
IFD: An Intelligent Fast Detection for Real-Time Image Information in Industrial IoT


Abstract
:1. Introduction
- Too large downsampling rate.Assume that the current small object size is 15 × 15. In general object detection, the convolution downsampling rate is 16, so in the feature map, a too large downsampling rate makes small objects unable to occupy even one pixel.
- Too large receptive field.In the convolution network, the receptive field of the feature points on the feature map is much larger than the downsampling rate, resulting in fewer features occupied by small objects in a point on the feature map, which will contain a large number of features of the surrounding area, thus affecting its detection results.
- Contradiction between semantics and space.The backbones of current detection algorithms are mostly from top to bottom, and the deep and shallow feature maps do not achieve a better balance between semantics and space. For example, the YOLO algorithm can meet the real-time requirements, but the detection accuracy is low.
- Tradeoff between detection speed and accuracy.Faster detection speed sometimes implies that the scale of the network model is small, resulting in light-weight feature extraction. However, the larger model improves the recognition accuracy, but it wants high computing power and so the detection speed is slow, which cannot meet the amount of desired time of the instrumentation with very little computing power in IoT.
- An Intelligent Fast Detection for Real-time Image Information in industrial IoT is proposed, which adopts the improved YOLOv3-tiny framework and can meet the detection speed necessities of a real-time system and effectively improve the detection accuracy.
