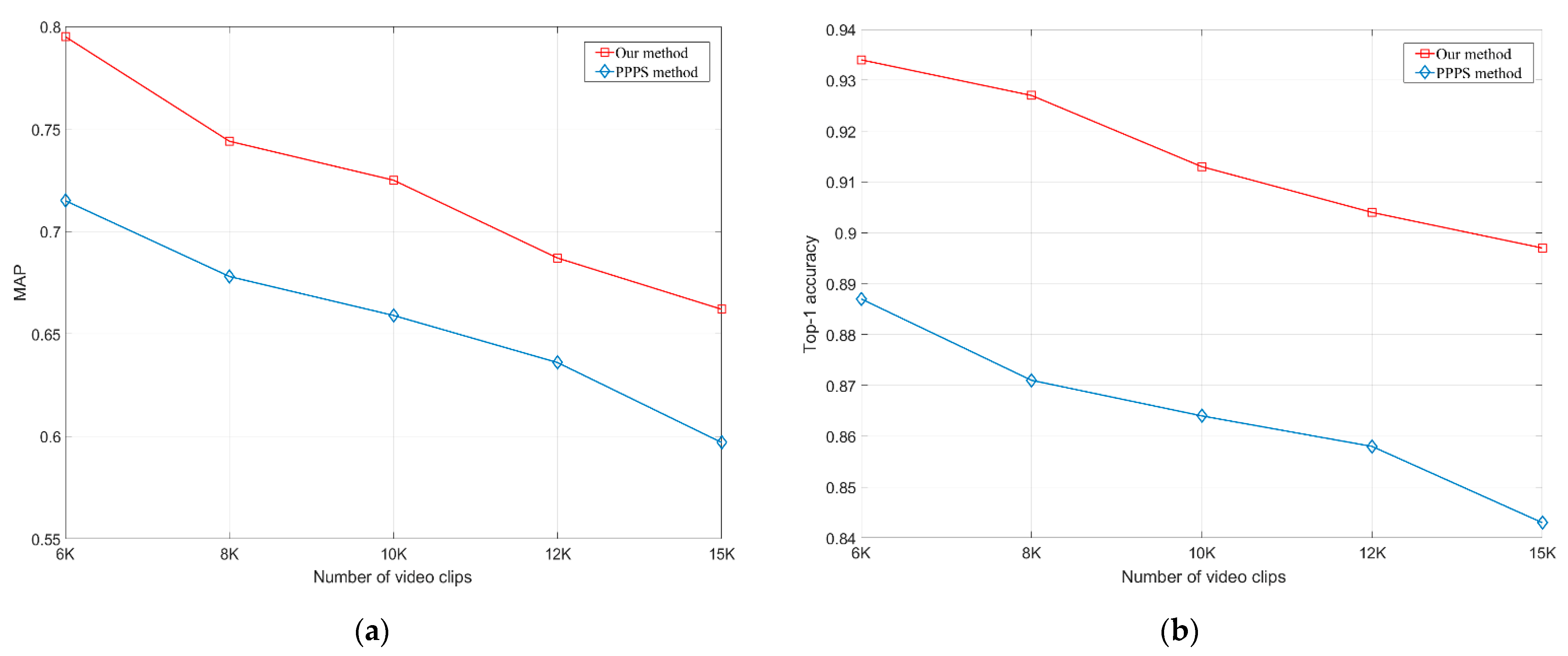
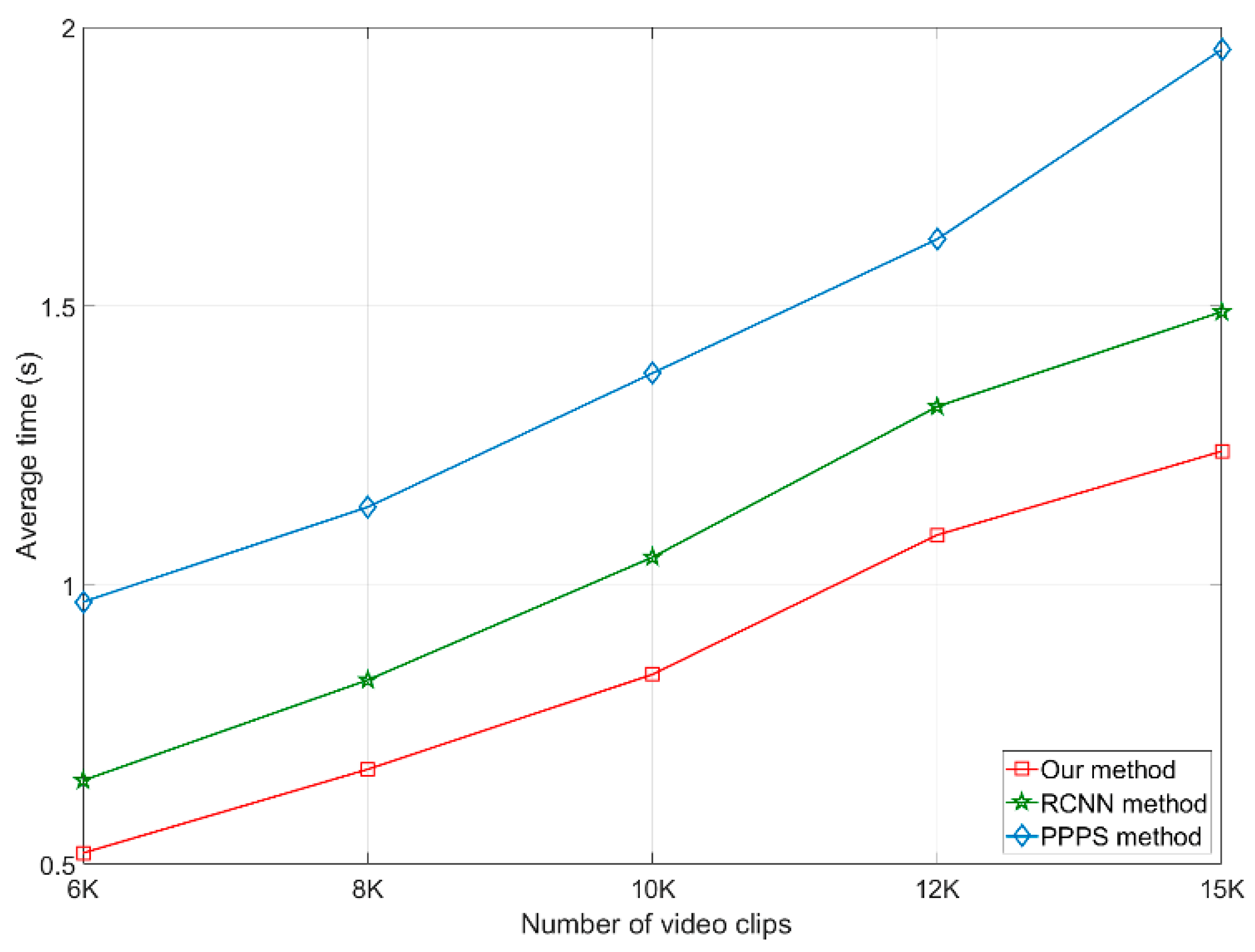
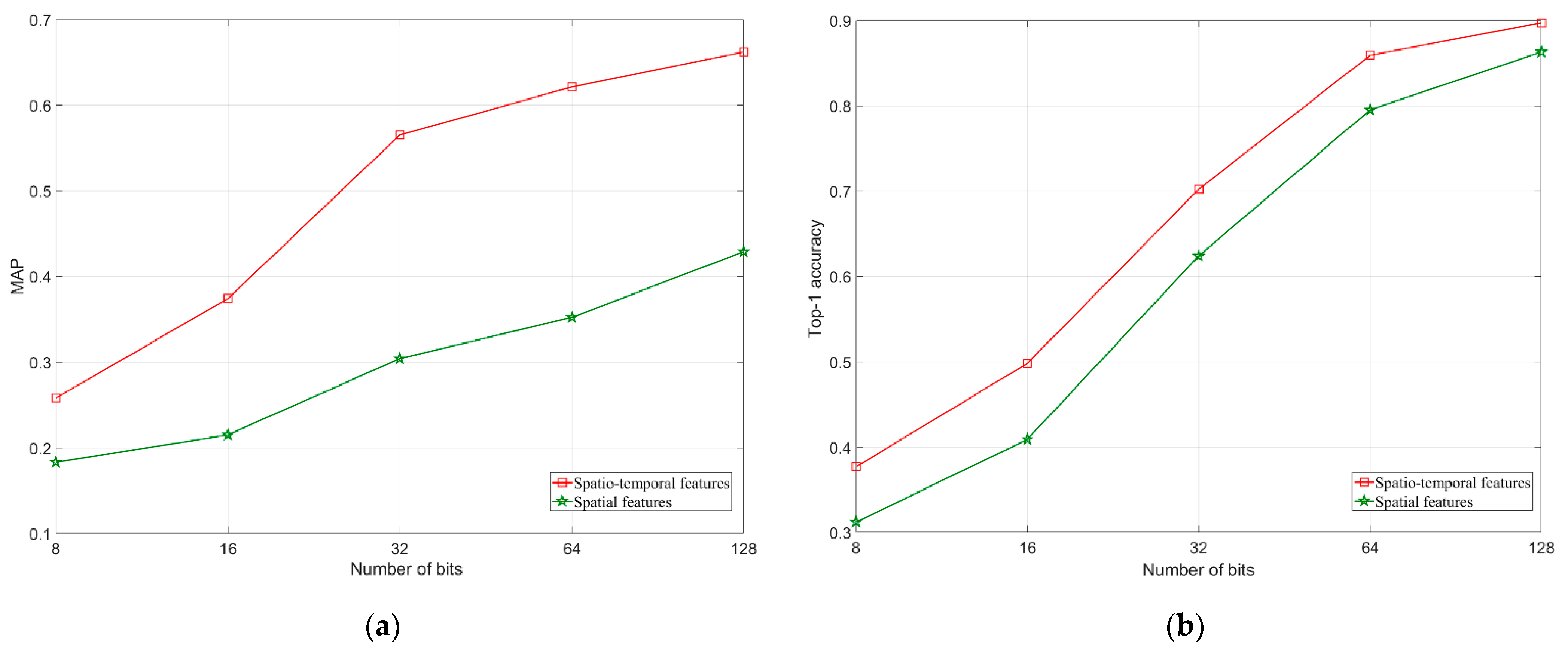
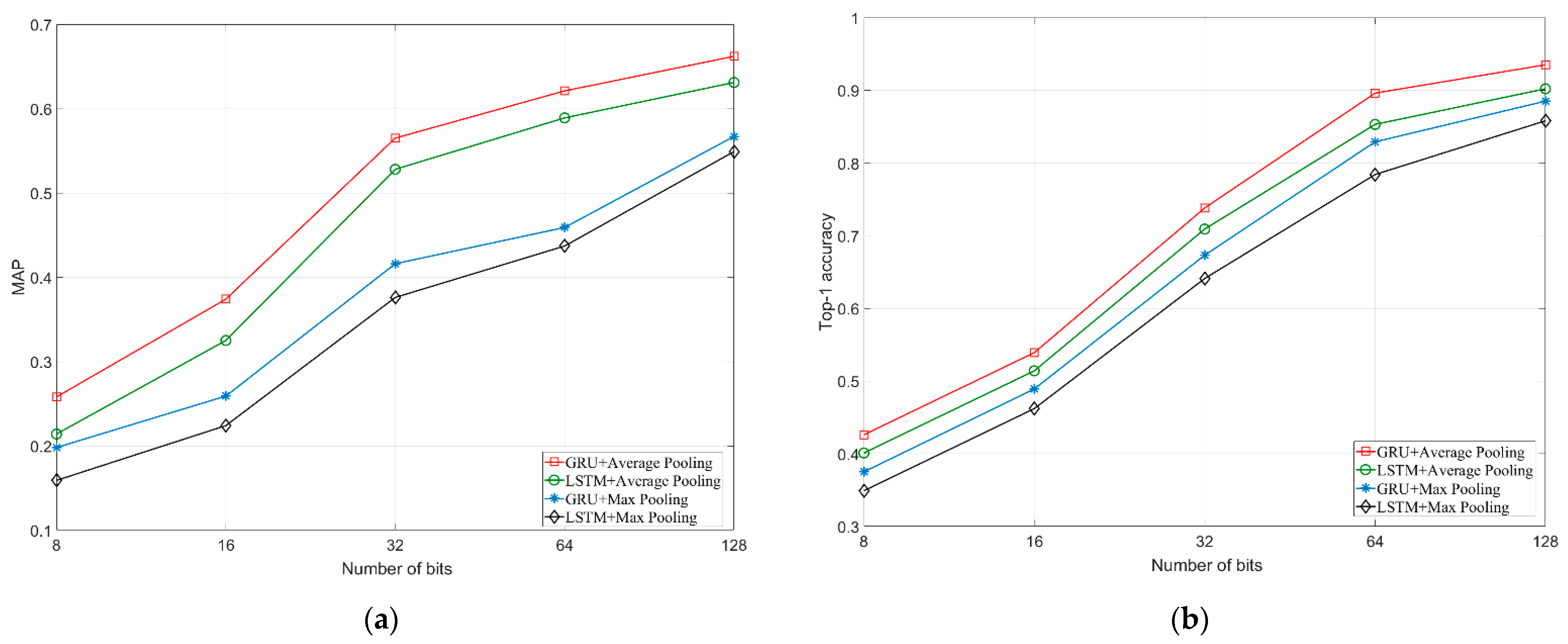
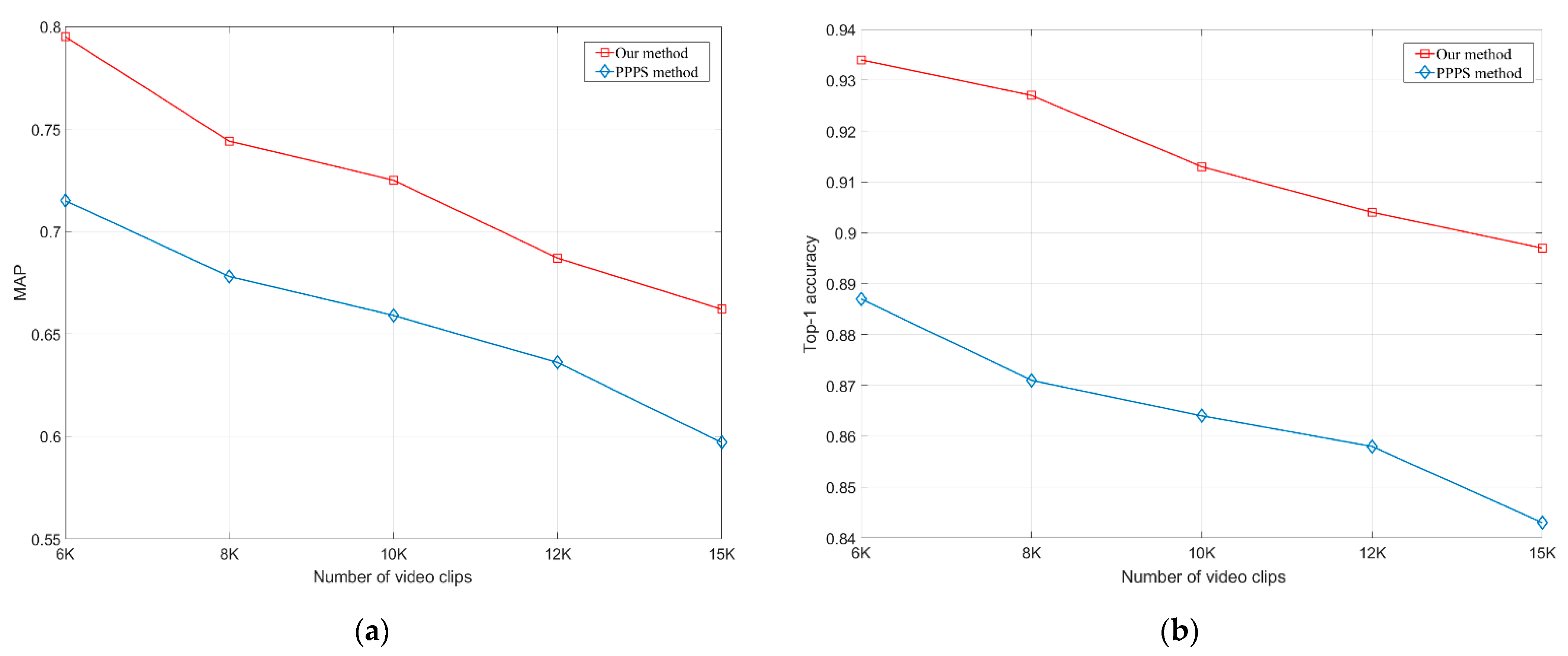
4.4. Experimental Results
4.5. Experimental Summary and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable person re-identification: A benchmark. In Proceedings of the International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1116–1124. [Google Scholar]
- Xu, J.; Zhao, R.; Zhu, F.; Wang, H.; Ouyang, W. Attention-aware compositional network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2119–2128. [Google Scholar]
- Borgia, A.; Hua, Y.; Kodirov, E.; Robertson, N.M. Cross-view discriminative feature learning for person re-identification. Proc. IEEE Trans. Image Process. 2018, 27, 5338–5349. [Google Scholar] [CrossRef] [Green Version]
- Sun, X.; Zheng, L. Dissecting person re-identification from viewpoint of viewpoint. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 608–617. [Google Scholar]
- Zheng, K.; Liu, W.; He, L.; Mei, T.; Luo, J.; Zha, Z.J. Group-aware label transfer for domain adaptive person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 5310–5319. [Google Scholar]
- Matsukawa, T.; Okabe, T.; Suzuki, E.; Sato, Y. Hierarchical Gaussian descriptor for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1363–1372. [Google Scholar]
- Zheng, L.; Bie, Z.; Sun, Y.; Wang, J.; Su, C.; Wang, S.; Tian, Q. Mars: A video benchmark for large-scale person re-identification. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 868–884. [Google Scholar]
