1. Introduction
Vehicular congestion is a growing problem and one of the main challenges in most cities in Mexico. Only in the metropolitan area of the Mexico valley,
million of trips are made daily in a private vehicle, where the average number of occupants per vehicle is barely
users [
1]. Within this area, Mexico City stands out as the city with the highest traffic congestion in North America, with a time lost in rush hours per year of four days and twenty-three hours (
Tomtom Traffic Index Ranking 2021. Available at:
https://www.tomtom.com/en_gb/traffic-index/mexico-city-traffic/ (date of consultation: 25 July 2022)). This traffic congestion is in part because most users tend to use private vehicles rather than public transport, despite the adverse impact both economically and environmentally [
2,
3]. Traffic congestion also implies a considerable economic investment in road infrastructure and security controls.
Some public policies and technological solutions have been proposed to mitigate the problem of vehicular congestion. An example of a public policy in this vein is the implementation of the ‘today does not circulate’ program in Mexico (“hoy no circula” in Spanish), in which some restrictions are applied to the usage of the vehicle for certain days [
4]. Some technological solutions raised to cope with this problem are autonomous vehicles [
5,
6], vehicular networks [
7], Internet of Things [
8], among others [
9]. From these technological solutions, ridesharing systems stand out by their current applicability [
10,
11]. A ridesharing system is a mode of transportation where two or more users share the same vehicle and divide travel expenses (such as fuel, tolls, and parking fees) based on similar routes and itineraries [
12,
13]. Compared to other conventional means of transport, a ridesharing system maintains the flexibility and comfort of a particular vehicle in combination with rates and prices similar to public transportation [
14].
Nowadays, ridesharing systems support a dynamic allocation process between participants considering times and routes [
13]. The demand of multiple users (passengers and drivers) seeking to share a trip implies defining a relationship between them. Establishing this relationship of users based on their preferences is known as the ride-matching problem [
15,
16]. Current ridesharing systems provided by companies such as Uber (
https://www.uber.com/, accessed on 25 July 2022), Flinc (
https://flinc.org/, accessed on 25 July 2022), and Lyft (
http://www.lyft.me, accessed on 25 July 2022) are based on a simple matching algorithm that allocates users only based on their traveling route [
17,
18]. According to [
18,
19], these commercial systems employ a user-matching scheme limited by two main aspects: (1) the driver’s destination depends on the passenger’s destination; (2) the cost of the service is defined by a provider based on distances and times, without considering the cost-sharing of both the passenger and the driver.
According to [
20], the extant literature on the ride-matching problem focuses mainly on settings considering ridesharing optimization, dynamic ridesharing pricing, and cost-sharing schemes. Some works regarding ridesharing optimization address issues about vehicle routes and the improvement of ridesharing matching rates [
13,
21]. For example, Guan et al. [
22] studied the bounded rational users’ travel decision-making from a perspective of a multi-objective problem. In particular, they sought to maximize the number of users willing to share a trip while minimizing the total vehicle usage cost. On the other hand, research on dynamic ridesharing pricing commonly addresses several problems with the pricing and dispatching rules governing the ridesharing platforms [
23]. A particular concern in these works is that trips may be mispriced relative to each other, especially when spatial imbalance and temporal variation of supply and demand incentivize drivers [
24]. Finally, other research efforts study cost-sharing schemes about allocating cost savings as an important factor in the adoption of ridesharing by the users [
25,
26,
27]. In [
25], Hsieh et al. proposed a simple cost-sharing scheme based on a double auction mechanism involving the passenger and the driver. Their solution approach includes a particle swarm optimization algorithm to maximize cost savings while respecting timing constraints. In [
26], a study to compare metaheuristic algorithms intended to optimize monetary incentives in ridesharing systems is performed. A theoretical study on the comparison of cost-sharing schemes in ridesharing literature is proposed in [
27] to provide a guideline for characterizing the performance of proportional methods. Nevertheless, compared with the current research on these topics, a limited number of works on the ride-matching problem deal with stable matching (a matching in which no user prefers another different from the assigned one).