- We distinguish whether an object belongs to a smaller object according to the number of pixels occupied by the object in the image, and then, we use WANG to expand the dataset of smaller objects. We expanded the amount of smaller objects in the dataset but reduce the larger objects. This is to reduce the preference for larger objects in network training.
- The k-means++ clustering algorithm is employed to obtain the predetermined boundary box to enhance the accuracy of the classification results.
2. Related Work
2.1. Non-CNN Feature Extraction
2.2. CNN-Based Feature Extraction
- Small object detection.Downsampling and convolution operations in today’s object detection algorithms result in a significant loss of image information, which has a significant influence on the recognition of objects of varied scales, particularly small objects.
- The weakness of the real-time detecting system’s accuracy.To fulfill the real-time requirements for detection speed, the initial network must be simplified, which results in a large reduction in picture information extracted by the network, and whether the network can extract adequate image information directly influences detection accuracy.
3. Our Proposed Object Detection Algorithm Combined with Varyblock
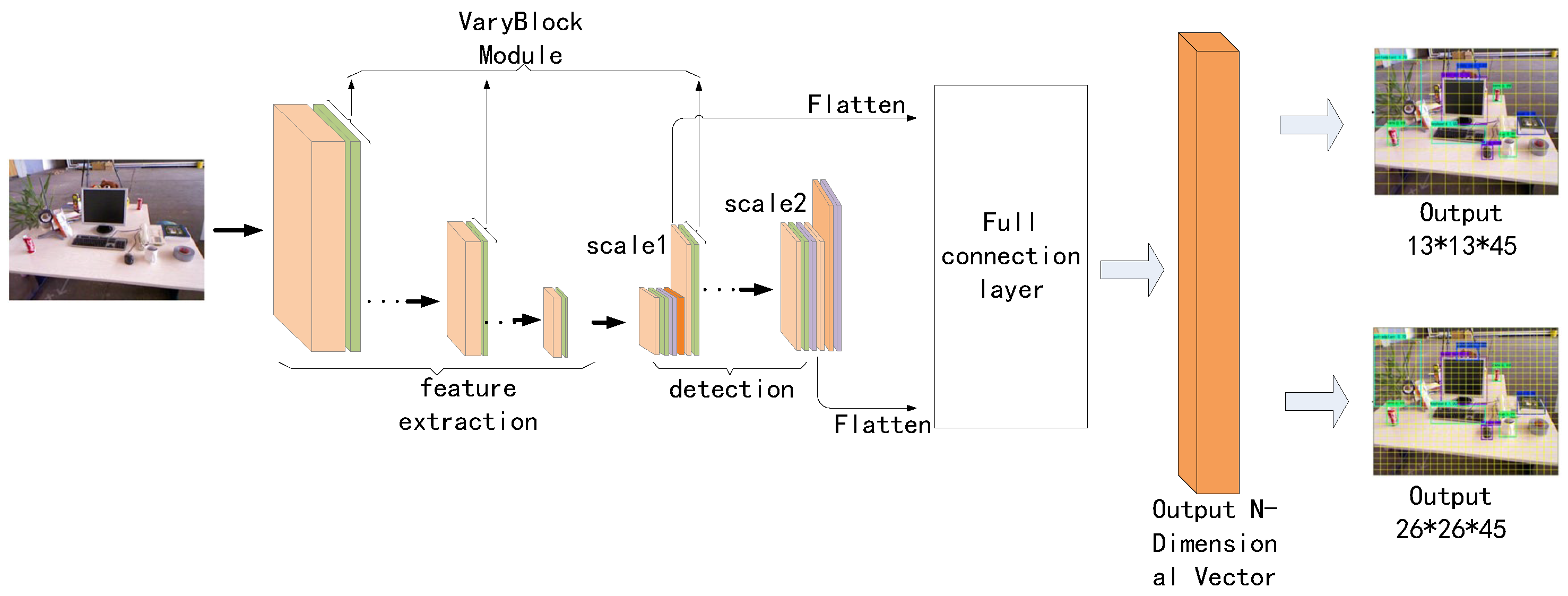
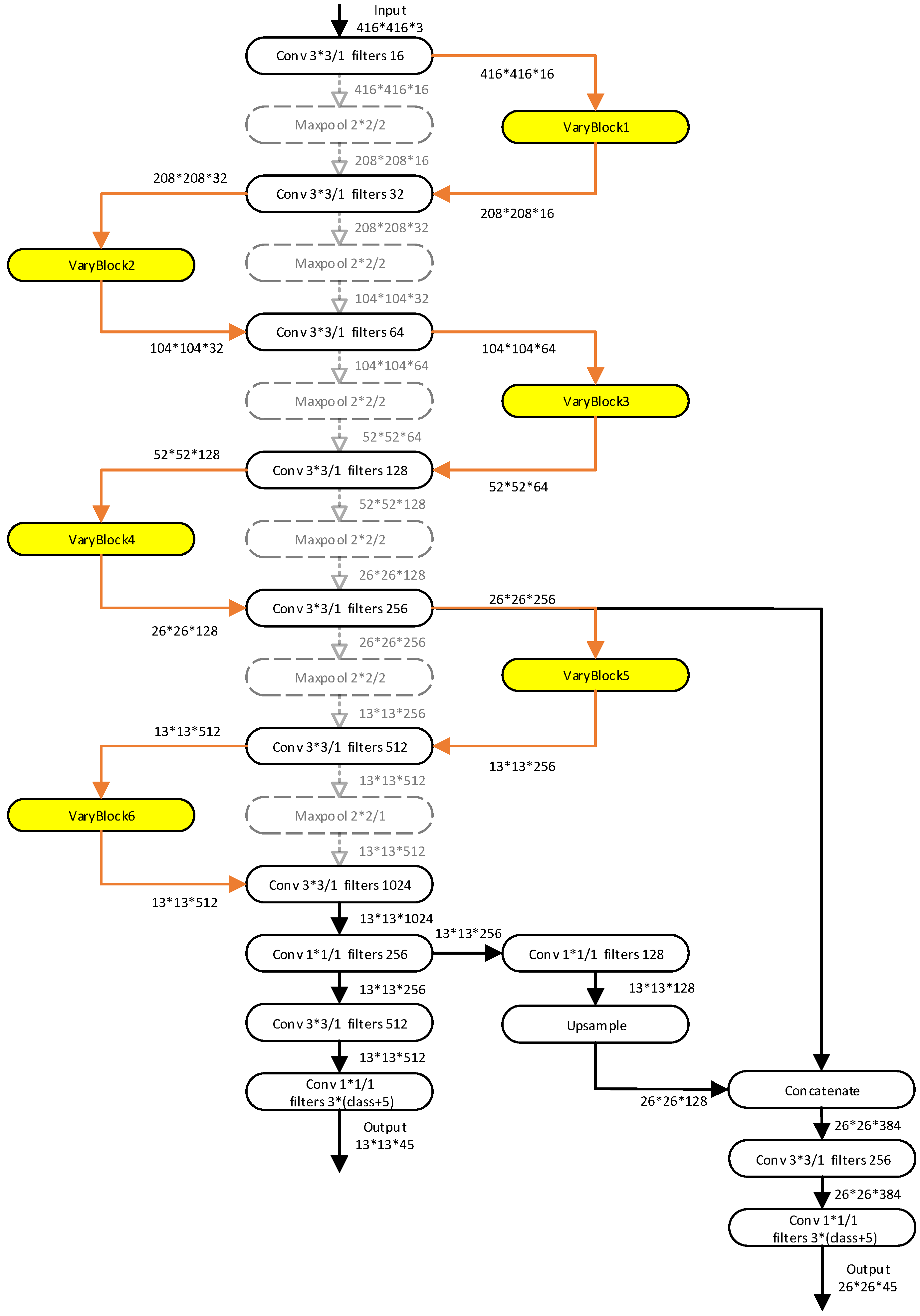
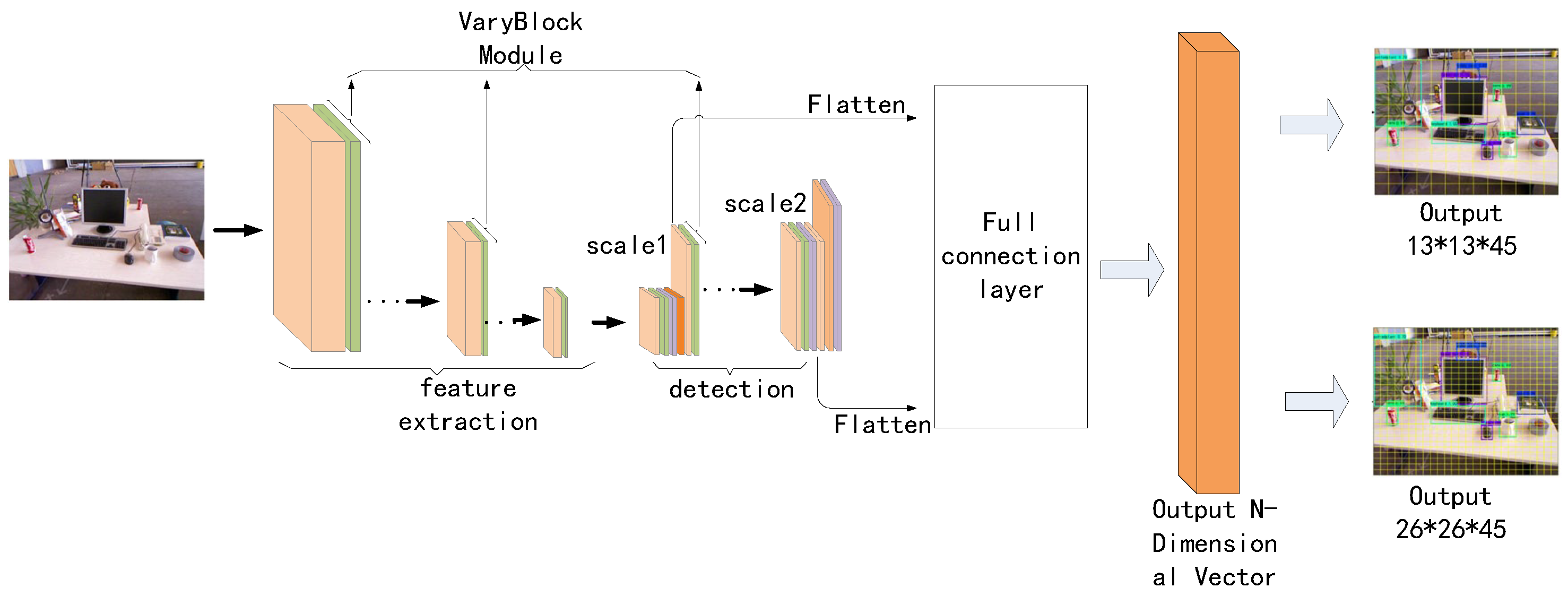
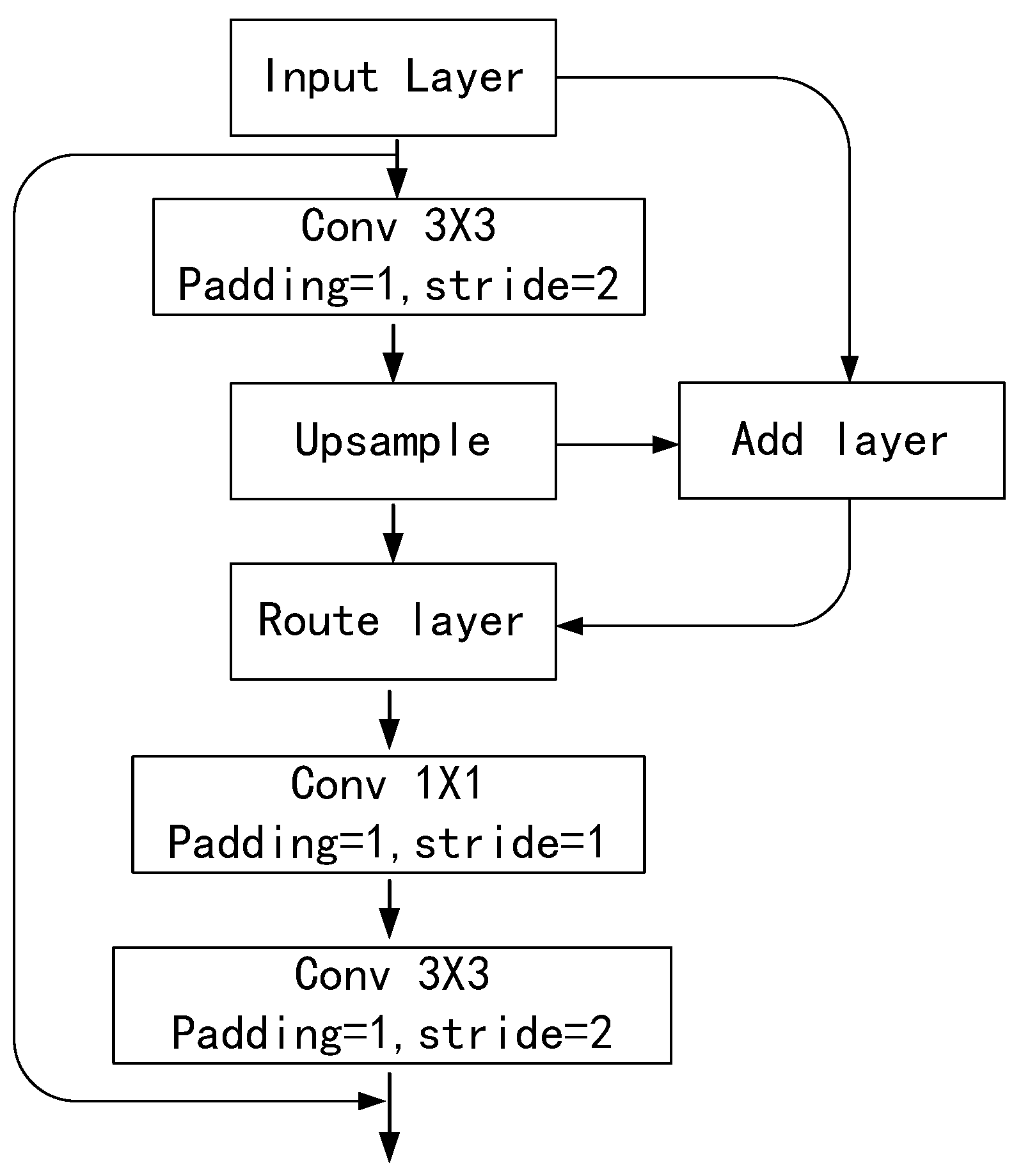
3.1. Overall Architecture
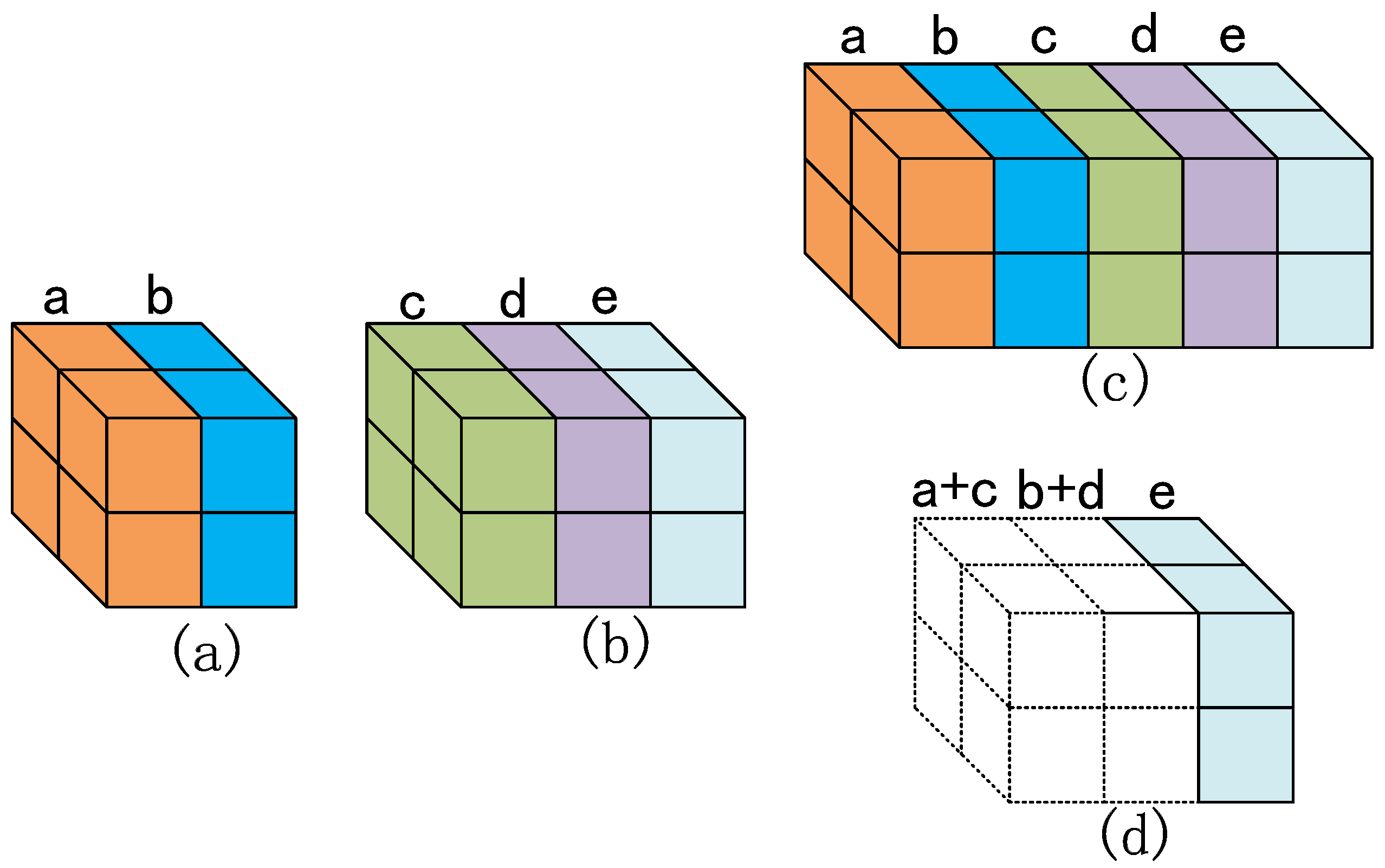
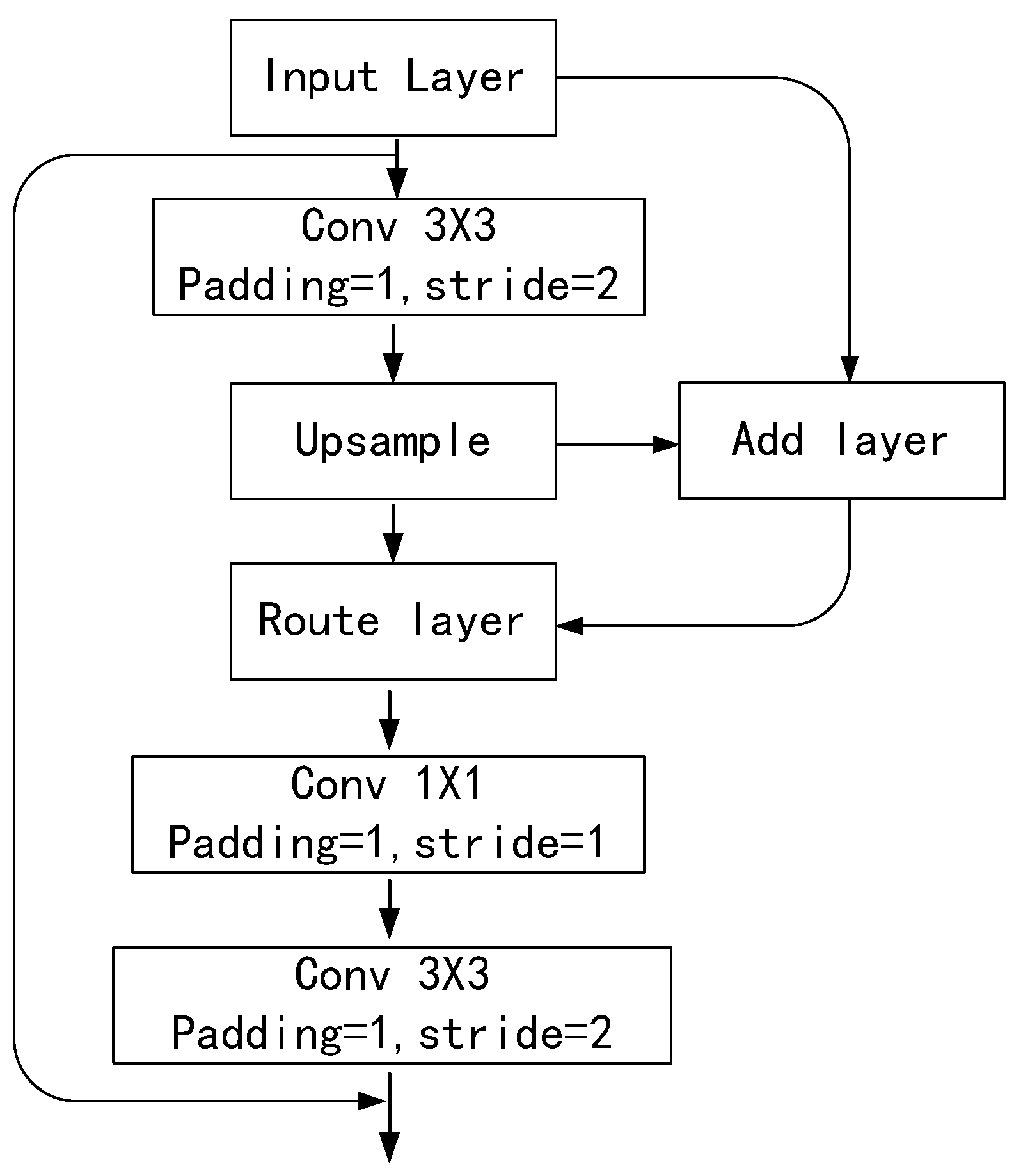