- Xiao, T.; Li, S.; Wang, B.; Lin, L.; Wang, X. Joint detection and identification feature learning for person search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3376–3385. [Google Scholar]
- Shi, W.; Liu, H.; Meng, F.; Huang, W. Instance enhancing loss: Deep identity-sensitive feature embedding for person search. In Proceedings of the IEEE International Conference on Image Processing, Athens, Greece, 7–10 October 2018; pp. 4108–4112. [Google Scholar]
- Dai, J.; Zhang, P.; Lu, H.; Wang, H. Dynamic imposter based online instance matching for person search. Pattern Recognit. 2020, 100, 107120. [Google Scholar] [CrossRef]
- Munjal, B.; Amin, S.; Tombari, F.; Galasso, F. Query-guided end-to-end person search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 811–820. [Google Scholar]
- Zheng, L.; Zheng, H.; Sun, S.; Chandraker, M.; Yang, Y.; Tian, Q. Person re-identification in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honlulu, HI, USA, 21–26 July 2017; pp. 3346–3355. [Google Scholar]
- Yi, D.; Liao, S.; Li, S.Z. Deep metric learning for person re-identification. In Proceedings of the International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 34–39. [Google Scholar]
- Li, W.; Zhao, R.; Xiao, T.; Wang, X. DeepReID: Deep filter pairing neural network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 152–159. [Google Scholar]
- Ksibi, S.; Mejdoub, M.; Amar, C.B. Deep salient-Gaussian Fisher vector encoding of the spatio-temporal trajectory structures for person re-identification. Multimed. Tools Appl. 2018, 78, 1583–1611. [Google Scholar] [CrossRef]