Formally, the
stable matching problem represents a pairwise relationship
M between users of two disjoint sets, passengers and drivers, where no user prefers to other one different from the current assigned [
28]. Given two passengers,
and
, and two drivers,
and
, where the assigned pairs
and
are part of a matching
M. A blocking pair
exists with respect to
M if
prefers to
more than
, and
prefers to
more than
. Formally, a stable matching exists if there is no blocking pairs. The concept of stability can be applied to different matching models such as one-to-one [
28], many-to-one [
29], and many-to-many [
30]. However, finding a stable matching (in any of its variants) of maximum cardinality is NP-hard [
31].
In particular, the ride-matching problem can be studied through the well-known hospital/resident problem proposed in [
31], in which a set of medical residents seek a position in a set of hospitals. While each resident ranks hospitals according to their preferences, each hospital ranks the applicant residents for its available positions. If the number of available hospital resident positions and the number of medical applicants is different, the problem is the stable matching with incomplete lists. Stability is not possible for different cardinalities in the matching sets [
31].
A variety of matching models explore the concept of stability for dynamic ridesharing considering relationships of one-to-one or many-to-one. While one-to-one matching applies to a simple setting with unit vehicle capacity [
32,
33,
34,
35,
36], many-to-one matching allows multi-capacity settings. Regarding the many-to-one matching, where one vehicle can serve multiple passengers simultaneously, some research efforts have been proposed [
37,
38,
39]. For example, a recent taxi-sharing model considering many-to-one matching is proposed in [
37]. The passenger’s preference depends on the taxi and the co-riders in their model, which is reformulated to a scheme-based set partitioning model that a branch-and-price algorithm can solve. The proposed branch-and-price algorithm achieves stable matchings and, in some cases, nearly stable matchings. In [
38], a many-to-one matching model involving shared autonomous vehicles (SAV) is proposed. Their model characterizes the waiting times of an SAV and multiple passengers who share rides in the SAV during online matching. A new multimodal autonomous ridesharing user equilibrium is introduced in their work in order to characterize the SAV traveler flow while considering seat capacity utilization. Passengers, dedicated drivers, and SAV have different behaviors impacting the matching decisions regarding these works. On the other hand, from the game-theoretical perspective, a many-to-one matching game is proposed to address stable solutions focused on the route-cost-assignment in [
39]. Their model outputs a stable payoff space for the post-evaluation of cost allocation mechanisms. A current comprehensive review of all these topics can be found in [
40]. However, most many-to-one matching models providing stable solutions do not consider diverse types of trips between users.
This paper addresses the stable matching of users in ridesharing systems. The contribution of this work is twofold. First, a new ridesharing system model is introduced. This model considers users’ preferences based on two fundamental aspects of the service: travel savings and the reputation of users (both passengers and drivers). Travel savings consider three types of trips (identical, inclusive, and partial), where one of them is novel in the literature. The reputation of users is computed through a modified version of the EigenTrust algorithm [
41] for peer-to-peer systems. In the proposed model, a driver may pick up more than one passenger during the trip while respecting timing and capacity constraints, such as the slack time and the number of available seats. To address these constraints, the model assumes that the driver–passenger utility evaluation is independent of interacting with other users. Second, a new stable matching algorithm for the ridesharing system services is presented. This algorithm consists of a new iterated version of the Gale–Shapley algorithm [
28]. In contrast with [
33,
35], in the proposed model, the capacity of each driver can be greater or equal than one, and it does not require that passengers and drivers sets have the same cardinality. To achieve this, the assumption of complete and strict preferences are relaxed through the concept of a ‘waiting list’. A demonstration that the algorithm always guarantees a stable matching solution (as well as its execution time analysis) is provided. Besides, the proposed model and the algorithm’s convergence were also verified empirically through experimental simulations involving a benchmarking of 2880 random bipartite graphs as test cases. Experimental results show that the proposed algorithm always converges to a stable matching solution for all test cases.
This paper is organized as follows.
Section 2 defines a new ridesharing model based on two main aspects of the services: the savings and the reputation of users.
Section 3 presents the proposed algorithm to solve the stable matching in ridesharing systems.
Section 4 describes the experimental simulations conducted to measure the efficiency of the proposed algorithm empirically. Finally,
Section 5 presents some concluding remarks and future work.