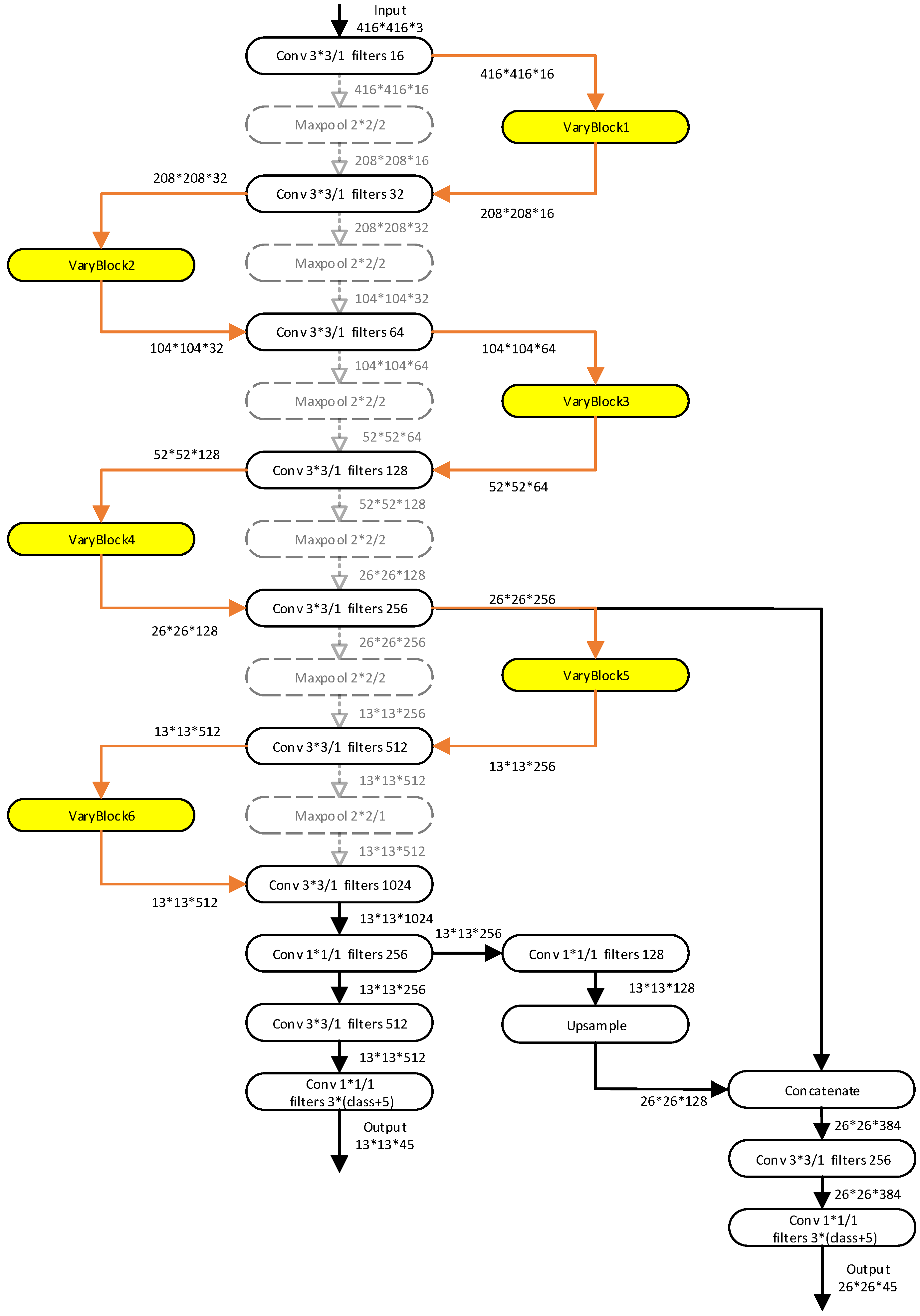
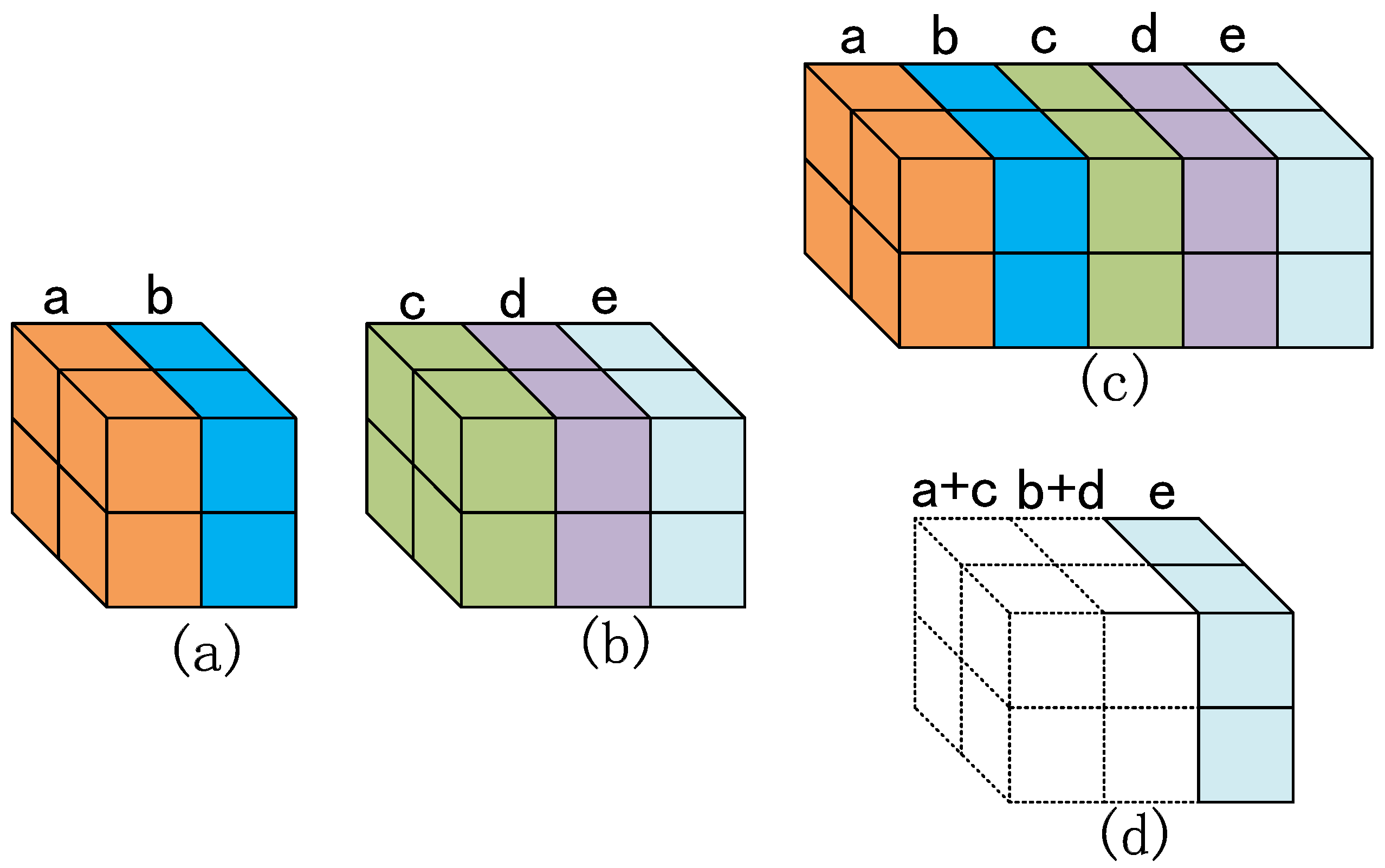
3.2. YOLO-Tiny Integrated VaryBlock
3.3. Data Expansion
3.3.1. Distinction of Object Size
3.3.2. Extended Object Area
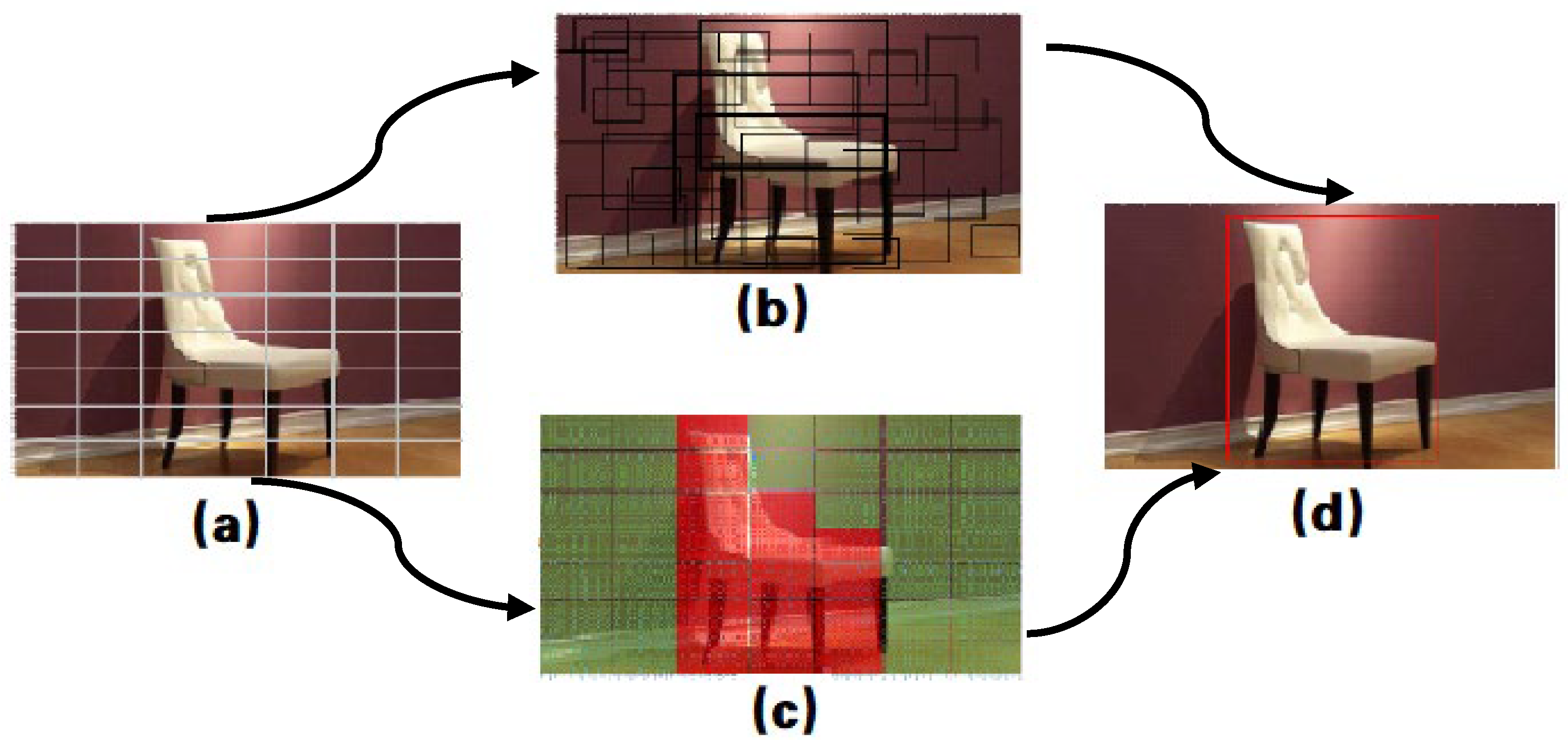
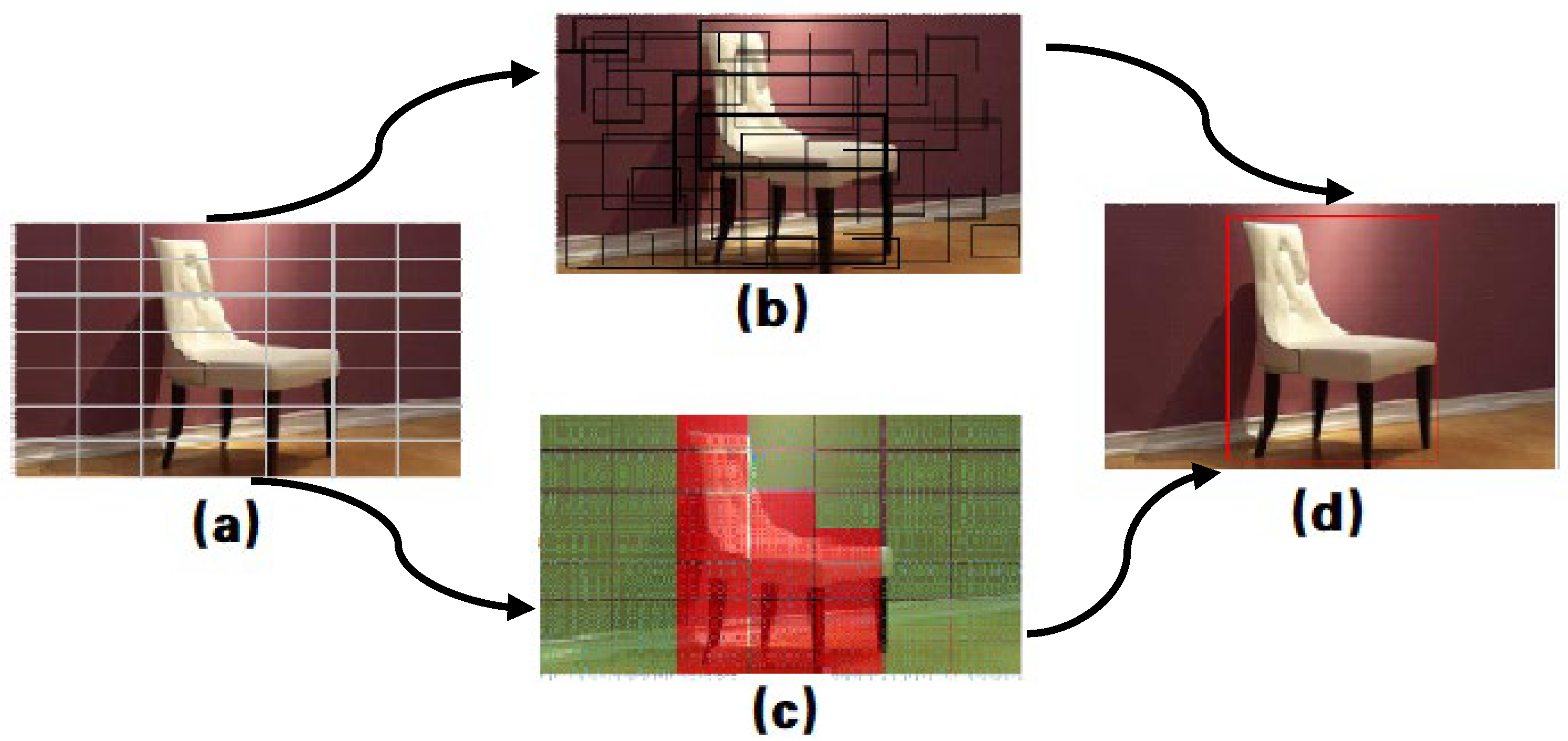
3.4. Preset Bounding Box
| Algorithm 1: The process by which the K-means++ clustering algorithm generates the preset bounding box. |
Input: The bounding box set X of the object in the dataset. Output:
|
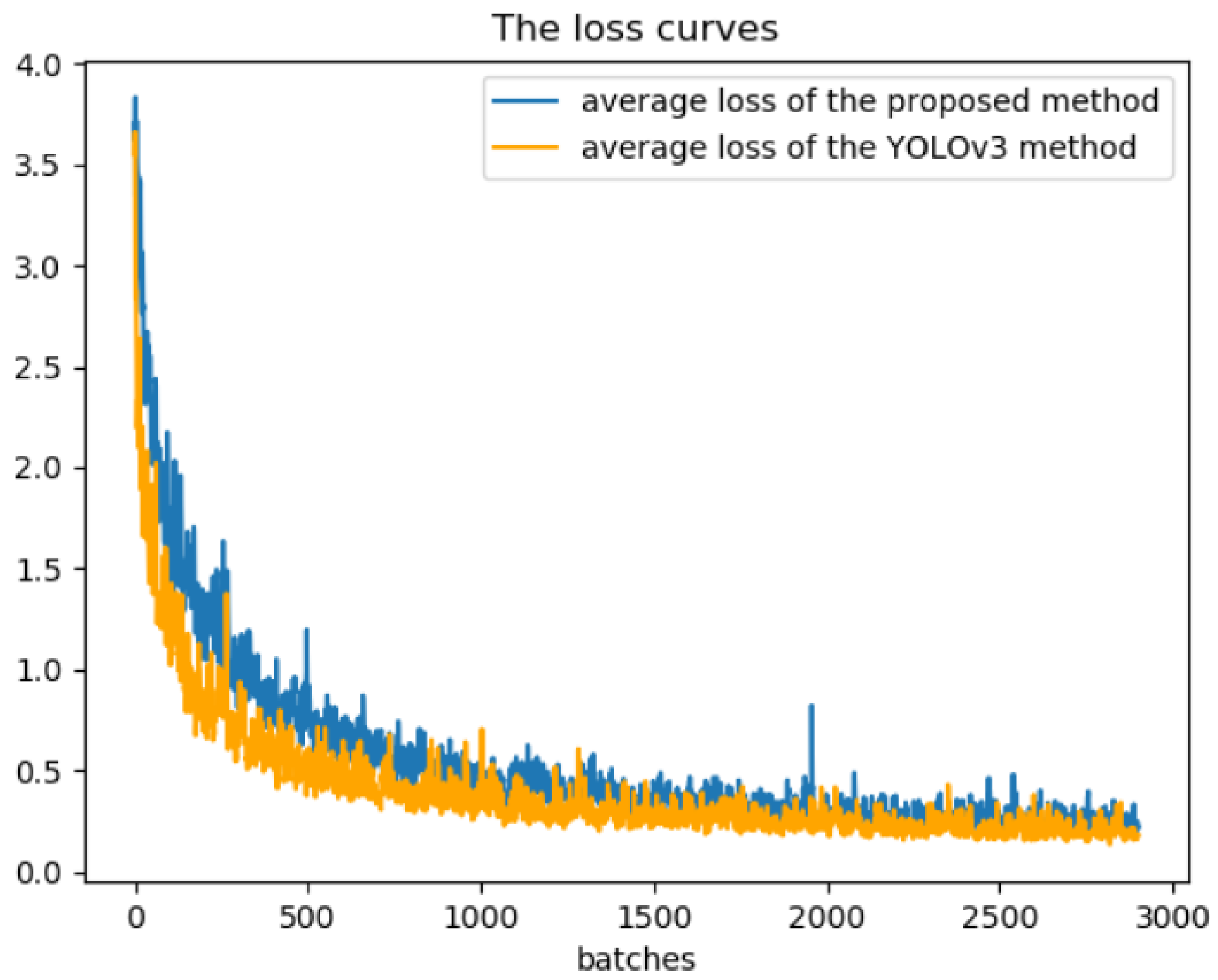
3.5. Training and Prediction of Network Model
| Algorithm 2: The prediction process of the improved YOLOv3 object detection algorithm |
Input: Image X and model weight M. Output: The prediction category and probability P of all objects in image X as well as the corresponding bounding box position.