- Li, M.; Shen, F.; Wang, J.; Guan, C.; Tang, J. Person re-identification with activity prediction based on hierarchical spatial-temporal model. Neurocomputing 2018, 275, 1200–1207. [Google Scholar] [CrossRef]
- Dai, Z.; Chen, M.; Gu, X.; Zhu, S.; Tan, P. Batch DropBlock network for person re-identification and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3691–3701. [Google Scholar]
- Rambhatla, S.S.; Jones, M. Body part alignment and temporal attention for video-based person re-Identification. In Proceedings of the British Machine Vision Conference, Cardiff, UK, 25 September 2019; pp. 1–12. [Google Scholar]
- Liu, C.T.; Wu, C.W.; Wang, Y.C.F.; Chien, S.Y. Spatially and temporally efficient non-local attention network for video-based person re-identification. In Proceedings of the British Machine Vision Conference, Cardiff, UK, 5 August 2019; pp. 1–13. [Google Scholar]
- Aich, A.; Zheng, M.; Karanam, S.; Chen, T.; Roy-Chowdhury, A.K.; Wu, Z. Spatio-Temporal Representation Factorization for Video-based Person Re-Identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 152–162. [Google Scholar]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Chen, D.; Zhang, S.; Ouyang, W.; Yang, J.; Tai, Y. Person search via a mask-guided two-stream CNN model. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 764–781. [Google Scholar]
- Lan, X.; Zhu, X.; Gong, S. Person search by multi-scale matching. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 553–569. [Google Scholar]