2. The Proposed Model
A network of roads is modeled through a directed multi-graph , where the set of vertices V represents the intersections or corners in the network, and the set of edges A the road segments. Let u be a user traveling through a path (or route) in G. The route of u, from to , is a sequence , where , , and each connects to , . A route is a proper subroute of iff y . Additionally, a weight function denotes the length of each road segment in G. The total length of is computed through the function , included in .
Two types of users, passenger and driver, are defined. Let p be a passenger requesting a ridesharing service to reduce either the costs generated by using its own vehicle or the travel times spent by using public transportation. On the other hand, let d be a driver bidding a ridesharing service by considering available places in its vehicle over the route . Both types of users, p and d, can travel together by establishing a joint route as follows:
Identical ridesharing: , then is also the same.
Inclusive ridesharing: is a proper subroute of (or the opposite). For this case, is equal to this proper subroute.
Partial ridesharing: is the longest proper subroute that is common between and when .
The type of ridesharing 3 differs from that described in the literature [
12,
40]. In the partial ridesharing proposed here, it may be that none of the origin or destination points are included in
.
Figure 1 illustrates the types of ridesharing allowed in the proposed model.
Let
be the
utility of
p when he/she shares its trip with
d through
. Equation (
1) models this utility based on two fundamental aspects of the ridesharing service: (1) the
travel savings of
p by sharing its trip with
d expressed by the function
; and (2) the global
reputation of
d calculated by function
. The coefficients
and
are two constants weighting the relevance levels for both aspects of the ridesharing service, where
.
Note that is not necessarily equal to .
An important assumption of the presented model is that the driver–passenger utility evaluation is independent of interacting with other users. In this vein, travel savings and reputations are computed involving only two users, discarding the information of the others.
2.1. Travel Savings
The
cost of the ridesharing service provided by
p and
d depend on the spatial and temporal characteristics of the trip. Consider a user
u (of the type
p or
d, interchangeably) traveling through the route
. The
transfer cost of
u traveling by
is expressed in Equation (
2) by considering the unit price of fuel (
gas), the vehicle performance measured by miles per gallon (
mpg), and the payment of services such as tolls, parking fees, or public transportation (
fees). Note that if
u does not have a particular vehicle, the transfer cost only depends on the fees.
Let
be the
cost savings when
u shares its trip with another user
v through the joint route
. The cost savings depend on the type of user, as expressed in Equation (
3).
Let
be the estimated
length of time in which
u travel from its origin to its destination through
. Then, the time savings of
u following a joint route
with a user
v (instead of its original route) is expressed as
. On the other hand, a
slack time indicates the time interval in which
u is willing to wait for
v at the origin point of
. Let
be the
instant of time in which
u estimates to arrive to the origin point of
. Equation (
4) computes the
total time savings for
u considering the joint route
.
Note that, traditionally,
is positive; however, it could be negative depending of the times saving estimated for the joint route
. Thus, the
travel savings generated by
u when sharing its trip with
v through
are calculated by Equation (
5).
where the coefficient
weights the importance assigned by the user about the times, and it allows the comparison between different magnitudes.
2.2. Reputation System
The proposed model uses a
reputation system to assign a level of trust to each user regarding the quality of the service provided. In particular, this work uses a version of the EigenTrust algorithm of [
41] to obtain, manage, and assign a reputation to each user (of type
p or
d) in the ridesharing system. This algorithm uses the notion of
transitive trust, where the trust value of each user is generated from the authentic opinion of those with whom they have directly interacted. All users participate in the calculation of the trust values in a distributed way in peer-to-peer systems, making it easily scalable and efficient in terms of computational complexity [
42,
43]. The EigenTrust algorithm outputs a global trust value, or global reputation, for each user on the system.
Assume a set of users
in the ridesharing system, where every
is a user of type
p or
d interchangeably. By using the EigenTrust algorithm, a user
evaluates every transaction or service received by a user
in the ridesharing system. Let
be the set of services that
received from
, then the
local reputation of
consists of the aggregation of the evaluation results performed by
. The local reputation of
from the perspective of
is defined in Equation (
6).
where
is a function that evaluates the transaction or the service provided by
based on the following metrics:
Punctuality. This metric has a value of if the service provided by starts on time; otherwise, the value is .
Cordiality. This metric has a value of if the service of was kind and respectful; otherwise, the value is .