|
4. Performance Analysis
4.1. Evaluation Indicator
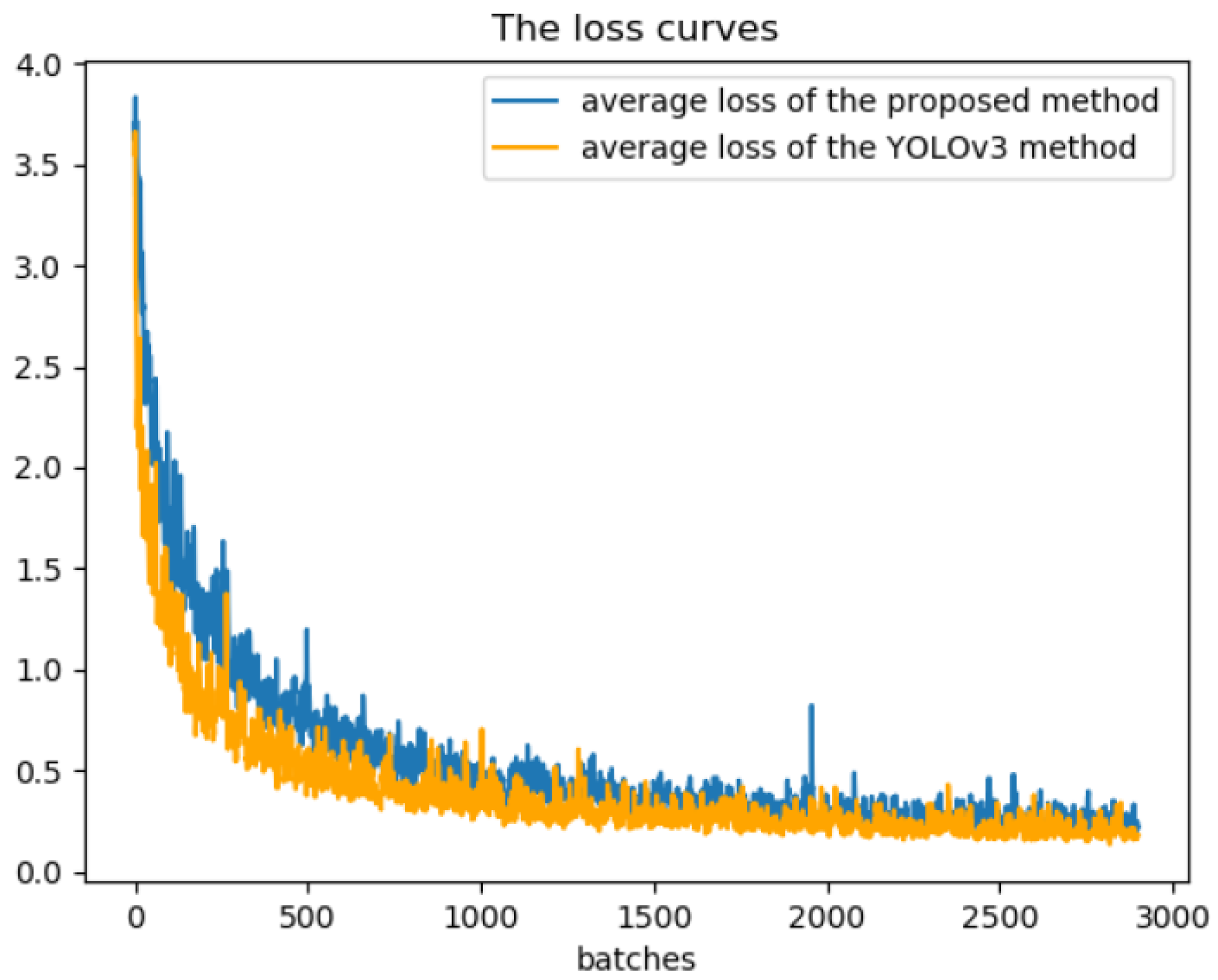
4.2. Experimental Verification and Result Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| IFD | An Intelligent Fast Detection for Real-time Image Information in Industrial IoT |
| CNN | Convolutional Neural Networks |
| YOLO | You Only Look Once |
| GAN | Generative Adversarial Networks |
| WGAN | Wasserstein Generative Adversarial Networks |
| R-CNN | Region Convolutional Neural Networks |
| RPN | Region Proposal Network |
| FPN | Feature Pyramid Networks for Object Detection |
| k-means | k-means clustering algorithm |
| MS-COCO | Microsoft Common Objects in Context |
| IoT | Internet of Things |
| IIoT | Industrial Internet of Things |
| SIFT | Distinctive Image Features from Scale-Invariant Keypoints |
| HOG | Histograms of Oriented Gradients for Human Detection |
| DPM | Deformable Part Model |
| BoVW | Bags-of-Visual-Words |
| PAN-Net | Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation |
| Network | |
| GC-YOLOv3 | You Only Look Once with Global Context Block |
| Resnet | Deep Residual Learning for Image Recognition |
| DenseNet | Densely Connected Convolutional Networks |
| SGD | Stochastic Gradient Descent Algorithm |
| IOU | Intersection Over Union |
| SSD | Single Shot MultiBox Detector |
| ELAN | Efficient Long-range Attention Network |
| SVM | Support Vector Machine |
| SSP-net | Spatial pyramid pooling in deep convolutional networks for visual recognition |
References
- Laghari, A.A.; Wu, K.; Laghari, R.A.; Ali, M.; Khan, A.A. A review and state of art of Internet of Things (IoT). Arch. Comput. Methods Eng. 2021, 29, 1395–1413. [Google Scholar] [CrossRef]
- Chegini, H.; Naha, R.K.; Mahanti, A.; Thulasiraman, P. Process automation in an IoT-fog-cloud ecosystem: A survey and taxonomy. IoT 2021, 2, 92–118. [Google Scholar] [CrossRef]
- Centenaro, M.; Costa, C.E.; Granelli, F.; Sacchi, C.; Vangelista, L. A Survey on Technologies, Standards and Open Challenges in Satellite IoT. IEEE Commun. Surv. Tutor. 2021, 23, 1693–1720. [Google Scholar] [CrossRef]
- Sathyan, M. Chapter six-industry 4.0: Industrial internet of things (IIOT). Adv. Comput. 2020, 117, 129–164. [Google Scholar]
- Sisinni, E.; Saifullah, A.; Han, S.; Jennehag, U.; Gidlund, M. Industrial internet of things: Challenges, opportunities, and directions. IEEE Trans. Ind. Inf. 2018, 14, 4724–4734. [Google Scholar] [CrossRef]
- Mao, K.; Srivastava, G.; Parizi, R.M.; Khan, M.S. Multi-source fusion for weak target images in the Industrial Internet of Things. Comput. Commun. 2021, 173, 150–159. [Google Scholar] [CrossRef]
- Sun, X.J.; Lin, J.C.W. A target recognition algorithm of multi-source remote sensing image based on visual Internet of Things. Mob. Netw. Appl. 2022, 27, 784–793. [Google Scholar] [CrossRef]
- Huang, X. Intelligent remote monitoring and manufacturing system of production line based on industrial Internet of Things. Comput. Commun. 2020, 150, 421–428. [Google Scholar] [CrossRef]
- Sadeeq, M.A.; Zeebaree, S.R.; Qashi, R.; Ahmed, S.H.; Jacksi, K. Internet of Things security: A survey. In Proceedings of the 2018 International Conference on Advanced Science and Engineering (ICOASE), Duhok, Irak, 9–11 October 2018; pp. 162–166. [Google Scholar]
- Darvishi, H.; Ciuonzo, D.; Eide, E.R.; Rossi, P.S. Sensor-fault detection, isolation and accommodation for digital twins via modular data-driven architecture. IEEE Sens. J. 2020, 21, 4827–4838. [Google Scholar] [CrossRef]
- Jacob, I.J.; Darney, P.E. Design of deep learning algorithm for IoT application by image based recognition. J. ISMAC 2021, 3, 276–290. [Google Scholar] [CrossRef]
- Latif, S.; Driss, M.; Boulila, W.; Huma, Z.E.; Jamal, S.S.; Idrees, Z.; Ahmad, J. Deep learning for the industrial internet of things (iiot): A comprehensive survey of techniques, implementation frameworks, potential applications, and future directions. Sensors 2021, 21, 7518. [Google Scholar] [CrossRef] [PubMed]
- Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z.; Qu, R. A survey of deep learning-based object detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- Wang, H.; Zheng, X. Survey of Deep Learning Based Object Detection. In Proceedings of the 2nd International Conference on Big Data Technologies, Nanjing, China, 17–19 June 2019; Association for Computing Machinery: New York, NY, USA, 2019. ICBDT2019. pp. 149–153. [Google Scholar] [CrossRef]
- Sharma, L.; Lohan, N. Internet of things with object detection: Challenges, applications, and solutions. In Handbook of Research on Big Data and the IoT; IGI Global: Hershey, PA, USA, 2019; pp. 89–100. [Google Scholar]
- Pathak, A.R.; Pandey, M.; Rautaray, S. Application of Deep Learning for Object Detection. Procedia Comput. Sci. 2018, 132, 1706–1717. [Google Scholar] [CrossRef]
- Sharma, K.; Thakur, N. A review and an approach for object detection in images. Int. J. Comput. Vis. Robot. 2017, 7, 196–237. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vision 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo Algorithm Developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Zhang, X.; Zeng, H.; Guo, S.; Zhang, L. Efficient Long-Range Attention Network for Image Super-resolution. arXiv 2022, arXiv:2203.06697. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE/cvf Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13029–13038. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar] [CrossRef] [Green Version]
- Sivic, J.; Zisserman, A. Video Google: A text retrieval approach to object matching in videos. In Proceedings of the 9th IEEE International Conference on Computer Vision, Nice, France, 14–17 October 2003; Volume 2, pp. 1470–1477. [Google Scholar] [CrossRef]