- Wang, C.; Ma, B.; Chang, H.; Shan, S.; Chen, X. TCTS: A task-consistent two-stage framework for person search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11952–11961. [Google Scholar]
- He, Z.; Zhang, L.; Jia, W. End-to-end detection and re-identification integrated net for person search. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; pp. 264–349. [Google Scholar]
- Dong, W.; Zhang, Z.; Song, C.; Tan, T. Bi-directional interaction network for person search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2839–2848. [Google Scholar]
- Zhong, Y.; Wang, X.; Zhang, S. Robust partial matching for person search in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6827–6835. [Google Scholar]
- Yan, Y.; Li, J.; Qin, J.; Bai, S.; Liao, S.; Liu, L.; Zhu, F.; Shao, L. Anchor-free person search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 7690–7699. [Google Scholar]
- Han, C.; Zheng, Z.; Gao, C.; Sang, N.; Yang, Y. Decoupled and memory-reinforced networks: Towards effective feature learning for one-step person search. In Proceedings of the 35th AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021. [Google Scholar]
- Zhang, X.; Wang, X.; Bian, J.W.; Shen, C.; You, M. Diverse knowledge distillation for end-to-end person search. In Proceedings of the 35th AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021. [Google Scholar]
- Li, Z.; Miao, D. Sequential end-to-end network for efficient person search. In Proceedings of the 35th AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021. [Google Scholar]