Satisfaction. This metric has a value of if the service provided by fulfilled the expectations; otherwise, the value is .
Safety. This metric has a value of if the service provided by and the users involved in it are considered ‘trustworthy’; otherwise, the value is .
The reputation that
locally assigns to
, denoted as
, is normalized considering the previous rated users. This normalization seeks to avoid that arbitrary values can be assigned to ‘malicious’ users and that users with more services prevail over others. Equation (
7) presents a normalized version of
when
. If
does not know anyone or does not trust anyone, then
where
.
Note that negative scores are truncated to 0 in Equation (
7). This truncation prevents the ‘selfishness’ of some users from assigning arbitrarily low values to good users. It also avoids the
whitewashing of poor services since there is no distinction between those services and the new ones.
Local reputation values are disseminated and aggregated based on a
transitive reputation schema to compute a global reputation in the system. Under this scheme,
estimates the reputation
from any unknown user
. To perform such an estimation,
requests the local reputation of
to each user of type
with whom
has interacted, i.e.,
. Thus, the trust value that
assigns to
is based on the opinions of its acquaintances, as expressed in Equation (
8).
Let
M be a matrix
of dimension
, and let
be the trust vector of
with respect to each user in the system. Then,
represents the trust values of
based on the opinions of its acquaintances. Additionally,
can request the opinion of the acquaintances of its acquaintances by computing
. After
iterations, and for a large
,
represents a global opinion about each user in the system. Under the assumptions that
M is irreducible and not periodic [
41], the confidence vectors of each
in the system converge to a single vector
representing the left main eigenvector of
M. Thus, the global reputation of any user (of type
p or
d) computed by
is considered in the utility expression of Equation (
1).
3. Stable Matching
In this work, an algorithm is proposed to solve the stable matching problem in ridesharing systems according to the model described in
Section 2. This algorithm is an “iterated” version of the well-known Gale–Shapley algorithm [
28], relaxing the original restrictions concerning the equality in the size of the sets and the assumption of complete and strict preference lists.
The set of users U of the ridesharing system consists of elements of the type p and d, respectively. The number of available seats in the vehicle driven by a user of type d is , where . When a matching occurs between a pair of users p and d, a seat is assigned to p, decreasing in one. Let be the total of available seats in the ridesharing system, i.e., . Without loss of generality, assume that and . To ensure convergence to a stable matching, a waiting list is assumed. This waiting list contains remaining seats intended to those users of type p that do not find a place in a vehicle. Since the waiting list represents the last option for any passenger p, the model assigns , and .
The proposed algorithm takes as input a complete bipartite graph
, where the set of vertices
and the set of edges
E represents all possible allocations between users.
Figure 2 illustrates an example of a complete bipartite graph where
and
.
Every user
has a preference ranking to every user
and vice versa. These preferences are computed through the estimated utility for each ridesharing service. Thus, each edge
can be seen as two directed edges with a different weight according to their directions, where
and
represent the utilities
and
, respectively.
Figure 3 illustrates an example of a pairwise relationship between the vertices
and
, modeled as two directed edges in the graph.
Let
be a bipartite graph after
k iterations of the Gale–Shapley algorithm. The matching in the
k-th iteration consists of selecting a set
, for
, such that no pair of edges have a common vertex in
. In this context, the matching means assigning a user
to a user
with
available seats. Then, every matched vertex
“hosts” one vertex of type
p, decreasing its available seats by one at each iteration
k. Any hosting vertex of type
d in the iteration
k represents a single vertex, called a ‘supervertex’, for the iteration
. For each iteration
k, a subgraph
is generated. Thus,
contains the supervertices and the remaining vertices that were not chosen in
, and
contains the edges of
. Iteration matching ends in two cases. The first case occurs when there are no available seats in vertices of type
d; in this case, the remaining users of type
p match to the waiting list
with its
seats. The second case occurs when all the vertices of type
p match a user of type
d. Notice that this case only occurs when
.
Figure 4 illustrates an example of a resulting bipartite graph
after one iteration of the Gale–Shapley algorithm. Note that for this iteration
where vertices
,
, and
are supervertices.