- Yan, J.; Lei, Z.; Wen, L.; Li, S.Z. The Fastest Deformable Part Model for Object Detection; IEEE Computer Society: Washington, DC, USA, 2014; CVPR’14; pp. 2497–2504. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; CVPR ’14. pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), IEEE Computer Society, Santiago, Chile, 7–13 December 2015; ICCV ’15. pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Los Alamitos, CA, USA, 2017; pp. 6517–6525. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lin, T.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Los Alamitos, CA, USA, 2017; pp. 936–944. [Google Scholar] [CrossRef] [Green Version]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, W.; Xie, E.; Song, X.; Zang, Y.; Wang, W.; Lu, T.; Yu, G.; Shen, C. Efficient and Accurate Arbitrary-Shaped Text Detection With Pixel Aggregation Network. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 8439–8448. [Google Scholar] [CrossRef] [Green Version]
- Chai, E.; Ta, L.; Ma, Z.; Zhi, M. ERF-YOLO: A YOLO algorithm compatible with fewer parameters and higher accuracy. Image Vis. Comput. 2021, 116, 104317. [Google Scholar] [CrossRef]
- Gong, H.; Li, H.; Xu, K.; Zhang, Y. Object Detection Based on Improved YOLOv3-tiny. In Proceedings of the 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 3240–3245. [Google Scholar] [CrossRef]
- Jiang, Z.; Zhao, L.; Li, S.; Jia, Y. Real-time object detection method based on improved YOLOv4-tiny. arXiv 2020, arXiv:2011.04244. [Google Scholar]
- Zhang, Z.D.; Tan, M.L.; Lan, Z.C.; Liu, H.C.; Pei, L.; Yu, W.X. CDNet: A real-time and robust crosswalk detection network on Jetson nano based on YOLOv5. Neural Comput. Appl. 2022, 34, 10719–10730. [Google Scholar] [CrossRef]
- Karthi, M.; Muthulakshmi, V.; Priscilla, R.; Praveen, P.; Vanisri, K. Evolution of YOLO-V5 Algorithm for Object Detection: Automated Detection of Library Books and Performace validation of Dataset. In Proceedings of the 2021 International Conference on Innovative Computing, Intelligent Communication and Smart Electrical Systems (ICSES), Chennai, India, 24–25 September 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Long, X.; Deng, K.; Wang, G.; Zhang, Y.; Dang, Q.; Gao, Y.; Shen, H.; Ren, J.; Han, S.; Ding, E.; et al. PP-YOLO: An Effective and Efficient Implementation of Object Detector. arXiv 2020, arXiv:2007.12099. [Google Scholar]
- Huang, X.; Wang, X.; Lv, W.; Bai, X.; Long, X.; Deng, K.; Dang, Q.; Han, S.; Liu, Q.; Hu, X.; et al. PP-YOLOv2: A Practical Object Detector. arXiv 2021, arXiv:2104.10419. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. You only learn one representation: Unified network for multiple tasks. arXiv 2021, arXiv:2207.02696. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Zheng, L.; Fu, C.; Zhao, Y. Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network. arXiv 2018, arXiv:1801.05918. [Google Scholar]
- Yang, Y. GC-YOLOv3: You Only Look Once with Global Context Block. Electronics 2020, 9, 1235. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Maaten, L.V.D.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE Computer Society, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems–Volume 2, Bangkok, Thailand, 23–27 November 2014; NIPS’14. pp. 2672–2680. [Google Scholar]
- Walczak, S.M. Metric Diffusion for Non-compact Foliations: Remarks. In Metric Diffusion Along Foliations; Springer International Publishing: Cham, Switzerland, 2017; pp. 49–52. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein Generative Adversarial Networks. In Proceedings of the 34th International Conference on Machine Learning—Volume 70, Sydney, Australia, 6–11 August 2017; ICML’17. pp. 214–223. [Google Scholar]
- Wang, Z.; Li, L.; Li, L.; Pi, J.; Li, S.; Zhou, Y. Object detection algorithm based on improved Yolov3-tiny network in traffic scenes. In Proceedings of the 2020 4th CAA International Conference on Vehicular Control and Intelligence (CVCI), Hangzhou, China, 18–20 December 2020; pp. 514–518. [Google Scholar] [CrossRef]
- Yi, Z.; Yongliang, S.; Jun, Z. An improved tiny-yolov3 pedestrian detection algorithm. Optik 2019, 183, 17–23. [Google Scholar] [CrossRef]
- Gong, X.; Ma, L.; Ouyang, H. An improved method of Tiny YOLOV3. IOP Conf. Ser. Earth Environ. Sci. 2020, 440, 052025. [Google Scholar] [CrossRef]
- Cao, C.; Wang, B.; Zhang, W.; Zeng, X.; Yan, X.; Feng, Z.; Liu, Y.; Wu, Z. An Improved Faster R-CNN for Small Object Detection. IEEE Access 2019, 7, 106838–106846. [Google Scholar] [CrossRef]
- Nascita, A.; Montieri, A.; Aceto, G.; Ciuonzo, D.; Persico, V.; Pescapé, A. XAI meets mobile traffic classification: Understanding and improving multimodal deep learning architectures. IEEE Trans. Netw. Serv. Manag. 2021, 18, 4225–4246. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Yes or No CNN-Based | One or Two Stage | Loss Description | Backbone | Main Strategy |
|---|---|---|---|---|---|
| SIFT | NO | - | - | - | Keeping invariance to rotation, scaling, brightness change, etc. |
| HOG | NO | - | - | - | Using the distribution of light intensity or edge direction on the surface of the object to describe the whole object. |
| BoVW | NO | - | - | - | Applying Bag-of-Words algorithm to image representation. |
| DPM | NO | - | - | - | Adopting the improved HOG feature, SVM classifier and sliding windows detection idea. |
| R-CNN | Yes | Two | - | Pre-trained AlexNet | Using the selective search algorithm [20] to improve the filtering speed of candidate boxes. |