- Yu, R.; Du, D.; LaLonde, R.; Davila, D.; Funk, C.; Hoogs, A.; Clipp, B. Cascade Transformers for End-to-End Person Search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 7267–7276. [Google Scholar]
- Huang, Q.; Liu, W.; Lin, D. Person search in videos with one portrait through visual and temporal links. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 425–441. [Google Scholar]
- Alcazaar, J.L.; Heilbron, F.C.; Mai, L.; Perazzi, F. APES: Audiovisual person search in untrimmed video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Virtual, 19–25 June 2021; pp. 1720–1729. [Google Scholar]
- Kumar, S.; Yaghoubi, E.; Das, A.; Harish, B.; Proenca, H. The P-DESTRE: A fully annotated dataset for pedestrian detection, tracking, and short/long-term re-identification from aerial devices. IEEE Trans. Inf. Forensics Secur. 2020, 16, 1696–1708. [Google Scholar] [CrossRef]
- Rehman, S.; Riaz, F.; Hassan, A.; Liaquat, M.; Young, R. Human detection in sensitive security areas through recognition of omega shapes using Mach filters. In Optical Pattern Recognition XXVI; SPIE: Bellingham, WA, USA, 2015; p. 947708. [Google Scholar]
- Malviya, V.; Kala, R. Trajectory prediction and tracking using a multi-behaviour social particle filter. Appl. Intell. 2022, 52, 7158–7200. [Google Scholar] [CrossRef]
- Ma, C.; Gu, Y.; Gong, C.; Yang, J.; Feng, D. Unsupervised video hashing via deep neural network. Neural Process. Lett. 2018, 47, 877–890. [Google Scholar] [CrossRef]