Algorithm 1 presents the proposed solution for the stable matching problem in ridesharing systems. An important assumption of this algorithm is that the evaluation of the utilities does not change during each iteration. Therefore, every output matching
maintains their original utility values.
| Algorithm 1:Stable matching for the ridesharing system. |
- Input:
A complete bipartite graph with a preference ranking computed by . - Output:
The sequence of stable matchings . - 1:
- 2:
- 3:
while exists a vertex in which do - 4:
Executes the Gale–Shapley algorithm to reach a stable matching as a result - 5:
for each pair of vertices and connected by an edge of do - 6:
The vertex hosts the vertex - 7:
- 8:
end for - 9:
Generates such that contains the supervertices and the no matched vertices of , and contains the edges from - 10:
- 11:
end while - 12:
if exists a not matched vertex then - 13:
Match every vertex to the waiting list and generate the matching - 14:
end if - 15:
return the sequence of stable matchings
|
Let
be the sum of the utilities of each vertex incident to an edge of
. Equation (
9) shows this expression.
The
social welfare of the ridesharing system is the sum of the individual utilities of the final sequence of matchings. Equation (
10) describes the social welfare function SW, where
K is the total matching iterations of
.
The following lemma proves that the proposed algorithm reaches a stable matching.
Lemma 1. Algorithm 1 always generates a stable matching.
Proof. The proof is by mathematical induction in the number of iterations k of the algorithm.
Base case. Let be the set of pairs matched at the first round. There exists a blocking pair in any of the following two cases. The first case would occur when . In this case, the users are assigned to the waiting list . The second case would occur if any and both prefer to match with another user rather than with their current one assigned in . However, this is not possible, because after the execution of Gale–Shapley algorithm, all users in match with their corresponding user of their highest preference.
Inductive hypothesis. Assume that after iterations there are no blocking pairs in the matching .
Inductive step. Consider the iteration . Let be the bipartite graph obtained after the r-th iteration. Let be the set of pairs matched at the round . There exists a blocking pair in any of the following two cases. The first case would occur if the number of available seats at iteration r is less than the remaining users of type p for that iteration, i.e., . In this case, the remaining users of type p are assigned to the waiting list . The second case would occur if any and both preferred to match with another user rather than their current one assigned in . Notice that this is not possible because, by inductive hypothesis and by Gale–Shapley algorithm, all users in match with the user with their highest preference.
Therefore, Algorithm 1 always generates a stable matching. □
Corollary 1. Algorithm 1 requires time to generate a stable matching.
Proof. The result follows that each iteration of Gale–Shapley requires , and there exist k iterations. □
5. Conclusions and Future Work
This paper studies the stable ride-matching problem, an allocation process of ridesharing users in which no user prefers another different from the assigned one. With the aim to address this problem, a new ridesharing model using a specific pairwise utility function is introduced. This utility function is based on two fundamental aspects of the ridesharing service: travel savings and the reputation of users. While travel savings consider some spatial and temporal characteristics of the trip, the users’ reputation is calculated based on community members’ positive and negative opinions. In particular, the reputation system proposed here is a modified version of the well-known EigenTrust algorithm, where each user evaluates a service based on punctuality, cordiality, satisfaction, and trust.
A small case study was developed to show how and whether the proposed ridesharing model applies in practice. The case study focuses on public transportation users in the Metropolitan Zone of Guadalajara, the third largest city in Mexico, who are willing to improve their travel options through a ridesharing service. Although using public transportation is commonly seen as an option to reduce traffic congestion, resulting data shows that ridesharing services provide a higher utility in terms of cost and time savings (commuting public services could take hours in Mexico). In this vein, a model suitable to these contexts could motivate the use of ridesharing services, increasing the occupancy rates of vehicles, one of the significant factors behind road traffic congestion. However, mitigating traffic congestion is regarded as a result rather than a factor.