| Fast R-CNN | Yes | Two | Classification, regression | VGG-16 | Absorbing the characteristics of SPP-net [21] to improve the speed based on R-CNN. |
| Mask R-CNN | Yes | Two | Classification, regression, mask | Pre-trained ResNet or FPN | Adding a branch of prediction segmentation mask based on Fast R-CNN. |
| YOLOv1 | Yes | One | Bounding box, confidence, probability, etc. | VGG-16 | Regression of object bounding box. |
| YOLOv2 | Yes | One | Same as YOLOv1 | Darknet-19 | Multiscale training, full convolution network, anchor mechanism of fast R-CNN, more training skills, etc. |
| YOLOv3 | Yes | One | Binary cross entropy in classification | Darknet-53 | Integrating FPN, using Softmax in classifier. |
| YOLOv4 | Yes | One | CIOU in anchor | CSPDarkNet53 | Changes in input images, neck and head based on V3. |
| YOLOv5 | Yes | One | CIOU in anchor | BottleneckCSP | Not much better than V4. |
| YOLOv3-Tiny | Yes | One | Same as YOLOv3 | Simplified Darknet-53 | Removing some feature layers, retaining two independent prediction branches based on YOLOv3. |
| YOLOv6 | Yes | One | SIOU in anchor | EfficientRep, Rep-PAN | Introducing Repvgg [22]. The backbone and neck are redesigned based on the idea of hardware perception. |
| YOLOv7 | Yes | One | CIOU in anchor | ELAN-Net [23] | Putting forward Extended-ELAN based on ELAN [23], model scaling based on concatenate model. |
| YOLOr | Yes | One | Explicit loss, implicit loss | YOLOV4-CSP [24] | Applying implicit knowledge hidden in CNN. |
| YOLOx | Yes | One | IOU in anchor | Darknet53 | Adding Decoupled Head, adopting Mosaic and Mixup data enhancement based on YOLOv3. |
| PP-YOLO | Yes | One | IOU Aware branch | ResNet50-vd-dcn | Detection Neck adopting FPN. |
| Item | Object Count | Images | Total Object Area |
|---|---|---|---|
| Small | 41.43% | 51.82% | 1.23% |
| Large | 24.24% | 82.28% | 88.59% |
| Width | 21 | 25 | 41 | 61 | 89 | 56 |
| Height | 30 | 53 | 37 | 75 | 63 | 105 |
| Model | Train Data | Test Data | (%) | (%) | (%) | (%) | Parameters (M) | |
|---|---|---|---|---|---|---|---|---|
| SSD(300) | COCO2017_trainval +TUM_train | COCO2017_test-dev +TUM_test | 43.2 | 49.1 | 44.5 | 41.3 | 40 | - |
| RCNN | COCO2017_trainval +TUM_train | COCO2017_test-dev +TUM_test | 59.3 | 60.2 | 55.1 | 43.2 | 37 | - |
| Faster RCNN | COCO2017_trainval +TUM_train | COCO2017_test-dev +TUM_test | 64.4 | 68.2 | 64.1 | 46.7 | 49 | 31.5 |
| YOLOv3-Tiny | COCO2017_trainval +TUM_train | COCO2017_test-dev +TUM_test | 55.3 | 63.7 | 58.1 | 52.2 | 74 | 8.7 |
| Ours (v3) | COCO2017_trainval +TUM_train | COCO2017_test-dev +TUM_test | 60.4 | 67.2 | 64.9 | 60.3 | 65 | 12 |
| YOLOv4-Tiny | COCO2017_trainval +TUM_train | COCO2017_test-dev +TUM_test | 59.4 | 65.3 | 60.1 | 58.6 | 85 | 27.6 |
| Ours (v4) | COCO2017_trainval +TUM_train | COCO2017_test-dev +TUM_test | 64.5 | 68.8 | 65.7 | 65.6 | 81 | 31 |
| YOLOv5s | COCO2017_trainval +TUM_train | COCO2017_test-dev +TUM_test | 37.0 | 56.8 | 37.4 | 35.0 | 416 | 7.2 |
| YOLOv5m | COCO2017_trainval +TUM_train | COCO2017_test-dev +TUM_test | 44.3 | 64.1 | 45.4 | 40.0 | 294 | 21.2 |
| YOLOv5l | COCO2017_trainval +TUM_train | COCO2017_test-dev +TUM_test | 47.7 | 67.3 | 49.0 | 47.2 | 227 | 46.2 |
| YOLOv5x | COCO2017_trainval +TUM_train | COCO2017_test-dev +TUM_test | 50.8 | 68.9 | 50.7 | 47.3 | 144 | 86.7 |
| Network Structure | FPS | mAP (%) | APS (%) |
|---|---|---|---|
| YOLOv3-Tiny | 74 | 55.3 | 52.2 |
| YOLOv3-Tiny+ VaryBlock 1-3 | 70 | 57.6 | 55.2 |
| YOLOv3-Tiny+ VaryBlock 1-6 | 68 | 61.5 | 57.2 |
| Network Structure | FPS | mAP(%) | APS (%) | APM (%) | APL (%) |
|---|---|---|---|---|---|
| YOLOv3-Tiny | 74 | 55.3 | 52.2 | 57.2 | 60.3 |
| YOLOv3-Tiny+WGAN | 74 | 57.3 | 55.7 | 59.1 | 60.4 |
| Our method | 65 | 60.4 | 57.1 | 60.8 | 60.3 |
| Network Structure | FPS | mAP (%) |
|---|---|---|
| YOLOv3-Tiny + standard k-means | 74 | 55.3 |
| YOLOv3-Tiny + k-means++ | 78 | 56.6 |
| YOLOv3-Tiny + VaryBlock + standard k-means | 60 | 59.2 |
| YOLOv3-Tiny + VaryBlock + k-means++ | 65 | 60.6 |
| SSD(300) | RCNN | Faster RCNN | YOLOv3-Tiny | Ours(v3) | YOLOv4-Tiny | Ours(v4) | |
|---|---|---|---|---|---|---|---|
| keyboard | 45.4 | 44.9 | 48.7 | 45.5 | 57.2 | 52.3 | 61.2 |
| book | 33.7 | 38.2 | 40.7 | 52.2 | 49.5 | 60.5 | 66.8 |
| plant | 56 | 60.2 | 65.8 | 56.5 | 59.6 | 56.1 | 66.4 |
| cans | 28.8 | 29.4 | 36.8 | 55.1 | 58.9 | 57.4 | 64.2 |
| mouse | 20.7 | 15.2 | 45.9 | 56.1 | 56.8 | 56.7 | 63.9 |
| chair | 36.8 | 37.6 | 54.8 | 60.1 | 56.4 | 61.4 | 55.3 |
| tvmonitor | 56.7 | 41.6 | 60.6 | 42.1 | 54.5 | 57.5 | 57.3 |
| cup | 35.8 | 22.8 | 50.7 | 51.7 | 68.6 | 53.4 | 70.3 |
| person | 35.3 | 39.9 | 56.4 | 62.1 | 64.1 | 62.4 | 61.2 |
| laptop | 40.7 | 34.4 | 50.2 | 49.0 | 56.5 | 53.6 | 58.7 |
| mAP(%) | 39.2 | 39.4 | 51.1 | 51.7 | 59.4 | 58.9 | 62.5 |
| FPS | 40 | 37 | 49 | 74 | 65 | 85 | 81 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Wang, Y.; Liu, Y.; Xiong, N. IFD: An Intelligent Fast Detection for Real-Time Image Information in Industrial IoT. Appl. Sci. 2022, 12, 7847. https://doi.org/10.3390/app12157847
Zhang H, Wang Y, Liu Y, Xiong N. IFD: An Intelligent Fast Detection for Real-Time Image Information in Industrial IoT. Applied Sciences. 2022; 12(15):7847. https://doi.org/10.3390/app12157847
Chicago/Turabian StyleZhang, Heng, Yingzhou Wang, Yanli Liu, and Naixue Xiong. 2022. "IFD: An Intelligent Fast Detection for Real-Time Image Information in Industrial IoT" Applied Sciences 12, no. 15: 7847. https://doi.org/10.3390/app12157847
APA StyleZhang, H., Wang, Y., Liu, Y., & Xiong, N. (2022). IFD: An Intelligent Fast Detection for Real-Time Image Information in Industrial IoT. Applied Sciences, 12(15), 7847. https://doi.org/10.3390/app12157847