- Redom, J.; Divvla, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, S. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Cho, K.; Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Gionis, A.; Indyk, P.; Motwani, R. Similarity Search in High Dimensions via Hashing. In Proceedings of the 25th International Conference on Very Large Data Bases, Edinburgh, UK, 7–10 September 1999; pp. 518–529. [Google Scholar]
- ultralytics. yolov5. Available online: https://github.com/ultralytics/yolov5 (accessed on 5 December 2021).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 8024–8035. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | Video Clips | Person Identities | Training Data | Testing Data |
|---|---|---|---|---|
| Surveillance Video | 15,000 | 897 | 11,546 | 3454 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, D.; Yang, J.; Wei, Y.; Xiao, H.; Zhang, L. An Efficient Person Search Method Using Spatio-Temporal Features for Surveillance Videos. Appl. Sci. 2022, 12, 7670. https://doi.org/10.3390/app12157670
Feng D, Yang J, Wei Y, Xiao H, Zhang L. An Efficient Person Search Method Using Spatio-Temporal Features for Surveillance Videos. Applied Sciences. 2022; 12(15):7670. https://doi.org/10.3390/app12157670
Chicago/Turabian StyleFeng, Deying, Jie Yang, Yanxia Wei, Hairong Xiao, and Laigang Zhang. 2022. "An Efficient Person Search Method Using Spatio-Temporal Features for Surveillance Videos" Applied Sciences 12, no. 15: 7670. https://doi.org/10.3390/app12157670
APA StyleFeng, D., Yang, J., Wei, Y., Xiao, H., & Zhang, L. (2022). An Efficient Person Search Method Using Spatio-Temporal Features for Surveillance Videos. Applied Sciences, 12(15), 7670. https://doi.org/10.3390/app12157670