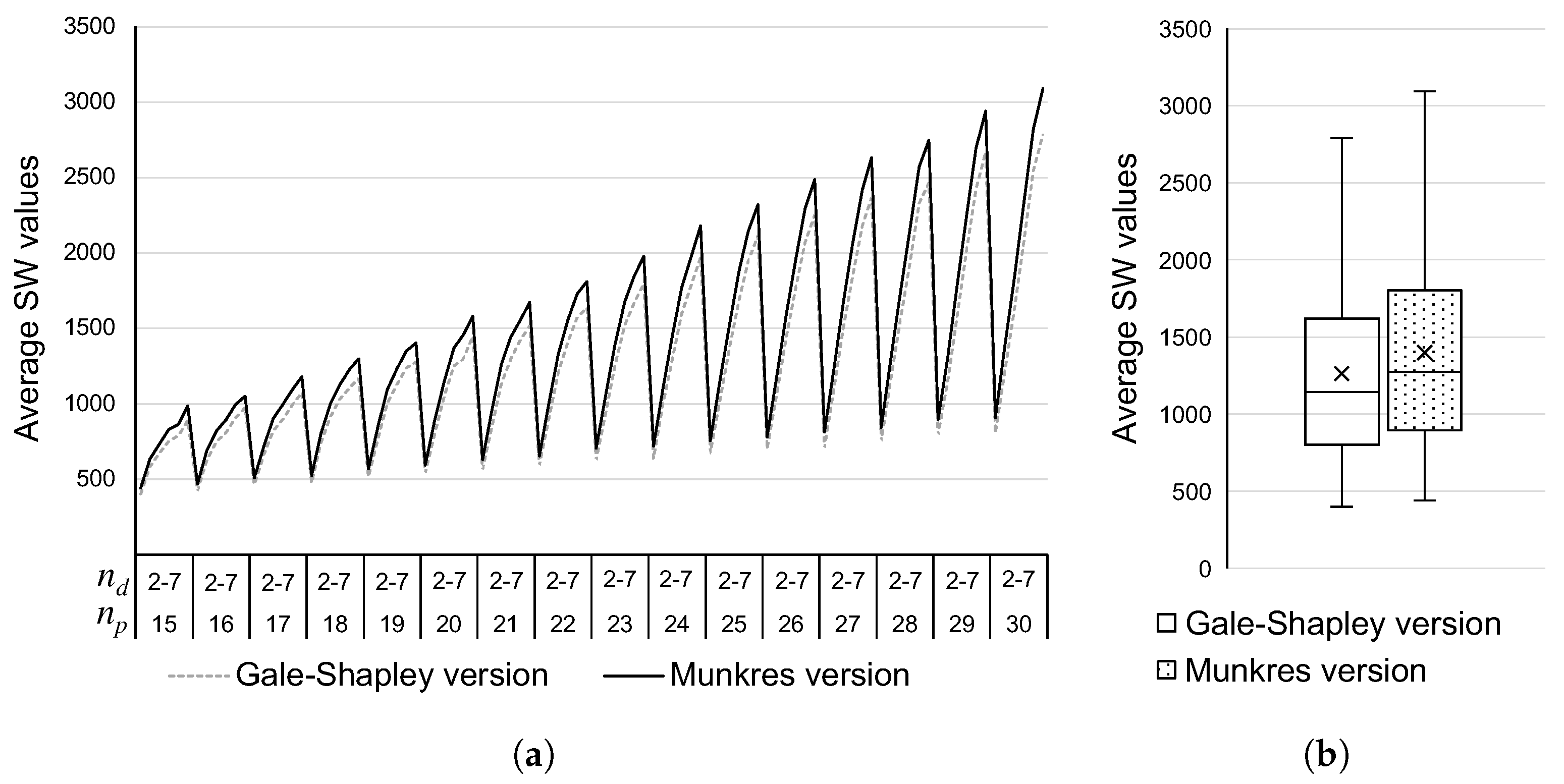
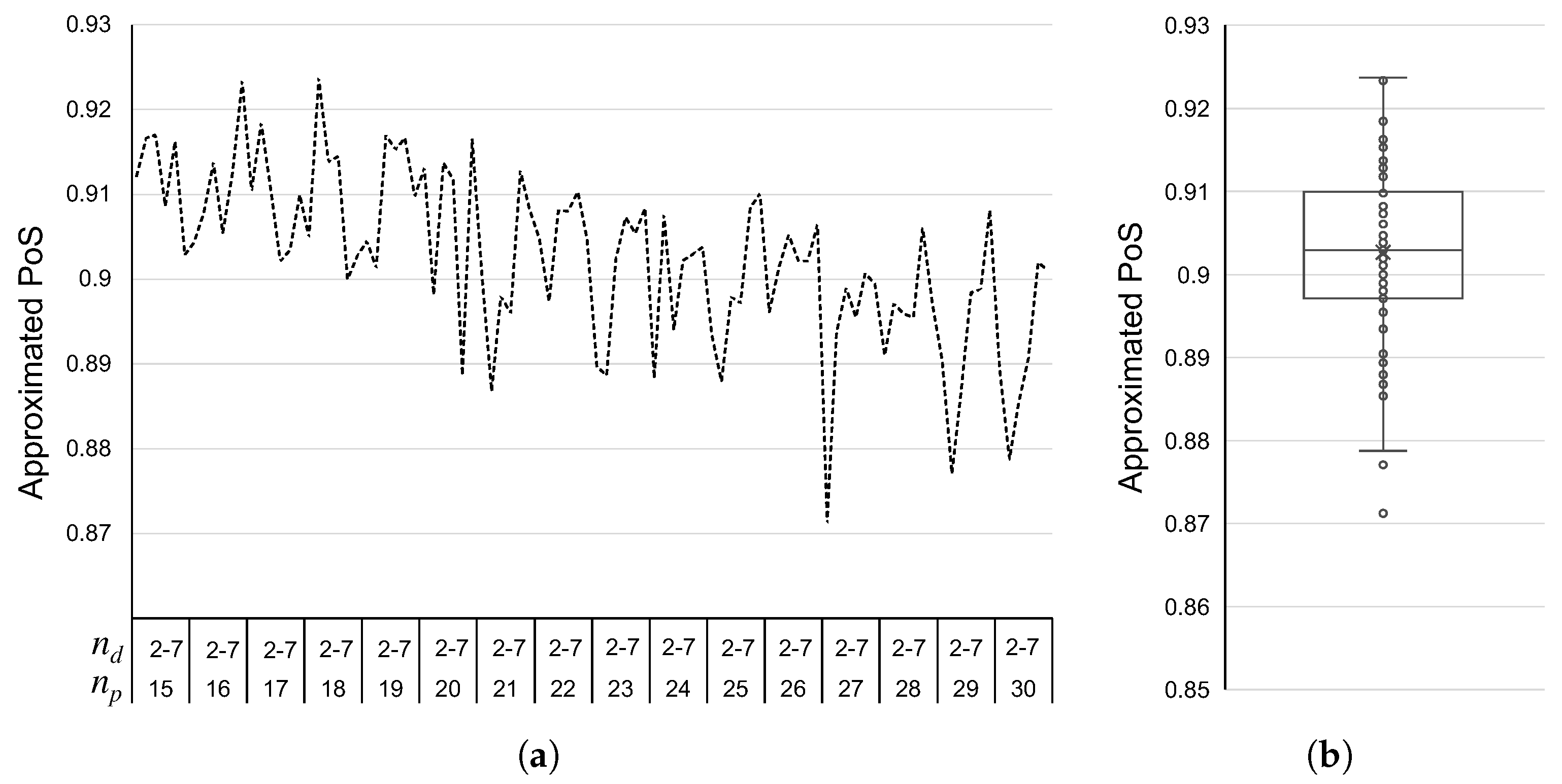
The proposed ridesharing model is used to introduce an algorithm designed to produce stable matching solutions in ridesharing systems. This algorithm consists of an iterated version of the Gale–Shapley algorithm, in which restrictions about the equality in the size of the sets and the assumption of complete and strict preferences are relaxed through the concept of a ‘waiting list’. Experimental simulations were conducted by considering a benchmarking of 2880 random bipartite graphs as test cases. Experimental results show that the proposed algorithm always converges to a stable matching solution for all test cases. An experimental price of stability indicates a level of degradation of in the social welfare due to the stable solutions.
This study may be extended in several directions for future work. One consists of adjusting the proposed ridesharing model to incorporate trips with deviation, where no common proper subroute exists between passenger and driver. This adjustment would be in addition to the three supported types of trips: identical, inclusive, and partial. Another interesting direction would be to implement a reputation system that considers not only the service’s evaluation but also the users’ identity. Finally, a critical question is whether this ridesharing model can reduce traffic congestion. It would be interesting to evaluate if this is possible considering a critical mass of shareable trips in terms of specific factors like trip density, city scale, and demand heterogeneity, among others.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}